搜索到
349
篇与
的结果
-
 Java 接口与多态 上一篇说了Java面向对象中的继承关系,在继承中说到:调用对象中的成员变量时,根据引用类型来决定调用谁,而调用成员方法时由于多态的存在,具体调用谁的方法需要根据new出来的对象决定,这篇主要描述的是Java中的多态以及利用多态形成的接口多态当时在学习C++时,要使用多态需要定义函数为virtual,也就是虚函数。类中存在虚函数时,对象会有一个虚函数表的头指针,虚函数表会存储虚函数的地址,在使用父类的指针或者引用来调用方法时会根据虚函数表中的函数地址来调用函数,会形成多态。当时学习C++时对多态有一个非常精炼的定义:基类的指针指向不同的派生类,其行为不同。这里行为不同指的是调用同一个虚函数时,会调用不同的派生类函数。这里我们说形成多态的几个基本条件:1)指针或者引用类型是基类;2)需要指向派生类;3)调用的函数必须是基类重写的函数。public class Parent{ public void sayHelllo(){ System.out.println("Hello Parent"); } public void sayHello(String name){ System.out.println("Hello" + name); } } public class Child extends Parent{ public void sayHello(){ System.out.println("Hello Child"); } }根据上述的继承关系,我们来看下面几个实例代码,分析一下哪些是多态Parent obj = new Child(); obj.sayHello();该实例构成了多态,它满足了多态的三个条件:Parent 类型的 obj 引用指向了 new 出来的Child子类、并且调用了二者共有的方法。Parent obj = new Child(); obj.sayHello("Tom");这个例子没有构成多态,虽然它满足基类的引用指向派生类,但是它调用了父类特有的方法。Parent obj = new Parent(); obj.sayHello();这个例子也不满足多态,它使用父类的引用指向了父类,这里就是一个正常的类方法调用,它会调用父类的方法Child obj = new Child(); obj.sayHello();这个例子也不满足多态,它使用子类的引用指向了子类,这里就是一个正常的类方法调用,它会调用子类的方法那么多态有什么好处呢?引入多态实质上也是为了避免重复的代码,而且程序更具有扩展性,我们通过println函数来说明这个问题。public void println(Object x) { String s = String.valueOf(x); synchronized (this) { print(s); newLine(); } } //Class String public static String valueOf(Object obj) { return (obj == null) ? "null" : obj.toString(); }函数println实现了一个传入Object的重载,该函数调用了String类的静态方法 valueOf, 进一步跟到String类中发现,该方法只是调用了类的 toString 方法,传入的obj可以是任意继承Object的类(在Java中只要是对象就一定是继承自Object),只要类重写了 toString 方法就可以直接打印。这样一个函数就实现了重用,相比于需要后来的人额外重载println函数来说,要方便很多。类类型转化上面的println 函数,它需要传入的是Object类的引用,但是在调用该方法时,从来都没有进行过类型转化,都是直接传的,这里是需要进行类型转化的,在由子类转到父类的时候,Java进行了隐式类型转化。大转小一定是安全的(这里的大转小是对象的内存包含关系),子类一定可以包含父类的成员,所以即使转化为父类也不存在问题。而父类引用指向的内存不一定就是包含了子类成员,所以小转大不安全。为什么要进行小转大呢?虽然多态给了我们很大的方便,但是多态最大的问题就是父类引用无法看到子类的成员,也就是无法使用子类中的成员。这个时候如果要使用子类的成员就必须进行小转大的操作。之前说过小转大不安全,由于父类可能有多个实现类,我们无法确定传进来的参数就是我们需要的子类的对象,所以java引入了一个关键字 instanceof 来判断是否可以进行安全的转化,只要传进来的对象引用是目标类的对象或者父类对象它就会返回true,比如下面的例子Object obj = "hello" System.out.println(obj instanceof String); //true System.out.println(obj instanceof Object); //true System.out.println(obj instanceof StringBuffer); //false System.out.println(obj instanceof CharSequence); //true抽象方法和抽象类我们说有了多态可以使代码重用性更高。但是某些时候我们针对几个有共性的类,抽象出了更高层面的基类,但是发现基类虽然有一些共性的内容,但是有些共有的方法不知道如何实现,比如说教科书上经常举例的动物类,由于不知道具体的动物是什么,所以也无法判断该动物是食草还是食肉。所以一般将动物的 eat 定义为抽象方法,拥有抽象方法的类一定必须是抽象基类。抽象方法是不需要写实现的方法,它只需提供一个函数的原型。而抽象类不能创建实例,必须有派生类重写抽象方法。为什么抽象类不能创建对象呢?对象调用方法本质上是根据函数表找到函数对应代码所在的内存地址,而抽象方法是未实现的方法,自然就无法给出方法的地址了,如果创建了对象,而我的对象又想调用这个抽象方法那不就冲突了吗。所以规定无法实例化抽象类。抽象方法的定义使用关键字 abstract,例如public abstract class Life{ public abstract void happy(); } public class Cat{ public void happy(){ System.out.println("猫吃鱼"); } } public class Cat{ public void happy(){ System.out.println("狗吃肉"); } } public class Altman{ public void happy(){ System.out.println("奥特曼打小怪兽"); } }上面定义了一个抽象类Life 代表世间的生物,你要问生物的幸福是什么,可能没有人给你答案,不同的生物有不同的回答,但是具体到同一种生物,可能就有答案了,这里简单的给出了答案:幸福就是猫吃鱼狗吃肉奥特曼爱打小怪兽。使用抽象类需要注意下面几点:不能直接创建抽象类的对象,必须使用实现类来创建对象实现类必须实现抽象类的所有抽象方法,否则该实现类也必须是抽象类抽象类可以有自己的构造方法,该方法仅供子类构造时使用抽象类可以没有抽象方法,但是有抽象方法的一定要是抽象类接口接口就是一套公共的规范标准,只要符合标准就能通用,比如说USB接口,只要一个设备使用了USB接口,那么我的电脑不管你的设备是什么,插上就应该能用。在代码中接口就是多个类的公共规范。Java中接口也是一个引用类型。接口与抽象类非常相似,同样不能创建对象,必须创建实现类的方法。但是接口与抽象类还是有一些不同的。 抽象类也是一个类,它是从底层类中抽象出来的更高层级的类,但是接口一般用来联系多个类,是多个类需要实现的一个共同的标准。是从顶层一层层扩展出来的。接口的一个常见的使用场景就是回调,比如说常见的窗口消息处理函数。这个场景C++中一般使用函数指针,而Java中主要使用接口。接口使用关键字 interface 来定义, 比如public interface USB{ public final String deviceType = "USB"; public abstract void open(); public abstract void close(); }接口中常见的一个成员是抽象方法,抽象方法也是由实现类来实现,注意事项也与之前的抽象类相同。除了有抽象方法,接口中也可以有常量。接口中的抽象方法是没有方法体的,它需要实现类来实现,所以实现类与接口中发生重写现象时会调用实现类,那么常量呢?public class Mouse implements USB{ public final String deviceType = "鼠标"; public void open(){ } public void close(){ } } public class Demo{ public static void main(String[] args){ USB usb = new Mouse(); System.out.println(usb.deviceType); } }常量的调用遵循之前说的重载中的属性成员调用的方式。使用的是什么类型的引用,调用哪个类型中的成员。与抽象类中另一个重要的不同是,接口运行多继承,那么在接口的多继承中是否会出现冲突的问题呢public interface Storage{ public final String deviceType = "存储设备"; public abstract void write(); public abstract void read(); } public class MobileHardDisk implements USB, Storage{ public void open(){ } public void close(){ } public void write(){ } public void read(){ } } public class Demo{ public static void main(String[] args){ MobileHardDisk mhd = new MobileHardDisk(); System.out.println(mhd.deviceType); } }编译上述代码时会发现报错了,提示 USB 中的变量 deviceType 和 Storage 中的变量 deviceType 都匹配 ,也就是说Java中仍然没有完全避免冲突问题。接口中的默认方法有的时候可能会出现这样的情景,当项目完成后,可能客户需求有变,导致接口中可能会添加一个方法,如果使用抽象方法,那么接口所有的实现类都得重复实现某个方法,比如说上述的代码中,USB接口需要添加一个方法通知PC设备我这是什么类型的USB设备,以便操作系统匹配对应的驱动。那么可能USB的实现类都需要添加一个,这样可能会引入大量重复代码,针对这个问题,从Java 8开始引入了默认方法。默认方法为了解决接口升级的问题,接口中新增默认方法时,不用修改之前的实现类。默认方法的使用如下:public interface USB{ public final String deviceType = "USB"; public abstract void open(); public abstract void close(); public default String getType(){ return this.deviceType; } }默认方法同样可以被所有的实现类覆盖重写。接口中的静态方法从Java 8中开始,允许在接口中定义静态方法,静态方法可以使用实现类的对象进行调用,也可以使用接口名直接调用接口中的私有方法从Java 9开始运行在接口中定义私有方法,私有方法可以解决在默认方法中存在大量重复代码的情况。虽然Java为接口中新增了这么多属性和扩展,但是我认为不到万不得已,不要随便乱用这些东西,毕竟接口中应该定义一系列需要实现的标准,而不是自己去实现这些标准。最后总结一下使用接口的一些注意事项:接口没有静态代码块或者构造方法一个类的父类只能是一个,但是类可以实现多个接口如果类实现的多个接口中有重名的默认方法,那么实现类必须重写这个实现方法,不然会出现冲突。如果接口的实现类中没有实现所有的抽象方法,那么这个类必须是抽象类父类与接口中有重名的方法时,优先使用父类的方法,在Java中继承关系优于接口实现关系接口与接口之间是多继承的,如果多个父接口中存在同名的默认方法,子接口中需要重写默认方法,不然会出现冲突final关键字之前提到过final关键字,用来表示常量,也就是无法在程序中改变的量。除了这种用法外,它还有其他的用法修饰类,表示类不能有子类。可以将继承关系理解为改变了这个类,既然final表示常量,不能修改,那么类自然也不能修改修饰方法:被final修饰的方法不能被重写修饰成员变量:表示成员变量是常量,不能被修改修饰局部变量:表示局部变量是常量,在对应作用域内不可被修改
Java 接口与多态 上一篇说了Java面向对象中的继承关系,在继承中说到:调用对象中的成员变量时,根据引用类型来决定调用谁,而调用成员方法时由于多态的存在,具体调用谁的方法需要根据new出来的对象决定,这篇主要描述的是Java中的多态以及利用多态形成的接口多态当时在学习C++时,要使用多态需要定义函数为virtual,也就是虚函数。类中存在虚函数时,对象会有一个虚函数表的头指针,虚函数表会存储虚函数的地址,在使用父类的指针或者引用来调用方法时会根据虚函数表中的函数地址来调用函数,会形成多态。当时学习C++时对多态有一个非常精炼的定义:基类的指针指向不同的派生类,其行为不同。这里行为不同指的是调用同一个虚函数时,会调用不同的派生类函数。这里我们说形成多态的几个基本条件:1)指针或者引用类型是基类;2)需要指向派生类;3)调用的函数必须是基类重写的函数。public class Parent{ public void sayHelllo(){ System.out.println("Hello Parent"); } public void sayHello(String name){ System.out.println("Hello" + name); } } public class Child extends Parent{ public void sayHello(){ System.out.println("Hello Child"); } }根据上述的继承关系,我们来看下面几个实例代码,分析一下哪些是多态Parent obj = new Child(); obj.sayHello();该实例构成了多态,它满足了多态的三个条件:Parent 类型的 obj 引用指向了 new 出来的Child子类、并且调用了二者共有的方法。Parent obj = new Child(); obj.sayHello("Tom");这个例子没有构成多态,虽然它满足基类的引用指向派生类,但是它调用了父类特有的方法。Parent obj = new Parent(); obj.sayHello();这个例子也不满足多态,它使用父类的引用指向了父类,这里就是一个正常的类方法调用,它会调用父类的方法Child obj = new Child(); obj.sayHello();这个例子也不满足多态,它使用子类的引用指向了子类,这里就是一个正常的类方法调用,它会调用子类的方法那么多态有什么好处呢?引入多态实质上也是为了避免重复的代码,而且程序更具有扩展性,我们通过println函数来说明这个问题。public void println(Object x) { String s = String.valueOf(x); synchronized (this) { print(s); newLine(); } } //Class String public static String valueOf(Object obj) { return (obj == null) ? "null" : obj.toString(); }函数println实现了一个传入Object的重载,该函数调用了String类的静态方法 valueOf, 进一步跟到String类中发现,该方法只是调用了类的 toString 方法,传入的obj可以是任意继承Object的类(在Java中只要是对象就一定是继承自Object),只要类重写了 toString 方法就可以直接打印。这样一个函数就实现了重用,相比于需要后来的人额外重载println函数来说,要方便很多。类类型转化上面的println 函数,它需要传入的是Object类的引用,但是在调用该方法时,从来都没有进行过类型转化,都是直接传的,这里是需要进行类型转化的,在由子类转到父类的时候,Java进行了隐式类型转化。大转小一定是安全的(这里的大转小是对象的内存包含关系),子类一定可以包含父类的成员,所以即使转化为父类也不存在问题。而父类引用指向的内存不一定就是包含了子类成员,所以小转大不安全。为什么要进行小转大呢?虽然多态给了我们很大的方便,但是多态最大的问题就是父类引用无法看到子类的成员,也就是无法使用子类中的成员。这个时候如果要使用子类的成员就必须进行小转大的操作。之前说过小转大不安全,由于父类可能有多个实现类,我们无法确定传进来的参数就是我们需要的子类的对象,所以java引入了一个关键字 instanceof 来判断是否可以进行安全的转化,只要传进来的对象引用是目标类的对象或者父类对象它就会返回true,比如下面的例子Object obj = "hello" System.out.println(obj instanceof String); //true System.out.println(obj instanceof Object); //true System.out.println(obj instanceof StringBuffer); //false System.out.println(obj instanceof CharSequence); //true抽象方法和抽象类我们说有了多态可以使代码重用性更高。但是某些时候我们针对几个有共性的类,抽象出了更高层面的基类,但是发现基类虽然有一些共性的内容,但是有些共有的方法不知道如何实现,比如说教科书上经常举例的动物类,由于不知道具体的动物是什么,所以也无法判断该动物是食草还是食肉。所以一般将动物的 eat 定义为抽象方法,拥有抽象方法的类一定必须是抽象基类。抽象方法是不需要写实现的方法,它只需提供一个函数的原型。而抽象类不能创建实例,必须有派生类重写抽象方法。为什么抽象类不能创建对象呢?对象调用方法本质上是根据函数表找到函数对应代码所在的内存地址,而抽象方法是未实现的方法,自然就无法给出方法的地址了,如果创建了对象,而我的对象又想调用这个抽象方法那不就冲突了吗。所以规定无法实例化抽象类。抽象方法的定义使用关键字 abstract,例如public abstract class Life{ public abstract void happy(); } public class Cat{ public void happy(){ System.out.println("猫吃鱼"); } } public class Cat{ public void happy(){ System.out.println("狗吃肉"); } } public class Altman{ public void happy(){ System.out.println("奥特曼打小怪兽"); } }上面定义了一个抽象类Life 代表世间的生物,你要问生物的幸福是什么,可能没有人给你答案,不同的生物有不同的回答,但是具体到同一种生物,可能就有答案了,这里简单的给出了答案:幸福就是猫吃鱼狗吃肉奥特曼爱打小怪兽。使用抽象类需要注意下面几点:不能直接创建抽象类的对象,必须使用实现类来创建对象实现类必须实现抽象类的所有抽象方法,否则该实现类也必须是抽象类抽象类可以有自己的构造方法,该方法仅供子类构造时使用抽象类可以没有抽象方法,但是有抽象方法的一定要是抽象类接口接口就是一套公共的规范标准,只要符合标准就能通用,比如说USB接口,只要一个设备使用了USB接口,那么我的电脑不管你的设备是什么,插上就应该能用。在代码中接口就是多个类的公共规范。Java中接口也是一个引用类型。接口与抽象类非常相似,同样不能创建对象,必须创建实现类的方法。但是接口与抽象类还是有一些不同的。 抽象类也是一个类,它是从底层类中抽象出来的更高层级的类,但是接口一般用来联系多个类,是多个类需要实现的一个共同的标准。是从顶层一层层扩展出来的。接口的一个常见的使用场景就是回调,比如说常见的窗口消息处理函数。这个场景C++中一般使用函数指针,而Java中主要使用接口。接口使用关键字 interface 来定义, 比如public interface USB{ public final String deviceType = "USB"; public abstract void open(); public abstract void close(); }接口中常见的一个成员是抽象方法,抽象方法也是由实现类来实现,注意事项也与之前的抽象类相同。除了有抽象方法,接口中也可以有常量。接口中的抽象方法是没有方法体的,它需要实现类来实现,所以实现类与接口中发生重写现象时会调用实现类,那么常量呢?public class Mouse implements USB{ public final String deviceType = "鼠标"; public void open(){ } public void close(){ } } public class Demo{ public static void main(String[] args){ USB usb = new Mouse(); System.out.println(usb.deviceType); } }常量的调用遵循之前说的重载中的属性成员调用的方式。使用的是什么类型的引用,调用哪个类型中的成员。与抽象类中另一个重要的不同是,接口运行多继承,那么在接口的多继承中是否会出现冲突的问题呢public interface Storage{ public final String deviceType = "存储设备"; public abstract void write(); public abstract void read(); } public class MobileHardDisk implements USB, Storage{ public void open(){ } public void close(){ } public void write(){ } public void read(){ } } public class Demo{ public static void main(String[] args){ MobileHardDisk mhd = new MobileHardDisk(); System.out.println(mhd.deviceType); } }编译上述代码时会发现报错了,提示 USB 中的变量 deviceType 和 Storage 中的变量 deviceType 都匹配 ,也就是说Java中仍然没有完全避免冲突问题。接口中的默认方法有的时候可能会出现这样的情景,当项目完成后,可能客户需求有变,导致接口中可能会添加一个方法,如果使用抽象方法,那么接口所有的实现类都得重复实现某个方法,比如说上述的代码中,USB接口需要添加一个方法通知PC设备我这是什么类型的USB设备,以便操作系统匹配对应的驱动。那么可能USB的实现类都需要添加一个,这样可能会引入大量重复代码,针对这个问题,从Java 8开始引入了默认方法。默认方法为了解决接口升级的问题,接口中新增默认方法时,不用修改之前的实现类。默认方法的使用如下:public interface USB{ public final String deviceType = "USB"; public abstract void open(); public abstract void close(); public default String getType(){ return this.deviceType; } }默认方法同样可以被所有的实现类覆盖重写。接口中的静态方法从Java 8中开始,允许在接口中定义静态方法,静态方法可以使用实现类的对象进行调用,也可以使用接口名直接调用接口中的私有方法从Java 9开始运行在接口中定义私有方法,私有方法可以解决在默认方法中存在大量重复代码的情况。虽然Java为接口中新增了这么多属性和扩展,但是我认为不到万不得已,不要随便乱用这些东西,毕竟接口中应该定义一系列需要实现的标准,而不是自己去实现这些标准。最后总结一下使用接口的一些注意事项:接口没有静态代码块或者构造方法一个类的父类只能是一个,但是类可以实现多个接口如果类实现的多个接口中有重名的默认方法,那么实现类必须重写这个实现方法,不然会出现冲突。如果接口的实现类中没有实现所有的抽象方法,那么这个类必须是抽象类父类与接口中有重名的方法时,优先使用父类的方法,在Java中继承关系优于接口实现关系接口与接口之间是多继承的,如果多个父接口中存在同名的默认方法,子接口中需要重写默认方法,不然会出现冲突final关键字之前提到过final关键字,用来表示常量,也就是无法在程序中改变的量。除了这种用法外,它还有其他的用法修饰类,表示类不能有子类。可以将继承关系理解为改变了这个类,既然final表示常量,不能修改,那么类自然也不能修改修饰方法:被final修饰的方法不能被重写修饰成员变量:表示成员变量是常量,不能被修改修饰局部变量:表示局部变量是常量,在对应作用域内不可被修改 -
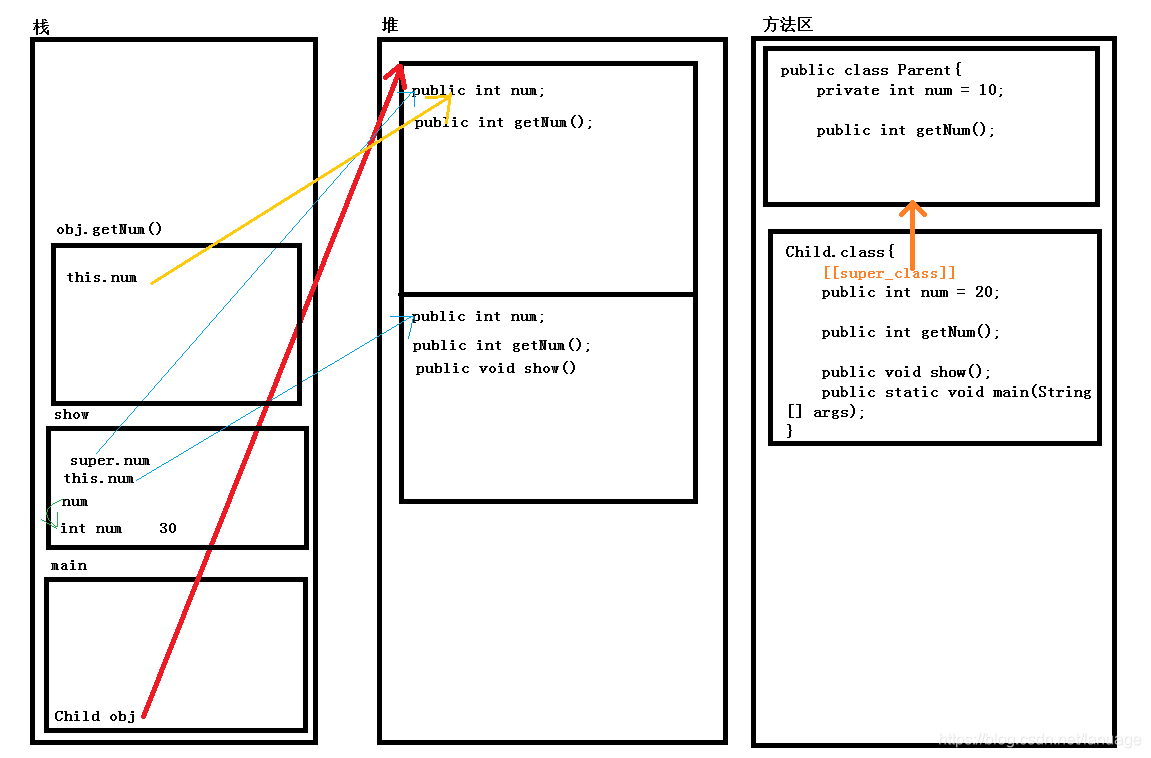
Java 继承 之前说过了Java中面向对象的第一个特征——封装,这篇来讲它的第二个特征——继承。一般在程序设计中,继承是为了减少重复代码。继承的基本介绍public class Child extends Parent{ //TODO } 使用继承后,子类中就包含了父类所有内容的一份拷贝。子类与父类重名成员的访问。重名属性当子类与父类中有重名的数据成员时,如果使用子类对象的引用进行调用,那么优先调用子类的成员,如果子类成员中没有找到那么会向上查找找到父类成员。例如public class Parent{ public int num = 10; } public class Child extends Parent{ public int num = 20; public static void main(String[] args){ Parent obj = new Child(); System.out.println(obj.num); //输出10 Child c = new Child(); System.out.println(c.num); //输出20 } }二者同样是创建的Child对象,那么为何一个是10,而一个是20 呢? 在C/C++中经常提到一个概念就是,指针本身存储的是一个地址值,指针本身是没有任何数据类型的,而指针指向的地址有,我们在程序中定义的指针类型决定了代码在访问指针所指向的内存时是如何翻译这段内存的。Java中虽然说没有开放操作内存的能力,但是引用本身也是一个指针。如果将父类类型的引用来保存子类对象的地址,那么从引用类型来看,它只能看到父类的相关内容,所以这里它将对象所在内存当做父类的类型,所以第一个打印语句访问到的是父类的 num 成员。而第二个它能看到子类的整个内存,所以说它优先使用子类的 num 成员。上面是第一种情况,即在外部直接调用,如果通过方法来访问呢public class Parent{ private int num = 10; public int getNum(){ return this.num; } } public class Child extends Parent{ public int num = 20; public int getNum(){ return this.num; } public static void main(String[] args){ Parent obj = new Child(); System.out.println(obj.getNum()); //输出20 Child c = new Child(); System.out.println(c.getNum()); //输出20 } }第一条输出语句实际上使用了Java中的多态特性,这个时候会调用子类的方法,而第二条直接调用子类方法,而在子类方法中通过this调用自身的 num 成员,所以这里会输出两个20不管哪种情况,在通过对象的引用调用对象成员的时候会根据引用类型来翻译对应的内存,找到需要访问的变量,如果子类中未找到则向上查找父类,如果父类也未找到,则会报错。下面来看看Java中继承的内存图来加深这个的理解public class Parent{ public int num = 10; public int getNum(){ return this.num; } } public class Child extends Parent{ public int num = 20; public int getNum(){ return this.num; } public void show(){ int num = 30; System.out.println(num); //30 System.out.println(this.num); //20 System.out.println(super.num); //10 } public static void main(String[] args){ Child obj = new Child(); obj.Show(); obj.getNum(); //20 } }对象的内存分布大致如下:首先JVM加载程序的时候将类定义放到方法区中,此时方法区中有两个类的定义,其中子类中有一个 [[class_super]] 标志,用于标明它的父类是哪个。然后创建main的栈并执行main函数,在main函数中创建了一个Child的对象,那么JVM会根据方法区中的相关内容在堆中创建子类对象, 子类对象中包含一整份的父类的拷贝。然后调用Show方法,它首先根据方法区中的标识查找,在子类中找到了这个方法创建方法栈并调用。在方法中,定义了一个局部变量 num,当访问 num这个变量时会首先在栈中查找,如果找到则访问,如果没有则在子类中查找,如果子类中也没有,则会访问父类。就这样在栈中找到了num。接着访问 this.num。 这个时候JVM会首先到子类中查找,找不到则会进一步查找父类。发现在子类中找到了。接着访问 super.num,那么JVM会主动去父类中查找。show方法执行完了之后,JVM回收它的堆栈,接着调用getNum() 方法,查找方式与调用show的相同。后面的就不再说了,与之前的类似。重写向上面的例子中这样的。当子类与父类的方法名、参数列表相同时,如果用子类对象进行调用,那么会调用子类方法,这个时候父类的同名方法就被重写了。注意:这里并没有强调返回值也一样,其实这里只需要返回值能正常的发生隐式转换即可。这里也没有规定它的访问权限,这里只要求子类方法的访问权限大于等于父类方法的访问权限,也就是在同一条件下保证二者都能访问。虽然没有这两方面的限制,但是一般情况下父类的方法与子类重写的方法在形式上应该是完全一样的。public class Parent{ public int num = 10; public int getNum(int n){ return this.num; } } public class Child extends Parent{ public int num = 20; public int getNum(float f){ return this.num; } }上面的代码并没有实现重写的功能,但是如果程序员自己理解不到为,认为这是一个重写,并且在代码中按照重写在使用,那么编译虽然不会报错,但是在运行过程中可能会出现问题,这个时候可以使用 @Overwrite 注解,来告诉编译器,这里是一个重写,如果编译器判断这个不是重写,那么编译会报错,这样就将运行时错误提升到了编译时,有注意bug的排除。注解与注释有什么相同与区别呢:我认为二者都是用于对程序做一个说明,但是注释是给人看的,注解是给机器看的。重写与重载有什么区别呢?重写是发生在类的继承关系中的,要求函数名、参数列表相同重载并没有规定使用的场合,要求函数名相同、而参数列表不同既然说到重载,我想起来了java与c++中重载的一个区别void sayHello(long f); void sayHello(int);根据上述函数的定义,java和c++中都形成了一个重载的关系,如果在C中使用代码 sayHello(10) 来调用的时候,因为这里的10既可以理解为long也可以理解为int,所以这里发生了二义性,编译会报错,而java中 10 默认为int,所以这里会调用int参数的函数,而想要调用long型的参数,得写成 sayHello(10L)。这算是二者之间和有趣的一个现象。构造函数与C/C++中的相同,调用构造的时候会优先调用父类构造,像上面的代码中,并没有明显的调用构造,在创建类的时候会隐式的调用构造,并在子类构造中隐式调用父类构造。但是一旦手工定义了构造,那么编译器将不再额外提供构造。public class Parent{ Parent(int n){ System.out.println(n); } } public class Child extends Parent{ Child(){ //这个会编译报错 System.out.println("Child"); } }Child构造函数默认会调用父类的无参构造,但是由于父类提供了构造,此时编译器不再提供默认的无参构造,所以这里找不到父类的无参构造,报错。这个代码可以进行如下的修改public class Child extends Parent{ Child(){ //这个会编译报错 super(19); System.out.println("Child"); } //或者 Child(int n){ //隐式调用super(n) System.out.println("Child"); } }这里使用super关键字显示调用父类的带参构造。或者定义一个带参构造,编译器会默认为你添加上调用父类带参构造的过程。在Java中super关键字的作用主要有以下几点:在子类中访问父类成员在子类中调用父类构造函数,这种用法必须保证super在子类构造中是第一条被执行的语句,而且只能有唯一的一条我们说super代表父类,那么this代表的就是类本身,那么它有什么具体的作用,又有哪些需要注意的点呢?this可以访问本类成员变量在本类的成员方法中访问另一个成员方法在本类构造方法中访问另一个构造注意:第3中用法中,this关键字必须是构造方法执行的第一条语句,而且只能有唯一的一条。这条规则与super关键字的相同,那么在构造中既有this又有super的时候该怎么办呢?答案是无法这么使用,Java中规定this和super关键字在构造函数中只能出现一个。Java中的 继承关系在C++中,最让人头疼的是多继承的菱形继承关系,为了防止二义性,Java禁止多继承,只允许单继承。但是java中运行多继承,并且一个父类运行有多个子类。在Java的多级继承中如果出现同名的情况,访问时该怎么办呢?原则仍然相同,根据new出来的对象和左侧保存对象的引用类型来判断,如果是父类类型,则访问成员变量时只能访问父类,如果是访问方法则需要考虑多态。如果创建的是父类则只能访问父类的成员变量和方法
-
java 常见类 上次提前说了java中的面向对象,主要是为了使用这些常见类做打算,毕竟Java中一切都是对象,要使用一些系统提供的功能必须得通过类对象调用方法。其实Java相比于C来说强大的另一个原因是Java中提供了大量可用的标准库字符串字符串可以说是任何程序都离不开的东西,就连一个简单的hello world程序都用到了字符串,当时C语言中对字符串的支持并不太好,C语言中的字符串实质上是一个字符数组。为了方便不同的C/C++库都有自己的字符串实现。而Java中内置了对字符串的支持,Java中的字符串是一个叫做String的对象。根据jdk文档的描述,我们需要注意一下几点:Java程序中的所有字符串文字(例如"abc" )都被实现为此类的实例String对象是可以共享的String对象是不可变的字符串的内存分布一般把类似于 "abc" 这样直接通过字面值表示的字符串作为字面常量,这种在Java中也是一个字符串,只是它与普通的new出来的字符串在内存的存储上有点不一样,下面请看下面的代码class StringDemo{ public static void main(String[] args){ String a = "abc"; String b = "abc"; String c = new String("abc"); System.out.println(a == b); System.out.println(a == c); System.out.println(b == c); } }针对字符串来说 == 比较的是它们的地址是否相同,这个程序分别输出的是 true、false、false,也就是说a b 是指向的同一个地址空间,而c则不是。它们的内存分布如下:一般程序在加载到内存地址空间后,会被划分为4个部分,全局数据段、代码段、堆、栈。而全局代码段是用来存放全局变量的。在C中如果我们写下这样的代码:char* psz1 = "abc"; char* psz2 = "abc";那么在程序加载到内存中时,在全局数据段中会存在一个连续的内存空间保存的是 'a','b','c','\0' 这4个值,一旦有char型指针指向"abc" 这样的字符串,那么系统会自动将这段内存的地址给赋值到对应的指针变量中,而且这个内存是只读内存,如果尝试往里面写入数据,则会造成程序崩溃。Java中也是类似的,当出现 "abc" 的时候,其实系统早就为它在堆中创建了一个String对象,如果去阅读String的源码就会发现String中负责保存字符串的是一个 byte型的数组,所以在初始化的时候会再创建一个byte型数组,然后由字符串中成员变量保存它的地址,所以在内存图中看到有String也有byte[]。而且这个字符串是保存在堆中的常量字符串池中的,它的生命周期与程序相同(或者说与主线程相同)。每当直接使用 "abc" 这样的字面常量的时候会自动将常量字符串池中相关的字符串对象的指针赋值给对应的对象。这样造成了上述程序中 a == b 为true的情况。而c是通过new关键字在程序运行期间动态创建的。所以JVM会在程序执行到这步的时候额外创建一个对象,并将 "abc" 这个字符串对应的byte[] 中的值拷贝到新的内存中。这样就很容易理解上面的前两条了,至于字符串不可变,可以参考我之前写的关于类型中的说明(字符串的值发生改变时,在内存中其实是开辟了一块新的内存用于保存新的字符串内容,而丢弃了从前的字符串)常见字符串方法这里再简单的列举一下字符串中常见的方法,这些方法都可以在JDK文档都可以查到。String(); //初始化新创建的 String对象,使其表示空字符序列 String(byte[] bytes); //通过使用平台的默认字符集解码指定的字节数组来构造新的 String String(byte[] bytes, int offset, int length); //从bytes[] 数组中的第offset 位置开始,截取length个成员来初始化一个String char charAt(int index); //返回指定位置处的索引 int compareTo(String anotherString); // 按字典顺序比较两个字符串的大小,为0表示两个字符串相同 int compareToIgnoreCase(String str); //比较两个字符串的大小,忽略大小写 String concat(String str) ; //字符串拼接 byte[] getBytes(Charset charset); //将字符串转化为byte型数组,并返回新的byte数组 int indexOf(String str); //返回字串第一次出现的位置 int length() ; //返回字符串的长度 String[] split(String regex); //按正则表达式进行分割,并返回对应的字符串数组注意一下,这里返回数组或者新字符串的,都是在函数内部新建的,与原来的无关。所以这里是没办法拿到字符串底层的数组对象再来修改内存值的。数组java中数组的定义如下:int[] Array1 = new int[10]; //定义了一个拥有10个整型数据的数组 int[] Array2 = new int[]{1, 2, 3, 4, 5, 6, 7,8, 9, 0}; //创建数组并初始化 int[] Array3 = {1,2 ,3,4,5,6,7,8,9,0}; 相比于C中数组的定义来说,Java中的定义更容易让人理解,对应数据类型后面加一对 [] 就是对应的数组类型了。而C中,中括号是写在变量后面的,相比于Java中的定义来说就显的有点怪异了。或者说C中从根本上来说数组并不算是一种特别的数据类型,仅仅只是开辟相同数据类型的一块连续的内存而已。至于[] 在C中应该只是表示寻址而已,毕竟汇编中我们经常看到类似于 esp:[eax] 这样的东西。Java中的数组是一种单独的数据类型,它是一种引用类型,也就是说它的变量名中保存的是它的地址。它的使用十分的简单,与C/C++中数组的使用基本相同,注意事项也是基本相同。但是有一点很重要的不同,Java中的数组允许动态指定长度,也就是通过变量来指定长度,而C中必须静态的指定长度,也就是在程序运行之前就需要知道它的长度。这是因为Java中数组是引用类型,是new在堆上的,而C中数组是分配在全局变量区或者栈上的,在程序运行之初就需要为数组分配内存。//这样的代码是可以编译通过的 int length = 10; int array[] = new int[length];数组作为函数参数import java.util.Arrays; class Demo{ public static void main(String[] args){ int length = 10; int array[] = new int[length]; System.out.println(Arrays.toString(array)); test(array); System.out.println(Arrays.toString(array)); } public static void test(int[] array){ for(int i = 0; i < array.length; i++) { array[i] = i; } } }运行上述的代码,发现函数中修改array的值在函数结束后也可以生效,这是因为数组是一个引用类型,在C中我们说要想改变实参的值,需要传入对应的引用或者指针。在函数中通过引用访问,实际上在访问对应的内存,所以这里其实是在修改对应内存的值。当然可以修改实参的值了。ArrayList类之前在数组中,我们说数组一旦定义,是不能改变大小的,那么如果我后续需要使用可变大小的数组呢?Java中提供了ArrayList这样的容器。由于它是一个通用的容器,而java又是一个强类型的语言,所以在定义的时候需要事先指定我们需要使用容器存储何种类型的数据。一般ArrayList的定义如下:ArrayList<String> array = new ArrayList(); 表示容器内部存储的是字符串。需要注意的是容器中只能存储引用类型,不能存储像int、double、char这样的基本类型,如果要存储这样的数据,需要存储它们对应的封装类。比如int 类型对应的封装类为 Integer。它的常用方法如下:ArrayList(); //构造方法 boolean add(E e);//添加元素 void clear(); //清空 E get(int index); //获取指定位置的元素 int indexOf(Object o); //查询元素第一次出现的位置 E remove(int index); //删除指定位置的元素 E remove(Object o); //从列表中删除指定元素的第一个出现(如果存在) int size(); //获取容器中元素个数 void sort(Comparator<? super E> c); //使用提供的 Comparator对此列表进行排序键盘输入Java中的键盘输入主要通过Scanner类来实现,Scanner需要提供一个输入流,从输入流中获取输入。一般常用的输入流是 System.in 表示从键盘输入,例如:Scanner sc = new Scanner(System.in);Scanner类中常用方法是一系列的next方法,next方法主要功能是根据指定 的分割符,从输入流中取出下一个输入并做相应的转化,比如nextInt()会转化为int,nextBoolean() 会转化为boolean类型等等,next()方法会直接转化为字符串。默认情况下next函数会通过空格进行转化。import java.util.Scanner; import java.util.ArrayList; class Demo{ public static void main(String[] args){ ArrayList<String> array = new ArrayList<String>(); Scanner sc = new Scanner(System.in); String str = sc.next(); array.add(str); while(sc.hasNext()){ array.add(sc.next()); } for(int i = 0; i < array.size(); i++) { System.out.println(array.get(i)); } } }这段代码,会将输入的数据依次存储到ArrayList容器中。因为程序事先不知道用户会输入多少数据,所以这里采用可以可变长度的容器来存储//输入(> 表示cmd的提示符) >hello world python java c++ c lisp // 输入ctrl + c来退出sc.next的输入 > ctrl+c //输出 >hello world python java c++ c lisp上述代码首先执行到sc.next位置,并且中断下来,我们输入上述的一些字符串,然后回车,然后程序继续执行,在循环中根据空格,依次从里面取出每一个值,并放到容器中。当没有值时,程序会再次中断在sc.next()的位置,这个时候输入 ctrl + c ,此时程序再次执行到 sc.hasNext() 这个地方会返回false,这个时候循环退出,并依次打印这些内容。这个程序证明了上面说的,next方法会根据指定的分割符,依次从输入流中取出下一个输入。当然如果想要一次读取一行,可以使用 nextLine方法。更多内容请查阅JDK文档。
-
Java 面向对象 现在一般的语言都支持面向对象,而java更是将其做到很过分的地步,java是强制使用面向对象的写法,简单的写一个Hello Word都必须使用面向对象,这也是当初我很反感它的一点,当然现在也是很不喜欢它这一点。但是不得不说它设计的很优秀也很流行。面向对象面向对象一般是将一些独立有相似功能的模块封装起来组成一个类,然后调用者不必关注实现细节而只需要关注调用某个类方法即可。面向对象简化了程序设计。与之相对应的是面向过程,而C就是典型的面向过程的程序设计语言。面向对象一般有3种特性:封装、继承、多态。这次主要讲述的是java中的封装型。在java中类的定义与C++中类的定义类似,只是在java中每定义一个方法或者成员变量都需要在前面添加一个访问的权限修饰符,比如下面的定义class Student { private String name; private int age; public Student(){ } public Student(String name, int age){ this.name = name; this.age = age; } public int getAge(){ return this.age; } public String getName(){ return this.name; } public void setAge(int age){ this.age = age; } public void setName(String name){ this.name = name; } }而C++中只需要将具有相同访问属性的放到一块,用一次修饰符即可。比如上面java代码对应的C++代码如下:class Student { private: string name; int age; public: Student(){ } Student(string name, int age){ this->name = name; this->age = age; } int getAge(){ return this->age; } String getName(){ return this->name; } void setAge(int age){ this->age = age; } void setName(String name){ this->name = name; } }访问权限在C++中类中的成员如果不给访问权限,默认是private, 而java中默认的访问权限是friendly,但是这个friendly在java中并不是关键字,而且java中的public、private、protected 都必须明确指定,在java中这些关键字对应的访问权限如下:访问权限当前类同一个package子孙类其他packagepublicyesyesyesyesprotectedyesyesyesnofirendlyyesyesnonoprivateyesnonono从上一个表中可以看到public 对于类成员的访问完全没有限制、而protected仅仅保护类成员不被其他包访问,默认的friendly只允许同一个包或者同一个类的成员访问,最后的private仅允许同一个类的成员访问,它们的访问权限是递增的,也就是public > protected > friendly > private封装性面向对象的封装性就体现在仅仅允许通过类方法访问类成员。这有助于保护类成员不被其他代码随意的篡改,而且如果类成员在进行修改时如果会涉及到其他变化,我们只需要在get/set方法中控制即可,不需要外部使用人员了解这个细节。假设现在有一个教务系统,里面需要存储学生的信息,那么如果不采用封装的方式而直接在类代码外进行访问的话,而且成员被访问的位置较多,一旦发现数据库中存储的数据发生错误,那么将无法确定是在哪给定了错误的值,而且要对输入值进行判断的时候,每个被访问的位置都要添加这些判断的代码,修改量较大,而且无法保证每个位置都正常修改了。如果后续业务逻辑修改,那么这些工作又得重新做一遍。如果我们将成员变量使用set和get方法进行封装,查看数据错误的问题只需要关注get/set方法,而且业务逻辑变更时只需要修改get/set方法。这点体现了封装性对数据的保护作用。在假设这里我们采用多线程的方式来访问数据,那么为了保护数据,就需要添加相应的同步代码,如果直接访问,那么每当访问一次数据,就需要添加保护代码。这样就为使用人员添加了不必要的麻烦,如果我们将这些进行封装,然后告诉使用人员,这个类是线程安全的,那么使用人员直接调用而不用管其中的细节,后续如果我们换一种同步的方式,也不影响其他人的使用。this关键字C++中this关键字就是一个指针,通过eax寄存器传入到类的成员函数中,在成员函数中,通过this + 偏移地址来定位类中所有成员。而java中this除了能像c++中那样用于表示访问类成员外,还有另外两个作用使用this表示调用类其他的构造函数,比如下面的代码:class Student { private String name; private int age; public Student(){ } public Student(String name){ this(); //调用无参构造 this.name = name; } public Student(String name, int age){ this(name); // 调用有一个参数的构造方法 this.age = age; } public int getAge(){ return this.age; } public String getName(){ return this.name; } public void setAge(int age){ this.age = age; } public void setName(String name){ this.name = name; } }用来表示类的对象,其实这个作用与C++中this指针的作用相同,而且二者本质也一样,只是Java中不能直接访问内存地址,所以这里与C++有些许不同。class Student { private String name; private int age; public Student(){ } public Student(String name){ this(); //调用无参构造 this.name = name; } public Student(String name, int age){ this(name); // 调用有一个参数的构造方法 this.age = age; } public int getAge(){ return this.age; } public String getName(){ return this.name; } public void setAge(int age){ this.age = age; } public void setName(String name){ this.name = name; } public boolean compare(Student stu){ return this == stu; //这里简单实用二者的地址进行比较 } }构造函数与析构函数java中的构造函数与C++中的相同。是在new对象的时候调用的函数。注意这里只是说它在new的时候调用的函数,并不是在使用类的时候第一次调用的函数。Java 中的构造方法必须与该类具有相同的名字,并且没有方法的返回类型。每个类至少有一个构造方法。如果不写一个构造方法,Java 编程语言将提供一个默认的,该构造方法没有参数,而且方法体为空。如果一个类中已经定义了构造方法则系统不再提供默认的构造方法。java中不能直接访问内存,虽然它的类都是new出来的,但是资源的回收由垃圾回收机制来完成,那么它有析构函数吗?答案是肯定的,java中也是有析构函数的。在C++中进行栈资源回收或者手工调用delete的时候才会进行析构函数的调用。而在java中,当垃圾回收器将要释放无用对象的内存时,先调用该对象的finalize()方法。这个finalize方法就是类的析构函数,这个方法是由Object这个基类提供的一个方法,Object子类可以选择重写它或者就用默认的。这个方法严格上应该是一个接口函数,与C++的析构并不相同。Java 虚拟机的垃圾回收操作对程序完全是透明的,因此程序无法预料某个无用对象的finalize()方法何时被调用。类的静态代码块上面说构造函数并不是使用类时第一个调用的函数,第一个调用的函数应该是静态代码块(这个代码块应该不能被称之为函数)。静态代码块是第一次使用类的时候被调用,而且仅仅只调用这一次。它的定义如下:class Student{ staic { System.out.println("调用静态代码块"); } }
-
Java 函数 之前的几篇文章中,总结了java中的基本语句和基本数据类型等等一系列的最基本的东西,下面就来说说java中的函数部分函数基础在C/C++中有普通的全局函数、类成员函数和类的静态函数,而java中所有内容都必须定义在类中。所以Java中是没有全局函数的,Java里面只有普通的类成员函数(也叫做成员方法)和静态函数(也叫做静态方法)。这两种东西在理解上与C/C++基本一样,定义的格式分别为:public static void test(arglist){ } public void test(arglist){ }基本格式为:修饰符 [static] 返回值 函数名称 形参列表修饰符主要是用来修饰方法的访问限制,比如public 、private等等;如果是静态方法需要加上static 如果是成员方法则不需要;后面是返回值,Java函数可以返回任意类型的值;函数名用来确定一个函数,最后形参列表是传递给函数的参数列表。函数中的内存分布Java中函数的使用方式与C/C++中基本相同,这里就不再额外花费篇幅说明它的使用,我想将重点放在函数调用时内存的分配和使用上,更深一层了解java中函数的运行机制。我们说在X86架构的机器上,每个进程拥有4GB的虚拟地址空间。Java程序也是一个进程,所以它也拥有4GB的虚拟地址空间。每当启动一个Java程序的时候,由Java虚拟机读取.class 文件,然后解释执行其中的二进制字节码。启动java程序时,在进程列表中看到的是一个个的Java虚拟机程序。java虚拟机在加载.class 文件时将它的4GB的虚拟地址空间划分为5个部分,分别是栈、堆、方法区、本地方法栈、寄存器区。其中重点需要关注前3个部分。栈:与C/C++中栈的作用相同,就是用来保存函数中的局部变量和实参值的。堆:与C/C++中堆的作用相同,用来存储Java中new出来的对象方法区:用来保存方法代码和方法名与地址的这么一张表,类似于C/C++中的函数表基本数据类型作为函数的参数class Demo{ public static void main(String[] args){ int n = 10; test(10); System.out.println(n); } public static void test(int i){ System.out.println(i); i++; } }上述代码在函数中改变了形参值,那么在调用之后n的值会不会发生变化呢?答案是:不会变化,在C/C++中很好理解,形参i只是实参n的一个拷贝,i改变不会改变原来的n。这里我们从内存的角度来回答这个问题如上图所示,方法区中存储了两个方法的相关信息,main和test,在调用main的时候,首先从方法区中查找main函数的相关信息,然后在栈中进行参数入栈等操作。然后初始化一个局部变量n,接着调用test函数,调用test函数时首先根据方法区中的函数表找到方法对应的代码位置,然后进行栈寄存器的偏移为函数test分配一个栈空间,接着进行参数入栈,这个时候会将n的值——10拷贝到i所在内存中。这个时候在test中修改了i的值,改变的是形参中拷贝的值,与n无关。所以这里n的值不变引用类型作为函数参数class Demo{ public static void main(String[] args){ String s = "Hello"; test(s); System.out.println(s); //"Hello" } public static void test(String s){ System.out.println(s); //"Hello" s = "World"; } }在C/C++中,经常有这么一句话:“按值传递不能改变实参的值,按引用传递可以改变实参的值”,我们知道String 是一个引用,那么这里传递的是String的引用,我们在函数内部改变了s的值,在外部s的值是不是也改变了呢?我们首先估计会打印一个 "Hello"、一个"World"; 实际运行结果却是打印了两个 "Hello",那么是不是有问题呢?Java中到底存不存在按引用传递呢?为了回答这个问题,我们还是来一张内存图:从上面的内存图来看,在函数中修改的仍然是形参的值,而对实参的值完全没有影响。如果想做到在函数中修改实参的值,请记住一点:拿到实参的地址,通过地址直接修改内存。下面再来看一个例子:class Demo{ public static void main(String[] args){ int[] array = new int[]{1, 2, 3, 4, 5}; test(array); for(int i = 0; i < array.length; i++){ System.out.print(array[i]); } System.out.println(); //98345 } public static void test(int[] array){ for(int i = 0; i < array.length; i++){ System.out.print(array[i]); } System.out.println(); //12345 array[0] = 9; array[1] = 8; } }运行这个实例,可以看到这里它确实改变了,那么这里它发生了什么?跟上面一个字符串的例子相比有什么不同呢?还是来看看内存图这段代码执行的过程中经历了3个主要步骤:new一个数组对象,并且将数组对象的地址赋值给array 实参调用test函数时将array实参中保存的地址复制一份压入函数的参数列表中在test函数中,通过这个地址值来修改对应内存中的内容这段代码与上面两段本质上的区别在于,这段代码通过引用类型中保存的地址值找到并修改了对应内存中内容,而上面的两段代码仅仅是在修改引用类型这个变量本身的值。说到传递引用类型,那么我就想到在C/C++中一个经典的漏洞——缓冲区溢出漏洞,那么java程序中是否也存在这个问题呢?这里我准备了这样一段代码:class Demo{ public static void main(String[] args){ byte[] buf = new byte[7]; test(buf); } public static void test(byte[] buf){ for(int i = 0; i < 10; i++){ buf[i] = (byte)i; } } }如果是在C/C++中,这段代码可以正常执行只是最后可能会报错或者崩溃,但是赋值是成功的,这也就留给了黑客可利用的空间。在Java中执行它会发现,它会报一个越界访问的异常,也就说这里赋值是失败的,不能直接往内存里面写,也就不存在这个漏洞了。返回引用类型Java方法返回基本类型的情况很简单,也就是将函数返回值放到某块内存中,然后进行一个复制操作。这里重点了解一下它在返回引用类型时与C/C++不同的点在C/C++中返回一个类对象的时候,会调用拷贝构造将需要返回的类对象拷贝到对应保存类对象的位置,然后针对函数中的类对象调用它的析构函数进行资源回收,那么Java中返回类对象会进行哪些操作?C/C++中返回一个类对象的指针时,外部需要自己调用delete或者其他操作进行析构。java中的类对象都是引用类型,在函数外部为何不需要额外调用析构呢?带着这些问题,来看下面这段代码:class Demo{ public static void main(String[] args){ String s = test(); System.out.println(s); } public static String test(){ // return new String("hello world"); return "Hello World"; } }这段代码 不管是用new也好还是直接返回也好,效果其实是一样的,下面是对应的内存分布图这段代码首先在函数test中new一个对象,此时对应在堆内存中开辟一块空间来保存"hello world" 值,然后保存内存地址在寄存器或者其他某个位置,接着将这个地址值拷贝到main函数中的s中,最后回收test函数的栈空间。这里实质上是返回了一个堆中的地址值,这里就回答了第一个问题:在返回类对象的时候其实返回的值对象所在的堆内存的地址。接着来回答第二个问题:java中资源回收依赖与一个引用计数。每当对地址值进行一次拷贝时计数器加一,当回收拷贝值所在内存时计数器减一。这里在返回时,先将地址值保存到某个位置(比如C/C++中是将返回值保存在eax寄存器中)。此时计数器 + 1;然后将这个值拷贝到 main 函数的s变量中,此时计数器的值再 + 1,变为2,接着回收test函数栈空间,计数器 - 1,变为1,在main函数指向完成之后,main的栈空间也被回收,此时计数器 - 1,变为0,此时new出来的对象由Java的垃圾回收器进行回收。
-
Java 基本语句、控制结构 上一篇中简单谈了一下自己对Java的一些看法并起了一个头,现在继续总结java的相关语法。java语法总体上与C/C++一样,所以对于一个C/C++程序员来说,天生就能看懂Java代码。在学习java的时候,上手非常快。我感觉自己就是这样,看代码,了解其中一些重点或者易错点的时候发现,与C/C++里面基本类似,甚至很多东西不用刻意去记,好像自己本身就知道坑在哪。所以这里我想简单列举一下语法点,然后尝试用C/C++的视角来解读这些特性。引用类型引用中的指针与内存上一次,我总结一下java中的数据类型,在里面提到,Java中有两大数据类型,分为基本数据类型和引用数据类型。并且说明了简单数据类型,这次就从引用数据类型说起;引用数据类型一般有:数组、字符串、类对象、接口、lambda表达式;这次主要通过数组和字符串来说明它引用数据类型在C/C++中对应指针或者引用。其实关注过我之前C/C++反汇编系列文章的朋友知道,在C/C++中引用实质上就是一个指针。所以这里我也将java中引用类型理解为指针。所以从本质上讲,引用类型都是分配在堆上的动态内存。然后使用一个指针指向这块内存。这是理解引用类型很重要的一点。数组的定义如下char[] a = new char[10]; char[] b = new char[] {'a', 'b', 'c'}; char[] c = {'a', 'b', 'c'};其实这种形式更符合 变量类型 变量名 = 变量值 这种语法结构, char[] 就像是一种数据类型一样,char表示数组中元素类型, []表示这是一个数组类型字符串的简单定义如下:String s = "Hello world";上面说到引用类型都是分配在堆上的。所以字符串和数组实质上都是new 出来的。即使有的写法上并没有new 这个关键字,但是虚拟机还是帮助我们进行了new 操作。有new就一定有delete了。那么哪里会delete呢?这些操作一般都由java的垃圾回收器来处理。我们只管分配。这就帮助程序员从资源回收的工作中解放出来了。这也是java相比于C/C++来说比较优秀的地方。有人可能会说C++中有智能指针,也有垃圾回收机制。确实是这样。但是我觉得还是有点不一样。java是天生就支持垃圾回收,就好像从娘胎生出来就有这个本能,而C/C++是由后天学会的,或者说要刻意的去进行操作。二者还是不一样的。下面有这样一段代码:char[] a = new char[10]; System.out.println(a);我们打印这个a变量,发现它出现的是一个类似16进制数的一个东西。这个东西其实是一个地址的hash值,为什么不用原始值呢?我估计是因为有大神能够根据变量的内存地址进行逆向破解,所以这里为了安全对地址值进行了一个加密。或者为了彻底贯彻Java不操作内存的信念。(我这个推断不知道是不是真的,如果有误,请评论区大牛指正。)这也就证明了我之前说的,引用类型本质上是一个指针。char[] a = new char[]{'a', 'b', 'c'}; char[] b = new char[]{'a', 'b', 'c'}; System.out.println(a); System.out.println(b);上面这段代码,我想学过C/C++的人应该一眼就能看出,这里打印出来的a和b应该是不同的值,这里创建了两块内存。只是内存中放的东西是一样的。char[] a = new char[]{'a', 'b', 'c'}; char[] b = a; b[0] = '0'; b[1] = '1'; b[2] = '2'; System.out.println(a); System.out.println(b);这里从C/C++的角度来看,也很容易理解:定义了两个引用类型的变量,a、b都指向同一块内存,不管通过a还是b来寻址并写内存,下次通过a、b访问对应内存的时候肯定会发现值与最先定义的不同。String s = "hello"; System.out.println(s.hashCode()); s += "world"; System.out.println(s.hashCode());由于Java不具备直接访问内存的能力,不能直接打印出它的内存地址,所以这里用hashCode 得到地址的hash值。通过打印结果说明这个时候s指向的地址已经变了。也就是说虽然可以实现字符串的拼接,但是虚拟机在计算得出拼接的结果后又分配了一块内存用来保存新的值。但是任然用s这个变量来存储地址值,用赵本山的话来说就是“大爷还是那个大爷,大妈已经不是原来的那个大妈了”。也就是说Java分配内存的时候应该是按需分配,需要多少分配多少。不够就回收之前的,再重新按需分配。这就导致了java中字符串和数组的长度是不能改变的。String s = "hello"; System.out.println(s.hashCode()); (s.toCharArray())[0] = 'H'; System.out.println(s.hashCode()); System.out.println(s); // 这里字符串的值不变上述这段代码,通过toCharArray将字符串转化为char类型的数组,然后修改数组中的某一个元素的值,我原来以为这样做相当于在String所在内存中修改,最终打印s时会出现 "Hello" ,但是从结果上来看并没有出现这样的情况,s指向的地址确实没变,但是s也是没变的,那只能解释为toCharArray 又开辟了一块内存,将String中的值一一复制到数组中。在学习中我尝试过各种数据类型强转String s = "Hello World"; char[] a = (char[]) s; int p = (int)s;像这样的代码我发现并不能通过编译。在C/C++中,可以进行任意类型到整型或者指针类型的转化,常见的转化方式就是将变量所在地址进行赋值或者将变量对应的前四个字节进行转化作为int或者指针类型。但是在java中这点好像行不通。Java中强转好像只能在基本数据类型中实现,而在引用类型中通常由函数完成,并且完成时并不是简单的赋值,还涉及到新内存空间的分配问题。越界访问由于C/C++中提供了访问内存的能力,而且由于现代计算机的结构问题,C/C++中存在越界访问的问题,越界访问可以带来程序编写的灵活性,但是也带来的一些安全隐患。对于灵活性,相信学习过Windows或者Linux编程的朋友应该深有体会,系统许多数据结构的定义经常有这类:struct s { char c; } s *p = (s*)new char[100]; 这样就简单的创建了一个字符串的结构。这里C变量只是提供了一个地址值,后续可以根据c的地址来访问它后续的内存。安全问题就是大名鼎鼎的缓冲区溢出漏洞,我在相关博客中也详细谈到了缓冲区溢出漏洞的危害以及基本的利用方式。这里就不在赘述。那么Java中针对这种问题是如何处理的呢? Java中由于不具有内存访问的能力,所以这里它简单记录当前对象的长度,只要访问超过这个长度,立马就会报异常,报一个越界访问的异常。(这里我暂时没有想到对应的java演示代码,所以简单说一下吧)空指针访问还记得C/C++指针中常见的一个NULL吧,既然Java中引用类型相当于一个指针,那么它肯定也存在空指针问题。在Java中空指针定义为null。如果直接访问null引用,一般会报空指针访问异常。char[] c = null; c[0] = 'A'; //异常语句关于引用类型我暂时了解了这么多东西。下面简单列举一下java中的运算符和相关语句结构运算符java中的运算符主要有下列几个:算数运算符: + 、-、 *、 /、 %、 ++、 --、赋值运算符: = 、+=、 -=、%=、/=、*=比较运算符: ==、 >、 <、 >=、 <=、 !=逻辑运算符: &&、 ||、 !、三目运算符位运算符: >>、 <<、 >>>(无符号右移)、 <<<、&、|、~这些运算符用法、要点、执行顺序与C/C++中完全相同。所以这里简单列举。不做任何说明语句结构java中的顺序结构与其他语言中一样,主要有3种顺序结构判断结构: if、if...else、 if...else if...else if...else循环结构:while、for、do while用于与其他语言一样,这里需要注意的是,Java中需要判断的地方只能使用bool值作为判断条件,比如 5 == 3 、 a == 5这样的。在C/C++中有一条编程规范,像判断语句中将常量写在前面就像这样if(5 == a){ //.... }这样主要是为了防止将 == 误写成 = ,因为在C/C++中 只要表达式的值不为0 就是真,像 if(a = 5) 这样的条件是恒成立的。而Java中规定判断条件必须是真或者假,并且规定boolean类型不能转化为其他类型,其他类型也不能转化为boolean,所以 if(a = 5) 这样的语句在Java中编译是不会通过的。
-
java基础语法 最近抽时间在学习Java,目前有了一点心得,在此记录下来。由于我自己之前学过C/C++,而Java的语法与C/C++基本类似,所以这一系列文章我并不想从基础一点点的写,我想根据我已有的C/C++经验,补充一些需要注意的点,或者java中独特的内容,或者将C/C++进行对比来总结一下学习的内容。为什么要学习java最开始接触到Java还是在学校中开设的一门java编程语言的课,那个时候感觉java很麻烦,写个helloworld要那么多代码。后来学到web编程,我自己搭建的环境总是报错,而且还是jar包的错误。从这个时候起,我对java就没什么好感。后来很多培训机构来学校招生,做讲演,难道大学学了4年,最后还是去了培训机构,而那些培训机构号称4个月完全掌握java,这时我感觉如果我去学了java,那么大学4年出来跟培训班4个月出来有什么差别,既然上了大学,学了计算机,要跟培训机构出来的人不一样,既然是学计算机的,当然得学计算机里面最难的语言,所以我大学从3年级开始学了大半年汇编,又从汇编转到C和C++。但是万事逃不过真香定律,在工作之后,慢慢接触了Java,也了解了java,其实Java并不像我想想的那么简单。但是我心里一直抗拒学它。但是最近工作中确实要用到它,之前在一些博文中提到过,现在我开始带领几个人的小队,里面有java的,有做C的,有Python的,我想作为一个leader,虽然不用干他们的活,但是至少得懂。最主要的还是Java那边提个需求实在太难,java程序员总会跟我说很难,要改代码,动不动就说这个需求得改架构。最后做出来的跟我预计的差别太大。为了有理有据的回怼,也为了更好的带队,我想Java还是得会。说到这里我有感而发:领导给你活,并不是要听你抱怨有多难,要很多东西。既然能告诉你要做这个,那么可行性方面肯定提前做过研究,不要说什么很难,做不了。既然给你了,领导要的是你提出一个解决方案,然后告诉我要多长时间。中间出了问题及时反馈就OK。一直抱怨难,动不动就改架构什么的,只会让领导对你的个人能力产生怀疑,甚至会萌发出换人的想法。所以领导拍下来的活,干就对了。上述是一个原因,还有一个原因;我在关注安全漏洞的时候经常会报出来什么Struts2 漏洞、WebLogic 漏洞,这些都是java的开发框架,很多时候大牛们的博客或者公众号上已经写了漏洞原理,甚至有的还有它验证以及构造POC的思路,但是我就是看不懂,不出POC,我完全不知道如何去检测。为了以后能更好的理解这些java漏洞,我想还是需要好好学一下Java从hello world 开始任何语言都是从hello world开始的,java也不例外,这里我给出hello world的代码public class HelloWorld{ public static void main(String[] args){ System.out.println("hello world"); } }将这段代码保存到HelloWord.java文件中,这里文件的名称必须是HelloWorld.java,文件名与主类的名称相同。然后调用javac进行编译javac HelloWorld.java这个时候会生成.class 文件,这里使用java执行代码java HelloWorld注意执行的时候java指令后面跟的是类名而不是具体的.class文件名。这里我想应该是在执行的时候,java命令根据类名去找对应的.class 文件,将文件中的二进制字节码放到虚拟机中执行。然后由虚拟机去类中查找main函数,从main函数中执行。因此这里文件名必须与类名相同,而且必须要有main函数。再来说说这个main函数前面的修饰词,public 应该表示这个是一个公共方法,也就是外部可以访问,static 表示这个方法是一个静态方法,独立与类存在的。这两个修饰符是必须的要的。java强制使用面向对应,一切都定义在类中,但是程序必须要一个入口函数。根据java的逻辑,这个main函数也得定义到类中。但是如果定义成普通函数的话行不行呢。答案是不行的,由于main函数是一个入口函数,一切都从它开始,如果它是一个类函数,那么势必要定义一个类的对象然后再调用对象的main方法,可是既然main是程序的开始,请问如何在调用main之前定义对象呢,因此这里必须得定义成静态的;这个public能不能不加或者改成private或者其他的呢?当然也不行,既然你要将它作为入口函数,那么必然需要由虚拟机调用这个函数,而且是在类外调用,所以这里一定得定义成public,对外开放。在Java中一切即对象,它强制你采用面向对象,这也是当时我拒绝学java的一个理由,认为它太死板。java的跨平台据说SUN公司当年是卖服务器,服务器上的主要程序是由C/C++开发而来的,而C/C++,每次在换一个平台都需要重新编译。这个时候SUN公司的工程师需要一种跨平台的语言,就那种代码写完,编译完成之后不需要再做任何操作,随便放到一个平台上都能跑的那种。而且当时C++ 指针、多继承满天飞,造成程序编写、理解的困难。基于这几点理由,开发出了Java,Java脱胎于C++,但是砍掉了C++中复杂的指针和多继承的内容,在现在看来应该是一个比较正确的决定。相比于现在C++各种新特性的眼花缭乱,java还是很朴实很简单的东西。java的跨平台取决于它的虚拟机。每个平台都需要一个对应的虚拟机。虚拟机就好像一个翻译,而程序就像一个到不同国家旅行的人,比如说一个中国游客可以去美国、去日本、去英国旅行,他在酒店前台时用中文吩咐前台的工作人员给他一间房,去不同的国家有不同的翻译将开房这条指令翻译为前台能听懂的语言。而我们的游客只需要说中文即可。java的虚拟机的工作原理也是这样的。按照统一的规则,根据具体的平台将规则中定义的指令翻译为对应平台上的机器码。比如在Windows上+1操作是 ADD 1, 在Linux上+1操作是 +1, 而在MAC中对应 1+ ,那么在java代码中这个指令可能会编译为 1++, 这个指令不管在哪个平台都不用变,当它放在windows主机上由Windows版的虚拟机将它翻译为 ADD 1,在Linux上由Linux版的虚拟机翻译为+1,在MAC上由MAC版的虚拟机翻译为 1+。java代码执行需要经过两个步骤,首先编译为虚拟机能识别的字节码,然后有虚拟机解释并执行这个字节码。所以java具有两面性,即需要编译,也需要解释执行,那么它到底是解释性的语言还是编译型的呢?我也不知道。基本语法它的语法与C/C++基本类似,类似到你即使没接触过java,看它的代码基本能看懂每条语句都在干嘛。所以针对我来说,我并不关注每个代码怎么写,我只需要知道每个语法点有哪些需要注意的即可。常量与变量常量在java中一般是指那种用字面值表示出来的量比如说 整型的1,浮点型的1.234, 字符 'A' 字符串 'hello world',或者是用关键字 const 定义的。java里面的常量分为:整型常量、字符串常量、浮点数常量、字符常量、布尔常量和空常量(null)。从常量类型可以看出这些也是java中主要的数据类型,java中数据类型主要有:整数类型: byte、short、int、long浮点数类型: float、double字符类型: char布尔类型:boolean这些都是基本数据类型,java中还有引用类型,像字符串、对象、数组、接口、lambda表达式都是引用类型。需要注意的是java中long 是8个字节,而C/C++中long一般是4个字节,longlong才是8个。java中的char占两个字节,所以在C/C++中会将需要一个字节一个字节处理的缓冲定义为char型数组,而在java中就不能这么干了,因为它的char占两个字节,java中对于这种情况一般是定义为byte类型的数组。由于java中的char占两个字节,所以java中char是可以表示中文的char c = '中' //这在java中是正确的,但是C/C++中不能这么写有数据类型自然就涉及到数据类型转化的问题。java与C/C++类似都有显示转化和隐式转化。而且写法也类似。需要注意的几点是:整型字面值会被java编译器默认当做int类型来处理,像 byte num = 5、short s = 5 这样的表达式中5 这个字面值都是int,也就是它里面都发生了强制类型转化,如果想让编译器将其当做long需要在5后面加上L,写成 long l = 5L浮点数字面值会被默认当做double 来处理,如果想让其被作为float处理,需要在后面加上F在进行整数运算的时候,运算符号两侧的变量 或者常量会被先转化为int 在进行处理。例如 下面的代码:short s1 = 5, s2 = 10; short result = s1 + s2;这段代码java会报错,由于在运算的时候s1 与 s2 会被转化为int,然后运算得到的结果也是int,在最后进行结果赋值的时候将int赋值为short会发生错误。要让他不报错可以改为 short result = (short)(s1 + s2);隐式类型转化发生在由表示范围小的向表示范围大的类型,一般是 byte-->short-->int-->long-->float-->double。再来看下面一个例子:short n = 5 + 10;这段代码,从理论上讲,它应该会首先把5 和 10 转化为int,在计算,最后把结果的int转化为short赋值,根据上面说的,它应该会报错才对,但是实际试验的结果却是,它通过了。这就很奇怪了。还记得在学习C/C++中提到的编译器的优化吗。在C/C++中如果你写上面的一段代码,在release版本中,你看不到类似mov eax, 5 add eax, 10 mov n, eax这样的机器指令,只看得到mov n, 15这里编译器进行了优化,你代码中采用了字面值常量进行相加,而常量是不会变化的,因此在程序运行之前就已经知道计算的结果,我就没必要在运行的时候浪费CPU给你计算这个加法值,我直接给你一个结果也是一样的。所以这里java编译器采用了同样的策略。它直接将上面的代码翻译为了 short n = 15。但是这也不对啊,15应该会被当做int,而n是一个short,将int这个表示范围大的转化为short这个表示范围小的,应该会报错才对啊。但是编译确实不报错。这又涉及到java编译器的另一个策略了。当我们直接用字面值常量进行赋值操作的时候,如果字面值没有超过左侧变量的表示范围时,编译器会自动进行强制类型转化。最后的最后我想在你已经拥有其他语言的开发经验的时候,学习新语言的过程无外乎是数据类型、基本语句、控制结构、函数、面向对象、以及常用库这些东西,所以我想我自己的java笔记也按照这些框架来组织。这次是数据类型,下次就是基本语句与控制结构了。
-
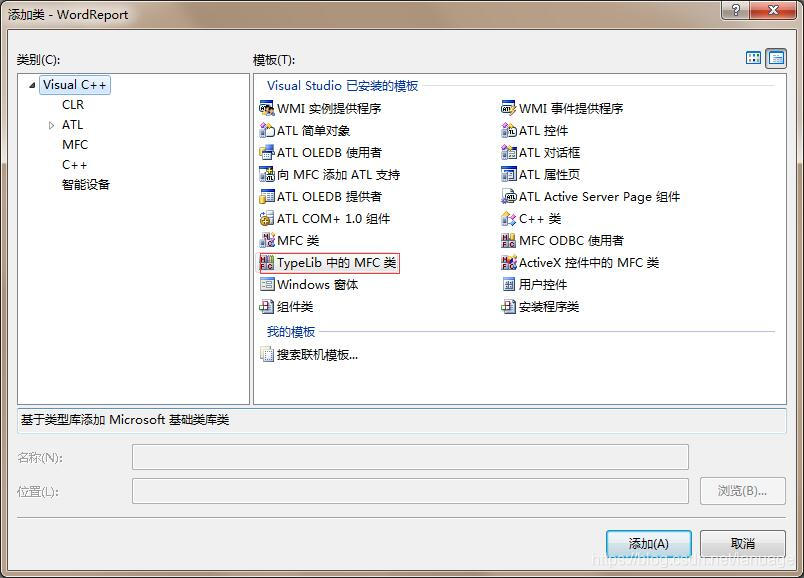
VC+++ 操作word 最近完成了一个使用VC++ 操作word生成扫描报告的功能,在这里将过程记录下来,开发环境为visual studio 2008导入接口首先在创建的MFC项目中引入word相关组件右键点击 项目 --> 添加 --> 新类,在弹出的对话框中选择Typelib中的MFC类。然后在弹出的对话框中选择文件,从文件中导入MSWORD.OLB组件。这个文件的路径一般在C:\Program Files (x86)\Microsoft Office\Office14 中,注意:最后一层可能不一定是Office14,这个看机器中安装的office 版本。选择之后会要求我们决定导入那些接口,为了方便我们导入所有接口。导入之后可以看到项目中省成本了很多代码文件,这些就是系统生成的操作Word的相关类。这里编译可能会报错,error C2786: “BOOL (HDC,int,int,int,int)”: __uuidof 的操作数无效解决方法:修改对应头文件#import "C:\\Program Files\\Microsoft Office\\Office14\\MSWORD.OLB" no_namespace为:#import "C:\\Program Files\\Microsoft Office\\Office14\\MSWORD.OLB" no_namespace raw_interfaces_only \ rename("FindText","_FindText") \ rename("Rectangle","_Rectangle") \ rename("ExitWindows","_ExitWindows")再次编译,错误消失常见接口介绍要了解一些常见的类,我们首先需要明白这些接口的层次结构:Application(WORD 为例,只列出一部分) Documents(所有的文档) Document(一个文档) ...... Templates(所有模板) Template(一个模板) ...... Windows(所有窗口) Window Selection View Selection(编辑对象) Font Style Range这些组件其实是采用远程调用的方式调用word进程来完成相关操作。Application:相当于一个word进程,每次操作之前都需要一个application对象,这个对象用于创建一个word进程。Documents:相当于word中打开的所有文档,如果用过word编辑多个文件,那么这个概念应该很好理解Templates:是一个模板对象,至于word模板,不了解的请自行百度Windows:word进程中的窗口Selection:编辑对象。也就是我们要写入word文档中的内容。一般包括文本、样式、图形等等对象。回忆一下我们手动编写word的情景,其实使用这些接口是很简单的。我们在使用word编辑的时候首先会打开word程序,这里对应在代码里面就是创建一个Application对象。然后我们会用word程序打开一个文档或者新建一个文档。这里对应着创建Documents对象并从中引用一个Document对象表示一个具体的文档。当然这个Document对象可以是新建的也可以是打开一个现有的。接着就是进行相关操作了,比如插入图片、插入表格、编写段落文本等等了。这些都对应着创建类似于Font、Style、TypeText对象,然后将这些对象进行添加的操作了。说了这么多。这些接口这么多,我怎么知道哪个接口对应哪个对象呢,而且这些参数怎么传递呢?其实这个问题很好解决。我们可以手工进行相关操作,然后用宏记录下来,最后我们再将宏中的VB代码转化为VC代码即可。相关操作为了方便在项目中使用,这里创建一个类用于封装Word的相关操作class CCreateWordReport { private: CApplication m_wdApp; CDocuments m_wdDocs; CDocument0 m_wdDoc; CSelection m_wdSel; CRange m_wdRange; CnlineShapes m_wdInlineShapes; CnlineShape m_wdInlineShape; public: CCreateWordReport(); virtual ~CCreateWordReport(); public: //操作 //**********************创建新文档******************************************* BOOL CreateApp(); //创建一个新的WORD应用程序 BOOL CreateDocuments(); //创建一个新的Word文档集合 BOOL CreateDocument(); //创建一个新的Word文档 BOOL Create(); //创建新的WORD应用程序并创建一个新的文档 void ShowApp(); //显示WORD文档 void HideApp(); //隐藏word文档 //**********************打开文档********************************************* BOOL OpenDocument(CString fileName);//打开已经存在的文档。 BOOL Open(CString fileName); //创建新的WORD应用程序并打开一个已经存在的文档。 BOOL SetActiveDocument(short i); //设置当前激活的文档。 //**********************保存文档********************************************* BOOL SaveDocument(); //文档是以打开形式,保存。 BOOL SaveDocumentAs(CString fileName);//文档以创建形式,保存。 BOOL CloseDocument(); void CloseApp(); //**********************文本书写操作***************************************** void WriteText(CString szText); //当前光标处写文本 void WriteNewLineText(CString szText, int nLineCount = 1); //换N行写字 void WriteEndLine(CString szText); //文档结尾处写文本 void WholeStory(); //全选文档内容 void Copy(); //复制文本内容到剪贴板 void InsertFile(CString fileName); //将本地的文件全部内容写入到当前文档的光标处。 void InsertTable(int nRow, int nColumn, CTable0& wdTable); //**********************图片插入操作***************************************** void InsertShapes(CString fileName);//在当前光标的位置插入图片 //**********************超链接插入操作***************************************** void InsertHyperlink(CString fileLink);//超级链接地址,可以是相对路径。 //***********************表格操作表格操作********************************** BOOL InsertTableToMarkBook(const CString csMarkName, int nRow, int nColumn, CTable0& wdTable); //表格行数与列数 BOOL WriteDataToTable(CTable0& wdTable, int nRow, int nColumn, const CString &csData); //往表格中写入输入 };BOOL CCreateWordReport::CreateApp() { if (FALSE == m_wdApp.CreateDispatch("word.application")) { AfxMessageBox("Application创建失败,请确保安装了word 2000或以上版本!", MB_OK|MB_ICONWARNING); return FALSE; } return TRUE; } BOOL CCreateWordReport::CreateDocuments() { if (FALSE == CreateApp()) { return FALSE; } m_wdDocs = m_wdApp.get_Documents(); if (!m_wdDocs.m_lpDispatch) { AfxMessageBox("Documents创建失败!", MB_OK|MB_ICONWARNING); return FALSE; } return TRUE; } BOOL CCreateWordReport::CreateDocument() { if (!m_wdDocs.m_lpDispatch) { AfxMessageBox("Documents为空!", MB_OK|MB_ICONWARNING); return FALSE; } COleVariant varTrue(short(1),VT_BOOL),vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR); CComVariant Template(_T("")); //没有使用WORD的文档模板 CComVariant NewTemplate(false),DocumentType(0),Visible; m_wdDocs.Add(&Template,&NewTemplate,&DocumentType,&Visible); //得到document变量 m_wdDoc = m_wdApp.get_ActiveDocument(); if (!m_wdDoc.m_lpDispatch) { AfxMessageBox("Document获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到selection变量 m_wdSel = m_wdApp.get_Selection(); if (!m_wdSel.m_lpDispatch) { AfxMessageBox("Select获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到Range变量 m_wdRange = m_wdDoc.Range(vOptional,vOptional); if(!m_wdRange.m_lpDispatch) { AfxMessageBox("Range获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } return TRUE; } BOOL CCreateWordReport::Create() { if (FALSE == CreateDocuments()) { return FALSE; } return CreateDocument(); } BOOL CCreateWordReport::OpenDocument(CString fileName) { if (!m_wdDocs.m_lpDispatch) { AfxMessageBox("Documents为空!", MB_OK|MB_ICONWARNING); return FALSE; } COleVariant vTrue((short)TRUE), vFalse((short)FALSE), vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR), vZ((short)0); COleVariant vFileName(_T(fileName)); //得到document变量 m_wdDoc = m_wdDocs.Open( vFileName, // FileName vTrue, // Confirm Conversion. vFalse, // ReadOnly. vFalse, // AddToRecentFiles. vOptional, // PasswordDocument. vOptional, // PasswordTemplate. vOptional, // Revert. vOptional, // WritePasswordDocument. vOptional, // WritePasswordTemplate. vOptional, // Format. // Last argument for Word 97 vOptional, // Encoding // New for Word 2000/2002 vOptional, // Visible /*如下4个是word2003需要的参数。本版本是word2000。*/ vOptional, // OpenAndRepair vZ, // DocumentDirection wdDocumentDirection LeftToRight vOptional, // NoEncodingDialog vOptional ); if (!m_wdDoc.m_lpDispatch) { AfxMessageBox("Document获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到selection变量 m_wdSel = m_wdApp.get_Selection(); if (!m_wdSel.m_lpDispatch) { AfxMessageBox("Select获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到全部DOC的Range变量 m_wdRange = m_wdDoc.Range(vOptional,vOptional); if(!m_wdRange.m_lpDispatch) { AfxMessageBox("Range获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } return TRUE; } BOOL CCreateWordReport::Open(CString fileName) { if (FALSE == CreateDocuments()) { return FALSE; } return OpenDocument(fileName); } BOOL CCreateWordReport::SetActiveDocument(short i) { COleVariant vIndex(_T(i)),vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR); m_wdDoc.AttachDispatch(m_wdDocs.Item(vIndex)); m_wdDoc.Activate(); if (!m_wdDoc.m_lpDispatch) { AfxMessageBox("Document获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到selection变量 m_wdSel = m_wdApp.get_Selection(); if (!m_wdSel.m_lpDispatch) { AfxMessageBox("Select获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到全部DOC的Range变量 m_wdRange = m_wdDoc.Range(vOptional,vOptional); if(!m_wdRange.m_lpDispatch) { AfxMessageBox("Range获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } // HideApp(); return TRUE; } BOOL CCreateWordReport::SaveDocument() { if (!m_wdDoc.m_lpDispatch) { AfxMessageBox("Document获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } m_wdDoc.Save(); return TRUE; } BOOL CCreateWordReport::SaveDocumentAs(CString fileName) { if (!m_wdDoc.m_lpDispatch) { AfxMessageBox("Document获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } COleVariant covOptional((long)DISP_E_PARAMNOTFOUND,VT_ERROR); COleVariant varZero((short)0); COleVariant varTrue(short(1),VT_BOOL); COleVariant varFalse(short(0),VT_BOOL); COleVariant vFileName(_T(fileName)); m_wdDoc.SaveAs( vFileName, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional, covOptional ); return TRUE; } BOOL CCreateWordReport::CloseDocument() { COleVariant vTrue((short)TRUE), vFalse((short)FALSE), vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR); m_wdDoc.Close(vFalse, // SaveChanges. vTrue, // OriginalFormat. vFalse // RouteDocument. ); m_wdDoc.AttachDispatch(m_wdApp.get_ActiveDocument()); if (!m_wdDoc.m_lpDispatch) { AfxMessageBox("Document获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到selection变量 m_wdSel = m_wdApp.get_Selection(); if (!m_wdSel.m_lpDispatch) { AfxMessageBox("Select获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } //得到全部DOC的Range变量 m_wdRange = m_wdDoc.Range(vOptional,vOptional); if(!m_wdRange.m_lpDispatch) { AfxMessageBox("Range获取失败!", MB_OK|MB_ICONWARNING); return FALSE; } return TRUE; } void CCreateWordReport::CloseApp() { COleVariant vTrue((short)TRUE), vFalse((short)FALSE), vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR); m_wdDoc.Save(); m_wdApp.Quit(vFalse, // SaveChanges. vTrue, // OriginalFormat. vFalse // RouteDocument. ); //释放内存申请资源 m_wdInlineShape.ReleaseDispatch(); m_wdInlineShapes.ReleaseDispatch(); //m_wdTb.ReleaseDispatch(); m_wdRange.ReleaseDispatch(); m_wdSel.ReleaseDispatch(); //m_wdFt.ReleaseDispatch(); m_wdDoc.ReleaseDispatch(); m_wdDocs.ReleaseDispatch(); m_wdApp.ReleaseDispatch(); } void CCreateWordReport::WriteText(CString szText) { m_wdSel.TypeText(szText); } void CCreateWordReport::WriteNewLineText(CString szText, int nLineCount /* = 1 */) { int i; if (nLineCount <= 0) { nLineCount = 0; } for (i = 0; i < nLineCount; i++) { m_wdSel.TypeParagraph(); } WriteText(szText); } void CCreateWordReport::WriteEndLine(CString szText) { m_wdRange.InsertAfter(szText); } void CCreateWordReport::WholeStory() { m_wdRange.WholeStory(); } void CCreateWordReport::Copy() { m_wdRange.CopyAsPicture(); } void CCreateWordReport::InsertFile(CString fileName) { COleVariant vFileName(fileName), vTrue((short)TRUE), vFalse((short)FALSE), vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR), vNull(_T("")); /* void InsertFile(LPCTSTR FileName, VARIANT* Range, VARIANT* ConfirmConversions, VARIANT* Link, VARIANT* Attachment); */ m_wdSel.InsertFile( fileName, vNull, vFalse, vFalse, vFalse ); } void CCreateWordReport::InsertShapes(CString fileName) { COleVariant vTrue((short)TRUE), vFalse((short)FALSE), vOptional((long)DISP_E_PARAMNOTFOUND, VT_ERROR); m_wdInlineShapes=m_wdSel.get_InlineShapes(); m_wdInlineShape=m_wdInlineShapes.AddPicture(fileName,vFalse,vTrue,vOptional); } void CCreateWordReport::InsertHyperlink(CString fileLink) { COleVariant vAddress(_T(fileLink)),vSubAddress(_T("")); CRange aRange = m_wdSel.get_Range(); CHyperlinks vHyperlinks(aRange.get_Hyperlinks()); vHyperlinks.Add( aRange, //Object,必需。转换为超链接的文本或图形。 vAddress, //Variant 类型,可选。指定的链接的地址。此地址可以是电子邮件地址、Internet 地址或文件名。请注意,Microsoft Word 不检查该地址的正确性。 vSubAddress, //Variant 类型,可选。目标文件内的位置名,如书签、已命名的区域或幻灯片编号。 vAddress, //Variant 类型,可选。当鼠标指针放在指定的超链接上时显示的可用作“屏幕提示”的文本。默认值为 Address。 vAddress, //Variant 类型,可选。指定的超链接的显示文本。此参数的值将取代由 Anchor 指定的文本或图形。 vSubAddress //Variant 类型,可选。要在其中打开指定的超链接的框架或窗口的名字。 ); aRange.ReleaseDispatch(); vHyperlinks.ReleaseDispatch(); }这样我们就封装好了一些基本的操作,其实这些操作都是我自己根据网上的资料以及VB宏转化而来得到的代码。特殊操作在这里主要介绍一些比较骚的操作,这也是这篇文章主要有用的内容,前面基本操作网上都有源代码直接拿来用就OK了,这里的骚操作是我在项目中使用的主要操作,应该有应用价值。先请各位仔细想想,如果我们要根据前面的代码,从0开始完全用代码生成一个完整的报表是不是很累,而且一般报表都会包含一些通用的废话,这些话基本不会变化。如果将这些写到代码里面,如果后面这些话变了,我们就要修改并重新编译,是不是很麻烦。所以这里介绍的第一个操作就是利用模板和书签在合适的位置插入内容。书签的使用首先我们在Word中的适当位置创建一个标签,至于如何创建标签,请自行百度。然后在代码中的思路就是在文档中查找我们的标签,再获取光标的位置,最后就是在该位置处添加相应的内容了,这里我们举一个在光标位置插入文本的例子:void CCreateWordReport::WriteTextToBookMark(const CString& csMarkName, const CString& szText) { CBookmarks bks = m_wdDoc.get_Bookmarks(); //获取文档中的所有书签 CBookmark0 bk; COleVariant bk_name(csMarkName); bk = bks.Item(&bk_name); //查询对应名称的书签 CRange hRange = bk.get_Range(); //获取书签位置 if (hRange != NULL) { hRange.put_Text(szText); //在该位置处插入文本 } //最后不要忘记清理相关资源 hRange.ReleaseDispatch(); bk.ReleaseDispatch(); bks.ReleaseDispatch(); }表格的使用在word报表中表格应该是一个重头戏,表格中常用的接口如下:CTables0: 表格集合CTable0: 某个具体的表格,一般通过CTables来创建CTableCColumn: 表格列对象CRow:表格行对象CCel:表格单元格对象创建表格一般的操作如下:void CCreateWordReport::InsertTable(int nRow, int nColumn, CTable0& wdTable) { VARIANT vtDefault; COleVariant vtAuto; vtDefault.vt = VT_INT; vtDefault.intVal = 1; vtAuto.vt = VT_INT; vtAuto.intVal = 0; CTables0 wordtables = m_wdDoc.get_Tables(); wdTable = wordtables.Add(m_wdSel.get_Range(), nRow, nColumn, &vtDefault, &vtAuto); wordtables.ReleaseDispatch(); }往表格中写入内容的操作如下:BOOL CCreateWordReport::WriteDataToTable(CTable0& wdTable, int nRow, int nColumn, const CString &csData) { CCell cell = wdTable.Cell(nRow, nColumn); cell.Select(); //将光标移动到单元格 m_wdSel.TypeText(csData); cell.ReleaseDispatch(); return TRUE; }合并单元格的操作如下:CTable0 wdTable; InsertTable(5, 3, wdTable); //创建一个5行3列的表格 CCell cell = wdTable.Cell(1, 1); //获得第一行第一列的单元格 //设置第二列列宽 CColumns0 columns = wdTable.get_Columns(); CColumn col; col.AttachDispatch(columns.Item(2)); col.SetWidth(40, 1); cell.Merge(wdTable.Cell(5, 1)); //合并单元格,一直合并到第5行的第1列。 cell.SetWidth(30, 1); cell.ReleaseDispatch();合并单元格用的是Merge函数,该函数的参数是一个单元格对象,表示合并结束的单元格。这里合并类似于我们画矩形时提供的左上角坐标和右下角坐标移动光标跳出表格当时由于需要连续的生成多个表格,当时我将前一个表格的数据填完,光标位于最后一个单元格里面,这个时候如果再插入的时候会在这个单元格里面插入表格,这个时候需要我手动向下移动光标,让光标移除到表格外。移动光标的代码如下:m_wdSel.MoveDown(&COleVariant((short)wdLine), &COleVariant((short)1), &COleVariant((short)wdNULL)); 这里wdLine 是word相关接口定义的,表示希望以何种单位来移动,这里我是以行为单位。后面的1表示移动1行。但是我发现在面临换页的时候一次移动根本移动不出来,这个时候我又添加了一行这样的代码移动两行。但是问题又出现了,这一系列表格后面跟着另一个大标题,多移动几次之后可能会造成它移动到大标题的位置,而破坏我原来定义的模板,这个时候该怎么办呢?我采取的办法是,判断当前光标是否在表格中,如果是则移动一行,知道出了表格。这里的代码如下://移动光标,直到跳出表格外 while (TRUE) { m_wdSel.MoveDown(&COleVariant((short)wdLine), &COleVariant((short)1), &COleVariant((short)wdNULL)); m_wdSel.Collapse(&COleVariant((short)wdCollapseStart)); if (!m_wdSel.get_Information((long)wdWithInTable).boolVal) { break; } }样式的使用在使用样式的时候当然也可以用代码来定义,但是我们可以采取另一种方式,我们可以事先在模板文件中创建一系列样式,然后在需要的时候直接定义段落或者文本的样式即可m_wdSel.put_Style(COleVariant("二级标题")); //在当前光标处的样式定义为二级标题样式,这里的二级标题样式是我们在word中事先定义好的 m_wdSel.TypeText(csTitle); //在当前位置输出文本 m_wdSel.TypeParagraph(); //插入段落,这里主要为了换行,这个时候光标也会跟着动 m_wdSel.put_Style(COleVariant("正文")); //定义此处样式为正文样式 m_wdSel.TypeText(csText;插入图表我自己尝试用word生成的图表样式还可以,但是用代码插入的时候,样式就特别丑,这里没有办法,我采用GDI+绘制了一个饼图,然后将图片插入word中。BOOL CCreateWordReport::DrawVulInforPic(const CString& csMarkName, int nVulCnt, int nVulCris, int nHigh, int nMid, int nLow, int nPossible) { CBookmarks bks = m_wdDoc.get_Bookmarks(); COleVariant bk_name(csMarkName); CBookmark0 bk = bks.Item(&bk_name); bk.Select(); CnlineShapes isps = m_wdSel.get_InlineShapes(); COleVariant vFalse((short)FALSE); COleVariant vNull(""); COleVariant vOptional((long)DISP_E_PARAMNOTFOUND,VT_ERROR); //创建一个与桌面环境兼容的内存DC HWND hWnd = GetDesktopWindow(); HDC hDc = GetDC(hWnd); HDC hMemDc = CreateCompatibleDC(hDc); HBITMAP hMemBmp = CreateCompatibleBitmap(hDc, PICTURE_WIDTH + GLOBAL_MARGIN, PICTURE_LENGTH + 2 * GLOBAL_MARGIN + LENGED_BORDER_LENGTH); SelectObject(hMemDc, hMemBmp); //绘制并保存图表 DrawPie(hMemDc, nVulCnt, nVulCris, nHigh, nMid, nLow, nPossible); COleVariant vTrue((short)TRUE); CnlineShape isp=isps.AddPicture("D:\\Program\\WordReport\\WordReport\\test.png",vFalse,vTrue,vOptional); //以图片的方式插入图表 //设置图片的大小 isp.put_Height(141); isp.put_Width(423); bks.ReleaseDispatch(); bk.ReleaseDispatch(); isps.ReleaseDispatch(); isp.ReleaseDispatch(); DeleteObject(hMemDc); DeleteDC(hMemDc); ReleaseDC(hWnd, hDc); return TRUE; }最后,各个接口的参数可以参考下面的链接:.net Word office组件接口文档
-
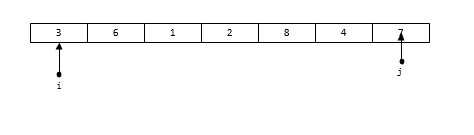
算法与数据结构(七):快速排序 在上一篇中,回顾了一下针对选择排序的优化算法——堆排序。堆排序的时间复杂度为O(nlogn),而快速排序的时间复杂度也是O(nlogn)。但是快速排序在同为O(n*logn)的排序算法中,效率也是相对较高的,而且快速排序使用了算法中一个十分经典的思想——分治法;因此掌握快速排序还是很有必要的。快速排序的基本思想如下:在一组无序元素中,找到一个数作为基准数。将大于它的数全部移动到它的右侧,小于它的全部移动到右侧。在分成的两个区中,再次重复1到2 的步骤,直到所有的数全部有序下面还是来看一个例子[3,6,1,2,8,4,7]首先选取一个基准数,一般选择序列最左侧的数为基准数,也就是3,将小于3的数移动到3的左边,大于3的移动到3的右边,得到如下的序列[2,1,3,6,8,4,7]接着针对左侧的[2, 1] 这个序列和 [6, 8, ,4, 7]这两个序列再次执行这种操作,直到所有的数都变为有序为止。知道了具体的思路下面就是写算法了。void QSort(int a[], int n) { int nIdx = adjust(a, 0, n -1); //针对调整之后的数据左右两侧序列都再次进行调整 if(nIdx != -1) { QSort(&a[0], nIdx); QSort(&a[nIdx + 1], n - nIdx - 1); } }这里定义了一个函数作为快速排序的函数,函数需要传入序列的首地址以及序列中间元素的长度。在排序函数中只需要关注如何进行调整即可。这里进行了一个判断,当调整函数返回-1时表示不需要调整,也就是说此时已经都是有序的了,这个时候就不需要调整了。程序的基本框架已经完成了,剩下的就是如何编写调整函数了。调整的算法如下:首先定义两个指针,指向最右侧和最左侧,最左侧指针指向基准数所在位置先从右往左扫描,当发现右侧数小于基准值时,将基准值位置的数替换为该数,并且立刻从左往右扫描,直到找到一个数大于基准值,再次进行替换接着再次从右往左扫描,直到找到小于基准数的值;并再次改变扫描顺序,直到调整完毕最后直到两个指针重合,此时重合的位置就是基准值所在位置根据这个思路,可以编写如下代码int QuickSort(int a[], int nLow, int nHigh) { if (nLow >= nHigh) { return -1; } int tmp = a[nLow]; int i = nLow; int j = nHigh; while (i != j) { //先从右往左扫描,只到找到比基准值小的数 //将该数放到基准值的左侧 while (a[j] > tmp && j > i) { j--; } if (a[j] < tmp) { a[i]= a[j]; i++; } //接着从左往右扫描,直到找到比基准值大的数 //将该数放入到基准值的右侧 while (a[i] < tmp && i < j) { i++; } if (a[i] > tmp) { a[j] = a[i]; j--; } } a[i] = tmp; return i; }到此已经完成了快速排序的算法编写了。在有大量的数据需要进行排序时快速排序的效果比较好,如果数据量小,或者排序的序列已经是一个逆序的有序序列,它退化成O(n^2)。快速排序是一个不稳定的排序算法。
-
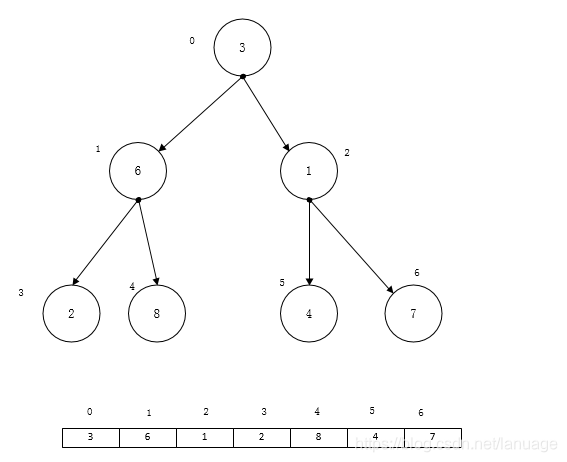
算法与数据结构(六):堆排序 上一次说到了3种基本的排序算法,三种基本的排序算法时间复杂度都是O(n^2),虽然比较简单,但是效率相对较差,因此后续有许多相应的改进算法,这次主要说说堆排序算法。堆排序算法是对选择排序的一种优化。那么什么是堆呢?堆是一种树形结构。在维基百科上的定义是这样的“给定堆中任意节点 P 和 C,若 P 是 C 的母节点,那么 P 的值会小于等于(或大于等于) C 的值”。这句话通俗一点就是,树的根节点需要大于(小于)它的孩子节点,而每个左右子树都满足这个条件。当树的根节点大于它的左右孩子节点时称为大顶推,否则称为小顶堆。排序算法的思路是这样的,首先将序列中的元素组织成一个大顶堆,将树的根节点放到序列的最后面,然后将剩余的元素再组织成一个大顶堆,然后放到倒数第二个位置,以此类推。先假定它们的对应关系如下图所示:我们从树的最后一个非叶子节点开始,从这个子树中选择最大的一个数,将它交换到子树的根节点,也就是如下图所示接着再从后往前查找下一个非叶子节点经过这样一轮,一直调整到树的根节点,让后将根节点放到序列的最后一个元素,接着再将剩余元素重新组织为一个新的堆,直到所有元素都完成排序现在已经对堆排序的基本思路有了一定的了解,在写代码之前需要建立树节点与它在序列中的相关位置做一个对应关系,假设一个非叶子节点在序列中的位置为n,那么它的两个子节点分别是2n + 1与 2n + 2。而且小于n的一定是位于n前方的非叶子节点,所以在调整堆时,从n开始一直到0,前面的一定是非叶子节点,根据这点可以写出这样的代码void HeapSort(int a[], int nLength) { //从最后一个非叶子节点开始调整 for (int n = nLength / 2 - 1; n >= 0; n--) { HeapAdjust(a, n, nLength); } for (int n = nLength - 1; n > 0; n--) { //取堆顶与最后一个叶子节点互换 int tmp = a[0]; a[0] = a[n]; a[n] = tmp; //调整剩余堆 HeapAdjust(a, 0, n); } }上述代码首先取最后一个叶子节点,对所有非叶子节点进行调整,得到堆顶的最大元素。然后将最大元素与序列最后一个做交换,接着使用循环,对序列中剩余元素进行同样的操作。调整堆时,首先比较子树的根节点与它下面的所有子节点,并保存最大数的位置,然后将最大数与根节点的数进行交换,这样一直进行,直到完成了堆根节点的交换。void HeapAdjust(int a[], int nIdx, int nLength) { int child = 0; //child 保存当前最大数的下标 while (2 * nIdx + 1 < nLength) { child = 2 * nIdx + 1; //先找子节点的最大值(保证存在右节点的情况下) if (child < nLength - 1 && a[child] < a[child + 1]) { child++; } if (a[nIdx] < a[child]) { int tmp = a[nIdx]; a[nIdx] = a[child]; a[child] = tmp; }else { break; } //如果进行了交换,为了防止对子节点对应子树的破坏,要对子树也进行调整 nIdx = child; } }从算法上来看,它循环的次数与堆的深度有关,而二叉树的深度应该是log2(n) 向下取整,所以调整的时候需要进行log2(n)次调整,而外层需要从0一直到n - 1的位置每次都需要重组堆并进行调整,所以它的时间复杂度应该为O(nlogn), 它在效率上比选择排序要高,它的速度主要体现在每次查找选择最大的数这个方面。