搜索到
17
篇与
的结果
-
 数组的剖析 C语言中数组是十分重要的一种结构,数组采用的是连续存储的方式,下面通过反汇编的方式来解析编译器对数组的操作。数组作为局部变量在任意一个函数当中定义的变量都会被当做局部变量,它们的生命周期与函数的调用有关,下面是一个例子:int main() { int nArray[5] = {1, 2, 3, 4, 5}; int num1 = 1; int num2 = 2; int num3 = 3; int num4 = 4; int num5 = 5; printf("%d\n", num1); printf("%d\n", nArray[0]); printf("%d\n", nArray[1]); return 0; }下面是它对应的反汇编代码00401268 mov dword ptr [ebp-14h],1 0040126F mov dword ptr [ebp-10h],2 00401276 mov dword ptr [ebp-0Ch],3 ... 10: int num1 = 1; 0040128B mov dword ptr [ebp-18h],1 11: int num2 = 2; 00401292 mov dword ptr [ebp-1Ch],2 12: int num3 = 3; ... 16: printf("%d\n", num1); 004012AE mov eax,dword ptr [ebp-18h] 004012B1 push eax ... 17: printf("%d\n", nArray[0]); 004012BF mov ecx,dword ptr [ebp-14h] 004012C2 push ecx ... 18: printf("%d\n", nArray[1]); 004012D0 mov edx,dword ptr [ebp-10h] 004012D3 push edx ...为了节省篇幅,上面的汇编代码只截取了部分有代表性的内容,从上面的部分可以看到,数组采用连续的存储方式,在内存中从低地址部分到高地址部分依次存储,而普通的局部变量则是先定义的在高地址部分。在使用上也都是采用寄存器间接寻址的方式。在初始化时数组是从第0项开始依次向后赋值。但是如果我们将所有的数组成员都赋值为相同值时会怎样?9: int nArray[5] = {1}; 00401268 mov dword ptr [ebp-14h],1 0040126F xor eax,eax 00401271 mov dword ptr [ebp-10h],eax 00401274 mov dword ptr [ebp-0Ch],eax 00401277 mov dword ptr [ebp-8],eax 0040127A mov dword ptr [ebp-4],eax从上面的汇编代码可以看到,当初始化的值相同的时候,仍是采用依次赋值的方式。下面再来看看字符数组的初始化。0040126E mov eax,[string "Hello World!" (0042e01c)] 00401273 mov dword ptr [ebp-100h],eax 00401279 mov ecx,dword ptr [string "Hello World!"+4 (0042e020)] 0040127F mov dword ptr [ebp-0FCh],ecx 00401285 mov edx,dword ptr [string "Hello World!"+8 (0042e024)] 0040128B mov dword ptr [ebp-0F8h],edx 00401291 mov al,[string "Hello World!"+0Ch (0042e028)] 00401296 mov byte ptr [ebp-0F4h],al 0040129C mov ecx,3Ch 004012A1 xor eax,eax 004012A3 lea edi,[ebp-0F3h] 004012A9 rep stos dword ptr [edi] 004012AB stos word ptr [edi] 10: char *pszBuf = "Hello World!"; 004012AD mov dword ptr [ebp-104h],offset string "Hello World!" (0042e01c)字符串是特殊的字符数组,约定字符串的最后一个值为NULL。上面的代码显示出,对于字符串的初始化采用的是用寄存器的方式依次赋值4个字节的内容,而对于字符指针,在初始化的时候在程序的全局变量中存储了一个字符串,并将这个字符串的首地址赋值给对应的变量,这个字符串是位于常量内存区,所以只能寻址,而不能更改它。数组作为函数的参数当数组作为函数参数时传递的是数组的首地址,而不会拷贝整个内存区,这点许多人容易搞错。下面通过反汇编的方式来说明:void ShowArray(int a[5]) { for (int i = 0; i < 5; i++) { printf("%d\n", a[i]); } } int main() { int nArray[5] = {1, 2, 3, 4, 5}; ShowArray(nArray); return 0; }19: ShowArray(nArray); 004012FB lea eax,[ebp-14h];取[ebp - 14h]的地址 004012FE push eax 004012FF call @ILT+0(ShowArray) (00401005) 00401304 add esp,4 ;ShowArray函数 00401268 mov dword ptr [ebp-4],0;初始化i = 0 0040126F jmp ShowArray+2Ah (0040127a) 00401271 mov eax,dword ptr [ebp-4] 00401274 add eax,1 00401277 mov dword ptr [ebp-4],eax 0040127A cmp dword ptr [ebp-4],5 ;比较 i 与 5 0040127E jge ShowArray+49h (00401299);当i >= 5时跳出循环 11: { 12: printf("%d\n", a[i]); 00401280 mov ecx,dword ptr [ebp-4] ;ecx = i 00401283 mov edx,dword ptr [ebp+8] ;edx = 数组的首地址 00401286 mov eax,dword ptr [edx+ecx*4];寻址数组中的第i个元素 00401289 push eax 从上面的反汇编代码可以看出,在传值时只是将数组的首地址作为参数传入,而在函数的使用中直接通过传入的首地址来寻址数组中的各个元素,如果再函数的代码中添加一句sizeof来求这个数组的长度,那么返回的一定是4,而不是20。由于数组作为函数参数时函数不会记录数组的长度,那么为了防止越界,需要通过某种方式告知函数内部数组的长度,一般有两种方式,一种是想字符串那样规定一个结束标记,当到达这个结束标记时不再访问其下一个元素,二是通过传入一个参数表示数组的长度。另外数组作为返回值时与数组作为参数相同,都是通过指针的方式返回,但是需要牢记的一点是不要返回局部变量的地址或者引用。数组的成员的访问方式数组成员可以采用下标访问方式,也可以采用指针寻址方式,指针寻址不仅没有下标寻址方便,效率也没有下标寻址方式高。下面来看这两种方式的具体差距。11: int nArray[5] = {1, 2, 3, 4, 5}; 00401268 mov dword ptr [ebp-14h],1 ... 12: int *p = nArray; 0040128B lea eax,[ebp-14h] 0040128E mov dword ptr [ebp-18h],eax 13: printf("%d\n", nArray[3]); 00401291 mov ecx,dword ptr [ebp-8] 00401294 push ecx ... 14: printf("%d\n", p + 3); 004012A2 mov edx,dword ptr [ebp-18h] 004012A5 add edx,0Ch 004012A8 push edx从上面的代码可以看出,指针寻址会另外开辟一个4字节的内存空间用来存储这个指针变量,同时使用指针也需要进行地址变换,首先通过指针p的地址找到p的值,然后通过p存储的值再次间接寻址找到对应的值。而数组下标法寻址,只通过直接寻址找到对应的元素并取出即可。如果下标中是整型变量,则直接通过公式addr + sizeof(type) * n(其中addr为数组的首地址,type为数组元素的值,n为下标值)来寻址,而下标为整型表达式,则先计算表达式的值,然后在通过这一公式来寻址。多维数组多维数组,我们主要来说明二维数组11: int nArray[2][3] = {{1, 2, 3}, {4, 5, 6}}; 00401268 mov dword ptr [ebp-18h],1 0040126F mov dword ptr [ebp-14h],2 00401276 mov dword ptr [ebp-10h],3 0040127D mov dword ptr [ebp-0Ch],4 00401284 mov dword ptr [ebp-8],5 0040128B mov dword ptr [ebp-4],6通过汇编代码,对于多维数组在内存中存储的方式仍然为线性存储方式,对于多维数组会转化为一维数组数组,然后再依次存储各个一维数组的值,例如上面的例子中将二维数组转化为两个一维数组,然后分别在内存中对它们进行初始化。对于多维数组的寻址,例如int nArray2这样的数组,首先拆分为2个有3个元素的一维数组,在寻址时首先找到对应的一维数组的首地址,然后在对应的一维数组中寻址找到对应元素的值。这样对于多维数组都是转化为多个低一级的多维数组最终转化为一维数组的方式来解决。虽说多维数组是采用线性存储的方式来存储数据,但是在理解上我们可以将高维数组看成存储多个低维数组的特殊一维数组,比如int a4 可以看成一个有四个元素的一维数组,每一一维数组都存储了一个5个整型元素的一维数组,通过图来表示就是这样:上述的数组看做一个一维数组,这个一维数组有4个成员,每个成员都存储了一个5个一维数组的数组名,这样就可以很好的理解a 表示的是二维数组的首地址,而a[0]则表示的是第一个元素的首地址,同时也可以很好理解为何定义二维数组的指针时为何需要第二个下标,因为二维数组存储的是一维数组,它的类型就是多个一维数组,所以需要将一维数组的大小作为类型值来定义指针。函数指针函数指针的定义格式如下type (*pname)(args);函数的内容存储在代码段中,函数指针指向的就是函数的第一句代码所在的内存位置,而在调用函数需要知道函数的返回值,以及函数的参数列表,特别是参数列表,只有知道这些信息,在通过函数指针调用时才能知道其栈环境是如何配置的,函数类型其实是函数的返回值加上其参数列表,所以在定义函数时需要知道这些信息。
数组的剖析 C语言中数组是十分重要的一种结构,数组采用的是连续存储的方式,下面通过反汇编的方式来解析编译器对数组的操作。数组作为局部变量在任意一个函数当中定义的变量都会被当做局部变量,它们的生命周期与函数的调用有关,下面是一个例子:int main() { int nArray[5] = {1, 2, 3, 4, 5}; int num1 = 1; int num2 = 2; int num3 = 3; int num4 = 4; int num5 = 5; printf("%d\n", num1); printf("%d\n", nArray[0]); printf("%d\n", nArray[1]); return 0; }下面是它对应的反汇编代码00401268 mov dword ptr [ebp-14h],1 0040126F mov dword ptr [ebp-10h],2 00401276 mov dword ptr [ebp-0Ch],3 ... 10: int num1 = 1; 0040128B mov dword ptr [ebp-18h],1 11: int num2 = 2; 00401292 mov dword ptr [ebp-1Ch],2 12: int num3 = 3; ... 16: printf("%d\n", num1); 004012AE mov eax,dword ptr [ebp-18h] 004012B1 push eax ... 17: printf("%d\n", nArray[0]); 004012BF mov ecx,dword ptr [ebp-14h] 004012C2 push ecx ... 18: printf("%d\n", nArray[1]); 004012D0 mov edx,dword ptr [ebp-10h] 004012D3 push edx ...为了节省篇幅,上面的汇编代码只截取了部分有代表性的内容,从上面的部分可以看到,数组采用连续的存储方式,在内存中从低地址部分到高地址部分依次存储,而普通的局部变量则是先定义的在高地址部分。在使用上也都是采用寄存器间接寻址的方式。在初始化时数组是从第0项开始依次向后赋值。但是如果我们将所有的数组成员都赋值为相同值时会怎样?9: int nArray[5] = {1}; 00401268 mov dword ptr [ebp-14h],1 0040126F xor eax,eax 00401271 mov dword ptr [ebp-10h],eax 00401274 mov dword ptr [ebp-0Ch],eax 00401277 mov dword ptr [ebp-8],eax 0040127A mov dword ptr [ebp-4],eax从上面的汇编代码可以看到,当初始化的值相同的时候,仍是采用依次赋值的方式。下面再来看看字符数组的初始化。0040126E mov eax,[string "Hello World!" (0042e01c)] 00401273 mov dword ptr [ebp-100h],eax 00401279 mov ecx,dword ptr [string "Hello World!"+4 (0042e020)] 0040127F mov dword ptr [ebp-0FCh],ecx 00401285 mov edx,dword ptr [string "Hello World!"+8 (0042e024)] 0040128B mov dword ptr [ebp-0F8h],edx 00401291 mov al,[string "Hello World!"+0Ch (0042e028)] 00401296 mov byte ptr [ebp-0F4h],al 0040129C mov ecx,3Ch 004012A1 xor eax,eax 004012A3 lea edi,[ebp-0F3h] 004012A9 rep stos dword ptr [edi] 004012AB stos word ptr [edi] 10: char *pszBuf = "Hello World!"; 004012AD mov dword ptr [ebp-104h],offset string "Hello World!" (0042e01c)字符串是特殊的字符数组,约定字符串的最后一个值为NULL。上面的代码显示出,对于字符串的初始化采用的是用寄存器的方式依次赋值4个字节的内容,而对于字符指针,在初始化的时候在程序的全局变量中存储了一个字符串,并将这个字符串的首地址赋值给对应的变量,这个字符串是位于常量内存区,所以只能寻址,而不能更改它。数组作为函数的参数当数组作为函数参数时传递的是数组的首地址,而不会拷贝整个内存区,这点许多人容易搞错。下面通过反汇编的方式来说明:void ShowArray(int a[5]) { for (int i = 0; i < 5; i++) { printf("%d\n", a[i]); } } int main() { int nArray[5] = {1, 2, 3, 4, 5}; ShowArray(nArray); return 0; }19: ShowArray(nArray); 004012FB lea eax,[ebp-14h];取[ebp - 14h]的地址 004012FE push eax 004012FF call @ILT+0(ShowArray) (00401005) 00401304 add esp,4 ;ShowArray函数 00401268 mov dword ptr [ebp-4],0;初始化i = 0 0040126F jmp ShowArray+2Ah (0040127a) 00401271 mov eax,dword ptr [ebp-4] 00401274 add eax,1 00401277 mov dword ptr [ebp-4],eax 0040127A cmp dword ptr [ebp-4],5 ;比较 i 与 5 0040127E jge ShowArray+49h (00401299);当i >= 5时跳出循环 11: { 12: printf("%d\n", a[i]); 00401280 mov ecx,dword ptr [ebp-4] ;ecx = i 00401283 mov edx,dword ptr [ebp+8] ;edx = 数组的首地址 00401286 mov eax,dword ptr [edx+ecx*4];寻址数组中的第i个元素 00401289 push eax 从上面的反汇编代码可以看出,在传值时只是将数组的首地址作为参数传入,而在函数的使用中直接通过传入的首地址来寻址数组中的各个元素,如果再函数的代码中添加一句sizeof来求这个数组的长度,那么返回的一定是4,而不是20。由于数组作为函数参数时函数不会记录数组的长度,那么为了防止越界,需要通过某种方式告知函数内部数组的长度,一般有两种方式,一种是想字符串那样规定一个结束标记,当到达这个结束标记时不再访问其下一个元素,二是通过传入一个参数表示数组的长度。另外数组作为返回值时与数组作为参数相同,都是通过指针的方式返回,但是需要牢记的一点是不要返回局部变量的地址或者引用。数组的成员的访问方式数组成员可以采用下标访问方式,也可以采用指针寻址方式,指针寻址不仅没有下标寻址方便,效率也没有下标寻址方式高。下面来看这两种方式的具体差距。11: int nArray[5] = {1, 2, 3, 4, 5}; 00401268 mov dword ptr [ebp-14h],1 ... 12: int *p = nArray; 0040128B lea eax,[ebp-14h] 0040128E mov dword ptr [ebp-18h],eax 13: printf("%d\n", nArray[3]); 00401291 mov ecx,dword ptr [ebp-8] 00401294 push ecx ... 14: printf("%d\n", p + 3); 004012A2 mov edx,dword ptr [ebp-18h] 004012A5 add edx,0Ch 004012A8 push edx从上面的代码可以看出,指针寻址会另外开辟一个4字节的内存空间用来存储这个指针变量,同时使用指针也需要进行地址变换,首先通过指针p的地址找到p的值,然后通过p存储的值再次间接寻址找到对应的值。而数组下标法寻址,只通过直接寻址找到对应的元素并取出即可。如果下标中是整型变量,则直接通过公式addr + sizeof(type) * n(其中addr为数组的首地址,type为数组元素的值,n为下标值)来寻址,而下标为整型表达式,则先计算表达式的值,然后在通过这一公式来寻址。多维数组多维数组,我们主要来说明二维数组11: int nArray[2][3] = {{1, 2, 3}, {4, 5, 6}}; 00401268 mov dword ptr [ebp-18h],1 0040126F mov dword ptr [ebp-14h],2 00401276 mov dword ptr [ebp-10h],3 0040127D mov dword ptr [ebp-0Ch],4 00401284 mov dword ptr [ebp-8],5 0040128B mov dword ptr [ebp-4],6通过汇编代码,对于多维数组在内存中存储的方式仍然为线性存储方式,对于多维数组会转化为一维数组数组,然后再依次存储各个一维数组的值,例如上面的例子中将二维数组转化为两个一维数组,然后分别在内存中对它们进行初始化。对于多维数组的寻址,例如int nArray2这样的数组,首先拆分为2个有3个元素的一维数组,在寻址时首先找到对应的一维数组的首地址,然后在对应的一维数组中寻址找到对应元素的值。这样对于多维数组都是转化为多个低一级的多维数组最终转化为一维数组的方式来解决。虽说多维数组是采用线性存储的方式来存储数据,但是在理解上我们可以将高维数组看成存储多个低维数组的特殊一维数组,比如int a4 可以看成一个有四个元素的一维数组,每一一维数组都存储了一个5个整型元素的一维数组,通过图来表示就是这样:上述的数组看做一个一维数组,这个一维数组有4个成员,每个成员都存储了一个5个一维数组的数组名,这样就可以很好的理解a 表示的是二维数组的首地址,而a[0]则表示的是第一个元素的首地址,同时也可以很好理解为何定义二维数组的指针时为何需要第二个下标,因为二维数组存储的是一维数组,它的类型就是多个一维数组,所以需要将一维数组的大小作为类型值来定义指针。函数指针函数指针的定义格式如下type (*pname)(args);函数的内容存储在代码段中,函数指针指向的就是函数的第一句代码所在的内存位置,而在调用函数需要知道函数的返回值,以及函数的参数列表,特别是参数列表,只有知道这些信息,在通过函数指针调用时才能知道其栈环境是如何配置的,函数类型其实是函数的返回值加上其参数列表,所以在定义函数时需要知道这些信息。 -
C语言中不同变量的访问方式 C语言中的变量大致可以分为全局变量,局部变量,堆变量和静态局部变量,这些不同的变量存储在不同的位置,有不同的生命周期。一般程序将内存分为数据段、代码段、栈段、堆段,这几类变量存储在不同的段中,造成了它们有不同的生命周期。全局变量全局变量的生命周期是整个程序的生命周期,随着程序的运行而存在,随着程序的结束而消亡,全局变量位于程序的数据段。每个应用程序有4GB的虚拟地址空间,在程序开始时系统将这个程序加载到内存中,为其分配内存,这个时候,会根据程序文件的内容,为全局变量分配内存,并为之进行初始化,当程序的生命周期结束时,系统回收进程所消耗的资源,这个时候,全局变量所占的内存被销毁。下面来看一段具体的代码:int i= 0; int main(int argc, char* argv[]) { printf("%d\n", i); return 0; }11: printf("%d\n", i); 00401268 mov eax,[i (00432e24)] 0040126D push eax 0040126E push offset string "%d\n" (0042e01c)从上述的汇编代码中可以看到,i所对应的地址为0x00432e24,在调用全局变量时,使用的是一个具体的地址,但是并没有看对应初始化i变量的反汇编代码,这是因为在程序开始运行之前,在准备进程环境的时候就为i分配的了存储空间,并进行了初始化。另外在使用时采用的是直接寻址的方式,并没有用寄存器来进行间接寻址,从这点上来看,i变量的地址不会随着程序的运行而改变,这个地址一直可以使用,所以全局变量的生命周期与程序的生命周期相同。静态变量静态变量有两个作用,一是将变量名所能使用的区域限定在对应位置,比如我们在一个函数中定义了一个静态变量,那么久只能在这个函数中使用这个变量,二是静态变量的生命周期是全局的,不会随着堆栈环境的改变而改变,下面是一个简单的例子int Func() { static int i = 0; i++; return i; } int main() { printf("%d\n", Func()); printf("%d\n", Func()); return 0; }9: static int i = 0; 10: i++; 00401268 mov eax,[_Ios_init+3 (00433e24)] 0040126D add eax,1 00401270 mov [_Ios_init+3 (00433e24)],eax 11: return i; 上面的汇编代码也采用的是直接寻址的方式,而这个静态变量的地址为0x433e24,与上面的全局变量的地址进行比较,我们可以看出,其实它也是在全局作用域的,在初始化时也没有发现有任何的初始化代码,所以我们可以说,它的生命周期也是全局的,但是由于static将其可见域限定在函数中,所以在函数外不能通过这个变量名来访问这块内存区域。局部静态变量的工作方式上面说到局部静态变量的生命周期不随函数的结束而结束,不管进入函数多少次,局部静态变量只有一个内存地址,而且只初始化一次,具体编译器是如何做到的,将用下面这一段代码来说明:int test(int n) { static int i = n; return i; } int main(int argc, char* argv[]) { for (int i = 0; i < 5; i++) { printf("%d\n", test(i)); } return 0; }12: static int i = n; 00401268 xor eax,eax 0040126A mov al,[`test'::`2'::$S25 (00433e24)];用一个字节存储了一个标志位 0040126F and eax,1 00401272 test eax,eax 00401274 jne test+3Eh (0040128e);当该标志位为1则表明进行了初始化,直接跳过初始化的步骤 00401276 mov cl,byte ptr [`test'::`2'::$S25 (00433e24)] 0040127C or cl,1;没有进行初始化的话,先初始化然后将标志位赋值为1 0040127F mov byte ptr [`test'::`2'::$S25 (00433e24)],cl 00401285 mov edx,dword ptr [ebp+8] 00401288 mov dword ptr [__pInconsistency+39Ch (00433e20)],edx 13: return i; 0040128E mov eax,[__pInconsistency+39Ch (00433e20)]在上面这段代码中我们企图多次对静态变量进行初始化,但是通过运行程序最终得到的结果都是一样的,上述的代码并没有改变静态变量的值,通过查看汇编代码我们可以看到,编译器在处理局部静态变量时多用了一个字节的内存保存了一个标志位,当该静态变量进行了初始化的时候,就跳过初始化的代码,否则进行初始化并将标志位赋相应的值。局部变量局部变量,的生命周期随着函数的调用而存在,当函数结束时它的生命周期就结束了。在我的上一篇将函数的博客中,已经说明了它寻址方式和生命周期。在函数调用时,会首先根据函数中局部变量所占的空间,初始化栈环境,并对这些局部变量进行初始化,当函数调用完成后,会首先回收栈环境,这样局部变量所在的内存被回收,用于下一个函数调用或者用作其他用途,因为栈是动态变化的,为了防止使用不当造成程序错误,所以在函数外是不能使用函数中定义的局部变量。另外一个需要说明的就是在语句块内的局部变量,它的生命周期只在语句块中,但是真实的情况是,它所在的内存与局部变量相同,都是在函数栈中,它的生命周期只在语法层面上进行限制。堆变量堆变量需要程序员自己申请并释放,需要程序员自己管理,程序不会自动管理这些内存,当调用malloc或者new 的时候,系统分配一块内存,直到调用free 或者delete的时候才释放。
-
C语言循环的实现 在C语言中采用3中语法来实现循环,它们分别是while、for、do while,本文将分别说明这三种循环的实现,并对它们的运行效率进行比较。do while首先来看do while的实现:下面是简单的代码:int nCount = 0; int nMax = 10; do { nCount++; } while (nCount < nMax); return 0; 下面对应的是它的汇编代码:9: int nCount = 0; 00401268 mov dword ptr [ebp-4],0 10: int nMax = 10; 0040126F mov dword ptr [ebp-8],0Ah 11: do 12: { 13: nCount++; 00401276 mov eax,dword ptr [ebp-4] 00401279 add eax,1 0040127C mov dword ptr [ebp-4],eax 14: } while (nCount < nMax); 0040127F mov ecx,dword ptr [ebp-4];exc = nCount 00401282 cmp ecx,dword ptr [ebp-8];比较nCount 和 nMax的值 00401285 jl main+26h (00401276);跳转到循环体中 15: return 0; 00401287 xor eax,eax在汇编代码中首先执行了一次循环体中的操作,然后判断,当条件满足时会跳转回循环体,然后再次执行,当条件不满足时会接着执行后面的语句。这个过程可以用goto来模拟: int nCount = 0; int nMax = 10; __WHILE: nCount++; if(nCount < nMax) goto __WHILE;while循环不同于do while的先执行再比较,while采取的是先比较再循环的方式,下面是一个while的例子: int nCount = 0; int nMax = 10; while (nCount < nMax) { nCount++; }00401268 mov dword ptr [ebp-4],0 10: int nMax = 10; 0040126F mov dword ptr [ebp-8],0Ah 11: while (nCount < nMax) 00401276 mov eax,dword ptr [ebp-4] 00401279 cmp eax,dword ptr [ebp-8] 0040127C jge main+39h (00401289) 12: { 13: nCount++; 0040127E mov ecx,dword ptr [ebp-4] 00401281 add ecx,1 00401284 mov dword ptr [ebp-4],ecx 14: } 00401287 jmp main+26h (00401276) 15: return 0; 00401289 xor eax,eax 从汇编代码上可以看出,执行while循环时会有两次跳转,当条件不满足时会执行一次跳转,跳转到循环体外,而条件满足,执行完一次循环后,会再次跳转到循环体中,再次进行比较。相比于do while来说,while执行了两次跳转,效率相对较低。for 循环for循环是首先进行初始化操作然后进行比较,条件满足时执行循环,再将循环变量递增,最后再次比较,执行循环或者跳出。下面是for的简单例子: int nMax = 10; for (int i = 0; i < nMax; i++) { printf("%d\n", i); }下面是它对应的汇编代码:9: int nMax = 10; 00401268 mov dword ptr [ebp-4],0Ah 10: for (int i = 0; i < nMax; i++) 0040126F mov dword ptr [ebp-8],0 ;初始化循环变量 00401276 jmp main+31h (00401281);跳转到比较操作处 00401278 mov eax,dword ptr [ebp-8] 0040127B add eax,1 0040127E mov dword ptr [ebp-8],eax;这三句话实现的是循环变量自增操作 00401281 mov ecx,dword ptr [ebp-8];ecx = i 00401284 cmp ecx,dword ptr [ebp-4];比较ecx与i 00401287 jge main+4Ch (0040129c);跳转到循环体外 11: { 12: printf("%d\n", i); 00401289 mov edx,dword ptr [ebp-8] 0040128C push edx 0040128D push offset string "%d\n" (0042e01c) 00401292 call printf (00401540) 00401297 add esp,8 13: } 0040129A jmp main+28h (00401278);跳转到i++位置 14: return 0; 0040129C xor eax,eax从上面的汇编代码可以看出for循环的效率最低,它经过了3次跳转,生成对应的汇编代码上,初始化操作后面紧接着是循环变量自增操作,所以首先在完成初始化后会进行一次跳转,跳转到判断,然后根据判断条件再次跳转或者接着执行循环体,最后当循环完成后会再次跳转到循环变量自增的位置,同样采用goto语句来模拟这个操作: int nMax = 10; int i = 0; goto __CMP; __ADD: i++; __CMP: if (i >= nMax) { goto __RETURN; } __LOOP: printf("%d\n", i); goto __ADD; __RETURN: return 0;continue语句continue用于结束这次循环进入下一次循环,下面采用最复杂的for循环来说明continue语句:int nMax = 10; int i = 0; for(;i < nMax; i++) { if (i == 6) { continue; } }下面是它对应的汇编代码:00401268 mov dword ptr [ebp-4],0Ah 10: int i = 0; 0040126F mov dword ptr [ebp-8],0 11: for(;i < nMax; i++) 00401276 jmp main+31h (00401281) 00401278 mov eax,dword ptr [ebp-8] 0040127B add eax,1 0040127E mov dword ptr [ebp-8],eax 00401281 mov ecx,dword ptr [ebp-8] 00401284 cmp ecx,dword ptr [ebp-4] 00401287 jge main+43h (00401293) 12: { 13: if (i == 6) 00401289 cmp dword ptr [ebp-8],6; 0040128D jne main+41h (00401291);条件不满足组跳转到循环结束处 14: { 15: continue; 0040128F jmp main+28h (00401278) 16: } 17: } 00401291 jmp main+28h (00401278) 18: return 0; 00401293 xor eax,eax 从上面的汇编代码可以看到,continue语句也是一个跳转语句,它会直接跳转到循环体的开始位置。对于for来说相对特殊一些(我觉得循环变量自增并不属于循环体),由于第一次进入循环时并没有执行循环变量自增,所以它会跳转到循环变量自增的位置,其他则直接到循环开始处。慎用gotogoto 语句就像汇编中的 jmp 一样,是直接跳转到对应的标识位置,从上面我们使用goto来模拟各种循环来看,goto语句的可读性不强,而且有可能跳过变量的初始化等过程造成一些难以察觉的问题,但有些时候goto确实好用,例如在写socket或者其他需要清理资源的代码时,goto可以显著的增加程序的可读性并且也会减少相关代码的编写,例如一个典型的服务端socket例子#include <winsock2.h> #include <stdio.h> #include <stdlib.h> #pragma comment(lib, "ws2_32.lib") // Winsock Library #define PORT 8080 #define BUFFER_SIZE 1024 int main() { WSADATA wsaData; SOCKET serverSocket, clientSocket; struct sockaddr_in serverAddr, clientAddr; int addrLen = sizeof(clientAddr); char buffer[BUFFER_SIZE]; // 初始化 Winsock if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0) { printf("Failed to initialize Winsock. Error Code: %d\n", WSAGetLastError()); return EXIT_FAILURE; } // 创建 socket serverSocket = socket(AF_INET, SOCK_STREAM, 0); if (serverSocket == INVALID_SOCKET) { printf("Could not create socket. Error Code: %d\n", WSAGetLastError()); WSACleanup(); return EXIT_FAILURE; } // 设置服务器地址结构 serverAddr.sin_family = AF_INET; serverAddr.sin_addr.s_addr = INADDR_ANY; // 监听所有可用的接口 serverAddr.sin_port = htons(PORT); // 转换为网络字节序 // 绑定 socket if (bind(serverSocket, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) == SOCKET_ERROR) { printf("Bind failed. Error Code: %d\n", WSAGetLastError()); closesocket(serverSocket); WSACleanup(); return EXIT_FAILURE; } // 开始监听 if (listen(serverSocket, 3) == SOCKET_ERROR) { printf("Listen failed. Error Code: %d\n", WSAGetLastError()); closesocket(serverSocket); WSACleanup(); return EXIT_FAILURE; } printf("Server is listening on port %d...\n", PORT); // 接受客户端连接 clientSocket = accept(serverSocket, (struct sockaddr *)&clientAddr, &addrLen); if (clientSocket == INVALID_SOCKET) { printf("Accept failed. Error Code: %d\n", WSAGetLastError()); closesocket(serverSocket); WSACleanup(); return EXIT_FAILURE; } printf("Client connected.\n"); // 发送消息给客户端 const char *message = "Hello from server!"; send(clientSocket, message, strlen(message), 0); // 关闭 sockets closesocket(clientSocket); closesocket(serverSocket); WSACleanup(); return EXIT_SUCCESS; }中间有好几次执行了closesocket、以及最后的WSACleanup操作、前面每一步出错都要写一次这些清理资源的操作。如果使用goto将会简单的多#include <winsock2.h> #include <stdio.h> #include <stdlib.h> #pragma comment(lib, "ws2_32.lib") // Winsock Library #define PORT 8080 #define BUFFER_SIZE 1024 int main() { WSADATA wsaData; SOCKET serverSocket, clientSocket; struct sockaddr_in serverAddr, clientAddr; int addrLen = sizeof(clientAddr); char buffer[BUFFER_SIZE]; int err = EXIT_SUCCESS; // 初始化 Winsock if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0) { printf("Failed to initialize Winsock. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; goto __CLEANUP; } // 创建 socket serverSocket = socket(AF_INET, SOCK_STREAM, 0); if (serverSocket == INVALID_SOCKET) { printf("Could not create socket. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; goto __CLEANUP; } // 设置服务器地址结构 serverAddr.sin_family = AF_INET; serverAddr.sin_addr.s_addr = INADDR_ANY; // 监听所有可用的接口 serverAddr.sin_port = htons(PORT); // 转换为网络字节序 // 绑定 socket if (bind(serverSocket, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) == SOCKET_ERROR) { printf("Bind failed. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; goto __CLEANUP; } // 开始监听 if (listen(serverSocket, 3) == SOCKET_ERROR) { printf("Listen failed. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; goto __CLEANUP; } printf("Server is listening on port %d...\n", PORT); // 接受客户端连接 clientSocket = accept(serverSocket, (struct sockaddr *)&clientAddr, &addrLen); if (clientSocket == INVALID_SOCKET) { printf("Accept failed. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; goto __CLEANUP; } printf("Client connected.\n"); // 发送消息给客户端 const char *message = "Hello from server!"; send(clientSocket, message, strlen(message), 0); // 关闭 sockets __CLEANUP: if(clientSocket != INVALID_SOCKET) { closesocket(clientSocket) } if(serverSocket != INVALID_SOCKET) { closesocket(serverSocket); } WSACleanup(); return err; }如果在不允许使用goto的情况下,可以考虑使用 do while 来模拟这种情况,上面的代码可以修改为#include <winsock2.h> #include <stdio.h> #include <stdlib.h> #pragma comment(lib, "ws2_32.lib") // Winsock Library #define PORT 8080 #define BUFFER_SIZE 1024 int main() { WSADATA wsaData; SOCKET serverSocket, clientSocket; struct sockaddr_in serverAddr, clientAddr; int addrLen = sizeof(clientAddr); char buffer[BUFFER_SIZE]; int err = EXIT_SUCCESS; do{ // 初始化 Winsock if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0) { printf("Failed to initialize Winsock. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; break; } // 创建 socket serverSocket = socket(AF_INET, SOCK_STREAM, 0); if (serverSocket == INVALID_SOCKET) { printf("Could not create socket. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; break; } // 设置服务器地址结构 serverAddr.sin_family = AF_INET; serverAddr.sin_addr.s_addr = INADDR_ANY; // 监听所有可用的接口 serverAddr.sin_port = htons(PORT); // 转换为网络字节序 // 绑定 socket if (bind(serverSocket, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) == SOCKET_ERROR) { printf("Bind failed. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; break; } // 开始监听 if (listen(serverSocket, 3) == SOCKET_ERROR) { printf("Listen failed. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; break; } printf("Server is listening on port %d...\n", PORT); // 接受客户端连接 clientSocket = accept(serverSocket, (struct sockaddr *)&clientAddr, &addrLen); if (clientSocket == INVALID_SOCKET) { printf("Accept failed. Error Code: %d\n", WSAGetLastError()); err = EXIT_FAILURE; break; } printf("Client connected.\n"); // 发送消息给客户端 const char *message = "Hello from server!"; send(clientSocket, message, strlen(message), 0); }while (FALSE); // 关闭 sockets if(clientSocket != INVALID_SOCKET) { closesocket(clientSocket) } if(serverSocket != INVALID_SOCKET) { closesocket(serverSocket); } WSACleanup(); return err; }这里的while不是为了循环,而是利用了do while 无论如何都会先执行循环体中代码的特性,只执行一次上述主体代码,利用break来跳转到最后的清理模块,实现与goto 类似的效果。使用goto 的方案比do while的方案要显得简洁易懂,goto使用的好,也能使得程序简单易懂。具体使用哪种方案是个见仁见智的事情,看个人喜好。如果遇上公司要求不能使用 goto,那么就可以采用do while的实现方案
-
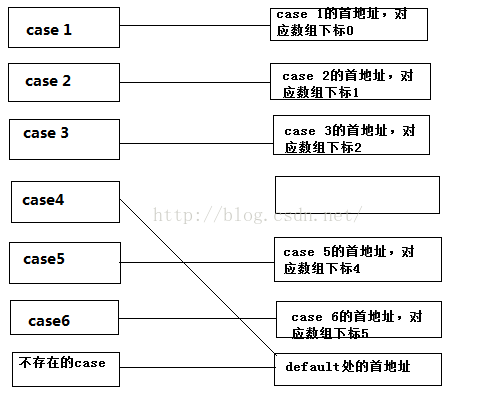
IF和SWITCH的原理 在C语言中,if和switch是条件分支的重要组成部分。ifif的功能是计算判断条件的值,根据返回的值的不同来决定跳转到哪个部分。值为真则跳转到if语句块中,否则跳过if语句块。下面来分析一个简单的if实例:if(argc > 0) { printf("argc > 0\n"); } if (argc <= 0) { printf("argc <= 0\n"); } printf("argc = %d\n", argc);它对应的汇编代码如下:9: if(argc > 0) cmp dword ptr [ebp+8],0 0040102C jle main+2Bh (0040103b) ;argc <= 0就跳转到下一个if处 10: { 11: printf("argc > 0\n"); 0040102E push offset string "argc > 0\n" (0042003c) call printf (00401090) add esp,4 12: } 13: if (argc <= 0) ;argc > 0跳转到后面的printf语句输出argc的值 0040103B cmp dword ptr [ebp+8],0 0040103F jg main+3Eh (0040104e) 14: { 15: printf("argc <= 0\n"); push offset string "argc <= 0\n" (0042002c) call printf (00401090) 0040104B add esp,4 16: } 17: printf("argc = %d\n", argc); 0040104E mov eax,dword ptr [ebp+8] push eax push offset string "argc = %d\n" (0042001c) call printf (00401090) 0040105C add esp,8根据汇编代码我们看到,首先执行第一个if中的比较,jle表示当cmp得到的结果≤0时会进行跳转,第二个if在汇编中的跳转条件是>0,从这个上面可以看出在代码执行过程当中if转换的条件判断语句与if的判断结果时相反的,也就是说cmp比较后不成立则跳转,成立则向下执行。同时每一次跳转都是到当前if语句的下一条语句。if ...else下面来看看if...else...语句的跳转。if(argc > 0) { printf("argc > 0\n"); }else { printf("argc <= 0\n"); } printf("argc = %d\n", argc);它所对应的汇编代码如下:00401028 cmp dword ptr [ebp+8],0 0040102C jle main+2Dh (0040103d) ;条件不满足则跳转到else语句块中 10: { 11: printf("argc > 0\n"); 0040102E push offset string "argc > 0\n" (0042003c) 00401033 call printf (00401090) 00401038 add esp,4 12: }else 0040103B jmp main+3Ah (0040104a);如果执行if语句块就会执行这条语句跳出else语句块 13: { 14: printf("argc <= 0\n"); 0040103D push offset string "argc <= 0\n" (0042002c) 00401042 call printf (00401090) 00401047 add esp,4 15: } 16: printf("argc = %d\n", argc); 0040104A mov eax,dword ptr [ebp+8]上述的汇编代码指出,对于if...else..语句,首先进行条件判断,if表达式为真,则继续执行if快中的语句,然后利用jmp跳转到else语句块外,否则会利用jmp跳转到else语句块中,然后依次执行其后的每一句代码。if ... else if... else最后再来展示if...else if...else这种分支结构:if(argc > 0) { printf("argc > 0\n"); }else if(argc < 0) { printf("argc < 0\n"); }else { printf("argc == 0\n"); } printf("argc = %d\n", argc);汇编代码如下:9: if(argc > 0) 00401028 cmp dword ptr [ebp+8],0 0040102C jle main+2Dh (0040103d);条件不满足则会跳转到下一句else if中 10: { 11: printf("argc > 0\n"); 0040102E push offset string "argc > 0\n" (00420f9c) 00401033 call printf (00401090) 00401038 add esp,4 12: }else if(argc < 0) 0040103B jmp main+4Fh (0040105f) ;当上述条件符合则执行这条语句跳出分支外,跳转的地址正是else语句外的printf语句 0040103D cmp dword ptr [ebp+8],0 00401041 jge main+42h (00401052) 13: { 14: printf("argc < 0\n"); 00401043 push offset string "argc < 0\n" (0042003c) 00401048 call printf (00401090) 0040104D add esp,4 15: }else 00401050 jmp main+4Fh (0040105f) 16: { 17: printf("argc == 0\n"); 00401052 push offset string "argc <= 0\n" (0042002c) 00401057 call printf (00401090) 0040105C add esp,4 18: } 19: printf("argc = %d\n", argc); 0040105F mov eax,dword ptr [ebp+8]通过汇编代码可以看到对于这种结构,会依次判断每个if语句中的条件,当有一个满足,执行完对应语句块中的代码后,会直接调转到分支结构外部,当前面的条件都不满足则会执行else语句块中的内容。这个逻辑结构在某些情况下可以利用if return if return 这种结构来替代。当某一条件满足时执行完对应的语句后直接返回而不执行其后的代码。一条提升效率的做法是将最有可能满足的条件放在前面进行比较,这样可以减少比较次数,提升效率。switchswitch是另一种比较常用的多分支结构,在使用上比较简单,效率上也比if...else if...else高,下面将分析switch结构的实现switch(argc) { case 1: printf("argc = 1\n"); break; case 2: printf("argc = 2\n"); break; case 3: printf("argc = 3\n"); break; case 4: printf("argc = 4\n"); break; case 5: printf("argc = 5\n"); break; case 6: printf("argc = 6\n"); break; default: printf("else\n"); break; }对应的汇编代码如下:0040B798 mov eax,dword ptr [ebp+8] ;eax = argc 0040B79B mov dword ptr [ebp-4],eax 0040B79E mov ecx,dword ptr [ebp-4] ;ecx = eax 0040B7A1 sub ecx,1 0040B7A4 mov dword ptr [ebp-4],ecx 0040B7A7 cmp dword ptr [ebp-4],5 0040B7AB ja $L544+0Fh (0040b811) ;argc 》 5则跳转到default处,至于为什么是5而不是6,看后面的说明 0040B7AD mov edx,dword ptr [ebp-4] ;edx = argc 0040B7B0 jmp dword ptr [edx*4+40B831h] 11: case 1: 12: printf("argc = 1\n"); 0040B7B7 push offset string "argc = 1\n" (00420fc0) 0040B7BC call printf (00401090) 0040B7C1 add esp,4 13: break; 0040B7C4 jmp $L544+1Ch (0040b81e) 14: case 2: 15: printf("argc = 2\n"); 0040B7C6 push offset string "argc = 2\n" (00420fb4) 0040B7CB call printf (00401090) 0040B7D0 add esp,4 16: break; 0040B7D3 jmp $L544+1Ch (0040b81e) 17: case 3: 18: printf("argc = 3\n"); 0040B7D5 push offset string "argc = 3\n" (00420fa8) 0040B7DA call printf (00401090) 0040B7DF add esp,4 19: break; 0040B7E2 jmp $L544+1Ch (0040b81e) 20: case 4: 21: printf("argc = 4\n"); 0040B7E4 push offset string "argc = 4\n" (00420f9c) 0040B7E9 call printf (00401090) 0040B7EE add esp,4 22: break; 0040B7F1 jmp $L544+1Ch (0040b81e) 23: case 5: 24: printf("argc = 5\n"); 0040B7F3 push offset string "argc < 0\n" (0042003c) 0040B7F8 call printf (00401090) 0040B7FD add esp,4 25: break; 0040B800 jmp $L544+1Ch (0040b81e) 26: case 6: 27: printf("argc = 6\n"); 0040B802 push offset string "argc <= 0\n" (0042002c) 0040B807 call printf (00401090) 0040B80C add esp,4 28: break; 0040B80F jmp $L544+1Ch (0040b81e) 29: default: 30: printf("else\n"); 0040B811 push offset string "argc = %d\n" (0042001c) 0040B816 call printf (00401090) 0040B81B add esp,4 31: break; 32: } 33: 34: return 0; 0040B81E xor eax,eax上面的代码中并没有看到像if那样,对每一个条件都进行比较,其中有一句话 “jmp dword ptr [edx*4+40B831h]” 这句话从表面上看应该是取数组中的元素,再根据元素的值来进行跳转,而这个元素在数组中的位置与eax也就是与argc的值有关,下面我们跟踪到数组中查看数组的元素值:0040B831 B7 B7 40 00 0040B835 C6 B7 40 00 0040B839 D5 B7 40 00 0040B83D E4 B7 40 00 0040B841 F3 B7 40 00 0040B845 02 B8 40 00通过对比可以发现0x0040b7b7是case 1处的地址,后面的分别是case 2、case 3、case 4、case 5、case 6处的地址,每个case中的break语句都翻译为了同一句话“jmp $L544+1Ch (0040b81e)”,所以从这可以看出,在switch中,编译器多增加了一个数组用于存储每个case对应的地址,根据switch中传入的整数在数组中查到到对应的地址,直接通过这个地址跳转到对应的位置,减少了比较操作,提升了效率。编译器在处理switch时会首先校验不满足所有case的情况,当这种情况发生时代码调转到default或者switch语句块之外。然后将传入的整数值减一(数组元素是从0开始计数)。最后根据参数值找到应该跳转的位置。上述的代码case是从0~6依次递增,这样做确实可行,但是当我们在case中的值并不是依次递增的话会怎样?此时根据不同的情况编译器会做不同的处理。一般任然会建立这样的一个表,将case中出现的值填写对应的跳转地址,没有出现的则将这个地址值填入default对应的地址或者switch语句结束的地址,比如当我们上述的代码去掉case 5, 这个时候填入的地址值如下图所示:如果每两个case之间的差距大于6,或者case语句数小于4则不会采取这种做法,如果再采用这种方式,那么会造成较大的资源消耗。这个时候编译器会采用索引表的方式来进行地址的跳转。下面有这样一个例子:switch(argc) { case 1: printf("argc = 1\n"); break; case 2: printf("argc = 2\n"); break; case 5: printf("argc = 5\n"); break; case 6: printf("argc = 6\n"); break; case 255: printf("argc = 255\n"); default: printf("else\n"); break; }它对应的汇编代码如下:0040B798 mov eax,dword ptr [ebp+8] 0040B79B mov dword ptr [ebp-4],eax 0040B79E mov ecx,dword ptr [ebp-4] ;到此eax = ecx = argc 0040B7A1 sub ecx,1 0040B7A4 mov dword ptr [ebp-4],ecx 0040B7A7 cmp dword ptr [ebp-4],0FEh 0040B7AE ja $L542+0Dh (0040b80b) ;当argc > 255则跳转到default处 0040B7B0 mov eax,dword ptr [ebp-4] 0040B7B3 xor edx,edx 0040B7B5 mov dl,byte ptr (0040b843)[eax] 0040B7BB jmp dword ptr [edx*4+40B82Bh] 11: case 1: 12: printf("argc = 1\n"); 0040B7C2 push offset string "argc = 1\n" (00420fb4) 0040B7C7 call printf (00401090) 0040B7CC add esp,4 13: break; 0040B7CF jmp $L542+1Ah (0040b818) 14: case 2: 15: printf("argc = 2\n"); 0040B7D1 push offset string "argc = 3\n" (00420fa8) 0040B7D6 call printf (00401090) 0040B7DB add esp,4 16: break; 0040B7DE jmp $L542+1Ah (0040b818) 17: case 5: 18: printf("argc = 5\n"); 0040B7E0 push offset string "argc = 5\n" (00420f9c) 0040B7E5 call printf (00401090) 0040B7EA add esp,4 19: break; 0040B7ED jmp $L542+1Ah (0040b818) 20: case 6: 21: printf("argc = 6\n"); 0040B7EF push offset string "argc < 0\n" (0042003c) 0040B7F4 call printf (00401090) 0040B7F9 add esp,4 22: break; 0040B7FC jmp $L542+1Ah (0040b818) 23: case 255: 24: printf("argc = 255\n"); 0040B7FE push offset string "argc <= 0\n" (0042002c) 0040B803 call printf (00401090) 0040B808 add esp,4 25: default: 26: printf("else\n"); 0040B80B push offset string "argc = %d\n" (0042001c) 0040B810 call printf (00401090) 0040B815 add esp,4 27: break; 28: } 29: 30: return 0; 0040B818 xor eax,eax这段代码与上述的线性表相比较区别并不大,只是多了一句 “mov dl,byte ptr (0040b843)[eax]” 这似乎又是一个数组,通过查看内存可以知道这个数组的值分别为:00 01 05 05 02 03 05 05 ... 04,下一句根据这些值在另外一个数组中查找数据,我们列出另外一个数组的值:C2 B7 40 00 D1 B7 40 00 E0 B7 40 00 EF B7 40 00 FE B7 40 00 0B B8 40 00通过对比我们发现,这些值分别是每个case与default入口处的地址,编译器先查找到每个值在数组中对应的元素位置,然后根据这个位置值再在地址表中从、找到地址进行跳转,这个过程可以用下面的图来表示:这样通过一个每个元素占一个字节的表,来表示对应的case在地址表中所对应的位置,从而跳转到对应的地址,这样通过对每个case增加一个字节的内存消耗来达到,减少地址表对应的内存消耗。在上述的汇编代码中,是利用dl寄存器来存储对应case在地址表中项,这样就会产生一个问题,当case 值大于 255,也就是超出了一个字节的,超出了dl寄存器的表示范围时,又该如何来进行跳转这个时候编译器会采用判定树的方式来进行判定,在根节点保存的是所有case值的中位数, 左子树都是大于这个大于这个值的数,右字数是小于这个值的数,通过每次的比较来得到正确的地址。比如下面的这个判定树:首先与10进行比较,根据与10 的大小关系进入左子树或者右子树,再看看左右子树的分支是否不大于3,若不大于3则直接转化为对应的if...else if... else结构,大于3则检测分支是否满足上述的优化条件,满足则进行对应的地址表或者索引表的优化,否则会再次对子树进行优化,以便减少比较次数。
-
C/C++中define定义的常量与const常量 常量是在程序中不能更改的量,在C/C++中有两种方式定义常量,一种是利用define宏定义的方式,一种是C++中新提出来的const型常变量,下面主要讨论它们之间的相关问题;define定义的常量:define是预处理指令的一种,它用来定义宏,宏只是一个简单的替换,将宏变量所对应的值替换,如下面的代码:#define NUM 2 int main() { printf("%d", NUM); }编译器在编译时处理的并不是这样的代码,编译器会首先处理预处理指令,根据预处理指令生成相关的代码文件,然后编译这个文件,得到相关的.obj文件,最后通过链接相关的.obj文件得到一个可执行文件,最典型的是我们一般在.cpp文件中写的#include指令,在处理时首先将所需包含的头文件整个拷贝到这个.cpp文件中,并替换这个#include指令,然后再编译生成的文件,这个中间文件在Windows中后缀为.i,在Visual C++ 6.0中以此点击Project-->Settings-->C/C++,在Project Options最后一行加上'/P'(P为大写)这样在点击编译按钮时不会编译生成obj文件,只会生成.i文件,通过这个.i文件可以看到在做预处理的时候会将 NUM替换成2然后在做编译处理,这个时候点击生成时会出错,因为我们将编译选项修改后没有生成.obj文件但是在生成时需要这个文件,因此会报错,所以在生成时要去掉这个/P选项。而我们看到在使用const 定义的时候并没有这个替换的操作,与使用正常的变量无异。const型变量只是在语法层面上限定这个变量的值不可以修改,我们可以通过强制类型转化或者通过内嵌汇编的形式修改这个变量的值,比如下面的代码:// 强制类型转化 int main(int argc, char* argv[]) { const nNum = 10; int *pNum = (int*)&nNum; printf("%d\n", nNum); return 0; }//嵌入汇编的形式 const nNum = 10; __asm { mov [ebp - 4], 10 } printf("%d\n", nNum); return 0;但是我们看到,这两种方式修改后,输出的值仍然是10,这个原因我们可以通过查看反汇编代码查看;printf("%d\n", nNum); 00401036 push 0Ah 00401038 push offset string "%d\n" (0042001c) 0040103D call printf (00401070) 00401042 add esp,8在调用printf的时候,入栈的参数是10,根本没有取nNum值得相关操作,在利用const定义的常量时,编译器认为既然这是一个常量,应该不会修改,为了提升效率,在使用时并不会去对应的内存中寻址,而是直接将它替换为初始化时的值,为了防止这种事情的发生,可以利用C++中的关键字:volatile。这个关键字保证每次在使用变量时都去内存中读取。我们可以总结出const和define的几个不同之处:define是一个预处理指令,const是一个关键字。define定义的常量编译器不会进行任何检查,const定义的常量编译器会进行类型检查,相对来说比define更安全define的宏在使用时是替换不占内存,而const则是一个变量,占内存空间define定义的宏在代码段中不可寻址,const定义的常量是可以寻址的,在数据段或者栈段中。define定义的宏在编译前的预处理操作时进行替换,而const定义变量是在编译时决定define定义的宏是真实的常量,不会被修改,const定义的实际上是一个变量,可以通过相关的手段进行修改。
-
地址、指针与引用 计算机本身是不认识程序中给的变量名,不管我们以何种方式给变量命名,最终都会转化为相应的地址,编译器会生成一些符号常量并且与对应的地址相关联,以达到访问变量的目的。 变量是在内存中用来存储数据以供程序使用,变量主要有两个部分构成:变量名、变量类型,其中变量名对应了一块具体的内存地址,而变量类型则表明该如何翻译内存中存储的二级制数。我们知道不同的类型翻译为二进制的值不同,比如整型是直接通过数学转化、浮点数是采用IEEE的方法、字符则根据ASCII码转化,同样变量类型决定了变量所占的内存大小,以及如何在二进制和变量所表达的真正意义之间转化。而指针变量也是一个变量,在内存中也占空间,不过比较特殊的是它存储的是其他变量的地址。在32位的机器中,每个进程能访问4GB的内存地址空间,所以程序中的地址采用32位二进制数表示,也就是一个整型变量的长度,地址值一般没有负数所以准确的说指针变量的类型应该是unsigned int 即每个指针变量占4个字节。还记得在定义结构体中可以使用该结构体的指针作为成员,但是不能使用该结构的实例作为成员吗?这是因为编译器需要根据各个成员变量的大小分配相关的内存,用该结构体的实例作为成员时,该结构体根本没有定义完整,编译器是不会知道该如何分配内存的,而任何类型的指针都只占4个字节,编译器自然知道如何分配内存。我们在书写指针变量时给定的类型是它所指向的变量的类型,这个类型决定了如何翻译所对应内存中的值,以及该访问多少个字节的内存。对指针的间接访问会先先取出值,访问到对应的内存,再根据指针所指向的变量的类型,翻译成对应的值。一般指针只能指向对应类型的变量,比如int类型的指针只能指向int型的变量,而有一种指针变量可以指向所有类型的变量,它就是void类型的指针变量,但是由于这种类型的变量没有指定它所对应的变量的类型,所以即使有了对应的地址,它也不知道该取多大内存的数据,以及如何解释这些数据,所以这种类型的指针不支持间接访问,下面是一个间接访问的例子:int main() { int nValue = 10; float fValue = 10.0f; char cValue = 'C'; int *pnValue = &nValue; float *pfValue = &fValue; char *pcValue = &cValue; printf("pnValue = %x, *pnValue = %d\n", pnValue, *pnValue); printf("pfValue = %x, *pfValue = %f\n", pfValue, *pfValue); printf("pcValue = %x, *pcValue = %c\n", pcValue, *pcValue); return 0; }下面是它对应的反汇编代码(部分):10: int nValue = 10; 00401268 mov dword ptr [ebp-4],0Ah 11: float fValue = 10.0f; 0040126F mov dword ptr [ebp-8],41200000h 12: char cValue = 'C'; 00401276 mov byte ptr [ebp-0Ch],43h 13: int *pnValue = &nValue; 0040127A lea eax,[ebp-4] 0040127D mov dword ptr [ebp-10h],eax 14: float *pfValue = &fValue; 00401280 lea ecx,[ebp-8] 00401283 mov dword ptr [ebp-14h],ecx 15: char *pcValue = &cValue; 00401286 lea edx,[ebp-0Ch] 00401289 mov dword ptr [ebp-18h],edx 16: printf("pnValue = %x, *pnValue = %d\n", pnValue, *pnValue); 0040128C mov eax,dword ptr [ebp-10h] 0040128F mov ecx,dword ptr [eax] 00401291 push ecx 00401292 mov edx,dword ptr [ebp-10h] 00401295 push edx 00401296 push offset string "pnValue = %x, *pnValue = %d\n" (00432064) 0040129B call printf (00401580) 004012A0 add esp,0Ch从上面的汇编代码可以看到指针变量会占内存空间,它们的地址分别是:[ebp - 10h] 、 [ebp - 14h]、 [ebp - 18h],在给指针变量赋值时首先将变量的地址赋值给临时寄存器,然后将寄存器的值赋值给指针变量,而通过间接访问时也经过了一个临时寄存器,先将指针变量的值赋值给临时寄存器(mov eax,dword ptr [ebp-10h])然后通过这个临时寄存器访问变量的地址空间,得到变量值( mov ecx,dword ptr [eax]),由于间接访问进过了这几步,所以在效率上是比不上直接使用变量。下面是对char型变量的间接访问:004012BF mov edx,dword ptr [ebp-18h] 004012C2 movsx eax,byte ptr [edx] 004012C5 push eax首先也是将指针变量的值取出来,放到寄存器中,然后根据寄存器寻址找到变量对应的地址,访问变量。其中”bye ptr“表示只操作该地址中的一个字节。对于地址我们可以进行加法和减法操作,地址的加法主要用于向下寻址,一般用于数组等占用连续内存空间的数据结构,一般是地址加上一个数值,表示向后偏移一定的单位,指针同样也有这样的操作,但是与地址值不同的是指针每加一个单位,表示向后偏移一个元素,而地址值加1则就是在原来的基础上加上一。指针偏移是根据其所指向的变量类型来决定的,比如有下面的程序:int main(int argc, char* argv[]) { char szBuf[5] = {0x01, 0x23, 0x45, 0x67, 0x89}; int *pInt = (int*)szBuf; short *pShort = (short*)szBuf; char *pChar = szBuf; pInt += 1; pShort += 1; pChar += 1; return 0; }它的汇编代码如下:9: char szBuf[5] = {0x01, 0x23, 0x45, 0x67, 0x89}; 00401028 mov byte ptr [ebp-8],1 0040102C mov byte ptr [ebp-7],23h 00401030 mov byte ptr [ebp-6],45h 00401034 mov byte ptr [ebp-5],67h 00401038 mov byte ptr [ebp-4],89h 10: int *pInt = (int*)szBuf; 0040103C lea eax,[ebp-8] 0040103F mov dword ptr [ebp-0Ch],eax 11: short *pShort = (short*)szBuf; 00401042 lea ecx,[ebp-8] 00401045 mov dword ptr [ebp-10h],ecx 12: char *pChar = szBuf; 00401048 lea edx,[ebp-8] 0040104B mov dword ptr [ebp-14h],edx 13: 14: pInt += 1; 0040104E mov eax,dword ptr [ebp-0Ch] 00401051 add eax,4 00401054 mov dword ptr [ebp-0Ch],eax 15: pShort += 1; 00401057 mov ecx,dword ptr [ebp-10h] 0040105A add ecx,2 0040105D mov dword ptr [ebp-10h],ecx 16: pChar += 1; 00401060 mov edx,dword ptr [ebp-14h] 00401063 add edx,1 00401066 mov dword ptr [ebp-14h],edx根据其汇编代码可以看出,对于int型的指针,每加1个会向后偏移4个字节,short会偏移2个字节,char型的会偏移1个,所以根据以上的内容,可以得出一个公式:TYPE P p + n = p + sizeof(TYPE) n根据上面的加法公式我们可以推导出两个指针的减法公式,TYPE p1, TYPE p2: p2 - p1 = ((int)p2 - (int)p1) / sizeof(TYPE),两个指针相减得到的结果是两个指针之间拥有元素的个数。只有同类型的指针之间才可以相减。而指针的乘除法则没有意义,地址之间的乘除法也没有意义。引用是在C++中提出的,是变量的一个别名,提出引用主要是希望减少指针的使用,引用于指针在一个函数中想上述例子中那样使用并没有太大的意义,大量使用它们是在函数中,作为参数传递,不仅可以节省效率,同时也可以传递一段缓冲,作为输出参数来使用。这大大提升了程序的效率以及灵活性。但是在一些新手程序员看来指针无疑是噩梦般的存在,所以C++引入了引用,希望代替指针。在一般的C++书中都说引用是变量的一个别名是不占内存的,但是我通过查看反汇编代码发现引用并不是向书上说的那样,下面是一段程序及它的反汇编代码:int nValue = 10; int &rValue = nValue; printf("%d\n", rValue);10: int nValue = 10; 00401268 mov dword ptr [ebp-4],0Ah 11: int &rValue = nValue; 0040126F lea eax,[ebp-4] 00401272 mov dword ptr [ebp-8],eax 12: printf("%d\n", rValue); 00401275 mov ecx,dword ptr [ebp-8] 00401278 mov edx,dword ptr [ecx] 0040127A push edx 0040127B push offset string "%d\n" (0042e01c) 00401280 call printf (00401520)从汇编代码中可以看到,在定义引用并为它赋值的过程中,编译器其实是将变量的地址赋值给了一个新的变量,这个变量的地址是[ebp - 8h],在调用printf函数的时候,编译器将地址取出并将它压到函数栈中。下面是将引用改为指针的情况:10: int nValue = 10; 00401268 mov dword ptr [ebp-4],0Ah 11: int *pValue = &nValue; 0040126F lea eax,[ebp-4] 00401272 mov dword ptr [ebp-8],eax 12: printf("%d\n", *pValue); 00401275 mov ecx,dword ptr [ebp-8] 00401278 mov edx,dword ptr [ecx] 0040127A push edx 0040127B push offset string "%d\n" (0042e01c) 00401280 call printf (00401520)两种情况的汇编代码完全一样,也就是说引用其实就是指针,编译器将其包装了一下,使它的行为变得和使用变量相同,而且在语法层面上做了一个限制,引用在定义的时候必须初始化,且初始化完成后就不能指向其他变量,这个行为与常指针相同。
-
C/C++中整数与浮点数在内存中的表示方式 在C/C++中数字类型主要有整数与浮点数两种类型,在32位机器中整型占4字节,浮点数分为float,double两种类型,其中float占4字节,而double占8字节。下面来说明它们在内存中的具体表现形式:整型整型变量占4字节,在计算机中都是用二进制表示,整型有无符号和有符号两种形式。无符号变量在定义时只需要在相应类型名前加上unsigned 无符号整型变量用32位的二进制数字表示,在与十进制进行转化时只需要知道计算规则即可轻松转化。需要注意的是在计算机中一般使用主机字节序,即采用“高高低低的方式”,数字高位在高地址位,低位在低地址位,例如我们有一个整数0x10203040那么它在内存中存储的格式为:04 03 02 01。有符号数将最高位表示为符号位,0为正数,1为负数其余位都表示具体的数值,对于负数采用的是补码的方式,补码的规则是用0x100000000减去这个数的绝对值,也可以简单的几位将这个数的绝对值取反加1,这样做是为了方便将减法转化为加法,在数学中两个互为相反数的和为0,比如现在有一个负数数x,那么这个x + |x| = 0这个x的绝对值是一个正数,但是用二级制表示的两个数相加不会等于0,而计算机对于溢出采用的是简单的将溢出位丢弃,所以令x + |x| = 0x100000000,这个最高位1,已经溢出,所以这个结果用四字节保存结果肯定会是0,所以最终得到的x = 0x100000000 - |x|。浮点数:早期的小数表示采用的固定小数点的方式,比如规定在32位二级制数字当中,哪几位表示整数部分,其余的表示小数部分,这样表示的数据范围有限,后来采用的是小数点浮动变化的表示方式,也就是所谓的浮点数。浮点数采用的是IEEE的表示方式,最高位表示符号位,在剩余的31位中,从左往右8位表示的是科学计数法的指数部分,其余的表示整数部分。例如我们将12.25f化为浮点数的表示方式:首先将它化为二进制表示1100.01,利用科学计数法可以表述为:1.10001 * 2^3分解出各个部分:指数部分3 + 127= 011 + 0111111、尾数数部分:10001需要注意的是:因为用科学计数法来表示的话,最高位肯定为1所以这个1不会被表示出来指数部分也有正负之分,最高位为1表示正指数,为0表示负指数,所以算出来指数部分后需要加上127进行转化。将这个转化为对应的32位二级制,尾数部分从31位开始填写,不足部分补0即:0 | 10000010 | 10001 |000000000000000000,隔开的位置分别为符号位、指数位,尾数位。因为有的浮点数没有办法完全化为二进制数,会产生一个无限值,编译器会舍弃一部分内容,也就说只能表示一个近似的数,所以在比较浮点数是否为0的时候不要用==而应该用近似表示,允许一定的误差,比如下面的代码:float fTemp = 0.0001f if(fFloat >= -fTemp && fFloat <= fTemp) { //这个是比较fFloat为0 }double类型的浮点数的编码方式与float相同,只是位数不同。double用11位表示指数部分,其余的表示尾数部分。浮点数的计算在CPU中有专门的浮点数寄存器,和对应的计算指令,在效率上比整型数据的低。在写程序的时候,我们利用变量名来进行变量的识别,但是计算机根本不认识这些变量名,计算机中采用的是直接使用地址的方式找到对应的变量,同时为了能准确找到对应的变量,编译器会生成一个结构专门用于保存变量的标识名与对应的地址,这个标识名不是我们定义的变量名,而是在此基础上添加了一些符号,如下面的例子:extern int nTemp; int main() { cout<<nTemp<<endl; }我们申明一个变量,然后在不定义它的情况下,直接使用,这个时候编译器会报错,表示找不到这个变量,报错的截图如下:我们可以看到编译器为这个变量准备的名称并不是我们所定义的nTemp,而是添加了其他标示。在声明变量的时候编译器会为它准备一个标示名称,在定义时会给它一个对应的内存地址,以后在访问这个标示的时候编译器直接去它对应的内存位置去寻找它,下面我们添加这个变量的定义代码:extern int nTemp;int nTemp = 0;int main(){cout<<nTemp<<endl; return 0;}我们查看对应的汇编代码:11: ;int nTemp = 0;00401798 mov dword ptr [ebp-4],012: ;cout<<nTemp<<endl;我们可以看到在为这个变量初始化的时候编译器是直接找到对应的地址[ebp - 4],没有出现相关的变量名,所以说我们定义的变量名只是为了程序员能够识别,而计算机是直接采用寄存器寻址的方式来取用变量。在编译器中同时也看不到与变量类型相关的代码,编译器在使用变量是只关心它的位置,存储的值,以及如何将其中的二进制翻译为对应的内容,代码如下:int main(){int nTemp = 0x00010101; float *pFloat = (float*)&nTemp; char *pChar = (char*)&nTemp; cout<<nTemp<<endl; cout<<*pFloat<<endl; cout<<pChar<<endl; return 0;}结果如下:从这可以看出同一块内存因为编译器根据类型将它翻译为不同的内容,所展现的内容不同。