搜索到
349
篇与
的结果
-
 VC++ IPv6的支持 最近根据项目需要,要在产品中添加对IpV6的支持,因此研究了一下IPV6的相关内容,Ipv6 与原来最直观的改变就是地址结构的改变,IP地址由原来的32位扩展为128,这样原来的地址结构肯定就不够用了,根据微软的官方文档,只需要对原来的代码做稍许改变就可以适应ipv6。修改地址结构Windows Socket2 针对Ipv6的官方描述根据微软官方的说法,要做到支持Ipv6首先要做的就是将原来的SOCKADDR_IN等地址结构替换为SOCKADDR_STORAGE 该结构的定义如下:typedef struct sockaddr_storage { short ss_family; char __ss_pad1[_SS_PAD1SIZE]; __int64 __ss_align; char __ss_pad2[_SS_PAD2SIZE]; } SOCKADDR_STORAGE, *PSOCKADDR_STORAGE;ss_family:代表的是地址家族,IP协议一般是AF_INET, 但是如果是IPV6的地址这个参数需要设置为 AF_INET6。后面的成员都是作为保留字段,或者说作为填充结构大小的字段,这个结构兼容了IPV6与IPV4的地址结构,跟以前的SOCKADDR_IN结构不同,我们现在不能直接从SOCKADDR_STORAGE结构中获取IP地址了。也没有办法直接往结构中填写IP地址。使用兼容函数除了地址结构的改变,还需要改变某些函数,有的函数是只支持Ipv4的,我们需要将这些函数改为即兼容的函数,根据官方的介绍,这些兼容函数主要是下面几个:WSAConnectByName : 可以直接通过主机名建立一个连接WSAConnectByList: 从一组主机名中建立一个连接getaddrinfo: 类似于gethostbyname, 但是gethostbyname只支持IPV4所以一般用这个函数来代替GetAdaptersAddresses: 这个函数用来代替原来的GetAdaptersInfoWSAConnectByName函数:函数原型如下:BOOL PASCAL WSAConnectByName( __in SOCKET s, __in LPSTR nodename, __in LPSTR servicename, __inout LPDWORD LocalAddressLength, __out LPSOCKADDR LocalAddress, __inout LPDWORD RemoteAddressLength, __out LPSOCKADDR RemoteAddress, __in const struct timeval* timeout, LPWSAOVERLAPPED Reserved ); s: 该参数为一个新创建的未绑定,未与其他主机建立连接的SOCKET,后续会采用这个socket来进行收发包的操作nodename: 主机名,或者主机的IP地址的字符串servicename: 服务名称,也可以是对应的端口号的字符串,传入服务名时需要传入那些知名的服务,比如HTTP、FTP等等, 其实这个字段本身就是需要传入端口的,传入服务名,最后函数会根据服务名称转化为这些服务的默认端口LocalAddressLength, LocalAddress, 返回当前地址结构,与长度RemoteAddressLength, RemoteAddress,返回远程主机的地址结构,与长度timeout: 超时值Reserved: 重叠IO结构为了使函数能够支持Ipv6,需要在调用前使用setsockopt函数对socket做相关设置,设置的代码如下:iResult = setsockopt(ConnSocket, IPPROTO_IPV6, IPV6_V6ONLY, (char*)&ipv6only, sizeof(ipv6only) );调用函数的例子如下(该实例为微软官方的例子):SOCKET OpenAndConnect(LPWSTR NodeName, LPWSTR PortName) { SOCKET ConnSocket; DWORD ipv6only = 0; int iResult; BOOL bSuccess; SOCKADDR_STORAGE LocalAddr = {0}; SOCKADDR_STORAGE RemoteAddr = {0}; DWORD dwLocalAddr = sizeof(LocalAddr); DWORD dwRemoteAddr = sizeof(RemoteAddr); ConnSocket = socket(AF_INET6, SOCK_STREAM, 0); if (ConnSocket == INVALID_SOCKET){ return INVALID_SOCKET; } iResult = setsockopt(ConnSocket, IPPROTO_IPV6, IPV6_V6ONLY, (char*)&ipv6only, sizeof(ipv6only) ); if (iResult == SOCKET_ERROR){ closesocket(ConnSocket); return INVALID_SOCKET; } bSuccess = WSAConnectByName(ConnSocket, NodeName, PortName, &dwLocalAddr, (SOCKADDR*)&LocalAddr, &dwRemoteAddr, (SOCKADDR*)&RemoteAddr, NULL, NULL); if (bSuccess){ return ConnSocket; } else { return INVALID_SOCKET; } }WSAConnectByList该函数从传入的一组hostname中选取一个建立连接,函数内部会调用WSAConnectByName,它的原型,使用方式与WSAConnectByName类似,这里就不再给出具体的原型以及调用方法了。getaddrinfo该函数的作用与gethostbyname类似,但是它可以同时支持获取V4、V6的地址结构,函数原型如下:int getaddrinfo( const char FAR* nodename, const char FAR* servname, const struct addrinfo FAR* hints, struct addrinfo FAR* FAR* res );nodename: 主机名或者IP地址的字符串servname: 知名服务的名称或者端口的字符串hints:一个地址结构,该结构规定了应该如何进行地址转化。res:与gethostbyname类似,它也是返回一个地址结构的链表。后续只需要遍历这个链表即可。使用的实例如下:char szServer[] = "www.baidu.com"; char szPort[] = "80"; addrinfo hints = {0}; struct addrinfo* ai = NULL; getaddrinfo(szServer, szPort, NULL, &ai); while (NULL != ai) { SOCKET sConnect = socket(ai->ai_family, SOCK_STREAM, ai->ai_protocol); connect(sConnect, ai->ai_addr, ai->ai_addrlen); shutdown(sConnect, SD_BOTH); closesocket(sConnect); ai = ai->ai_next; } freeaddrinfo(ai); //最后别忘了释放链表针对硬编码的情况针对这种情况一般是修改硬编码,如果希望你的应用程序即支持IPV6也支持IPV4,那么就需要去掉这些硬编码的部分。微软提供了一个工具叫"Checkv4.exe" 这个工具一般是放到VS的安装目录中,作为工具一起安装到本机了,如果没有可以去官网下载。工具的使用也非常简单checkv4.exe 对应的.h或者.cpp 文件这样它会给出哪些代码需要进行修改,甚至会给出修改意见,我们只要根据它的提示修改代码即可。几个例子因为IPV6 不能再像V4那样直接往地址结构中填写IP了,因此在IPV6的场合需要大量使用getaddrinfo函数,来根据具体的IP字符串或者根据主机名来自动获取地址信息,然后根据地址信息直接调用connect即可,下面是微软的例子int ResolveName(char *Server, char *PortName, int Family, int SocketType) { int iResult = 0; ADDRINFO *AddrInfo = NULL; ADDRINFO *AI = NULL; ADDRINFO Hints; memset(&Hints, 0, sizeof(Hints)); Hints.ai_family = Family; Hints.ai_socktype = SocketType; iResult = getaddrinfo(Server, PortName, &Hints, &AddrInfo); if (iResult != 0) { printf("Cannot resolve address [%s] and port [%s], error %d: %s\n", Server, PortName, WSAGetLastError(), gai_strerror(iResult)); return SOCKET_ERROR; } if(NULL != AddrInfo) { SOCKET sConnect = socket(AddrInfo->ai_family, SOCK_STREAM, AddrInfo->ai_protocol); connect(sConnect, AddrInfo->ai_addr, AddrInfo->ai_addrlen); shutdown(sConnect, SD_BOTH); closesocket(sConnect); } freeaddrinfo(AddrInfo); return 0; }这个例子需要传入额外的family参数来规定它使用何种地址结构,但是如果我只有一个主机名,而且事先并不知道需要使用何种IP协议来进行通信,这种情况下又该如何呢?针对服务端,不存在这个问题,服务端是我们自己的代码,具体使用IPV6还是IPV4这个实现是可以确定的,因此可以采用跟上面类似的写法:BOOL Create(int af_family) { //这里不建议使用IPPROTO_IP 或者IPPROTO_IPV6,使用TCP或者UDP可能会好点,因为它们是建立在IP协议之上的 //当然,具体情况具体分析 s = socket(af_family, SOCK_STREAM, IPPROTO_TCP); } BOOL Bind(int family, UINT nPort) { addrinfo hins = {0}; hins.ai_family = family; hins.ai_flags = AI_PASSIVE; /* For wildcard IP address */ hins.ai_protocol = IPPROTO_TCP; hins.ai_socktype = SOCK_STREAM; addrinfo *lpAddr = NULL; CString csPort = ""; csPort.Format("%u", nPort); if (0 != getaddrinfo(NULL, csPort, &hins, &lpAddr)) { closesocket(s); return FALSE; } int nRes = bind(s, lpAddr->ai_addr, lpAddr->ai_addrlen); freeaddrinfo(lpAddr); if(nRes == 0) return TRUE; return FALSE; } //监听,以及后面的收发包并没有区分V4和V6,因此这里不再给出跟他们相关的代码针对服务端,我们自然没办法事先知道它使用的IP协议的版本,因此传入af_family参数在这里不再适用,我们可以利用getaddrinfo函数根据服务端的主机名或者端口号来提前获取它的地址信息,这里我们可以封装一个函数int GetAF_FamilyByHost(LPCTSTR lpHost, int nPort, int SocketType) { addrinfo hins = {0}; addrinfo *lpAddr = NULL; hins.ai_family = AF_UNSPEC; hins.ai_socktype = SOCK_STREAM; hins.ai_protocol = IPPROTO_TCP; CString csPort = ""; csPort.Format("%u", nPort); int af = AF_UNSPEC; char host[MAX_HOSTNAME_LEN] = ""; if (lpHost == NULL) { gethostname(host, MAX_HOSTNAME_LEN);// 如果为NULL 则获取本机的IP地址信息 }else { strcpy_s(host, MAX_HOSTNAME_LEN, lpHost); } if(0 != getaddrinfo(host, csPort, &hins, &lpAddr)) { return af; } af = lpAddr->ai_family; freeaddrinfo(lpAddr); return af; }有了地址家族信息,后面的代码即可以根据地址家族信息来分别处理IP协议的不同版本,也可以使用上述服务端的思路,直接使用getaddrinfo函数得到的addrinfo结构中地址信息,下面给出第二种思路的部分代码:if(0 != getaddrinfo(host, csPort, &hins, &lpAddr)) { connect(s, lpAddr->ai_addr, lpAddr->ai_addrlen); }当然,也可以使用前面提到的 WSAConnectByName 函数,不过它需要针对IPV6来进行特殊的处理,需要事先知道服务端的IP协议的版本。VC中各种地址结构在学习网络编程中,一个重要的概念就是IP地址,而巴克利套接字中提供了好几种结构体来表示地址结构,微软针对WinSock2 又提供了一些新的结构体,有的时候众多的结构体让人眼花缭乱,在这我根据自己的理解简单的回顾一下这些常见的结构SOCKADD_IN 与sockaddr_in结构在Winsock2 中这二者是等价的, 它们的定义如下:struct sockaddr_in{ short sin_family; unsigned short sin_port; struct in_addr sin_addr; char sin_zero[8]; };sin_family: 地址协议家族sin_port:端口号sin_addr: 表示ip地址的结构sin_zero: 用于与sockaddr 结构体的大小对齐,这个数组里面为全0in_addr 结构如下:struct in_addr { union { struct{ unsigned char s_b1, s_b2, s_b3, s_b4; } S_un_b; struct { unsigned short s_w1, s_w2; } S_un_w; unsigned long S_addr; } S_un; }; 这个结构是一个公用体,占4个字节,从本质上将IP地址仅仅是一个占4个字节的无符号整型数据,为了方便读写才会采用点分十进制的方式。仔细观察这个结构会发现,它其实定义了IP地址的几种表现形式,我们可以将IP地址以一个字节一个字节的方式拆开来看,也可以以两个字型数据的形式拆开,也可以简单的看做一个无符号长整型。当然在写入的时候按照这几种方式写入,为了方便写入IP地址,微软定义了一个宏:#define s_addr S_un.S_addr因此在填入IP地址的时候可以简单的使用这个宏来给S_addr这个共用体成员赋值一般像bind、connect等函数需要传入地址结构,它们需要的结构为sockaddr,但是为了方便都会传入SOCKADDR_IN结构sockaddr SOCKADDR结构这两个结构也是等价的,它们的定义如下struct sockaddr { unsigned short sa_family; char sa_data[14];};从结构上看它占16个字节与 SOCKADDR_IN大小相同,而且第一个成员都是地址家族的相关信息,后面都是存储的具体的IPV4的地址,因此它们是可以转化的,为了方便一般是使用SOCKADDR_IN来保存IP地址,然后在需要填入SOCKADDR的时候强制转化即可。sockaddr_in6该结构类似于sockaddr_in,只不过它表示的是IPV6的地址信息,在使用上,由于IPV6是128的地址占16个字节,而sockaddr_in 中表示地址的部分只有4个字节,所以它与之前的两个是不能转化的,在使用IPV6的时候需要特殊的处理,一般不直接填写IP而是直接根据IP的字符串或者主机名来连接。sockaddr_storage这是一个通用的地址结构,既可以用来存储IPV4地址也可以存储IPV6的地址,这个地址结构在前面已经说过了,这里就不再详细解释了。各种地址之间的转化一般我们只使用从SOCKADDR_IN到sockaddr结构的转化,而且仔细观察socket函数族发现只需要从其他结构中得到sockaddr结构,而并不需要从sockaddr转化为其他结构,因此这里重点放在如何转化为sockaddr结构从SOCKADDR_IN到sockaddr只需要强制类型转化即可从addrinfo结构中只需要调用其成员即可从SOCKADDR_STORAGE结构到sockaddr只需要强制转化即可。其实在使用上更常用的是将字符串的IP转化为对应的数值,针对IPV4有我们常见的inet_addr、inet_ntoa 函数,它们都是在ipv4中使用的,针对v6一般使用inet_pton,inet_ntop来转化,它们两个分别对应于inet_addr、inet_ntoa。但是在WinSock中更常用的是WSAAddressToString 与 WSAStringToAddressINT WSAAddressToString( LPSOCKADDR lpsaAddress, DWORD dwAddressLength, LPWSAPROTOCOL_INFO lpProtocolInfo, OUT LPTSTR lpszAddressString, IN OUT LPDWORD lpdwAddressStringLength );lpsaAddress: ip地址dwAddressLength: 地址结构的长度lpProtocolInfo: 协议信息的结构体,这个结构一般给NULLlpszAddressString:目标字符串的缓冲lpdwAddressStringLength:字符串的长度而WSAStringToAddress定义与使用与它类似,这里就不再说明了。
VC++ IPv6的支持 最近根据项目需要,要在产品中添加对IpV6的支持,因此研究了一下IPV6的相关内容,Ipv6 与原来最直观的改变就是地址结构的改变,IP地址由原来的32位扩展为128,这样原来的地址结构肯定就不够用了,根据微软的官方文档,只需要对原来的代码做稍许改变就可以适应ipv6。修改地址结构Windows Socket2 针对Ipv6的官方描述根据微软官方的说法,要做到支持Ipv6首先要做的就是将原来的SOCKADDR_IN等地址结构替换为SOCKADDR_STORAGE 该结构的定义如下:typedef struct sockaddr_storage { short ss_family; char __ss_pad1[_SS_PAD1SIZE]; __int64 __ss_align; char __ss_pad2[_SS_PAD2SIZE]; } SOCKADDR_STORAGE, *PSOCKADDR_STORAGE;ss_family:代表的是地址家族,IP协议一般是AF_INET, 但是如果是IPV6的地址这个参数需要设置为 AF_INET6。后面的成员都是作为保留字段,或者说作为填充结构大小的字段,这个结构兼容了IPV6与IPV4的地址结构,跟以前的SOCKADDR_IN结构不同,我们现在不能直接从SOCKADDR_STORAGE结构中获取IP地址了。也没有办法直接往结构中填写IP地址。使用兼容函数除了地址结构的改变,还需要改变某些函数,有的函数是只支持Ipv4的,我们需要将这些函数改为即兼容的函数,根据官方的介绍,这些兼容函数主要是下面几个:WSAConnectByName : 可以直接通过主机名建立一个连接WSAConnectByList: 从一组主机名中建立一个连接getaddrinfo: 类似于gethostbyname, 但是gethostbyname只支持IPV4所以一般用这个函数来代替GetAdaptersAddresses: 这个函数用来代替原来的GetAdaptersInfoWSAConnectByName函数:函数原型如下:BOOL PASCAL WSAConnectByName( __in SOCKET s, __in LPSTR nodename, __in LPSTR servicename, __inout LPDWORD LocalAddressLength, __out LPSOCKADDR LocalAddress, __inout LPDWORD RemoteAddressLength, __out LPSOCKADDR RemoteAddress, __in const struct timeval* timeout, LPWSAOVERLAPPED Reserved ); s: 该参数为一个新创建的未绑定,未与其他主机建立连接的SOCKET,后续会采用这个socket来进行收发包的操作nodename: 主机名,或者主机的IP地址的字符串servicename: 服务名称,也可以是对应的端口号的字符串,传入服务名时需要传入那些知名的服务,比如HTTP、FTP等等, 其实这个字段本身就是需要传入端口的,传入服务名,最后函数会根据服务名称转化为这些服务的默认端口LocalAddressLength, LocalAddress, 返回当前地址结构,与长度RemoteAddressLength, RemoteAddress,返回远程主机的地址结构,与长度timeout: 超时值Reserved: 重叠IO结构为了使函数能够支持Ipv6,需要在调用前使用setsockopt函数对socket做相关设置,设置的代码如下:iResult = setsockopt(ConnSocket, IPPROTO_IPV6, IPV6_V6ONLY, (char*)&ipv6only, sizeof(ipv6only) );调用函数的例子如下(该实例为微软官方的例子):SOCKET OpenAndConnect(LPWSTR NodeName, LPWSTR PortName) { SOCKET ConnSocket; DWORD ipv6only = 0; int iResult; BOOL bSuccess; SOCKADDR_STORAGE LocalAddr = {0}; SOCKADDR_STORAGE RemoteAddr = {0}; DWORD dwLocalAddr = sizeof(LocalAddr); DWORD dwRemoteAddr = sizeof(RemoteAddr); ConnSocket = socket(AF_INET6, SOCK_STREAM, 0); if (ConnSocket == INVALID_SOCKET){ return INVALID_SOCKET; } iResult = setsockopt(ConnSocket, IPPROTO_IPV6, IPV6_V6ONLY, (char*)&ipv6only, sizeof(ipv6only) ); if (iResult == SOCKET_ERROR){ closesocket(ConnSocket); return INVALID_SOCKET; } bSuccess = WSAConnectByName(ConnSocket, NodeName, PortName, &dwLocalAddr, (SOCKADDR*)&LocalAddr, &dwRemoteAddr, (SOCKADDR*)&RemoteAddr, NULL, NULL); if (bSuccess){ return ConnSocket; } else { return INVALID_SOCKET; } }WSAConnectByList该函数从传入的一组hostname中选取一个建立连接,函数内部会调用WSAConnectByName,它的原型,使用方式与WSAConnectByName类似,这里就不再给出具体的原型以及调用方法了。getaddrinfo该函数的作用与gethostbyname类似,但是它可以同时支持获取V4、V6的地址结构,函数原型如下:int getaddrinfo( const char FAR* nodename, const char FAR* servname, const struct addrinfo FAR* hints, struct addrinfo FAR* FAR* res );nodename: 主机名或者IP地址的字符串servname: 知名服务的名称或者端口的字符串hints:一个地址结构,该结构规定了应该如何进行地址转化。res:与gethostbyname类似,它也是返回一个地址结构的链表。后续只需要遍历这个链表即可。使用的实例如下:char szServer[] = "www.baidu.com"; char szPort[] = "80"; addrinfo hints = {0}; struct addrinfo* ai = NULL; getaddrinfo(szServer, szPort, NULL, &ai); while (NULL != ai) { SOCKET sConnect = socket(ai->ai_family, SOCK_STREAM, ai->ai_protocol); connect(sConnect, ai->ai_addr, ai->ai_addrlen); shutdown(sConnect, SD_BOTH); closesocket(sConnect); ai = ai->ai_next; } freeaddrinfo(ai); //最后别忘了释放链表针对硬编码的情况针对这种情况一般是修改硬编码,如果希望你的应用程序即支持IPV6也支持IPV4,那么就需要去掉这些硬编码的部分。微软提供了一个工具叫"Checkv4.exe" 这个工具一般是放到VS的安装目录中,作为工具一起安装到本机了,如果没有可以去官网下载。工具的使用也非常简单checkv4.exe 对应的.h或者.cpp 文件这样它会给出哪些代码需要进行修改,甚至会给出修改意见,我们只要根据它的提示修改代码即可。几个例子因为IPV6 不能再像V4那样直接往地址结构中填写IP了,因此在IPV6的场合需要大量使用getaddrinfo函数,来根据具体的IP字符串或者根据主机名来自动获取地址信息,然后根据地址信息直接调用connect即可,下面是微软的例子int ResolveName(char *Server, char *PortName, int Family, int SocketType) { int iResult = 0; ADDRINFO *AddrInfo = NULL; ADDRINFO *AI = NULL; ADDRINFO Hints; memset(&Hints, 0, sizeof(Hints)); Hints.ai_family = Family; Hints.ai_socktype = SocketType; iResult = getaddrinfo(Server, PortName, &Hints, &AddrInfo); if (iResult != 0) { printf("Cannot resolve address [%s] and port [%s], error %d: %s\n", Server, PortName, WSAGetLastError(), gai_strerror(iResult)); return SOCKET_ERROR; } if(NULL != AddrInfo) { SOCKET sConnect = socket(AddrInfo->ai_family, SOCK_STREAM, AddrInfo->ai_protocol); connect(sConnect, AddrInfo->ai_addr, AddrInfo->ai_addrlen); shutdown(sConnect, SD_BOTH); closesocket(sConnect); } freeaddrinfo(AddrInfo); return 0; }这个例子需要传入额外的family参数来规定它使用何种地址结构,但是如果我只有一个主机名,而且事先并不知道需要使用何种IP协议来进行通信,这种情况下又该如何呢?针对服务端,不存在这个问题,服务端是我们自己的代码,具体使用IPV6还是IPV4这个实现是可以确定的,因此可以采用跟上面类似的写法:BOOL Create(int af_family) { //这里不建议使用IPPROTO_IP 或者IPPROTO_IPV6,使用TCP或者UDP可能会好点,因为它们是建立在IP协议之上的 //当然,具体情况具体分析 s = socket(af_family, SOCK_STREAM, IPPROTO_TCP); } BOOL Bind(int family, UINT nPort) { addrinfo hins = {0}; hins.ai_family = family; hins.ai_flags = AI_PASSIVE; /* For wildcard IP address */ hins.ai_protocol = IPPROTO_TCP; hins.ai_socktype = SOCK_STREAM; addrinfo *lpAddr = NULL; CString csPort = ""; csPort.Format("%u", nPort); if (0 != getaddrinfo(NULL, csPort, &hins, &lpAddr)) { closesocket(s); return FALSE; } int nRes = bind(s, lpAddr->ai_addr, lpAddr->ai_addrlen); freeaddrinfo(lpAddr); if(nRes == 0) return TRUE; return FALSE; } //监听,以及后面的收发包并没有区分V4和V6,因此这里不再给出跟他们相关的代码针对服务端,我们自然没办法事先知道它使用的IP协议的版本,因此传入af_family参数在这里不再适用,我们可以利用getaddrinfo函数根据服务端的主机名或者端口号来提前获取它的地址信息,这里我们可以封装一个函数int GetAF_FamilyByHost(LPCTSTR lpHost, int nPort, int SocketType) { addrinfo hins = {0}; addrinfo *lpAddr = NULL; hins.ai_family = AF_UNSPEC; hins.ai_socktype = SOCK_STREAM; hins.ai_protocol = IPPROTO_TCP; CString csPort = ""; csPort.Format("%u", nPort); int af = AF_UNSPEC; char host[MAX_HOSTNAME_LEN] = ""; if (lpHost == NULL) { gethostname(host, MAX_HOSTNAME_LEN);// 如果为NULL 则获取本机的IP地址信息 }else { strcpy_s(host, MAX_HOSTNAME_LEN, lpHost); } if(0 != getaddrinfo(host, csPort, &hins, &lpAddr)) { return af; } af = lpAddr->ai_family; freeaddrinfo(lpAddr); return af; }有了地址家族信息,后面的代码即可以根据地址家族信息来分别处理IP协议的不同版本,也可以使用上述服务端的思路,直接使用getaddrinfo函数得到的addrinfo结构中地址信息,下面给出第二种思路的部分代码:if(0 != getaddrinfo(host, csPort, &hins, &lpAddr)) { connect(s, lpAddr->ai_addr, lpAddr->ai_addrlen); }当然,也可以使用前面提到的 WSAConnectByName 函数,不过它需要针对IPV6来进行特殊的处理,需要事先知道服务端的IP协议的版本。VC中各种地址结构在学习网络编程中,一个重要的概念就是IP地址,而巴克利套接字中提供了好几种结构体来表示地址结构,微软针对WinSock2 又提供了一些新的结构体,有的时候众多的结构体让人眼花缭乱,在这我根据自己的理解简单的回顾一下这些常见的结构SOCKADD_IN 与sockaddr_in结构在Winsock2 中这二者是等价的, 它们的定义如下:struct sockaddr_in{ short sin_family; unsigned short sin_port; struct in_addr sin_addr; char sin_zero[8]; };sin_family: 地址协议家族sin_port:端口号sin_addr: 表示ip地址的结构sin_zero: 用于与sockaddr 结构体的大小对齐,这个数组里面为全0in_addr 结构如下:struct in_addr { union { struct{ unsigned char s_b1, s_b2, s_b3, s_b4; } S_un_b; struct { unsigned short s_w1, s_w2; } S_un_w; unsigned long S_addr; } S_un; }; 这个结构是一个公用体,占4个字节,从本质上将IP地址仅仅是一个占4个字节的无符号整型数据,为了方便读写才会采用点分十进制的方式。仔细观察这个结构会发现,它其实定义了IP地址的几种表现形式,我们可以将IP地址以一个字节一个字节的方式拆开来看,也可以以两个字型数据的形式拆开,也可以简单的看做一个无符号长整型。当然在写入的时候按照这几种方式写入,为了方便写入IP地址,微软定义了一个宏:#define s_addr S_un.S_addr因此在填入IP地址的时候可以简单的使用这个宏来给S_addr这个共用体成员赋值一般像bind、connect等函数需要传入地址结构,它们需要的结构为sockaddr,但是为了方便都会传入SOCKADDR_IN结构sockaddr SOCKADDR结构这两个结构也是等价的,它们的定义如下struct sockaddr { unsigned short sa_family; char sa_data[14];};从结构上看它占16个字节与 SOCKADDR_IN大小相同,而且第一个成员都是地址家族的相关信息,后面都是存储的具体的IPV4的地址,因此它们是可以转化的,为了方便一般是使用SOCKADDR_IN来保存IP地址,然后在需要填入SOCKADDR的时候强制转化即可。sockaddr_in6该结构类似于sockaddr_in,只不过它表示的是IPV6的地址信息,在使用上,由于IPV6是128的地址占16个字节,而sockaddr_in 中表示地址的部分只有4个字节,所以它与之前的两个是不能转化的,在使用IPV6的时候需要特殊的处理,一般不直接填写IP而是直接根据IP的字符串或者主机名来连接。sockaddr_storage这是一个通用的地址结构,既可以用来存储IPV4地址也可以存储IPV6的地址,这个地址结构在前面已经说过了,这里就不再详细解释了。各种地址之间的转化一般我们只使用从SOCKADDR_IN到sockaddr结构的转化,而且仔细观察socket函数族发现只需要从其他结构中得到sockaddr结构,而并不需要从sockaddr转化为其他结构,因此这里重点放在如何转化为sockaddr结构从SOCKADDR_IN到sockaddr只需要强制类型转化即可从addrinfo结构中只需要调用其成员即可从SOCKADDR_STORAGE结构到sockaddr只需要强制转化即可。其实在使用上更常用的是将字符串的IP转化为对应的数值,针对IPV4有我们常见的inet_addr、inet_ntoa 函数,它们都是在ipv4中使用的,针对v6一般使用inet_pton,inet_ntop来转化,它们两个分别对应于inet_addr、inet_ntoa。但是在WinSock中更常用的是WSAAddressToString 与 WSAStringToAddressINT WSAAddressToString( LPSOCKADDR lpsaAddress, DWORD dwAddressLength, LPWSAPROTOCOL_INFO lpProtocolInfo, OUT LPTSTR lpszAddressString, IN OUT LPDWORD lpdwAddressStringLength );lpsaAddress: ip地址dwAddressLength: 地址结构的长度lpProtocolInfo: 协议信息的结构体,这个结构一般给NULLlpszAddressString:目标字符串的缓冲lpdwAddressStringLength:字符串的长度而WSAStringToAddress定义与使用与它类似,这里就不再说明了。 -
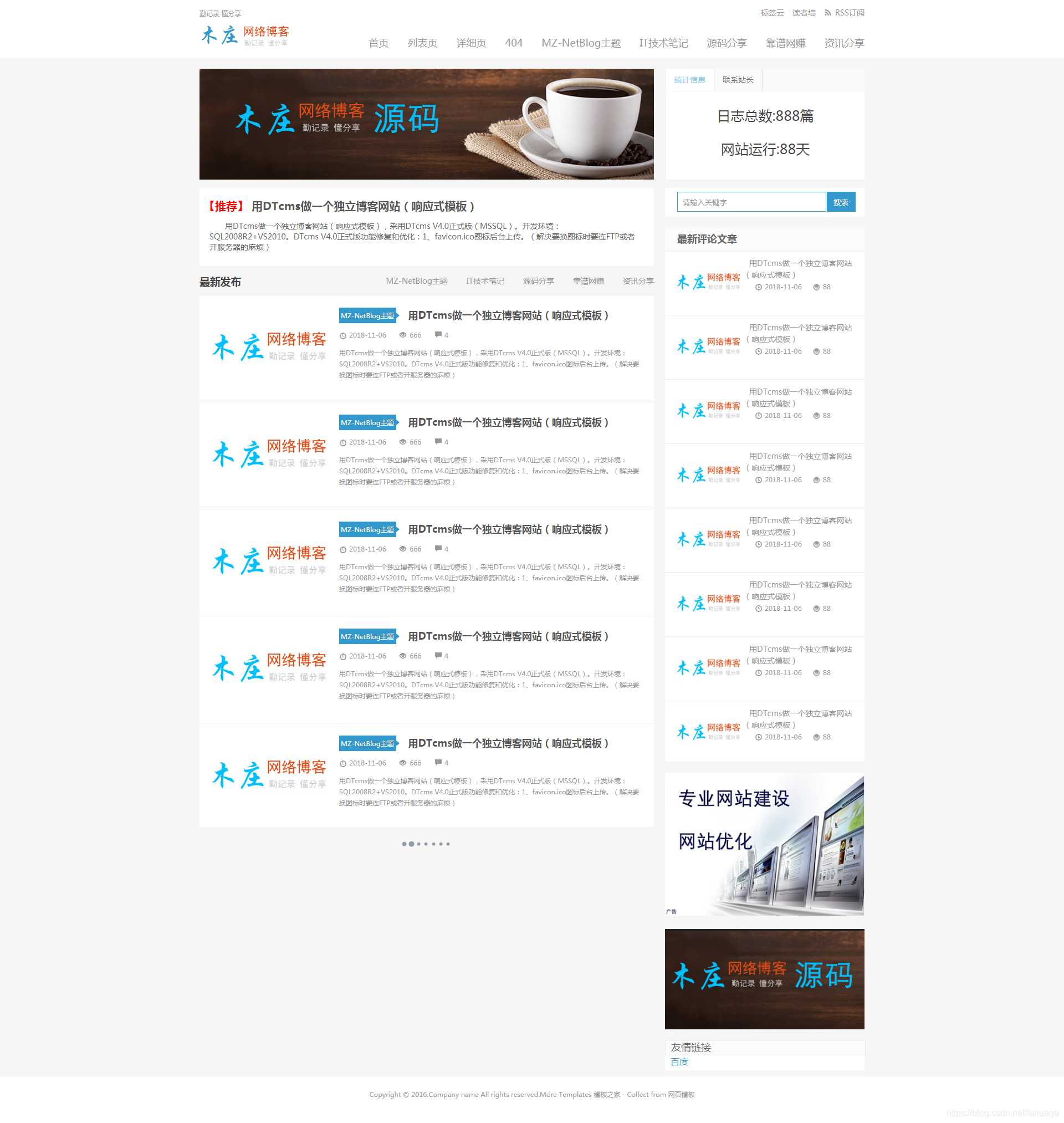
从项目中学习HTML+CSS 最近由于工作原因以及自己的懈怠,已经很久都没有更新过博客了。通过这段时间,我发现坚持一件事情是真的很难,都说万事开头难,但是在放弃这件事上好像开头了后面就顺理成章的继续下去了。中间即使不怎么情愿也在努力的每周更新博客,但是自从9月份以来,第一次因为工作需要加班而断更之后,后面好像很容易找到理由断更。从这件事上我学到了一点:在坚持一件事的时候千万要坚持,只要中间放弃一次,后续就可以心安理得的将其抛之脑后。这次在这里也是希望自己能够再次坚持之前的每周至少一更。即使没有内容。。。。感想就这么多,现在进入真正的主题——HTML+CSS相关内容的整理,因为网上针对HTML+CSS的相关知识已经很多了,而且都是很零碎的点,大多是对应的代码,也可以说是应用性极强的,我本人是不太喜欢大段大段的帖代码的。学习的过程中我喜欢从理论或者从实践开始,根据需求或者理论来写代码,需求清楚了,流程出来了,代码就是水到渠成的事。所以这次就根据具体的一个网页项目来梳理一下我这段时间学习这些东西的成果。最终的效果图如下:我希望自己通过对Web开发的学习能够自己独立的开发一套博客系统,因此我在选择练手项目的时候主要找的是博客的相关页面。这是从站长之家上找的一个博客网站模板的首页,它相对其他的模板来说显的比较中规中矩,而且对初学者来说实现起来更加简单。基本布局从大体上看,它可以分为几个部分:大体上分为3个部分,头部、内容部分,以及下方的页脚部分。头部可以分为上面的标题以及下方的导航部分,内容部分又可以分为左边和右边两个部分。然后根据区域的划分,可以写下大体的代码:<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>CSS + HTML项目博客首页</title> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="css/style.css"> </head> <body> <!--顶部--> <div class = "header"> <div class = "title"> </div> <div class = "nav"> </div> </div> <div class = "container"> <div class = "left"> </div> <div class = "right"> </div> </div> <!--底部--> <div class = "footer"> </div> </body> </html>然后再使用CSS的样式规定具体的布局颜色:*{ margin:auto; /*只有设置了对应的宽度,才会默认居中*/ padding:0px; font-family: "Microsoft YaHei","微软雅黑","Lantinghei SC","Open Sans",Arial,"Hiragino Sans GB","STHeiti","WenQuanYi Micro Hei",SimSun,sans-serif; } .header{ margin-top:15px; } .title{ height: 20px; line-height: 15px; width:1200px; color:#999; } .nav{ width:1200px; margin-top:8px; } .container{ width:1200px; margin-top:15px; } .left{ float:left; width:820px; } .right{ float:left; margin-left:20px;; } .footer{ height:60px; width:100%; background-color:#fff; text-align: center; padding-top:24px; font-size:12px; color:#999; }这里有一个问题,我当时一直以为margin:auto;这个会直接将对应的元素居中,但是我在实践中发现它好像并没有,原来当时我忘记了设置元素的宽度,而元素默认的宽度是与父元素相同的,这样就导致margin:auto这个属性认为不需要给外边距,所以也就没有居中,只有给了宽度,它才会将元素相对于父元素居中。导航栏的实现这里导航栏使用无序列表 + a链接来实现,我们先写上对应的HTML代码<ul> <li><a href="index.html">首页</a></li> <li><a href="index.html">列表页</a></li> <li><a href="index.html">详细页</a></li> <li><a href="index.html">404</a></li> <li><a href="index.html">MZ-NetBlog主题</a></li> <li><a href="index.html">IT技术笔记</a></li> <li><a href="index.html">源码分享</a></li> <li><a href="index.html">靠谱网赚</a></li> <li style = "margin-right: 0px;"><a href="index.html">资讯分享</a></li> </ul>然后通过CSS样式来调整/*先去掉列表前的小圆点*/ .nav ul { list-style-type: none; } /*让列表项左浮动,以便导航项可以横向排列,同时设置右外边距,让各项可以分割开来*/ .nav ul li{ float:left; margin-right:34px; } /*上述内容已经有了导航栏的雏形,剩下的就是设置导航项的字体、颜色、以及点击的相关属性*/ .nav ul li a{ text-decoration:none; color:#999; font-size:18px; } .nav ul li a:hover{ color:lightskyblue; } .nav ul li a:active{ color:lightskyblue; }通过上述的简单的CSS就可以制作对应的导航栏了左上角标签页的制作从原始的网页效果图来看,标签页可以看成上下两个部分,上方是一个导航栏,而下方则是一个div,这个div根据点击导航上的具体项来显示不同的内容。因此它的大致内容结构可以用下面的HTML来定义<div class = "about"> <!--上方是一个导航栏--> <div class = "tab-header"> <ul> <li><a href = "#" style = "color:lightskyblue;background-color:#fff;">统计信息</a></li> <li><a href = "#">联系站长</a></li> </ul> </div> <!--下方是用来显示具体的内容--> <div class = "info"> <p>日志总数:888篇</p> <p>网站运行:88天</p> </div> </div>上方的导航可以沿用之前的导航栏的CSS代码,而下方只需要设置对应的北京颜色即可,这里就不再贴出了文章列表文章列表采用的仍然是列表的方式,我们可以针对列表的每个项设置对应的边框,以及长度和宽度即可。下面只贴出对应的CSS代码/**列表本身属性**/ .article-list{ width:820px; height:960px; background-color:#fff; margin-top:15px; } /**列表项属性**/ .article{ width:820px; height: 192px; border-top: solid 1px rgb(234,234,234); }文章项的制作文章列表中有具体的文章项,这个文章项可以简单的分为几个部分:图片、标题、文章属性等等内容、文章的摘要;在这里我将它们都作为同级元素,然后调整浮动以及大小,它自然就会按照这样的布局进行排列。<div class ="article"> <a class = "article-img"><img src = "images/article.jpg"></a> <div class = "label"> <div class = "rect"><span>MZ-NetBlog主题</span></div> <div class = "arrow"></div> <a href = "#">用DTcms做一个独立博客网站(响应式模板)</a> </div> <div class = "time-watch-comment"> <span class = "time"><img src = "images/clock.jpg"><span>2018-11-06</span></span> <span class = "watch"><img src = "images/eye.jpg"><span>666</span></span> <span class = "comment"><img src = "images/comment.jpg"><span>4</span></span> </div> <p>用DTcms做一个独立博客网站(响应式模板),采用DTcms V4.0正式版(MSSQL)。开发环境:SQL2008R2+VS2010。DTcms V4.0正式版功能修复和优化:1、favicon.ico图标后台上传。(解决要换图标时要连FTP或者开服务器的麻烦)</p> </div>这个部分我感觉最需要提出来的是对标签的制作,这里的标签是文章标题前面的那个蓝色背景,白色字体的矩形后带有箭头的东西,这个的制作我采用的是前方一个标签,而后方利用另一个div 来制作的小箭头。想要制作小箭头首先需要回归一下CSS中讲到的border属性,我们知道border表示的是边框,我们可以通过设置border的值来规定边框的大小颜色等等属性,那么当我们在四个边上都规定边框的时候,边框是如何来显示的呢,我们写下如下的实例<div class = "div1"></div>.div1{ width:100px; height:100px; background: orange; float: left; border-top:10px solid black; border-bottom:12px solid green; border-left:15px solid red; border-right:20px solid blue; border-style: solid; }刷新浏览器,我们发现它产生的是这样的一个效果之前在学习的时候我一直实验的是border为1个像素,但是没想到给边框加粗后能产生这样的效果,它能够产生这样一种像话框的效果,随着边框的加粗,中间的内容越小,而这个画框的边框就越大。这个时候很容易就产生一种想法,随着边框的加粗,最终上下或者左右边框完全占据元素的所有空间,而另一侧为空,那么就可以产生一个类似于箭头的效果,根据这个想法,我们再修改一下上面的CSS代码.div1{ width:0px; height:0px; border-top:50px solid black; border-bottom:50px solid green; border-left:15px solid red; border-style: solid; }这个时候它的效果如下:这样我们把上下两个边框的眼色设置为父元素的背景色,左边框设置为需要的颜色,就可以做一个小的箭头了。而要调整它的宽度、角度等等只需要调整上下边框的宽度即可。下面是箭头最终的CSS代码/*方向向右的小箭头*/ .arrow{ float:left; background-color:#fff; width:0; height:0; border-top:5px solid transparent; border-bottom: 5px solid transparent; border-left: 6px solid #3399CC; margin-top: 31px; }搜索框的实现这个搜索框我简单的使用了一个带边框的文本输入框加一个按钮。它的HTML代码如下:<input class = "search-box" type = "text" value = "请输入关键字"/> <input class = "search-submit" type = "submit" value = "搜索"/>对应的CSS代码如下:.search-box{ width:258px; height:34px; border:solid 1px rgb(51, 153, 204); margin-top:7px; margin-left:22px; margin-right:0px; color:#999; padding-left:9px; } .search-submit{ width:52px; height:36px; background-color:rgb(51, 153, 204); border-style:none; margin-left:-4px; color:#fff; }项目后记这个页面虽然说完成了,但是也是有一些不足的地方:页面中几乎每一个元素写了它的属性,而且有的属性是几乎类似的,代码只是简单的完成了页面没有考虑到重用页面是静态的,简单的利用HTML+CSS来做展示,没有交互的东西,而原始的模板是有的,交互这个的部分我想学习了JavaScript 和 JQuery之后再来加虽然我主要用C/C++ 与Python做过一些服务程序和其他的Web程序,但是对于前端的相关内容也仅仅是会用HTML,关于布局和CSS的东西几乎不懂,而这次我想抽点时间学习一下这方面的内容。为什么会想要学习前端呢?之前不知道在哪看到这么一句话: "黑客一定是程序员,而程序员不一定是黑客", 作为一个初步迈入Web安全大门的我来说,想要深入Web安全就必须学会Web开发,而Web开发是绕不开前端的。虽然不要求有很高的前端水平,但是基本的布局、css、JavaScript、jQuery还是得会的,所以我想先抽点时间好好补一下这方面的内容。
-
xampp 中 mysql的相关配置 最近开始接触PHP,而一般搭建PHP环境使用的都是xampp 这个集成环境,由于之前我的系统中已经安装了mysql服务,所以在启动mysql的时候出现一些列错误,我通过查询各种资料解决了这个问题,现在记录一下,方便日后遇到同样的问题时能够快速解决,也为遇到同样问题的朋友提供一种解决的思路。启动刚开始时我在点击启动mysql的时候发现它一直卡在尝试启动mysql这个位置,xampp提示内容如下:Attempting to start MySQL service...它启动不成功但是也不提示出错,而且查询日志发现没有错误的日志,这个时候我想到应该是我本地之前安装了mysql,导致失败。而且我还将mysql安装成为了服务,后来查询相关资料,有网友说需要将mysql服务的地址改为xampp下mysql所在地址,具体怎么改我就不写了,一般都可以找到,但是我想说的是,这个方式好像在我这边不起作用。那么就干脆一点直接删除服务就好了。sc delete mysql上述命令直接删除mysql这个服务。然后重启xampp,再次启动mysql,它终于报错了。只要报错就好说了,现在来查询日志,发现日志如下:2018-10-13 22:52:19 37d0 InnoDB: Warning: Using innodb_additional_mem_pool_size is DEPRECATED. This option may be removed in future releases, together with the option innodb_use_sys_malloc and with the InnoDB's internal memory allocator. 2018-10-13 22:52:19 14288 [Note] InnoDB: innodb_empty_free_list_algorithm has been changed to legacy because of small buffer pool size. In order to use backoff, increase buffer pool at least up to 20MB. 2018-10-13 22:52:19 14288 [Note] InnoDB: Using mutexes to ref count buffer pool pages 2018-10-13 22:52:19 14288 [Note] InnoDB: The InnoDB memory heap is disabled 2018-10-13 22:52:19 14288 [Note] InnoDB: Mutexes and rw_locks use Windows interlocked functions 2018-10-13 22:52:19 14288 [Note] InnoDB: _mm_lfence() and _mm_sfence() are used for memory barrier 2018-10-13 22:52:19 14288 [Note] InnoDB: Compressed tables use zlib 1.2.3 2018-10-13 22:52:19 14288 [Note] InnoDB: Using generic crc32 instructions 2018-10-13 22:52:19 14288 [Note] InnoDB: Initializing buffer pool, size = 16.0M 2018-10-13 22:52:19 14288 [Note] InnoDB: Completed initialization of buffer pool 2018-10-13 22:52:19 14288 [Note] InnoDB: Highest supported file format is Barracuda. 2018-10-13 22:52:19 14288 [Warning] InnoDB: Resizing redo log from 2*3072 to 2*320 pages, LSN=1600607 2018-10-13 22:52:19 14288 [Warning] InnoDB: Starting to delete and rewrite log files. 2018-10-13 22:52:19 14288 [Note] InnoDB: Setting log file C:\xampp\mysql\data\ib_logfile101 size to 5 MB 2018-10-13 22:52:19 14288 [Note] InnoDB: Setting log file C:\xampp\mysql\data\ib_logfile1 size to 5 MB 2018-10-13 22:52:19 14288 [Note] InnoDB: Renaming log file C:\xampp\mysql\data\ib_logfile101 to C:\xampp\mysql\data\ib_logfile0 2018-10-13 22:52:19 14288 [Warning] InnoDB: New log files created, LSN=1601036 2018-10-13 22:52:19 14288 [Note] InnoDB: 128 rollback segment(s) are active. 2018-10-13 22:52:19 14288 [Note] InnoDB: Waiting for purge to start 2018-10-13 22:52:19 14288 [Note] InnoDB: Percona XtraDB (http://www.percona.com) 5.6.39-83.1 started; log sequence number 1600607 2018-10-13 22:52:20 3508 [Note] InnoDB: Dumping buffer pool(s) not yet started 2018-10-13 22:52:20 14288 [Note] Plugin 'FEEDBACK' is disabled. 2018-10-13 22:52:20 14288 [ERROR] Could not open mysql.plugin table. Some plugins may be not loaded 2018-10-13 22:52:20 14288 [ERROR] Can't open and lock privilege tables: Table 'mysql.servers' doesn't exist 2018-10-13 22:52:20 14288 [Note] Server socket created on IP: '::'. 2018-10-13 22:52:20 14288 [ERROR] Fatal error: Can't open and lock privilege tables: Table 'mysql.user' doesn't exist 2018-10-13 22:55:18 3024 InnoDB: Warning: Using innodb_additional_mem_pool_size is DEPRECATED. This option may be removed in future releases, together with the option innodb_use_sys_malloc and with the InnoDB's internal memory allocator. 2018-10-13 22:55:18 12324 [Note] InnoDB: innodb_empty_free_list_algorithm has been changed to legacy because of small buffer pool size. In order to use backoff, increase buffer pool at least up to 20MB.找到其中的ERROR项,发现它提示mysql.user这个表不存在,这个表保存的是mysql的账号信息,如果没有这个,它无法知道哪些是合法用户,合法用户又有哪些权限,因此这里就需要创建这个表。通过查询资料发现这是由于未进行mysql数据初始化的缘故,这个错误经常见于通过源码包在编译安装的时候。这个时候需要使用命令 mysql_install_db 来初始化数据库表mysql_install_db --user=mysql -d C:\xampp\mysql\data\-d 后面跟上mysql表数据所在路径执行之后发现程序又报错了,这次提示mysql的版本不对Can't find messagefile "D:\mysql-8.0.11-winx64\share\errmsg.sys". Probably from another version of MariaDB这个时候就很奇怪了,我启动的是xampp中的mysql,为何它给我定位的是之前安装的MySQL所在路径呢?出现这种现象肯定是系统中的相关配置的路径不对,之前已经删掉了mysql服务,那么应该不可能会是服务配置导致的,剩下的应该就是环境变量了,通过一个个的查看环境变量,终于发现了 MYSQL_HOME这个变量给的是 D:\mysql-8.0.11-winx64 这个路径,我们将这个环境变量的值修改为xampp中mysql的路径然后再执行命令初始化mysql表数据,这个时候成功了。完成了这些操作,我这边就可以通过xampp面板启动mysql了。数据库配置刚开始时使用root账户登录是不需要密码的,这样是很危险的操作,容易发生数据泄露,为了安全起见,首先给root账户输入一个复杂的密码mysqladmin -uroot -p password回车之后它会让你输入新的密码,如果是修改密码可以使用下面的命令mysqladmin -uroot -p"test" password其中test为原始密码在回车之后它会让你输入新的密码我们为root设置了一个相对复杂的密码,但是与Linux系统相似,为了安全一般不能随便给出root账户,这个时候就需要一个非root账户并为它设置相关权限,我们可以在进入mysql后,使用grant 命令来创建账户以及分配权限grant all privileges on *.* to masimaro@localhost identified by "masimarotest"; flush privileges;它的语法格式为: grant 权限 on 数据库.表 to 用户名@主机 identified by "密码" 权限,all privileges 表示所有权限,如果不想分配所有权限,可以考虑使用 select,insert,update,delete,create,drop,index,alter,grant,references,reload,shutdown,process,file 权限中的任意一个或者多个。数据库,表:我们可以指定具体的用户对具体的数据库表有何种权限主机:主机可以是localhost,%(任意主机),或者具体的主机名、ip等等,表示这个账户只能通过对应的主机来登录分配完成之后通过 flush privileges; 语句来保存我们分配的账户和权限为了方便操作,还可以对phpmyadmin进行配置,以便能够使用phpmyadmin来连接并操作mysql数据库。可以在phpmyadmin目录中找到 config.inc.php 文件,找到这么几行$cfg['Servers'][$i]['user'] = ''; //连接数据库的用户 $cfg['Servers'][$i]['password'] = ''; //连接数据库的用户密码 $cfg['Servers'][$i]['host'] = '127.0.0.1'; //数据库所在主机 $cfg['Servers'][$i]['controluser'] = 'root'; //phpmyadmin 所使用的配置账户 $cfg['Servers'][$i]['controlpass'] = ''; //配置账户的密码根据具体情况配置这些信息之后,就可以直接连上PHPmyadmin了,然后根据它的提示来初始化相关数据库和表即可
-
VC 在调用main函数之前的操作 在C/C++语言中规定,程序是从main函数开始,也就是C/C++语言中以main函数作为程序的入口,但是操作系统是如何加载这个main函数的呢,程序真正的入口是否是main函数呢?本文主要围绕这个主题,通过逆向的方式来探讨这个问题。本文的所有环境都是在xp上的,IDE主要使用IDA 与 VC++ 6.0。为何不选更高版本的编译器,为何不在Windows 7或者更高版本的Windows上实验呢?我觉得主要是VC6更能体现程序的原始行为,想一些更高版本的VS 它可能会做一些优化与检查,从而造成反汇编生成的代码过于复杂不利于学习,当逆向的功力更深之后肯定得去分析新版本VS 生成的代码,至于现在,我的水平不够只能看看VC6 生成的代码首先通过VC 6编写这么一个简单的程序#include <stdio.h> #include <windows.h> #include <tchar.h> int main() { wchar_t str[] = L"hello world"; size_t s = wcslen(str); return 0; }通过单步调试,打开VC6 的调用堆栈界面,发现在调用main函数之前还调用了mainCRTStartup 函数:在VC6 的反汇编窗口中好像不太好找到mainCRTStartup函数的代码,因此在这里改用IDA pro来打开生成的exe,在IDA的 export窗口中双击 mainCRTStartup 函数,代码就会跳转到函数对应的位置。它的代码比较长,刚开始也是进行函数的堆栈初始化操作,这个初始化主要是保存原始的ebp,保存重要寄存器的值,并且改变ESP的指针值初始化函数堆栈,这些就不详细说明了,感兴趣的可以去看看我之前写的关于函数反汇编分析的内容:C函数原理在初始化完成之后,它有这样的汇编代码.text:004010EA push offset __except_handler3 .text:004010EF mov eax, large fs:0 .text:004010F5 push eax .text:004010F6 mov large fs:0, esp这段代码主要是用来注册主线程的的异常处理函数的,为什么它这里的4行代码就可以设置线程的异常处理函数呢?这得从SEH的结构说起。每个线程都有自己的SEH链,当发生异常的时候会调用链中存储的处理函数,然后根据处理函数的返回来确定是继续运行原先的代码,还是停止程序还是继续将异常传递下去。这个链表信息保存在每个线程的NT_TIB结构中,这个结构每个线程都有,用来记录当前线程的相关内容,以便在进行线程切换的时候做数据备份和恢复。当然不是所有的线程数据都保存在这个结构中,它只保留部分。该结构的定义如下:typedef struct _NT_TIB { PEXCEPTION_REGISTRATION_RECORD ExceptionList; PVOID StackBase; PVOID StackLimit; PVOID SubSystemTib; union { PVOID FiberData; ULONG Version; }; PVOID ArbitraryUserPointer; PNT_TIB Self; } NT_TIB, *PNT_TIB;这个结构的第一个参数是一个异常处理链的链表头指针,链表结构的定义如下:typedef struct _EXCEPTION_REGISTRATION_RECORD { PEXCEPTION_REGISTRATION_RECORD Next; PEXCEPTION_DISPOSITION Handler; } EXCEPTION_REGISTRATION_RECORD, *PEXCEPTION_REGISTRATION_RECORD;这个结构很简单的定义了一个链表,第一个成员是指向下一个节点的指针,第二个参数是一个异常处理函数的指针,当发生异常的时候会去调用这个函数。而这个链表的头指针被存到fs寄存器中知道了这点之后再来看这段代码,首先将异常函数入栈,然后将之前的链表头指针入栈,这样就组成了一个EXCEPTION_REGISTRATION_RECORD结构的节点而这个节点的指针现在就是ESP中保存的值,之后再将链表的头指针更新,也就是最后一句对fs的重新赋值,这是一个典型的使用头插法新增链表节点的操作。通过这样的几句代码就向主线程中注入了一个新的异常处理函数。之后就是进行各种初始化的操作,调用GetVersion 获取版本号,调用 __heap_init 函数初始化C运行时的堆栈,这个函数后面有一个 esp + 4的操作,这里可以看出这个函数是由调用者来做堆栈平衡的,也就是说它并不是Windows提供的api函数(API函数一般都是stdcall的方式调用,并且命名采用驼峰的方式命名)。调用GetCommandLineA函数获取命令行参数,调用 GetEnvironmentStringsA 函数获取系统环境变量,最后有这么几句话:.text:004011B0 mov edx, __environ .text:004011B6 push edx ; envp .text:004011B7 mov eax, ___argv .text:004011BC push eax ; argv .text:004011BD mov ecx, ___argc .text:004011C3 push ecx ; argc .text:004011C4 call _main_0这段代码将环境变量、命令行参数和参数个数作为参数传入main函数中。 在C语言中规定了main函数的三种形式,但是从这段代码上看,不管使用哪种形式,这三个参数都会被传入,程序员使用哪种形式的main函数并不影响在VC环境在调用main函数时的传参。只是我们代码中不使用这些变量罢了。到此,这篇博文简单的介绍了下在调用main函数之前执行的相关操作,这些汇编代码其实很容易理解,只是在注册异常的代码有点难懂。最后总结一下在调用main函数之前的相关操作注册异常处理函数调用GetVersion 获取版本信息调用函数 __heap_init初始化堆栈调用 __ioinit函数初始化啊IO环境,这个函数主要在初始化控制台信息,在未调用这个函数之前是不能进行printf的调用 GetCommandLineA函数获取命令行参数调用 GetEnvironmentStringsA 函数获取环境变量调用main函数
-
Windows下的代码注入 木马和病毒的好坏很大程度上取决于它的隐蔽性,木马和病毒本质上也是在执行程序代码,如果采用独立进程的方式需要考虑隐藏进程否则很容易被发现,在编写这类程序的时候可以考虑将代码注入到其他进程中,借用其他进程的环境和资源来执行代码。远程注入技术不仅被木马和病毒广泛使用,防病毒软件和软件调试中也有很大的用途,最近也简单的研究过这些东西,在这里将它发布出来。想要将代码注入到其他进程并能成功执行需要解决两个问题:第一个问题是如何让远程进程执行注入的代码。原始进程有它自己的执行逻辑,想要破坏原来的执行流程,使EIP寄存器跳转到注入的代码位置基本是不可能的第二个问题是每个进程中地址空间是独立的,比如在调用某个句柄时,即使是同一个内核对象,在不同进程中对应的句柄也是不同的,这就需要进行地址转化。要进行远程代码注入的要点和难点主要就是这两个问题,下面给出两种不同的注入方式来说明如何解决这两个问题DLL注入DLL注入很好的解决了第二个问题,DLL被加载到目标进程之后,它里面的代码中的地址就会自动被转化为对应进程中的地址,这个特性是由于DLL加载的过程决定的,它会自己使用它所在进程中的资源和地址空间,所以只要DLL中不存在硬编码的地址,基本不用担心里面会出现函数或者句柄需要进行地址转化的问题。那么第一个问题改怎么解决呢?要执行用户代码,在Windows中最常见的就是使用回调的方式,Windows采用的是事件驱动的方式,只要发生了某些事件就会调用回调,在众多使用回调的场景中,线程的回调是最简单的,它不会干扰到目标进程的正常执行,也就不用考虑最后还原EIP的问题,因此DLL注入采用的最常见的就是创建一个远程线程,让线程加载DLL代码。DLL注入中一般的思路是:使用CreateRemoteThread来在目标进程中创建一个远程的线程,这个线程主要是加载DLL到目标进程中,由于DLL在入口函数(DLLMain)中会处理进程加载Dll的事件,所以将注入代码写到这个事件中,这样就能执行注入的代码了。那么如何在远程进程中执行DLL的加载操作呢?我们知道加载DLL主要使用的是函数LoadLibrary,仔细分析线程的回调函数和LoadLibrary函数的原型,会发现,它们同样都是传入一个参数,而CreateRemoteThread函数正好需要一个函数的地址作为回调,并且传入一个参数作为回调函数的参数。这样就有思路了,我们让LoadLibrary作为线程的回调函数,将对应dll的文件名和路径作为参数传入,这样就可以在对应进程中加载dll了,进一步也就可以执行dllmain中的对应代码了。还有一个很重要的问题,我们知道不同进程中,地址空间是隔离的,那么我在注入的进程中传入LoadLibrary函数的地址,这算是一个硬编码的地址,它在目标进程中是否是一样的呢?答案是,二者的地址是一样的,这是由于kernel32.dll在32位程序中加载的基地址是一样的,而LoadLibrary在kernel32.dll中的偏移是一定的(只要不同的进程加载的是同一份kernel32.dll)那么不同进程中的LoadLibrary函数的地址是一样的。其实不光是LoadLibrary函数,只要是kernel32.dll中导出的函数,在不同进程中的地址都是一样的。注意这里只是32位,如果想要使用32位程序往64位目标程序中注入,可能需要考虑地址转换的问题,只要知道kernel32.dll在64位中的偏移,就可以计算出对应函数的地址了。LoabLibrary函数传入的代表路径的字符串的首地址在不同进程中同样是不同的,而且也没办法利用偏移来计算,这个时候解决的办法就是在远程进程中申请一块虚拟地址空间,并将目标字符串写入对应的地址中,然后将对应的首地址作为参数传入即可。最后总结一下DLL注入的步骤:获取LoadLibrary函数的地址调用VirtualAllocEx 函数在远程进程中申请一段虚拟内存调用WriteProcessMemory 函数将参数写入对应的虚拟内存调用CreateRemoteThread 函数创建远程线程,线程的回调函数为LoadLibrary,参数为对应的字符串的地址按照这个思路可以编写如下的代码:typedef HMODULE(WINAPI *pfnLoadLibrary)(LPCWSTR); if (!DebugPrivilege()) //提权代码,在Windows Vista 及以上的版本需要将进程的权限提升,否则打开进程会失败 { return FALSE; } //打开目标进程 HANDLE hRemoteProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, dwPid); //dwPid是对应的进程ID if (NULL == hRemoteProcess) { AfxMessageBox(_T("OpenProcess Error")); } //查找LoadLibrary函数地址 pfnLoadLibrary lpLoadLibrary = (pfnLoadLibrary)GetProcAddress(GetModuleHandle(_T("kernel32.dll")), "LoadLibraryW"); //在远程进程中申请一块内存用于保存对应线程的参数 PVOID pBuffer = VirtualAllocEx(hRemoteProcess, NULL, MAX_PATH, MEM_COMMIT, PAGE_READWRITE); //在对应内存位置处写入参数值 DWORD dwWritten = 0; WriteProcessMemory(hRemoteProcess, pBuffer, m_csDLLName.GetString(), (m_csDLLName.GetLength() + 1) * sizeof(TCHAR), &dwWritten); //创建远程线程并传入对应参数 HANDLE hRemoteThread = CreateRemoteThread(hRemoteProcess, NULL, 0, (LPTHREAD_START_ROUTINE)lpLoadLibrary, pBuffer, 0, NULL); WaitForSingleObject(hRemoteThread, INFINITE); VirtualFreeEx(hRemoteProcess, pBuffer, 0, MEM_RELEASE); CloseHandle(hRemoteThread); CloseHandle(hRemoteProcess);卸载远程DLL上面进行了代码的注入,作为一个文明的程序,自然得考虑卸载dll,毕竟现在提倡环保,谁使用,谁治理。这里既然注入了,自然得考虑卸载。卸载的思路与注入的类似,只是函数变为了FreeLibrary,传入的参数变成了对应的dll的句柄了。如何获取这个模块的句柄呢?我们可以枚举进程中的模块,根据模块的名称来找到对应的模块并获取它的句柄。枚举的方式一般是使用toolhelp32中对应的函数,下面是卸载的例子代码HANDLE hSnapshot = CreateToolhelp32Snapshot(TH32CS_SNAPMODULE, m_dwPid); if (INVALID_HANDLE_VALUE == hSnapshot) { AfxMessageBox(_T("CreateToolhelp32Snapshot Error")); return; } MODULEENTRY32 me = {0}; me.dwSize = sizeof(MODULEENTRY32); BOOL bRet = Module32First(hSnapshot, &me); while (bRet) { CString csModuleFile = _tcsupr(me.szExePath); if (csModuleFile == _tcsupr((LPTSTR)m_csDLLName.GetString()) != -1) { break; } ZeroMemory(&me, sizeof(me)); me.dwSize = sizeof(PROCESSENTRY32); bRet = Module32Next(hSnapshot, &me); } CloseHandle(hSnapshot); typedef BOOL (*pfnFreeLibrary)(HMODULE); pfnFreeLibrary FreeLibrary = (pfnFreeLibrary)GetProcAddress(GetModuleHandle(_T("kernel32.dll")), "FreeLibrary"); HANDLE hRemoteProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, m_dwPid); if (hRemoteProcess == NULL) { AfxMessageBox(_T("OpenProcess Error")); return; } HANDLE hRemoteThread = CreateRemoteThread(hRemoteProcess, NULL, 0, (LPTHREAD_START_ROUTINE)FreeLibrary, me.modBaseAddr, 0, NULL); WaitForSingleObject(hRemoteThread, INFINITE); CloseHandle(hRemoteThread); CloseHandle(hRemoteProcess);无DLL的注入注入不一定需要使用DLL,虽然使用DLL比较简单一点,无DLL注入在解决上述两个问题的第一个思路是一样的,也是使用CreateRemoteThread来创建一个远程线程来执行目标代码。无dll的注入主要麻烦是在进行地址转化上,在调用API的时候,如果无法保证对应的dll的基地址不变的话,就得在目标进程中自行调用LoadLibrary来动态获取函数地址,并调用。在动态获取API函数的地址的时候,主要使用的函数是LoadLibrary、GetModuleHandle、GetProcAddress这三个函数,而线程的回调函数只能传入一个参数,所以我们需要将对应的需要传入的参数组成一个结构体,并将结构体对应的数据写入到目标进程的内存中,特别要注意的是,里面不要使用指针或者句柄这种与地址有关的东西。例如我们想在目标进程中注入一段代码,让它弹出一个对话框,以便测试是否注入成功。这种情况除了要传入上述三个函数的地址外,还需要MesageBox,而MessageBox是在user32.dll中,user32.dll在每个进程中的基地址并不相同,因此在注入的代码中需要动态加载,因此可以定义下面一个结构typedef struct REMOTE_DATA { DWORD dwLoadLibrary; DWORD dwGetProcAddress; DWORD dwGetModuleHandle; DWORD dwGetModuelFileName; //辅助函数 char szUser32dll[MAX_PATH]; //存储user32dll的路径,以便调用LoadLibrary加载 char szMessageBox[128]; //存储字符串MessageBoxA 这个字符串,以便使用GetProcAddress加载MesageBox函数 char szMessage[512]; //弹出对话框上显示的字符 }不使用DLL注入与使用DLL注入的另一个区别是,不使用DLL注入的时候需要自己加载目标代码到对应的进程中,这个操作可以借由WriteProcessMemory 将函数代码写到对应的虚拟内存中。最后注入的代码主要如下:DWORD WINAPI RemoteThreadProc(LPVOID lpParam) { LPREMOTE_DATA lpData = (LPREMOTE_DATA)lpParam; typedef HMODULE (WINAPI *pfnLoadLibrary)(LPCSTR); typedef FARPROC (WINAPI *pfnGetProcAddress)(HMODULE, LPCSTR); typedef HMODULE (*pfnGetModuleHandle)(LPCSTR); typedef DWORD (WINAPI *pfnGetModuleFileName)( HMODULE,LPSTR, DWORD); pfnGetModuleHandle MyGetModuleHandle = (pfnGetModuleHandle)lpData->dwGetModuleHandle; pfnGetModuleFileName MyGetModuleFileName = (pfnGetModuleFileName)lpData->dwGetModuleFileName; pfnGetProcAddress MyGetProcAddress = (pfnGetProcAddress)lpData->dwGetProcAddress; pfnLoadLibrary MyLoadLibrary = (pfnLoadLibrary)lpData->dwGetProcAddress; typedef int (WINAPI *pfnMessageBox)(HWND, LPCSTR, LPCSTR, UINT); //加载User32.dll HMODULE hUser32Dll = MyLoadLibrary(lpData->szUerDll); //加载MessageBox函数 pfnMessageBox MyMessageBox = (pfnMessageBox)MyGetProcAddress(hUser32Dll, lpData->szMessageBox); char szTitlte[MAX_PATH] = ""; MyGetModuleFileName(NULL, szTitlte, MAX_PATH); MyMessageBox(NULL, lpData->szMessage, szTitlte, MB_OK); return 0; } m_dwPid = GetPid(); //获取目标进程ID DebugPrivilege(); //进程提权 HANDLE hRemoteProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, m_dwPid); if (NULL == hRemoteProcess) { AfxMessageBox(_T("OpenProcess Error")); return; } LPREMOTE_DATA lpData = new REMOTE_DATA; ZeroMemory(lpData, sizeof(REMOTE_DATA)); //获取对应函数的地址 lpData->dwGetModuleFileName = (DWORD)GetProcAddress(GetModuleHandle(_T("kernel32.dll")), "GetModuleFileNameA"); lpData->dwGetModuleHandle = (DWORD)GetProcAddress(GetModuleHandle(_T("kernel32.dll")), "GetModuleHandleA"); lpData->dwGetProcAddress = (DWORD)GetProcAddress(GetModuleHandle(_T("kernel32.dll")), "GetProcAddress"); lpData->dwLoadLibrary = (DWORD)GetProcAddress(GetModuleHandle(_T("kernel32.dll")), "LoadLibraryA"); // 拷贝对应的字符串 StringCchCopyA(lpData->szMessage, MAX_STRING_LENGTH, "Inject Success!!!"); StringCchCopyA(lpData->szUerDll, MAX_PATH, "user32.dll"); StringCchCopyA(lpData->szMessageBox, MAX_PROC_NAME_LENGTH, "MessageBoxA"); //在远程空间中申请对应的内存,写入参数和函数的代码 LPVOID lpRemoteBuf = VirtualAllocEx(hRemoteProcess, NULL, sizeof(REMOTE_DATA), MEM_COMMIT, PAGE_READWRITE); // 存储data结构的数据 LPVOID lpRemoteProc = VirtualAllocEx(hRemoteProcess, NULL, 0x4000, MEM_COMMIT, PAGE_EXECUTE_READWRITE); // 存储函数的代码 DWORD dwWrittenSize = 0; WriteProcessMemory(hRemoteProcess, lpRemoteProc, &RemoteThreadProc, 0x4000, &dwWrittenSize); WriteProcessMemory(hRemoteProcess, lpRemoteBuf, lpData, sizeof(REMOTE_DATA), &dwWrittenSize); HANDLE hRemoteThread = CreateRemoteThread(hRemoteProcess, NULL, 0, (LPTHREAD_START_ROUTINE)lpRemoteProc, lpRemoteBuf, 0, NULL); WaitForSingleObject(hRemoteThread, INFINITE); VirtualFreeEx(hRemoteProcess, lpRemoteBuf, 0, MEM_RELEASE); VirtualFreeEx(hRemoteProcess, lpRemoteProc, 0, MEM_RELEASE); CloseHandle(hRemoteThread); CloseHandle(hRemoteProcess); delete[] lpData;
-
C 堆内存管理 在Win32 程序中每个进程都占有4GB的虚拟地址空间,这4G的地址空间内部又被分为代码段,全局变量段堆段和栈段,栈内存由函数使用,用来存储函数内部的局部变量,而堆是由程序员自己申请与释放的,系统在管理堆内存的时候采用的双向链表的方式,接下来将通过调试代码来分析堆内存的管理。堆内存的双向链表管理下面是一段测试代码#include <iostream> using namespace std; int main() { int *p = NULL; __int64 *q = NULL; int *m = NULL; p = new int; if (NULL == p) { return -1; } *p = 0x11223344; q = new __int64; if (NULL == q) { return -1; } *q = 0x1122334455667788; m = new int; if (NULL == m) { return -1; } *m = 0x11223344; delete p; delete q; delete m; return 0; }我们对这段代码进行调试,当代码执行到delete p;位置的时候(此时还没有执行delete语句)查看变量的值如下:p q m变量的地址比较接近,这三个指针变量本身保存在函数的栈中。从图中看存储这三个变量内存的地址好像不像栈结构,这是由于在高版本的VS中默认开启了地址随机化,所以这里看不出来这些地址的关系,但是如果在VC6里面可以很明显的看到它们在一个栈结构中。我们将p, q, m这三者所指向的内存都减去 0x20 得到p - 0x20 = 0x00035cc8 - 0x20 = 0x00035ca8 q - 0x20 = 0x00035d08 - 0x20 = 0x00035ce8 m - 0x20 = 0x00035d50 - 0x20 = 0x00035d30在内存窗口中分别查看p - 0x20, q- 0x20, m- 0x20 位置的内存如下通过观察发现p - 0x20处前8个字节存储了两个地址分别是 0x00035c38、0x00035ce8。是不是对0x00035ce8 这个地址感到很熟悉呢,它就是q - 0x20 处的地址,按照这个思路我们观察这些内存发现内存地址前四个字节后四个字节0x00035ca80x00035c380x00035ce80x00035ce80x00035ca80x00035d300x00035d300x00035ce80x00000000看到这些地址有没有发现什么呢?没错,这个结构有两个指针域,第一个指针域指向前一个节点,后一个指针域指向后一个节点,这是一个典型的双向链表结构,你没有发现?没关系,我们将这个地址整理一下得到下面这个图表既然知道了它的管理方式,那么接着往后执行delete语句,这个时候再看这些地址对应的内存中保存的值内存地址前四个字节后四个字节0x00035CA80x00035d700x000300c40x00035ce80x00035c380x00035d300x00035d300x00035ce80x00000000系统已经改变了后面两个节点中next和pre指针域的内容,将p节点从双向链表中除去了。而这个时候仔细观察p节点中存储内容发现里面得值已经变为 0xfeee 了。我们在delete的时候并没有传入对应的参数告知系统该回收多大的内存,那么它是怎么知道该如何回收内存的呢。我们回到之前的那个p - 0x20 内存的图上看,是不是在里面发现了一个0x00000004的值,其实这个值就是当前节点占了多少个字节,如果不相信,可以看看q- 0x20 和m - 0x20 内存处保存的值看看,在对应的偏移处是不是有 8和4。系统根据这个值来回收对应的内存。
-
VC++ 崩溃处理以及打印调用堆栈 我们在程序发布后总会面临崩溃的情况,这个时候一般很难重现或者很难定位到程序崩溃的位置,之前有方法在程序崩溃的时候记录dump文件然后通过windbg来分析。那种方法对开发人员的要求较高,它需要程序员理解内存、寄存器等等一系列概念还需要手动加载对应的符号表。Java、Python等等语言在崩溃的时候都会打印一条异常的堆栈信息并告诉用户那块出错了,根据这个信息程序员可以很容易找到对应的代码位置并进行处理,而C/C++则会弹出一个框告诉用户程序崩溃了,二者对比来看,C++似乎对用户太不友好了,而且根据它的弹框很难找到对应的问题,那么有没有可能使c++像Java那样打印异常的堆栈呢?这个自然是可能的,本文就是要讨论如何在Windows上实现类似的功能异常处理一般当程序发生异常时,用户代码停止执行,并将CPU的控制权转交给操作系统,操作系统接到控制权后,将当前线程的环境保存到结构体CONTEXT中,然后查找针对此异常的处理函数。系统利用结构EXCEPTION_RECORD保存了异常描述信息,它与CONTEXT一同构成了结构体EXCEPTION_POINTERS,一般在异常处理中经常使用这个结构体。异常信息EXCEPTION_RECORD的定义如下:typedef struct _EXCEPTION_RECORD { DWORD ExceptionCode; //异常码 DWORD ExceptionFlags; //标志异常是否继续,标志异常处理完成后是否接着之前有问题的代码 struct _EXCEPTION_RECORD* ExceptionRecord; //指向下一个异常节点的指针,这是一个链表结构 PVOID ExceptionAddress; //异常发生的地址 DWORD NumberParameters; //异常附加信息 ULONG_PTR ExceptionInformation[EXCEPTION_MAXIMUM_PARAMETERS]; //异常的字符串 } EXCEPTION_RECORD, *PEXCEPTION_RECORD;Windows平台提供的这一套异常处理的机制,我们叫它结构化异常处理(SEH),它的处理过程一般如下:如果程序是被调试运行的(比如我们在VS编译器中调试运行程序),当异常发生时,系统首先将异常信息交给调试程序,如果调试程序处理了那么程序继续运行,否则系统便在发生异常的线程栈中查找可能的处理代码。若找到则处理异常,并继续运行程序如果在线程栈中没有找到,则再次通知调试程序,如果这个时候仍然不能处理这个异常,那么操作系统会对异常进程默认处理,这个时候一般都是直接弹出一个错误的对话框然后终止程序。系统在每个线程的堆栈环境中都维护了一个SEH表,表中是用户注册的异常类型以及它对应的处理函数,每当用户在函数中注册新的异常处理函数,那么这个信息会被保存在链表的头部,也就是说它是采用头插法来插入新的处理函数,从这个角度上来说,我们可以很容易理解为什么在一般的高级语言中一般会先找与try块最近的catch块,然后在找它的上层catch,由里到外依次查找。与try块最近的catch是最后注册的,由于采用的是头插法,自然它会被首先处理。在Windows中针对异常处理,扩展了__try 和 __except 两个操作符,这两个操作符与c++中的try和catch非常相似,作用也基本类似,它的一般的语法结构如下:__try { //do something } __except(filter) { //handle }使用 __try 和 __except 的时候它主要分为3个部分,分别为:保护代码体、过滤表达式、异常处理块保护代码体一般是try中的语句,它值被保护的代码,也就是说我们希望处理那个代码块产生的异常过滤表达式是 except后面扩号中的值,它只能是3个值中的一个,EXCEPTION_CONTINUE_SEARCH继续向下查找异常处理,也就是说这里的异常处理块不处理这种异常,EXCEPTION_CONTINUE_EXECUTION表示异常已被处理,这个时候可以继续执行直线产生异常的代码,EXCEPTION_EXECUTE_HANDLER表示异常已被处理,此时直接跳转到except里面的代码块中,这种方式下它的执行流程与一般的异常处理的流程类似.异常处理块,指的是except下面的扩号中的代码块.注意:我们说过滤表达式只能是这三个值中的一个,但是没有说这里一定得填这三个值,它还支持函数或者其他的表达式类型,只要函数或者表达式的返回值是这三个值中的一个即可。上述的方式也有他的局限性,也就是说它只能保护我们指定的代码,如果是在 __try 块之外的代码发生了崩溃,可能还是会造成程序被kill掉,而且每个位置都需要写上这么些代码实在是太麻烦了。其实处理异常还有一种方式,那就是采用 SetUnhandledExceptionFilter来注册一个全局的异常处理函数来处理所有未被处理的异常,其实它的主要工作原理就是往异常处理的链表头上添加一个处理函数,函数的原型如下:LPTOP_LEVEL_EXCEPTION_FILTER WINAPI SetUnhandledExceptionFilter(__in LPTOP_LEVEL_EXCEPTION_FILTER lpTopLevelExceptionFilter);它需要传入一个函数,以便发生异常的时候调用这个函数,这个回调函数的原型如下:LONG WINAPI UnhandledExceptionFilter( __in struct _EXCEPTION_POINTERS* ExceptionInfo );回调函数会传入一个表示当前堆栈和异常信息的结构体的指针,结构的具体信息请参考MSDN, 函数会返回一个long型的数值,这个数值为上述3个值中的一个,表示当系统调用了这个异常处理函数处理异常之后该如何继续执行用户代码。SetUnhandledExceptionFilter 函数返回一个函数指针,这个指针指向链表的头部,如果插入处理函数失败那么它将指向原来的链表头,否则指向新的链表头(也就是注册的这个回调函数的地址)而这次要实现这么一个能打印异常信息和调用堆栈的功能就是要使用这个方法。打印函数调用堆栈关于打印堆栈的内容,这里不再多说了,请参考本人之前写的博客windows平台调用函数堆栈的追踪方法这里的主要思路是使用StackWalker来根据当前的堆栈环境来获取对应的函数信息,这个信息需要根据符号表来生成,因此我们需要首先加载符号表,而获取当前线程的环境,我们可以像我博客中写的那样使用GetThreadContext来获取,但是在异常中就简单的多了,还记得异常处理函数的原型吗?异常处理函数本身会带入一个EXCEPTION_POINTERS结构的指针,而这个结构中就包含了异常堆栈的信息。还有一些需要注意的问题,我把它放到实现那块了,请小心的往下看^_^实现实现部分的源码我放到了github上,地址这个项目中主要分为两个类CBaseException,主要是对异常的一个简单的封装,提供了我们需要的一些功能,比如获取加载的模块的信息,获取调用的堆栈,以及解析发生异常时的相关信息。而这些的基础都在CStackWalker中。使用上,我把CBaseException中的大部分函数都定义成了virtual 允许进行重写。因为具体我还没想好这块后续会需要进行哪些扩展。但是里面最主要的功能是OutputString函数,这个函数是用来进行信息输出的,默认CBaseException是将信息输出到控制台上,后续可以重载这个函数把数据输出到日志中。CBaseException 类CBaseException 主要是用来处理异常,在代码里面我提供了两种方式来进行异常处理,第一种是通过 SetUnhandledExceptionFilter 来注册一个全局的处理函数,这个函数是类中的静态函数UnhandledExceptionFilter,在这个函数中我主要根据异常的堆栈环境来初始化了一个CBaseException类,然后简单的调用类的方法显示异常与堆栈的相关信息。第二种是通过 _set_se_translator 来注册一个将SEH转化为C++异常的方法,在对应的回调中我简单的抛出了一个CBaseException的异常,在具体的代码中只要简单的用c++的异常处理捕获这么一个异常即可CBaseException 类中主要用来解析异常的信息,里面提供这样功能的函数主要有3个ShowExceptionResoult: 这个函数主要是根据异常码来获取到异常的具体字符串信息,比如非法内存访问、除0异常等等GetLogicalAddress:根据发生异常的代码的地址来获取对应的模块信息,比如它在PE文件中属于第几个节,节的地址范围等等,它在实现上首先使用 VirtualQuery来获取对应的虚拟内存信息,主要是这个模块的首地址信息,然后解析PE文件获取节表的信息,我们循环节表中的每一项,根据节表中的地址范围来判断它属于第几个节,注意这里我们根据它在内存中的偏移计算了它在PE文件中的偏移,具体的计算方式请参考PE文件的相关内容.3.ShowRegistorInformation:获取各个寄存器的值,这个值保存在CONTEXT结构中,我们只需要简单打印它就好CStackWalker类这个类主要实现一些基础的功能,它主要提供了初始化符号表环境、获取对应的调用堆栈信息、获取加载的模块信息在初始化符号表的时候尽可以多的遍历了常见的几种符号表的位置并将这些位置中的符号表加载进来,以便能更好的获取到堆栈调用的情况。在获取到对应的符号表位置后有这样的代码if (NULL != m_lpszSymbolPath) { m_bSymbolLoaded = SymInitialize(m_hProcess, T2A(m_lpszSymbolPath), TRUE); //这里设置为TRUE,让它在初始化符号表的同时加载符号表 } DWORD symOptions = SymGetOptions(); symOptions |= SYMOPT_LOAD_LINES; symOptions |= SYMOPT_FAIL_CRITICAL_ERRORS; symOptions |= SYMOPT_DEBUG; SymSetOptions(symOptions); return m_bSymbolLoaded;这里将 SymInitialize的最后一个函数置为TRUE,这个参数的意思是是否枚举加载的模块并加载对应的符号表,直接在开始的时候加载上可能会比较浪费内存,这个时候我们可以采用动态加载的方式,在初始化的时候先填入FALSE,然后在需要的时候自己枚举所有的模块,然后手动加载所有模块的符号表,手动加载需要调用SymLoadModuleEx。这里需要提醒各位的是,这里如果填的是FALSE的话,后续一定得自己加载模块的符号表,否则在后续调用SymGetSymFromAddr64的时候会得到一堆的487错误(也就是地址无效)我之前就是这个问题困扰了我很久的时间。在获取模块的信息时主要提供了两种方式,一种是使用CreateToolhelp32Snapshot 函数来获取进程中模块信息的快照然后调用Module32Next 和 Module32First来枚举模块信息,还有一种是使用EnumProcessModules来获取所有模块的句柄,然后根据句柄来获取模块的信息,当然还有另外的方式,其他的方式可以参考我的这篇博客 枚举进程中的模块在枚举加载的模块的同时还针对每个模块调用了 GetModuleInformation 函数,这个函数主要有两个功能,获取模块文件的版本号和获取加载的符号表信息。接下来就是重头戏了——获取调用堆栈。获取调用堆栈首先得获取当前的环境,在代码中进行了相应的判断,如果当前传入的CONTEXT为NULL,则函数自己获取当前的堆栈信息。在获取堆栈信息的时候首先判断是否为当前线程,如果不是那么为了结果准确,需要先停止目标线程,然后获取,否则直接使用宏来获取,对应的宏定义如下:#define GET_CURRENT_THREAD_CONTEXT(c, contextFlags) \ do\ {\ memset(&c, 0, sizeof(CONTEXT));\ c.ContextFlags = contextFlags;\ __asm call $+5\ __asm pop eax\ __asm mov c.Eip, eax\ __asm mov c.Ebp, ebp\ __asm mov c.Esp, esp\ } while (0)在调用StackWalker时只需要关注esp ebp eip的信息,所以这里我们也只简单的获取这些寄存器的环境,而其他的就不管了。这样有一个问题,就是我们是在CStackWalker类中的函数中获取的这个线程环境,那么这个环境里面会包含CStackWalker::StackWalker,结果自然与我们想要的不太一样(我们想要的是隐藏这个库中的相关信息,而只保留调用者的相关堆栈信息)。这个问题我还没有什么好的解决方案。在获取到线程环境后就是简单的调用StackWalker以及那堆Sym开头的函数来获取各种信息了,这里就不再详细说明了。至此这个功能已经实现的差不多了。库的具体使用请参考main.cpp这个文件,相信有这篇博文以及源码各位应该很容易就能够使用它。据说这些函数不是多线程安全的,我自己没有在多线程环境下进行测试,所以具体它在多线程环境下表现如何还是个未知数,如果后续我有兴趣继续完善它的话,可能会加入多线程的支持。
-
毕业两年的反思 以下内容都是在醉酒状态下写的,各位就当看个热闹吧,千万不要当真,要真能给您一些启发那就谢天谢地了。到今年6月份,已经毕业两年了,在这两年中换过一家公司,从银行外包到安全行业,经历过加班,也经历过无所事事,心中有些感慨和想法与大家分享时间真的是不等人,之前刚入行时我也是由一位老大哥带着做项目,那个时候我差不多是项目组年龄最小的,而如今在现在的公司中,我成了唯二的老员工,我从去年入职现在的公司到现在公司经历了一轮大的换血,老员工差不多都走了,而现在我也从当初的被别人带转换了角色变成了带新人,新员工都是刚毕业的大学生,有志向,有抱负,有的也有能力,跟他们一比,真的有种长江后浪推前浪的感觉。心中不免有些惆怅,原来一年一年的混日子,时间过的这么快。现在我真正理解了作为程序员必须的具备终身学习的能力。以及那种随时都有可能被新人给淘汰掉的危机感第二个就是不能对技术太过于执着,现在很多程序员包括我在内总是唯技术,好像一些产品里面用了某种牛逼的技术那它就值钱,就牛逼。其实真的不是这样的,技术是为需求服务的,再好的技术也是为了解决现实中的问题,只要能解决现实问题就算你用最low的算法,它也是一个好的产品。从这个角度来说,一个程序员的薪资水平跟他自身的技术水平并不是正相关的关系,薪资水平高低在于他能够利用手中的技术为公司带来多大效益或者说它能为多少人产生多大的价值。技术就是这样没有最好的,也没有最坏的,没有什么所谓的最前言,也没有什么淘汰之说,只有最合适它的平台,就拿汇编来说,很多地方的确用不上汇编了,但是在某些场合,比如说做安全进行HOOK的时候可能会需要,或者在一些对性能有着变态需求的地方,有的实在不能再优化了,只有将C代码改为对应的汇编代码。没有最好的技术只有最合适的技术既然说到终身学习,那么下面就来说说程序员学习的事。学习首先得找一个方向,也就是经常说的职业规划,一般来说刚入行的程序员可能并不知道自己该从事何种方向,就知道一心写代码,公司让干啥就干啥,公司有啥业务就学啥业务。确实一般刚入行的新人可能对整个行业没有一个整体的把握。我觉得入行后可以花1到2年的时间来关注业界相关新闻,不断跳槽以便接触更多方向,然后从中选择一个适合自己的或者自己真正喜欢的方向,随后自己的精力需要完全投入到这个方向上来,学习的路线也应该围绕着这个方向来进行。比如说我现在从事Web安全的开发,刚开始也是什么都不懂,XSS、SQL注入等等完全不了解,这些涉及到的是Web的相关知识,因此针对这点我自己给的学习路线是,首先学习HTML、CSS这些前端的相关知识,然后学习Web开发、了解常见的一些框架和开发语言,比如PHP、Java等等,公司主要做的是一款扫描器,而扫描器中很重要的一个部分是爬虫,现在爬虫一般流行用Python,因此我又顺便学习了Python的相关内容,而扫描器用来检测漏洞的一些POC都是用Python写的,这样也必须的学习Python。而Web又是基于HTTP协议的因此必须得学习HTTP协议,顺便可以学习TCP/IP协议的整个架构。因此这样很容易就能理出一条学习的线路来。所以说在后续学习的时候需要找出自己真正喜欢的方向(不一定是喜欢,但是必须是自己不讨厌的),了解一下这个方向的主要内容,从中找出自己的不足来进行针对性的学习。然后可以尝试着利用学到的知识写点小工具等等,比如我自己常常使用Python搜集一些网上的POC来集成到自己的程序中用来制作简单的漏洞探测工具。我感觉现在整个IT行业存在一个浮夸、焦躁的环境。经常就是过段时间有一个新技术出来,然后大量的关于新技术的课程,文章,以及大量的招对应的开发人员,看着薪水好像挺高,似乎这个技术就是未来,其他的技术都过时了,而我们程序员很容易被这种风气给带歪了,他们会花时间去学习新技术,然后跳槽,然后从简历上看他似乎什么都做过,前端火的时候他是一个前端程序员,后来Python全栈火了,他又成了全栈,然后大数据火了,他又做大数据去了,而现在AI火了,然后他现在是一个AI的开发人员,似乎他什么都会,但是后来发现就一个调用框架然后复制粘贴。当然我不反对学习新技术,学习新技术应该与应用相结合或者说与现实中的问题相结合,比如做扫描器经常会有误报,怎么消除误报呢?AI是不是一个好方法,能不能用机器学习来减少误报?如果可行,那么就可以考虑去学习一下。还有我们如何从海量的日志信息中找出具有攻击行为的那些日志?这个可不可以利用大数据来进行检索?利用机器学习来准确识别?我觉得这才是学习新技术的真正原因,而不是光看重新行业的薪水。还是前面说的技术是为需求服务的,学习也是一样的,为现实中具体的需求来学习。归根到底,学习应该是为了用新技术来解决现实问题。在这两年中,我越来越觉得基础知识的重要性,当初在学校时总觉得很多东西会用就行,不需要纠结它的细节,什么快速排序,二叉树等等这些都有现成的库函数,没必要去了解它们,所以没有好好学习这些内容。现在看来这种看法很有问题,学习基础就好像当时很多人嘲讽买菜不用微积分那样觉得生活中用不到它们。现在也有很多人跟我说过,学习那些算法没有用,这些都由老外在写,人家那么大的组织机构来维护,你自己写的肯定效果上没有别人的好,到时候会用就行。但是我想如果作为一个程序员如果只是把自己限制在使用别人的库,只会复制粘贴别人的代码,这样永远是一个底层的码农,而做不了真正的程序员,还是那句话让它服务于具体的应用,比如你学习了HTTP协议之后,能不能仿照它,做一个能在嵌入式设备中使用的微型的HTTP服务器而不是直接上Apache,或者我能不能利用它的设计思想来提供类似的功能。而不是说为了使用HTTP而使用,学习这些算法与基础的意义并不在于会用别人写的库,而在于根据具体的情形选择并设计编写出适当的代码。或者能更好的使用这些开源库,而不是仅仅把别人demo的东西照搬过来。在当今互联网时代,学习东西比过去方便了许多,但是互联网也有许多问题,第一个就是互联网上资源太丰富了,以至于想学一个课程但是找不到合适的,比如说我想学下C语言,你会发现网上一大片C的内容,有视频有博客还有电子/实体书,但是各种资源的质量良莠不齐,很难抉择。经常听到有建议说自学能力强的选择看视频或者看书,但是对于初学者来说很难分辨一个资源的好坏,我当时自认为自学能力很强,在大学期间找了各种视频,看了各种书,吃过很多亏走过很多弯路,才学会了点C的皮毛,经常就是一个视频看完了,感觉基础学会了,想找一些实践的东西,然后发现很多都是前面一点快速把基础过一遍,然后开始做项目,最后发现跟着视频项目做出来了,但是并没有学到什么东西,反倒是丢了视频好像什么都不会,然后就会产生一定的挫败感。我自己当时也是被虐到怀疑人生也常常在思考我是不是适合这个行业。但是好在我从来没有在我应该学习C/C++这条路上产生过怀疑。说到这里,我想说说我对培训机构的看法,现在很多人说到培训机构总是一副喊打喊杀的语气,好像培训机构毁了整个IT行业。其实培训机构很不错的,他至少能带你入门,我们常说师傅领进门,修行在个人。跟着培训机构就好像有一个前辈一直在带你,给你分享他的见识,分享他的思路,而且培训机构能让你快速融入这个圈子,毕竟你的同学老师都是从事这个行业的。从这个角度来看好的培训结构能使你受用终身。每个行业都有好有坏,不要一杆子打倒一片。但是一般包就业,并承诺薪资的一般是坑。互联网的另一个坏处就是造就了一批伸手党,他们混迹于各大论坛,QQ 群,经常就是甩出一段代码然后告诉你这个跟他想的不一样,该怎么改。最可恨的是有的还给的是截图,你想给他调都没办法,难道要别人一个一个的照着敲,拜托大家都很忙好吧。其实很多问题都是你自己单步调试一下就可以解决的,很多人就是不愿意,一句我是初学者,我不会,所以你帮我看看,一般像这种看了真的是让人火大;另外一种人就是自认为是大神的,经常有初学者提问说,我想学下XXX,请问该怎么学,这个时候总有那么几个大神会告诉人家,你学这个没用,还不如去学XXX,或者说这个不用学,有现成的代码,然后甩一个连接给段代码,这种人也是令人火大的,人家初学者想学一个东西,你没有系统的学过就不要回答了,我觉得这样完全是误人子弟。所以你看:现在互联网虽然方便,但是学习的路并似乎没有变得轻松,它只是以另一种形式增加了你学习的成本而已,过去很多东西报个班或者找个老师花点钱就给你讲明白了,但是现在互联网时代很多人觉得资源应该共享,应该免费。但是从某种程度上学习成本其实基本没变,而且是以一种无形的成本来体现出来的,通常这种成本是最难发觉的,可能对你造成的误导是最深的。以上都是本人的一些突发奇想,写这些的时候是跟以前的同学一起喝过酒的,很多地方都有点胡言乱语的意思。请各位见谅。。。。。
-
WinSock Socket 池 之前在WinSock2.0 API 中说到,像DisConnectEx 函数这样,它具有回收SOCKET的功能,而像AcceptEx这样的函数,它不会自己在内部创建新的SOCKET,需要外部传入SOCKET作为传输数据用的SOCEKT,使用这两个函数,我们可以做到,事先创建大量的SOCKET,然后使用AcceptEx函数从创建的SOCKET中选择一个作为连接用的SOCKET,在不用这个SOCKET的时候使用DisConnectEx回收。这样的功能就是一个SOCKET池的功能。SOCKET池WinSock 函数就是为了提升程序的性能而产生的,这些函数主要使用与TCP协议,我们可以在程序启动的时候创建大量的SOCKET句柄,在必要的时候直接使用AcceptEx这样的函数来使用已有的SOCKET作为与客户端的连接,在适当的时候使用WSARecv、WSASend等函数金星秀数据收发操作。而在不用SOCKET的时候使用DisConnectEx 回收,这样在响应用户请求的时候就省去了大量SOCKET创建和销毁的时间,从而提高的响应速度。IOCP本身也是一个线程池,如果用它结合WinSock 的线程池将会是Windows系统上最佳的性能组合,当然在此基础上可以考虑加入线程池、内存池的相关技术来进一步提高程序的性能。这里我想顺便扯点关于程序优化的理解。程序优化主要考虑对函数进行优化,毕竟在C/C++中函数是最常用,最基本的语法块,它的使用十分常见。函数的优化一般有下面几个需要考虑的部分是否需要大量调用这个函数。针对需要大量调用某个函数的情况,可以考虑对算法进行优化,减少函数的调用函数中是否有耗时的操作,如果有可以考虑使用异步的方式,或者将函数中的任务放到另外的线程(只有当我们确实不关心这个耗时操作的结果的时候,也就是说不涉及到同步的时候)函数中是否有大量的资源调用,如果有,可以考虑使用资源池的方式避免大量资源的申请与释放操作下面是一个使用SOCKET池的客户端的实例#include <stdio.h> #include <process.h> #include "MSScokFunc.h" #define SERVICE_IP "119.75.213.61" #define MAX_CONNECT_SOCKET 500 unsigned int WINAPI IOCPThreadProc(LPVOID lpParam); LONG g_nPorts = 0; CMSScokFunc g_MsSockFunc; typedef struct _tag_CLEINT_OVERLAPPED { OVERLAPPED overlapped; ULONG ulNetworkEvents; DWORD dwFlags; DWORD wConnectPort; DWORD dwTransBytes; char *pBuf; DWORD dwBufSize; SOCKET sConnect; }CLIENT_OVERLAPPED, *LPCLIENT_OVERLAPPED; SOCKADDR_IN g_LocalSockAddr = {AF_INET}; int main() { WSADATA wd = {0}; WSAStartup(MAKEWORD(2, 2), &wd); SYSTEM_INFO si = {0}; const int on = 1; GetSystemInfo(&si); HANDLE hIOCP = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, NULL, si.dwNumberOfProcessors); HANDLE *pThreadArray = (HANDLE *)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(HANDLE) * 2 * si.dwNumberOfProcessors); for (int i = 0; i < 2 * si.dwNumberOfProcessors; i++) { HANDLE hThread = (HANDLE)_beginthreadex(NULL, 0, IOCPThreadProc, &hIOCP, 0, NULL); pThreadArray[i] = hThread; } g_MsSockFunc.LoadAllFunc(AF_INET, SOCK_STREAM, IPPROTO_IP); LPCLIENT_OVERLAPPED *pOverlappedArray = (LPCLIENT_OVERLAPPED *)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(LPCLIENT_OVERLAPPED) * MAX_CONNECT_SOCKET); SOCKET *pSocketsArray = (SOCKET *)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(SOCKET) * MAX_CONNECT_SOCKET); int nIndex = 0; g_LocalSockAddr.sin_addr.s_addr = INADDR_ANY; g_LocalSockAddr.sin_port = htons(0); //让系统自动分配 printf("开始端口扫描........\n"); for (int i = 0; i < MAX_CONNECT_SOCKET; i++) { g_nPorts++; SOCKET sConnectSock = WSASocket(AF_INET, SOCK_STREAM, IPPROTO_IP, NULL, NULL, WSA_FLAG_OVERLAPPED); //允许地址重用 setsockopt(sConnectSock, SOL_SOCKET, SO_REUSEADDR, (char *)&on, sizeof(on)); bind(sConnectSock, (SOCKADDR*)&g_LocalSockAddr, sizeof(SOCKADDR_IN)); SOCKADDR_IN sockAddr = {0}; sockAddr.sin_addr.s_addr = inet_addr(SERVICE_IP); sockAddr.sin_family = AF_INET; sockAddr.sin_port = htons(g_nPorts); LPCLIENT_OVERLAPPED lpoc = (LPCLIENT_OVERLAPPED)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(CLIENT_OVERLAPPED)); lpoc->ulNetworkEvents = FD_CONNECT; lpoc->wConnectPort = g_nPorts; lpoc->sConnect = sConnectSock; lpoc->pBuf = (char*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(SOCKADDR_IN)); lpoc->dwBufSize = sizeof(SOCKADDR_IN); CopyMemory(lpoc->pBuf, &sockAddr, sizeof(SOCKADDR_IN)); if(!g_MsSockFunc.ConnectEx(sConnectSock, (SOCKADDR*)lpoc->pBuf, sizeof(SOCKADDR_IN), NULL, 0, &lpoc->dwTransBytes, &lpoc->overlapped)) { if (WSAGetLastError() != ERROR_IO_PENDING) { printf("第(%d)个socket调用ConnectEx失败, 错误码为:%08x\n", i, WSAGetLastError()); HeapFree(GetProcessHeap(), HEAP_ZERO_MEMORY, lpoc); closesocket(sConnectSock); continue; } } CreateIoCompletionPort((HANDLE)sConnectSock, hIOCP, NULL, 0); pSocketsArray[nIndex] = sConnectSock; pOverlappedArray[nIndex] = lpoc; nIndex++; } g_nPorts = nIndex; WaitForMultipleObjects(2 * si.dwNumberOfProcessors, pThreadArray, TRUE, INFINITE); printf("端口扫描结束.......\n"); for (int i = 0; i < 2 * si.dwNumberOfProcessors; i++) { CloseHandle(pThreadArray[i]); } HeapFree(GetProcessHeap(), 0, pThreadArray); printf("清理对应线程完成........\n"); CloseHandle(hIOCP); printf("清理完成端口句柄完成........\n"); for (int i = 0; i < nIndex; i++) { closesocket(pSocketsArray[i]); HeapFree(GetProcessHeap(), 0, pOverlappedArray[i]); } HeapFree(GetProcessHeap(), 0, pSocketsArray); HeapFree(GetProcessHeap(), 0, pOverlappedArray); printf("清理sockets池成功...............\n"); WSACleanup(); return 0; } unsigned int WINAPI IOCPThreadProc(LPVOID lpParam) { HANDLE hIOCP = *(HANDLE*)lpParam; LPOVERLAPPED lpoverlapped = NULL; LPCLIENT_OVERLAPPED lpoc = NULL; DWORD dwNumbersOfBytesTransfer = 0; ULONG uCompleteKey = 0; while (g_nPorts < 65536) //探测所有的65535个端口号 { int nRet = GetQueuedCompletionStatus(hIOCP, &dwNumbersOfBytesTransfer, &uCompleteKey, &lpoverlapped, INFINITE); lpoc = CONTAINING_RECORD(lpoverlapped, CLIENT_OVERLAPPED, overlapped); switch (lpoc->ulNetworkEvents) { case FD_CONNECT: { int nErrorCode = WSAGetLastError(); if (ERROR_SEM_TIMEOUT != nErrorCode) { printf("当前Ip端口[%d]处于开放状态\n", lpoc->wConnectPort); } lpoc->ulNetworkEvents = FD_CLOSE; shutdown(lpoc->sConnect, SD_BOTH); g_MsSockFunc.DisConnectEx(lpoc->sConnect, lpoverlapped, TF_REUSE_SOCKET, 0); } break; case FD_CLOSE: { InterlockedIncrement(&g_nPorts); //进行原子操作的自增1 lpoc->wConnectPort = g_nPorts; lpoc->ulNetworkEvents = FD_CONNECT; SOCKADDR_IN sockAddr = {0}; sockAddr.sin_addr.s_addr = inet_addr(SERVICE_IP); sockAddr.sin_family = AF_INET; sockAddr.sin_port = htons(g_nPorts); lpoc->pBuf = (char*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(SOCKADDR_IN)); lpoc->dwBufSize = sizeof(SOCKADDR_IN); CopyMemory(lpoc->pBuf, &sockAddr, sizeof(SOCKADDR_IN)); g_MsSockFunc.ConnectEx(lpoc->sConnect, (SOCKADDR*)&sockAddr, sizeof(SOCKADDR), NULL, 0, &lpoc->dwTransBytes, &lpoc->overlapped); } break; default: { lpoc->ulNetworkEvents = FD_CLOSE; HeapFree(GetProcessHeap(), 0, lpoc->pBuf); lpoc->pBuf = NULL; lpoc->dwBufSize = 0; g_MsSockFunc.DisConnectEx(lpoc->sConnect, lpoverlapped, TF_REUSE_SOCKET, 0); } } } return 0; }这例子的主要功能是针对具体的IP或者主机名进行TCP的端口探测,这里的端口探测也是采用最简单的方式,向对应的端口发送TCP连接的请求,如果能连上则表示该端口开放,否则认为端口未开放。上述示例中,首先创建IOCP并绑定线程,这里我们绑定处理器数的2倍个线程,并且指定并行的线程数为CPU核数。接着创建对应的结构保存对应的连接信息。然后就是在循环中创建足够数量的SOCKET,这里我们只创建了500个,在每个SOCKET连接完成并回收后再次进行提交去探测后面的端口。注意这里我们先对每个SOCKET进行了绑定,这个在一般的SOCKET客户端服务器模型中没有这个操作,这个操作是WinSock API2.0需要的操作。 创建了足够的socket后,使用ConnectEx进行连接。在线程池中对相关的完成通知进行了处理,这里分了下面几种情况如果是连接成功了,表示这个端口是开放的,这个时候打印对应的端口并进行断开连接和回收SOCKET如果是断开连接的操作完成,再次进行提交如果是其他的通知我们认为是出错了,也就是这个端口没有开放,此时也是回收当前的SOCKET最后当所有端口都探测完成后完成端口线程退出,程序进入资源回收的阶段,这个阶段的顺序如下:关闭线程句柄关闭IOCP句柄关闭监听的SOCKET关闭其余套接字回收其他资源这个顺序也是有一定讲究的,我们先关闭IOCP的相关,如果后续还有需要处理的完成通知,由于此时IOCP已经关闭了,所以这里程序不再处理这些请求,接着关闭监听套接字表示程序已经不再接受连接的请求。这个时候程序已经与服务端彻底断开。后面再清理其余资源。WSABUF 参数在WSASend 和WSARecv的参数中总有一个WSABUF的参数,这个参数很简单的就只有一个缓冲区指针和缓冲区长度,加上函数后面表示WSABUF的个数的参数,很容易想到这些函数可以发送WSABUF的数组,从而可以发送多个数据,但是这就有问题了,发送大数据的话,我们直接申请大一点的缓冲就完了,为什么要额外的定义这么一个结构呢?回答这个问题的关键在于散播和聚集这种I/O处理的机制散播和聚集I/O是一种起源于高级硬盘I/O的技术,它的本质是将一组比较分散的小碎块数据组合成一个大块的IO数据操作,或者反过来是将一个大块的I/O操作拆分为几个小块的I/O操作。它的好处是,比如分散写入不同大小的几个小数据(各自是几个字节),这对于传统硬盘的写入来说是比较麻烦的一种操作,传统的磁盘需要经历几次机械臂的转动寻址,而通过聚集写操作,它会在驱动层将这些小块内存先拼装成一个大块内存,然后只调用一次写入操作,一次性写入硬盘。这样之后,就充分的发挥了高级硬盘系统(DMA/SCSI/RAID等)的连续写入读取的性能优势,而这些设备对于小块数据的读写是没有任何优势的,甚至性能是下降的。而在Winsock中将这种理念发挥到了SOCKET的传输上。WSABUF正是用于这个理念的产物。作为WSASend、WSASendto、WSARecv、WSARecvFrom等函数的数组参数,最终WSABUF数组可以描述多个分散的缓冲块用于收发。在发送的时候底层驱动会将多个WSABUF数据块组合成一个大块的内存缓冲,并一次发送出去,而在接收时会将收到的数据进行拆分,拆分成原来的小块数据,也就是说聚合散播的特性不仅能提高发送的效率,而且支持发送和接收结构化的数据。其实在使用聚合散播的时候主要是应用它来进行数据包的拆分,方便封装自定义协议。在一些应用中,每个数据包都是有自定义的结构的,这些结构就被称为自定义的协议。其中最常见的封装就是一个协议头用以说明包类型和长度,然后是包数据,最后是一个包尾里面存放用于校验数据的CRC码等。但是对于面向伪流的协议来说,这样的结构会带来一个比较头疼的问题——粘包,即多个小的数据包会被连在一起被接收端接收,然后就是头疼和麻烦的拆包过程。而如果使用了散播和聚集I/O方法,那么所有的工作就简单了,可以定义一个3元素的WSABUF结构数组分别发送包头/包数据/包尾。然后接收端先用一个WSABUF接收包头,然后根据包头指出的长度准备包数据/包尾的缓冲,再用2元素的WSABUF接收剩下的数据。同时对于使用了IOCP+重叠I/O的通讯应用来说,在复杂的多线程环境下散播和聚集I/O方法依然可以很可靠的工作。下面是一个使用聚合散播的服务器的例子:#include "MSScokFunc.h" #include <stdio.h> #include "MSScokFunc.h" #include <process.h> typedef struct _tag_CLIENT_OVERLAPPED { OVERLAPPED overlapped; char *pBuf; size_t dwBufSize; DWORD dwFlag; DWORD dwTransBytes; long lNetworkEvents; SOCKET sListen; SOCKET sClient; }CLIENT_OVERLAPPED, *LPCLIENT_OVERLAPPED; unsigned int WINAPI IOCPThreadProc(LPVOID lpParameter) { HANDLE hIOCP = *(HANDLE*)lpParameter; DWORD dwNumberOfTransfered; ULONG uKey = 0; LPOVERLAPPED lpOverlapped = NULL; LPCLIENT_OVERLAPPED lpoc = NULL; BOOL bLoop = TRUE; while (bLoop) { GetQueuedCompletionStatus(hIOCP, &dwNumberOfTransfered, &uKey, &lpOverlapped, INFINITE); lpoc = CONTAINING_RECORD(lpOverlapped, CLIENT_OVERLAPPED, overlapped); switch (lpoc->lNetworkEvents) { case FD_CLOSE: { if (lpoc->sListen == INVALID_SOCKET) { bLoop = FALSE; }else { //再次提交AcceptEx printf("线程(%08x)回收socket(%08x)成功\n", GetCurrentThreadId(), lpoc->sClient); lpoc->dwBufSize = 2 * (sizeof(SOCKADDR_IN) + 16); lpoc->lNetworkEvents = FD_ACCEPT; lpoc->pBuf = (char*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, 2 * (sizeof(SOCKADDR_IN) + 16)); g_MsSockFunc.AcceptEx(lpoc->sListen, lpoc->sClient, lpoc->pBuf, 0, sizeof(SOCKADDR_IN) + 16, sizeof(SOCKADDR_IN) + 16, &lpoc->dwTransBytes, &lpoc->overlapped); } } break; case FD_ACCEPT: { SOCKADDR_IN *pRemoteSockAddr = NULL; int nRemoteSockAddrLength = 0; SOCKADDR_IN *pLocalSockAddr = NULL; int nLocalSockAddrLength = 0; g_MsSockFunc.GetAcceptExSockAddrs(lpoc->pBuf, 0, sizeof(SOCKADDR_IN) + 16, sizeof(SOCKADDR_IN) + 16, (LPSOCKADDR*)&pLocalSockAddr, &nRemoteSockAddrLength, (LPSOCKADDR*)&pRemoteSockAddr, &nRemoteSockAddrLength); printf("有客户端[%s:%d]连接进来,当前通信地址[%s:%d]......\n", inet_ntoa(pRemoteSockAddr->sin_addr), ntohs(pRemoteSockAddr->sin_port), inet_ntoa(pLocalSockAddr->sin_addr), ntohs(pLocalSockAddr->sin_port)); //设置当前通信用socket继承监听socket的相关属性 int nRet = ::setsockopt(lpoc->sClient, SOL_SOCKET, SO_UPDATE_ACCEPT_CONTEXT, (char *)&lpoc->sListen, sizeof(SOCKET)); //投递WSARecv消息, 这里仅仅是为了发起WSARecv调用而不接受数据,设置缓冲为0可以节约内存 WSABUF buf = {0, NULL}; HeapFree(GetProcessHeap(), 0, lpoc->pBuf); lpoc->lNetworkEvents = FD_READ; lpoc->pBuf = NULL; lpoc->dwBufSize = 0; WSARecv(lpoc->sClient, &buf, 1, &lpoc->dwTransBytes, &lpoc->dwFlag, &lpoc->overlapped, NULL); } break; case FD_READ: { WSABUF buf[2] = {0}; DWORD dwBufLen = 0; buf[0].buf = (char*)&dwBufLen; buf[0].len = sizeof(DWORD); //当调用此处的时候已经完成了接收数据的操作,此时只要调用WSARecv将数据放入指定内存即可,这个时候不需要使用重叠IO操作了 int nRet = WSARecv(lpoc->sClient, buf, 1, &lpoc->dwTransBytes, &lpoc->dwFlag, NULL, NULL); DWORD dwBufSize = dwBufLen; buf[1].buf = (char*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwBufSize); buf[1].len = dwBufLen; WSARecv(lpoc->sClient, &buf[1], 1, &lpoc->dwTransBytes, &lpoc->dwFlag, NULL, NULL); printf("client>%s\n", buf[1].buf); lpoc->pBuf = buf[1].buf; //这块内存将在FD_WRITE事件中释放 lpoc->dwBufSize = buf[1].len; lpoc->lNetworkEvents = FD_WRITE; lpoc->dwFlag = 0; WSASend(lpoc->sClient, buf, 2, &lpoc->dwTransBytes, lpoc->dwFlag, &lpoc->overlapped, NULL); } break; case FD_WRITE: { printf("线程[%08x]完成事件(WSASend),缓冲(%d),长度(%d), 发送长度(%d)\n", GetCurrentThreadId(), lpoc->pBuf, lpoc->dwTransBytes, dwNumberOfTransfered); HeapFree(GetProcessHeap(), 0, lpoc->pBuf); lpoc->dwFlag = 0; lpoc->lNetworkEvents = FD_CLOSE; lpoc->pBuf = NULL; shutdown(lpoc->sClient, SD_BOTH); g_MsSockFunc.DisConnectEx(lpoc->sClient, &lpoc->overlapped, TF_REUSE_SOCKET, 0); } break; } } printf("线程[%08x] 退出.......\n", GetCurrentThreadId()); return 0; }这里没有展示main函数的内容,main函数的内容与之前的相似,在开始的时候进行一些初始化,在结束的时候进行资源的回收操作。这里需要注意的是在main函数中给定的退出条件:CLIENT_OVERLAPPED CloseOverlapped = {0}; CloseOverlapped.lNetworkEvents = FD_CLOSE; CloseOverlapped.sListen = INVALID_SOCKET; for (int i = 0; i < 2 * si.dwNumberOfProcessors; i++) { PostQueuedCompletionStatus(hIOCP, 0, NULL, (LPOVERLAPPED)&CloseOverlapped.overlapped); }在线程中,首先判断当前完成事件的类型如果是 FD_CLOSE 事件,首先判断socket是否为 INVALID_SOCKET,如果是则表明是主程序需要退出线程,此时退出,否则只进行回收与再提交的操作如果是 FD_ACCEPT 事件,则表明有客户端连接上来,此时解析客户端的信息并提交WSARecv的信息,注意这里在提交WSARecv时给的缓冲是NULL,这里表示我只需要一个完成的通知,在完成收到客户端数据后会触发FD_READ,而不需要进行数据的写入,一般在提交WSARecv后,系统内核会锁住我们提供的WSABUF结构所表示的那块内存直到,写入完成,而从我们提交WSARecv到真正获取到客户端传过来的数据,这个是需要一定时间的,而在这个时间中虽然CPU不会等待,但是这个内存被占用了,我们认为这也是一种浪费。特别是在服务端需要频繁的调用WSASend、WSARecv这样的操作,如果每一个都锁定一定的缓冲,这个内存消耗也是惊人的。所以这里传入NULL,只让其进行事件通知,而写入的操作由程序自己做。当事件是FD_READ时才正式进行数据的写入操作,此时再次调用WSARecv,这个时候需要注意,我们已经接收到了客户端的数据完成通知,也就是说现在明确的知道客户端已经发送了数据,而且内核已经收到数据,此时就不需要再使用异步了,只需要使用同步简单的读取数据即可。 在读取数据的时候首先根据WSABUF数组的第一个元素获取数据包的长度,然后分配对应的缓冲,接着接收后面真实的数据包。最后调用WSASend将数据原样返回。当完成通知事件是 FD_WRITE时表示我们已经完成了发送数据到客户端的操作,此时断开与客户端的连接并清理对应的缓冲。提高服务程序性能的一般方式对于实际的面向网络的服务(主要指使用TCP协议的服务应用)来说,大致可以分为两大类:连接密集型/传输密集型。连接密集型服务的主要设计目标就是以最大的性能响应尽可能多的客户端连接请求,比如一个Web服务传输密集型服务的设计目标就是针对每个已有连接做到尽可能大的数据传输量,有时以牺牲连接数为代价,比如一个FTP服务器。而针对像UDP这样无连接的协议,我们认为它主要负责传输数据,所以这里把它归结为传输密集型对于面向连接的服务(主要指使用TCP协议的服务)来说,主要设计考虑的是如下几个环节:接受连接数据传输IOCP+线程池接力其它性能优化考虑接收连接接收连接一般都采用AcceptEx的重叠IO方式来进行等待,并且一般需要加上SOCKET池的机制,开始时可能准备的AcceptEx数量可能会不足,此时可以另起线程在监听SOCKET句柄上等待FD_ACCEPT事件来决定何时再次投递大量的AcceptEx进行等待当然再次调用AcceptEx时需要创建大量的SOCKET句柄,这个工作最好不要在IOCP线程池线程中进行,以防创建过程耗时而造成现有SOCKET服务响应性能下降。最终需要注意的就是,任何处于"等待"AcceptEx状态的SOCKET句柄都不要直接调用closesocket,这样会造成严重的内核内存泄漏。应该先关闭监听套接字,防止在关闭SOCKET的时候有客户端连接进来,然后再调用closesocket来断开。数据传输在这个环节中可以将SOCKET句柄上的接收和发送数据缓冲区设置为0,这样可以节约系统内核的缓冲,尤其是在管理大量连接SOCKET句柄的服务中,因为一个句柄上这个缓冲大小约为17K,当SOCKET句柄数量巨大时这个缓冲耗费还是惊人的。设置缓冲为0的方法如下:int iBufLen= 0; setsockopt(skAccept,SOL_SOCKET,SO_SNDBUF,(const char*)&iBufLen,sizeof(int)); setsockopt(skAccept,SOL_SOCKET,SO_RCVBUF,(const char*)&iBufLen,sizeof(int));IOCP + 线程池为了性能的考虑,一般网络服务应用都使用IOCP+重叠I/O+SOCKET池的方式来实现具体的服务应用。这其中需要注意的一个问题就是IOCP线程池中的线程不要用于过于耗时或复杂的操作,比如:访问数据库操作,存取文件操作,复杂的数据计算操作等。这些操作因为会严重占用SOCKET操作的IOCP线程资源因此会极大降低服务应用的响应性能。但是很多实际的应用中确实需要在服务端进行这些操作,那么如何来平衡这个问题呢? 这时就需要另起线程或线程池来接力IOCP线程池的工作。比如在WSARecv的完成通知中,将接收到的缓冲直接传递给QueueUserWorkItem线程池方法,启动线程池中的线程去处理数据,而IOCP线程池则继续专心于网络服务。这也就是一般书上都会说的专门的线程干专门的事其他的性能考虑其他的性能主要是使用之前提到的聚合与散播机制,或者对函数和代码执行流程进行优化关于IOCP 聚合与散播的代码全放在码云上了: 示例代码
-
C++ 调用Python3 作为一种胶水语言,Python 能够很容易地调用 C 、 C++ 等语言,也能够通过其他语言调用 Python 的模块。Python 提供了 C++ 库,使得开发者能很方便地从 C++ 程序中调用 Python 模块。具体操作可以参考: 官方文档在调用Python模块时需要如下步骤:初始化Python调用环境加载对应的Python模块加载对应的Python函数将参数转化为Python元组类型调用Python函数并传入参数元组获取返回值根据Python函数的定义解析返回值初始化在调用Python模块时需要首先包含Python.h头文件,这个头文件一般在安装的Python目录中的 include文件中,所在VS中首先需要将这个路径加入到项目中包含完成之后可能会抱一个错误:找不到 inttypes.h文件,在个错误在Windows平台上很常见,如果报这个错误,需要去网上下载对应的inttypes.h文件然后放入到对应的目录中即可,我这放到VC的include目录中在包含这些文件完成之后可能还会抱一个错误,未找到Python36_d.lib 在Python环境中确实找不到这个文件,这个时候可以修改pyconfig.h文件,将这个lib改为python36.lib,具体操作请参考这个链接: https://blog.csdn.net/Chris_zhangrx/article/details/78947526还有一点要注意,下载的Python环境必须的与目标程序的类型相同,比如你在VS 中新建一个Win32项目,在引用Python环境的时候就需要引用32位版本的Python这些准备工作做完后在调用Python前先调用Py_Initialize 函数来初始化Python环境,之后我们可以调用Py_IsInitialized来检测Python环境是否初始化成功下面是一个初始化Python环境的例子BOOL Init() { Py_Initialize(); return Py_IsInitialized(); }调用Python模块调用Python模块可以简单的调用Python语句也可以调用Python模块中的函数。简单调用Python语句针对简单的Python语句(就好像我们在Python的交互式环境中输入的一条语句那样),可以直接调用 PyRun_SimpleString 函数来执行, 这个函数需要一个Python语句的ANSI字符串作为参数,返回int型的值。如果为0表示执行成功否则为失败void ChangePyWorkPath(LPCTSTR lpWorkPath) { TCHAR szWorkPath[MAX_PATH + 64] = _T(""); StringCchCopy(szWorkPath, MAX_PATH + 64, _T("sys.path.append(\"")); StringCchCat(szWorkPath, MAX_PATH + 64, lpWorkPath); StringCchCat(szWorkPath, MAX_PATH + 64, _T("\")")); PyRun_SimpleString("import sys"); USES_CONVERSION; int nRet = PyRun_SimpleString(T2A(szWorkPath)); if (nRet != 0) { return; } }这个函数主要用来将传入的路径加入到当前Python的执行环境中,以便可以很方便的导入我们的自定义模块函数首先通过字符串拼接的方式组织了一个 "sys.path.append('path')" 这样的字符串,其中path是我们传进来的参数,然后调用PyRun_SimpleString执行Python的"import sys"语句来导入sys模块,接着执行之前拼接的语句,将对应路径加入到Python环境中调用Python模块中的函数调用Python模块中的函数需要执行之前说的2~7的步骤加载Python模块(自定义模块)加载Python的模块需要调用 PyImport_ImportModule 这个函数需要传入一个模块的名称作为参数,注意:这里需要传入的是模块的名称也就是py文件的名称,不能带.py后缀。这个函数会返回一个Python对象的指针,在C++中表示为PyObject。这里返回模块的对象指针然后调用 PyObject_GetAttrString 函数来加载对应的Python模块中的方法,这个函数需要两个参数,第一个是之前获取到的对应模块的指针,第二个参数是函数名称的ANSI字符串。这个函数会返回一个对应Python函数的对象指针。后面需要利用这个指针来调用Python函数获取到函数的指针之后我们可以调用 PyCallable_Check 来检测一下对应的对象是否可以被调用,如果能被调用这个函数会返回true否则返回false接着就是传入参数了,Python中函数的参数以元组的方式传入的,所以这里需要先将要传入的参数转化为元组,然后调用 PyObject_CallObject 函数来执行对应的Python函数。这个函数需要两个参数第一个是上面Python函数对象的指针,第二个参数是需要传入Python函数中的参数组成的元组。函数会返回Python的元组对象,这个元组就是Python函数的返回值获取到返回值之后就是解析参数了,我们可以使用对应的函数将Python元组转化为C++中的变量最后需要调用 Py_DECREF 来解除Python对象的引用,以便Python的垃圾回收器能正常的回收这些对象的内存下面是一个传入空参数的例子void GetModuleInformation(IN LPCTSTR lpPyFileName, OUT LPTSTR lpVulName, OUT long& level) { USES_CONVERSION; PyObject *pModule = PyImport_ImportModule(T2A(lpPyFileName)); //加载模块 if (NULL == pModule) { g_OutputString(_T("加载模块[%s]失败"), lpPyFileName); goto __CLEAN_UP; } PyObject *pGetInformationFunc = PyObject_GetAttrString(pModule, "getInformation"); // 加载模块中的函数 if (NULL == pGetInformationFunc || !PyCallable_Check(pGetInformationFunc)) { g_OutputString(_T("加载函数[%s]失败"), _T("getInformation")); goto __CLEAN_UP; } PyObject *PyResult = PyObject_CallObject(pGetInformationFunc, NULL); if (NULL != PyResult) { PyObject *pVulNameObj = PyTuple_GetItem(PyResult, 0); PyObject *pVulLevelObj = PyTuple_GetItem(PyResult, 1); //获取漏洞的名称信息 int nStrSize = 0; LPTSTR pVulName = PyUnicode_AsWideCharString(pVulNameObj, &nStrSize); StringCchCopy(lpVulName, MAX_PATH, pVulName); PyMem_Free(pVulName); //获取漏洞的危险等级 level = PyLong_AsLong(pVulLevelObj); Py_DECREF(pVulNameObj); Py_DECREF(pVulLevelObj); } //解除Python对象的引用, 以便Python进行垃圾回收 __CLEAN_UP: Py_DECREF(pModule); Py_DECREF(pGetInformationFunc); Py_DECREF(PyResult); }在示例中调用了一个叫 getInformation 的函数,这个函数的定义如下:def getInformation(): return "测试脚本", 1下面是一个需要传入参数的函数调用BOOL CallScanMethod(IN LPPYTHON_MODULES_DATA pPyModule, IN LPCTSTR lpUrl, IN LPCTSTR lpRequestMethod, OUT LPTSTR lpHasVulUrl, int BuffSize) { USES_CONVERSION; //加载模块 PyObject* pModule = PyImport_ImportModule(T2A(pPyModule->szModuleName)); if (NULL == pModule) { g_OutputString(_T("加载模块[%s]失败!!!"), pPyModule->szModuleName); return FALSE; } //加载模块 PyObject *pyScanMethod = PyObject_GetAttrString(pModule, "startScan"); if (NULL == pyScanMethod || !PyCallable_Check(pyScanMethod)) { Py_DECREF(pModule); g_OutputString(_T("加载函数[%s]失败!!!"), _T("startScan")); return FALSE; } //加载参数 PyObject* pArgs = Py_BuildValue("ss", T2A(lpUrl), T2A(lpRequestMethod)); PyObject *pRes = PyObject_CallObject(pyScanMethod, pArgs); Py_DECREF(pArgs); if (NULL == pRes) { g_OutputString(_T("调用函数[%s]失败!!!!"), _T("startScan")); return FALSE; } //如果是元组,那么Python脚本返回的是两个参数,证明发现漏洞 if (PyTuple_Check(pRes)) { PyObject* pHasVul = PyTuple_GetItem(pRes, 0); long bHasVul = PyLong_AsLong(pHasVul); Py_DECREF(pHasVul); if (bHasVul != 0) { PyObject* pyUrl = PyTuple_GetItem(pRes, 1); int nSize = 0; LPWSTR pszUrl = PyUnicode_AsWideCharString(pyUrl, &nSize); Py_DECREF(pyUrl); StringCchCopy(lpHasVulUrl, BuffSize, pszUrl); PyMem_Free(pszUrl); return TRUE; } } Py_DECREF(pRes); return FALSE; }对应的Python函数如下:def startScan(url, method): if(method == "GET"): response = requests.get(url) else: response = requests.post(url) if response.status_code == 200: return True, url else: return FalseC++数据类型与Python对象的相互转化Python与C++结合的一个关键的内容就是C++与Python数据类型的相互转化,针对这个问题Python提供了一系列的函数。这些函数的格式为PyXXX_AsXXX 或者PyXXX_FromXXX,一般带有As的是将Python对象转化为C++数据类型的,而带有From的是将C++对象转化为Python,Py前面的XXX表示的是Python中的数据类型。比如 PyUnicode_AsWideCharString 是将Python中的字符串转化为C++中宽字符,而 Pyunicode_FromWideChar 是将C++的字符串转化为Python中的字符串。这里需要注意一个问题就是Python3废除了在2中的普通的字符串,它将所有字符串都当做Unicode了,所以在调用3的时候需要将所有字符串转化为Unicode的形式而不是像之前那样转化为String。具体的转化类型请参考Python官方的说明。上面介绍了基本数据类型的转化,除了这些Python中也有一些容器类型的数据,比如元组,字典等等。下面主要说说元组的操作。元组算是比较重要的操作,因为在调用函数的时候需要元组传参并且需要解析以便获取元组中的值。创建Python的元组对象创建元组对象可以使用 PyTuple_New 来创建一个元组的对象,这个函数需要一个参数用来表示元组中对象的个数。之后需要创建对应的Python对象,可以使用前面说的那些转化函数来创建普通Python对象,然后调用 PyTuple_SetItem 来设置元组中数据的内容,函数需要三个参数,分别是元组对象的指针,元组中的索引和对应的数据示例: PyObject* args = PyTuple_New(2); // 2个参数 PyObject* arg1 = PyInt_FromLong(4); // 参数一设为4 PyObject* arg2 = PyInt_FromLong(3); // 参数二设为3 PyTuple_SetItem(args, 0, arg1); PyTuple_SetItem(args, 1, arg2);或者如果元组中都是简单数据类型,可以直接使用 PyObject* args = Py_BuildValue(4, 3); 这种方式来创建元组解析元组Python 函数返回的是元组,在C++中需要进行对应的解析,我们可以使用 PyTuple_GetItem 来获取元组中的数据成员,这个函数返回PyObject 的指针,之后再使用对应的转化函数将Python对象转化成C++数据类型即可PyObject *pVulNameObj = PyTuple_GetItem(PyResult, 0); PyObject *pVulLevelObj = PyTuple_GetItem(PyResult, 1); //获取漏洞的名称信息 int nStrSize = 0; LPTSTR pVulName = PyUnicode_AsWideCharString(pVulNameObj, &nStrSize); StringCchCopy(lpVulName, MAX_PATH, pVulName); PyMem_Free(pVulName); //释放由PyUnicode_AsWideCharString分配出来的内存 //获取漏洞的危险等级 level = PyLong_AsLong(pVulLevelObj); //最后别忘了将Python对象解引用 Py_DECREF(pVulNameObj); Py_DECREF(pVulLevelObj); Py_DECREF(PyResult);Python中针对具体数据类型操作的函数一般是以Py开头,后面跟上具体的数据类型的名称,比如操作元组的PyTuple系列函数和操作列表的PyList系列函数,后面如果想操作对应的数据类型只需要去官网搜索对应的名称即可。这些代码实例都是我之前写的一个Demo中的代码,Demo放到了Github上: PyScanner