搜索到
190
篇与
的结果
-
 c++基础之语句 上一次总结了一下c++中表达式的相关内容,这篇博文主要总结语句的基础内容简单语句c++ 中语句主要是以分号作为结束符的,最简单的语句是一个空语句,空语句主要用于,语法上需要某个地方,但是逻辑上不需要;最常见的就是循环里面复合语句是用大括号括起来的语句块叫做复合语句,复合语句也叫做块。一个块就是一个作用域,在块中引入的名字只能在块内部以及嵌套在块里面的子块中访问。通常名字在有限的区域内可见,该区域从名字定义开始,到名字所在块的结尾为止。语法上需要一条语句,但是逻辑上需要多条语句的,应该使用语句块,例如if或者while等循环里面。块不以分号结束。{};, 算两条语句空块是指内部没有任何语句的一对花括号语句作用域语句中变量的作用域只在当前语句块中有效,如果其他代码也想访问控制变量,则变量必须定义在语句块的外部。条件语句条件语句需要注意:if语句每个分支尽量加上大括号,即好读,也能避免很多问题switch 语句中case后面必须跟上整型常量表达式一般不要省略case分支最后的break语句,如果是特殊逻辑需要这么做的,使用注释进行说明即使不准备在default分支中做任何事,最好也写上default分支。其目的在于告诉程序的读者,我们已经考虑到了默认的情况,只是目前什么也没有做要在case分支中定义变量应该定义在大括号中,并且只在当前分支中使用它迭代语句迭代语句又叫做循环语句,一般有while、do while、for三种形式这些语句一般的语言中都有,这里就不多做介绍,主要介绍c++ 11中新增的一种范围for的形式范围for可以遍历容器或者其他序列的所有元素,它的简单形式是for(declaration: expression) statementdeclaration 定义一个变量,序列中的每一个元素要都能转化为该变量的类型,然后执行拷贝操作,将每次迭代的值拷贝到该变量中。变量只是序列中元素的拷贝,无法修改元素的值,如果想要修改元素的值,需要将变量定义为引用类型。statement 是一个语句或者语句块,所有元素都处理完后,循环结束跳转语句跳转语句主要有break、continue以及goto语句。break:用于跳出离它最近的while、do while、for或者switch语句,并从这些语句之后的第一条语句开始执行。continue:终止最近的循环语句中当前迭代并立即进入下一次迭代,它只能出现在循环语句中。goto:跳转到对应标签处,标签可以定义在函数任意位置。注意只能作用于函数内部,不能由一个函数跳转到另一个函数。尽量少用goto,因为它可读性差,而且不好控制。异常处理语句c++中的异常处理包括这样几个部分:throw表达式:用于抛出一个异常try: 异常处理部分使用try语句块处理异常,try语句块以关键字try开始,并以一个或者多个catch子句结束。try语句块中代码抛出的异常通常会被某个catch子句处理。因为catch子句处理异常,所以它们也被称之为异常处理代码异常类:用于在throw表达式和相关的catch子句之间传递异常的具体信息throw 后面跟一个表达式,表达式返回值的类型就是抛出异常的类型。跟在try 语句块之后的是一个或者多个catch子句,当try中的异常与某一个catch中捕获的异常类型匹配,则执行该catch块中的内容。注意try块与catch子句是两个语句块,在try中定义的变量无法在catch块中使用。标准异常库标准异常库被分别定义在4个头文件中:exception 头文件定义了最为通用的异常类exception。它只报告异常的发生,不提供任何额外信息stdexcept 头文件中定义几种常见的异常类new 头文件中定义了bad_alloc 异常type_info 头文件定义了bad_cast 异常类型在stdexcept 头文件中定义的异常类主要有:exception: 最常见的问题runtime_error: 只有在运行时才能检测出来的问题range_error: 运行时错误,生成的结果超出了有意义的值域范围overflow_error: 运行时错误,计算上溢underflow_error: 运行时错误,计算下溢logic_error: 程序逻辑错误domain_error: 逻辑错误,参数对应的结果值不存在invalid_argument: 逻辑错误,无效的参数length_error: 逻辑错误,试图创建一个超出该类型最大长度的对象out_of_range: 逻辑就错误,使用一个超出有效范围的值标准库异常类只定义了几种运算,包括创建或者拷贝异常类型的对象,以及为异常类型的对象赋值异常类型中只定义了一个名为what的成员函数,返回值为const char* 的c风格的字符串,该字符串的目的是提供关于异常的一些文本信息。
c++基础之语句 上一次总结了一下c++中表达式的相关内容,这篇博文主要总结语句的基础内容简单语句c++ 中语句主要是以分号作为结束符的,最简单的语句是一个空语句,空语句主要用于,语法上需要某个地方,但是逻辑上不需要;最常见的就是循环里面复合语句是用大括号括起来的语句块叫做复合语句,复合语句也叫做块。一个块就是一个作用域,在块中引入的名字只能在块内部以及嵌套在块里面的子块中访问。通常名字在有限的区域内可见,该区域从名字定义开始,到名字所在块的结尾为止。语法上需要一条语句,但是逻辑上需要多条语句的,应该使用语句块,例如if或者while等循环里面。块不以分号结束。{};, 算两条语句空块是指内部没有任何语句的一对花括号语句作用域语句中变量的作用域只在当前语句块中有效,如果其他代码也想访问控制变量,则变量必须定义在语句块的外部。条件语句条件语句需要注意:if语句每个分支尽量加上大括号,即好读,也能避免很多问题switch 语句中case后面必须跟上整型常量表达式一般不要省略case分支最后的break语句,如果是特殊逻辑需要这么做的,使用注释进行说明即使不准备在default分支中做任何事,最好也写上default分支。其目的在于告诉程序的读者,我们已经考虑到了默认的情况,只是目前什么也没有做要在case分支中定义变量应该定义在大括号中,并且只在当前分支中使用它迭代语句迭代语句又叫做循环语句,一般有while、do while、for三种形式这些语句一般的语言中都有,这里就不多做介绍,主要介绍c++ 11中新增的一种范围for的形式范围for可以遍历容器或者其他序列的所有元素,它的简单形式是for(declaration: expression) statementdeclaration 定义一个变量,序列中的每一个元素要都能转化为该变量的类型,然后执行拷贝操作,将每次迭代的值拷贝到该变量中。变量只是序列中元素的拷贝,无法修改元素的值,如果想要修改元素的值,需要将变量定义为引用类型。statement 是一个语句或者语句块,所有元素都处理完后,循环结束跳转语句跳转语句主要有break、continue以及goto语句。break:用于跳出离它最近的while、do while、for或者switch语句,并从这些语句之后的第一条语句开始执行。continue:终止最近的循环语句中当前迭代并立即进入下一次迭代,它只能出现在循环语句中。goto:跳转到对应标签处,标签可以定义在函数任意位置。注意只能作用于函数内部,不能由一个函数跳转到另一个函数。尽量少用goto,因为它可读性差,而且不好控制。异常处理语句c++中的异常处理包括这样几个部分:throw表达式:用于抛出一个异常try: 异常处理部分使用try语句块处理异常,try语句块以关键字try开始,并以一个或者多个catch子句结束。try语句块中代码抛出的异常通常会被某个catch子句处理。因为catch子句处理异常,所以它们也被称之为异常处理代码异常类:用于在throw表达式和相关的catch子句之间传递异常的具体信息throw 后面跟一个表达式,表达式返回值的类型就是抛出异常的类型。跟在try 语句块之后的是一个或者多个catch子句,当try中的异常与某一个catch中捕获的异常类型匹配,则执行该catch块中的内容。注意try块与catch子句是两个语句块,在try中定义的变量无法在catch块中使用。标准异常库标准异常库被分别定义在4个头文件中:exception 头文件定义了最为通用的异常类exception。它只报告异常的发生,不提供任何额外信息stdexcept 头文件中定义几种常见的异常类new 头文件中定义了bad_alloc 异常type_info 头文件定义了bad_cast 异常类型在stdexcept 头文件中定义的异常类主要有:exception: 最常见的问题runtime_error: 只有在运行时才能检测出来的问题range_error: 运行时错误,生成的结果超出了有意义的值域范围overflow_error: 运行时错误,计算上溢underflow_error: 运行时错误,计算下溢logic_error: 程序逻辑错误domain_error: 逻辑错误,参数对应的结果值不存在invalid_argument: 逻辑错误,无效的参数length_error: 逻辑错误,试图创建一个超出该类型最大长度的对象out_of_range: 逻辑就错误,使用一个超出有效范围的值标准库异常类只定义了几种运算,包括创建或者拷贝异常类型的对象,以及为异常类型的对象赋值异常类型中只定义了一个名为what的成员函数,返回值为const char* 的c风格的字符串,该字符串的目的是提供关于异常的一些文本信息。 -
c++基础之表达式 这次接着更新《c++ primer》 这本书的读书笔记,上一篇博文更新到了书中的第三章,本次将记录书中的第四章——表达式左值与右值在理解表达式之前需要先理解c++中左值和右值的概念。c++ 的表达式要么是右值,要么是左值,这两个名词是从c语言中继承过来的,在c语言中,左值指的是可以位于赋值语句左侧的表达式,右值则不能。在c++中二者的区别就相对复杂一些了。在c++要区分左值和右值,可以采取一个原则:一般来说当一个对象被用作左值时,用的是对象的地址,也就是在内存中的位置,而右值可以采取排他性原则,只要不是左值的都是右值。不同运算符对运算对象的要求各不相同,有的要求左值、有的要求右值;返回值也有差异,有的作为左值返回,有的作为右值返回。一个重要的原则是:凡事需要右值的地方可以使用左值来代替,但是不能把左值当成右值来使用。一般下列运算符需要用到左值赋值运算符的左侧需要一个左值。返回的结果也是一个左值取地址运算符作用于一个左值运算对象,返回一个指向该对象的指针,结果是一个右值内置解引用运算符、下表运算符迭代器解引用运算符、string、vector的下标运算符的求值结果都是左值内置类型和迭代器的递增递减运算符作用于左值对象,其前置版本所得到的结果也是左值优先级与结合律复合表达式是指含有两个或者多个运算符的表达式,计算复合表达式的值需要将运算符和运算对象合理的组织在一起,优先级与结合律决定了运算对象的组合方式。表达式中的括号无视运算优先级与结合律的规则,如果表达式中有括号,先运算括号中的内容。表达式的最终值取决与子表达式的结合方式,在计算表达式的值时,先看运算符的优先级,先处理优先级高的子表达式,而优先级相同的情况下,则由其结合律规则决定3 + 4 * 5 //根据运算符的优先级,乘法高于加法,所以先计算4 * 5 为20,再计算3 + 20 得到23 20 - 15 - 3 //先看运算符的优先级,都是减法优先级相同,再看结合律,减法的结合律是从左到右,所以先计算20 -15 得到 5,然后再计算5 - 3 得到2 6 + 3 * 4 / 2 + 2 //先看运算符的优先集,乘法除法的优先级大于加法,而乘法除法的结合律都是从左到右结合,所以这个表达式先计算 3 * 4 得到12,再计算 12 / 2 得到 6 ,最后加法的结合律也是从左到右,最后计算 6 + 6 + 2 得到 14求值顺序优先级规定了运算对象的组合方式,但是并没有规定运算对象按照什么顺序求值,在大多数情况下不会明确指定求值顺序。例如在表达式 int i = f1() * f2(); 中,先计算函数的返回值,然后再将结果赋值进行乘法运算,最后将结果赋值给i变量,但是究竟是先计算f1函数还是先计算f2函数,这个c++标准没有明确规定。对于没有指定执行顺序的运算符来说,如果表达式指向并修改了同一个对象,将会引发错误并产生未定义的行为,例如int i = 0; int j = i + ++i;根据结合律,会先计算i和 ++i但是不确定是该先计算i还是先计算++i 这里会产生未定义行为。如果先计算i则表达式可以转化为 j = 0 + 1 如果先计算 ++i,则表达式可以转化为 j = 1 + 1;有4中表达式明确规定了求值顺序逻辑与(&&):只有当左侧的结果为真时,才计算右侧的结果逻辑或(||):只有当左侧的运算结果为假时,才会计算右侧结果三目运算符(?:)当条件为真时,计算:左侧的表达式,否则计算右侧的表达式逗号表达式:运算顺序是从左到右,最后返回最右侧的表达式的值在处理复合表达式时,有下面两条准则:在不清楚运算对象的优先级和结合律的时候,按照实际的结合逻辑使用括号如果改变了某个运算对象的值,在表达式的其他地方不要使用这个运算对象,但是能明确知道求值顺序的时候这个规则就不适用了算术运算符算术运算符的求值对象和求值结果都是右值。算术运算符的优先级顺序为:单目运算符(+表示取当前值,-表示取相反数) > 乘除法 > 加减法;结合律:采用从左至右结合的方式算术运算符能作用与所有的算术类型,算术类型的数据在运算前会被转化为精度较大的类型(运算对象只有byte,char, short时会被统一转化为int),在转化为同一类型后执行再进行运算bool b = false; int k = 1; bool i = +k + -b;在上述代码中,bool类型参与算术运算时,会将true变为1,false变为0,然后针对0和1进行操作,根据优先级得到 i = 1 + 0; 最后再将算术类型转化为bool类型赋值,i最终为true除法运算中如果除数和被除数符号相同,商为正数,否则为负数,c++11 标准中规定负数商一律向0取整取余运算,要求除数和被除数都是整数,如果m/n的结果不为0,则m%n的结果符号与m相同(m/n)*n + m%n = m(-m)/n=m/(-n)=-(m/n)(-m)%n=-(m%n); m%(-n)=m%n逻辑运算符逻辑运算符作用与任何能转化为boo类型的运算对象上优先级为 逻辑非 > 大于/小于/大于等于/小于等于 > 相等/不等 > 逻辑与 > 逻辑非逻辑运算符一般的语言中都有,而且用法基本类似,这里就不再详细说明了,需要注意的是:使用非bool类型来做判断时,不要写成 if(!val) 或者 if(val == true);同样的使用bool类型来判断时,也不要写成 if(val == true) 或者 if(val == 1)在进行数值相等的比较时,为了防止少写=,习惯上把常量写在前面例如 if(1 == val)赋值运算符赋值运算符一般作用与初始化给对象赋值或者在后续修改对象的值,但是需要注意区分二者的不同,这点在初始化或者给类对象赋初始值的时候尤其重要赋值运算符的左侧必须是一个可修改的左值。赋值运算符的结果是它左侧的运算对象,并且是一个左值。结果的类型就是左侧运算对象的类型,如果赋值运算符左右两个运算对象的类型不同,则运算对象将转化成左侧运算对象的类型。int i, j; i = j = 10; const k = 10; //这里是初始化,不是赋值 k = i; //错误,左侧需要可以修改的左值新的c++ 标准中允许使用初始化列表来给对象进行赋值i = {3.14}; //错误,使用初始化列表时,不能出现精度丢失 i = 3.14; //正确,值为3 vector<int> vi; vi = {0, 1, 2, 3, 4, 5};对于内置类型,初始化列表赋值时,列表中最多只能有一个值,而且值的精度不能大于左侧对象的精度赋值运算符满足右结合律,对于多重赋值语句中的每一个对象,它的类型或者与右边的对象相同,或者可以又右边对象的类型转化得到赋值运算符的优先级较低赋值运算符也包括复合赋值运算符,例如 += 、-=、*= /=递增和递减运算符递增和递减运算符为对象的加一和减一提供了一种简洁的书写形式。这两个运算符还可以应用于迭代器。递增和递减运算符有前置版本和后置版本,前置版本是先加一,然后将改变后对象的值作为求值结果;后置版本是先将对象的结果作为求值结果返回,然后再改变对象的值。在性能上,在涉及复杂的迭代运算时,前置版本会大大优于后置版本,因此尽量养成使用前置版本的习惯。auto pbeg = v.begin() while(pbeg != v.end() && *pbeg >= 0) { cout << *pbeg++ << endl; }这里后置递增运算符的优先级要大于解引用的优先级,所以这里等价于 *(pbeg++),即先进行后置递增运算,但是返回变化之前的迭代器,然后将变化之前的迭代器进行解引用操作,得到具体元素的值递增和递减运算符可以修改对象的值,而一般的运算符没有严格规定求值的顺序,所以在复合表达式中需要额外注意,不要在可能修改变量值的位置访问该变量string s = "hello world"; auto beg = s.begin(); while(beg != s.end() && !isspace(*beg)) { *beg = toupper(*beg++); }上述例子由于赋值运算符未定义两侧运算对象的求值顺序,可能先求值左侧,那么循环中的语句等效于 beg = toupper(beg); 如果先求值右侧,则等效于 (beg + 1) = toupper(beg);条件运算符条件运算符也叫做三目运算符。cond ? expr1:expr2;条件运算符也可以嵌套使用, 条件运算符满足右结合律。随着嵌套层数的增加,代码的可读性极具下降,因此条件运算的嵌套最好不要超过三层。条件运算符的优先级非常低,一般使用的时候建议加上括号cout << ((grade > 60) ? "pass" : "fail"); // 输出pass 或者 fail cout << (grade > 60)? "pass" : "fail"; // 输出 1或者0,运算结果 是 "pass" 或者 "fail" cout << grade > 60 ? "pass" : "fail"; // 试图将cout 与 60 进行比较,错误位运算符位运算是作用与对象的二进制值的,理论上它可以处理任何对象,但是为了代码安全和可读性,建议只处理整型数据,而且最好是无符号整型运算符功能用法~按位求反~expr<<左移expr << expr2>>右移expr >> expr2&位与expr & expr2^位异或expr ^ expr2\ 位或exprexpr2sizeof 运算符sizeof 返回一个类型或者一个表达式所占的字节数。它满足右结合律针对表达式,sizeof并不计算表达式的值,只返回表达式结果类型的大小由于sizeof 不计算表达式的值,因此即使在sizeof中解引用指针也不会有什么影响逗号表达式逗号运算符含有两个表达式,按照从左至右的顺序依次求值逗号表达式先对左侧表达式进行求值,然后丢弃返回的结果,然后再对右侧表达式进行求值。逗号表达式的返回值是右侧的表达式的值类型转换何时发生隐式转换大多数情况下,比int小的整型值会被转化为int条件中,非布尔值会被转化为布尔类型初始化过程中,初始值转化为变量类型;赋值语句中右侧运算对象转化成左侧运算对象的类型如果是算术运算或者关系运算的运算对象有多种类型,需要转化为同一种类型。而且会尽量往精度较大的一方转化调用函数时也可能会发生类型转化算术类型转换算术转换总是朝着精度更高的一级转换较小的整型会被转化为int,较大的整型会被转化为long、unsigned long、unsigned longlong 等其他隐式类型转换除了算术类型的隐式转换外,还有下面几种数组转化为指针:当数组被用作 decltype、sizeof、取地址符一级typeid 等运算符的运算对象时,该转换不会发生指针的转化:常量整数0和nullptr可以转化为任意类型的指针,指向任意非常量的指针能转化成void,指向任意对象的指针能转化为const void转化为布尔类型: 算术类型或者指针,值为0或者nullptr的被转化为false,其他的值被转化为true转化为常量:常量的指针或者引用可以指向非常量对象,反过来则不行;类类型定义的转化:由程序员预先定义,在需要转化时,由编译器自动调用进行转化显式类型转换显式类型转换绕过了编译器的类型检查,是不安全的一种转化方式显示类型转换的语法规则如下:cast-name<type>(express);其中type是目标类型,express是要转化的值,如果type是引用类型则结果是一个左值。cast-name是 static_cast、dynamic_cast、const_cast 和 reinterpret_cast 中的一种static_cast 只要不包含底层const,都可以使用static_cast,在对指针进行强制类型转化时,要保证转化前与转化后指针所指向的对象类型相同,用于同类型数据之前的转化,如算术类型之前的相互转化。const_cast 只能改变运算对象的底层const、与static_const互相补充reinterpret_cast 重新解释比特位,通常为运算对象的位模式提供较低层次上的重新解释。一般用于指针之间的转化,它没有限制,任何类型间都可以进行转化。但是也十分危险dynamic_cast 动态类型转化,主要用于多重继承类类型之间的转化
-
c++基础之字符串、向量和数组 上一次整理完了《c++ primer》的第二章的内容。这次整理本书的第3章内容。这里还是声明一下,我整理的主要是自己不知道的或者需要注意的内容,以我本人的主观意志为准,并不具备普适性。第三章就开始慢慢的接触连续、线性存储的数据结构了。字符串、数组、vector等都是存储在内存的连续空间中,而且都是线性结构。算是c++语言中的基础数据结构了。命名空间与using使用方式如下using namespace::name;其中name表示命名空间的具体名字如标准库都在std 这个命名空间,如果要引用这个命名空间的内容就写作 using namespace::std;另外namespace可以表示作为关键字,也可以作为具体的命名空间,如果作为具体命名空间的话,name此时应该是命名空间中的类或者函数等等成员,例如要引用cin这个函数的话,可以这样写 using std::cin在使用时除了使用命名空间之外也可以直接带上命名空间的名称,例如要使用cout 做输出时可以这么写 std::cout << "hell world" << std::endl;使用using 可以直接引入命名空间,减少代码编写的字符数,但是当引入多个命名空间,而命名空间中又有相同的成员时,容易引发冲突。所以在使用命名空间时有下面几条建议头文件中不要包含using声明尽量做到每个成员单独使用using声明string 对象定义和初始化string对象初始化string对象有如下几种方式:string() : 初始化一个空字符串string(const string&): 使用一个字符串来初始化另一个字符串,新字符串是传入字符串的一个副本string(char*): 使用一个字符数组来初始化字符串string(int, char): 新字符串是由连续几个相同字符组成需要注意的是,在定义的语句中使用赋值操作符相当于调用对应的初始化语句。而在其他位置使用赋值操作符在执行复写操作string str = "hello world"; //此处调用拷贝构造,并没有调用赋值重载函数string 对象的操作string的操作主要有:os << s: 将s的值写入到os流中,返回osis >> s: 从is流中读取字符串,并赋值给s,字符串以空白分分隔,返回isgetline(is, s): 从is中读取一行,赋值给s,返回iss.empty(): 判断字符串是否为空,为空则返回true,否则返回falses.size(): 返回字符串中字符个数, 类型为string::size_type。它是一个无符号类型的值,而且编译器需要保证它能够存放任何string对象的大小。不要使用size()的返回值与int进行混合运算s[n]: 返回第n个字符s+s1: 返回s和s1拼接后的结果s1=s2: 将s2的值赋值给s1,执行深拷贝s1 == s2: 判断两个字符串是否相等s1 != s2:判断两个字符串不等<, <=, >, >=:字符串比较处理string 中的字符string 本身是一个字符的容器,我们可以使用迭代的方式来访问其中的每一个字符。例如// 字符转化为大写 string s = "hello world"; for(auto it = s.begin(); it != s.end(); it++) { *it = toupper(*it); }针对这种需要在循环中迭代访问每个元素的情况,c++针对for语句进行扩展,使其能够像Java等语言那样支持自动迭代每一个元素,这种语句一般被称之为范围for。// 统计可打印字符 string s = "hello world"; int punctt_count = 0; for(auto c : s){ if(ispunct(c)){ ++punct_count; } }上述代码中c 只是s中每一个字符的拷贝,如果想像之前那样修改字符串中的字符,可以在迭代时使用引用类型//字符串转化为大写 s = "hello world"; for(auto& c : s){ c = toupper(c); }所有同时具有连续存储和线性存储两个特点的数据结构都可以使用下标访问其中的元素。字符串中字符是采用线性和连续存储的。所以这里它也可以采用下标运算符// 字符串转化为大写 string s = "hello world"; for(auto index = 0; index < s.size(); ++index) { s[index] = toupper(s[index]); } 在使用下标时需要注意下标是否超过容器中存储的元素个数。由于在编译与链接时不会检查这个,如果超出在运行时将会产生未定义结果。标准库 vector标准库vector 表示对象的集合,里面需要存储相同类型的对象。可以看作是一个动态数组。vector 被定义在头文件 vector中由于vector中存储的是对象,而引用不是对象,所以不存在存储引用的vector定义和初始化除了可以使用与string相同的初始化方法外,新的标准还支持使用初始化列表来初始化vectorvector<string> vec = {"Hello", "World", "Boy", "Next", "Door"};一般来说都是预先定义一个空的vector对象,在需要的时候使用push_back或者push_front添加元素。需要注意的是在使用迭代器的过程中,不要针对容器做删减操作同样的vector可以使用下标来访问元素,但是需要注意下标只能访问已有元素不能使用下标来添加元素,同时使用下标时需要注意范围。访问超过范围的元素,会引起越界的问题迭代器迭代器是一组抽象,是用来统一容器中元素访问方式的抽象。它能保证不管什么类型的容器,只要使用迭代器,就能使用相同的方式方法从头到尾访问到容器中的所有元素。在这里不用过于纠结跌打器究竟是如何实现的,只需要知道如何使用它。另外提一句,我当初在初学的时候一直把c语言的思路带入到c++中,导致我一直认为跌迭代器就是指针或者下标,我试图使用指针和下标的方式来理解,然后发现很多地方搞的很乱,也很模糊。这个概念我是一直等待学习python和Java这种没有指针、完全面向对象的语言之后,才纠正过来。这里我想起《黑客与画家》书中提到的,编程语言的高度会影响我们看待问题高度。从我的经历来看,我慢慢的理解了这句话的意思。所以这也是我当初学习lisp的一个原因。我想看看被作者称之为数学语言,抽象程度目前最高的语言是什么样的,对我以后看问题有什么影响迭代器提供了两种重要的抽象:提供统一的接口来遍历容器中所有元素;另外迭代器提供统一接口,让我们实际操作容器中的元素使用迭代器迭代器的使用如下:迭代器都是使用begin 获取容器中的第一个元素;使用end获取尾元素的下一个元素迭代器自身可以像操作对象的指针一样操作容器中的对象迭代器比较时,比较的是两个迭代器指向的是否是同一个元素,不支持 >、<比较++ 来使迭代器指向容器中下一个位置的对象,--来指向上一个位置的对象如果不想通过迭代器改变容器中元素的值,可以使用const类型的迭代器,即 const_iterator类型的迭代器#+BEGIN_SRC c++ string s = "Hello World"; for(string::const_iterator it = s.begin(); it != s.end(); it++) { cout << *it << endl; } #+END_SRCbegin 和end返回的是普通类型的迭代器,c++ 11中提供了一套新的方法来获取const类型的迭代器,cbegin和 cend迭代器的常见运算迭代器常见运算:iter + n: 迭代器向前可以加上一个整数,类似于指针加上一个整数,表示迭代器向前移动了若干个元素iter - n: 迭代器往前移动了若干个元素,类似于指针减去一个整数iter1 - iter2: 表示两个迭代器之间的间距,类似于指针的减法、<、>=、<=:根据迭代器的位置来判断迭代器的大小,类似于指针的大小比较迭代器与整数运算,如果超过了原先容器中元素的个数,那么最多只会返回容器中最后一个元素的下一个跌打器,也就是返回值为 end函数的返回迭代器相减得到迭代器之间的距离,这个距离指的是右侧的迭代器移动多少个元素后到达左侧迭代器的位置,其类型定义为difference_type使用迭代器来访问元素时,与使用指针访问指向的对象的方式一样,它重载了解引用运算符和箭头运算符。使我们能够像使用指针那样使用迭代器数组数组与vector相似二者都是线性存储二者存储的都是相同类型的元素与vector不同的是:数组大小固定由于大小在初始化就已经确定,所以在性能上优于vector,灵活性上有些不足定义和初始化内置数组在初始化数组的时候需要注意:数组大小的值可以是字面值常量、常量表达式、或者普通常量定义数组时必须指明类型,不允许用auto由初始化值来进行推断const unsigned int cnt = 42; //常量 constexpr unsigned int sz = 42; //常量表达式 int arr[10]; //使用字面常量指定大小 int arr2[cnt]; //使用常量初始化 int arr3[sz]; //使用常量表达式初始化可以在初始化时不指定大小,后续会根据初始化列表中的元素个数自动推导出数组大小同时指定了数组大小和初始化列表,如果指定大小大于初始化列表中的元素个数,那么前面几个元素按照初始化列表中的值进行初始化,后面多余的元素则初始化为默认值如果指定大小小于初始化列表中元素个数,则直接报错const unsigned int sz = 3; int arr1[sz] = {1, 2, 3}; int arr2[sz] = {1}; // 等价与 arr2[sz] = {1, 0, 0} int arr3[] = {1, 2, 3}; int arr4[sz] = {1, 2, 3, 4}; //错误,初始化列表中元素个数不能大于数组中定义的元素个数字符数组可以直接使用字符串常量进行赋值,数组大小等于字符串长度加一我们可以对数组中某个元素进行赋值,但是数组之间不允许直接进行拷贝和赋值和vector中一样,数组中存储的也是对象,所以不存在存储引用的数组。在理解关于数组的复杂声明时,采用的也是从右往左看理解的方式。或者说我们先找到与[] 结合的部分来理解,与[]结合的部分去掉之后就是数组中元素的类型。int * ptrs[10]; int & refs[10]; int (*Parry)[10]; int (&arrRef)[10];上面的例子中:ptrs,首先与[]结合最紧密的是ptrs 去掉这两个部分,剩下的就是int 这部分表示数组中元素类型是int , 也就是这里定义了一个包含10个int指针元素的数组refs, 首先与[]结合最紧密的是ref2,去掉这个部分,剩下的就是int&,这部分表示数组中元素类型是int&,也就是这里定义了一个包含10个指向int数据的引用的数组,由于不存在存储引用的数组,所以这里是错误的Parry,由于有了括号,与[]结合最紧密的就变成了 int,也就是我们先定义了一个包含10个int类型的数组,而Parry本身是一个指针,所以这里定义的其实是一个指向存储了10个int类型数据的数组的指针同样的方式分析,得到arrRef 其实是一个指向存储了10个int类型数据的数组的引用指针和数组在上面的例子中,已经见过了指针和数组的一些定义方式,例如ptrs 是一个存储了指针的数组,这种数组一般称之为指针数组;Parry是一个指向数组的指针,这种指针被称之为数组指针在某些时候使用数组的时候,编译器会直接将它转化为指针,其中在使用数组名时,编译器会自动转化为数组首元素的地址。int ia[] = {1, 2, 3, 4, 5}; auto ia2 = ia; ia2[2] = 10; // 这里ia2是指向ia数组首元素的指针,这里其实是在修改ia第3个元素的值需要注意的是在使用decltype时,该现象不会发生,decltype只会根据表达式推断出类型,而不会具体计算表达式的值,所以它遇到数组名时,根据上下文知道它是一个数组,而不会实际取得数组首元素的地址int ia[] = {1, 2, 3, 4, 5}; decltype(ia) ia2 = {0}; //这里ia2 是一个独立的数组,与ia无关 ia2[2] = 10;指针也可以看作迭代器的一种,进行迭代时终止条件是数组尾元素下一个位置的地址int ai[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; int *pbegin = &ai[0]; int *pend = &ai[10]; for(int* it = pbegin; it != pend; it++) { cout << *it << endl; }c++ 11中引入两个函数来获取数组的begin位置和end位置,分别为begin() 与 end()int ai[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; for(int *p = begin(ai); p != end(ai); p++) { cout << *p << endl; }c 风格的字符串string转化为char 可以使用string.c_str()函数,该函数返回的是const char,以取保无法通过这个指针修改字符串本身的值,另外该函数返回的地址一直有效,如果后续修改了string的值,那么根据字符串的算法,字符串中保存字符的地址可能发生变化,此时再使用原来返回的指针访问新的字符串,可能会出现问题如果执行完c_str函数后,程序想一直访问其返回的数组,最好将该数组重新拷贝一份string s = "hello world"; const char* pszBuf = s.c_str() char* pBuff = new char[s.size() + 1]; memset(pBuff, 0x00, sizeof(char) * s.size() + 1); strcpy(pBuff, pszBuff); //后面可以直接使用pbuf,即使s字符串改变 s = "boy next door"; //do something delete[] pBuf;为了与旧代码兼容,允许使用数组来初始化一个vector容器,只需要指明需要拷贝的首元素地址和尾元素地址int arr[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ,10}; vector<int> va(begin(arr), end(arr));多维数组多维数组是数组的数组,数组中每一个成员都是一个数组。当一个数组的元素仍是数组时,需要多个维度来表示,一个表示数组本身的大小,一个维度表示元素中数组大小对于二维数组来说,一般把第一个维度称之为行,第二个维度称之为列。int ia[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} }; //等价于 int ia[3][4] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11};多维数组的初始化可以用打括号初始化每个维度的数据,也可以省略中间的大括号,这样它会按照顺序初始化但是需要注意int ia[3][4] = { {0}, {1, 2}, {3, 4, 5} }; int ia[3][4] = {0, 1, 2, 3, 4, 5};上述代码中,二者含义完全不一样,上一个表示每个子元素中的数组如何初始化,最终结果为{0, 0, 0, 0, 1, 2, 0, 0, 3, 4, 5, 0}。下面一个是从第一行开始依次初始化所有元素,最终结果为{0, 1, 2, 3, 4, 5, 0, 0, 0, 0, 0, 0}可以使用下标访问数组元素,一个维度对应一个下标int ai[3][4] = {0}; cout << ai[2][3] << endl; //如果下标个数和数组维度一样,将得到具体类型的值 cout << ai[2] << endl; //下标数小于数组维度,得到对应子数组的首地址可以使用for循环遍历数组int a[3][4] = {0}; for(auto row : a){ for(auto i : row) //错误不能对指针使用迭代 { cout << i << endl; } }上述例子中,由于多维数组中存储的是数组元素,所以row默认是数组元素,也就是数组首地址,是指针类型,也就不能使用内层的迭代了我们可以稍微做一些修改int a[3][4] = {0}; for(auto& row : a){ for(auto i : row) //错误不能对指针使用迭代 { cout << i << endl; } }使用引用声明之后,row就表示指向内层子数组的一个数组的引用,也就是一个子数组本身,针对数组就可以使用范围for了注意:使用for范围遍历时,除了最内层元素,其余的都需要声明为引用类型多维数组的名称也是数组的首地址定义多维数组的指针时,需要明确,多维数组是存储数组的特殊数组int ai[3][4] = {0}; int (*p)[4] = ai; // int *p[4] 表示的是指针数组,数组有4个成员,每个成员都是一个int* 上述代码,ai是一个存储3个数组元素的数组,每个元素又是存储4个整型元素的数组,因此定义它的指针的时候,需要明确,指针类型应该是数组元素的类型,也就是有4个int型元素的数组的指针当然如果嫌麻烦或者不会写,可以使用auto来定义一般来说,书写多维数组的指针是比较麻烦的一件事,可以使用类型别名让它变得简单点,上面的例子可以改写一下//typedef int int_array_4[4]; 二者是完全等价的 using int_array_4 = int[4]; int_array_4 *pArr = ai; for(; pArr != ai + 3; ++pArr) { for(int *p = *pArr; p != *pArr+4; ++p) { cout << *p << " "; } cout << endl; } 数组名代表的是数组的首元素,多维数组又可以看作是一个存储数组的数组。所以这里ai的名称代表的是一个存储了3个元素的数组,每个元素都是存储4个整型数据的数组。pArr 的类型是存储了4个整型元素的数组的指针,所以这里与ai表示的指针的类型相同。这里我们将ai的值赋值给指针。在循环中,外层循环用来找到ai数组中每个子数组的指针。内层循环中,使用pArr解引用得到指针指向的每一个对象,也就是一个存储了4个整型元素的数组。针对这个数组进行循环,依次取出数组中每一个元素。
-
c++基础之变量和基本类型 之前我写过一系列的c/c++ 从汇编上解释它如何实现的博文。从汇编层面上看,确实c/c++的执行过程很清晰,甚至有的地方可以做相关优化。而c++有的地方就只是一个语法糖,或者说并没有转化到汇编中,而是直接在编译阶段做一个语法检查就完了。并没有生成汇编代码。也就是说之前写的c/c++不能涵盖它们的全部内容。而且抽象层次太低,在应用上很少会考虑它的汇编实现。而且从c++11开始,加入了很多新特性,给人的感觉就好像是一们新的编程语言一样。对于这块内容,我觉得自己的知识还是有欠缺了,因此我决定近期重新翻一翻很早以前买的《c++ primer》 学习一下,并整理学习笔记背景介绍为什么会想到再次重新学习c++的基础内容呢?目前来看我所掌握的并不是最新的c++标准,而是“c with class” 的内容,而且很明显最近在关注一些新的cpp库的时候,发现它的语法我很多地方都没见过,虽然可以根据它的写法来大致猜到它到底用了什么东西,或者说在实现什么功能,但是要自己写,可能无法写出这种语法。而且明显感觉到新的标准加入了很多现代编程语言才有的内容,比如正则表达式、lambda表达式等等。这些都让写c++变得容易,写出的代码更加易读,使其脱离了上古时期的烙印更像现代的编程语言,作为一名靠c++吃饭的程序员,这些东西必须得会的。看书、学编程总少不了写代码并编译运行它。这次我把我写代码的环境更换到了mac平台,在mac平台上使用 vim + g++的方式。这里要提一句,在mac 的shell中,g++和gcc默认使用的是4.8的版本,许多新的c++标准并不被支持,需要下载最新的编译器并使用替换环境中使用的默认编译器,使其更新到最新版本gcc / g++ 使用在shell环境中,不再像visual studio开发环境中那样,只要点击build就一键帮你编译链接生成可执行程序了。shell中所有一切都需要你使用命令行来搞定,好在gcc/g++的使用并不复杂,记住几个常用参数就能解决日常80%的使用场景了,下面罗列一些常用的命令-o 指定生成目标文件位置和名称-l 指定连接库文件名称,一般库以lib开头但是在指定名称时不用加lib前缀,例如要链接libmath.o 可以写成-lmath-L 指定库所在目录-Wall 打印所有警告,一般编译时打开这个-E 仅做预处理,不进行编译-c 仅编译,不进行链接-static 编译为静态库-share 编译为动态库-Dname=definition 预定义一个值为definition的,名称为name的宏-ggdb -level 生成调试信息,level可以为1 2 3 默认为2-g -level 生成操作系统本地格式的调试信息 -g相比于-ggdb 来说会生成额外的信息-O0/O1/O2/O3 尝试优化-Os 对生成的文件大小进行优化常用的编译命令一般是 g++ -Wall -o demo demo.cpp开启所有警告项,并编译demo.cpp 生成demo程序 ## 基本数据类型与变量 ### 算术类型 这里说的基本数据类型主要是算术类型,按占用内存空间从小到大排序 char、bool(这二者应该是相同的)、short、wchar_t、int、long、longlong、float、double、long double。当然它们有的还有有符号与无符号的区别,这里就不单独列出了 一般来说,我们脑袋中记住的它们的大小好像是固定,比如wchar_t 占2个字节,int占4个字节。单实际上c++ 并没有给这些类型的大小都定义死,而是固定了一个最小尺寸,而具体大小究竟定义为多少,不同的编译器有不同的实现,比如我尝试的wchar_t 类型在vc 编译环境中占2个字节,而g++编译出来的占4一个字节。下面的表是c++ 规定的部分类型所占内存空间大小 | 类型 | 含义 | 最小尺寸 | |:----------|:--------------|:-----| | bool | 布尔类型 | 未定义 | | char | 字符 | 8位 | | wchar_t | 宽字符 | 16位 | | char16_t | Unicode字符 | 16位 | | char32_t | Unicode字符 | 32位 | | short | 短整型 | 16位 | | int | 整型 | 32位 | | long | 长整型 | 32位 | | longlong | 长整型 | 64位 | | float | 单精度浮点数 | 32位 | | double | 双精度浮点数 | 64位 | 另外c++的标准还规定 一个int类型至少和一个short一样大,long至少和int一样大、一个longlong至少和一个long一样大。 ### 有符号数与无符号数 数字类型分为有符号和无符号的,默认上述都是有符号的,在这些类型中加入unsigned 表示无符号,而char分为 signed char、char、unsigned char 三种类型。但是实际使用是只能选有符号或者无符号的。根据编译器不同,char的表现不同。 一般在使用这些数据类型的时候有如下原则 1. 明确知晓数值不可能为负的情况下使用unsigned 类型 2. 使用int进行算数运行,如果数值超过的int的表示范围则使用 longlong类型 3. 算术表达式中不要使用char或者bool类型 4. 如果需要使用一个不大的整数,必须指定是signed char 还是unsigned char 5. 执行浮点数运算时使用double ### 类型转化 当在程序的某处我们使用了一种类型,而实际对象应该取另一种类型时,程序会自动进行类型转化,类型转化主要分为隐式类型转化和显示类型转化。 数值类型进行类型转化时,一般遵循如下规则: 1. 把数字类型转化为bool类型时,0值会转化为false,其他值最后会被转化为true 2. 当把bool转化为非bool类型时,false会转化为0,true会被转化为1 3. 把浮点数转化为整型时,仅保留小数点前面的部分 4. 把整型转化为浮点数时,小数部分为0;如果整数的大小超过浮点数表示的范围,可能会损失精度 5. 当给无符号类型的整数赋值一个超过它表示范围的数时,会发生溢出。实际值是赋值的数对最大表示数取余数的结果 6. 当给有符号的类型一个超出它表示范围的值时,具体结果会根据编译器的不同而不同 7. 有符号数与无符号数混用时,结果会自动转化为无符号数 (使用小转大的原则,尽量不丢失精度) **由于bool转化为数字类型时非0即1,注意不要在算术表达式中使用bool类型进行运算** 下面是类型转化的具体例子 ```cpp bool b = 42; // b = true int i = b; // i = 1 i = 3.14; // i = 3; double d = i; // d = 3.0 unsigned char c = -1; // c = 256 signed char c2 = c; // c2 = 0 gcc 中 255在内存中的表现形式为0xff,+1 变为0x00 并向高位溢出,所以结果为0 ``` 上述代码的最后一个语句发生了溢出,**对于像溢出这种情况下。不同的编译器有不同的处理方式,得到的结果可能不经相同,在编写代码时需要避免此类情况的出现** 尽管我们知道不给一个无符号数赋一个负数,但是经常会在不经意间犯下这样的错误,例如当一个算术表达式中既有无符号数,又有有符号数的时候。例如下面的代码 ```cpp unsigned u = 10; int i = -42; printf("%d\r\n", u + i); // -32 printf("%u\r\n", u + i); //4294967264 ``` 那么该如何计算最后的结果呢,这里直接根据它们的二进制值来进行计算,然后再转化为具体的10进制数值,例如u = 0x0000000A,i = 0xffffffd6;二者相加得到 0xffffffEO, 如果转化为int类型,最高位是1,为负数,其余各位取反然后加一得到0x20,最终的结果就是-32,而无符号,最后的值为4294967264 ### 字面值常量 一般明确写出来数值内容的称之为字面值常量,从汇编的角度来看,能直接写入代码段中数值。例如32、0xff、"hello world" 这样内容的数值 #### 整数和浮点数的字面值 整数的字面值可以使用二进制、8进制、10进制、16进制的方式给出。而浮点数一般习惯上以科学计数法的形式给出 1. 二进制以 0b开头,八进制以0开头,十六进制以0x开头 2. 数值类型的字面值常量最终会以二进制的形式写入变量所在内存,如何解释由变量的类型决定,默认10进制是带符号的数值,其他的则是不带符号的 3. 十进制的字面值类型是int、long、longlong中占用空间最小的(前提是类型能容纳对应的数值) 4. 八进制、十六进制的字面值类型是int、unsigned int、long、unsigned long、longlong和unsigned longlong 中尺寸最小的一个(同样的要求对应类型能容纳对应的数值) 5. 浮点数的字面值用小数或者科学计数法表示、指数部分用e或者E标示 #### 字符和字符串的字面值常量 由单引号括起来的一个字符是char类型的字面值,双引号括起来的0个或者多个字符则构成字符串字面值常量。字符串实际上是一个字符数组,数组中的每个元素存储对应的字符。**这个数组的大小等于字符串中字符个数加1,多出来一个用于存储结尾的\0** 有两种类型的字符程序员是不能直接使用的,一类是不可打印的字符,如回车、换行、退格等格式控制字符,另一类是c/c++语言中有特殊用途的字符,例如单引号表示字符、双引号表示一个字符串,在这些情况下需要使用转义字符. 1. 转义以\开头,后面只转义仅接着的一个字符 2. 转义可以以字符开始,也可以以数字开始,数字在最后会被转化为对应的ASCII字符 3. \x后面跟16进制数、\后面跟八进制数、八进制数只取后面的3个;十六进制数则只能取两个数值(最多表示一个字节) ```cpp '\\' // 表示一个\字符 "\"" //表示一个" "\155" //表示一个 155的8进制数,8进制的155转化为10进制为109 从acsii表中可以查到,109对应的是M "\x6D" ``` 一般来讲我们很难通过字面值常量知道它到底应该是具体的哪种类型,例如 15既可以表示short、int、long、也是是double等等类型。为了准确表达字面值常量的类型,我们可以加上特定的前缀或者后缀来修饰它们。常用的前缀和后缀如下表所示: | 前缀 | 含义 | |:------|:-----------------------| | L'' | 宽字节 | | u8"" | utf-8字符串 | | 42ULL | unsgined longlong | | f | 单精度浮点数 | | 3L | long类型 | | 3.14L | long double | | 3LL | longlong | | u'' | char16_t Unicode16字符 | | U'' | char32_t Unicode32字符 | ## 变量 变量为程序提供了有名的,可供程序操作的内存空间,变量都有具体的数据类型、所在内存的位置以及存储的具体值(即使是未初始化的变量,也有它的默认值)。变量的类型决定它所占内存的大小、如何解释对应内存中的值、以及它能参与的运算类型。在面向对象的语言中,变量和对象一般都可以替换使用 ### 变量的定义与初始化 变量的定义一般格式是类型说明符其后紧随着一个或者多个变量名组成的列表,多个变量名使用逗号隔开。最后以分号结尾。 一般在定义变量的同时赋值,叫做变量的初始化。而赋值语句结束之后,在其他地方使用赋值语句对其进行赋值,被称为赋值。从汇编的角度来看,变量的初始化是,在变量进入它的生命有效期时,对那块内存执行的内存拷贝操作。而赋值则需要分解为两条语句,一个寻址,一个值拷贝。 c++11之后支持初始化列表进行初始化,在使用初始化列表进行初始化时如果出现初始值存在精度丢失的情况时会报错 c++11之后的列表初始化语句,支持使用赋值运算幅、赋值运算符加上{}、或者直接使用{}、直接使用() ```cpp int i = 3.14; //正常 int i(3.14); //正常 int i{3.14}; //报错,使用初始化列表进行初始化时,由double到int可能会发生精度丢失 int i(3.14); //正常 ``` 如果变量在定义的时候未给定初始值,则会执行默认初始化操作,全局变量会被赋值为0,局部变量则是未初始化的状态;它的值是不确定的。这个所谓的默认初始化操作,其实并不是真的那个时候执行了什么初始化语句。全局变量被初始化为0,主要是因为,在程序加载之初,操作系统会将数据段的内存都初始化为0,而局部变量,则是在进入函数之后,初始化栈,具体初始化为何值,根据平台的不同而不同 ### 声明与定义的关系 为了允许把程序拆分为多个逻辑部分来编写,c++支持分离式编译机制,该机制允许将程序分割为若干个文件,每个文件可被独立编译。 如果将程序分为多个文件,则需要一种在文件中共享代码的方法。c++中这种方法是将声明与定义区分开来。在我之前的博客中,有对应的说明。声明只是告诉编译器这个符号可以使用,它是什么类型,占多少空间,但前对它执行的这种操作是否合法。最终会生成一个符号表,在链接的时候根据具体地址,再转化为具体的二进制代码。而定义则是真正为它分配内存空间,以至于后续可以通过一个具体的地址访问它。 声明只需要在定义语句的前面加上extern关键字。如果extern 关键字后面跟上了显式初始化语句,则认为该条语句是变量的定义语句。变量可以声明多次但是只能定义一次。另外在函数内部不允许初始化一个extern声明的变量 ```cpp int main() { extern int i = 0; //错误 return 0; } ``` 一个好的规范是声明都在放在对应的头文件中,在其他地方使用时引入该头文件,后续要修改,只用修改头文件的一个地方。一个坏的规范是,想用了,就在cpp文件中使用extern声明,这样会导致声明有多份,修改定义,其他声明都得改,项目大了,想要找起来就不那么容易了。 ### 变量作用域 变量的作用域始于声明语句,终结于声明语句所在作用域的末端 1. 局部变量在整个函数中有效 2. 普通全局变量在整个程序中都有效果 3. 花括号中定义的变量仅在这对花括号中有效 作用域可以存在覆盖,并且以最新的定义的覆盖之前的 ```cpp int i = 10; void func() { int i = 20; { string i = "hello world"; cout
-
记一次内存泄露调试 首先介绍一下相关背景。最近在测试一个程序时发现,在任务执行完成之后,从任务管理器上来看,内存并没有下降到理论值上。程序在启动完成之后会占用一定的内存,在执行任务的时候,会动态创建一些内存,用于存储任务的执行状态,比如扫描了哪些页面,在扫描过程中一些收发包的记录等等信息。这些中间信息在任务结束之后会被清理掉。任务结束之后,程序只会保存执行过的任务列表,从理论上讲,任务结束之后,程序此时所占内存应该与程序刚启动时占用内存接近,但是实际观察的结果就是任务结束之后,与刚启动之时内存占用差距在100M以上,这很明显不正常,当时我的第一反应是有内存泄露内存泄露排查既然有内存泄露,那么下一步就是开始排查,由于程序是采用MFC编写的,那么自然就得找MFC的内存泄露排查手段。根据网上找到的资料,MFC在DEBUG模式中可以很方便的集成内存泄露检查机制的。首先在 stdafx.h 的头文件中加入#define _CRTDBG_MAP_ALLO #include <crtdbg.h>再在程序退出的地方加入代码_CrtDumpMemoryLeaks();如果发生内存泄露的话,在调试运行结束之后,观察VS的输出情况可以看到如下内容Detected memory leaks! Dumping objects -> .\MatriXayTest.cpp(38) : {1301} normal block at 0x0000000005584D30, 40 bytes long. Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD Object dump complete.在输出中会提示有内存泄露,下面则是泄露的具体内容,MatriXayTest.cpp 是发生泄露的代码文件,括号中的38代表代码所在行数,大括号中1301代表这是程序的第1301次分配内存,或者说第1301次执行malloc操作,再往后就是内存泄露的地址,以及泄露的大小,这个地址是进程启动之后随机分配的地址,参考意义不大。下面一行表示,当前内存中的具体值,从值上来看应该是分配了内存但是没有初始化。根据这个线索,我们来排查,找到第38行所在位置int *p = new int[10]; _CrtDumpMemoryLeaks(); return nRetCode;内存泄露正是出现在new了10个int类型的数据,但是后面没有进行delete操作,正是这个操作导致了内存泄露。到此为止,检测工具也找到了,下面就是加上这段代码,运行发生泄露的程序,查看结果再漫长的等待任务执行完成并自动停止之后,我发现居然没有发现内存泄露!!!我又重复运行任务多次,发现结果是一样的,这个时候我开始怀疑是不是这个库不准,于是我在数据节点的类中添加构造函数,统计任务执行过程中创建了多少个节点,再在析构中统计析构了多少个节点,最终发现这两个数据完全相同。也就是说真的没有发生内存泄露。在这里我也疑惑了,难道是任务管理器有问题?带着这个疑问,我自己写了一段代码,在程序中不定时打印内存占用情况,结果发现虽然与任务管理器有差异,但是结果是类似的,释放之后内存并没有大幅度的下降。我带着疑问查找资料的过程的漫长过程中,发现任务管理器的显示内存占用居然降下去了,我统计了一下时间,应该是在任务结束之后的30分钟到40分钟之间。带着这个疑问,我又重新发起任务,在任务结束,并等待一定时间之后,内存占用果然降下去了。这里我得出结论 程序中执行delete操作之后,系统并不会真的立即回收操作,而是保留这个内存一定时间,以便后续该进程在需要分配时直接使用结论验证科学一般来说需要大胆假设,小心求证,既然上面根据现象做了一些猜想,下面就需要对这个猜想进行验证。首先来验证操作系统在程序调用delete之后不会真的执行delete操作。我使用下面的代码进行验证//定义一个占1M内存的结构 struct data{ char c[1024 * 1024]; } data* pa[1024] = {0}; for (int i = 0; i < 1024; i++) { pa[i] = new data; //这里执行一下数据清零操作,以便操作系统真正为程序分配内存 //有时候调用new或者malloc操作,操作系统只是保留对应地址,但是并未真正分配物理内存 //操作会等到进程真正开始操作这块内存或者进程需要分配的内存总量达到一个标准时才真正进行分配 memset(pa[i], 0x00, sizeof(data)); } printf("内存分配完毕,按任意键开始释放内存...\n"); getchar(); for (int i = 0; i < 1024; i++) { delete pa[i]; } printf("内存释放完毕,按任意键退出\n"); _CrtDumpMemoryLeaks(); char c = getchar();通过调试这段代码,在刚开始运行,没有执行到new操作的时候,进程占用内存在2M左右,运行到第一个循环结束,分配内存后,占用内存大概为1G,在执行完delete之后,内存并没有立马下降到初始的2M,而是稳定在150M左右,过一段时间之后,程序所占用内存会将到2M左右。接着对上面的代码做进一步修改,来测试内存使用时间长度与回收所需时间的长短的关系。这里仍然使用上面定义的结构体来做尝试data* pa[1024] = {0}; for (int i = 0; i < 1024; i++) { pa[i] = new data; memset(pa[i], 0x00, sizeof(data)); } printf("内存分配完毕,按任意键开始写数据到内存\n"); getchar(); //写入随机字符串 srand((unsigned) time(NULL)); DWORD dwStart = GetTickCount(); DWORD dwEnd = dwStart; printf("开始往目标内存中写入数据\n"); while ((dwEnd - dwStart) < 1 * 60 * 1000) //执行时间为1分钟 { for (int i = 0; i < 1024; i++) { for (int j = 0; j < 1024; j++) { int flag = rand() % 3; switch (flag) { case 1: { //生成大写字母 pa[i]->c[j] = (char)(rand() % 26) + 'A'; } break; case 2: { //生成小写字母 pa[i]->c[j] = (char)(rand() % 26) + 'a'; } break; case 3: { //生成数字 pa[i]->c[j] = (char)(rand() % 10) + '0'; } break; default: break; } } } dwEnd = GetTickCount(); } printf("数据写入完毕,按任意键开始释放内存...\n"); getchar(); for (int i = 0; i < 1024; i++) { delete pa[i]; } printf("内存释放完毕,按任意键退出\n"); _CrtDumpMemoryLeaks(); char c = getchar();后面就不放测试的结果了,我直接说结论,同一块内存使用时间越长,操作系统真正保留它的时间也会越长。短时间内差别可能不太明显,长时间运行,这个差别可以达到秒级甚至分。我记得当初上操作系统这门课程的时候,老师说过一句话:一个在过去使用时间越长的资源,在未来的时间内会再次使用到的概率也会越高,基于这一原理,操作会保留这块内存一段时间,如果程序在后面再次申请对应结构时,操作系统会直接将之前释放的内存拿来使用。为了验证这一现象,我来一个小的测试int *p1 = new int[1024]; memset(p, 0x00, sizeof(int) * 1024); delete[] p; int* p2= new int[1024];通过调试发现两次返回的地址相同,也就验证了之前说的内容总结最后来总结一下结论,有时候遇到delete内存后任务管理器或者其他工具显示内存占用未减少或者减少的量不对时,不一定是发生了内存泄露,也可能是操作系统的内存管理策略:程序调用delete后操作系统并没有真的立即回收对应内存,它只是暂时做一个标记,后续真的需要使用相应大小的内存时会直接将对应内存拿出来以供使用。而具体什么时候真正释放,应该是由操作系统进行宏观调控。我觉得这次暴露出来的问题还是自己基础知识掌握不扎实,如果当时我能早点回想起来当初上课时所讲的内容,可能也就不会有这次针对一个错误结论,花费这么大的精力来测试。当然这个世界上没有如果,我希望看到这篇博文的朋友,能少跟风学习新框架或者新语言,少被营销号带节奏,沉下心了,补充计算机基础知识,必将受益匪浅。
-
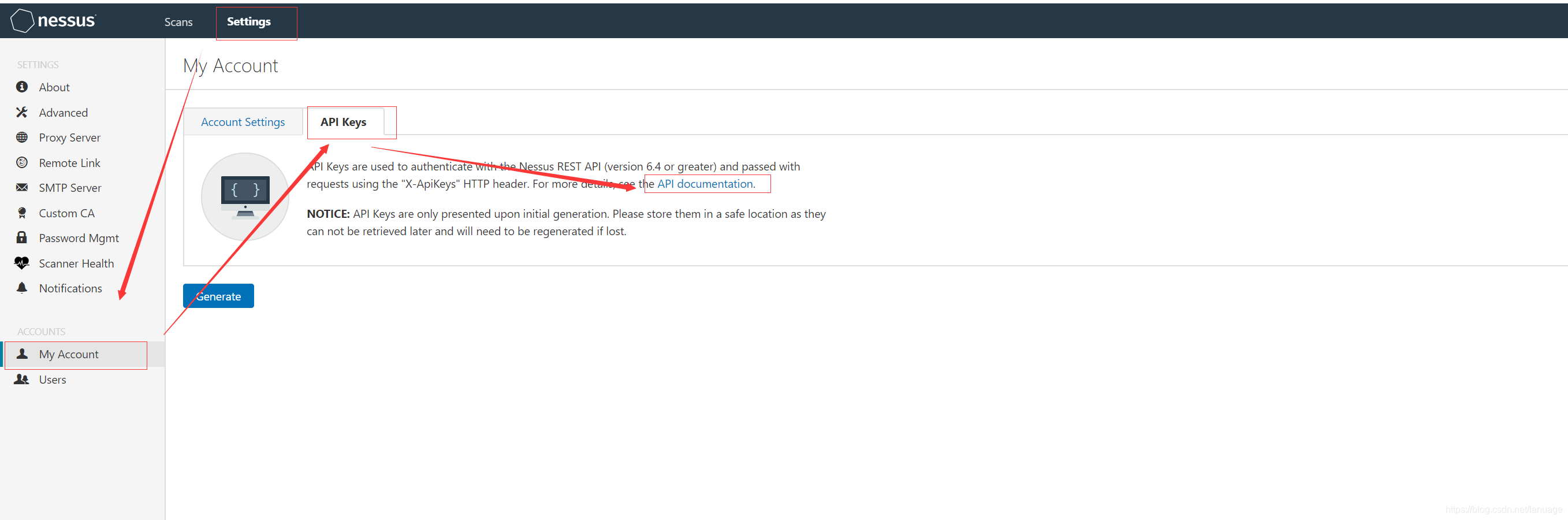
使用Python调用Nessus 接口实现自动化扫描 之前在项目中需要接入nessus扫描器,研究了一下nessus的api,现在将自己的成果分享出来。Nessus提供了丰富的二次开发接口,无论是接入其他系统还是自己实现自动化扫描,都十分方便。同时Nessus也提供了完备的API文档,可以在 Settings->My Account->API Keys->API documentation认证nessus提供两种认证方式,第一种采用常规的登录后获取token的方式,在https://localhost:8834/api#/resources/session条目中可以找到这种方式,它的接口定义如下:POST /session { "username":{string}, "password":{string} }输入正确的用户名和密码,登录成功后会返回一个token{ "token": {string} }在后续请求中,将token放入请求头信息中请求头的key为X-Cookie,值为 token=xxxx,例如 :X-Cookie: token=5fa3d3fd97edcf40a41bb4dbdfd0b470ba45dde04ebc37f8;,下面是获取任务列表的例子import requests import json def get_token(ip, port, username, password): url = "https://{0}:{1}/session".format(ip, port) post_data = { 'username': username, 'password': password } respon = requests.post(url, data=post_data, verify=False) if response.status_code == 200: data = json.loads(response.text) return data["token"] def get_scan_list() # 这里ip和port可以从配置文件中读取或者从数据库读取,这里我省略了获取这些配置值得操作 url = "https://{ip}:{port}/scans".format(ip, port) token = get_token(ip, port, username, password) if token: header = { "X-Cookie":"token={0}".format(token), "Content-Type":"application/json" } response = requests.get(url, headers=header, verify=False) if response.status_code == 200: result = json.loads(respon.text) return result第二种方式是使用Nessus生成的API Key,这里我们可以依次点击 Settings->My Account->API Keys-->Generate按钮,生成一个key,后续使用时填入头信息中,还是以获取扫描任务列表作为例子def get_scan_list() accessKey = "XXXXXX" #此处填入真实的内容 secretKey = "XXXXXX" #此处填入真实内容 url = "https://{ip}:{port}/scans".format(ip, port) token = get_token(ip, port, username, password) if token: header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accessKey, secretkey=secretKey) "Content-Type":"application/json" } response = requests.get(url, headers=header, verify=False) if response.status_code == 200: result = json.loads(respon.text) return result对比来看使用第二种明显方便一些,因此后续例子都采用第二种方式来呈现策略模板配置策略模板的接口文档在 https://localhost:8834/api#/resources/policies 中。创建策略模板创建策略模板使用的是 策略模板的create接口,它里面有一个必须填写的参数 uuid 这个参数是一个uuid值,表示以哪种现有模板进行创建。在创建之前需要先获取系统中可用的模板。获取的接口是 /editor/{type}/templates,type 可以选填policy或者scan。这里我们填policy一般我们都是使用模板中的 Advanced 来创建,如下图下面是获取该模板uuid的方法,主要思路是获取系统中所有模板,然后根据模板名称返回对应的uuid值def get_nessus_template_uuid(ip, port, template_name = "advanced"): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/editor/scan/templates".format(ip=ip, port=port) response = requests.get(api, headers=header, verify=False) templates = json.loads(response.text)['templates'] for template in templates: if template['name'] == template_name: return template['uuid'] return None有了这个id之后,下面来创建策略模板,这个接口的参数较多,但是很多参数都是选填项。这个部分文档写的很简陋,很多参数不知道是干嘛用的,当时我为了搞清楚每个参数的作用,一个个的尝试,然后去界面上看它的效果,最后终于把我感兴趣的给弄明白了。 它的主体部分如下:{ "uuid": {template_uuid}, "audits": { "feed": { "add": [ { "id": {audit_id}, "variables": { "1": {audit_variable_value}, "2": {audit_variable_value}, "3": {audit_variable_value} } } ] } }, "credentials": { "add": { {credential_category}: { {credential_name}: [ { {credential_input_name}: {string} } ] } } }, "plugins": { {plugin_family_name}: { "status": {string}, "individual": { {plugin_id}: {string} } } }, "scap": { "add": { {scap_category}: [ { {scap_input_name}: {string} } ] } }, "settings": { "acls": [ permission Resource ], //其他的减值对,这里我将他们都省略了 }他们与界面上配置的几个大项有对应关系,能对应的上的我给做了标记,但是有的部分对应不上。settings 是给策略模板做基础配置的,包括配置扫描的端口范围,服务检测范围等等。credentials 是配置登录扫描的,主要包括 windows、ssh、telnet等等plugins 配置扫描使用的插件,例如服务扫描版本漏洞等等在settings中,对应关系如下图所示下面是创建扫描策略模板的实际例子:def create_template(ip, port, **kwargs): # kwargs 作为可选参数,用来配置settings和其他项 header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } policys = {} # 这里 grouppolicy_set 存储的是策略模板中各个脚本名称以及脚本是否启用的信息 for policy in grouppolicy_set: enabled = "enabled" if policy.enable else "disabled" policys[policy.name] = { "status": enabled } # settings里面的各小项必须得带上,否则会创建不成功 "settings": { "name": template.name, "watchguard_offline_configs": "", "unixfileanalysis_disable_xdev": "no", "unixfileanalysis_include_paths": "", "unixfileanalysis_exclude_paths": "", "unixfileanalysis_file_extensions": "", "unixfileanalysis_max_size": "", "unixfileanalysis_max_cumulative_size": "", "unixfileanalysis_max_depth": "", "unix_docker_scan_scope": "host", "sonicos_offline_configs": "", "netapp_offline_configs": "", "junos_offline_configs": "", "huawei_offline_configs": "", "procurve_offline_configs": "", "procurve_config_to_audit": "Saved/(show config)", "fortios_offline_configs": "", "fireeye_offline_configs": "", "extremeos_offline_configs": "", "dell_f10_offline_configs": "", "cisco_offline_configs": "", "cisco_config_to_audit": "Saved/(show config)", "checkpoint_gaia_offline_configs": "", "brocade_offline_configs": "", "bluecoat_proxysg_offline_configs": "", "arista_offline_configs": "", "alcatel_timos_offline_configs": "", "adtran_aos_offline_configs": "", "patch_audit_over_telnet": "no", "patch_audit_over_rsh": "no", "patch_audit_over_rexec": "no", "snmp_port": "161", "additional_snmp_port1": "161", "additional_snmp_port2": "161", "additional_snmp_port3": "161", "http_login_method": "POST", "http_reauth_delay": "", "http_login_max_redir": "0", "http_login_invert_auth_regex": "no", "http_login_auth_regex_on_headers": "no", "http_login_auth_regex_nocase": "no", "never_send_win_creds_in_the_clear": "yes" if kwargs["never_send_win_creds_in_the_clear"] else "no", "dont_use_ntlmv1": "yes" if kwargs["dont_use_ntlmv1"] else "no", "start_remote_registry": "yes" if kwargs["start_remote_registry"] else "no", "enable_admin_shares": "yes" if kwargs["enable_admin_shares"] else "no", "ssh_known_hosts": "", "ssh_port": kwargs["ssh_port"], "ssh_client_banner": "OpenSSH_5.0", "attempt_least_privilege": "no", "region_dfw_pref_name": "yes", "region_ord_pref_name": "yes", "region_iad_pref_name": "yes", "region_lon_pref_name": "yes", "region_syd_pref_name": "yes", "region_hkg_pref_name": "yes", "microsoft_azure_subscriptions_ids": "", "aws_ui_region_type": "Rest of the World", "aws_us_east_1": "", "aws_us_east_2": "", "aws_us_west_1": "", "aws_us_west_2": "", "aws_ca_central_1": "", "aws_eu_west_1": "", "aws_eu_west_2": "", "aws_eu_west_3": "", "aws_eu_central_1": "", "aws_eu_north_1": "", "aws_ap_east_1": "", "aws_ap_northeast_1": "", "aws_ap_northeast_2": "", "aws_ap_northeast_3": "", "aws_ap_southeast_1": "", "aws_ap_southeast_2": "", "aws_ap_south_1": "", "aws_me_south_1": "", "aws_sa_east_1": "", "aws_use_https": "yes", "aws_verify_ssl": "yes", "log_whole_attack": "no", "enable_plugin_debugging": "no", "audit_trail": "use_scanner_default", "include_kb": "use_scanner_default", "enable_plugin_list": "no", "custom_find_filepath_exclusions": "", "custom_find_filesystem_exclusions": "", "reduce_connections_on_congestion": "no", "network_receive_timeout": "5", "max_checks_per_host": "5", "max_hosts_per_scan": "100", "max_simult_tcp_sessions_per_host": "", "max_simult_tcp_sessions_per_scan": "", "safe_checks": "yes", "stop_scan_on_disconnect": "no", "slice_network_addresses": "no", "allow_post_scan_editing": "yes", "reverse_lookup": "no", "log_live_hosts": "no", "display_unreachable_hosts": "no", "report_verbosity": "Normal", "report_superseded_patches": "yes", "silent_dependencies": "yes", "scan_malware": "no", "samr_enumeration": "yes", "adsi_query": "yes", "wmi_query": "yes", "rid_brute_forcing": "no", "request_windows_domain_info": "no", "scan_webapps": "no", "start_cotp_tsap": "8", "stop_cotp_tsap": "8", "modbus_start_reg": "0", "modbus_end_reg": "16", "hydra_always_enable": "yes" if kwargs["hydra_always_enable"] else "no", "hydra_logins_file": "" if kwargs["hydra_logins_file"] else kwargs["hydra_logins_file"], # 弱口令文件需要事先上传,后面会提到上传文件接口 "hydra_passwords_file": "" if kwargs["hydra_passwords_file"] else kwargs["hydra_passwords_file"], "hydra_parallel_tasks": "16", "hydra_timeout": "30", "hydra_empty_passwords": "yes", "hydra_login_as_pw": "yes", "hydra_exit_on_success": "no", "hydra_add_other_accounts": "yes", "hydra_postgresql_db_name": "", "hydra_client_id": "", "hydra_win_account_type": "Local accounts", "hydra_win_pw_as_hash": "no", "hydra_cisco_logon_pw": "", "hydra_web_page": "", "hydra_proxy_test_site": "", "hydra_ldap_dn": "", "test_default_oracle_accounts": "no", "provided_creds_only": "yes", "smtp_domain": "example.com", "smtp_from": "[email protected]", "smtp_to": "postmaster@[AUTO_REPLACED_IP]", "av_grace_period": "0", "report_paranoia": "Normal", "thorough_tests": "no", "detect_ssl": "yes", "tcp_scanner": "no", "tcp_firewall_detection": "Automatic (normal)", "syn_scanner": "yes", "syn_firewall_detection": "Automatic (normal)", "wol_mac_addresses": "", "wol_wait_time": "5", "scan_network_printers": "no", "scan_netware_hosts": "no", "scan_ot_devices": "no", "ping_the_remote_host": "yes", "tcp_ping": "yes", "icmp_unreach_means_host_down": "no", "test_local_nessus_host": "yes", "fast_network_discovery": "no", "arp_ping": "yes" if kwargs["arp_ping"] else "no", "tcp_ping_dest_ports": kwargs["tcp_ping_dest_ports"], "icmp_ping": "yes" if kwargs["icmp_ping"] else "no", "icmp_ping_retries": kwargs["icmp_ping_retries"], "udp_ping": "yes" if kwargs["udp_ping"] else "no", "unscanned_closed": "yes" if kwargs["unscanned_closed"] else "no", "portscan_range": kwargs["portscan_range"], "ssh_netstat_scanner": "yes" if kwargs["ssh_netstat_scanner"] else "no", "wmi_netstat_scanner": "yes" if kwargs["wmi_netstat_scanner"] else "no", "snmp_scanner": "yes" if kwargs["snmp_scanner"] else "no", "only_portscan_if_enum_failed": "yes" if kwargs["only_portscan_if_enum_failed"] else "no", "verify_open_ports": "yes" if kwargs["verify_open_ports"] else "no", "udp_scanner": "yes" if kwargs["udp_scanner"] else "no", "svc_detection_on_all_ports": "yes" if kwargs["svc_detection_on_all_ports"] else "no", "ssl_prob_ports": "Known SSL ports" if kwargs["ssl_prob_ports"] else "All ports", "cert_expiry_warning_days": kwargs["cert_expiry_warning_days"], "enumerate_all_ciphers": "yes" if kwargs["enumerate_all_ciphers"] else "no", "check_crl": "yes" if kwargs["check_crl"] else "no", } credentials = { "add": { "Host": { "SSH": [], "SNMPv3": [], "Windows": [], }, "Plaintext Authentication": { "telnet/rsh/rexec": [] } } } try: if kwargs["snmpv3_username"] and kwargs["snmpv3_port"] and kwargs["snmpv3_level"]: level = kwargs["snmpv3_level"] if level == NessusSettings.LOW: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "No authentication and no privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"] }) elif level == NessusSettings.MID: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "Authentication without privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"], "auth_algorithm": NessusSettings.AUTH_ALG[kwargs["snmpv3_auth"][1]], "auth_password": kwargs["snmpv3_auth_psd"] }) elif level == NessusSettings.HIGH: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "Authentication and privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"], "auth_algorithm": NessusSettings.AUTH_ALG[kwargs["snmpv3_auth"]][1], "auth_password": kwargs["snmpv3_auth_psd"], "privacy_algorithm": NessusSettings.PPIVACY_ALG[kwargs["snmpv3_hide"]][1], "privacy_password": kwargs["snmpv3_hide_psd"] }) if kwargs["ssh_username"] and kwargs["ssh_psd"]: credentials["add"]["Host"]["SSH"].append( { "auth_method": "password", "username": kwargs["ssh_username"], "password": kwargs["ssh_psd"], "elevate_privileges_with": "Nothing", "custom_password_prompt": "", }) if kwargs["windows_username"] and kwargs["windows_psd"]: credentials["add"]["Host"]["Windows"].append({ "auth_method": "Password", "username": kwargs["windows_username"], "password": kwargs["windows_psd"], "domain": kwargs["ssh_host"] }) if kwargs["telnet_username"] and kwargs["telnet_password"]: credentials["add"]["Plaintext Authentication"]["telnet/rsh/rexec"].append({ "username": kwargs["telnet_username"], "password": kwargs["telnet_password"] }) data = { "uuid": get_nessus_template_uuid(terminal, "advanced"), "settings": settings, "plugins": policys, "credentials": credentials } api = "https://{0}:{1}/policies".format(ip, port) response = requests.post(api, headers=header, data=json.dumps(data, ensure_ascii=False).encode("utf-8"), # 这里做一个转码防止在nessus端发生中文乱码 verify=False) if response.status_code == 200: data = json.loads(response.text) return data["policy_id"] # 返回策略模板的id,后续可以在创建任务时使用 else: return None策略还有copy、delete、config等操作,这里就不再介绍了,这个部分主要弄清楚各参数的作用,后面的这些接口使用的参数都是一样的任务任务部分的API 在https://localhost:8834/api#/resources/scans 中创建任务创建任务重要的参数如下说明如下:uuid: 创建任务时使用的模板id,这个id同样是我们上面说的系统自带的模板idname:任务名称policy_id:策略模板ID,这个是可选的,如果要使用上面我们自己定义的扫描模板,需要使用这个参数来指定,并且设置上面的uuid为 custom 的uuid,这个值表示使用用户自定义模板;当然如果就想使用系统提供的,这个字段可以不填text_targets:扫描目标地址,这个参数是一个数组,可以填入多个目标地址,用来一次扫描多个主机创建任务的例子如下:def create_task(task_name, policy_id, hosts): # host 是一个列表,存放的是需要扫描的多台主机 uuid = get_nessus_template_uuid(terminal, "custom") # 获取自定义策略的uuid if uuid is None: return False data = {"uuid": uuid, "settings": { "name": name, "policy_id": policy_id, "enabled": True, "text_targets": hosts, "agent_group_id": [] }} header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/scans".format(ip=terminal.ip, port=terminal.port) response = requests.post(api, headers=header, data=json.dumps(data, ensure_ascii=False).encode("utf-8"), verify=False) if response.status_code == 200: data = json.loads(response.text) if data["scan"] is not None: scan = data["scan"] # 新增任务扩展信息记录 return scan["id"] # 返回任务id启动/停止任务启动任务的接口为 POST /scans/{scan_id}/launch scan_id 是上面创建任务返回的任务ID, 它有个可选参数 alt_targets,如果这个参数被指定,那么该任务可以扫描这个参数中指定的主机,而之前创建任务时指定的主机将被替代停止任务的接口为: POST /scans/{scan_id}/stop下面给出启动和停止任务的方法def start_task(task_id, hosts): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} data = { "alt_targets": [hosts] # 重新指定扫描地址 } api = "https://{ip}:{port}/scans/{scan_id}/launch".format(ip=ip, port=port, scan_id=scan_id) response = requests.post(api, data=data, verify=False, headers=header) if response.status_code != 200: return False else: return True def stop_task(task_id): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=terminal.reserved1, secretkey=terminal.reserved2), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/scans/{scan_id}/stop".format(ip=ip, port=port, task_id) response = requests.post(api, headers=header, verify=False) if response.status_code == 200 or response.status_code == 409: # 根据nessus api文档可以知道409 表示任务已结束 return True return False获取扫描结果使用接口 GET /scans/{scan_id} 可以获取最近一次扫描的任务信息,从接口文档上看,它还可以获取某次历史扫描记录的信息,如果不填这个参数,接口中会返回所有历史记录的id。如果不填历史记录id,那么会返回最近一次扫描到的漏洞信息,也就是说新扫描到的信息会把之前的信息给覆盖下面是返回信息的部分说明{ "info": { "edit_allowed": {boolean}, "status": {string}, //当前状态 completed 字符串表示结束,cancel表示停止 "policy": {string}, "pci-can-upload": {boolean}, "hasaudittrail": {boolean}, "scan_start": {string}, "folder_id": {integer}, "targets": {string}, "timestamp": {integer}, "object_id": {integer}, "scanner_name": {string}, "haskb": {boolean}, "uuid": {string}, "hostcount": {integer}, "scan_end": {string}, "name": {string}, "user_permissions": {integer}, "control": {boolean} }, "hosts": [ //按主机区分的漏洞信息 host Resource ], "comphosts": [ host Resource ], "notes": [ note Resource ], "remediations": { "remediations": [ remediation Resource ], "num_hosts": {integer}, "num_cves": {integer}, "num_impacted_hosts": {integer}, "num_remediated_cves": {integer} }, "vulnerabilities": [ vulnerability Resource //本次任务扫描到的漏洞信息 ], "compliance": [ vulnerability Resource ], "history": [ history Resource //历史扫描信息,可以从这个信息中获取历史记录的id ], "filters": [ filter Resource ] }这个信息里面vulnerabilities和host里面都可以拿到漏洞信息,但是 vulnerabilities中是扫描到的所有漏洞信息,而host则需要根据id再次提交请求,也就是需要额外一次请求,但它是按照主机对扫描到的漏洞进行了分类。而使用vulnerabilities则需要根据漏洞信息中的host_id 手工进行分类下面是获取任务状态的示例:def get_task_status(task_id): header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } api = "https://{ip}:{port}/scans/{task_id}".format(ip=ip, port=port, task_id=task_id) response = requests.get(api, headers=header, verify=False) if response.status_code != 200: return 2, "Data Error" data = json.loads(response.text) hosts = data["hosts"] for host in hosts: get_host_vulnerabilities(scan_id, host["host_id"]) # 按主机获取漏洞信息 if data["info"]["status"] == "completed" or data["info"]["status"] =='canceled': # 已完成,此时更新本地任务状态 return 1, "OK"获取漏洞信息在获取任务信息中,已经得到了本次扫描中发现的弱点信息了,只需要我们解析这个json。它具体的内容如下:"host_id": {integer}, //主机id "host_index": {string}, "hostname": {integer},//主机名称 "progress": {string}, //扫描进度 "critical": {integer}, //危急漏洞数 "high": {integer}, //高危漏洞数 "medium": {integer}, //中危漏洞数 "low": {integer}, //低危漏洞数 "info": {integer}, //相关信息数目 "totalchecksconsidered": {integer}, "numchecksconsidered": {integer}, "scanprogresstotal": {integer}, "scanprogresscurrent": {integer}, "score": {integer}根据主机ID可以使用 GET /scans/{scan_id}/hosts/{host_id} 接口获取主机信息,它需要两个参数,一个是扫描任务id,另一个是主机id。下面列举出来的是返回值得部分内容,只列举了我们感兴趣的部分:{ "info": { "host_start": {string}, "mac-address": {string}, "host-fqdn": {string}, "host_end": {string}, "operating-system": {string}, "host-ip": {string} }, "vulnerabilities": [ { "host_id": {integer}, //主机id "hostname": {string}, //主机名称 "plugin_id": {integer}, //策略id "plugin_name": {string}, //策略名称 "plugin_family": {string}, //所属策略组 "count": {integer}, //该种漏洞数 "vuln_index": {integer}, "severity_index": {integer}, "severity": {integer} } ], }根据上面获取任务信息中得到的主机id和任务id,我们可以实现这个功能def get_host_vulnerabilities(scan_id, host_id): header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } scan_history = ScanHistory.objects.get(id=scan_id) api = "https://{ip}:{port}/scans/{task_id}/hosts/{host_id}".format(ip=ip, port=port, task_id=scan_id, host_id=host_id) response = requests.get(api, headers=header, verify=False) if response.status_code != 200: return 2, "Data Error" data = json.loads(response.text) vulns = data["vulnerabilities"] for vuln in vulns: vuln_name = vuln["plugin_name"] plugin_id = vuln["plugin_id"] #插件id,可以获取更详细信息,包括插件自身信息和扫描到漏洞的解决方案等信息 #保存漏洞信息获取漏洞输出信息与漏洞知识库信息我们在nessus web页面中可以看到每条被检测到的漏洞在展示时会有输出信息和知识库信息,这些信息也可以根据接口来获取获取漏洞的知识库可以通过接口 GET /scans/{scan_id}/hosts/{host_id}/plugins/{plugin_id} , 它的路径为: https://localhost:8834/api#/resources/scans/plugin-output它返回的值如下:{ "info": { "plugindescription": { "severity": {integer}, //危险等级,从info到最后的critical依次为1,2,3,4,5 "pluginname": {string}, "pluginattributes": { "risk_information": { "risk_factor": {string} }, "plugin_name": {string}, //插件名称 "plugin_information": { "plugin_id": {integer}, "plugin_type": {string}, "plugin_family": {string}, "plugin_modification_date": {string} }, "solution": {string}, //漏洞解决方案 "fname": {string}, "synopsis": {string}, "description": {string} //漏洞描述 }, "pluginfamily": {string}, "pluginid": {integer} } }, "output": [ plugin_output:{ "plugin_output": {string}, //输出信息 "hosts": {string}, //主机信息 "severity": {integer}, "ports": {} //端口信息 } ] }有了这些信息,我们可以通过下面的代码获取这些信息:def get_vuln_detail(scan_id, host_id, plugin_id) header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } api = "https://{ip}:{port}/scans/{scan_id}/hosts/{host_id}/plugins/{plugin_id}".format(ip=ip, port=port, scan_id=scan_id, host_id=host_id, plugin_id=plugin_id) response = requests.get(api, headers=header, verify=False) data = json.loads(response.text) outputs = data["outputs"] return outputs最后总结这篇文章我们主要介绍了nessus API从扫描设置到扫描任务创建、启动、停止、以及结果的获取的内容,当然nessus的api不止这些,但是最重要的应该是这些,如果能帮助各位解决手头上的问题自然是极好的,如果不能或者说各位朋友需要更细致的控制,可以使用浏览器抓包的方式来分析它的请求和响应包。在摸索时最好的两个帮手是浏览器 F12工具栏中的 network和nessus api文档页面上的test工具了。我们可以先按 f12 打开工具并切换到network,然后在页面上执行相关操作,观察发包即可发现该如何使用这些API,因为Nessus Web端在操作时也是使用API。如下图:或者可以使用文档中的test工具,例如下面是测试 获取插件输出信息的接口
-
Mybatis框架 在之前的内容中,我写了Java的基础知识、Java Web的相关知识。有这些内容就可以编写各种各样丰富的程序。但是如果纯粹手写所有代码,工作量仍然很大。为了简化开发,隐藏一些不必要的细节,专心处理业务相关内容 ,Java提供了许多现成的框架可以使用Mybatis介绍在程序开发中讲究 MVC 的分层架构,其中M表示的是存储层,也就是与数据库交互的内容。一般来说使用jdbc时,需要经历:导入驱动、创建连接、创建statement对象,执行sql、获取结果集、封装对象、关闭连接这样几个过程。里面很多过程的代码都是固定的,唯一有变化的是执行sql并封装对象的操作。而封装对象时可以利用反射的机制,将返回字段的名称映射到Java实体类的各个属性上。这样我们很自然的就想到了,可以编写一个框架或者类库,实现仅配置sql语句和对应的映射关系,来实现查询到封装的一系列操作,从而简化后续的开发。Mybatis帮助我们实现了这个功能。Mybatis实例假设现在有一个用户表,存储用户的相关信息,我们现在需要使用mybatis来进行查询操作,可能要经历如下步骤:定义对应的实体类public class User { private Integer id; private String username; private String birthday; private char sex; private String address; //后面省略对应的getter和setter方法 //为了方便后面的实体类都会省略这些内容 } 编辑主配置文件,主要用来配置mybati的数据库连接信息以及指定对应dao的配置文件<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTDConfig3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <!--mybatis主配置文件--> <configuration> <!--配置环境--> <environments default="mybatis_demo"> <environment id="mybatis_demo"> <!--配置事务的类型--> <transactionManager type="JDBC"></transactionManager> <!--配置连接池--> <dataSource type="POOLED"> <!--配置数据库连接的4个基本信息--> <property name="driver" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/mybatis_demo"/> <property name="username" value="root"/> <property name="password" value="masimaro_root"/> </dataSource> </environment> </environments> <!--指定配置文件的位置,配置文件是每个dao独立的配置文件--> <mappers> <mapper resource="com/MybatisDemo/Dao/IUserDao.xml"></mapper> </mappers> </configuration>编写dao接口public interface IUserDao { public List<User> findAll(); }并提供dao的xml配置文件<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTDMapper3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!--每个函数配置一条,标签名是要进行的数据库操作,resultType是需要返回的数据类型--> <mapper namespace="com.MyBatisDemo.Dao.IUserDao"> <!--标签里面的文本是sql语句--> <select id="findAll" resultType="com.MyBatisDemo.domain.User"> select * from user; </select> </mapper>写完了对应的配置代码,接下来就是通过简单的几行代码来驱动mybatis,完成查询并封装的操作InputStream is = null; SqlSession = null; try { //加载配置文件 is = Resources.getResourceAsStream("dbconfig.xml"); //创建工厂对象 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(is); //创建sqlsession对象 sqlSession = factory.openSession(); //使用sqlsession对象创建dao接口的代理对象 IUserDao userDao = sqlSession.getMapper(IUserDao.class); //使用对象执行方法 List<User> users = this.userDao.findAll(); System.out.println(users); } catch (IOException e) { e.printStackTrace(); }finally{ // 清理资源 if (null != this.is){ try { this.sqlSession.commit(); this.is.close(); } catch (IOException e) { e.printStackTrace(); } } if (null != this.sqlSession){ this.sqlSession.close(); } }mybatis大致的执行过程根据我们传入的InputStream对象来获取配置xml中对应对象的值接着根据配置信息创建连接并生成数据库的连接池对象根据配置文件中的mapper项获取到对应的Dao接口的配置文件,在读取该文件时会准备一个Map结构,其中key是mapper中的namespace + id,value是对应的sql语句,例如上述例子中得到的map结构为{"com.MyBatisDemo.Dao.IUserDao.findAll", "select * from user"}在创建sqlsession时从连接中获取到一个Statement对象在我们调用dao接口时,首先根据dao接口得到详细的类名,然后获取到当前调用的接口名称,由这两项得到一个key,比如在上述例子中,dao接口的名称为com.MyBatisDemo.Dao.IUserDao, 而调用的方法是 findAll,将这两个字符串进行拼接,得到一个key,根据这个key去map中查找对应的sql语句。并执行执行sql语句获取查询的结果集根据resultType中指定的对象进行封装并返回对应的实体类使用mybatis实现增删改查操作在之前的代码上可以看出,使用mybatis来实现功能时,只需要提供dao接口中的方法,并且将方法与对应的sql语句绑定。在提供增删改查的dao方法时如果涉及到需要传入参数的情况下该怎么办呢?下面以根据id查询内容为例:我们先在dao中提供这样一个方法:public User findById(int id);然后在dao的配置文件中编写sql语句<!--parameterType 表示传入的参数的类型--> <select id="findById" resultType="com.MyBatisDemo.domain.User" parameterType="int"> select * from user where id = #{id} </select>从上面的配置可以看到,mybatis中, 使用#{} 来表示输入参数,使用属性parameterType属性来表示输入参数的类型。一般如果使用Java内置对象是不需要使用全限定类名,也不区分大小写。当我们使用内置类型的时候,这里的id 仅仅起到占位符的作用,取任何名字都可以看完了使用内置对象的实例,再来看看使用使用自定义类类型的情况,这里我们使用update的例子来说明,首先与之前的操作一样,先定义一个upate的方法:void updateUser(User user);然后使用如下配置<update id="updateUser" parameterType="User"> update user set username=#{username}, birthday=#{birthday}, sex=#{sex}, address=#{address} where id = #{id} </update>与使用id查询的配置类似,当我们使用的是自定义类类型时,在对应的字段位置需要使用类的属性表示,在具体执行的时候,mybatis会根据传入的类对象来依据配置取出对应的属性作为sql语句的参数。上面在使用内置对象时我们说它可以取任何的名称,但是这里请注意 名称只能是自定义对象的属性名,而且区分大小写这里使用的都是确定的值,如果要使用模糊查询时该如何操作呢,这里我们按照名称来模糊查询,首先在dao中提供一个对应的方法User findByName(String name);接着再来进行配置<select resultType="com.MyBatisDemo.domain.User" parameterType="String"> select * from User where username like #{username} </select>从sql语句来看我们并没有实现模糊的方式,这时候在传入参数的时候就需要使用模糊的方式,调用时应该在参数中添加 %%, 就像这样 userDao.findByName("%" + username + "%")当然我们可以使用另外一种配置<select resultType="com.MyBatisDemo.domain.User" parameterType="String"> select * from User where username like %${username}% </select>这样我们在调用时就不需要额外添加 % 了。既然他们都可以作为参数,那么这两个符号有什么区别呢?区别在于他们进行查询的方式,$ 使用的是字符串拼接的方式来组成一个完成的sql语句进行查询,而#使用的是参数话查询的方式。一般来说拼接字符串容易造成sql注入的漏洞,为了安全一定要使用参数话查询的方式mybatis的相关标签resultMap标签在之前的配置中,其实一直保持着数据库表的字段名与对应的类属性名同名,但是有些时候我们不能保证二者同名,为了解决这问题也为了以后进行一对多和多对多的配置,可以使用resultMap来定义数据库表字段名和类属性名的映射关系下面是一个使用它的例子。我们简单修改一下User类的属性定义public class User { private Integer uid; private String name; private String userBirthday; private char userSex; private String userAddress; //后面省略对应的getter和setter方法 }这样直接使用之前的配置执行会报错,报找不到对应属性的错误,这个时候就可以使用resultMap属性来解决这个问题<resultMap id="UserMapper" type="User"> <id column="id" property="uid"></id> <result column="username" property="username"></result> <result column="sex" property="sex"></result> <result column="birthday" property="birthday"></result> <result column="address" property="address"></result> </resultMap> <select id="findAll" resultMap="UserMapper"> select * from user; </select>其中 id属性来唯一标示这个映射关系,在需要使用到这个映射关系的地方,使用resultMap这个属性来指定type属性表示要将这些值封装到哪个自定义的类类型中resultMap中有许多子标签用来表示这个映射关系id用来表明表结构中主键的映射关系result表示其他字段的映射关系每个标签中的column属性表示的是对应的表字段名标签中的property对应的是类属性的名称properties 标签properties标签可以用来定义数据库的连接属性,主要用于引入外部数据库连接属性的文件,这样我们可以通过直接修改连接属性文件而不用修改具体的xml配置文件。假设现在在工程中还有一个database.properties文件jdbc.driver ="com.mysql.jdbc.Driver" jdbc.url = "jdbc:mysql://localhost:3306/mybatis_demo" jdbc.username ="root" jdbc.password" ="masimaro_root"然后修改对应的主配置文件<!--引入properties文件--> <properties resource="database.properties"> </properties> <!--修改对应的dataSource标签--> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource>typeAliases 标签之前我们说过,使用内置类型时不需要写全限定类名,而且它不区分大小写。而使用自定义类型时需要写很长一串,如何使自定义类型与内置类型一样呢?这里可以使用typeAliases标签。它用来定义类名的别名<typeAliases> <!--typeAlias中来定义具体类的别名,type表示真实类名,alias表示别名--> <typeAlias type="com.MyBatisDemo.domain.User" alias="user"></typeAlias> </typeAliases>使用typeAlias标签时,每个类都需要提供一条对应的配置,当实体类多了,写起来就很麻烦了,这个时候可以使用package子标签来代替typeAlias<typeAliases> <package name="com.MyBatisDemo.domain"/> </typeAliases>它表示这里包中的所有类都使用别名,别名就是它的类名package标签在定义对应的mapper xml文件时,一个dao接口就需要一条配置。dao接口多了,一条条的写很麻烦,为了减轻编写的工作量可以使用package标签<mappers> <!--它表示这个包中的所有xml都是mapper配置文件--> <package name="com/MyBatis/Dao"/> </mappers>连接池在配置数据库连接 dataSource 标签中有一个type属性,它用来定义使用的连接池,该属性有三个取值:POOLE:使用连接池,采用javax.sql.DataSource 规范中的连接池,mybatis中有针对它的数据库连接池的实现UNPOOLED:与POOLED相同,使用的都是javax.sql.DataSource 规范,但是它使用的是常规的连接方式,没有采用池的思想JNDI:根据服务器提供的jndi基础来获取数据库的连接 ,具体获取到的连接对象又服务器提供动态sql当我们自己拼接sql的时候可以根据传入的参数的不同来动态生成不同的sql语句执行,而在之前的配置中,我们事先已经写好了使用的sql语句,但是如果碰上使用需要按照条件搜索,而且又不确定用户会输入哪些查询条件,在这样的情况下,没办法预先知道该怎么写sql语句。这种情况下可以使用mybatis中提供的动态sql假设我们提供一个findByValue的方法,根据值来进行查询。public List<User> findByValue(User user);事先并不知道user的哪些属性会被赋值,我们需要做的就是判断user的哪些属性不为空,根据这些不为空的属性来进行and的联合查询。这种情况下我们可以使用if标签<select id="findByValue" resultType="User" parameterType="User"> select * from user where <if test="id != null"> id = #{id} and </if> <if test="username != null"> username=#{username} and </if> ..... 1=1 </select>if标签中使用test来进行条件判断,而判断条件可以完全使用Java的语法来进行。这里在最后用了一个1=1的条件来结束判断,因为事先并不知道用户会传入哪些值,不知道哪条语句是最后一个条件,因此我们加一个恒成立的条件来确保sql语句的完整当然mybatis中也有办法可以省略最后的1=1,我们可以使用 where标签来包裹这些if,表明if中的所有内容都是作为查询条件的,这样mybatis在最后会在生成查询条件后自动帮助我们进行格式的整理使用if标签我们搞定了不确定用户会使用哪些查询条件的问题,如果有这样一个场景:用户只知道某个字段的名字有几种可能,我们在用户输入的几种可能值中进行查找,也就是说,用户可以针对同一个查询条件输入多个可能的值,根据这些个可能的值进行匹配,只要有一个值匹配上即可返回;针对这种情况没办法使用if标签了,我们可以使用循环标签,将用户输入的多个值依次迭代,最终组成一个in的查询条件我们在这里提供一个根据多个id查找用户的方法public List<User> findByIds(List<Integer> ids);这里我们为了方便操作,额外提供一个类用来存储查询条件public class QueryVo { List<Integer> ids; }<select id="findUserByIds" resultType="User" parameterType="QueryVo"> select * from user <where> <if test="ids != null and ids.size() != 0"> <foreach collection="ids" open="and id in (" close=")" item= "id" separator=","> ${id} </foreach> </if> </where> </select>在上面的例子中使用foreach来迭代容器其中使用collection表示容器,这里取的是parameterType中指定类的属性,open表示在迭代开始时需要加入查询条件的sql语句,close表示在迭代结束后需要添加到查询语句中的sql,item表示每个元素的变量名,separator表示每次迭代结束后要添加到查询语句中的字符串。当我们迭代完成后,整个sql语句就变成了这样: select * from user where 1=1 and id in (id1, id2, ...)多表查询一对多查询在现实中存在着这么一些一对多的对应关系,像什么学生和班级的对应关系,用户和账户的对应关系等等。关系型数据库在处理这种一对多的情况下,使用的是在多对应的那张表中添加一个外键,这个外键就是对应的一那张表的主键,比如说在处理用户和账户关系时,假设一个用户可以创建多个账户,那么在账户表中会有一个外键,指向的是用户表的ID在上面例子的基础之上,来实现一个一对多的关系。首先添加一个账户的实体类,并且根据关系账户中应该有一个唯一的用户类对象,用来表示它所属的用户public class Account { private int id; private int uid; private double money; private User user; }同时需要在User这个实体类上添加一个Account的列表对象,表示一个User下的多个Accountpublic class User { private Integer id; private String username; private String birthday; private char sex; private String address; private List<Account> accounts; }首先根据user来查询多个account,我们可以写出这样的sql语句来查询select u.*, a.id as aid, a.money, a.uid from user as u left join account as a on a.uid = u.id;那么它查询出来的结果字段名称应该是id, username, sex, birthday, address, aid, money, uid 这些,前面的部分可以封装为一个User对象,但是后面的部分怎么封装到Accounts中去呢,这里可以在resultMap中使用collection标签,该标签中对应的对象会被封装为一个容器。因此这里的配置可以写为:<resultMap id="UserAccountMap" type="user"> <id property="id" column="id"></id> <result property="username" column="username"></result> <result property="birthday" column="birthday"></result> <result property="sex" column="sex"></result> <result property="address" column="address"></result> <collection property="accounts" ofType="account"> <id property="id" column="aid"></id> <result property="money" column="money"></result> <result property="uid" column="uid"></result> </collection> </resultMap> <select id="findAll" resultMap="UserAccountMap"> select u.*, a.ID as aid, a.MONEY, a.UID from user as u left join acc ount as a on u.id = a.uid </select>我们需要一个resultMap来告诉Mybatis,这些多余的字段该怎么进行封装,为了表示一个容器,我们使用了一个coolection标签,标签中的property属性表示这个容器被封装到resultType对应类的哪个属性中,ofType表示的是,容器中每一个对象都是何种类型,而它里面的子标签的含义与resultMap子标签的含义完全相同从User到Account是一个多对多的关心,而从Account到User则是一个一对一的关系,当我们反过来进行查询时,需要使用的配置是 association 标签,它的配置与使用与collection相同<resultMap id="AccountUserMap" type="Account"> <id property="id" column="aid"></id> <result property="uid" column="uid"></result> <result property="money" column="money"></result> <association property="user" column="uid" javaType="user"> <id property="id" column="uid"></id> <result property="username" column="username"></result> <result property="birthday" column="birthday"></result> <result property="sex" column="sex"></result> <result property="address" column="address"></result> </association> </resultMap> <select id="findUserAccounts" resultType="Account" parameterType="User"> select * from account where uid = ${id} </select>多对多查询说完了一对多,再来说说多对多查询。多对多在关系型数据库中使用第三张表来体现,第三张表中记录另外两个表的主键作为它的外键。这里使用用户和角色的关系来演示多对多查询与之前一样,在两个实体类中新增对方的一个list对象,表示多对多的关系public class Role implements Serializable { private int id; private String roleName; private String roleDesc; private List<User> users; }利用之前一对多的配置,我们只需要修改一下ResultMap和sql语句就可以完成多对多的查询<mapper namespace="com.liuhao.Dao.IUserDao"> <resultMap id="UserRoleMapper" type="User"> <id property="id" column="id"></id> <result column="username" property="username"></result> <result column="sex" property="sex"></result> <result column="address" property="address"></result> <result column="birthday" property="birthday"></result> <collection property="roles" ofType="role"> <id property="id" column="rid"></id> <result column="role_desc" property="roleDesc"></result> <result column="role_name" property="roleName"></result> </collection> </resultMap> <select id="findAll" resultMap="UserRoleMapper"> select user.*, role.ID as rid, role.ROLE_DESC, role.ROLE_NAME from u ser left outer join user_role on user_role.uid = user.id left OUTER join role on user_role.RID = role.ID </select> </mapper>另一个多对多的关系与这个类似,这里就不再单独说明了延迟加载之前说了该如何做基本的单表和多表查询。这里有一个问题,在多表查询中,我们是否有必要一次查询出它所关联的所有数据,就像之前的一对多的关系中,在查询用户时是否需要查询对应的账户,以及查询账户时是否需要查询它所对应的用户。如果不需要的话,我么采用上面的写法会造成多执行一次查询,而且当它关联的数据过多,而这些数据我们用不到,这个时候就会造成内存资源的浪费。这个时候我们需要考虑使用延迟加载,只有需要才进行查询。之前的sql语句一次会同时查询两张表,当然不满足延迟加载的要求,延迟加载应该将两张表的查询分开,先只查询需要的一张表数据,另一张表数据只在需要的时候查询。根据这点我们进行拆分,假设我们要针对User做延迟加载,我们先不管accounts的数据,只查询user表,可以使用sql语句select * from user, 在需要的时候执行select * from account where uid = id在xml配置中可以在collection标签中使用select属性,该属性指向一个方法,该方法的功能是根据id获取所有对象的列表。也就说我们需要在AccountDao接口中提供这么一个方法,并且编写它的xml配置public List<Account> findByUid(int uid);接着我们对之前的xml进行改写<resultMap id="UserMapper" type="User"> <id column="id" property="id"></id> <result column="username" property="username"></result> <result column="sex" property="sex"></result> <result column="birthday" property="birthday"></result> <result column="address" property="address"></result> <collection property="accounts" ofType="Account" select="com.liuhao.Dao.IAccountDao.findByUid" column="id"> </collection> </resultMap> <select id="findAll" resultMap="UserMapper"> select * from user; </select>完成了接口的编写与配置,还需要对主配置文件做一些配置,我们在主配置文件中添加settings节点,开启延迟加载<settings> <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> </settings>缓存缓存用来存储一些不经常变化的内容,使用缓存可以减少查询数据库的次数,提高效率。mybatis有两种缓存,一种是在每个sqlsession中的缓存,一种是在每个SqlSessionFactory中的缓存在SqlSession中的缓存又被叫做是Mybatis的一级缓存。每当完成一次查询操作时,会在SqlSession中形成一个map结构,用来保存调用了哪个方法,以及方法返回的结果,下一次调用同样的方法时会优先从缓存中取当我们执行insert、update、delete等sql操作,或者执行SqlSession的close或者clearCache等方法时缓存会被清理在SqlSessionFactory中的缓存被称做二级缓存,所有由同一个SqlSessionFactory创建出来的SqlSessin共享同一个二级缓存。二级缓存是一个结果的二进制值,每当我们使用它时,它会取出这个二进制值,并将这个值封装为一个新的对象。在我们多次使用同一片二级缓存中的数据,得到的对象也不是同一个使用二级缓存需要进行一些额外的配置:在主配置文件中添加配置 在settings的子标签setting 中添加属性 enableCache=True开启二级缓存在对应的dao xml配置中添加 cache标签(标签中不需要任何属性或者文本内容),使接口支持缓存在对应的select、update等标签上添加属性 useCache=true,为方法开启二级缓存
-
EL表达式与JSTL JSP标准标签库(JSTL)是一个JSP标签集合,它封装了JSP应用的通用核心功能。JSTL支持通用的、结构化的任务,比如迭代,条件判断,XML文档操作,国际化标签,SQL标签。 除了这些,它还提供了一个框架来使用集成JSTL的自定义标签。JSTL安装要使用jstl需要导入对应的库,可以去官方站点下载, 点击这里下载然后解压文件将得到的jar包放入到WEB-INF的lib中导入之后,在要使用它的jsp文件中使用taglib 导入库<%@taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>prefix 是标签的前缀,类似于命名空间,在使用库中的标签时需要加上这个前缀常用标签if 标签if标签用来做判断,当条件成立时,执行标签体的内容,条件写在test属性中,注意:只有if标签而没有对应的else标签。下面是一个例子:<c:if test="${not empty requestScope.error}"> <div style="color:red;width:100%;" align = "center">${requestScope.error}</div> </c:if>上述这个例子表示,当服务器返回错误信息时,将错误信息显示到页面上choose 标签choose 标签相当于switch 语句,该标签中可以包含 when 和 otherwise 作为字标签,相当于switch语句中的case和default,例如下面的例子<p>当前薪水为 : <c:out value="${salary}"/></p> <c:choose> <c:when test="${salary <= 2000}"> 老板我是你爹, 这个工作谁爱干谁干 </c:when> <c:when test="${salary > 50000}"> 公司是我家,工作就是我的价值,我热爱工作 </c:when> <c:otherwise> 心中无半点波澜,甚至想提前下班 </c:otherwise> </c:choose>foreach 标签foreach 用来迭代容器中的元素,或者完成一些重复的操作。当使用foreach标签来进行重复性的操作时可以使用begin、end、var来控制循环,begin表示循环变量开始的值,end表示循环变量结束的值,与正常的for循环不同,循环变量的值可以等于end的值;使用var标签来定义循环变量的名称,使用step表示步进。例如:<c:foreach begin = "1" end = "10" var = "i step = "1"> ${i} <br /> </c:foreach>等价于for(int i = 1; i <= 10; i++){ System.out.println(i); }当使用 foreach来迭代容器时使用item和 var来迭代,其中item为需要迭代的容器,var表示获取到的容器中的元素。例如<c:foreach items = "list" var = "l"> ${l} </c:foreach>等价于for(String l:list){ System.out.println(l); }ELEL 表达式:Expression Language 表达式语言,用于替换和简化jsp页面中java代码的编写。EL 表达式使用 ${} 来表示jsp 默认支持el表达式,在page指令中可以使用 isELIgnored 来指定是否忽略jsp页面中的el表达式;当然也可以使用 \ 来作为转义符,表示 这个el表达式原样输出,例如 \${cookie}EL表达式中可以支持算数运算符、比较运算符、逻辑运算符合empty 空运算符;empty用于判断字符串、集合、数组对象是否为null或者长度为0。在使用el表达式时需要注意以下几点:el表达式只能从域对象中获取值el表达式中如果是类对象,可以根据Java Bean规范来获取属性值针对list这种有序集合可以使用 ${域对象.键名[索引].属性}针对Map集合,使用 ${域对象.键名.key名}或者 ${域对象.键名["key名"]}el 表达式中对域对象都做了重命名,pageScope 对应于 pageContext、requestScope对应于request、sessionScope对应于session、applicationScope对应于applicate(ServletContext)表达式${键名} 依次从最小的域中去查找对应的键值,直到找到为止
-
jsp 之前聊过用java处理web请求,处理cookie和session等等,但是唯独没有提及如何返回信息。作为一个web程序,肯定需要使用HTML作为用户界面,这个界面需要由服务端返回。返回信息可以使用HttpResponse中的OutputStream对象来写入数据。但是既要在里面写入HTML,又要写入相应的值,造成程序很难编写,同时HTML代码长了也不容易维护。我们需要一种机制来专门处理返回给浏览器的信息。JSP就是用来专门处理这种需求的。JSP概述JSP (Java Server Page):Java 服务端页面。是由 Sun Microsystems 公司倡导和许多公司参与共同创建的一种使软件开发者可以响应客户端请求,而动态生成 HTML、XML 或其他格式文档的Web网页的技术标准。jsp可以很方便的在页面中通过java代码嵌入动态页面JSP原理分析下面是一个简单的hello world程序<%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>index</title> </head> <body> <% out.println("hello world"); %> </body> </html>我们将其部署到tomcat服务器上,启动并访问它之后会在tomcat所在目录的 work\Catalina\localhost\JSPDemo\org\apache\jsp (其中JSPDemo是项目名称), 在这个目录下面可以看到生成了一个index_jsp.java、index_jsp.class下面是这个jsp生成的部分源码package org.apache.jsp; import javax.servlet.*; import javax.servlet.http.*; import javax.servlet.jsp.*; public final class index_jsp extends org.apache.jasper.runtime.HttpJspBase implements org.apache.jasper.runtime.JspSourceDependent, org.apache.jasper.runtime.JspSourceImports { static { _jspx_imports_packages = new java.util.HashSet<>(); _jspx_imports_packages.add("javax.servlet"); _jspx_imports_packages.add("javax.servlet.http"); _jspx_imports_packages.add("javax.servlet.jsp"); _jspx_imports_classes = null; } public void _jspInit() { } public void _jspDestroy() { } public void _jspService(final javax.servlet.http.HttpServletRequest request, final javax.servlet.http.HttpServletResponse response) throws java.io.IOException, javax.servlet.ServletException { final javax.servlet.jsp.PageContext pageContext; javax.servlet.http.HttpSession session = null; final javax.servlet.ServletContext application; final javax.servlet.ServletConfig config; javax.servlet.jsp.JspWriter out = null; final java.lang.Object page = this; javax.servlet.jsp.JspWriter _jspx_out = null; javax.servlet.jsp.PageContext _jspx_page_context = null; try { response.setContentType("text/html;charset=UTF-8"); out.write("\n"); out.write("\n"); out.write("<html>\n"); out.write(" <head>\n"); out.write(" <title>index</title>\n"); out.write(" </head>\n"); out.write(" <body>\n"); out.write(" "); //这里是java代码的开始 out.println("hello world"); //这里是java代码的结尾 out.write("\n"); out.write(" </body>\n"); out.write("</html>\n"); } catch (java.lang.Throwable t) { //todo someting } finally { //todo someting } } }我们查询一下HttpJspBase这个类可以得到如下继承关系java.lang.Object | +--javax.servlet.GenericServlet | +--javax.servlet.http.HttpServlet | +--org.apache.jasper.runtime.HttpJspBase也就是说jsp本质上还是一个Servlet类,当我们第一次访问这个jsp页面时,服务器会根据jsp代码生成一个Servlet类的.java源码文件然后编译。对比jsp代码可以看得出来,在翻译的时候它逐行翻译,将html代码采用out.write进行输出,对应的java代码则原封不动的放在对应的位置。既然它是一个servlet,那么他的生命周期与相关注意事项就与Servlet相同了。jsp语法jsp确实简化了用户界面的编写,但是如果只知道原理,而不知道如何使用它仍然是白瞎,这部分来简单聊聊如何使用它jsp的代码主要放在3种标签中<% code %>: 这种格式中的代码,主要放的是要执行的java代码,它们最后会被解析到类的service方法中<%! code %>: 这种格式中的代码,主要包含的是成员变量的定义,它们最后会被解析到类的成员变量定义中<%= code %>: 这种格式中的代码,最终会被输出到页面上,会被解析到 out.print中进行输出下面我们对index.jsp进行改造,做一个简单的统计页面访问量的功能:<%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>index</title> </head> <body> <%! private int totalVisited = 0; %> <% totalVisited++; %> <%= "客户请求次数:" + totalVisited %> </body> </html>然后再看看生成的java代码public final class index_jsp extends org.apache.jasper.runtime.HttpJspBase implements org.apache.jasper.runtime.JspSourceDependent, org.apache.jasper.runtime.JspSourceImports { private int totalVisited = 0; public void _jspInit() { } public void _jspDestroy() { } public void _jspService(final javax.servlet.http.HttpServletRequest request, final javax.servlet.http.HttpServletResponse response) throws java.io.IOException, javax.servlet.ServletException { final java.lang.String _jspx_method = request.getMethod(); final javax.servlet.jsp.PageContext pageContext; javax.servlet.http.HttpSession session = null; final javax.servlet.ServletContext application; final javax.servlet.ServletConfig config; javax.servlet.jsp.JspWriter out = null; final java.lang.Object page = this; javax.servlet.jsp.JspWriter _jspx_out = null; javax.servlet.jsp.PageContext _jspx_page_context = null; try { response.setContentType("text/html;charset=UTF-8"); out.write("\n"); out.write("\n"); out.write("<html>\n"); out.write(" <head>\n"); out.write(" <title>index</title>\n"); out.write(" </head>\n"); out.write(" <body>\n"); out.write(" "); out.write("\n"); out.write("\n"); out.write(" "); totalVisited++; out.write("\n"); out.write("\n"); out.write(" "); out.print( "客户请求次数:" + totalVisited ); out.write("\n"); out.write(" </body>\n"); out.write("</html>\n"); } }jsp内置对象我们在写jsp页面时关注的其实是Servlet的service 方法,谈及jsp内置对象的时候主要关注的是service中定义的相关变量,从生成的代码上来看,我们可以使用的是service方法中的输入参数request和response 再加它事先定义好的9个局部变量。它们的含义如下:HttpServletRequest request: 请求对象,之前在HttpServlet中已经了解了它该如何使用javax.servlet.jsp.PageContext pageContext: 页面的上下文,提供对JSP页面所有对象以及命名空间的访问。可以用它拿到request、cookie、session等一系列页面中可以访问到的对象HttpSession session: 当前会话ServletContext application: servlet上下文,我们可以拿到servlet的相关对象。比如获取当前servlet对象的名称,然后拼接一个路径。这样就不用考虑如何部署的问题JspWriter out: 输出对象HttpServletResponse response: HTTP响应对象Object page: 从定义和初始化值来看,它代表的是当前Servlet对象ServletConfig config: ServletConfig类的实例,获取当前servlet的配置信息Except: 当前异常,只有当jsp页面是错误页面是才能使用这个对象。其他的东西基本上用不上,这里也就不再介绍了。指令通过上面的相关知识点,现在已经能写相关的jsp代码了,但是既然本质上是servlet类,那么java其他的操作,比如导入相关库文件怎么办呢?这就需要用到对应的jsp指令。jsp指令放在 <%@ code %>中,jsp指令主要有3大类:page: 定义网页依赖属性,比如脚本语言、error页面、缓存需求等等include: 包含其他文件,可以利用这个属性事先抽取出页面的公共部分(比如页面的头部导航栏和页脚部分),最后再用include做拼接。taglib: 引入标签库的定义, 这个在使用jstl 和es表达式等第三方jsp扩展库的时候使用每条指令可以有多个属性,page 指令的相关属性如下:属性含义contentType等同于 response.setContentType方法,用于设置响应头的Content-Type属性pageEncoding设置jsp页面自身的编码方式language定义jsp脚本所使用的语言,目前只支持java 语言import导入java包errorPage当前页面发生异常后会自动跳转到指定错误页面isErrorPage标识当前页面是否是错误页面,错误页面中可以使用exception 对象,用来捕获异常include 指令的相关属性如下:属性含义file包含的文件路径taglib 的属性如下:属性含义prefix前缀,它们是自定义的,将来要用lib中的标签时用它作为前缀uri第三方库所在路径
-
Servlet 会话 在网络的七层模型中,会话层位于传输层之上,它定义如何开始、控制和结束一个会话。七层模式目前仅仅处于理论阶段,但是Web中借鉴了其中的一些思路。在Web中浏览器第一次发送请求到服务器开始直到一方断开为止算作一个会话。HTTP协议本身没有状态,那么Web服务如何知道这次请求是否在一个会话中呢?Web提供了Cookie和Session两种技术。服务器在第一次收到请求之后,会在HTTP响应头的Set-Cookie中,设置Cookie值,浏览器收到响应后,保存这个Cookie在本地。后续再进行请求的时候在HTTP的请求头中设置Cookie值,服务器根据此Cookie来识别请求的状态。Cookie值本身是一个键值对,例如 Cookie: name=value;Servlet 使用Cookie在Servlet中,使用Cookie的步骤如下:创建Cookie对象 new Cookie(String name, String value)发送cookie到浏览器 response.addCookie(Cookie)获取浏览器中发送过来的cookie request.getCookies() 返回所有Cookie遍历Cookies 获取所有cookie对象调用Cookie.getName(), Cookie.getValue()获取Cookie中的键和值使用的注意事项如下:一次可以返回多个Cookie,多次调用response.addCookie即可默认情况下浏览器关闭页面后cookie失效,但是可以设置cookie失效时间Cookie虽然可以用来识别一次会话,但是也不能滥用,第一Cookie是存储在浏览器端的,可以被伪造,一般做过爬虫自动登录的都这样干过,第二浏览器对于单个cookie大小有限制,一般是4kb。同时浏览器对于单个域名的cookie也有限制,默认是20个。由于cookie本身是类似于小饼干的小料,一般来说不会把小料作为主菜。SessionCookie一般作为小料,作为会话标识来说,用Session更为常见。与 Cookie相比Session存储在服务器端,Session没有cookie的那些限制。实现原理Session的实现是基于Cookie的。第一次调用request.getSession获取Session,没有Cookie 会在内存中创建一个新的Cookie对象,名称为JSESSION值是一个唯一的ID,作为session的唯一标识在给客户端响应时会包含一个cookie值,Set-Cookie: JSESSION=ID浏览器在下一次访问web中的其他资源时会将cookie作为请求头发送到服务器。服务器会从cookie中取出ID值,并根据ID从内存中查找对应的Session对象使用 HttpSession session = request.getSession(); 来获取一个Session对象函数列表Session 对象常用函数如下:public Object getAttribute(String name); //该方法返回在该 session 会话中具有指定名称的对象,如果没有指定名称的对象,则返回 null。 public Enumeration getAttributeNames(); //该方法返回 String 对象的枚举,String 对象包含所有绑定到该 session 会话的对象的名称。 public long getCreationTime(); //该方法返回该 session 会话被创建的时间,自格林尼治标准时间 1970 年 1 月 1 日午夜算起,以毫秒为单位。 public String getId(); //该方法返回一个包含分配给该 session 会话的唯一标识符的字符串。 public long getLastAccessedTime(); //该方法返回客户端最后一次发送与该 session 会话相关的请求的时间自格林尼治标准时间 1970 年 1 月 1 日午夜算起,以毫秒为单位。 public int getMaxInactiveInterval(); //该方法返回 Servlet 容器在客户端访问时保持 session 会话打开的最大时间间隔,以秒为单位。 public void invalidate(); //该方法指示该 session 会话无效,并解除绑定到它上面的任何对象。 public boolean isNew(); //如果客户端还不知道该 session 会话,或者如果客户选择不参入该 session 会话,则该方法返回 true。 public void removeAttribute(String name); //该方法将从该 session 会话移除指定名称的对象。 public void setAttribute(String name, Object value); //该方法使用指定的名称绑定一个对象到该 session 会话。 public void setMaxInactiveInterval(int interval); //该方法在 Servlet 容器指示该 session 会话无效之前,指定客户端请求之间的时间,以秒为单位。