搜索到
84
篇与
的结果
-
 驱动程序的同步处理 驱动程序运行在系统的内核地址空间,而所有进程共享这2GB的虚拟地址空间,所以绝大多数驱动程序是运行在多线程环境中,有的时候需要对程序进行同步处理,使某些操作是严格串行化的,这就要用到同步的相关内容。异步是指两个线程各自运行互不干扰,而当某个线程运行取决与另一个线程,也就是要在线程之间进行串行化处理时就需要同步机制。中断请求级别在进行I/O操作时会产生中断,以便告知CPU当前I/O操作已完成,此时CPU会停下手头的工作,来处理这个中断请求,在Windows操作系统中,分为硬件中断和软件中断。并且将这些中断映射为不同级别的中断请求级。硬件中断是由硬件产生的中断,软件中断是由int指令产生的。在传统的PC中,一般可以接收16种中断信号,每个信号对应一个中断号。硬件中断分为可屏蔽中断和不可屏蔽中断。可屏蔽中断是由可编程中断控制器(PIC)产生,这是一个硬件设备。在后面的PC机中采用了高级可编程中断控制器(APIC)代替。在APIC中将中断扩展为24个,每个都有对应的优先级,一般正在运行的线程可以被中断打断,进入中断处理程序,当优先级高的中断来临时处在低优先级的中断也会被打断。在Windows中中断请求级别有32个,但是在编程或者在MSDN上只需要关心两类级别,PASSIVE_LEVEL:用户级别,这个中断级别最低。DISPATCH_LEVEL:级别相对较高。在运用内核函数时可以查看MSDN,运行在低优先级的函数不能进行高优先级的一些操作。下面是一些常用函数的优先级函数优先级DriverEntry AddDevice DriverUnload等函数PASSIVE_LEVEL各种分发派遣函数PASSIVE_LEVEL完成函数DISPATCH_LEVELNDIS回调函数DISPATCH_LEVEL在内核模式中可以调用KeGetCurrentIrql得到当前的IRQL需要注意的是,线程优先级只针对于应用程序,只有在IRQL处于PASSIVE_LEVEL级别才有意义。当线程运行在PASSIVE_LEVEL级别的时候可以进行线程切换,而当IRQL提升到DISPATCH_LEVEL,就不再出现线程切换PASSIVE_LEVEL是应用层的中断级别,可以有线程切换,处在这个IRQL下的程序是位于进程上下文,可以进行线程的切换休眠等操作,而处于DISPACTH_LEVEL的程序属于中断上下文,CPU会一直执行这个环境下的代码,没有线程切换,不能进行线程的休眠操作,否则,一旦休眠则没有线程能够唤醒。在内存的使用上,PASSIVE_LEVEL级别的程序可以使用分页内存,一旦发生缺页中断,系统可以进行线程切换,切换到其他进程,将缺页装载在内存,但是在DISPATCH_LEVEL没有线程切换,一旦发生缺页中断就会导致系统崩溃,所以DISPATCH_LEVEL只能使用非分页内存。我们可以在程序中手动提升和降低当前的IRQL。VOID KeRaiseIrql( IN KIRQL NewIrql, //新IRQL OUT PKIRQL OldIrql//当前的IRQL ); VOID KeLowerIrql( IN KIRQL NewIrql //新IRQL );自旋锁自旋锁是一种同步机制,他能保证某个资源只被一个线程所拥有。在初始化自旋锁的时候,处于解锁状态,这个时候线程可以获取自旋锁并访问同步资源,一旦有一个线程获取到自旋锁,必须等到它释放以后,才能被其他线程获取。自旋锁被锁上之后当切换到另外的线程时,线程会不停的询问是否可以获取自旋锁。此时线程处于空转的情况,白白浪费了CPU资源,所以一般要慎用自旋锁使用方法自旋锁用结构体KSPIN_LOCK来表示使用自旋锁的时候需要对其进行初始化,初始化可以使用函数KeInitializeSpinLock,一般在驱动加载函数DriverEntry或者AddDevice函数中初始化自旋锁。VOID KeInitializeSpinLock( IN PKSPIN_LOCK SpinLock );申请自旋锁可以使用函数KeAcquireSpinLock。VOID KeAcquireSpinLock( IN PKSPIN_LOCK SpinLock, OUT PKIRQL OldIrql //自旋锁以前所处的IRQL );释放自旋锁可以使用函数KeReleaseSpinLock内核模式下线程的创建在内核模式中线程使用PsCreateSystemThread;该函数的原型如下:NTSTATUS PsCreateSystemThread( OUT PHANDLE ThreadHandle, //线程的句柄指针,这个参数作为一个输出参数 IN ULONG DesiredAccess,//新线程的权限,在驱动中这个值一般给0 IN POBJECT_ATTRIBUTES ObjectAttributes OPTIONAL,//线程的属性,一般给NULL IN HANDLE ProcessHandle OPTIONAL,//该线程所属的进程句柄,如果给NULL表示创建一个系统进程的线程 OUT PCLIENT_ID ClientId OPTIONAL,//指向客户结构的一个指针,在驱动中这个值一般给NULL IN PKSTART_ROUTINE StartRoutine,//新线程的函数地址 IN PVOID StartContext//线程函数的参数 );第4个参数表示创建线程的类型,如果给NULL则表示创建一个系统线程,否则表示将创建一个用户线程,DDK提供了一个宏NtCurrentThread()来获取当前进程的句柄,这个当前进程表示的是像驱动发送IRP请求的进程的句柄。获取进程名在XP中EPROCESS结构的0X174偏移位置记录着线程名,我们可以使用IoGetCurrentProcess()函数来获取当前进程的EPROCESS结构,这样我们 可以利用这样的代码来获取进程名:PEPROCESS pEprocess = IoGetCurrentProcess(); ASSERT(NULL != pEprocess); DbgPrint("the process name is %S\n", (PTSTR)((ULONG)pEprocess + 0x174));下面是一个使用线程的例子VOID MyProcessThread(PVOID pContext) { //获取当前发送IRP请求的线程名 PEPROCESS pCurrProcess = IoGetCurrentProcess(); PTSTR pProcessName = (PTSTR)((CHAR*)pCurrProcess + 0x174); // UNREFERENCED_PARAMETER(pContext); DbgPrint("MyProcessThread Current Process %s\n", pProcessName); PsTerminateSystemThread(0); } VOID SystemThread(PVOID pContext) { //获取系统进程名 PEPROCESS pCurrProcess = IoGetCurrentProcess(); PTSTR pProcessName = (PTSTR)((CHAR*)pCurrProcess + 0x174); // UNREFERENCED_PARAMETER(pContext); DbgPrint("MyProcessThread Current Process %s\n", pProcessName); PsTerminateSystemThread(0); } VOID CreateThread_Test() { HANDLE hSysThread = NULL; HANDLE hMyProcThread = NULL; NTSTATUS status; //创建系统进程 status = PsCreateSystemThread(&hSysThread, 0, NULL, NULL, NULL, SystemThread, NULL); //创建用户进程 status = PsCreateSystemThread(&hMyProcThread, 0, NULL, NtCurrentProcess(), NULL, MyProcessThread, NULL); } 内核模式下的同步对象内核模式下的同步对象与应用层的大致相同,所以理解了应用的线程同步对象,那么内核层的也很好理解内核模式下的等待函数内核模式下的等待函数是KeWaitForSingleObject 和 KeWaitForMultipleObjects,一个是用来等待单个事件,一个是用来等待多个事件。NTSTATUS KeWaitForSingleObject( IN PVOID Object, /第一个参数是一个指向同步对象的指针 IN KWAIT_REASON WaitReason,//第二个参数是等待原因,在驱动中这个值应该被设置为Executive IN KPROCESSOR_MODE WaitMode,//等待模式,处在低优先级的驱动应该将这个值设置为KernelMode IN BOOLEAN Alertable,//是否是警惕的 IN PLARGE_INTEGER Timeout OPTIONAL//等待时间,如果是正数则表示从1601年1月1日到现在的时间如果是负数则表示从现在算起的时间,单位是100ns );函数如果是等待到了对应的事件则返回STATUS_SUCCESS如果是由于等待时间到了,则返回STATUS_TIMEOUT内核模式下的事件对象在内核中用KEVENT来表示一个事件对象,在使用事件对象时需要对其进行初始化,使用函数KeInitializeEventVOID KeInitializeEvent( IN PRKEVENT Event, //事件对象的指针 IN EVENT_TYPE Type, //事件类型,一般分为两种:NotificationEvent 通知事件和同步事件SynchronizationEvent IN BOOLEAN State//是否是激发状态 );所谓的激发状态就是有信号状态,没有线程拥有这个事件。在这个状态下其他线程中的等待函数可以等到这个事件这两种类型的事件对象的区别在于如果是通知事件需要程序员手动的更改事件的状态,如果是同步事件,在等待函数等到这个事件对象后会自动将这个对象设置为无信号状态可以使用函数KeSetEvent设置事件为有信号,这样其他线程的等待函数就可以等到这个事件LONG KeSetEvent( IN PRKEVENT Event, //事件对象的指针 IN KPRIORITY Increment,//被唤起的线程将以何种优先级执行,这个参数与IoCompleteRequest的第二个参数含义相同 IN BOOLEAN Wait //一般给FALSE );下面是这个它的使用例子VOID Event_Test() { KEVENT keEvent; HANDLE hThread; //初始化事件对象,并设置为无信号 KeInitializeEvent(&keEvent, NotificationEvent, FALSE); //创建新线程,将事件对象传入线程函数中,新线程将会设置事件对象为有状态 PsCreateSystemThread(&hThread, 0, NULL, NULL, NULL, EventThread, &keEvent); if(NULL == hThread) { DbgPrint("Create Event Thread Error!\n"); return; } KeWaitForSingleObject(&keEvent, Executive, KernelMode, FALSE, NULL); } VOID EventThread(PVOID pContext) { PKEVENT pEvent = (PKEVENT)pContext; DbgPrint("This is Event Thread\n"); KeSetEvent(pEvent, IO_NO_INCREMENT, FALSE); PsTerminateSystemThread(0); }驱动程序与应用程序交互事件对象本质上用户层和内核层的事件对象是同一个东西,在用户层用句柄代替,看不到它的具体结构,在内核层是一个KEVENT,能知道它的具体数据成员。我们可以先在应用层创建一个事件对象的句柄,然后通过DeviceIoControl传到应用层,然后利用函数ObReferenceObjectByHandle将这个句柄转化为对应的事件对象,在利用这个函数转化成功后会将事件对象的计数 + 1所以在使用完后应该调用函数ObDereferenceObject使计数减1NTSTATUS ObReferenceObjectByHandle( IN HANDLE Handle, //用户层传下来的内核对象句柄 IN ACCESS_MASK DesiredAccess, //访问权限对于同步事件一般给EVENT_MODIFY_STATE IN POBJECT_TYPE ObjectType OPTIONAL,//转化何种类型的内核结构 IN KPROCESSOR_MODE AccessMode,//模式,一般有KernelMode和UserMode OUT PVOID *Object,//对应结构的指针 OUT POBJECT_HANDLE_INFORMATION HandleInformation OPTIONAL//这个参数在内核模式下为NULL );第三个参数根据转化的内核结构的不同可以有下面的结构。参数值对应的结构*IoFileObjectTypePFILE_OBJECT*ExEventObjectTypePKEVENT*PsProcessTypePEPROCESS或者PKPROCESS*PsThreadTypePETHREAD或者PKTHREAD下面是内核层的例子else if(IOCTL_TRANS_EVENT == pIrps->Parameters.DeviceIoControl.IoControlCode) { //接收从应用层下发的下来的事件句柄 hEvent = *(PHANDLE)(Irp->AssociatedIrp.SystemBuffer); if(NULL == hEvent) { DbgPrint("Invalied Handle\n"); goto __RET; } status = ObReferenceObjectByHandle(hEvent, EVENT_MODIFY_STATE, *ExEventObjectType, KernelMode, &pkEvent, NULL); if(!NT_SUCCESS(status)) { //失败 DbgPrint("Translate Event Error\n"); goto __RET; } //将事件设置为有信号 KeSetEvent(pkEvent, IO_NO_INCREMENT, FALSE); //引用计数 -1 ObDereferenceObject(pkEvent); }驱动程序与驱动程序交互事件对象在内核驱动中可以通过给某个内核对象创建一个命名对象,然后在另一个驱动中通过名字来获取这个对象,然后操作它来实现两个驱动之间的内核对象的通讯,针对事件对象来说,要实现两个驱动交互事件对象,通过这样几步:在驱动A中调用IoCreateNotificationEvent或者IoCreateSynchronizationEvent来创建一个通知事件对象或者同步事件对象在驱动B中调用 IoCreateNotificationEvent或者IoCreateSynchronizationEvent获取已经有名字的内核对象的句柄在驱动B中调用ObReferenceObjectByHandle根据上面两个函数返回的句柄来获取A中的事件对象,并操作它操作完成后调用ObDereferenceObject解引用PKEVENT IoCreateNotificationEvent( IN PUNICODE_STRING EventName, OUT PHANDLE EventHandle );如果指定名称的事件存在那么将会通过EventHandle来返回这个事件对象的句柄,如果不存在则会创建一个事件并通过返回值直接返回这个事件对象的结构指针,需要注意的是这个名字必须以L"\BaseNamedObjects\” 开头另外不能在DriverEntry中等待过长时间,否则会造成系统蓝屏内核模式下的信号量在操作系统相关的书籍中但凡说到线程的同步问题就会涉及到信号量,当多个线程共享一个公共资源时在某一时刻只能有一个线程在运行,这个时候一般用事件对象控制,而当多个线程共享多个公共资源时,可以有多个线程同时在运行,这个时候就可以用信号量,可以把信号量想象成一个盒子,里面有多盏灯,当只要有一盏灯是亮的,就有线程可以执行,每当有一个线程在访问共享资源时,亮灯的数量-1,当线程不再访问共享资源时,亮灯的数目 +1而当灯全部熄灭时就不再允许线程访问。当盒子中只有一盏灯的时候,就相当于一个互斥体信号量的初始化函数为KeInitializeSemaphoreVOID KeInitializeSemaphore( IN PRKSEMAPHORE Semaphore,//将要被初始化的信号量的指针 IN LONG Count,//当前信号量中有多少个灯亮 IN LONG Limit//总共有多少灯 );释放信号量会增加信号灯计数。对应的函数是KeReleaseSemaphore。可以利用这个函数指定增量值,获得的信号灯可以使用Wait函数等待如果获得就熄灭一盏灯,否则就陷入等待。。利用函数KeReadStateSemaphore可以得到当前有多少盏灯是亮的下面是使用的例子VOID Semaphore_Test() { KSEMAPHORE keSemaphore; HANDLE hThread; NTSTATUS status = STATUS_SUCCESS; ULONG uCount = 0;//当前有多少盏灯亮着 //初始化,使其里面有两盏灯,两盏灯全亮 KeInitializeSemaphore(&keSemaphore, 2, 2); if(!NT_SUCCESS(status)) { DbgPrint("Initialize Semaphore Error\n"); return; } //当前有多少盏灯亮着 uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //函数会成功返回并熄灭一盏灯 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //函数会成功返回并熄灭一盏灯 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //创建新线程 PsCreateSystemThread(&hThread, 0, NULL, NULL, NULL, SemaphoreThread, &keSemaphore); //这时没有灯亮,函数会陷入等待状态 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); }VOID SemaphoreThread(PVOID pContext) { //线程函数 PKSEMAPHORE pkeSemaphore = (PKSEMAPHORE)pContext; DbgPrint("Entry My Thread\n"); //点亮其中的一盏灯 KeReleaseSemaphore(pkeSemaphore, IO_NO_INCREMENT, 1, FALSE); //结束线程 PsTerminateSystemThread(0); }内核模式下的互斥体互斥体在内核结构中的定义为KMUTEX使用前需要使用函数KeInitializeMutex进行初始化VOID KeInitializeMutex( IN PRKMUTEX Mutex, IN ULONG Level//系统保留参数一般给0 );初始化之后就可以使用Wait系列的函数进行等待,一旦函数返回,那么该线程就拥有了该互斥体,线程可以调用函数KeReleaseMutex来主动释放互斥体LONG KeReleaseMutex( IN PRKMUTEX Mutex, IN BOOLEAN Wait );与同步对象相比,互斥体可以在某个线程中递归获取,这个时候每当获取一次,那么它被引用的次数也将加1,在释放时,被引用多少次就应该释放多少次,只有当计数为0时才能被其他线程获取互锁操作进行同步互锁操作就是定义了一个原子操作,当原子操作没有完成时,线程是不允许切换的,系统会保证原子操作要么都完成了,要么都没有完成。在Windows中为一些常用的操作定义了一组互锁操作函数
驱动程序的同步处理 驱动程序运行在系统的内核地址空间,而所有进程共享这2GB的虚拟地址空间,所以绝大多数驱动程序是运行在多线程环境中,有的时候需要对程序进行同步处理,使某些操作是严格串行化的,这就要用到同步的相关内容。异步是指两个线程各自运行互不干扰,而当某个线程运行取决与另一个线程,也就是要在线程之间进行串行化处理时就需要同步机制。中断请求级别在进行I/O操作时会产生中断,以便告知CPU当前I/O操作已完成,此时CPU会停下手头的工作,来处理这个中断请求,在Windows操作系统中,分为硬件中断和软件中断。并且将这些中断映射为不同级别的中断请求级。硬件中断是由硬件产生的中断,软件中断是由int指令产生的。在传统的PC中,一般可以接收16种中断信号,每个信号对应一个中断号。硬件中断分为可屏蔽中断和不可屏蔽中断。可屏蔽中断是由可编程中断控制器(PIC)产生,这是一个硬件设备。在后面的PC机中采用了高级可编程中断控制器(APIC)代替。在APIC中将中断扩展为24个,每个都有对应的优先级,一般正在运行的线程可以被中断打断,进入中断处理程序,当优先级高的中断来临时处在低优先级的中断也会被打断。在Windows中中断请求级别有32个,但是在编程或者在MSDN上只需要关心两类级别,PASSIVE_LEVEL:用户级别,这个中断级别最低。DISPATCH_LEVEL:级别相对较高。在运用内核函数时可以查看MSDN,运行在低优先级的函数不能进行高优先级的一些操作。下面是一些常用函数的优先级函数优先级DriverEntry AddDevice DriverUnload等函数PASSIVE_LEVEL各种分发派遣函数PASSIVE_LEVEL完成函数DISPATCH_LEVELNDIS回调函数DISPATCH_LEVEL在内核模式中可以调用KeGetCurrentIrql得到当前的IRQL需要注意的是,线程优先级只针对于应用程序,只有在IRQL处于PASSIVE_LEVEL级别才有意义。当线程运行在PASSIVE_LEVEL级别的时候可以进行线程切换,而当IRQL提升到DISPATCH_LEVEL,就不再出现线程切换PASSIVE_LEVEL是应用层的中断级别,可以有线程切换,处在这个IRQL下的程序是位于进程上下文,可以进行线程的切换休眠等操作,而处于DISPACTH_LEVEL的程序属于中断上下文,CPU会一直执行这个环境下的代码,没有线程切换,不能进行线程的休眠操作,否则,一旦休眠则没有线程能够唤醒。在内存的使用上,PASSIVE_LEVEL级别的程序可以使用分页内存,一旦发生缺页中断,系统可以进行线程切换,切换到其他进程,将缺页装载在内存,但是在DISPATCH_LEVEL没有线程切换,一旦发生缺页中断就会导致系统崩溃,所以DISPATCH_LEVEL只能使用非分页内存。我们可以在程序中手动提升和降低当前的IRQL。VOID KeRaiseIrql( IN KIRQL NewIrql, //新IRQL OUT PKIRQL OldIrql//当前的IRQL ); VOID KeLowerIrql( IN KIRQL NewIrql //新IRQL );自旋锁自旋锁是一种同步机制,他能保证某个资源只被一个线程所拥有。在初始化自旋锁的时候,处于解锁状态,这个时候线程可以获取自旋锁并访问同步资源,一旦有一个线程获取到自旋锁,必须等到它释放以后,才能被其他线程获取。自旋锁被锁上之后当切换到另外的线程时,线程会不停的询问是否可以获取自旋锁。此时线程处于空转的情况,白白浪费了CPU资源,所以一般要慎用自旋锁使用方法自旋锁用结构体KSPIN_LOCK来表示使用自旋锁的时候需要对其进行初始化,初始化可以使用函数KeInitializeSpinLock,一般在驱动加载函数DriverEntry或者AddDevice函数中初始化自旋锁。VOID KeInitializeSpinLock( IN PKSPIN_LOCK SpinLock );申请自旋锁可以使用函数KeAcquireSpinLock。VOID KeAcquireSpinLock( IN PKSPIN_LOCK SpinLock, OUT PKIRQL OldIrql //自旋锁以前所处的IRQL );释放自旋锁可以使用函数KeReleaseSpinLock内核模式下线程的创建在内核模式中线程使用PsCreateSystemThread;该函数的原型如下:NTSTATUS PsCreateSystemThread( OUT PHANDLE ThreadHandle, //线程的句柄指针,这个参数作为一个输出参数 IN ULONG DesiredAccess,//新线程的权限,在驱动中这个值一般给0 IN POBJECT_ATTRIBUTES ObjectAttributes OPTIONAL,//线程的属性,一般给NULL IN HANDLE ProcessHandle OPTIONAL,//该线程所属的进程句柄,如果给NULL表示创建一个系统进程的线程 OUT PCLIENT_ID ClientId OPTIONAL,//指向客户结构的一个指针,在驱动中这个值一般给NULL IN PKSTART_ROUTINE StartRoutine,//新线程的函数地址 IN PVOID StartContext//线程函数的参数 );第4个参数表示创建线程的类型,如果给NULL则表示创建一个系统线程,否则表示将创建一个用户线程,DDK提供了一个宏NtCurrentThread()来获取当前进程的句柄,这个当前进程表示的是像驱动发送IRP请求的进程的句柄。获取进程名在XP中EPROCESS结构的0X174偏移位置记录着线程名,我们可以使用IoGetCurrentProcess()函数来获取当前进程的EPROCESS结构,这样我们 可以利用这样的代码来获取进程名:PEPROCESS pEprocess = IoGetCurrentProcess(); ASSERT(NULL != pEprocess); DbgPrint("the process name is %S\n", (PTSTR)((ULONG)pEprocess + 0x174));下面是一个使用线程的例子VOID MyProcessThread(PVOID pContext) { //获取当前发送IRP请求的线程名 PEPROCESS pCurrProcess = IoGetCurrentProcess(); PTSTR pProcessName = (PTSTR)((CHAR*)pCurrProcess + 0x174); // UNREFERENCED_PARAMETER(pContext); DbgPrint("MyProcessThread Current Process %s\n", pProcessName); PsTerminateSystemThread(0); } VOID SystemThread(PVOID pContext) { //获取系统进程名 PEPROCESS pCurrProcess = IoGetCurrentProcess(); PTSTR pProcessName = (PTSTR)((CHAR*)pCurrProcess + 0x174); // UNREFERENCED_PARAMETER(pContext); DbgPrint("MyProcessThread Current Process %s\n", pProcessName); PsTerminateSystemThread(0); } VOID CreateThread_Test() { HANDLE hSysThread = NULL; HANDLE hMyProcThread = NULL; NTSTATUS status; //创建系统进程 status = PsCreateSystemThread(&hSysThread, 0, NULL, NULL, NULL, SystemThread, NULL); //创建用户进程 status = PsCreateSystemThread(&hMyProcThread, 0, NULL, NtCurrentProcess(), NULL, MyProcessThread, NULL); } 内核模式下的同步对象内核模式下的同步对象与应用层的大致相同,所以理解了应用的线程同步对象,那么内核层的也很好理解内核模式下的等待函数内核模式下的等待函数是KeWaitForSingleObject 和 KeWaitForMultipleObjects,一个是用来等待单个事件,一个是用来等待多个事件。NTSTATUS KeWaitForSingleObject( IN PVOID Object, /第一个参数是一个指向同步对象的指针 IN KWAIT_REASON WaitReason,//第二个参数是等待原因,在驱动中这个值应该被设置为Executive IN KPROCESSOR_MODE WaitMode,//等待模式,处在低优先级的驱动应该将这个值设置为KernelMode IN BOOLEAN Alertable,//是否是警惕的 IN PLARGE_INTEGER Timeout OPTIONAL//等待时间,如果是正数则表示从1601年1月1日到现在的时间如果是负数则表示从现在算起的时间,单位是100ns );函数如果是等待到了对应的事件则返回STATUS_SUCCESS如果是由于等待时间到了,则返回STATUS_TIMEOUT内核模式下的事件对象在内核中用KEVENT来表示一个事件对象,在使用事件对象时需要对其进行初始化,使用函数KeInitializeEventVOID KeInitializeEvent( IN PRKEVENT Event, //事件对象的指针 IN EVENT_TYPE Type, //事件类型,一般分为两种:NotificationEvent 通知事件和同步事件SynchronizationEvent IN BOOLEAN State//是否是激发状态 );所谓的激发状态就是有信号状态,没有线程拥有这个事件。在这个状态下其他线程中的等待函数可以等到这个事件这两种类型的事件对象的区别在于如果是通知事件需要程序员手动的更改事件的状态,如果是同步事件,在等待函数等到这个事件对象后会自动将这个对象设置为无信号状态可以使用函数KeSetEvent设置事件为有信号,这样其他线程的等待函数就可以等到这个事件LONG KeSetEvent( IN PRKEVENT Event, //事件对象的指针 IN KPRIORITY Increment,//被唤起的线程将以何种优先级执行,这个参数与IoCompleteRequest的第二个参数含义相同 IN BOOLEAN Wait //一般给FALSE );下面是这个它的使用例子VOID Event_Test() { KEVENT keEvent; HANDLE hThread; //初始化事件对象,并设置为无信号 KeInitializeEvent(&keEvent, NotificationEvent, FALSE); //创建新线程,将事件对象传入线程函数中,新线程将会设置事件对象为有状态 PsCreateSystemThread(&hThread, 0, NULL, NULL, NULL, EventThread, &keEvent); if(NULL == hThread) { DbgPrint("Create Event Thread Error!\n"); return; } KeWaitForSingleObject(&keEvent, Executive, KernelMode, FALSE, NULL); } VOID EventThread(PVOID pContext) { PKEVENT pEvent = (PKEVENT)pContext; DbgPrint("This is Event Thread\n"); KeSetEvent(pEvent, IO_NO_INCREMENT, FALSE); PsTerminateSystemThread(0); }驱动程序与应用程序交互事件对象本质上用户层和内核层的事件对象是同一个东西,在用户层用句柄代替,看不到它的具体结构,在内核层是一个KEVENT,能知道它的具体数据成员。我们可以先在应用层创建一个事件对象的句柄,然后通过DeviceIoControl传到应用层,然后利用函数ObReferenceObjectByHandle将这个句柄转化为对应的事件对象,在利用这个函数转化成功后会将事件对象的计数 + 1所以在使用完后应该调用函数ObDereferenceObject使计数减1NTSTATUS ObReferenceObjectByHandle( IN HANDLE Handle, //用户层传下来的内核对象句柄 IN ACCESS_MASK DesiredAccess, //访问权限对于同步事件一般给EVENT_MODIFY_STATE IN POBJECT_TYPE ObjectType OPTIONAL,//转化何种类型的内核结构 IN KPROCESSOR_MODE AccessMode,//模式,一般有KernelMode和UserMode OUT PVOID *Object,//对应结构的指针 OUT POBJECT_HANDLE_INFORMATION HandleInformation OPTIONAL//这个参数在内核模式下为NULL );第三个参数根据转化的内核结构的不同可以有下面的结构。参数值对应的结构*IoFileObjectTypePFILE_OBJECT*ExEventObjectTypePKEVENT*PsProcessTypePEPROCESS或者PKPROCESS*PsThreadTypePETHREAD或者PKTHREAD下面是内核层的例子else if(IOCTL_TRANS_EVENT == pIrps->Parameters.DeviceIoControl.IoControlCode) { //接收从应用层下发的下来的事件句柄 hEvent = *(PHANDLE)(Irp->AssociatedIrp.SystemBuffer); if(NULL == hEvent) { DbgPrint("Invalied Handle\n"); goto __RET; } status = ObReferenceObjectByHandle(hEvent, EVENT_MODIFY_STATE, *ExEventObjectType, KernelMode, &pkEvent, NULL); if(!NT_SUCCESS(status)) { //失败 DbgPrint("Translate Event Error\n"); goto __RET; } //将事件设置为有信号 KeSetEvent(pkEvent, IO_NO_INCREMENT, FALSE); //引用计数 -1 ObDereferenceObject(pkEvent); }驱动程序与驱动程序交互事件对象在内核驱动中可以通过给某个内核对象创建一个命名对象,然后在另一个驱动中通过名字来获取这个对象,然后操作它来实现两个驱动之间的内核对象的通讯,针对事件对象来说,要实现两个驱动交互事件对象,通过这样几步:在驱动A中调用IoCreateNotificationEvent或者IoCreateSynchronizationEvent来创建一个通知事件对象或者同步事件对象在驱动B中调用 IoCreateNotificationEvent或者IoCreateSynchronizationEvent获取已经有名字的内核对象的句柄在驱动B中调用ObReferenceObjectByHandle根据上面两个函数返回的句柄来获取A中的事件对象,并操作它操作完成后调用ObDereferenceObject解引用PKEVENT IoCreateNotificationEvent( IN PUNICODE_STRING EventName, OUT PHANDLE EventHandle );如果指定名称的事件存在那么将会通过EventHandle来返回这个事件对象的句柄,如果不存在则会创建一个事件并通过返回值直接返回这个事件对象的结构指针,需要注意的是这个名字必须以L"\BaseNamedObjects\” 开头另外不能在DriverEntry中等待过长时间,否则会造成系统蓝屏内核模式下的信号量在操作系统相关的书籍中但凡说到线程的同步问题就会涉及到信号量,当多个线程共享一个公共资源时在某一时刻只能有一个线程在运行,这个时候一般用事件对象控制,而当多个线程共享多个公共资源时,可以有多个线程同时在运行,这个时候就可以用信号量,可以把信号量想象成一个盒子,里面有多盏灯,当只要有一盏灯是亮的,就有线程可以执行,每当有一个线程在访问共享资源时,亮灯的数量-1,当线程不再访问共享资源时,亮灯的数目 +1而当灯全部熄灭时就不再允许线程访问。当盒子中只有一盏灯的时候,就相当于一个互斥体信号量的初始化函数为KeInitializeSemaphoreVOID KeInitializeSemaphore( IN PRKSEMAPHORE Semaphore,//将要被初始化的信号量的指针 IN LONG Count,//当前信号量中有多少个灯亮 IN LONG Limit//总共有多少灯 );释放信号量会增加信号灯计数。对应的函数是KeReleaseSemaphore。可以利用这个函数指定增量值,获得的信号灯可以使用Wait函数等待如果获得就熄灭一盏灯,否则就陷入等待。。利用函数KeReadStateSemaphore可以得到当前有多少盏灯是亮的下面是使用的例子VOID Semaphore_Test() { KSEMAPHORE keSemaphore; HANDLE hThread; NTSTATUS status = STATUS_SUCCESS; ULONG uCount = 0;//当前有多少盏灯亮着 //初始化,使其里面有两盏灯,两盏灯全亮 KeInitializeSemaphore(&keSemaphore, 2, 2); if(!NT_SUCCESS(status)) { DbgPrint("Initialize Semaphore Error\n"); return; } //当前有多少盏灯亮着 uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //函数会成功返回并熄灭一盏灯 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //函数会成功返回并熄灭一盏灯 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //创建新线程 PsCreateSystemThread(&hThread, 0, NULL, NULL, NULL, SemaphoreThread, &keSemaphore); //这时没有灯亮,函数会陷入等待状态 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); }VOID SemaphoreThread(PVOID pContext) { //线程函数 PKSEMAPHORE pkeSemaphore = (PKSEMAPHORE)pContext; DbgPrint("Entry My Thread\n"); //点亮其中的一盏灯 KeReleaseSemaphore(pkeSemaphore, IO_NO_INCREMENT, 1, FALSE); //结束线程 PsTerminateSystemThread(0); }内核模式下的互斥体互斥体在内核结构中的定义为KMUTEX使用前需要使用函数KeInitializeMutex进行初始化VOID KeInitializeMutex( IN PRKMUTEX Mutex, IN ULONG Level//系统保留参数一般给0 );初始化之后就可以使用Wait系列的函数进行等待,一旦函数返回,那么该线程就拥有了该互斥体,线程可以调用函数KeReleaseMutex来主动释放互斥体LONG KeReleaseMutex( IN PRKMUTEX Mutex, IN BOOLEAN Wait );与同步对象相比,互斥体可以在某个线程中递归获取,这个时候每当获取一次,那么它被引用的次数也将加1,在释放时,被引用多少次就应该释放多少次,只有当计数为0时才能被其他线程获取互锁操作进行同步互锁操作就是定义了一个原子操作,当原子操作没有完成时,线程是不允许切换的,系统会保证原子操作要么都完成了,要么都没有完成。在Windows中为一些常用的操作定义了一组互锁操作函数 -
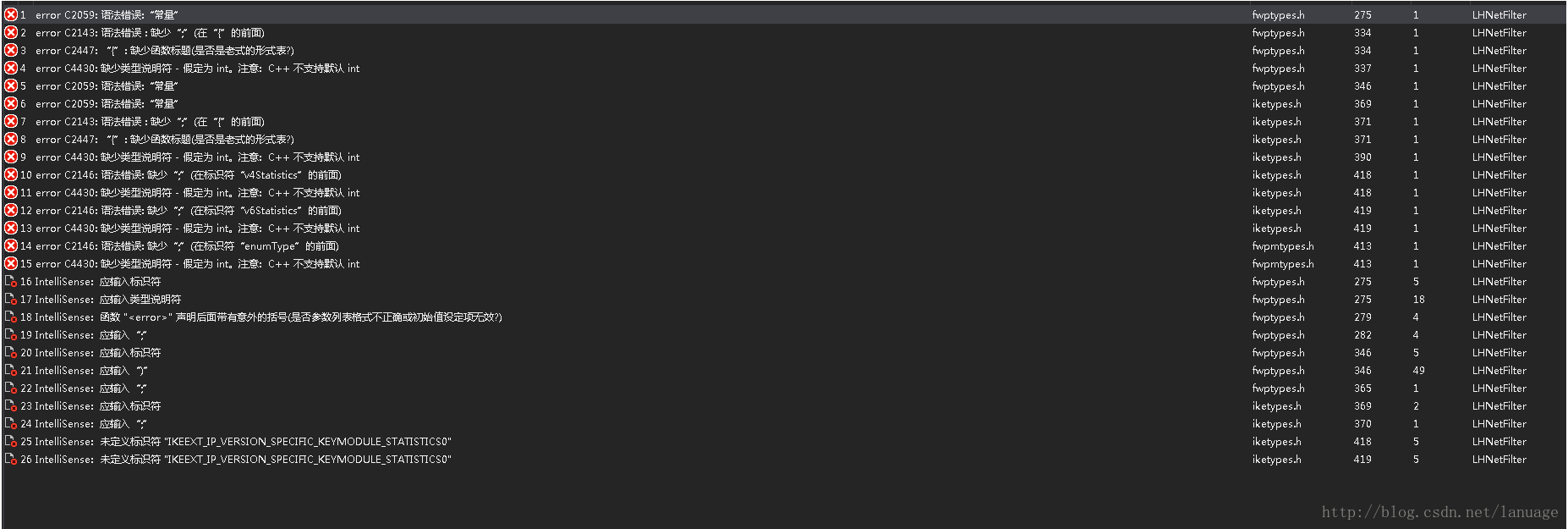
WFP在包含fwpmu.h头的时候出错 最近在学WFP驱动框架,在使用VS2013写代码调用WFP的函数时会包含fwpmu.h这个头,但是在包含这个头的时候会报错,就像下面这个图这样:我百度了一下,然后在这个网站上面找到了解决方案:https://social.msdn.microsoft.com/Forums/windowsdesktop/en-US/8fd93a3d-a794-4233-9ff7-09b89eed6b1f/compiling-with-wfp?forum=wfp虽然我不太看得懂英文,但是根据上面的说明,我们点击第一个错误,然后定位到这个网上说的位置:在FwpTypes.h的第275行,343行出现这样的错误:从上面的错误来看,很明显是在定义宏的时候明明有换行的标志,但是它居然新换了一行,不知道是安装WDK的时候出现的还是什么原因,总之我们把这些换行去掉,然后再次编译就OK了。
-
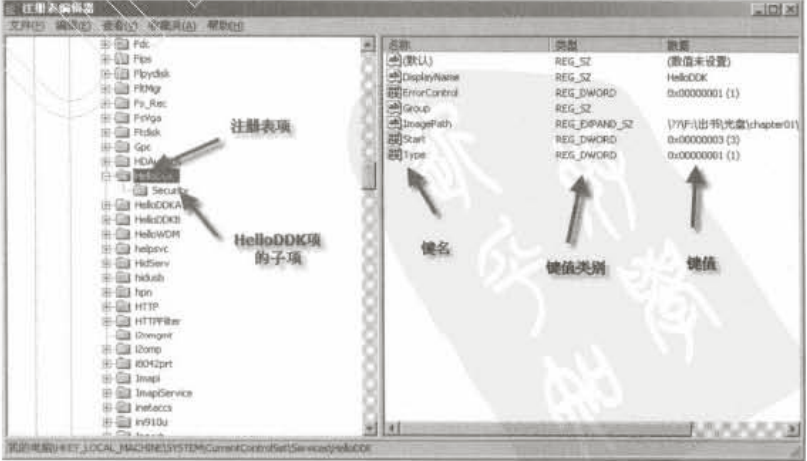
Windows内核函数 字符串处理在驱动中一般使用的是ANSI字符串和宽字节字符串,在驱动中我们仍然可以使用C中提供的字符串操作函数,但是在DDK中不提倡这样做,由于C函数容易导致缓冲区溢出漏洞,针对字符串的操作它提供了一组函数分别用来处理ANSI字符串和UNICODE字符串。针对两种字符串,首先定义了它们的结构体typedef struct _STRING { USHORT Length;//字符串的长度 USHORT MaximumLength;//字符缓冲的长度 PCHAR Buffer;//字符缓冲的地址 } ANSI_STRING, *PANSI_STRING; typedef struct _UNICODE_STRING { USHORT Length; USHORT MaximumLength; PWSTR Buffer; } UNICODE_STRING, *PUNICODE_STRING;对于这两个字符串的打印,可以使用%wZ打印UNICODE_STRING用%Z打印ANSI_STRING字符串的初始化VOID RtlInitAnsiString( IN OUT PANSI_STRING DestinationString, IN PCSZ SourceString ); VOID RtlInitUnicodeString( IN OUT PUNICODE_STRING DestinationString, IN PCWSTR SourceString );这两个函数只是简单的将SourceString 的首地址赋值给Buffer成员,并初始化相关的长度,所以在使用时需要考虑缓冲的生命周期,权限,同时如果我们改变SourceString 里面存储的字符串,那么对应的UNICODE_STRING 或者ANSI_STRING中的值也会改变,比如下面的代码RtlInitUnicodeString(&uTest, L"Hello World"); RtlCopyMemory(uTest.Buffer, L"Test");由于Buffer指向的是不可修改的常量内存部分,所以后面试图修改它的时候会造成程序崩溃。void InitString(&pUnicodeString) { WCHAR szBuf[255] = L"Hello world"; RtlInitUnicodeString(pUnicodeString, szBuffer); } void test() { UNICODE_STRING uTest; InitString(&uTest); //后面的操作 }我们在另外一个函数中利用局部变量来初始化这个字符串的时候由于当函数调用完成,函数中局部变量被销毁,这个时候指向的那块内存可能已经被其他函数所占用,而我们后面通过操作UNICODE_STRING,又要操作这段内存,这个时候一定会出现问题,所以一般如果要在多个函数中使用这个UNICODE_STRING时一般申请一段堆内存,但是在使用完成后一定要记得自己回收这段内存,否则会造成内存泄露,对此DDK专门提供了一组函数来销毁字符串中的堆内存VOID RtlFreeAnsiString( IN PANSI_STRING AnsiString ); VOID RtlFreeUnicodeString( IN PUNICODE_STRING UnicodeString );字符串拷贝:VOID RtlCopyString( IN OUT PSTRING DestinationString, IN PSTRING SourceString OPTIONAL ); VOID RtlCopyUnicodeString( IN OUT PUNICODE_STRING DestinationString, IN PUNICODE_STRING SourceString );字符串比较LONG RtlCompareString( IN PSTRING String1, IN PSTRING String2, BOOLEAN CaseInSensitive//是否忽略大小写 ); LONG RtlCompareUnicodeString( IN PUNICODE_STRING String1, IN PUNICODE_STRING String2, IN BOOLEAN CaseInSensitive );字符串转化为大写VOID RtlUpperString( IN OUT PSTRING DestinationString, IN PSTRING SourceString ); NTSTATUS RtlUpcaseUnicodeString( IN OUT PUNICODE_STRING DestinationString, IN PCUNICODE_STRING SourceString, IN BOOLEAN AllocateDestinationString//是否要求该函数自行为输出参数分配内存 );这两个函数在调用是目标字符串和源字符串可以是同一个字符串字符串与整形数字之间的转化可以使用函数NTSTATUS RtlUnicodeStringToInteger( IN PUNICODE_STRING String, IN ULONG Base OPTIONAL,//需要的数的进制 OUT PULONG Value ); NTSTATUS RtlIntegerToUnicodeString( IN ULONG Value, IN ULONG Base OPTIONAL, IN OUT PUNICODE_STRING String );ANSI与UNICODE字符串的相互转化可以使用下面的函数NTSTATUS RtlUnicodeStringToAnsiString( IN OUT PANSI_STRING DestinationString, IN PUNICODE_STRING SourceString, IN BOOLEAN AllocateDestinationString ); NTSTATUS RtlAnsiStringToUnicodeString( IN OUT PUNICODE_STRING DestinationString, IN PANSI_STRING SourceString, IN BOOLEAN AllocateDestinationString );文件操作创建或者打开一个文件文件的创建和打开都是使用函数ZwCreateFileNTSTATUS ZwCreateFile( OUT PHANDLE FileHandle, IN ACCESS_MASK DesiredAccess, IN POBJECT_ATTRIBUTES ObjectAttributes, OUT PIO_STATUS_BLOCK IoStatusBlock, IN PLARGE_INTEGER AllocationSize OPTIONAL, IN ULONG FileAttributes, IN ULONG ShareAccess, IN ULONG CreateDisposition, IN ULONG CreateOptions, IN PVOID EaBuffer OPTIONAL, IN ULONG EaLength );FileHandle:这个函数通过这个参数返回文件句柄DesiredAccess:以何种权限打开或者创建这个文件,GENERIC_READ可读,GENERIC_WRITE可写,GENERIC_EXECUTE可执行,GENERIC_ALL所有权限ObjectAttributes:这是一个文件属性的结构体,里面包含有要打开的文件的名称IoStatusBlock:接受函数操作文件的结果状态AllocationSize:指定在创建爱女或者写文件时初始大小,如果给0,则文件大小会随着写入数据的增加而动态的增加FileAttributes:指定新创建文件的属性,一般给0或者FILE_ATTRIBUTE_NORMALShareAccess:文件的共享权限,其他线程或者进程通过这个句柄访问文件的权限,给0表示不允许其他进程通过这个句柄访问,FILE_SHARE_READ读, FILE_SHARE_WRITE写,FILE_SHARE_DELETE删除CreateDisposition:指定当文件存在或者不存在时这个函数的动作。它的取值可以有下面几个取值文件存在文件不存在FILE_SUPERSEDE新建一个文件替代新建文件FILE_CREATE返回一个错误创建文件FILE_OPEN打开文件返回一个错误FILE_OPEN_IF打开文件创建文件FILE_OVERWRITE打开,并且将之前的内容覆盖返回错误FILE_OVERWRITE_IF打开,并且将之前的内容覆盖创建文件CreateOptions打开或者创建文件时的附加操作,一般给FILE_SYNCHRONOUS_IO_NONALERTEaBuffer指向扩展空间的指针EaLength扩展空间的大小这个函数与应用层的CreateFile不同的时,在指定打开或者创建文件名时是使用结构OBJECT_ATTRIBUTES来指定,针对这个结构,有一个函数能够初始化它VOID InitializeObjectAttributes( OUT POBJECT_ATTRIBUTES InitializedAttributes, IN PUNICODE_STRING ObjectName,//文件名 IN ULONG Attributes, IN HANDLE RootDirectory, IN PSECURITY_DESCRIPTOR SecurityDescriptor );Attributes:该对象的描述信息,一般给OBJ_CASE_INSENSITIVE 表示对大小写敏感RootDirectory :该文件的根目录,一般给NULLSecurityDescriptor :安全描述符,一般也是给NULL另外这里的名称必须使用符号链接名或者设备名,而不是我们熟悉的“C:\”这种形式对于C盘可以使用名称“\??\C”或者“\Device\HarddiskVolum1”这种形式当程序结束时需要调用ZwClose来清理文件句柄这个函数的参数比较简单,只是简单的传入文件句柄即可获取和设置文件的相关信息可以下面两个函数分别获取和设置文件的相关信息NTSTATUS ZwQueryInformationFile( IN HANDLE FileHandle, OUT PIO_STATUS_BLOCK IoStatusBlock, OUT PVOID FileInformation, IN ULONG Length, IN FILE_INFORMATION_CLASS FileInformationClass ); NTSTATUS ZwSetInformationFile( IN HANDLE FileHandle, OUT PIO_STATUS_BLOCK IoStatusBlock, IN PVOID FileInformation, IN ULONG Length, IN FILE_INFORMATION_CLASS FileInformationClass );其中FileInformationClass是一个枚举值,根据这个值得不同FileInformation可以被解析成不同的内容。当这个参数为FileStandardInformation时,使用结构体FILE_STANDARD_INFORMATIONtypedef struct FILE_STANDARD_INFORMATION { LARGE_INTEGER AllocationSize; //为文件分配簇所占空间的大小 LARGE_INTEGER EndOfFile;//距离文件结尾还有多少字节,当文件指针位于文件头时,这个值就是文件本身大小 ULONG NumberOfLinks;//有多少个链接文件 BOOLEAN DeletePending;//是否准备删除 BOOLEAN Directory;//是否为目录 } FILE_STANDARD_INFORMATION, *PFILE_STANDARD_INFORMATION;当这个参数为FileBasicInformation使用结构体FILE_BASIC_INFORMATIONtypedef struct FILE_BASIC_INFORMATION { LARGE_INTEGER CreationTime; //创建时间 LARGE_INTEGER LastAccessTime;//上次访问时间 LARGE_INTEGER LastWriteTime;//上次写文件时间 LARGE_INTEGER ChangeTime;//上次修改时间 ULONG FileAttributes;//文件属性 } FILE_BASIC_INFORMATION, *PFILE_BASIC_INFORMATION;其中时间参数是一个LARGE_INTEGER类型的整数,代表从1601年到现在经过多少个100ns。文件属性参数如果为FILE_ATTRIBUTE_DIRECTORY表示这是一个目录文件,FILE_ATTRIBUTE_NORMAL表示是一个普通文件,FILE_ATTRIBUTE_HIDDEN表示这是一个隐藏文件,FILE_ATTRIBUTE_SYSTEM表示这是一个系统文件,FILE_ATTRIBUTE_READONLY表示这是一个只读文件当这个参数为FileNameInformation时,使用结构体FILE_NAME_INFORMATIONtypedef struct _FILE_NAME_INFORMATION { ULONG FileNameLength;//文件名长度 WCHAR FileName[1];//文件名 } FILE_NAME_INFORMATION, *PFILE_NAME_INFORMATION;当这个参数是FilePositionInformation时,使用结构体FILE_POSITION_INFORMATIONtypedef struct FILE_POSITION_INFORMATION { LARGE_INTEGER CurrentByteOffset;//当前文件指针的位置 } FILE_POSITION_INFORMATION, *PFILE_POSITION_INFORMATION;读写文件写文件调用函数ZwCreateFileNTSTATUS ZwWriteFile( IN HANDLE FileHandle,//文件句柄 IN HANDLE Event OPTIONAL,//时间对象一般给NULL IN PIO_APC_ROUTINE ApcRoutine OPTIONAL,//一般给NULL IN PVOID ApcContext OPTIONAL,//一般给NULL OUT PIO_STATUS_BLOCK IoStatusBlock,//记录写操作的状态用里面的Information成员记录实际写了多少字节 IN PVOID Buffer,//写入文件中缓冲区的指针 IN ULONG Length,//缓冲区中数据的长度 IN PLARGE_INTEGER ByteOffset OPTIONAL,//从文件的多少地址开始写 IN PULONG Key OPTIONAL//一般给NULL );读文件使用函数ZwReadFileNTSTATUS ZwReadFile( IN HANDLE FileHandle,//文件句柄 IN HANDLE Event OPTIONAL,//一般给NULL IN PIO_APC_ROUTINE ApcRoutine OPTIONAL,//一般给NULL IN PVOID ApcContext OPTIONAL,//一般给NULL OUT PIO_STATUS_BLOCK IoStatusBlock, //读取的字节数保存在结构的成员Information中 OUT PVOID Buffer,//缓冲区的指针 IN ULONG Length,//缓冲区的长度 IN PLARGE_INTEGER ByteOffset OPTIONAL,//从文件的多少位置开始读 IN PULONG Key OPTIONAL//一般给NULL );注册表操作注册表中有下面几个概念:注册表项:注册表项类似于目录的概念,下面可以有子项或者注册表的键-值对注册表子项:类似于子目录的概念键名:通过键名可以寻找到相应的键值键值类别:每个键值在存储的时候有不同的类型,相当于变量的类型,主要有字符串和整型键值:键名下对应存储的数据创建和关闭注册表创建注册表使用函数ZwCreateKeyNTSTATUS ZwCreateKey( OUT PHANDLE KeyHandle, IN ACCESS_MASK DesiredAccess, IN POBJECT_ATTRIBUTES ObjectAttributes, IN ULONG TitleIndex, IN PUNICODE_STRING Class OPTIONAL, IN ULONG CreateOptions, OUT PULONG Disposition OPTIONAL );KeyHandle:输出一个注册表对应项的句柄,以后针对这个项操作都是以这个句柄作为标示DesiredAccess:访问权限,一般都设置为KEY_ALL_ACCESSObjectAttributes:用法与文件操作中的用法相同其中应用层中注册表项与内核中注册表项的对应关系如下:应用层中的子健内核中的路径HKEY_CLASSES_ROOT没有对应的路径HKEY_CURRENT_USER没有简单的对应路径,但是可以求得HKEY_USERS\Registry\UserHKEY_LOCAL_MACHINE\Registry\MachineTitleIndex:一般设置为0Class 一般给NULLCreateOptions:创建选项,一般给REG_OPTION_NON_VOLATILEDisposition:返回创建的状态,如果是REG_CREATED_NEW_KEY表示创建了一个新的注册表项如果是REG_OPENED_EXISTING_KEY表示打开一个已有的注册表项添加、修改注册表键注册表中的键是类似与字典中的键值对,通过键名找到对应的值,键值的类型大致可以分为下面几种分类描述REG_BINARY键值采用二进制存储REG_SZ键值用宽字符串,以\0结尾REG_EXPAND_SZ与上面的REG_SZ相同,它是上面那个字符串的扩展字符REG_MULTI_SZ能够存储多个字符串,每个都以\0隔开REG_DWORD键值用4字节整型存储(这个类型的数据在驱动中使用ULONG来替代)REG_QWORD键值用8字节存储(这个用LONGLONG)用函数ZwSetValueKey可以添加和修改注册表的一项内容 NTSTATUS ZwSetValueKey( IN HANDLE KeyHandle, //注册表句柄 IN PUNICODE_STRING ValueName,//要修改或者新建的键名 IN ULONG TitleIndex OPTIONAL,//一般设置为0 IN ULONG Type,//在上面的表中选择一个 IN PVOID Data,//键值 IN ULONG DataSize//键值数据的大小 );当传入的键值不存在则创建一个新键值,否则就修改原来的键值查询注册表查询注册表使用函数ZwQueryValueKeyNTSTATUS ZwQueryValueKey( IN HANDLE KeyHandle, //注册表句柄 IN PUNICODE_STRING ValueName,//注册表键名 IN KEY_VALUE_INFORMATION_CLASS KeyValueInformationClass, OUT PVOID KeyValueInformation,//接收返回信息的缓冲区 IN ULONG Length,//缓冲区的大小 OUT PULONG ResultLength//真实缓冲区的大小 );使用这个函数时利用参数KeyValueInformationClass来指定接收数据的类型,根据这个值的不同,函数会返回不同的结构体放到一个缓冲区中。一般这个值可取:KeyValueBasicInformation 返回注册表项的基础信息KeyValueFullInformation 返回注册表的全部信息KeyValuePartialInformation 返回注册表的部分信息一般情况下使用KeyValuePartialInformation查询键值数据利用这个函数来查询时一般也是采用两次调用的方式,第一次返回数据所需缓冲,然后分配缓冲并进行第二次调用枚举子项DDK提供了两个函数用于这个功能NTSTATUS ZwQueryKey( IN HANDLE KeyHandle,//注册表句柄 IN KEY_INFORMATION_CLASS KeyInformationClass,//保存注册表信息的结构体的类型 OUT PVOID KeyInformation,//返回查询到信息的缓冲 IN ULONG Length,//缓冲的大小 OUT PULONG ResultLength//真正信息的大小 ); NTSTATUS ZwEnumerateKey( IN HANDLE KeyHandle,//句柄 IN ULONG Index,//这个值是表示第几个子项 IN KEY_INFORMATION_CLASS KeyInformationClass,//查询到的信息的结构体 OUT PVOID KeyInformation,//返回信息的缓冲 IN ULONG Length,//缓冲长度 OUT PULONG ResultLength//返回信息的长度 );其中ZwQueryKey函数用于查询某个注册表项中有多少个子项,在调用这个函数时传入的KeyInformationClass的值一般给KeyFullInformation,在这个结构体中的SubKeys表示有多少个子项,而ZwEnumerateKey则是用于查询各个子项中的具体内容,通过指定Index表示我们要查询该项中的第几个子项,将KeyInformationClass填入KeyBasicInformation,这样在结构体的Name里面可以得到具体的注册表子项的名称枚举子健枚举子键的方法于上面的大致相同,首先利用ZwQueryKey查询注册表,然后取结构体KeyFullInformation的成员Values,根据这个值在循环中依次调用函数ZwEnumerateValueKey,结构体类填入 KeyValueBasicInformation查询基本信息即可删除子项删除子项使用的内核函数是ZwDeleteKeyNTSTATUS ZwDeleteKey( IN HANDLE KeyHandle );这个函数只能删除没有子项的项目,如果有子项,则需要先删除所有子项。其他注册表函数为了简化注册表操作,DDK提供了另外一组以Rtl开头的函数,把之前的Zw函数进行了封装,下面是这些函数与它们功能的对应关系函数名描述RtlCreateRegistryKey创建注册表项RtlCheckRegistryKey查看注册表中的某项是否存在RtlWriteRegistryValue写注册表RtlDeleteRegistryValue删除注册表的子键
-
Windows内核中的内存管理 内存管理的要点内核内存是在虚拟地址空间的高2GB位置,且由所有进程所共享,进程进行切换时改变的只是进程的用户分区的内存驱动程序就像一个特殊的DLL,这个DLL被加载到内核的地址空间中,DriverEntry和AddDevice例程在系统的system进程中运行,派遣函数会运行在应用程序的进程上下文中所能访问的地址空间是这个进程的虚拟地址空间利用_EPROCESS结构可以查看该进程的相关信息当程序的中断级别在DISPATCH_LEVEL之上时,必须使用非分页内存,否则会造成系统蓝屏,在编译WDK相关例程时,可以使用如下的宏指定某个例程或者某个全局变量是位于分页内存还是运行于非分页内存#define PAGEDCODE code_seg("PAGE") //分页内存 #define LOCKEDCODE code_seg() //非分页内存 #define INITCODE code_seg("INIT") //指定在相关函数执行完成后就从内存中卸载下来 #define PAGEDDATA data_seg("PAGE") #define LOCKEDDATA data_seg() #define INITDATA data_seg("INIT")在使用时直接使用#pragma直接加载这些宏即可比如:#pragma PAGEDCODE VOID DoSomething() { PAGED_CODE() //函数体 }其中PAGED_CODE是一个WDK中提供的一个宏,只在debug版本中生效,用于判断当前的中断请求级别,当级别高于DISPATCH_LEVEL(包含这个级别)时会产生一个断言内核中的堆申请函数PVOID ExAllocatePool( IN POOL_TYPE PoolType, IN SIZE_T NumberOfBytes ); PVOID ExAllocatePoolWithTag( IN POOL_TYPE PoolType, IN SIZE_T NumberOfBytes, IN ULONG Tag ); PVOID ExAllocatePoolWithQuota( IN POOL_TYPE PoolType, IN SIZE_T NumberOfBytes ); PVOID ExAllocatePoolWithQuotaTag( IN POOL_TYPE PoolType, IN SIZE_T NumberOfBytes, IN ULONG Tag );PoolType:这是一个枚举变量,用来表示分配内存的种类,如果为PagedPool表示分配的是分页内存,如果是NonPagedPool表示分配的是非分页内存NumberOfBytes:分配内存的大小,为了效率最好分配4的倍数上面这些函数主要分为带有标记和不带标记的两种,其中有Quota的是按配额分配,带有标记的函数可以通过这个标记来判断这块内存最后有没有被分配,标记是一个字符串,但是这个字符串是用单引号引起来的。一般给4个字符,由于IntelCPU采用的是高位优先的存储方式,所以为了阅读方便,一般将这个字符串倒着写这些函数分配的内存一般使用下面的函数来释放VOID ExFreePool( IN PVOID P ); NTKERNELAPI VOID ExFreePoolWithTag( IN PVOID P, IN ULONG Tag ); 在驱动中使用链表WDK给程序员提供了两种基本的链表结构,分别是单向链表和双向链表双向链表的结构体定义如下:typedef struct _LIST_ENTRY { struct _LIST_ENTRY *Flink; //指向下一个节点 struct _LIST_ENTRY *Blink; //指向上一个节点 } LIST_ENTRY, *PLIST_ENTRY;初始化链表使用宏InitializeListHead,它需要传入一个链表的头节点指针它的定义如下VOID InitializeListHead( IN PLIST_ENTRY ListHead );这个宏只是简单的将链表头的Flink和Blink指针指向它本身。利用宏IsListEmpty可以检查一个链表是否为空,它也是只简单的检查这两个指针是否指向其自身在定义自己的数据结构的时候需要将这个结构体放到自定义结构体中,比如typedef struct _MYSTRUCT { LIST_ENTRY listEntry; ULONG i; ULONG j; }MYSTRUCT, *PMYSTRUCT一般插入链表有两种方法,头插法和尾插法,DDK根据这两种方法都给出了具体的函数可供操作://头插法,采用头插法只改变链表数据的顺序,链表头仍然是链表中的第一个元素 VOID InsertHeadList( IN PLIST_ENTRY ListHead, //链表头指针 IN PLIST_ENTRY Entry //对应节点中的LIST_ENTRY指针 ); //尾插法 VOID InsertTailList( IN PLIST_ENTRY ListHead, IN PLIST_ENTRY Entry );删除节点使用的是这样两个函数,同样采用的是从头部开始删除和从尾部开始删除,就是查找链表中节点的方向不同。//从头部开始删除 PLIST_ENTRY RemoveHeadList( IN PLIST_ENTRY ListHead ); //从尾部开始删除 PLIST_ENTRY RemoveTailList( IN PLIST_ENTRY ListHead );这两个函数都是传入头节点的指针,返回被删除那个节点的指针,这里有一个问题,我们如何根据返回PLIST_ENTRY结构找到对应的用户定义的数据,如果我们将LIST_ENTRY,这个节点放在自定义结构体的首部的时候,返回的地址就是结构体的地址,如果是放在其他位置,则需要根据结构体的定义来进行转化,对此WDK提供了这样一个宏来帮我们完成这个工作:PCHAR CONTAINING_RECORD( IN PCHAR Address, IN TYPE Type, IN PCHAR Field );这个宏返回自定义结构体的首地址,传入的是第一个参数是结构体中某个成员的地址,第二个参数是结构体名,第三个参数是我们传入第一个指针的类型在结构体中对应的成员变量值,比如对于上面那个MYSTRUCT结构体可以这样使用typedef struct _MY_LIST_DATA { LIST_ENTRY list; ULONG i; }MY_LIST_DATA, *PMY_LIST_DATA; PLIST_ENTRY pListData = RemoveHeadList(&head);//head是链表的头节点 PMYSTRUCT pData = CONTAINING_RECORD(pListData, MYSTRUCT, list);Lookaside结构频繁的申请和释放内存将造成内存空洞,即出现大量小块的不连续的内存片段,这个时候即使内存仍有剩余,但是我们也申请不了内存,一般在操作系统空闲的时候会进行内存整理,将空洞内存进行合并,如果驱动需要频繁的从内存中申请释放相同大小的内存块,DDK提供了Lookaside内存容器,在初始时它先向系统申请了一块比较大的内存,以后程序每次申请内存的时候不是直接在Windows堆中进行分配,而是在这个容器中,Lookaside结构会智能的避免产生内存空洞,如果申请的内存过多,lookaside结构中的内存不够时,他会自动向操作系统申请更多的内存,如果lookaside内部有大量未使用的内存时,他会自动释放一部分,总之它是一个智能的自动调整内存大小的一个容器。一般应用于以下几个方面:程序每次申请固定大小的内存申请和回收的操作十分频繁使用时首先初始化Lookaside对象,调用函数VOID ExInitializeNPagedLookasideList( IN PNPAGED_LOOKASIDE_LIST Lookaside, IN PALLOCATE_FUNCTION Allocate OPTIONAL, IN PFREE_FUNCTION Free OPTIONAL, IN ULONG Flags, IN SIZE_T Size, IN ULONG Tag, IN USHORT Depth );或者VOID ExInitializePagedLookasideList( IN PPAGED_LOOKASIDE_LIST Lookaside, IN PALLOCATE_FUNCTION Allocate OPTIONAL, IN PFREE_FUNCTION Free OPTIONAL, IN ULONG Flags, IN SIZE_T Size, IN ULONG Tag, IN USHORT Depth );这两个函数一个是操作的是非分页内存,一个是分页内存。Lookaside:这个参数是一个NPAGED_LOOKASIDE_LIST的指针,在初始化前需要创建这样一个结构体的变量,但是不用填写其中的数据。Allocate:这个参数是一个分配内存的回调函数,一般这个值填NULLFree:这是一个释放的函数,一般也填NULL这两个函数有点类似于C++中的构造与析构函数,如果我们对申请的内存没有特殊的初始化的操作,一般这个两个都给NULLFlags:这是一个保留字节,必须为NULLSize:指明明我们每次在lookaside容器中申请的内存块的大小每次申请的内存块的标志,这个标志与上面的WithTag函Tag:数申请内存时填写的标志相同Depth:系统保留,必须填0创建容器之后,可以用下面两个函数来分配内存PVOID ExAllocateFromNPagedLookasideList( IN PNPAGED_LOOKASIDE_LIST Lookaside ); PVOID ExAllocateFromPagedLookasideList( IN PPAGED_LOOKASIDE_LIST Lookaside );用下面两个函数来释放内存VOID ExFreeToNPagedLookasideList( IN PNPAGED_LOOKASIDE_LIST Lookaside, IN PVOID Entry ); VOID ExFreeToPagedLookasideList( IN PPAGED_LOOKASIDE_LIST Lookaside, IN PVOID Entry );最后可以使用下面两个函数来释放Lookaside对象VOID ExDeleteNPagedLookasideList( IN PNPAGED_LOOKASIDE_LIST Lookaside ); VOID ExDeletePagedLookasideList( IN PPAGED_LOOKASIDE_LIST Lookaside );其他内存函数内存拷贝函数VOID RtlCopyMemory( IN VOID UNALIGNED *Destination, IN CONST VOID UNALIGNED *Source, IN SIZE_T Length );需要注意的是这个函数没有考虑到内存重叠的情况,假如内存发生重叠例如这样:这个时候AC内存块和BD内存块有部分重叠,如果将AC拷贝到BD那么会改变AC的值,这样在拷贝到BD中的值也会发生变化,有可能造成错误,为了保证重叠也可以正常拷贝,可以使用函数void MoveMemory( __in PVOID Destination, __in const VOID* Source, __in SIZE_T Length );填充内存一般使用函数void FillMemory( [out] PVOID Destination, [in] SIZE_T Length, [in] BYTE Fill );另外DDK另外提供了一个将内存清零的函数VOID RtlZeroMemory( IN VOID UNALIGNED *Destination, IN SIZE_T Length );内存比较函数ULONG RtlEqualMemory( CONST VOID *Source1, CONST VOID *Source2, SIZE_T Length );这个函数返回的是两块内存中相同的字节数,如果要比较两块内存是否完全相同,可以将返回值与Length相比较,如果相等则说明两块内存相同,否则不相同,另外为了实现这个功能DDK提供了一个与该函数同名的宏来判断,具体在编写代码时可以根据情况判断调用的是函数还是宏。在内核中,对于内存的读写要相当的谨慎,稍不注意就可能产生一个新漏洞或者造成系统的蓝屏崩溃,有时在读写内存前需要判断该内存是否合法可供读写,DDK提供了两个函数来判断内存是否可读可写VOID ProbeForRead( IN CONST VOID *Address, IN SIZE_T Length, IN ULONG Alignment//当前内存是以多少字节对齐的 ); VOID ProbeForWrite( IN CONST VOID *Address, IN SIZE_T Length, IN ULONG Alignment );这两个函数在内存不可读写的时候引发一个异常,需要用结构化异常进行处理,这里使用结构化异常的方式与在应用层的使用方式相同其他数据结构typedef union _LARGE_INTEGER { struct { DWORD LowPart; LONG HighPart; }; struct { DWORD LowPart; LONG HighPart; } u; LONGLONG QuadPart; } LARGE_INTEGER, *PLARGE_INTEGER;这个结构用来表示64位二进制的整形数据,它是一个共用体,占内存大小是64位8个字节,从定义上来看可以看做一个LONGLONG型数据,也可以看做两个4字节的数据。
-
windbg蓝屏调试 一般在写Windows内核程序的时候,经常会出现蓝屏的问题,这个时候一般是采用记录下dump文件然后用windbg查看得方式,具体的过程就不说了,网上一大堆的内容。现在我主要记录自己当初按照网上的方案出现windbg的open crashdump项呈现灰色的情况。就像下面这样这个问题曾今百思不得其解,曾今一度以为是自己的win10不能很好的兼容这个,后来发现自己想多了( ^_^ ),现在公布这个问题的解决方案。主要是确保下面的工作完成1)首先需要在虚拟机上确保我们打开了抓取dump文件的功能,怎么打开百度上有一大堆。2)接着就是真实机上也要打开这个功能3)然后最重要的就是关闭虚拟机,不要让windbg连上了虚拟机,它连上了虚拟机就会呈现选项变灰的情况,查看dump文件是我们在真实机里面进行的,之前一直不知道这点,结果怎么试都不行。如果还是不行,可以考虑关了虚拟机之后重启windbg。然后可以看到已经能使用这个选项了。在调试dump文件时要确保自己已经下载了Windows内核的符号表,然后打开dump文件就可以分析出错的位置了
-
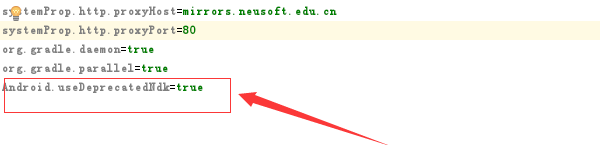
Error: Your project contains C++ files but it is not using a supported native build system 我在编写有关JNI的代码的时候回报这个错误,我在网上搜了相关的资料后,找到了一篇文章解决了这个问题,点击这里查看这篇文章,我在照着这篇文章尝试的时候,总有一些错误,现在我把自己详细的解决流程贴出来,供大家参考。首先在工程目录下的gradle.properties文件的末尾加上一句:Android.useDeprecatedNdk=true如图:然后再在文件build.gradle(Module:app)里面的buildTypes类中添加一个这样的方法sourceSets { main { jni.srcDirs = [] } }如下图所示这样就可以编译成功了
-
用call和ret实现子程序 ret和call是另外两种转移指令,它们与jmp的主要区别是,它们还包含入栈和出栈的操作。具体的原理如下:ret操作相当于:pop ip(直接将栈顶元素赋值给ip寄存器)call s的操作相当于:push ip jmp s(先将ip的值压栈,再跳转)retf的操作相当于:pop ip pop cscall dword ptr s相当于:push cs push ip这两组指令为我们编写含子函数的程序提供了便利,一般的格式如下:main: ......... call s ........ a s: ........ call s1 .......... b ret s1: .......... call s2 ......... c ret s2: ......... d call s3 ret s3: ........ ret分析以上的程序,假设call的下一条指令的偏移地址分别为:a、b、c、d随着程序的执行,ip指向call指令,CPU将这条指令放入指令缓冲器,执行上一条指令,然后ip指向下一条指令,ip = a。执行call指令,根据call的原理先执行a入栈,此时栈中的情况如下然后跳转到s,执行到call指令处时,ip = b,b首先入栈,然后跳转到s1执行到s1处的call指令时,ip = c,c入栈,然后跳转到s2执行到s2处的call指令时,ip = d,d入栈,然后跳转到s3执行到s3处的ret指令时,栈顶元素出栈,ip = d,程序返回到s2中,到ret时,ip = c,程序返回到s1,再次执行ret,ip = b,程序返回到s,执行ret,ip = a,程序返回到main中,接下来正常执行main中的代码,知道整个程序结束。
-
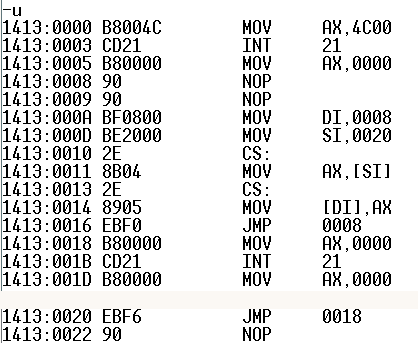
汇编转移指令jmp原理 在计算机中存储的都是二进制数,计算机将内存中的某些数当做代码,某些数当做数据。在根本上,将cs,ip寄存器所指向的内存当做代码,指令转移就是修改cs,ip寄存器的指向,汇编中提供了一种修改它们的指令——jmp。jmp指令可以修改IP或cs和IP的值来实现指令转移,指令格式为:”jmp 标号“将指令转移到标号处,例如:CODES SEGMENT ASSUME CS:CODES START: MOV AX,0 jmp s inc ax s: mov ax,3 MOV AH,4CH INT 21H CODES ENDS END START通过单步调试可以看出在执行jmp后直接执行s标号后面的代码,此时ax为3,。jmp s所对应的机器码为"EB01",在“Inc ax”后面再加其他的指令(加两个 nop指令)此时jmp所对应的机器码为"EB03",每一个nop指令占一个字节,在添加或删除它们之间的代码可以看到jmp指令所对应的机器码占两个字节,第一个字节的机器码并不发生改变,改变的是第二个字节的内容,并且第二个字节的内容存储的是跳转目标指令所在内存与jmp指令所在内存之间的位移。其实cup在执行jmp指令时并不会记录标号所在的内存地址,而是通过标号与jmp指令之间的位移,假设jmp指令的下一条指令的地址为org,位移为idata,则目标的内存地址为dec = org + idata。(idata有正负之分)在CPU中有指令累加器称之为CA寄存器, 程序每执行一条,CA的值加1,jmp指令后可以有4中形式“jmp short s、jmp、 s jmp near ptr s、jmp far ptr s”编译器在翻译时,位移所对应的内粗大小为1、2、2、4(分别是cs和ip所对应的位移)。都是带符号的整型。jmp指令的跳转分为两种情况:向前跳转和向后跳转。向后跳转:jmp (.....)s ...... ...... s:......这种情况下,编译器将jmp指令读完后,读下一条指令,并将CA加1,一直读到相应的标号处,此时CA的值就是位移,根据具体的伪指令来分配内存的大小(此时的数应该为正数)向前跳转 :s:....... ........ jmp (......) s编译器在遇到标号时会在标号后添加几个nop指令("jmp short s、jmp、 s jmp near ptr s、jmp far ptr s"分别添加1,2,2,4个),读下一条指令时将CA寄存器的值加1,得到对应的位移,生成机器码(此时为负数).这两种方式分别得到位移后,在执行过程中,利用上述公式计算出对应的地址,实现指令的转移下面的一段代码充分说明了jmp的这种实现跳转的机制:assume cs:code code segment mov ax,4c00h int 21h start: mov ax,0 s: nop nop mov di,offset s mov si,offset s2 mov ax,cs:[si] mov cs:[di],ax s0: jmp short s s1: mov ax,0 int 21h mov ax,0 s2: jmp short s1 nop code ends end start通过以上的分析可以得出,几个jmp指令所占的空间为2个字节,一个保存jmp本省的机器码,EB,另一个保存位移。因此两个nop指令后面的四句是将s2处的“jmp short s1”所对应的机器码拷贝到s处,利用debug下的-u命令可以看出该处的机器码为“EB F6” f6转化为十进制是-10.执行到s0处时,jmp指令使CPU下一次执行s处的代码,“EB F6”对应的操作利用公式可以得出IP = A - A = 0,下一步执行的代码是“MOV AX,4C00H”,也就是说该程序在此处结束。用-t命令单步调试:
-
C语言中处理结构体的原理 汇编中有几种寻址方式,分别是直接寻址:(ds:[idata])、寄存器间接寻址(ds:[bx])、寄存器相对寻址(ds:[bx + idata]、ds:[bx + si])基址变址寻址(ds:[bx + si])、相对基址变址寻址([bx + si + idata])。结构体的存储逻辑图如下:(以下数据表示某公司的名称、CEO、CEO的福布斯排行、收入、代表产品)现在假设公司的CEO在富豪榜上的排名为38,收入增加了70,代表产品变为VAX,通过汇编编程修改上述信息,以下是相应的汇编代码:(假设数据段为seg)mov ax,seg mov ds,ax mov bx,0 mov word ptr ds:[bx + 12],38 add [bx + 14],70 mov si,0 mov byte ptr [bx + 10 + si],'V' inc si mov byte ptr [bx + 10 + si],'A' inc si mov byte ptr [bx + 10 + si],'X'对应的C语言代码可以写成:struct company { char cn[3]; char name[9]; int pm; int salary; char product[3]; }; company dec = {"DEC","Ken Olsen",137,40,"PDP"}; int main() { int i; dec.pm = 38; dec.salary += 70; dec.product[i] = 'V'; ++i; dec.product[i] = 'A'; ++i; dec.product[i] = 'X'; return 0; }对比C语言代码和汇编代码,可以看出,对于结构体变量,系统会先根据定义分配相应大小的空间,并将各个变量名与内存关联起来,结构体对象名与系统分配的空间的首地址相对应(定义的结构体对象的首地址在段中的相对地址存储在bx中),即在使用dec名时实际与汇编代码“mov ax,seg” "mov ds,ax"对应,将数据段段首地址存入ds寄存器中,系统根据对象中的变量名找到对应的偏移地址,偏移地址的大小由对应的数据类型决定,如cn数组前没有变量,cn的偏移地址为0,cn所在的地址为 ds:[bx],cn为长度为3的字符型数组,在上一个偏移地址的基础上加上上一个变量所占空间的大小即为下一个变量的偏移地址,所以name数组的首地址为ds:[bx + 3],这样给出了对象名就相当于给定了该对象在段中的相对地址(上述代码中的bx),给定了对象中的成员变量名就相当于给定了某一内存在对象中的偏移地址(ds:[bx + idata])。根据数组名可以找到数组的首地址,但数组中具体元素的访问则需要给定元素个数,即si的值来定位数组中的具体内存,C语言中的 ++i 相当于汇编中的 (add si ,数组中元素的长度)。根据以上的分析可以看出,构建一个结构体对象时,系统会在代码段中根据结构体的定义开辟相应大小的内存空间,并将该空间在段中的偏移地址与对象名绑定。对象中的变量名与该变量在对象所在内存中的偏移地址相关联,数组中的标号用于定位数组中的元素在数组中的相对位置。(对象名决定bx,变量名决定bx + idata,数组中的元素标号决定bx + idata + si)。
-
汇编debug与masm命令 汇编语言这块是我之前写在网易博客上的,不过那个账号基本已经作废了,所以现在抽个时间把当时的博客搬到CSDN上。汇编命令(编译器masm命令):找到masm所在的文件夹,我的在d:\MASM中,用cmd打开dos界面,输入“d:”切换到D盘,再输入“d:\MASM\masm”打开编译器中的masm程序得到如下结果:再输入路径+含".asm"的文件(若在当前文件夹中则不必输入路径),这个表示生成了一个“.obj”文件,在第二行若不输入任何内容则默认在当前文件夹下生成一个与“.asm”同名的“.obj”文件。下面几个直接输入空格,不生成这几个文件,知道提示所有工作都完成(0 warning error)再按照上述格式找到MASM文件中的link程序,输入所需的“.obj”文件的相对路径 ".exe"行后不输入任何内容表示在该文件夹下生成一个与“.obj”文件同名的“.exe”文件,到这里汇编程序的编译链接工作就完成了。下面是该程序的调试,输入“debug” + 执行程序的路径进入程序,-u命令:查看汇编代码;-t命令:执行下一条语句-g + 的内存:跳转到该内存所对应的语句(再用t命令执行该条命令)-r命令:查看寄存器的内容(后可直接接寄存器的名称,就只查看该寄存器的内容)-d命令:后接内存地址,查看改地址后面8 * 16个字节空间的地址(每行16个字节,共8行)后面是对应的字符‘.’表示没有该数字对应的字符加上地址范围的话就只查看该地址范围内存储的数据