搜索到
84
篇与
的结果
-
 Emacs 折腾日记(十七)——文本属性 我们在上一篇中介绍了如何对文件中的文本进行操作,本篇主要来介绍关于文本的属性。是的,文本也有属性。这里的文本属性有点类似于Word中的文字属性,文本中对应的字符只是文本属性的一种,它还包括文本大小、字体、颜色等等内容。Emacs中的文本也是类似的。于符号的属性类似,文本的属性也是由键值对构成。名 字和值都可以是一个 lisp 对象,但是通常名字都是一个符号,这样可以用这个 符号来查找相应的属性值。复制文本通常都会复制相应的字符的文本属性,但是 也可以用相应的函数只复制文本字符串,比如 substring-no-properties、 insert-buffer-substring-no-properties、buffer-substring-no-properties。产生一个带属性的字符串可以用 propertize 函数。(propertize "abc" 'face 'bold) ;; ⇒ #("abc" 0 3 (face bold))这里我们使用 face 来设置它的字体为粗体。或者我们可以使用C-x C-f 任意的打开或者创建一个文本文件,在文件中输入(insert (propertize "abc" 'face 'bold))我们可以看到它会在当前光标后面插入一个粗体的 abc 字符串。需要注意的是,我们在*scratch* buffer 中是无法看到这个效果的。因为*scratch* buffer 中开启了font-lock-mode。正如它的名字表示的那样,它锁定了字体,它里面的字体属性都是实时计算出来的。在插入文本之后它的属性很快就被修改了。因为*scratch* buffer 本质上还是一个elisp的编程环境,它里面有关于elisp的语法高亮、自动对齐等特性。它会自动的修改输入的文本属性。我们可以使用 (font-lock-mode - 1) 来关闭这个mode,然后执行上述代码就可以看到具体的效果了。虽然文本属性的名字可以是任意的,但是一些名字是有特殊含义的。属性名含义category值必须是一个符号,这个符号的属性将作为这个字符的属性face控制文本的字体和颜色font-lock-face和 face 相似,可以作为 font-lock-mode 中静态文本的 facemouse-face当鼠标停在文本上时的文本 facefontified记录是否使用 font lock 标记了 facedisplay改变文本的显示方式,比如高、低、长短、宽窄,或者用图片代替help-echo鼠标停在文本上时显示的文字keymap光标或者鼠标在文本上时使用的按键映射local-map和 keymap 类似,通常只使用 keymapsyntax-table字符的语法表read-only不能修改文本,通过 stickness 来选择可插入的位置invisible不显示在屏幕上intangible把文本作为一个整体,光标不能进入field一个特殊标记,有相应的函数可以操作带这个标记的文本cursor(不知道具体用途)pointer修改鼠标停在文本上时的图像line-spacing新的一行的距离line-height本行的高度modification-hooks修改这个字符时调用的函数insert-in-front-hooks与 modification-hooks 相似,在字符前插入调用的函数insert-behind-hooks与 modification-hooks 相似,在字符后插入调用的函数point-entered当光标进入时调用的函数point-left当光标离开时调用的函数composition将多个字符显示为一个字形这些东西我觉得也不需要记住,在需要的时候查查文档就好了。但是我参考的教程把它列出来了,那么我也在这里列出来把。由于字符串和缓冲区都可以有文本属性(如果没有特别指定文本对象的属性,那么默认使用缓冲区定义的文本属性),所以下面的函数通常不提供特定参数就是检 查当前缓冲区的文本属性,如果提供文本对象,则是操作对应的文本属性。查看文本属性查看文本对象在某处的文本属性可以用 get-text-property 函数。(setq foo (propertize "abc" 'face 'bold)) ;; ⇒ #("abc" 0 3 (face bold)) (get-text-property 0 'face foo) ;; ⇒ bold这里有两个问题需要注意一下,首先我们使用 propertize 为abc设置了文本属性face的值为bold,也就是将字符串设置为粗体。但是其中的0 和 3 代表什么呢?这里的0和3代表的是采用这个属性的字符在字符串中的范围,上面的代码中,整个abc字符串都采用整个属性,所以它的范围是[0, 3) 这个区间。要验证这一点我们可以使用下列代码(setq foo (concat "abc" (propertize "cde" 'face 'bold))) ;; ⇒ #("abccde" 3 6 (face bold)) (insert foo) 我们插入foo发现,它会插入 "abccde" 这么几个字符串,但是只有 "cde" 三个是加粗的根据这个提示,很明显的,get-text-property 中输入的0代表的就是“abc”字符串第0个,也就是字符a的属性。get-char-property 和 get-text-property 相似,但是它是先查找 overlay 的 文本属性。overlay 是缓冲区文字在屏幕上的显示方式,它属于某个缓冲区,具 有起点和终点,也具有文本属性,可以修改缓冲区对应区域上文本的显示方式。get-text-property 是查找某个属性的值,用 text-properties-at 可以得到某 个位置上文本的所有属性。修改文本属性put-text-property 可以给文本对象添加一个属性。它也是需要传入一个范围值,例如我们在前面foo的基础上使用以下代码(put-text-property 0 3 'face 'italic foo)我们再针对 foo 执行插入操作,此时会发现 abc 这个子串变成斜体了。和 put-text-property 类似,add-text-properties 可以给文本对象添加一系列的属性。和 add-text-properties 不同,可以用 set-text-properties 直接设置文本属性列表。你可以用 (set-text-properties start end nil) 来除去 某个区间上的文本属性。也可以用 remove-text-properties 和 remove-list-of-text-properties 来除去某个区域的指定文本属性。这两个函数的属性列表参数只有名字起作用,值是被忽略的。以下的例子还是建立在之前的 foo 变量之上,此时它的值为 #("baccde" 0 3 (face italic) 3 6 (face bold))。也就是前三个字符是斜体,后三个是加粗(set-text-properties 0 1 nil foo) ;; 取消了 a 字符的文本属性 foo ;; ⇒ #("abccde" 1 3 (face italic) 3 6 (face bold)) (remove-text-properties 2 4 '(face nil) foo) foo ;; ⇒ #("abccde" 1 2 (face italic) 4 6 (face bold)) (remove-list-of-text-properties 4 6 '(face nil) foo) foo ;; ⇒ #("abccde" 1 2 (face italic))查找文本属性文本属性通常都是连成一个区域的,所以查找文本属性的函数是查找属性变化的 位置。这些函数一般都不作移动,只是返回查找到的位置。使用这些函数时最好 使用 LIMIT 参数,这样可以提高效率,因为有时一个属性直到缓冲区末尾也没 有变化,在这些文本中可能就是多余的。next-property-change 查找从当前位置起任意一个文本属性发生改变的位置。 next-single-property-change 查找指定的一个文本属性改变的位置。 next-char-property-change 把 overlay 的文本属性考虑在内查找属性发生改 变的位置。next-single-property-change 类似的查找指定的一个考虑 overlay 后文本属性改变的位置。这四个函数都对应有 previous- 开头的函数,用于查找当前位置之前文本属性改变的位置(setq foo (concat "abc" (propertize "edf" 'face 'bold) (propertize "hij" 'pointer 'hand))) ;; ⇒ #("abcdefhji" 3 6 (face italic) 6 9 (face bold)) (next-property-change 1 foo) ;; ⇒ 3 (next-single-property-change 1 'pointer foo) ;; ⇒ 6text-property-any 查找区域内第一个指定属性值为给定值的字符位置。 text-property-not-all 和它相反,查找区域内第一个指定属性值不是给定值的 字符位置。(text-property-any 0 9 'face 'bold foo) ;; ⇒ 3 (text-property-not-all 3 9 'face 'bold foo) ;; ⇒ 6
Emacs 折腾日记(十七)——文本属性 我们在上一篇中介绍了如何对文件中的文本进行操作,本篇主要来介绍关于文本的属性。是的,文本也有属性。这里的文本属性有点类似于Word中的文字属性,文本中对应的字符只是文本属性的一种,它还包括文本大小、字体、颜色等等内容。Emacs中的文本也是类似的。于符号的属性类似,文本的属性也是由键值对构成。名 字和值都可以是一个 lisp 对象,但是通常名字都是一个符号,这样可以用这个 符号来查找相应的属性值。复制文本通常都会复制相应的字符的文本属性,但是 也可以用相应的函数只复制文本字符串,比如 substring-no-properties、 insert-buffer-substring-no-properties、buffer-substring-no-properties。产生一个带属性的字符串可以用 propertize 函数。(propertize "abc" 'face 'bold) ;; ⇒ #("abc" 0 3 (face bold))这里我们使用 face 来设置它的字体为粗体。或者我们可以使用C-x C-f 任意的打开或者创建一个文本文件,在文件中输入(insert (propertize "abc" 'face 'bold))我们可以看到它会在当前光标后面插入一个粗体的 abc 字符串。需要注意的是,我们在*scratch* buffer 中是无法看到这个效果的。因为*scratch* buffer 中开启了font-lock-mode。正如它的名字表示的那样,它锁定了字体,它里面的字体属性都是实时计算出来的。在插入文本之后它的属性很快就被修改了。因为*scratch* buffer 本质上还是一个elisp的编程环境,它里面有关于elisp的语法高亮、自动对齐等特性。它会自动的修改输入的文本属性。我们可以使用 (font-lock-mode - 1) 来关闭这个mode,然后执行上述代码就可以看到具体的效果了。虽然文本属性的名字可以是任意的,但是一些名字是有特殊含义的。属性名含义category值必须是一个符号,这个符号的属性将作为这个字符的属性face控制文本的字体和颜色font-lock-face和 face 相似,可以作为 font-lock-mode 中静态文本的 facemouse-face当鼠标停在文本上时的文本 facefontified记录是否使用 font lock 标记了 facedisplay改变文本的显示方式,比如高、低、长短、宽窄,或者用图片代替help-echo鼠标停在文本上时显示的文字keymap光标或者鼠标在文本上时使用的按键映射local-map和 keymap 类似,通常只使用 keymapsyntax-table字符的语法表read-only不能修改文本,通过 stickness 来选择可插入的位置invisible不显示在屏幕上intangible把文本作为一个整体,光标不能进入field一个特殊标记,有相应的函数可以操作带这个标记的文本cursor(不知道具体用途)pointer修改鼠标停在文本上时的图像line-spacing新的一行的距离line-height本行的高度modification-hooks修改这个字符时调用的函数insert-in-front-hooks与 modification-hooks 相似,在字符前插入调用的函数insert-behind-hooks与 modification-hooks 相似,在字符后插入调用的函数point-entered当光标进入时调用的函数point-left当光标离开时调用的函数composition将多个字符显示为一个字形这些东西我觉得也不需要记住,在需要的时候查查文档就好了。但是我参考的教程把它列出来了,那么我也在这里列出来把。由于字符串和缓冲区都可以有文本属性(如果没有特别指定文本对象的属性,那么默认使用缓冲区定义的文本属性),所以下面的函数通常不提供特定参数就是检 查当前缓冲区的文本属性,如果提供文本对象,则是操作对应的文本属性。查看文本属性查看文本对象在某处的文本属性可以用 get-text-property 函数。(setq foo (propertize "abc" 'face 'bold)) ;; ⇒ #("abc" 0 3 (face bold)) (get-text-property 0 'face foo) ;; ⇒ bold这里有两个问题需要注意一下,首先我们使用 propertize 为abc设置了文本属性face的值为bold,也就是将字符串设置为粗体。但是其中的0 和 3 代表什么呢?这里的0和3代表的是采用这个属性的字符在字符串中的范围,上面的代码中,整个abc字符串都采用整个属性,所以它的范围是[0, 3) 这个区间。要验证这一点我们可以使用下列代码(setq foo (concat "abc" (propertize "cde" 'face 'bold))) ;; ⇒ #("abccde" 3 6 (face bold)) (insert foo) 我们插入foo发现,它会插入 "abccde" 这么几个字符串,但是只有 "cde" 三个是加粗的根据这个提示,很明显的,get-text-property 中输入的0代表的就是“abc”字符串第0个,也就是字符a的属性。get-char-property 和 get-text-property 相似,但是它是先查找 overlay 的 文本属性。overlay 是缓冲区文字在屏幕上的显示方式,它属于某个缓冲区,具 有起点和终点,也具有文本属性,可以修改缓冲区对应区域上文本的显示方式。get-text-property 是查找某个属性的值,用 text-properties-at 可以得到某 个位置上文本的所有属性。修改文本属性put-text-property 可以给文本对象添加一个属性。它也是需要传入一个范围值,例如我们在前面foo的基础上使用以下代码(put-text-property 0 3 'face 'italic foo)我们再针对 foo 执行插入操作,此时会发现 abc 这个子串变成斜体了。和 put-text-property 类似,add-text-properties 可以给文本对象添加一系列的属性。和 add-text-properties 不同,可以用 set-text-properties 直接设置文本属性列表。你可以用 (set-text-properties start end nil) 来除去 某个区间上的文本属性。也可以用 remove-text-properties 和 remove-list-of-text-properties 来除去某个区域的指定文本属性。这两个函数的属性列表参数只有名字起作用,值是被忽略的。以下的例子还是建立在之前的 foo 变量之上,此时它的值为 #("baccde" 0 3 (face italic) 3 6 (face bold))。也就是前三个字符是斜体,后三个是加粗(set-text-properties 0 1 nil foo) ;; 取消了 a 字符的文本属性 foo ;; ⇒ #("abccde" 1 3 (face italic) 3 6 (face bold)) (remove-text-properties 2 4 '(face nil) foo) foo ;; ⇒ #("abccde" 1 2 (face italic) 4 6 (face bold)) (remove-list-of-text-properties 4 6 '(face nil) foo) foo ;; ⇒ #("abccde" 1 2 (face italic))查找文本属性文本属性通常都是连成一个区域的,所以查找文本属性的函数是查找属性变化的 位置。这些函数一般都不作移动,只是返回查找到的位置。使用这些函数时最好 使用 LIMIT 参数,这样可以提高效率,因为有时一个属性直到缓冲区末尾也没 有变化,在这些文本中可能就是多余的。next-property-change 查找从当前位置起任意一个文本属性发生改变的位置。 next-single-property-change 查找指定的一个文本属性改变的位置。 next-char-property-change 把 overlay 的文本属性考虑在内查找属性发生改 变的位置。next-single-property-change 类似的查找指定的一个考虑 overlay 后文本属性改变的位置。这四个函数都对应有 previous- 开头的函数,用于查找当前位置之前文本属性改变的位置(setq foo (concat "abc" (propertize "edf" 'face 'bold) (propertize "hij" 'pointer 'hand))) ;; ⇒ #("abcdefhji" 3 6 (face italic) 6 9 (face bold)) (next-property-change 1 foo) ;; ⇒ 3 (next-single-property-change 1 'pointer foo) ;; ⇒ 6text-property-any 查找区域内第一个指定属性值为给定值的字符位置。 text-property-not-all 和它相反,查找区域内第一个指定属性值不是给定值的 字符位置。(text-property-any 0 9 'face 'bold foo) ;; ⇒ 3 (text-property-not-all 3 9 'face 'bold foo) ;; ⇒ 6 -
Emacs 折腾日记(十五)——窗口 在上一节提到,当前buffer不一定是当前显示在屏幕上的那个buffer,想要修改显示的buffer,可以使用窗口相关的api。这节来介绍一些窗口的操作。窗口是屏幕上用于显示一个缓冲区 的部分。和它要区分开来的一个概念是 frame。frame 是 Emacs 能够使用屏幕的 部分。可以用窗口的观点来看 frame 和窗口,一个 frame 里可以容纳多个(至 少一个)窗口,而 Emacs 可以有多个 frame。不知道各位读者是否学习过MFC或者QT,这里的窗口就是MFC中的View,而frame则是整个界面框架,包括菜单栏工具栏、标题栏、状态栏等等部分。而窗口仅仅是最中间显示buffer的那一部分。分割窗口刚启动时,emacs 都是只有一个 frame 一个窗口。多个窗口都是用分割窗口的函 数生成的。分割窗口的内建函数是split-window。这个函数的参数如下:(split-window &optional window size horizontal)这个函数的功能是把当前或者指定窗口进行分割,默认分割方式是水平分割,可 以将参数中的 horizontal 设置为 non-nil 的值,变成垂直分割。如果不指定 大小,则分割后两个窗口的大小是一样的。分割后的两个窗口里的缓冲区是同 一个缓冲区。使用这个函数后,光标仍然在原窗口,而返回的新窗口对象:(split-window) ;; ==> #<window 7 on *scratch*>根据前面对于 optional 后参数的介绍,要填入 horizontal 的值实现竖直切分,需要填充前面的几个参数,如果不给则默认是nil。实际上上面的代码传入的可选参数都是nil,那么我们可以进行如下调用实现竖直分割窗口:(split-window nil nil 1) ;; ==> #<window 10 on *scratch*>我们也可以使用 selected-window 来获取当前选中的窗口,当前选中的窗口就是光标所在的窗口(split-window (selected-window) nil 1) ;; ==> #<window 11 on *scratch*>在进行实验的时候发现,分割的时候是在当前窗口的基础之上分割的,它是类似于这样的一个过程,它只在Win1所在的窗口区域进行划分,除非改变当前窗口。 +---------------+ +---------------+ | | | | | | win1 | | win1 | win2 | | | --> | | | | | | | | | | | | | +---------------+ +---------------+ | v +---------------+ +---------------+ | 4 | 5 | | | | | | | | win2 | | win1 | win2 | |--------| | <-- |-------| | | win3 | | | win3 | | | | | | | | +---------------+ +---------------+可以看成是这样一种结构(win1) -> (win1 win2) -> ((win1 win3) win2) -> (((win4 win5) win3) win2)删除窗口如果要让一个窗口不显示在屏幕上,要使用 delete-window 函数。如果没有指定 参数,删除的窗口是当前选中的窗口,如果指定了参数,删除的是这个参数对应 的窗口。删除的窗口多出来的空间会自动加到它的邻接的窗口中。如果要删除除 了当前窗口之外的窗口,可以用 delete-other-windows 函数。当一个窗口不可见之后,这个窗口对象也就消失了(setq foo (selected-window)) (delete-window foo) (windowp foo) ;; ==> t (window-live-p foo) ;; ==> nil (delete-other-windows foo) ;; ==> error, 因为先删除foo所对应的窗口,现在已经无法找到这个窗口了,所以这里删除它以外的会报错窗口配置窗口配置(window configuration) 包含了 frame 中所有窗口的位置信息:窗口 大小,显示的缓冲区,缓冲区中光标的位置和 mark,还有 fringe,滚动条等等。 用 current-window-configuration 得到当前窗口配置,用 set-window-configuration 来还原。(setq foo (selected-window)) (split-window foo nil t) (split-window) (setq wc (current-window-configuration)) (delete-other-windows foo) (set-window-configuration wc)我们一行一行的执行上述代码,会发现调用 delete-other-windows 删除之前的窗口之后再次调用 set-window-configuration 会恢复上次保存的结果。看到这里各位读者是否有这么一个想法:利用这两个函数实现一个自动保存和恢复窗口结构的功能呢?但是经过测试,current-window-configuration 得到的对象并不能持久化的保存的到文件中,即使写到文件中,读取的时候也会报错。下面是我的测试代码(setq workspace-file-path "~/.session") ;; 保存窗口的配置 (defun my/save-current-workspace () (with-temp-file workspace-file-path (print (current-window-configuration) (current-buffer)))) ;; 加载窗口的配置 (defun my/load-current-workspace () (when (file-exists-p workspace-file-path) (with-temp-buffer (insert-file-contents workspace-file-path) (set-window-configuration (read (current-buffer))))))在执行保存之后,我们查看文件得到的是一个类似于 #<window-configuration> 的字符串,并没有别的内容,在调用 set-window-configuration的时候会报错。选择窗口前面提到过可以使用 selected-window 来获取当前光标所在的窗口。我们可以使用 select-window 来选择某个窗口作为当前窗口。使用 other-window 来选择另外的窗口。该函数是一个在不同窗口之间快速跳转的一个函数,它按照窗口创建的时间的逆序进行排序,根据传入的整数参数来决定跳转到第几个窗口。(progn (setq foo (selected-window)) (message "Original window: %S" foo) (other-window 1) (message "Current window: %S" (selected-window)) (select-window foo) (message "Back to original window: %S" foo))这里有两个特殊的宏 save-selected-window 和 with-selected-window。它的作用是在执行语句之后,选择的窗口回到之前选择的窗口。with-selected-window 和 save-selected-window 几乎相同, 只不过 save-selected-window 选择了其它窗口。这两个宏不会保存窗口的位置 信息,如果执行语句结束后,保存的窗口已经消失,则会选择最后一个选择的窗口(save-selected-window (select-window (next-window)) (goto-char (point-min)))上述代码会选择另一个窗口并将光标移动到缓冲的开始位置。当前 frame 里所有的窗口可以用 window-list 函数得到。可以用 next-window 来得到在 window-list 里排在某个 window 之后的窗口。对应的用 previous-window 得到排在某个 window 之前的窗口walk-windows 可以遍历窗口,相当于 (mapc proc (window-list))。 get-window-with-predicate 用于查找符合某个条件的窗口窗口大小信息窗口是一个长方形区域,所以窗口的大小信息包括它的高度和宽度。用来度量窗 口大小的单位都是以字符数来表示,所以窗口高度为 45 指的是这个窗口可以容 纳 45 行字符,宽度为 140 是指窗口一行可以显示 140 个字符mode line 和 header line 都包含在窗口的高度里,所以有 window-height 和 window-body-height 两个函数,后者返回把 mode-line 和 header line 排除后 的高度(window-body-height) ;; ==> 53 (window-height) ;; ==> 54滚动条和 fringe 不包括在窗口的亮度里,window-width 返回窗口的宽度。所以 window-body-width 和 window-width 返回的结果一样(window-body-width) ;; ==> 234 (window-width) ;; ==> 234也可以用 window-edges 返回各个顶点的坐标信息。window-edges 返回的区域包含了 滚动条、fringe、mode line、header line 在内,如果单纯的想要返回文本所在区域可以使用 window-inside-edges(window-edges);; ==> (0 0 238 54) (window-inside-edges) ;; ==> (1 0 236 54) 如果需要的话也可以得到用像素表示的窗口位置信息,这里用到的函数是 window-pixel-edges 和 window-inside-pixel-edges(window-pixel-edges) ;; ==> (0 0 1908 922) (window-inside-pixel-edges) ;; ==> (8 0 1884 905)到目前为止,我们有了手段可以遍历窗口以及获取窗口的坐标,那么利用这些数据就可以做到记录和恢复之前的窗口布局了。我最开始的思路是采用 walk-windows 来遍历窗口,并且使用 window-pixel-edges 来记录每个窗口的区域。但是这么做有一些问题无法解决:首先还原的时候创建窗口只能采用 split-window,而 split-window 是基于之前的窗口来创建的,walk-windows 无法反映出这种层级关系。另外就是emacs 中没有函数来设置窗口左上角的坐标,我们只能通过函数来改变窗口的宽和高,窗口的位置在使用 split-window 创建的时候已经决定了。所以我们需要一种能表示层级关系的结构来存储窗口的信息。这个时候就要引入 window-tree 函数了。这个函数可以返回当前 frame 窗口布局的树状结构。为了说明它的返回值,我们先来举一个例子。首先打开emacs,此时看到只有一个窗口,暂时叫它窗口A在窗口上垂直分割一个窗口,新生成的窗口叫做窗口B,此时左侧的窗口是A,右侧的是B在B窗口上水平分割一个窗口,生成一个新的C窗口此时应该有3个窗口,它们的布局如下:+---------------+ | | | | A | B | | |-------| | | C | | | | +---------------+如果用树来表示这个布局,可以组成这么一颗树 frame / \ left right (win A) / \ / \ top bottom win B win C对于叶子节点来说,window-tree 返回的数据形式是 (DIR EDGES CHILD1 CHILD2 ...) 各部分代表的含义如下:DIR,表示分割类型,t表示竖直分割,nil表示水平分割EDGES, 表示窗口区域的坐标,格式为 (LEFT TOP RIGHT BOTTOM),以字符为单位CHILDREN, 子节点列表,可以是分支节点或叶子节点而叶子节点是一个窗口对象。上面的窗口布局,使用 window-tree 得到的结果如下( (nil (0 0 84 35) #<window 3 on *scratch*> (t (42 0 84 35) #<window 7 on *scratch*> #<window 9 on *scratch*>)) #<window 4 on *Minibuf-0*>)去除掉minibuffer部分,着重分析一下文本区域的分割(nil (0 0 84 35) #<window 3 on *scratch*> (t (42 0 84 35) #<window 7 on *scratch*> #<window 9 on *scratch*>))首先水平分割,占区域大小为 (0 0 84 35)。此时上面一个部分是 win3。下半部分右进行了分割。下半部分采用竖直方式进行分割,占区域为 (42 0 84 35)。这个部分有两个子窗口win7 和 win9。感觉分割的顺序与我们的直觉相悖。但是仔细想想好像又能产生之前那种结果 (42 0) +---------------+ | | | | win3 | win7 | | |-------| | | win9 | | | | +---------------+ (84 35)我们可以写下如下代码来进行这个结构的解析(defun my-current-window-configuration () ;; pai chu minibuffer de shu ju (my-window-tree-to-list (car (window-tree)))) (defun my-window-tree-to-list (tree) (if (windowp tree) 'win (let ((dir (car tree)) (children (cddr tree))) (list (if dir 'vertical 'horizontal) (if dir (my-window-height (car children)) (my-window-width (car children))) (my-window-tree-to-list (car children)) (if (> (length children) 2) (my-window-tree-to-list (cons dir (cons nil (cdr children)))) (my-window-tree-to-list (cadr children))))))) (defun my-window-height (win) (if (windowp win) (window-height win) (let ((edge (cadr win))) (- (nth 3 edge) (nth 1 edge))))) (defun my-window-width (win) (if (windowp win) (window-width win) (let (edge (cadr win)) (- (nth 2 edge) (car edge)))))根据这个结构编写一个还原的功能(defun my-list-to-window-tree (conf) (when (listp conf) (let (newwin) (setq newwin (split-window nil (cadr conf) (eq (car conf) 'horizontal))) (my-list-to-window-tree (nth 2 conf)) (select-window newwin) (my-list-to-window-tree (nth 3 conf))))) (defun my-set-window-configuration (winconf) (delete-other-windows) (my-list-to-window-tree winconf))可以使用如下代码进行调用(setq foo (my-current-window-configuration)) ;; do something (my-set-window-configuration foo)窗口对应的缓冲区窗口对应的缓冲区可以用 window-buffer 函数得到:(window-buffer) ;; ==> #<buffer *scratch*>缓冲区对应的窗口也可以用 get-buffer-window 得到。如果有多个窗口显示同一 个缓冲区,那这个函数只能返回其中的一个,由window-list 决定。如果要得到 所有的窗口,可以用 get-buffer-window-list(get-buffer-window (get-buffer "*scratch*")) (get-buffer-window-list (get-buffer "*scratch*"))让某个窗口显示某个缓冲区可以用 set-window-buffer 函数。 让一个缓冲区可见可以用 display-buffer。默认的行为是当缓冲区已经显示在某个窗口中时,如果不是当前选中窗口,则返回那个窗口,如果是当前选中窗口, 且如果传递的 not-this-window 参数为 non-nil 时,会新建一个窗口,显示缓 冲区。如果没有任何窗口显示这个缓冲区,则新建一个窗口显示缓冲区,并返回 这个窗口。display-buffer 是一个比较高级的命令,用户可以通过一些变量来改 变这个命令的行为。比如控制显示的 pop-up-windows, display-buffer-reuse-frames,pop-up-frames,控制新建窗口高度的 split-height-threshold,even-window-heights,控制显示的 frame 的 special-display-buffer-names,special-display-regexps, special-display-function,控制是否应该显示在当前选中窗口 same-window-buffer-names,same-window-regexps 等等。这里的函数实在是太多了,我想暂时不用都记住,现在又有各种大模型,到时候有需求直接使用问就行。或者记住这一个函数,后面要扩展自己去查文档
-
Emacs折腾日记(十四)——buffer操作 教程 中的下一节应该是正则表达式。但是我觉得目前来说正则表达式对我来说不是重点,而且正则表达式我还是比较了解,没必要专门去学习,在使用的时候看看相应的章节就好。况且现在有AI这个利器,在处理正则表达式应该问题不大。所以这里就略过这节,直接进入后面的学习截止到前面的一些文章,我觉得应该已经涉及到了emacs lisp中的语法要点,现在去看一些emacs配置中的代码不太会一头雾水了。离攒自己的配置又进了一步。期间我想过是不是可以跳过教程后面的内容直接进入配置的过程呢?仔细考虑了一下,我觉得还是有必要跟着教程深入了解一下操作emacs对象的一些API。就像我之前学习C/C++编程一样,如果只学语法部分,最多也就能写写基于链表等数据结构的黑框框的信息管理系统。如果想要写点带界面的或者带网络功能的或者稍微复杂点的程序就离不开操作系统,网络编程,数据库等等知识。emacs的学习可能也是这样,现在也只能写点算术运算或者say-hello 这样的玩具。想要跟emacs结合起来,真正流畅的操作emacs,还需要学一些emacs自身的知识。缓冲区名称在学习vim的时候已经很详细的了解过什么是缓冲区,以及缓冲区与文件有什么区别。在这里我想就没有必要再谈论了,如果有读者不太清楚这方面的内容,欢迎阅读我博客中关于vim缓冲区的部分。emacs中缓冲区的概念与vim基本没什么区别。唯一的区别可能是emacs中一些内置的缓冲区与vim的不太一样。emacs 里的所有缓冲区都有一个不重复的名字。所以和缓冲区相关的函数通常都是可以接受一个缓冲区对象或一个字符串作为缓冲区名查找对应的缓冲区。有一个习惯是名字以空格开头的缓冲区是临时的,用户不需要关心的缓冲区。所以现在一般显示缓冲区列表的命令都不会显示这样的变量,除非这个缓冲区关联一个文件。要得到缓冲区的名字,可以用 buffer-name 函数,它的参数是可选的,如果不指定参数,则返回当前缓冲区的名字,否则返回指定缓冲区的名字。更改一个缓冲区的名字用 rename-buffer,这是一个命令,所以你可以用 M-x 调用来修改当前缓冲区的名字。如果你指定的名字与现有的缓冲区冲突,则会产生一个错误,除非你使用第二个可选参数以产生一个不相同的名字,通常是在名字后加上 <序号> 的方式使名字变得不同。你也可以用 generate-new-buffer-name 来产生一个唯一的缓冲区名。它需要传入一个参数,表示buffer的名称,如果当前buffer有名称与指定名称冲突,它会在你提供的名称后面加一些后缀,否则就采用传入的名称;; scratch buffer 中 (buffer-name) ;; ==> *scratch* ;; 此时 *scratch* 已经被重命名成了 scratch (rename-buffer (generate-new-buffer-name "scratch")) ;; ==> scratch当前缓冲区可以使用 current-buffer 来获取当前缓冲区,需要注意的是当前缓冲区不一定是显示在当前屏幕上的那个缓冲区。这个跟工作目录有点像,当前目录并不一定就是程序所在的目录或者当前打开的文件所在的目录。我们可以使用 set-buffer 来设置当前缓冲区,但是前面我们说过当前缓冲区并不一定是显示在屏幕上的那个缓冲区,即使修改当前缓冲区,也不会改变当前窗口上显示的缓冲区(set-buffer "*Messages*") ;; ==> #<buffer *Messages*>,但是屏幕上显示的缓冲区没有变化如果要切换当前屏幕显示的缓冲区需要配置窗口相关的函数,例如我们可以使用 switch-to-buffer(switch-to-buffer "*Messages*")前面提到 set-buffer 可以改变当前缓冲区,但是我们调用 buffer-name 获取当前缓冲区的名称时得到还是 scratch buffer(set-buffer "*Messages*") ;; ==> #<buffer *Messages*> (buffer-name) ;; ==> #<buffer *scratch*> (buffer-name) ;; ==> "*scratch*"这是因为我们如果采用 C-x C-e 来分别执行,这就相当于在命令行执行命令一样,每次语句结束之后,emacs会重新刷新上下文环境。而 buffer-name获取的是当前上下文环境中的当前缓冲区名称。上下文环境随着上一条语句的结束而更新,这就导致了当前缓冲区变化。这个过程可以描述为如下的过程[主进程环境] │ ├── [逐行执行L1] → 创建临时子环境 → 执行set-buffer → 销毁子环境 └── [逐行执行L2] → 创建新子环境 → 读取buffer-name → 返回主环境值 所以如果要得到正确的结果,就是一次性执行完这两条语句,按照我当前的知识储备有三种办法:第一个办法就是使用 eval-buffer,从messages buffer 中获取输出信息第二个办法,使用 progn 将两条语句包含起来第三个办法就是将它包装成一个函数或者宏来执行(progn (set-buffer "*Messages*") (buffer-name)) ;; ==> "*Messages*"但是我们不能仅仅依靠这种包裹代码的方式来实现切换buffer的效果。因为这个命令很可以会被另一个程序员来调用。你也不能直接用 set-buffer 设置成原来的缓冲区,因为set-buffer不能处理错误或退出情况。正确的作法是使用 save-current-buffer、with-current-buffer 和 save-excursion 等方法save-current-buffer 能保存当前缓冲区,执行其中的表达式,最后恢复为原来的缓冲区。如果原来的缓冲区被关闭了,则使用最后使用的那个当前缓冲区作为语句返回后的当前缓冲区。lisp 中很多以 with 开头的宏,这些宏通常是在不改变当前状态下,临时用另一个变量代替现有变量执行语句。比如 with-current-buffer 使用另一个缓冲区作为当前缓冲区,语句执行结束后恢复成执行之前的那个缓冲区save-excursion 与 save-current-buffer 不同之处在于,它不仅保存当前缓冲区,还保存了当前的位置和 mark。在 scratch 缓冲区中运行下面两个语句就能看出它们的差别了(save-current-buffer (set-buffer "*scratch*") (goto-char (point-min)) (save-excursion (set-buffer "*scratch*") (goto-char (point-min))上面两段代码,都是先保存当前缓冲区,然后使用 set-buffer 保证当前缓冲区是 scratch buffer,接着调用goto-char移动鼠标光标到buffer最开始的位置。随着代码块的结束,会自动切换回对应的buffer。但是因为 save-excursion 会额外保存当前位置和 mark,所以我们发现第一段代码光标位置跑到缓冲区最开始的位置,而第二段代码光标位置不变在对比一下它们与 with-current-buffer 的区别,with-current-buffer 调用时已经帮我们使用 set-buffer设置好了当前缓冲区,而且也会保存当前缓冲区,在结束之后也会还原当前缓冲区。但是它使用的是 save-current-buffer。我们可以使用 C-h C-f 来查看并找到它的源代码(defmacro with-current-buffer (buffer-or-name &rest body) (declare (indent 1) (debug t)) `(save-current-buffer (set-buffer ,buffer-or-name) ,@body))我们发现它其实就是用 save-current-buffer 做了一次封装。如果我们对上面的测试代码稍加修改使用 with-current-buffer 实现,例如(with-current-buffer "*Messages*" (goto-char (point-min)))执行之后我们发现,它的光标位置也改变了。创建和关闭缓冲区产生一个缓冲区必须用给这个缓冲区一个名字,所以两个能产生新缓冲区的函数都是以一个字符串为参数:get-buffer-create 和 generate-new-buffer。这两个函数的差别在于前者如果给定名字的缓冲区已经存在,则返回这个缓冲区对象,否则新建一个缓冲区,名字为参数字符串,而后者在给定名字的缓冲区存在时,会使用加上后缀 (N 是一个整数,从2开始) 的名字创建新的缓冲区。(get-buffer-create "temp") (with-current-buffer "temp" (insert "this is temp buffer")) (switch-to-buffer "temp")上面的代码,我们先创建一个新的temp buffer,并且切换到这个buffer,然后在这个buffer中调用insert函数,插入一段话。最后可以让窗口显示这个buffer来验证结果关闭一个缓冲区可以用 kill-buffer。当关闭缓冲区时,如果要用户确认是否要关闭缓冲区,可以加到 kill-buffer-query-functions 里。如果要做一些善后处理,可以用 kill-buffer-hook。通常一个接受缓冲区作为参数的函数都需要参数所指定的缓冲区是存在的。如果要确认一个缓冲区是否依然还存在可以使用 buffer-live-p。要对所有缓冲区进行某个操作,可以用 buffer-list获得所有缓冲区的列表。如果你只是想使用一个临时的缓冲区,而不想先建一个缓冲区,使用结束后又需要关闭这个缓冲区,可以用 with-temp-buffer 这个宏。从这个宏的名字可以看出,它所做的事情是先新建一个临时缓冲区,并把这个缓冲区作为当前缓冲区,使用结束后,关闭这个缓冲区,并恢复之前的缓冲区为当前缓冲区。在缓冲区内移动在学会移动函数之前,先要理解两个概念:位置(position)和标记(mark)。位置是指某个字符在缓冲区内的下标,它从1开始。更准确的说位置是在两个字符之间,所以有在位置之前的字符和在位置之后的字符之说。但是通常我们说在某个位置的字符都是指在这个位置之后的字符。这点很符合我们的直觉,一般在编写代码或者文档的时候当前的光标就是在文本之间移动。标记和位置的区别在于位置会随文本插入和删除而改变位置。一个标记包含了缓冲区和位置两个信息。在插入和删除缓冲区里的文本时,所有的标记都会检查一遍,并重新设置位置。这对于含有大量标记的缓冲区处理是很花时间的,所以当你确认某个标记不用的话应该释放这个标记。创建一个标记使用函数 make-marker。这样产生的标记不会指向任何地方。你需要用 set-marker 命令来设置标记的位置和缓冲区。(setq foo (make-marker)) ; ==> #<marker in no buffer> (set-marker foo (point)) ; ==> #<marker at 195 in *scratch*>point 函数其实返回一个整数,表示当前光标在哪个位置,既然这里只用传入位置就可以正确的将foo这个标签绑定到对应的缓冲区,这里set-marker 应该是以当前缓冲区作为标签的缓冲区,我们可以使用下面的代码来验证(with-current-buffer "*Messages*" (set-marker foo (point))) ;; ==> #<marker at 477 in *Messages*>也可以用 point-marker 直接得到 point 处的标记。或者用 copy-marker 复制一个标记或者直接用位置生成一个标记(point-marker) ;; ==> #<marker at 211 in *scratch*> (copy-marker 20) ;; ==> #<marker at 20 in *scratch*> (copy-marker foo) ;; ==> #<marker at 195 in *scratch*>如果要得一个标记的内容,可以用 marker-position,marker-buffer(marker-position foo) ;; ==> 195 (marker-buffer foo) ;; ==> #<buffer *scratch*>位置就是一个整数,而标记在一般情况下都是以整数的形式使用,所以很多接受整数运算的函数也可以接受标记为参数。比如加减乘。(goto-char (+ (marker-position foo) 10)例如上面的代码我们移动光标到第205个字符的位置。和缓冲区相关的变量,有的可以用变量得到,比如缓冲区关联的文件名,有的只能用函数来得到,比如 point。point 是一个特殊的缓冲区位置,许多命令在这个位置进行文本插入。每个缓冲区都有一个 point 值,它总是比函数 point-min 大,比另一个函数 point-max 返回值小。注意,point-min 的返回值不一定是 1,point-max 的返回值也不定是比缓冲区大小函数 buffer-size 的返回值大 1 的数,因为 emacs 可以把一个缓冲区缩小(narrow)到一个区域,这时 point-min 和 point-max 返回值就是这个区域的起点和终点位置。所以要得到 point 的范围,只能用这两个函数,而不能用 1 和 buffer-size 函数。按单个字符位置来移动的函数主要使用 goto-char 和 forward-char、backward-char。前者是按缓冲区的绝对位置移动,而后者是按 point 的偏移位置移动比如(goto-char (point-min)) ; 跳到缓冲区开始位置 (forward-char 10) ; 向前移动 10 个字符 (forward-char -10) ; 向后移动 10 个字符 (backward-char 10) ; 向后移动 10 个字符 (backward-char -10) ; 向前移动 10 个字符按词移动使用 forward-word 和 backward-word。至于什么是词,这就要看语法表格的定义了。按行移动使用 forward-line。没有 backward-line。forward-line 每次移动都是移动到行首的。所以,如果要移动到当前行的行首,使用 (forward-line 0)。如果不想移动就得到行首和行尾的位置,可以用 line-beginning-position 和 line-end-position。得到当前行的行号可以用 line-number-at-pos。需要注意的是这个行号是从当前状态下的行号,如果使用 narrow-to-region 或者用 widen 之后都有可能改变行号。由于 point 只能在 point-min 和 point-max 之间,所以 point 位置测试有时是很重要的,特别是在循环条件测试里。常用的测试函数是 bobp(beginning of buffer predicate)和 eobp(end of buffer predicate)。对于行位置测试使用 bolp(beginning of line predicate)和 eolp(end of line predicate)缓冲区的内容要得到整个缓冲区的文本,可以用 buffer-string 函数。如果只要一个区间的文本,使用 buffer-substring 函数。point 附近的字符可以用 char-after 和 char-before 得到。point 处的词可以用 current-word 得到,其它类型的文本,比如符号,数字,S 表达式等等,可以用 thing-at-point 函数得到。ting-at-point 可以获取光标处的很多类型的内容,它需要传入一个符号作为类型,例如 'word、'symbol、'url。不同的类型包含有不同的文本属性,第二个参数表示是否去除文本属性。如果当前位置有内容,则返回内容,否则返回nil(defun show-current-word () (interactive) (let ((word (thing-at-point 'word t))) ;; 'word 类型,t 表示去除文本属性 (if word (message "当前单词: %s" word) (message "光标位置没有单词"))))修改缓冲区的内容要修改缓冲区的内容,最常见的就是插入、删除、查找、替换了。下面就分别介绍这几种操作。插入文本最常用的命令是 insert。它可以插入一个或者多个字符串到当前缓冲区的 point 后。也可以用 insert-char 插入单个字符。插入另一个缓冲区的一个区域使用 insert-buffer-substring。删除一个或多个字符使用 delete-char 或 delete-backward-char。删除一个区间使用 delete-region。如果既要删除一个区间又要得到这部分的内容使用 delete-and-extract-region,它返回包含被删除部分的字符串。最常用的查找函数是 re-search-forward 和 re-search-backward。这两个函数参数如下(re-search-forward REGEXP &optional BOUND NOERROR COUNT) (re-search-backward REGEXP &optional BOUND NOERROR COUNT)其中 BOUND 指定查找的范围,默认是 point-max(对于 re-search-forward)或 point-min(对于 re-search-backward),NOERROR 是当查找失败后是否要产生一个错误,一般来说在 elisp 里都是自己进行错误处理,所以这个一般设置为 t,这样在查找成功后返回区配的位置,失败后会返回 nil。COUNT 是指定查找匹配的次数。替换一般都是在查找之后进行,也是使用 replace-match 函数。和字符串的替换不同的是不需要指定替换的对象了。
-
Emacs折腾日记(十三)——函数、宏以及命令 之前在开篇介绍简单的elisp时候就提到过函数,后面的一些示例中也用到了一些函数,但是都是一些基本的概念,这篇将深入了解函数的一些特性。首先要判断一个符号是否是函数,可以使用 functionp 来判断。(defun foo() 1) (foo) (functionp 'foo) ;; ==> t (setq var 1) (functionp 'var) ;; ==> nil不光函数,以下几种functionp也返回t函数。这里的函数特指用 lisp 写的函数。原子函数(primitive)。用 C 写的函数,比如 car、append。lambda 表达式特殊表达式宏(macro)。宏是用 lisp 写的一种结构,它可以把一种 lisp 表达式转换成等价的另一个表达式。命令。命令能用 command-execute 调用。函数也可以是命令。参数列表的语法过去我们的所有函数都是定参的函数,也就是说是确定了参数个数的函数。但是实际使用中会大量使用不定参函数,也就是参数不确定的函数。在C/C++ 以及 Python中会大量使用。它的一个使用场景就是某些时候不传就采用默认值,否则就采用用户定义的值。另一个场景就是像printf这样事先无法确定到底要输出多少内容。elisp中的函数完整定义如下(defun func (REQUIRED-VARS... [&optional OPTIONAL-VARS...] [&rest REST-VAR]))前面是确定的参数列表,也就是说前面的参数在调用函数时必须传入,而&optional 之后是可选参数,如果要传入可选参数这个 &optional 关键字是必须写上的。这里的可选参数也是需要在定义时一个个的指定出来,但是&rest 之后定义的只用一个变量来使用,在传入的时候可以传入任意个参数。例如下面的例子(defun foo (var1 var2 &optional op1 op2 &rest rest) (list var1 var2 op1 op2 rest)) (foo 1 2) ;; ==> (1 2 nil nil nil) (foo 1 2 3) ;; ==> (1 2 3 nil nil) (foo 1 2 3 4) ;; ==> (1 2 3 4 nil) (foo 1 2 3 4 5) ;; ==> (1 2 3 4 (5)) (foo 1 2 3 4 5 6) ;; ==> (1 2 3 4 (5 6))从这个例子我们可以得出以下几个结论:当可选参数没有提供时,在函数体里,对应的参数值都是 nil。我们可以通过判断是否为nil来判断用户是否传了参&rest 要捕获后面所有传入的参数,所以它必须在参数列表的最后面,它的值是一个list当 &rest 与 &optional 共存时,优先匹配 &optional 参数,最后如果有剩余的参数则分配给 &rest教程原文中是有关于文档字符串的描述的。但是我想现在我作为一个菜鸟,将来要组织自己的配置也主要依靠拷贝粘贴别人现有的东西再组合,没有多少机会参与那种高大上的开源项目,自己将来弄的配置估计也没什么人用,而且我也会详细记录自己攒配置的过程,所以这里就不需要给函数写过于详细的文档说明。这里我就跳过这块了。如果有读者对这块感兴趣可以看原文。函数调用在编写程序的时候会有这种需求,一个框架负责处理大块的内容,比如数据解析、转发等等,它会预留一些接口来让用户在此基础之上处理自己的业务逻辑,比较典型的就是http server,或者gui程序框架。在C/C++ 中一般会预留一些函数指针类型的参数进行回调或者提供接口供使用方重载实现自己的逻辑。在elisp中也有这样的操作,但是它就没有虚函数、虚基类或者函数指针的概念。在elisp中通过符号调用一个函数使用的方法是 funcall 和 apply。它们都是通过符号来调用函数的,唯一的区别在于如何处理传入参数。我们通过一个例子来看看它们有什么不同。我们还是用上面定义的foo函数来测试(funcall 'foo 1 2 3 4 5 6) ;; ==> (1 2 3 4 (5 6)) (apply 'foo 1 2 3 4 5 6) ;; ==> error (apply 'foo 1 2 3 4 '(5 6)) ;; ==> (1 2 3 4 (5 6)) (apply 'foo 1 2) ;; ==> error (apply 'foo '(1 2)) ;; ==> (1 2 nil nil nil) (apply 'foo 1 2 3 4) ;; ==> error (apply 'foo 1 2 '(3 4)) ;; ==> (1 2 3 4 nil) (apply 'foo 1 2 3 4 5) ;; ==> error (apply 'foo 1 2 3 4 '(5)) ;; ==> (1 2 3 4 (5))从上面的结果可以看出,funcall 直接按照对应函数定义的参数列表进行传参即可。而apply在传参的时候最后一个参数必须是list,并且在嗲用时会自动将list参数给展开并传入各个参数。从上面的区别可以看出,如果在调用函数的时候,参数已经通过list进行了组织的话,那么使用apply更为合适,否则使用funcall。宏宏是lisp家族中一个非常重要,也非常灵活的内容,可以说宏是lisp的灵魂。之前在看到一些lisp相关的教程时都说,宏实现了利用代码生成代码,并且因为宏的存在导致lisp中扩展出了大量的方言。可以说没有宏,lisp就不是lisp了,或者说lisp就没这么灵活了。但是C/C++中也有宏的概念,C/C++中的宏是在预处理阶段进行简单的文本替换,然后编译替换之后的结果。虽然利用宏,C/C++中可以实现很多非常复杂的功能,但是它远远没有lisp的宏灵活。要详细了解宏的相关内容,我们先回忆一下之前介绍的elisp的知识。首先elisp或者lisp的代码本身就是一颗语法树。它被写作一个list。也就是说list既可以作为代码执行,也可以作为数据,例如 (setq x 1) 它是一段代码。而 '(setq x 1) 它是一个列表,列表中有3个元素,分别是 setq 、x、1 这么三个符号和数字。再者elisp特有的符号系统,例如 x 表示一个变量,可以对它进行求值,'x 代表一个符号,根据前面所学的,我们可以通过符号找到符号中记录的值、函数、属性等等。基于这两个内容,我们可以通过操作list来实现生成一段代码。例如下列的例子(defun my-inc (var) (list 'setq var (list '1+ var))) (setq x 0) (eval (my-inc 'x)) ;; ==> 1上面的其实就是返回了一个list, (setq var (1+ var))。后面我们通过 eval 来执行这个返回的list。需要注意的时,函数调用时会首先将变量进行求值,然后将值作为参数传入,但是这里我们希望并不希望传入一个具体的值,而是希望他能操作我们传入的变量值,并改变它,要做到这点需要传入一个符号。这里有点像C++ 中的引用传递定义宏其实跟定义函数非常相似。我们只需要将关键字由 defun 改为 defmacro。(defmacro my-inc(var) (list 'setq var (list '1+ var))) (setq x 0) (my-inc x) ;; ==> 1我们发现宏与函数的一个不同点,函数中代码在函数被调用时执行,并且参数是在调用时进行求值并传入。而宏调用时需要展开它返回的表达式(或者这里直接就是一个list)。然后将参数作为符号传入。宏最后需要返回一段可执行的list数据,如果没有返回,会影响展开执行,最终可能会报错,例如下面的例子(defmacro my-inc (var) (setq var (1+ var))) (setq x 0) (my-inc x) ;; ==> error这里的问题在于这个宏定义的代码是一个直接执行的代码,并不是一个list,所以在调用它的时候会直接执行,但是又需要将参数作为符号绑定,所以它在被调用的时候会执行(setq 'x (1+ 'x)) 这段代码,而这里的x是一个符号,无法直接对符号进行赋值,所以它会报x的类型错误。这里已经显示出了,elisp中的宏与C/C++中宏的不同。首先C/C++中的宏只是简单的字符串替换,可以将它理解为它生成了新的C/C++源码的代码,它在预处理阶段来执行代码的替换。而elisp中并没有简单的进行替换,根据之前介绍lisp表达式的解析,其实宏返回的是一颗抽象语法树。在扩展宏的时候不断的进行抽象语法树的修改和重建,最后在执行的时候将传入的参数作为符号放入到这颗树中的对应节点。我们可以使用 macroexpand 来查看宏展开的样子。(defmacro bad-inc (var) (setq var (1+ var))) (macroexpand '(bad-inc 0)) ;; ==> 1我们发现之前错误的实现并没有生成可执行的代码,而是直接返回一个常数。因为宏中的代码首先在展开的时候就已经执行了。相当于返回了 setq var (1+ 0) 的值,也就是1。(defmacro my-inc (var) (list 'setq var (list '1+ var))) (macroexpand '(my-inc x)) ;; ==> (setq x (1+ x))使用 macroexpand 可以使宏的编写变得容易一些。但是如果不能进行 debug 是很不方便的。在宏定义里可以引入 declare 表达式,它可以增加一些信息。目前只支持两类声明:debug 和 indent。debug 可选择的类型很多,具体参考 info elisp - Edebug 一章,一般情况下用 t 就足够了。indent 的类型比较简单,它可以使用这样几种类型:nil 也就是一般的方式缩进defun 类似 def 的结构,把第二行作为主体,对主体里的表达式使用同样的缩进整数 表示从第 n 个表达式后作为主体。比如 if 设置为 2,而 when 设置为 1符号 这个是最坏情况,你要写一个函数自己处理缩进。从前面的例子就可以看到,如果在定义宏的时候使用list cons 等来构建list是非常麻烦的,一旦要构造非常复杂的程序,可能直接就歇菜了。为了方便,elisp中提供了一些符号来简化操作。 ` 读作backquote,表示被它包裹的表达式都是quote,可以理解为它里面的直接构建了一个list如果希望它里面的某个位置不作为quote的一部分,而是直接作为列表的元素,可以使用 , , 也就是它会对后面的内容进行求值如果要让一个列表作为整个列表的一部分(slice),可以用 ",@",它会将后面的内容作为列表参数依次添加到当前列表中。我想起来了之前接触过的quote,也就是 ' 。它表示后面的内容不进行求值,作为符号,虽然它也可以构造一个list,但是二者还是有些不同,例如'(list x (+ 1 2)) ;; ==> (list x (+ 1 2)) `(list x (+ 1 2)) ;; ==> (list x (+ 1 2)) '(list x ,(+ 1 2)) ;; ==> (list x (\, (+ 1 2))) `(list x ,(+ 1 2)) ;; ==> (list x 3) (setq var '(2 3)) '(list x ,@var) ;; ==> (list x (\,@ var)) `(list x ,@var) ;; ==> (list x 2 3)我们使用上面的方法稍微弄一个复杂一点的宏(defmacro max(a b) `(if (> ,a ,b) ,a ,b)) (max 4 5) (max (1+ 2) (+ 3 6)) '(macroexpand '(max (1+ 2) (+ 3 6))) ;; ==> (if (> (1+ 2) (+ 3 6)) (1+ 2) (+ 3 6))这里是一个经典的C/C++ 中的max宏。虽然实现不严谨,有一些副作用,但是可以从上面看到一些用法。首先使用 ` 表示返回一个列表,以供调用的时候进行展开。再者对于传入的a和b需要使用, 来表示需要求解它们的值,实现参数的绑定,否则将会得到一个错误,例如(defmacro max(a b) `(if (> a b) a b)) (macroexpand '(max 4 5))) ;; ==> (if (> a b) a + b)如果将上述的 , 全部替换成 ,@ 就不太合适了,因为 ,@ 是将列表中的值取出来组成新的列表,并不会想 , 那样进行求值。例如(defmacro max(a b) `(if (> ,@a ,@b) ,@a ,@b)) (macroexpand '(max (1+ 2) (+ 3 6))) ;; ==> (if (> 1+ 2 + 3 6) 1+ 2 + 3 6)命令emacs 运行时就是处于一个命令循环中,不断从用户那得到按键序列,然后调用对应命令来执行。emacs 中的命令可以说就是一个函数,它是一个特殊的函数,是里面包含了 interactive 表达式的函数。这个表达式指明了这个命令的参数。比如下面这个命令(defun say-hello (name) (interactive "swhat's your name:") (message "hello, %s" name))当解释器加载了该函数之后就可以使用 M-x 来调用这个函数。我们根据提示输入一个名字,emacs会在minibuffer中输出一段话。我们发现,在interactive 表达式后面跟的字符串前面多了一个 s 字符。我们可以通过这个多加的字符来控制命令参数的类型和行为,例如使用 s 表示字符串参数,n 表示数字参数,f 代表文件,r 代表区域。interactive 的字符十分复杂,而且繁多。用的时候看 interactive 函数的文档还是很有必要的。但是不是所有时候都参数类型都能使用代码字符,而且一个好的命令,应该尽可能的让提供默认参数以让用户少花时间在输入参数上,这时,就有可能要自己定制参数。首先学习和代码字符等价的几个函数。s 对应的函数是 read-string,n 代表的是 read-file,f代表的是 read-file-name。其实大部分代码字符都是有这样对应的函数或替换的方法。我们可以使用这些方法来替代前面的代码字符,假如传入的是一个表达式,那么对表达式进行计算之后返回的列表元素就是命令的参数,例如我们用 read-string 来代替之前例子中的s。(defun say-hello (name) (interactive (list (read-string "what's your name: "))) (message "hello, %s" name))教程 中还列举了一些常见的字符代表的函数,这里我就不列出来了。各位读者有兴趣的话也可以去看看。
-
Emacs 折腾日记(十二)——变量 本文是依据 emacs lisp 简明教程 而来在此之前我们已经了解了elisp中的全局变量和函数中的局部变量,也了解了elisp中各种数据类型。这一篇主要谈谈elisp中各种变量的生命周期和作用域let 绑定的变量使用let绑定的变量只在let范围内有效,如果是多层嵌套的let,只有最里层的那个变量是有效的,用 setq 改变的也只是最里层的变量,而不影响外层的变量。比如(progn (setq foo "I'm global variable!") (let ((foo 5)) (message "foo value is: %S" foo) ;; ==> "foo value is: 5" (let (foo) (setq foo "I'm local variable!") (message foo)) ;; ==> "i’m local variable!" (message "foo value is still: %S" foo)) ;; ==> "foo value is still: 5" (message foo)) ;; ==> "i’m global variable!"这个有点像C/C++中的{} 定义的语句块中的变量只在当前 {} 内有效,当内部变量与外部变量重名的时候只影响{}内,而不影响外部。我们可以给出这样的c++代码int n = 0; printf("n = %d\n", n); { int n = 10; printf("n = %d\n", n); } printf("n = %d\n", n);elisp中的let两边的括号就有点像这里的 {},出了这个范围定义的变量就无效了。但是定义变量使用的是栈空间,而程序的栈空间是有大小限制的,一旦超过这个范围就会发生栈溢出。在C/C++程序中一般发生在递归层数过大。我们可以在编译时修改这个栈空间的大小。在elisp中也有变量控制递归层数,它就是 max-specpdl-size 但是在最新的29中已经将它弃用,新版的emacs可以使用 max-lisp-eval-depth 来限制specpdl堆栈的大小,该堆栈主要用于 存储动态变量绑定和 unwind-protect 激活等。buffer-local 变量顾名思义,它的值只在当前buffer中生效,在其他buffer中可能是另外的值。它有点像之前介绍的vim中的setlocal变量,仅在当前缓冲区内生效。该特性常用于实现缓冲区特定的配置和行为。声明一个 buffer-local 的变量可以用 make-variable-buffer-local 或用 make-local-variable。这两个函数的区别在于前者是在所有缓冲区都创建一个 buffer-local 的变量。而后者只在声明时所在的缓冲区内产生一个局部变量,而其它缓冲区仍然使用的是全局变量。一般来说推荐使用 make-local-variable。下面来举例说明它们的区别,在举例之前介绍例子中用到的函数或者宏with-current-buffer, 它的使用方式是(with-current-buffer buffer body)其中 buffer 可以是一个缓冲区对象,也可以是缓冲区的名字。它的作用是使其中的 body 表达式在指定的缓冲区里执行。default-value 可以访问符号所对应的全局变量下面是使用 make-local-variable 创建buffer-local变量的例子(setq foo "i'm a global variable!") (make-local-variable 'foo) foo ;; ==> "i'm a global variable!" (setq foo "i'm buffer-local variable in scratch buffer") foo ;; ==> "i'm buffer-local variable in scratch buffer" (with-current-buffer "*Messages*" (progn (message "%s" foo) ;; ==> "i'm a global variable!" (setq foo "i'm buffer-local variable in message buffer") (message "%s" foo))) ;; ==> "i'm buffer-local variable in message buffer" (default-value 'foo) ;; ==> i'm buffer-local variable in message buffer上述代码因为message buffer 中未定义foo的buffer-local 变量,所以它修改的是全局变量的值,我们使用 default-value 发现全局变量的值被修改了。(setq foo "i'm a global variable!") (make-variable-buffer-local 'foo) foo (setq foo "i'm buffer-local variable in scratch buffer") foo (with-current-buffer "*Messages*" (progn (message "%s" foo) (setq foo "i'm buffer-local variable in message buffer") (message "%s" foo))) (default-value 'foo) ;; ==> "i'm a global variable!"前面的结果都一样,但是我们关注一下最后输出的全局的 foo 变量,它的值没有被修改,而使用 make-local-variable 的时候它被修改了。这是因为 make-variable-buffer-local 会在每一个缓冲区内都创建一个 buffer-local 的拷贝,所以后面在 message 缓冲区中修改的是缓冲区内自己的 buffer-local 变量而不影响全局变量的值,而 make-local-variable则不同,它会在 message 缓冲区中为foo也创建一个buffer-local变量。message 缓冲区中修改的是 buffer-local 变量,不影响全局的foo变量。一般来说根据实际情况选择使用哪种,我并不是资深的elisp开发者,以我浅薄的认知,一般使用 make-local-variable情况较多,它影响面较小,仅仅影响当前缓冲区。而make-variable-buffer-local 影响面较大,一旦使用它设置了local-buffer 变量,那么在后面其他缓冲区中想要使用 setq 设置全局的值就没那么简单了。这种一般是需要隐藏起来的核心变量,例如某些功能依靠这个变量来驱动,一旦修改了可能导致后面的代码运行行为不准确。可能会使用 make-variable-buffer-local 定义,不让用户自己随便修改全局的值。我们可以使用 setq-default 来设置全局变量的值。这里的例子就不给出了,各位读者可以根据上面的例子稍加修改就可以了。测试一个变量是不是 buffer-local 可以用 local-variable-p。这里我们再介绍一个新的函数 get-buffer。它需要一个buffer的名称作为参数,返回这个buffer的对象,如果未找到对应的buffer,则返回nil。(setq foo 5) (make-local-variable 'foo) (local-variable-p 'foo) ;; ==> t (local-variable-p 'foo (get-buffer "*Messages*")) ;; ==> nil如果要在当前缓冲区里得到其它缓冲区的 buffer-local 变量的值可以用 buffer-local-value(setq foo "i'm a global variable!") (make-local-variable 'foo) (setq foo "i'm buffer-local variable in scratch buffer") (with-current-buffer "*Messages*" (buffer-local-value 'foo (get-buffer "*scratch*"))) ;; ==> "i'm buffer-local variable in scratch buffer"变量的作用域在之前我们已经介绍过几种变量,分别是使用 setq 或者 defvar 定义的变量,它们是全局变量,即使在一些语法块或者函数中定义的,在外围也可以正常访问使用 let 或者 let* 定义的变量,只在 let 语法块中有效使用 make-local-variable 或者 make-variable-buffer-local 定义的buffer-local 变量,在当前buffer中有效但是函数参数列表的变量生命周期与我们平常在C/C++、Java、Python等语言中有些不同。作用域(scope)是指变量在代码中能够访问的位置。emacs lisp 这种绑定称为 indefinite scope。indefinite scope 也就是说可以在任何位置都可能访问一个变量名。而 lexical scope(词法作用域)指局部变量只能作用在函数中和一个块里(block)。比如 let 绑定和函数参数列表的变量在整个表达式内都是可见的,这有别于其它语言词法作用域的变量。先看下面这个例子(defun foo(x) (getx)) (defun getx() x) (message "%s" (foo "hello,x")) ;; ==> "hello,x"我们可以看到最终成功输出了结果,而根据之前学习C/C++的经验,在C、C++等语言中,这样的代码是无法执行成功的,因为在getx中并未定义x的值。但是在elisp 中,foo函数执行期间,x变量的都是有效的且可以正常访问到的。当然,在elisp中,let也具有这一效果,在let的语法块中,定义的变量总是有效的。例如(let ((x "hello, x")) (message "%s" (getx))) (defun getx() x)在let语句块中 x 是一直有效的,如果脱离let,在最外层调用 getx 将会得到一个x未定义的错误需要注意的是,上面的例子无法再使用 C-x C-e 来一条条的执行了,这个时候需要使用 eval-buffer 来执行整个缓冲区的代码。emacs 从 24.1 版本开始,引入了 lexical binding 这一特性,在代码中如果启用这个属性,那么它将采用C/C++ 等普通编程语言的那种 lexical scope 的作用形式。官方文档中提到使用 lexical binding 特性可以提高代码的运行效率,并且鼓励使用。可以在代码文件最开始的位置添加这么一个注释 -*- lexical-binding: t -*- 来开启这一特性。上面的代码只要加上这一特性就能得到不一样的结果;; -*- lexical-binding: t -*- (let ((x "hello, x")) (message "%s" (getx))) (defun getx() x)这个时候执行将会得到一个错误信息 "Symbol’s value as variable is void: x",x这个符号是一个未定义的变量。生存期是指程序运行过程中,变量什么时候是有效的。全局变量和 buffer-local 变量都是始终存在的,前者只能当关闭emacs 或者用 unintern 从 obarray 里除去时才能消除。而 buffer-local 的变量也只能关闭缓冲区或者用 kill-local-variable 才会消失。而对于局部变量,elisp 使用的方式称为动态生存期:只有当绑定了这个变量的表达式运行时才是有效的。在 emacs lisp 简明教程 中举了一个闭包的例子,在elisp中并不支持闭包,它采用的是与普通编程语言一样的变量生存周期,这里我就不列出来了。JavaScript等语言中是支持闭包的,有兴趣的读者可以去看看JavaScript中的闭包。其他函数一个符号如果值为空,直接使用可能会产生一个错误。可以用 boundp 来测试一个变量是否有定义。这通常用于 elisp 扩展的移植(用于不同版本或 XEmacs)。对于一个 buffer-local 变量,它的缺省值可能是没有定义的,这时用 default-value 函数可能会出错。这时就先用 default-boundp 先进行测试。使一个变量的值重新为空,可以用 makunbound。要消除一个 buffer-local 变量用函数 kill-local-variable。可以用 kill-all-local-variables 消除所有的 buffer-local 变量。但是有属性 permanent-local 的不会消除,带有这些标记的变量一般都是和缓冲区模式无关的,比如输入法。(setq foo "I'm local variable!") foo ; ==> "I'm local variable!" (boundp 'foo) ; ==> t (default-boundp 'foo) ; ==> t (with-current-buffer "*Messages*" (boundp 'foo)) ; ==> t (makunbound 'foo) ; ==> foo foo ; This will signal an error (boundp 'foo) ; ==> t (default-boundp 'foo) ; ==> t (kill-local-variable 'foo) ; ==> foo (with-current-buffer "*Messages*" (boundp 'foo)) ; ==> t上面的例子需要注意以下几点这里只是使变量的值为空,并没有消除这个变量的符号。所以在执行makunbound 之后,关于foo 是否绑定的测试都是tkill-local-variable 只是消除了foo作为buffer-local变量,并没有影响到全局变量,所以在messages-buffer中测试它仍然是有效的变量变量命名习惯对于变量的命名,有一些习惯,这样可以从变量名就能看出变量的用途:hook 一个在特定情况下调用的函数列表,比如关闭缓冲区时,进入某个模式时。function 值为一个函数functions 值为一个函数列表flag 值为 nil 或 non-nilpredicate 值是一个作判断的函数,返回 nil 或 non-nilprogram 或 -command 一个程序或 shell 命令名form 一个表达式forms 一个表达式列表。map 一个按键映射(keymap)
-
Emacs折腾日记(十一)——求值规则 截至到现在,我觉得我自己的elisp水平有了一定的提高,希望各位读者借助之前的文章也能有一些收获。现在已经可以尝试写一点elisp的程序了,但是如果想深入了解一下 lisp 是如何工作的,不妨先花些时间看看 lisp 的求值过程。对于我这样一个日常使用C/C++的程序员来说,习惯了C/C++的语法和写法,初次见到lisp这样使用括号并且主要是S-表达式的语言,开始总会有点不习惯,但是在尝试自己写了这么些文章之后,对lisp有那么一点感觉。这篇我想就着 求值规则 这篇文章以及自己的一些理解来尝试梳理一下自己是如何理解elisp表达式的。S表达式要理解S表达式,我们先从如何解析四则运算开始。在之前我鸽了一个系列就是使用C来实现C语言解析器的系列。在那个系列中提到,一个普通的4则运算最终会生成一个抽象语法树,例如 a * b - (c + d) 最终可以生成如下的抽象语法树 - / \ * + / \ / \ a b c d二叉树的每个节点,或者是叶节点,或者有2个子节点,叶节点可以用来存储数据。而每颗子树的根节点存储操作符,或者说表示要对数据进行的操作,而如果操作符需要一个或者多个操作数,那么可以对抽象语法树进行调整。可以用上面的图来表示树的话有些麻烦了,后来发明了点对表示法, 如果只关心叶子节点,每颗子树的根节点采用.来表示,那么这颗二叉树可以表示为 ((a . b) . (c . d)) 。看到这里各位读者想到了什么呢?cons cell。S表达式是点对表示法的形式定义:原子 -> 数字 | 符号 S表达式 -> 原子 | (S表达式 . S表达式)所以,S表达式或者是原子,或者是递归的由其他S表达式构成的点对。虽然抽象语法树可以使用这种点对来描述,但是语法树大了,点的数量大了,其实也挺麻烦的,所以lisp中有一些简单的写法。回顾一下之前学习列表和cons cell的知识,简化也就得到了列表,例如'((a . b) . (c . d)) ⇒ ((a . b) c . d) '((a . b) . (c . (d . nil))) ⇒ ((a . b) c d)如果我们考虑这颗树的根节点,并且采用先序遍历的方式访问,结果仍然采用点对来表示,那么将得到这样的结果 (- (* a b) (+ c d))。 这样我们得到了计算这个四则运算的lisp代码,这个它可以作为列表,也可以让lisp解释器来执行。到此为止,各位读者应该理解了S表达式。它其实就是对应了一颗语法树。现在看到S表达式也不那么恐惧了,解释器如何执行它似乎也慢慢的清晰起来了呢S表达式的求值理解了S表达式,再回过头来看看它的求值过程。所有的表达式可以分为三种:符号、列表和其它类型。我们来分别说明最简单的就是自求值表达式,前面说过数字、字符串、向量都是自求值表达式。还有两个特殊的符号 t 和 nil 也可以看成是自求值表达式。第二种表达式是符号。符号的求值结果就是符号的值。如果它没有值,就会出现 void-variable 的错误。第三种表达式是列表表达式。而列表表达式又可以根据第一个元素分为函数调用、宏调用和特殊表达式(special form)三种。根据上面对S表达式的理解,这里的第一个元素也就是放在语法树的每颗子树的根节点上,表示对它的子节点进行的操作,例如上面的加减乘除,或者使用car之类的函数。而它的子节点可以是一颗语法树,也可以是简单的值,对应在elisp中的话,就是这个操作可以针对上面两种自求值表达式或者符号值,也可以是另一个S表达式。整个求值过程就是不断的求子树然后使用根节点来对子树进行操作,例如针对上面的二叉树可以写下这么一段伪代码来实现求值float calc-ast(ast* pRoot) { switch(pRoot->eOprType) { case function: //函数调用 return function(calc-ast(pRoot->left), calc-ast(pRoot->right)); case math: // 数学计算 return calc-ast(pRoot->left) + calc-ast(pRoot->right); //这里以加法为例 .... default: calc-ast(pRoot->left); calc-ast(pRoot->right); break } }第一个元素如果是一个特殊表达式时,它的参数可能并不会全求值。这些特殊表达式通常是用于控制结构或者变量绑定。每个特殊表达式都有对应的求值规则。这个就根据具体的语法来定,例如 and 和 or 这些操作符具有短路的特性。本文内容到此就结束了,本文比较简单,算是对之前的一个总结,对lisp有一个大概的了解。最后,本文可能是年前最后一篇文章了,在这里提前祝各位读者新年快乐!
-
Emacs 折腾日记(十)——elisp符号 符号是有名字的对象,这么说可能有点抽象。我们先来回忆一下C/C++中关于符号的内容。C/C++ 最终被编译成机器码直接执行,在机器码中不存在变量名称,函数名称等字符,它只有一串地址。但是在写C/C++代码的时候有变量名,函数名,类名,对象名等等名称。编译器是如何做到将符号和地址关联起来的呢?答案是,编译器在编译阶段会提供一个符号表,符号表如何实现的我也不太清楚,但是它做到了关联一个地址和字符串符号的作用。在Windows平台的 vs下,debug版本一般会生成与exe同名的pdb文件,这个是调试文件,它里面保存了一些调试信息,包括符号表。这里的符号与C/C++中的符号表中的符号类似,可以通过它来找到具体的变量。可以理解成elisp提供了这么一种操作符号表的功能。首先必须知道的是符号的命名规则。符号名字可以含有任何字符。与之对应的,一般的编程语言在定义变量的时候有些特殊符号不能用,而且不能以数字开头,有些关键字也不能作为变量名。而elisp中没有这些限制,只是在使用特殊符号的时候需要使用转义字符。(symbolp '+1) ;; ==> nil (symbolp '\+1) ;; ==> t (symbol-name '+1) ;; error (symbol-name '\+1) ;; ==> "+1"上面的代码 symbolp 是在判断一个对象是否是一个符号的函数,symbol-name 用于取符号的名称,它会返回给定符号的名称的字符串。上面的代码说明了,elisp中符号没有什么特别要求,只是对于特定的字符需要使用转义字符。与c/c++中类似,elisp中的符号名也是区分大小写的。符号创建在C/C++中符号表由编译器来创建和操作。而elisp中则提供了操作符号表的方式。符号名要有唯一性,所以一定会有一个表与名字关联,这个表在 elisp 里称为 obarray。从这个名字可以看出这个表是用数组类型,事实上它是一个向量。对于一个新的符号,解释器会首先取字符串的hash值,根据hash值来放入数组对应的位置。同时我们也将这种保存符号的数据结构称之为obarray。也就是说obarray不仅是一个保存符号的变量,也是一种结构。我们也可以在符号上建立这么一个结构用来保存符号对应的属性。也可以作为参数传入emacs 相关函数中当 elisp 读入一个符号时,通常会先查找这个符号是否在 obarray 里出现过,如果没有则会把这个符号加入到 obarray 里。这样查找并加入一个符号的过程称为是 intern。intern 函数可以查找或加入一个名字到 obarray 里,返回对应的符号。默认是全局的obarray,也可以指定一个 obarray。intern-soft 与 intern 不同的是,当名字不在 obarray 里时,intern-soft 会返回 nil,而 intern 会加入到 obarray里。(setq foo (make-vector 10 0)) ;; ==> [0 0 0 0 0 0 0 0 0 0] (intern-soft "abc" foo) ;; ==> nil (intern "abc" foo) ;; ==> abc (intern-soft "abc") ;; ==> abc (intern-soft "abc") ;; ==> nillisp 每读入一个符号都会 intern 到 obarray 里,如果想避免,可以用在符号名前加上 #:(intern-soft "abc") ;; ==> nil 'abc (intern-soft "abc") ;; ==> abc '#:abcd ;; ==> abcd (intern-soft "abcd") ;; ==> nil可以使用 untern 从obarray中删除对应的符号,如果成功删除,会返回t,如果没有对应的符号,则会返回 nil(intern "abc") ;; ==> abc (intern-soft "abc") ;; ==> abc (unintern "abc") ;; ==> t (intern-soft "abc") ;; ==> nil(setq foo 1) (intern-soft "foo") (unintern "foo") (intern-soft "foo") (1+ foo) ;; error通过setq,我们让elisp将foo这个变量放入到obarray中,后续使用unintern 删除这个变量后再使用foo的时候就会报错,foo是一个空变量与hash-table一样,obarray 也提供一个mapatom 函数来遍历整个obarray,例如下面是一个计算所有符号数量的例子(setq count 0) (defun count-sys(s) (setq count (1+ count))) (mapatoms 'count-sys) count ;; ==> 95733 (length obarray) ;; ==> 15121这里我们看到,数组的长度小于符号的数量。这根hash-table的实现是一样的。各位读者在学习hash-table的时候应该了解过,hash-table 中 hash值不同的元素存储在数组的不同位置,相同的元素通过链表进行串联,一般的hash-table在内存中的结构如下图.符号的组成在计算机中,所有的内容都是使用二进制来进行存储的,我们人为的将二进制数据划分为代码和数据。如果单纯的给出一个内存的地址,如何知道它是数据还是代码呢?例如在C/C++中定义了一个int类型的变量a,为什么在后续使用a(1) 这样的语句会报错呢?又例如一个函数指针 pfn,使用 *pfn = 1 这样也会报错呢?编译器怎么知道哪个地址存的是变量,哪个地址存的是函数指针呢?还是通过符号表来解决,符号表中针对每个符号名称都会给定它的类型,例如这个符号对应的地址是一个整数,或者指针,又或者是函数指针。符号名称类比C/C++ 中的符号表,elisp中每个符号都可以有4个组成部分,一个是符号名称,它可以类比到符号表中的名称,可以用symbol-name 来访问。它返回一个符号的字符串名称,关于使用的例子在最开始已经给出了。符号值第二个组成部分是符号值,可以类比成普通变量的值,可以通过set函数来设置,通过 symbol-value 来获取。(set 'abc "i am abc") ;; ==> "i am abc" (symbol-value 'abc) ;; ==> "i am abc" abc ;; ==> "i am abc"set 以及 symbol-value 需要提供一个符号,表示对哪个符号进行操作。解释器执行第一行代码的时候未发现 abc 这个符号,那么它会将abc放入符号表中,然后这个符号就可以作为普通变量来使用了。最后一行代码我们直接将它作为普通变量那样使用,直接对它进行求值,发现它也可以获取到具体的值我们使用 setq 也可以达到这样的效果(setq val 123) ;; ==> 123 (symbol-value 'val) ;; ==> 123 val ;; ==>123 (set 'val 1234) ;; ==> 1234 (symbol-value 'val) ;; ==> 1234 val ;; ==> 1234从上面的代码中发现,setq 直接使用变量名来对变量进行赋值,而set 则需要对符号进行quote操作。我们可以将setq 看做是一个宏(至于宏是什么,会在后面进行介绍),也就是 set quote,自动将后面的符号进行quote操作。但是setq只能对全局的obarray中的符号进行赋值,如果我们想放到指定的obarray中进行,此时就不能使用setq 了(setq foo (make-vector 10 0)) (set (intern "value" foo) 123) (symbol-value 'value) ;; ==> error (symbol-value (intern-soft "value" foo)) ;; ==> 123set 和 symbol-value 没有直接的参数来指定符号所在的obarray,如果想要使用自定义的obarray,那么就需要借助 intern、intern-soft、这样可以指定obarray 的函数来进行辅助操作。如果一个符号的值已经有设置过的话,则 boundp 测试返回 t,否则为 nil。对于 boundp 测试返回 nil 的符号,使用符号的值会引起一个变量值为 void 的错误(intern "null") (boundp 'null) ;; ==> nil null ;; error (set 'null 123) (boundp 'null) ;; ==> t null ;;==> 123函数第三个组成部分是函数,它可以类比成函数指针, 它可以用 symbol-function 来访问,用 fset 来设置。在之前一篇文章中,有知乎大牛指出我的问题,根据大牛的描述,在绑定lambda表达式时将函数部分绑定到符号的函数部分,使用funcall 调用的时候是在取函数部分的内容执行。这里详细了解符号相关的知识之后上述表达就很容易理解了。(setq foo (make-vector 10 0)) (fset (intern "abc" foo) (lambda (name) message "hello,%s" name)) (funcall (intern-soft "abc" foo) "Emacs") ;; ==> error上述的代码会报告一个错误,因为这里我们使用的obarray 是自定义的foo,它里面没有message这个符号,当然我们可以使用 intern来获取全局的 message 函数,并将它放入到foo中。这里的代码可以这么改(fset (intern "abc" foo) (lambda (name) (funcall (intern-soft "message") "hello,%s" name))) (funcall (intern-soft "abc" foo) "Emacs") ;; ==> "hello,Emacs"类似的,可以用 fboundp 测试一个符号的函数部分是否有设置。(fboundp 'message) (fboundp (intern-soft "message" foo)) ;; ==> nil (fset (intern "message" foo) (symbol-function 'message)) (fboundp (intern-soft "message" foo)) ;; ==>t属性列表第4个组成部分是属性列表,关于这部分我暂时还没想到该怎么用C/C++进行类比,如果非要一个类比的话,可以用这个类比。C/C++的编译器在看待变量的时候是将变量转变成对应的内存地址,操作变量实际上就是在操作变量所对应的内存。从CPU的角度来讲,CPU并没有规定哪些内存是只读的,哪些是数据,哪些是代码。编译器是如何做的呢?答案应该是编译器会在符号表中对各个符号做一些标记,例如const型变量所对应的内存不能修改。具体编译器是如何实现我也不太清楚,先这么生搬硬套吧,至少在了解elisp的符号这块,这么理解可能会稍微具体一点elisp中的属性列表,用于存储和符号相关的信息,比如变量和函数的文档,定义的文件名和位置,语法类型。属性名和值可以是任意的 lisp 对象,但是通常名字是符号,可以用 get 和 put 来访问和修改属性值,用 symbol-plist 得到所有的属性列表:(put (intern "abc" foo) 'doc "this is abc") (get (intern-soft "abc" foo) 'doc) ;; ==> "this is abc" (symbol-plist (intern-soft "abc" foo)) ;; ==> (doc "this is abc")符号的属性列表在内部表示上是用(prop1 value1 prop2 value2 ...) 的形式, 在存取上有点像C/C++中的map,但是在elisp中并不是所谓的map结构。另外还可以用 plist-get 和 plist-put 的方法来访问和设置属性列表,在上一段代码的基础之上(也就是设置了符号 abc 的 doc 属性的前提下),使用如下代码来进行测试(plist-get (symbol-plist (intern-soft "abc" foo)) 'doc) ;; ==> "this is abc" (plist-put (symbol-plist (intern-soft "abc" foo)) 'foo 69) (get (intern-soft "abc" foo) 'foo) ;; ==> 69 (setq my-plist '(doc "this is abc")) ;; ==> "this is abc" (plist-put my-plist 'foo 89) (plist-get my-plist 'doc) ;; ==> "this is abc" (plist-get my-plist 'foo) (get (intern-soft "abc" foo) 'foo) ;; ==> 69从上面的代码来看,plist-get 和 plist-put 需要一个额外的属性列表的操作表示要操作的属性列表,但是它也可以通过传入符号的真实属性列表直接来操作符号的属性列表。
-
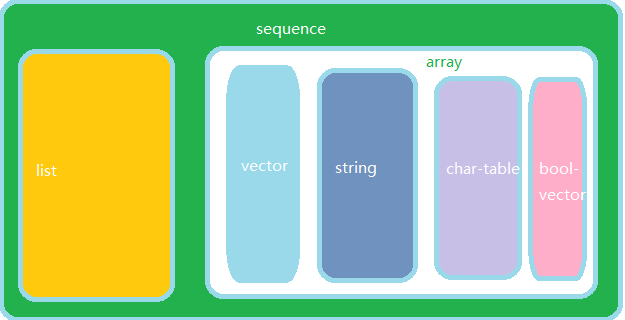
Emacs 折腾日记(九)——elisp 数组与序列 elisp 中序列是数组和列表的统称,序列的共性是内部数据有一个先后的顺序,它与C/C++ 中有序列表类似。elisp 中的数组包括向量、字符串、char-table 和布尔向量,它们的关系如下:在之前一章中已经介绍了序列中的一种类型——列表,本篇将介绍序列中的另外一种数据类型——数组数组简介与C/C++ 中的数组类似,elisp中的数组有如下特征在创建之初给定长度之后不允许后期修改长度数组中的每个元素都可以通过索引来获取,并且获取的算法时间复杂度为O(1)数组是自求值的数组中的的元素可以通过 aref 来获得,并且通过aset 来设置值根据上图,向量是数组中的一种。字符串也是特殊的数组,它是内部全部都是字符的数组(虽然elisp中没有字符这种数据类型)。教程中没有介绍 char-table 和 bool-vector,所以这里我也不打算介绍,后面要是真遇到了再看。测试函数测试函数是用同名带p的函数来进行测试,例如 sequencep 来测试是否是一个序列,stringp 测试是否是一个字符串, vectorp 测试是否是一个向量,arrayp 测试是否是一个数组。char-table-p 和 bool-vector-p 分别测试对象是否是 char-table、bool-vector(arrayp [1 2 3]) ;; ==> t (vectorp [1 2 3]) ;; ==> t (stringp [?A ?B ?C]) ;; ==> nil (stringp "ABC") ;; ==>t (vectorp "ABC") ;; ==> nil (arrayp "ABC") ;; ==> t通过上面的测试发现字符串和向量是不同的类型,但是字符串也是一种数组上述代码创建了一个向量,然后判断向量是否是一个数组。在elisp中向量也是数组的一种,所以这里返回t序列的通用函数在字符串中提到过,可以使用 length 来获取字符串的长度。其实它是一个序列的函数,它可以获取序列的长度。对于列表来说,它只能获取真列表的长度,对于点列表它会报错,而对于循环列表则会陷入死循环。它的算法应该是跟C/C++ 中获取链表的长度的算法一样,根据最后一个节点的next指针域是否为空来进行判断。对于点列表和循环列表,可以使用 safe-length 来获取,从名称上看,它是一个安全的获取长度的函数。(length [1 2 3 4]) ;; ==> 4 (safe-length '(1 2 3 4)) ;; ==> 4 (safe-length '(1 2 3 . 4)) ;; ==>3这里不要疑惑为什么第二个参数表达式返回的结果会是3,表达式中列表真正的表达形式应该是'(1 (2 (3 . 4)))虽然写法上使用 (1 2 3 . 4) 比较清爽干净也容易理解,但是要时刻记住它真正的形式应该是多个cons cell组成。插一个题外话,不知道各位读者还记不记得当初在学数据结构时,学到的如何判断环形链表的算法。那个算法被叫做两个指针跑步法,脱胎于小学时学的一道数学题;“在一个环形跑道,小明以每秒1米的速度匀速跑,小华以每秒2米的速度匀速跑,多久之后小明落后小华一圈”。这个算法也是这样的,一个慢指针每次往后移动一个节点,一个快指针一次移动两个节点,下一次两个指针能相遇,那么它就是一个环形列表。根据这个算法我们也可以提供一个lisp版本的判断环形列表的代码(defun circle-list-p (list) (and (consp list) (circle-list-p-1 (cdr list) (cdr (cdr list))))) (defun circle-list-p-1 (slow fast) (if (or (null slow) (null fast)) nil (if (not (consp slow)) nil (if (eq (car fast) (car slow)) t (circle-list-p-1 (cdr slow) (cdr (cdr fast))))))) (circle-list-p '(1 2 3 4)) ;; ==> nil (circle-list-p '#1=(1 2 . #1#)) ;; ==> t获取序列的第n个元素可以使用 elt,但是对于已知数据类型最好使用对应的函数,例如针对列表应该使用 nth,数组使用 aref。一来该对象是何种数据类型更加直观,二来省去了 elt 内部类型判断的操作。copy-sequence 在前面已经提到了。不过同样 copy-sequence 不能用于点列表和环形列表。对于点列表可以用 copy-tree 函数。环形列表就没有办法复制了。 好在这样的数据结构很少用到。数组操作创建向量可以使用 vector 函数,或者使用[], 来包裹一组数据,后者是向量的读入语法(vector 1 2 3) ;; ==> [1 2 3] (setq foo '(a b)) [foo] ;; ==> [foo] (vector 'foo) ;; ==> [foo] (vector foo 1 2 3) ;; ==> [(a b) 1 2 3]上述代码中我们使用两个方式分别构造一个向量。采用vector的时候会对其中的每个符号进行求值。而使用[]来构造时则没有进行求值,等效于使用 quote使用 make-vector 可以生成元素相同的向量(make-vector 9 "foo") ;; ==> ["foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo"]fillarray 可以将数组的每个元素使用对应值进行填充(fillarray [1 2 3 4] 'foo) ;; ==> [foo foo foo foo]aref 和 aset 可以访问和设置数组中对应索引的元素。但是需要注意数组的长度,如果传入索引超过数组长度则会报错。可以使用 vconcat 可以将多个序列合并成一个向量,这里可以传入非向量,例如传入列表。针对列表仅限真列表。(vconcat [1 2 3] [3 4 5]) ;; ==> [1 2 3 3 4 5] (vconcat [1 2 3] '(3 4 5)) ;; ==> [1 2 3 3 4 5] (vconcat [1 2 3] '(4 . 5)) ;; ==> error将向量转化成列表可以使用 append函数(append [a b]) ;; ==> [a b] (append [a b] nil) ;; ==> (a b) (append [a b] '(c)) ;; ==> (a b c) (append [a b] "cd") ;; ==> (a b . "cd") (append [a b] "cd" nil) ;; ==> (a b "cd")在列表那一章中,append是将列表的最后一个节点的cdr替换为对应参数。在这里它可以将序列的元素转化为列表,但是需要注意,转换时同样需要两个参数。它会将第一个参数转化为列表,然后执行列表中添加元素的操作
-
Emacs 折腾日记(八)——CONS CELL和列表 本篇我们来介绍emacs lisp中的第一种复核结构——列表类型。cons cell从概念上讲 cons cell 非常简单,就是两个有顺序的元素。第一个元素叫 CAR、第二个元素叫 CDR。CAR 和 CDR 名字来自于 Lisp。根据 emacs lisp 简明教程 上的说法:它最初在IBM 704机器上的实现。在这种机器有一种取址模式,使人可以访问一个存储地址中的“地址(address)”部分和“减量(decrement)”部分。CAR 指令用于取出地址部分,表示(Contents of Address part of Register),CDR 指令用于取出地址的减量部分(Contents of the Decrement part of Register)。cons cell 也就是 construction of cells。至于历史出处我们并不需要特别关心,也不用掌握,我们只需要掌握相关用法即可。其实我们可以将它想象成一个有两个抽屉的柜子,有一个抽屉叫 car 另一个叫cdr 。具体里面放什么东西没有限制,可以放基本的数据类型,也可以同样的放入这么一个柜子。首先使用 cons 来构建一个cons cell。例如(setq my-cons (cons 1 "hello")) ;; ⇒ (1 . "hello") (setq my-cons (cons 1 nil)) ;; ⇒ (1)因为一个cons cell 包含 car 和 cdr 两个元素,所以一般我们传入的时候需要两个参数。但是第二个参数可以为nil。根据emacs在mini-buffer上的输出,其实还可以使用另一种方式来构建一个cons cell(setq my-cons '(1 . "hello"))我们看到在前面的代码中我们带了一个单引号,这个单引号用于表示符号(symbol)或字面量(literal)。具体来说,它的作用是防止后面的表达式被求值。Lisp的语句是一个S-表达式,在解释器读到到一个S-表达式的时候会尝试对这个S-表达式求值。在出现括号的表达式的时候,会将括号内第一个元素作为函数进行调用,而将其他元素作为参数。如果不加引号,那么上面的代码就变成了(setq my-cons (1 . "hello"))这个表达式的含义就是调用1 这个函数,传入 "hello" 参数,并将函数的返回值设置成变量 my-cons 的值。因为没有这么一个函数,所以它执行会报错。这里的引号就是 quote 函数,它用来表示对后面的内容不求值,仅仅作为一个符号传入。上面的代码也可以改成(setq my-cons (quote (1 . "hello")))再举一个例子(setq my-cons '(a . b));; error上述的代码会报错,虽然我们指定了 (a . b) 是一个符号,是一个cons cell,但是对于里面的 a 和 b 却没有指定,因此解释器会尝试解释 a和b,然后发现a和b未定义,所以也会报错,我们可以使用单引号单独的指定a、b都是符号,或者给a、b变量设定值。虽然都不报错,但是它们的含义却是不同的。(setq my-cons ('a . 'b)) (let ((a 1) (b 2)) (setq my-cons '(a . b)))cons cell还有一个特殊的值,那就是 nil 它表示一个空的 cons cell。它可以使用如下形式来给出nil '()空表并不是一个真正的 cons cell , 但是为了编程方便,还是可以通过 car 和 cdr 来取值,结果都是空。(car '()) ;; ⇒ nil (cdr '()) ;; ⇒ nil (car nil) ;; ⇒ nil列表lisp的全程是 List Processing ,列表处理,从这点上看列表在lisp中的比重非常重,非常重要。列表可以看作一个特殊形式的cons cell。在上面的介绍中,cons cell有两个元素,car和cdr,列表第一个元素是car,其余的是cdr。以此规律往下递归。我们可以使用 list 函数来构建(list 1 2 3) ;; ⇒ (1 2 3)也可以使用上面的 quote 来构造'(1 2 3) ;; ⇒ (1 2 3)二者定义的时候有什么区别呢?quote 方式是直接将内容作为一个列表,而list 函数则是先解释执行后面的代码,再将结果构建成列表,下面是二者不同的一个例子(list (+ 1 2 ) 3) ;; ⇒ (3 3) '((+ 1 2) 3) ;; ⇒ '((+ 1 2) 3)再来看一个例子'(a b c) ;; ⇒ (a b c) (list a b c) ;; ⇒ error, 因为a b c都未定义,无法解释执行如果要使用 list 来生成类似于 (a b c) 这样的列表,关键点在于要告诉解释器a b c 它们不需要解释执行,可以使用 quote 来做到这点(list 'a 'b 'c) ;; ⇒ (a b c)测试函数可以使用 consp 来判断一个对象是否是cons cell。使用 listp 来判断对象是否是列表,但是我们说列表是特殊的 cons cell 所以使用 consp 来检测列表,也会返回真(consp '(1 2 3)) ⇒ t除此之外,elisp 将cons cell也视为一种特殊的列表,因此下面的代码也返回t(listp (cons 1 2)) ;; ⇒ t但是nil 或者 '() 它们不是cons cell 也不是 list,所以判断它们都会返回 nil(consp nil) (consp '())深入理解 cons cell 和列表上面提到我们可以使用 cons 和 list 来分别构造一个 cons cell 和列表,但是它们构造一个新的,不影响之前的,例如(setq my-cons (cons 1 2)) (cons my-cons my-cons) my-cons ;; ⇒ (1 . 2)同时 cons 也可以在列表前增加一个元素,例如(setq foo '(a b)) (cons 'x foo) ;; ⇒ (x a b) foo ;; ⇒ (a b)从上面返回的结果来看,cons 会创建一个新的列表,并且在新列表的最前面加上指定元素,但是它不会修改原有的列表。cons 会返回新元素,不修改老元素还可以理解,因为它本来就是用来构建新的 cons cell 的。那么还有一个问题需要解释,为什么这样一个用来构建cons cell的函数会用来添加列表元素呢?要回答这个问题,我们可以需要回归到列表的本质了。先看这么一个例子'(1 . (2 . (3 . nil))) ;; ⇒ (1 2 3)我们执行它,发现它会返回一个列表,从这个例子上看,列表本身就是一个cons cell。它是一个特殊的cons cell 。按照列表最后一个 cdr 来区分的话,可以分成三类:第一类就是上述例子这样的,它的最后一个cdr是nil,它也被叫做真列表第二类,既不是cons cell也不是nil,这种被称之为点列表第三类,最后一个cdr 指向之前一个cons cell'(1 . #1=(2 3 . #1#)) ; => (1 2 3 . #1)这个是教程中给出的环形列表的表示形式,它比较复杂。但是它的结构与当初学过的数据结构中的环形链表类似。'(1 . (2 . (3 . 4))) ;; ⇒ (1 2 3 . 4)上述代码是第二类列表的形式,它的最后一个cdr 是 4,既不是cons cell 也不是nil。上述的代码中也可以看出来,并不是说有 . 的都是 cons cell,没有. 的就是列表。还是以前面的抽屉来类比,第二个抽屉里放的是nil或者其他基本数据类型,那么它就是一个 cons cell。如果放的是另外一个同样类型的抽屉,那么它就是一个列表。用数据结构中的概念来类比的话,cons cell是一个不带指针的结构体,而列表就是一个带有指向自身结构体类型的指针域。即使它只有一个这种结构的对象也是一个列表的节点。(cons 1 nil) ;; ⇒ (1)上述代码就是这样的,第二节点域指向空,没有指向下一个节点,虽然只有一个节点,但它也是一个列表。我个人的理解是,不应该严格区分cons cell 和列表,就像C/C++中的struct 和list,struct是组成list的基础,而list中每个节点又都是一个struct, 所以前面使用 consp 和 listp 无法区分cons cell 和 lisp。而. 则可以看作是分隔符,分隔数据域和指针域的数据,指针域同样可以放入其他类型的数据,也可以放入 cons cell列表的操作函数添加列表元素如果希望修改原始列表可以使用 push ,与栈操作类似,它是将当前值添加到列表头,例如(setq foo '(a b)) (push 'x foo) foo ;; ⇒ (x a b)在列表前面添加元素使用 cons ,在列表后面添加元素可以使用 append。(setq foo '(a b)) (append foo '(x)) ;; ⇒ (a b x) foo ;; ⇒ (a b)(setq foo '(a b)) (append foo 'x) ;; ⇒ (a b . x) foo ;; ⇒ (a b)(setq foo '(a . b)) (append foo 'x) ;; error foo与cons 类似,它同样不修改原始列表的值。 用上面C/C++结构体和链表的类比话术来说的话,它的作用是将第一个参数的最后一个节点的指针域的空指针替换成第二个参数。上面的第一个例子,原本列表应该是 (a . (b . nil)) 它的最后一节点的指针域就是 nil,它被替换成了 (x), 可以写成 (x . nil) 。最后的结果就是 (a . (b . (x . nil))) 它是一个真列表,(a b x) 。第二个例子,还是先将列表展开 (a . (b . nil)) ,将nil替换成 x ,最后的结果就是 (a . (b . x)) 第三个例子,使用cdr 取出来的最后一个例子并不是空,所以它会报错与C中链表类似,采用头插法的速度要比使用尾插法快得多。即使用 cons 速度要比使用 append 快获取列表元素列表就是一个个cons cell 串起来组成的,可以使用 car 和 cdr 来获取元素,我们可以自己尝试仿照着C中对链表的操作来写一个函数获取列表中任意位置的元素(defun my-get-list-item(lst index) (let ((i 0)) (while (and (cdr lst) (< i index)) (setq lst (cdr lst)) (setq i (+ i 1))) (if (<= index i) (car lst) nil))) (my-get-list-item '(0 1 2 3 4 5) 2) ;; ⇒ 2当然也可以使用递归来完成(defun my-get-list-item(lst index) (if (or (not lst) (= 0 index)) (car lst) (my-get-list-item (cdr lst) (1- index)))) (my-get-list-item '(0 1 2 3 4 5) 2)递归版本相对于上面的循环来说要简单的多,代码量也少。递归版本中当列表为空或者当前索引为0时,停止递归并返回。利用空列表表的car 和 cdr 都是空这个特性,来将两种不同的情况使用同一操作进行处理。条件不满足时对cdr进行递归处理。虽然可以自己写这样的算法来取列表的第n个元素,但是elisp中也提供的对应的操作函数。使用 nth 来获取第n个元素,使用 nthcdr 来获取第n次调用cdr 的结果,也就是获取包含第n个元素的子列表(nth 2 '(0 1 2 3 4 5)) ;; ⇒ 2 (nthcdr 2 '(0 1 2 3 4 5)) ;; ⇒ (2 3 4 5)同时还提供了 last 来返回从右往左数第n个元素的子列表。和 butlast 来返回last之外的其它列表元素。(last '(0 1 2 3 4 5) 3) ;; ⇒ (3 4 5) (butlast '(0 1 2 3 4 5) 3) ;; ⇒ (0 1 2)利用这些函数可以实现取某一范围的子列表(defun my-get-sub-items (lst start end) (if (nthcdr start lst) (butlast (nthcdr start lst) (- (length lst) end)))) (my-get-sub-items '(0 1 2 3 4 5) 2 5) ;; ⇒ (2 3 4)上面的代码比较简单,首先使用 nthcdr 来取start后面的内容,然后使用 butlast 来去掉 end 后面的内容。不知道各位读者还记不记得 length 这个函数,前面我们用它来获取字符串的长度,这里我们用它来获取列表的长度。设置列表元素一般情况下,我们可以放心的递归和对列表进行操作,因为上述的一些函数都不会修改原列表的值,在递归或者循环的过程中我们使用的是产生的临时列表。但是有时候会希望修改列表的值,例如在将列表作为栈来使用的时候,就需要出栈和压栈的操作。设置元素的值,可以使用 setcar 和 setcdr 这两个函数。如果我想设置任意索引位置的值该怎么办呢?可以配合使用 nthcdr 和 setcar。(setq foo '(a b c)) (setcar foo 'x) foo ;; ⇒ (x b c) (setq foo '(a b c)) (setcdr foo '(x y)) foo ;; ⇒ (a x y) (setq foo '(a b c)) (setcdr foo 'x) foo ;; ⇒ (a . x) (setq foo '(a b c)) (setcar (nthcdr 1 foo) 'x) ;; ⇒ x foo ;; ⇒ (a x c)前面提到使用 push 在表头添加元素,这里再介绍一个 pop 函数,它用来删除表头元素,它们两个配合使用就能组成一个栈的数据结构(setq foo '(a b c)) (push 'x foo) ;; ⇒ foo (pop foo)列表排序将列表从尾到头进行反转可以使用 reverse ,例如(setq foo '(a b c)) (reverse foo) ;; ⇒ (c b a) foo ;; ⇒ (a b c)我们可以看到,reverse也是不修改原始的列表,而是返回一个新的列表。如果想要修改原始列表可以使用 nreverse(setq foo '(a b c)) (reverse foo) ;; ⇒ (c b a) foo ;; ⇒ (a)为什么这里foo 指向了列表的最后一个元素呢?使用当初学习C/C++链表操作时掌握的知识很好解释,原本foo指向的是列表头,但是反转之后,原来的链表头就变成最后一个元素,而没有修改foo指针指向的情况下,它就是指向链表的最后一个元素(这个原因是我猜的,不知道对不对)。我们还可以对列表进行排序,可以使用sort 函数进行排序,它接收一个列表,并且接收一个排序方式的函数。例如(setq foo '(3 4 5 1 2 0)) (sort foo '<) ;; ⇒ (0 1 2 3 4 5) foo ;; ⇒ (0 1 2 3 4 5)这里的 '< 是一个排序函数,有点像C++ 11 标准里面的 sort 函数,它可以传入一个函数用来表示排序时比较大小的一个过程。而且这里我们并不需要在这个时候调用 < 这个函数,所以先使用 quote 。在后续真正执行排序要比较大小的时候会调用它。这里我们可以自己定义比较函数,比如这里我们按照字符串长度进行排序(defun strlen-cmp (str1 str2) (< (length str1) (length str2))) (setq foo '("hello" "emacs" "aaa" "bbbbbb")) (sort foo 'strlen-cmp) ;; ⇒ ("aaa" "hello" "emacs" "bbbbbb") foo ;; ⇒ ("aaa" "hello" "emacs" "bbbbbb") ;; 这里也可以使用lambda表达式 (setq foo '("hello" "emacs" "aaa" "bbbbbb")) (sort foo (lambda (str1 str2) (< (length str1) (length str2)))) ;; ⇒ ("aaa" "hello" "emacs" "bbbbbb") foo ;; ⇒ ("aaa" "hello" "emacs" "bbbbbb")这里我们发现sort 已经将修改了原始列表,如果想要保留原始列表,可以使用 copy-sequence(setq foo '(3 4 5 1 2 0)) (let ((temp (copy-sequence foo))) (sort temp '<)) ;; ⇒ (0 1 2 3 4 5) foo ;; ⇒ (3 4 5 1 2 0)还有像 nconc 和 append 功能相似,但是它会修改除最后一个参数以外的所有的参数,nbutlast 和 butlast 功能相似,也会修改参数。这些函数都是在效率优先时才使用。总而言之,以 n 开头的函数都要慎用遍历列表前面我们已经使用 car 和 cdr 能做到遍历列表,这里再介绍一下专门用来遍历的函数 mapc 和 mapcar 。它们都可以遍历列表中的所有元素,它们的第一个参数是一个函数,每次遍历到一个元素的时候会调用这个函数并将元素作为参数传入这个函数。C++中没有提供这样的函数,但是也有类似的操作。例如使用 foreach 获取每个元素,然后根据元素来执行操作。(setq foo '(0 1 2 3 4)) (mapc '1+ foo) ;; ⇒ (0 1 2 3 4) foo ;; ⇒ (0 1 2 3 4) (setq foo '(0 1 2 3 4)) (mapcar '1+ foo) ;; ⇒ (1 2 3 4 5) foo ;; ⇒ (0 1 2 3 4)这两个遍历函数的区别就是,是否使用返回值来构建新的列表,其中 mapcar 会根据返回值构建新的列表,而 mapc 则返回原列表。我们发现无论是哪个函数都无法修改原始列表,要修改原始列表当然也有方法,我能想到的一个方法就是循环,然后配合 setcar 和 ntdcdr 根据索引来设置。好了,本篇的内容就到此为止了。本篇按照 emacs lisp 简明教程 的内容修改而来的。原教程还有好多其他数据结构的操作,但是我作为初学者还是希望本篇内容专注在列表上,至于教程中涉及的其他操作或者数据结构,等后面学到了再了解也不迟。
-
Emacs折腾日记(四)——elisp控制结构 目前我们接着学习elisp相关语法,这里我是按照 elisp 简明教程 来进行学习。与其说这是我自己写得教程到不如说是在这个上面做得注释。目前我不知道这样是否侵犯相关的知识产权。目前就先这样继续学习,继续写记录吧。闲话少说,进入本篇的正题,关于elisp的控制结构。一般编程语言都有三种控制结构:顺序结构、条件结构、循环结构。elisp同样有这三种控制结构。顺序结构和复合语句一般默认elisp的语句是顺序执行的,例如下面的代码(setq name "Emacs") (message "hello, %s" name)它先执行前面的 setq 语句,先给变量name 定义并赋值为 Emacs 。后面接着执行第二行代码,调用message 函数来输出一段文字。在其他语言一般都有一个复合语句。它是有多个语句共同组成的,例如 C/C++中使用{} 来将多个语句整合成一条复合语句。针对C/C++ 我们在很多地方会用到复合语句。例如如果 if , while 等语句后只需要一条语句,那么可以直接使用一条语句,例如下面的代码// 这么写代码不太正规但是符合语法规范,也能编译过 int main() { int i = 0; while(i++ < 10) printf("%d\n", i); //打印1到10,这么10个数字 return(0); }但是如果在循环或者if条件成立后,执行多条语句,就需要使用复合语句,也就是用大括号括起来。那么在elisp中也有这样的操作,在条件和循环语句中需要执行不止一条语句,也需要使用复合语句。elisp 中符合语句使用 progn 来包含一组语句组成复合语句,它的语法规则是(progn statement1 statement2 ... statement3)例如我们将上面的代码用 progn 包装一下(progn (setq name "Emacs") (message "hello, %s" name)) ;; => "hello, Emacs"使用 progn 包装的复核语句可以使用 C-x C-e 也就是 eval-last-sexp 来同时执行里面的两个子语句。如果我们将它们分开写,则使用 eval-last-sexp 做不到这点,它只能一条条的执行# 条件语句 我们使用 if 和 cond来表示条件分支,if的语法如下(if condition then else)需要注意的是 这里的 then 和 else 并不是关键字,而是对应的语句,也就说紧跟着if条件的语句表示条件成立时执行的代码,下一条则是条件不成立时执行的代码。例如我们使用下面的代码来获取两个数的最大值(defun get-max(a b) (if (> a b) a b)) (get-max 3 4) ; => 4与 C/C++ 的函数不同,elisp 函数的返回值不需要使用 return 或者其他的关键字特意指出,它是将函数最后执行的语句的返回值作为函数的返回值,这里当 a > b 时条件成立,执行 a 然后结束函数,也就是这个时候函数的最后一个语句是 a ,函数返回 a 的值。否则执行 b ,此时函数的最后执行的语句就是 b ,这个时候函数就返回 b 的值而 cond 有点像 C/C++ 中的 switch ,它的语法如下(cond (case1 do-when-case1) (case2 do-when-case2) ... (t do-when-none-meet))它的语法特点是,它与 switch 类似,由一堆 case 和 default 组成。每个case 都使用一对 () 来区分,最后可以使用 t 来表示未匹配到前面的 case 时执行的语句,类似于default语句。这里我们使用当初学习C/C++ switch 语法时的经典代码来作为示例(defun score-report (score) (cond ((>= score 90) "优秀") ((>= score 80) "良好") ((>= score 60) "及格") (t "不及格"))) (score-report 75); => 及格我们可以看到,cond 语句的使用比 switch 更为的灵活,switch case 只能进行整型变量的相等比较,而 cond 可以进行其他变量类型的不同形式的条件判断,它只是在形式上更像 switch,但是在使用的范围上更像 if-else if-else。另外 elisp 简明教程中 提供了一个使用 cond 计算 斐波那契数列的例子(defun fib(n) (cond ((= n 0) 0) ((= n 1) 1) (t (+ (fib (- n 1)) (fib (- n 2)))))) (fib 10) ; => 55因为 elisp 中使用 setq 来进行赋值操作,所以它里面的= 就是数学意义上比较相等的操作符,而 其他语言中的 == 在lisp中无效。这里如果写成 == 将会报错。上面的例子也很好理解 当 n 等于 0时返回0,等于 1 时返回1,否则返回 fib(n - 1) + fib(n - 2) 使用 C/C++ 的话可能更容易理解int fib(int n) { if(i == 0) return 0; else if (i == 1) return 1; else return fib(n - 1) + fib (n - 2) }循环结构循环使用 while 关键字,它的语法结构如下(while condition body)我们可以将上述循环打印的C代码使用 elisp 实现(setq i 0) (while (< i 10) (progn (message "%d" i) (setq i (+ i 1))))我们执行完代码之后使用 switch-buffer,切换到 *message* ,可以看到它打印了从0到9的数据。上面的斐波那契数列的例子我们可以使用 while 来实现(defun fib (n) (cond ((= n 0) 0) ((= n 1) 1) (t (let ((first 1) (second 1) (third 1)) (setq n (- n 2)) (while (> n 0) (progn (setq third (+ first second)) (setq first second) (setq second third) (setq n (- n 1)))) third)))) (fib 10) ; => 55因为 elisp 中没有提供 += ++ 这样算术运算符,所以我们需要使用 setq 来赋值。下面还有一个计算阶乘的例子(defun factorial (n) (let ((res 1)) (while (> n 1) (setq res (* res n)) (setq n (- n 1))) res)) (factorial 10) ; => 3628800我们也可以提供一个递归的版本(defun factorial (n) (if (= n 1) 1 (* (factorial (- n 1)) n))) (factorial 10) ; => 3628800到此为止,本篇就结束了。本篇涉及到的elisp 代码其实也不算复杂,如果能熟练掌握一门编程语言的话,到此为止的代码应该不算太难理解。在编写这些示例代码的时候我觉得还好,主要注意括号的匹配,算法什么的就是照搬C/C++中一些经典写法就差不多了。但是即使上面的代码并不多,代码量并不大,我也能明显感觉到上述代码在阅读上不那么直观。