搜索到
190
篇与
的结果
-
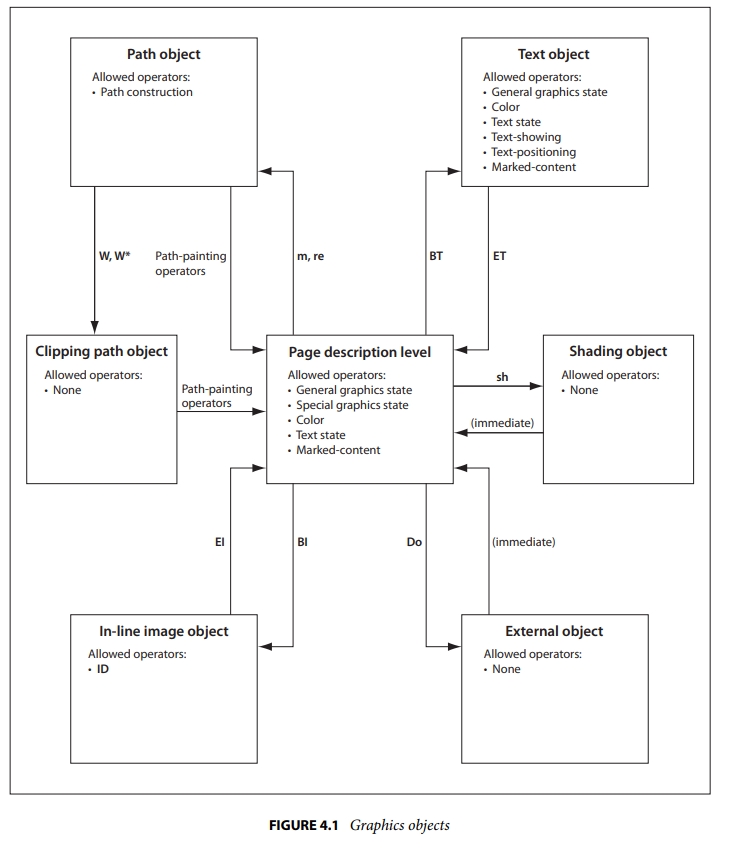
 PDF标准详解(五)——图形状态 在第三节中,我们说到Q/q 这一对操作符是用来保存和还原图形状态的,那个时候只有一个简单的概念,变换矩阵是图形状态的一员,那么什么是图形状态,以及有哪些图形状态呢?本节将要描述这部分的内容图形状态一个PDF应用程序维护内部数据结构称为图形状态,它保存了当前图形控制参数。这些参数定义在全局框架,在全局框架内可执行图形操作符。例如:f(填充)操作符隐式调用当前颜色这个参数,S(描边)操作符调用了当前线框这个参数从图形状态。这个说法比较的官方,我个人的理解就是它保存了画笔画刷,线性等一系列跟画图相关的属性,在调用图形操作符时,直接采用图形状态中的参数来填充画笔画刷等。目前设备无关的图形状态参数主要有下面几个参数类型值CTMarray当前变换矩阵,例如: a b c d e f cmclipping path(internal)当前剪切路径,初始值:CropBoxcolor spaceName or array当前颜色空间,分为 fill color(填充色) & stroke color(描边色),初始值:DeviceGraycolor(various)当前颜色。初始值:blacktext statevarious有9个图形状态参数组成,用于文本显示。line widthnumber线宽。初始值:1.0line capinteger线帽,线2端的样式。初始值:0 J(square butt cap)line joininteger线连接的样式 。初始值:0 j (miter join)miter limitinteger尖角限量。 初始值:10 M (11.5°)dash patternarray and number虚线。初始值:[] 0 dblend modename or array当前混合模式。初始值:Normalsoft maskdictionary or name指定阴影的形状或阴影不透明值用于透明图像模式。初始值:Nonealpha constantnumber透明度。初始值:1.0。 CA(for stroke) ca(fill)alpha sourcebooleanTrue: 由 SMask 指定透明模式 <br/>false:由 CA 或 ca 指定透明值我们目前介绍过的图形状态主要有变换矩阵以及裁剪区域。剩下的会在后面的内容中依次介绍图形对象的状态变更在pdf 1.7 的标准中,有这么一张图这张图描述了图形状态描述对象的变更。图最中间的是页面对象层,包括图形状态、颜色、文本状态和标记对象等等。坐上角的连线表示,图形对象可以通过 m/re 等操作符进入对路径对象的描述,路径对象在描述完毕后可以使用f、s等操作符显示路径并回到页面对象层,或者可以通过W/W* 来进入对裁剪区域对象的描述。其他的连线也是同样的道理。理解了这个图,也就理解了基本的PDF图形操作逻辑,一般想要的绘制的图形未显示或者裁剪区域未发生作用,一般都是进入的状态不对。按照此思路进行查漏补缺一般可以解决问题本节的内容,不涉及到具体的操作符,仅仅是概念的介绍。后续将会陆续介绍上面提到的图形状态
PDF标准详解(五)——图形状态 在第三节中,我们说到Q/q 这一对操作符是用来保存和还原图形状态的,那个时候只有一个简单的概念,变换矩阵是图形状态的一员,那么什么是图形状态,以及有哪些图形状态呢?本节将要描述这部分的内容图形状态一个PDF应用程序维护内部数据结构称为图形状态,它保存了当前图形控制参数。这些参数定义在全局框架,在全局框架内可执行图形操作符。例如:f(填充)操作符隐式调用当前颜色这个参数,S(描边)操作符调用了当前线框这个参数从图形状态。这个说法比较的官方,我个人的理解就是它保存了画笔画刷,线性等一系列跟画图相关的属性,在调用图形操作符时,直接采用图形状态中的参数来填充画笔画刷等。目前设备无关的图形状态参数主要有下面几个参数类型值CTMarray当前变换矩阵,例如: a b c d e f cmclipping path(internal)当前剪切路径,初始值:CropBoxcolor spaceName or array当前颜色空间,分为 fill color(填充色) & stroke color(描边色),初始值:DeviceGraycolor(various)当前颜色。初始值:blacktext statevarious有9个图形状态参数组成,用于文本显示。line widthnumber线宽。初始值:1.0line capinteger线帽,线2端的样式。初始值:0 J(square butt cap)line joininteger线连接的样式 。初始值:0 j (miter join)miter limitinteger尖角限量。 初始值:10 M (11.5°)dash patternarray and number虚线。初始值:[] 0 dblend modename or array当前混合模式。初始值:Normalsoft maskdictionary or name指定阴影的形状或阴影不透明值用于透明图像模式。初始值:Nonealpha constantnumber透明度。初始值:1.0。 CA(for stroke) ca(fill)alpha sourcebooleanTrue: 由 SMask 指定透明模式 <br/>false:由 CA 或 ca 指定透明值我们目前介绍过的图形状态主要有变换矩阵以及裁剪区域。剩下的会在后面的内容中依次介绍图形对象的状态变更在pdf 1.7 的标准中,有这么一张图这张图描述了图形状态描述对象的变更。图最中间的是页面对象层,包括图形状态、颜色、文本状态和标记对象等等。坐上角的连线表示,图形对象可以通过 m/re 等操作符进入对路径对象的描述,路径对象在描述完毕后可以使用f、s等操作符显示路径并回到页面对象层,或者可以通过W/W* 来进入对裁剪区域对象的描述。其他的连线也是同样的道理。理解了这个图,也就理解了基本的PDF图形操作逻辑,一般想要的绘制的图形未显示或者裁剪区域未发生作用,一般都是进入的状态不对。按照此思路进行查漏补缺一般可以解决问题本节的内容,不涉及到具体的操作符,仅仅是概念的介绍。后续将会陆续介绍上面提到的图形状态 -
PDF标准详解(四)——图形操作符 上一节,我们了解了PDF中cm操作符,它是定义变换矩阵的。同时也了解到re是创建一个矩阵的。上一节也说过,它用来构建一个路径,具体什么是路径,路径有什么作用呢?这些将在本节给出解释图形操作符是用来在pdf中构建内容并输出到相关设备上进行显示的。pdf中我们能看到的内容几乎都是由图形操作构成的。PDF中主要有6中图形操作符:图形状态操作符(Graphics state operator):CTM当前变换矩阵、 current color、 current clipping path。路径构造操作符(Path construction operators):线的轨迹,,各种图形。绘制路径操作符(Path-painting operators):填充, 描边, 或定义一个剪切区域。其他绘图操作符(自我描述图形对象): 图像(image),shading。文本操作符(Text operator):从字体(代表文本字符的字面/版式(TYPE-FACES)的描述)中选择,显示字符字形字符操作,例如前面显示hello,world 用到的Tj 操作符标记内容操作符(Marked-content Operator): Layers这一次我们主要介绍前两个,后面的等后续慢慢介绍路径路径构建操作符路径对象主要由直线、矩形框(re)、3次贝塞尔曲线构成。对于直线来说,我们需要先使用m(moveto) 来将画笔移动到指定位置,然后使用l(lineto) 来表示将画笔移动到某一个点。例如有下面的例子3 0 obj % 页面内容流 << >> stream % 流的开始 400 400 m 100 100 l s endstream % 流结束 endobj这里我们定义了一个从 (400, 400) 到(100, 100) 的直线。在画直线的时候,m只能有一个,作为起点,而l可以有多个,每有一个l都表示从画笔的上一个点画一条直线到新的位置。例如我们可以模拟一个画一个矩形3 0 obj % 页面内容流 << >> stream % 流的开始 400 400 m 100 100 l s 100 100 m 300 100 l 300 300 l 100 300 l 100 100 l S endstream % 流结束 endobj矩形的例子比较简单,这里就不给出了。我们只需要指定起点坐标并且加上长宽最后用re 操作符作为结束符即可构建对于贝塞尔曲线来说,我们需要4个点来画出一条曲线,它们的位置如下图所示我们需要一个起始和结束位置的点,并且加上两个控制点共同组成一条贝塞尔曲线。贝塞尔曲线我们使用c来作为操作符,在构建的时候需要使用m来规定起始位置的坐标,然后再跟上上图p1, p2, p3 的坐标来控制曲线。例如下面的例子3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c S endstream % 流结束 endobj这样我们构建了一条如下图所示的曲线我们对上面出现的操作符做一个总结操作符含义m设置点的起始位置(moveto)l从当前位置构建一条直线到对应位置 (lineto)re构建矩形路径c构建贝塞尔曲线路径显示操作符上述操作符只能构建一个路径,而这个路径究竟该如何显示,用作何种用途,需要另外给出操作,如果仅仅构建路径,那么页面上是不会有任何显示的,例如上述的内容流,我们稍微做一下更改,去掉最后的S 操作符,我们可以发现之前显示的内容现在不显示了3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c % 只构建路径,而不对路径做任何操作,页面不会有路径的内容 endstream % 流结束 endobj想要显示路径,我们需要使用 S 操作符。上面的路径,我们在最后加上S 就能显示出图形了。另外我们可以使用h操作符来构建一个闭合的路径,它是在原来图形的基础之上,使用一条直线将起始点到终点的两个点连接起来构成要给封闭的区间。例如上面使用直线画矩形的例子,我们可以删掉最后一个l 操作符,并使用h 闭合,照样能形成矩形3 0 obj % 页面内容流 << >> stream % 流的开始 400 400 m 100 100 l s 100 100 m 300 100 l 300 300 l 100 300 l h S endstream % 流结束 endobj去掉h 我们将得到一个开口的矩形。这个读者可以自行尝试,这里就不给出结果了。对于上面的贝塞尔曲线的例子3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c h S endstream % 流结束 endobj加上h 之后将得到下面的结果描边与填充操作这里我们采用S对路径勾画出了边框,也就是描边路径,它对应的英文单词是stroke,我们也可以使用f 或者F(fill)来对路径构成的封闭区间进行填充。默认采用黑色进行填充。3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c h f endstream % 流结束 endobj当然也可以提前指定画刷颜色,这个我们在后面介绍颜色空间的时候再介绍如何定义画刷和画笔。另外也可以使用b或者B(both) 来同时进行描边和填充操作。非0缠绕规则和奇偶绕组规则上述图形,我们很明确的仅定义了一个简单的区域,当出现重叠的复杂区域时,该如何进行填充呢?这里有两套不同的填充规则,即非0缠绕规则和奇偶绕组规则。3 0 obj % 页面内容流 << >> stream % 流的开始 100 350 200 200 re %生成矩形左上角坐标 (100, 350) 宽高都是200 120 370 160 160 re f %按照非0缠绕规则 400 350 200 200 re %生成矩形左上角坐标 (400, 350) 宽高都是200 420 370 160 160 re f* %按照奇偶缠绕规则 endstream % 流结束 endobj这里显示的效果如下我们在这里定义了两组矩形,每组有两个矩形路径进行了重叠。第一组采用非0缠绕规则,第二组采用奇偶规则来填充。我们先以这两个图形为例,来说明这两个规则非0规则:初始化环绕数到 0 。从图形中的任意一点 P 向外任意引一条射线。每遇到一条与该线的交叉线,如果射线与路劲的顺时针相交则计数加一,否则计数减一假如环绕数不等于 0 ,则点 P 在多边形内。但是这个方法有局限性 , 不适合相交 , 或者选一条正切的射线 . 因为射线的方向是任意的 , 这个规则简单的选用射线并不碰到这些情况例如上面我们定义了两个矩形,这两个矩形划分出了两个区域,也就是图中A和B所在区域。我们从A区域随意一点往外引一条射线。从图上看,射线与两条路劲相交,并且都是顺时针相交,所以这里的技术是2。同理,B点与一条顺时针路径路径计数是1。这两个区域的计数都不是0,所以他们都需要进行填充,因此它显示的是上图左侧的效果奇偶规则:从区域内某一点向外引一条射线。简单计算与该射线相交线的数量。如果这个数是奇数,则认为点在图形内。根据这个规则,我们看到A点的计数是2,是偶数,Bdian的计数是1,是奇数。按照奇偶规则,B点需要填充,而A点不需要进行填充。所以它显示的是上图右侧的效果我们再看一个例子3 0 obj % 页面内容流 << >> stream % 流的开始 150 50 m 150 250 l 250 50 l 50 150 l 350 150 l h f 550 50 m 550 250 l 650 50 l 450 150 l 750 150 l h f* endstream % 流结束 endobj这里我们画了两个五角星,线条的顺序按照m给出的为起点,每一个l代表笔画移动的一个端点,根据上述给出的值我们可以得到对应路径的环绕方向,具体的分析过程这里就不展开了,有兴趣的小伙伴可以自己尝试着画图分析一下,然后使用pdf阅读软件打开看看效果与预估的是否一样定义裁剪区域我们利用一些操作符来定义一个路径,这些路径可以作为图形显示出来,也可以作为一个裁剪区域,在该区域中的内容显示出来,不在该区域的内容则丢弃。对于给出的路径,我们使用W (非0缠绕)或者 W*(奇偶规则)来定义一个裁剪区域。例如下面有一个例子3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 200 200 re h W %将上述路径设置为裁剪路径 150 150 m 200 200 l S %在裁剪路径中,所以会显示 0 0 m 500 800 l S %只显示裁剪路径中的内容 endstream % 流结束 endobj这里我们定义了一个长宽都为200的矩形,并且使用h 将矩形区域封闭,然后使用W来将矩形内部作为裁剪区域,然后在(150, 150) 的位置画一条直线到 (200, 200) 的位置。这两个点都在矩形内部,所以会显示出来,另外再画一条从 (0, 0) 到 (500, 800) 的线条,因为这条线有一部分在裁剪区域外,一部分在裁剪区域内,所以只会显示一部分线条。最终图形呈现的效果如下总结本文主要介绍PDF中基本的图形操作符。一般构建图形的操作符有3中使用m 定义画笔的起始位置,然后使用 l 来画一条直线或者直接使用 re 操作符来绘制一个矩形还可以使用c 来构建贝塞尔曲线对于构建的路径,可以使用 h 来进行画笔起始位置和终点位置的连线,这个连线一般是一条直线。对于这个路径我们可以使用 S (stroke) 来对路劲进行描边显示或者使用 f(非0缠绕) f*(奇偶规则)进行内容的填充,又或者使用 b(B) 来描边和填充。我们可以使用 W (非0缠绕)或者 W*(奇偶规则) 来将路径作为一个裁剪区域
-
PDF标准详解(三)—— PDF坐标系统和坐标变换 之前我们了解了PDF文档的基本结构,并且展示了一个简单的hello world。这个hello world 虽然只在页面中显示一个hello world 文字,但是包含的内容却是不少。这次我们仍然以它为切入点,来了解PDF的坐标系统以及坐标变换的相关知识图形学中二维图形变换中学我们学习了平面直角坐标系,x轴沿着水平方向从左往右递增,Y轴沿着竖直方向,从下往上坐标递增。而PDF的坐标系与数学中的坐标系相同。但是PDF的坐标是有单位的,PDF的坐标单位为磅,一般来说他们与英寸等的转化关系为1 磅 = 1/72 英寸因为PDF需要做到设备无关,也是就是在不同的显示像素和打印机上,显示的长度都一致,所以这里不能采用像素做单位。但是我们可以通过相关的接口来将这个单位转化为像素。例如在Windows平台可以通过下列的代码来获取一英寸有多少像素HDC hdc = GetDC(NULL); short cxInch = GetDeviceCaps(hdc, LOGPIXELSX); short cyInch = GetDeviceCaps(hdc, LOGPIXELSY); ReleaseDC(NULL, hdc);对于我的显示器来说,水平和竖直方向都是 1英寸=96像素有了这些概念之后,我们来看一个例子,下面是在页面的(200, 200) 位置画一个 长宽都为100的正方形3 0 obj % 页面内容流<< >>stream % 流的开始200 200 100 100 re Sendstream % 流结束endobj之前说过,页面显示内容在页面流中,因此这里我们将内容放置到页面流对象中。前面的200 200 是矩形的起始位置。后面的100 100 分别是长和宽。re 代表我们要构建一个矩形,最后的S表示要显示这个图形。严格意义上来说,re 和S都是路径构造所使用的操作符。这里的矩形也不单单是一个图形,它是一个路径。关于他们的概念将在后面继续介绍。下面我们来介绍基本的2D图形变换平移假设一个点原始坐标是(x1, x2),那么沿着x轴平移a,y轴平移b,那么平移之后点的坐标为 (x1 + a, x2 + b) ,转换成矩阵就是$$ \begin{bmatrix} x & y & 1\end{bmatrix} \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ a & b & 1 \end{bmatrix} = \begin{bmatrix}x + a & y + b & 1\end{bmatrix} $$旋转利用中学的知识可以知道$$ x_1 = r * cos(\theta+\psi) \ = r*(cos\theta*cos\psi-sin\theta*sin\psi) \ = x*cos\theta-ysin\theta $$同理,我们可以得到$$ y_1 = r * sin(\theta+\psi) \ = r * (sin\theta*cos\psi+cos\theta*sin\psi)\ = x*sin\theta+y*cos\theta $$转换成矩阵就是$$ \begin{bmatrix} x & y & 1\end{bmatrix} \begin{bmatrix} cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ 0 & 0 & 1 \end{bmatrix} = \begin{bmatrix}x*cos\theta - y*sin\theta & x*sin\theta+y*cos\theta & 1\end{bmatrix} $$缩放缩放就是将坐标扩大或者缩小为原来的多少倍,我们可以很清楚的知道$$ x_1=x*a y_1=y*b $$这里的a和b都是缩放的系数利用矩阵表示就是$$ \begin{bmatrix} x & y & 1\end{bmatrix} \begin{bmatrix} a & 0 & 0 \\ 0 & b & 0 \\ 0 & 0 & 1\end{bmatrix} $$pdf 矩阵变换还有另外几种变换,这里就不一一列举了。现在我们知道二维图形的变换使用一个矩阵就能进行描述。所以PDF在变换图形的时候直接使用的是变换的矩阵。另外我们观察到对于二维变换来说,最后一列一直都是 0 0 1这三个数字。所以pdf中设置变换矩阵时忽略最后一列,仅仅保留前两列,采用6个数字$$ \begin{bmatrix}a & b & 0 \\ c & d & 0 \\ e & f & 1\end{bmatrix} $$这个矩阵在PDF中表现为 a b c d e f。回到我们之前hello的例子中,我们在 hello world 字符流开始的时候,给定了几个数字1. 0. 0. 1. 50. 700. cm各个数字之间采用空格隔开,这里数字后面跟的点表示它是一个浮点数。我们可以将这一列数字写成如下的矩阵$$ \begin{bmatrix}1.0 & 0.0 & 0 \\ 0.0 & 1.0 & 0 \\ 50.0 & 700.0 & 1 \end{bmatrix} $$这个矩阵我们叫做当前变换矩阵 (Current Transformation Matrix CTM),最后的cm表示使用该矩阵进行图形变换。它是current matrix 的缩写所以上述这一串数值的意思就是将 hello world 这个字符串平移到页面坐标 (50, 700) 的位置PDF 中控制图形变换的操作符现在我们利用这个上述知识来做一个小练习。我们将一个长宽都为100 的矩形在 (200, 200) 位置逆时针旋转45°绕任意点旋转,可以先将该点移动到坐标原点,然后按照坐标原点的进行旋转的公式进行计算,最后再将坐标点平移回原来的位置。这个过程产生3个变换矩阵平移矩阵$$ \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ -C_x & -C_y & 1\end{bmatrix} $$旋转矩阵$$ \begin{bmatrix}cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ 0 & 0 & 1\end{bmatrix} $$平移矩阵$$ \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ C_x & C_y & 1\end{bmatrix} $$我们将这三个矩阵相乘$$ \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ -C_x & -C_y & 1\end{bmatrix} * \begin{bmatrix}cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ 0 & 0 & 1\end{bmatrix} * \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ C_x & C_y & 1\end{bmatrix} $$最终得到这样一个矩阵$$ \begin{bmatrix}cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ C_x - C_xcos\theta+C_ysin\theta & C_y-C_xsin\theta-C_ycos\theta & 1\end{bmatrix} $$因此这里可以这样写3 0 obj % 页面内容流 << >> stream % 流的开始 200 200 100 100 re S %原始矩形 0.7 0.7 -0.7 0.7 200 -80 cm%进行坐标变换 200 200 100 100 re S %变换后的矩形 endstream % 流结束 endobj这样我们可以得到如下所示的图形这个时候我们会发现,同样是(200, 200) 的位置,在变换前和变换后,得到不一样的图形,这就说明我们的坐标系统被改变了。不再是水平和竖直方向的x y轴了。如果我们想要它变回原来的位置该怎么办?在GDI或者其他框架的图形编程中,在改变画笔、画刷等图形状态的时候,会首先保存原来的,然后更新,最后再还原。同样在PDF中,也存在有这样的保存和还原的操作符。我们使用q/Q这么一对操作符来完成保存和还原的操作。我在原来的基础上,再加一个矩形,在(400, 400) 位置画一个长宽都是100的矩形3 0 obj % 页面内容流 << >> stream % 流的开始 200 200 100 100 re S %原始矩形 0.7 0.7 -0.7 0.7 200 -80 cm%进行坐标变换 200 200 100 100 re S %变换后的矩形 400 400 100 100 re S % 这个矩形是相对于 (200, 200) 这个点旋转了45°的矩形 endstream % 流结束 endobj我们再采用q/Q这一对操作符来保存和还原图形状态3 0 obj % 页面内容流 << >> stream % 流的开始 200 200 100 100 re S %原始矩形 q 0.7 0.7 -0.7 0.7 200 -80 cm%进行坐标变换 200 200 100 100 re S %变换后的矩形 Q 400 400 100 100 re S endstream % 流结束 endobj这个时候我们发现它已经在(400, 400) 这个位置画了一个矩形。没有任何的图形变换PDF中将图形状态保存成一个栈结构,每次执行q就是将当前图形状态进行入栈,使用Q将之前保存在栈顶的图形状态进行出栈,并还原成当前图形状态。一般来说q/Q必须成对出现。好了,本节到这里就结束了。本节主要介绍了图形变换矩阵以及PDF中变换矩阵的操作符cm以及q/Q 这一对保存和还原图形状态的操作符
-
PDF标准详解(二)——PDF 对象 上一篇文章我们介绍了一个PDF文档应该包含的最基本的结构,并且手写了一个最简单的 “Hello World” 的PDF文档。后面我们介绍新的PDF标准给出示例时将以这个文档为基础,而不再给出完整的文档示例,小伙伴想自己测试可以根据上一节的文档来进行配置。对象上一节我们看到一个个奇奇怪怪的元素,可能也好奇它们的写法,现在我们来正式介绍它们的相关内容,它们就是PDF文档中一个个的对象。PDF 支持5种基本对象:整数和实数:例如43和12.2 这种数字字符串,PDF种字符串被包裹在小括号中,例如上一节中的 (hello world), 我们也可以给字符串制定编码,这个在后面介绍名称:一般用于字典中的键,以/ 开头,例如上一节中的 /Page 就是一个名称的对象布尔值: 由关键字 true 和 false表示null 对象,由关键字 null 表示PDF支持3种复合对象数组: 包含其他对象的有序集合,数组中的元素可以是其他任何类型的对象,例如可以像 [0 0 0 0 1] 这样只包含数字,也可以像上一节中的 [2 0 R] 包含其他对象的一个引用字典: 字典是由无序对的集合组成,将名称映射到对象。字典中的映射被包含在 <<>> 对中,例如 <</Kids [2 0 R]>> 就是一个字典,它将Kids这个名称映射到 [2 0 R] 这个间接引用的对象上流:流中一般包含二进制的数据流以及描述属性的字典,一般page中的content都是一个个的流对象。间接引用间接引用形成从一个对象到另一个对象的链接,为了将PDF拆分成一个个单独的对象,我们通过间接引用将它们链接在一起,例如上一篇文章中提到的1 0 obj << /Kids [2 0 R] /Count 1 /Type /Pages >>对象中就包含间接引用,PDF解析器,知道这个对象是一个Pages对象之后,可以通过Kids 对象指定的间接引用对象知道,当前PDF文档只有一页,这个页面对象就是2 0 这个对象。 这里的R 代表 reference 也就是引用,它是一个关键字,前面的 2 0 代表的是对象编号是2,世代号是0(这里我们不考虑世代号,默认的世代号都是0)流和过滤器流用于存储二进制数据,它们由字典和一大块二进制数据组成,字典根据流所放置的特定用途,列出数据的长度,以及可选的其他参数。从语法上将,流由字典组成,后跟 stream 关键字,换行符,0个或者多个字节的数据,另一个换行符,最后是一个endstream 关键字。根据上一篇文章中给出的页面流对象的定义来看4 0 obj << /Length 202 % 流的长度 >> stream %关键字 1. 0. 0. 1. 50. 700. cm % 202 字节的数据,这里是图形流,下面是图形流的数据 BT /F0 36. Tf (Hello, World!) Tj ET endstream % 流对象结束的关键字 endobj
-
PDF标准详解(一)——PDF文档结构 已经很久没有写博客记录自己学到的一些东西了。但是在过去一年的时间中自己确实又学到了一些东西。一直攒着没有系统化成一篇篇的文章,所以今年的博客打算也是以去年学到的一系列内容为主。通过之前Vim系列教程的启发,我发现还是写一些系列文章对自己的帮助最大。它能最大化自己的学习成果,并强迫自己深入了解一些内容。所以今年我想还是以系列文章为主,如果中间有需要穿插一些bug处理或者语言特性相关的,可能也会有这方面的内容吧。好了,废话就到这里,下面开始正式介绍PDF相关的内容PDF简介PDF的全称是 Portable document format(可移植文档格式),是描述打印页面的世界领先语言。最早于1990年代由Adobe Systems创造。早期是Adobe专有格式,直到2008年作为开放标准发布。后续经过一系列的发展,目前已经发展到了2.0版本,由于PDF完全向后兼容,并且大部分都是向前兼容的,因此,这里不打算固定在某个具体的版本,而是介绍一些PDF通用的标准和规则。PDF的文档结构PDF主要由四个部分构成,文件头、文件体、交叉引用表以及文件尾文件头将文件标识为PDF并给出它的版本号,例如%PDF-1.0 % PDF 版本号为 1.0 的文件头文件体是PDF文档的主体内容,主要由对象组成,它规定了页面信息和页面内容元素等信息交叉引用表给出了每个对象距离文件首部的地址偏移,这样在解析PDF的时候就不用从头到尾解析每个对象,而是根据需要通过交叉引用表来寻址到具体的对象地址,只单独解析某个对象,提高了解析效率文件尾给出交叉引用表的位置并且以%%EOF作为结尾PDF文件的逻辑结构一个标准的PDF文档需要在文件体中包含下列元素对象:根节点元素,类似于xml的根节点,它是整个文档的根节点对象Pages对象,它包含了PDF文档的页面信息,一般通过它来定义整个PDF文档有多少页Page 页面对象,它用来描述每个具体的页Page Content 对象,它来描述每个具体页中都有哪些对象,一般是一个字节流用来表示将在页面中显示哪些内容Page Resource 对象,它是内容的资源字典,供Content对象引用,资源包括字体、画刷、画笔等等trailer 字典,可以将它看作pdf文档对象的入口,通过它我们可以知道当前PDF文档的一些具体信息,例如根节点的位置,交叉引用表的大小它们之间的关系如下图:PDF版的Hello World说了这么多,我们来试试来自己编辑一个hello world文档,首先建立一个文本文件,将后缀改为.PDF 。我们先写上文件头:%PDF-1.0 % PDF 版本号为 1.0 的文件头主要对象我们按照之前的分析的PDF文档中需要包含的对象,来逐一定义首先给出Pages节点的定义1 0 obj % 对象1 << /Type /Pages % 这是一个页面列表 /Count 1 % 只有一页 /Kids [2 0 R] % 页面对象编号列表。这里只是对象2 >> endobj % 对象1结束对象的内容我们在后续会专门介绍,所以这里不需要额外关注它的语法,这里只需要知道1 0 obj定义了一个对象1,后续通过1 这个编号可以找到这个对象。这个对象中定义了他的类型是 Pages表示它是一个pages对象,/Count表示整个PDF文档只有一页,Kids是一个数组,表示每一页的页面对象,这里它只有一个页面对象,就是对象2接着我们定义页面对象2 0 obj << /Type /Page % 这是一个页面 /MediaBox [0 0 612 792] % 纸张尺寸为美国信肖像(612点x792点) /Resources 3 0 R % 对象3的资源引用 /Contents [4 0 R] % 图形内容在对象4中 >> endobj页面对象中我们定义了页面纸张的大小,单位是磅。因为PDF是可移植文档,它需要在不同设备上显示同样的内容,这里不能使用像素,如果使用像素,在同样尺寸的显示器上如果显示器的像素分辨率不同,那么显示的结果将会不同。所以这里一般使用磅作为单位。同时在页面对象中定义了页面中将要使用的资源以及将要显示的内容接着我们来定义资源对象3 0 obj << /Font % 字体字典 << /F0 % 只有一种字体,称为/F0 << /Type /Font % 这三行引用了内置字体Times Italic /BaseFont /Times-Italic /Subtype /Type1 >> >> >> endobj资源对象中,我们定义了一个字体资源,字体为 Times Italic,并且定义了这种字体资源的名称为 F0, 后面可以通过F0 这个名称来直接引用这个字体然后我们来定义页面内容对象4 0 obj % 页面内容流 << >> stream % 流的开始 1. 0. 0. 1. 50. 700. cm % 位置在(50,700) BT % 开始文本块 /F0 36. Tf % 在36pt选择/F0字体 (Hello, World!) Tj % 放置文本字符串 ET % 结束文本块 endstream % 流结束 endobj通过stream来定义一个流对象,在这个流对象中,我们定义它在页面的 (50, 700) 坐标位置显示字符,显示字符内容通过后面的 (Hello, World!) Tj来定义,并且定义了字符采用F0 字体,也就是上面定义的Times-Italic字体页面相关的内容我们已经定义完了,接着我们需要定义一些结构相关的对象,方便PDF解析器找到并解析页面内容。我们来定义根节点5 0 obj << /Type /Catalog %文件目录 /Pages 1 0 R %参考页面列表 >> endobj根节点包含了一个Pages定义,通过根节点就可以找到Pages节点接着我们来定义交叉引用表xref %这里我们跳过了交叉引用表的开始 0 6交叉引用表包含一些偏移地址信息,我们单纯的通过文本文档很难计算各个对象的偏移,所以这里我们只给出文档中对象数量为6,具体的地址我们先不给出,这样PDF解析器也能解析出各个对象之前我们给出了5个对象的定义,但是交叉引用表的条目却是6,这是因为交叉引用表的第一条一般是一个没有什么用处的,有效的对象从第二条定义开始。下面给出 Trailer 字典的定义trailer << /Size 6 %交叉引用表的行数 /Root 5 0 R % 参考文档目录 >>Trailer 字典以 trailer关键字开始。条目下面包括了交叉引用表的行数以及根节点的对象最后我们给出交叉引用表在PDF文档中的偏移,由于交叉引用表的内容为空,所以这里我们直接给0startxref 0 %xref表开始的字节偏移量,这里设置成0最后我们以%%EOF结尾来表示整个PDF文档结束到这里我们已经得到了一个PDF阅读器可以打开的PDF文档。我们使用PDF阅读器可以得到如下的页面PDF文档一般的读取过程不知道各位小伙伴们是否能看懂上面 Hello World 文档的定义。下面我们通过一个完整的 PDF文档来将上面所有定义的对象串起来,希望各位能对PDF文档有一个完整的认识。我们不用纠结各个部分的写法,以及为什么要这么写,只需要明白各个对象的功能即可。具体对象定义相关的语法和每个对象的详细解释将会在后面一系列文章中给出,相信那个时候再来看这个 Hello Word 文档一定会有一个更清晰的认识。再说明文档读取的过程前,我们先使用一些工具来补全这个文档,这里使用 pdftk 工具。可以在这里 进行下载,完成之后,使用如下命令进行补全pdftk hello.pdf output hello-full.pdf成功后会得到如下内容%PDF-1.0 %忏嫌 1 0 obj << /Kids [2 0 R] /Count 1 /Type /Pages >> endobj 2 0 obj << /Resources 3 0 R /MediaBox [0 0 612 792] /Contents [4 0 R] /Type /Page >> endobj 3 0 obj << /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> endobj 4 0 obj << /Length 202 >> stream % 娴佺殑寮€濮? 1. 0. 0. 1. 50. 700. cm % 浣嶇疆鍦紙50,700锛? BT % 寮€濮嬫枃鏈潡 /F0 36. Tf % 鍦?6pt閫夋嫨/F0瀛椾綋 (Hello, World!) Tj % 鏀剧疆鏂囨湰瀛楃涓? ET % 缁撴潫鏂囨湰鍧? endstream endobj 5 0 obj << /Pages 1 0 R /Type /Catalog >> endobj xref 0 6 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000168 00000 n 0000000267 00000 n 0000000523 00000 n trailer << /Root 5 0 R /Size 6 >> startxref 573 %%EOF 这个我将整个PDF文档都粘贴了出来,从这里我们可以看到,它已经为我们补全了交叉引用表。下面通过整个文档来说明一般读取过程PDF解析程序,先通过文件头来确定是否是PDF文件,并且得到PDF文件的版本在文件末尾找到%%EOF 关键子,确定文件尾。接着向上查找到 startxref 关键字,该关键字后面将会给出交叉引用表的偏移,通过这个偏移地址可以找到交叉引用表接着查找trailer关键字,通过trailer关键字可以得到文档的一些信息,这里关键的是得到 Root 节点的对象。根据交叉引用表可以很块定位到Root 节点对象,也就是对象5根据Root 对象中的 Pages属性可以找到Pages对象,也就是PDF页面信息对象根据Pages对象中的Kids 数组,可以找到PDF包含的所有页面对象,这个文档只有一个页面对象找到Page 对象后可以根据 Resources 和Contents属性可以找到页面内容和页面引用的资源。例如该文档就可以使用Times-Italic字体显示 hello world字符串
-
从0开始自制解释器——重构代码 在上一篇文章中,完成了对括号的支持,这样整个程序就可以解析普通的算术表达式了。但是在解析两个括号的过程中发现有大量的地方需要进行索引的回退操作,索引的操作应该保证能得到争取的token,这个步骤应该放在词法分析的阶段,如果在语法分析阶段还要考虑下层词法分析的过程,就显得有些复杂了。而且随着后续支持的符号越来越多,可能又得在大量的地方进行这种索引变更的操作,代码将难以理解和维护。因此这里先停下来进行一次代码的重构。基本架构这里的代码我按照教程里面的结构进行组织。将按照程序的逻辑分为3层,最底层负责操作字符串的索引保证下次获取token的时候索引能在正确的位置。第二层是词法分析部分,负责给字符串的每个部分都打上对应的token。第三个部分是语法分析的部分,它负责解析之前设计的BNF范式,并计算对应的结果。详细的代码上面给出模块划分的概要可能没怎么说清楚,下面将通过代码来进行详细的说明。Token 模块为了支持这个设计,首先变更一下全局变量的定义,现在定义的全局变量如下所示extern Token g_currentToken; //当前token extern int g_nPosition; //当前字符索引的位置 extern char g_currentChar; //当前字符串之前通过 get_next_char() 来返回当前指向的token并变更索引的时候发现我们在任何时候想获取当前指向的字符时永远要变更索引,这样就不得不考虑在某些时候要进行索引的回退。比如在解析整数退出的时候,此时当前字符已经指向下一个字符了,但是我们在接下来解析其他符号的时候调用 get_next_char() 导致索引多增加了一个。这种情况经常出现,因此这里使用全局变量保存当前字符,只在需要进行索引增加的时候进行增加。另外我们不希望上层来直接操作这个索引,因此在最底层的Token模块提供一个名为 advance() 的函数用于将索引加一,并获取之后的字符。它的定义如下void advance() { g_nPosition++; // 如果到达字符串尾部,索引不再增加 if (g_nPosition >= strlen(g_pszUserBuf)) { g_currentChar = '\0'; } else { g_currentChar = g_pszUserBuf[g_nPosition]; } }这样在对应需要用到当前字符的位置就不再使用 get_next_char() , 而是改用全局变量 g_currentChar。例如现在的 skip_whitespace 函数现在的定义如下void skip_whitespace() { while (is_space(g_currentChar)) { advance(); } }这样我们在获取下一个token的时候只在必要的时候进行索引的递增。lex 模块由于打标签的工作交个底层的Token模块了,该模块主要用来实现词法分析的功能,也就是给各个部分打上标签,根据之前Token部分提供的接口,需要对 get_next_token 函数进行修改。bool get_next_token() { dyncstring_reset(&g_currentToken.value); while (g_currentChar != '\0') { if (is_digit(g_currentChar)) { g_currentToken.type = CINT; parser_number(&g_currentToken.value); return true; } else if (is_space(g_currentChar)) { skip_whitespace(); } else { switch (g_currentChar) { case '+': g_currentToken.type = PLUS; dyncstring_catch(&g_currentToken.value, '+'); advance(); break; case '-': g_currentToken.type = MINUS; dyncstring_catch(&g_currentToken.value, '-'); advance(); break; case '*': g_currentToken.type = DIV; dyncstring_catch(&g_currentToken.value, '*'); advance(); break; case '/': g_currentToken.type = MUL; dyncstring_catch(&g_currentToken.value, '/'); advance(); break; case '(': g_currentToken.type = LPAREN; dyncstring_catch(&g_currentToken.value, '('); advance(); break; case ')': g_currentToken.type = RPAREN; dyncstring_catch(&g_currentToken.value, ')'); advance(); break; case '\0': g_currentToken.type = END_OF_FILE; break; default: return false; } return true; } } return true; }在这个函数中,将不再通过输出参数来返回当前的token,而是直接修改全局变量。同时也不再使用get_next_char 函数来获取当前指向的字符,而是直接使用全局变量。并且在适当的时机调用advance 来实现递增。另外在上层我们直接使用 g_currentToken 拿到当前的token,而在适当的时机调用新增的eat() 函数来实现更新token的操作。bool eat(LPTOKEN pToken, ETokenType eType) { if (pToken->type == eType) { get_next_token(); return true; } return false; }该函数接受两个参数,第一个是当前token的值,第二个是我们期望当前token是何种类型。如果当前token的类型与期望的不符则报错,否则更新token。interpreter 模块该模块主要负责解析根据前面的BNF范式来完成计算并解析内容。这个模块提供三个函数get_factor、get_term、expr。这三个函数的功能没有变化,只是在实现上依靠lex 模块提供的功能。主要思路是直接使用 g_currentToken 这个全局变量来获得当前的token,使用 eat() 来更新并获得下一个token的值。这里我们以get_factor() 函数为例int get_factor(bool* pRet) { int value = 0; if (g_currentToken.type == CINT) { value = atoi(g_currentToken.value.pszBuf); *pRet = eat(&g_currentToken, CINT); } else { if (g_currentToken.type == LPAREN) { bool bValid = true; bValid = eat(&g_currentToken, LPAREN); value = expr(&bValid); bValid = eat(&g_currentToken, RPAREN); *pRet = bValid; } } return value; }与前面分析的相同,该函数主要负责获取整数和计算括号中子表达式的值。在解析完整数和括号中的子表达式之后,需要调用eat分别跳过对应的值。只是在识别到括号之后需要跳过左右两个括号。这样就完成了对应的分层,每层只负责自己该做的事。不用在上层考虑修改索引的问题,结构也更加清晰,未来在添加功能的时候也更加方便。剩下几个函数就不再贴出代码了,感兴趣的小伙伴可以去对应的GitHub仓库上查阅相关代码。
-
从0开始自制解释器——添加对括号的支持 在上一篇我们添加了对乘除法的支持,也介绍了BNF范式,并且针对当前的算术表达式写出了对应的范式,同时根据范式给出相应的代码实现。这篇我们将继续为算数表达式添加对括号的支持。对应的BNF 范式在上一篇我们给出了乘除法对应的范式<expr>::=<term>{(PLUS|MINUS)<term>} <term>::=<factor>{(DIV|MUL)<factor>} <factor>::={(0|1|2|3|4|5|6|7|8|9)}针对乘除法的优先级比加减法高,我们的做法是将乘除法单独作为一个部分,然后在最外层表达式中只处理加减法。基于这种思路,我们来看如何处理括号的问题。例如下面的算数表达式((1+2)*3+4) - (5 - 6 / 3)这里我们直接给出对应的文法,然后再来分析一下该如何由这个文法得到对应的表达式<expr>::=<term>{(PLUS|MINUS)<term>} <term>::=<factor>{(DIV|MUL)<factor>} <factor>::=({(0|1|2|3|4|5|6|7|8|9|)})|LPAREN<expr>RPAREN首先根据表达式,它应该由两个term来组成 expr = term - term接着看看两个term,它们并不是单纯的加法运算,所以两个term应该只有单纯的一个factor,也就是 expr = factor - factor因为最外层都有括号,所以再次展开 expr = (expr1) - (expr2)这时就又到了分析expr的过程了,左侧的expr最外层是一个加法,所以这里可以得到 expr1 = term + term右侧的expr 最外层是一个减法,也就是 expr2 = term - term结合最外层的表达式可以得到 expr = (term1 + term2) - (term3 - term4)term1 部分有一个乘法,所以它可以解析为 term1 = factor * factorterm2 部分就是单独的数字所以可以得到 term2 = factor,并且进一步得到 term2=4term3 部分就是单纯的数字,可以得到 term3 = factor,并且进一步得到 term3=5term4 部分有一个除法,所以它可以解析为 term3 = factor / factor此时整个表达式可以表示为 expr = (factor1 * factor2 + 4) - (5 - factor3 / factor4)factor1 本身也是一个括号,加表达式,所以它可以表示为 factor1 = (expr)factor2 是一个数字,所以它表示为 factor2 = 3factor3 是一个数字,所以它表示为 factor3 = 6factor4 是一个数字,所以它表示为 factor4 = 3此时表达式可以是 expr = ((expr1) * 3 + 4) - (5 - 6 / 3)此时再次分析这个 expr1 可以得到 expr1 = 1+2这个时候,整个表达式就出来了 expr = ((1+2) * 3 + 4) - (5 - 6 / 3)用图来表示大概可以表示如下代码实现有了范式,我们就可以按照范式来组织代码实现。首先我们先在 ETokenType 中添加针对括号的标签typedef enum e_TokenType { CINT = 0, //整数 PLUS, //加法 MINUS, //减法 DIV, //乘法 MUL, //除法 LPAREN, //左括号 RPAREN, //右括号 END_OF_FILE // 字符串末尾结束符号 }ETokenType;然后在 get_next_token 函数中添加对括号进行词法分析并打标签的功能bool get_next_token(LPTOKEN pToken) { char c = get_next_char(); dyncstring_reset(&pToken->value); if (is_digit(c)) { dyncstring_catch(&pToken->value, c); pToken->type = CINT; parser_number(&pToken->value); } else if(is_space(c)) { skip_whitespace(); return get_next_token(pToken); } else { switch (c) { case '+': pToken->type = PLUS; break; case '-': pToken->type = MINUS; break; case '*': pToken->type = DIV; break; case '/': pToken->type = MUL; break; case '(': pToken->type = LPAREN; break; case ')': pToken->type = RPAREN; break; case '\0': pToken->type = END_OF_FILE; break; default: return false; } } return true; }这里我对这个函数进行了一些改写,针对依靠单个字符就能打上标签的采用switc来进行处理,像空白字符、数字这种有多种字符类型的就采用普通的if处理。然后在get_oper 中添加对括号的识别 if (get_next_token(&token) && (token.type == PLUS || token.type == MINUS || token.type == DIV || token.type == MUL || token.type == LPAREN || token.type == RPAREN)) { oper = token.type; if (pRet) *pRet = true; }然后根据文法,get_factor 需要能够返回一个 expr的结果,所以这里需要添加以下代码 if (token.type == LPAREN) { bool bValid = true; value = expr(&bValid); if (!bValid) *pRet = false; if (get_next_token(&token) && token.type == RPAREN) *pRet = true; else *pRet = false; }如果我们得到的标签不为括号则按照原来的处理方式来处理,如果是括号,则将括号中的内容作为表达式并计算表达式的值,作为整数来返回。之前的expr 函数我们仅仅将结果打印并返回是否解析成功,这里需要做一些改进。我们使用一个传出参数来返回解析是否成功,而将计算结果作为值进行返回。另外需要特别注意的是,我们将反括号的判断放到了 get_factor 函数中,所以在 get_term 和 expr 中,遇到反括号应该考虑对位置索引进行递减,并且遇到反括号应该认为到达末尾并推出。这里的代码就不贴出来了。有兴趣的小伙伴可以看github上上传的代码。地址
-
从0开始自制解释器——添加对乘除法的支持 在上一篇中,我们实现了对减法的支持,并且介绍了语法图。针对简单的语法进行描述,用语法图描述当然是没问题的。但是针对一些复杂的语法进行描述,如果每个部分都通过语法图来描述就显得有些繁琐了。这篇我们先介绍另一种描述语法的方式,并进一步介绍一些关于语法分析的知识。BNF范式与上下文无关文法巴科斯范式 以美国人巴科斯(Backus)和丹麦人诺尔(Naur)的名字命名的一种形式化的语法表示方法,用来描述语法的一种形式体系,是一种典型的元语言。又称巴科斯-诺尔形式(Backus-Naur form)。它不仅能严格地表示语法规则,而且所描述的语法是与上下文无关的。它以递归方式描述语言中的各种成分,凡遵守其规则的程序就可保证语法上的正确性。它具有语法简单,表示明确,便于语法分析和编译的特点。BNF表示语法规则的方式为:非终结符用尖括号括起。每条规则的左部是一个非终结符,右部是由非终结符和终结符组成的一个符号串,中间一般以“::=”分开。具有相同左部的规则可以共用一个左部,各右部之间以直竖“|”隔开。所谓非终结符就是语言中某些抽象的概念不能直接出现在语言中的符号,终结符就是可以直接出现在语言中的符号。其实这些都是一些官话,初看起来只觉得拗口和难以理解,但是它的形式非常简单。它主要是用下面几个符号来表达含义使用<>来表示必须包含的部分使用[]来表示可选部分使用{}来表示可以重复0次或者无数次使用|来表示左右两边任选一部分,相当于OR使用::=来表示被定义为现在来给出具体的例子,我们都看过《西游记》,里面的取经4人组包括唐僧、孙悟空、猪八戒和沙僧。使用BNF范式进行定义,可以写成 <取经团队>::=<唐僧><孙悟空><猪八戒><沙僧>。我们再来举一个例子,我们知道一个文章由若干个段落组成、一个段落由若干个句子组成、一个句子由符合一定语法规则的汉字组成并且以句号作为结尾。我们简单的将句子的语法规则定义为主谓宾三个部分。而这里的主谓宾我们简单的用一些名词和动词来定义。因此这里的一系列结构可以定义为如下内容<文章>::={<段落>}<段落>::={<句子>}<句子>::=<主语><谓语><宾语>。<主语>::=人|狗|猫|天<谓语>::=吃|抓|下<宾语>::=饭|雨|肉|鱼根据这个表达式我们很容易的推出类似 人吃饭。、天下雨。、猫抓鱼。 这样的句子。相信到这里小伙伴应该明白BNF范式的一些基本概念和使用方式了。我们再来插入一个题外话,既然这里提到BNF范式是一种上下文无关文法,那什么是上下文、什么是上下文无关。先别着急了解概念,我们仍然通过例子来说明。在上述的句子的定义中,我们一共可以生成 4 * 3 * 4 = 48 种 结果,我们可以获得类似 人吃饭。、猫抓鱼。这种有意义的句子,也可能产生像天吃鱼。、人下雨 这种读起来感觉别扭的非正常语句。但是在上下文无关的语法中,主语宾语和谓语的内容没有相互关联,也就是说谓语和宾语的产生与主语无关。那上下文有关的文法呢?这里为了产生一些有意义的句子,我们给它加上一些限定。例如人后面只能接 吃 抓作为谓语、而当吃作为谓语时只能将 饭、肉、鱼作为宾语。针对这种需求,我们可以进行如下定义<句子>::=<主语><谓语><宾语>。<主语>::=人|狗|猫|天人<谓语>::=人(吃|抓)吃<宾语>::=吃(饭|肉|鱼)这样我们对这个产生式进行了一些限定,当主语是人的时候,谓语只能产生吃和抓这样的宾语。这种情况下的描述就被称之为上下文有关。上下文无关我自己的理解就是后续表达式的产生不依赖前面已产生的内容。而上下文有关的含义则与之相法。这个上下文就跟我们这么多年阅读理解题里面写的“请根据上下文来理解某个词表达了作者怎样的心情”这里的上下文类似。当然更加规范的说法就是,在应用一个产生式进行推导时,前后已经推导出的部分结果就是上下文。上下文无关就是只要文法的定义里面有一个定义,不管前面的产生串是什么都可以应用相应的产生推导后面的内容。代码编写上面的定义只是开胃菜,希望通过上面的描述,小伙伴能够理解BNF范式的应用,至于上下文无关和上下文有关。这些暂时不用考虑,毕竟我们目前还是在做上下文无关文法相关的内容。这里我们要支持乘法和除法,首先要做的就是在 ETokenType 结构中添加对乘法和除法相关的定义typedef enum e_TokenType { CINT = 0, //整数 PLUS, //加法 MINUS, //减法 DIV, //乘法 MUL, //除法 END_OF_FILE // 字符串末尾结束符号 }ETokenType;接着在 get_next_token和 get_oper() 函数中添加对这两个运算符的支持// get_next_token else if (c == '*') { pToken->type = DIV; dyncstring_catch(&pToken->value, '*'); } else if (c == '/') { pToken->type = MUL; dyncstring_catch(&pToken->value, '/'); } // get_oper if (get_next_token(&token) && (token.type == PLUS || token.type == MINUS || token.type == DIV || token.type == MUL)) { oper = token.type; if (pRet) *pRet = true; }现在词法分析部分已经可以支持乘除法的符号解析了。接着来完成语法分析的部分。首先我们来定义一下这个简单计算器的文法。<expr>::=<term>{<oper><term>} <term>::={0|1|2|3|4|5|6|7|8|9} <oper>::=PLUS|MINUS|DIV|MUL回忆一下上一节给出的语法图,理解这个表达式并不算困难。但是这里我们定义的文法有一个问题,就是从文法上体现不出运算的优先级。学过小学数学的都知道算数运算中优先计算乘除法,最后算加减法。但是根据这个文法我们无法体现出乘除法的优先级。因此这里我们需要修改定义。优先计算乘除法在文法上可以理解成,乘除法单独成一个部分,我们获取这个部分的计算结果最后与其他部分一起计算加减法。用BNF范式来体现就是<expr>::=<term>{(PLUS|MINUS)<term>} <term>::=<factor>{(DIV|MUL)<factor>} <factor>::={0|1|2|3|4|5|6|7|8|9}与语法图类似,范式也可以很容易转化为代码。允许出现多次的我们在代码实现上体现为循环。而文法中相关的定义我们直接采用一些get方式来获取对应被打上标记的值即可。上述文法描述可以转化为如下的c 代码int expr() { bool bRet = false; int result = get_term(&bRet); int bEOF = false; do { ETokenType oper = get_oper(&bRet); switch (oper) { case PLUS: { int num = get_term(&bRet); if(bRet) result += num; } break; case MINUS: { int num = get_term(&bRet); if(bRet) result -= num; } break; case END_OF_FILE: printf("%d\n", result); bEOF = true; break; default: bRet = false; break; } } while (bRet && !bEOF); if (!bRet) { printf("Syntax Error!\n"); } return 0; }上述expr的定义就是由一个term加若干个 +|- 和后面的若干个term 来组成,因此这里有一个循环。来取出所有term 和所有加减法,并进行计算。int get_term(bool* pValid) { int result = get_factor(pValid); int bEOF = false; do { ETokenType oper = get_oper(pValid); switch (oper) { case DIV: { int num = get_factor(pValid); if (*pValid) result *= num; } break; case MUL: { int num = get_factor(pValid); if (*pValid) result /= num; } break; case PLUS: case MINUS: { g_pPosition--; bEOF = true; } break; case END_OF_FILE: { g_pPosition--; bEOF = true; } } } while (pValid && !bEOF); return result; }而term 则是由整数以及若干个乘除法和另一个整数组成,所以代码中也用循环来取一直到取到不是这个term 定义所组成的部。注意这里与之前一样,当取到term的结束部分,我们仍然需要将索引进行递减。而最终的oper 和 factor 则保持原来的算法不变。好了,本篇到此也就结束了,小伙伴可以到该位置 取出代码来进行阅读和修改。
-
从0开始自制解释器——实现多个整数的加减法 在上一篇我们实现了一个可以计算两个多位整数加减法的计算器。本章我们继续来给这个计算器添加功能,这次要给它添加可以连续计算多个整数相加减的功能。例如我们可以计算 1 + 2 + 3 这样的表达式。语法图在正式写代码之前让我们先来学习一下一些基本的理论知识。这次要介绍的理论是语法图。什么是语法图呢?语法图是编程语言语法语法规则的图形表示。它体现了词法分析的运行规则。语法图直观的展示了在编程语言中哪些语句是符合语法的,哪些是不符合语法规范的。语法图的阅读非常容易,它类似于程序的流程图,只要顺着箭头指向的路径来读即可。与程序流程图类似,语法图中有些路径表示选择,有些表示循环。我们试着来读一下下面的语法图这张语法图表示的含义是,一个术语(term) 可选的跟上一个加号或者减号,而后面又需要跟上另一个术语。接着又可以有选择的跟上另一个加号或者减号。但是加号或者减号后面必须跟上另一个术语。这里又提到另一个单词,term 它的中文意思是术语。似乎很难用其他文字来解释何为术语。你只需要知道在这里它代表的是一个整数,它并不影响我们阅读这个语法图代码展示在上一篇中我们提到,将Token流识别为对应结构的过程被称之为词法分析,我们代码中的词法分析的实现主要在函数 expr 中。在这个函数中我们主要实现了词法分析以及最后的解释执行。我们按照语法图修改一下词法分析的代码我们先给出下面的伪代码获取第一个整数作为计算结果保存 while(解析到最后一个字符) { 获取操作符(+/-) switch(操作符) { case +: 获取下一个整数,如果不是整数则退出并报错 与结果相加 break; case -: 获取下一个整数,如果不是整数则退出并报错 与结果相减 break; } } 最终打印计算结果或者打印语法错误基于这个思路我们给出具体的实现代码int expr() { bool bRet = false; int result = get_term(&bRet); int bEOF = false; do { ETokenType oper = get_oper(&bRet); switch (oper) { case PLUS: { int num = get_term(&bRet); if(bRet) result += num; } break; case MINUS: { int num = get_term(&bRet); if(bRet) result -= num; } break; case END_OF_FILE: printf("%d\n", result); bEOF = true; break; default: bRet = false; break; } } while (bRet && !bEOF); if (!bRet) { printf("Syntax Error!\n"); } }这里为了便于理解,我将获取整数和操作符的模块又进行了一次封装,提供了两个函数分别是 get_term() 和 get_oper()。它们的代码如下int get_term(bool *pRet) { Token token = { 0 }; dyncstring_init(&token.value, DEFAULT_BUFFER_SIZE); int value = 0; if (get_next_token(&token) && token.type == CINT) { value = atoi(token.value.pszBuf); if (pRet) *pRet = true; } else { if (pRet) *pRet = false; } dyncstring_free(&token.value); return value; }ETokenType get_oper(bool* pRet) { Token token = { 0 }; dyncstring_init(&token.value, DEFAULT_BUFFER_SIZE); int oper = 0; if (get_next_token(&token) && (token.type == PLUS || token.type == MINUS)) { oper = token.type; if (pRet) *pRet = true; } else if (token.type == END_OF_FILE) { oper = END_OF_FILE; if (pRet) *pRet = true; } else { oper = -1; if (pRet) *pRet = false; } dyncstring_free(&token.value); return oper; }到此为止,就实现了多个整数的算术运算。整个实现过程的代码我都放到该位置。有兴趣的小伙伴可以自己对照着代码跟着我一起来实现属于自己的解释器。
-
从0开始自制解释器——实现多位整数的加减法计算器 上一篇我们实现了一个简单的加法计算器,并且了解了基本的词法分析、词法分析器的概念。本篇我们将要对之前实现的加法计算器进行扩展,我们为它添加以下几个功能计算减法能自动识别并跳过空白字符不再局限于单个整数,而是能计算多位整数提供一些工具函数首先为了支持减法,我们需要重新定义一下TokenType这个类型,也就是需要给 - 定义一个标志。现在我们的TokenType的定义如下typedef enum e_TokenType { CINT = 0, PLUS, MINUS, END_OF_FILE }ETokenType;由于需要支持多个整数,所以我们也不知道最终会有多少个字符,因此我们提供一个END_OF_FILE 表示我们访问到了最后一个字符,此时应该退出词法分析的过程。另外因为整数个数不再确定,我们也就不能按照之前的提供一个固定大小的数组。虽然可以提供一个足够大的空间来作为存储数字的缓冲,但是数字少了会浪费空间。而且考虑到之后要支持自定义变量和函数,采用固定长度缓冲的方式就很难找到合适的大小,太大显得浪费空间,太小有时候无法容纳得下用户定义的变量和函数名。因此这里我们采用动态长度的字符缓冲来保存。我们提供一个DyncString 的结构来保存这些内容#define DEFAULT_BUFFER_SIZE 16 // 动态字符串结构,用于保存任意长度的字符串 typedef struct DyncString { int nLength; // 字符长度 int capacity; //实际分配的空间大小 char* pszBuf; //保存字符串的缓冲 }DyncString, *LPDyncString; // 动态字符串初始化 // str: 被初始化的字符串 // size: 初始化字符串缓冲的大小,如果给0则按照默认大小分配空间 void dyncstring_init(LPDyncString str, int size); // 动态字符串空间释放 void dyncstring_free(LPDyncString str); //重分配动态字符串大小 void dyncstring_resize(LPDyncString str, int newSize); //往动态字符串中添加字符 void dyncstring_catch(LPDyncString str, char c); // 重置动态数组 void dyncstring_reset(LPDyncString str);它们的实现如下/*----------------------------动态数组的操作函数-------------------------------*/ void dyncstring_init(LPDyncString str, int size) { if (NULL == str) return; if (size == 0) str->capacity = DEFAULT_BUFFER_SIZE; else str->capacity = size; str->nLength = 0; str->pszBuf = (char*)malloc(sizeof(char) * str->capacity); if (NULL == str->pszBuf) { error("分配内存失败\n"); } memset(str->pszBuf, 0x00, sizeof(char) * str->capacity); } void dyncstring_free(LPDyncString str) { if (NULL == str) return; str->capacity = 0; str->nLength = 0; if (str->pszBuf == NULL) return; free(str->pszBuf); } void dyncstring_resize(LPDyncString str, int newSize) { int size = str->capacity; for (; size < newSize; size = size * 2); char* pszStr = (char*)realloc(str->pszBuf, size); str->capacity = size; str->pszBuf = pszStr; } void dyncstring_catch(LPDyncString str, char c) { if (str->capacity == str->nLength + 1) { dyncstring_resize(str, str->capacity + 1); } str->pszBuf[str->nLength] = c; str->nLength++; } void dyncstring_reset(LPDyncString str) { dyncstring_free(str); dyncstring_init(str, DEFAULT_BUFFER_SIZE); } /*----------------------------End 动态数组的操作函数-------------------------------*/另外提供一些额外的工具函数,他们的定义如下void error(char* lpszFmt, ...) { char szBuf[1024] = ""; va_list arg; va_start(arg, lpszFmt); vsnprintf(szBuf, 1024, lpszFmt, arg); va_end(arg); printf(szBuf); exit(-1); } bool is_digit(char c) { return (c >= '0' && c <= '9'); } bool is_space(char c) { return (c == ' ' || c == '\t' || c == '\r' || c == '\n'); }主要算法我们还是延续之前的算法,一个字符一个字符的解析,只是现在需要额外的将多个整数添加到一块作为一个整数处理。而且需要添加跳过空格的处理。首先我们对上次的代码进行一定程度的重构。我们添加一个函数专门用来获取下一个字符char get_next_char() { // 如果到达字符串尾部,索引不再增加 if (g_pPosition == '\0') { return '\0'; } else { char c = *g_pPosition; g_pPosition++; return c; } }expr() 函数里面大部分结构不变,主要算法仍然是按次序获取第一个整数、获取算术运算符、获取第二个整数。只是现在的整数都变成了采用 dyncstring 结构来存储int expr() { int val1 = 0, val2 = 0; Token token = { 0 }; dyncstring_init(&token.value, DEFAULT_BUFFER_SIZE); if (get_next_token(&token) && token.type == CINT) { val1 = atoi(token.value.pszBuf); } else { printf("首个操作数必须是整数\n"); dyncstring_free(&token.value); return -1; } int oper = 0; if (get_next_token(&token) && (token.type == PLUS || token.type == MINUS)) { oper = token.type; } else { printf("第二个字符必须是操作符, 当前只支持+/-\n"); dyncstring_free(&token.value); return -1; } if (get_next_token(&token) && token.type == CINT) { val2 = atoi(token.value.pszBuf); } else { printf("操作符后需要跟一个整数\n"); dyncstring_free(&token.value); return -1; } switch (oper) { case PLUS: { printf("%d+%d=%d\n", val1, val2, val1 + val2); } break; case MINUS: { printf("%d-%d=%d\n", val1, val2, val1 - val2); } break; default: printf("未知的操作!\n"); break; } dyncstring_free(&token.value); }最后就是最终要的 get_next_token 函数了。这个函数最主要的修改就是添加了解析整数和跳过空格的功能bool get_next_token(LPTOKEN pToken) { char c = get_next_char(); dyncstring_reset(&pToken->value); if (is_digit(c)) { dyncstring_catch(&pToken->value, c); pToken->type = CINT; parser_number(&pToken->value); } else if (c == '+') { pToken->type = PLUS; dyncstring_catch(&pToken->value, '+'); } else if (c == '-') { pToken->type = MINUS; dyncstring_catch(&pToken->value, '-'); } else if(is_space(c)) { skip_whitespace(); return get_next_token(pToken); } else if ('\0' == c) { pToken->type = END_OF_FILE; } else { return false; } return true; }在这个函数中我们先获取第一个字符,如果字符是整数则获取后面的整数并直接拼接为一个完整的整数。如果是空格则跳过接下来的空格。这两个是可能要处理多个字符所以这里使用了单独的函数来处理。其余只处理单个字符可以直接返回。parser_number 和 skip_whitespace 函数比较简单,主要的过程是不断从输入中取出字符,如果是空格则直接将索引往后移动,如果是整数则像对应的整数字符串中将整数字符加入。void skip_whitespace() { char c = '\0'; do { c = get_next_char(); } while (is_space(c)); // 遇到不是空白字符的,下次要取用它,这里需要重复取用上次取出的字符 g_pPosition--; } void parser_number(LPDyncString dyncstr) { char c = get_next_char(); while(is_digit(c)) { dyncstring_catch(dyncstr, c); c = get_next_char(); } // 遇到不是数字的,下次要取用它,这里需要重复取用上次取出的字符 g_pPosition--; }唯一需要注意的是,最后都有一个 g_pPosition-- 的操作。因为当我们发现下一个字符不符合条件的时候,它已经过了最后一个数字或者空格了,此时应该已经退回到get_next_token 函数中了,这个函数第一步就是获取下一个字符,因此会产生字符串被跳过的现象。所以这里我们执行 -- 退回到上一个位置,这样再取下一个就不会有问题了。最后为了能够获取空格的输入,我们将之前的scanf 改成 gets。这样就大功告成了。我们来测试一下结果最后的总结最后来一个总结。本篇我们对上一次的加法计算器进行了简单的改造,支持加减法、能跳过空格并且能够计算多位整数。在上一篇文章中,我们提到了Token,并且说过,像 get_next_token 这样给字符串每个部分打上Token的过程就是词法分析。get_next_token 这部分代码可以被称之为词法分析器。这篇我们再来介绍一下其他的概念。词位(lexeme): 词位的中文解释是语言词汇的基本单位。例如汉语的词位是汉字,英语的词位是基本的英文字母。对于我们这个加法计算器来说基本的词位就是数字以及 +\- 这两个符号parsing(语法分析)和 parser(语法分析器) 我们所编写的expr函数主要工作流程是根据token来组织代码行为。它的本质就是从Token流中识别出对应的结构,并将结构翻译为具体的行为。例如这里找到的结构是 CINT oper CINT。并且将两个int 按照 oper 指定的运算符进行算术运算。这个将Token流中识别出对应的结构的过程我们称之为语法分析,完成语法分析的组件被称之为语法分析器。expr 函数中即实现了语法分析的功能,也实现了解释执行的功能。