搜索到
349
篇与
的结果
-
 Java 注解与单元测试 注解Java注解是在JDK1.5 之后出现的新特性,用来说明程序的,注解的主要作用体现在以下几个方面:编译检查,例如 @Override编写文档,java doc 会根据注解生成对应的文档代码分析,通过注解对代码进行分析[利用反射机制]JDK 中有一些常用的内置注解,例如:Override:检查被该注解修饰的方法是否是重写父类的方法Deprecatedd:被该注解标注的内容已过时SuppressWarnning: 压制警告,传入参数all表示压制所有警告自定义注解JDK中虽然内置了大量注解,但是它也允许我们自定义注解,这样就为程序编写带来了很大的便利,像有些框架就大量使用注解。java注解本质上是一个继承了 java.lang.annotation.Annotation 接口的一个接口,但是如果只是简单的使用关键字 interface来定义接口,仍然不是注解,仅仅是一个普通的接口,在定义注解时需要使用关键字 @interface, 该关键字会默认继承 Annotation 接口,并将定义的接口作为注解使用注解中可以定义方法,这些方法的返回值只能是基本类型、String、枚举类型、注解以及这些类型的数组,我们称这些方法叫做属性。在使用注解时需要注意以下几个事情必须给注解的属性赋值,如果不想赋值可以使用default来设置默认值如果属性列表中只有一个名为value的属性,那么在赋值时可以不用指定属性名称多个属性值之间使用逗号隔开数组属性的赋值使用 {}, 而当数组属性中只有一个值时, {} 可以省略不写元注解元注解是用来描述注解的注解,Java中提供的元注解有下列几个Target描述注解能够作用的位置,即哪些Java代码元素能够使用该注解,注解的源代码如下:@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Target { ElementType[] value(); }这个注解只有一个value属性,属性需要传入一个 ElementType枚举类型的数组,该枚举类型可以取下列几个值ElementType含义TYPE接口、类(包括注解)、枚举类型上使用FIELD字段声明(包括枚举常量)METHOD方法PARAMETER参数声明CONSTRUCTOR构造函数LOCAL_VARIABLE局部变量声明ANNOTATION_TYPE注解类型声明PACKAGE包声明Retention表示该注解类型的注解保留的时长,主要有3个阶段: 源码阶段,类对象阶段,运行阶段;源码阶段是只只存在与源代码中,类对象阶段是指被编译进 .class 文件中,类对象阶段是指执行时被加载到内存.则默认保留策略为RetentionPolicy.CLASS。它的源码如下:@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Retention { RetentionPolicy value(); }Documented表示拥有该注解的元素可通过javadoc此类的工具进行文档化。源码如下:@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Documented { }Inherited表示该注解类型被自动继承@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Inherited { }内置注解解读下面通过几个JDK内置注解的解读来说明注解相关使用Override@Target(ElementType.METHOD) @Retention(RetentionPolicy.SOURCE) public @interface Override { }该注解用于编译时检查,被该注解注释的方法是否是重写父类的方法。从源码上看,它只能在方法上使用,并且它仅仅存在于源码阶段不会被编译进 .class 文件中Deprecatedd@Documented @Retention(RetentionPolicy.RUNTIME) @Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE}) public @interface Deprecated { }用于告知编译器,某一程序元素(例如类、方法、属性等等)不建议使用从源码上看,几乎所有的Java程序元素都可以使用它,而且会被加载到内存中SuppressWarnning@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE}) @Retention(RetentionPolicy.SOURCE) public @interface SuppressWarnings { String[] value(); }告知编译器忽略特定类型的警告它需要传入一个字符串的数组,取值如下:参数含义deprecation使用了过时的类或方法时的警告unchecked执行了未检查的转换时的警告fallthrough当Switch程序块进入进入下一个case而没有Break时的警告path在类路径、源文件路径等有不存在路径时的警告serial当可序列化的类缺少serialVersionUID定义时的警告finally任意finally子句不能正常完成时的警告all以上所有情况的警告在程序中解析注解一般通过反射技术来解析自定义注解,要通过反射技术来识别注解,前提条件就是注解要在内存中被加载也就是要使它的范围为 RUNTIME;JDK提供了以下常用API方便我们使用返回值方法解释TgetAnnotation(Class annotationClass)当存在该元素的指定类型注解,则返回相应注释,否则返回nullAnnotation[]getAnnotations()返回此元素上存在的所有注解Annotation[]getDeclaredAnnotations()返回直接存在于此元素上的所有注解。booleanisAnnotationPresent(Class<? extends Annotation> annotationClass)当存在该元素的指定类型注解,则返回true,否则返回false实战下面使用一个完整的例子来说明自定义注解以及在程序中使用注解的例子,现在来模仿JUnit 定义一个MyTest的注解,只要被这个注解修饰的方法将来都会被自动执行import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; import java.lang.annotation.ElementType; @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface MyTest { }首先定义一个注解,后续来执行用这个注解修饰了的所有方法,通过Target来修饰标明注解只能用于方法上,通过Retention修饰标明注解会被保留到运行期import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; public class Test { @MyTest public void test1(){ System.out.println("this is test1"); } @MyTest public void test2(){ System.out.println("this is test2"); } public static void main(String[] args) { Method[] methods = Test.class.getMethods(); for (Method method:methods){ if (method.isAnnotationPresent(MyTest.class)){ try { method.invoke(new Test()); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } } } } } 在测试类中定义了两个测试函数都使用 @MyTest 修饰,在主方法中,首先通过反射机制获取该类中所有方法,然后调用方法的 isAnnotationPresent 函数判断该方法是否被 @Test修饰,如果是则执行该方法。这样以后即使再添加方法,只要被 @MyTest 修饰就会被调用。Junit框架在软件开发中为了保证软件质量单元测试是必不可少的一个环节,Java中提供了Junit 测试框架来进行单元测试一般一个Java项目每一个类都会对应一个test类用来做单元测试,例如有一个Person类,为了测试Person类会定义一个PersonTest类来测试所有代码JUnit 中定义了一些注解来方便我们编写单元测试@Test:测试方法,被该注解修饰的方法就是一个测试方法@Before:在测试方法被执行前会执行该注解修饰的方法@After:在测试方法被执行后会执行该注解修饰的方法除了注解JUnit定义了一些断言函数来实现自动化测试,常用的有如下几个:void assertEquals(boolean expected, boolean actual):检查两个变量或者等式是否平衡void assertTrue(boolean expected, boolean actual):检查条件为真void assertFalse(boolean condition):检查条件为假void assertNotNull(Object object):检查对象不为空void assertNull(Object object):检查对象为空void assertSame(boolean condition):assertSame() 方法检查两个相关对象是否指向同一个对象void assertNotSame(boolean condition):assertNotSame() 方法检查两个相关对象是否不指向同一个对象void assertArrayEquals(expectedArray, resultArray):assertArrayEquals() 方法检查两个数组是否相等这些函数在断言失败后会抛出异常,后续只要查看异常就可以哪些测试没有通过假设先定义一个计算器类,来进行两个数的算数运算public class Calc { public int add(int a, int b){ return a + b; } public int sub(int a, int b){ return a - b; } public int mul(int a, int b){ return a * b; } public float div(int a, int b){ return a / b; } }为了测试这些方法是否正确,我们来定义一个测试类import org.junit.Test; import static org.junit.Assert.assertEquals; public class CalcTest { @Test public void addTest(){ int result = new Calc().add(1,2); assertEquals(result, 3); } @Test public void subTest(){ int result = new Calc().sub(1,2); assertEquals(result, -1); } @Test public void mulTest(){ int result = new Calc().mul(1,2); assertEquals(result, 2); } @Test public void divTest(){ float result = new Calc().div(1,2); assertEquals(result, 0.5, 0.001); //会报异常 } }经过测试发现,最后一个divTest方法 会报异常,实际值是0,因为我们使用 / 来计算两个int时只会保留整数位,也就是得到的是0,与预期的0.5不匹配,因此会报异常
Java 注解与单元测试 注解Java注解是在JDK1.5 之后出现的新特性,用来说明程序的,注解的主要作用体现在以下几个方面:编译检查,例如 @Override编写文档,java doc 会根据注解生成对应的文档代码分析,通过注解对代码进行分析[利用反射机制]JDK 中有一些常用的内置注解,例如:Override:检查被该注解修饰的方法是否是重写父类的方法Deprecatedd:被该注解标注的内容已过时SuppressWarnning: 压制警告,传入参数all表示压制所有警告自定义注解JDK中虽然内置了大量注解,但是它也允许我们自定义注解,这样就为程序编写带来了很大的便利,像有些框架就大量使用注解。java注解本质上是一个继承了 java.lang.annotation.Annotation 接口的一个接口,但是如果只是简单的使用关键字 interface来定义接口,仍然不是注解,仅仅是一个普通的接口,在定义注解时需要使用关键字 @interface, 该关键字会默认继承 Annotation 接口,并将定义的接口作为注解使用注解中可以定义方法,这些方法的返回值只能是基本类型、String、枚举类型、注解以及这些类型的数组,我们称这些方法叫做属性。在使用注解时需要注意以下几个事情必须给注解的属性赋值,如果不想赋值可以使用default来设置默认值如果属性列表中只有一个名为value的属性,那么在赋值时可以不用指定属性名称多个属性值之间使用逗号隔开数组属性的赋值使用 {}, 而当数组属性中只有一个值时, {} 可以省略不写元注解元注解是用来描述注解的注解,Java中提供的元注解有下列几个Target描述注解能够作用的位置,即哪些Java代码元素能够使用该注解,注解的源代码如下:@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Target { ElementType[] value(); }这个注解只有一个value属性,属性需要传入一个 ElementType枚举类型的数组,该枚举类型可以取下列几个值ElementType含义TYPE接口、类(包括注解)、枚举类型上使用FIELD字段声明(包括枚举常量)METHOD方法PARAMETER参数声明CONSTRUCTOR构造函数LOCAL_VARIABLE局部变量声明ANNOTATION_TYPE注解类型声明PACKAGE包声明Retention表示该注解类型的注解保留的时长,主要有3个阶段: 源码阶段,类对象阶段,运行阶段;源码阶段是只只存在与源代码中,类对象阶段是指被编译进 .class 文件中,类对象阶段是指执行时被加载到内存.则默认保留策略为RetentionPolicy.CLASS。它的源码如下:@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Retention { RetentionPolicy value(); }Documented表示拥有该注解的元素可通过javadoc此类的工具进行文档化。源码如下:@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Documented { }Inherited表示该注解类型被自动继承@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Inherited { }内置注解解读下面通过几个JDK内置注解的解读来说明注解相关使用Override@Target(ElementType.METHOD) @Retention(RetentionPolicy.SOURCE) public @interface Override { }该注解用于编译时检查,被该注解注释的方法是否是重写父类的方法。从源码上看,它只能在方法上使用,并且它仅仅存在于源码阶段不会被编译进 .class 文件中Deprecatedd@Documented @Retention(RetentionPolicy.RUNTIME) @Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE}) public @interface Deprecated { }用于告知编译器,某一程序元素(例如类、方法、属性等等)不建议使用从源码上看,几乎所有的Java程序元素都可以使用它,而且会被加载到内存中SuppressWarnning@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE}) @Retention(RetentionPolicy.SOURCE) public @interface SuppressWarnings { String[] value(); }告知编译器忽略特定类型的警告它需要传入一个字符串的数组,取值如下:参数含义deprecation使用了过时的类或方法时的警告unchecked执行了未检查的转换时的警告fallthrough当Switch程序块进入进入下一个case而没有Break时的警告path在类路径、源文件路径等有不存在路径时的警告serial当可序列化的类缺少serialVersionUID定义时的警告finally任意finally子句不能正常完成时的警告all以上所有情况的警告在程序中解析注解一般通过反射技术来解析自定义注解,要通过反射技术来识别注解,前提条件就是注解要在内存中被加载也就是要使它的范围为 RUNTIME;JDK提供了以下常用API方便我们使用返回值方法解释TgetAnnotation(Class annotationClass)当存在该元素的指定类型注解,则返回相应注释,否则返回nullAnnotation[]getAnnotations()返回此元素上存在的所有注解Annotation[]getDeclaredAnnotations()返回直接存在于此元素上的所有注解。booleanisAnnotationPresent(Class<? extends Annotation> annotationClass)当存在该元素的指定类型注解,则返回true,否则返回false实战下面使用一个完整的例子来说明自定义注解以及在程序中使用注解的例子,现在来模仿JUnit 定义一个MyTest的注解,只要被这个注解修饰的方法将来都会被自动执行import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; import java.lang.annotation.ElementType; @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface MyTest { }首先定义一个注解,后续来执行用这个注解修饰了的所有方法,通过Target来修饰标明注解只能用于方法上,通过Retention修饰标明注解会被保留到运行期import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; public class Test { @MyTest public void test1(){ System.out.println("this is test1"); } @MyTest public void test2(){ System.out.println("this is test2"); } public static void main(String[] args) { Method[] methods = Test.class.getMethods(); for (Method method:methods){ if (method.isAnnotationPresent(MyTest.class)){ try { method.invoke(new Test()); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } } } } } 在测试类中定义了两个测试函数都使用 @MyTest 修饰,在主方法中,首先通过反射机制获取该类中所有方法,然后调用方法的 isAnnotationPresent 函数判断该方法是否被 @Test修饰,如果是则执行该方法。这样以后即使再添加方法,只要被 @MyTest 修饰就会被调用。Junit框架在软件开发中为了保证软件质量单元测试是必不可少的一个环节,Java中提供了Junit 测试框架来进行单元测试一般一个Java项目每一个类都会对应一个test类用来做单元测试,例如有一个Person类,为了测试Person类会定义一个PersonTest类来测试所有代码JUnit 中定义了一些注解来方便我们编写单元测试@Test:测试方法,被该注解修饰的方法就是一个测试方法@Before:在测试方法被执行前会执行该注解修饰的方法@After:在测试方法被执行后会执行该注解修饰的方法除了注解JUnit定义了一些断言函数来实现自动化测试,常用的有如下几个:void assertEquals(boolean expected, boolean actual):检查两个变量或者等式是否平衡void assertTrue(boolean expected, boolean actual):检查条件为真void assertFalse(boolean condition):检查条件为假void assertNotNull(Object object):检查对象不为空void assertNull(Object object):检查对象为空void assertSame(boolean condition):assertSame() 方法检查两个相关对象是否指向同一个对象void assertNotSame(boolean condition):assertNotSame() 方法检查两个相关对象是否不指向同一个对象void assertArrayEquals(expectedArray, resultArray):assertArrayEquals() 方法检查两个数组是否相等这些函数在断言失败后会抛出异常,后续只要查看异常就可以哪些测试没有通过假设先定义一个计算器类,来进行两个数的算数运算public class Calc { public int add(int a, int b){ return a + b; } public int sub(int a, int b){ return a - b; } public int mul(int a, int b){ return a * b; } public float div(int a, int b){ return a / b; } }为了测试这些方法是否正确,我们来定义一个测试类import org.junit.Test; import static org.junit.Assert.assertEquals; public class CalcTest { @Test public void addTest(){ int result = new Calc().add(1,2); assertEquals(result, 3); } @Test public void subTest(){ int result = new Calc().sub(1,2); assertEquals(result, -1); } @Test public void mulTest(){ int result = new Calc().mul(1,2); assertEquals(result, 2); } @Test public void divTest(){ float result = new Calc().div(1,2); assertEquals(result, 0.5, 0.001); //会报异常 } }经过测试发现,最后一个divTest方法 会报异常,实际值是0,因为我们使用 / 来计算两个int时只会保留整数位,也就是得到的是0,与预期的0.5不匹配,因此会报异常 -
Java数据库操作 数据库操作是程序设计中十分重要的一个部分,Java内置JDBC来操作数据库JDBC使用JDBC——Java Database connecting Java数据库连接;本质上JDBC定义了操作数据库的一套接口,作为应用程序的开发人员来说只需要创建接口对应的对象即可,而接口的实现由各个数据库厂商去完成。要在应用程序中使用JDBC,需要根据数据库的不同导入对应的jar包。使用步骤如下:导入相应jar包注册驱动获取数据库连接对象定义sql语句获取执行sql语句的对象执行sql并获取结果集对象从结果集中获取数据释放资源相关对象的描述DriverManager在使用JDBC之前需要先注册驱动,也就是告诉JDBC,我们需要导入哪个jar包,这个工作由DriverManager对象来实现,可以调用它里面的方法 registerDriver 来实现,该方法的定义如下:static void registerDriver(Driver driver);这个方法需要传入一个driver 对象,driver对象是具体的数据库厂商来实现,后续相关操作其实是根据这个driver对象来调用相关代码,实现同一套接口操作不同数据库我们查阅相关实现类的代码如下:public class Driver extends NonRegisteringDriver implements java.sql.Driver { // // Register ourselves with the DriverManager // static { try { java.sql.DriverManager.registerDriver(new Driver()); } catch (SQLException E) { throw new RuntimeException("Can't register driver!"); } } /** * Construct a new driver and register it with DriverManager * * @throws SQLException * if a database error occurs. */ public Driver() throws SQLException { // Required for Class.forName().newInstance() } }在Driver对象中发现,它在静态代码块中执行了registerDriver方法,也就是说我们只要加载对应的类,类就会自动帮助我们进行注册的操作。所以在第一步注册驱动的代码中可以这样写:Class.forName("org.mariadb.jdbc.Driver"); //加载对应的Driver类到内存中Connection对象注册了驱动之后就是获取数据库的连接对象,在DriverManager中使用getConnection方法获取,它的定义如下:static Connection getConnection(String url); static Connection getConnection(String url, Properties info); static Connection getConnection(String url, String user, String password);上述3个方法中,常用的是第3个,参数分别为: 连接字串、用户名、密码连接字串的格式为: jdbc:数据库类型://数据库IP:端口/数据库名称,比如 jdbc:mariadb://localhost:3306/test获取连接字串的代码如下:Connection conn = DriverManager.getConnection("jdbc:mariadb://localhost:3306/study", "root", "root");执行sql语句获取连接对象之后,需要向数据库传递sql语句并执行它,执行sql语句需要使用对象 Statement, 常用的方法如下:boolean execute(String sql); ResultSet executeQuery(String sql); int executeUpdate(String sql);一般可以使用execute来执行相关操作,如果是查询语句,可以使用executeQuery来执行并获取返回的结果集,如果需要执行DELTE、UPDATE、INSERT等语句可以使用executeUpdate来更新数据库我们可以通过 Connection对象的createStatement方法获取一个Statement对象,代码如下:Statement statement = conn.createStatement(); String strSql = "INSERT INTO student VALUES(2, '2b', 28, 78.9, '2017-12-30', NULL)"; statement.execute(strSql); statement.close(); //最后别忘了关闭对象获取返回结果如果我们执行了像insert、delete、update等等语句,可能不需要关注具体的返回结果,但是如果使用的是select语句,则需要获取返回的结果获取select语句返回的结果可以使用 executeQuery 方法,该方法会返回一个结果集对象可以将结果集对象想象成一个二维的数组,保存了查询到的相关数据,每一行代表一条数据,行中的每一列是一个字段的数据。结果集中使用游标来遍历每一行数据。使用get相关函数来获取对应索引的数据。一行遍历完了使用next移动到下一行;其中get相关方法主要有:Blob getBlob(int columnIndex); Blob getBlob(String columnLabel); boolean getBoolean(int columnIndex); boolean getBoolean(String columnLabel); byte getByte(int columnIndex); byte getByte(String columnLabel); byte[] getBytes(int columnIndex); byte[] getBytes(String columnLabel); Date getDate(int columnIndex); Date getDate(int columnIndex, Calendar cal); Date getDate(String columnLabel); Date getDate(String columnLabel, Calendar cal); double getDouble(int columnIndex); double getDouble(String columnLabel); float getFloat(int columnIndex); float getFloat(String columnLabel); int getInt(int columnIndex); int getInt(String columnLabel); long getLong(int columnIndex); long getLong(String columnLabel);在获取了结果之后需要关闭对应对象清理资源,这部分只需要调用对应的cloase方法即可最终一个完整的demo 如下:public class JDBCDemo1 { public static void main(String[] args) { Connection conn = null; Statement statement = null; ResultSet resultSet = null; try { Class.forName("org.mariadb.jdbc.Driver"); conn = DriverManager.getConnection("jdbc:mariadb://localhost:3306/test", "root", "root"); String sql = "select * from student"; statement = conn.createStatement(); resultSet = statement.executeQuery(sql); while (resultSet.next()){ int id = resultSet.getInt(1); //注意:这里面的索引是从1开始的 String name = resultSet.getString(2); int age = resultSet.getInt(3); double score = resultSet.getDouble(4); Date birthday = resultSet.getDate(5); Timestamp insertTime = resultSet.getTimestamp(6); System.out.println(id + "\t" + name + "\t" + age + "\t" + score + "\t" + birthday + "\t" + insertTime); } } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); }finally { try{ if (resultSet != null){ resultSet.close(); } if (statement != null){ statement.close(); } if (conn != null){ conn.close(); } }catch (SQLException e){ e.printStackTrace(); } } } }参数化查询我们知道使用sql拼接的方式来执行sql语句容易造成sql注入漏洞,即使针对某些关键字进行过滤也很难消除这个漏洞,一旦存在sql注入,那么数据库中的数据很容易就会被黑客窃取。而使用参数化查询的方式可以从根本上消除这个漏洞。jdbc中参数化查询使用的对象是 PreparedStatement, 它与Statement对象不同在于,它会提前将sql语句进行编译,后续只会接收固定类型的参数;而Statement只会简单的去执行用户输入的sql语句。在进行参数化查询的时候需要先准备sql语句,但是在查询参数中需要使用 ? 做标记,表示这个位置是一个参数,后续在真正执行前再传入,比如说可以准备这样的sql语句 update student set score = 100 where name = ?。准备好sql语句之后,需要设置对应参数位置的值,我们可以使用 setXxx 方法来设置,setXxx 方法与之前介绍的get方法类似,根据不同的数据类型 Xxx 有不同的取值。设置完参数之后,与Statement 一样,调用对应的execute方法来执行即可.String sql = "update student set score = 100 where name = ?"; ps = conn.prepareStatement(sql); ps.setString(1, "2b"); ps.executeUpdate();数据库连接池在需要频繁操作数据库的应用中,使用数据库连接池技术可以对数据库操作进行一定程度的优化。原理请自行百度。如果要自己实现数据库连接池需要实现 javax.sql.DataSource 的getConnection方法。当然我学习Java只是为了学习一下Web相关的内容,并不想太过于深入,所以自然不会去管怎么实现的,只要调用第三方实现,然后使用就好了。常见的开源的第三方库有: Apache commons-dbcp、C3P0 、Apache Tomcat内置的连接池(apache dbcp)、druid(由阿里巴巴提供)。本着支持国产的心态,这次使用的主要是 druid。druid 连接池需要提供一个配置文件来保存数据库的相关内容driverClassName=org.mariadb.jdbc.Driver url=jdbc:mariadb://localhost:3306/study username=root password=masimaro_1992 # 初始化时连接池中保留连接数 initialSize=5 # 最大连接数 maxActive=10 # 最大时间,超过这个时间没有任何操作则会关闭连接 maxWait=3000在使用时主要需要如下步骤:加载配置文件调用 DruidDataSourceFactory.createDataSource 方法传入 配置,获取到 DataSource 对象调用DataSource.getConnection 方法获取Connection 对象执行后续操作相关代码如下:Connection conn = null; Statement statement = null; Properties properties = new Properties(); try { properties.load(JDBCDemo3.class.getResourceAsStream("druid.properties")); DataSource dataSource = DruidDataSourceFactory.createDataSource(properties); conn = dataSource.getConnection(); statement = conn.createStatement(); //do something } catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); }
-
Java反射 Java中的类文件最终会被编译为.class 文件,也就是Java字节码。这个字节码中会存储Java 类的相关信息。在JVM执行这些代码时首先根据 java 命令中指定的类名找到.class 文件然后使用类加载器将class字节码文件加载到内存,在加载时会调用Class类的classLoader方法,读取.class 文件中保存类的成员变量、方法、构造方法,并将这些内容在需要时创建对应的对象。这个就是java中的反射机制。反射机制提供了由字符串到具体类对象的映射,提高了程序的灵活性,在一些框架中大量使用映射,做到根据用户提供的xml配置文件来动态生成并创建类对象反射机制最关键的就是从字节码文件中加载类信息并封装为对应的结构。在Java中专门提供了一个 Class 类,用于存储从.class 文件中读取出来的类的信息。 该类的定义和常用方法如下:public final class Class<?> extends Object implements Serializable, GenericDeclaration, Type, AnnotatedElement{ String getName(); //获取类名 ClassLoader getClassLoader(); //返回类的加载器 static Class<T> forName(String className); //根据类名返回对应类的Class对象 Field getField(String name); //根据名称返回对应的Filed对象 Field[] getFields(); //返回所有的Filed 对象 Field getDeclaredField(String name) //;返回一个 Field对象。 Field[] getDeclaredFields();//返回的数组 Field对象 Constructor<T> getConstructor(Class<?>... parameterTypes); Constructor<?>[] getConstructors(); Constructor<T> getDeclaredConstructor(Class<?>... parameterTypes); Constructor<?>[] getDeclaredConstructors(); Method getDeclaredMethod(String name, Class<?>... parameterTypes); Method[] getDeclaredMethods(); Method getMethod(String name, Class<?>... parameterTypes); Method[] getMethods(); }获取 Class 对象获取Class对象常见的有3种:可以通过 Class 类的静态方法 forName 传入类名获取可以通过具体对象的getClass 方法获取,这种方式的前提是我们拿到了目标对象,也就是需要内存中已经加载了对应的对象,相对来说第一种方法相对方便。通过类的静态class 成员来获取。下面是3中方式对应的代码 //1. 使用forName 来获取 try { Class<?> student = Class.forName("Student"); System.out.println(student.getName()); } catch (ClassNotFoundException e) { e.printStackTrace(); } //2. 使用getClass 对象 Class<? extends Student> aClass = new Student().getClass(); System.out.println(aClass.getName()); //3. 使用class 静态变量 Class<Student> studentClass = Student.class; System.out.println(studentClass.getName());需要注意的是在每个进程中 一个类的 Class 只有一个,拿上面的代码来说,即使 我们获取了3次,在内存中只有一个对应的Class 对象。获取类成员变量通过一定的方法,我们已经获取到了对应的Class 成员,之前说过Class是对字节码中记录的类信息的封装,类的成员变量被封装到了Field对象中,我们可以使用上述4个与Field有关的方法来获取对应的成员变量。public class Student { public String name; private int age; public String sex; private float gress; } //main try { Class<?> student = Class.forName("Student"); Field name = student.getField("name"); System.out.println(name.getName()); Field[] fields = student.getFields(); for (Field field: fields) { System.out.println(field.getName()); } } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (NoSuchFieldException e) { e.printStackTrace(); }上述的代码执行后会发现只能得到两个变量名,这两个函数只能获取 public 修饰的变量。要获取所有的可以使用 getDeclaredField(s) 函数组获取类方法Class 对象将类方法的信息封装到了 Method 对象中。我们可以使用 Method 对应的获取方法,同样的对应的Declared 方法能获取所有的,其他的只能获取公共的。这次我们实现一个 给Java Bean对象赋值的通用类。Java Bean是指满足这样一些条件的标准Java类:类必须被public 修饰类必须提供对应的getter 与 setter方法类必须提供空参的构造方法成员变量必须用private 修饰为了方便代码的编写,针对Java bean对象的getter/setter 方法命名有一个规定,尽量使用 get + 成员变量名(第一个字母大写)的方式来命名。同时定义类的属性值是 getter/setter 方法名去掉get/set 并将剩余词第一个字母小写得到属性名。针对这些定义,我们来实现一个根据字典值来给Java Bean赋值的方法。//默认已经给上述的student类添加了对应的getter/setter 方法,并且为了方便将所有成员都改为String static void BeanPopulate(Object bean, Map properties) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException { Iterator iterator = properties.entrySet().iterator(); while(iterator.hasNext()){ Map.Entry entry = (Map.Entry)iterator.next(); String key = (String) entry.getKey(); //首字母转大写 char[] chars = key.toCharArray(); chars[0] = (char) (chars[0] + ('A' - 'a')); String name = "set" + new String(chars); Method method = bean.getClass().getMethod(name, String.class); //第二个参数是方法的参数列表 method.invoke(bean, entry.getValue()); ////第一个参数是对象,第二个是方法的参数列表 } } Student student = new Student(); HashMap<String, String> map = new HashMap<>(); map.put("name", "tom"); map.put("age", "23"); map.put("sex", "男"); map.put("gress", "89.9"); try { BeanPopulate(student, map); } catch (NoSuchMethodException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); }通过Class创建对象上述的方法还有 Constructor 函数组没有说,这个函数组用来获取类的构造方法,有了这个方法,我们就可以创建对象了,那么我们将上面的例子给改一改,实现动态创建类并根据传入的map来设置值static Object BeanPopulate(Class beanClass, Map properties) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException { Iterator iterator = properties.entrySet().iterator(); Constructor constructor = beanClass.getConstructor(null); //构造方法的参数列表 Object bean = constructor.newInstance(null); //根据构造方法创建一个对象 while(iterator.hasNext()){ Map.Entry entry = (Map.Entry)iterator.next(); String key = (String) entry.getKey(); char[] chars = key.toCharArray(); chars[0] = (char) (chars[0] + ('A' - 'a')); String name = "set" + new String(chars); Method method = bean.getClass().getMethod(name, String.class); method.invoke(bean, entry.getValue()); } return bean; }
-
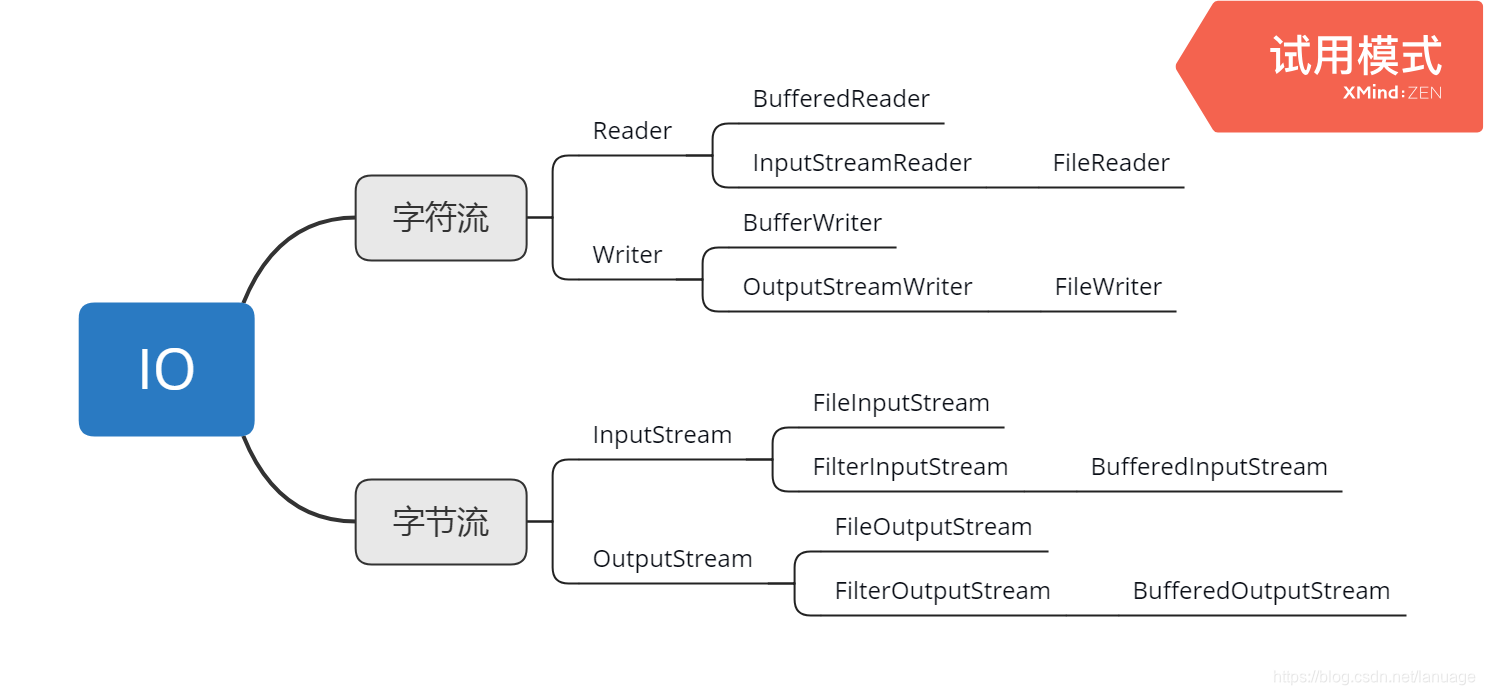
Java 文件操作 java文件操作主要封装在Java.io.File中,而文件读写一般采用的是流的方式,Java流封装在 java.io 包中。Java中流可以理解为一个有序的字符序列,从一端导向到另一端。建立了一个流就好似在两个容器中建立了一个通道,数据就可以从一个容器流到另一个容器文件操作Java文件操作使用 java.io.File 类进行。该类中常见方法和属性有:static String pathSeparator: 多个路径间的分隔符,这个分隔符常用于系统的path环境变量中。Linux中采用 : Windows中采用 ;static String separator: 系统路径中各级目录的分隔符,比如Windows路劲 c:\windows\ 采用的分隔符为 \, 而Linux中 /root 路径下的 分隔符为 /为了达到跨平台的效果,在写路径时一般不会写死,而是使用上述几个静态变量来进行字符串的拼接构造方法有:File(String pathname); 传入一个路径的字符串File(String parent, String child); 传入父目录和子目录的路径,系统会自动进行路径拼接为一个完整的路径File(File parent, String child); 传入父目录的File对象和子目录的路径,生成一个新的File对象常见方法:以can开头的几个方法,用于判断文件的相关权限,比如可读、可写、可执行String getAbsolutePath() 获取文件绝对路径的字符串String getPath() 获取文件的路径,这个方法会根据构造时传入的路径来决定返回绝对路径或者相对路径String getName() 获取文件或者路径的名称long length() 返回文件的大小,以字节为单位,目录会返回0;boolean exists(); 判断文件或者目录是否存在boolean isDirectory(); 判断对应的File对象是否为目录boolean isFile(); 判断对应的File对象是否为文件boolean delete(); 删除对应的文件或者目录boolean mkdir(); 创建目录boolean mkdirs(); 递归创建目录String[] list(); 遍历目录,将目录中所有文件路径字符串放入到数组中File[] listFiles(); 遍历目录,将目录中所有文件和目录对应的File对象保存到数组中返回下面是一个遍历目录中文件的例子public static void ResverFile(String path){ File f = new File(path); ResverFile_Core(f); } public static void ResverFile_Core(File f){ //System.out.println("开始遍历目录:" + f.getAbsolutePath()); File[] subFile = f.listFiles(); for(File sub : subFile){ if(sub.isDirectory()){ if(".".equals(sub.getName()) || "..".equals(sub.getName())){ continue; } ResverFile_Core(sub); }else{ System.out.println(sub.getAbsolutePath()); } } }上述代码根据传入的路径,递归遍历路径下所有文件。从 JDK文档中可以看到 list 和listFiles方法都可以传入一个FileFilter 或者FilenameFilter 的过滤器, 查看一下这两个过滤器:public interface FilenameFilter{ boolean accept(File dir, String name); } public interface FileFilter{ boolean accept(File pathname); }上述接口都是用来进行过滤的,FilenameFilter 会传入一个目录的File对象和对应文件的名称,我们在实现时可以根据这两个值来判断文件是否是需要遍历的,如果返回true则结果会包含在返回的数组中,false则会舍去结果将上述的代码做一些改变,该成遍历所有.java 的文件public static void ResverFile(String path){ File f = new File(path); ResverFile_Core(f); } public static void ResverFile_Core(File f){ //System.out.println("开始遍历目录:" + f.getAbsolutePath()); File[] subFile = f.listFiles(pathname->pathname.isDirectory() || pathname.getName().toLowerCase().endsWith(".java")); for(File sub : subFile){ if(sub.isDirectory()){ if(".".equals(sub.getName()) || "..".equals(sub.getName())){ continue; } ResverFile_Core(sub); }else{ System.out.println(sub.getAbsolutePath()); } } }IO 流Java将所有IO操作都封装在了 java.io 包中,java中流分为字符流(Reader、Writer)和字节流(InputStream、OutputStream), 它们的结构如下:字节流读写文件在读写任意文件时都可以使用字节流进行,文件字节流是 FileInputStream和FileOutputStream//可以使用路径作为构造方式 //FileInputStream fi = new FileInputStream("c:/test.dat"); //可以使用File对象进行构造 FileInputStream fi = new FileInputStream(new File("c:/test.dat")); int i = fi.read(); byte[] buffer = new byte[1024]; while(fi.read(buffer) > 0 ){ //do something } fi.close();下面是一个copy文件的例子public static void CopyFile() throws IOException{ FileInputStream fis = new FileInputStream("e:\\党的先进性学习.avi"); FileOutputStream fos = new FileOutputStream("党的先进性副本学习.avi"); int len = 0; byte[] buff = new byte[1024]; long start = System.currentTimeMillis(); while((len = fis.read(buff)) > 0){ fos.write(buff, 0, len); } long end = System.currentTimeMillis(); System.out.println("耗时:" + (end - start)); fos.close(); fis.close(); }字符流读写文件一般在读写文本文件时,为了读取到字符串,使用的是文件的字符流进行读写。文件字节流是FileReader和FileWriterFileReader fr = new FileReader(new File("c:/test.dat")); char[] buffer = new char[] while(fr.read(buffer) > 0 ){ //do something } fr.close();下面是一个拷贝文本文件的例子public static void CopyFile() throws IOException{ FileReader fr = new FileInputStream("e:\\党的先进性学习.txt"); FileWriter fw = new FileOutputStream("党的先进性副本学习.txt"); int len = 0; char[] buff = new char[1024]; long start = System.currentTimeMillis(); while((len = fr.read(buff)) > 0){ fw.write(buff, 0, len); } long end = System.currentTimeMillis(); System.out.println("耗时:" + (end - start)); fr.close(); fw.close(); }读写IO流的其他操作IO流不仅能够读写磁盘文件,在Linux的哲学中,一切皆文件。根据这点IO流是可以读写任意设备的。比如控制台;之前在读取控制台输入的时候使用的是Scanner,这里也可以使用InputStream或者InputStreamReader。Java中定义了用于控制台输入输出的InputStream 和 OutputStream 对象: System.in 和 System.out//多次读取单个字符 char c; InputStreamReader isr = new InputStreamReader(System.in); System.out.println("输入字符, 按下 'q' 键退出。"); // 读取字符 do { c = (char) isr.read(); System.out.println(c); } while (c != 'q'); isr.close(); //读取字符串 // 使用 System.in 创建 BufferedReader BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); String str; System.out.println("Enter lines of text."); System.out.println("Enter 'end' to quit."); do { str = br.readLine(); System.out.println(str); } while (!str.equals("end")); br.close();控制台的写入与读取类似OutputStreamWriter ow = new OutputStreamWriter(System.out); char[] buffer = new char{'a', 'b', 'c'}; ow.write(buffer); ow.flush(); ow.close();由于write函数的功能有限,所以在打印时经常使用的是 System.out.println 函数。缓冲流在操作系统中提到内存的速度是超过磁盘的,在使用流进行读写操作时,CPU向磁盘下达了读写命令后会长时间等待,影响程序效率。而缓冲流在调用write和read方法时并没有真正的进行IO操作。而是将数据缓存在一个缓冲中,当缓冲满后或者显式调用flush 后一次性进行读写操作,从而减少了IO操作的次数,提高了效率。常用的缓冲流有下面几个BufferedInputStreamBufferedOutputStreamBufferReaderBufferWriter分别对应字节流和字符流的缓冲流。它们需要传入对应的Stream 或者Reader对象。下面是一个使用缓冲流进行文件拷贝的例子,与上面不使用缓冲流的拷贝进行对比,当文件越大,效率提升越明显BufferedInputStream bis = new BufferedInputStream(new FileInputStream("E:\\test.avi")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("test.avi")); int len = 0; byte[] buff = new byte[1024]; long start = System.currentTimeMillis(); while((len = bis.read(buff)) > 0){ bos.write(buff, 0, len); } long end = System.currentTimeMillis(); System.out.println("耗时:" + (end - start)); bos.close(); bis.close();文件编码转换在读取文件时经常出现乱码的情况,乱码出现的原因是文件编码与读取时的解码方式不一样,特别是出现中文的情况。上面说过Java 中主要有字符流和字节流。从底层上来说,在读取文件时都是二进制的数据。然后将二进制数据转化为字符串。也就是先有InputStream/OutputStream 读出二进制数据,然后根据默认的编码规则将二进制数据转化为字符也就是 Reader/Writer。如果读取时的编码方式与文件的编码方式不同,则会出现乱码。我们在程序中使用 InputStreamReader和 OutputStreamWriter 来设置输入输出流的编码方式。//以UTF-8方式写文件 FileOutputStream fos = new FileOutputStream("test.txt"); OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8"); osw.write(FileContent); osw.flush(); //以UTF-8方式读文件 FileInputStream fis = new FileInputStream("test.txt"); InputStreamReader isr = new InputStreamReader(fis, "UTF-8"); BufferedReader br = new BufferedReader(isr); String line = null; while ((line = br.readLine()) != null) { FileContent += line; }序列化与反序列化在程序中经常需要保存类的数据,如果直接使用OutputStream 也是可以保存类数据的,但是需要考虑类中有引用的情况,如果里面有引用,需要保存引用所对应的那块内存。每个类都需要额外提供一个方法来处理存在引用成员的情况。针对这种需求,Java提供了序列化与反序列化的功能Java序列化与反序列化可以使用ObjectOutputStream 和 ObjectInputStream。public class Student{ public String name; public int age; public Date birthday; }比如我们要序列化 上述的 Student 类,可以使用下面的代码ObjectOutputStream oos = ObjectOutputStream(new FileOutputStream("student.dat")); Student stu = new Student(); stu.name = "Tom"; stu.age = 22; stu.brithday = new Date(); oos.writeObject(stu);当然如果要进行序列化和反序列化操作,必须要在类中实现Serializable接口, 这个接口没有任何方法它仅仅作为一个标志,拥有这个标志的方式才能进行序列化。也就是得将上述的Student 类做一个修改public class Student implements Serializable{ public String name; public int age; public Date birthday; }类的静态变量在类的对象创建之前就加载到了内存中。它与具体的类对象无关,所以在序列化时不会序列化静态成员。如果有的成员不想被序列化,可以将它变为静态成员;但是从设计上来说,也不是所有的类成员都可以变为静态成员。为了保证非静态成员可以不被序列化,可以使用 transient 关键字实现了serialiable 接口的类在保存为.class文件 时会增加 一个SerializableID, 序列化时会在对应文件中保存序列号,如果类发生了修改而没有进行序列化操作时,二者不同会抛出一个异常。例如说上述的Student类中先进行了一次序列化,在文件中保存了一个ID,后来根据需求又增加了一个 id 字段,在编译后又生成了一个ID,如果这个时候用之前的文件来反序列化,此时就会报错。为了解决上述问题,可以采用以下几种方法:改类代码文件后重新序列化。增加一个 static final long serialVerssionID = xxxx; 这个ID是之前序列化文件保存的ID。这个操作是为了让新修改的类ID与文件中的ID相同。调用 writeObject 方法时一个文件只能保存一个对象的内容。为了使一个文件保存多个对象,可以使用集合保存多个对象,在序列化时序列化 这个集合
-
Java lambda 表达式 在写Java代码的时候,如果某个地方需要一个接口的实现类,一般的做法是新定义一个实现类,并重写接口中的方法,在需要使用的时候new一个实现类对象使用,为了一个简单的接口或者说为了一个回调函数就得额外编写一个新类,即使说使用匿名内部类来实现,这样似乎比较麻烦。C中的做法是直接传入一个函数指针,而Java中就需要上述麻烦的操作,能不能简单点呢?为此Java中引入了一个lambda表达式的功能。lambda 表达式简介看看之前线程的例子:public class ThreadDemo{ public static void main(String[] args){ //使用匿名内部类的方式 Runnable thread1 = new Runnable(){ @Override public void run(){ System.out.println("当前线程:" + Thread.currentThread().getName() + "正在运行"); } } new Thread(thread1).start(); new Thread(thread1).start(); } }上面使用了匿名内部类的方式来简化了书写。使用lambda之后,可以写的更加简单public class ThreadDemo{ public static void main(String[] args){ //使用匿名内部类的方式 new Thread(()->{ System.out.println("当前线程:" + Thread.currentThread().getName() + "正在运行"); }); } }相比于之前使用匿名内部类的例子,lambda表达式更加关注的是函数实现的功能,而不再关注使用哪个类来实现。写法上更加的简洁。lambda 表达式的基本格式为 (参数列表)->{函数体}; JDK 会根据使用的接口自动创建对应的接口实现类并创建对象。也就是说,这里我们虽然简写了,但是底层仍然是需要通过创建实现类的对象来执行。上述的代码,JVM在执行时根据 Thread类 构造的情况,自动推导出此时应该需要一个Runnable的实现类,并且将lambda表达式中的函数体作为重写接口方法的函数体。需要注意使用lambda表达式的一些约束条件:lambda表达式只能用于重写接口类中的抽象方法。接口中应该只有一个抽象方法。当然上述的代码可以进一步简写。lambda表达式中凡是可以根据定义推导出来的东西就可以省略不写,例如:括号中参数列表中,参数类型可以不写。这个可以根据接口中方法的定义知道需要传哪些类型的参数括号中参数只有一个,那么类型和括号都可以省略如果函数体中代码只有一行,那么不管它是否有返回值,return和大括号以及语句末尾的分号可以都省略(注意,这里需要都省略)根据这些简写的规则,上述代码可以进一步简化public class ThreadDemo{ public static void main(String[] args){ //使用匿名内部类的方式 new Thread(()->System.out.println("当前线程:" + Thread.currentThread().getName() + "正在运行")); } }函数式接口上面说到,lambda表达式的条件是需要接口中只有一个抽象方法。像这种接口也被叫做是函数式接口。可以使用注解 @FunctionalInterface 来标明定义了一个函数式接口。在 java.util.function 包中提供了一些函数式接口。Supplier 生产者接口,它的定义如下@FunctionalInterface public interface Supplier<T>{ T get(); }这个接口的get方法可以产生一个结果供外部程序使用。Consumer,消费者接口需要传入一个结果供其处理,它的定义如下:@FunctionalInterface public interface Consumer<T>{ void accept(T t); }Predicate:判断的接口,根据给定的值返回True或者False@FunctionalInterface public interface Predicate<T>{ default Predicate<T> and(Predicate<? super T> other); //返回一个组合的谓词,表示该谓词与另一个谓词的短路逻辑AND。 static <T> Predicate<T> isEqual(Object targetRef); //返回根据 Objects.equals(Object, Object)测试两个参数是否相等的 谓词 。 default Predicate<T> negate(); //返回表示此谓词的逻辑否定的谓词。 default Predicate<T> or(Predicate<? super T> other); //返回一个组合的谓词,表示该谓词与另一个谓词的短路逻辑或。 boolean test(T t); //在给定的参数上评估这个谓词。 }Function 接口:接受一个参数并产生结果的函数@FunctionalInterface public interface Function<T,R>{ default <V> Function<T,V> andThen(Function<? super R,? extends V> after); //返回一个组合函数,首先将该函数应用于其输入,然后将 after函数应用于结果。 default <V> Function<V,R> compose(Function<? super V,? extends T> before); //返回一个组合函数,首先将 before函数应用于其输入,然后将此函数应用于结果。 static <T> Function<T,T> identity(); //返回一个总是返回其输入参数的函数。 R apply(T t); //接收指定参数处理并返回一个处理结果 }方法引用方法引用通过方法的名字来指向一个方法。方法引用可以使语言的构造更紧凑简洁,减少冗余代码。它主要用来针对lambda表达式做进一步的优化方法引用需要保证被引用的方法已经存在。方法引用使用一对冒号来表示 ::List names = new ArrayList(); names.add("Google"); names.add("Runoob"); names.add("Taobao"); names.add("Baidu"); names.add("Sina"); names.forEach(t->System.out.println(t));上述代码是采用lambda表达式的写法,接下来采用方法引用的方式,进一步简化代码List names = new ArrayList(); names.add("Google"); names.add("Runoob"); names.add("Taobao"); names.add("Baidu"); names.add("Sina"); names.forEach(System.out::println);方法引用的常见方式有:通过对象名引用对象方法通过类名引用静态方法通过this关键字,引用本类的成员方法通过构造函数引用:类名::newclass Car { public static Car create(final Supplier<Car> supplier) { return supplier.get(); } public static void collide(final Car car) { System.out.println("Collided " + car.toString()); } public void follow(final Car another) { System.out.println("Following the " + another.toString()); } public void repair() { System.out.println("Repaired " + this.toString()); } } //使用构造函数的引用 final Car car = Car.create( Car::new ); final List< Car > cars = Arrays.asList( car ); //静态方法的引用 cars.forEach( Car::collide ); //
-
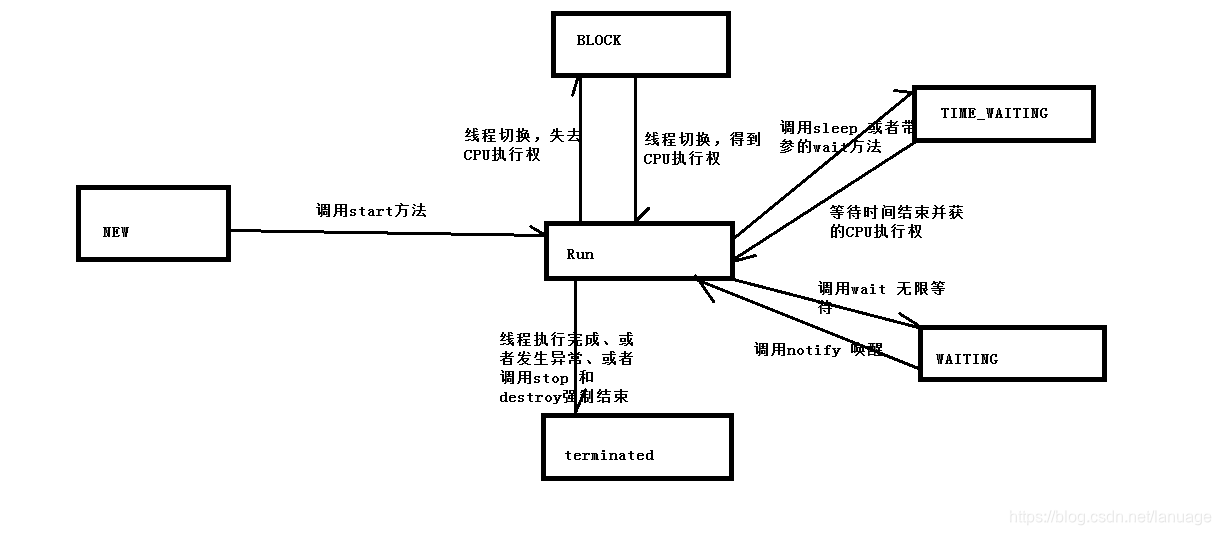
Java 多线程 Java内部提供了针对多线程的支持,线程是CPU执行的最小单位,在多核CPU中使用多线程,能够做到多个任务并行执行,提高效率。使用多线程的方法创建Thread类的子类,并重写run方法,在需要启动线程的时候调用类的start() 方法,每一个子类对象只能调用一次start()方法,如果需要启动多个线程执行同一个任务就需要创建多个线程对象实现Runnable 接口并重写run 方法,传入这个接口的实现类构造一个Thread类,然后调用Thread类的start方法实现Callable 接口并重写call方法,然后使用Future 来包装 Callable 对象,使用 Future 对象构造一个Thread对象,并调用Thread 类的start方法启动线程平时在使用上第一个方式用的很少,一般根据情况使用第2中或者第3中,与第一种方式相比,它们具有的优势如下:降低了程序的耦合性,它将设置线程任务和开启线程进行了分离避免了单继承的局限性,一旦继承了Thread 类,那么他就不能继承其他类。使用重写接口的方式可以再继承一个别的类第3中方式相比第二种方式来说,它提供了一个获取线程返回值的方式。我们在call函数中返回值,通过 FutureTask 对象的get方法来获取返回值public class ThreadTask extends Thread{ @Override public void run(){ System.out.println("当前线程:" + getName() + "正在运行"); } } public class ThreadDemo{ public static void main(String[] args){ new ThreadTask().start(); new ThreadTask().start(); } }public class ThreadDemo{ public static void main(String[] args){ //使用匿名内部类的方式 Runnable thread1 = new Runnable(){ @Override public void run(){ System.out.println("当前线程:" + Thread.currentThread().getName() + "正在运行"); } } new Thread(thread1).start(); new Thread(thread1).start(); } }public class ThreadDemo implements Callable<Integer>{ public static void main(String[] args){ FutureTask<Integer> ft = new new FutureTask<>(new ThreadDemo()); new Thread(ft).start(); System.out.println("线程返回值:" + ft.get()); } @Override public Integer call() throws Exception { System.out.println("当前线程:" + Thread.currentThread().getName() + "正在运行"); return 1; } }thread 状态在操作系统原理中讲到,线程有这么几种状态:新建、运行、阻塞、结束。而Java中将线程状态进行了进一步的细分,根据阻塞原因将阻塞状态又分为:等待(调用等待函数主动让出CPU执行权), 阻塞(线程的时间片到达,操作系统进行线程切换)它们之间的状态如下:等待唤醒入上图所示,可以使用wait/sleep方法让线程处于等待状态。在另一个线程中使用wait线程对象的notify方法可以唤醒wait线程。wait/notify 方法定义于 Object 方法,也就是说所以的对象都可以有wait/notify 方法。void wait() ;调用该函数,使线程无限等待,直到有另外的线程将其唤醒 void wait(long timeout);调用该函数,使线程进行等待,直到另外有线程将其唤醒或者等待时间已过 void notify(); 唤醒正在等待对象监视器的单个线程 void notifyAll(); 唤醒正在等待对象监视器的所有线程。上面说过这些方法都是在 Object 类中实现的,也就是说所有的对象都可以调用。上面的等待监视器就是随意一个调用了wait 的对象。这个对象会阻塞它所在的线程。线程同步我们知道在访问多个线程共享的资源时可能会发生数据的安全性问题。因此这个时候需要做线程的同步Java中同步的方法有: 同步代码块、同步方法和Lock锁的机制同步代码块同步代码块是使用synchronized来修饰需要进行同步的代码块同步代码块需要提供一个锁对象,当一个线程执行到这个代码块时,该线程获得锁对象。当另外的线程也执行到同一个锁对象的同步代码块时,由于无法获取到锁对象因此会陷入等待。直到获得锁对象的线程执行完同步代码块,并释放锁。这里获取、释放锁由Java虚拟机自己完成。例如public static void synchronizedCode(){ Runnable thread = new Runnable(){ private int ticket = 100; @Override public void run(){ synchronized (this){ while(ticket > 0){ //这里休眠10s,用来表示提交订单后的付款等操作 try{ Thread.sleep(10); }catch(Exception e){ e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "正在卖票:" + ticket); ticket--; } System.out.println(Thread.currentThread().getName() + "票已售罄"); } } }; new Thread(thread).start(); new Thread(thread).start(); new Thread(thread).start(); }同步方法同步方法是使用 synchronized 关键字修饰的方法。它与同步代码块的原理相同,保证了多个线程只有一个处于同步代码块中。同步方法中也有一个锁对象,这个锁对象是this这个对象,静态方法的锁对象是本类的class文件对象。public static void synchronizedMethod(){ Runnable thread = new Runnable(){ private int ticket = 100; @Override public void run(){ payTicket(); } public synchronized void payTicket(){ while(ticket > 0){ //这里休眠10s,用来表示提交订单后的付款等操作 try{ Thread.sleep(10); }catch(Exception e){ e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "正在卖票:" + ticket); ticket--; } System.out.println(Thread.currentThread().getName() + "票已售罄"); } }; new Thread(thread).start(); new Thread(thread).start(); new Thread(thread).start(); }Lock 锁机制除了上述方法,可以使用lock锁来进行同步,在执行代码前先调用 lock方法获得锁,执行完成之后使用unlock 来释放锁。例如下列的例子public static void lockMethod(){ Runnable thread = new Runnable(){ private int ticket = 100; private Lock lock = new ReentrantLock(); @Override public void run(){ try{ lock.lock(); while(ticket > 0){ //这里休眠10s,用来表示提交订单后的付款等操作 Thread.sleep(10); System.out.println(Thread.currentThread().getName() + "正在卖票:" + ticket); ticket--; } }catch(Exception e){ e.printStackTrace(); }finally{ lock.unlock(); } System.out.println(Thread.currentThread().getName() + "票已售罄"); } }; new Thread(thread).start(); new Thread(thread).start(); new Thread(thread).start(); }
-
Java 异常处理 异常是程序中的一些错误,但并不是所有的错误都是异常,并且错误有时候是可以避免的。比如说,你的代码少了一个分号,那么运行出来结果是提示是错误 java.lang.Error;如果你用System.out.println(11/0),那么你是因为你用0做了除数,会抛出 java.lang.ArithmeticException 的异常。Java中的异常主要分为下列几类:检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。运行时异常: 运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。错误: 错误不是异常,而是脱离程序员控制的问题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。所有的异常类是从 java.lang.Exception 类继承的子类。 Exception 类是 Throwable 类的子类。除了Exception类外,Throwable还有一个子类Error 。它们之间的关系入下图:从Exception继承的类都是异常,异常可以被处理,处理完后程序仍然可以继续运行。从Error继承来的类都是错误,在运行时错误无法被处理,只能修改代码逻辑。从Runtime中继承的类都是运行时异常,这类异常在程序中可以处理,也可以不处理。而非运行时异常在代码中必须处理。不然编译会报错。Java中异常处理的方式Java中的异常处理主要有下列几种:使用 throw 在指定方法中抛出指定异常。比如 throw IOException(); 在方法中抛出了一个IO异常使用 throws 将异常抛出给调用者处理。在函数声明时使用。方法声明时可以抛出多个异常,如果多个异常有继承关系,那么只需要抛出父类异常即可。如果父类的方法没有抛出异常,子类在重写父类方法时也不能使用这种方式抛出异常try...catch 处理异常。在使用try 处理异常时需要注意:如果catch 中捕获的有多个异常,且异常间有继承关系,那么必须把子类写在前面,父类在后面异常中的常用方法Throwable 中定义了3个异常处理的方法:String getMessage(): 返回异常的详细信息String toString() : 返回异常的简短信息void printStackTrace(): 打印异常的调用信息这些异常信息一般在try...catch 中使用,例如try { //do something }catch(Exception e){ e.printStackTrace(); }finally 关键字无论异常是否发生,finally中的代码都会执行。一般finally中编写释放资源的代码,比如释放文件对象。需要注意的是,finally中会改变return的执行顺序,不管return在哪,都会最后执行finally中的returntry{ //do some thing return; }catch(Exception e) { return; } finally{ return; //会执行这个 } return;自定义异常类自定义异常时需要注意:异常类都必须继承自 Throwable类,如果要定义检查性异常,需要继承 Exception,要定义运行时异常,需要继承 RuntimeException。class MyException extends Exception{ }假设我们定义一个异常类,表示取钱的异常,当取钱数少于1000时报异常,提示用户去ATM取,可以这样写class TooLittleMoneyException extends Exception { private int money; private String message; TooLittleMoneyException(int money){ message = "" + money + "太少,请到ATM自助取款机去取"; } String getMessage(){ return message; } } //取钱方法 //打开交易通道 //校验账户是否合法 try{ if (money < 1000){ throw TooLittleMoneyException(money); } //取钱,并在对应账户中减少相应的金额 }catch(TooLittleMoneyException e){ System.out.println(e.getMessage()); }finally{ //关闭交易通道 }
-
Java 容器 之前学习了java中从语法到常用类的部分。在编程中有这样一类需求,就是要保存批量的相同数据类型。针对这种需求一般都是使用容器来存储。之前说过Java中的数组,但是数组不能改变长度。Java中提供了另一种存储方式,就是用容器类来处理这种需要动态添加或者删除元素的情况概述Java中最常见的容器有一维和多维。单维容器主要是一个节点上存储一个数据。比如列表和Set。而多维是一个节点有多个数据,例如Map,每个节点上有键和值。单维容器的上层接口是Collection,它根据存储的元素是否为线性又分为两大类 List与Set。它们根据实现不同,List又分为ArrayList和LinkedList;Set下面主要的实现类有TreeSet、HashSet。它们的结构大致如下图:Collection 接口Collection 是单列容器的最上层的抽象接口,它里面定义了所有单列容器都共有的一些方法:boolean add(E e):向容器中添加元素void clear(): 清空容器boolean contains(Object o): 判断容器中是否存在对应元素boolean isEmpty(): 容器是否为空boolean remove(Object o): 移除指定元素<T> T[] toArray(T[] a) : 转化为指定类型的数组Listlist是Collection 中的一个有序容器,它里面存储的元素都是按照一定顺序排序的,可以使用索引进行遍历。允许元素重复出现,它的实现中有 ArrayList和 LinkedListArrayList 底层是一个可变长度的数组,它具有数组的查询快,增删慢的特点LinkedList 底层是一个链表,它具有链表的增删快而查询慢的特点SetSet集合是Collection下的另一个抽象结构,Set类似于数学概念上的集合,不关心元素的顺序,不能存储重复元素。TreeSet是一颗树,它拥有树形结构的相关特定HashSet: 为了加快查询速度,它的底层是一个hash表和链表。但是从JDK1.8以后,为了进一步加快具有相同hash值的元素的查询,底层改为hash表 + 链表 + 红黑树的结构。相同hash值的元素个数不超过8个的采用链表存储,超过8个之后采用红黑树存储。它的结构类似于下图的结构在存储元素的时候,首先计算它的hash值,根据hash值,在数组中查找,如果没有,则在数组对应位置存储hash值,并在数组对应位置添加元素的节点。如果有,则先判断对应位置是否有相同的元素,如果有则直接抛弃否则在数组对应位置下方的链表或者红黑树中添加节点。从上面的描述看,想要在HashSet中添加元素,需要首先计算hash值,在判断集合中是否存在元素。这样在存储自定义类型的元素的时候,需要保证类能够正确计算hash值以及进行类型的相等性判断。因此要重写类的hashCode和equals 方法。例如下面的例子class Person{ private String name; private int age; Person(){ } Person(String name, int age){ this.name = name; this.age = age; } public int getAge(){ return this.age; } public String getName(){ return this.name; } public void setAge(int age){ this.age = age; } public void setName(String name){ this.name = name; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } @Override public int hashCode() { return Objects.hash(this.name, this.age); } }上面说到HashSet是无序的结构,如果我们想要使用hashSet,但是又想它有序,该怎么办?在Set中提供了另一个实现,LinkedHashMap。它的底层是一个Hash表和一个链表,Hash表用来存储真正的数据,而链表用来存储元素的顺序,这样就结合了二者的优先。MapMap是一个双列的容器,一个节点存储了两个值,一个是元素的键,另一个是值。其中Key 和 Value既可以是相同类型的值,也可以是不同类型的值。Key和Value是一一对应的关系。一个key只能对应一个值,但是多个key可以指向同一个value,有点像数学中函数的自变量和值的关系。Map常用的实现类有: HashMap和LinkedHashMap。常用的方法有:void clear(): 清空集合boolean containsKey(Object key): map中是否包含对应的键V get(Object key): 根据键返回对应的值V put(K key, V value): 添加键值对boolean isEmpty(): 集合是否为空int size(): 包含键值对的个数遍历针对列表类型的,元素顺序固定,我们可以使用循环依据索引进行遍历,比如for(int i = 0; i < list.size(); i++){ String s = list.get(i); }而对于Set这种不关心元素的顺序的集合来说,不能再使用索引了。针对单列集合,有一个迭代器接口,使用迭代器可以实现遍历迭代器迭代器可以理解为指向集合中某一个元素的指针。使用迭代器可以操作元素本身,也可以根据当前元素寻找到下一个元素,它的常用方法有:boolean hasNext() : 当前迭代器指向的位置是否有下一个元素E next(): 获取下一个元素并返回。调用这个方法后,迭代器指向的位置发生改变使用迭代器的一般步骤如下:使用集合的 iterator() 返回一个迭代器循环调用迭代器的 hasNext方法,判断集合中是否还有元素需要遍历使用 next方法,找到迭代器指向的下一个元素//假设set是一个 HashSet<String>集合 Iterator<String> it = set.iterator(); while(it.hasNext()){ Stirng s = it.next(); }Map遍历索引和迭代器的方式只能遍历单列集合,像Map这样的多列集合不能使用上述方式,它有额外的方法,主要有两种方式获取key的一个集合,遍历key集合并通过get方法获取value获取键值对组成的一个集合,遍历这个新集合来得到键值对的值针对第一种方法,Map中有一个 keySet() 方法。这个方法会获取到所有的key值并保存将这些值保存为一个新的Set返回,我们只要遍历这个Set并调用 Map的get方法即可获取到对应的Value, 例如:// 假设map 是一个 HashMap<String, String> 集合 Set<String> kSet = map.keySet(); Iterator<String> key = kSet.iterator(); while(it.hasNext()){ String key = it.next(); String value = map.get(key); }针对第二种方法,可以先调用 Map的 entrySet() 获取一个Entry结构的Set集合。Entry 中保存了一个键和它对应的值。使用结构中的 getKey() 和 getValue() 分别获取key和value。这个结构是定义在Map中的内部类,因此在使用的时候需要使用Map这个类名调用// 假设map 是一个 HashMap<String, String> 集合 Set<Map.Entry<String,String>> entry = map.entrySet(); Iterator<Map.Entry<String, String>> it = entry.iterator(); while(it.hasNext()){ Map.Entry<String, String> me = it.next(); String key = me.getKey(); String value = me.getValue(); }for each 循环在上述遍历的代码中,不管是使用for或者while都显得比较麻烦,我们能像 Python 等脚本语言那样,直接在 for 中使用迭代吗?从JDK1.5 以后引入了for each写法,使Java能够直接使用for迭代,而不用手工使用迭代器来进行迭代。for (T t: set); 上述是它的简单写法。例如我们对遍历Set的写法进行简化//假设set是一个 HashSet<String>集合 for(String s: set){ //TODO:do some thing }我们说使用 for each写法主要是为了简化迭代的写法,它在底层仍然采用的是迭代器的方式来遍历,针对向Map这样无法直接使用迭代的结构来说,自然无法使用这种简化的写法,针对Map来说需要使用上述的两种遍历方式中的一种,先转化为可迭代的结构,然后使用for each循环// 假设map 是一个 HashMap<String, String> 集合 Set<Map.Entry<String, String>> set = map.entrySet(); for(Map.Entry<String, String> entry: set){ String key = entry.getKey(); String value = entry.getValue(); System.out.println(key + "-->" + value); }泛型在上述的集合中,我们已经使用了泛型。泛型与C++ 中的模板基本类似,都是为了重复使用代码而产生的一种语法。由于这些集合在创建,增删改查上代码基本类似,只是事先不知道要存储的数据的类型。如果没有泛型,我们需要将所有类型对应的这些结构的代码都重复写一遍。有了泛型我们就能更加专注于算法的实现,而不用考虑具体的数据类型。在定义泛型的时候,只需要使用 <>中包含表示泛型的字母即可。常见的泛型有:T 表示TypeE 表示 Element<> 中可以使用任意标识符来表示泛型,只要符合Java的命名规则即可。使用 T 或者 E 只是为了方便而已,比如下面的例子public static <Element> void print(Element e){ System.out.println(e); }当然也可以使用Object 对象来实现泛型的重用代码的功效,在对元素进行操作的时候主要使用java的多态来实现。但是使用多态的一个缺点是无法使用元素对象的特有方法。泛型的使用泛型可以在类、接口、方法中使用在定义类时定义的泛型可以在类的任意位置使用class DataCollection<T>{ private T data; public T getData(){ return this.data; } public void SetData(T data){ this.data = data; } }在定义类的时候定义的泛型在创建对象的时候指定具体的类型.也可以在定义接口的时候定义泛型public interface DataCollection<T>{ public abstract T getData(); public abstract void setData(T data); }定义接口时定义的泛型可以在定义实现类的时候指定泛型,或者在创建实现类的对象时指定泛型public class StringDataCollectionImpl implements DataCollection<String>{ private String data; public String getData(){ return this.data; } public void SetData(String data){ this.data = data; } } public interface DataCollection<T> implements DataCollection<T>{ private T data; public T getData(){ return this.data; } public void SetData(T data){ this.data = data; } }除了在定义类和接口时使用外,还可以在定义方法的时候使用,针对这种情况,不需要显示的指定使用哪种类型,由于接收返回数据和传入参数的时候已经知道了public static <Element> Element print(Element e){ System.out.println(e); return e; } String s = print("hello world");泛型的通配符在使用通配符的时候可能有这样的需求:我想要使用泛型,但是不希望它传入任意类型的值,我只想要处理继承自某一个类的类型,就比如说我只想保存那些实现了某个接口的类。我们当然可以将数据类型定义为某个接口,但是由于多态的这一个缺陷,实现起来总不是那么完美。这个时候可以使用泛型的通配符。泛型中使用 ? 作为统配符。在通配符中可以使用 super 或者 extends 表示泛型必须是某个类型的父类或者是某个类型的实现类class Fruit{ } class Apple extends Fruit{ } class Bananal extends Fruit{ } static void putFruit(<? extends Fruit> data){ }上述代码中 putFruit 函数中只允许 传递 Fruit 类的子类或者它本身作为参数。当然也可以使用 <? super T> 表示只能取 T类型的父类或者T类型本身。
-
Java 常用类 之前将Java的大部分语法都回顾完了,后面添加一些常见的操作,基础语法就结束了。至于在这里再次提到常用类是由于有一部分体现在使用它的继承类或者接口之类的。这些需要有面向对象编程的基础Object类Object类是所有类的基类,只要定义了类,即使没有显式的声明继承自Object类,也会从该类继承。这个类没有什么是需要显式调用的,很多东西都需要重写类的方法来达到相关效果,比如常用的两个方法:String toString() : 将类转化为字符串。一般来说直接打印新定义的类都会打印出对象的地址值,如果需要打印里面的相关值,需要重写toString方法boolean equals(Object obj): 一般来说,== 比较的是对象的地址值,而针对字符串或者其他对象可能需要根据别的值来比较是否相等,这个时候需要重写这个方法。protected Object clone(): 在C++中如果直接使用内存拷贝来拷贝对象的话,如果对象中有指针变量,可能会导致一系列的问题,这种拷贝方法叫做浅拷贝。这个方法用来执行深度拷贝操作。public String toString() { return getClass().getName() + "@" + Integer.toHexString(hashCode()); }上述代码是Object类的 toString 方法,从代码上看,默认会调用对象的hashCode 方法获取hash值,并转化为字符串。时间操作Date 类Date 类用来处理时间,它能精确到毫秒Date(): 获取当前时刻的Unix时间戳Date(long date): 根据一个时间戳初始化一个对象long getTime(): 获取当前对象对应的时间戳这个方法目前只是用来进行这些操作,后续其他时间的格式化,获取对应的年、月、日操作在后续的JDK版本都用另外的类来进行SimpleDateFormat 类上面提到,Date类只用来进行时间戳相关转化的操作,而具体与时间相关的操作都用这个类来进行。该类继承自 DataFormat 类, DataFormat是一个抽象类。SimpleDateFormat() : 使用默认的模式来格式化Date类SimpleDateFormat(String pattern): 按照指定格式来格式化Date类SimpleDateFormat(String pattern, Locale locale): 构造一个 SimpleDateFormat使用给定的模式和给定的区域设置的默认日期格式符号模式类似于格式化字符串,与常见语言的格式化时间的方式类似。String format(Date date): 按照构造时提供的模式来将传入的date 对象格式化为字符串Date parse(String source): 从给定字符串的开始解析文本以生成日期Calendar 类上述两个与时间相关的类已经解决了时间的获取以及格式化输出的操作。但是关于时间还需要进行年、月、日相关的操作。比如加一年、减一个月等等。跟具体年月相关的操作使用 Calendar类。这个类也是一个抽象类,但是可以使用它的相关静态方法来创建对象static Calendar getInstance(): 使用默认时区和区域设置获取日历。static Calendar getInstance(Locale aLocale): 使用默认时区和指定的区域设置获取日历。常见的方法如下:int get(int field): 返回指定字段的日历值void set(int year, int month, int date, int hourOfDay, int minute, int second): 设置字段中的值 YEAR , MONTH , DAY_OF_MONTH , HOUR_OF_DAY , MINUTE和 SECONDabstract void add(int field, int amount): 根据日历的规则,将指定的时间量添加或减去给定的日历字段Date getTime(): 根据日历对象返回一个对应的Date类void setTime(Date date): 将Date类转化为日历类这些get和set方法有的需要一个值表示需要修改日历中的哪个值。比如 YEAR表示年、MONTH表示月、DAY_OF_MONTH表示月中的天数、HOUR_OF_DAY表示小时等等从这3个类的相关操作来说,Date类作为沟通其他两个类的桥梁,常见的策略是: DateFormat -->Date -->Calender 或者 Calender-->Date-->DateFormat下面是一个简单的例子DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date date = df.parse("2018-10-1 12:12:12"); Calendar c = Calendar.getInstance(); c.set(Calendar.YEAR, 2019); date = c.getTime(); System.out.println("Time:" + df.format(date));System 类这个类用于获取系统相关的内容,里面都是一些静态方法。常用的方法有:static long currentTimeMillis(): 返回当前系统时间,以毫秒为单位static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length): 数组复制方法StringBuilder 类我们说String方法中的字符不能修改,如果要修改,必须重新分配一个String,并舍弃原来的String方法。当String操作过多,频繁的分配回收,影响程序效率。StringBuilder类与String相比,可以修改里面的字符值。相比String来说效率更高StringBuilder(): 构造一个能容纳16个字符的字符容器StringBuilder(int capacity) :构造一个容纳指定字符的容器StringBuilder(String str): 构造一个初始化为指定字符串内容的字符串构建器。append方法:它有一系列的重载方法。往字符容器中添加指定的内容toString(): 转化为String 对象包装类Java中针对 普通类型都有一个对应的类,封装了一系列的操作,比如int 类的包装类是 Integer, double 类的是 Double等等。一般来说,将对应的基本类型转化为包装类的过程称为装箱;将包装类转化为基本类型的过程称为拆箱,从JDK1.5之后支持自动装箱和自动拆箱,比如Double d = 1.5; int i = Integer(10); int i1 = Integer("10");
-
Java 匿名对象与内部类 一般在编写代码时可能会遇到这样的场景——在某些时候,我需要定义并某个类,但是只会使用这一次,或者是某个类对象只会使用一次,为它们专门取名可能会显的很麻烦。为了应对这种情况,Java中允许使用匿名对象和匿名内部类的方式来解决这个矛盾匿名对象普通的类对象在使用时会定义一个类类型的变量,用来保存new出来的类所在的地址。而匿名类取消掉了这个变量,这个地址由编译器来处理,并且在new出来之后,它占用的内存会有JVM自动回收掉。后续无法再使用了。例如public class Student{ public void classBegin(){ System.out.println("good morning teacher!"); } } new Student().classBegin();匿名对象最常用的方式是作为函数的参数,比如上述的打印语句 "good morning teacher!" 它就是一个匿名对象,由于字符串是以对象的形式存储的,所以这里实际上就是一个没有使用对象引用的匿名对象。当然也可以将匿名对象作为函数的返回值。内部类内部类的种类:成员内部类、静态内部类、局部内部类、匿名内部类成员内部类java中允许在一个类中定义另一个类。例如public class Car{ public class Engine{ } }上述例子在Car这个类中定义了一个Engine类,那么Car就是外部类,而Engine就是内部类。使用内部类需要注意:外部类是包含内部类的,所以内部类可以看到外部类的所有属性和方法,包括private方法。但是反过来则不行;使用内部类主要有两种方式:在外部类中使用内部类的成员(间接使用)。这种方法一般是在外部类的方法中创建内部类的对象,并调用对象的方法直接使用:根据上面的定义,可以这样使用 `Car.Engine eng = new Car().new Engine()比如下面的例子public class Car{ public class Engine{ public void start(){ System.out.println("引擎启动"); } } //间接调用 public void start(){ System.out.println("打火"); new Engine().start(); } public static void main(String[] args){ new Car().start(); //直接调用 Car.Engine engine = new Car().new Engine(); engine.start(); } }当外部类和内部类的成员发生命名冲突的时候在内部类中可以使用 外部类.this.成员变量 来访问外部类的成员比如说public class Car{ public String type = "奥迪"; public class Engine{ public String type = "奥迪引擎"; public void start(){ System.out.println("引擎启动"); } public void carType(){ System.out.println(Car.this.type); } } //间接调用 public void start(){ System.out.println("打火"); new Engine().start(); } public static void main(String[] args){ Car car = new Car(); //直接调用 Car.Engine engine = new Car().new Engine(); engine.start(); engine.carType(); } }局部内部类内部类不光可以直接定义在外部类中作为成员内部类,也可以定义在方法中,作为局部内部类局部内部类也叫区域内嵌类,局部内部类与成员内部类类似,不过,区域内嵌类是定义在一个方法中的内嵌类主要特定有:局部内部类只能在对应方法中访问,在方法外无效不能使用private,protected,public修饰符。不能包含静态成员局部内部类如果想要访问方法中的局部变量时,局部变量必须是常量。因为局部变量时分配在栈中,而局部内部类是分配在堆中的,有可能出现这样的情况,外部类的方法执行完了,内存被回收了,但是局部内部类可能还在,所以在访问局部变量时,做了一个拷贝将局部变量拷贝到局部内部类所在的堆中。为了保证数据的完整性,所以这里被拷贝的变量不允许再做修改。public class carShow(){ public void showCar(){ final float price = 10000000f; final String type = "奔驰"; class Car(){ public void show(){ System.out.println("这个车是" + type + ",售价:" + price); } } } }静态内部类内部类如果使用static声明,则此内部类就称为静态内部类。它可以通过 外部类 . 内部类 的方式来访问。由于静态内部类是与对象无关的,在使用静态类的成员时是不需要创建对象的。所以如果想要在静态内部类中来访问外部类的成员变量,必须通过外部类的对象实例来访问。public class Company { String companyNam; static String country; static class Clear{ String name; public Clear() { } public Clear(String name) { super(); this.name = name; } public void work(String name){ String na = new Company().companyNam="联想"; country="中国"; System.out.println(name+"为"+na+"打扫卫生,该公司属于"+country); } } }匿名内部类如果一个内部类在整个操作中只使用一次的话,就可以定义为匿名内部类。匿名内部类也就是没有名字的内部类,这是java为了方便我们编写程序而设计的一个机制,因为有时候有的内部类只需要创建一个它的对象就可以了,以后再不会用到这个类,这时候使用匿名内部类就比较合适。匿名内部类,一般都伴随着接口一起使用比如public interface USB{ public abstract void open(); public abstract void close(); } public class Demo{ public static void main(String[] args){ USB usb = new USB(){ public void open(){} public void close(){} } usb.open(); usb.close(); //使用匿名内部类的匿名对象的方式 USB usb = new USB(){ public void open(){} public void close(){} }.open(); } }在Demo这个类的main方法中创建了一个局部的内部类,这个内部类没有名字,也就是创建了一个匿名内部类。