搜索到
348
篇与
的结果
-
 COM学习(四)——COM中的数据类型 上一次说到,COM为了跨语言,有一套完整的规则,只要COM组件按照规则编写,而不同的语言也按照对应的规则调用,那么就可以实现不同语言间相互调用。但是根据那套规则,只能识别接口,并调用没有参数和返回类型的接口,毕竟不同语言里面的基本数据类型不同,可能在VC++中char * 就表示字符串,而在Java或者c#中string是一个对象,二者的内存结构不同,不能简单的进行内存数据类型的强制转化。为了实现数据的正常交互,COM中又定义了一组公共的数据类型。HRESULT类型:在COM中接口的返回值强制定义为该类型,用于表示当前执行的状态是完成或者是出错,这个类型一般在VC中使用,别的语言在调用时根据接口的这个值来确定接下来该如何进行。HRESULT类型的定义如下:typedef _Return_type_success_(return >= 0) long HRESULT;其实它就是一个32位的整数,微软将这个整数分成几个部分,各个部分都有详细的含义,这个值的详细解释在对应的winerror.h中。// // Note: There is a slightly modified layout for HRESULT values below, // after the heading "COM Error Codes". // // Search for "**** Available SYSTEM error codes ****" to find where to // insert new error codes // // Values are 32 bit values laid out as follows: // // 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 // 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 // +-+-+-+-+-+---------------------+-------------------------------+ // |S|R|C|N|r| Facility | Code | // +-+-+-+-+-+---------------------+-------------------------------+ // // where // // S - Severity - indicates success/fail // // 0 - Success // 1 - Fail (COERROR) // // R - reserved portion of the facility code, corresponds to NT's // second severity bit. // // C - reserved portion of the facility code, corresponds to NT's // C field. // // N - reserved portion of the facility code. Used to indicate a // mapped NT status value. // // r - reserved portion of the facility code. Reserved for internal // use. Used to indicate HRESULT values that are not status // values, but are instead message ids for display strings. // // Facility - is the facility code // // Code - is the facility's status code // // // Define the facility codes //根据上面的注释可以看到,以及我自己查阅相关资料,它里面总共有7个部分,各个部分代表的含义如下:S - 严重性 - 表示成功或失败0 - 成功,1 - 失败R - 设施代码的保留部分,对应于NT的第二严重性位。1 - 严重故障C - 第三方。 此位指定值是第三方定义还是Microsoft定义的。0 - Microsoft-定义,1 - 第三方定义N - 保留部分设施代码。 用于指示映射的NT状态值。X - 保留部分设施代码。 保留供内部使用。 用于指示不是状态值的HRESULT值,而是用于显示字符串的消息标识。Facility - 表示引发错误的系统服务. 示例Facility代码如下所示:2 - 调度(COM调度)3 - 存储 (OLE存储)4 - ITF (COM/OLE 接口管理)7 - (原始 Win32 错误代码)8 - Windows9 - SSPI10 - 控制11 - CERT (客户端或服务器认证)...Code - 设施的状态代码其实这些没有必要知道的很详细,只需要知道里面常用的几个即可:S_OK:成功S_FALSE:失败E_NOINTERFACE:没有接口,一般是由QueryInterface或者CoCreateInterface函数返回,当我们传入的ID不对它找不到对应的接口时返回该值E_OUTOFMEMORY:当内存不足时返回该值。一般在COM的调用者看来,有的时候只要最高位不为0就表示成功,这个时候可能会继续使用,所以在我们自己编写组件的时候要根据具体情况选择返回值,不要错误了就返回S_FALSE,其实我们看它的定义可以知道它是等于1的,最高位为0,仍然是成功的。如果返回S_FALSE可能会造成意想不到的错误,而且还难以调试。BSTRCOM中规定了一种通用的字符串类型BSTR,查看BSTR的定义如下:typedef /* [wire_marshal] */ OLECHAR *BSTR; typedef WCHAR OLECHAR;从上面的定义上不难看出BSTR其实就是一个WCHAR ,也就是一个指向宽字符的指针。COM中使用的是UNICODE字符串,在编写COM程序的时候经常涉及到CString、WCHAR、char等的相互转化,其实本质上就是多字节字符与宽字节字符之间的转化。我们平时在进行char 与WCHAR*之间转化的函数像WideCharToMultiByte和MultiByteToWideChar,以及W2A和A2W等。COM为了方便使用,另外也提供了一组转化函数_com_util::ConvertBSTRToString以及_com_util::ConvertStringToBSTR用在在char*与BSTR之间进行转化。需要注意的是,这组函数返回的字符串是在堆上分配出来的,使用完后需要自己释放。在BSTR类型中,定义了两个函数SysAllocString(),和SysFreeString()用来分配和释放一个BSTR的内存空间。在这总结一下他们之间的相互转化:char*----->BSTR: _com_util::ConvertStringToBSTRWCHAR*---->BSTR:可以直接用 = 进行赋值,也可以使用SysAllocStringBSTR---->WCHAR:一般是直接使用等号即可,但是在WCHAR使用完之前不能释放,所以一般都是赋值给一个CStringBSTR---->char*:_com_util::ConvertBSTRToStringConvert函数是定义在头文件atlutil.h中并且需要引用comsupp.lib文件另外COM封装了一个_bstr_t的类,使用这个类就更加方便了,它封装了与char*之间的相互转化,可以直接使用赋值符号进行相互转化,同时也不用考虑回收内存的问题,它自己会进行内存回收。VARIANT 万能类型现代编程语言一般有强类型的语言和弱类型的语言,强类型的像C/C++、Java这样的,必须在使用前定义变量类型,而弱类型像Python这样的可以直接定义变量而不用管它的类型,甚至可以写出像:i = 0 i = "hello world"这样的代码,而且不同语言中可能同一种类型的变量在内存布局上也可能不一样。解决不同语言之间变量类型的冲突,COM定义了一种万能类型——VARIANT。typedef struct tagVARIANT VARIANT; typedef struct tagVARIANT VARIANTARG; struct tagVARIANT { union { struct __tagVARIANT { VARTYPE vt; WORD wReserved1; WORD wReserved2; WORD wReserved3; union { LONGLONG llVal; LONG lVal; BYTE bVal; SHORT iVal; FLOAT fltVal; DOUBLE dblVal; VARIANT_BOOL boolVal; _VARIANT_BOOL bool; SCODE scode; CY cyVal; DATE date; BSTR bstrVal; IUnknown *punkVal; IDispatch *pdispVal; SAFEARRAY *parray; BYTE *pbVal; SHORT *piVal; LONG *plVal; LONGLONG *pllVal; FLOAT *pfltVal; DOUBLE *pdblVal; VARIANT_BOOL *pboolVal; _VARIANT_BOOL *pbool; SCODE *pscode; CY *pcyVal; DATE *pdate; BSTR *pbstrVal; IUnknown **ppunkVal; IDispatch **ppdispVal; SAFEARRAY **pparray; VARIANT *pvarVal; PVOID byref; CHAR cVal; USHORT uiVal; ULONG ulVal; ULONGLONG ullVal; INT intVal; UINT uintVal; DECIMAL *pdecVal; CHAR *pcVal; USHORT *puiVal; ULONG *pulVal; ULONGLONG *pullVal; INT *pintVal; UINT *puintVal; struct __tagBRECORD { PVOID pvRecord; IRecordInfo *pRecInfo; } __VARIANT_NAME_4; } __VARIANT_NAME_3; } __VARIANT_NAME_2; DECIMAL decVal; } __VARIANT_NAME_1; };从定义上看出,它其实是一个巨大的联合体,将所有C/C++的基本类型都包含进来,甚至包含了像BSTR, 这样的COM中使用的类型。它通过成员vt来表示它当前使用的是哪种类型的变量。vt的类型是一个枚举类型,详细的定义请参见MSDN。为了简化操作,COM中也对它进行了一个封装——_variant_t,该类型可以直接使用任何类型的数据对其进行初始化操作。但是在使用里面的值时还是得判断它的vt成员的值COM中的其他操作最后附上一张COM常用函数表以供参考:
COM学习(四)——COM中的数据类型 上一次说到,COM为了跨语言,有一套完整的规则,只要COM组件按照规则编写,而不同的语言也按照对应的规则调用,那么就可以实现不同语言间相互调用。但是根据那套规则,只能识别接口,并调用没有参数和返回类型的接口,毕竟不同语言里面的基本数据类型不同,可能在VC++中char * 就表示字符串,而在Java或者c#中string是一个对象,二者的内存结构不同,不能简单的进行内存数据类型的强制转化。为了实现数据的正常交互,COM中又定义了一组公共的数据类型。HRESULT类型:在COM中接口的返回值强制定义为该类型,用于表示当前执行的状态是完成或者是出错,这个类型一般在VC中使用,别的语言在调用时根据接口的这个值来确定接下来该如何进行。HRESULT类型的定义如下:typedef _Return_type_success_(return >= 0) long HRESULT;其实它就是一个32位的整数,微软将这个整数分成几个部分,各个部分都有详细的含义,这个值的详细解释在对应的winerror.h中。// // Note: There is a slightly modified layout for HRESULT values below, // after the heading "COM Error Codes". // // Search for "**** Available SYSTEM error codes ****" to find where to // insert new error codes // // Values are 32 bit values laid out as follows: // // 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 // 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 // +-+-+-+-+-+---------------------+-------------------------------+ // |S|R|C|N|r| Facility | Code | // +-+-+-+-+-+---------------------+-------------------------------+ // // where // // S - Severity - indicates success/fail // // 0 - Success // 1 - Fail (COERROR) // // R - reserved portion of the facility code, corresponds to NT's // second severity bit. // // C - reserved portion of the facility code, corresponds to NT's // C field. // // N - reserved portion of the facility code. Used to indicate a // mapped NT status value. // // r - reserved portion of the facility code. Reserved for internal // use. Used to indicate HRESULT values that are not status // values, but are instead message ids for display strings. // // Facility - is the facility code // // Code - is the facility's status code // // // Define the facility codes //根据上面的注释可以看到,以及我自己查阅相关资料,它里面总共有7个部分,各个部分代表的含义如下:S - 严重性 - 表示成功或失败0 - 成功,1 - 失败R - 设施代码的保留部分,对应于NT的第二严重性位。1 - 严重故障C - 第三方。 此位指定值是第三方定义还是Microsoft定义的。0 - Microsoft-定义,1 - 第三方定义N - 保留部分设施代码。 用于指示映射的NT状态值。X - 保留部分设施代码。 保留供内部使用。 用于指示不是状态值的HRESULT值,而是用于显示字符串的消息标识。Facility - 表示引发错误的系统服务. 示例Facility代码如下所示:2 - 调度(COM调度)3 - 存储 (OLE存储)4 - ITF (COM/OLE 接口管理)7 - (原始 Win32 错误代码)8 - Windows9 - SSPI10 - 控制11 - CERT (客户端或服务器认证)...Code - 设施的状态代码其实这些没有必要知道的很详细,只需要知道里面常用的几个即可:S_OK:成功S_FALSE:失败E_NOINTERFACE:没有接口,一般是由QueryInterface或者CoCreateInterface函数返回,当我们传入的ID不对它找不到对应的接口时返回该值E_OUTOFMEMORY:当内存不足时返回该值。一般在COM的调用者看来,有的时候只要最高位不为0就表示成功,这个时候可能会继续使用,所以在我们自己编写组件的时候要根据具体情况选择返回值,不要错误了就返回S_FALSE,其实我们看它的定义可以知道它是等于1的,最高位为0,仍然是成功的。如果返回S_FALSE可能会造成意想不到的错误,而且还难以调试。BSTRCOM中规定了一种通用的字符串类型BSTR,查看BSTR的定义如下:typedef /* [wire_marshal] */ OLECHAR *BSTR; typedef WCHAR OLECHAR;从上面的定义上不难看出BSTR其实就是一个WCHAR ,也就是一个指向宽字符的指针。COM中使用的是UNICODE字符串,在编写COM程序的时候经常涉及到CString、WCHAR、char等的相互转化,其实本质上就是多字节字符与宽字节字符之间的转化。我们平时在进行char 与WCHAR*之间转化的函数像WideCharToMultiByte和MultiByteToWideChar,以及W2A和A2W等。COM为了方便使用,另外也提供了一组转化函数_com_util::ConvertBSTRToString以及_com_util::ConvertStringToBSTR用在在char*与BSTR之间进行转化。需要注意的是,这组函数返回的字符串是在堆上分配出来的,使用完后需要自己释放。在BSTR类型中,定义了两个函数SysAllocString(),和SysFreeString()用来分配和释放一个BSTR的内存空间。在这总结一下他们之间的相互转化:char*----->BSTR: _com_util::ConvertStringToBSTRWCHAR*---->BSTR:可以直接用 = 进行赋值,也可以使用SysAllocStringBSTR---->WCHAR:一般是直接使用等号即可,但是在WCHAR使用完之前不能释放,所以一般都是赋值给一个CStringBSTR---->char*:_com_util::ConvertBSTRToStringConvert函数是定义在头文件atlutil.h中并且需要引用comsupp.lib文件另外COM封装了一个_bstr_t的类,使用这个类就更加方便了,它封装了与char*之间的相互转化,可以直接使用赋值符号进行相互转化,同时也不用考虑回收内存的问题,它自己会进行内存回收。VARIANT 万能类型现代编程语言一般有强类型的语言和弱类型的语言,强类型的像C/C++、Java这样的,必须在使用前定义变量类型,而弱类型像Python这样的可以直接定义变量而不用管它的类型,甚至可以写出像:i = 0 i = "hello world"这样的代码,而且不同语言中可能同一种类型的变量在内存布局上也可能不一样。解决不同语言之间变量类型的冲突,COM定义了一种万能类型——VARIANT。typedef struct tagVARIANT VARIANT; typedef struct tagVARIANT VARIANTARG; struct tagVARIANT { union { struct __tagVARIANT { VARTYPE vt; WORD wReserved1; WORD wReserved2; WORD wReserved3; union { LONGLONG llVal; LONG lVal; BYTE bVal; SHORT iVal; FLOAT fltVal; DOUBLE dblVal; VARIANT_BOOL boolVal; _VARIANT_BOOL bool; SCODE scode; CY cyVal; DATE date; BSTR bstrVal; IUnknown *punkVal; IDispatch *pdispVal; SAFEARRAY *parray; BYTE *pbVal; SHORT *piVal; LONG *plVal; LONGLONG *pllVal; FLOAT *pfltVal; DOUBLE *pdblVal; VARIANT_BOOL *pboolVal; _VARIANT_BOOL *pbool; SCODE *pscode; CY *pcyVal; DATE *pdate; BSTR *pbstrVal; IUnknown **ppunkVal; IDispatch **ppdispVal; SAFEARRAY **pparray; VARIANT *pvarVal; PVOID byref; CHAR cVal; USHORT uiVal; ULONG ulVal; ULONGLONG ullVal; INT intVal; UINT uintVal; DECIMAL *pdecVal; CHAR *pcVal; USHORT *puiVal; ULONG *pulVal; ULONGLONG *pullVal; INT *pintVal; UINT *puintVal; struct __tagBRECORD { PVOID pvRecord; IRecordInfo *pRecInfo; } __VARIANT_NAME_4; } __VARIANT_NAME_3; } __VARIANT_NAME_2; DECIMAL decVal; } __VARIANT_NAME_1; };从定义上看出,它其实是一个巨大的联合体,将所有C/C++的基本类型都包含进来,甚至包含了像BSTR, 这样的COM中使用的类型。它通过成员vt来表示它当前使用的是哪种类型的变量。vt的类型是一个枚举类型,详细的定义请参见MSDN。为了简化操作,COM中也对它进行了一个封装——_variant_t,该类型可以直接使用任何类型的数据对其进行初始化操作。但是在使用里面的值时还是得判断它的vt成员的值COM中的其他操作最后附上一张COM常用函数表以供参考: -
COM学习(三)——COM的跨语言 COM是基于二进制的组件模块,从设计之初就以支持所有语言作为它的一个目标,这篇文章主要探讨COM的跨语言部分。idl文件一般COM接口的实现肯定是以某一具体语言来实现的,比如说使用VC++语言,这就造成了一个问题,不同的语言对于接口的定义,各个变量的定义各不相同,如何让使用vc++或者说Java等其他语言定义的接口能被别的语言识别?为了达到这个要求,定义了一种文件格式idl——(Interface Definition Language)接口定义语言,IDL提供一套通用的数据类型,并以这些数据类型来定义更为复杂的数 据类型。一般来说,一个文件有下面几个部分说明接口的定义组件库的定义实现类的定义而各个部分又包括他们的属性定义,以及函数成员的定义属性:属性是在接口定义的上方,使用“[]”符号包裹,一般在属性中使用下面几个关键字:object:标明该部分是一个对象(可以理解为c++中的对象,包括接口和具体的实现类)uuid:标明该部分的GUIDversion:该部分的版本接口定义接口定义采用关键字interface,接口函数定义在一对大括号中,它的定义与类的定义相似,其中函数定义需要修饰函数各个参数的作用,比如使用in 表示它作为输入参数,out表示作为输出参数,retval表示该参数作为返回值,一般在VC++定义的接口中,函数返回值为HRESULT,但是需要返回一个值供外界调用,此时就使用输出参数并加上retval表示它将在其他语言中作为函数的返回值。组件库定义库使用library关键字定义,在定义库的时候,它的属性一般定义GUID和版本信息,而在库中通常定义库中的实现类的相关信息,库中的信息也是写在一对大括号中实现类的定义接口实现类使用关键字coclass,接口类的属性一般定义一个object,一个GUID,然后一般定义实现类不需要向在C++中那样定义它的各个接口,各个数据成员,只需要告知它实现哪些接口即可,也就是说它继承自哪些接口。下面是一个具体的例子:import "unknwn.idl"; [ object, uuid(CF809C44-8306-4200-86A1-0BFD5056999E) ] interface IMyString : IUnknown { HRESULT Init([in] BSTR bstrInit); HRESULT GetLength([out, retval] ULONG *pretLength); HRESULT Find([in] BSTR bstrFind, [out, retval] BSTR* bstrSub); }; [ uuid(ADF50A71-A8DD-4A64-8CCA-FFAEE2EC7ED2), version(1.0) ] library ComDemoLib { importlib("stdole32.tlb"); [ uuid(EBD699BA-A73C-4851-B721-B384411C99F4) ] coclass CMyString { interface IMyString; }; };上面的例子中定义了一个IMyString接口继承自IUnknown接口,函数参数列表中in表示参数为输入参数,out表示它为输出参数,retval表示该参数是函数的返回值。import导入了一个库文件类似于include。而importlib导入一个tlb文件,我们可以将其看成VC++中的#pragma comment导入一个lib库从上面不难看出一个IDL文件至少有3个ID,一个是接口ID,一个是库ID,还有一个就是实现类的ID在VC环境中通过midl命令可以对该文件进行编译,编译会生成下面几个我们在编写实现时会用到的重要文件:一个.h文件:包含各个部分的声明,以及接口的定义一个_i.c文件:包含各个部分的定义,主要是各个GUI的定义需要实现的导出函数一般我们需要在dll文件中导出下面几个全局的导出函数:STDAPI DllRegisterServer(void); STDAPI DllUnregisterServer(void); STDAPI DllGetClassObject(const CLSID & rclsid, const IID & riid, void ** ppv); STDAPI DllCanUnloadNow(void);其中DllRegisterServer用来向注册表中注册模块的相关信息,主要注测在HKEY_CLASSES_ROOT中,主要定义下面几项内容:字符串名称项,该项中包含一个默认值,一般给组件的字符串名称;CLSID子健,一般给实现类的GUID;CurVer子健一般是子健的版本以版本字符串为键的注册表项,该项中主要保存:默认值,当前版本的项目名称;CLSID当前版本库的实现类的GUID在HKEY_CLASSES_ROOT/CLSID子健中注册以实现类GUID字符串为键的注册表项,里面主要包含:默认值,组件字符串名称;InprocServer32,组件所在模块的全路径;ProgID组件名称;TypeLib组件类型库的ID,也就是在定义IDL文件时,定义的实现库的GUID。下面是具体的定义:const TCHAR *g_RegTable[][3] = { { _T("CLSID\\{EBD699BA-A73C-4851-B721-B384411C99F4}"), 0, _T("FirstComLib.MyString")}, //组件ID { _T("CLSID\\{EBD699BA-A73C-4851-B721-B384411C99F4}\\InprocServer32"), 0, (const TCHAR*)-1 }, //组建路径 { _T("CLSID\\{EBD699BA-A73C-4851-B721-B384411C99F4}\\ProgID"), 0, _T("FirstComLib.MyString")}, //组件名称 { _T("CLSID\\{EBD699BA-A73C-4851-B721-B384411C99F4}\\TypeLib"), 0, _T("{ADF50A71-A8DD-4A64-8CCA-FFAEE2EC7ED2}") }, //类型库ID { _T("FirstComLib.MyString"), 0, _T("FirstComLib.MyString") }, //组件的字符串名称 { _T("FirstComLib.MyString\\CLSID"), 0, _T("{EBD699BA-A73C-4851-B721-B384411C99F4}")}, //组件的CLSID { _T("FirstComLib.MyString\\CurVer"), 0, _T("FirstComLib.MyString.1.0") }, //组件版本 { _T("FirstComLib.MyString.1.0"), 0, _T("FirstComLib.MyString") }, //当前版本的项目名称 { _T("FirstComLib.MyString.1.0\\CLSID"), 0, _T("{EBD699BA-A73C-4851-B721-B384411C99F4}")} //当前版本的CLSID };使用上一篇博文的代码,来循环注册这些项即可DllGetClassObject:该函数用来生成对应的工厂类,而工厂类负责产生对应接口的实现类。DllCanUnloadNow:函数用来询问是否可以卸载对应的dll,一般在COM中有两个全局的引用计数,用来记录当前内存中有多少个模块中的类,以及当前有多少个线程在使用它,如果当前没有线程使用或者存在的对象数为0,则可以卸载实现类的定义实现部分的整体结构图如下:由于所有类都派生自IUnknown,所在在这里就不显示这个基类了。每个实现类都对应了一个它具体的类工厂,而项目中CMyString类的类厂的定义如下:class CMyClassFactory : public IClassFactory { public: CMyClassFactory(); ~CMyClassFactory(); STDMETHOD(CreateInstance)(IUnknown *pUnkOuter, REFIID riid, void **ppvObject); STDMETHOD(LockServer)(BOOL isLock); STDMETHOD(QueryInterface)(REFIID riid, void **ppvObject); STDMETHOD_(ULONG, AddRef)(void); STDMETHOD_(ULONG, Release)(void); protected: ULONG m_refs; };STDMETHOD宏展开如下:#define STDMETHOD(method) virtual HRESULT __stdcall method所以上面的代码展开后就变成了:virtual HRESULT __stdcall CreateInstance((IUnknown *pUnkOuter, REFIID riid, void **ppvObject);另外3个派生自IUnknown接口就没什么好说的,主要说说另外两个:CreateInstance:主要用来生成对应的实现类,然后再调用实现类——CMyString的QueryInterface函数生成对应的接口LockServer:当前是否被锁住:如果传入的值为TRUE,则表示被锁住,对应的锁计数器+1, 否则 -1至于CMyString类的代码与之前的大同小异,也就没什么说的。其他语言想要调用,以该项目为例,一般会经历下面几个步骤:调用对应语言提供的产生接口的函数,该函数参数一般是传入一个组件的字符串名称。如果要引用该项目中的组件则会传入FirstComLib.MyString在注册表的HKEY_CLASSES_ROOT\组件字符串名\CLSID(比如HKEY_CLASSES_ROOT\FirstComLib.MyString\CLSID)中找到对应的CLSID值在HKEY_CLASSES_ROOT\CLSID\对应ID\InprocServer32(CLSID\{EBD699BA-A73C-4851-B721-B384411C99F4}\InprocServer32)位置处找到对应模块的路径加载该模块根据IDL文件告知其他语言里面存在的接口,由语言调用对应的创建接口的函数创建接口调用模块的导出函数DllGetClassObject将查询到的CLSID作为第一个参数,并将接口ID作为第二个参数传入,得到一个接口6.后面根据idl文件中的定义,直接调用接口中提供的函数真实ATLCOM项目的解析最后来看看一个正式的ATLCOM项目里面的内容,来复习前面的内容,首先通过VC创建一个ATLCOM的dll项目在项目上右键-->New Atl Object,输入接口名称,IDE会根据名称生成一个对应的接口,还是以MyString接口为例,完成这一步后,整个项目的类结构如下:这些全局函数的作用与之前的相同,它里面多了一个_Module的全局对象,该对象类似于MFC中的CWinApp类,它用来表示整个项目的实例,里面封装了对于引用计数的管理,以及对项目中各个接口注册信息的管理,所以看DllRegisterServer等函数就会发现它们里面其实很简单,大部分的工作都由_Module对象完成。整个IDL文件的定义如下:import "oaidl.idl"; import "ocidl.idl"; [ object, uuid(E3BD0C14-4D0C-48F2-8702-9F8DBC96E154), dual, helpstring("IMyString Interface"), pointer_default(unique) ] interface IMyString : IDispatch { }; [ uuid(A61AC54A-1B3D-4D8E-A679-00A89E2CBE93), version(1.0), helpstring("FirstAtlCom 1.0 Type Library") ] library FIRSTATLCOMLib { importlib("stdole32.tlb"); importlib("stdole2.tlb"); [ uuid(11CBC0BE-B2B7-4B5C-A186-3C30C08A7736), helpstring("MyString Class") ] coclass MyString { [default] interface IMyString; }; };里面的内容与上一次的内容相差无几,多了一个helpstring属性,该属性用于产生帮助信息,当使用者在调用接口函数时IDE会将此提示信息显示给调用者。由于有系统框架给我们做的大量的工作,我们再也不用关心像引用计数的问题,只需要将精力集中在编写接口的实现上,减少了不必要的工作量。至此从结构上说明了为了实现跨语言COM组件内部做了哪些工作,当然只有这些工作是肯定不够的,后面会继续说明它所做的另一块工作——提供的一堆通用的变量类型。
-
COM学习(二)——COM的注册和卸载 COM组件是跨语言的,组件被注册到注册表中,在加载时由加载函数在注册表中查找到对应模块的路径并进行相关加载。它的存储规则如下:在注册表的HKEY_CLASSES_ROOT中以模块名的方式保存着COM模块的GUID,比如HKEY_CLASSES_ROOT\ADODB.Error\CLSID键中保存着模块ADODB.Error的GUID为{00000541-0000-0010-8000-00AA006D2EA4}在HKEY_CLASSES_ROOT\CLSID中以GUID为项名保存着对应组件的详细信息,比如之前的{00000541-0000-0010-8000-00AA006D2EA4}这个GUID在注册表中的位置为HKEY_CLASSES_ROOT\CLSID\{00000541-0000-0010-8000-00AA006D2EA4}\InprocServer32\项的默认键中保存着模块所在路径为%CommonProgramFiles%\System\ado\msado15.dll一般的COM模块都是使用regsvr32程序注册到注册表中,该程序在注册时会在模块中查找DllRegisterServer函数,卸载时调用模块中提供的DllUnregisterServer,所以要实现注册的功能主要需要实现这两个函数这两个函数的原型如下:STDAPI DllRegisterServer(); STDAPI DllUnregisterServer();通过VS的F12功能查找STDAPI 的定义如下:#define STDAPI EXTERN_C HRESULT STDAPICALLTYPE在查看STDAPICALLTYPE得到如下结果:#define STDAPICALLTYPE __stdcall所以这个宏展开也就是extern "C" HRESULT __stdcall DllRegisterServer();为了实现注册功能,首先定义一个全局的变量,用来表示需要写入到注册表中的项const TCHAR *g_regTable[][3] = { {_T("SOFTWARE\\ComDemo"), 0, _T("ComDemo")}, {_T("SOFTWARE\\ComDemo\\InporcServer32"), 0, (const TCHAR*)-1}这三项分别为注册表项,注册表项中的键名和键值,当键名为0时会创建一个默认的注册表键,最后一个-1我们会在程序中判断,如果键值为-1,那么值取为模块的路径下面是注册的函数STDAPI DllRegisterServer() { HKEY hKey = NULL; TCHAR szFileName[MAX_PATH] = _T(""); GetModuleFileName(g_hDllIns, szFileName, MAX_PATH); int nCount = sizeof(g_regTable) / sizeof(*g_regTable); for (int i = 0; i < nCount; i++) { LPCTSTR pszKeyName = g_regTable[i][0]; LPCTSTR pszValueName = g_regTable[i][1]; LPCTSTR pszValue = g_regTable[i][2]; if (pszValue == (const TCHAR*)-1) { pszValue = szFileName; } long err = RegCreateKey(HKEY_LOCAL_MACHINE, pszKeyName, &hKey); if (err != ERROR_SUCCESS) { return SELFREG_E_LAST; } err = RegSetValueEx(hKey, pszValueName, 0, REG_SZ, (const BYTE*)pszValue, _tcslen(pszValue) * sizeof(TCHAR)); if (err != ERROR) { return SELFREG_E_LAST; } RegCloseKey(hKey); } return S_OK; }在程序中会循环读取上述全局变量中的值,将值保存到注册表中,在上面的代码中有一句sizeof(g_regTable) / sizeof(*g_regTable);这个是算需要循环多少次,第一个sizeof得到的是这个二维数组的总大小。在C语言中我们说二维数组可以看做是由一维数组组成的,这个二维数组可以看成是由两个一维数组——一个由3个const TCHAR 成员组成的一维数组组成。所以g_regTab自然就是这个一维数组的首地址,第二个sizeof就是这个一维数组的大小,两个相除得到的就是一维数组的个数。卸载函数如下:STDAPI DllUnregisterServer() { int nCount = sizeof(g_regTable) / sizeof(*g_regTable); for (int i = nCount - 1; i >= 0; i--) { LPCTSTR pszKeyName = g_regTable[i][0]; long err = RegDeleteKey(HKEY_LOCAL_MACHINE, pszKeyName); if (err != ERROR_SUCCESS) { return SELFREG_E_LAST; } } return S_OK; }至此已经实现注册和卸载函数。后面就可以直接使用regsvr32这个程序进行注册和卸载了.
-
COM学习(一)——COM基础思想 概述学习微软技术COM是绕不开的一道坎,最近做项目的时候发现有许多功能需要用到COM中的内容,虽然只是简单的使用COM中封装好的内容,但是许多代码仍然只知其然,不知其所以然,所以我决定从头开始好好学习一下COM基础的内容,因此在这记录下自己学习的内容,以便日后参考,也给其他朋友提供一点学习思路。COM的全称是Component Object Module,组件对象模型。组件就我自己的理解就是将各个功能部分编写成可重用的模块,程序就好像搭积木一样由这些可重用模块构成,这样将各个模块的耦合降到最低,以后升级修改功能只需要修改某一个模块,这样就大大降低了维护程序的难度和成本,提高程序的可扩展性。COM是微软公司提出的组件标准,同时微软也定义了组件程序之间进行交互的标准,提供了组件程序运行所需的环境。COM是基于组件化编程的思想,在COM中每一个组件成为一个模块,它可以是动态链接库或者可执行文件,一个组件程序可以包含一个或者多个组件对象,COM对象不同于OOP(面向对象)中的对象,COM对象是定义在二进制机器代码基础之上,是跨语言的。而OOP中的对象是建立在语言之上的。脱离了语言对象也就不复存在.COM是独立在编程语言之上的,是语言无关的。COM的这一特性使得不同语言开发的组件之间的互相交互成为可能。COM对象和接口COM中的对象类似于C++中的对象,对象是某个类中的实例。而类则是一组相关的数据和功能组合在一起的一个定义。使用对象的应用(或另一个对象)称为客户,有时也称为对象的用户。 接口是一组逻辑相关的函数的集合,比如一组处理URL的接口,处理HTTP请求的接口等等。在习惯上接口通常是以"I"开头。对象通过接口成员函数为客户提供各种形式的服务。一个对象可以拥有多个不同的接口,以表现不同的功能集合。 在C++语言中,一个接口就是一个虚基类,而对象就是该接口的实现类,派生自该接口并实现接口的功能。class IBook { public: virtual void NextPage() = 0; virtual void ForwardPage() = 0; } class IAppliances { public: virtual void charge() = 0; virtual void shutdown() = 0; } class CKindle: public IBook, IAppliances { public: virtual void NextPage(); virtual void ForwardPage(); virtual void charge(); virtual void shutdown(); }就像上面的例子,上面的例子中提供了一个书本的接口,书本可以翻到上一页,下一页,而电器有充电和关机的接口,最后我们利用kindle这个类来实现这两个接口。所以在使用上我们可以利用下面的伪代码来使用pInterface = CreateInterface(ID_IBOOK, ID_KINDLE); pInterface->NextPage(); if(Late()) { pInter2 = pInterface->QueryInterface(ID_APPLIANCES); pInter2->shutdown(); }在平时我们使用kindle的翻页功能来看书,因为翻页功能在接口IBook,所以首先调用一个创建接口的函数,传入对应接口以及接口实现类的标识,用来生成相应的接口,其实在内部也就是根据类ID来创建一个对应的实现类的实例。然后根据需要转化为对应基类的指针。在看书看累的时候,将接口转化为电子产品的接口,调用对应的关机功能,关闭电子书。在之后比如说kindle进行了升级,也就是重写了实现这些接口的代码,但是接口原型不变,这样使用接口的代码不用改变,也就是说即使kindle对内部进行了升级,优化某些功能,用户在使用上仍然是那样在用,不必改变使用习惯。再比如kindle出了一个新款,提供了背光功能,这个时候可能提供一个新接口:class IAppliances2 : public IAppliances { public: virtual void Light() = 0; }然后只需要稍微更新一下CKindle这个实现类,新增一个Light接口的实现,在使用上如果不用背光功能原来的代码就够用了,如果要使用背光功能,只需要将原来的接口类型改为IAppliances2 ,并且添加调用背光功能的函数,而其余的功能也不变,这与实际生活相似,某个产品提供新功能时,一般保持原始功能的使用方法不变,新功能会有新的按钮或者其他方法进行打开。再比如说我不想用kindle了改用其他的电子阅读器,只要接口不变,我的使用方法基本不变,唯一改变的可能是我以前拿着kindle,现在拿着其他品牌的阅读器,也就是说可能要改变传入CreateInterface函数中的类标识。COM基本接口COM中所有接口都派生自该接口:struct IUnknown { virtual HRESULT QueryInterface(REFIID riid,void **ppvObject) = 0; virtual ULONG AddRef( void) = 0; virtual ULONG Release( void) = 0; };所有类都应该实现上述三个方法,AddRef主要将接口的引用计数+1, 而Release则是将引用计数 -1,当对象的引用计数为0,则会调用析构函数,释放对象的存储空间。每一次接口的创建和转化都会增加引用计数,而每次不再使用调用Release,都会把引用计数 -1,当引用计数为0时会释放对象的空间。QueryInterface主要用来进行接口转化,将对象的指针转化为另外一个接口的指针,就好像上面例子中pInter2 = pInterface->QueryInterface(ID_APPLIANCES);这句代码将之前的Ibook接口转化为电子产品的接口。在C++中也就是做了一次强制类型转化。对象和接口的唯一标识在COM中,对象本身对于客户来说是不可见的,客户请求服务时,只能通过接口进行。每一个接口都由一个128位的全局唯一标识符(GUID,Global Unique Identifier)来标识。客户通过GUID来获得接口的指针,再通过接口指针,客户就可以调用其相应的成员函数。与接口类似,每个组件也用一个 128 位 GUID 来标识,称为 CLSID(class identifer,类标识符或类 ID),用 CLSID 标识对象可以保证(概率意义上)在全球范围内的唯一性。实际上,客户成功地创建对象后,它得到的是一个指向对象某个接口的指针,因为 COM 对象至少实现一个接口(没有接口的 COM 对象是没有意义的),所以客户就可以调用该接口提供的所有服务。根据 COM 规范,一个 COM 对象如果实现了多个接口,则可以从某个接口得到该对象的任意其他接口。由此可看出,客户与 COM 对象只通过接口打交道,对象对于客户来说只是一组接口。在COM中GUID的定义如下:typedef struct _GUID { unsigned long Data1; unsigned short Data2; unsigned short Data3; unsigned char Data4[ 8 ]; } GUID;一般我们在程序中只是作为一个标志来使用,并不对它进行特别的操作。生成它一般是使用VS自带的GUID生成工具。而CLSID的定义如下:typedef GUID CLSID;其实在COM中一般涉及到ID的都是GUID,只是利用typedef另外定义了一个名称而已另外COM也提供了一组函数用来对GUID进行操作:函数功能IsEqualGUID判断GUID是否相等IsEqualCLSID判断CLSID是否相等IsEqualIID判断IID是否相等CLSIDFromProgID把字符串形式的CLSID转化为CLSID结构形式(类似于将字符串的234转化为数字,也是把字面上的CLSID转化为计算机能识别的CLSID)StringFromCLSID把CLSID转化为字符串形式IIDFromString把字符串形式的IID转化为IID接口形式StringFromIID把IID结构转化为字符串StringFromGUID2把GUID形式转化为字符串形式COM接口的一般使用步骤一般使用COM中的时候首先使用CoInitialize初始化COM环境,不用的时候使用CoUninitialize卸载COM环境,在使用接口中一般需要进行下面的步骤调用CoCreateInstance函数传入对应的CLSID和对应的IID,生成对应对象并传入相应的接口指针。使用该指针进行相关操作调用接口的QueryInterface函数,转化为其他形式的接口在最后分别调用各个接口的Release函数,释放接口下面提供一个小例子,以供参考,也方便更好的理解COM//组件部分 extern "C" __declspec(dllexport) void __stdcall ComCreateObject(GUID clsID, GUID interfaceID, void** pObj); void __stdcall ComCreateObject(GUID clsID, GUID interfaceID, void** pObj) { if (clsID == CLSID_COMSTRING) { CComString *pComObject = new CComString; *pObj = pComObject->QueryInterface(interfaceID); } } class IComBase { public: virtual void* QueryInterface(GUID gInterfaceId) = 0; virtual void AddRef() = 0; virtual void Release() = 0; }; static const GUID IID_ICOMSTRING = { 0xb2fcd22c, 0x63fa, 0x4f61, { 0xbf, 0x12, 0xd3, 0xd2, 0x5a, 0x99, 0x59, 0x24 } }; class IComString : public IComBase { public: virtual void Init(LPCTSTR pStr) = 0; virtual int Find(LPCTSTR lpSubStr) = 0; virtual int GetLength() = 0; }; static const GUID CLSID_COMSTRING = { 0xf57f3489, 0xff2d, 0x4c97, { 0xb1, 0xf6, 0xc, 0x60, 0x7e, 0xf7, 0xae, 0xfc } }; class CComString : public IComString { public: virtual void* QueryInterface(GUID gInterfaceId); virtual void AddRef(); virtual void Release(); virtual void Init(LPCTSTR pStr); virtual int Find(LPCTSTR lpSubStr); virtual int GetLength(); protected: int m_nCnt = 0; CString m_csString; }; //cpp void* CComString::QueryInterface(GUID gInterfaceId) { if (gInterfaceId == IID_ICOMSTRING) { //该接口的引用计数+1 AddRef(); return dynamic_cast<IComString*>(this); } //如果它还实现了其他接口,可以再写判断,生成其他类型的接口 return NULL; } void CComString::AddRef() { m_nCnt++; } void CComString::Release() { m_nCnt--; //引用计数为0,此时没有该类的接口被使用,应该释放该类 if (m_nCnt == 0) { delete this; } } void CComString::Init(LPCTSTR pStr) { m_csString = pStr; } int CComString::Find(LPCTSTR lpSubStr) { return m_csString.Find(lpSubStr); } int CComString::GetLength() { return m_csString.GetLength(); }这些代码被封装在一个dll中,dll中导出一个函数ComCreateObject,外部在使用时调用该函数传入对应的ID,以便生成对应的接口。在这个dll里面提供一个接口的基类IComBase,这个是仿照了COM种的IUnknow基类,另外定义了一个IComString字符串的接口,同时定义了它的实现类CComString,为了简单,它的功能方法我直接使用了一个CString类实现。在函数ComCreateObject,会根据传入对应的类ID,来生成对应的类实例,然后调用实例的QueryInterface,转化成对应的接口,在实现类中实现了这个方法,实现类中的QueryInterface方法主要完成了类型转化并将引用计数+1。而Release函数在每次-1的时候会进行判断,当引用计数为0时销毁该类的实例由于类是new出来创建在堆上的,所以每次用完一定要记得调用Release释放,否则会造成内存泄露注意:在使用这里使用的是dynamic_cast进行类型转化,在进行类的强制类型转化时,特别是在有多重继承的情况下,最好使用dynamic_cast方式进行转化,当一个类拥有多个基类时,类中有多个虚函数表,为了能正常找到对应的虚函数表,就需要进行对应的偏移量的计算,C中的强制类型转化是直接将对象的首地址进行转化,这样在寻址虚函数表时可能会出错。而dynamic_cast会进行对应的计算。详细情形请参考这里在使用上void ComInitialize(); void ComUninitialize(); typedef void(__stdcall *pfnCreateInstance)(GUID, GUID, void**); pfnCreateInstance CreateInstance; HMODULE hComDll = NULL; int _tmain(int argc, _TCHAR* argv[]) { ComInitialize(); IComString *pIString = NULL; CreateInstance(CLSID_COMSTRING, IID_ICOMSTRING, (void**)&pIString); pIString->Init(_T("Hello World")); IComString* pIString2 = (IComString*)(pIString->QueryInterface(IID_ICOMSTRING)); int nLength = pIString2->GetLength(); int iPos = pIString2->Find(_T("World")); printf("%d, %d\n", nLength, iPos); pIString->Release(); pIString2->Release(); return 0; } void ComInitialize() { hComDll = LoadLibrary(_T("ComInterface.dll")); if (NULL != hComDll) { CreateInstance = (pfnCreateInstance)GetProcAddress(hComDll, "ComCreateObject"); } } void ComUninitialize() { FreeLibrary(hComDll); }给使用者使用时只需要提供对应类和接口的GUID,然后将函数ComCreateObject原型提供给调用者,以便生成对应的接口。这里为了模仿COM的使用定义了ComInitialize和ComUninitialize这两个函数,真实的初始化函数怎么写的,我也不知道,在这里只是为了模仿COM的使用。至此相信各位小伙伴应该对COM有了一个初步的了解
-
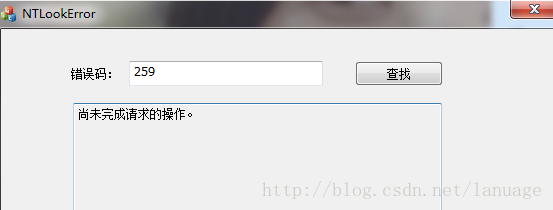
使用FormatMessage函数编写一个内核错误码查看器 在编写驱动程序的时候,常用的一个结构是NTSTATUS,它来表示操作是否成功,但是对于失败的情况它的返回码过多,不可能记住所有的情况,应用层有一个GetLastError函数,根据这个函数的返回值可以通过错误查看器来查看具体的错误原因,但是内核中就没有这么方便了,我之前在网上找资料的时候发现很多人都是把错误码和它的具体原因都列举出来,然后人工进行对照查找,这样很不方便,有没有类似于应用层上错误码查看工具的东西呢?终于皇天不负有心人,我在微软官网上找到了FormatMessage的说明,自己实现了这个功能,现在讲这个部分记录下来,以供大家参考void CNTLookErrorDlg::OnBnClickedBtnLookup() { // TODO: 查找错NTSTATUS值对应的错误 LPVOID lpMessageBuffer; HMODULE Hand = LoadLibrary(_T("NTDLL.DLL")); DWORD dwErrCode = 0; dwErrCode = GetDlgItemInt(IDC_EDIT_ERRCODE); FormatMessage( FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_FROM_HMODULE, Hand, dwErrCode, MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT), (LPTSTR) &lpMessageBuffer, 0, NULL ); // Now display the string. GetDlgItem(IDC_EDIT_ERRMSG)->SetWindowText((LPTSTR)lpMessageBuffer); // Free the buffer allocated by the system. LocalFree( lpMessageBuffer ); FreeLibrary(Hand); }这是用mfc写的一段代码,首先加载NTDLL.dll文件,然后调用FormatMessage,第一个参数需要新加入FORMAT_MESSAGE_FROM_HMODULE表示需要从某个模块中取出错误码和具体字符串之间的对应关系,然后将第二个参数传入dll的句柄,这个dll中记录了内核中错误码和对应字符串的信息。如果不加这个标志,那么默认从系统中获取,也就是获取应用层的GetLastError中返回的信息与错误字符串的对应关系。有了这个信息,剩下的就交给FormatMessage来进行格式化啦。这样一个简单的工具就完成了,再也不用满世界的找对应关系然后手工对比了,程序的运行结果如下:
-
Windows服务框架与服务的编写 从NT内核开始,服务程序已经变为一种非常重要的系统进程,一般的驻守进程和普通的程序必须在桌面登录的情况下才能运行,而许多系统的基础程序必须在用户登录桌面之前就要运行起来,而利用服务,可以很方便的实现这种功能,而且服务程序一般不予用户进行交互,可以安静的在后台执行,合理的利用服务程序可以简化我们的系统设计,比如Windows系统的日志服务,IIS服务等等。服务程序本身是依附在某一个可执行文件之中,系统将服务安装在注册表中的HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services位置,当需要执行服务程序时,由系统的服务控制管理器在注册表中对应的位置读取服务信息,并启动对应的程序。下面从几个方面详细说明服务程序的基本框架服务程序的框架服务程序本身也是依附在exe或者dll文件中,一般一个普通的可执行文件中可以包含一个或者多个服务,但是为了代码的维护性,一般一个程序总是只包含一个服务。服务程序是由服务管理器负责调度,控制的,所以我们在编写服务程序的时候必须满足服务控制管理器的调度,必须包含:立即调用StartServiceCtrlDispatchar函数把进程的主线程连接到ServiceControlManager的主函数在进程中运行的各个服务的入口点函数ServiceMain在进程中运行的各个服务的控制处理函数HandlerServiceControlManager函数的原型如下:BOOL WINAPI StartServiceCtrlDispatcher( __in const SERVICE_TABLE_ENTRY* lpServiceTable );函数参数是一个SERVICE_TABLE_ENTRY类型的指针,这个类型的定义如下:typedef struct _SERVICE_TABLE_ENTRY { LPTSTR lpServiceName; LPSERVICE_MAIN_FUNCTION lpServiceProc; } SERVICE_TABLE_ENTRY, *LPSERVICE_TABLE_ENTRY;这个结构是一个服务名称和对应入口函数指针的映射。在传入的时候必须给一个该类型的数组,数组的每一项都代表一个服务与其入口函数指针的映射,同时这个数组的最后一组必须为NULL当启动服务的时候,系统会启动对应的进程,当进程代码执行到StartServiceCtrlDispatcher时,程序由服务控制管理器接管,服务控制管理器根据需要启动的服务名称,在传入的数组指针中,找到对应的入口函数,然后调用它,当对应的入口函数返回时结束服务,并将后续代码的控制权转交给对应主进程,由主进程接着执行后面的代码在入口函数中我们必须给服务一个控制管理程序,这个程序主要是用来处理服务程序接受到的各种控制消息,比如启动服务,暂停服务,停止服务等,这个函数有点类似于Windows 窗口程序中的窗口过程。这个函数由我们自己编写,然后调用函数RegisterServiceCtrlHandler(Ex) 将服务名称与对应的控制函数绑定,每当有一个控制事件发生时都会调用我们注册的函数进行处理,RegisterServiceCtrlHandler函数会返回一个句柄,作为服务的控制句柄。当我们要自己向服务控制管理器报告服务的当前状态时需要这个句柄。服务的启动过程已经安装的服务,被系统存储在注册表的HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services位置处,这个注册表项纪录了服务所依赖的exe或者dll文件,它的启动类型等信息,当我们尝试启动服务的时候,系统会在注册表的对应位置查找是否存在对应服务的表项,如果存在则启动对应的进程。当进程的代码执行到StartServiceCtrlDispatcher函数时,该进程将由服务控制管理器接管,服务控制管理器将会根据填入的SERVICE_TABLE_ENTRY,找到服务所对应的入口函数开启对应的服务线程并调用,在入口函数处会注册一个控制句柄,然后应该向服务控制管理程序报告当前状态为正在启动,然后执行服务的正式代码。(注意:由于服务的入口函数需要自己编写,所以这里提到的注册控制句柄,报告状态都应该是由程序员自己编写代码实现)Handler函数handler函数用来处理服务的控制请求,这个函数由RegisterServiceCtrlHandler(Ex)函数注册到系统,当服务控制请求到来时,由服务的主线程的控制分发线程来调用。综合上面的内容,可以看到一个服务程序应该是至少涉及到3个线程,进程的主线程,服务线程,控制分发线程,RegisterServiceCtrlHandler(Ex)的原型如下:SERVICE_STATUS_HANDLE WINAPI RegisterServiceCtrlHandlerEx( __in LPCTSTR lpServiceName, __in LPHANDLER_FUNCTION_EX lpHandlerProc, __in_opt LPVOID lpContext );不带Ex的版本只有前两个参数,带Ex版本的第3个参数是一个传入到对应的控制函数中的参数。对应提供的控制管理函数的原型如下:DWORD WINAPI HandlerEx( __in DWORD dwControl, __in DWORD dwEventType, __in LPVOID lpEventData, __in LPVOID lpContext );第一个参数是一个控制码,类似于GUI程序中的消息,根据这个控制码就可以知道对应的控制消息,下面列举常见的控制码:控制码含义SERVICE_CONTROL_STOP请求服务停止SERVICE_CONTROL_PAUSE请求暂停服务SERVICE_CONTROL_CONTINUE请求恢复暂停的服务SERVICE_CONTROL_INTERROGATE请求服务立即更新它的当前状态信息给服务控制管理程序SERVICE_CONTROL_SHUTDOWN请求服务执行清理任务,因为系统正在关机.由于只有非常有限的时间用来关机,所以这个控制只应由绝对需要关机的服务使用.例如:事件登录服务需要清理维护的文件中的脏字节,或服务需要关机以便当系统在关机状态时网络连接不能进行. 如果服务关键要花时间,并发出STOP_PENDING状态信息,强烈建议这些消息包括一个等待提示使得服务控制程序知道在给系统指明服务关机完成之前要等多长时间.系统给服务控制管理器有限的时间(约20秒)完成服务关机,在这个时间后无论服务关机动作是否完成都进行系统关机第二个参数是事件类型,对于有的控制码,它可能含有子控制类型来详细描述它,就好像WM_COMMAND消息中有子控件的相关消息第三个参数是事件参数,这个参数是子控制码对应的参数第四个参数是上面带Ex的函数第三个参数传进来的内容每次Handler函数被调用时,服务必须调用SetServiceStatus函数把状态报告给服务管理器程序注意:即使状态无变化也要报告服务控制管理器在服务中一般有3类对象(在这并不是指Windows系统的内核对象,这里只是为了便于理解给出的一个分类):服务程序对象:服务本身的代码,一般是服务主要完成的功能代码服务控制对象:用来控制服务,向服务发送执行服务管理对象:用来响应对应的控制码,主要是指服务的handler函数与GUI程序相类比,服务对象就好比GUI程序本身,服务控制对象就好像我们在操作GUI程序,比如点击鼠标,而服务控制对象就像窗口的窗口过程服务管理器由SCManager对象代表。SCManager对象是持有服务对象的容器对象。SCManager对象和服务对象的句柄类型是SC_HANDLE。我们可以使用函数OpenService来在服务管理器中打开对应服务获取服务对象的句柄,或者使用函数CreateService在服务管理器中创建一个新服务并返回服务的句柄后面关于服务的控制操作请参考本人之前写的一篇关于服务控制管理器的编写的博客点击这里下面通过一个封装的Service库来说明服务程序的框架。这个简单的类的详细代码请点击这里下载该项目中主要定义了三个类,其中CFSZService类是所有服务类的基类,CServiceCtrl是服务的控制类,该类用于控制服务,这个类中的所有函数都是静态函数。另外为了测试我从CFSZService类上派生了一个类——CTestService,用来编写服务的具体代码。如果以后想要使用这个项目中的代码,可以进行如下操作:FSZService类中派生一个新类,并重载基类的RunService,在这个服务中编写具体的服务代码即可在相应位置调用DECLARE_SERVICE_TABLE_ENTRY宏,用来声明一个SERVICE_TABLE_ENTRY变量,用来绑定服务和对应的入口函数在相应位置添加代码:IMPLAMENT_SERVICE_MAIN(GetSystemInfoService, CTestService) BEGIN_SERVICE_MAP() ON_SERVICE_MAP(GetSystemInfoService, CTestService) END_SERIVCE_MAP()第一个宏用来定义了一个函数,该函数是服务的入口函数,需要传入服务名称,服务的类名称。第二个宏用来将服务名和它对应的入口函数进行绑定。在主函数处调用CFSZService::RegisterService(),在该函数里面会调用StartServiceCtrlDispatcher,一遍让服务控制管理程序来接管服务代码代码的整体说明服务基类的定义如下:class CFSZService { public: typedef CAtlMap<CString, CFSZService *> CFSZServiceMap; //服务名称和对应的服务对象 CFSZService(const CString& csSrvName); ~CFSZService(void); virtual DWORD Run(DWORD dwArgc, LPTSTR* lpszArgv); virtual BOOL OnInitService(DWORD dwArgc, LPTSTR* lpszArgv); //初始化服务 virtual DWORD RunService(); //运行服务 void SetServiceStatusHandle(SERVICE_STATUS_HANDLE); static DWORD WINAPI HandlerEx(DWORD dwControl, DWORD dwEventType, LPVOID lpEventData, LPVOID lpContext); static BOOL RegisterService(); //服务命令处理函数 protected: virtual DWORD OnStop(); virtual DWORD OnUserControl(DWORD dwControl); virtual DWORD OnStart(); virtual DWORD OnContinue(); virtual DWORD OnPause(); virtual DWORD OnShutdown(); virtual DWORD OnInterrogate(); virtual DWORD OnShutDown(); protected://设备变更事件通知处理 SERVICE_CONTROL_DEVICEEVENT virtual DWORD OnDeviceArrival(PDEV_BROADCAST_HDR pDbh){return 0;} virtual DWORD OnDeviceRemoveComplete(PDEV_BROADCAST_HDR pDbh){return 0;} virtual DWORD OnDeviceQueryRemove(PDEV_BROADCAST_HDR pDbh){return 0;} virtual DWORD OnDeviceQueryRemoveFailed(PDEV_BROADCAST_HDR pDbh){return 0;} virtual DWORD OnDeviceRemovePending(PDEV_BROADCAST_HDR pDbh){return 0;} virtual DWORD OnCustomEvent(PDEV_BROADCAST_HDR pDbh){return 0;} protected://硬件配置文件发生变动 SERVICE_CONTROL_HARDWAREPROFILECHANGE virtual DWORD OnConfigChanged(){return 0;} virtual DWORD OnQueryChangeConfig(){return 0;} virtual DWORD OnConfigChangeCanceled(){return 0;} protected://设备电源事件 SERVICE_CONTROL_POWEREVENT virtual DWORD OnPowerSettingChange(PPOWERBROADCAST_SETTING pPs){return 0;} protected://session 发生变化 SERVICE_CONTROL_SESSIONCHANGE virtual DWORD OnWTSConsoleConnect(PWTSSESSION_NOTIFICATION pWn){return 0;} virtual DWORD OnWTSConsoleDisconnect(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSRemoteConnect(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSRemoteDisconnect(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSSessionLogon(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSSessionLogoff(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSSessionLock(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSSessionUnLock(PWTSSESSION_NOTIFICATION pWns){return 0;} virtual DWORD OnWTSSessionRemoteControl(PWTSSESSION_NOTIFICATION pWns){return 0;} protected: //内部的工具方法,设置服务为一个指定的状态 BOOL SetStatus(DWORD dwStatus,DWORD dwCheckPoint = 0,DWORD dwWaitHint = 0 ,DWORD dwExitCode = 0,DWORD dwAcceptStatus = SERVICE_CONTROL_INTERROGATE); BOOL SetStartPending(DWORD dwCheckPoint = 0,DWORD dwWaitHint = 0); //设为正在启动状态 BOOL SetContinuePending(DWORD dwCheckPoint = 0,DWORD dwWaitHint = 0); //设为正在继续运行状态 BOOL SetPausePending(DWORD dwCheckPoint = 0,DWORD dwWaitHint = 0); //设为正在暂停状态 BOOL SetPause(); //设为暂停状态 BOOL SetRunning(); //设为以启动状态 BOOL SetStopPending(DWORD dwCheckPoint = 0,DWORD dwWaitHint = 0); //设为正在停止状态 BOOL SetStop(DWORD dwExitCode = 0); //设为以停止状态 BOOL ReportStatus(DWORD, DWORD, DWORD);//向服务管理器报告当前服务状态 protected: CString m_csSrvName; //服务名称 DWORD m_dwCurrentStatus; //当前状态 SERVICE_STATUS_HANDLE m_hCtrl; //控制句柄 public: static CFSZServiceMap ms_SrvMap; };在这个基类中主要定义了3类函数,分别是:服务本身的代码函数:用来处理服务的业务,实现服务的功能服务控制管理函数:包括各种控制消息的响应函数和服务控制句柄的管理函数服务状态设置函数:主要用来设置服务的状态该项目使用Atl 和CString,一般在控制台程序中想要使用这二者只需要包含头文件:atlcoll.h、atlstr.h即可CFSZServiceMap 成员该成员是用来将服务名称和对应的类对象关联起来,这样以后根据服务名称就可以找到对应的服务类的对象指针,该类型定义如下:typedef CAtlMap<CString, CFSZService *> CFSZServiceMap;在每个类的构造函数中进行初始化:CFSZService::CFSZService(const CString& csSrvName) { m_csSrvName = csSrvName; ms_SrvMap.SetAt(m_csSrvName, this); }服务的入口函数服务的入口函数是利用宏定义的一个函数,每当需要添加一个服务的时候都需要调用宏IMPLAMENT_SERVICE_MAIN来定义一个对应的服务入口ServiceMain,该函数的定义如下:#define IMPLAMENT_SERVICE_MAIN(srvName, className)\ VOID WINAPI _ServiceMain_##className(DWORD dwArgc, LPTSTR* lpszArgv)\ {\ CFSZService *pThis = NULL;\ if(!CFSZService::ms_SrvMap.Lookup(_T(#srvName), pThis))\ {\ pThis = dynamic_cast<CFSZService*>( new className(_T(#srvName)) );\ }\ else\ {\ return;\ }\ assert(NULL != pThis);\ SERVICE_STATUS_HANDLE hss = RegisterServiceCtrlHandlerEx(_T(#srvName), CFSZService::HandlerEx, reinterpret_cast<LPVOID>(pThis));\ assert(NULL != hss);\ pThis->SetServiceStatusHandle(hss);\ pThis->Run(dwArgc, lpszArgv);\ delete dynamic_cast<##className*>(pThis);\ }上面的代码首先根据传入的类名动态创建了一个服务类(由于这里服务对象都是动态创建和销毁的,所以在其他地方不需要创建服务对象),然后调用RegisterServiceCtrlHandlerEx构造了一个服务控制句柄,然后调用类的SetServiceStatusHandle函数来将对应的服务控制句柄保存起来最后调用Run函数来运行服务的正式代码,最后当Run函数执行完毕后,服务的相应工作也做完了,这个时候删除了这个类。Run函数的定义如下:DWORD CFSZService::Run(DWORD dwArgc, LPTSTR* lpszArgv) { assert(NULL != this); if (OnInitService(dwArgc, lpszArgv)) { RunService(); } return 0; }这个函数中使用了OnInitService函数来进一步初始化服务相关信息,该函数提供了一个服务初始化的时机。比如调用相关函数进行socket的初始化或者对com环境进行初始化等等。然后调用RunService执行服务正式的代码。HandlerEx函数在前面的宏IMPLAMENT_SERVICE_MAIN中调用了RegisterServiceCtrlHandlerEx将函数HandlerEx作为服务控制码的处理函数,调用的时候将服务类对象的指针通过第四个参数传入,这样在静态函数中就可以使用服务的类成员函数,函数HandlerEx的部分代码如下: DWORD dwRet = ERROR_SUCCESS; if( NULL == lpContext ) { return ERROR_INVALID_PARAMETER; } CFSZService*pService = reinterpret_cast<CFSZService*>(lpContext); if( NULL == pService ) { return ERROR_INVALID_PARAMETER; } switch(dwControl) { case SERVICE_CONTROL_STOP: //0x00000001 停止服务器 { dwRet = pService -> OnStop(); } break; ... }在该函数中,将所有的控制吗都列举出来,针对不同的控制吗都调用的对应的处理函数,并且这些函数都是虚函数,所以在派生类中需要处理某个控制消息就重写某个对应的函数即可。最后再重新屡一下这个类在调用时的基本情况:在主函数中调用CFSZService::RegisterService();函数将之前我们通过一组BEGIN_SERVICE_MAP、ON_SERVICE_MAP、END_SERVICE_MAP组成的映射关系注册到系统的服务控制管理器中。这个函数单独调用了StartServiceCtrlDispatcher函数,一旦代码执行到这个地方,服务控制管理器会根据之前绑定的服务名称与入口函数的对应关系调用对应的入口函数入口函数是通过宏IMPLAMENT_SERVICE_MAIN定义的,在入口函数中首先动态创建了一个服务类,然后给这个服务注册服务控制句柄,并且服务控制函数为HandlerEx。接着,服务的入口函数调用对应服务的Run函数,在Run函数中调用OnInitService进行服务的初始化和调用RunService执行服务的正式代码,所以在重载类中可以重载这两个方法进行初始化和进行服务的相关操作当外部对服务进行控制时,服务控制管理器调用HandleEx函数进行相关的操作在HandleEx中会解析对应的控制事件,并调用对应的虚函数,所以如果想要处理某个消息,则重写对应的控制函数即可
-
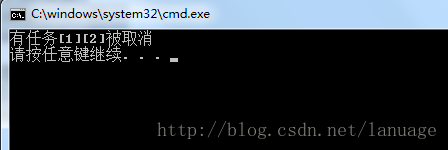
Vista 及后续版本的新线程池 在上一篇的博文中,说了下老版本的线程池,在Vista之后,微软重新设计了一套线程池机制,并引入一组新的线程池API,新版线程池相对于老版本的来说,它的可控性更高,它允许程序员自己定义线程池,并规定线程池中的线程数量和其他一些属性。线程池使用线程池的使用主要需要下面的四步:创建工作项提交工作项等待工作项完成清理工作项在前面说的四种线程池在使用上都是这4步,只是使用的API函数不同,每种线程池的每一步都有一个对应的API,总共有16个API普通线程池创建工作项的API为PTP_WORK WINAPI CreateThreadpoolWork( __in PTP_WORK_CALLBACK pfnwk, __inout_opt PVOID pv, __in_opt PTP_CALLBACK_ENVIRON pcbe );第一个参数是一个回调函数,当提交后,线程池中的线程会执行这个回调函数第二个参数是传递给回调函数的参数第三个参数是一个表示回调环境的结构,这个在后面会说回调函数的原型VOID CALLBACK WorkCallback( __inout PTP_CALLBACK_INSTANCE Instance, __inout_opt PVOID Context, __inout PTP_WORK Work );第一个参数用于表示线程池当前正在处理的一个工作项的实例,在后面会说它怎么用第二个参数是传给回调函数的参数的指针第三个参数是当前工作项的结构创建工作项完成之后调用SubmitThreadpoolWork将工作项提交到对应的线程池,由线程池中的线程处理这个工作项,该函数原型如下:VOID WINAPI SubmitThreadpoolWork( __inout PTP_WORK pwk );这个函数只有一个参数那就是工作项的指针,即我们想将哪个工作项提交。提交工作项之后,在需要同步的地方,调用函数WaitForThreadpoolWorkCallbacks,等待线程池中的工作项完成,该函数原型如下VOID WINAPI WaitForThreadpoolWorkCallbacks( __inout PTP_WORK pwk, __in BOOL fCancelPendingCallbacks );最后一个参数表示线程池是否需要执行未执行的工作项,注意它只能取消执行还没有开始执行的工作项,而不能取消已经有线程开始执行的工作项,最后调用函数CloseThreadpoolWork清理工作项,该函数的原型如下:VOID WINAPI CloseThreadpoolWork( __inout PTP_WORK pwk );就我个人的理解,TP_WORK应该保存的是一个工作项的信息,包含工作项的回调以及传递个回调函数的参数,每当提交一个工作项就是把这个结构放入到线程池的队列中,当线程池中有空闲线程的时候从队列中取出这个结构,将结构中的回调函数参数传递给回调函数,并调用它。我们可以重复提交同一个工作项多次,但是每个工作项一旦定义好了,那么传递给对应回调函数的参数应该是固定的,后期是没办法更改它的。它的等待函数调用时根据第二个参数,如果为TRUE则将线程池队列中的工作项清除,然后等待所有线程都为空闲状态时返回,而当参数为FALSE时,就不对队列中的工作项进行操作,并且一直等到线程池中的所有线程为空闲。下面是一个具体的使用例子:VOID CALLBACK MyWorkCallback( PTP_CALLBACK_INSTANCE Instance, PVOID Parameter, PTP_WORK Work ) { int nWaitTime = 4; printf("线程[%04x]将等待%ds\n", GetCurrentThreadId(), nWaitTime); Sleep(nWaitTime * 1000); printf("线程[%04x]执行完毕\n", GetCurrentThreadId()); } int _tmain(int argc, _TCHAR* argv[]) { PTP_WORK_CALLBACK workcallback = MyWorkCallback; PTP_WORK work = CreateThreadpoolWork(workcallback, NULL, NULL); //创建工作项 for (int i = 0; i < 4; i++) { SubmitThreadpoolWork(work); //提交工作项 } //等待线程池中的所有工作项完成 WaitForThreadpoolWorkCallbacks(work, FALSE); //关闭工作项 CloseThreadpoolWork(work); return 0; }定时器线程池定时器线程池中使用的对应的API分别为CreateThreadpoolTimer、SetThreadpoolTimer、WaitForThreadpoolTimerCallbacks和CloseThreadpoolTimer,这些函数的参数与之前的函数参数基本类似,区别比较大的是SetThreadpoolTimer,由于涉及到定时器,所以这里的参数稍微复杂一点VOID WINAPI SetThreadpoolTimer( __inout PTP_TIMER pti, __in_opt PFILETIME pftDueTime, __in DWORD msPeriod, __in_opt DWORD msWindowLength );第二个参数表示定时器触发的时间,它是一个64位的整数,如果为正数表示一个绝对的时间,表示从1960年到多少个100ns的时间后触发,如果为负数则表示从设置之时起经过多少时间后触发,单位为微秒(转化为秒是1000 * 1000)第三个参数每隔多长时间触发一次,如果只是想把这个定时器作为一次性的,和第四个参数没有用处,而如果想让线程池定期的触发它,这个值就是定期触发的间隔 时间,单位为毫秒第四个参数是用来给回调函数的执行时机增加一定的随机性,如果这个定时器是一个定期触发的定时器,那么这个值告诉线程池,可以在自定时器设置时间起,在(msPeriod - msWindowLength, mePeriod + msWindowsLong)这个区间之后的任意时间段触发另外我自己在编写测试代码的时候发现有的时候调用WaitForThreadpoolTimerCallbacks可能立即就返回了,后来我自己分析可能的原因是这个函数会在线程池队列中没有需要处理的工作项,并且线程池中线程为空闲的时候返回,当我使用定时器的时候,在等待时可能这个时候定时器上的时间未到,而线程池中又没有需要处理的定时器的工作项,所以它就返回了从而未达到等待的效果。下面是一个使用的具体例子,这个例子是《Windows核心编程》这本书中的例子,我觉得它里面有一个更改MessageBox显示信息的功能,所以将其修改了下作为例子int g_nWaitTime = 10; TCHAR g_szTitle[] = _T("提示"); #define ID_MSGBOX_STATIC_TEXT 0x0000ffff //MessageBox上内容部分的控件ID VOID CALLBACK TimerCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context, PTP_TIMER Timer) { HWND hWnd = FindWindow(NULL, g_szTitle); //找到MessageBox所对应的窗口句柄 if (NULL != hWnd) { TCHAR szText[1024] = _T(""); StringCchPrintf(szText, 1024, _T("您将有%ds的时间"), --g_nWaitTime); SetDlgItemText(hWnd, ID_MSGBOX_STATIC_TEXT, szText); //更改显示信息 } if (g_nWaitTime == 0) { ExitProcess(0); } } int _tmain(int argc, _TCHAR* argv[]) { //创建定时器历程 PTP_TIMER pTimer = CreateThreadpoolTimer(TimerCallback, NULL, NULL); //将定时器历程加入到线程池 ULARGE_INTEGER uDueTime = {0}; FILETIME FileDueTime = {0}; uDueTime.QuadPart = (LONGLONG) -(1 * 10 * 1000 * 1000); //时间为1s FileDueTime.dwHighDateTime = uDueTime.HighPart; FileDueTime.dwLowDateTime = uDueTime.LowPart; SetThreadpoolTimer(pTimer, &FileDueTime, 1000, 0); //每1s调用一次 WaitForThreadpoolTimerCallbacks(pTimer, FALSE); //此处调用等待函数会立即返回 TCHAR szText[] = _T("您将有10s的时间"); MessageBox(NULL, szText, g_szTitle, MB_OK); //关闭工作项 CloseThreadpoolTimer(pTimer); return 0; }同步对象线程池对这种线程池的使用主要调用这样几个函数: CreateThreadpoolWait、SetThreadpoolWait、WaitForThreadpoolWaitCallbacks、CloseThreadpoolWait ,这几个函数的使用与之前的普通线程池的使用类似,在这就不再进行说明直接给例子VOID CALLBACK WaitCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context, PTP_WAIT Wait, TP_WAIT_RESULT WaitResult) { if (WaitResult == WAIT_OBJECT_0) { printf("[%04x] wait the event\n", GetCurrentThreadId()); }else if (WaitResult == WAIT_TIMEOUT) { printf("[%04x] time out\n", GetCurrentThreadId()); } } int _tmain(int argc, _TCHAR* argv[]) { //创建等待线程池 PTP_WAIT pWait = CreateThreadpoolWait(WaitCallback, NULL, NULL); //创建事件 HANDLE hEvent = CreateEvent(NULL, FALSE, FALSE, NULL); //等待时间为1s FILETIME ft = {0}; ULARGE_INTEGER uWaitTime = {0}; uWaitTime.QuadPart = (LONGLONG) - 1 * 1000 * 1000; ft.dwHighDateTime = uWaitTime.HighPart; ft.dwLowDateTime = uWaitTime.LowPart; for (int i = 0; i < 5; i++) { //模拟等待5次 SetThreadpoolWait(pWait, hEvent, &ft); Sleep(1000); //休眠 SetEvent(hEvent); } WaitForThreadpoolWaitCallbacks(pWait, FALSE); CloseThreadpoolWait(pWait); CloseHandle(hEvent); return 0; }这种类型的回调函数的WaitResult参数实际上是一个DWORD类型,表示调用这个回调的原因,WAIT_OBJECT_0表示同步对象变为有信号,WAIT_TIMEOUT表示超时WAIT_ABANDONED_0表示穿入的互斥量被遗弃(只有在同步对象为互斥量的时候才会有这种值)完成端口线程池完成端口线程池的使用主要用这些API:CreateThreadpoolIo、StartThreadpoolIo、WaitForThreadpoolIoCallbacks、CloseThreadpoolIo,这些函数的使用也是十分的简单,下面再次将之前的完成端口写日志的例子进行改写:int _tmain(int argc, _TCHAR* argv[]) { TCHAR szAppPath[MAX_PATH] = _T(""); GetAppPath(szAppPath); StringCchCat(szAppPath, MAX_PATH, _T("NewIocpLog.txt")); HANDLE hFile = CreateFile(szAppPath, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, FILE_FLAG_OVERLAPPED | FILE_ATTRIBUTE_NORMAL, NULL); if (hFile == INVALID_HANDLE_VALUE) { return 0; } //创建IOCP线程池 g_pThreadpoolIO = CreateThreadpoolIo(hFile, IoCompletionCallback, hFile, NULL); StartThreadpoolIo(g_pThreadpoolIO); //写入Unicode字节码 LPIOCP_OVERLAPPED pIocpOverlapped = (LPIOCP_OVERLAPPED)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(IOCP_OVERLAPPED)); pIocpOverlapped->dwDataLen = sizeof(WORD); pIocpOverlapped->hFile = hFile; WORD dwUnicode = MAKEWORD(0xff, 0xfe); //构造Unicode前缀 pIocpOverlapped->pData = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(WORD)); CopyMemory(pIocpOverlapped->pData, &dwUnicode, sizeof(WORD)); //偏移文件指针 pIocpOverlapped->Overlapped.Offset = g_FilePointer.LowPart; pIocpOverlapped->Overlapped.OffsetHigh = g_FilePointer.HighPart; g_FilePointer.QuadPart += pIocpOverlapped->dwDataLen; //写文件 WriteFile(hFile, pIocpOverlapped->pData, pIocpOverlapped->dwDataLen, &pIocpOverlapped->dwWrittenLen, &pIocpOverlapped->Overlapped); //创建线程进行写日志操作 HANDLE hWrittenThreads[MAX_WRITE_THREAD]; for (int i = 0; i < MAX_WRITE_THREAD; i++) { hWrittenThreads[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)WriteThread, &hFile, 0, NULL); } //等待所有写线程执行完成 WaitForMultipleObjects(MAX_WRITE_THREAD, hWrittenThreads, TRUE, INFINITE); for (int i = 0; i < MAX_WRITE_THREAD; i++) { CloseHandle(hWrittenThreads[i]); } //等待线程池中待处理的IO完成请求 WaitForThreadpoolIoCallbacks(g_pThreadpoolIo, FALSE); CloseHandle(hFile); //关闭IOCP线程池 CloseThreadpoolIo(g_pThreadpoolIO); return 0; } VOID CALLBACK WriteThread(LPVOID lpParam) { TCHAR szBuf[255] = _T("线程[%04x]模拟写入一条日志记录\r\n"); TCHAR szWrittenBuf[255] = _T(""); StringCchPrintf(szWrittenBuf, 255, szBuf, GetCurrentThreadId()); for (int i = 0; i < EVERY_THREAD_WRITTEN; i++) { //提交一个IOCP历程 StartThreadpoolIo(g_pThreadpoolIO); LPIOCP_OVERLAPPED lpIocpOverlapped = (LPIOCP_OVERLAPPED)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(IOCP_OVERLAPPED)); size_t dwBufLen = 0; StringCchLength(szWrittenBuf, 255, &dwBufLen); lpIocpOverlapped->dwDataLen = dwBufLen * sizeof(TCHAR); lpIocpOverlapped->pData = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, (dwBufLen + 1) * sizeof(TCHAR)); CopyMemory(lpIocpOverlapped->pData, szWrittenBuf, dwBufLen * sizeof(TCHAR)); lpIocpOverlapped->hFile = *(HANDLE*)lpParam; //同步文件指针 *((LONGLONG*)&(lpIocpOverlapped->Overlapped.Pointer)) = InterlockedCompareExchange64(&g_FilePointer.QuadPart, g_FilePointer.QuadPart + lpIocpOverlapped->dwDataLen, g_FilePointer.QuadPart); //写文件 WriteFile(lpIocpOverlapped->hFile, lpIocpOverlapped->pData, lpIocpOverlapped->dwDataLen, &lpIocpOverlapped->dwWrittenLen, &lpIocpOverlapped->Overlapped); } } VOID CALLBACK IoCompletionCallback(PTP_CALLBACK_INSTANCE Instance,PVOID Context,PVOID Overlapped,ULONG IoResult,ULONG_PTR NumberOfBytesTransferred,PTP_IO Io) { LPIOCP_OVERLAPPED pIOCPOverlapped = (LPIOCP_OVERLAPPED)Overlapped; //释放对应的内存空间 printf("线程[%04x]得到IO完成通知,写入长度%d\n", GetCurrentThreadId(), pIOCPOverlapped->dwDataLen); if (pIOCPOverlapped->pData != NULL) { HeapFree(GetProcessHeap(), 0, pIOCPOverlapped->pData); } if (NULL != pIOCPOverlapped) { HeapFree(GetProcessHeap(), 0, pIOCPOverlapped); pIOCPOverlapped = NULL; } }在新版的完成端口的线程池中,每当需要进行IO操作时,要保证在IO操作之前调用StartThreadpoolIo提交请求。如果没有那么我们的回调函数将不会被执行。注意:后面两种线程池与旧版的相比,最大的区别在于新版的是一次性的,也就是每提交一次,它只会执行一次,要想让其不停触发就需要不停的进行提交,而旧版的只需要绑定,一旦相应的事件发生,他就会不停地的执行线程池控制回调函数的终止操作线程池提供了一种便利的方法,用来描述当我们的回调函数返回之后,应该执行的一些操作,通过这种方式,可以通知其他线程,回调函数已经执行完毕。通过调用下面的一些API可以设置对应的同步对象,在线程池外的其他线程等待同步对象就可以知道什么时候回调执行完毕函数终止操作LeaveCriticalWhenCallbackReturns当回调函数返回时,线程池会自动调用LeaveCritical,并在参数中传入指定的CRITICAL_SECTION结构ReleaseMutexWhenCallbackReturns当回调函数返回时,线程池会自动调用ReleaseMutexWhen并在参数中传入指定的HANDLEReleaseSemaphoreWhenCallbackReturns当回调函数返回时,线程会自动调用ReleaseSemphore并在参数中传入指定的HANDLESetEventWhenCallbackReturns当回调函数返回时,线程会自动调用SetEvent,并在参数中传入指定的HANDLEFreeLibraryWhenCallbackReturns当回调函数返回时,线程会自动调用FreeLibrary并在参数中传入指定的HANDLE前4个函数给我们提供了一种方式来通知另外一个线程,回调函数调用完成,而最后一个函数则提供了一种在回调函数调用完成之时,清理动态库的方式,如果回调函数是在dll中实现的,但是在回调函数结束之时,我们希望卸载这个dll,这个时候不能调用FreeLibrary,这个时候回调函数虽然完成了任务,但是在后面还有函数栈平衡的操作,如果在返回时,我们将dll从内存中卸载,必然会导致最后的栈平衡操作访问非法内存,从而时应用程序崩溃。但是我们可以调用FreeLibraryWhenCallbackReturns,完成这个任务。下面是一个具体的例子:typedef struct tagWAIT_STRUCT { HANDLE hEvent; DWORD dwThreadId; }WAIT_STRUCT, *LPWAIT_STRUCT; WAIT_STRUCT g_waitStruct = {0}; VOID CALLBACK WorkCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context, PTP_WORK Work) { g_waitStruct.dwThreadId = GetCurrentThreadId(); Sleep(1000 * 10); SetEventWhenCallbackReturns(Instance, *(HANDLE*)&g_waitStruct); } int _tmain(int argc, _TCHAR* argv[]) { PTP_WORK pWork = CreateThreadpoolWork(WorkCallback, NULL, NULL); g_waitStruct.hEvent = CreateEvent(NULL, FALSE, FALSE, NULL); SubmitThreadpoolWork(pWork); WaitForSingleObject(g_waitStruct.hEvent, INFINITE); printf("线程池中线程[%04x]执行完成\n", g_waitStruct.dwThreadId); CloseThreadpoolWork(pWork); return 0; }上面的代码首先创建一个无信号的event对象,然后在回调函数中调用SetEventWhenCallbackReturns,当回调函数完成之时就会将event设置为有信号,这样我们在主线程中就可以等待,一旦回调函数执行完成,event变为有信号,wait函数就会返回。同时我们定义一个结构体尝试着从线程池中带出一个线程ID,并在主线程中使用它对线程池进行定制上面在讨论四种线程池的时候,使用的都是系统自带的线程池,这些线程池由系统管理,我们只能使用,而不能对它们的一些属性进行定制,但是新版本的线程池中提供了这样的方式,要对线程池进行定制,不能使用系统已经定义好的线程池,得自己定义,定义线程池使用API函数CreateThreadPool,这个函数只有一个参数,这个参数是Windows的保留参数目前应该赋值为NULL。该函数会返回一个PTP_POOL 类型的值,这个值是一个指针,用来标识一个线程池。创建完成之后,我们可以函数SetThreadpoolThreadMaximum 或者SetThreadpoolThreadMinimum来规定线程池中的最大和最小线程。当不需要自定义的线程池的时候可以使用函数CloseThreadPool,来清理自定义线程池。线程池的回调环境线程池的回调环境规定了回调函数的执行环境,比如由哪个线程池中的线程来调用,对应线程池的版本,对应的清理器和其他的属性等等。环境的结构定义如下:typedef struct _TP_CALLBACK_ENVIRON { TP_VERSION Version; //线程池的版本 PTP_POOL Pool; //关联的线程池 PTP_CLEANUP_GROUP CleanupGroup; //对应的环境清理组 PTP_CLEANUP_GROUP_CANCEL_CALLBACK CleanupGroupCancelCallback; PVOID RaceDll; struct _ACTIVATION_CONTEXT *ActivationContext; PTP_SIMPLE_CALLBACK FinalizationCallback; union { DWORD Flags; struct { DWORD LongFunction : 1; DWORD Private : 31; } s; } u; } TP_CALLBACK_ENVIRON, *PTP_CALLBACK_ENVIRON;虽然这个结构微软对外公布,而且是可以在程序中直接使用的,但是最好不要这么做,我们应该使用它提供的API对其进行操作,首先可以调用InitializeThreadpoolEnvironment来创建一个对应的回调环境,对我们传入的TP_CALLBACK_ENVIRON变量进行初始化。然后可以调用函数SetThreadpoolCallbackPool来规定由哪个线程池来调用对应的回调函数,如果将参数ptpp传入NULL,则使用系统默认的线程池。另外还可以调用SetThreadpoolCallbackRunsLong 来告诉线程池,我们的任务需要较长的时间来执行。最后当我们不需要这个回调环境的时候可以使用函数DestroyThreadpoolEnvironment来清理这个结构。我自己在看这一块的时候很长时间都转不过弯来,总觉得回调环境是由线程池持有的,每个线程池都有自己的回调环境,其实这个是错误的,既然它叫做回调环境,自然与线程池无关,它是用来控制回调行为的。当我们在创建对应的任务时,最后一个参数就是回调环境的指针,在提交任务时会首先将任务提交到回调环境所规定的线程池中,由对应的线程池来处理。函数SetThreadpoolCallbackPool从表面意思来看是未线程池设置一个回调环境其实这个意思正好相反,是为某个回调指定对应调用的线程池。在后面就可以看到,回调环境可比线程池大的多线程池的清理组为了得体的销毁自定义的线程池(系统自定义线程池不会被销毁),我们需要知道系线程池中各个任务何时完成,只有当所有任务都完成时销毁线程池才算得体的销毁,只有这样才能顺利的清理相关资源。但是由于线程池中的各项任务可能由不同的线程提交,提交的时机,任务执行完所需要的时间各不相同,所以基本上不可能知道线程池中的任务何时完成。为了解决这个问题,新版的线程池提供了清理组的概念。TP_CALLBACK_ENVIRON结构的PTP_CLEANUP_GROUP就为对应的执行环境绑定了一个清理组。当线程池中的任务都处理完成时能够得体的清理线程池可以调用CreateThreadpoolCleanupGroup来创建一个清理组,然后调用SetThreadpoolCallbackCleanupGroup来将线程池与对应的清理组。它的原型如下:VOID SetThreadpoolCallbackCleanupGroup( __inout PTP_CALLBACK_ENVIRON pcbe, __in PTP_CLEANUP_GROUP ptpcg, __in_opt PTP_CLEANUP_GROUP_CANCEL_CALLBACK pfng );第一个参数是一个回调环境第二个参数是一个对应的清理组,这两个参数就将对应的回调环境和清理组关联起来第三个参数是一个回调函数,每当一个工作项被取消,这个函数将会被调用。对应的回调函数的原型如下:VOID NTAPI CleanupGroupCancelCallback(PVOID pvObjectContext, PVOID CleanupContext);每当创建一个任务时,如果最后一个参数不为NULL,那么对应的清理组中会增加一项,表示又增加一个需要潜在清理的任务。最后我们调用对应的清理工作项的函数时,相当于显示的将需要清理的项从对应的清理组中去除。当我们的应用程序想要销毁线程池时,调用函数CloseThreadpoolCleanupGroupMembers。这个函数相比于之前的WaitForThreadpoolTimerCallbacks来说,它可以等待线程池中的所有工作项,而不管工作项是哪种类型,而对应的wait函数只能等待对应类型的工作项。VOID WINAPI CloseThreadpoolCleanupGroupMembers( __inout PTP_CLEANUP_GROUP ptpcg, __in BOOL fCancelPendingCallbacks, __inout_opt PVOID pvCleanupContext );CloseThreadpoolCleanupGroupMembers函数的第二个参数也是一个BOOL类型,它的作用与对应的wait函数中第二个参数的作用相同。如果第二个参数设置为NULL,那么每当该函数取消一个工作项,对应的PTP_CLEANUP_GROUP_CANCEL_CALLBACK 类型的回调就要被调用一次CleanupGroupCancelCallback函数中第一个参数是被取消项的上下文,这个上下文是由对应的创建工作项的函数的pvContext参数传递进来的,而第二个参数是由CloseThreadpoolCleanupGroupMembers函数的第三个参数传递进来的。当所有的工作项被取消后调用CloseThreadpoolCleanupGroup来释放清理组所占的资源。最后调用DestroyThreadpoolEnviroment和CloseThreadPool这样就可以得体的关闭线程池下面是使用的一个例子:VOID NTAPI CleanupGroupCancelCallback(PVOID pvObjectContext, PVOID CleanupContext) { printf("有任务[%d][%d]被取消\n", *(int*)pvObjectContext, *(int*)CleanupContext); } VOID CALLBACK TimerCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context, PTP_TIMER Timer) { Sleep(1000); printf("有对应的定时器历程被调用\n"); } int _tmain(int argc, _TCHAR* argv[]) { TP_CALLBACK_ENVIRON environ = {0}; //创建回调环境 InitializeThreadpoolEnvironment(&environ); PTP_CLEANUP_GROUP pCleanUp = CreateThreadpoolCleanupGroup(); //创建清理组 PTP_POOL pool = CreateThreadpool(NULL); //创建自定义线程池 //设置线程池中的最大、最小线程数 SetThreadpoolThreadMinimum(pool, 2); SetThreadpoolThreadMaximum(pool, 8); //设置对应的回调环境和清理组 SetThreadpoolCallbackPool(&environ, pool); SetThreadpoolCallbackCleanupGroup(&environ, pCleanUp, CleanupGroupCancelCallback); //创建对应的工作项 int i = 1; PTP_TIMER pTimerWork = CreateThreadpoolTimer(TimerCallback, &i, &environ); ULARGE_INTEGER uDueTime = {0}; FILETIME ft = {0}; uDueTime.QuadPart = (LONGLONG) - 10 * 1000 *1000; //设置时间为10s ft.dwHighDateTime = uDueTime.HighPart; ft.dwLowDateTime = uDueTime.LowPart; SetThreadpoolTimer(pTimerWork, &ft, 10 * 1000, 0); //休眠1s保证定时器历程被提交 Sleep(1000); int j = 2; //等待所有历程执行完成,并清理资源 CloseThreadpoolCleanupGroupMembers(pCleanUp, TRUE, &j); CloseThreadpoolCleanupGroup(pCleanUp); DestroyThreadpoolEnvironment(&environ); CloseThreadpool(pool); return 0; }上面的例子中,首先定义了一个回调环境并进行初始化,然后定义自定义线程和对应的清理环境,并将他们绑定。并且在定义清理器时指定对应的回调函数。接着又定义了一个定时器线程并给一个上下文。然后提交这个定时器历程。为了保证能顺利提交,在主程序中等待1s。最后我们直接取消它,由于定时器触发的时间为10s这个时候肯定还没有执行,而根据之前说的,当我们取消一个已提交但是未执行的工作项时会调用对应的清理组规定的回调,这个时候CleanupGroupCancelCallback会被调用。它的参数的值分别由CreateThreadpoolTimer和CloseThreadpoolCleanupGroupMembers给出,所以最终输出结果如下:自定义线程池可以很方便的控制它的行为。但是为了要得体的清理它所以得加上一个清理组,最终当我们使用自定义线程池时,基本步骤如下:调用函数InitializeThreadpoolEnvironment初始化一个回调环境调用CreateThreadpoolCleanupGroup创建一个清理组,并根据需要给出对应的清理回调调用CreateThreadpool创建自定义线程池调用对应的函数,设置自定义线程池的相关属性调用函数SetThreadpoolCallbackPool将线程池与回调环境绑定调用函数SetThreadpoolCallbackCleanupGroup将回调环境与对应的清理组绑定调用对应的函数创建工作项,并提交调用函数CloseThreadpoolCleanupGroupMembers等待清理组中的所有工作项被执行完或者被取消调用CloseThreadpoolCleanupGroup关闭清理组并释放资源调用DestroyThreadpoolEnvironment清理回调环境调用CloseThreadpool函数关闭自定义的线程池使用清理组的方式清理工作项相比于调用对应的close函数清理工作项来说,显得更方便,一来自定义线程池中工作项的种类繁多,每个工作项都调用一个Close函数显得太复杂,而且当工作项过多时,不知道何时哪个工作项执行完,这个时候如果强行调用函数关闭工作项,显得有点暴力,所以用工作组的方式更为优雅一些
-
老版VC++线程池 在一般的设计中,当需要一个线程时,就创建一个,但是当线程过多时可能会影响系统的整体效率,这个性能的下降主要体现在:当线程过多时在线程间来回切换需要花费时间,而频繁的创建和销毁线程也需要花费额外的机器指令,同时在某些时候极少数线程可能就可以处理大量,比如http服务器可能只需要几个线程就可以处理用户发出的http请求,毕竟相对于用户需要长时间来阅读网页来说,CPU只是找到对应位置的页面返回即可。在这种情况下为每个用户连接创建一个线程长时间等待再次处理用户请求肯定是不划算的。为了解决这种问题,提出了线程池的概念,线程池中保存一定数量的 线程,当需要时,由线程池中的某一个线程来调用对应的处理函数。通过控制线程数量从而减少了CPU的线程切换,而且用完的线程还到线程池而不是销毁,下一次再用时直接从池中取,在某种程度上减少了线程创建与销毁的消耗,从而提高效率在Windows上,使用线程池十分简单,它将线程池做为一个整体,当需要使用池中的线程时,只需要定义对应的回调函数,然后调用API将回调函数进行提交,系统自带的线程池就会自动执行对应的回调函数。从而实现任务的执行,这种方式相对于传统的VC线程来说,程序员不再需要关注线程的创建与销毁,以及线程的调度问题,这些统一由系统完成,只需要将精力集中到逻辑处理的回调函数中来,这样将程序员从繁杂的线程控制中解放出来。同时Windows中线程池一般具有动态调整线程数量的自主行为,它会根据线程中执行任务的工作量来自动调整线程数,即不让大量线程处于闲置状态,也不会因为线程过少而有大量任务处于等待状态。在windows上主要有四种线程池普通线程池同步对象等待线程池定时器回调线程池完成端口回调线程池这些线程池最大的特点是需要提供一个由线程池中线程调用的回调函数,当条件满足时回调函数就会被线程池中的对应线程进行调用。从设计的角度来说,这样的设计大大简化了应用程序考虑多线程设计时的难度,此时只需要考虑回调函数中的处理逻辑和被调用的条件即可,而不必考虑线程的创建销毁等等问题(一些设计还可以绕开繁琐的同步处理)。需要注意的就是一般不要在这些回调函数中设计处理类似UI消息循环那样的循环,即不要长久占用线程池中的线程。下面来依次说明各种线程池的使用:普通线程池普通线程池在使用时主要是调用QueueUserWorkItem函数将回调函数加入线程池队列,线程池中一旦有空闲的线程就会调用这个回调,函数原型如下:BOOL WINAPI QueueUserWorkItem( __in LPTHREAD_START_ROUTINE Function, __in_opt PVOID Context, __in ULONG Flags );第一个参数是一个回调函数地址,函数原型与线程函数原型相同,所以在设计时可以考虑使用宏开关来指定这个回调函数作为线程函数还是作为线程池的回调函数第二个参数是传给回调函数的参数指针第三个参数是一个标志值,它的主要值及其含义如下:标志含义WT_EXECUTEDEFAULT线程池的默认标志WT_EXECUTEINIOTHREAD以IO可警告状态运行线程回调函数WT_EXECUTEINPERSISTENTTHREAD该线程将一直运行而不会终止WT_EXECUTELONGFUNCTION执行一个运行时间较长的任务(这会使系统考虑是否在线程池中创建新的线程)WT_TRANSFER_IMPERSONATION以当前的访问字串运行线程并调用回调函数下面是一个具体的例子:void CALLBACK ThreadProc(LPVOID lpParam); int _tmain(int argc, _TCHAR* argv[]) { int nWaitTime; while (TRUE) { printf("请输入线程等待事件:"); scanf_s("%d", &nWaitTime); printf("\n"); if (0 == nWaitTime) { break; } //将任务放入到队列中进行排队 QueueUserWorkItem((LPTHREAD_START_ROUTINE)ThreadProc, &nWaitTime, WT_EXECUTELONGFUNCTION); } //结束主线程 printf("主线程[%04x]\n", GetCurrentThreadId()); return 0; } void CALLBACK ThreadProc(LPVOID lpParam) { int nWaitTime = *(int*)lpParam; printf("线程[%04x]将等待%ds\n", GetCurrentThreadId(), nWaitTime); Sleep(nWaitTime * 1000); printf("线程[%04x]执行完毕\n", GetCurrentThreadId()); }这段代码上我们加入了WT_EXECUTELONGFUNCTION标识,其实在计算机中,只要达到毫秒级的,这个时候已经达到了系统进行线程切换的时间粒度,这个时候它就是一个需要长时间执行的任务定时器回调线程池定时器回调主要经过下面几步:调用CreateTimerQueue:创建定时器回调的队列调用CreateTimerQueueTimer创建一个指定时间周期的计时器对象,并指定对应的回调函数及参数之后当指定的时间片到达,就会将对应的回调历程放入到队列中,一旦线程池中有空闲的线程就执行它另外可以调用对应的函数对其进行相关的操作:可以调用ChangeTimerQueueTimer修改一个已有的计时器对象的计时周期调用DeleteTimerQueueTimer删除一个计时器对象调用DeleteTimerQueue删除这样一个线程池对象,在删除这个线程池的时候它上面绑定的回调也会被删除,所以在编码时可以直接删除线程池对象而不用调用DeleteTimerQueueTimer删除每一个绑定的计时器对象。但是为了编码的完整性,最好加上删除计时器对象的操作下面是一个使用的具体例子VOID CALLBACK TimerCallback(PVOID lpParameter, BOOLEAN TimerOrWaitFired); int _tmain(int argc, _TCHAR* argv[]) { HANDLE hTimeQueue = CreateTimerQueue(); HANDLE hEvent = CreateEvent(NULL, FALSE, FALSE, NULL); HANDLE hTimer; CreateTimerQueueTimer(&hTimer, hTimeQueue, (WAITORTIMERCALLBACK)TimerCallback, &hEvent, 10000, 0, WT_EXECUTEDEFAULT); //等待定时器历程被调用 WaitForSingleObject(hEvent, INFINITE); //关闭事件对象 CloseHandle(hEvent); //删除定时器与定时器线程池的绑定 DeleteTimerQueueTimer(hTimeQueue, hTimer, NULL); //删除定时器线程池 DeleteTimerQueue(hTimeQueue); return 0; } VOID CALLBACK TimerCallback(PVOID lpParameter, BOOLEAN TimerOrWaitFired) { HANDLE hEvent = *(HANDLE*)lpParameter; if (TimerOrWaitFired) { printf("定时器回调历程[%04x]被执行\n", GetCurrentThreadId()); } SetEvent(hEvent); }上述的代码中我们定义了一个同步事件对象,这个事件对象将在定时器历程中设置为有信号,这样方便我们在主线程中等待计时器历程执行完成同步对象等待线程池使用同步对象等待线程池只需要调用函数RegisterWaitForSingalObject,将一个同步对象绑定,当这个同步对象变为有信号或者等待的时间到达时,会调用对应的回调历程。该函数原型如下:BOOL WINAPI RegisterWaitForSingleObject( __out PHANDLE phNewWaitObject, __in HANDLE hObject, __in WAITORTIMERCALLBACK Callback, __in_opt PVOID Context, __in ULONG dwMilliseconds, __in ULONG dwFlags ); 第一个参数是一个输出参数,返回一个等待对象的句柄,我们可以将其看做这个线程池的句柄第二个参数是一个同步对象第三个参数是对应的回调函数第四个参数是传入到回调函数中的参数指针第五个参数是等待的时间第六个参数是一个标志与函数QueueUserWorkItem中的标识含义相同对应回调函数的原型如下:VOID CALLBACK WaitOrTimerCallback( __in PVOID lpParameter, __in BOOLEAN TimerOrWaitFired );当同步对象变为有信号或者等待的时间到达时都会调用这个回调,它的第二个参数就表示它所等待的对象是否为有信号。下面是一个使用的例子void WaitEventCallBackProc(PVOID lpParameter, BOOLEAN TimerOrWaitFired); int _tmain(int argc, _TCHAR* argv[]) { HANDLE hWait; HANDLE hEvent = CreateEvent(NULL, FALSE, FALSE, NULL); //注册等待同步对象的线程池 RegisterWaitForSingleObject(&hWait, hEvent, (WAITORTIMERCALLBACK)WaitEventCallBackProc, NULL, 5000, WT_EXECUTELONGFUNCTION); for(int i = 0; i < 5; i++) { SetEvent(hEvent); Sleep(5000); } UnregisterWaitEx(hWait, hEvent); CloseHandle(hEvent); CloseHandle(hWait); return 0; } void WaitEventCallBackProc(PVOID lpParameter, BOOLEAN TimerOrWaitFired) { if (TimerOrWaitFired) { printf("线程[%04x]等到事件对象\n"); }else { printf("线程[%04x]等待事件对象超时\n"); } }完成端口线程池在前面讲述文件操作的博文中,讲解了在文件中完成端口的使用,其实完成端口本质上就是一个线程池,或者说,windows上自带的线程池是使用完成端口的基础之上编写的。所以在这,完成端口线程池的使用将比IO完成端口来的简单通过调用BindIoCompletionCallback函数来将一个IO对象句柄与对应的完成历程绑定,这样在对应的IO操作完成后,对应的历程将会被丢到线程池中准备执行相比于前面的文件中的完成端口,这个完成端口线程池要简单许多,文件的完成端口需要自己创建完成多个线程,创建完成端口,并且将线程与完成端口绑定。另外还需要在线程中调用相应的等待函数等待IO操作完成,而线程池则不需要这些操作,我只需要准备一个完成历程,然后调用BindIoCompletionCallback,这样一旦历程被调用,就可以肯定IO操作一定完成了。这样我们只需要将主要精力集中在完成历程的编写中函数BindIoCompletionCallback的原型如下:BOOL WINAPI BindIoCompletionCallback( __in HANDLE FileHandle, __in LPOVERLAPPED_COMPLETION_ROUTINE Function, __in ULONG Flags );第一个参数是一个对应IO操作的句柄第二个参数是对应的完成历程函数指针第三个参数是一个标志,与之前的标识相同完成历程的函数原型如下:VOID CALLBACK FileIOCompletionRoutine( __in DWORD dwErrorCode, __in DWORD dwNumberOfBytesTransfered, __in LPOVERLAPPED lpOverlapped );第一个参数是一个错误码,当IO操作发生错误时可以通过这个参数获取当前错误原因第二个参数是当前IO操作操作的字节数第三个参数是一个OVERLAPPED结构这函数的使用与之前文件完成端口中完成历程一样下面我们将之前文件完成端口的例子进行改写,如下:typedef struct tagIOCP_OVERLAPPED { OVERLAPPED Overlapped; HANDLE hFile; //操作的文件句柄 DWORD dwDataLen; //当前操作数据的长度 LPVOID pData; //操作数据的指针 DWORD dwWrittenLen; //写入文件中的数据长度 }IOCP_OVERLAPPED, *LPIOCP_OVERLAPPED; #define MAX_WRITE_THREAD 20 //写线程总数 #define EVERY_THREAD_WRITTEN 100 //每个线程写入信息数 LARGE_INTEGER g_FilePointer; //全局的文件指针 void GetAppPath(LPTSTR lpAppPath) { TCHAR szExePath[MAX_PATH] = _T(""); GetModuleFileName(NULL, szExePath, MAX_PATH); size_t nPathLen = 0; StringCchLength(szExePath, MAX_PATH, &nPathLen); for (int i = nPathLen; i > 0; i--) { if (szExePath[i] == _T('\\')) { szExePath[i + 1] = _T('\0'); break; } } StringCchCopy(lpAppPath, MAX_PATH, szExePath); } VOID CALLBACK WriteThread(LPVOID lpParam); VOID CALLBACK FileIOCompletionRoutine(DWORD dwErrorCode, DWORD dwNumberOfBytesTransfered, LPOVERLAPPED lpOverlapped); int _tmain(int argc, _TCHAR* argv[]) { TCHAR szAppPath[MAX_PATH] = _T(""); GetAppPath(szAppPath); StringCchCat(szAppPath, MAX_PATH, _T("IocpLog.txt")); HANDLE hFile = CreateFile(szAppPath, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, FILE_FLAG_OVERLAPPED | FILE_ATTRIBUTE_NORMAL, NULL); if (hFile == INVALID_HANDLE_VALUE) { return 0; } //绑定IO完成端口 BindIoCompletionCallback(hFile, (LPOVERLAPPED_COMPLETION_ROUTINE)FileIOCompletionRoutine, 0); //往日志文件中写入Unicode前缀 LPIOCP_OVERLAPPED pIocpOverlapped = (LPIOCP_OVERLAPPED)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(IOCP_OVERLAPPED)); pIocpOverlapped->dwDataLen = sizeof(WORD); pIocpOverlapped->hFile = hFile; WORD dwUnicode = MAKEWORD(0xff, 0xfe); //构造Unicode前缀 pIocpOverlapped->pData = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(WORD)); CopyMemory(pIocpOverlapped->pData, &dwUnicode, sizeof(WORD)); //偏移文件指针 pIocpOverlapped->Overlapped.Offset = g_FilePointer.LowPart; pIocpOverlapped->Overlapped.OffsetHigh = g_FilePointer.HighPart; g_FilePointer.QuadPart += pIocpOverlapped->dwDataLen; //写文件 WriteFile(hFile, pIocpOverlapped->pData, pIocpOverlapped->dwDataLen, &pIocpOverlapped->dwWrittenLen, &pIocpOverlapped->Overlapped); //创建线程进行写日志操作 HANDLE hWrittenThreads[MAX_WRITE_THREAD]; for (int i = 0; i < MAX_WRITE_THREAD; i++) { hWrittenThreads[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)WriteThread, &hFile, 0, NULL); } //等待所有写线程执行完成 WaitForMultipleObjects(MAX_WRITE_THREAD, hWrittenThreads, TRUE, INFINITE); for (int i = 0; i < MAX_WRITE_THREAD; i++) { CloseHandle(hWrittenThreads[i]); } CloseHandle(hFile); return 0; } VOID CALLBACK FileIOCompletionRoutine(DWORD dwErrorCode, DWORD dwNumberOfBytesTransfered, LPOVERLAPPED lpOverlapped) { LPIOCP_OVERLAPPED pIOCPOverlapped = (LPIOCP_OVERLAPPED)lpOverlapped; //释放对应的内存空间 printf("线程[%04x]得到IO完成通知,写入长度%d\n", GetCurrentThreadId(), pIOCPOverlapped->dwDataLen); if (pIOCPOverlapped->pData != NULL) { HeapFree(GetProcessHeap(), 0, pIOCPOverlapped->pData); } if (NULL != pIOCPOverlapped) { HeapFree(GetProcessHeap(), 0, pIOCPOverlapped); pIOCPOverlapped = NULL; } } VOID CALLBACK WriteThread(LPVOID lpParam) { TCHAR szBuf[255] = _T("线程[%04x]模拟写入一条日志记录\r\n"); TCHAR szWrittenBuf[255] = _T(""); StringCchPrintf(szWrittenBuf, 255, szBuf, GetCurrentThreadId()); for (int i = 0; i < EVERY_THREAD_WRITTEN; i++) { LPIOCP_OVERLAPPED lpIocpOverlapped = (LPIOCP_OVERLAPPED)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(IOCP_OVERLAPPED)); size_t dwBufLen = 0; StringCchLength(szWrittenBuf, 255, &dwBufLen); lpIocpOverlapped->dwDataLen = dwBufLen * sizeof(TCHAR); lpIocpOverlapped->pData = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, (dwBufLen + 1) * sizeof(TCHAR)); CopyMemory(lpIocpOverlapped->pData, szWrittenBuf, dwBufLen * sizeof(TCHAR)); lpIocpOverlapped->hFile = *(HANDLE*)lpParam; //同步文件指针 *((LONGLONG*)&(lpIocpOverlapped->Overlapped.Pointer)) = InterlockedCompareExchange64(&g_FilePointer.QuadPart, g_FilePointer.QuadPart + lpIocpOverlapped->dwDataLen, g_FilePointer.QuadPart); //写文件 WriteFile(lpIocpOverlapped->hFile, lpIocpOverlapped->pData, lpIocpOverlapped->dwDataLen, &lpIocpOverlapped->dwWrittenLen, &lpIocpOverlapped->Overlapped); } }
-
windows 纤程 纤程本质上也是线程,是多任务系统的一部分,纤程为一个线程准并行方式调用多个不同函数提供了一种可能,它本身可以作为一种轻量级的线程使用。它与线程在本质上没有区别,它也有上下文环境,纤程的上下文环境也是一组寄存器和调用堆栈。它是比线程更小的调度单位。注意一般我们认为线程是操作系统调用的最小单位,而纤程相比于线程来说更小,但是它是有程序员自己调用,而不由操作系统调用。系统在调度线程的时候会陷入到内核态,线程对象本身也是一种内核对象,而纤程完全是建立在用户层上,它不是内核对象也没有对象的句柄。通过纤程的机制实际就绕开了Windows的随机调度线程执行的行为,调度算法由应用程序自己实现,这对一些并行算法非常有意义。因为纤程和线程本质上的类同性,所以也要按照理解线程为函数调用器的方式来理解纤程。纤程的创建纤程的创建需要必须建立在线程的基础之上。在线程中调用函数ConvertThreadToFiber可以将一个线程转化为纤程(或者说将一个线程与纤程绑定,以后可以将该纤程看做主纤程)。其他的纤程函数必须在纤程中调用,也就是说,如果目前在线程中,需要调用ConverThreadToFiber将线程转化为纤程,才能调用对应的API。这个函数的原型如下:LPVOID WINAPI ConvertThreadToFiber( LPVOID lpParameter ); 这个函数传入一个参数,类似于CreateThread函数中的线程函数参数,如果我们在主纤程中需要使用到它,可以使用宏GetFiberData取得这个参数。在调用这个函数创建新纤程后,系统大概会给纤程分配200字节的栈空间,用来执行纤程函数,和保存纤程环境。这个环境由下面几个部分的内容组成:用户定义的值,这个值就是纤程回调函数中传入的参数新的结构化异常处理的链表头纤程内存栈的最高和最低地址,当线程转换为纤程的时候,这也是线程的内存栈。之前说过纤程栈是在建立在线程的基础之上,保留这两个值是为了当纤程还原为线程后,用来还原线程栈环境各种CPU寄存器环境,相当于线程的CONTENT,但是没有这个结构那么复杂,它只是保存了几个简单的寄存器的值。需要特别注意的一点是,它并没有保存对应浮点数寄存器FPU的值,所以在纤程中使用浮点数计算可能会出现未知错误。如果一定要计算浮点数,那么可以使用ConverThreadToFiberEx,在第二个参数的位置传入FIBER_FLAG_FLOAT_SWITCH值,表示将初始化并保存FPU。可以在主纤程中调用CreateFiber函数创建子纤程。该函数原型如下:LPVOID WINAPI CreateFiber( DWORD dwStackSize, LPFIBER_START_ROUTINE lpStartAddress, LPVOID lpParameter );第一个参数是纤程的堆栈大小,默认给0的话,它会根据实际需求创建对应大小的堆栈,纤程的堆栈是建立在线程的基础之上,我们可以这样理解,它是从线程的堆栈中隔离一块作为纤程的堆栈。本质上它的堆栈是放在线程的堆栈上。第二个参数是一个回调,与线程函数类似,这个函数是一个纤程函数。第三个参数是传递到回调函数中的参数。函数CreateFiber 和 ConvertThreadToFiber 函数都返回一个void* 的指针,用来唯一标识一个纤程,在这我们可以将它理解为纤程的HANDLE .纤程的删除当纤程结束时需要调用DeleteFiber来删除线程,类似于CloseHandle来结束对应的内核对象。如果是调用转化函数由线程转化而来,调用DeleteFiber相当于调用ExitThread来终止线程,所以对于这种情况,最好是将纤程转化为线程,然后再设计一套合理的线程退出机制。纤程的调度在任何一个纤程内部调用SwitchToFiber函数,将纤程的void*指针传入,即可切换到对应的纤程,该函数可以在任意几个纤程中进行切换,不管这些纤程是在一个线程中或者在不同的线程中。但是最好不要在不同线程中的纤程中进行切换,它可能会带来意想不到的情况,假设存在这样一种情况,线程A创建纤程FA,线程B创建纤程FB,当我们在系统运行线程A时将纤程从FA切换到FB,由于纤程的堆栈是建立在线程之上的,所以这个时候纤程B仍然使用线程A的堆栈,但是它应该使用的线程B的堆栈,这样可能会对线程A的堆栈造成一定的破坏。下面是纤使用的一个具体的例子:#define PRIMARY_FIBER 0 #define WRITE_FIBER 1 #define READ_FIBER 2 #define FIBER_COUNT 3 #define COPY_LENGTH 512 VOID CALLBACK ReadFiber(LPVOID lpParam); VOID CALLBACK WriteFiber(LPVOID lpParam); typedef struct _tagFIBER_STRUCT { DWORD dwFiberHandle; HANDLE hFile; LPVOID lpParam; }FIBER_STRUCT, *LPFIBER_STRUCT; char *g_lpBuffer = NULL; LPVOID g_lpFiber[FIBER_COUNT] = {}; void GetApp(LPTSTR lpPath, int nBufLen) { TCHAR szBuf[MAX_PATH] = _T(""); GetModuleFileName(NULL, szBuf, MAX_PATH); int nLen = _tcslen(szBuf); for(int i = nLen; i > 0; i--) { if(szBuf[i] == '\\') { szBuf[i + 1] = _T('\0'); break; } } nLen = _tcslen(szBuf) + 1; int nCopyLen = min(nLen, nBufLen); StringCchCopy(lpPath, nCopyLen, szBuf); } int _tmain(int argc, _TCHAR* argv[]) { g_lpBuffer = (char*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, COPY_LENGTH); FIBER_STRUCT fs[FIBER_COUNT] = {0}; TCHAR szDestPath[MAX_PATH] = _T(""); TCHAR szSrcPath[MAX_PATH] = _T(""); GetApp(szDestPath, MAX_PATH); GetApp(szSrcPath, MAX_PATH); StringCchCat(szSrcPath, MAX_PATH, _T("2.jpg")); StringCchCat(szDestPath, MAX_PATH, _T("2_Cpy.jpg")); HANDLE hSrcFile = CreateFile(szSrcPath, GENERIC_READ, 0, NULL, OPEN_EXISTING, 0, NULL); HANDLE hDestFile = CreateFile(szDestPath, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); fs[PRIMARY_FIBER].hFile = INVALID_HANDLE_VALUE; fs[PRIMARY_FIBER].lpParam = NULL; fs[PRIMARY_FIBER].dwFiberHandle = 0x00001234; fs[WRITE_FIBER].hFile = hDestFile; fs[WRITE_FIBER].lpParam = NULL; fs[WRITE_FIBER].dwFiberHandle = 0x12345678; fs[READ_FIBER].hFile = hSrcFile; fs[READ_FIBER].dwFiberHandle = 0x78563412; fs[READ_FIBER].lpParam = NULL; g_lpFiber[PRIMARY_FIBER] = ConvertThreadToFiber(&fs[PRIMARY_FIBER]); g_lpFiber[READ_FIBER] = CreateFiber(0, (LPFIBER_START_ROUTINE)ReadFiber, &fs[READ_FIBER]); g_lpFiber[WRITE_FIBER] = CreateFiber(0, (LPFIBER_START_ROUTINE)WriteFiber, &fs[WRITE_FIBER]); //切换到读纤程 SwitchToFiber(g_lpFiber[READ_FIBER]); //删除纤程 DeleteFiber(g_lpFiber[WRITE_FIBER]); DeleteFiber(g_lpFiber[READ_FIBER]); CloseHandle(fs[READ_FIBER].hFile); CloseHandle(fs[WRITE_FIBER].hFile); //变回线程 ConvertFiberToThread(); return 0; } VOID CALLBACK ReadFiber(LPVOID lpParam) { //拷贝文件 while (TRUE) { LPFIBER_STRUCT pFS = (LPFIBER_STRUCT)lpParam; printf("切换到[%08x]纤程\n", pFS->dwFiberHandle); DWORD dwReadLen = 0; ZeroMemory(g_lpBuffer, COPY_LENGTH); ReadFile(pFS->hFile, g_lpBuffer, COPY_LENGTH, &dwReadLen, NULL); SwitchToFiber(g_lpFiber[WRITE_FIBER]); if(dwReadLen < COPY_LENGTH) { break; } } SwitchToFiber(g_lpFiber[PRIMARY_FIBER]); } VOID CALLBACK WriteFiber(LPVOID lpParam) { while (TRUE) { LPFIBER_STRUCT pFS = (LPFIBER_STRUCT)lpParam; printf("切换到[%08x]纤程\n", pFS->dwFiberHandle); DWORD dwWriteLen = 0; WriteFile(pFS->hFile, g_lpBuffer, COPY_LENGTH, &dwWriteLen, NULL); SwitchToFiber(g_lpFiber[READ_FIBER]); if(dwWriteLen < COPY_LENGTH) { break; } } SwitchToFiber(g_lpFiber[PRIMARY_FIBER]); } 上面这段代码中首先将主线程转化为主纤程,然后创建两个纤程,分别用来读文件和写文件,然后保存这三个纤程。并定义了一个结构体用来向各个纤程函数传入对应的参数。在主线程的后面首先切换到读纤程,在读纤程中利用源文件的句柄,读入512字节的内容,然后切换到写纤程,将读到的这些内容写回到磁盘的新文件中完成拷贝,然后切换到读纤程,这样不停的在读纤程和写纤程中进行切换,直到文件拷贝完毕。再切换回主纤程,最后在主纤程中删除读写纤程,将主纤程转化为线程并结束线程。
-
windows 下进程池的操作 在Windows上创建进程是一件很容易的事,但是在管理上就不那么方便了,主要体现在下面几个方面:各个进程的地址空间是独立的,想要在进程间共享资源比较麻烦进程间可能相互依赖,在进程间需要进行同步时比较麻烦在服务器上可能会出现一个进程创建一大堆进程来共同为客户服务,这组进程在逻辑上应该属于同一组进程为了方便的管理同组的进程,Windows上提供了一个进程池来管理这样一组进程,在VC中将这个进程池叫做作业对象。它主要用来限制池中内存的一些属性,比如占用内存数,占用CPU周期,进程间的优先级,同时提供了一个同时关闭池中所有进程的方法。下面来说明它的主要用法作业对象的创建调用函数CreateJobObject,可以来创建作业对象,该函数有两个参数,第一个参数是一个安全属性,第二个参数是一个对象名称。作业对象本身也是一个内核对象,所以它的使用与常规的内核对象相同,比如可以通过命名实现跨进程访问,可以通过对应的Open函数打开命名作业对象。添加进程到作业对象可以通过AssignProcessToJobObject ,该函数只有两个参数,第一个是对应的作业对象,第二个是对应的进程句柄关闭作业对象中的进程可以使用TerminateJobObject 函数来一次关闭作业对象中的所有进程,它相当于对作业对象中的每一个进程调用TerminateProcess,相对来说是一个比较粗暴的方式,在实际中应该劲量避免使用,应该自己设计一种更好的退出方式控制作业对象中进程的相关属性可以使用SetInformationJobObject函数设置作业对象中进程的相关属性,函数原型如下:BOOL WINAPI SetInformationJobObject( __in HANDLE hJob, __in JOBOBJECTINFOCLASS JobObjectInfoClass, __in LPVOID lpJobObjectInfo, __in DWORD cbJobObjectInfoLength );第一个参数是一个作业对象的句柄,第二个是一系列的枚举值,用来限制其中进程的各种信息。第三个参数根据第二参数的不同,需要传入对应的结构体,第四个参数是对应结构体的长度。下面是各个枚举值以及它对应的结构体枚举值含义对应的结构体JobObjectAssociateCompletionPortInformation设置各种作业对象事件的完成端口JOBOBJECT_ASSOCIATE_COMPLETION_PORTJobObjectBasicLimitInformation设置作业对象的基本信息(如:进程作业集大小,进程亲缘性,进程CPU时间限制值,同时活动的进程数量等)JOBOBJECT_BASIC_LIMIT_INFORMATIONJobObjectBasicUIRestrictions对作业中的进程UI进行基本限制(如:指定桌面,限制调用ExitWindows函数,限制剪切板读写操作等)一般在服务程序上这个很少使用JOBOBJECT_BASIC_UI_RESTRICTIONSJobObjectEndOfJobTimeInformation指定当作业时间限制到达时,系统采取什么动作(如:通知与作业对象绑定的完成端口一个超时事件等)JOBOBJECT_END_OF_JOB_TIME_INFORMATIONJobObjectExtendedLimitInformation作业进程的扩展限制信息(限制进程的内存使用量等)JOBOBJECT_EXTENDED_LIMIT_INFORMATIONJobObjectSecurityLimitInformation限制作业对象进程中的安全属性(如:关闭一些组的特权,关闭某些特权等)要求作业对象所属进程或线程要具备更改这些作业进程安全属性的权限JOBOBJECT_SECURITY_LIMIT_INFORMATION限制进程异常退出的行为在Windows中,如果进程发生异常,那么它会寻找处理该异常的对应的异常处理模块,如果没有找到的话,它会弹出一个对话框,让用户选择,但是这样对服务程序来说很不友好,而且有的服务器是在远程没办法操作这个对话框,这个时候需要使用某种方法让其不弹出这个对话框。在作业对象中的进程,我们可以使用SetInformationJobObject函数中的JobObjectExtendedLimitInformation枚举值,将结构体JOBOBJECT_EXTENDED_LIMIT_INFORMATION中的BasicLimitInformation.LimitFlags成员设置为JOB_OBJECT_LIMIT_DIE_ON_UNHANDLED_EXCEPTION。这相当于强制每个进程调用SetErrorMode并指定SEM_NOGPFAULTERRORBOX标志获取作业对象属性和统计信息调用QueryInformationJobObject函数来获取作业对象属性和统计信息。该函数的使用方法与之前的SetInformationJobObject函数相同。下面列举下它可选择枚举值:枚举值含义对应的结构体JobObjectBasicAccountingInformation基本统计信息JOBOBJECT_BASIC_ACCOUNTING_INFORMATIONJobObjectBasicAndIoAccountingInformation基本统计信息和IO统计信息JOBOBJECT_BASIC_AND_IO_ACCOUNTING_INFORMATIONJobObjectBasicLimitInformation基本的限制信息JOBOBJECT_BASIC_LIMIT_INFORMATIONJobObjectBasicProcessIdList获取作业进程ID列表JOBOBJECT_BASIC_PROCESS_ID_LISTJobObjectBasicUIRestrictions查询进程UI的限制信息JOBOBJECT_BASIC_UI_RESTRICTIONSJobObjectExtendedLimitInformation查询作业进程的扩展限制信息JOBOBJECT_EXTENDED_LIMIT_INFORMATIONJobObjectSecurityLimitInformation查询作业对象进程中的安全属性JOBOBJECT_SECURITY_LIMIT_INFORMATION这些信息基本上与上面的设置限制信息是对应的。使用上也是类似的作业对象与完成端口设置作业对象的完成端口一般是使用SetInformationJobObject,并将第二个参数的枚举值指定为JobObjectAssociateCompletionPortInformation,这样就可以完成一个作业对象和完成端口的绑定。当作业对象发生某些事件的时候可以向完成端口发送对应的事件,这个时候在完成端口的线程中调用GetQueuedCompletionStatus可以获取对应的事件,但是这个函数的使用与之前在文件操作中的使用略有不同,主要体现在它的各个返回参数的含义上。各个参数函数如下:lpNumberOfBytes:返回一个事件的ID,它的事件如下:事件事件含义JOB_OBJECT_MSG_ABNORMAL_EXIT_PROCESS进程异常退出JOB_OBJECT_MSG_ACTIVE_PROCESS_LIMIT同时活动的进程数达到设置的上限JOB_OBJECT_MSG_ACTIVE_PROCESS_ZERO作业对象中没有活动的进程了JOB_OBJECT_MSG_END_OF_JOB_TIME作业对象的CPU周期耗尽JOB_OBJECT_MSG_END_OF_PROCESS_TIME进程的CPU周期耗尽JOB_OBJECT_MSG_EXIT_PROCESS进程正常退出JOB_OBJECT_MSG_JOB_MEMORY_LIMIT作业对象消耗内存达到上限JOB_OBJECT_MSG_NEW_PROCESS有新进程加入到作业对象中JOB_OBJECT_MSG_PROCESS_MEMORY_LIMIT进程消耗内存数达到上限lpCompletionKey: 返回触发这个事件的对象的句柄,我们将完成端口与作业对象绑定后,这个值自然是对应作业对象的句柄lpOverlapped: 指定各个事件对应的详细信息,在于进程相关的事件中,它返回一个进程ID既然知道了各个参数的含义,我们可以使用PostQueuedCompletionStatus函数在对应的位置填充相关的值,然后往完成端口上发送自定义事件。只需要将lpNumberOfBytes设置为我们自己的事件ID,然后在线程中处理即可下面是作业对象操作的完整例子#include "stdafx.h" #include <Windows.h> DWORD IOCPThread(PVOID lpParam); //完成端口线程 int GetAppPath(LPTSTR pAppName, size_t nBufferSize) { TCHAR szAppName[MAX_PATH] = _T(""); DWORD dwLen = ::GetModuleFileName(NULL, szAppName, MAX_PATH); if(dwLen == 0) { return 0; } for(int i = dwLen; i > 0; i--) { if(szAppName[i] == _T('\\')) { szAppName[i + 1] = _T('\0'); break; } } _tcscpy_s(pAppName, nBufferSize, szAppName); return 0; } int _tmain(int argc, _TCHAR* argv[]) { //获取当前进程的路径 TCHAR szModulePath[MAX_PATH] = _T(""); GetAppPath(szModulePath, MAX_PATH); //创建作业对象 HANDLE hJob = CreateJobObject(NULL, NULL); if(hJob == INVALID_HANDLE_VALUE) { return 0; } //创建完成端口 HANDLE hIocp = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, NULL, 1); if(hIocp == INVALID_HANDLE_VALUE) { return 0; } //启动监视进程 CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)IOCPThread, (PVOID)hIocp, 0, NULL); //将作业对象与完成端口绑定 JOBOBJECT_ASSOCIATE_COMPLETION_PORT jacp = {0}; jacp.CompletionKey = hJob; jacp.CompletionPort = hIocp; SetInformationJobObject(hJob, JobObjectAssociateCompletionPortInformation, &jacp, sizeof(jacp)); //为作业对象设置限制条件 JOBOBJECT_BASIC_LIMIT_INFORMATION jbli = {0}; jbli.PerProcessUserTimeLimit.QuadPart = 20 * 1000 * 10i64; //限制执行的用户时间为20ms jbli.MinimumWorkingSetSize = 4 * 1024; jbli.MaximumWorkingSetSize = 256 * 1024; //限制最大内存为256k jbli.LimitFlags = JOB_OBJECT_LIMIT_PROCESS_TIME | JOB_OBJECT_LIMIT_JOB_MEMORY; SetInformationJobObject(hJob, JobObjectBasicLimitInformation, &jbli, sizeof(jbli)); //指定不显示异常对话框 JOBOBJECT_EXTENDED_LIMIT_INFORMATION jeli = {0}; jeli.BasicLimitInformation.LimitFlags = JOB_OBJECT_LIMIT_DIE_ON_UNHANDLED_EXCEPTION; SetInformationJobObject(hJob, JobObjectExtendedLimitInformation, &jeli, sizeof(jeli)); //创建新进程 _tcscat_s(szModulePath, MAX_PATH, _T("JobProcess.exe")); STARTUPINFO si = {0}; PROCESS_INFORMATION pi = {0}; CreateProcess(szModulePath, NULL, NULL, NULL, FALSE, CREATE_SUSPENDED | CREATE_BREAKAWAY_FROM_JOB, NULL, NULL, &si, &pi); //将进程加入到作业对象中 AssignProcessToJobObject(hJob, pi.hProcess); //运行进程 ResumeThread(pi.hThread); //查询作业对象的运行情况,在这查询基本统计信息和IO信息 JOBOBJECT_BASIC_AND_IO_ACCOUNTING_INFORMATION jbaai = {0}; DWORD dwRetLen = 0; QueryInformationJobObject(hJob, JobObjectBasicAndIoAccountingInformation, &jbaai, sizeof(jbaai), &dwRetLen); //等待进程退出 WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hThread); CloseHandle(pi.hProcess); //给完成端口线程发送退出命令 PostQueuedCompletionStatus(hIocp, 0, (ULONG_PTR)hJob, NULL); //等待线程退出 WaitForSingleObject(hIocp, INFINITE); CloseHandle(hIocp); CloseHandle(hJob); return 0; } DWORD IOCPThread(PVOID lpParam) { BOOL bLoop = TRUE; HANDLE hIocp = (HANDLE)lpParam; DWORD dwReasonId = 0; HANDLE hJob = NULL; OVERLAPPED *lpOverlapped = {0}; while (bLoop) { BOOL bSuccess = GetQueuedCompletionStatus(hIocp, &dwReasonId, (PULONG_PTR)&hJob, &lpOverlapped, INFINITE); if(!bSuccess) { return 0; } switch (dwReasonId) { case JOB_OBJECT_MSG_ABNORMAL_EXIT_PROCESS: { //进程异常退出 DWORD dwProcessId = (DWORD)lpOverlapped; HANDLE hProcess = OpenProcess(PROCESS_QUERY_INFORMATION, FALSE, dwProcessId); if(INVALID_HANDLE_VALUE != hProcess) { DWORD dwExit = 0; GetExitCodeProcess(hProcess, &dwExit); printf("进程[%08x]异常退出,退出码为[%04x]\n", dwProcessId, dwExit); } } break; case JOB_OBJECT_MSG_ACTIVE_PROCESS_LIMIT: { printf("同时活动的进程数达到上限\n"); } break; case JOB_OBJECT_MSG_ACTIVE_PROCESS_ZERO: { printf("没有活动的进程了\n"); } break; case JOB_OBJECT_MSG_END_OF_JOB_TIME: { printf("作业对象CPU时间周期耗尽\n"); } break; case JOB_OBJECT_MSG_END_OF_PROCESS_TIME: { DWORD dwProcessID = (DWORD)lpOverlapped; printf("进程[%04x]CPU时间周期耗尽\n", dwProcessID); } break; case JOB_OBJECT_MSG_EXIT_PROCESS: { DWORD dwProcessId = (DWORD)lpOverlapped; HANDLE hProcess = OpenProcess(PROCESS_QUERY_INFORMATION, FALSE, dwProcessId); if(INVALID_HANDLE_VALUE != hProcess) { DWORD dwExit = 0; GetExitCodeProcess(hProcess, &dwExit); printf("进程[%08x]正常退出,退出码为[%04x]\n", dwProcessId, dwExit); } } break; case JOB_OBJECT_MSG_JOB_MEMORY_LIMIT: { printf("作业对象消耗内存数量达到上限\n"); } break; case JOB_OBJECT_MSG_NEW_PROCESS: { DWORD dwProcessID = (DWORD)lpOverlapped; printf("进程[ID:%u]加入作业对象[h:0x%08X]\n",dwProcessID,hJob); } break; case JOB_OBJECT_MSG_PROCESS_MEMORY_LIMIT: { DWORD dwProcessID = (DWORD)lpOverlapped; printf("进程[%04x]消耗内存数量达到上限\n",dwProcessID); } break; default: bLoop = FALSE; break; } } }在上面的例子中需要注意一点,在创建进程的时候我们给这个进程一个CREATE_BREAKAWAY_FROM_JOB标志,由于Windows在创建进程时,默认会将这个子进程丢到父进程所在进程池中,如果父进程属于某一个进程池,那么我们再将子进程放到其他进程池中,自然会导致失败,这个标志表示,新创建的子进程不属于任何一个进程池,这样在后面的操作才会成功