搜索到
109
篇与
的结果
-
 Emacs折腾日记(二十八)——代码片段 在前面的章节中,介绍了 vertico 体系的补全,已经实现了在各个buffer中的补全功能,但是作为程序员,使用Emacs主要用来编程,对于编程来说上述的补全体系仍然不够完整,我们还需要基于lsp的补全以及基于代码片段模板的补全,这里先介绍代码片段。在之前写vim的配置时已经介绍过代码片段的概念以及基于vim 的配置,感兴趣的读者可以自行在我往期的博客中寻找,这里就不对它进行详细的介绍了。直接来使用它。在Emacs中,我们使用插件 yasnippet 来支持这个功能(use-package yasnippet :ensure t :hook ((after-init . yas-reload-all) ((prog-mode LaTeX-mode org-mode) . yas-minor-mode)) :config (setq yas-snippet-dirs '("~/.emacs.d/snippets")))我们通过上面的代码就能把它启用起来,yas-reload-all 表示在Emacs启动时重新加载所有已启动的代码片段;yas-minor-mode代表启动代码片段补全的功能。但是我们做了限制,只在编写代码、LaTeX和org-mode 文件时启动。如果各位读者希望在markdown 中也启动的话,也可以加上 markdown-mode 的选项。但是既然使用了Emacs,当然要用比 markdown 更加强大的 org-mode 了现在Emacs已经支持了代码片段,它的快捷键与vim中的一致都是使用tab 来进行补全。那么接下来就是通过代码片段文件来提高我们编程的效率了。添加代码片段文件我们可以使用已经写好的,也可以自己根据自己的习惯来定制。下载通用的代码片段官方虽然提供了一些代码片段,但是数量较少,使用起来并不那么方便,我们可以下载网络上的一些公共库来丰富我们的代码片段。这里我介绍一下 Doom Emacs Snippets Library。它是专门为doom emacs 用户打造的代码片段库,使用者不少。其他的代码片段库的安装与使用与它类似,读者可以依葫芦画瓢来安装。 首先找到官方的代码仓库,然后将它克隆下来,我将它放到 ~/.emacs.d/emacs-snippets 目录中。然后通过(use-package doom-snippets :ensure nil :load-path "~/.emacs.d/doom-snippets" :after yasnippet)来加载它。之后需要 Yasnippet 插件能找到这个目录,所以我们修改一下上面的配置(use-package yasnippet :ensure t :hook ((after-init . yas-reload-all) ((prog-mode LaTeX-mode org-mode) . yas-minor-mode)) :config (setq yas-snippet-dirs '("~/.emacs.d/snippets" "~/.emacs.d/doom-snippets"))) ;; 添加一行代码片段的加载路径此时再编写代码发现多了一些代码片段自定义代码片段与 doom emacs snippets library 代码片段类似,我们也需要按照具体的mode来组织代码片段的文件目录。每一个关键字一个文件例如~/.emacs.d/snippets/ ├── python-mode/ │ ├── for ; for 循环模板 │ └── class ; 类定义模板 └── c++-mode/ └── foreach ; for-each 循环模板有了这些准备的前提条件,我们可以自行创建自己的代码片段了。在emacs 中执行 yas-new-snippet 可以打开一个新的buffer,并显示代码片段的模板# -*- mode: snippet -*- # name: # key: # -- name后面跟着的是代码片段的名称,在补全时会以补全项显示这个名称;key代表关键字,表示用哪个缩写来触发。例如我们定义一个 prt 来展开成 printf 语句,那么就可以写成 name:prt key: prt尝试生成第一个代码片段后面的写具体展开的代码,例如我们编写一个自动生成hello world的模板# -*- mode: snippet -*- # name: create-hello # key: hello # -- #include <stdio.h> int main(int argc, char* argv[]) { printf("hello world\n"); return 0; } 在编写完成之后使用快捷键 C-c C-c 来保存,Emacs在保存时会让你输入对应的 mode 并且给出需要保存的位置。当我们修改完适用的 mode 和 保存的位置之后,我们发现它在对应位置生成了文件。重启Emacs或者 使用命令 yas-reload-all 来重新加载所有的代码片段。之后输入hello就可以看到它为我们生成了 c 版本的 hello world 程序占位符我们希望的代码大体上不变但是关键地方由我们自己来填充,这个时候可以使用占位符。占位符的格式为 ${} 大括号中填入数字序号。或者使用 ${1: default} 来表示这个位置默认填写default字符。下面是一个具体的例子# -*- mode: snippet -*- # name: qt-class # key: qcls # -- class ${1} : public ${2:QObject} { Q_OBJECT public: ${1}(${2}* parent = nullptr); ${1}(const ${1}& other); ${1}& operator=(const ${1}& other); ~${1}(); signals: slots: protected: }上面我们定义了一个快速生成继承自 QObject 类的子类的模板,上面有两个占位符,第一个占位符表示名称,它没有默认值,一旦确定了它的也就是类型,它会自动生成类的无参构造、拷贝构造、赋值运算符重载和析构函数的定义。第二个占位符指出了它的父类,它的默认值是 QObject 类,它的效果如下使用elisp代码生成动态信息我们可以使用 `` 来包裹elisp代码,生成动态信息。一般在C/C++ 代码的头文件中会包含一些注释信息,用来说明文件的用途包含的接口信息等等。我们希望生成这么一段注释的代码片段# -*- mode: snippet -*- # name: Custom File Header # key: hdoc # -- /** * @file `(file-name-nondirectory (buffer-file-name))` * @bref ${1:brief description} * @details ${2:detailed explanation} * @date `(format-time-string "%Y-%m-%d")` * @commit history: * \t v${3:1.0}: ${4:Initial version} */ $0上面我们使用 elisp代码 (file-name-nondirectory (buffer-file-name)) 来获取对应的文件名,通过 (format-time-string "%Y-%m-%d") 来获取时间。并且最后使用 $0 来将光标定位到这个位置,这个位置将会在我们使用tab处理过所有tab之后自动跳转。本文到此就结束了。本文主要介绍了在Emacs中使用代码片段,并且介绍了编写代码片段的一些方式。有了这些在编写代码时会更加得心应手。
Emacs折腾日记(二十八)——代码片段 在前面的章节中,介绍了 vertico 体系的补全,已经实现了在各个buffer中的补全功能,但是作为程序员,使用Emacs主要用来编程,对于编程来说上述的补全体系仍然不够完整,我们还需要基于lsp的补全以及基于代码片段模板的补全,这里先介绍代码片段。在之前写vim的配置时已经介绍过代码片段的概念以及基于vim 的配置,感兴趣的读者可以自行在我往期的博客中寻找,这里就不对它进行详细的介绍了。直接来使用它。在Emacs中,我们使用插件 yasnippet 来支持这个功能(use-package yasnippet :ensure t :hook ((after-init . yas-reload-all) ((prog-mode LaTeX-mode org-mode) . yas-minor-mode)) :config (setq yas-snippet-dirs '("~/.emacs.d/snippets")))我们通过上面的代码就能把它启用起来,yas-reload-all 表示在Emacs启动时重新加载所有已启动的代码片段;yas-minor-mode代表启动代码片段补全的功能。但是我们做了限制,只在编写代码、LaTeX和org-mode 文件时启动。如果各位读者希望在markdown 中也启动的话,也可以加上 markdown-mode 的选项。但是既然使用了Emacs,当然要用比 markdown 更加强大的 org-mode 了现在Emacs已经支持了代码片段,它的快捷键与vim中的一致都是使用tab 来进行补全。那么接下来就是通过代码片段文件来提高我们编程的效率了。添加代码片段文件我们可以使用已经写好的,也可以自己根据自己的习惯来定制。下载通用的代码片段官方虽然提供了一些代码片段,但是数量较少,使用起来并不那么方便,我们可以下载网络上的一些公共库来丰富我们的代码片段。这里我介绍一下 Doom Emacs Snippets Library。它是专门为doom emacs 用户打造的代码片段库,使用者不少。其他的代码片段库的安装与使用与它类似,读者可以依葫芦画瓢来安装。 首先找到官方的代码仓库,然后将它克隆下来,我将它放到 ~/.emacs.d/emacs-snippets 目录中。然后通过(use-package doom-snippets :ensure nil :load-path "~/.emacs.d/doom-snippets" :after yasnippet)来加载它。之后需要 Yasnippet 插件能找到这个目录,所以我们修改一下上面的配置(use-package yasnippet :ensure t :hook ((after-init . yas-reload-all) ((prog-mode LaTeX-mode org-mode) . yas-minor-mode)) :config (setq yas-snippet-dirs '("~/.emacs.d/snippets" "~/.emacs.d/doom-snippets"))) ;; 添加一行代码片段的加载路径此时再编写代码发现多了一些代码片段自定义代码片段与 doom emacs snippets library 代码片段类似,我们也需要按照具体的mode来组织代码片段的文件目录。每一个关键字一个文件例如~/.emacs.d/snippets/ ├── python-mode/ │ ├── for ; for 循环模板 │ └── class ; 类定义模板 └── c++-mode/ └── foreach ; for-each 循环模板有了这些准备的前提条件,我们可以自行创建自己的代码片段了。在emacs 中执行 yas-new-snippet 可以打开一个新的buffer,并显示代码片段的模板# -*- mode: snippet -*- # name: # key: # -- name后面跟着的是代码片段的名称,在补全时会以补全项显示这个名称;key代表关键字,表示用哪个缩写来触发。例如我们定义一个 prt 来展开成 printf 语句,那么就可以写成 name:prt key: prt尝试生成第一个代码片段后面的写具体展开的代码,例如我们编写一个自动生成hello world的模板# -*- mode: snippet -*- # name: create-hello # key: hello # -- #include <stdio.h> int main(int argc, char* argv[]) { printf("hello world\n"); return 0; } 在编写完成之后使用快捷键 C-c C-c 来保存,Emacs在保存时会让你输入对应的 mode 并且给出需要保存的位置。当我们修改完适用的 mode 和 保存的位置之后,我们发现它在对应位置生成了文件。重启Emacs或者 使用命令 yas-reload-all 来重新加载所有的代码片段。之后输入hello就可以看到它为我们生成了 c 版本的 hello world 程序占位符我们希望的代码大体上不变但是关键地方由我们自己来填充,这个时候可以使用占位符。占位符的格式为 ${} 大括号中填入数字序号。或者使用 ${1: default} 来表示这个位置默认填写default字符。下面是一个具体的例子# -*- mode: snippet -*- # name: qt-class # key: qcls # -- class ${1} : public ${2:QObject} { Q_OBJECT public: ${1}(${2}* parent = nullptr); ${1}(const ${1}& other); ${1}& operator=(const ${1}& other); ~${1}(); signals: slots: protected: }上面我们定义了一个快速生成继承自 QObject 类的子类的模板,上面有两个占位符,第一个占位符表示名称,它没有默认值,一旦确定了它的也就是类型,它会自动生成类的无参构造、拷贝构造、赋值运算符重载和析构函数的定义。第二个占位符指出了它的父类,它的默认值是 QObject 类,它的效果如下使用elisp代码生成动态信息我们可以使用 `` 来包裹elisp代码,生成动态信息。一般在C/C++ 代码的头文件中会包含一些注释信息,用来说明文件的用途包含的接口信息等等。我们希望生成这么一段注释的代码片段# -*- mode: snippet -*- # name: Custom File Header # key: hdoc # -- /** * @file `(file-name-nondirectory (buffer-file-name))` * @bref ${1:brief description} * @details ${2:detailed explanation} * @date `(format-time-string "%Y-%m-%d")` * @commit history: * \t v${3:1.0}: ${4:Initial version} */ $0上面我们使用 elisp代码 (file-name-nondirectory (buffer-file-name)) 来获取对应的文件名,通过 (format-time-string "%Y-%m-%d") 来获取时间。并且最后使用 $0 来将光标定位到这个位置,这个位置将会在我们使用tab处理过所有tab之后自动跳转。本文到此就结束了。本文主要介绍了在Emacs中使用代码片段,并且介绍了编写代码片段的一些方式。有了这些在编写代码时会更加得心应手。 -
Emacs 折腾日记(二十七)——终端管理 Emacs 号称一个伪装成文本编辑器的操作系统,你几乎可以在Emacs中干任何事情。在Emacs中运行终端自然是小菜一碟。Emacs中有许多其他类型的shell,例如 eshell、term、vetrmterm 终端其中 term 是Emacs中自带的shell,它最终是调用系统中安装的其他shell环境。我们可以直接使用 M-x 调用 term命令,来选择启用一个系统终端。我们可以在这个终端上进行一些操作。但是还有一些执行细节需要优化。控制term窗口的显示首先我们看到在启动终端之后,它占用了一整个窗口,这对于我来说并不友好。一般情况下我只是希望在编写代码之后临时的调用终端执行一些命令,例如编译或者运行代码之类的操作。因此我希望它可以放到下方并且可以快速的关闭退出我们可以通过 shackle 插件来控制窗口的行为。主要有:方向、大小和弹出方式等等。配置 shackle 插件最重要的是变量 shackle-rules 。它的构成如下: CONDITION(:regexp) :select :inhibit-window-quit :size+:align|:other :same|:popupCONDITION 是相关的条件,表示我们要定义哪一类窗口的行为。这个条件可以是正则表达式,可以是字符串,可以是modeselect 控制弹出窗口后是否选中size: 0到1间的数字,控制窗口宽度和高度占整个窗口区域的百分比inhibit-window-quit: 按q退出时不删除这个缓冲区align: 弹出窗口的对齐方式,取值有 ’left, ‘right, ‘below, ‘aboveother: 如果当前 frame 有多个 window,是否复用另外一个 windowpopup: 弹出一个新的 window,而不是复用当前 windowsame: 不弹出 window,复用当前 windowignore: 禁止显示该窗口我们当前的配置可以这么写(use-package shackle :ensure t :hook (after-init . shackle-mode) :custom (shackle-default-size 0.5) (shackle-default-alignment 'below) :config (setq shackle-rules '((term-mode :regexp t :select t :size 0.3 :align t :popup t :quit t))))这里表示 term 窗口在弹出之后占据下方30%的区域进行显示,并且退出后直接关闭窗口。这样我们可以看到使用 term 之后窗口显示在下方,并且像普通buffer那样可以使用vim的命令 :q 来退出快速切换显示和隐藏状态对于终端这种临时窗口,我们一般不会让它长时间驻留在buffer中。想要的时候随时调用、不要的时候随时关闭或者隐藏。对于这种快速打开关闭的需求,我们可以使用 popper 插件。它通过赋予任意缓冲区“弹出”状态,让这些缓冲区不打扰你的核心工作区,只需一键即可调用或隐藏,完美适用于那些需要即时访问但又希望不影响视线的场景。popper-toggle、popper-cycle 和 popper-toggle-type 是三个核心命令。popper-toggle: 快速切换最新一个弹出缓冲区的显示/隐藏状态popper-cycle: 循环切换所有标记为弹出的缓冲区popper-toggle-type: 切换特定类型缓冲区的显示/隐藏状态另外它需要通过 popper-reference-buffers 来定义特定类型的缓冲区,插件会将符合这些规则的缓冲区标记为 POP并且进行管理。popper-reference-buffers 支持正则表达式来匹配缓冲区名。我们可以使用下面简单的配置(use-package popper :ensure t :hook (after-init . popper-mode) :init (setq popper-reference-buffers '("\\*Messages\\*" "\\*Async Shell Command\\*" term-mode help-mode helpful-mode "^\\*eshell.*\\*$" eshell-mode "^\\*shell.*\\*$" shell-mode ("\\*corfu\\*" . hide))) :config (my-leader-def "/" #'popper-toggle "t" #'popper-cycle "T" #'popper-toggle-type) )最终它的效果如下:eshelleshell 与 term 最大的不同在于eshell 是Emacs 自己通过elisp实现的一个仿制的终端,而 term 是真实的系统终端,它调用系统中的shell环境。目前来说使用 term 来打开系统终端能应付大部分的情况,但是学习Emacs,eshell似乎是一个绕不开的坎,并且eshell配置好了,同样好用。eshell里面实现了普通shell里面常用的命令,例如 ls、cd、cp 等等。同时也可以执行elisp代码,例如可以通过find-file 打开一个文件。或者输入简单的算术表达式像 (+ 1 1) 来进行一些数学计算。封装shell命令到eshelleshell里面实现了常见的shell 命令,但是我们在后续会经常性的安装一些好用的工具,来简化我们的工作流程,所以在使用eshell的第一件事就是将shell命令封装到eshell这里我以 autojump 为例。autojump 是一个快速跳转到指定目录的工具,当你通过cd进入过的目录会被记录下来,下一次通过 autojump 不再需要输入全路径,而是直接模糊匹配进行跳转,例如我们多次进入了 ~/.emacs.d/lisp 目录,下一次不管当前目录在哪里只需要输入 j lisp 即可进入。我们希望复刻这种行为到eshell中。定义eshell 中的命令可以通过定义一个以 eshell/ 开头的函数来实现,函数名后面的名称就是可以输入eshell的命令名称,所以这里我们要定义一个名为 eshell/j 的函数。同理,我们想要使用eshll中定义好的命令例如 cd ,可以直接调用 eshell/cd 函数。我们还是使用 use-package 来管理关于 eshell 的配置,最终实现的代码如下:(use-package eshell :ensure nil :config (defun eshell/j (&rest args) (let* ((argstr (mapconcat 'identity args " ")) (target (shell-command-to-string (concat "autojump " argstr)))) (setq target (replace-regexp-in-string "\n" "" target)) (if (file-directory-p target) (eshell/cd target) (error "目录不存在: %s" target)))))上述代码主要通过 autojump 命令来根据输入的目录名称来匹配一个实际对应的路径全名,然后通过 eshell/cd 来完成跳转操作。为什么不直接执行 j 来实现跳转呢?eshell是emacs模拟的shell并不是真实的shell,它是与Emacs绑定的,外部的shell命令无法改变 eshell的环境包括它当前所在的目录。因此我们需要调用eshell自身的命令来改变它的环境。最终的效果如下eshell 的 alias在普通的shell中,我们可以通过 alias 定义命令的别名,例如常用的 ll 或者我喜欢将 vi 和 vim 改成 nvim。eshell中也可以设置别名eshell 中使用 alias 来设置别名,它的语法如下:alias 别名 '命令 [参数] $@*'参数部分传入 $1、$2 等等,代表传入的第一个、第二个参数,或者直接使用 $@* 表示接受输入的所有参数,例如我们定义一下 ll 这个别名alias ll 'ls -l $@*' ; 输入 `ll` 等价于 `ls -l`在 eshell 中输入的 alias 命令仅仅在当前 eshell 环境中生效,想要永久生效可以将上述命令写入到 ~/.emacs/eshell/alias 文件中。eshell 会通过函数 eshell-read-aliases-list 加载对应文件中定义的别名,保存别名的文件路径被保存在 eshell-aliases-file 中,它默认的值为 ~/.emacs.d/eshell/aliaseshell history普通shell中有一个 history 命令可以查看保存的历史,并且可以使用方向键的上和下来输入上一条或者下一条命令。eshell 虽然也能这么干,但是eshell 因为是elisp模拟的终端,背靠Emacs这座大山,它可以配合Emacs的相关插件更高效的利用history命令。这里我们可以配合 consult-history + orderless 来模糊匹配命令(use-package em-history :ensure nil :defer t :custom (eshell-history-size 1024) (eshell-his-ignoredups t) (eshell-save-history-on-exit t)) (use-package esh-mode :ensure nil :hook (eshell-mode . (lambda () (local-set-key (kbd "C-r") #'consult-history))) :bind (:map eshell-mode-map ("C-r" . consult-history)) :config (with-eval-after-load 'evil (evil-define-key '(normal insert) eshell-mode-map (kbd "C-r") #'consult-history))) eshell 直接使用 term 命令上面我们提到,想要调用shell命令,可以通过编写lisp代码封装进行封装,能否直接使用shell命令呢?答案是可以的,eshell中有 eshell-visual-commands、eshell-visual-subcommands、eshell-visual-options 这么三个变量来共同决定哪些命令需要启用term 终端.eshell-visual-commands 接受一个字符串的列表,我们输入的命令在这个字符串列表中,那么就会启用term终端来执行命令eshell-visual-subcommands 来处理带子命令的复杂命令,在特定子命令下才需终端模拟eshell-visual-options 根据命令选项动态启用终端模拟。某些命令仅在特定选项(如 -i 交互式模式)出现时才需终端支持三者优先级:eshell-visual-commands > eshell-visual-subcommands > eshell-visual-options。Eshell 按此顺序检查,匹配任意条件即触发终端模拟。例如我们常见的 git、man、lazygit 等命令无法使用 eshell 中的 elisp 进行模拟,我们可以通过上述函数来封装这些命令。(use-package em-term :ensure nil :defer t :custom (eshell-visual-commands '("top" "htop" "less" "more" "lazygit")) (eshell-visual-subcommands '(("git" "help" "lg" "log" "diff" "show"))) (eshell-visual-options '(("git" "--help" "--paginate"))) (eshell-destroy-buffer-when-process-dies t))结合上述对这些函数的说明,来分析一下这段代码。首先是 eshell-visual-command 中定义的 top、htop、less、more 这些命令需要完成的term终端支持。当运行这些命令时,Eshell 自动切换到term终端,确保交互式界面正常显示(如分页、高亮等)eshell-visual-subcommands 为特定命令(如 git)的子命令启用图形终端,也就是说我们执行 git help 时会触发切换到term终端的操作,而执行 git status 时不会eshell-visual-options 当命令携带特定选项时会切换到term 终端。下面是在eshell 中执行 lazygit 的界面eshell 美化上面介绍了eshell的一些基本用法,现在来介绍如何将eshell进行简单的美化。首先介绍的是 eshell-git-prompt 。它提供了好多好看的主题在安装完插件后,可以在eshell中输入 use-theme 来列出它支持的所有主题,或者输入 use-theme name 来设定一个主题。想要持久化,可以通过函数 eshell-git-prompt-use-theme 来指定一个主题(use-package eshell-git-prompt :ensure t :after esh-mode :config (eshell-git-prompt-use-theme 'powerline))接着介绍 eshell-syntax-highlighting,它是eshell中语法高亮的插件,它是继承自 zsh 中的 zsh-syntax-highlighting。(use-package eshell-syntax-highlighting :after eshell-mode :ensure t ;; Install if not already installed. :config ;; Enable in all Eshell buffers. (eshell-syntax-highlighting-global-mode +1))接下来要介绍的插件是 capf-autosuggest 。它是一个自动补全的插件(use-package capf-autosuggest :ensure t :hook ((eshell-mode comint-mod) . capf-autosuggest-mode) )这样基本上就把我在终端上常用的一些插件和操作习惯给挪到eshell中了。当然我常用的还有一个名为 autojump 的插件。对应的 eshell 中也有一个名为 eshell-autojump 的插件。但是我已经通过别名简单的实现了一个eshell 上的 j 命令,这个插件的实现原理也是这样的,这里就不介绍这个插件了。
-
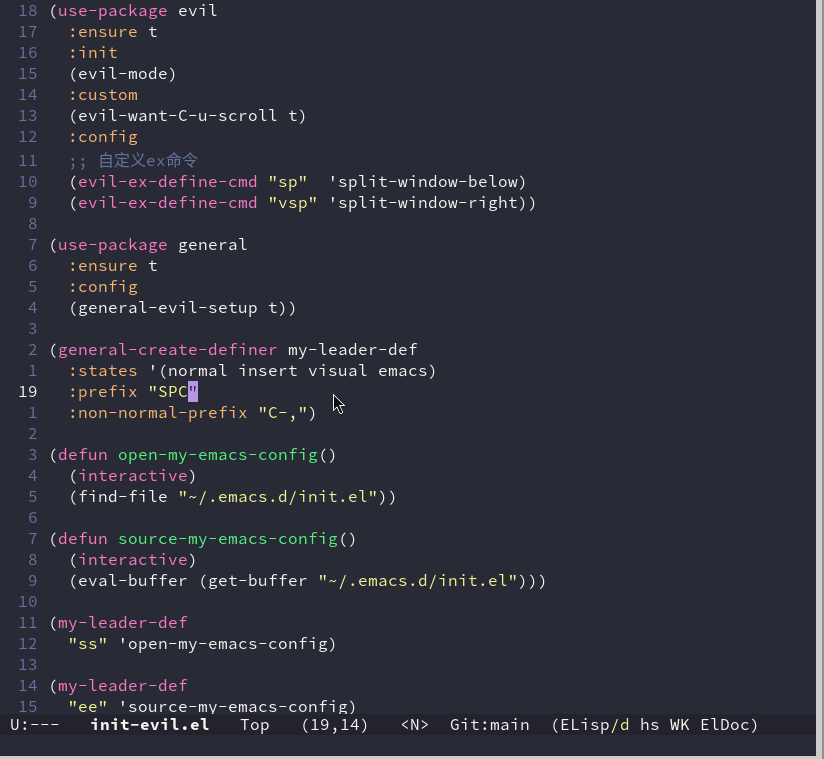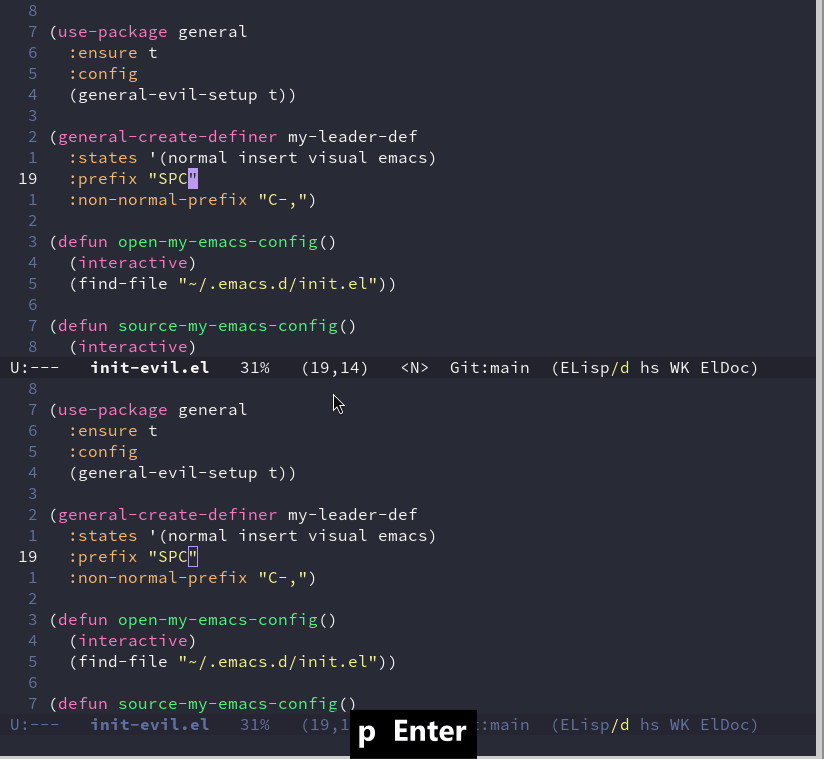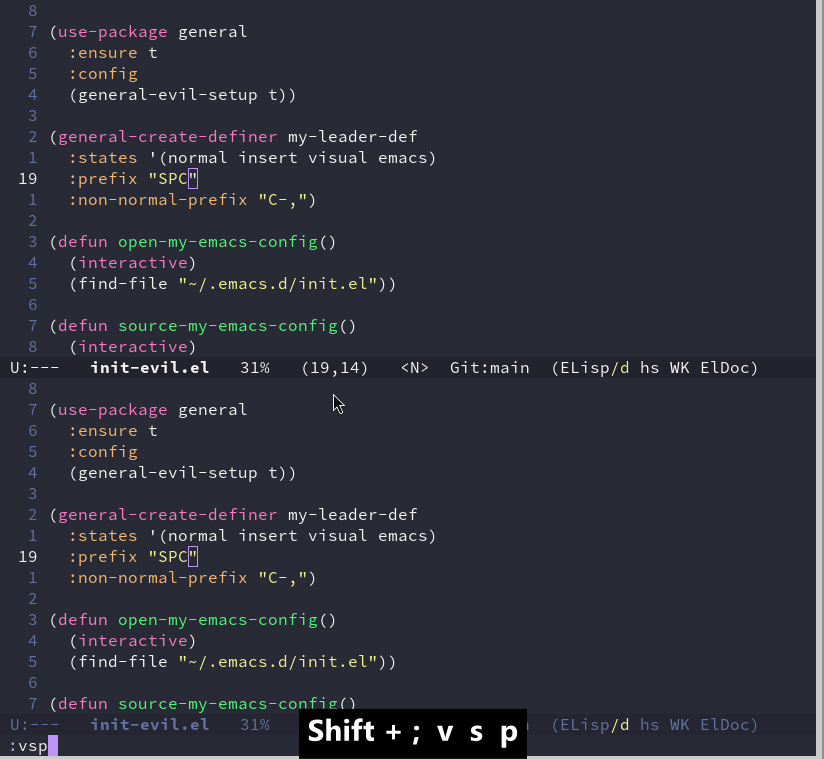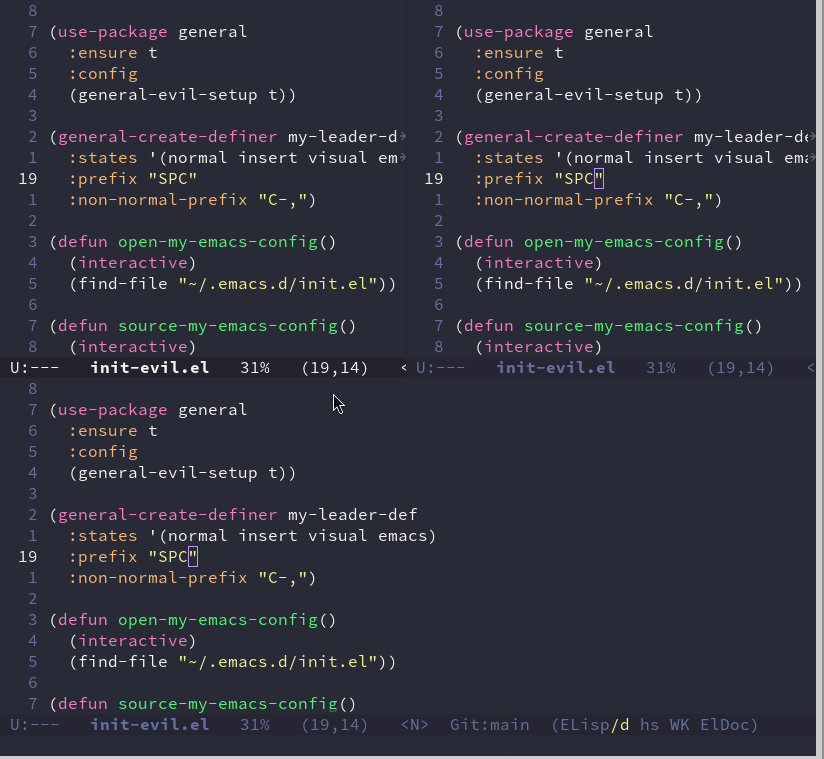
Emacs 折腾日记(二十六)——buffer与窗口管理 本节我们将介绍如何在Emacs中的buffer与窗口管理,目标是快速管理窗口,以及快速在不同buffer中进行切换基本概念介绍Emacs与vim相比的一个特点是,Emacs是一个窗口程序,或者说是一个gui程序。而vim是一个终端字符界面程序(当然Emacs也可以启用终端模式),那么与vim相比,Emacs多了了一个frame的概念。有时候有些初学者(包括我自己)总是将frame当作窗口。frame:Emacs整个程序,包括标题栏、工具栏、显示文本的界面等等部分window: 真正用来显示文本的区域被称之为window。我们经常说的分屏就是创建了一个window,frame里可以包含多个windowbuffer: Emacs 从磁盘中读取的文本保存在buffer中,buffer不一定都在window上显示。也不是所有buffer都对应一个文件针对frame来说,虽然也有相关的函数可以控制,但是一般我不太喜欢在多个frame之间进行切换,也不习惯创建多个frame。所以这里先略过window 管理关于 window。在之前介绍了window相关的函数,包括 split-window、selected-window、delete-window、以及跟窗口设置相关的 current-window-configuration、set-window-configuration。基于evil插件,我们可以使用vim的窗口创建命令。例如可以使用 :vsp 来将窗口进行纵向分割。但是我发现 :sp 和 :vsp 都是纵向分割的,这个跟vim就不太一样了。好在evil提供了一个名为 evil-ex-define-cmd 函数用来修改ex命令。所以这里我们在evil的配置中进行修改,添加下面的代码(evil-ex-define-cmd "sp" 'split-window-below) (evil-ex-define-cmd "vsp" 'split-window-right)窗口创建完成之后,我们可以使用vim 的方式来关闭窗口,例如使用 :q 命令来关闭当前窗口,或者使用 :on (或者它的全称 :only) 命令来关闭其他所有窗口。在窗口之间的移动,当初我在介绍vim配置的时候介绍过我习惯使用 leader + 'h/j/k/l' 的方式来在各个窗口间移动。但是在Emacs中,我们有比这更高效的移动方式。ace-window 是一个在各个窗口之间进行快速跳转的插件,在激活ace-window 之后,它会在各个窗口上标记一个数字,我们可以按下这个数字快速跳转到对应的窗口(use-package ace-window :ensure t :after general :hook (dired-mode . (lambda () (setq-local aw-ignore-on t))) ;; dired-mode 下禁用 ace-window :config (my-leader-def :states '(normal visual) ";" #'ace-window "l" #'evil-window-left "h" #'evil-window-right "j" #'evil-window-down "k" #'evil-window-up) )这里我们绑定 leader + ; 来调用 ace-window 执行窗口的跳转buffer 管理在介绍neovim 的配置的时候,介绍过一个名为 buffer-line 的插件,它可以很方便的将 buffer 以 tab 的形式给列出来,并且可以根据当前打开的buffer上的编号来进行跳转,我们绑定了 leader + 1~9 的数字来分别跳转到编号为 1~9 的buffer。Emacs中我也希望实现这样的功能,可以将vim上的操作无缝的转移到Emacs上来。要实现这个功能,我们可以安装 awesome-tab 包。它并没有被包含在Emacs 的官方源中,我们需要自行下载git clone --depth=1 https://github.com/manateelazycat/awesome-tab.git将它下载到对应的位置之后,如果要加载它,则需要将它所在的路径放到 load-path 中如果使用 use-package 来加载可以使用如下的代码(use-package awesome-tab :load-path "path/to/your/awesome-tab" :config (awesome-tab-mode t))启用之后,当我们多开了几个buffer之后,它们被显示到不同的tab上了。如果希望能像 buffer-line 那样根据编号跳转,首先可以通过 awesome-tab-show-tab-index 来显示tab上的编号,然后绑定数字键到 awesome-tab-select-visible-tab 进行跳转。解决了这个问题,剩下的函数官方文档上都有介绍,所以我们还是沿用vim上的快捷键,最终的配置如下:(use-package awesome-tab :load-path "~/.emacs.d/awesome-tab" :after general :custom (awesome-tab-show-tab-index 1) :config (awesome-tab-mode t) (my-leader-def :states '(normal) "gb" #'awesome-tab-ace-jump "gT" #'awesome-tab-backward-tab "gt" #'awesome-tab-forward-tab "1" #'awesome-tab-select-visible-tab "2" #'awesome-tab-select-visible-tab "3" #'awesome-tab-select-visible-tab "4" #'awesome-tab-select-visible-tab "5" #'awesome-tab-select-visible-tab "6" #'awesome-tab-select-visible-tab "7" #'awesome-tab-select-visible-tab "8" #'awesome-tab-select-visible-tab "9" #'awesome-tab-select-visible-tab))awesome-tab还可以针对不同的buffer进行分组,然后对分组的buffer进行统一的操作,这里就不介绍了,有兴趣的读者可以自行阅读相关的文档。本节到此就结束了,本节通过 ace-window 和 awesome-tab 插件基本复刻了vim中有关窗口的配置和快捷键。
-
Emacs 折腾日记(二十五)——目录管理 在之前的文章中,分了几篇着重介绍了Emacs编辑方面的功能改造。作为一个文本编辑器,要想坚持用下去首先应该改造成自己熟悉的编辑方式。本节我们来介绍Emacs的目录管理Dired ModeEmacs自带一个名为 Dired (Directory Editor) 的插件,它负责对目录进行操作。默认的,我们可以使用 C-x d 来进入Dired Mode。启动后它会等待用户输入想进入的目录,默认是当前目录。Dired Mode 是提供了一种类似操作文本的方式来操作目录。我们可以像操作文本那样来对目录进行类似于拷贝剪切粘贴删除创建跳转查找重命名批量操作得益于前面的篇章配置的一些插件,可以很方便的使用Dired Modedired 美化在正式介绍dired 使用之前,先稍微对它进行一些美化,原始的界面太素了,看着不太好看。首先介绍 diredfl ,原始的dired 只能使用两种颜色来区别文件和目录,而 diredfl 可以使用多种颜色,让dired显示的更加漂亮(use-package diredfl :ensure t :hook (dired-mode . diredfl-mode))接着我们再使用 all-the-icons-dired 来给dired显示的前面加上一个图标。这个插件依赖 all-the-icons 插件。(use-package all-the-icons :ensure t :when (display-graphic-p) :commands all-the-icons-install-fonts) ;; 安装完成之后需要执行 all-the-icons-install-fonts 命令安装对应字体 (use-package all-the-icons-dired :ensure t :hook (dired-mode . all-the-icons-dired-mode))我们也可以通过安装 all-the-icons-completion 插件,给minibuffer中的补全系统也加上图标(use-package all-the-icons-completion :ensure t :hook ((after-init . all-the-icons-completion-mode) (marginalia-mode . all-the-icons-completion-mode)))dirvish 增强direddirvish 是在dired 基础之上的文件管理增强插件。相对与dired 它提供快速跳转、实时预览、并且能兼容对dired的一些扩展。(use-package dirvish :ensure t :hook (after-init . dirvish-override-dired-mode) :bind( ("C-x d" . dirvish) )) 我们使用命令 dirvish 就能打开对应的窗口,或者像上面那样绑定快捷键来打开对应的窗口使用vim的方式来操作目录这里的使用vim的方式来操作多少有点标题党的意思。我无法做到完全按照vim编辑文本那样来编辑目录,但是这里我可以修改以下对应的快捷键已达到某些操作可以使用vim的快捷键。(use-package dirvish :ensure t :hook (after-init . dirvish-override-dired-mode) :bind(:map dired-mode-map ("C-x d" . dirvish) ("y" . dired-do-copy) ;; 拷贝粘贴 ("d" . dired-do-delete) ;; 删除 ("r" . dired-do-rename) ;; 重命名 ("a" . dired-create-empty-file) ;; 创建空文件 ("+" . dired-create-directory) ;; 创建文件 ("SPC" . nil) ;; 取消空格键的绑定 ) :config (with-eval-after-load 'evil (evil-define-key 'normal dired-mode-map "r" 'dired-do-rename)) ;; 排除evil模式下默认键的覆盖 (my-leader-def "j" #'dired-goto-file) )在上述的配置中,我绑定的快捷键如下快捷键功能C-x d打开diredy拷贝d删除r重命名a创建空文件+创建空目录SPC j跳转到指定文件需要注意的是,在 config 中调用了这样的语句 (with-eval-after-load 'evil (evil-define-key 'normal dired-mode-map "r" 'dired-do-rename))with-eval-after-load 表示在某个插件加载之后,这句代码的意思是,在evil插件加载后,在normal模式下,我们定义dired mode 下快捷键 r 绑定到 dired-do-rename,也就是重命名这个功能。之所以要这么做是因为在evil插件加载后会覆盖我们定义的快捷键。另外为了正常使用 leader键,这里特意取消了空格键在dired 中的定义,原本它被定义为跳转到下一行。这些功能都比较简单,所以这里就不演示了。搜索文件并跳转正常情况下,当项目文件和代码量上来之后,再一个目录一个目录的找就不太现实了。常见的是根据代码中函数定义来找文件或者根据文件来找函数定义。前者我们通过consult-rg 已经实现了。这里介绍以下如何通过文件名来查找并快速打开文件我们可以使用 consult-locate 来搜索文件,结合前面介绍的orderless,我们只需要对文件有一个相对的映像就可以找到。想要使用 consult-locate 需要安装 locate 程序,在Arch Linux 中可以使用下面的命令安装sudo pacman -S mlocate sudo updatedb ;; 更新数据库我们以打开配置文件中的 init-completion.el 为例。我们可以直接使用 M-x 输入命令 consult-locate并回车 , 接着在命令提示符后输入一个大概的内容,然后在minibuffer的候选项中找到对应的文件即可我们也可以结合 embark-act 命令来做到跳转到文件所在的 dired 中,这里我们在 embark 的配置中添加一个快捷键定义(use-package embark :ensure t :after consult :bind (("C-e" . embark-export) ("C-;" . embark-act))) ;; 添加 embark-act 快捷键这样在定位到文件之后,可以直接使用 C-; 调出对应的动作,最后使用 j 来完成进入dired的动作有了 consult-locate 和 embark-act,前面介绍的 dired中的跳转操作的实用性就大大降低了,如果我们记得文件的全路径,直接使用 find-file 打开就好了。如果只有一个模糊的映像,那么使用 consult-locate 配合 orderless,比进入dired 然后执行跳转要快的多到这里,Emacs中关于目录管理的部分就介绍完了。使用dired配合键盘操作能极大的提升的效率
-
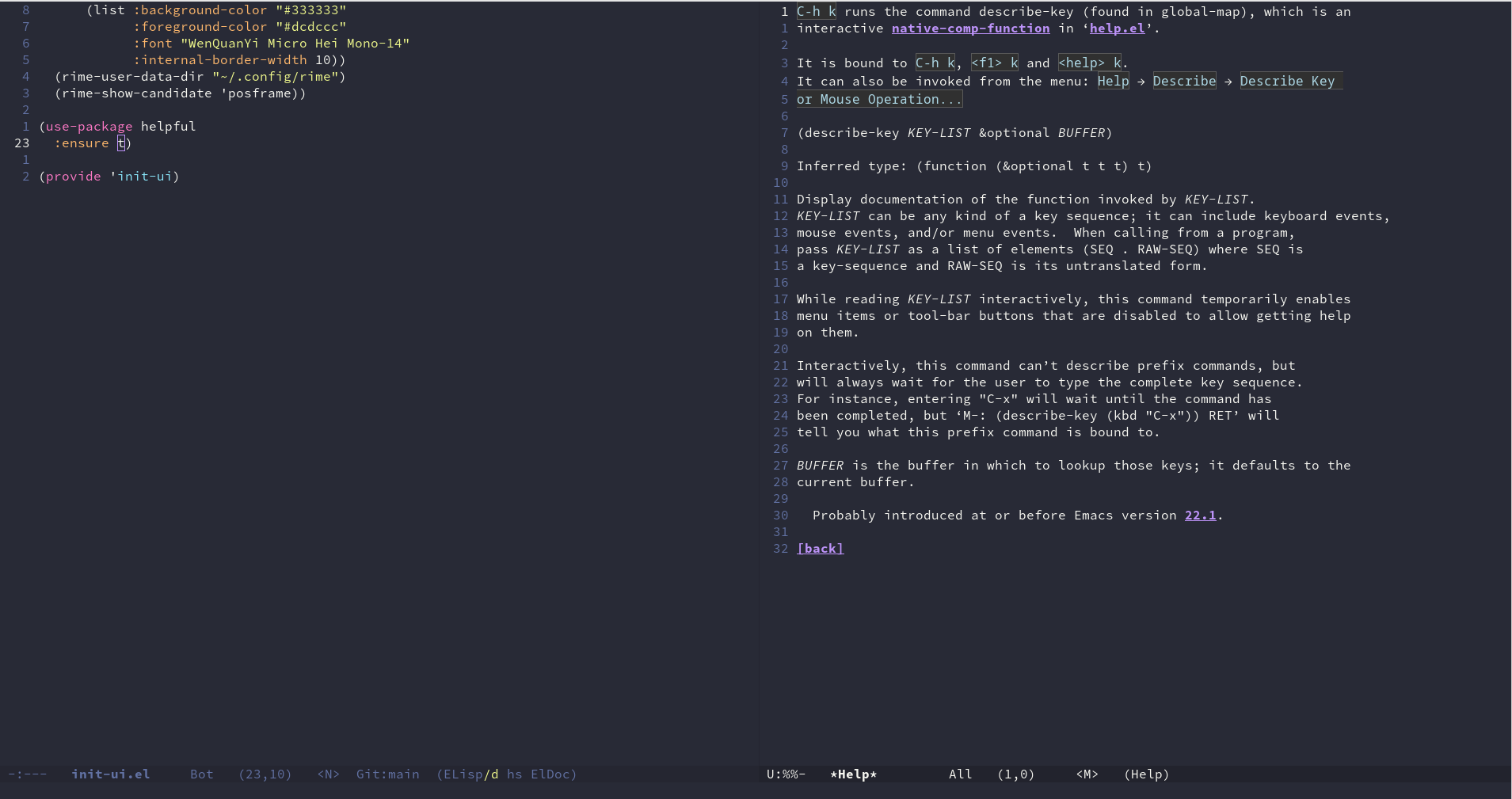
Emacs 折腾日记(二十四)——帮助信息的一些优化 Emacs 是一个自文档的系统,任何有关Emacs的信息都可以通过Emacs自身查阅。包括基础的入门手册、elisp手册、以及各种插件的相关说明信息。一般遇到不懂的变量直接使用 C-h v。查看它的说明。使用 C-h f 查阅相关函数、使用 C-h k 来查找对应快捷键绑定的函数。一般来说阅读官方一手的文档比从任何论坛或者搜索引擎来的更快更准确,而且有不少Emacs高手都推荐多多阅读Emacs的官方文档。本节就着重介绍一下我了解的关于阅读文档的一些姿势。查找相关定义最开始介绍过使用 C-h f 之类的查看相关文档,Emacs所谓的子文档不光指的是查看文档,而且还可以查看相关的源代码。有些我们可以通过文档中给出的源码链接点进去看,但是还是不如直接查看源码。直接查看源码可以使用 find-function、find-variable、find-function-on-key。它们分别对应着查找函数、变量、以及快捷键绑定的函数定义。我们可以绑定一些快捷键(global-set-key (kbd "C-h C-f") 'find-function) (global-set-key (kbd "C-h C-v") 'find-variable) (global-set-key (kbd "C-h C-k") 'find-function-on-key)对默认文档显示的优化我觉得官方的文档显得比较素,比较原始。为了提高阅读的体验我们可以对文档进行美化。这里可以使用 helpful来增强一下。(use-package helpful :ensure t :bind (("C-h f" . helpful-callable) ("C-h v" . helpful-variable) ("C-h k" . helpful-key) ("C-h s" . helpful-symbol) ))我们针对 C-h k 这个快捷键来对比一下原始的文档和 helpful 增强之后的文档显示效果对比发现,helpful 不光对显示效果进行了一些改进,而且显示的内容更加丰富。特别是它已经可以直接显示出相关定义的源代码,在某种程度上替换默认的 find-function 等函数。which-key在介绍配置 neovim 的时候,介绍了 which-key 插件,它可以根据用户输入的快捷键前缀显示所有可能的匹配,使我们记忆快捷键的负担减轻。Emacs上也有类似的插件。在Emacs 30以后内置了 which-key 插件,我们只需要启用(use-package which-key :ensure t :hook (after-init . which-key-mode) :custom (which-key-idle-delay 0.7))
-
Emacs 折腾日记(二十三)——进一步提升编辑效率 在前面的几篇,我们完成了Emacs的vim模拟器、中文输入、多行编辑以及基本的补全功能的添加。这一篇没有具体的提升哪一方面的能力,这一篇我想整合我在其他教程中看到的我认为对我比较有用的用法和插件,算是对前期功能的一个总结。让Emacs记住一些信息一般的编辑器都会在下次打开时记住上次的一些信息,例如记住之前打开过的文件,执行过的命令,或者记住上次的窗口布局。记住上次执行的命令我们每次使用 M-x 执行命令时,minibuffer中显示的提示都是一样的,那些常用命令要么不在上面要么太靠下了,我们希望能记住某些命令,以便能快速找到它。记住上次执行的命令可以使用 savehist 插件。它是一个Emacs自带的插件,默认是关闭的状态,我们可以通过将 use-package 来加载它,但是因为是自带的,不需要从镜像中下载所以它的 :ensure 项应该设置为 nil(use-package savehist :ensure nil :hook (after-init . savehist-mode) :custom (savehist-file (locate-user-emacs-file "custom/savehist")) ;; 设置保存文件的位置 (savehist-additional-variables '(kill-rings shell-command-history)) ;; 额外保存剪切板和shell命令行历史 (savehist-ignored-variables '(message-history)) ;; 不保存消息历史 (history-delete-duplicates t) ;; 自动去重 (history-length 1000) ;; 保存历史数据条目 )在执行一些操作关掉Emacs之后,我们会发现它在 ~/.emacs.d/custom 生成了一个名为 savehist 的文件,它记录了之前在minibuffer中执行的命令。为了保持git工程的干净,我打算将这种历史文件排除在git管理之外,所以单独将它放到custom目录,并忽略它其实该插件不光可以保留执行的命令,minibuffer中的许多信息它都可以保存和持久化。minibuffer-history (所有 minibuffer 输入历史)command-history (执行过的命令)search-ring (搜索历史)regexp-search-ring (正则搜索历史)extended-command-history (M-x 命令历史)file-name-history (文件路径历史)记住上次打开的文件一般的编辑器都可以记录上次打开的文件,并列出来。Emacs也有一个类似的内置插件—— recentf(use-package recentf :ensure nil :hook (after-init . recentf-mode) :custom (recentf-max-menu-item 10) ;; 最多只记录10条历史记录 (recentf-save-file (locate-user-emacs-file "custom/.recentf")) ;; 定义保存历史记录的临时文件路径 )搜索功能的增强实现全局搜索我们可以依赖Linux上的命令行工具 grep 和最近(也不算近了)的 ripgrep。之前在介绍vim的时候,vim内部集成了 grep。但是我们使用更为强大的 ripgrep。在Emacs中可以配合插件 consult 和 ripgrep,调用 consult-ripgrep 来进行全局搜索。它会自动搜索当前项目下的所有目录。我们对之前 consult 插件的配置代码进行一些修改,并添加 ripgrep 的配置(use-package consult :ensure t) (use-package ripgrep :ensure t :after consult :bind (("C-s" . consult-ripgrep)) )这里我们将 C-s 绑定的快捷键修改为 consult-ripgrep。神奇的是,配合之前安装的orderless,我们只需要按照一个模糊的记忆来匹配想要的内容。同时它也能支持输入中文批量替换批量替换这个功能,根据我找到的教程,它需要依赖 embark、consult、和 wgrep 这么三个插件。其中 consult 用来进行搜索,而 embark 可以为不同场景下的文本/候选项(如搜索结果、补全列表、文件路径等)提供动态的快捷操作菜单。简化了minibuffer上的一些操作。而 wgrep 则是其中的核心插件,用来批量修改内容并保存(use-package embark :ensure t :after consult :bind (("C-e" . embark-export))) (use-package embark-consult :ensure t :after embark) (use-package wgrep :ensure t :custom (wgrep-auto-save-buffer t) ;; 自动保存修改 )这里我们使用 :after 来保证插件的加载顺序依次为 consult、embark、embark-consult,特别是 embark-consult,它依赖 consult 和 embark,一定要将它放到后面加载。下面来演示如何进行批量替换,这里我们将配置中所有 use-package 修改为 package-install,修改之前记得使用git等版本管理工具进行备份首先,使用 C-s 搜索 use-package 关键字接着使用 C-e, 也就是上面绑定的快捷键来将结果从 minibuffer 导出到 buffer然后使用 C-c C-p 调用 wgrep-change-to-wgrep-mode 将 buffer 的mode由 grep-mode 修改为 wgrep-mode接着使用 M-% 调用 query-replace 进行替换,这个时候它需要输入被替换的字符和替换后的字符确定后,对于每个待替换的位置使用 y 或者 n 来表示替换或者不替换。也可以使用 ! 替换所有最后使用 C-c C-c 调用 wgrep-finish-edit 来结束编辑,配置之前设置的自动保存,此时修改内容已经被保存了修改之后如何不满意,可以使用 C-c C-k 撤销修改小节这应该是最后一篇关于Emacs自身编辑功能的增强了,在这一块我没有使用太多的Emacs经验。倒是在vim上有点经验,所以很多东西我不自觉地就往vim上面靠,总想着vim在编辑上有些功能Emacs上还没有,该如何进行添加,这几篇就显得比较分散,总是想到什么功能就往上面堆。为此造成各位读者阅读体验不佳,我表示道歉。谢谢各位读者的支持和鼓励!
-
Emacs 折腾日记(二十二)——补全强化 在之前的一系列文章中,我们对Emacs做了一些小范围的定制,目前它已经可以很好的模拟vim的一些基础功能。我们也在模拟vim基础功能之上做了一些能力的提升。本篇我们将对Emacs自带的补全系统做一个升级,并且给出一些搜索和替换的方案,进一步提升Emacs的效率Emacs上有很多很好用的补全插件,著名的有前期的 ivy 体系和当前社区比较火的vertico 体系。为了与时俱进,而且Emacs-China中的很多帖子也推荐使用vertico,所以这里我也介绍这个体系中的插件。vertico 体系中包括下面几个插件:verticoconsultcorfumarginaliaorderlessconsultconsult 插件提供了一系列的查找和补全命令(use-package consult :ensure t :bind (("C-s" . consult-line)))这样我们可以通过使用 C-s 来进行搜索vertico默认情况下,我们使用M-x 输入命令时没有补全提示,但是可以使用TAB 键补全。我们可以通过命令 icomplete-mode 来启用这个mode,以便在输入命令时能拥有一个补全。但是这个补全采用的是横向排版的方式,显示上也不太直观。这里我们可以通过vertico 插件对补全进行增强。vertico 提供了一个垂直样式的补全系统。我们可以通过下列代码来安装并启用它(use-package vertico :ensure t :hook (after-init . vertico-mode))重启emacs之后,再执行 M-x 之后发现它已经可以竖直的显示命令,并且会列出可能的命令了。可以使用 C-n、C-p 来选择下一个或者上一个命令orderless顾名思义,orderless 提供一种无序补全。它可以将一个搜索的范式变成数个以空格分隔的部分,各部分之间没有顺序,你要做的就是根据记忆输入关键词、空格、关键词。它改变了我们使用和思考的习惯,我们不再需要关心信息的顺序,我们只需要在脑海中搜索关键信息片段,然后把这些片段组合起来即可,剩下的都交给Emacs。例如我们要输入 package-refresh-contents 来刷新包管理里面的源。常规的做法我们需要先输入 pack 等等字符,然后由补全信息给我们提示,加入 orderless 之后,可以凭借模糊的记忆输入类似 refre pack 这样的片段来进行匹配(use-package orderless :ensure t :init (setq completion-styles '(orderless)))orderless 是针对整个minibuffer进行增强的,只要是使用minibuffer的地方都可以使用。例如我们上面使用了 consult 插件并且绑定了 C-s 来进行搜索,这里我们就可以使用orderless 来配合完成搜索功能marginaliamarginalia 可以给minibuffer中候选条目显示一段注释或者其他信息。其实不光是执行命令的时候marginalia是启用的,现在只要是minibuffer中的选项,marginalia都是可以使用的,例如使用 switch-buffer 和 find-file 或者使用帮助信息的时候也可以展示相关信息corfucorfu 可以让我们通过弹窗进行补全。(use-package corfu :ensure t :hook (after-init . global-corfu-mode) :custom (corfu-auto t) (corfu-auto-deply 0) (corfu-min-width 1) :init (corfu-history-mode) (corfu-popupinfo-mode))在安装完成之后,我们在编写相关配置的时候可以配合orderless,只输入函数的部分,仅仅凭借模糊的记忆让Emacs自己来匹配我们想要的内容,极大的提高了输入的效率capecorfu 插件仅仅是一个补全的前端,它需要补全后端提供数据。好在Emacs 自己提供了有关elisp 的补全后端,所以上面在测试corfu补全的时候可以出现。但是在其他文本类型不会产生补全选项。而cape则是集成了多种补全后端,它与corfu联合起来可以起到很好的补全效果(use-package cape :ensure t :init (add-to-list 'completion-at-point-functions #'cape-dabbrev) (add-to-list 'completion-at-point-functions #'cape-file) (add-to-list 'completion-at-point-functions #'cape-keyword) (add-to-list 'completion-at-point-functions #'cape-ispell) (add-to-list 'completion-at-point-functions #'cape-dict) (add-to-list 'completion-at-point-functions #'cape-symbol) (add-to-list 'completion-at-point-functions #'cape-line))上述代码中 completion-at-point-functions 保存的是Emacs在补全时调用的相关函数来获取补全项,我们将cape 的相关函数添加到这个列表中,供Emacs在触发补全时调用。到此为止,我们对Emacs自身的补全进行了加强。进一步提升了编辑的效率
-
Emacs 折腾日记(二十一)——编辑能力提升 上一篇文章,我们补充了一些基本的配置,并且关闭了一些默认的行为。这里我们继续对它进行配置。本篇将要使用一些插件来修改默认的编辑行为进一步提高编辑文本的效率。avy 插件基础用法在vim中有 easymotion 可以使用,在Emacs中可以使用 avy 插件。它的功能于前面介绍的easymotion 类似。通过下面的代码来安装(use-package avy :ensure t :after general ;; 确保 general 插件已经安装 :config (setq avy-timeout-seconds 0.5) (my-leader-def "f" 'avy-goto-char-timer))我们在安装配置的时候使用之前定义的leader键来定义它的一些行为。首先定义 SPC-f 来进行快速跳转。avy-goto-char-timer 的功能与 easymotion 类似,将要查找的字符使用不同的字母进行标识,然后根据下一步的输入来确定光标的位置,例如下面的例子我们可以连续输入一段内容减少待筛选项。当然这个速度要快,否则在一定时间内没有输入文本之后,avy会认为已经结束输入了。这个等待的时间我们在上面通过 avy-timeout-seconds 定义的是 0.5。当然也可以扩大这个时间范围进阶用法这个简单的功能只是 avy 功能的冰山一角。它还有许多有用的功能,如果能熟练使用将会极大的提高编辑文本的效率。实际上avy 在筛选、跳转之前可以执行用户指定的动作,它支持哪些动作呢?我们可以在输入筛选的部分文本后输入?,查看支持的动作。我们来举一个例子:下面有一段文本,我希望将text1复制到最后一行,那么可以这么操作使用<leader>f 激活 avy,然后输入筛选文本输入 Y 表示复制整行输入对应字符表示选中text1 所在行此时我们会发现,text1 已经被复制到光标所在行了多行操作和块操作在vim中我们介绍了多行操作,主要是使用C-v 来选中某些行,然后通过使用A 或者 I 来选中行尾或者行首,并进入插入模式。这种方式可以同时在对应位置插入多个相同的字符。emacs 中的 evil 插件也可以进行相同的操作。但是对于行间或者每行在不同位置插入的情况就不适用了。我们可以使用插件 evil-multiedit 来达到这一效果。evil-multiedit 深度绑定了vim的快捷键,在选中区域之后可以直接使用vim中的 I/A 来编辑选中区域的首部或者尾部。也可以使用 ciw 之类的同时修改多个选中区域。在选区时既可以使用vim 中的 * 来查找并选中,也可使用 / 来搜索并且同时选中多个。这个插件相当于增强了vim的多行编辑功能我们使用下列的代码来安装和简单的配置(use-package evil-multiedit :ensure t :after evil :config (evil-multiedit-default-keybinds) (my-leader-def "m m" #'evil-multiedit-match-and-next ; 标记当前符号并跳转下一个 "m M" #'evil-multiedit-match-and-prev ; 标记当前符号并跳转上一个 "m a" #'evil-multiedit-match-all ; 标记所有相同符号 "m r" #'evil-multiedit-restore ; 恢复单光标模式 "m c" #'evil-multiedit-toggle-or-restrict ; 切换选区/限制编辑区域 ))我们可以使用 <leader> mm 来选中符合条件的项也可以使用 <leader> ma 来选择所有符合条件的项好了,本节到此也就结束了,本节依靠两个插件,进一步模拟vim相关的功能,并且对vim原有的功能进行了一定程度的补强。熟练使用这两个插件将会对编程的效率有一个进一步的提升。作为一个普通的文本编辑器也足够了。
-
使用CMake跨平台的一些经验 使用CMake构建工程的一个原因是不希望Windows上有一个工程文件,Linux又单独配置一套工程文件。我们希望对于整个工程只配置一便,就可以直接编译运行。CMake本身也具备这样的特性,脚本只用写一次,在其他平台能自动构建工程。这里谈的跨平台主要是如何组织工程和编写CMake来针对Windows和Linux进行一些特殊的处理,在这里说说我常用的几种办法介绍这些方法的前提是有一些代码只能在Windows上跑,例如调用Win32 API或者使用GDI/GDI+,而在Linux上也有一些Windows不支持的代码。我们就需要一些方法来隔离开这两套代码。假设现在有一个项目,它有一套共同的接口对外提供功能,而在Windows上和Linux上各有一份代码来实现这些接口。可以假设有一套图形相关的功能,对外采用统一的接口,具体实现时Windows上使用GDI+,而Linux上使用其他方案来实现。现在整个项目的目录结构如下. ├── include └── platform ├── linux └── windowsinclude 目录用来对外提供接口,是导出的头文件。platform隔离了Windows和Linux上的实现代码。使用宏来控制我们知道Windows和Linux平台有特定编译器定义的宏,根据这些宏是否定义我们可以知道当前是在Linux还是Windows上编译,是需要编译成32位或者64位程序,又或者编译成debug版本或者release版本。例如下面是我用的简单的判断版本的方式#define MY_PLATFORM_WINDOWS 0 #define MY_PLATFORM_LINUX 1 #define MY_PLATFORM_APPLE 2 #define MY_PLATFORM_ANDROID 3 #define MY_PLATFORM_UNIX 4 #define MY_ARCH32 1 #define MY_ARCH64 2 #if defined(_WIN32) || defined(_WIN64) #define MY_PLATFORM MY_PLATFORM_WINDOWS #ifdef _WIN64 #define PLATFORM_NAME "Windows 64-bit" #define MY_ARCH MY_ARCH64 #else #define PLATFORM_NAME "Windows 32-bit" #define MY_ARCH MY_ARCH32 #endif #elif defined(__APPLE__) #include "TargetConditionals.h" #define MY_PLATFORM MY_PLATFORM_APPLE #ifdef ARCHX64 #define MY_ARCH MO_ARCH64 #else #define MY_ARCH MO_ARCH32 #endif #if TARGET_IPHONE_SIMULATOR #define PLATFORM_NAME "iOS Simulator" #elif TARGET_OS_IPHONE #define PLATFORM_NAME "iOS" #elif TARGET_OS_MAC #define PLATFORM_NAME "macOS" #endif #elif defined(__linux__) #define MY_PLATFORM MY_PLATFORM_LINUX #if defined (ARCHX64) || defined (__x86_64__) #define MY_ARCH MY_ARCH64 #else #define MY_ARCH MY_ARCH32 #endif #define PLATFORM_NAME "Linux" #elif defined(__unix__) #ifdef ARCHX64 #define MY_ARCH MY_ARCH64 #else #define MY_ARCH MY_ARCH32 #endif #define PLATFORM_NAME "Unix" #define MY_PLATFORM MY_PLATFORM_UNIX #else #error "Unknown platform" #endif上面代码根据一些常见的编译器宏来决定是什么版本,并且根据不同的版本将MY_PLATFORM 进行赋值。后面只需要使用 MY_PLATFORM 进行版本判断即可。同样的关于架构使用 MY_ARCH 来判断。例如根据架构来定义不同的数据长度#if (MY_PLATFORM == MY_PLATFORM_WINDOWS) typedef __int64 MY_INT64; typedef unsigned __int64 MY_UINT64; #else typedef long long MY_INT64; typedef unsigned long long MY_UINT64; #endif #if (MY_ARCH == MY_ARCH64) typedef MY_UINT64 MY_ULONG_PTR; typedef MY_INT64 MY_INT_PTR; #else typedef MY_UINT MY_ULONG_PTR; typedef MY_INT MY_INT_PTR; #endif定义的常见的数据结构之后,对于一些接口的视线就可以利用宏来隔开// platform/windows/image.c #if (MY_PLATFORM == MY_PLATFORM_WINDOWS) // todo something #endif// platform/linux/image.c #if (MY_PLATFORM == MY_PLATFORM_LINUX) // todo something #endif这样我们可以利用上一节介绍过的 cmake 的 file 或者 aux_source_directory 将整个platform目录都包含到工程里面。使用cmake来判断版本除了在C/C++ 源码中利用编译器特定的宏来判断版本,其实CMake自身也有一些方式来判断编译的版本。CMake 检测操作系统使用 CMAKE_SYSTEM_NAME 来判断。这里要提一句,CMake中的变量本质上都是一个字符串值,没有严格的区分类型,所以 set(variable 1) 和 set(variable "1") 在底层存储都是字符串 1。所以cmake在定义变量的时候可以不使用双引号,但是对于特殊的字符串,例如带有空格的字符串,为了避免语法上的歧义,可以带上双引号。虽然说底层存储的都是字符串,但是在上层判断变量是否相等的时候却又区分数字和字符串。判断变量是否等于某个值可以使用 EQUAL 或者 STREQUAL。EQUAL 是用来判断数字类型是否相等,一般判断版本号或者数字参数。而 STREQUAL 来判断字符串是否相等,一般用来判断配置选项、路径、平台标识符。例如这里的 CMAKE_SYSTEM_NAME 就需要采用 STREQUAL 来判断# 检测平台 set(PLATFORM_WINDOWS 1) set(PLATFORM_LINUX 2) set(PLATFORM_MACOS 3) if(CMAKE_SYSTEM_NAME STREQUAL "Windows") set(PLATFORM ${PLATFORM_WINDOWS}) elseif(CMAKE_SYSTEM_NAME STREQUAL "Linux") set(PLATFORM ${PLATFORM_LINUX}) elseif(CMAKE_SYSTEM_NAME STREQUAL "Darwin") set(PLATFORM ${PLATFORM_MACOS}) endif()判断架构可以使用 CMAKE_SIZEOF_VOID_P。顾名思义,它表示一个void* 指针变量的大小,8位就是64位,4位则是32位架构。if(CMAKE_SIZEOF_VOID_P EQUAL 8) set(PLATFORM_ARCH "x64") elseif(CMAKE_SIZEOF_VOID_P EQUAL 4) set(PLATFORM_ARCH "x86") else() message(FATAL_ERROR "Unsupported architecture pointer size: ${CMAKE_SIZEOF_VOID_P}") endif()至于判断当前编译的版本是debug 还是 release 可以使用 CMAKE_BUILD_TYPE 来判断,它的值主要有4个,分别是 Debug、RelWithDebInfo、MinSizeRel、Release。它们四个各有特色。其中 RelWithDebInfo 是带有符号表的发布版,便于调试,它的优化级别最低。MinSizeRel和Release在优化上各有千秋,前者追求最小体积,后者追求最快的速度,所以后者有时候会为了运行速度添加一些额外的内容导致体积变大。我们可以在cmake文件中判断对应的值以便做出一些额外的设置。例如if(CMAKE_BUILD_TYPE STREQUAL "Debug") add_compile_definitions(-D_DEBUG) else() add_compile_definitions(-DNDEBUG) endif()有了这些基础,我们可以在不同的条件下,定义不同的编译宏,然后根据编译宏的不同在C/C++ 源码中判断这些宏从而隔离不同平台的实现代码通过cmake list 来隔离不同平台的代码使用 file 或者 aux_source_directory 的到的是一个源代码文件的列表。我们可以操作这个列表来达到控制编译文件的需求。cmake 中针对列表的操作符是 list,它的定义如下:Reading list(LENGTH <list> <out-var>) list(GET <list> <element index> [<index> ...] <out-var>) list(JOIN <list> <glue> <out-var>) list(SUBLIST <list> <begin> <length> <out-var>) Search list(FIND <list> <value> <out-var>) Modification list(APPEND <list> [<element>...]) list(FILTER <list> {INCLUDE | EXCLUDE} REGEX <regex>) list(INSERT <list> <index> [<element>...]) list(POP_BACK <list> [<out-var>...]) list(POP_FRONT <list> [<out-var>...]) list(PREPEND <list> [<element>...]) list(REMOVE_ITEM <list> <value>...) list(REMOVE_AT <list> <index>...) list(REMOVE_DUPLICATES <list>) list(TRANSFORM <list> <ACTION> [...]) Ordering list(REVERSE <list>) list(SORT <list> [...])官方提供了这么一些操作list的操作符,但是在这个需求中我们只需要两个操作符APPEND 和 REMOVE_ITEM 即可。后面的参数分别是源列表,以及需要增加或者删除的项,它们都可以传入多项。但是删除时它是根据传入字符串,从列表中进行字符串比较,如果相等则进行删除。所以在传入路径的时候需要特别注意,不能一个传入全路径一个传入相对路径或者一个传入 / 开头的路径,另一个传入 ~ 开头的路径。上述两个操作都可以传入多个单个的字符串也可以传入一个列表。如果我们有下列目录结构src/platform/windows src/platform/linux src/*.cpp src/other/*.cpp也就说我们将不同平台的代码放入到src目录,并且src目录也有其他代码,我们如果使用 file 操作符来查找src目录中的源码文件必定会包含两个平台的实现代码。这个时候就可以考虑使用REMOVE_ITEM 根据平台来舍弃一些代码,例如file(GLOB_RECURSE SOURCES ${PROJECT_SOURCE_DIR}/src/*.c ) if(CMAKE_SYSTEM_NAME STREQUAL "Windows") file(GLOB_RECURSE NOT_INCLUDE ${PROJECT_SOURCE_DIR}/src/platform/linux/*.cpp ) elseif(CMAKE_SYSTEM_NAME STREQUAL "Linux") file(GLOB_RECURSE NOT_INCLUDE ${PROJECT_SOURCE_DIR}/src/platform/windows/*.cpp ) endif() list( REMOVE_ITEM SOURCES SOURCE ${NOT_INCLUDE} )又或者我们采用最上面的给出的目录结构,也就是说platform 目录位于src目录之外,相对于src来说是额外添加的代码文件,那么就可以使用 APPEND 来进行添加if(CMAKE_SYSTEM_NAME STREQUAL "Windows") aux_source_directory(${PROJECT_SOURCE_DIR}/platform/windows PLATFORM_SOURCE) elseif(CMAKE_SYSTEM_NAME STREQUAL "Linux") aux_source_directory(${PROJECT_SOURCE_DIR}/platform/linux PLATFORM_SOURCE) endif() list(APPEND SOURCES ${PLATFORM_SOURCE})通过 toolchain 文件来组织平台特殊配置cmake 允许我们在生成Makefile的时候指定toolchain 文件来实现一些自定义的配置。例如可以根据平台的不同将生成路径指定在对应的toolchain中。toolchain 的语法与cmake语法相同,例如针对Windows和Linux可以创建 win32_toolchain.cmake win64_toolchain.cmake linux_86_toolchain.cmake 和 linux_x64_toolchain.cmake 文件来区别我还是以上一篇文章中多工程嵌套的例子作为示例来演示如何使用,它的目录结构如下. ├── calc │ ├── add.cpp │ ├── CMakeLists.txt │ ├── div.cpp │ ├── mult.cpp │ └── sub.cpp ├── CMakeLists.txt ├── include │ ├── calc.h │ └── sort.h ├── sort │ ├── CMakeLists.txt │ ├── insert_sort.cpp │ └── select_sort.cpp ├── test_calc │ ├── CMakeLists.txt │ └── main.cpp └── test_sort ├── CMakeLists.txt └── main.cpp这个例子我们只需要改动根目录下的生成库和可执行程序的路径。cmake_minimum_required(VERSION 3.15) project(test) add_subdirectory(sort) add_subdirectory(calc) add_subdirectory(test_calc) add_subdirectory(test_sort)这个文件只需要保留最基础的配置即可,而生成程序的路劲都在 toolchain 中。下面是 linux_x86_toolchain.cmake 文件的内容set(LIBPATH ${PROJECT_SOURCE_DIR}/lib/linux/x86) set(EXECPATH ${PROJECT_SOURCE_DIR}/bin/linux/x86) set(HEADPATH ${PROJECT_SOURCE_DIR}/include) if(CMAKE_BUILD_TYPE STREQUAL "Debug") set(CALCLIB calc_d) set(SORTLIB sort_d) set(CALCAPP test_calc_d) set(SORTAPP test_sort_d) else() set(CALCLIB calc) set(SORTLIB sort) set(CALCAPP test_calc) set(SORTAPP test_sort) endif() set(CMAKE_SYSTEM_PROCESSOR i686) set(CMAKE_C_FLAGS "-m32 -L/usr/lib32" CACHE STRING "" FORCE) set(CMAKE_CXX_FLAGS "-m32 -L/usr/lib32" CACHE STRING "" FORCE) set(CMAKE_EXE_LINKER_FLAGS "-m32 -L/usr/lib32" CACHE STRING "" FORCE)这个文件我们定义了debug和release的库名称和生成的路径,并且指定相关参数用于生成32位程序。CMAKE 中定义了一堆 CMAKE_LANGUAGE_FLAGS 这些都是相关工具的参数,这里的FLAGS 分别是 gcc 和 ld 编译链接的参数。在使用时直接用命令 cmake .. -DCMAKE_TOOLCHAIN_FILE=../linux_x32_toolchain.cmake -DCMAKE_BUILD_TYPE=Debug 生成Makefile。Windows平台上上面的参数稍微有些差距。例如下面是 windows_x32_toolchain.cmake 的定义# 静态库生成路径 set(LIBPATH ${PROJECT_SOURCE_DIR}/lib/windows/x86) # 可执行程序的存储目录 set(EXECPATH ${PROJECT_SOURCE_DIR}/bin/windows/x86) # 头文件路径 set(HEADPATH ${PROJECT_SOURCE_DIR}/include) if(CMAKE_BUILD_TYPE STREQUAL "Debug") # calc库名称 set(CALCLIB calc_d) # sort 库名称 set(SORTLIB sort_d) # 测试程序的名字 set(CALCAPP test_calc_d) set(SORTAPP test_sort_d) else() # calc库名称 set(CALCLIB calc) # sort 库名称 set(SORTLIB sort) # 测试程序的名字 set(CALCAPP test_calc) set(SORTAPP test_sort) endif() set(CMAKE_GENERATOR_PLATFORM "Win32" CACHE STRING "Target Platform") # 指定32位编译器路径 set(CMAKE_C_COMPILER "$ENV{VCToolsInstallDir}/bin/Hostx86/x86/cl.exe") set(CMAKE_CXX_COMPILER "$ENV{VCToolsInstallDir}/bin/Hostx86/x86/cl.exe") set(CMAKE_SYSTEM_PROCESSOR x86)需要注意的是 CMAKE_GENERATOR_PLATFORM 对应的是VS 中的解决方案平台,也就是 Win32 和 x64 这两个选项。 而 CMAKE_SYSTEM_PROCESSOR 对应的是VS中的目标计算机选项,一般是X86、X64 或者 ARM64 和 AMD64。我们可以使用命令 cmake -G "Visual Studio 15 2017" -A "win32" -DCMAKE_BUILD_TYPE=Debug -DCMAKE_TOOLCHAIN_FILE="..\windows_x86_toolchain.cmake" .. 这里指定使用 VS 2017 进行构建,构建架构是32位,版本是Debug。命令成功执行之后会生成一个.sln 文件,我们可以用VS打开然后在VS中编译,也可以执行使用命令 cmake --build . --config Debug 来编译。一般来说我习惯使用后者,过去使用vs 打开.sln 可以在vs中进行开发,如今vs 已经可以打开并编译cmake工程,所以现在我基本不使用 .sln 文件了,除非公司项目要求使用 .sln。好了,目前我掌握的关于cmake的内容就是这些了,我利用这些知识已经完成了公司项目的跨平台开发和部署。后续如果有新的需求说不定我会学点新的内容,到时候再来更新这一系列文章吧!!!
-
CMake 基础 很遗憾直到现在才开始接触cmake,过去都在微软的vs IDE上编写c++程序,即使引用第三方的库直接使用cmake也能编译成功,很少关注它本身的内容。但是现在我有一项工作的内容就是将在Windows平台上的c++程序移植到Linux平台上。我想选择cmake作为支持跨平台的构建工具。因此提前学了点cmake的基础知识。cmake本身并不能直接编译和链接程序,它是一个构建程序。主要作用就是根据cmake脚本来生成Makefile文件,以供nmake、gun make等工具来生成可执行程序。编译exe简单的hello world使用cmake需要提供一个CMakeLists.txt 的脚本文件,这个名称是固定的,位置一般在项目的根目录。假设现在有一个简单的hello world程序,它的项目目录可能如下v1 ├── CMakeLists.txt ├── main.cpp我们可以使用如下cmake脚本cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) add_executable(hello ./main.cpp)第一句的含义是指定使用cmake最小的版本为3.15;第二句的含义是使用c++ 11标准第三句的含义是指定项目名称第四句的含义是生成可执行程序的名称为hello,并且指定要编译的源文件是当前目录下的 main.cpp 文件。工程中有多个源文件时,add_executable 后面可以加多个源文件路径一般来说cmake脚本都会包含这么几条语句脚本编写完毕后,需要使用cmake命令进行编译。该命令可以接受一个参数用于指定CMakeLists.txt 文件所在的路径,执行之后会生成一大堆中间文件和对应的Makefile文件。这些都会生成在当前执行cmake命令时所在路径。所以为了便于管理,一般会在适当位置建立一个新的build目录。这个时候整个命令如下mkdir build cd build cmake .. make前面我们在项目根目录下新建一个build目录用于保存中间文件,然后切换到build目录中。接着执行cmake命令并给出对应CMakeLists.txt 所在的路径。执行成功后会在build目录中生成一个Makefile文件,最后就是执行make命令来生成可执行程序这样最简单的一个hello world工程就编译完成了。指定可执行程序的路径生成的可执行文件路径就在当前的build目录下,如果我们要指定可执行程序的路径,可以使用变量 EXECUTABLE_OUTPUT_PATH。它是cmake内置的变量,保存的是可执行程序输出的路径。在cmake中可以使用set来给变量赋值。到此我们的cmake脚本可能是这样的cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) add_executable(hello ./main.cpp)这里涉及到cmake中变量的定义和使用。其实cmake中变量特别简单,cmake中的变量全都是字符串,定义和设置变量值都是用set 操作符。而要取变量的值则使用 ${} 来包住一个变量名。另外cmake使用 EXECUTABLE_OUTPUT_PATH 作为可执行程序的输出路径,这里我们设置输出路径为工程目录下的bin目录下面。这里的 PROJECT_SOURCE_DIR 表示的是当前项目的目录指定头文件所在路径这里我们来一个复杂一点的项目作为演示,这个项目的目录结构如下. ├── include │ └── calc.h └── src ├── add.cpp ├── div.cpp ├── main.cpp ├── mul.cpp └── sub.cpp这种工程中,include目录放头文件,src目录放源文件,calc.h 中定义了4个函数分别实现加减乘除四则运算。它们的实现分别在 add.cpp、sub.cpp、mul.cpp、div.cpp 中,而main.cpp主要负责调用这些函数实现。main.cpp 的代码如下#include <stdio.h> #include "calc.h" int main (int argc, char *argv[]) { int a = 30; int b = 10; printf("a + b = %d\n", add(a, b)); printf("a - b = %d\n", sub(a, b)); printf("a * b = %d\n", mul(a, b)); printf("a / b = %d\n", div(a, b)); return 0; }这里我们要解决一个问题,因为main.cpp在src中,而 calc.h在include目录中,它们并不在同一目录下,代码中直接引用它会提示找不到对应的头文件。我们当然可以写出 include "../include/calc.h" 来修正它,但是项目中文件多了,不同路径的源文件要写这种相对路径就是一种折磨了。一般的经验是给出头文件的路径,后面所有源文件都根据这个路劲来组织包含头文件的相对路径。这里我们需要指定include作为头文件的路径。cmake中使用 include_directories 来指定头文件路径,它可以接受多个目录表示可以从这些目录中去查找头文件。所以这个项目的cmake文件可以这么写cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) include_directories(${PROJECT_SOURCE_DIR}/include) add_executable(hello ./src/add.cpp ./src/sub.cpp ./src/mul.cpp ./src/div.cpp ./src/main.cpp)遍历目录中的源文件上面的示例中我们发现 add_executable 后面加了好多cpp文件,这个项目比较小只有这么几个文件,如果一个项目有几百个源文件,并且每个源文件都在不同的目录,我们把每个源文件都这样一个个的写出来,不知道要写到什么时候呢。是否有办法能一次获取目录中的所有cpp文件,并保存在一个变量中,在需要指定源文件的场合直接使用这个变量,这样就简单很多了。cmake中当然有这个方法,它提供了两种方式来实现这个需求。第一种方式是使用 aux_source_directory。它接受一个目录,将指定目录中的所有源文件以list的形式放入到指定变量中,使用它可以将之前的cmake文件改写成下列形式cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) aux_source_directory(${PROJECT_SOURCE_DIR}/src SOURCES) include_directories(${PROJECT_SOURCE_DIR}/include) add_executable(hello ${SOURCES})这里我们遍历src目录中的所有源文件,将结果放入到变量SOURCES中。最后在add_executable中将这个结果传入,作为源文件参与最后的编译。第二种方式是可以使用file函数,它能遍历指定目录中的指定文件,并且将结果返回到对应参数中,它的使用方式如下file(<GLOB|GLOB_RECURSE> <variable> [LIST_DIRECTORIES])第一个参数是 GLOB 或者是 GLOB_RECURSE。后者表示递归遍历所有子目录中的文件。第二个参数是变量,最后会将遍历的结果放入到这个变量中。第三个参数是一个可选的,它表示筛选条件,可以填入多个条件。我们可以将上面的aux_source_directories 替换成 file,写成如下形式file(GLOB_RECURSE SOURCES ${PROJECT_SOURCE_DIR}/src/*.cpp)编译静态库和动态库我们再来修改一下这个工程。我们将四则运算的操作独立出来编译为一个静态库,然后在另一个工程中链接这个库并调用这些函数。这个时候可以这么组织工程,在上一个工程的基础上删除main.cpp 就可以了。编译静态库可以使用 add_library 操作符,它用来生成库文件。它可以编译动态库或者静态库。第一个参数是库的名称,最终会生成一个名称为 libname.a 或者 libname.so 的文件,其中name是我们指定的第一个参数;第二个参数是STATIC 或者 SHARED 分别是编译静态库和动态库。第三个参数是编译时需要参与便于的代码源文件。 所以我们的CMakeLists.txt 文件可以这样写cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) set(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) file(GLOB_RECURSE SOURCES ${PROJECT_SOURCE_DIR}/src/*.cpp) include_directories(${PROJECT_SOURCE_DIR}/include) # 编译动态库 # add_library(mylib SHARED ${SOURCES}) # 编译静态库 add_library(mylib STATIC ${SOURCES})上面的配置中,使用 LIBRARY_OUTPUT_PATH 来指定库文件生成的路径,最终会在bin目录下生成一个名为 libmylib.so 或者 libmylib.a 的库文件链接静态库和动态库上面我们编译生成了静态库和动态库,该如何在工程中引用它们呢?引用动态库或者静态库可以使用 target_link_libraries。它可以链接静态库或者动态库。在指定要链接的库名称为name 之后,它默认会优先从用户指定的位置查找名为 libname.a 或者 libname.so 的库,如果用户未指定位置或者在指定位置未找到对应的库,那么它会到系统库中查找,都找不到则会报错。我们可以通过 link_directories 来指定库文件的路径,下面是一个示例cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) include_directories(${PROJECT_SOURCE_DIR}/include) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) link_directories(${PROJECT_SOURCE_DIR}/lib) add_executable(hello ${PROJECT_SOURCE_DIR}/main.cpp) target_link_libraries(hello mylib )target_link_library 需要放到 add_executable 或者 add_library 之后,它的第一个参数就是我们在 add_executable 或者 add_library 中给定的生成程序的名称。添加编译宏一般来说,在代码中对于debug版本会额外的输出一些日志信息用于调试,或者根据不同版本来调整某个数据结构的定义,例如#ifdef X64 typedef unsigned long long ULONG_PTR #else typedef unsigned long ULONG_PTRVS 中可以通过预处理器来指定编译时的宏,而GCC 可以通过-D 来指定宏。cmake中也类似,它可以通过 add_compile_definies 来指定宏。它传入的参数于GCC定义宏类似,以-D开头后面跟宏的名称,例如要定义名为 _DEBUG 的宏,可以写成 -D_DEBUG。定义宏后面还可以使用 = 来指定宏的值。下面是一个具体的例子#include <stdio.h> int main (int argc, char *argv[]) { #ifdef _DEBUG printf("this is debug version\n"); #endif printf("the app version is %s\n", VERSION); return 0; }cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) add_compile_definitions( -D_DEBUG -DVERSION="1.0.1") add_executable(hello ${PROJECT_SOURCE_DIR}/main.cpp)多个工程嵌套一般在项目中,可能有多个子项目,例如一个web商场可能有前后端之分。在cmake中项目有子工程的话,将各个子工程放到主工程的子目录下,然后使用 add_subdirectory 将各个子项目连接起来。下面是一个具体的例子. ├── calc │ ├── add.cpp │ ├── CMakeLists.txt │ ├── div.cpp │ ├── mult.cpp │ └── sub.cpp ├── CMakeLists.txt ├── include │ ├── calc.h │ └── sort.h ├── sort │ ├── CMakeLists.txt │ ├── insert_sort.cpp │ └── select_sort.cpp ├── test_calc │ ├── CMakeLists.txt │ └── main.cpp └── test_sort ├── CMakeLists.txt └── main.cpp上述项目有4个子工程,分别是四则运算的calc 、排序算法的 sort。以及对应的测试用例test_calc 和 test_sort。算法编译成静态库,测试工程直接链接对应的静态库。基于以上布局,我们在主工程的 CMakeLists.txt 可以这么写cmake_minimum_required(VERSION 3.15) project(test) # 定义变量 # 静态库生成路径 set(LIBPATH ${PROJECT_SOURCE_DIR}/lib) # 可执行程序的存储目录 set(EXECPATH ${PROJECT_SOURCE_DIR}/bin) # 头文件路径 set(HEADPATH ${PROJECT_SOURCE_DIR}/include) # calc库名称 set(CALCLIB calc) # sort 库名称 set(SORTLIB sort) # 测试程序的名字 set(CALCAPP test_calc) set(SORTAPP test_sort) # 添加子目录 add_subdirectory(sort) add_subdirectory(calc) add_subdirectory(test_calc) add_subdirectory(test_sort)在这个文件我们定义了一些其他工程都会用到的一些配置,例如包含的头文件路径、生成程序的路径。以及项目中包含的子项目。在最外层定义的变量可以直接在子工程的cmake 配置文件中使用。这里有点像派生类可以使用基类定义的变量。在calc 子工程中,可以这么配置cmake_minimum_required(VERSION 3.15) project(calc) # 指定要编译的源文件 aux_source_directory(./ SOURCES) # 指定头文件的路径 include_directories(${HEADPATH}) # 指定生成库的路径 set(LIBRARY_OUTPUT_PATH ${LIBPATH}) # 指定生成库的名称 add_library(${CALCLIB} STATIC ${SOURCES})calc 子工程使用根目录工程中定义的变量指定了生成库的路径、库名称。并且直接定义编译成静态库在test_calc 这个测试程序中,可以这么配置cmake_minimum_required(VERSION 3.15) project(test_calc) # 指定头文件的路径 include_directories(${HEADPATH}) # 指定生成exe的路径 set(EXECUTABLE_OUTPUT_PATH ${EXECPATH}) # 指定库文件的目录 link_directories(${LIBPATH}) # 生成可执行文件名称 add_executable(${CALCAPP} ./main.cpp) target_link_libraries( ${CALCAPP} ${CALCLIB} )在测试工程中使用父工程中定义的变量指定了生成程序的路径以及链接库的路径。其他的工程与上面两个子工程的配置类似,只需要改一些变量。就可以运行了。至此, 已经介绍完了使用cmake配置工程的一些基本配置。我们几乎可以将VS 中的项目配置一比一的使用上述内容使用cmake复刻一遍。至于跨平台的配置,无外乎是一些常见的标志判断,根据条件设置变量即可。后续如果我还有好的cmake使用实践也会分享出来。