搜索到
17
篇与
的结果
-
 VC 在调用main函数之前的操作 在C/C++语言中规定,程序是从main函数开始,也就是C/C++语言中以main函数作为程序的入口,但是操作系统是如何加载这个main函数的呢,程序真正的入口是否是main函数呢?本文主要围绕这个主题,通过逆向的方式来探讨这个问题。本文的所有环境都是在xp上的,IDE主要使用IDA 与 VC++ 6.0。为何不选更高版本的编译器,为何不在Windows 7或者更高版本的Windows上实验呢?我觉得主要是VC6更能体现程序的原始行为,想一些更高版本的VS 它可能会做一些优化与检查,从而造成反汇编生成的代码过于复杂不利于学习,当逆向的功力更深之后肯定得去分析新版本VS 生成的代码,至于现在,我的水平不够只能看看VC6 生成的代码首先通过VC 6编写这么一个简单的程序#include <stdio.h> #include <windows.h> #include <tchar.h> int main() { wchar_t str[] = L"hello world"; size_t s = wcslen(str); return 0; }通过单步调试,打开VC6 的调用堆栈界面,发现在调用main函数之前还调用了mainCRTStartup 函数:在VC6 的反汇编窗口中好像不太好找到mainCRTStartup函数的代码,因此在这里改用IDA pro来打开生成的exe,在IDA的 export窗口中双击 mainCRTStartup 函数,代码就会跳转到函数对应的位置。它的代码比较长,刚开始也是进行函数的堆栈初始化操作,这个初始化主要是保存原始的ebp,保存重要寄存器的值,并且改变ESP的指针值初始化函数堆栈,这些就不详细说明了,感兴趣的可以去看看我之前写的关于函数反汇编分析的内容:C函数原理在初始化完成之后,它有这样的汇编代码.text:004010EA push offset __except_handler3 .text:004010EF mov eax, large fs:0 .text:004010F5 push eax .text:004010F6 mov large fs:0, esp这段代码主要是用来注册主线程的的异常处理函数的,为什么它这里的4行代码就可以设置线程的异常处理函数呢?这得从SEH的结构说起。每个线程都有自己的SEH链,当发生异常的时候会调用链中存储的处理函数,然后根据处理函数的返回来确定是继续运行原先的代码,还是停止程序还是继续将异常传递下去。这个链表信息保存在每个线程的NT_TIB结构中,这个结构每个线程都有,用来记录当前线程的相关内容,以便在进行线程切换的时候做数据备份和恢复。当然不是所有的线程数据都保存在这个结构中,它只保留部分。该结构的定义如下:typedef struct _NT_TIB { PEXCEPTION_REGISTRATION_RECORD ExceptionList; PVOID StackBase; PVOID StackLimit; PVOID SubSystemTib; union { PVOID FiberData; ULONG Version; }; PVOID ArbitraryUserPointer; PNT_TIB Self; } NT_TIB, *PNT_TIB;这个结构的第一个参数是一个异常处理链的链表头指针,链表结构的定义如下:typedef struct _EXCEPTION_REGISTRATION_RECORD { PEXCEPTION_REGISTRATION_RECORD Next; PEXCEPTION_DISPOSITION Handler; } EXCEPTION_REGISTRATION_RECORD, *PEXCEPTION_REGISTRATION_RECORD;这个结构很简单的定义了一个链表,第一个成员是指向下一个节点的指针,第二个参数是一个异常处理函数的指针,当发生异常的时候会去调用这个函数。而这个链表的头指针被存到fs寄存器中知道了这点之后再来看这段代码,首先将异常函数入栈,然后将之前的链表头指针入栈,这样就组成了一个EXCEPTION_REGISTRATION_RECORD结构的节点而这个节点的指针现在就是ESP中保存的值,之后再将链表的头指针更新,也就是最后一句对fs的重新赋值,这是一个典型的使用头插法新增链表节点的操作。通过这样的几句代码就向主线程中注入了一个新的异常处理函数。之后就是进行各种初始化的操作,调用GetVersion 获取版本号,调用 __heap_init 函数初始化C运行时的堆栈,这个函数后面有一个 esp + 4的操作,这里可以看出这个函数是由调用者来做堆栈平衡的,也就是说它并不是Windows提供的api函数(API函数一般都是stdcall的方式调用,并且命名采用驼峰的方式命名)。调用GetCommandLineA函数获取命令行参数,调用 GetEnvironmentStringsA 函数获取系统环境变量,最后有这么几句话:.text:004011B0 mov edx, __environ .text:004011B6 push edx ; envp .text:004011B7 mov eax, ___argv .text:004011BC push eax ; argv .text:004011BD mov ecx, ___argc .text:004011C3 push ecx ; argc .text:004011C4 call _main_0这段代码将环境变量、命令行参数和参数个数作为参数传入main函数中。 在C语言中规定了main函数的三种形式,但是从这段代码上看,不管使用哪种形式,这三个参数都会被传入,程序员使用哪种形式的main函数并不影响在VC环境在调用main函数时的传参。只是我们代码中不使用这些变量罢了。到此,这篇博文简单的介绍了下在调用main函数之前执行的相关操作,这些汇编代码其实很容易理解,只是在注册异常的代码有点难懂。最后总结一下在调用main函数之前的相关操作注册异常处理函数调用GetVersion 获取版本信息调用函数 __heap_init初始化堆栈调用 __ioinit函数初始化啊IO环境,这个函数主要在初始化控制台信息,在未调用这个函数之前是不能进行printf的调用 GetCommandLineA函数获取命令行参数调用 GetEnvironmentStringsA 函数获取环境变量调用main函数
VC 在调用main函数之前的操作 在C/C++语言中规定,程序是从main函数开始,也就是C/C++语言中以main函数作为程序的入口,但是操作系统是如何加载这个main函数的呢,程序真正的入口是否是main函数呢?本文主要围绕这个主题,通过逆向的方式来探讨这个问题。本文的所有环境都是在xp上的,IDE主要使用IDA 与 VC++ 6.0。为何不选更高版本的编译器,为何不在Windows 7或者更高版本的Windows上实验呢?我觉得主要是VC6更能体现程序的原始行为,想一些更高版本的VS 它可能会做一些优化与检查,从而造成反汇编生成的代码过于复杂不利于学习,当逆向的功力更深之后肯定得去分析新版本VS 生成的代码,至于现在,我的水平不够只能看看VC6 生成的代码首先通过VC 6编写这么一个简单的程序#include <stdio.h> #include <windows.h> #include <tchar.h> int main() { wchar_t str[] = L"hello world"; size_t s = wcslen(str); return 0; }通过单步调试,打开VC6 的调用堆栈界面,发现在调用main函数之前还调用了mainCRTStartup 函数:在VC6 的反汇编窗口中好像不太好找到mainCRTStartup函数的代码,因此在这里改用IDA pro来打开生成的exe,在IDA的 export窗口中双击 mainCRTStartup 函数,代码就会跳转到函数对应的位置。它的代码比较长,刚开始也是进行函数的堆栈初始化操作,这个初始化主要是保存原始的ebp,保存重要寄存器的值,并且改变ESP的指针值初始化函数堆栈,这些就不详细说明了,感兴趣的可以去看看我之前写的关于函数反汇编分析的内容:C函数原理在初始化完成之后,它有这样的汇编代码.text:004010EA push offset __except_handler3 .text:004010EF mov eax, large fs:0 .text:004010F5 push eax .text:004010F6 mov large fs:0, esp这段代码主要是用来注册主线程的的异常处理函数的,为什么它这里的4行代码就可以设置线程的异常处理函数呢?这得从SEH的结构说起。每个线程都有自己的SEH链,当发生异常的时候会调用链中存储的处理函数,然后根据处理函数的返回来确定是继续运行原先的代码,还是停止程序还是继续将异常传递下去。这个链表信息保存在每个线程的NT_TIB结构中,这个结构每个线程都有,用来记录当前线程的相关内容,以便在进行线程切换的时候做数据备份和恢复。当然不是所有的线程数据都保存在这个结构中,它只保留部分。该结构的定义如下:typedef struct _NT_TIB { PEXCEPTION_REGISTRATION_RECORD ExceptionList; PVOID StackBase; PVOID StackLimit; PVOID SubSystemTib; union { PVOID FiberData; ULONG Version; }; PVOID ArbitraryUserPointer; PNT_TIB Self; } NT_TIB, *PNT_TIB;这个结构的第一个参数是一个异常处理链的链表头指针,链表结构的定义如下:typedef struct _EXCEPTION_REGISTRATION_RECORD { PEXCEPTION_REGISTRATION_RECORD Next; PEXCEPTION_DISPOSITION Handler; } EXCEPTION_REGISTRATION_RECORD, *PEXCEPTION_REGISTRATION_RECORD;这个结构很简单的定义了一个链表,第一个成员是指向下一个节点的指针,第二个参数是一个异常处理函数的指针,当发生异常的时候会去调用这个函数。而这个链表的头指针被存到fs寄存器中知道了这点之后再来看这段代码,首先将异常函数入栈,然后将之前的链表头指针入栈,这样就组成了一个EXCEPTION_REGISTRATION_RECORD结构的节点而这个节点的指针现在就是ESP中保存的值,之后再将链表的头指针更新,也就是最后一句对fs的重新赋值,这是一个典型的使用头插法新增链表节点的操作。通过这样的几句代码就向主线程中注入了一个新的异常处理函数。之后就是进行各种初始化的操作,调用GetVersion 获取版本号,调用 __heap_init 函数初始化C运行时的堆栈,这个函数后面有一个 esp + 4的操作,这里可以看出这个函数是由调用者来做堆栈平衡的,也就是说它并不是Windows提供的api函数(API函数一般都是stdcall的方式调用,并且命名采用驼峰的方式命名)。调用GetCommandLineA函数获取命令行参数,调用 GetEnvironmentStringsA 函数获取系统环境变量,最后有这么几句话:.text:004011B0 mov edx, __environ .text:004011B6 push edx ; envp .text:004011B7 mov eax, ___argv .text:004011BC push eax ; argv .text:004011BD mov ecx, ___argc .text:004011C3 push ecx ; argc .text:004011C4 call _main_0这段代码将环境变量、命令行参数和参数个数作为参数传入main函数中。 在C语言中规定了main函数的三种形式,但是从这段代码上看,不管使用哪种形式,这三个参数都会被传入,程序员使用哪种形式的main函数并不影响在VC环境在调用main函数时的传参。只是我们代码中不使用这些变量罢了。到此,这篇博文简单的介绍了下在调用main函数之前执行的相关操作,这些汇编代码其实很容易理解,只是在注册异常的代码有点难懂。最后总结一下在调用main函数之前的相关操作注册异常处理函数调用GetVersion 获取版本信息调用函数 __heap_init初始化堆栈调用 __ioinit函数初始化啊IO环境,这个函数主要在初始化控制台信息,在未调用这个函数之前是不能进行printf的调用 GetCommandLineA函数获取命令行参数调用 GetEnvironmentStringsA 函数获取环境变量调用main函数 -
C 堆内存管理 在Win32 程序中每个进程都占有4GB的虚拟地址空间,这4G的地址空间内部又被分为代码段,全局变量段堆段和栈段,栈内存由函数使用,用来存储函数内部的局部变量,而堆是由程序员自己申请与释放的,系统在管理堆内存的时候采用的双向链表的方式,接下来将通过调试代码来分析堆内存的管理。堆内存的双向链表管理下面是一段测试代码#include <iostream> using namespace std; int main() { int *p = NULL; __int64 *q = NULL; int *m = NULL; p = new int; if (NULL == p) { return -1; } *p = 0x11223344; q = new __int64; if (NULL == q) { return -1; } *q = 0x1122334455667788; m = new int; if (NULL == m) { return -1; } *m = 0x11223344; delete p; delete q; delete m; return 0; }我们对这段代码进行调试,当代码执行到delete p;位置的时候(此时还没有执行delete语句)查看变量的值如下:p q m变量的地址比较接近,这三个指针变量本身保存在函数的栈中。从图中看存储这三个变量内存的地址好像不像栈结构,这是由于在高版本的VS中默认开启了地址随机化,所以这里看不出来这些地址的关系,但是如果在VC6里面可以很明显的看到它们在一个栈结构中。我们将p, q, m这三者所指向的内存都减去 0x20 得到p - 0x20 = 0x00035cc8 - 0x20 = 0x00035ca8 q - 0x20 = 0x00035d08 - 0x20 = 0x00035ce8 m - 0x20 = 0x00035d50 - 0x20 = 0x00035d30在内存窗口中分别查看p - 0x20, q- 0x20, m- 0x20 位置的内存如下通过观察发现p - 0x20处前8个字节存储了两个地址分别是 0x00035c38、0x00035ce8。是不是对0x00035ce8 这个地址感到很熟悉呢,它就是q - 0x20 处的地址,按照这个思路我们观察这些内存发现内存地址前四个字节后四个字节0x00035ca80x00035c380x00035ce80x00035ce80x00035ca80x00035d300x00035d300x00035ce80x00000000看到这些地址有没有发现什么呢?没错,这个结构有两个指针域,第一个指针域指向前一个节点,后一个指针域指向后一个节点,这是一个典型的双向链表结构,你没有发现?没关系,我们将这个地址整理一下得到下面这个图表既然知道了它的管理方式,那么接着往后执行delete语句,这个时候再看这些地址对应的内存中保存的值内存地址前四个字节后四个字节0x00035CA80x00035d700x000300c40x00035ce80x00035c380x00035d300x00035d300x00035ce80x00000000系统已经改变了后面两个节点中next和pre指针域的内容,将p节点从双向链表中除去了。而这个时候仔细观察p节点中存储内容发现里面得值已经变为 0xfeee 了。我们在delete的时候并没有传入对应的参数告知系统该回收多大的内存,那么它是怎么知道该如何回收内存的呢。我们回到之前的那个p - 0x20 内存的图上看,是不是在里面发现了一个0x00000004的值,其实这个值就是当前节点占了多少个字节,如果不相信,可以看看q- 0x20 和m - 0x20 内存处保存的值看看,在对应的偏移处是不是有 8和4。系统根据这个值来回收对应的内存。
-
用call和ret实现子程序 ret和call是另外两种转移指令,它们与jmp的主要区别是,它们还包含入栈和出栈的操作。具体的原理如下:ret操作相当于:pop ip(直接将栈顶元素赋值给ip寄存器)call s的操作相当于:push ip jmp s(先将ip的值压栈,再跳转)retf的操作相当于:pop ip pop cscall dword ptr s相当于:push cs push ip这两组指令为我们编写含子函数的程序提供了便利,一般的格式如下:main: ......... call s ........ a s: ........ call s1 .......... b ret s1: .......... call s2 ......... c ret s2: ......... d call s3 ret s3: ........ ret分析以上的程序,假设call的下一条指令的偏移地址分别为:a、b、c、d随着程序的执行,ip指向call指令,CPU将这条指令放入指令缓冲器,执行上一条指令,然后ip指向下一条指令,ip = a。执行call指令,根据call的原理先执行a入栈,此时栈中的情况如下然后跳转到s,执行到call指令处时,ip = b,b首先入栈,然后跳转到s1执行到s1处的call指令时,ip = c,c入栈,然后跳转到s2执行到s2处的call指令时,ip = d,d入栈,然后跳转到s3执行到s3处的ret指令时,栈顶元素出栈,ip = d,程序返回到s2中,到ret时,ip = c,程序返回到s1,再次执行ret,ip = b,程序返回到s,执行ret,ip = a,程序返回到main中,接下来正常执行main中的代码,知道整个程序结束。
-
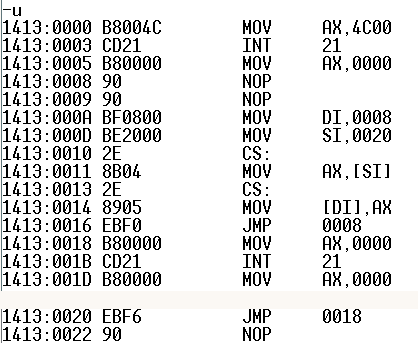
汇编转移指令jmp原理 在计算机中存储的都是二进制数,计算机将内存中的某些数当做代码,某些数当做数据。在根本上,将cs,ip寄存器所指向的内存当做代码,指令转移就是修改cs,ip寄存器的指向,汇编中提供了一种修改它们的指令——jmp。jmp指令可以修改IP或cs和IP的值来实现指令转移,指令格式为:”jmp 标号“将指令转移到标号处,例如:CODES SEGMENT ASSUME CS:CODES START: MOV AX,0 jmp s inc ax s: mov ax,3 MOV AH,4CH INT 21H CODES ENDS END START通过单步调试可以看出在执行jmp后直接执行s标号后面的代码,此时ax为3,。jmp s所对应的机器码为"EB01",在“Inc ax”后面再加其他的指令(加两个 nop指令)此时jmp所对应的机器码为"EB03",每一个nop指令占一个字节,在添加或删除它们之间的代码可以看到jmp指令所对应的机器码占两个字节,第一个字节的机器码并不发生改变,改变的是第二个字节的内容,并且第二个字节的内容存储的是跳转目标指令所在内存与jmp指令所在内存之间的位移。其实cup在执行jmp指令时并不会记录标号所在的内存地址,而是通过标号与jmp指令之间的位移,假设jmp指令的下一条指令的地址为org,位移为idata,则目标的内存地址为dec = org + idata。(idata有正负之分)在CPU中有指令累加器称之为CA寄存器, 程序每执行一条,CA的值加1,jmp指令后可以有4中形式“jmp short s、jmp、 s jmp near ptr s、jmp far ptr s”编译器在翻译时,位移所对应的内粗大小为1、2、2、4(分别是cs和ip所对应的位移)。都是带符号的整型。jmp指令的跳转分为两种情况:向前跳转和向后跳转。向后跳转:jmp (.....)s ...... ...... s:......这种情况下,编译器将jmp指令读完后,读下一条指令,并将CA加1,一直读到相应的标号处,此时CA的值就是位移,根据具体的伪指令来分配内存的大小(此时的数应该为正数)向前跳转 :s:....... ........ jmp (......) s编译器在遇到标号时会在标号后添加几个nop指令("jmp short s、jmp、 s jmp near ptr s、jmp far ptr s"分别添加1,2,2,4个),读下一条指令时将CA寄存器的值加1,得到对应的位移,生成机器码(此时为负数).这两种方式分别得到位移后,在执行过程中,利用上述公式计算出对应的地址,实现指令的转移下面的一段代码充分说明了jmp的这种实现跳转的机制:assume cs:code code segment mov ax,4c00h int 21h start: mov ax,0 s: nop nop mov di,offset s mov si,offset s2 mov ax,cs:[si] mov cs:[di],ax s0: jmp short s s1: mov ax,0 int 21h mov ax,0 s2: jmp short s1 nop code ends end start通过以上的分析可以得出,几个jmp指令所占的空间为2个字节,一个保存jmp本省的机器码,EB,另一个保存位移。因此两个nop指令后面的四句是将s2处的“jmp short s1”所对应的机器码拷贝到s处,利用debug下的-u命令可以看出该处的机器码为“EB F6” f6转化为十进制是-10.执行到s0处时,jmp指令使CPU下一次执行s处的代码,“EB F6”对应的操作利用公式可以得出IP = A - A = 0,下一步执行的代码是“MOV AX,4C00H”,也就是说该程序在此处结束。用-t命令单步调试:
-
C语言中处理结构体的原理 汇编中有几种寻址方式,分别是直接寻址:(ds:[idata])、寄存器间接寻址(ds:[bx])、寄存器相对寻址(ds:[bx + idata]、ds:[bx + si])基址变址寻址(ds:[bx + si])、相对基址变址寻址([bx + si + idata])。结构体的存储逻辑图如下:(以下数据表示某公司的名称、CEO、CEO的福布斯排行、收入、代表产品)现在假设公司的CEO在富豪榜上的排名为38,收入增加了70,代表产品变为VAX,通过汇编编程修改上述信息,以下是相应的汇编代码:(假设数据段为seg)mov ax,seg mov ds,ax mov bx,0 mov word ptr ds:[bx + 12],38 add [bx + 14],70 mov si,0 mov byte ptr [bx + 10 + si],'V' inc si mov byte ptr [bx + 10 + si],'A' inc si mov byte ptr [bx + 10 + si],'X'对应的C语言代码可以写成:struct company { char cn[3]; char name[9]; int pm; int salary; char product[3]; }; company dec = {"DEC","Ken Olsen",137,40,"PDP"}; int main() { int i; dec.pm = 38; dec.salary += 70; dec.product[i] = 'V'; ++i; dec.product[i] = 'A'; ++i; dec.product[i] = 'X'; return 0; }对比C语言代码和汇编代码,可以看出,对于结构体变量,系统会先根据定义分配相应大小的空间,并将各个变量名与内存关联起来,结构体对象名与系统分配的空间的首地址相对应(定义的结构体对象的首地址在段中的相对地址存储在bx中),即在使用dec名时实际与汇编代码“mov ax,seg” "mov ds,ax"对应,将数据段段首地址存入ds寄存器中,系统根据对象中的变量名找到对应的偏移地址,偏移地址的大小由对应的数据类型决定,如cn数组前没有变量,cn的偏移地址为0,cn所在的地址为 ds:[bx],cn为长度为3的字符型数组,在上一个偏移地址的基础上加上上一个变量所占空间的大小即为下一个变量的偏移地址,所以name数组的首地址为ds:[bx + 3],这样给出了对象名就相当于给定了该对象在段中的相对地址(上述代码中的bx),给定了对象中的成员变量名就相当于给定了某一内存在对象中的偏移地址(ds:[bx + idata])。根据数组名可以找到数组的首地址,但数组中具体元素的访问则需要给定元素个数,即si的值来定位数组中的具体内存,C语言中的 ++i 相当于汇编中的 (add si ,数组中元素的长度)。根据以上的分析可以看出,构建一个结构体对象时,系统会在代码段中根据结构体的定义开辟相应大小的内存空间,并将该空间在段中的偏移地址与对象名绑定。对象中的变量名与该变量在对象所在内存中的偏移地址相关联,数组中的标号用于定位数组中的元素在数组中的相对位置。(对象名决定bx,变量名决定bx + idata,数组中的元素标号决定bx + idata + si)。
-
汇编debug与masm命令 汇编语言这块是我之前写在网易博客上的,不过那个账号基本已经作废了,所以现在抽个时间把当时的博客搬到CSDN上。汇编命令(编译器masm命令):找到masm所在的文件夹,我的在d:\MASM中,用cmd打开dos界面,输入“d:”切换到D盘,再输入“d:\MASM\masm”打开编译器中的masm程序得到如下结果:再输入路径+含".asm"的文件(若在当前文件夹中则不必输入路径),这个表示生成了一个“.obj”文件,在第二行若不输入任何内容则默认在当前文件夹下生成一个与“.asm”同名的“.obj”文件。下面几个直接输入空格,不生成这几个文件,知道提示所有工作都完成(0 warning error)再按照上述格式找到MASM文件中的link程序,输入所需的“.obj”文件的相对路径 ".exe"行后不输入任何内容表示在该文件夹下生成一个与“.obj”文件同名的“.exe”文件,到这里汇编程序的编译链接工作就完成了。下面是该程序的调试,输入“debug” + 执行程序的路径进入程序,-u命令:查看汇编代码;-t命令:执行下一条语句-g + 的内存:跳转到该内存所对应的语句(再用t命令执行该条命令)-r命令:查看寄存器的内容(后可直接接寄存器的名称,就只查看该寄存器的内容)-d命令:后接内存地址,查看改地址后面8 * 16个字节空间的地址(每行16个字节,共8行)后面是对应的字符‘.’表示没有该数字对应的字符加上地址范围的话就只查看该地址范围内存储的数据
-
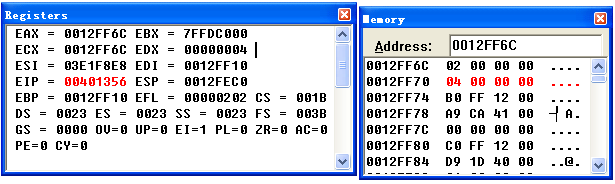
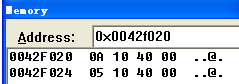
C++继承分析 面向对象的三大特性之一就是继承,继承运行我么重用基类中已经存在的内容,这样就简化了代码的编写工作。继承中有三种继承方式即:public protected private,这三种方式规定了不同的访问权限,这些权限的检查由编译器在语法检查阶段进行,不参与生成最终的机器码,所以在这里不对这三中权限进行讨论,一下的内容都是采用的共有继承。单继承首先看下面的代码:class CParent { public: CParent(){ printf("CParent()\n"); } ~CParent(){ printf("~CParent()\n"); } void setNumber(int n){ m_nParent = n; } int getNumber(){ return m_nParent; } protected: int m_nParent; }; class CChild : public CParent { public: void ShowNumber(int n){ setNumber(n); m_nChild = 2 *m_nParent; printf("child:%d\n", m_nChild); printf("parent:%d\n", m_nParent); } protected: int m_nChild; }; int main() { CChild cc; cc.ShowNumber(2); return 0; }上面的代码中定义了一个基类,以及一个对应的派生类,在派生类的函数中,调用和成员m_nParent,我们没有在派生类中定义这个变量,很明显这个变量来自于基类,子类会继承基类中的函数成员和数据成员,下面的汇编代码展示了它是如何存储以及如何调用函数的:41: CChild cc; 004012AD lea ecx,[ebp-14h];将类对象的首地址this放入ecx中 004012B0 call @ILT+5(CChild::CChild) (0040100a);调用构造函数 004012B5 mov dword ptr [ebp-4],0 42: cc.ShowNumber(2); 004012BC push 2 004012BE lea ecx,[ebp-14h] 004012C1 call @ILT+10(CChild::ShowNumber) (0040100f);调用自身的函数 43: return 0; 004012C6 mov dword ptr [ebp-18h],0 004012CD mov dword ptr [ebp-4],0FFFFFFFFh 004012D4 lea ecx,[ebp-14h] 004012D7 call @ILT+25(CChild::~CChild) (0040101e);调用析构函数 004012DC mov eax,dword ptr [ebp-18h] ;构造函数 0040140A mov dword ptr [ebp-4],ecx 0040140D mov ecx,dword ptr [ebp-4];到此ecx和ebp - 4位置的值都是对象的首地址 00401410 call @ILT+35(CParent::CParent) (00401028);调用父类的构造 00401415 mov eax,dword ptr [ebp-4] ;ShowNumber函数 00401339 pop ecx;还原this指针 0040133A mov dword ptr [ebp-4],ecx;ebp - 4存储的是this指针 31: setNumber(n); 0040133D mov eax,dword ptr [ebp+8];ebp + 8是showNumber参数 00401340 push eax 00401341 mov ecx,dword ptr [ebp-4] 00401344 call @ILT+0(CParent::setNumber) (00401005) 32: m_nChild = 2 *m_nParent; 00401349 mov ecx,dword ptr [ebp-4] 0040134C mov edx,dword ptr [ecx];取this对象的头4个字节的值到edx中 0040134E shl edx,1;edx左移1位,相当于edx = edx * 2 00401350 mov eax,dword ptr [ebp-4] 00401353 mov dword ptr [eax+4],edx ;将edx的值放入到对象的第4个字节处 33: printf("child:%d\n", m_nChild); 00401356 mov ecx,dword ptr [ebp-4] 00401359 mov edx,dword ptr [ecx+4] 0040135C push edx 0040135D push offset string "child:%d\n" (0042f02c) 00401362 call printf (00401c70) 00401367 add esp,8 34: printf("parent:%d\n", m_nParent); 0040136A mov eax,dword ptr [ebp-4] 0040136D mov ecx,dword ptr [eax] 0040136F push ecx 00401370 push offset string "parent:%d\n" (0042f01c) 00401375 call printf (00401c70) 0040137A add esp,8 ;setNumber函数 16: m_nParent = n; 004013CD mov eax,dword ptr [ebp-4] 004013D0 mov ecx,dword ptr [ebp+8] 004013D3 mov dword ptr [eax],ecx;给对象的头四个字节赋值从上面的汇编代码可以看到大致的执行流程,首先调用编译器提供的默认构造函数,在这个构造函数中调用父类的构造函数,然后在showNumber中调用setNumber为父类的m_nParent赋值,然后为m_nChild赋值,最后执行输出语句。上面的汇编代码在执行为m_nParent赋值时操作的内存地址是this,而为m_nChild赋值时操作的是this + 4通过这一点可以看出,类CChild在内存中的分布,首先在低地址位分步的是基类的成员,高地址为分步的是派生类的成员,我们随着代码的执行,查看寄存器和内存的值也发现,m_nParent在低地址位m_nChild在高地址位:当父类中含有构造函数,而子类中没有时,编译器会提供默认构造函数,这个构造只调用父类的构造,而不做其他多余的操作,但是如果子类中构造,而父类中没有构造,则不会为父类提供默认构造。但是当父类中有虚函数时又例外,这个时候会为父类提供默认构造,以便初始化虚函数表指针。在析构时,为了可以析构父类会首先调用子类的析构,当析构到父类的部分时,调用父类的构造,也就是说析构的调用顺序与构造正好相反。子类在内存中的排列顺序为先依次摆放父类的成员,后安排子类的成员。C++中的函数符号名称与C中的有很大的不同,编译器根据这个符号名称可以知道这个函数的形参列表,和作用范围,所以在继承的情况下,父类的成员函数的作用范围在父类中,而派生类则包含了父类的成员,所以自然包含了父类的作用范围,在进行函数调用时,会首先在其自身的范围中查找,然后再在其父类中查找,因此子类可以调用父类的函数。在子类中将父类的成员放到内存的前段是为了方便子类调用父类中的成员。但是当子类中有对应的函数,这个时候会直接调用子类中的函数,这个时候发生了覆盖。当类中定义了其他类成员,并定义了初始化列表时,构造的顺序又是怎样的呢?class CParent { public: CParent(){ m_nParent = 0; } protected: int m_nParent; }; class CInit { public: CInit(){ m_nNumber = 0; } protected: int m_nNumber; }; class CChild : public CParent { public: CChild(): m_nChild(1){} protected: CInit m_Init; int m_nChild; };34: CChild cc; 00401288 lea ecx,[ebp-0Ch] 0040128B call @ILT+5(CChild::CChild) (0040100a) ;构造函数 004012C9 pop ecx 004012CA mov dword ptr [ebp-4],ecx 004012CD mov ecx,dword ptr [ebp-4] 004012D0 call @ILT+25(CParent::CParent) (0040101e);先调用父类的构造 004012D5 mov ecx,dword ptr [ebp-4] 004012D8 add ecx,4 004012DB call @ILT+0(CInit::CInit) (00401005);然后调用类成员的构造 004012E0 mov eax,dword ptr [ebp-4] 004012E3 mov dword ptr [eax+8],1;最后调用初始化列表中的操作 004012EA mov eax,dword ptr [ebp-4]综上分析,编译器在对对象进行初始化时是根据各个部分在内存中的排放顺序来进行初始化的,就上面的例子来说,最上面的是基类的所以它首先调用的是基类的构造,然后是类的成员,所以接着调用成员对象的构造函数,最后是自身定义的变量,所以最后初始化自身的变量,但是初始化列表中的操作是先于类自身构造函数中的代码的。由于父类的成员在内存中的分步是先于派生类自身的成员,所以通过派生类的指针可以很容易寻址到父类的成员,而且可以将派生类的指针转化为父类进行操作,并且不会出错,但是反过来将父类的指针转化为派生类来使用则会造成越界访问。下面我们来看一下对于虚表指针的初始化问题,如果在基类中存在虚函数,而且在派生类中重写这个虚函数的话,编译器会如何初始化虚表指针。class CParent { public: virtual void print(){ printf("CParent()\n"); } }; class CChild : public CParent { public: virtual void print(){ printf("CChild()\n"); } }; int main() { CChild cc; return 0; } ;函数地址 @ILT+0(?print@CParent@@UAEXXZ): 00401005 jmp CParent::print @ILT+10(?print@CChild@@UAEXXZ): 0040100F jmp CChild::print ;派生类构造函数 004012C9 pop ecx 004012CA mov dword ptr [ebp-4],ecx 004012CD mov ecx,dword ptr [ebp-4] 004012D0 call @ILT+30(CParent::CParent) (00401023) 004012D5 mov eax,dword ptr [ebp-4] 004012D8 mov dword ptr [eax],offset CChild::`vftable' (0042f01c) 004012DE mov eax,dword ptr [ebp-4] ;基类构造函数 00401379 pop ecx 0040137A mov dword ptr [ebp-4],ecx 0040137D mov eax,dword ptr [ebp-4] 00401380 mov dword ptr [eax],offset CParent::`vftable' (0042f02c)上述代码的基本流程是首先执行基类的构造函数,在基类中首先初始化虚函数指针,从上面的汇编代码中可以看到,这个虚函数指针的值为0x0042f02c查看这块内存可以看到,它保存的值为0x00401005上面我们列出的虚函数地址可以看到,这个值正是基类中虚函数的地址。当基类的构造函数调用完成后,接着执行派生类的虚表指针的初始化,将它自身虚函数的地址存入到虚表中。通过上面的分析可以知道,在派生类中如果重写了基类中的虚函数,那么在创建新的类对象时会有两次虚表指针的初始化操作,第一次是将基类的虚表指针赋值给对象,然后再将自身的虚表指针赋值给对象,将前一次的覆盖,如果是在基类的构造中调用虚函数,这个时候由于还没有生成派生类,所以会直接寻址,找到基类中的虚函数,这个时候不会构成多态,但是如果在派生类的构造函数中调用,这个时候已经初始化了虚表指针,会进行虚表的间接寻址调用派生类的虚函数构成多态。析构函数与构造函数相反,在执行析构时,会首先将虚表指针赋值为当前类的虚表地址,调用当前类的虚函数,然后再将虚表指针赋值为其基类的虚表地址,执行基类的虚函数。多重继承多重继承的情况与单继承的情况类似,只是其父类变为多个,首先来分析多重继承的内存分布情况class CParent1 { public: virtual void fnc1(){ printf("CParent1 fnc1\n"); } protected: int m_n1; }; class CParent2 { public: virtual void fnc2(){ printf("CParent2 fnc2\n"); } protected: int m_n2; }; class CChild : public CParent1, public CParent2 { public: virtual void fnc1(){ printf("CChild fnc1()\n"); } virtual void fnc2(){ printf("CChild fnc2()\n"); } protected: int m_n3; }; int main() { CChild cc; CParent1 *p = &cc; p->fnc1(); CParent2 *p1 = &cc; p1->fnc2(); p = NULL; p1 = NULL; return 0; }上述代码中,CChild类有两个基类,CParent1 CParent2 ,并且重写了这两个类中的函数:fnc1 fnc2,然后在主函数中分别将cc对象转化为它的两个基类的指针,通过指针调用虚函数,实现多态。下面是它的反汇编代码43: CChild cc; 004012A8 lea ecx,[ebp-14h];对象的this指针 004012AB call @ILT+15(CChild::CChild) (00401014) 44: CParent1 *p = &cc; 004012B0 lea eax,[ebp-14h] 004012B3 mov dword ptr [ebp-18h],eax;[ebp - 18h]是p的值 45: p->fnc1(); 004012B6 mov ecx,dword ptr [ebp-18h] 004012B9 mov edx,dword ptr [ecx];对象的头四个字节是虚函数表指针 004012BB mov esi,esp 004012BD mov ecx,dword ptr [ebp-18h] 004012C0 call dword ptr [edx];通过虚函数地址调用虚函数 ;部分代码略 46: CParent2 *p1 = &cc; 004012C9 lea eax,[ebp-14h];eax = this 004012CC test eax,eax 004012CE je main+48h (004012d8);校验this是否为空 004012D0 lea ecx,[ebp-0Ch];this指针向下偏移8个字节 004012D3 mov dword ptr [ebp-20h],ecx 004012D6 jmp main+4Fh (004012df) 004012D8 mov dword ptr [ebp-20h],0;如果this为null会将edx赋值为0 004012DF mov edx,dword ptr [ebp-20h];edx = this + 8 004012E2 mov dword ptr [ebp-1Ch],edx;[ebp - 1CH]是p1的值 47: p1->fnc2(); 004012E5 mov eax,dword ptr [ebp-1Ch] 004012E8 mov edx,dword ptr [eax] 004012EA mov esi,esp 004012EC mov ecx,dword ptr [ebp-1Ch] 004012EF call dword ptr [edx] 004012F1 cmp esi,esp 004012F3 call __chkesp (00401680) ;CChild构造函数 0040135A mov dword ptr [ebp-4],ecx 0040135D mov ecx,dword ptr [ebp-4] 00401360 call @ILT+40(CParent1::CParent1) (0040102d) 00401365 mov ecx,dword ptr [ebp-4] 00401368 add ecx,8;将指向对象首地址的指针向下偏移了8个字节 0040136B call @ILT+45(CParent2::CParent2) (00401032) 00401370 mov eax,dword ptr [ebp-4] 00401373 mov dword ptr [eax],offset CChild::`vftable' (0042f020) 00401379 mov ecx,dword ptr [ebp-4] 0040137C mov dword ptr [ecx+8],offset CChild::`vftable' (0042f01c) 00401383 mov eax,dword ptr [ebp-4] ;CParent1构造函数 00401469 pop ecx 0040146A mov dword ptr [ebp-4],ecx 0040146D mov eax,dword ptr [ebp-4] 00401470 mov dword ptr [eax],offset CParent1::`vftable' (0042f04c);初始化虚表指针 00401476 mov eax,dword ptr [ebp-4] ;CParent2构造函数 004014F9 pop ecx 004014FA mov dword ptr [ebp-4],ecx 004014FD mov eax,dword ptr [ebp-4] 00401500 mov dword ptr [eax],offset CParent2::`vftable' (0042f064);初始化虚表指针 00401506 mov eax,dword ptr [ebp-4] ;虚函数地址 @ILT+0(?fnc2@CChild@@UAEXXZ): 00401005 jmp CChild::fnc2 (00401400) @ILT+5(?fnc1@CParent1@@UAEXXZ): 0040100A jmp CParent1::fnc1 (00401490) @ILT+10(?fnc1@CChild@@UAEXXZ): 0040100F jmp CChild::fnc1 (004013b0) @ILT+20(?fnc2@CParent2@@UAEXXZ): 00401019 jmp CParent2::fnc2 (00401520)内存地址存储的值0012FF6C20 F0 42 000012FF70CC CC CC CC0012FF741C F0 42 000012FF78CC CC CC CC0012FF7CCC CC CC CC从上面的汇编代码中可以看到,在为该类对象分配内存时,会根据继承的顺序,依次调用基类的构造函数,在构造函数中,与单继承类似,在各个基类的构造中,先将虚表指针初始化为各个基类的虚表地址,然后在调用完各个基类的构造函数后将虚表指针覆盖为对象自身的虚表地址,唯一不同的是,派生类有多个虚表指针,有几个派生类就有几个虚表指针。另外派生类的内存分布与单继承的分布情况相似,根据继承顺序从低地址到高地址依次摆放,最后是派生类自己定义的部分,每个基类都会在其自身所在位置的首地址处构建一个虚表。在调用各自基类的构造函数时,并不是笼统的将对象的首地址传递给基类的构造函数,而是经过相应的地址偏移之后,将偏移后的地址传递给对应的构造。在转化为父类的指针时也是经过了相应的地址偏移。在析构时首先析构自身,然后按照与构造相反的顺序调用基类的析构函数。dynamic_cast强制类型转化与static_cast类型转化根据上面的说明我们可以简单的画一张图:这个对象中有三个虚表,分别位于各个基类所在内存的首地址处,如果我们利用多态的特性进行类型转化的话如果采用static_cast的方式会进行静态转化,也就是说它只是简单的将对象的首地址进行类型转化,这个时候如果调用CParent2的函数,在编译的时候不会报错,但是在运行时可能在虚表中(注意如果是这种情况它找到的虚表其实是CParent1的虚表)找不到想要的虚函数,这个时候调用会引起非法内存访问,造成程序崩溃。但是用dynamic_cast可以进行偏移地址的计算,自动偏移到CParent2内存部分的首地址,这个时候调用虚函数不会产生崩溃的问题。所以在有多重继承和多继承的时候尽量使用dynamic_cast进行类型转化。抽象类抽象类是不能实例化的类,只要有纯虚函数就是一个抽象类。纯虚函数是只有定义而没有实现的函数,由于虚函数的地址需要填入虚表,所以必须提供虚函数的定义,以便编译器能够将虚函数的地址放入虚表,所以虚函数必须定义,但是纯虚函数不一样,它不能定义。class CParent { public: virtual show() = 0; }; class CChild : public CParent { public: virtual show(){ printf("CChild()\n"); } }; int main() { CChild cc; CParent *p = &cc; p->show(); return 0; }上面的代码定义了一个抽象类CParent,而CChild继承这个抽象类并实现了其中的纯虚函数,在主函数中通过基类的指针掉用虚函数,形成多态。22: CChild cc; 00401288 lea ecx,[ebp-4] 0040128B call @ILT+0(CChild::CChild) (00401005) 23: CParent *p = &cc; 00401290 lea eax,[ebp-4] 00401293 mov dword ptr [ebp-8],eax 24: p->show(); 00401296 mov ecx,dword ptr [ebp-8] 00401299 mov edx,dword ptr [ecx] 0040129B mov esi,esp 0040129D mov ecx,dword ptr [ebp-8] 004012A0 call dword ptr [edx] ;CChild构造函数 004012F0 call @ILT+25(CParent::CParent) (0040101e) 004012F5 mov eax,dword ptr [ebp-4] 004012F8 mov dword ptr [eax],offset CChild::`vftable' (0042f01c) CParent构造函数 00401399 pop ecx 0040139A mov dword ptr [ebp-4],ecx 0040139D mov eax,dword ptr [ebp-4] 004013A0 mov dword ptr [eax],offset CParent::`vftable' (0042f02c) 004013A6 mov eax,dword ptr [ebp-4]构造函数中仍然是调用了基类的构造函数,并在基类的构造中对虚表指针进行了赋值,但是基类中并没有定义show函数,而是将它作为纯虚函数,那么虚表中存储的的是什么东西呢,这个位置存储的是一个_purecall函数,主要是为了防止误调纯虚函数。菱形继承菱形继承是最为复杂的一种继承方式,它结合了单继承和多继承class CGrand { public: virtual void func1(){ printf("CGrand func1()\n"); } protected: int m_nNum1; }; class CParent1 : public CGrand { public: virtual void func2(){ printf("CParent1 func2()\n"); } virtual void func3(){ printf("CParent1 func3()\n"); } protected: int m_nNum2; }; class CParent2 : public CGrand { public: virtual void func4(){ printf("CParent2 func4()\n"); } virtual void func5(){ printf("CParent2 func5()\n"); } protected: int m_nNum3; }; class CChild : public CParent1, public CParent2 { public: virtual void func2(){ printf("CChild func2()\n"); } virtual void func4(){ printf("CChild func4()\n"); } protected: int m_nNum4; }; int main() { CChild cc; CParent1 *p1 = &cc; CParent2 *p2 = &cc; return 0; }上面的代码中有4个类,其中CGrand类为祖父类,而CParent1 CParent2为父类,他们都派生自组父类,而子类继承与CParent1 CParent2,根据前面的经验可以知道sizeof(CGrand) = 4(vt) + 4(int) = 8,而sizeof(CParent1) = sizeof(CParent2) = sizeof(CGrand) + 4(int) = 12, sizeof(CChild) = sizeof(CParent1) + sizeof(CParent2) + 4(int) = 28;大致可以知道CChild对象的内存分布是CParent1 CParent2 int这种情况,通过反汇编的方式我们可以看出对象的内存分布如下:内存的分步来看,CParent1 CParent2都继承自CGrand类,所以他们都有CGrand类的成员,而CChild类继承自两个类,所以CGrand类的成员在CChild类中有两份,所以在调用m_nNum1成员时会产生二义性,编译器不知道你准备调用那个m_nNum1成员,所以一般这个时候需要指定调用的是哪个部分的m_nNum1成员。同时在转化为祖父类的时候也会产生二义性。而虚继承可以有效的解决这个问题。一般来说虚继承可以有效的避免二义性是因为重复的内容在对象中只有一份。下面对上述例子进行相应的修改,为每个类添加构造函数构造初始化这些成员变量:m_nNum1 = 1;m_nNum2 = 2; m_nNum3 = 3; m_nNum4 = 4;另外再为CParent1 CParent2类添加虚继承。这个时候我们运行程序输入类CChild的大小:sizeof(CChild) = 36;按照之前所说的同样的内容只保留的一份,那内存大小应该会减少才对,为何突然增大了8个字节呢,下面来看看对象在内存中的分步:0012FF5C 30 F0 42 000012FF60 48 F0 42 00 0012FF64 02 00 00 000012FF68 24 F0 42 000012FF6C 3C F0 42 000012FF70 03 00 00 000012FF74 04 00 00 000012FF78 20 F0 42 000012FF7C 01 00 00 00上述内存的分步与我们之前想象的有很大的不同,所有变量的确只有一份,但是总内存大小还是变大了,同时它的存储顺序也不是按照我们之前所说的父类的排在子类的前面,而且还多了一些我们并不了解的数据下面通过反汇编代码来说明这些数值的作用:;主函数部分 73: CChild cc; 004012D8 push 1;是否构造祖父类1表示构造,0表示不构造 004012DA lea ecx,[ebp-24h] 004012DD call @ILT+5(CChild::CChild) (0040100a) 74: printf("%d\n", sizeof(cc)); 004012E2 push 24h 004012E4 push offset string "%d\n" (0042f01c) 004012E9 call printf (00401a70) 004012EE add esp,8 75: CParent1 *p1 = &cc; 004012F1 lea eax,[ebp-24h] 004012F4 mov dword ptr [ebp-28h],eax 76: CParent2 *p2 = &cc; 004012F7 lea ecx,[ebp-24h] 004012FA test ecx,ecx 004012FC je main+46h (00401306) 004012FE lea edx,[ebp-18h] 00401301 mov dword ptr [ebp-34h],edx 00401304 jmp main+4Dh (0040130d) 00401306 mov dword ptr [ebp-34h],0 0040130D mov eax,dword ptr [ebp-34h] 00401310 mov dword ptr [ebp-2Ch],eax 77: CGrand *p3 = &cc; 00401313 lea ecx,[ebp-24h] 00401316 test ecx,ecx;this指针不为空 00401318 jne main+63h (00401323);不为空则跳转 0040131A mov dword ptr [ebp-38h],0 00401321 jmp main+70h (00401330) 00401323 mov edx,dword ptr [ebp-20h];edx = 0x0040f048 00401326 mov eax,dword ptr [edx+4];eax = 0x18这个可以通过查看内存获得 00401329 lea ecx,[ebp+eax-20h]; ebp + eax - 20h = 0x0012ff78, ecx = 0x0012FF78 0040132D mov dword ptr [ebp-38h],ecx;经过偏移后获得这个地址 00401330 mov edx,dword ptr [ebp-38h] 00401333 mov dword ptr [ebp-30h],edx ;CChild构造 0040135A mov dword ptr [ebp-4],ecx 0040135D cmp dword ptr [ebp+8],0 00401361 je CChild::CChild+42h (00401382) 00401363 mov eax,dword ptr [ebp-4] 00401366 mov dword ptr [eax+4],offset CChild::`vbtable' (0042f048) 0040136D mov ecx,dword ptr [ebp-4] 00401370 mov dword ptr [ecx+10h],offset CChild::`vbtable' (0042f03c) 00401377 mov ecx,dword ptr [ebp-4] 0040137A add ecx,1Ch 0040137D call @ILT+0(CGrand::CGrand) (00401005);this 指针向下偏移1ch,开始构造父类 00401382 push 0;保证父类只构造一次 00401384 mov ecx,dword ptr [ebp-4] 00401387 call @ILT+60(CParent1::CParent1) (00401041) 0040138C push 0 0040138E mov ecx,dword ptr [ebp-4] 00401391 add ecx,0Ch 00401394 call @ILT+65(CParent2::CParent2) (00401046) 00401399 mov edx,dword ptr [ebp-4] 0040139C mov dword ptr [edx],offset CChild::`vftable' (0042f030) 004013A2 mov eax,dword ptr [ebp-4] 004013A5 mov dword ptr [eax+0Ch],offset CChild::`vftable' (0042f024) 004013AC mov ecx,dword ptr [ebp-4] 004013AF mov edx,dword ptr [ecx+4] 004013B2 mov eax,dword ptr [edx+4] 004013B5 mov ecx,dword ptr [ebp-4] 004013B8 mov dword ptr [ecx+eax+4],offset CChild::`vftable' (0042f020) 57: m_nNum4 = 4; 004013C0 mov edx,dword ptr [ebp-4] 004013C3 mov dword ptr [edx+18h],4 58: } ;CGrand构造 00401429 pop ecx 0040142A mov dword ptr [ebp-4],ecx 0040142D mov eax,dword ptr [ebp-4] 00401430 mov dword ptr [eax],offset CGrand::`vftable' (0042f054);虚表指针后期会被替代 10: m_nNum1 = 1; 00401436 mov ecx,dword ptr [ebp-4] 00401439 mov dword ptr [ecx+4],1 11: } ;CParent1构造 04014C9 pop ecx 004014CA mov dword ptr [ebp-4],ecx 004014CD cmp dword ptr [ebp+8],0;不再调用祖父类构造 004014D1 je CParent1::CParent1+38h (004014e8) 004014D3 mov eax,dword ptr [ebp-4] 004014D6 mov dword ptr [eax+4],offset CParent1::`vbtable' (0042f07c) 004014DD mov ecx,dword ptr [ebp-4] 004014E0 add ecx,0Ch 004014E3 call @ILT+0(CGrand::CGrand) (00401005);这个时候会跳过这个构造函数的调用通过上面的代码可以看出,为了使得相同的内容只有一份,在程序中额外传入一个参数作为标记,用于表示是否调用祖父类构造函数,当初始化完祖父类后将此标记置0以后不再初始化,另外程序在每个父类中都多添加了一个四字节的成员用来存储一个一个偏移地址,以便能正确的将派生类转化为父类。所以每当多出一个虚继承就多了一个记录偏移量的4字节内存,所以这个类总共多出了8个字节。所以这时候的类所占内存大小为28 + 4 * 2 = 36字节。
-
C++多态 面向对象的程序设计的三大要素之一就是多态,多态是指基类的指针指向不同的派生类,其行为不同。多态的实现主要是通过虚函数和虚表来完成,虚表保存在对象的头四个字节,要调用虚函数必须存在对象,也就是说虚函数必须作为类的成员函数来使用。编译器为每个拥有虚函数的对象准备了一个虚函数表,表中存储了虚函数的地址,类对象在头四个字节中存储了虚函数表的指针。下面是一个具体的例子class CVirtual { public: virtual void showNumber(){ printf("%d\n", nNum); } virtual void setNumber(int n){ nNum = n; } private: int nNum; }; int main() { CVirtual cv; cv.setNumber(2); cv.showNumber(); return 0; }上述这段代码定义了两个虚函数setNumber和showNumber,并在主函数中调用了他们,下面通过反汇编的方式来展示编译器是如何调用虚函数的26: CVirtual cv; 00401288 lea ecx,[ebp-8];对象中有一个整形数字占4个字节,同时又有虚函数,头四个字节用来存储虚函数表指针,总共占8个字节 0040128B call @ILT+25(CVirtual::CVirtual) (0040101e);调用构造函数 27: cv.setNumber(2); 00401290 push 2 00401292 lea ecx,[ebp-8] 00401295 call @ILT+0(CVirtual::setNumber) (00401005);调用虚函数 28: cv.showNumber(); 0040129A lea ecx,[ebp-8] 0040129D call @ILT+5(CVirtual::showNumber) (0040100a);调用虚函数 29: return 0; 004012A2 xor eax,eax ;构造函数 0401389 pop ecx;还原ecx使得ecx保存对象的首地址 0040138A mov dword ptr [ebp-4],ecx 0040138D mov eax,dword ptr [ebp-4] 00401390 mov dword ptr [eax],offset CVirtual::`vftable' (0042f020);将虚函数表的首地址赋值到对象的头4个字节 00401396 mov eax,dword ptr [ebp-4] 00401399 pop edi 0040139A pop esi 0040139B pop ebx 0040139C mov esp,ebp 0040139E pop ebp 0040139F ret ;setNumber(int n) 0040134A mov dword ptr [ebp-4],ecx 18: nNum = n; 0040134D mov eax,dword ptr [ebp-4];eax = ecx 00401350 mov ecx,dword ptr [ebp+8] 00401353 mov dword ptr [eax+4],ecx 从上面的汇编代码可以看到,当类中有虚函数的时候,编译器会提供一个默认的构造函数,用于初始化对象的头4个字节,这四个字节存储的是一个指针值,我们定位到这个指针所在的内存如下图:这段内存中存储了两个值,分别为0x0040100AH和0x00401005H,我们执行后面的代码发现,这两个地址给定的是虚函数所在的地址。在调用时编译器直接调用对应的虚函数,并没有通过虚表来寻址到对应的函数地址。下面看另外一个例子:class CParent { public: virtual void showClass() { printf("CParent\n"); } }; class CChild:public CParent { public: virtual void showClass() { printf("CChild\n"); } }; int main() { CParent *pClass = NULL; CParent cp; CChild cc; pClass = &cp; pClass->showClass(); pClass = &cc; pClass->showClass(); pClass = NULL; return 0; }上述代码定义了一个基类和派生类,并且在派生类中重写了函数showClass,在调用时用分别利用基类的指针指向基类和派生类的对象来调用这个虚函数,得到的结果自然是不同的,这样构成了多态。下面是它的反汇编代码,这段代码基本展示了多态的实现原理29: CParent *pClass = NULL; 00401288 mov dword ptr [ebp-4],0 30: CParent cp; 0040128F lea ecx,[ebp-8] 00401292 call @ILT+30(CParent::CParent) (00401023);调用构造函数 31: CChild cc; 00401297 lea ecx,[ebp-0Ch] 0040129A call @ILT+0(CChild::CChild) (00401005) 32: pClass = &cp; 0040129F lea eax,[ebp-8];取对象的首地址 004012A2 mov dword ptr [ebp-4],eax; 33: pClass->showClass(); 004012A5 mov ecx,dword ptr [ebp-4] 004012A8 mov edx,dword ptr [ecx];将指针值放入到edx中 004012AA mov esi,esp 004012AC mov ecx,dword ptr [ebp-4];获取虚函数表指针 004012AF call dword ptr [edx];调转到虚函数指针所对应的位置执行代码 004012B1 cmp esi,esp 004012B3 call __chkesp (00401560) 34: pClass = &cc; 004012B8 lea eax,[ebp-0Ch] 004012BB mov dword ptr [ebp-4],eax 35: pClass->showClass(); 004012BE mov ecx,dword ptr [ebp-4] 004012C1 mov edx,dword ptr [ecx] 004012C3 mov esi,esp 004012C5 mov ecx,dword ptr [ebp-4] 004012C8 call dword ptr [edx] 004012CA cmp esi,esp 004012CC call __chkesp (00401560) 36: pClass = NULL; 004012D1 mov dword ptr [ebp-4],0 37: return 0; 004012D8 xor eax,eax从上述代码来看,在调用虚函数时首先根据头四个字节的值找到对应的虚函数表,然后根据虚函数表中存储的内容来找到对应函数的地址,最后根据函数地址跳转到对应的位置,执行函数代码。由于虚函数表中的虚函数是在编译时就根据对象的不同将对应的函数装入到各自对象的虚函数表中,因此,不同的对象所拥有的虚函数表不同,最终根据虚函数表寻址到的虚函数也就不同,这样就构成了多态。对于虚函数的调用,先后经历了几次间接寻址,比直接调用函数效率低了一些,通过虚函数间接寻址访问的情况只有利用类对象的指针或者引用来访问虚函数时才会出现,利用对象本身调用虚函数时,没有必要进行查表,因为已经明确调用的是自身的成员函数,没有构成多态,查表只会降低程序的运行效率。
-
C++类的构造函数与析构函数 C++中每个类都有其构造与析构函数,它们负责对象的创建和对象的清理和回收,即使我们不写这两个,编译器也会默认为我们提供这些构造函数。下面仍然是通过反汇编的方式来说明C++中构造和析构函数是如何工作的。编译器是否真的会默认提供构造与析构函数在一般讲解C++的书籍中都会提及到当我们不为类提供任何构造与析构函数时编译器会默认提供这样六种成员函数:不带参构造,拷贝构造,“=”的重载函数,析构函数,以及带const和不带const的取地址符重载。但是编译器具体是怎么做的,下面来对其中的部分进行说明不带参构造下面是一个例子:class test { private: char szBuf[255]; public: static void print() { cout<<"hello world"; } }; void printhello(test t) { t.print(); } int main(int argc, char* argv[]) { test t; printhello(t); return 0; }下面是对应的汇编源码:00401400 push ebp 00401401 mov ebp,esp 00401403 sub esp,140h;栈顶向上抬了140h的空间用于存储类对象的数据 00401409 push ebx 0040140A push esi 0040140B push edi 0040140C lea edi,[ebp-140h] 00401412 mov ecx,50h 00401417 mov eax,0CCCCCCCCh 0040141C rep stos dword ptr [edi] 26: test t; 27: printhello(t); 0040141E sub esp,100h从上面可以看到,在定义类的对象时并没有进行任何的函数调用,在进行对象的内存空间分配时仅仅是将栈容量扩大,就好像定义一个普通变量一样,也就是说在默认情况下编译器并不会提供不带参的构造函数,在初始化对象时仅仅将其作为一个普通变量,在编译之前计算出它所占内存的大小,然后分配,并不调用函数。再看下面一个例子:class test { private: char szBuf[255]; public: virtual void sayhello() { cout<<"hello world"; } static void print() { cout<<"hello world"; } }; void printhello(test t) { t.print(); } int main(int argc, char* argv[]) { test t; printhello(t); return 0; }30: test t; 0040143E lea ecx,[ebp-104h] 00401444 call @ILT+140(test::test) (00401091) ;构造函数 004014A0 push ebp 004014A1 mov ebp,esp 004014A3 sub esp,44h 004014A6 push ebx 004014A7 push esi 004014A8 push edi 004014A9 push ecx 004014AA lea edi,[ebp-44h] 004014AD mov ecx,11h 004014B2 mov eax,0CCCCCCCCh 004014B7 rep stos dword ptr [edi] 004014B9 pop ecx 004014BA mov dword ptr [ebp-4],ecx 004014BD mov eax,dword ptr [ebp-4] 004014C0 mov dword ptr [eax],offset test::`vftable' (0042f02c) 004014C6 mov eax,dword ptr [ebp-4] 004014C9 pop edi 004014CA pop esi 004014CB pop ebx 004014CC mov esp,ebp 004014CE pop ebp这段C++代码与之前的仅仅是多了一个虚函数,这个时候编译器为这个类定义了一个默认的构造函数,从汇编代码中可以看到,这个构造函数主要初始化了类对象的头4个字节,将虚函数表的地址放入到这个4个字节中,因此我们得出结论,一般编译器不会提供不带参的构造函数,除非类中有虚函数。下面请看这样一个例子:class Parent { public: Parent() { cout<<"parent!"<<endl; } }; class child: public Parent { private: char szBuf[10]; }; int main() { child c; return 0; } 下面是它的汇编代码:27: child c; 004013A8 lea ecx,[ebp-0Ch] 004013AB call @ILT+100(child::child) (00401069) ;构造函数 ;函数初始化代码略 004013E9 pop ecx 004013EA mov dword ptr [ebp-4],ecx 004013ED mov ecx,dword ptr [ebp-4] 004013F0 call @ILT+80(Parent::Parent) (00401055) ;最后函数的收尾工作,代码略从上面的代码看,当父类存在构造函数时,编译器会默认为子类添加构造函数,子类的构造函数主要是调用父类的构造函数。class Parent { public: virtual sayhello() { cout<<"hello"<<endl; } }; class child: public Parent { private: char szBuf[10]; }; int main() { child c; return 0; }27: child c; 004013B8 lea ecx,[ebp-10h] 004013BB call @ILT+100(child::child) (00401069) ;构造函数 004013FA mov dword ptr [ebp-4],ecx 004013FD mov ecx,dword ptr [ebp-4] 00401400 call @ILT+80(Parent::Parent) (00401055);调用父类的构造函数 00401405 mov eax,dword ptr [ebp-4] 00401408 mov dword ptr [eax],offset child::`vftable' (0042f01c);初始化虚函数表 0040140E mov eax,dword ptr [ebp-4]从上面的代码中可以看到,当父类有虚函数时,编译器也会提供构造函数,主要用于初始化头四个字节的虚函数表的指针。拷贝构造当我们不写拷贝构造的时候,仍然能用一个对象初始化另一个对象,下面是这样的一段代码int main(int argc, char* argv[]) { test t1; test t(t1); printhello(t); return 0; }我们还是用之前定义的那个test类,将类中的虚函数去掉,下面是对应的反汇编代码30: test t1; 31: test t(t1); 0040141E mov ecx,3Fh 00401423 lea esi,[ebp-100h] 00401429 lea edi,[ebp-200h] 0040142F rep movs dword ptr [edi],dword ptr [esi] 00401431 movs word ptr [edi],word ptr [esi] 00401433 movs byte ptr [edi],byte ptr [esi]从这段代码中可以看到,利用一个已有的类对象来初始化一个新的对象时,编译器仍然没有为其提供所谓的默认拷贝构造函数,在初始化时利用串操作,将一个对象的内容拷贝到另一个对象。当类中有虚函数时,会提供一个拷贝构造,主要用于初始化头四个字节的虚函数表,在进行对象初始化时仍然采用的是直接内存拷贝的方式。由于默认的拷贝构造是进行简单的内存拷贝,所以当类中的成员中有指针变量时尽量自己定义拷贝构造,进行深拷贝,否则在以后进行析构时会崩溃。另外几种就不再一一进行说明,它们的情况与上面的相似,有兴趣的可以自己编写代码验证。另外需要注意的是,只要定义了任何一个类型的构造函数,那么编译器就不会提供默认的构造函数。最后总结一下默认情况下编译器不提供这些函数,只有父类自身有构造函数,或者自身或父类有虚函数时,编译器才会提供默认的构造函数。何时会调用构造函数当对一个类进行实例化,也就是创建一个类的对象时,会调用其构造函数。对于栈中的局部对象,当定义一个对象时会调用构造函数对于堆对象,当用户调用new新建对象时调用构造函数对于全局对象和静态对象,当程序运行之处会调用构造函数下面重点说明当对象作为函数参数和返回值时的情况作为函数参数当对象作为函数参数时调用的是拷贝构造,而不是普通的构造函数下面是一个例子代码:class CA { public: CA() { cout<<"构造函数"<<endl; } CA(CA &ca) { cout<<"拷贝构造"<<endl; } private: char szBuf[255]; }; void Test(CA a) { return; } int main() { CA a; Test(a); return 0; }对应的汇编代码如下:33: Test(a); 004013F9 sub esp,100h 004013FF mov ecx,esp 00401401 lea eax,[ebp-100h];eax保存对象的首地址 00401407 push eax 00401408 call @ILT+15(CA::CA) (00401014) 0040140D call @ILT+35(Test) (00401028) ;拷贝构造代码 cout<<"拷贝构造"<<endl; 0040152D push offset @ILT+50(std::endl) (00401037) 00401532 push offset string "\xbf\xbd\xb1\xb4\xb9\xb9\xd4\xec" (0042f028) 00401537 push offset std::cout (00434088) 0040153C call @ILT+170(std::operator<<) (004010af) 00401541 add esp,8 00401544 mov ecx,eax 00401546 call @ILT+125(std::basic_ostream<char,std::char_traits<char> >::operator<<) (00401082) 21: } 0040154B mov eax,dword ptr [ebp-4] 0040154E pop edi 0040154F pop esi 00401550 pop ebx 00401551 add esp,44h 00401554 cmp ebp,esp 00401556 call __chkesp (004025d0) 0040155B mov esp,ebp 0040155D pop ebp 0040155E ret 4从上面的代码来看,当对象作为函数参数时,首先调用构造函数,将参数进行拷贝。作为函数的返回值class CA { public: CA() { cout<<"构造函数"<<endl; } CA(CA &ca) { cout<<"拷贝构造"<<endl; } private: char szBuf[255]; }; CA Test() { CA a; return a; } int main() { CA a = Test(); return 0; }34: CA a = Test(); 0040155E lea eax,[ebp-200h];eax保存的是对象a 的首地址 00401564 push eax 00401565 call @ILT+145(Test) (00401096);调用test函数 0040156A add esp,4 0040156D push eax;函数返回的临时存储区的地址 0040156E lea ecx,[ebp-100h] 00401574 call @ILT+15(CA::CA) (00401014);调用拷贝构造 ;test函数 28: CA a; 004013BE lea ecx,[ebp-100h] 004013C4 call @ILT+10(CA::CA) (0040100f) 29: return a; 004013C9 lea eax,[ebp-100h] 004013CF push eax 004013D0 mov ecx,dword ptr [ebp+8] 004013D3 call @ILT+15(CA::CA) (00401014);调用拷贝构造 004013D8 mov eax,dword ptr [ebp+8];ebp + 8是用来存储对象的临时存储区 通过上面的反汇编代码可以看到,在函数返回时会首先调用拷贝构造,将对象的内容拷贝到一个临时存储区中,然后通过eax寄存器返回,在需要利用函数返回值时再次调用拷贝构造,将eax中的内容拷贝到对象中。另外从这些反汇编代码中可以看到,拷贝构造以对象的首地址为参数,返回新建立的对象的地址。当需要对对象的内存进行拷贝时调用拷贝构造,拷贝构造只能传递对象的地址或者引用,不能传递对象本身,我们知道对象作为函数参数时会调用拷贝构造,如果以对象作为拷贝构造的参数,那么回造成拷贝构造的无限递归。何时调用析构函数对于析构函数的调用我们仍然分为以下几个部分:局部类对象:当对象所在的生命周期结束后,即一般语句块结束或者函数结束时会调用全局对象和静态类对象:当程序结束时会调用构造函数堆对象:当程序员显式调用delete释放空间时调用参数对象下面是一个例子代码:class CA { public: ~CA() { printf("~CA()\n"); } private: char szBuf[255]; }; void Test(CA a) { printf("test()\n"); } int main() { CA a; Test(a); return 0; }下面是它的反汇编代码;Test(a) 0040133A sub esp,100h;在main函数栈外开辟一段内存空间用于保存函数参数 00401340 mov ecx,3Fh;类大小为255个字节,为了复制这块内存,每次复制4字节,共需要63次 00401345 lea esi,[ebp-10Ch];esi保存的是对象的首地址 0040134B mov edi,esp;参数首地址 0040134D rep movs dword ptr [edi],dword ptr [esi];执行复制操作 0040134F movs word ptr [edi],word ptr [esi] 00401351 movs byte ptr [edi],byte ptr [esi];将剩余几个字节也复制 00401352 call @ILT+5(Test) (0040100a);调用test函数 ;调用Test函数 23: printf("test()\n"); 00401278 push offset string "test()\n" (0042f01c) 0040127D call printf (00401640) 00401282 add esp,4 24: } 00401285 lea ecx,[ebp+8];参数首地址 00401288 call @ILT+0(CA::~CA) (00401005)从上面的代码看,当类对象作为函数参数时,首先会调用拷贝构造(当程序不提供拷贝构造时,系统默认在对象之间进行简单的内存复制,这个就是提供的默认拷贝构造函数)然后当函数结束,程序执行到函数大括号初时,首先调用析构完成对象内存的释放,然后执行函数返回和做最后的清理工作函数返回对象下面是函数返回对象的代码:class CA { public: ~CA() { printf("~CA()\n"); } private: char szBuf[255]; }; CA Test() { printf("test()\n"); CA a; return a; } int main() { CA a = Test(); return 0; }30: CA a = Test(); 0040138E lea eax,[ebp-100h];eax保存了对象的地址 00401394 push eax 00401395 call @ILT+20(Test) (00401019) 0040139A add esp,4 31: return 0; 0040139D mov dword ptr [ebp-104h],0 004013A7 lea ecx,[ebp-100h] 004013AD call @ILT+0(CA::~CA) (00401005);调用类的析构函数 004013B2 mov eax,dword ptr [ebp-104h] 32: } ;test函数 24: CA a; 25: return a; 004012AA mov ecx,3Fh 004012AF lea esi,[ebp-10Ch];esi保存的是类对象的首地址 004012B5 mov edi,dword ptr [ebp+8];ebp+8是当初调用这个函数时传进来的类的首地址 004012B8 rep movs dword ptr [edi],dword ptr [esi] 004012BA movs word ptr [edi],word ptr [esi] 004012BC movs byte ptr [edi],byte ptr [esi] 004012BD mov eax,dword ptr [ebp-110h] 004012C3 or al,1 004012C5 mov dword ptr [ebp-110h],eax 004012CB lea ecx,[ebp-10Ch] 004012D1 call @ILT+0(CA::~CA) (00401005);调用析构函数 004012D6 mov eax,dword ptr [ebp+8]当类作为返回值返回时,如果定义了一个变量来接收这个返回值,那么在调用函数时会首先保存这个值,然后直接复制到这个内存中,但是接着执行类的析构函数析构在函数中定义的类对象,接受返回值得这块内存一直等到它所在的语句块结束才调用析构如果不要这个返回值时又如何呢,下面的代码说明了这个问题int main() { Test(); printf("main()\n"); return 0; } 30: Test(); 0040138E lea eax,[ebp-100h] 00401394 push eax 00401395 call @ILT+20(Test) (00401019) 0040139A add esp,4 0040139D lea ecx,[ebp-100h] 004013A3 call @ILT+0(CA::~CA) (00401005) 31: printf("main()\n"); 004013A8 push offset string "main()\n" (0042f030) 004013AD call printf (00401660) 004013B2 add esp,4同样可以看到当我们不需要这个返回值时,函数仍然会将对象拷贝到这块临时存储区中,但是会立即进行析构对这块内存进行回收。
-
结构体和类 在C++中类与结构体并没有太大的区别,只是默认的成员访问权限不同,类默认权限为私有,而结构体为公有,所以在这将它们统一处理,在例子中采用类的方式。类对象在内存中的分布在类中只有数据成员占内存空间,而类的函数成员主要分布在代码段中,不占内存空间,一般对象所占的内存空间大小为sizeof(成员1) + sizeof(成员2) + ... + sizeof(成员n)但是有几种情况不符合这个公式,比如虚函数和继承,空类,内存对齐,静态数据成员。只要出现虚函数就会多出4个字节的空间,作为虚函数表,继承时需要考虑基类的大小,另外出现静态成员时静态成员由于存在于数据段中,并不在类对象的空间中,所以静态成员不计算在类对象的大小中这些不在此处讨论,主要说明其余的三种情况:空类按照上述公式,空类应该不占内存,但是实际情况却不是这样,下面来看一个具体的例子:class Test { public: int Print(){printf("Hello world!\n");} }; int main() { Test test; printf("%d\n", sizeof(test)); return 0; }运行程序发现,输出结果为1,这个结果与我们预想的可能有点不一样,按理来说,空类中没有数据成员,应该不占内存空间才对,但是我们知道每个类都有一个this指针指向具体的内存,以便成员函数的调用,即使定义一个类什么都不写,编译器也会提供默认的构造函数用来初始化类,但是如果类的实例不占内存空间,那么该如何初始化?所以编译器为它分配一个1字节的空间以便初始化this指针。所以空类占一个字节。内存对齐下面看这样一个类class Test { public: short s; int n; };当在程序中定义这样一个类,通过sizeof来输出大小得到的是8,上面的公式又不满足了,我们知道为了程序的运行效率,编译器并不会依次申请内存用于存储变量,而会采用内存对齐的方式,以牺牲一定内存空间的代价来换取程序的效率,这个类的大小为8,也是内存对齐的结果,查看类工各个成员的地址我们发现 n的地址为0x0012ff44,而s的地址为0x0012ff40,s本来是占2个字节,但是n并没有出现在其后的42的位置,我所用的VC++6.0默认采用的是8个字节的对齐方式,假设编译器采用的是n个字节的对齐方式,而类中某成员实际所占内存空间的大小为m,那么该成员所在的内存地址必须为p的整数倍,而p = min(m, n),所以对于s来说,采用的是2个字节的对齐方式,分配到的首地址为40是2的倍数,而其后的整型成员n占4个字节,采用上述公式,得到它的内存地址应该是4的倍数,所以取其后的44作为它的地址,中间有两个字节没有使用,所以这个类占8个字节。下面再来看一个例子:class Test { public: short s; //8 double d; //8 char c; };通过程序得出当前结果体的大小为24,根据上面的分析,首先在为s分配空间的时候采用的是2个字节的对齐方式,假设分配到的地址为0x0012ff40,那么d采用的是8个字节的对齐方式,它的地址应该为0x0012ff48,最后为c分配内存的时候,应该是用1个字节的对齐方式,总共应该占的空间为8 + 8 + 1 = 17但是结果却并不是这样。在内存对齐时编译器实际采用对齐方式是:假设结构体成员的最大成员占n个字节,编译器默认采用m个字节的对齐方式,那么实际对齐大小应该为min(m, n)的整数倍,所以实际采用的是8个字节的对齐方式,而结构体的大小应该是实际对齐方式的整数倍,所以占24个字节。在编写程序时可以使用#pragma pack(n)的方式来改变编译器的默认对齐方式。另外对于嵌套定义的结构体,对齐情况也有少许不同。class One { public: short s; double d; char c; }; class Two { One one; int n; };输出class two的大小为32个字节,嵌套定义的结构体仍然能够满足上述两个法则,首先其中的成员结构体one大小为24,然后另外一个成员n占4个字节,得到总共占28个字节,然后根据第二个对齐的规则在24和8之间取最小值8,可以得到结构体的大小应该为8的整数倍32个字节。类的成员函数类的成员函数在调用时直接利用对象打点调用,在函数中直接使用类中的成员,函数操作的是不同对象的数据成员,能够达到这个目的实际上类的对象在调用类的成员函数时默认传入的第一个参数是一个指向这个对象地址的指针叫做this指针,具体this指针的原理看下面一段代码:class test { private: int i; public: test(){i = 0;} int GetNum() { i = 10; return i; }; }; int main(int argc, char* argv[]) { test t; t.GetNum(); return 0; } 下面对应的反汇编代码:;主函数 24: test t; 00401278 lea ecx,[ebp-4] 0040127B call @ILT+20(test::test) (00401019) 25: t.GetNum(); 00401280 lea ecx,[ebp-4] 00401283 call @ILT+0(test::GetNum) (00401005) 26: return 0; 00401288 xor eax,eax ;GetNum()函数 18: i = 10; 0040130D mov eax,dword ptr [ebp-4] 00401310 mov dword ptr [eax],0Ah 19: return i; 00401316 mov ecx,dword ptr [ebp-4] 00401319 mov eax,dword ptr [ecx]在主函数中定义类的对象时首先会调用其构造函数,在调用函数之前首先通过lea指令获取到对象的首地址并将它保存到了ecx寄存器中,在函数GetNum中,首先是在函数栈中定义了一个局部变量,将这个局部变量的值赋值为10,然后将这个局部变量的值赋值到ecx所在地址的内存中,最后再将这块内存中的值放到eax中作为参数返回。通过这部分代码可以看到,this指针并不是通过参数栈的方式传递给成员函数的,而是通过一个寄存器来传递,但是成员函数中若有参数,则仍然通过参数栈的方式传递参数。通过寄存器传递给成员方法作为this指针,然后根据数据成员定义的顺序和类型进行指针偏移找到对应的内存地址,对其进行操作。类的静态成员静态数据成员类的静态成员与之前所说的函数中的局部静态变量相似,它们都存储在数据段中,它们的生命周期与它们所在的位置无关,都是全局的生命周期,它们的可见性被封装到了它们所在的位置,对于函数中的局部静态变量来说,只在函数中可见,对于在文件中的全局静态变量来说,它们只在当前文件中可见,类中的局部静态变量可见性只在类中可见。类的静态数据成员的生命周期与类对象的无关,这样我们可以通过类名::变量名的方式来直接访问这块内存,而不需要通过对象访问,由于静态数据成员所在的内存不在具体的类对象中,所以在C++中所有类的对象中的局部静态变量都是使用同一块内存区域,随便一个修改了静态变量的值,其他的对象中,这个静态变量的值都会发生变化。静态函数成员类中的函数成员也可以是静态的,下面看一个静态函数成员的例子。class test { public: static void print() { cout<<"hello world"; } }; int main(int argc, char* argv[]) { test t; t.print(); return 0; }下面是对应的汇编代码:21: test t; 22: t.print(); 00401388 call @ILT+80(test::print) (00401055)我们可以看到,在调用类的静态函数时并没有取对象的地址到ecx的操作,也就说,静态成员函数并不会传递this指针,由于静态成员的生命周期与对象无关,可以通过类名直接访问,那么如果静态成员函数也需要传递this指针的话,那么对于这种通过类名访问的时候,它要怎么传递this指针呢。另外由于静态成员函数不传递this指针,这样会造成另外一个问题,如果需要在这个静态函数中操作类的数据成员,那么通过对象调用时,它怎么能找到这个数据成员所在的地址,另外在还没有对象,通过类直接调用时,这个数据成员还没有分配内存地址,所以说在C++中为了避免这些问题直接规定静态函数不能调用类的非静态成员,但是静态数据成员虽然说由所有类共享,但是能够找到对应的内存地址,所以非静态成员函数是可以访问静态数据成员的。类作为函数参数前面在写函数原理的那篇博文时说过结构体是如何参数传递的,其实类也是一样的,当类作为参数时,会调用拷贝构造,拷贝到函数的参数栈中,下面通过一个简单的例子来说明class test { private: char szBuf[255]; public: static void print() { cout<<"hello world"; } }; void printhello(test t) { t.print(); } int main(int argc, char* argv[]) { test t; printhello(t); return 0; }26: test t; 27: printhello(t); 0040141E sub esp,100h 00401424 mov ecx,3Fh 00401429 lea esi,[ebp-100h] 0040142F mov edi,esp 00401431 rep movs dword ptr [edi],dword ptr [esi] 00401433 movs word ptr [edi],word ptr [esi] 00401435 movs byte ptr [edi],byte ptr [esi] 00401436 call @ILT+130(printhello) (00401087) 0040143B add esp,100h从上面的汇编代码上可以看出,在进行参数传递时通过rep mov这个指令来将对象所在内存中的内容拷贝到函数栈中。在函数参数需要对象时,直接传递对象会进行一次拷贝,这样不仅浪费内存空间,而且在效率上不高,可以通过传递指针或者引用的方式来实现,这样只消耗4个字节的空间,而且不用拷贝,如果希望函数中不修改对象的内容,可以加上const限定。类作为函数返回值类作为函数的返回值时也与之前所说的结构体作为函数的返回值类似,都是需要先将类拷贝到对应函数栈外部的内存中,然后在随着函数栈由系统统一回收,在这就不做特别的说明了。但是与作为参数不同,为了安全起见一般不要返回局部变量的指针或者引用,在某些需要返回类对象的场合一般只能返回类对象。