搜索到
109
篇与
的结果
-
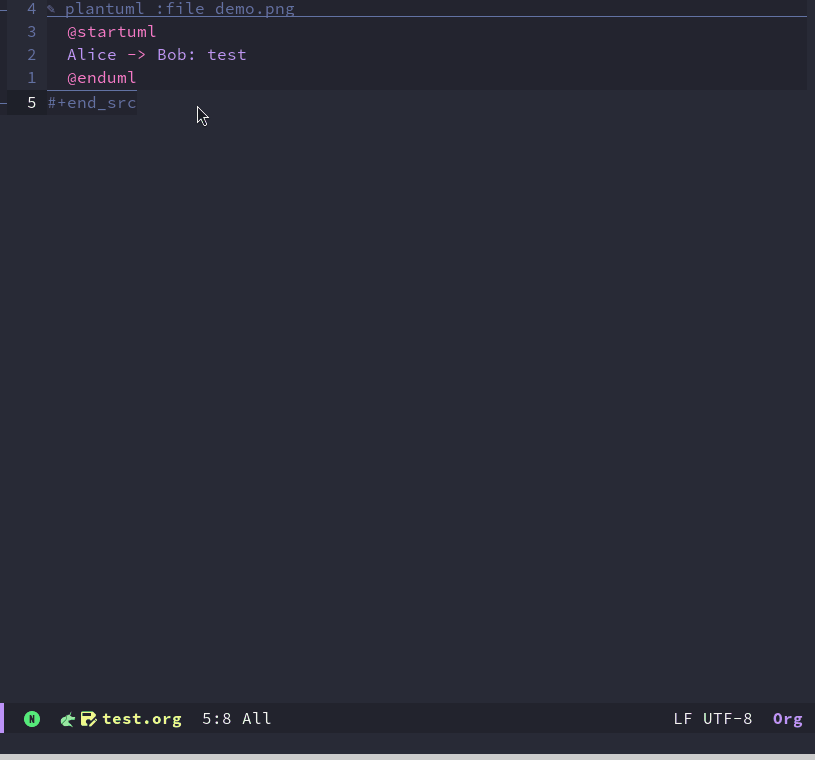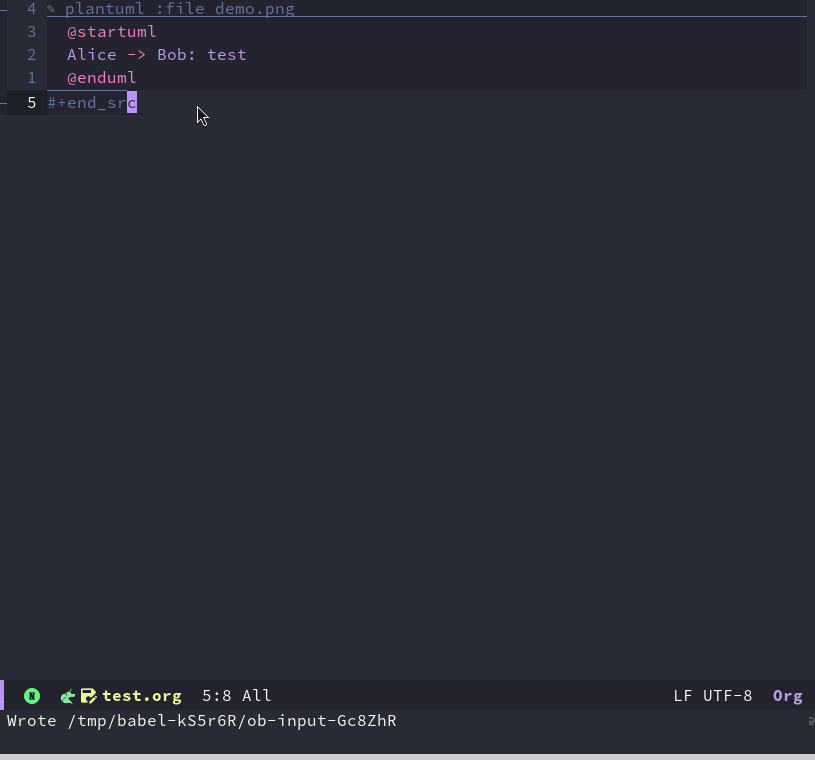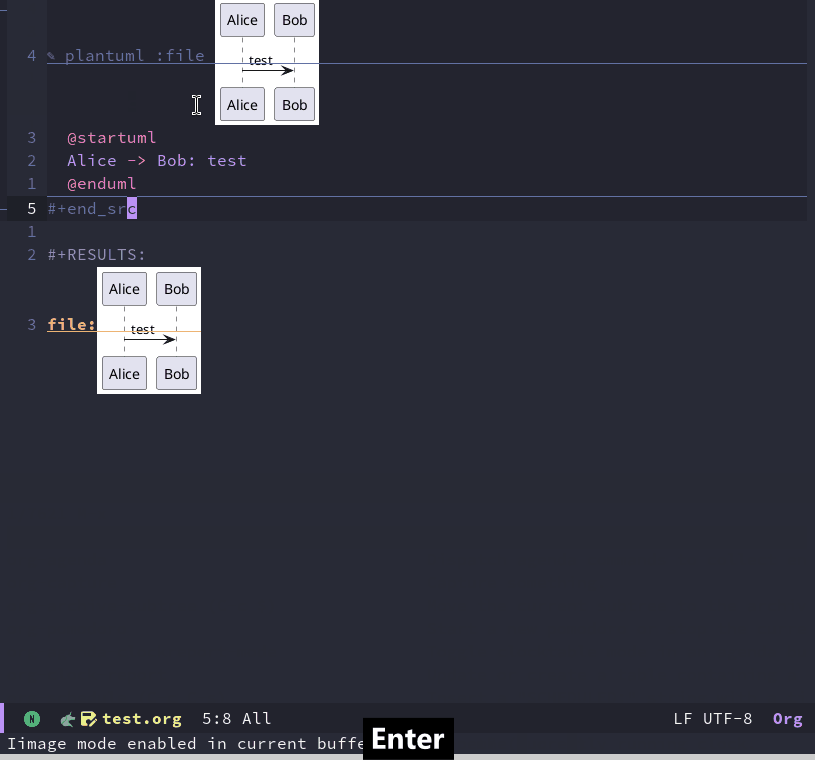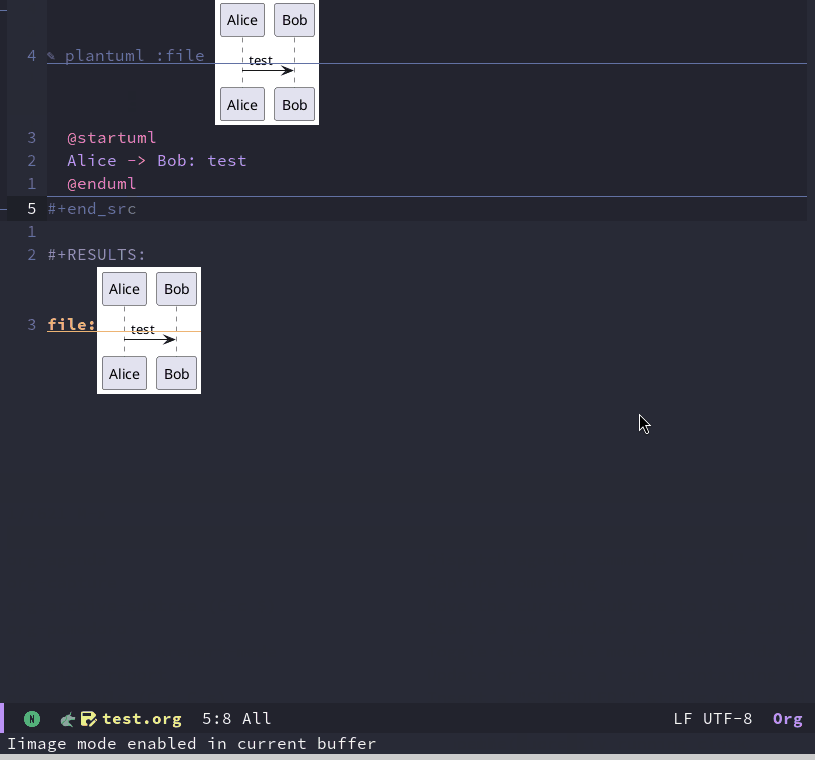
 Emacs折腾日记(三十六)——打造个人笔记系统 在前面我介绍了如何使用 org mode 来实践 gtd 的理念。其实org mode 和其他工具的结合可以打造一个强大的个人笔记系统嵌入 plantuml作为程序员,对 uml 自然不会陌生,虽然时至今日可能有些显老,但是对我来说它仍然是我不可或缺的工具。而 plantuml 是一种将文本转化为图片的工具。我们可以在 plantuml 入门 找到对应的安装步骤。对于archlinux 来说,我需要首先保证java 安装sudo pacman -S jdk21-openjdk根据 plantuml 的官方介绍,只需要jdk8就可以运行,但是我比较喜欢安装最新的版本。plantuml 中某些图需要依赖 graphviz 来生成,所以这里需要再安装一个 graphvizsudo pacman -S graphviz完成了这些基础组件的安装,下面我们就可以下载 程序这个 jar 包放在哪里都可以,既然是Emacs配合,那么我打算将它放置到 ~/.emacs.d/lib 中作为功能的依赖库我们可以使用官网的测试用例来测试一下是否正常@startuml Alice -> Bob: test @enduml将上述文本保存为 test.txt。然后执行 plantuml.jar -jar test.txt。默认在当前目录中生成同名的png图片。如果显示正常,那么我们就可以进行Emacs的改造工作了根据 官方 的文档,针对Emacs,它提供了名为 plantuml-mode 的扩展插件。我们可以通过以下简单的配置来进行org和plantuml 的联动(use-package plantuml-mode :ensure t :mode ("\\.puml\\'" "\\.plantuml\\'") :config (setq plantuml-default-exec-mode 'jar) (setq plantuml-jar-path (expand-file-name "~/.emacs.d/lib/plantuml.jar")) ;; 设置plantuml jar包的位置 ;; 让org代码块能识别plantuml语法 (add-to-list 'org-src-lang-modes '("plantuml" . "plantuml")) (org-babel-do-load-languages 'org-babel-load-languages '((plantuml . t))) (setq org-plantuml-jar-path plantuml-jar-path) )我们还是可以用官方给的示例来看看具体的效果#+begin_src plantuml :file demo.png @startuml Alice -> Bob: test @enduml #+end_src这里必须通过 :file 来指定生成图片的链接这里可以为 plantuml 做一个代码片段以便快速进行进入画图的流程。具体细节就不再深入介绍了。各位读者有兴趣可以自行探索。另外关于画图的一些其他技巧和配置,可以参考 面向产品经理的Emacs教程:15. 在Org mode里用纯文本画图构建笔记系统我个人习惯使用双链笔记,简单来说它就像wiki一样随意插入链接,各种知识结构是一个网状的。传统的笔记是树状结构(这里主要是指马克飞象那样的笔记软件对笔记的组织形式),某一条笔记输入某个单元,而这个单元又属于某个父级单元中,就像一本书一样。但我们在学习的过程中,很难在一开始就把知识整理成体系,而是先零散学习,之后随着知识面的增加逐渐形成体系。另外有些跨学科的知识可能会在多个地方被提及到,就像芒格说的跨学科思维。我们无法将某条知识仅仅归于一个大类里面。而当前双链笔记它是没有层级的,它是一个网络结构,任何知识都可以随意引用其他知识。更符合我们的认知习惯,学到新知识了先记下来,未来知识成体系了可以通过链接随意将它放置到任何体系下。在Emacs中可以使用 org-roam 插件来实现(use-package org-roam :ensure t :after org :init (setq org-oram-v2-ack t) :config (org-roam-setup) :custom (org-roam-directory "~/org/roam/") :bind (("C-c n f" . org-roam-node-find) (:map (("C-c n i" . org-roam-node-insert) ("C-c n o" . org-id-get-create) ("C-c n t" . org-roam-tag-add) ("C-c n a" . org-roam-alias-add) ("C-c n l" . org-roam-buffer-toggle)))))在 org-roam 中,一个文件就是一个note,我们可以通过 org-roam-node-find 来打开或者新建一个节点。新建的文件会被保存到我们定义的 org-roam-directory 目录中。在我们编写笔记的时候如果需要关联另一个笔记,可以通过 org-roam-node-insert 在随意位置插入对另一个文件的引用。当我们对知识有了一定的理解之后可以通过 org-roam-tag-add 来添加一些标签方便我们日后查找。另外有些时候我们组织某个知识点时,它下面有一些小的知识点,我将它们作为当前文件中的一个子标题,日后如果希望能链接到这个子标题,我们可以在子标题上使用 org-id-get-create 来创建。请记住在 org-roam中无法直接链接标题和子标题,它实际链接的是一个id,我们在创建新的知识点时使用 org-roam-node-find 本身就完成了创建id的过程。另外我们可以通过 org-roam-ui 来将笔记的节点进行可视化(use-package org-roam-ui :vc (:url "https://github.com/org-roam/org-roam-ui" :rev :newest) :after org-roam :config (setq org-roam-ui-sync-theme t org-roam-ui-follow t org-roam-ui-update-on-save t org-roam-ui-open-on-start t))在Emacs 29及以上版本内置了通过github下载的功能,mepla 本身没有提供org-roam-ui 包,所以这里我使用内置的从GitHub下载的功能。在安装好之后可以通过 org-roam-mode 来开启笔记节点的可视化。它会创建一个web服务并打开浏览器访问 http://127.0.0.1:35901/具体的细节可以查看它的官方文档org-roam-ui因为我的笔记暂时都记录在 obsidian 中,还没有迁移过来,暂时不贴我的截图了。总结到此为止对我来说Emacs已经可以成为日常使用的代码编辑器、笔记管理、日程管理软件了。所以我的折腾就暂时告一段落了。但是这并不意味着这个系列的完结。后续如果当前的配置有问题或者我看到好的点子,又或者自己有什么想法实践之后觉得不错的也会更新到这个系列中。但是这个系列不会像现在这样大规模的更新了。我个人对Emacs的了解并不深入,当前的配置也仅仅是一个可用的状态。但是在编写此系列中仍然受到许多读者的喜爱,在这里感谢各位读者的支持与鼓励。在前面我的博客出现错误或者我有疑惑时也有比我强的读者给出意见,指出我的问题,在这里对他们进行感谢。终于从对Emacs的一知半解到拥有了自己的一套配置,虽然不完美甚至显得幼稚,但是在这个折腾的过程中我收获许多,下一阶段我想实践一下 懒猫说的认真读一读 Elisp reference manual 加深自己的理解。最后列举一下我在这个系列中参考的一些教程专业Emacs入门面向产品经理的Emacs教程21天学会Emacs还有其他一些我引用了但是忘记了具体链接的博客或者教程。
Emacs折腾日记(三十六)——打造个人笔记系统 在前面我介绍了如何使用 org mode 来实践 gtd 的理念。其实org mode 和其他工具的结合可以打造一个强大的个人笔记系统嵌入 plantuml作为程序员,对 uml 自然不会陌生,虽然时至今日可能有些显老,但是对我来说它仍然是我不可或缺的工具。而 plantuml 是一种将文本转化为图片的工具。我们可以在 plantuml 入门 找到对应的安装步骤。对于archlinux 来说,我需要首先保证java 安装sudo pacman -S jdk21-openjdk根据 plantuml 的官方介绍,只需要jdk8就可以运行,但是我比较喜欢安装最新的版本。plantuml 中某些图需要依赖 graphviz 来生成,所以这里需要再安装一个 graphvizsudo pacman -S graphviz完成了这些基础组件的安装,下面我们就可以下载 程序这个 jar 包放在哪里都可以,既然是Emacs配合,那么我打算将它放置到 ~/.emacs.d/lib 中作为功能的依赖库我们可以使用官网的测试用例来测试一下是否正常@startuml Alice -> Bob: test @enduml将上述文本保存为 test.txt。然后执行 plantuml.jar -jar test.txt。默认在当前目录中生成同名的png图片。如果显示正常,那么我们就可以进行Emacs的改造工作了根据 官方 的文档,针对Emacs,它提供了名为 plantuml-mode 的扩展插件。我们可以通过以下简单的配置来进行org和plantuml 的联动(use-package plantuml-mode :ensure t :mode ("\\.puml\\'" "\\.plantuml\\'") :config (setq plantuml-default-exec-mode 'jar) (setq plantuml-jar-path (expand-file-name "~/.emacs.d/lib/plantuml.jar")) ;; 设置plantuml jar包的位置 ;; 让org代码块能识别plantuml语法 (add-to-list 'org-src-lang-modes '("plantuml" . "plantuml")) (org-babel-do-load-languages 'org-babel-load-languages '((plantuml . t))) (setq org-plantuml-jar-path plantuml-jar-path) )我们还是可以用官方给的示例来看看具体的效果#+begin_src plantuml :file demo.png @startuml Alice -> Bob: test @enduml #+end_src这里必须通过 :file 来指定生成图片的链接这里可以为 plantuml 做一个代码片段以便快速进行进入画图的流程。具体细节就不再深入介绍了。各位读者有兴趣可以自行探索。另外关于画图的一些其他技巧和配置,可以参考 面向产品经理的Emacs教程:15. 在Org mode里用纯文本画图构建笔记系统我个人习惯使用双链笔记,简单来说它就像wiki一样随意插入链接,各种知识结构是一个网状的。传统的笔记是树状结构(这里主要是指马克飞象那样的笔记软件对笔记的组织形式),某一条笔记输入某个单元,而这个单元又属于某个父级单元中,就像一本书一样。但我们在学习的过程中,很难在一开始就把知识整理成体系,而是先零散学习,之后随着知识面的增加逐渐形成体系。另外有些跨学科的知识可能会在多个地方被提及到,就像芒格说的跨学科思维。我们无法将某条知识仅仅归于一个大类里面。而当前双链笔记它是没有层级的,它是一个网络结构,任何知识都可以随意引用其他知识。更符合我们的认知习惯,学到新知识了先记下来,未来知识成体系了可以通过链接随意将它放置到任何体系下。在Emacs中可以使用 org-roam 插件来实现(use-package org-roam :ensure t :after org :init (setq org-oram-v2-ack t) :config (org-roam-setup) :custom (org-roam-directory "~/org/roam/") :bind (("C-c n f" . org-roam-node-find) (:map (("C-c n i" . org-roam-node-insert) ("C-c n o" . org-id-get-create) ("C-c n t" . org-roam-tag-add) ("C-c n a" . org-roam-alias-add) ("C-c n l" . org-roam-buffer-toggle)))))在 org-roam 中,一个文件就是一个note,我们可以通过 org-roam-node-find 来打开或者新建一个节点。新建的文件会被保存到我们定义的 org-roam-directory 目录中。在我们编写笔记的时候如果需要关联另一个笔记,可以通过 org-roam-node-insert 在随意位置插入对另一个文件的引用。当我们对知识有了一定的理解之后可以通过 org-roam-tag-add 来添加一些标签方便我们日后查找。另外有些时候我们组织某个知识点时,它下面有一些小的知识点,我将它们作为当前文件中的一个子标题,日后如果希望能链接到这个子标题,我们可以在子标题上使用 org-id-get-create 来创建。请记住在 org-roam中无法直接链接标题和子标题,它实际链接的是一个id,我们在创建新的知识点时使用 org-roam-node-find 本身就完成了创建id的过程。另外我们可以通过 org-roam-ui 来将笔记的节点进行可视化(use-package org-roam-ui :vc (:url "https://github.com/org-roam/org-roam-ui" :rev :newest) :after org-roam :config (setq org-roam-ui-sync-theme t org-roam-ui-follow t org-roam-ui-update-on-save t org-roam-ui-open-on-start t))在Emacs 29及以上版本内置了通过github下载的功能,mepla 本身没有提供org-roam-ui 包,所以这里我使用内置的从GitHub下载的功能。在安装好之后可以通过 org-roam-mode 来开启笔记节点的可视化。它会创建一个web服务并打开浏览器访问 http://127.0.0.1:35901/具体的细节可以查看它的官方文档org-roam-ui因为我的笔记暂时都记录在 obsidian 中,还没有迁移过来,暂时不贴我的截图了。总结到此为止对我来说Emacs已经可以成为日常使用的代码编辑器、笔记管理、日程管理软件了。所以我的折腾就暂时告一段落了。但是这并不意味着这个系列的完结。后续如果当前的配置有问题或者我看到好的点子,又或者自己有什么想法实践之后觉得不错的也会更新到这个系列中。但是这个系列不会像现在这样大规模的更新了。我个人对Emacs的了解并不深入,当前的配置也仅仅是一个可用的状态。但是在编写此系列中仍然受到许多读者的喜爱,在这里感谢各位读者的支持与鼓励。在前面我的博客出现错误或者我有疑惑时也有比我强的读者给出意见,指出我的问题,在这里对他们进行感谢。终于从对Emacs的一知半解到拥有了自己的一套配置,虽然不完美甚至显得幼稚,但是在这个折腾的过程中我收获许多,下一阶段我想实践一下 懒猫说的认真读一读 Elisp reference manual 加深自己的理解。最后列举一下我在这个系列中参考的一些教程专业Emacs入门面向产品经理的Emacs教程21天学会Emacs还有其他一些我引用了但是忘记了具体链接的博客或者教程。 -
lazygit 规范提交记录 背景随着项目的进程,我们经常面临一个问题:发现之前的代码有bug,但是我不知道当初为什么这么写,如果改了会影响哪些?会不会把原来改好的bug又改出来了。我们可以通过 git 的提交记录来查看当初为什么改的。但是 git 提交记录的增长,一个文件提交记录可能有成千上万,要是从头到尾找一遍不知道要找到什么时候。更糟糕的是,好不容易找到了结果提交记录就一条 update at 2026/01/29。这种情况着实令人抓狂。要防止这种情况,我们可以从两个方面着手:要求整个团队规范git 的提交记录在IDE中能快速找到每行代码对应的提交记录规范提交记录git 原版的提交信息模板提交记录我们可以采取国际通用的 Conventional Commits (约定式提交)。它的格式如下:<类型>(影响范围): 一句话总结 <空行> [正文:详细解释为什么这么做,解决了什么痛点] <空行> [脚注:关联的任务单号 ID]正文部分我希望用 Why、How 这两个关键词,也就是为什么要改,如何改。git本身支持自定义 commit 信息的格式,我们可以将一个模板添加到 ~/.gitmessage。然后通过命令git config --global commit.template ~/.gitmessage来指定使用定义的模板,这里我定义的模板如下:<type>(scope): <subject> # --- 为什么修改 (Why) --- # 描述导致问题的现象,或为什么要增加这个功能 # --- 解决方案 (How) --- # 简述核心算法或处理逻辑 # --- 关联单号 --- # Fixes: #这里的 <type> 可以是修改的类型,这个部分是必须的,我一般喜欢定义这么几种类型bugfix (修改bug)feature (添加新功能)doc (更新文档或者注释)forspell (拼写修改)scope 代表的是影响范围,可以根据项目情况灵活的定义,例如在一个前后端分离的项目中,可以定义范围为UI、数据传输、权限等等模块最后的 subject 就是一句话总结,例如"修改普通用户可以访问其他用户隐私文件的bug"后面我可以通过 git commit 来触发模板,后续通过git 默认的编辑器(一般是vi 或者 nano)。lazygit 的配置lazygit 本身也支持自定义配置,它主要通过 config.yml 文件配置,默认的配置文件位置如下:Windows: %LOCALAPPDATA%\lazygit\config.ymlMacOs: ~/Library/Application Support/lazygit/config.ymlLinux: ~/.config/lazygit/config.yml我们可以通过一个命令快捷键触发一个规范化提交的功能。用户自定义命令的模板可以在这里找到。它以 customCommands 作为根节点。后面接 key,command 和 prompts。各个部分的含义如下:key: 用来触发命令的快捷键command: 真实触发的命令prompts: 触发时的行为prompts 是另一个根节点,用于定义详细的行为。它的子元素如下:type: 输入项的类型,有 menu 表示下拉列表框;input代表输入框;menuFromCommand根据用户提供的外部shell命令来生成一个下拉列表框title: 输入框的标题,提示我们这个框用来输入什么信息key: 在command中,需要填入一些数据,我们暂时利用占位符来表示,key代表的是某个具体占位符,需要与占位符对应如果我们的类型是 menu 的话,还需要利用 options 标签来表示具体的选项。最终我的配置如下:customCommands: - key: 'X' command: "git commit -m '{{.Form.Type}}{{.Form.Scope}}: {{.Form.Subject}}' -m 'Why: {{.Form.Why}}' -m 'How: {{.Form.How}}' -m '用例文档或者jira单: {{.Form.TestCase}}'" context: 'files' description: '规范化提交 (Gitmoji + Scope)' prompts: - type: 'menu' title: '选择提交类型 (Type)' key: 'Type' options: - name: '✨ feat (新功能)' value: '✨' - name: '🐛 fix (修复Bug)' value: '🐛' - name: '🚀 更新流水线或者部署脚本' value: '🚀' - name: '📝 docs (文档修改)' value: '📝' - name: '⚡ perf (性能优化)' value: '⚡' - name: '🎨 style (格式/美化)' value: '🎨' - name: '🍎 修复苹果系统上的问题' value: '🍎' - name: '🐧 修复linux 系统上的问题' value: '🐧' - name: '🏁 修复Windows上的问题' value: '🏁' - name: '🤖 修复安卓上的问题' value: '🤖' - name: '⬆️ 升级依赖' value: '️⬆️' - name: '⬇️ 降低依赖' value: '⬇️' - name: '♻️ 代码重构' value: '♻️' - name: '➕ 添加依赖' value: '➕' - name: '➖ 删除依赖' value: '➖' - name: '⏪ 代码回滚' value: '⏪' - name: '🔀 代码合并' value: '🔀' - name: '👽 因外部API改动而更新代码' value: '👽' - type: 'menu' title: '选择影响范围 (Scope)' key: 'Scope' options: - name: 'layout' value: '(layout)' - name: 'render' value: '(render)' - name: 'data' value: '(data)' - name: 'none (无特定范围)' value: '' - type: 'input' title: '简短总结 (Subject)' key: 'Subject' - type: 'input' title: '为什么修改 (Why)' key: 'Why' - type: 'input' title: '具体做法 (How)' key: 'How' - type: 'input' title: '用例文档或者jira单 (TestCase)' key: 'TestCase'在command 中利用git命令来生成一条记录详细提交信息的内容。{{}} 中包裹的都是占位符, .Form.Type 表示这部分内容来自用户后续提交的表单项 Type 中的内容。后续在 prompts 中某一个key的名称需要为 Type 以便进行对应上述提交的内容我仍然采用 Conventional Commits 的格式,首先 type 部分我采用 gitmoji 中规定的符号来表示提交的类型。影响范围我根据我当前的项目模块暂时定了 layout、render、data 等范围。正文部分我提供了三项,即 Why、How、TestCase表示为什么这么改,可以描述一下bug现象,产生的原因。How 表示如何修改的,可以简短的描述一下算法或者具体修改项。最后加上一个用例或者bug管理系统中的单子,因为我公司采用的是jira,所以这里我可以关联上jira单号IDE 中查看提交记录因为我在公司中主要采用 Visual Studio 和 Visual Studio Code,所以这里主要介绍它们上面可以使用的插件,至于我钟爱的NeoVim 和 Emacs,我还没来得及研究,暂时不介绍它们的配置了Visual Studio 中可以使用 Git Line Blame 插件。Visual Studio Code 上可以使用 GitLens 它们的作用都是显示光标所在行对应的提交记录。它们的效果各位读者可以自行到插件官方文档中找到截图。我们在上面记录了测试用例或者bug 单子的另一个好处时可以根据测试用例和bug单快速查找与之相关的提交记录。可以使用下列命令git log --grep jira-111实际上它就是一个 grep 过滤,如果使用管道加 grep ,它只会找到对应的输出无法关联到具体的提交记录,但是通过git log 提供的grep它会显示匹配上的具体的提交记录到此我觉得已经可以解决我个人的问题了,不知道上述内容对各位读者是否有用。各位读者如果有更好的想法可以在评论区留言,欢迎读者给我介绍新的解决思路
-
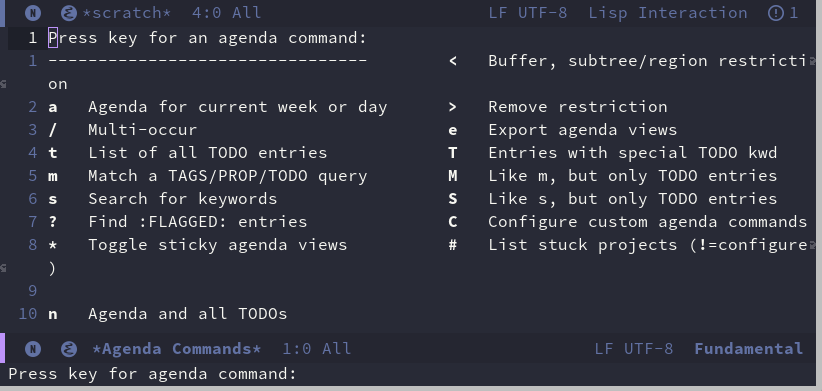
Emacs 折腾日记(三十四)—— org todo 在上一篇文章中,我们简单介绍了 gtd 的一些理念,并且也通过org capture 完成了 gtd 中收集的操作。gtd分为收集任务、整理、执行、回顾。本篇我想通过org todo 来聚焦整理和执行这两个步骤整理上一篇文章中,我们通过org capture 收集到了一些任务,针对这些任务我们还需要给每个任务安排优先级并且根据优先级来确定开始执行的时间。显示待办事项我们在前面的模板中,待办任务前面都是以 TODO 开头,这里的TODO就是org 中待办事项的一个标识。我们可以通过 org-agenda 来查看相关的任务。打开该页面之后,它列举出了所有的支持的一些快捷键。例如使用 t 显示所有的待办事项,使用 m 来根据 PROP、TODO、TAGS 来查找任务。但是第一次使用时会发现自己兴冲冲的咔咔一顿添加任务,结果到头来通过 org-ageda 的 t 来列举之前添加的待办任务毛都没看到,顿时好奇兴奋的心情一下跌倒谷底。别着急这是因为我们没有告诉 org-agenda 该去哪里找这些待办事项。我们可以通过 org-agenda-files 来告诉org-agenda 这个信息就像名称显示的那样 org-agenda-files 是一个列表成员,我们指定它去这些文件中查找待办事项; (use-package org-agenda :ensure nil :custom (org-agenda-files (list "~/org/reading.org" "~/org/blog.org" "~/org/working.org")))这里我设置了三个 org 文档,这三个文档分别记录待读书目、需要完成的博客以及工作任务。需要注意的是我们需要这几个文件真实存在否则就会报错。设置好了这个变量之后效果如下:设定优先级列举出所有任务之后,针对每个任务我们可以考虑如何安排这些任务,首先需要的就是考虑给它从那四个维度安排一个优先级。上面说到我们可以使用A、B、C、D 做一个标识,这里我规定优先级的顺序是:A > B > C > D为了达到这个需求,首先我们要解决的是优先级的定义问题,因为Emacs默认只支持A/B/C这三种优先级,我需要它能支持4种。Emacs种有两个变量分别控制优先级最大值和优先级最小值,它们是 org-highest-priority 和 org-lowest-priority。另外还有一个变量可以设置默认的优先级 org-default-priority。理论上它可以设置优先级从A到Z,但是过多的优先级并不适合。我们可以在上面的 :custom 下使用下列的语句进行设置 (org-highest-priority ?A) (org-lowest-priority ?D) (org-default-priority ?D)设置完成之后可以使用 S-UP (Shift + 上箭头)或者 S-Down(Shift+下箭头)来调整优先级设置计划执行时间和结束时间安排好了优先级,我们就需要为每个任务安排时间了,这里可以安排计划开始时间和结束时间。开始时间和结束时间在 org agenda 中分别是命令 org-agenda-schedule 和 org-agenda-deadline。它们被绑定到了快捷键 C-c C-s 和 C-c C-d上面。当我们通过快捷键或者 M-x 调用这两个命令的时候,Emacs会弹出日历菜单供我们选择日期,默认提供了三个月的日期可供选择。如果不够的化,日历下方两个各有一个箭头可以向上或者向下再显示一个月。另外可以在下方 mini-buffer 处输入 +1d 这样的字符表示在当前时间的1天以后,根据这个规律我们可以输入 + 后面跟任意的数字,然后后面加 d/w/m/y 来表示天、周、月、年。设置任务属性和标签有些任务,特别是工作中的任务我们自己可能无法单独完成,例如某个bug需要前端或者后端一起完成又或者这个bug不光前端要改后端也需要改,这个时候我们修改完了自己的部分,这个时候可以显示我们将任务派发给了其他同事。又或者这个bug牵扯到其他bug,又或者有时候需要开会或者整理需求文档,这个时候我们需要记录该任务的场地例如对于会议可以记录一下在 D-01 会议室。这些可以通过设置属性和标签来描述这些信息。我个人认为它们二者在记录任务的额外信息时没有什么大的区别。主要区别在显示方面,标签一般于TODO 信息展示在一行,而属性默认是被折叠起来的,所以对于一些简要的信息,例如任务目前是谁在处理、开会的地点这类信息我习惯放置到标签上、而属性放置一些不那么重要的信息。对于标签,我们可以在设置任务时,在任务后面使用 :TAG1:TAG2: 这种方式添加多个标签。在前面介绍 org-capture 的文章中我给出了一个创建工作任务的模板 * TODO %^{任务描述} :%^{任务类型|dev|bugfix|env|doc|meeting}:\n SCHEDULED: %^t\n PRIORITY: %^{优先级|A|B|C|D}\n %?\n %i"。任务类型部分就是一个标签,这里我只设置了一个标签。我们可以事先使用 org-tag-alist 来规定一组标签以及打上这个标签所需要的快捷键。这个变量是一个列表类型,每个列表包含一个cell,cell的第一个元素是一个标签的名称,第二个元素是对应的快捷键。同时它也可以通过 :groupstart 和 :groupend 来定义一组互斥的标签项。例如针对任务我们可以定义如下的标签 (org-tag-alist `((:startgroup) ("dev" . ?d) ("bugfix" . ?B) ("env" . ?E) ("doc" . ?D) ("meeting" . ?M) ("reading" . ?R) (:endgroup) ("Sendto Tom" . ?T) ("Sendto Jerry" . ?J) ))需要注意这里标签过多的话,我们需要避免出现快捷键重复的情况。设置了标签,我们可以使用 C-c C-q属性是放到 :PROPERTIES: 下的一组键值对,默认情况下是被折叠的。属性相对于标签来说更加灵活,能显示的信息也更加多样化。我们可以使用 C-c C-x p 来设置属性设置子任务有时候一个大的任务分为几个小任务,例如某个bug可能包含几个方面的问题甚至需要不同组的开发人员进行协调。这个时候我们可以将一个任务分解为几个子任务org mode 中对于子任务的表现比较简单。子任务就是任务下的一个次级的 headline。我们可以在主任务后面加上 [/] 或者 [%] 来根据子任务的完成情况自动更新主任务的完成进度从上面的截图上看,关于子任务还有两个问题没有解决,首先在将任务状态由TODO 切换到DONE时,checkbox的状态应该是勾选的。第二个问题就是当所有的子任务都完成之后应该将主任务的状态改为done。这些我暂时没有找到好的解决方案,所以不展开说明了。任务状态切换上面我们看到可以通过 C-c C-t 来切换状态,但是我们只能在TODO|DONE之间进行切换。以我个人的习惯来说,我还需要几个关键字:WAIT: 等待,一般是任务完成需要等待其他人的配合,例如bug的产生可能是多个模块共同作用,需要等待其他人修改完ABORT:终止DOING: 正在执行这里我说的是关键字,但是它并不代表org todo 中任务实际的状态。事实上org todo中只有两种状态,TODO和DONE表示未完成和终结,我们无法在中间插入新的状态,能做的也只有在两种状态之间插入一些新的关键字。插入新的关键字可以通过设置变量 org-todo-keywords。根据Emacs的文档显示,org-todo-keywords 原始的值为 ((sequence "TODO" "DONE"))。因为这里需要一个有序列表,也就是说Emacs会保证状态切换时按照我们定义的顺序进行切换,并且切换到最后一个关键字时会认定任务已经处于终止状态,后续可以针对这个终止状态来进行一些操作。所以这里需要通过 sequence 函数来保证设置的是一个有序的列表这里我们针对终止状态设置了两个关键字DONE和ABORT,我们可以通过在中间插入 | 的方式告知Emacs,| 之前的关键字是未完成的状态,| 之后的是终止的状态。我们可以在 :custom 下加入 (org-todo-keywords '( (sequence "TODO(t)" "DOING(i)" "WAIT(w@/!)" "|" "DONE(d!)" "ABORT(a@)") ))) 这里后面括号中的字母表示可以在 C-c C-t 之后按字母快捷键快速选择状态,@表示需要由用户填写理由,例如针对等待的任务可以写明需要等待某个子模块修改完成。而后面的 !表示会插入一条包括时间戳的记录。至于 / 则是中间的一个分隔符现在它的效果如下:接入番茄工作法前面介绍了关于任务的定义和关键字的切换,现在我们的流程可能就变成了:通过 org-capture 收集任务将分析任务确定任务的优先级以及计划执行和结束时间通过org-agenda 查看当天需要执行的任务执行任务任务完成之后切换状态在执行任务的过程中我们可以采用番茄工作法来保证时间的高效利用。Emacs中可以嵌入有关番茄工作法的插件来做到。这里推荐使用 org-pomodoro 插件(use-package org-pomodoro :ensure t :custom (org-prmodoro-length 25) ;每个番茄钟25分钟 (org-pomodoro-short-break-length 5) ;; 短休5分钟 (org-pomodoro-long-break-length) ;; 长休15分钟 (每4个番茄钟之后) (org-pomodoro-play-sounds-t) ;; 启用提示音 )在使用时我们可以将鼠标放置到需要执行的任务上,然后执行命令 org-pomodoro。如果出现打扰的情况,例如有同事突然找到你,希望你提供帮助或者外卖电话到了要去拿外卖这个时候可以通过再次执行 org-pomodoro 停止计时。我们可以看到在番茄钟启动之后下方的 minibuffer 中有番茄钟的倒计时。到此为止,我们现在自建的任务管理系统已经可以到执行这步了,这个系统后续只剩下如何进行进行归档与回顾了。关于这部分将在下篇文章中给出我的一些实践,谢谢各位读者的关注
-
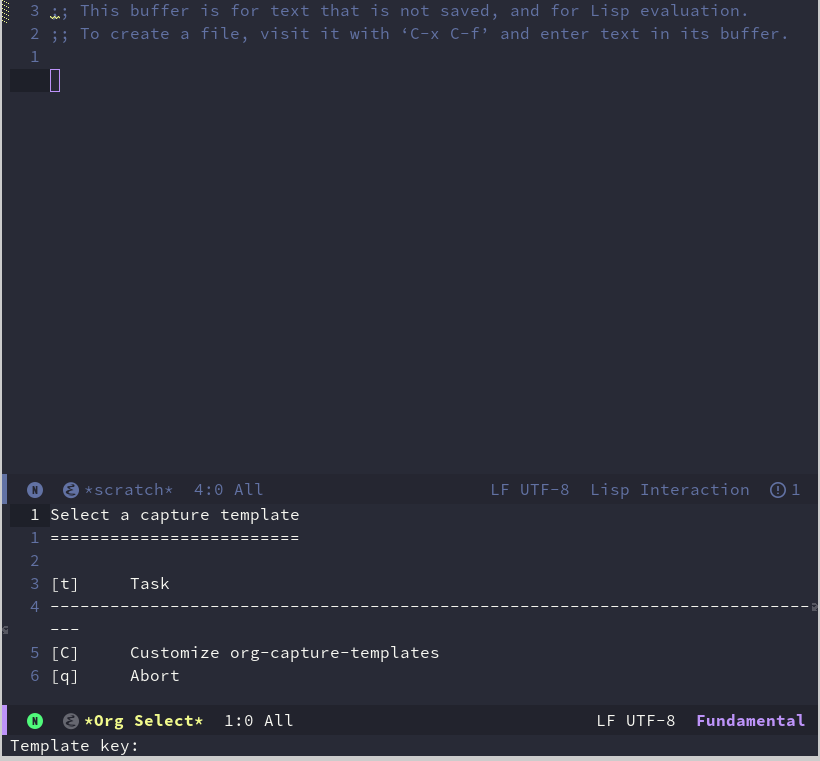
Emacs折腾日记(三十三)——org capture 在日常的工作生活中有各种各样的琐事,如果不及时记录下来很可能后面就忘了。或者在日常软件开发中有很多想法想要实现但是时间一长自己就忘了。这种情况下我们需要一个系统来记录收集想法并且后续需要追踪甚至回顾。我们需要一套适合的管理系统让大脑摆脱待办事项的纠缠,让大脑专注于当前要做的事物。目前我采取的方式是GTD+ 番茄工作法。GTD 简介GTD(Getting Things Done),是由戴维·艾伦于2002年提出的时间管理方法。其核心在于通过收集、整理、组织、回顾、执行五个步骤,将任务从大脑中移出,减轻心理压力以提升效率,强调两分钟内可完成事项立即处理的原则。用我的理解,我们需要事先准备几个速记的笔记本,一旦脑海中出现了想法就将它记录下来,这步叫做收集。在一天中的空闲时间例如下班前或者睡觉前打开看看之前记录的内容,将内容按照一定的规则重新组织例如分为工作、生活、学习之类的想法,将它们转化成可以执行的任务。并且为每个事项定一个紧急程度,这个就是整理、组织。在每天开始的时候或者结束的时候可以根据上面的分类安排一下当前或者明天的任务,这个是执行任务。在每周或者每天的时候回忆一下当前的任务看看哪些完成了、哪些未完成、从任务中有何感想,有哪些可以记录下来作为重要的日志或者日后博客的灵感来源,这个就是最后的回顾总结过程。番茄工作法再完美的系统,如果不执行或者不认真执行也是白搭的。对我来说GTD主要解决的是要做哪些事,如何安排时间的问题。至于如何高效的执行任务专注到任务上,我采用的番茄工作法。番茄工作法的简单理解就是将任务的时间拆分成几个不可分割的最小单元,在这个时间片单元内一心一意、专心到任务上。一旦分心就需要终止当前番茄钟,并记录分心的原因,如果是有新来的新任务就需要采用记录的方式记录,如果是紧急且重要的任务可能还要修改当前的任务计划。当然番茄工作法有一整套的收集、整理、执行、归纳总结的流程,但是对我来说我喜欢GTD的流程和番茄工作法的时间管理方式,所以我采用的是它们二者的结合。但是主要用在工作中,日常生活中的场景都是一些简单的琐事,例如收拾卫生、做饭、对我来说不合适这种形式。org capture目前来说市面上没有完全符合我心目中最佳时间管理理论的工具,但是Emacs中的org 是十分强大的,完全可以稍加改造成符合自己心意的时间管理系统。首先要解决的就是如何收集想法的问题。这个功能可以使用 org-capture,顾名思义它就是使用org的格式来快速记录当前的想法。我们使用 org-capture 命令可以看到下面的界面下方提示我们可以使用前面的字母符号来选择一个模板,默认只提供了一个名为 Task 的模板。我们可以使用 org-capture 中 来实现GTD中的分类记录的功能。在我们选定需要使用的模板之后,Emacs会调用 org-capture-select-template 函数来选中模板并且根据模板来创建默认的org 模板。默认的Task 模板如下:("t" "Task" entry (file+headline "" "Tasks") "* TODO %?\n %u\n %a")它们的含义如下t 标识选择模板时的快捷键。Task 模板的描述,让用户了解当前模板作用的说明文字。后面一个部分就是新增的内容新增的内容比较复杂,我们一个个的说。第一个部分是新增模板的type。type 可以是下面的内容type描述entry带有 headline 的一个 Org mode 节点item一个列表项checkitem一个 checkbox 列表项table-line一个表格行plain普通文本type 的不同,后面跟的内容也不一样。例如如果当前是 entry 的话,后面需要添加 "* headline" 作为标题行的形式,如果是 item 后面需要跟上 - item 作为一个项。如果是 checkitem 需要跟 [ ] item 作为一个checkbox项。如果使用 table-line,需要跟 | colum 1 | colum 2 | colum3 | 作为一个表格项目。如果是 plain 则没有特殊要求。接下来看看 (file+headline "" "Tasks") 中各个部分的含义,前面的 file+headline 表示将记录的内容保存到哪个位置。除了这两个标识还有其他的一些常用标识标识含义file文件id某个特定id的headlinefile+headline某个文件中的某个headlinefile+olp文件中某个headline的路径file+regexp文件以及被正则匹配的headlinefile+datetree文件中当日所在的datetreefile+datetree+prompt文件中的datetree 会弹出日期选择file+weektree文件中当日所属的 weektreefile+weektree+prompt文件中 weektree 会弹出日期选择file+function文件中被函数匹配的headlineclock当前正在计时中的任务所在位置function自定义函数的所定义的位置后面两个参数根据前面的内容来决定,例如如果使用 file+headline 的话,第二个参数就是文件路径,第三个参数就是具体的 headline 的名称。如果文件名参数为空的话,那么会使用 org-default-notes-file 所对应的文件路径为 ~/.notes 这些内容如果觉得有些比较难以理解的,可以查看 org-capture-tempetes 变量的详细说明"* TODO %?\n %u\n %a" 部分都是一些格式字符串和占位符,在选中模板之后会自动生成我们想要的模板文字。这里的占位符如果写过代码应该很容易理解,首先占位符都是 以%开头,后面根据不同的字符表示不同的含义时间相关的占位符占位符含义%<>表示自定义时间的时间戳,两个<>之间可以使用字符表示不同的时间格式,例如 %<%Y-%m-%d> 表示年月日的格式,年是4位字符的形式%t当前仅包含日期的时间戳%T当前包含日期时间的时间戳%u包含当前未激活的时间戳%U表示当前未激活的包含日期时间的时间戳%^t类似于 %t,但是会弹出日历供用户选择%^T类似于%T,但是会弹出日期和时间供用户选择%^u与上面的类似%^U与上面类似这里所谓的激活,在Emacs的文档中使用的词是 interactive 我不知道翻译为激活是否准确。未激活的时间戳日后不会出现在 org-agenda 中,至于什么是 org-agenda 请继续往下看剪切板相关的占位符占位符含义%c当前 kill ring 中的第一条内容%x当前系统剪贴板中的内容%^C交互式地选择 kill ring 或剪贴板中的内容%^L类似 %^C,但是将选中的内容作为链接插入后面还有更多更复杂的占位符,但是目前来说我用不到那么多,也就不一一列举了,各位读者如果感兴趣可以查看 org-capture-templetes 来查阅更多类型的占位符,至于 %?它什么也不往文件里面添加,它会在模板文本添加成功后将光标移动到它所在位置,方便用于自己输入内容除此以外,它还支持自定义函数的形式来插入内容,它的形式为 %(sexp) 括号中间就是lisp函数,假设我们有一个 custom-placeholder 那么这里就可以写成 %(custom-placeholder) 有了这些内容我们就可以定义自己的各种任务的模板个人日常任务模板对我个人来说,日常任务主要有:阅读清单、博客计划、工作任务。下面我希望通过这三大类任务来定制一些模板阅读清单首先是阅读清单,阅读清单主要记录一些我通过各种渠道了解到的并计划在后续需要读的书。根据我之前读的《如何有效阅读一本书:超实用笔记读书法》 的说法,记录要读的书,可以记录下面几个内容:书名作者出版社其他(可以是ISBN号)如果只根据书名可能会有书名重复的现象,所以根据这几条信息就可以唯一确认一本书因为Emacs提供的默认模板我不太喜欢,所以这里我先使用 (setq org-capture-templates nil) 来清空模板,后续由我自己实现各种模板(use-package org-capture :ensure nil :custom (org-capture-templates nil) (org-capture-templates '(("r" "Reading List" entry (file+olp "~/org/reading.org" "Reading" "Book") "*** TODO 《%^{书名}》\n作者:%^{作者}\n出版社:%^{出版社}:\n备注:%^{备注}\n添加时间:%U\n" :clock-int t :clock-resume t))))我们按照之前分析的模板中各个部分的组成来看看它是什么意思。首先第一个部分,我们定义通过快捷键 r 来选中并生成这个模板,Reading List 表示在模板展示时显示的内容。后面的entry 表示我需要添加一个带有 headline 的 org mode 节点,它后面跟着的子列表里面使用 file+olp 表示我需要在文件中的某个headline 下添加这条记录作为它的子内容部分。后面跟的就是文件路径、以及需要插入到当前文件下Reading 里面的 Book 下,作为子节点。最后定义的就是具体的内容了, 因为Reading 作为一级标题,它下面的 Book 作为二级标题,所以这里添加的阅读清单记录就是三级标题,所以我在它前面加了一个 *** 作为三级标题。前面的TODO是关键词,表示待做。后面就是输入的常规的内容了,包括出版社、作者等信息。它的运行效果如下:新建博客文章org-mode实际上是支持转换成markdown并通过hugo之类的静态网站生成程序来生成博客的。对于hugo 来说如果希望将markdown格式的内容转化成博客,我们需要在markdown文件头位置加入这些内容title: "Test" date: categories: blog tags: blog draft: true根据这些信息我们可以很容易的搭建基础的模板。针对这种场景,我希望它能在固定的位置生成一个以时间命名的 .md文档,这个位置一般位于hugo安装目录下的 posts 目录下。我们可以写下这样的配置 (add-to-list 'org-capture-templates `("b" "Blog" plain (file ,(concat "~/org/" (format-time-string "%Y-%m-%d.md"))) ,(concat "---\n" "tile: %^{标题}\n" "date: %U\n" "categories: %^{分类}\n" "tags: %^{标签}\n" "draft: %^{草稿|true|false}\n" "---\n" "%?")))它的效果如下:最终在我们保存之后它会在~/org 目录下生成一个以时间命名的markdown文件这种模式我个人不太喜欢,因为对我而言org-capture 仅仅只是一个收集的动作,我们应该快速记录想要写的博客以及博客的主要论点,而不应该开始编写具体的内容。至于如何使用org-mode来写博客,后面我想单独写一篇博客来介绍创建工作计划作为一个程序员来说,日常工作总会与程序打交道,比如开发新功能、写接口文档、修改bug、搭建开发测试环境、开会等等。有时候需要一个人负责多个多个项目。对于工作任务我们还需要分一个轻重缓急,我一般习惯于将它们分为:重要且紧急、重要但不紧急、紧急但不重要、不重要不紧急。那么对于工作任务的需求就很明确了。首先任务可以归属到不同的项目中,日后可以根据任务进行筛选任务可以细分为开发新功能、修复bug、搭建环境、写文档、开会等等任务可以划分轻重缓急日后通过todolist可以看到任务的轻重缓急,目前使用重要且紧急、重要但不紧急、不重要但紧急、不紧急不重要我们采用下面的代码 (add-to-list 'org-capture-templates `("w" "Work Task" entry (file+headline "~/org/working.org" "Work") "* TODO %^{任务描述} :%^{任务类型|dev|bugfix|env|doc|meeting}:\n SCHEDULED: %^t\n PRIORITY: %^{优先级|A|B|C|D}\n %?\n %i")))它的效果如下:到目前为止,介绍了关于org capture的相关内容,并演示了如何利用capture 实现一个任务的捕捉功能。gtd 后面的流程还有任务的分配、执行、记录等等功能,这些内容将在后面介绍。感谢各位读者的支持
-
Emacs折腾日记(三十二)——org mode的基本美化 在上一篇,已经介绍了org mode的基础知识,它与markdown非常相似,并且也十分容易上手,但是它的可扩展性比markdown要强很多。如果将来打算重度使用org mode,那么此时可以对它进行一些基本的配置和美化基本配置org mode 的配置可以通过Emacs自带的org 包来进行管理,可以配置一些标签显示的图形以及一些特殊语句块的高亮(use-package org :ensure nil :mode ("\\.org\\'" . org-mode) :hook ((org-mode . visual-line-mode) (org-mode . my/org-prettify-symbols)) :commands (org-find-exact-headline-in-buffer org-set-tags) :custom-face ;; 设置org mode标题以及美级标题行的大小 (org-document-title ((t (:height 1.75 :weight bold)))) (org-level-1 ((t (:height 1.4 :weight bold)))) (org-level-2 ((t (:height 1.35 :weight bold)))) (org-level-3 ((t (:height 1.3 :weight bold)))) (org-level-4 ((t (:height 1.25 :weight bold)))) (org-level-5 ((t (:height 1.2 :weight bold)))) (org-level-6 ((t (:height 1.15 :weight bold)))) (org-level-7 ((t (:height 1.1 :weight bold)))) (org-level-8 ((t (:height 1.05 :weight bold)))) (org-level-9 ((t (:height 1.0 :weight bold)))) ;; 设置代码块用上下边线包裹 (org-block-begin-line ((t (:underline t :background unspecified)))) (org-block-end-line ((t (:overline t :underline nil :background unspecified)))) :config ;; 设置org mode中某些标签的显示字符 (defun my/org-prettify-symbols() (setq prettify-symbols-alist '(("[ ]" . 9744) ;; ☐ ("[x]" . 9745) ;; ☑ ("[-]" . 8863) ;; ⊟ ("#+begin_src" . 9998) ;; ✎ ("#+end_src" . 9633) ;; □ ("#+results:" . 9776) ;; ☰ ("#+attr_latex:" . "🄛") ("#+attr_html:" . "🄗") ("#+attr_org:" . "🄞") ("#+name:" . "🄝") ("#+caption:" . "🄒") ("#+date:" . 128197) ;; 📅 ("#+author:" . 128100) ;; 💁 ("#+setupfile:" . 128221) ;;📝 ("#+email:" . 128231) ;;📧 ("#+startup" . 10034) ;; ✲ ("#+options:" . 9965) ;; ⛭ ("#+title:" . 10162) ;; ➲ ("#+subtitle:" . 11146) ;; ⮊ ("#+downloaded" . 8650) ;; ⇊ ("#+language:" . 128441) ;;🖹 ("#+begin_quote" . 187) ;; » ("#+end_quote" . 171) ;; « ("#+begin_results" . 8943) ;; ⋯ ("#+end_results" . 8943) ;; ⋯ )) (setq prettify-symbols-unprettify-at-point t) (prettify-symbols-mode 1)) :custom (org-fontify-whole-heading-line t) ;; 设置折叠符号 (org-ellipsis " ▾") ) 上述配置比较简单,核心部分就是我们使用 prettify-symbols-alist 来使将这些特定的 property 字符串替换成更加美观的图标。它是一个列表,列表种的每个子元素又是一个cell,用cell的两个元素来表示替换关系。配置之后,一个org文件大致的效果如下:org-modern 美化为了使文档的显示效果更好,我们需要依靠一个名为 org-modern 的插件,它是一个为Emacs Org模式提供现代化视觉美化的项目,它通过精心设计的样式和布局,能够显著的提升Org文档的可读性和美观度。我们可以使用 use-package 直接安装(use-package org-modern :ensure t :hook (after-init . (lambda () (setq org-modern-hide-stars 'leading) (global-org-modern-mode t))) :config ;; 定义各级标题行字符 (setq org-modern-star ["◉" "○" "✸" "✳" "◈" "◇" "✿" "❀" "✜"]) (setq-default line-spacing 0.1) (setq org-modern-label-border 1) (setq org-modern-table-vectical 2) (setq org-modern-table-horizontal 0) ;; 复选框美化 (setq org-modern-checkbox '((?X . #("▢✓" 0 2 (composition ((2))))) (?- . #("▢–" 0 2 (composition ((2))))) (?\s . #("▢" 0 1 (composition ((1))))))) ;; 列表符号美化 (setq org-modern-list '((?- . "•") (?+ . "◦") (?* . "▹"))) ;; 代码块左边加上一条竖边线 (setq org-modern-block-fringe t) ;; 属性标签使用上述定义的符号,不由 org-modern 定义 (setq org-modern-block-name nil) (setq org-modern-keyword nil) )现在org 文档显示的就更加漂亮了到此我们对org-mode 显示的效果进行了初步的美化,现在的文档看起来比原始的要好看多了,用org来编写文档至少也显得赏心悦目了。
-
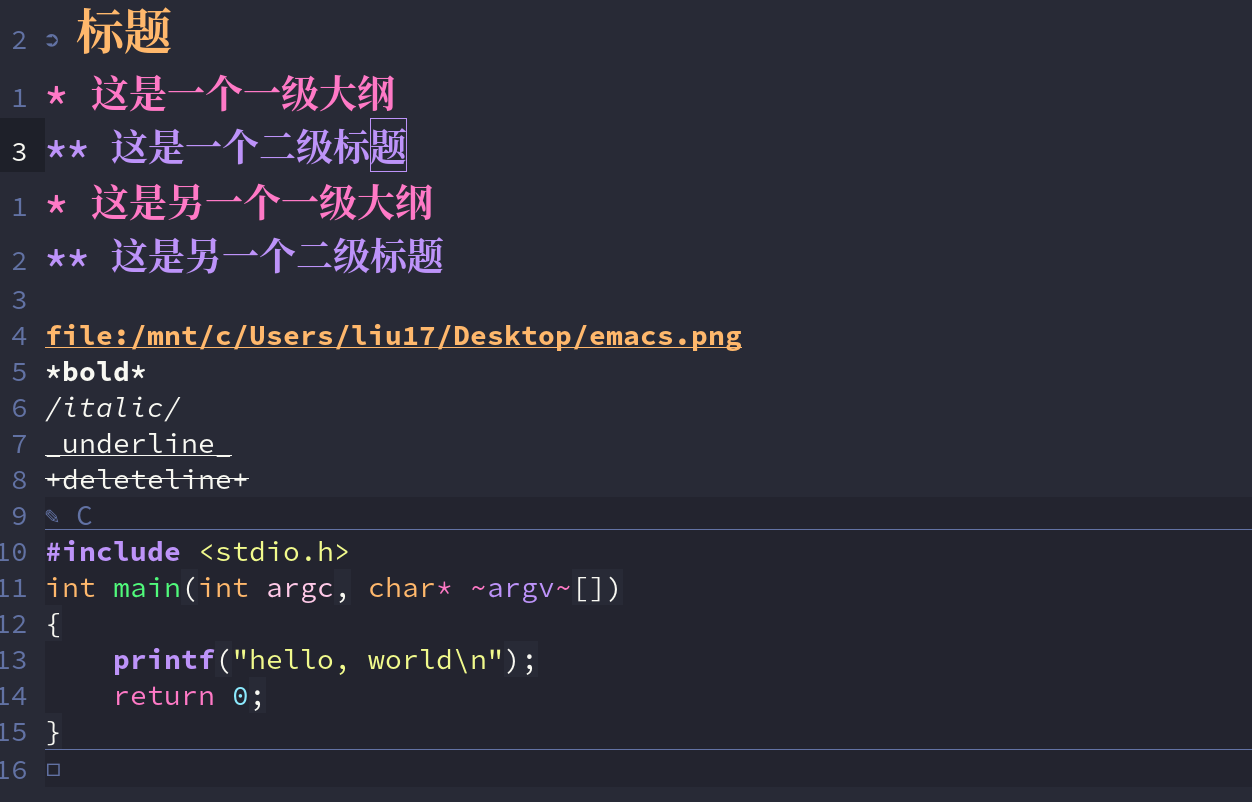
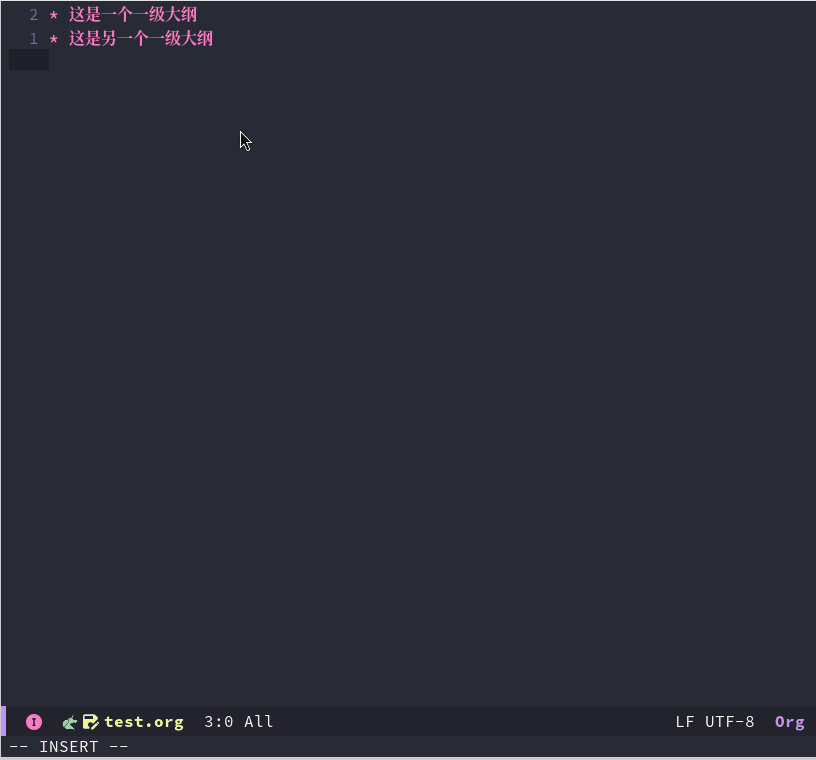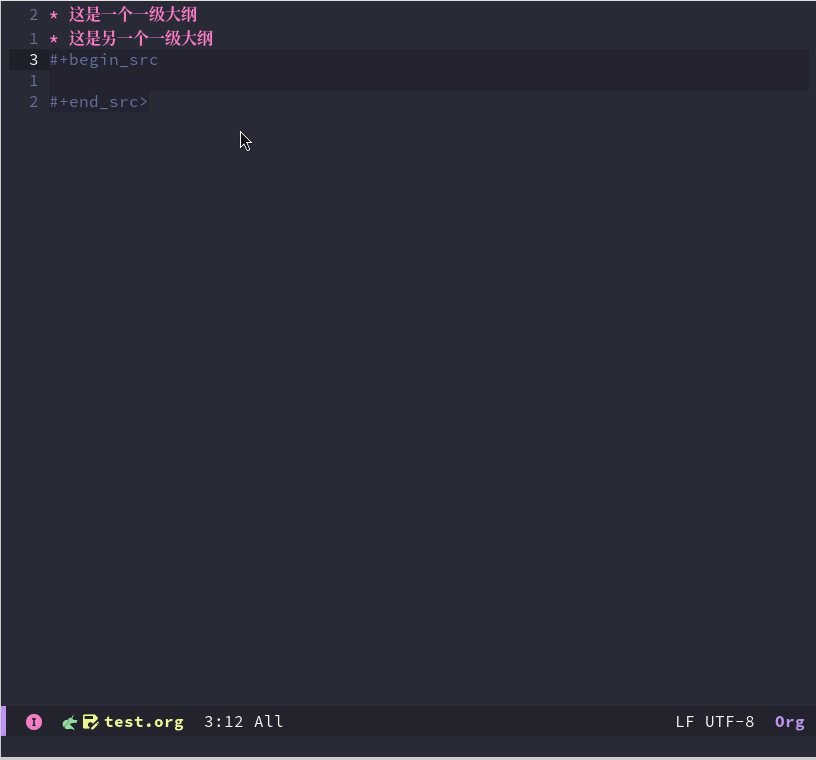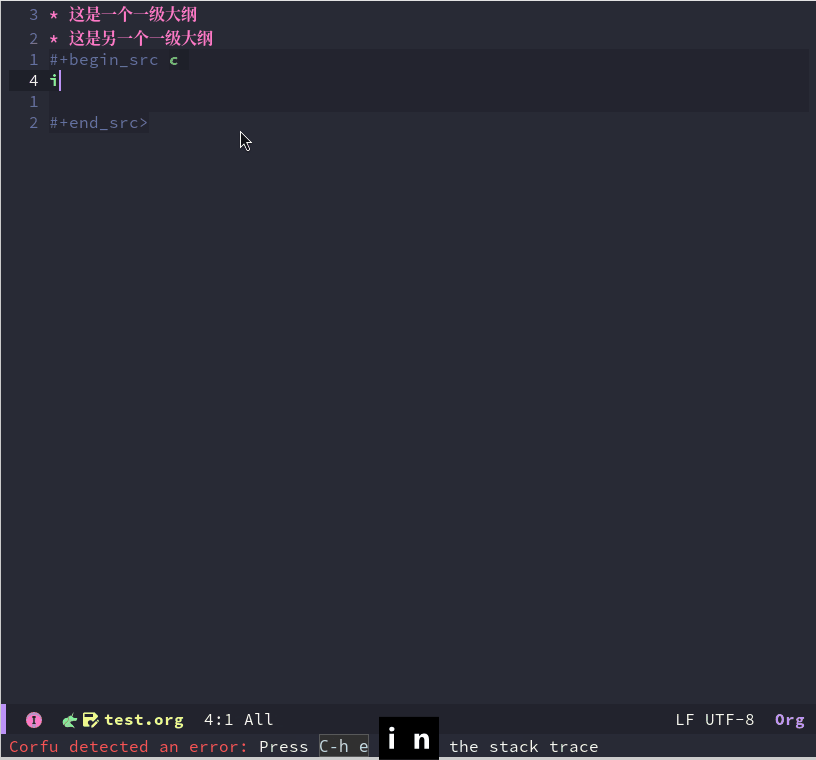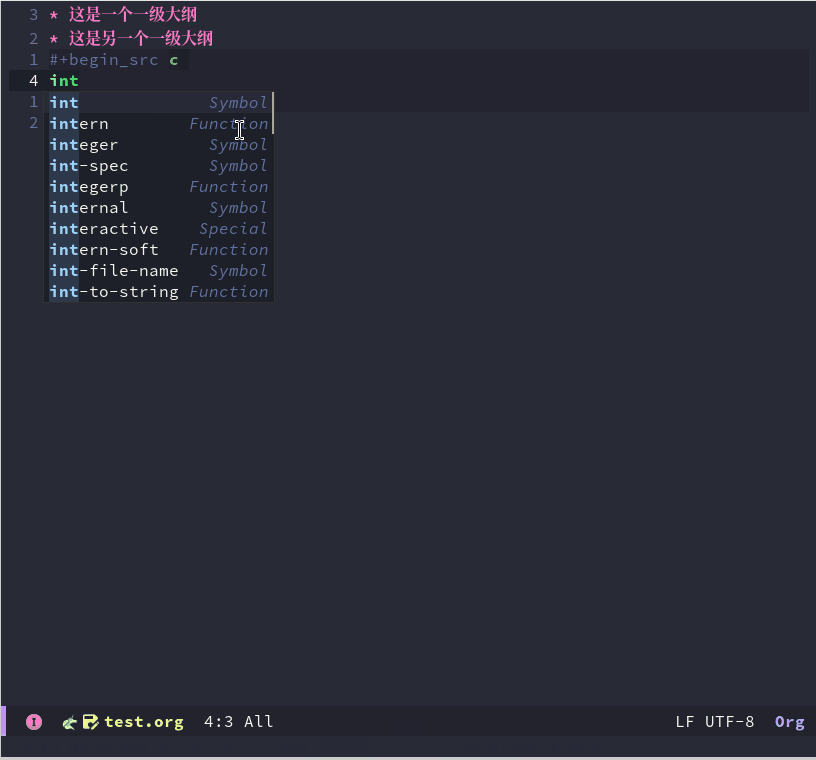
Emacs折腾日记(三十一)——org mode入门 之前我介绍了Emacs相关配置以及对应的知识,主要包括:vim模式、编辑的优化、补全、代码跳转、调试等等,旨在将它打造成另一个vscode、也许是我技术能力有限,不仅在使用体验上赶不上vscode,在配置的简便化以及开箱即用的程度上都比不上。如果是使用Emacs仅仅因为它复杂一般人不那么容易学会,那么就有点装x的嫌疑了。我使用Emacs的原因主要有三点:高度自由、elisp语言的魅力以及org mode。可以说没有org mode我可能不会考虑Emacs。我认为 org mode是Emacs的灵魂也是目前市面上没有任何一款软件能替代的。什么是org mode、它与markdown相比有什么优势呢?本文将对org mode做一个入门的介绍什么是org mode实际上 Org mode 是一种轻量级标记语言,它与markdown、RST类似,但是功能上要比它们强得多,不仅可以用来完成日常的文章编写,还可以进行任务管理、项目规划、笔记收集整理等各种操作。并且配合elisp编程可以千变万化。作为一门标记语言org mode实际是十分容易的,它保存的文档以 .org 作为扩展名基本使用大纲大纲可以理解为多级的标题,了解markdown的肯定知道这个意思。一个 * 代表一级大纲,两个代表二级大纲,然后依次类推。对于大纲我们可以手动输入 *,可以使用Emacs提供的快捷键快捷键功能备注在后面创建一个与光标所在位置同级的大纲如果没有大纲则默认创建一个新的一级大纲M-降低当前大纲的等级 M-升高当前大纲的等级 M-将当前大纲及其内容整体向上移动 M-将当前大纲以及内容整体向下移动 大纲这部分有点像思维导图,我们可以将某些知识点以这种大纲的形式组织起来。有些思维导图软件可以点击某个模块将它的子模块隐藏起来,与这类似的,org mode也可以在大纲上按tab键来显示或者隐藏大纲底下的内容。我们可以定义和切换整个org 文档的大纲显示样式,它主要有三种Folded: 对于当前的大纲只显示大纲本身不显示其子大纲以及内容children: 只显示当前大纲的子大纲,不显示更下一级的内容subtree: 完全展开整个大纲代码块代码块放在 #+BEGIN_SRC 和 #+END_SRC 之间,在Emacs中有一个快捷键 <s <TAB> 来快速输入这个标识. 另外也可以在 后面接上 语言类型,例如下面是一段对应的c++代码#+BEGIN_SRC c++ int main(int argc, char* argv[]) { return 0; } #+END_SRC当我们进入到代码块中编写代码时它会开启对应语言的major mode,前面我们配置了c++ lsp 补全相关的内容也可以在编辑代码块时使用超链接超链接我们可以采用 [[<link url>][<text>]] 的语法,例如 [[https://www.baidu.com][百度一下,你就知道]]图片本地图片可以使用 file:/path/to/image.png 的形式来写上本地图片的位置,然后开启 iimage-mode 显示图片字体样式字体样式主要有:粗体:我们可以使用 ** 来包裹文字以便显示为粗体斜体: 可以使用 // 来包裹文字显示斜体下划线: 可以使用 一前一后两个 _ _来包裹文字将它显示为带下划线的样式删除线: 可以使用 + 前后包裹来显示为删除线其实org mode 与markdown一样都非常简单,日常写博客或者写文档的话,我觉得这些基本知识差不多就够用了。
-
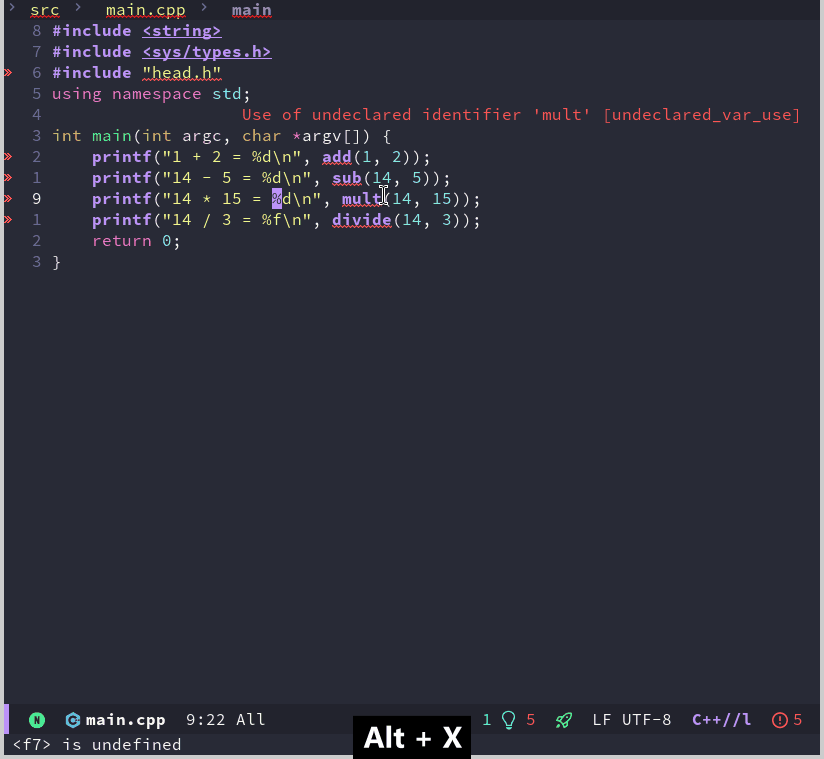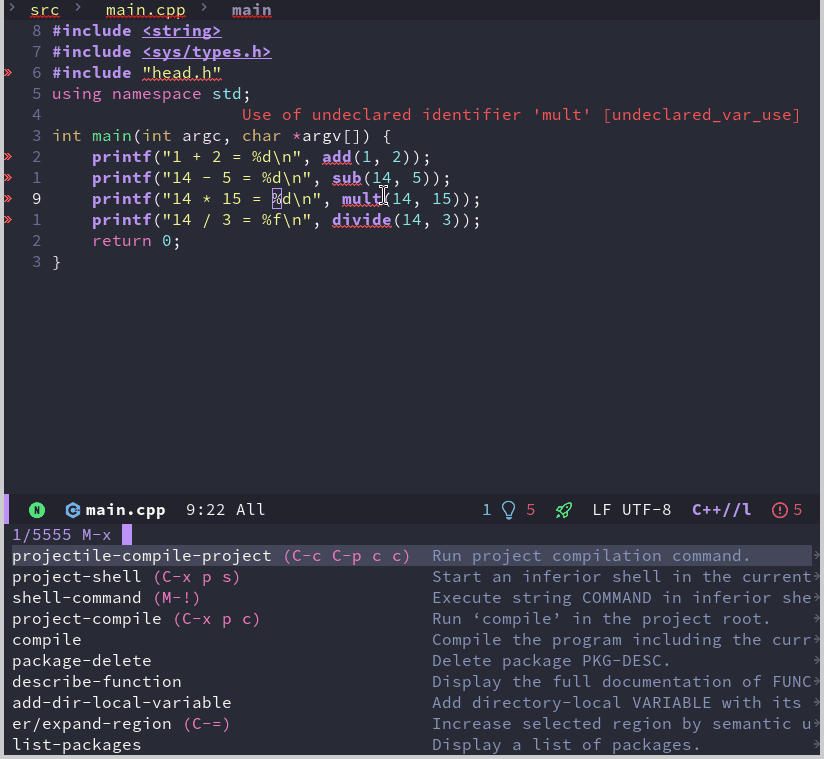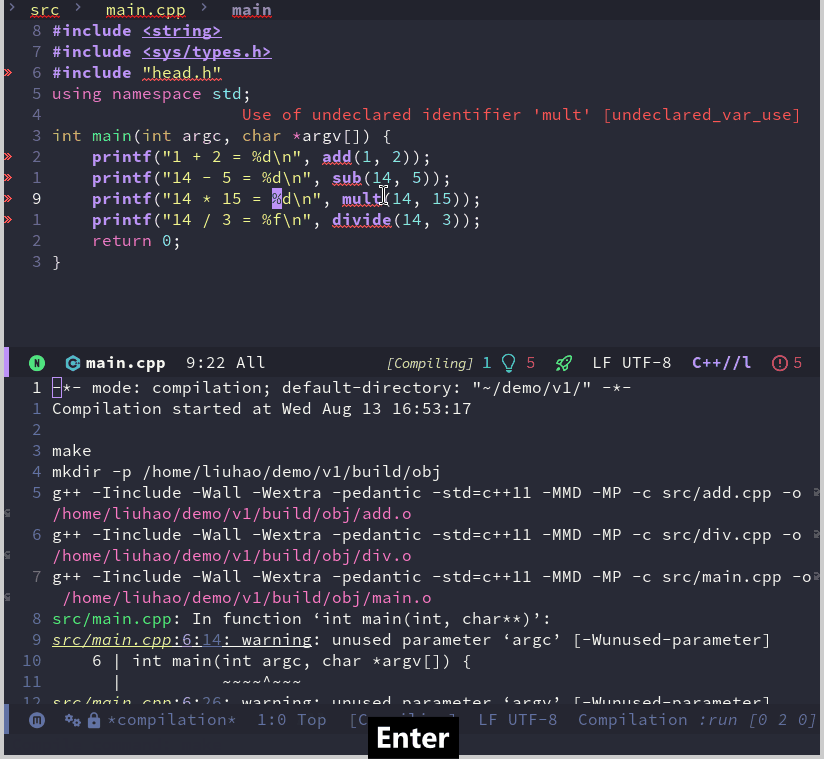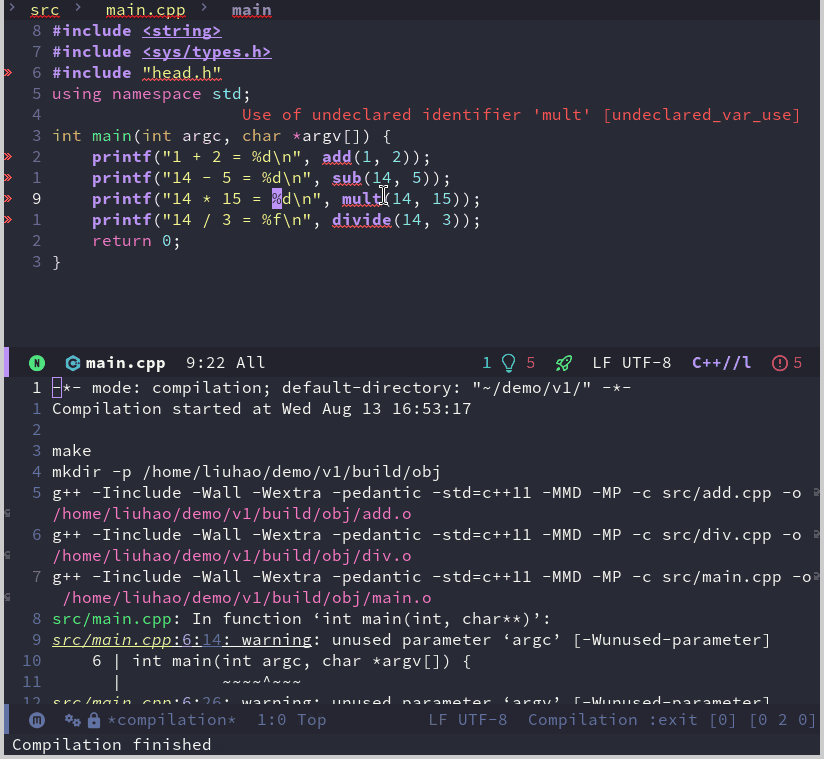
Emacs 折腾日记(三十)——打造C++ IDE 续 上一篇博客中,我完成了C++ IDE初步工作,包括代码的高亮、折叠、跳转以及补全等工作。但是作为IDE来说功能还有点不够,就我个人而言作为IDE来说它还需要具备一键编译运行和调试功能。这篇文章就来记录我是如何实现上述功能的编译运行我使用的演示项目比较简单,它的文件结构如下:. ├── include │ └── head.h └── src ├── add.cpp ├── div.cpp ├── main.cpp ├── mult.cpp └── sub.cpp它分为两个目录分别保存头文件和源文件。其中头文件只有一个定义各个接口函数,而接口函数的实现就放到各自定义的cpp文件中。这里使用加减乘除的四则运算的实现来作为演示。这里我分别演示一下Make文件和CMake构建的项目是如何实现一键编译运行的。Make构建的项目针对上前面介绍的简单项目,我们可以写出如下的Makefile# 编译器设置 # 定义项目根目录 ROOT_DIR := $(dir $(abspath $(lastword $(MAKEFILE_LIST)))) CXX := g++ CXXFLAGS := -Iinclude -Wall -Wextra -pedantic -std=c++11 -MMD -MP LDFLAGS := EXE_OUTPUT := $(ROOT_DIR)bin TARGET := $(EXE_OUTPUT)/app $(info TARGET = $(TARGET)) # 源文件和对象文件设置 SRC_DIR := src SRCS := $(wildcard $(SRC_DIR)/*.cpp) OBJ_DIR := $(ROOT_DIR)build/obj OBJS := $(patsubst $(SRC_DIR)/%.cpp,$(OBJ_DIR)/%.o,$(SRCS)) DEPS := $(OBJS:.o=.d) # 默认目标(第一个目标) all: $(TARGET) # 链接生成可执行文件 $(TARGET): $(OBJS) @mkdir -p $(@D) $(CXX) $(LDFLAGS) $^ -o $@ # 编译源文件并生成依赖 $(OBJ_DIR)/%.o: $(SRC_DIR)/%.cpp | $(OBJ_DIR) $(CXX) $(CXXFLAGS) -c $< -o $@ # 创建对象文件目录 $(OBJ_DIR): mkdir -p $@ # 包含自动生成的依赖关系 -include $(DEPS) # 清理生成的文件 clean: rm -rf $(TARGET) build .PHONY: all clean 上面我们定义了头文件路径为include 目录,并且规定了中间文件生成在 build/obj 中,最后定义了生成可执行程序在 bin/app 中对于编译来说,Emacs内置了 compile 命令,它会自动执行 make -k 命令,但是如果我在使用Emacs的过程中切换到了其他目录的话,还需要特别指定Makefile 所在的路径,对我来说我希望能在尽可能少输入参数的情况下完成同样的操作,不太希望每次都指定项目根目录,好在之前配置的projectile 插件帮助我们识别出来了项目的根目录。所以这里可以使用 projectile-compile-project 来自动指定根目录并编译。从上面的截图可以看到,flycheck 提示了几个错误,这是因为项目没有生成 compile_commands.json文件,所以lsp服务器无法跨文件分析,导致找不到头文件。原始的make 命令并不支持生成 compile_commands.json 文件,我们可以通过 bear 命令来完成这个工作,它的用法比较简单,只需要使用 bear -- <your-build-command> 即可, 对于使用make编译的项目来说 <your-build-command> 代表的就是 make 命令。我们需要考虑的一个问题是,如何将bear加入到编译命令中,也就是将它自动生成的 make -k 给替换掉,第二个问题是如果当前目录在其他目录下,如何保证 compile_commands.json 永远生成在根目录下Emacs中有一个变量 compile-command 保存了编译的命令,如果我们使用Emacs自带的compile来编译可以通过修改它来实现,而 projectile-compile-project 则是通过变量 projectile-project-compilation-cmd 来保存编译命令,默认是nil,对于使用 projectile 我们通过修改这个变量的值从而修改编译时使用的命令。另外既然 projectile 可以得到项目的根目录,我们就可以利用这个插件来获取项目的根目录,有了这些信息通过一个函数就可以重新生成一个编译命令(defun my/general-compile-command() (concat "bear --output " projectile-project-root "compile_commands.json" " -- make -k"))这个函数的代码非常简单,通过 projectile-project-root 来获取项目的根目录,然后通过字符串拼接的方式来得到编译命令生成 compile_commands.json 成功之后,我们重启 lsp 服务后可以看到错误都消失了,只有两个警告了了解了编译的一些情况,下面来看看如何在Emacs中执行生成的可执行程序。Emacs中可以使用 shell-command 来执行可执行 shell 命令。例如我们可以在项目的根目录下执行 shell-command ./bin/app。很明显如果每次都指定程序的路径是非常麻烦的事,我希望能有一个命令或者函数来自动执行可执行程序。但是Makefile构建的项目比较古老也灵活,Makefile中没有一个固定的方式或者写法来指定可执行程序的生成路径,也就是说没有一个通用的方式来根据Makefile获取可执行文件的路径。一种折中的方案就是针对每个项目都定义一个 execuable-path 的变量来指定可执行程序的路径,然后再通过elisp代码来根据这个变量执行程序(defun my/run-program() (interactive) (shell-command (concat projectile-project-root executable-path)))我们可以针对每个项目单独设置一个 executable-path 变量。Emacs会读取项目根目录中的 .dir-locals.el 文件,并且将文件中定义的变量作为项目的局部变量,所以我们只需要在该文件中定义好 executable-path 就可以了。我们可以通过命令 add-dir-local-variable 来往该文件中添加一个局部变量,也可以自己手写该文件实现这一操作添加完变量之后,项目根目录中的 .dir-locals.el 文件内容如下;;; Directory Local Variables -*- no-byte-compile: t -*- ;;; For more information see (info "(emacs) Directory Variables") ((c++-mode . ((executable-path . "bin/app"))))在重启Emacs之后,执行这个函数就可以做到一键运行了有了这些,我希望能将它们有机的组合起来,也就是说按下某个快捷键,这里我暂时定义为 <F7>。它直接同时执行编译和运行的操作。通过 C-<F7> 来完成重编译的操作。;; 重新编译 (defun my/rebuild-program () (interactive) (let ((root (file-name-as-directory (projectile-project-root)))) (shell-command (concat "make clean -C " root)) (setq compile-command (concat "bear --output " root "compile_commands.json" " -- make -k -C " root)) (compile compile-command))) ;; 绑定快捷键 (setq compilation-read-command nil) ;; 取消编译时确定命令行 (evil-define-key 'normal c++-mode-map (kbd "<f7>") #'projectile-compile-project) (evil-define-key 'normal c++-mode-map (kbd "C-<f7>") #'my/rebuild-program))) 这里的代码比较简单,对于编译来说只需要将之前执行的 projectile-compile-project 绑定到对应的快捷键;对于重编译,我通过函数 my/rebuild-program 来完成。这个函数主要操作是先执行 make clean 命令然后重新执行 make。在正式绑定快捷键之前,有一句 (setq compilation-read-command nil) 。projectile-compile-project 和 compile 命令都是交互式命令,执行时会首先显示对应的编译命令,需要用户手动执行回车确认命令,这句代码的意思是不取消它们需要确认的步骤,直接执行命令。本来我打算在重编译函数中也采用 projectile-compile-project 但是它这个交互式我一直取消不了,所以这里我直接采用 compile 指定根目录的方式来完成这个操作。如果想要绑定一键运行的操作也可以采用这个思路,将快捷键绑定到 my/run-program 函数中,这个函数也可以添加一个编译命令确保执行的是最新代码生成的可执行程序CMake工程CMakeLists.txt 文件内容如下:cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) # aux_source_directory(${PROJECT_SOURCE_DIR} source) file(GLOB source ${CMAKE_SOURCE_DIR}/src/*.cpp) include_directories(${CMAKE_SOURCE_DIR}/include) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) add_executable(app ${source})这个CMakeLists.txt 文件中主要定义了编译使用到的源文件、头文件目录路径和生成的exe路径emacs 中有一个名为 cmake-ide 的包,它用于读取cmake配置中的各项参数并将参数传递到对应的包中,虽然用它可以很方便的针对cmake配置,但是它依赖rtags,并且没有支持lsp-mode。所以这里就淘汰它,还是想办法自己实现针对cmake来说,要生成 compile_commands.json 比较简单,我们可以在命令行中使用cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1也可以在cmake配置文件中,project命令之后添加set (CMAKE_EXPORT_COMPILE_COMMANDS ON)这里我采用将命令写到cmake文件中的方式。对于cmake 编译的过程主要由两个部分组成,首先是cmake构建项目生成Makefile,然后使用make 命令编译项目。我们要实现自动编译也需要模拟这两个命令。与上面类似,这里我只需要将 my/general-compile-command 函数做少许改动即可(defun my/cmake-general-compile-command () (concat "cmake -B " (projectile-project-root) "build -DCMAKE_BUILD_TYPE=Debug " (projectile-project-root) " && ln -sf " (projectile-project-root) "build/compile_commands.json " (projectile-project-root) "compile_commands.json" " && cmake --build " (projectile-project-root) "build --config Debug"))这个函数生成的命令主要完成三个工作,将构建编译生成的临时文件放到 build 目录下;因为生成的 compile_commands.json 文件也一起放在了 build 目录中,所以我加一个软链接到项目根目录的操作;最后就是执行编译操作了。至于重编译则于上面的步骤相似,cmake一般我习惯删除存放临时文件的build目录然后重新执行cmake构建。所以这里还是模拟这个过程(defun my/cmake-rebuild-program () (interactive) (let ((root (file-name-as-directory (projectile-project-root)))) (shell-command (concat "rm -rf " root "build")) (setq compile-command (my/cmake-general-compile-command)) (compile compile-command)))至于运行程序,我们还是可以采用上面介绍的指定程序生成路径的方式。也就是不管使用cmake或者Makefile 构建的工程都可以使用上面定义的 my/run-program 函数来运行程序调试作为IDE的一个重要或者说基础的功能,调试功能是必不可少的。emacs 自身支持使用gdb进行调试,我们可以执行 M-x gdb 来启动一个调试示例,这个时候我们一边通过gdb的调试命令来控制程序语句的执行一边观看代码的上下文。但是目前流行的方式是使用 dap 来调试程序,至于什么是dap,我在配置vim的时候已经介绍过了,这里就不再赘述了emacs 中有一个名为dap-mode 的插件通过这个插件可以实现dap相关的功能。因为在介绍vim配置的时候我使用的是vscode中的 cpptools插件,这里我打算也使用它来作为dap的调试后端,可以通过cpptools官方仓库 进行下载接着需要安装lldb-vscode,它是针对vscode的一个插件,我们可以在 官方仓库 中找到对应的下载包。下载完成之后可以直接解压到对应目录,这里我解压到 ~/.emacs.d/cpptools 目录中。此时对应的调试后端程序为 ~/.emacs.d/cpptools/extension/debugAdapters/bin/OpenDebugAD7。我们需要赋予它可执行的权限。在这些工作都做好之后,可以使用下面的代码来安装dap-mode(use-package dap-mode :ensure t :after (lsp-mode) :config (dap-auto-configure-mode) ; 可选:启用自动配置 (setq dap-cpptools-debug-program '("~/.emacs.d/cpptools/extension/debugAdapters/bin/OpenDebugAD7")) )我们可以通过命令 dap-debug-edit-template 创建一个调试的模板。对给出的模板做一些简单的修改(dap-register-debug-template "cpptools::Run Configuration" (list :type "cppdbg" :request "launch" :name "cpptools::Run Configuration" :MIMode "gdb" :program "${workspaceFolder}/bin/hello" :cwd "${workspaceFolder}" :environment [] :miDebuggerPath "/usr/bin/gdb")) 我们执行一下这个代码就会向Emacs注册一个调试的模板。接着直接调用 dap-debug 即可启动调试。虽然我们可以将上述注册的代码放到主配置文件中,但是其中的一些关键的字段,例如程序的位置,使用的环境变量,以及对应的调试参数都无法做到所有程序都统一,所以这里我觉得还是需要的时候直接修改就好了。dap-mode 的一些命令如下:dap-debug 和 dap-continue : 启动调试或者运行到下一个断点处dap-next : 执行下一句代码dap-step-in : 执行下一行代码并进入函数内部dap-step-out : 执行到函数返回dap-breakpoint-toggle : 创建或者删除端点我们可以对这些命令进行键位绑定(use-package dap-mode :ensure t :after (lsp-mode) :config (dap-auto-configure-mode) ; 可选:启用自动配置 (require 'dap-cpptools) (setq dap-cpptools-debug-program '("~/.emacs.d/cpptools/extension/debugAdapters/bin/OpenDebugAD7")) (evil-define-key 'normal dap-mode-map (kbd "<f10>") #'dap-next) (evil-define-key 'normal dap-mode-map (kbd "<f9>") #'dap-breakpoint-toggle) (evil-define-key 'normal dap-mode-map (kbd "<f5>") #'dap-debug) )这样我们可以使用上述快捷键来进行调试操作总结这篇文章花了好长时间才弄出来,主要是我对于emacs和lisp语言不太熟悉,中间在尝试编写一键运行和配置dap时耗费了大量的时候。最终我还是成功了,至少我完成我当初想要的一些ide的基本功能,当然在使用上还是比不过vscode,但是在折腾中总能找到一丝乐趣。本文中的配置仅仅经过我自己机器的检验,本来想弄的更加灵活更加接近vscode的体验,有一些我自己想要的功能还没加上,仅仅做了一个可用的玩具。但是我没有想到什么办法,而且这篇文章已经憋了好久了,再不写点东西出来我感觉马上就要放弃了,我想先弄点东西出来给自己一个激励,让我有动力继续深入学习一下Emacs的其他内容。等我多学了一点Emacs多写了一点elisp代码之后可能会对调试和编译方面的代码做一个大的更新。最后如果有读者觉得这篇文章写的有那么一点帮助,那将是我的荣幸,感谢读者在百忙之中能读完本文。
-
Ubuntu 20.04 安装gcc5.4 与 cmake3.16 编译环境 因为公司的编译环境使用的是Ubuntu 20.04 搭配 gcc5.4 和 cmake3.16。所以我也在自己的开发机上安装了配套的环境Ubuntu 就使用 WSL2 直接安装就行,编译环境因为Ubuntu 20.04 默认使用的是gcc 9的版本,所以配置起来还是需要稍微费点功夫的。这里记录一下有效的步骤防止后续又需要配置这套环境的时候满世界找因为gcc5.4 相对来说比较老了,这一版Ubuntu 的官方软件源仓库中没有,需要添加额外的软件源仓库我们可以选择先备份原始的软件源,然后将下列源添加到 /etc/apt/sources.list 文件的末尾deb http://archive.ubuntu.com/ubuntu xenial main universe然后执行sudo apt update && sudo apt upgrade更新软件源接着安装gcc 5.4 以及对应的32位环境支持sudo apt install -y gcc-5 g++-5 gcc-5-multilib g++-5-multilib sudo apt install -y libc6-dev-i386 lib32stdc++6 lib32gcc1默认情况下,ubuntu 20.04 中安装的gcc版本是9.0,如果我们自行安装了 gcc5.4,系统中会有多个gcc版本有时候会导致冲突,我们可以使用下面的命令来管理多个gcc版本# 配置备选版本 sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50 sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 50 # 切换版本(选 5.4 对应的编号) sudo update-alternatives --config gcc sudo update-alternatives --config g++此时使用 gcc --version 将会看到当前gcc的版本是5.4Ubuntu 20.04 官方的软件源中cmake的版本就是 3.16,所以对于cmake直接使用sudo apt install cmake
-
wsl 启动报错:Wsl/0x80080005 周末结束过来上班的时候发现公司电脑上安装的wsl2 中的arch和Ubuntu 都无法打开了,表现出来的现象是通过终端打开系统时长时间无法进入系统,等待大概半小时左右会出现提示:Wsl/0x80080005通过网络上查找,这种一般是系统坏了,或者是服务没启动,又或者是网络协议栈出现问题。对应的办法就是重置Linux系统(这种是最坏的情况,一般留到最后实在没办法了再尝试)、启动 LxxManager 服务,重置网络协议。通过尝试我发现我的属于网络协议栈问题,通过powershell 命令(需要管理员权限)netsh winsock reset # 重置网络套接字 netsh int ip reset # 重置 IP 协议然后重启电脑问题就解决啦!
-
Emacs 折腾日记(二十九)—— 打造C++ IDE 在介绍vim配置的时候介绍过lsp的相关基础知识。简单来说lsp是一个协议,它以C/S架构的形式进行组织,lsp负责分析语法,给出具体的语法单元,完成跳转等功能的核心实现。而客户端则负责接收用户的操作请求并呈现具体结果。这样做的好处是将核心服务和客户端显示分离出来,核心部分重用,客户端则可以由各个编辑器自己实现,使各种编辑器都有相同的核心功能体验。对于Emacs来说,由lsp-mode 提供核心客户端库,管理服务器生命周期、消息路由及基础功能。另外也有 lsp-ui 这种增强UI模块,提供实时信息侧边栏(lsp-ui-sideline)、代码透镜(Code Lens)、悬浮文档等下面来介绍如何使用它们配置一个基础的lsp功能lsp-mode根据官方给出的配置,我们可以组一个基础的配置(use-package lsp-mode :ensure t :init ;; set prefix for lsp-command-keymap (few alternatives - "C-l", "C-c l") (setq lsp-keymap-prefix "C-c l") :hook ( ;; if you want which-key integration (lsp-mode . lsp-enable-which-key-integration)) :commands (lsp lsp-deferred))这里我们只是安装了一个客户端,想要真正实现lsp的功能,还需要针对具体的语言下载一个服务端,可以通过 lsp-install-server 来下载如果我们希望能像vscode那样,以悬浮窗口的形式显示符号的定义、声明或者注释文档,那么我们需要使用 lsp-ui 这个插件(use-package lsp-ui :ensure t :after (lsp-mode) :config (setq lsp-ui-doc-position 'top))这里我通过 lsp-ui-doc-position 来定义显示的窗口在上方,一般的编辑器默认是显示在光标所在的位置,但是我觉得显示在光标位置会影响我阅读后续的代码,所以我将它显示在上面,如果各位读者希望它像其他编辑器那样显示在光标位置可以修改参数为 at-point项目管理上述的lsp配置完之后,它只能使用当前buffer中的内容进行语法补全提示,也就是说我在其他的位置定义的函数和类在当前buffer中是无法识别到的。我们需要结合项目一起来使用。我们可以使用名为 projectile 的插件来进行项目管理(use-package projectile :ensure t :init (setq projectile-project-search-path '("~/projects/" "~/work/" "~/playground")) :config (define-key projectile-mode-map (kbd "C-c C-p") 'projectile-command-map) (global-set-key (kbd "C-c p") 'projectile-command-map) (projectile-mode +1)) (use-package counsel-projectile :ensure t :after(projectile) :init (counsel-projectile-mode))这里我们额外安装了 counsel-projectile 用来与 counsel 结合进行搜索语法检查语法检查方面,目前主流的插件是 flycheck 和 flymake,但是好像 flycheck 使用的人多一些,所以这里我也采用 flycheck。(use-package flycheck :ensure t :config (setq truncate-lines nil) ; 如果单行信息很长会自动换行 :hook (prog-mode . flycheck-mode))这里我们仅在编程的时候开启语法检查。同样的, flycheck 是一个前端,用来显示结果的,具体检查的核心功能是通过后端来实现的。后端的程序可以在官方网站上找到。状态栏显示相关的lsp信息现在是时候来修改以下状态栏的显示了,根据配置vim的经验,我还是希望主要显示当前编辑的模式、文件名、文件编码、lsp服务器、语法错误信息等。这里我使用 doom-modeline 来完成这个功能(use-package doom-modeline :ensure t :init (doom-modeline-mode 1) :config (setq doom-modeline-height 30) (setq doom-modeline-bar-width 5) (setq doom-modeline-icon t) (setq doom-modeline-lsp t) (setq doom-modeline-major-mode-icon t) (setq doom-modeline-buffer-state-icon t) (setq doom-modeline-buffer-file-name-style 'truncate-with-project) (setq doom-modeline-check-simple-format t) )通过上述代码来简单的配置一下,就可以有丰富的显示信息每种语言都对应了一个lsp的后端程序,lsp-mode官方网站 给出了每种语言对应的lsp后端程序,我们可以使用 lsp-install-server 来安装,这里我准备安装 clangd 这个后端在安装了lsp之后,再次打开一个cpp文件,可以发现它的界面如下:上面我们完成了lsp配置的基础准备工作,下面将要来针对具体的语言探索一下实际的使用方式和使用体验状态栏下分别显示了当前的模式(N代表normal模式)、文件类型、文件名称、当前编码方式等等,最后一个是flycheck 语法检查的结果,这里的代码比较简单,所以它没有检测出来任何问题,最后以绿色圆圈中的一个勾来显示。需要注意的是状态栏中的小火箭表示lsp服务已启用,如果没有这个标志可以手动的执行 lsp 命令选中项目的根目录C++ 项目实例C/C++ 项目需要明确的编译信息,clangd 通过 compile_commands.json 文件获取这些信息。对于cmake构建的项目cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1另外我希望每种语言对应的lsp配置放入到不同的配置文件中,做到模块化处理,因此我在配置中新建了一个lsp目录,并且按编程语言每种语言一个配置文件。目前c++语言的配置如下:(require 'lsp-mode) (add-hook 'c++-mode-hook (lambda () (setq lsp-project-identification-methods '(:root ("compile_commands.json" ".git" ".clangd" "CMakeLists.txt" "Makefile"))) (setq lsp-clients-clangd-args '("-background-index" "--clang-tidy" "--completion-style=detailed")) (setq-local completion-at-point-functions '( cape-file cape-keyword cape-dabbrev)) (lsp-deferred))) (provide 'cpp)为了实现不同的语言加载不同的配置,这里通过对应模式的hook来实现。一般每种模式都有一个对应的hook变量,它里面保存了一个函数,当启用该模式时会执行对应的代码,这里c++-mode 对应的是 c++-mode-hook。在这个hook中,主要做了四件事:第一,我们定义了项目根目录的标识;第二,定义了clangd启动的一些参数;最后也是最关键的一点,我们重新定义了补全端的函数。在配置Emacs的补全时,提供了一大堆补全方式,很多在编程时是用不到的,而且Emacs在补全时会依次根据 completion-at-point-functions 列表中保存的补全函数来查找补全项,一旦前一个函数返回了补全项,那么就不再往后查找。在编程的过程中前面定义的很多补全功能并没有lsp提供的补全好用,而且还会影响lsp的补全导致它出不来,所以我们去掉一些没用的,仅仅保留关键的部分。lsp-mode 会提供一个名为 lsp-completion-at-point 的补全函数注册到 completion-at-point-functions 中,因此这里我们不需要单独的写出来,当然写出来也没问题。我们可以通过 describe-variable 命令来查看 completion-at-point-functions 的值。Its value is (lsp-completion-at-point cape-file cape-keyword cape-dabbrev) Local in buffer main.cpp; global value is (cape-line cape-elisp-symbol cape-dict cape-ispell cape-keyword cape-file cape-dabbrev tags-completion-at-point-function) 最后一件事就是调用 lsp-deferred 来延迟加载lsp。因为 lsp-deferred 需要等到缓冲区完全加载完成之后才加载,所以将它放到最后面代码跳转在vim中,有几个关于跳转的关键的快捷键,gd 表示 goto declaration 跳转到定义,gD 表示 goto definition 跳转到定义,使用 gf 来跳转到头文件,跳转之后可以使用 ` 再次回来,这些快捷键 evil` 也为我们保留了,我们不需要额外的配置只要lsp能加载起来就能使用。显示符号文档信息vim配置中定义了 gh 显示符号的文档信息,我们可以使用 define-key 来定义快捷键。既然显示文档的功能由 lsp-ui 来提供,这里就将代码放入到 lsp-ui 位置(define-key lsp-ui-mode-map (kbd "gh") #'lsp-ui-doc-glance)tree-sitter在配置vim的时候提到过tree-sitter 是轻量级的语法分析器,而lsp是进行语义分析的重量级工具,tree-sitter 是对 lsp 的一个补充,并且我们用tree-sitter 进行了语法高亮和代码片段的折叠,这里尝试在Emacs中使用tree-sitter(use-package tree-sitter :ensure t :hook (prog-mode . tree-sitter-hl-mode) ;;启用语法高亮 :config (global-tree-sitter-mode)) (use-package tree-sitter-langs :ensure t :after tree-sitter)安装完成之后,我们通过命令 tree-sitter-langs-install-grammars 来安装对应的语言支持,默认是安装所有语言的支持,这里我就使用默认的就好下面尝试启用在vim中 zc、和 zo的功能。它们主要是用来折叠和展开代码块。我们来安装一个名为 ts-fold 的插件,该插件没有被放入到 elpa,所以需要手动下载然后加载(use-package ts-fold :load-path "~/.emacs.d/ts-fold" :config (global-ts-fold-mode 1) (with-eval-after-load 'evil (evil-define-key 'normal 'global "zc" #'ts-fold-close "zo" #'ts-fold-open)))最终的效果如下:基于tree-sitter,我们还可以实现一个非常重要的功能——增量选择代码块。在vim配置中我使用回车来扩大选区,使用退格键来减小选区,这里仍然沿用这种配置增量选择的功能可以使用 expand-region(use-package expand-region :ensure t ; 从ELPA自动安装 :bind ("C-=" . er/expand-region) :config (defun my/incremental-expand-region() (interactive) (if (region-active-p) (er/expand-region 1) (er/mark-word)) (setq deactivate-mark nil)) (defun my/contract-region() (interactive) (if (region-active-p) (er/contract-region 1) (call-interactively 'evil-backward-char))) (with-eval-after-load 'evil (dolist (state '(normal visual motion)) (evil-define-key state 'global (kbd "RET") nil) (evil-define-key state 'global (kbd "<backspace>") nil)) (evil-define-key 'normal 'global (kbd "RET") #'my/incremental-expand-region) (evil-define-key 'normal 'global (kbd "<backspace>") #'my/contract-region)))原版的增量选择,如果没有选中某个部分无法执行增量,所以对它进行稍微的改造,如果当前没有选中任何部分,先选中当前光标所在的单词。然后继续进行增量选择。与增加选区类似的,减少选区也是先判断如果已经没有选中区域的话还是延续vim中退格键的功能。本篇到此就先结束了,但是我们的IED的功能并没有配置完,后面我计划加上自动编译运行、调试等功能,这些就在后面的文章中给出