搜索到
84
篇与
的结果
-
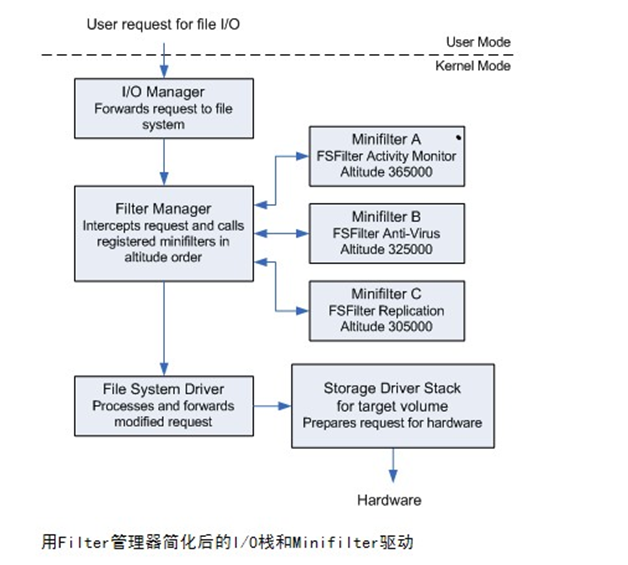
 Minfilter过滤框架 Minfilter过滤框架优势与传统的Sfilter过滤驱动相比,有这样几个优势Minfilter加载顺序更易控制,Sfilter加载是随意的,也就是说它在IO设备栈上的顺序是根据其创建的顺序决定的,越晚创建的,越排在设备栈的顶部,而Minfilter根据它的一个全局变量——altitude规定了它在设备栈上的顺序具有可卸载能力,一般的hook或者过滤框架在卸载时可能仍然有程序在访问它们的代码,所以如果在有程序访问其代码,而它又被卸载时容易导致蓝屏,这样就不具备可卸载能力。而Minfilter则不会导致蓝屏Minfilter是通过注册回调函数到Minfilter管理器中,由Minfilter管理器来负责调度这些函数,不直接与IO管理器接触,同时我们只需要注册我们感兴趣的回调函数,而不像Sfilter那样,需要提供一个统一的处理函数。所以相对来说更简单兼容性更好,由IO管理器下发的IRP 请求既可以交给Sfilter框架处理,也可以交给Minfilter处理,也可以给下层的设备驱动处理。名字处理处理更加容易,相对与Sfilter中需要另外顶一个一个NAME_CONTROL结构,还需要注意长短名来说,Minfilter更加简单,只需要一个简单的函数就可以获取文件的卷设备名称,文件全名,流名等信息Minfilter的基本框架应用层下发的IO请求首先交由IO管理器处理,IO管理器将请求封装为一个IRP请求包接着网下层分发,当分发到Minfilter管理器时,由Minfilter将IRP封装为一个CALLBACK_DATA结构,并根据不同的请求调用不同的回调函数,由回调函数处理并决定是否分发到下层。Altitude 变量这个变量是Minfilter提供的全局变量,用来规定这个Minfilter管理器在IO栈中的高度,值越大越位于上方,它们在IO管理器中的位置如下图在栈中的位置既不是越低越好也不是越高越好,而是根据其具体需求,比如杀毒操作应该放到加解密操作之前,加解密应该放到真实的读写操作之前,所以它们在栈中从上到下的顺序应该是杀毒、加解密、IO设备对象。所以微软为每个功能的Minfilter中的Altitude都提供了大致的位置值,杀毒的过滤驱动是在320000-329999,而加解密的是140000-149999Minfilter框架详解注册结构FLT_REGISTRATIONMinfilter中最主要的是各个回调函数,向其中注册回调函数实际是在填写一个叫做FLT_REGISTRATION的结构体,在Minfilter中定义了这样一个结构体的变量:const FLT_REGISTRATION fileMonitorRegistration = { sizeof( FLT_REGISTRATION ), // Size FLT_REGISTRATION_VERSION, // Version 0, // Flags ContextRegistration, // ContextRegistration fileMonitorCallbacks, // Operation callbacks fileMonUnload, // FilterUnload fileMonInstanceSetup, // InstanceSetup NULL, // InstanceQueryTeardown fileMonInstanceTeardownStart, // InstanceTeardownStart NULL, // InstanceTeardownComplete NULL, // GenerateFileName NULL, // GenerateDestinationFileName NULL // NormalizeNameComponent };fileMonitorCallbacks是一个函数的指针数组,保存了处理各种事件的回调函数,框架会根据具体的事件来调用这些函数。它的定义如下:const FLT_OPERATION_REGISTRATION fileMonitorCallbacks[] = { { IRP_MJ_CREATE, FLTFL_OPERATION_REGISTRATION_SKIP_PAGING_IO, HOOK_PreNtCreateFile, HOOK_PostNtCreateFile }, { IRP_MJ_CLEANUP, 0, HOOK_PreNtCleanup, NULL }, { IRP_MJ_WRITE, 0, HOOK_PreNtWriteFile, HOOK_PostNtWriteFile }, { IRP_MJ_SET_INFORMATION, 0, HOOK_PreNtSetInformationFile, HOOK_PostNtSetInformationFile }, { IRP_MJ_OPERATION_END } };利用这个结构体将各种IRP请求与处理它的回调函数绑定起来,每组请求都有两个两个处理它的回调函数,一个Pre表示具体设备处理这个请求之前,Post表示系统处理这个请求之后。拿Sfilter中的sfCreate举例来说,HOOK_PreNtCreateFile处理的是在它调用IoCallDriver之前的操作,而HOOK_PostNtCreateFile表示的是在sfCreate在等到底层设备完成文件创建之后的操作。fileMonUnload 这个函数相当于驱动中的DriverUnload函数,在进行驱动开发时由于很多时候不能进行安全的卸载所以很多驱动不提供DriverUnload函数,防止由于卸载时产生蓝屏,要卸载只能重启机器fileMonInstanceSetup :Minfilter像Sfilter一样,会遍历计算机中的所有卷设备,每当有一个被遍历到,就会绑定一个过滤驱动设备在卷设备上,这个过滤设备就是Minfilter中的Instance,这个函数会在绑定过滤设备对象时触发fileMonInstanceTeardownStart 在卸载这个过滤设备时调用它们的关系如下图所示Minfilter过滤驱动的注册启动与销毁在我们自己写的驱动中可以使用函数FltRegisterFilter来向Minfilter管理器注册这个驱动的相关信息,以便Minfilter管理器将我们的程序放入到IO设备栈的合适位置中,该函数的原型如下:NTSTATUS FltRegisterFilter( IN PDRIVER_OBJECT Driver, IN CONST FLT_REGISTRATION *Registration, OUT PFLT_FILTER *RetFilter ); 第一个参数就是驱动的驱动对象指针,这个可以从DriverEntry中获得。第二个参数是是我们定义的那个装有各种事件回调函数的一个结构体的指针,通过传入这个参数,将这组回调函数注册到Minfilter管理器中第三个参数是一个输出参数,如果注册成功,则会返回这个参数用来唯一标识这个过滤驱动,这个参数一般是保存在NULL_FILTER_DATA结构中的FilterHandle中注册完成后,就是启动这个过滤驱动,进行文件系统的过滤,启动使用函数FltStartFiltering,这个函数需要传入之前注册函数返回的那个过滤驱动的句柄当我们不需要使用这个过滤驱动时使用函数FltUnregisterFilter卸载,它同样需要传入这个过滤驱动句柄。下面是一个具体的例子NTSTATUS DriverEntry ( __in PDRIVER_OBJECT DriverObject, __in PUNICODE_STRING RegistryPath ) { NTSTATUS status; UNREFERENCED_PARAMETER( RegistryPath ); //注册回调函数 status = FltRegisterFilter( DriverObject, &FilterRegistration, &NullFilterData.FilterHandle ); ASSERT( NT_SUCCESS( status ) ); if (NT_SUCCESS( status )) { //如果注册成功则开启minfilter监控 status = FltStartFiltering( NullFilterData.FilterHandle ); if (!NT_SUCCESS( status )) { //如果失败则卸载注册的回调 FltUnregisterFilter( NullFilterData.FilterHandle ); } } DbgPrint("Minifilter started\n"); return status; }对于卸载来说,需要注意的是很多驱动本身是不支持卸载的也就是不提供DriverUnload函数,因为系统中的驱动是被所有进程调用的,如果某个进程正在调用而另外一个进程正在卸载这个驱动,那么很可能会产生蓝屏。回调函数Minfilter过滤驱动中处理各个请求的回调函数一般都有两个:一个在IO设备处理之前,一个在IO设备处理之后。下面将称它们问Pre函数和Post函数Pre函数typedef FLT_PREOP_CALLBACK_STATUS (*PFLT_PRE_OPERATION_CALLBACK) ( IN OUT PFLT_CALLBACK_DATA Data, IN PCFLT_RELATED_OBJECTS FltObjects, OUT PVOID *CompletionContext );这个函数中的Data是对IRP的一个封装,与操作IRP相似,Minfilter向R3层返回结果使用的代码与普通的NT模型中的相同Data->IoStatus.Status = STATUS_SUCCESS; Data->IoStatus.Information = 0;另外过滤函数返回的值时直接返回给Minfilter管理器进行处理,而Sfilter返回的值是直接交给IO管理器,回调函数的返回值一般有这样几个常用的:FLT_PREOP_SUCCESS_WITH_CALLBACK:表示处理请求成功,接着往下发这个请求,下层驱动处理完这个请求后可以触发POST函数的调用FLT_PREOP_SUCCESS_NO_CALLBACK:与上述返回值类似,只是下层驱动处理完这个请求后不会触发POST函数FLT_PREOP_COMPLETE:请求处理完成,返回这个值,Minfilter将不会将请求继续往下发Post函数Post函数的原型如下:typedef FLT_POSTOP_CALLBACK_STATUS (FLTAPI *PFLT_POST_OPERATION_CALLBACK) ( __inout PFLT_CALLBACK_DATA Data, __in PCFLT_RELATED_OBJECTS FltObjects, __in_opt PVOID CompletionContext, __in FLT_POST_OPERATION_FLAGS Flags );在该函数中的返回值一般有如下几个:FLT_POSTOP_FINISHED_PROCESSING:向Minfilter管理器返回成功FLT_POSTOP_MORE_PROCESSING_REQUIRED:需要Minfilter管理器另外开一个线程,用来作为工作者线程,处理需要在低IRQL请求中完成的工作判断DATA的操作类型的宏FLT_IS_IRP_OPERATION:判断这个是否是一个IRP请求FLT_IS_FASTIO_OPERATION:判断这个是否是一个FASTIO请求FLT_IS_FS_FILTER_OPERATION:判断这个是否是一个文件系统过滤的请求Minfilter的安装以inf文件安装inf文件是一个安装信息的配置文件,指明了安装的.sys文件路径,安装到哪个位置,以及写到注册表中的何种位置,下面是一个具体的例子,在这只列举了比较重要的部分:[Version] Signature = "$Windows NT$" Class = "ActivityMonitor" ;This is determined by the work this filter driver does ClassGuid = {b86dff51-a31e-4bac-b3cf-e8cfe75c9fc2} ;This value is determined by the Class Provider = %Msft% DriverVer = 06/16/2007,1.0.0.0 CatalogFile = nullfilter.cat [DestinationDirs] DefaultDestDir = 12 NullFilter.DriverFiles = 12 ;%windir%\system32\drivers ;; ;; Default install sections ;; [DefaultInstall] OptionDesc = %ServiceDescription% CopyFiles = NullFilter.DriverFiles [DefaultInstall.Services] AddService = %ServiceName%,,NullFilter.Service [DefaultUninstall] DelFiles = NullFilter.DriverFiles [DefaultUninstall.Services] DelService = %ServiceName%,0x200 ;Ensure service is stopped before deleting [NullFilter.Service] DisplayName = %ServiceName% Description = %ServiceDescription% ServiceBinary = %12%\%DriverName%.sys ;%windir%\system32\drivers\ Dependencies = "FltMgr" ServiceType = 2 ;SERVICE_FILE_SYSTEM_DRIVER StartType = 3 ;SERVICE_DEMAND_START ErrorControl = 1 ;SERVICE_ERROR_NORMAL LoadOrderGroup = "FSFilter Activity Monitor" AddReg = NullFilter.AddRegistry [NullFilter.AddRegistry] HKR,"Instances","DefaultInstance",0x00000000,%DefaultInstance% HKR,"Instances\"%Instance1.Name%,"Altitude",0x00000000,%Instance1.Altitude% HKR,"Instances\"%Instance1.Name%,"Flags",0x00010001,%Instance1.Flags% [NullFilter.DriverFiles] %DriverName%.sys [SourceDisksFiles] nullfilter.sys = 1,, [SourceDisksNames] 1 = %DiskId1%,,, [Strings] Msft = "Microsoft Corporation" ServiceDescription = "NullFilter mini-filter driver" ServiceName = "NullFilter" DriverName = "NullFilter" DiskId1 = "NullFilter Device Installation Disk" ;Instances specific information. DefaultInstance = "Null Instance" Instance1.Name = "Null Instance" Instance1.Altitude = "370020" Instance1.Flags = 0x1 ; Suppress automatic attachments下面对这些部分进行说明:以[]括起来的部分是一个节,inf文件就是由不同的节组成version节规定了程序的版本信息2.1 Class是程序的类,这个值是由驱动具体的功能决定的,这个值其实规定了Altitude的值,也就是驱动在IO栈上的位置。微软提供了不同用途的具体的class值,只需要去对应的网站查询,然后根据具体情况填写即可,点击这里查看2.2 ClassGuid:是上述Class所对应的GUID值,这个值在上面的链接中可以查到DestinationDirs 规定目标文件的路径,就是你希望将驱动文件安装到哪个目录下,填入的12表示是在C:\Windows\System32\Drivers目录DefaultInstall.Services节表示了要将这个驱动以服务的形式启动起来,AddService 表示添加一个服务,后面是服务的名称,标志,以及安装详细信息的节名称,这里指定安装详细信息在节NullFilter.Service中DefaultUninstall 表示卸载的节点,DelFiles值表名卸载的信息在节点NullFilter.DriverFiles中NullFilter.Service节点中规定了安装的详细信息:6.1 DisplayName表示的是服务的显示名称6.2 ServiceDescription 服务的描述信息6.3 ServiceBinary服务程序所在的路径6.4 Dependencies该服务的依赖项,就是这个服务要运行必须提前启动他的依赖项服务,Minfilter的驱动是依赖与"FltMgr"服务6.5 ServiceType 表示服务程序的类型,2 是表示文件系统的服务,这些值可以在MSDN中查到,只需要搜索关于Service的函数 即可,比如CreateService6.6 StartType 启动类型,3表示手动启动,这个信息也可以通过查询MSDN,方法与ServiceType值的查询相同6.7 ErrorControl,错误码,当驱动出错时系统怎么处理,1表示一个常规的处理方式6.8 LoadOrderGroup 加载这个驱动的用户组6.9 AddReg加入注册表信息所在的节点NullFilter.AddRegistry 加入注册表信息的节点,其中的每一项都是一个注册表的项String节中的内容可以看作是一组变量值的定义,当某些字符串过长或者需要反复使用,可以为它定义一个变量,为了以后使用时的方便。在使用时按照%变量名%的形式,最终在解析时会将其进行替换这份文件是一个通用的模板,以后在使用inf进行Minfilter驱动程序的安装时,只需要修改其中的名称,另外需要修改的可能就是服务启动的那部分内容了inf文件编写完成后,只需要点击右键-->安装即可,安装完成后在cmd下使用命令net start 驱动名 即可启动命令,卸载则使用net stop 驱动名用编程的方法动态加载安装驱动驱动安装主要的工作是将驱动加载到服务程序并填写相关注册表项,大致需要这样几步:调用OpenSCManager 打开服务控制管理器的句柄调用CreateService函数,为驱动创建一个服务设置注册表的值,其中打开注册表键使用函数RegCreateKeyEx,设置注册表的值用函数RegSetValueEx。BOOL InstallDriver(const char* lpszDriverName,const char* lpszDriverPath,const char* lpszAltitude) { char szTempStr[MAX_PATH]; HKEY hKey; DWORD dwData; char szDriverImagePath[MAX_PATH]; if( NULL==lpszDriverName || NULL==lpszDriverPath ) { return FALSE; } //得到完整的驱动路径 GetFullPathName(lpszDriverPath, MAX_PATH, szDriverImagePath, NULL); SC_HANDLE hServiceMgr=NULL;// SCM管理器的句柄 SC_HANDLE hService=NULL;// NT驱动程序的服务句柄 //打开服务控制管理器 hServiceMgr = OpenSCManager( NULL, NULL, SC_MANAGER_ALL_ACCESS ); if( hServiceMgr == NULL ) { // OpenSCManager失败 CloseServiceHandle(hServiceMgr); return FALSE; } // OpenSCManager成功 //创建驱动所对应的服务 hService = CreateService( hServiceMgr, lpszDriverName, // 驱动程序的在注册表中的名字 lpszDriverName, // 注册表驱动程序的DisplayName 值 SERVICE_ALL_ACCESS, // 加载驱动程序的访问权限 SERVICE_FILE_SYSTEM_DRIVER, // 表示加载的服务是文件系统驱动程序 SERVICE_DEMAND_START, // 注册表驱动程序的Start 值 SERVICE_ERROR_IGNORE, // 注册表驱动程序的ErrorControl 值 szDriverImagePath, // 注册表驱动程序的ImagePath 值 "FSFilter Activity Monitor",// 注册表驱动程序的Group 值 NULL, "FltMgr", // 注册表驱动程序的DependOnService 值 NULL, NULL); if( hService == NULL ) { if( GetLastError() == ERROR_SERVICE_EXISTS ) { //服务创建失败,是由于服务已经创立过 CloseServiceHandle(hService); // 服务句柄 CloseServiceHandle(hServiceMgr); // SCM句柄 return TRUE; } else { CloseServiceHandle(hService); // 服务句柄 CloseServiceHandle(hServiceMgr); // SCM句柄 return FALSE; } } CloseServiceHandle(hService); // 服务句柄 CloseServiceHandle(hServiceMgr); // SCM句柄 //------------------------------------------------------------------------------------------------------- // SYSTEM\\CurrentControlSet\\Services\\DriverName\\Instances子健下的键值项 //------------------------------------------------------------------------------------------------------- strcpy(szTempStr,"SYSTEM\\CurrentControlSet\\Services\\"); strcat(szTempStr,lpszDriverName); strcat(szTempStr,"\\Instances"); if(RegCreateKeyEx(HKEY_LOCAL_MACHINE,szTempStr,0,"",REG_OPTION_NON_VOLATILE,KEY_ALL_ACCESS,NULL,&hKey,(LPDWORD)&dwData)!=ERROR_SUCCESS) { return FALSE; } // 注册表驱动程序的DefaultInstance 值 strcpy(szTempStr,lpszDriverName); strcat(szTempStr," Instance"); if(RegSetValueEx(hKey,"DefaultInstance",0,REG_SZ,(CONST BYTE*)szTempStr,(DWORD)strlen(szTempStr))!=ERROR_SUCCESS) { return FALSE; } RegFlushKey(hKey);//刷新注册表 RegCloseKey(hKey); //------------------------------------------------------------------------------------------------------- // SYSTEM\\CurrentControlSet\\Services\\DriverName\\Instances\\DriverName Instance子健下的键值项 //------------------------------------------------------------------------------------------------------- strcpy(szTempStr,"SYSTEM\\CurrentControlSet\\Services\\"); strcat(szTempStr,lpszDriverName); strcat(szTempStr,"\\Instances\\"); strcat(szTempStr,lpszDriverName); strcat(szTempStr," Instance"); if(RegCreateKeyEx(HKEY_LOCAL_MACHINE,szTempStr,0,"",REG_OPTION_NON_VOLATILE,KEY_ALL_ACCESS,NULL,&hKey,(LPDWORD)&dwData)!=ERROR_SUCCESS) { return FALSE; } // 注册表驱动程序的Altitude 值 strcpy(szTempStr,lpszAltitude); if(RegSetValueEx(hKey,"Altitude",0,REG_SZ,(CONST BYTE*)szTempStr,(DWORD)strlen(szTempStr))!=ERROR_SUCCESS) { return FALSE; } // 注册表驱动程序的Flags 值 dwData=0x0; if(RegSetValueEx(hKey,"Flags",0,REG_DWORD,(CONST BYTE*)&dwData,sizeof(DWORD))!=ERROR_SUCCESS) { return FALSE; } RegFlushKey(hKey);//刷新注册表 RegCloseKey(hKey); return TRUE; }这里提供一个安装驱动的函数,在这个函数中将某些信息写入了注册表,注册表中变化的信息如下:HKEY_LOCAL_MACHINE中的SYSTEM\CurrentControlSet\Services\Nullfilter\Instances 中键 DefaultInstance = "nullfilter Instance"HKEY_LOCAL_MACHINE中的SYSTEM\CurrentControlSet\Services\Nullfilter\ nullfilter Instances 中键 altitude = “370020”,键Flags = 0启动驱动驱动的启动与普通的服务程序的启动方法一样,这里直接贴上代码:BOOL StartDriver(const char* lpszDriverName) { SC_HANDLE schManager; SC_HANDLE schService; if(NULL==lpszDriverName) { return FALSE; } schManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); if(NULL==schManager) { CloseServiceHandle(schManager); return FALSE; } schService=OpenService(schManager,lpszDriverName,SERVICE_ALL_ACCESS); if(NULL==schService) { CloseServiceHandle(schService); CloseServiceHandle(schManager); return FALSE; } if(!StartService(schService,0,NULL)) { CloseServiceHandle(schService); CloseServiceHandle(schManager); if( GetLastError() == ERROR_SERVICE_ALREADY_RUNNING ) { // 服务已经开启 return TRUE; } return FALSE; } CloseServiceHandle(schService); CloseServiceHandle(schManager); return TRUE; }停止驱动的运行BOOL StopDriver(const char* lpszDriverName) { SC_HANDLE schManager; SC_HANDLE schService; SERVICE_STATUS svcStatus; bool bStopped=false; schManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); if(NULL==schManager) { return FALSE; } schService=OpenService(schManager,lpszDriverName,SERVICE_ALL_ACCESS); if(NULL==schService) { CloseServiceHandle(schManager); return FALSE; } if(!ControlService(schService,SERVICE_CONTROL_STOP,&svcStatus) && (svcStatus.dwCurrentState!=SERVICE_STOPPED)) { CloseServiceHandle(schService); CloseServiceHandle(schManager); return FALSE; } CloseServiceHandle(schService); CloseServiceHandle(schManager); return TRUE; }删除驱动BOOL DeleteDriver(const char* lpszDriverName) { SC_HANDLE schManager; SC_HANDLE schService; SERVICE_STATUS svcStatus; schManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); if(NULL==schManager) { return FALSE; } schService=OpenService(schManager,lpszDriverName,SERVICE_ALL_ACCESS); if(NULL==schService) { CloseServiceHandle(schManager); return FALSE; } ControlService(schService,SERVICE_CONTROL_STOP,&svcStatus); if(!DeleteService(schService)) { CloseServiceHandle(schService); CloseServiceHandle(schManager); return FALSE; } CloseServiceHandle(schService); CloseServiceHandle(schManager); return TRUE; }Minfilter中如何获取各种信息的值Minfilter中将IRP进行了封装,但是在获取各种值时基本上变化不大,而且相对于之前的Sfilter简单了许多,下面假定在函数中有了它的CALL_BACK_DATA结构,有这样一条语句PFLT_CALLBACK_DATA Data获取当前进程的EPROCESS结构/*如果当前线程的ETHREAD结构不为NULL则根据线程ETHREAD来获取进程否则调用函数PsGetCurrentProcess()获取当前进程的EPROCESS结构*/ PEPROCESS processObject = Data->Thread ? IoThreadToProcess(Data->Thread) : PsGetCurrentProcess();向R3层返回数据Data->IoStatus.Status = ntStatus; Data->IoStatus.Information = 0;与使用IRP相似,在DATA中仍然使用IoStatus成员向R3返回,上述两句的意思与使用IRP时完全相同文件路径的获取文件路径的获取与Sfilter相比,简单了许多,只需要调用一个函数FltGetFileNameInformation,这个函数的定义在MSDN中可以查到,所以就不再这里做过多的说明,该函数会返回一个FLT_FILE_NAME_INFORMATION结构体用来保存文件名信息,结构体FLT_FILE_NAME_INFORMATION的定义如下所示typedef struct _FLT_FILE_NAME_INFORMATION { USHORT Size; FLT_FILE_NAME_PARSED_FLAGS NamesParsed; FLT_FILE_NAME_OPTIONS Format; UNICODE_STRING Name; UNICODE_STRING Volume; UNICODE_STRING Share; UNICODE_STRING Extension; UNICODE_STRING Stream; UNICODE_STRING FinalComponent; UNICODE_STRING ParentDir; } FLT_FILE_NAME_INFORMATION, *PFLT_FILE_NAME_INFORMATION;这个结构体记录了文件路径的各种信息,其中各个字符串都是根据Format的值来进行格式化得到的,需要注意的是在上述位置得到的文件名是类似与“\Device\HarddiskVolume1\Documents and Settings\MyUser\My Documents\Test Results.txt:stream1”的而不是我们之前熟悉的"C:\Documents and Settings\MyUser\My Documents\Test Results.txt:stream1",这就需要进行转化。需要注意的是在获取文件名时要在PostCreate函数中获取,因为当调用这个函数时说明根据传进来的文件路径已经正确打开了文件,这个时候的路径名一定是可靠的。 NTSTATUS ntStatus; PFLT_FILE_NAME_INFORMATION pNameInfo = NULL; UNREFERENCED_PARAMETER( Data ); UNREFERENCED_PARAMETER( FltObjects ); UNREFERENCED_PARAMETER( CompletionContext ); UNREFERENCED_PARAMETER( Flags ); //获取文件路径信息 ntStatus = FltGetFileNameInformation(Data, FLT_FILE_NAME_NORMALIZED| FLT_FILE_NAME_QUERY_DEFAULT, &pNameInfo); if (NT_SUCCESS(ntStatus)) { //解析获取到的信息 FltParseFileNameInformation(pNameInfo); DbgPrint("FileName:%wZ\n", &pNameInfo->Name); //使用完成后释放这个空间 FltReleaseFileNameInformation(pNameInfo); }函数FltGetFileNameInformation会自动为我们分配一个缓冲区来存储文件的信息,所以最后需要调用Release函数释放。另外通过调试的情况来看,FltGetFileNameInformation函数并不能获取文件路径的所有信息,一些扩展信息像Extension或者Parent这样的信息开始是没有的,只有通过FltParseFileNameInformation在已有信息的基础之上进行解析才会有。至于重命名的文件路径的获取使用下面的语句:PFILE_RENAME_INFORMATION pFileRenameInfomation = (PFILE_RENAME_INFORMATION)Data->Iopb->Parameters.SetFileInformation.InfoBuffer;在MInfilter中进行文件操作尽量使用以Flt开头的函数,不要使用Zw开头的那一组,以Zw开头的函数最终会触发Minfilter的回调函数,最终会造成无限递归Minfilter上下文在编程中,我们经常会遇到上下文这个概念,比如说进程上下文,线程上下文等等,在这里上下文表示某些代码执行的具体环境,系统一般位于进程上下文和中断上下文。当系统处理进程上下文时,系统在代替R3层做某些事,此时系统在调用系统API,执行系统功能,当系统处于进程上下文时是可以被挂起的。而当系统响应中断与具体硬件进行交互时处于中断上下文,此时的数据都位于非分页内存,而且不能睡眠而Minfilter上下文指的并不是代码运行的环境,而是一组数据,这组数据是附加到具体的设备对象上的,由用户自己定义。在使用时先利用函数AllocateContext分配一段内存空间,然后使用一组Set和Get函数来设置和获取设备上下文。具体的函数由不同的上下文来决定,下面是不同的上下文与他们对应的Set函数之间的关系|Context Type| Set-Context Routine||:--------------|:-||FLT_FILE_CONTEXT|Windows Vista and later only.) FltSetFileContext||FLT_INSTANCE_CONTEXT|FltSetInstanceContext||FLT_STREAM_CONTEXT|FltSetStreamContext||FLT_STREAMHANDLE_CONTEXT|FltSetStreamHandleContext||FLT_TRANSACTION_CONTEXT|(Windows Vista and later only.) FltSetTransactionContext||FLT_VOLUME_CONTEXT|FltSetVolumeContext|Get函数的使用与上述相同。最后使用完成后需要使用FltReleaseContext来释放这个上下文。下面是一个使用的具体例子typedef struct _INSTANCE_CONTEXT { … } INSTANCE_CONTEXT, *PINSTANCE_CONTEXT; PINSTANCE_CONTEXT pContext = NULL; //从设备对象上获取上下文 ntStatus = FltGetInstanceContext(FltObjects->Instance, & pContext); if(NT_SUCCESS(Status) == FALSE) { //设备上没有上下文则分配上下文的内存 ntStatus = FltAllocateContext(g_pFilter,FLT_INSTANCE_CONTEXT, sizeof(INSTANCE_CONTEXT), PagedPool,& pContext); if(NT_SUCCESS(Status) == FALSE) { //返回资源不足 return STATUS_INSUFFICIENT_RESOURCES; } RtlZeroMemory(pContext, sizeof(INSTANCE_CONTEXT)); } pContext ->m_DeviceType = VolumeDeviceType; pContext->m_FSType = VolumeFilesystemType; FltSetInstanceContext(FltObjects->Instance, FLT_SET_CONTEXT_REPLACE_IF_EXISTS,pContext,NULL); if (pContext) { FltReleaseContext(pContext); } //获取访问 PINSTANCE_CONTEXT pContext = NULL; Status = FltGetInstanceContext(FltObjects->Instance,&pContext); //下面是使用这个上下文,和一些其他的操作 pContext->xxx = xxx;回调函数运行的中断请求级别(IRQL)pre回调函数可以运行在APC_LEVEL或者PASSIVE_LEVEL 级别,但是一般是运行在PASSIVE_LEVEL级别如果一个Pre函数返回的是FLT_PREOP_SYNCHRONIZE,那么相对的,在同一个线程内部,它对应的POST函数将在IRQL <= APC_LEVEL级别运行。与对应的Pre在一个线程内时,fast IO请求对应的Post函数运行在PASSIVE_LEVEL级别Create回调的Post函数运行在PASSIVE_LEVEL级别当我们不确定当前代码所处的IRQL时可以使用函数KeCurrentIrql获取当前执行环境所在的IRQL。R3 与R0的通信R3在调用Minfilter中的相关函数时需要包含相关的库文件,与Lib文件,具体怎么包含这个我不太清楚,只需要在库项目属性的VC++目录下面这几项包含具体的路径即可包含目录 :“$(VC\_IncludePath);$(WindowsSDK_IncludePath);”库路径: "$(VC\_LibraryPath_x86);$(WindowsSDK\_LibraryPath\_x86);$(NETFXKitsDir)Lib\um\x86"之前R3与R0进行通信是通过R3调用DeviceIoControl函数将数据下发到R0层,然后R3等待一个事件,在R0处理完成R3的请求并准备好往上发的数据后将事件的对象设置为有信号,这样R3再从缓冲区中取数据,完成双方的通信,但是在Minfilter中准备了专门的函数用于双方通信。R3向R0下发数据R3层通过函数FilterSendMessage向R0下发数据,而R0通过fnMessageFromClient接收从R3发下来的数据。在Minfilter中R3与R0是通过各自的端口进行通讯的,这个端口与传统意义上的网络的通信端口不同,是一个抽象的概念,不需要太过于关注。在与R3进行通讯之前需要设置这个端口,端口的设置使用函数FltCreateComunicationPort,在这个函数调用时需要提供这样几个回调函数ConnectNotifyCallback:这个函数在R3层链接到R0的这个通讯端口时调用,在这个函数中可以拿到R3的进程句柄和R3的端口DisconnectNotifyCallback:当R3层与R0层断开时调用这个回调函数MessageNotifyCallback:当R3有数据下发下来调用这个回调,在这个函数中取R3发下来的数据R0向R3上报数据R0向R3上报数据时是一个双向的过程,R0既要上报数据,又要等待R3的返回,就好像之前的弹窗一样,当R0上报数据后就等待40s,在接收到R3的进一步指示时进行下一步,R0向R3上报大致经历这样的几个过程:R0通过函数FltSengMesage将数据发送到R3R3通过函数FilterGetMessage函数接收到R0的数据,并进行相应的处理处理完成后,调用函数FilterReplyMessage将处理结果返回给R0。另外需要注意一点,在进行通讯时需要两套数据结构,这两套分别运用在R3和R0两层,每一层都有两个数据结构,用来表示接收和返回的数据,拿R3来说,它需要一个MESSAGE结构体来接收从R0层发过来的数据,另外需要一个REPLY用于向R0返回数据。R3上报和下发的数据相比于R0需要多加一个FILTER_MESSAGE_HEADER的头,便于Minfilter分辨是哪个客户端下发的数据,Minfilter 根据这个头做相关的处理后将其于的数据发送到R0,所以R0能够正确知道是哪个进程在进行相关请求,而不需要添加额外的结构体下面是一个例子NTSTATUS ScannerpScanFileInUserMode ( __in PFLT_INSTANCE Instance, __in PFILE_OBJECT FileObject, __out PBOOLEAN SafeToOpen ) /*读取文件中的部分数据,然后交由R3处理,并根据R3返回的结果判断R3是否安全*/ { NTSTATUS status = STATUS_SUCCESS; PVOID buffer = NULL; ULONG bytesRead; PSCANNER_NOTIFICATION notification = NULL; FLT_VOLUME_PROPERTIES volumeProps; LARGE_INTEGER offset; ULONG replyLength, length; PFLT_VOLUME volume = NULL; *SafeToOpen = TRUE; if (ScannerData.ClientPort == NULL) { return STATUS_SUCCESS; } try { status = FltGetVolumeFromInstance( Instance, &volume ); if (!NT_SUCCESS( status )) { leave; } status = FltGetVolumeProperties( volume, &volumeProps, sizeof( volumeProps ), &length ); if (NT_ERROR( status )) { leave; } //取1024和扇区的最大值,保证读取的数据至少有一个扇区的大小 length = max( SCANNER_READ_BUFFER_SIZE, volumeProps.SectorSize ); /*分配一块内存用于从文件中读取数据,在minfilter中进行文件操作时申请缓冲区最好使用flt开头的一组函数,因为它不是简单的分配一块内存,还能保证在有程序使用这段内存时不会出现内存已被释放的情况,内部可能也用了引用计数*/ buffer = FltAllocatePoolAlignedWithTag( Instance, NonPagedPool, length, 'nacS' ); if (NULL == buffer) { status = STATUS_INSUFFICIENT_RESOURCES; leave; } //构建发送给R3层的结构体的内存 notification = ExAllocatePoolWithTag( NonPagedPool, sizeof( SCANNER_NOTIFICATION ), 'nacS' ); if(NULL == notification) { status = STATUS_INSUFFICIENT_RESOURCES; leave; } offset.QuadPart = bytesRead = 0; status = FltReadFile( Instance, FileObject, &offset, length, buffer, FLTFL_IO_OPERATION_NON_CACHED | FLTFL_IO_OPERATION_DO_NOT_UPDATE_BYTE_OFFSET, &bytesRead, NULL, NULL ); if (NT_SUCCESS( status ) && (0 != bytesRead)) { notification->BytesToScan = (ULONG) bytesRead; /*将这段信息发送到R3,这个函数是一个阻塞的函数,只有当超时值过了或者R3返回了数据才会返回,在这设置超时值为NULL表示会一直等待,在这返回值也是使用notification做为接受返回值的缓冲,在这不会出现覆盖的情况,因为这个函数在调用后首先是R3接受数据,然后进行处理,处理完成后R3才会主动调用另一个API返回数据,所以这里有一个时间差,当获取到返回值时之前传入的数据已经没有用了,这里将发送的缓冲与返回的缓冲定义为同一个只是为了节省内存*/ RtlCopyMemory( ¬ification->Contents, buffer, min( notification->BytesToScan, SCANNER_READ_BUFFER_SIZE ) ); replyLength = sizeof( SCANNER_REPLY ); //在这我们将 status = FltSendMessage( ScannerData.Filter, &ScannerData.ClientPort, notification, sizeof(SCANNER_NOTIFICATION), notification, &replyLength, NULL ); if (STATUS_SUCCESS == status) { *SafeToOpen = ((PSCANNER_REPLY) notification)->SafeToOpen; } else { DbgPrint( "!!! scanner.sys --- couldn't send message to user-mode to scan file, status 0x%X\n", status ); } } } finally { //最后清理内存 if (NULL != buffer) { FltFreePoolAlignedWithTag( Instance, buffer, 'nacS' ); } if (NULL != notification) { ExFreePoolWithTag( notification, 'nacS' ); } if (NULL != volume) { FltObjectDereference( volume ); } } return status; }这个例子演示了R0层如何从磁盘中读取文件内容,然后发送到R3,并从R3层上接受返回。下面这个例子将演示R3如何读取R0发上来的数据 while (TRUE) { //这是一个阻塞函数,当能从R0接受到数据的时候返回 result = GetQueuedCompletionStatus( Context->Completion, &outSize, &key, &pOvlp, INFINITE ); message = CONTAINING_RECORD( pOvlp, SCANNER_MESSAGE, Ovlp ); if (!result) { hr = HRESULT_FROM_WIN32( GetLastError() ); break; } printf( "Received message, size %d\n", pOvlp->InternalHigh ); notification = &message->Notification; assert(notification->BytesToScan <= SCANNER_READ_BUFFER_SIZE); /*R3层定义的这个SCANNER_MESSAGE结构体是在notification这个结构体的基础之上加了一个头,所以大小会大于这个notification*/ __analysis_assume(notification->BytesToScan <= SCANNER_READ_BUFFER_SIZE); //这个函数是一个自定义函数,用来扫描R0传上来的数据有没有特定的字符 result = ScanBuffer( notification->Contents, notification->BytesToScan ); replyMessage.ReplyHeader.Status = 0; replyMessage.ReplyHeader.MessageId = message->MessageHeader.MessageId; replyMessage.Reply.SafeToOpen = !result; printf( "Replying message, SafeToOpen: %d\n", replyMessage.Reply.SafeToOpen ); //向R0返回数据 hr = FilterReplyMessage( Context->Port, (PFILTER_REPLY_HEADER) &replyMessage, sizeof( replyMessage ) ); if (SUCCEEDED( hr )) { printf( "Replied message\n" ); } else { printf( "Scanner: Error replying message. Error = 0x%X\n", hr ); break; } memset( &message->Ovlp, 0, sizeof( OVERLAPPED ) ); //再次等待从R0下发的数据 hr = FilterGetMessage( Context->Port, &message->MessageHeader, FIELD_OFFSET( SCANNER_MESSAGE, Ovlp ), &message->Ovlp ); if (hr != HRESULT_FROM_WIN32( ERROR_IO_PENDING )) { break; } }
Minfilter过滤框架 Minfilter过滤框架优势与传统的Sfilter过滤驱动相比,有这样几个优势Minfilter加载顺序更易控制,Sfilter加载是随意的,也就是说它在IO设备栈上的顺序是根据其创建的顺序决定的,越晚创建的,越排在设备栈的顶部,而Minfilter根据它的一个全局变量——altitude规定了它在设备栈上的顺序具有可卸载能力,一般的hook或者过滤框架在卸载时可能仍然有程序在访问它们的代码,所以如果在有程序访问其代码,而它又被卸载时容易导致蓝屏,这样就不具备可卸载能力。而Minfilter则不会导致蓝屏Minfilter是通过注册回调函数到Minfilter管理器中,由Minfilter管理器来负责调度这些函数,不直接与IO管理器接触,同时我们只需要注册我们感兴趣的回调函数,而不像Sfilter那样,需要提供一个统一的处理函数。所以相对来说更简单兼容性更好,由IO管理器下发的IRP 请求既可以交给Sfilter框架处理,也可以交给Minfilter处理,也可以给下层的设备驱动处理。名字处理处理更加容易,相对与Sfilter中需要另外顶一个一个NAME_CONTROL结构,还需要注意长短名来说,Minfilter更加简单,只需要一个简单的函数就可以获取文件的卷设备名称,文件全名,流名等信息Minfilter的基本框架应用层下发的IO请求首先交由IO管理器处理,IO管理器将请求封装为一个IRP请求包接着网下层分发,当分发到Minfilter管理器时,由Minfilter将IRP封装为一个CALLBACK_DATA结构,并根据不同的请求调用不同的回调函数,由回调函数处理并决定是否分发到下层。Altitude 变量这个变量是Minfilter提供的全局变量,用来规定这个Minfilter管理器在IO栈中的高度,值越大越位于上方,它们在IO管理器中的位置如下图在栈中的位置既不是越低越好也不是越高越好,而是根据其具体需求,比如杀毒操作应该放到加解密操作之前,加解密应该放到真实的读写操作之前,所以它们在栈中从上到下的顺序应该是杀毒、加解密、IO设备对象。所以微软为每个功能的Minfilter中的Altitude都提供了大致的位置值,杀毒的过滤驱动是在320000-329999,而加解密的是140000-149999Minfilter框架详解注册结构FLT_REGISTRATIONMinfilter中最主要的是各个回调函数,向其中注册回调函数实际是在填写一个叫做FLT_REGISTRATION的结构体,在Minfilter中定义了这样一个结构体的变量:const FLT_REGISTRATION fileMonitorRegistration = { sizeof( FLT_REGISTRATION ), // Size FLT_REGISTRATION_VERSION, // Version 0, // Flags ContextRegistration, // ContextRegistration fileMonitorCallbacks, // Operation callbacks fileMonUnload, // FilterUnload fileMonInstanceSetup, // InstanceSetup NULL, // InstanceQueryTeardown fileMonInstanceTeardownStart, // InstanceTeardownStart NULL, // InstanceTeardownComplete NULL, // GenerateFileName NULL, // GenerateDestinationFileName NULL // NormalizeNameComponent };fileMonitorCallbacks是一个函数的指针数组,保存了处理各种事件的回调函数,框架会根据具体的事件来调用这些函数。它的定义如下:const FLT_OPERATION_REGISTRATION fileMonitorCallbacks[] = { { IRP_MJ_CREATE, FLTFL_OPERATION_REGISTRATION_SKIP_PAGING_IO, HOOK_PreNtCreateFile, HOOK_PostNtCreateFile }, { IRP_MJ_CLEANUP, 0, HOOK_PreNtCleanup, NULL }, { IRP_MJ_WRITE, 0, HOOK_PreNtWriteFile, HOOK_PostNtWriteFile }, { IRP_MJ_SET_INFORMATION, 0, HOOK_PreNtSetInformationFile, HOOK_PostNtSetInformationFile }, { IRP_MJ_OPERATION_END } };利用这个结构体将各种IRP请求与处理它的回调函数绑定起来,每组请求都有两个两个处理它的回调函数,一个Pre表示具体设备处理这个请求之前,Post表示系统处理这个请求之后。拿Sfilter中的sfCreate举例来说,HOOK_PreNtCreateFile处理的是在它调用IoCallDriver之前的操作,而HOOK_PostNtCreateFile表示的是在sfCreate在等到底层设备完成文件创建之后的操作。fileMonUnload 这个函数相当于驱动中的DriverUnload函数,在进行驱动开发时由于很多时候不能进行安全的卸载所以很多驱动不提供DriverUnload函数,防止由于卸载时产生蓝屏,要卸载只能重启机器fileMonInstanceSetup :Minfilter像Sfilter一样,会遍历计算机中的所有卷设备,每当有一个被遍历到,就会绑定一个过滤驱动设备在卷设备上,这个过滤设备就是Minfilter中的Instance,这个函数会在绑定过滤设备对象时触发fileMonInstanceTeardownStart 在卸载这个过滤设备时调用它们的关系如下图所示Minfilter过滤驱动的注册启动与销毁在我们自己写的驱动中可以使用函数FltRegisterFilter来向Minfilter管理器注册这个驱动的相关信息,以便Minfilter管理器将我们的程序放入到IO设备栈的合适位置中,该函数的原型如下:NTSTATUS FltRegisterFilter( IN PDRIVER_OBJECT Driver, IN CONST FLT_REGISTRATION *Registration, OUT PFLT_FILTER *RetFilter ); 第一个参数就是驱动的驱动对象指针,这个可以从DriverEntry中获得。第二个参数是是我们定义的那个装有各种事件回调函数的一个结构体的指针,通过传入这个参数,将这组回调函数注册到Minfilter管理器中第三个参数是一个输出参数,如果注册成功,则会返回这个参数用来唯一标识这个过滤驱动,这个参数一般是保存在NULL_FILTER_DATA结构中的FilterHandle中注册完成后,就是启动这个过滤驱动,进行文件系统的过滤,启动使用函数FltStartFiltering,这个函数需要传入之前注册函数返回的那个过滤驱动的句柄当我们不需要使用这个过滤驱动时使用函数FltUnregisterFilter卸载,它同样需要传入这个过滤驱动句柄。下面是一个具体的例子NTSTATUS DriverEntry ( __in PDRIVER_OBJECT DriverObject, __in PUNICODE_STRING RegistryPath ) { NTSTATUS status; UNREFERENCED_PARAMETER( RegistryPath ); //注册回调函数 status = FltRegisterFilter( DriverObject, &FilterRegistration, &NullFilterData.FilterHandle ); ASSERT( NT_SUCCESS( status ) ); if (NT_SUCCESS( status )) { //如果注册成功则开启minfilter监控 status = FltStartFiltering( NullFilterData.FilterHandle ); if (!NT_SUCCESS( status )) { //如果失败则卸载注册的回调 FltUnregisterFilter( NullFilterData.FilterHandle ); } } DbgPrint("Minifilter started\n"); return status; }对于卸载来说,需要注意的是很多驱动本身是不支持卸载的也就是不提供DriverUnload函数,因为系统中的驱动是被所有进程调用的,如果某个进程正在调用而另外一个进程正在卸载这个驱动,那么很可能会产生蓝屏。回调函数Minfilter过滤驱动中处理各个请求的回调函数一般都有两个:一个在IO设备处理之前,一个在IO设备处理之后。下面将称它们问Pre函数和Post函数Pre函数typedef FLT_PREOP_CALLBACK_STATUS (*PFLT_PRE_OPERATION_CALLBACK) ( IN OUT PFLT_CALLBACK_DATA Data, IN PCFLT_RELATED_OBJECTS FltObjects, OUT PVOID *CompletionContext );这个函数中的Data是对IRP的一个封装,与操作IRP相似,Minfilter向R3层返回结果使用的代码与普通的NT模型中的相同Data->IoStatus.Status = STATUS_SUCCESS; Data->IoStatus.Information = 0;另外过滤函数返回的值时直接返回给Minfilter管理器进行处理,而Sfilter返回的值是直接交给IO管理器,回调函数的返回值一般有这样几个常用的:FLT_PREOP_SUCCESS_WITH_CALLBACK:表示处理请求成功,接着往下发这个请求,下层驱动处理完这个请求后可以触发POST函数的调用FLT_PREOP_SUCCESS_NO_CALLBACK:与上述返回值类似,只是下层驱动处理完这个请求后不会触发POST函数FLT_PREOP_COMPLETE:请求处理完成,返回这个值,Minfilter将不会将请求继续往下发Post函数Post函数的原型如下:typedef FLT_POSTOP_CALLBACK_STATUS (FLTAPI *PFLT_POST_OPERATION_CALLBACK) ( __inout PFLT_CALLBACK_DATA Data, __in PCFLT_RELATED_OBJECTS FltObjects, __in_opt PVOID CompletionContext, __in FLT_POST_OPERATION_FLAGS Flags );在该函数中的返回值一般有如下几个:FLT_POSTOP_FINISHED_PROCESSING:向Minfilter管理器返回成功FLT_POSTOP_MORE_PROCESSING_REQUIRED:需要Minfilter管理器另外开一个线程,用来作为工作者线程,处理需要在低IRQL请求中完成的工作判断DATA的操作类型的宏FLT_IS_IRP_OPERATION:判断这个是否是一个IRP请求FLT_IS_FASTIO_OPERATION:判断这个是否是一个FASTIO请求FLT_IS_FS_FILTER_OPERATION:判断这个是否是一个文件系统过滤的请求Minfilter的安装以inf文件安装inf文件是一个安装信息的配置文件,指明了安装的.sys文件路径,安装到哪个位置,以及写到注册表中的何种位置,下面是一个具体的例子,在这只列举了比较重要的部分:[Version] Signature = "$Windows NT$" Class = "ActivityMonitor" ;This is determined by the work this filter driver does ClassGuid = {b86dff51-a31e-4bac-b3cf-e8cfe75c9fc2} ;This value is determined by the Class Provider = %Msft% DriverVer = 06/16/2007,1.0.0.0 CatalogFile = nullfilter.cat [DestinationDirs] DefaultDestDir = 12 NullFilter.DriverFiles = 12 ;%windir%\system32\drivers ;; ;; Default install sections ;; [DefaultInstall] OptionDesc = %ServiceDescription% CopyFiles = NullFilter.DriverFiles [DefaultInstall.Services] AddService = %ServiceName%,,NullFilter.Service [DefaultUninstall] DelFiles = NullFilter.DriverFiles [DefaultUninstall.Services] DelService = %ServiceName%,0x200 ;Ensure service is stopped before deleting [NullFilter.Service] DisplayName = %ServiceName% Description = %ServiceDescription% ServiceBinary = %12%\%DriverName%.sys ;%windir%\system32\drivers\ Dependencies = "FltMgr" ServiceType = 2 ;SERVICE_FILE_SYSTEM_DRIVER StartType = 3 ;SERVICE_DEMAND_START ErrorControl = 1 ;SERVICE_ERROR_NORMAL LoadOrderGroup = "FSFilter Activity Monitor" AddReg = NullFilter.AddRegistry [NullFilter.AddRegistry] HKR,"Instances","DefaultInstance",0x00000000,%DefaultInstance% HKR,"Instances\"%Instance1.Name%,"Altitude",0x00000000,%Instance1.Altitude% HKR,"Instances\"%Instance1.Name%,"Flags",0x00010001,%Instance1.Flags% [NullFilter.DriverFiles] %DriverName%.sys [SourceDisksFiles] nullfilter.sys = 1,, [SourceDisksNames] 1 = %DiskId1%,,, [Strings] Msft = "Microsoft Corporation" ServiceDescription = "NullFilter mini-filter driver" ServiceName = "NullFilter" DriverName = "NullFilter" DiskId1 = "NullFilter Device Installation Disk" ;Instances specific information. DefaultInstance = "Null Instance" Instance1.Name = "Null Instance" Instance1.Altitude = "370020" Instance1.Flags = 0x1 ; Suppress automatic attachments下面对这些部分进行说明:以[]括起来的部分是一个节,inf文件就是由不同的节组成version节规定了程序的版本信息2.1 Class是程序的类,这个值是由驱动具体的功能决定的,这个值其实规定了Altitude的值,也就是驱动在IO栈上的位置。微软提供了不同用途的具体的class值,只需要去对应的网站查询,然后根据具体情况填写即可,点击这里查看2.2 ClassGuid:是上述Class所对应的GUID值,这个值在上面的链接中可以查到DestinationDirs 规定目标文件的路径,就是你希望将驱动文件安装到哪个目录下,填入的12表示是在C:\Windows\System32\Drivers目录DefaultInstall.Services节表示了要将这个驱动以服务的形式启动起来,AddService 表示添加一个服务,后面是服务的名称,标志,以及安装详细信息的节名称,这里指定安装详细信息在节NullFilter.Service中DefaultUninstall 表示卸载的节点,DelFiles值表名卸载的信息在节点NullFilter.DriverFiles中NullFilter.Service节点中规定了安装的详细信息:6.1 DisplayName表示的是服务的显示名称6.2 ServiceDescription 服务的描述信息6.3 ServiceBinary服务程序所在的路径6.4 Dependencies该服务的依赖项,就是这个服务要运行必须提前启动他的依赖项服务,Minfilter的驱动是依赖与"FltMgr"服务6.5 ServiceType 表示服务程序的类型,2 是表示文件系统的服务,这些值可以在MSDN中查到,只需要搜索关于Service的函数 即可,比如CreateService6.6 StartType 启动类型,3表示手动启动,这个信息也可以通过查询MSDN,方法与ServiceType值的查询相同6.7 ErrorControl,错误码,当驱动出错时系统怎么处理,1表示一个常规的处理方式6.8 LoadOrderGroup 加载这个驱动的用户组6.9 AddReg加入注册表信息所在的节点NullFilter.AddRegistry 加入注册表信息的节点,其中的每一项都是一个注册表的项String节中的内容可以看作是一组变量值的定义,当某些字符串过长或者需要反复使用,可以为它定义一个变量,为了以后使用时的方便。在使用时按照%变量名%的形式,最终在解析时会将其进行替换这份文件是一个通用的模板,以后在使用inf进行Minfilter驱动程序的安装时,只需要修改其中的名称,另外需要修改的可能就是服务启动的那部分内容了inf文件编写完成后,只需要点击右键-->安装即可,安装完成后在cmd下使用命令net start 驱动名 即可启动命令,卸载则使用net stop 驱动名用编程的方法动态加载安装驱动驱动安装主要的工作是将驱动加载到服务程序并填写相关注册表项,大致需要这样几步:调用OpenSCManager 打开服务控制管理器的句柄调用CreateService函数,为驱动创建一个服务设置注册表的值,其中打开注册表键使用函数RegCreateKeyEx,设置注册表的值用函数RegSetValueEx。BOOL InstallDriver(const char* lpszDriverName,const char* lpszDriverPath,const char* lpszAltitude) { char szTempStr[MAX_PATH]; HKEY hKey; DWORD dwData; char szDriverImagePath[MAX_PATH]; if( NULL==lpszDriverName || NULL==lpszDriverPath ) { return FALSE; } //得到完整的驱动路径 GetFullPathName(lpszDriverPath, MAX_PATH, szDriverImagePath, NULL); SC_HANDLE hServiceMgr=NULL;// SCM管理器的句柄 SC_HANDLE hService=NULL;// NT驱动程序的服务句柄 //打开服务控制管理器 hServiceMgr = OpenSCManager( NULL, NULL, SC_MANAGER_ALL_ACCESS ); if( hServiceMgr == NULL ) { // OpenSCManager失败 CloseServiceHandle(hServiceMgr); return FALSE; } // OpenSCManager成功 //创建驱动所对应的服务 hService = CreateService( hServiceMgr, lpszDriverName, // 驱动程序的在注册表中的名字 lpszDriverName, // 注册表驱动程序的DisplayName 值 SERVICE_ALL_ACCESS, // 加载驱动程序的访问权限 SERVICE_FILE_SYSTEM_DRIVER, // 表示加载的服务是文件系统驱动程序 SERVICE_DEMAND_START, // 注册表驱动程序的Start 值 SERVICE_ERROR_IGNORE, // 注册表驱动程序的ErrorControl 值 szDriverImagePath, // 注册表驱动程序的ImagePath 值 "FSFilter Activity Monitor",// 注册表驱动程序的Group 值 NULL, "FltMgr", // 注册表驱动程序的DependOnService 值 NULL, NULL); if( hService == NULL ) { if( GetLastError() == ERROR_SERVICE_EXISTS ) { //服务创建失败,是由于服务已经创立过 CloseServiceHandle(hService); // 服务句柄 CloseServiceHandle(hServiceMgr); // SCM句柄 return TRUE; } else { CloseServiceHandle(hService); // 服务句柄 CloseServiceHandle(hServiceMgr); // SCM句柄 return FALSE; } } CloseServiceHandle(hService); // 服务句柄 CloseServiceHandle(hServiceMgr); // SCM句柄 //------------------------------------------------------------------------------------------------------- // SYSTEM\\CurrentControlSet\\Services\\DriverName\\Instances子健下的键值项 //------------------------------------------------------------------------------------------------------- strcpy(szTempStr,"SYSTEM\\CurrentControlSet\\Services\\"); strcat(szTempStr,lpszDriverName); strcat(szTempStr,"\\Instances"); if(RegCreateKeyEx(HKEY_LOCAL_MACHINE,szTempStr,0,"",REG_OPTION_NON_VOLATILE,KEY_ALL_ACCESS,NULL,&hKey,(LPDWORD)&dwData)!=ERROR_SUCCESS) { return FALSE; } // 注册表驱动程序的DefaultInstance 值 strcpy(szTempStr,lpszDriverName); strcat(szTempStr," Instance"); if(RegSetValueEx(hKey,"DefaultInstance",0,REG_SZ,(CONST BYTE*)szTempStr,(DWORD)strlen(szTempStr))!=ERROR_SUCCESS) { return FALSE; } RegFlushKey(hKey);//刷新注册表 RegCloseKey(hKey); //------------------------------------------------------------------------------------------------------- // SYSTEM\\CurrentControlSet\\Services\\DriverName\\Instances\\DriverName Instance子健下的键值项 //------------------------------------------------------------------------------------------------------- strcpy(szTempStr,"SYSTEM\\CurrentControlSet\\Services\\"); strcat(szTempStr,lpszDriverName); strcat(szTempStr,"\\Instances\\"); strcat(szTempStr,lpszDriverName); strcat(szTempStr," Instance"); if(RegCreateKeyEx(HKEY_LOCAL_MACHINE,szTempStr,0,"",REG_OPTION_NON_VOLATILE,KEY_ALL_ACCESS,NULL,&hKey,(LPDWORD)&dwData)!=ERROR_SUCCESS) { return FALSE; } // 注册表驱动程序的Altitude 值 strcpy(szTempStr,lpszAltitude); if(RegSetValueEx(hKey,"Altitude",0,REG_SZ,(CONST BYTE*)szTempStr,(DWORD)strlen(szTempStr))!=ERROR_SUCCESS) { return FALSE; } // 注册表驱动程序的Flags 值 dwData=0x0; if(RegSetValueEx(hKey,"Flags",0,REG_DWORD,(CONST BYTE*)&dwData,sizeof(DWORD))!=ERROR_SUCCESS) { return FALSE; } RegFlushKey(hKey);//刷新注册表 RegCloseKey(hKey); return TRUE; }这里提供一个安装驱动的函数,在这个函数中将某些信息写入了注册表,注册表中变化的信息如下:HKEY_LOCAL_MACHINE中的SYSTEM\CurrentControlSet\Services\Nullfilter\Instances 中键 DefaultInstance = "nullfilter Instance"HKEY_LOCAL_MACHINE中的SYSTEM\CurrentControlSet\Services\Nullfilter\ nullfilter Instances 中键 altitude = “370020”,键Flags = 0启动驱动驱动的启动与普通的服务程序的启动方法一样,这里直接贴上代码:BOOL StartDriver(const char* lpszDriverName) { SC_HANDLE schManager; SC_HANDLE schService; if(NULL==lpszDriverName) { return FALSE; } schManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); if(NULL==schManager) { CloseServiceHandle(schManager); return FALSE; } schService=OpenService(schManager,lpszDriverName,SERVICE_ALL_ACCESS); if(NULL==schService) { CloseServiceHandle(schService); CloseServiceHandle(schManager); return FALSE; } if(!StartService(schService,0,NULL)) { CloseServiceHandle(schService); CloseServiceHandle(schManager); if( GetLastError() == ERROR_SERVICE_ALREADY_RUNNING ) { // 服务已经开启 return TRUE; } return FALSE; } CloseServiceHandle(schService); CloseServiceHandle(schManager); return TRUE; }停止驱动的运行BOOL StopDriver(const char* lpszDriverName) { SC_HANDLE schManager; SC_HANDLE schService; SERVICE_STATUS svcStatus; bool bStopped=false; schManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); if(NULL==schManager) { return FALSE; } schService=OpenService(schManager,lpszDriverName,SERVICE_ALL_ACCESS); if(NULL==schService) { CloseServiceHandle(schManager); return FALSE; } if(!ControlService(schService,SERVICE_CONTROL_STOP,&svcStatus) && (svcStatus.dwCurrentState!=SERVICE_STOPPED)) { CloseServiceHandle(schService); CloseServiceHandle(schManager); return FALSE; } CloseServiceHandle(schService); CloseServiceHandle(schManager); return TRUE; }删除驱动BOOL DeleteDriver(const char* lpszDriverName) { SC_HANDLE schManager; SC_HANDLE schService; SERVICE_STATUS svcStatus; schManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); if(NULL==schManager) { return FALSE; } schService=OpenService(schManager,lpszDriverName,SERVICE_ALL_ACCESS); if(NULL==schService) { CloseServiceHandle(schManager); return FALSE; } ControlService(schService,SERVICE_CONTROL_STOP,&svcStatus); if(!DeleteService(schService)) { CloseServiceHandle(schService); CloseServiceHandle(schManager); return FALSE; } CloseServiceHandle(schService); CloseServiceHandle(schManager); return TRUE; }Minfilter中如何获取各种信息的值Minfilter中将IRP进行了封装,但是在获取各种值时基本上变化不大,而且相对于之前的Sfilter简单了许多,下面假定在函数中有了它的CALL_BACK_DATA结构,有这样一条语句PFLT_CALLBACK_DATA Data获取当前进程的EPROCESS结构/*如果当前线程的ETHREAD结构不为NULL则根据线程ETHREAD来获取进程否则调用函数PsGetCurrentProcess()获取当前进程的EPROCESS结构*/ PEPROCESS processObject = Data->Thread ? IoThreadToProcess(Data->Thread) : PsGetCurrentProcess();向R3层返回数据Data->IoStatus.Status = ntStatus; Data->IoStatus.Information = 0;与使用IRP相似,在DATA中仍然使用IoStatus成员向R3返回,上述两句的意思与使用IRP时完全相同文件路径的获取文件路径的获取与Sfilter相比,简单了许多,只需要调用一个函数FltGetFileNameInformation,这个函数的定义在MSDN中可以查到,所以就不再这里做过多的说明,该函数会返回一个FLT_FILE_NAME_INFORMATION结构体用来保存文件名信息,结构体FLT_FILE_NAME_INFORMATION的定义如下所示typedef struct _FLT_FILE_NAME_INFORMATION { USHORT Size; FLT_FILE_NAME_PARSED_FLAGS NamesParsed; FLT_FILE_NAME_OPTIONS Format; UNICODE_STRING Name; UNICODE_STRING Volume; UNICODE_STRING Share; UNICODE_STRING Extension; UNICODE_STRING Stream; UNICODE_STRING FinalComponent; UNICODE_STRING ParentDir; } FLT_FILE_NAME_INFORMATION, *PFLT_FILE_NAME_INFORMATION;这个结构体记录了文件路径的各种信息,其中各个字符串都是根据Format的值来进行格式化得到的,需要注意的是在上述位置得到的文件名是类似与“\Device\HarddiskVolume1\Documents and Settings\MyUser\My Documents\Test Results.txt:stream1”的而不是我们之前熟悉的"C:\Documents and Settings\MyUser\My Documents\Test Results.txt:stream1",这就需要进行转化。需要注意的是在获取文件名时要在PostCreate函数中获取,因为当调用这个函数时说明根据传进来的文件路径已经正确打开了文件,这个时候的路径名一定是可靠的。 NTSTATUS ntStatus; PFLT_FILE_NAME_INFORMATION pNameInfo = NULL; UNREFERENCED_PARAMETER( Data ); UNREFERENCED_PARAMETER( FltObjects ); UNREFERENCED_PARAMETER( CompletionContext ); UNREFERENCED_PARAMETER( Flags ); //获取文件路径信息 ntStatus = FltGetFileNameInformation(Data, FLT_FILE_NAME_NORMALIZED| FLT_FILE_NAME_QUERY_DEFAULT, &pNameInfo); if (NT_SUCCESS(ntStatus)) { //解析获取到的信息 FltParseFileNameInformation(pNameInfo); DbgPrint("FileName:%wZ\n", &pNameInfo->Name); //使用完成后释放这个空间 FltReleaseFileNameInformation(pNameInfo); }函数FltGetFileNameInformation会自动为我们分配一个缓冲区来存储文件的信息,所以最后需要调用Release函数释放。另外通过调试的情况来看,FltGetFileNameInformation函数并不能获取文件路径的所有信息,一些扩展信息像Extension或者Parent这样的信息开始是没有的,只有通过FltParseFileNameInformation在已有信息的基础之上进行解析才会有。至于重命名的文件路径的获取使用下面的语句:PFILE_RENAME_INFORMATION pFileRenameInfomation = (PFILE_RENAME_INFORMATION)Data->Iopb->Parameters.SetFileInformation.InfoBuffer;在MInfilter中进行文件操作尽量使用以Flt开头的函数,不要使用Zw开头的那一组,以Zw开头的函数最终会触发Minfilter的回调函数,最终会造成无限递归Minfilter上下文在编程中,我们经常会遇到上下文这个概念,比如说进程上下文,线程上下文等等,在这里上下文表示某些代码执行的具体环境,系统一般位于进程上下文和中断上下文。当系统处理进程上下文时,系统在代替R3层做某些事,此时系统在调用系统API,执行系统功能,当系统处于进程上下文时是可以被挂起的。而当系统响应中断与具体硬件进行交互时处于中断上下文,此时的数据都位于非分页内存,而且不能睡眠而Minfilter上下文指的并不是代码运行的环境,而是一组数据,这组数据是附加到具体的设备对象上的,由用户自己定义。在使用时先利用函数AllocateContext分配一段内存空间,然后使用一组Set和Get函数来设置和获取设备上下文。具体的函数由不同的上下文来决定,下面是不同的上下文与他们对应的Set函数之间的关系|Context Type| Set-Context Routine||:--------------|:-||FLT_FILE_CONTEXT|Windows Vista and later only.) FltSetFileContext||FLT_INSTANCE_CONTEXT|FltSetInstanceContext||FLT_STREAM_CONTEXT|FltSetStreamContext||FLT_STREAMHANDLE_CONTEXT|FltSetStreamHandleContext||FLT_TRANSACTION_CONTEXT|(Windows Vista and later only.) FltSetTransactionContext||FLT_VOLUME_CONTEXT|FltSetVolumeContext|Get函数的使用与上述相同。最后使用完成后需要使用FltReleaseContext来释放这个上下文。下面是一个使用的具体例子typedef struct _INSTANCE_CONTEXT { … } INSTANCE_CONTEXT, *PINSTANCE_CONTEXT; PINSTANCE_CONTEXT pContext = NULL; //从设备对象上获取上下文 ntStatus = FltGetInstanceContext(FltObjects->Instance, & pContext); if(NT_SUCCESS(Status) == FALSE) { //设备上没有上下文则分配上下文的内存 ntStatus = FltAllocateContext(g_pFilter,FLT_INSTANCE_CONTEXT, sizeof(INSTANCE_CONTEXT), PagedPool,& pContext); if(NT_SUCCESS(Status) == FALSE) { //返回资源不足 return STATUS_INSUFFICIENT_RESOURCES; } RtlZeroMemory(pContext, sizeof(INSTANCE_CONTEXT)); } pContext ->m_DeviceType = VolumeDeviceType; pContext->m_FSType = VolumeFilesystemType; FltSetInstanceContext(FltObjects->Instance, FLT_SET_CONTEXT_REPLACE_IF_EXISTS,pContext,NULL); if (pContext) { FltReleaseContext(pContext); } //获取访问 PINSTANCE_CONTEXT pContext = NULL; Status = FltGetInstanceContext(FltObjects->Instance,&pContext); //下面是使用这个上下文,和一些其他的操作 pContext->xxx = xxx;回调函数运行的中断请求级别(IRQL)pre回调函数可以运行在APC_LEVEL或者PASSIVE_LEVEL 级别,但是一般是运行在PASSIVE_LEVEL级别如果一个Pre函数返回的是FLT_PREOP_SYNCHRONIZE,那么相对的,在同一个线程内部,它对应的POST函数将在IRQL <= APC_LEVEL级别运行。与对应的Pre在一个线程内时,fast IO请求对应的Post函数运行在PASSIVE_LEVEL级别Create回调的Post函数运行在PASSIVE_LEVEL级别当我们不确定当前代码所处的IRQL时可以使用函数KeCurrentIrql获取当前执行环境所在的IRQL。R3 与R0的通信R3在调用Minfilter中的相关函数时需要包含相关的库文件,与Lib文件,具体怎么包含这个我不太清楚,只需要在库项目属性的VC++目录下面这几项包含具体的路径即可包含目录 :“$(VC\_IncludePath);$(WindowsSDK_IncludePath);”库路径: "$(VC\_LibraryPath_x86);$(WindowsSDK\_LibraryPath\_x86);$(NETFXKitsDir)Lib\um\x86"之前R3与R0进行通信是通过R3调用DeviceIoControl函数将数据下发到R0层,然后R3等待一个事件,在R0处理完成R3的请求并准备好往上发的数据后将事件的对象设置为有信号,这样R3再从缓冲区中取数据,完成双方的通信,但是在Minfilter中准备了专门的函数用于双方通信。R3向R0下发数据R3层通过函数FilterSendMessage向R0下发数据,而R0通过fnMessageFromClient接收从R3发下来的数据。在Minfilter中R3与R0是通过各自的端口进行通讯的,这个端口与传统意义上的网络的通信端口不同,是一个抽象的概念,不需要太过于关注。在与R3进行通讯之前需要设置这个端口,端口的设置使用函数FltCreateComunicationPort,在这个函数调用时需要提供这样几个回调函数ConnectNotifyCallback:这个函数在R3层链接到R0的这个通讯端口时调用,在这个函数中可以拿到R3的进程句柄和R3的端口DisconnectNotifyCallback:当R3层与R0层断开时调用这个回调函数MessageNotifyCallback:当R3有数据下发下来调用这个回调,在这个函数中取R3发下来的数据R0向R3上报数据R0向R3上报数据时是一个双向的过程,R0既要上报数据,又要等待R3的返回,就好像之前的弹窗一样,当R0上报数据后就等待40s,在接收到R3的进一步指示时进行下一步,R0向R3上报大致经历这样的几个过程:R0通过函数FltSengMesage将数据发送到R3R3通过函数FilterGetMessage函数接收到R0的数据,并进行相应的处理处理完成后,调用函数FilterReplyMessage将处理结果返回给R0。另外需要注意一点,在进行通讯时需要两套数据结构,这两套分别运用在R3和R0两层,每一层都有两个数据结构,用来表示接收和返回的数据,拿R3来说,它需要一个MESSAGE结构体来接收从R0层发过来的数据,另外需要一个REPLY用于向R0返回数据。R3上报和下发的数据相比于R0需要多加一个FILTER_MESSAGE_HEADER的头,便于Minfilter分辨是哪个客户端下发的数据,Minfilter 根据这个头做相关的处理后将其于的数据发送到R0,所以R0能够正确知道是哪个进程在进行相关请求,而不需要添加额外的结构体下面是一个例子NTSTATUS ScannerpScanFileInUserMode ( __in PFLT_INSTANCE Instance, __in PFILE_OBJECT FileObject, __out PBOOLEAN SafeToOpen ) /*读取文件中的部分数据,然后交由R3处理,并根据R3返回的结果判断R3是否安全*/ { NTSTATUS status = STATUS_SUCCESS; PVOID buffer = NULL; ULONG bytesRead; PSCANNER_NOTIFICATION notification = NULL; FLT_VOLUME_PROPERTIES volumeProps; LARGE_INTEGER offset; ULONG replyLength, length; PFLT_VOLUME volume = NULL; *SafeToOpen = TRUE; if (ScannerData.ClientPort == NULL) { return STATUS_SUCCESS; } try { status = FltGetVolumeFromInstance( Instance, &volume ); if (!NT_SUCCESS( status )) { leave; } status = FltGetVolumeProperties( volume, &volumeProps, sizeof( volumeProps ), &length ); if (NT_ERROR( status )) { leave; } //取1024和扇区的最大值,保证读取的数据至少有一个扇区的大小 length = max( SCANNER_READ_BUFFER_SIZE, volumeProps.SectorSize ); /*分配一块内存用于从文件中读取数据,在minfilter中进行文件操作时申请缓冲区最好使用flt开头的一组函数,因为它不是简单的分配一块内存,还能保证在有程序使用这段内存时不会出现内存已被释放的情况,内部可能也用了引用计数*/ buffer = FltAllocatePoolAlignedWithTag( Instance, NonPagedPool, length, 'nacS' ); if (NULL == buffer) { status = STATUS_INSUFFICIENT_RESOURCES; leave; } //构建发送给R3层的结构体的内存 notification = ExAllocatePoolWithTag( NonPagedPool, sizeof( SCANNER_NOTIFICATION ), 'nacS' ); if(NULL == notification) { status = STATUS_INSUFFICIENT_RESOURCES; leave; } offset.QuadPart = bytesRead = 0; status = FltReadFile( Instance, FileObject, &offset, length, buffer, FLTFL_IO_OPERATION_NON_CACHED | FLTFL_IO_OPERATION_DO_NOT_UPDATE_BYTE_OFFSET, &bytesRead, NULL, NULL ); if (NT_SUCCESS( status ) && (0 != bytesRead)) { notification->BytesToScan = (ULONG) bytesRead; /*将这段信息发送到R3,这个函数是一个阻塞的函数,只有当超时值过了或者R3返回了数据才会返回,在这设置超时值为NULL表示会一直等待,在这返回值也是使用notification做为接受返回值的缓冲,在这不会出现覆盖的情况,因为这个函数在调用后首先是R3接受数据,然后进行处理,处理完成后R3才会主动调用另一个API返回数据,所以这里有一个时间差,当获取到返回值时之前传入的数据已经没有用了,这里将发送的缓冲与返回的缓冲定义为同一个只是为了节省内存*/ RtlCopyMemory( ¬ification->Contents, buffer, min( notification->BytesToScan, SCANNER_READ_BUFFER_SIZE ) ); replyLength = sizeof( SCANNER_REPLY ); //在这我们将 status = FltSendMessage( ScannerData.Filter, &ScannerData.ClientPort, notification, sizeof(SCANNER_NOTIFICATION), notification, &replyLength, NULL ); if (STATUS_SUCCESS == status) { *SafeToOpen = ((PSCANNER_REPLY) notification)->SafeToOpen; } else { DbgPrint( "!!! scanner.sys --- couldn't send message to user-mode to scan file, status 0x%X\n", status ); } } } finally { //最后清理内存 if (NULL != buffer) { FltFreePoolAlignedWithTag( Instance, buffer, 'nacS' ); } if (NULL != notification) { ExFreePoolWithTag( notification, 'nacS' ); } if (NULL != volume) { FltObjectDereference( volume ); } } return status; }这个例子演示了R0层如何从磁盘中读取文件内容,然后发送到R3,并从R3层上接受返回。下面这个例子将演示R3如何读取R0发上来的数据 while (TRUE) { //这是一个阻塞函数,当能从R0接受到数据的时候返回 result = GetQueuedCompletionStatus( Context->Completion, &outSize, &key, &pOvlp, INFINITE ); message = CONTAINING_RECORD( pOvlp, SCANNER_MESSAGE, Ovlp ); if (!result) { hr = HRESULT_FROM_WIN32( GetLastError() ); break; } printf( "Received message, size %d\n", pOvlp->InternalHigh ); notification = &message->Notification; assert(notification->BytesToScan <= SCANNER_READ_BUFFER_SIZE); /*R3层定义的这个SCANNER_MESSAGE结构体是在notification这个结构体的基础之上加了一个头,所以大小会大于这个notification*/ __analysis_assume(notification->BytesToScan <= SCANNER_READ_BUFFER_SIZE); //这个函数是一个自定义函数,用来扫描R0传上来的数据有没有特定的字符 result = ScanBuffer( notification->Contents, notification->BytesToScan ); replyMessage.ReplyHeader.Status = 0; replyMessage.ReplyHeader.MessageId = message->MessageHeader.MessageId; replyMessage.Reply.SafeToOpen = !result; printf( "Replying message, SafeToOpen: %d\n", replyMessage.Reply.SafeToOpen ); //向R0返回数据 hr = FilterReplyMessage( Context->Port, (PFILTER_REPLY_HEADER) &replyMessage, sizeof( replyMessage ) ); if (SUCCEEDED( hr )) { printf( "Replied message\n" ); } else { printf( "Scanner: Error replying message. Error = 0x%X\n", hr ); break; } memset( &message->Ovlp, 0, sizeof( OVERLAPPED ) ); //再次等待从R0下发的数据 hr = FilterGetMessage( Context->Port, &message->MessageHeader, FIELD_OFFSET( SCANNER_MESSAGE, Ovlp ), &message->Ovlp ); if (hr != HRESULT_FROM_WIN32( ERROR_IO_PENDING )) { break; } } -
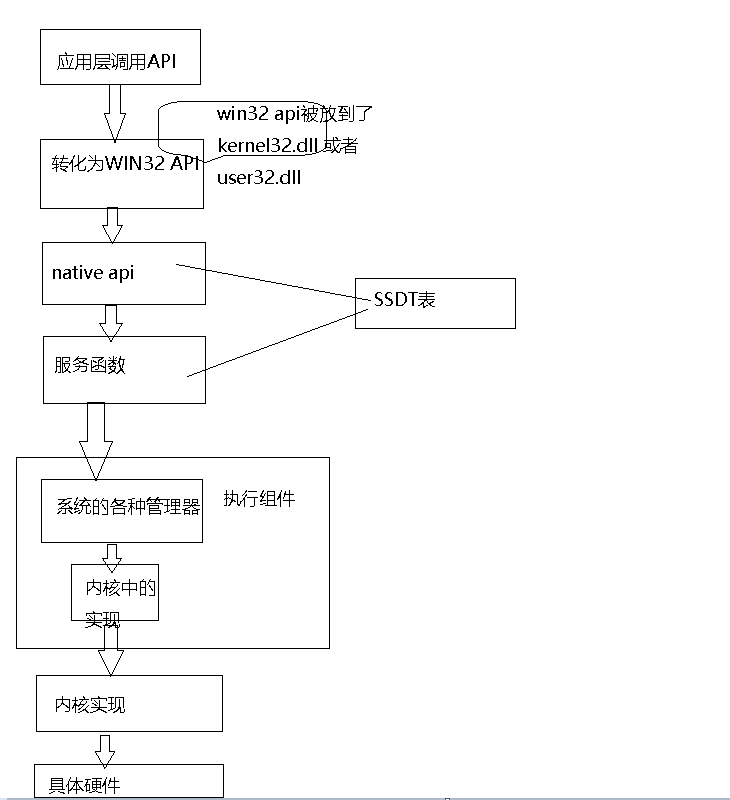
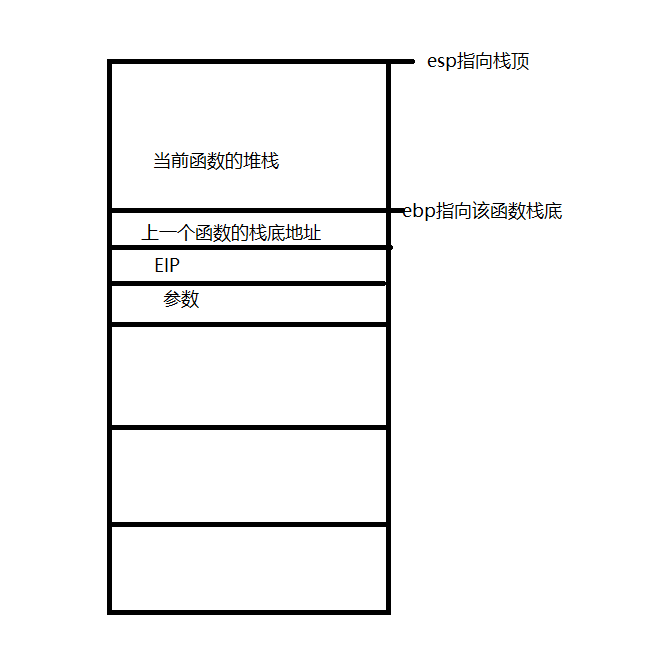
驱动开发入门——NTModel 上一篇博文中主要说明了驱动开发中基本的数据类型,认识这些数据类型算是驱动开发中的入门吧,这次主要说明驱动开发中最基本的模型——NTModel。介绍这个模型首先要了解R3层是如何通过应用层API进入到内核,内核又是如何将信息返回给R3,另外会介绍R3是如何直接向R0层下命令。API调用的基本流程一般在某些平台上进行程序开发,都需要使用系统提供的统一接口,linux平台直接提供系统调用,而windows上提供API,这两个并不是同一个概念(之前我一直分不清楚),虽然它们都是系统提供的实现某种功能的接口,但是它们有着本质的区别,系统调用在调用时会陷入到内核态,而API则不是这样,例如对于CreateFile这个我们不能说它是一个系统调用,在这个函数中并没有立即陷入到内核态,而是先进行参数检查,然后通过其他的一系列操作之后调用系统调用而进入到内核,所以它并不是系统调用。windows在应用层提供了3个重要的动态库,分别是kernel.dll uer32.dll gdi.dll (现在基本上将所有的API都封装到kernell.dll中)当用户程序调用一个API函数时,在这个API内部会调用用封装到ntdll.dll中以Zw或者Nt开头的同名函数,这些函数主要负责从用户态切换到内核态,这些函数叫做Native API,Native API进入到内核的方式是产生一个中断(XP及以前的版本)和调用sysenter(XP以上的版本),Native API在进入到内核中时会带上一个服务号,系统根据这个服务号在SSDT表中查找到相关的服务函数,最后调用这些服务函数完成相关功能,这个过程可以用下面的图来说明:下面以CreateFile为例说明具体的调用过程:应用层调用CreateFile函数这个函数实际上被封装到了kernel32.dll中,在这个函数中调用NtCreateFile,这就是调用ntdll.dll中的native api ,ntdll.dll中一般又两组函数——以Nt开头,以Zw开头的,这两组函数本身没有什么太大的区别。native api中通过中断 int 2eh(windows 2000 及以下),或者通过sysenter指令(windows xp及以上)进入内核,这种方式称为软中断,在产生中断时会带上一个服务号,根据服务号在ssdt表中以服务号进行查找(类似与8086中的中断机制)根据SSDT表中记录的服务函数地址,调用相关的服务函数。然后进入到执行组件中,对于CreateFile的操作,这个时候会调用IO管理器,IO管理器负责发起IO操作请求,并管理这些请求,主要时生成一个IRP结构,系统中有不同的管理器,主要有这样几个——虚拟内存管理器,IO管理器,对象管理器,进程管理器,线程管理器,配置管理器。管理器生成一个IRP请求,并调用内核中的驱动,来相应这个操作,对于CreateFile来说会调用NtCreateFile函数。最后调用内核实现部分,也就是硬件抽象层。最后由硬件抽象层操作硬件,完成打开或者创建文件的操作。NTModel详解R3与R0互相通信在驱动程序中,入口是DriverEntry,函数会带入一个DriverObject指针。这个对象中有许多回调函数,它会根据R3层下发的操作调用对应的回调函数,比如应用层调用CreatFile时在驱动层会调用DispatchCreate。这样我们只要写好DispatchCreate就可以处理由R3层下发的CreateFile命令。上述的一些函数只适用于一般的操作,对于一些特殊的,比如R3层要R0层产生一个输出语句等等,这个特殊的操作是通过DeviceIoControl向R0下发一个控制命令,在R0层根据这个控制码来识别具体是哪种控制,需要R0做哪种操作,函数原型如下:BOOL DeviceIoControl( HANDLE hDevice, //驱动的设备对象句柄 DWORD dwIoControlCode, //控制码 LPVOID lpInBuffer, //发往R0层的数据 DWORD nInBufferSize, //数据大小 LPVOID lpOutBuffer, //提供一个缓冲区,接受R0返回的数据 DWORD nOutBufferSize, //缓冲区的大小 LPDWORD lpBytesReturned, //R0实际返回数据的大小 LPOVERLAPPED lpOverlapped //完成例程 );IRP的简介R3与R0的通信是通过IRP进行数据的交换,IRP的定义如下:typedef struct DECLSPEC_ALIGN(MEMORY_ALLOCATION_ALIGNMENT) _IRP { CSHORT Type; USHORT Size; PMDL MdlAddress; ULONG Flags; union { struct _IRP *MasterIrp; PVOID SystemBuffer; } AssociatedIrp; ... IO_STATUS_BLOCK IoStatus; CHAR StackCount; CHAR CurrentLocation; ... PVOID UserBuffer; ... struct { union { struct _IO_STACK_LOCATION *CurrentStackLocation; ... }; } IRP;IRP主要分为两部分,一部分是头,另一部分是IRP栈,在上一篇分析驱动中的数据结构时,说过驱动设备时分层的,上层驱动设备完成后,需要发到下层驱动设备,所有驱动设备公用IRP的栈顶,但是每个驱动都各自有自己的IRP栈,它们的关系如下如所示:_IO_STACK_LOCATION 的结构如下:typedef struct _IO_STACK_LOCATION { UCHAR MajorFunction; UCHAR MinorFunction; UCHAR Flags; UCHAR Control; union { struct { PIO_SECURITY_CONTEXT SecurityContext; ULONG Options; USHORT POINTER_ALIGNMENT FileAttributes; USHORT ShareAccess; ULONG POINTER_ALIGNMENT EaLength; } Create; ... struct { ULONG Length; ULONG POINTER_ALIGNMENT Key; LARGE_INTEGER ByteOffset; } Read; struct { ULONG Length; ULONG POINTER_ALIGNMENT Key; LARGE_INTEGER ByteOffset; } Write; ... struct { ULONG OutputBufferLength; ULONG POINTER_ALIGNMENT InputBufferLength; ULONG POINTER_ALIGNMENT IoControlCode; PVOID Type3InputBuffer; } DeviceIoControl; ... struct { PVOID Argument1; PVOID Argument2; PVOID Argument3; PVOID Argument4; } Others; } Parameters; PDEVICE_OBJECT DeviceObject; PFILE_OBJECT FileObject; PIO_COMPLETION_ROUTINE CompletionRoutine; PVOID Context; } IO_STACK_LOCATION, *PIO_STACK_LOCATION;这个结构中有一个共用体,当处理不同的R3层请求时系统会填充对应的共用体。源代码分析//设备名 #define DEVICE_NAME L"\\device\\NtDevice" #define LINK_NAME L"\\??\\NtDevice" //DriverEntry NTSTATUS DriverEntry(PDRIVER_OBJECT pDriverObject, PUNICODE_STRING pRegisterPath) { PDEVICE_OBJECT pDeviceObject = NULL; UNICODE_STRING uDeviceName = { 0 }; UNICODE_STRING uLinkName = { 0 }; NTSTATUS status = 0; UNREFERENCED_PARAMETER(pRegisterPath); DbgPrint("Start Driver......\n"); pDriverObject->DriverUnload = UnloadDriver; //创建设备对象 RtlInitUnicodeString(&uDeviceName, DEVICE_NAME); status = IoCreateDevice(pDriverObject, 0, &uDeviceName, FILE_DEVICE_UNKNOWN, 0, FALSE, &pDeviceObject); if (!NT_SUCCESS(status)) { DbgPrint("create device error!\n"); return status; } pDeviceObject->Flags |= DO_BUFFERED_IO; //创建符号连接 RtlInitUnicodeString(&uLinkName, LINK_NAME); status = IoCreateSymbolicLink(&uLinkName, &uDeviceName); if (!NT_SUCCESS(status)) { DbgPrint("create link name error!\n"); return status; } //注册分发函数 for (ULONG i = 0; i < IRP_MJ_MAXIMUM_FUNCTION + 1; i++) { pDriverObject->MajorFunction[i] = IoDispatchCommon; } pDriverObject->MajorFunction[IRP_MJ_CREATE] = IoDispatchCreate; pDriverObject->MajorFunction[IRP_MJ_READ] = IoDispatchRead; pDriverObject->MajorFunction[IRP_MJ_WRITE] = IoDispatchWrite; pDriverObject->MajorFunction[IRP_MJ_DEVICE_CONTROL] = IoDispatchControl; pDriverObject->MajorFunction[IRP_MJ_CLOSE] = IoDispatchClose; pDriverObject->MajorFunction[IRP_MJ_CLEANUP] = IoDispatchClean; return STATUS_SUCCESS; }这个函数是驱动的入口函数,类似与main函数或者WinMain函数。在该函数中首先创建一个控制设备对象,并为它创建一个符号链接,因为R3层不能直接通过设备的名称来访问设备,必须通过其符号链接。需要注意,设备名称必须以“\\device”开头,而符号链接需要以“\\??”开头,否则创建设备和符号链接会失败。然后为这个驱动程序注册分发函数,分发函数保存在DriverObject结构中MajorFunction中,这个时一个数组,元素个数为IRP_MJ_MAXIMUM_FUNCTION,系统为每个位置定义一个宏,我们根据这个宏,在数据中填入对应 的函数指针,系统会根据R3层的操作来调用具体的函数。另外DriverObject中的DriverUnload 保存的是卸载驱动时系统回调用的函数,在这个函数中主要完成资源的释放工作//UnloadDriver VOID UnloadDriver(PDRIVER_OBJECT pDriverObject) { UNICODE_STRING uLinkName = { 0 }; UNREFERENCED_PARAMETER(pDriverObject); RtlInitUnicodeString(&uLinkName, LINK_NAME); IoDeleteSymbolicLink(&uLinkName); IoDeleteDevice(pDriverObject->DeviceObject); DbgPrint("Unload Driver......\n"); }在这个函数中主要释放了之前创建的符号链接和控制设备对象。NTSTATUS IoDispatchCommon(PDEVICE_OBJECT DeviceObject, PIRP pIrp) { UNREFERENCED_PARAMETER(DeviceObject); //向R3返回成功 pIrp->IoStatus.Status = STATUS_SUCCESS; //向R3返回的数据长度为0,不向R3返回数据 pIrp->IoStatus.Information = 0; //默认直接返回 IoCompleteRequest(pIrp, IO_NO_INCREMENT); return STATUS_SUCCESS; }这个函数是我们注册的默认处理函数,它每步的操作在注释中也写了,需要注意的是在pIrp->IoStatus.Status = STATUS_SUCCESS;语句是向R3返回执行的状态,而最后返回成功是给驱动程序看的。//IoDispatchRead NTSTATUS IoDispatchRead(PDEVICE_OBJECT DeviceObject, PIRP pIrp) { //处理R3层的读命令,将数据返回给R3层 WCHAR wHello[] = L"hello world"; ULONG uReadLength = 0; WCHAR *pBuffer = pIrp->AssociatedIrp.SystemBuffer; ULONG uBufferLen = 0; ULONG uMin = 0; PIO_STACK_LOCATION pCurrStack = IoGetCurrentIrpStackLocation(pIrp); UNREFERENCED_PARAMETER(DeviceObject); uBufferLen = pCurrStack->Parameters.Read.Length; uReadLength = sizeof(wHello); uMin = (uReadLength < uBufferLen) ? uReadLength : uBufferLen; RtlCopyMemory(pBuffer, wHello, uMin); pIrp->IoStatus.Status = STATUS_SUCCESS; pIrp->IoStatus.Information = uMin; IoCompleteRequest(pIrp, IO_NO_INCREMENT); return STATUS_SUCCESS; }这个函数主要用来处理应用层的ReadFile请求,这个函数主要是将一段字符串拷贝到通信用的缓冲区中,模拟读的操作。,需要注意的是这个地址要根据不同的设备类型来不同的对待,对于DO_BUFFERED_IO类型的设备,是保存在pIrp->AssociatedIrp.SystemBuffer中,对于DO_DIRECT_IO类型的设备,这个缓冲区的地址是MdlAddress。而对于ReadFile这个API来说,应用层在调用这个函数时会给一个缓冲区的大小,为了获取这个大小,首先得到当前的IRP栈,这个操作用函数IoGetCurrentIrpStackLocation可以得到,然后在当前栈的Parameters共用体中,调用Read部分的Length。当得到这个缓冲区大小后,取缓冲区大小和对应字符串的大小的最小值,为什么要这样做?我们不妨考虑如果用缓冲区的长度的话,当这个长度比字符串的长度长,那么在拷贝时就会将字符串后面的一些无用内存给拷贝进去了,一来效率不高,二来这样应用层得到了内核层中内存的部分数据,存在安全隐患,如果我们采用字符串的长度,可能会出现用户提供的缓冲区不够的情况,这样会造成越界。所以采用它们的最小值是最合理的。完成之后返回,这个时候要注意返回的长度这一项需要填上真实拷贝的大小,不然R3是得不到数据的,或者得到的数据不完整。NTSTATUS IoDispatchWrite(PDEVICE_OBJECT DeviceObject, PIRP pIrp) { //接受R3的写命令 UNICODE_STRING uWriteString = { 0 }; WCHAR *pBuffer = NULL; ULONG uWriteLength = 0; PIO_STACK_LOCATION pStackIrp = IoGetCurrentIrpStackLocation(pIrp); UNREFERENCED_PARAMETER(DeviceObject); uWriteLength = pStackIrp->Parameters.Write.Length; uWriteString.MaximumLength = uWriteLength; uWriteString.Length = uWriteLength - 1 * sizeof(WCHAR); uWriteString.Buffer = ExAllocatePoolWithTag(PagedPool, uWriteLength, 'TSET'); pBuffer = pIrp->AssociatedIrp.SystemBuffer; if (NULL == uWriteString.Buffer) { DbgPrint("Allocate Memory Error!\n"); pIrp->IoStatus.Status = STATUS_INSUFFICIENT_RESOURCES; pIrp->IoStatus.Information = 0; IoCompleteRequest(pIrp, IO_NO_INCREMENT); return STATUS_INSUFFICIENT_RESOURCES; } RtlCopyMemory(uWriteString.Buffer, pBuffer, uWriteLength); DbgPrint("Write Date: %wZ\n", &uWriteString); pIrp->IoStatus.Status = STATUS_SUCCESS; pIrp->IoStatus.Information = 0; IoCompleteRequest(pIrp, IO_NO_INCREMENT); return STATUS_SUCCESS; }这个函数用来处理WriteFile的请求,首先通过IRP中传进来的缓冲区的地址得到这个数据,然后将数据打印出来,通过这种方式来模拟向R3文件中写入数据。//定义的控制码 #define IOCTL_BASE 0x800 #define MYIOCTRL_CODE(i) CTL_CODE(FILE_DEVICE_UNKNOWN, (IOCTL_BASE + i), METHOD_BUFFERED, FILE_ANY_ACCESS) #define CTL_PRINT MYIOCTRL_CODE(1) #define CTL_HELLO MYIOCTRL_CODE(2) #define CTL_BYE MYIOCTRL_CODE(3) //IoDispatchControl函数 NTSTATUS IoDispatchControl(PDEVICE_OBJECT DeviceObject, PIRP pIrp) { UNREFERENCED_PARAMETER(DeviceObject); ULONG uBufferLength = 0; WCHAR *pBuffer = NULL; ULONG uIOCtrlCode = 0; PIO_STACK_LOCATION pStack = IoGetCurrentIrpStackLocation(pIrp); uBufferLength = pStack->Parameters.DeviceIoControl.InputBufferLength; uIOCtrlCode = pStack->Parameters.DeviceIoControl.IoControlCode; pBuffer = pIrp->AssociatedIrp.SystemBuffer; switch (uIOCtrlCode) { case CTL_BYE: DbgPrint("Good Bye"); break; case CTL_HELLO: DbgPrint("Hello World\n"); break; case CTL_PRINT: DbgPrint("%S", pBuffer); break; default: DbgPrint("unknow command\n"); } pIrp->IoStatus.Information = 0; pIrp->IoStatus.Status = STATUS_SUCCESS; IoCompleteRequest(pIrp, IO_NO_INCREMENT); return STATUS_SUCCESS; }这个宏CTL_CODE是微软官方定义的,主要用来将控制码和对应类型的设备进行绑定,主要传入4个参数,第一个是设备的类型,第二个是具体的控制码,需要注意的是:为了与微软官方的控制码区分,自定义的控制码需要在0x800以上。第三个参数是对应控制码传递参数的方式,主要的几种方式与设备对象和R3层传递数据的方式类似,我们在这传入的是METHOD_BUFFERED,表示的是通过内存拷贝的方式将R3的数据传入到R0。最后一个是操作权限,我们给它所有的权限。在函数中我们根据R3传入的控制码来进行不同的操作。R3部分的代码R3部分主要完成的是驱动程序的加载、卸载、以及向驱动程序发送命令。驱动的加载和卸载是通过注册并启动服务和关闭并删除服务的方式进行的,至于怎么操作一个服务,请看本人另外一篇关于服务操作的博客。需要注意的是在创建服务时需要填入服务程序所在的路径,这个时候需要填生成的.sys文件的路径,不要写之前定义的设备名或者符号链接名。在这主要贴出控制部分的代码://打开设备,获取它的设备句柄 HANDLE hDevice = CreateFileA("\\\\.\\NtDevice", GENERIC_WRITE | GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); if (NULL == hDevice) { printf("打开设备失败\n"); return; } //读 CHAR szBuf[255] = ""; ULONG uLength = 0; ReadFile(hDevice, szBuf, 255, &uLength, NULL); printf("Read Date:%s\n", szBuf); //写 WCHAR wHello[] = L"Hello world"; WriteFile(hDevice, wHello, (wcslen(wHello) + 1) * sizeof(WCHAR), &uLength, NULL); printf("写操作完成"); //向其发送控制命令 WCHAR wCtlString[] = L"C:\\test.txt"; DeviceIoControl(hDevice, CTL_PRINT, wCtlString, (wcslen(wCtlString) + 1) * sizeof(WCHAR), NULL, 0, NULL, NULL); DeviceIoControl(hDevice, CTL_HELLO, NULL, 0, NULL, 0, NULL, NULL); DeviceIoControl(hDevice, CTL_BYE, NULL, 0, NULL, 0, NULL, NULL); printf("控制操作完成"); CloseHandle(hDevice);要控制一个设备对象,必须先得到设备对象的句柄,获得这个句柄,我们是通过函数CreateFile来得到的,这个时候填入的文件名应该是之前注册的符号链接的名字,在R3中这个名字以“\\\\ .”开头并加上我们为它提供的符号链接名。在调用CreateFile时会触发之前定义的DispatchCreate函数。然后我们通过调用ReadFile和WriteFile分别触发读写操作,最后调用DeviceIoControl函数,发送控制命令,在R3层中也要定义一份与R0中一模一样的控制码。这样就基本实现了R3与R0通信。有的时候在加载驱动的时候,系统会报错,返回码为2,表示系统找不到驱动对应的文件,这个时候可能是文件的路径的问题,这个时候可以在系统的注册表HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\下,找到我们的驱动(还有可能是在ControlSet002)对应的路径,然后将R3程序拷贝到这个路径下,基本就可以解决这个问题
-
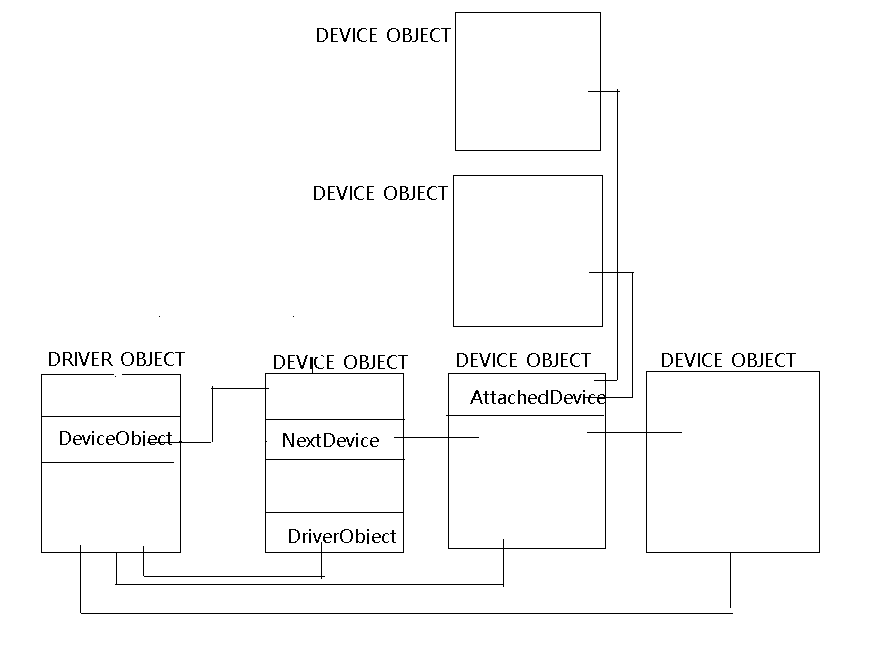
windows 驱动开发入门——驱动中的数据结构 最近在学习驱动编程方面的内容,在这将自己的一些心得分享出来,供大家参考,与大家共同进步,本人学习驱动主要是通过两本书——《独钓寒江 windows安全编程》 和 《windows驱动开发技术详解》。驱动开发过程中,主要使用的C语言,虽说C中定义了许多数据类型,但是一般来说在编码上还是习惯与使用WDK的规范,虽说这个不是必须的,比如有这样一句unsigned long ul = 0;这个数据的大小根据不同的机器不同的编译器环境略有不同,这样代码就产生了不可控的行为,但是WDK上专门定义了相关的宏,环境不同,只需要修改一下宏定义,这样就避免了这个问题。在这列举一些常用的数据类型,以免以后在编写代码或者查看例子代码时犯迷糊:普通数据类型#define ULONG unsigned long #define UCHAR unsigned char #define UINT unsigned int #define VOID void #define PULONG unsigned * #define PUCHAR unsigned char* #define PUINT unsigned int* #define PVOID void* 字符串类型在驱动的编程中,为字符串操作专门定义了一个数据类型UNICODE_STRING ANSI_STRING,他们的定义大致相同,只是一个是表示UNICODE字符串,一个表示ANSI字符串,下面主要来说明一下UNICODE_STRINGtypedef struct _UNICODE_STRING { USHORT Length; // 字符串的中字符所占的内存大小 USHORT MaximumLength;//用来存储字符串缓冲的大小 PWCHAR Buffer;//缓冲的地址 } UNICODE_STRING;这个结构体在使用是需要注意的是上述两个大小单位是字节数而不是字符个数,另外在操作UNICODE_STRING 的时候只是简单的操作Buffer指向的内存,并不会特意的为其分配另外的空间,字符串处理函数主要有这样几个:RtlInitUnicodeString(&uStr1, str1); RtlCopyUnicodeString(&uStr1, &uStr2); RtlAppendUnicodeToString(&uStr1, str1); RtlAppendUnicodeStringToString(&uStr1, &uStr2); RtlCompareUnicodeString(&uStr1, &uStr2, TRUE/FALSE); RtlAnsiStringToUnicodeString(&uStr1, &aStr1, TRUE/FALSE); RtlFreeUnicodeString(&uStr1);这些函数从字面上就可以知道它们是干什么用的,需要注意的是,除了Init,这些函数只是简单的操作Buffer已指向的内存,并不会改变指针的指向。所以在使用时要特别注意不要试图改变静态常量区的内容,也要特别注意指向的内存是在栈中还是在堆中。下面是一个简单的例子: UNICODE_STRING uStr1 = { 0 }; UNICODE_STRING uStr2 = { 0 }; UNICODE_STRING uStr3 = { 0 }; ANSI_STRING aStr = { 0 }; RtlInitUnicodeString(&uStr1, L"Hello"); RtlInitUnicodeString(&uStr2, L"Goodbye"); //打印字符串结构用%Z表示%wZ表示是宽字符 DbgPrint("uStr1 = %wZ\n", &uStr1); DbgPrint("uStr2 = %wZ\n", &uStr2); RtlInitAnsiString(&aStr, "Hello World"); DbgPrint("aStr = %Z\n", &aStr); /*这个操作是由于uStr3中的Buffer指向NULL,所以会失败*/ RtlCopyUnicodeString(&uStr3, &uStr1); DbgPrint("uStr3 = %wZ\n", &uStr3); //失败 /*下面两个失败是由于Str1 Str2 指向的是字符串常量区,不可修改*/ RtlAppendUnicodeToString(&uStr1, &uStr2); DbgPrint("uStr1 = %wZ\n", &uStr1); //失败 RtlAppendUnicodeStringToString(&uStr1, L"World"); DbgPrint("uStr1 = %wZ\n", &uStr1); //失败LARGE_INTEGER这个结构就像它的名字一样,用来表示一个比较大的整数,它的定义如下:typedef union _LARGE_INTEGER { struct { DWORD LowPart; LONG HighPart; }; struct { DWORD LowPart; LONG HighPart; } u; LONGLONG QuadPart; } LARGE_INTEGER, *PLARGE_INTEGER;这是一个公用体,可以认为它是由两部分组成高32位的HighPart和低32位的LowPart,它分了高位优先和低位优先两种情况,也可以认为它是一个64位的整形。在使用时根据需求来决定NTSTATUS绝大多数驱动函数都返回这个值,用来表示当前处理的状态,一般STATUS_SUCCESS表示成功,其余的都表示失败。微软根据不同情况定义了它的状态值,一般常用的有下面几个值含义STATUS_SUCCESS函数执行成功STATUS_UNSUCCESSFUL函数执行不成功STATUS_NOT_IMPLEMENTED函数违背实现STATUS_INVALID_INFO_CLASS输入参数是无效的类别STATUS_ACCESS_VIOLATION不允许访问STATUS_IN_PAGE_ERROR发生页面故障STATUS_INVALID_HANDLE输入的是无效的句柄STATUS_INVALID_PARAMETER输入的是无效的参数STATUS_NO_SUCH_DEVICE指定的设备不存在STATUS_NO_SUCH_FILE指定的文件不存在STATUS_INVALID_DEVICE_REQUEST无效的设备请求STATUS_END_OF_FILE文件已到结尾STATUS_INVALID_SYSTEM_SERVICE无效的系统调用STATUS_ACCESS_DENIED访问被拒绝STATUS_BUFFER_TOO_SMALL输入的缓冲区过小STATUS_OBJECT_TYPE_MISMATCH输入的对象类型不匹配STATUS_OBJECT_NAME_INVALIE输入的对象名无效STATUS_OBJECT_NAME_NOT_FOUND输入的对象没有找到STATUS_PORT_DISCONNNECTED需要连接的端口没有被连接STATUS_OBJECT_PATH_INVALID输入的对象路径无效另外在使用WinDbg进行调试的时候,一般都会得到函数调用的错误码,根据错误码可以找到对应的错误信息,微软提供了一种解决方案:LPVOID lpMessageBuffer; HMODULE Hand = LoadLibrary(_T("NTDLL.DLL")); DWORD dwErrCode = 0; //获取错误码 FormatMessage( FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_FROM_HMODULE, Hand, dwErrCode, MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT), (LPTSTR) &lpMessageBuffer, 0, NULL ); // Now display the string. // Free the buffer allocated by the system. LocalFree( lpMessageBuffer ); FreeLibrary(Hand);驱动对象驱动程序的入口函数是DriverEntry,函数会传入一个驱动对象的指针——PDRIVER_OBJECT,每个驱动都有一个唯一的驱动对象,就好像每个Win32应用程序有一个唯一的实例句柄。它的定义如下:typedef struct _DRIVER_OBJECT { CSHORT Type; CSHORT Size; PDEVICE_OBJECT DeviceObject; ULONG Flags; PVOID DriverStart; ULONG DriverSize; PVOID DriverSection; PDRIVER_EXTENSION DriverExtension; UNICODE_STRING DriverName; PUNICODE_STRING HardwareDatabase; PFAST_IO_DISPATCH FastIoDispatch; PDRIVER_INITIALIZE DriverInit; PDRIVER_STARTIO DriverStartIo; PDRIVER_UNLOAD DriverUnload; PDRIVER_DISPATCH MajorFunction[IRP_MJ_MAXIMUM_FUNCTION + 1]; } DRIVER_OBJECT;下面主要对几个重要的部分做介绍:DeviceObject:保存的是驱动中设备对象的指针,另外每个设备对象又有一个指向下一个设备对象的指针,这样同一个驱动程序中的不同设备对象就构成了一个链表DriverName:这个里面存储的是驱动程序的名称,该字符串一般为“\Driver\驱动名称”HardwareDatabase:这里记录的是设备的硬件数据库键名,这个数据库一般是注册表,字符串一般为“REGISTRY\MACHINE\HARDWARE\DESCRIPTION\SYSTEM”DriverStartIo:记录StartIo这个例程回调函数的地址DriverUnload:当驱动卸载时会调用这个指针所指向的函数MajorFunction,这是一个回调函数的指针数组,处理IRP包的不同请求,就好像应用层里面的消息处理函数,根据不同的请求,调用不同的函数。设备对象在windows平台将每个设备抽象为一个设备对象,驱动层一般通过设备对象来操作具体的设备,每个驱动可以有多个设备对象。typedef struct DECLSPEC_ALIGN(MEMORY_ALLOCATION_ALIGNMENT) _DEVICE_OBJECT { ... struct _DRIVER_OBJECT *DriverObject; struct _DEVICE_OBJECT *NextDevice; struct _DEVICE_OBJECT *AttachedDevice; struct _IRP *CurrentIrp; ULONG Flags; PVOID DeviceExtension; DEVICE_TYPE DeviceType; CCHAR StackSize; ... } DEVICE_OBJECT;设备对象本身定义是十分复杂的,在这我们只列举出部分,以后写程序会经常使用的部分,下面是对这些部分的说明:DriverObject: 指向所属驱动的驱动对象的指针NextDevice:指向下一个设备驱动的指针AttachedDevice:指向它被附加的驱动的指针,设备对象之上还可以在附加上其他的设备对象,这样每当有消息传来时总会由附加在它之上的设备对象处理,然后才会交由它自身处理,这个指针就是指向附加在它之上的设备对象的指针CurrentIrp:指向当前IRP域的指针Flags:表名该设备的一些标志信息,主要有下面几个值:标志描述DO_BUFFERED_IO读写使用缓冲方式,内核层在使用用户缓冲区时会将用户分区中的数据拷贝到内核分区中DO_EXCLUSIVE一次只允许一个线程使用这个设备对象DO_DIRECT_IO读写直接方式,应用层将某块内存锁定在内存,然后将内存映射到内核空间中,这种方式是最快的方式DO_DEVICE_INITIALIZING设备正在初始化DO_POWER_PAGABLE设备必须在PASSIVE_LEVEL上处理IRP_MJ_PNP请求DO_POWER_INRUSH设备上电期间需要大电流DeviceExtension:指向一块扩展的内存,系统允许用户在创建设备对象时自定义一块区域用来保存结构体中没有但是用户自己感兴趣的内容。在驱动程序中需要尽量避免使用全局变量,所以可以通过使用这块扩展内存来传输全局变量DeviceType:驱动的类型,主要有下面几个值设备类型描述FILE_DEVICE_BEEP该设备是一个蜂鸣器FILE_DEVICE_CD_ROM该设备时一个CD光驱FILE_DEVICE_CD_ROM_FILE_SYSTEMCD光驱文件系统设备FILE_DEVICE_CONTROLLER控制器设备FILE_DEVICE_DATALINK数据链设备FILE_DEVICE_DFSDFS设备对象FILE_DEVICE_DISK磁盘设备对象FILE_DEVICE_DISK_FILE_SYSTEM磁盘文件系统设备对象FILE_DEVICE_FILE_SYSTEM文件系统设备对象FILE_DEVICE_INPORT_PORT输入端口设备对象FILE_DEVICE_KEYBOARD键盘设备对象FILE_DEVICE_MAILSLOT邮件曹设备对象FILE_DEVICE_MIDI_INMIDI输入设备对象FILE_DEVICE_MIDI_OUTMIDI输出设备对象FILE_DEVICE_MOUSE鼠标设备对象FILE_DEVICE_MULTI_UNC_PROVIDER多UNC设备对象FILE_DEVICE_NAMED_PIPE命名管道设备对象FILE_DEVICE_NETWORK网络设备对象FILE_DEVICE_NETWORK_BROWSER网络浏览器设备对象FILE_DEVICE_NETWORK_FILE_SYSTEM网络文件系统设备对象FILE_DEVICE_NULL空设备对象FILE_DEVICE_PARALLEL_PORT并口设备对象FILE_DEVICE_PHYSICAL_NETCARD物理网卡设备对象FILE_DEVICE_PRINTER打印机设备对象FILE_DEVICE_SCANNER扫描仪设备对象FILE_DEVICE_SERIAL_MOUSE_PORT串口鼠标设备对象LE_DEVICE_SERIAL_PORT串口设备对象FILE_DEVICE_SCREEN屏幕设备对象FILE_DEVICE_SOUND声音设备对象FILE_DEVICE_STREAMS流设备对象LE_DEVICE_TAPE磁带设备对象FILE_DEVICE_TAPE_FILE_SYSTEM磁带文件系统设备对象FILE_DEVICE_TRANSPORT传输设备对象FILE_DEVICE_UNKNOWN未知设备对象FILE_DEVICE_VIDEO视频设备对象FILE_DEVICE_VIRTUAL_DISK虚拟磁盘设备对象FILE_DEVICE_WAVE_IN声音输入设备对象FILE_DEVICE_WAVE_OUT声音输出设备对象在创建设备对象时如果不知道这个设备对象是何种类型,可以直接给FILE_DEVICE_UNKNOWN;StackSize:之前说到过,设备对象存在附加的情况,附加时每个设备对象会存储它上层的设备对象的指针,这样就形成了类似堆栈的结构,而这个值就表示从该设备对象到栈底还有多少个设备对象为了便于理解我们做了这样一个示意图:
-
windows 线程 在windows中进程只是一个容器,用于装载系统资源,它并不执行代码,它是系统资源分配的最小单元,而在进程中执行代码的是线程,线程是轻量级的进程,是代码执行的最小单位。从系统的内核角度看,进程是一个内核对象,内核用这个对象来存储一些关于线程的信息,比如当前线程环境等等,从编程的角度看,线程就是一堆寄存器状态以及线程栈的一个结构体对象,本质上可以理解为一个函数调用,一般线程有一个代码的起始地址,系统需要执行线程,只需要将寄存器EIP指向这个代码的地址,那么CPU接下来就会自动的去执行这个线程,线程切换时也是修改EIP的值,那么CPU就回去执行另外的代码了。什么时候不用多线程?一般我们都讨论什么时候需要使用多线程,很多人认为只要计算任务能拆分成多个不想关的部分,就可以使用多线程来提升效率,但是需要知道的是,线程是很耗费资源的,同时CPU在线程之间切换也会消耗大量的时间,所以在使用上并不是多线程就是好的,需要慎重使用,在下列情况下不应该使用多线程:当一个计算任务是严重串行化的,也就是一个计算步骤严重依赖上一个计算步骤的时候。但是如果是针对不同的初始参数可以得到不同的结果那么可以考虑用多线程的方式,将每个传入参数当作一个线程,一次计算出多组数据。当多个任务有严格的先后逻辑关系的时候,这种情况下利用多线程需要额外考虑线程之间执行先后顺序的问题,实际上可能它的效率与普通的单线程程序差不多,它还需要额外考虑并发控制,这将得不偿失当一个服务器需要处理多个客户端连接的时候,优先考虑的是使用线程池,而不是简单的使用多线程,为每个客户端连接创建一个线程,这样会严重浪费资源,而且线程过的,CPU在进程调度时需要花大量的时间来执行轮询算法,会降低效率。主线程进程的入口函数就是主线程的入口函数,一般主线程推出进程退出(这是由于VC++中在主线程结束时会隐含的调用ExitProcess)线程入口地址在windows中需要为线程指定一个执行代码的开始地址,这个在VC++中体现为需要为每个进程制定一个函数指针,并制定一个void* 型的指针类型的参数。当CPU执行这个线程时会将寄存器环境改为这个线程指定的环境,然后执行代码(具体就是前面所说的更改EIP的值)创建线程在windows中创建线程所使用的API是CreateThread,这个函数的原型如下:HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpsa, DWORD cbStack, LPTHREAD_START_ROUTINE lpStartAddr, LPVOID lpvThreadParam, DWORD fdwCreate, LPDWORD lpIDThread );第一个参数是线程对象的安全描述符第二个参数是线程栈的大小,每个线程都有一个栈环境用来存储局部变量,以及调用函数,这个值可以给0,这个时候系统会根据线程中调用函数情况动态的增长,但是如果需要很大的线程栈,比如要进行深层的递归,并且每个递归都有大量的局部变量和函数时,运行一段时间后,可能会出现没有足够大的地址空间再来增长线程栈,这个时候就会出现栈溢出的异常,为了解决这个问题,我们可以填入一个较大的值,以通知系统预留足够大的地址空间。第三个参数是线程的入口函数地址,这个是一个函数指针,函数的原型是DWORD ThreadProc( LPVOID lpParameter); 函数中就是线程将要执行的代码。第四个参数是函数中将要传入的参数,为了方便传入多个参数,一般将要使用的过个参数定义为一个结构体,将这个结构体指针传入,然后再函数中将指针转化为需要的结构体指针,这样就可以使用多个参数。第五个参数是创建标志,默认一般传入0,但表示线程一被创建马上执行,如果传入CREATE_SUSPENDED,则表示线程先创建不执行,需要使用函数ResumeThread唤醒线程,另外在XP以上的系统中可以使用STACK_SIZE_PARAM_IS_A_RESERVATION结合上面的第二个参数,表示当前并不需要这么内存,只是先保留当前的虚拟地址空间,在需要时有程序员手动提交物理页面。如果没有指定那么回默认提交物理页面。第六个参数会返回一个线程的ID。下面是一个创建线程的例子:typedef struct tag_THREAD_PARAM { int nThreadNo; int nValue; }THREAD_PARAM, *LPTHREAN_PARAM; int _tmain(int argc, TCHAR *argv[]) { LPTHREAN_PARAM lpValues = (LPTHREAN_PARAM)HeapAlloc(GetProcessHeap(), 0, 10 * sizeof(THREAD_PARAM)); for (int i =0; i < 10; i++) { lpValues[i].nThreadNo = i; lpValues[i].nValue = i + 100; } HANDLE hHandle[10] = {NULL}; for(int i = 0; i < 10; i++) { hHandle[i] = CreateThread(NULL, 0, ThreadProc, &lpValues[i], 0, NULL); if (NULL == hHandle[i]) { return 0; } } WaitForMultipleObjects(10, hHandle, TRUE, INFINITE); return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { LPTHREAN_PARAM pThreadValues = (LPTHREAN_PARAM)lpParam; printf("%d, values = %d\n", pThreadValues->nThreadNo, pThreadValues->nValue); return 0; }上述代码中我们将两个整型数据定义为了一个结构体,并在创建线程中,将这个结构体地址作为参数传入,这样在线程中就可以使用这样的两个参数了。线程退出当满足下列条件之一时线程就会退出调用ExitThread线程函数返回调用ExitProcess用线程句柄调用TerminateThread用进程句柄调用TerminateProcess当线程终止时,线程对象的状态会变为有信号,线程状态码会由STILL_ACTIVE改为线程的退出码,可以用GetExitThreadCode得到推出码,然后根据推出码是否为STILL_ACTIVE判断线程是否在运行线程栈溢出的恢复使用C++时由于下标溢出而造成的栈溢出将无法恢复。当栈溢出时会抛出EXCEPTION_STACK_OVERFLOW的结构化异常,之后使用_resetstkflow函数可以恢复栈环境,这个函数只能在_except的语句块中使用。调用 SetThreadStackGuarantee函数可以保证当栈溢出时有足够的栈空间能使用结构话异常处理,SEH在底层仍然是使用栈进行异常的抛出和处理的,所以如果不保证预留一定的栈空间,可能在最后使用不了SEH。下面是一个使用的例子:void ArrayErr(); void Stackflow(); DWORD _exception_stack_overflow(DWORD dwErrorCcode); int g_nCnt = 0; int _tmain(int argc, TCHAR *argv[]) { for (int i = 0; i < 10; i++) { __try { /* ArrayErr();*/ Stackflow(); } __except(_exception_stack_overflow(GetExceptionCode())) { int nResult = _resetstkoflw(); if (!nResult) { printf("处理失败\n"); break; }else { printf("处理成功\n"); } } } return 0; } void ArrayErr() { int array[] = {1, 2}; array[10000] = 10; } void Stackflow() { g_nCnt++; int array[1024] = {0}; Stackflow(); } DWORD _exception_stack_overflow(DWORD dwErrorCcode) { if (EXCEPTION_STACK_OVERFLOW == dwErrorCcode) { return EXCEPTION_EXECUTE_HANDLER; }else { return EXCEPTION_CONTINUE_SEARCH; } }在上述的例子中定义两个会引起异常的函数,一个是下标越界,一个是深度的递归,两种情况都会引起栈溢出,但是下标越界是不可恢复的,所以这个异常不能被处理,在异常处理中我们使用函数_resetstkoflw来恢复栈,使得程序可以继续运行下去。线程本地存储当线程需要访问一个共同的全局变量,并且某个线程对这个变量的修改不会影响到其他的进程的时候可以给予每个线程一份拷贝,每个线程访问变量在它自己中的拷贝,而不用去争抢这一个全局变量,有时候我们可能会想出用数组的方式来存储这每份拷贝,每个线程访问数组中的固定元素,但是当线程是动态创建和销毁也就是线程数量动态变化时,维护这个数组将会非常困难,这个时候可以使用线程本地存储技术(TLS),它的基本思想是在访问全局变量时给每个线程一个实例,各个线程访问这个实例而不用去争抢一个全局变量。就好像系统为我们维护了一个动态数组,让每个线程拥有这个数组中的固定元素。使用TLS有两种方法关键字法和API法。关键字法: 使用关键字__declspec(thread)修饰一个变量,这样就可以为每个访问它的线程创建一份拷贝。动态API法,TlsAlloc为每个全局变量分配一个TLS索引, TlsSetValue为某个索引设置一个值,TlsGetValue获取某个索引的值TlsFree释放这个索引两中方式各有优缺点,第一种方式使用简单,但是仅仅局限于VC++,第二中方式使用相对复杂但是可以跨语言只要能使用windowsAPI就可以使用这种方式下面分别展示了使用这两种方式的例子:DWORD _declspec(thread) g_dwCurrThreadID = 0; DWORD WINAPI ThreadProc(LPVOID lpParam); int main() { g_dwCurrThreadID = GetCurrentThreadId(); HANDLE hThread[10] = {NULL}; for (int i = 0; i < 10; i++) { hThread[i] = CreateThread(NULL, 0, ThreadProc, NULL, 0, NULL); } printf("Main Thread id = %x, g_dwCurrThreadID = %x, the address g_dwCurrThreadID = %08x\n", GetCurrentThreadId(), g_dwCurrThreadID, &g_dwCurrThreadID); WaitForMultipleObjects(10, hThread, TRUE, INFINITE); for (int i = 0; i < 10; i++) { CloseHandle(hThread[i]); } return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { g_dwCurrThreadID = GetCurrentThreadId(); Sleep(100); printf("the thread id = %x, g_dwCurrThreadID = %x, the address g_dwCurrThreadID = %08x\n", GetCurrentThreadId(), g_dwCurrThreadID, &g_dwCurrThreadID); return 0; }首先定义了一个TLS的变量,然后在线程中引用,在输出结果中发现,没个线程中的值和它的地址值都不一样,所以说使用的只是一份拷贝而已DWORD g_dwTLSIndex = 0; DWORD WINAPI ThreadProc(LPVOID lpParam); int main() { HANDLE hThread[10] = {NULL}; g_dwTLSIndex = TlsAlloc(); TlsSetValue(g_dwTLSIndex, (LPVOID)GetCurrentThreadId()); for (int i = 0; i < 10; i++) { hThread[i] = CreateThread(NULL, 0, ThreadProc, NULL, CREATE_SUSPENDED, NULL); ResumeThread(hThread[i]); } printf("Main Thread id = %x, g_dwCurrThreadID = %x\n", GetCurrentThreadId(), TlsGetValue(g_dwTLSIndex)); WaitForMultipleObjects(10, hThread, TRUE, INFINITE); for (int i = 0; i < 10; i++) { CloseHandle(hThread[i]); } TlsFree(g_dwTLSIndex); return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { TlsSetValue(g_dwTLSIndex, (LPVOID)GetCurrentThreadId()); printf("the thread id = %x, g_dwCurrThreadID = %x\n", GetCurrentThreadId(), TlsGetValue(g_dwTLSIndex)); return 0; } 上述使用中,在主线程中申请和释放一个TLS变量,在每个进程中仍然是使用这个变量,输出的结果也是每个变量都不同。线程的挂起和恢复用函数SuspendThread和ResumeThread控制线程的暂停和恢复,一个暂停的线程无法用ResumeThread来唤醒自身,除非有其他线程调用ResumeThread来唤醒。暂停的线程总是立即被暂停,而不管它执行到了哪个指令。需要注意的是,线程这个内核对象中有一个暂停计数器,每当调用一个SuspendThread这个计数器会加一,而每当调用一次ResumeThread计数器会减一,只有当计数器为0时线程才会立即启动,所以可能会出现这样的情况,调用了ResumeThread之后线程并没有立即启动,这个是正常现象。另外可以使用Sleep函数使线程休眠一段时间后再启动,这个填入的时间只是一个参考值,并不是填入多少,就让线程暂停多久,比如说我们填入10ms,这个时候当线程真正陷入到休眠状态时CPU可能执行其他线程去了,如果没有特殊情况,CPU会一直执行到这个线程的时间片结束。然后运行调度程序,调度下一个线程,所以说线程休眠的时间理论上最少也有20ms,通常会比我们设置的时间长。在创建线程的时候可以使用CREATE_SUSPEND标志来明确表示以暂停的方式创建一个线程,如果不用这个方式,那么新创建线程的行为将难以掌握,有可能在CreateThread函数返回之后,线程就开始执行了,也有可能在返回前执行,所以推荐使用这个标志,创建完成后,进行想干的初始化操作,并在必要的时候调用ResumeThread启动它。线程的寄存器状态线程环境也就是线程在运行中,一大堆相关寄存器的值,这些值Windows维护在CONTEXT这个结构体中,在获取时可以通过设置结构体中成员的ContextFlag的值来表示我们需要获取哪些寄存器的值,一般填入CONTEXT_ALL或者CONTEXT_FULL获取所有寄存器的值,用SetThreadContext设置线程寄存器的值,用GetThreadContext获取线程的寄存器环境。需要注意的时,SetThreadContext只能用来修改通用寄存器的值,而像DS, CS这样的段寄存器是收到系统保护的,这些函数是处于RING3层,并不能进入到内核态。线程调度的优先级windows是抢占式多任务的,各个线程是抢占式的获取CPU,一般遵循先到先执行的顺序,windows中的带调度线程是存储在线程队列中的,但是这个队列并不是真正意义上的队列,这个队列是允许插队的,比如当用户点击了某个窗口,那么系统为了响应用户操作,系统会激活窗口并调整队列的顺序,将于窗口相关的线程排到较前的位置,这个插队时通过提高线程的优先级的方式实现的。我们在程序中可以使用SetThreadPriority调整线程的优先级。但是在程序中不要依赖这个值来判断线程的执行顺序,这个值对于系统来说只是一个参考值,当我们的线程进入到队列中时,系统会动态的调整它的优先级,如果某个进程由于优先级的问题长时间没有运行,系统可能会提高它的优先级,而有的线程由于优先级过高,已经执行了多次,系统可能会降低它的优先级。一来可以快速响应用户程序,二来可以防止某些恶意程序抢占式的使用CPU资源。线程的亲缘性线程的亲缘性与进程的相似,但是线程的亲缘性只能在进程亲缘性的子集之上,比如进程的亲缘性被设置在0 2 3 8这几个CPU上,线程就只能在这几个CPU上运行即使设置亲缘性为7,系统也不会将线程加载到这个7号CPU上运行。调用函数SetThreadAffinityMask可以设置亲缘性,使所有线程都在不同的CPU上运行,已达到真正的并发执行。下面是一个使用亲缘性的例子://设置CPU的位掩码 #define SETCPUMASK(i) (1<<(i)) DWORD WINAPI ThreadProc(LPVOID lpParam); #define FOREVER for(;;); int _tmain() { SYSTEM_INFO si = {0}; GetSystemInfo(&si); DWORD dwCPUCnt = si.dwNumberOfProcessors; for (int i = 0; i < dwCPUCnt; i++) { HANDLE hThread = CreateThread(NULL, 0, ThreadProc, NULL, CREATE_SUSPENDED, NULL); SetThreadAffinityMask(hThread, SETCPUMASK(i)); ResumeThread(hThread); printf("启动线程%x成功", GetCurrentThreadId()); system("PAUSE"); } //线程创建成功,并绑定到各个CPU上,理论上CPU的利用率能达到100%,在任务管理器上查看性能可以看到CPU的利用率 return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { //死循环 FOREVER }上述程序首先判断了CPU核数,然后有几个CPU就创建几个线程,通过亲缘性设置为每个CPU绑定一个线程,在线程中我们什么都不做,只是一个死循环,主要是为了耗干CPU资源,这样通过查看资源管理器中的CPU使用情况发现CPU的使用率达到了100%,但是系统却没有一丝卡顿,这也说明Windows还是比较智能的,并没有让用户进程占据所有资源。线程可警告状态与异步函数在程序中可以通过一些方法使线程暂停,如使用SleepEx,Wait族的函数(是以Wait开始并且以Ex结尾的函数)可以使线程进入一种可警告状态,这种状态本质上是暂停当前线程,保存当前线程环境,并用这个环境加载并执行新的函数,当这个函数执行完成后,再恢复线程环境,继续执行线程接下来的代码。这些函数被称为异步函数。也就是说这些函数是借用当前的线程环境来作为自生的环境执行里面的代码。这样就类似于创建了一个轻量级的线程,它与线程的区别就是没有自身的环境状态,而是使用其他线程的环境状态,并且也不用进入到线程队列,供调度程序调度。这些异步函数有自己的队列称为异步函数队列,当线程调用这些暂停或者等待的函数时,进入休眠状态,系统会保存当前线程环境,并从异步函数队列中加载异步函数,利用当前的线程环境继续运行,等到休眠时间到达后系统恢复之前保存的环境,继续执行线程的代码。在使用时需要注意的是这些异步函数不要进行复杂的算法或者进程长时间的I/O操作,否则当线程休眠时间达到,而异步函数却未执行完,这样会造成一定的错误。默认线程是不具有异步函数队列,可以利用函数QueueUserAPC将一个异步函数加入到队列中,然后利用上述所说的函数让线程进入假休眠状态,这样就会自动调用异步函数,下面是这样的一个例子:VOID CALLBACK APCProc(ULONG_PTR dwParam) { printf("%d Call APC Function!\n", dwParam); } int _tmain(int argc, TCHAR *argv[]) { for (int i = 0 ; i < 100; i++) { QueueUserAPC(APCProc, GetCurrentThread(), i); } //如果参数改为FALSE,或者注释掉这个函数,那么将不会调用这个APC函数 SleepEx(10000, true); return 0; }上述代码中,我们在主线程中插入100个异步函数,虽然它们执行的都是同样的操作,然后让主线程休眠,SleepEx函数的第二个参数表示是否调用异步函数,如果填入FALSE,或者调用Sleep函数则不会调用异步函数。线程的消息队列线程默认是不具有消息队列的,同时也没有创建消息队列的函数,一般只需要调用与消息相关的函数,系统就会默认创建消息队列。调用PostThreadMessage可以向指定的线程发送消息到消息队列,调用PostThread可以向当前线程发送消息到消息队列,在编写带有消息循环的线程时可能由于线程有耗时的初始化操作,发送到线程的消息可能还没有被接受就丢掉了,但是如果在进行初始化时调用消息函数,让其创建一个消息队列,可以解决这问题,下面是一段例子代码:DWORD WINAPI ThreadProc(LPVOID lpParam) { MSG msg = {0}; /*利用消息相关的函数让线程创建消息队列,如果不创建,可能所有消息都不能收到 这个时候子线程会陷入死循环,主线程会一直等待子进程*/ PeekMessage(&msg, NULL, 0, 0, PM_NOREMOVE); //模拟进行耗时的初始化操作 for (int i = 0; i < 10000000; i++); while (GetMessage(&msg, NULL, 0, 0)) { printf("receive msg %d\n", msg.message); } printf("子线程退出\n"); return 0; } int _tmain(int argc, TCHAR *argv[]) { DWORD dwThreadID = 0; HANDLE hThread = CreateThread(NULL, 0, ThreadProc, NULL, 0, &dwThreadID); //让主线程休眠一段时间,一遍子线程能创建消息队列 Sleep(10); //发送消息 PostThreadMessage(dwThreadID, 0x0001, 0, 0); PostThreadMessage(dwThreadID, 0x0002, 0, 0); PostThreadMessage(dwThreadID, 0x0003, 0, 0); PostThreadMessage(dwThreadID, WM_QUIT, 0, 0); //休眠一段时间让子进程能够执行完成 WaitForSingleObject(hThread, INFINITE); return 0; }线程执行时间在一些性能分析工具中可能需要使用得到具体执行某一算法的函数的执行时间,一般调用GetTickCount计算调用前时间然后在算法函数调用完成后再次调用GetTickCount再次得到时间,这两个时间详相减则得到具体算法的时间,一般这种算法没有问题,但是需要考虑的时,如果在多任务环境下,该线程的时间片到达,CPU切换到其他线程,该线程没有运行但是时间却在增加,所以这种方式得到的结果并不准确,替代的方案是使用GetThreadTimes。这个函数可以精确到100ns,并且得出系统执行该线程的具体时间,下面是函数的原型:BOOL GetThreadTimes ( HANDLE hThread, LPFILETIME lpCreationTime, LPFILETIME lpExitTime, LPFILETIME lpKernelTime, LPFILETIME lpUserTime );这个函数后面几个输出参数分别是线程的创建时间,线程的推出时间,执行内核的时间以及执行用户代码的时间。下面演示了他的具体用法:DWORD WINAPI ThreadProc(LPVOID lpParam) { DWORD dwStart = GetTickCount(); HANDLE hWait = (HANDLE)lpParam; //假设这是一个复杂的算法 while (TRUE) { if (WAIT_OBJECT_0 == WaitForSingleObject(hWait, 0)) { break; } } //模拟CPU调度其他线程 Sleep(3000); DWORD dwEnd = GetTickCount(); printf("子线程即将结束,当前执行算法所用的时间为:%d\n", dwEnd - dwStart); return 0; } int _tmain(int argc, TCHAR *argv[]) { HANDLE hWait = CreateEvent(NULL, TRUE, FALSE, NULL); DWORD dwCPUNum = 0; SYSTEM_INFO si = {0}; GetSystemInfo(&si); dwCPUNum = si.dwNumberOfProcessors; HANDLE* phThread = (HANDLE*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwCPUNum * sizeof(HANDLE)); DWORD dwExitCode = 0; for (int i = 0; i < dwCPUNum; i++) { phThread[i] = CreateThread(NULL, 0, ThreadProc, hWait, CREATE_SUSPENDED, NULL); SetThreadAffinityMask(phThread[i], 1 << i); ResumeThread(phThread[i]); } _tsystem(_T("PAUSE")); //通知所有线程停止 SetEvent(hWait); FILETIME tmCreate = {0}; FILETIME tmExit = {0}; FILETIME tmKernel = {0}; FILETIME tmUser = {0}; SYSTEMTIME sysTm = {0}; ULARGE_INTEGER bigTmp1 = {0}; ULARGE_INTEGER bigTmp2 = {0}; for (int i = 0; i < dwCPUNum; i++) { GetExitCodeThread(phThread[i], &dwExitCode); printf("线程[H:0x%08X]退出,退出码:%u,以下为时间统计信息:\n", phThread[i], dwExitCode); GetThreadTimes(phThread[i], &tmCreate, &tmExit, &tmKernel, &tmUser); //得到创建时间 FileTimeToLocalFileTime(&tmCreate, &tmCreate); FileTimeToSystemTime(&tmCreate, &sysTm); printf("\t创建时间:%2u:%02u:%02u.%04u\n", sysTm.wHour, sysTm.wMinute, sysTm.wSecond, sysTm.wMilliseconds); //得到退出时间 FileTimeToLocalFileTime(&tmExit, &tmExit); FileTimeToSystemTime(&tmExit, &sysTm); printf("\t退出时间:%2u:%02u:%02u.%04u\n", sysTm.wHour, sysTm.wMinute, sysTm.wSecond, sysTm.wMilliseconds); //得到执行内核代码的时间 FileTimeToLocalFileTime(&tmKernel, &tmKernel); FileTimeToSystemTime(&tmKernel, &sysTm); printf("\t退出时间:%2u:%02u:%02u.%04u\n", sysTm.wHour, sysTm.wMinute, sysTm.wSecond, sysTm.wMilliseconds); //得到执行用户代码的时间 FileTimeToLocalFileTime(&tmUser, &tmUser); FileTimeToSystemTime(&tmUser, &sysTm); printf("\t退出时间:%2u:%02u:%02u.%04u\n", sysTm.wHour, sysTm.wMinute, sysTm.wSecond, sysTm.wMilliseconds); //线程开始时间 bigTmp1.HighPart = tmCreate.dwHighDateTime; bigTmp1.LowPart = tmCreate.dwLowDateTime; bigTmp2.HighPart = tmExit.dwHighDateTime; bigTmp2.LowPart = tmExit.dwLowDateTime; //函数GetThreadTimes返回的时间单位是100ns,是微妙的10000倍 printf("\t间隔时间(线程存活周期):%I64dms\n", (bigTmp2.QuadPart - bigTmp1.QuadPart) / 10000); //内核执行时间 bigTmp1.HighPart = tmKernel.dwHighDateTime; bigTmp1.LowPart = tmKernel.dwLowDateTime; printf("\t内核模式(RING0)耗时:%I64dms!\n", bigTmp1.QuadPart / 10000); //执行用户程序的时间 bigTmp2.HighPart = tmUser.dwHighDateTime; bigTmp2.LowPart = tmUser.dwLowDateTime; printf("\t内核模式(RING0)耗时:%I64dms!\n", bigTmp2.QuadPart / 10000); //实际占用总时间(用户代码时间 + 内核代码执行时间) printf("\t内核模式(RING0)耗时:%I64dms!\n", (bigTmp1.QuadPart + bigTmp2.QuadPart)/ 10000); CloseHandle(phThread[i]); system("PAUSE"); } //释放资源 CloseHandle(hWait); HeapFree(GetProcessHeap(), 0, phThread); return 0; }以类成员函数的方式封装线程类一般在如果要将线程函数封装到C++类中时一般采用的是静态成员的方式,因为C++中默认总会多传入一个参数this,而CreateThread需要传入的函数指针并不包含this,所以为了解决这个问题,一般传入一个静态函数的指针,但是静态函数不能定义为虚函数,也就是不能在派生类中重写它,所以在这介绍一种新的封装方式,将其封装为成员函数,并且允许被派生类重写。它的基本思想:利用函数指针的强制转化让类成员函数指针强制转化为CreateThread需要的类型,这样在真正调用函数我们给定的函数地址时就不会传入this指针,但是为了使用类成员函数又需要这个指针,所以我们将this 指针的值变为参数,通过CreateThread的进行传递,这样就模拟了C++类成员函数的调用,下面是实现的部分代码://申明了这样一个线程的入口地址函数 DWORD WINAPI ThreadProc(LPVOID lpParam); //创建线程的代码 DWORD CMyThread::CreateThread(LPSECURITY_ATTRIBUTES lpsa, DWORD cbStack, DWORD fdwCreate) { typedef DWORD (WINAPI *LPTHREAD_START_ADDRESS)(LPVOID); typedef DWORD (WINAPI CMyThread::*PCLASS_PROC)(LPVOID); PCLASS_PROC pThreadProc = &CMyThread::ThreadProc; m_hThread = ::CreateThread(lpsa, cbStack, *(LPTHREAD_START_ADDRESS*)(&pThreadProc), this, fdwCreate, &m_dwThreadID); return (NULL != m_hThread) ? -1 : 0; }完整的代码 请戳这里下载
-
windows 多任务与进程 多任务,进程与线程的简单说明多任务的本质就是并行计算,它能够利用至少2处理器相互协调,同时计算同一个任务的不同部分,从而提高求解速度,或者求解单机无法求解的大规模问题。以前的分布式计算正是利用这点,将大规模问题分解为几个互不不相关的问题,将这些计算问题交给局域网中的其他机器计算完成,然后再汇总到某台机器上,显示结果,这样就充分利用局域网中的计算机资源。相对的,处理完一步接着再处理另外一步,将这样的传统计算模式称为串行计算。在提高处理器的相关性能主要有两种方式,一种是提高单个处理器处理数据的速度,这个主要表现在CPU主频的调高上,而当前硬件总有一个上限,以后再很难突破,所以现在的CPU主要采用的是调高CPU的核数,这样CPU的每个处理器都处理一定的数据,总体上也能带来性能的提升。在某些单核CPU上Windows虽然也提供了多任务,但是这个多任务是分时多任务,也就是每个任务只在CPU中执行一个固定的时间片,然后再切换到另一个任务,由于每个任务的时间片很短,所以给人的感觉是在同一时间运行了多个任务。单核CPU由于需要来回的在对应的任务之间切换,需要事先保存当前任务的运行环境,然后通过轮循算法找到下一个运行的任务,再将CPU中寄存器环境改成新任务的环境,新任务运行到达一定时间,又需要重复上述的步骤,所以在单核CPU上使用多任务并不能带来性能的提升,反而会由在任务之间来回切换,浪费宝贵的资源,多任务真正使用场合是多核的CPU上。windows上多任务的载体是进程和线程,在windows中进程是不执行代码的,它只是一个载体,负责从操作系统内核中分配资源,比如每个进程都有4GB的独立的虚拟地址空间,有各自的内核对象句柄等等。线程是资源分配的最小单元,真正在使用这些资源的是线程。每个程序都至少有一个主线程。线程是可以被执行的最小的调度单位。进程的亲缘性进程或者线程只在某些CPU上被执行,而不是由系统随机分配到任何可用的CPU上,这个就是进程的亲缘性。例如某个CPU有8个处理器,可以通过进程的亲缘性设置让该进程的线程只在某两个处理器上运行,这样就不会像之前那样在8个CPU中的任意几个上运行。在windows上一般更倾向于优先考虑将线程安排在之前执行它的那个处理器上运行,因为之前的处理器的高速缓存中可能存有这个线程之前的执行环境,这样就提高的高速缓存的命中率,减少了从内存中取数据的次数能从一定程度上提高性能。需要注意的是,在拥有三级高速缓存的CPU上,这么做意义就不是很大了,因为三级缓存一般作为共享缓存,由所有处理器共享,如果之前在2号处理器上执行某个线程,在三级缓存上留下了它的运行时的数据,那么由于三级缓存是由所有处理器所共享的,这个时候即使将这个线程又分配到5号处理器上,也能访问这个公共存储区,所以再设置线程在固定的处理器上运行就显得有些鸡肋,这也是拥有三级缓存的CPU比二级缓存的CPU占优势的地方。但是如果CPU只具有二级缓存,通过设置亲缘性可以发挥高速缓存的优势,提高效率。亲缘性可以通过函数SetProcessAffinityMask设置。该函数的原型如下:BOOL WINAPI SetProcessAffinityMask( __in HANDLE hProcess, __in DWORD_PTR dwProcessAffinityMask );第一个参数是设置的进程的句柄,第二个参数是DWORD类型的指针,是一个32位的整数,每一位代表一个处理器的编号,当希望设置进程中的线程在此处理器上运行的话,将该位设置为1,否则为0。为了设置亲缘性,首先应该了解机器上CPU的情况,根据实际情况来妥善安排,获取CPU的详细信息可以通过函数GetLogicalProcessInformation来完成。该函数的原型如下:BOOL WINAPI GetLogicalProcessorInformation( __out PSYSTEM_LOGICAL_PROCESSOR_INFORMATION Buffer, __in_out PDWORD ReturnLength );第一个参数是一个结构体的指针,第二个参数是需要缓冲区的大小,也就是说这个函数我们可以采用两次调用的方式来合理安排缓冲区的大小。结构体SYSTEM_LOGICAL_PROCESSOR_INFORMATION的定义如下: typedef struct _SYSTEM_LOGICAL_PROCESSOR_INFORMATION { ULONG_PTR ProcessorMask; LOGICAL_PROCESSOR_RELATIONSHIP Relationship; union { struct { BYTE Flags; } ProcessorCore; struct { DWORD NodeNumber; }NumaNode; CACHE_DESCRIPTOR Cache; ULONGLONG Reserved[2]; }; } SYSTEM_LOGICAL_PROCESSOR_INFORMATION, *PSYSTEM_LOGICAL_PROCESSOR_INFORMATION;ProcessorMask是一个位掩码,每个位代表一个逻辑处理器,第二个参数是一个标志,表示该使用第三个共用体中的哪一个结构体,这三个分别表示核心处理器,NUMA节点,以及高速缓存的信息。下面是使用的一个例子代码:#include <windows.h> #include <tchar.h> #include <stdio.h> #include <locale.h> DWORD CountBits(ULONG_PTR uMask); typedef BOOL (WINAPI *CPUINFO)(PSYSTEM_LOGICAL_PROCESSOR_INFORMATION Buffer, PDWORD ReturnLength); int _tmain(int argc, TCHAR *argv[]) { _tsetlocale(LC_ALL, _T("chs")); CPUINFO pGetCpuInfo = (CPUINFO)GetProcAddress(GetModuleHandle(_T("kernel32")), "GetLogicalProcessorInformation"); if (NULL == pGetCpuInfo) { _tprintf(_T("系统不支持该函数,程序结束\n")); return 0; } PSYSTEM_LOGICAL_PROCESSOR_INFORMATION plpt = NULL; DWORD dwLength = 0; if (!pGetCpuInfo(plpt, &dwLength)) { if (ERROR_INSUFFICIENT_BUFFER == GetLastError()) { plpt = (PSYSTEM_LOGICAL_PROCESSOR_INFORMATION)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); }else { _tprintf(_T("函数调用失败\n")); return 0; } } if (!pGetCpuInfo(plpt, &dwLength)) { _tprintf(_T("函数调用失败\n")); return 0; } DWORD dwSize = dwLength / sizeof(SYSTEM_LOGICAL_PROCESSOR_INFORMATION); PSYSTEM_LOGICAL_PROCESSOR_INFORMATION pOffsite = plpt; DWORD dwCacheCnt = 0; DWORD dwCoreCnt = 0; DWORD dwPackageCnt = 0; DWORD dwNodeCnt = 0; for (int i = 0; i < dwSize; i++) { switch (pOffsite->Relationship) { case RelationCache: dwCacheCnt++; break; case RelationNumaNode: dwNodeCnt++; break; case RelationProcessorCore: { if (pOffsite->ProcessorCore.Flags) { dwCoreCnt++; }else { dwCoreCnt += CountBits(pOffsite->ProcessorMask); } } break; case RelationProcessorPackage: dwPackageCnt++; break; default: break; } pOffsite++; } _tprintf(_T("处理器个数:%d\n"), dwPackageCnt); _tprintf(_T("处理器核数:%d\n"), dwCoreCnt); _tprintf(_T("NUMA个数:%d\n"), dwNodeCnt); _tprintf(_T("高速缓存的个数:%d\n"), dwCacheCnt); return 0; } DWORD CountBits(ULONG_PTR uMask) { DWORD dwTest = 1; DWORD LSHIFT = sizeof(ULONG_PTR) * 8 -1; dwTest = dwTest << LSHIFT; DWORD dwCnt = 0; for (int i = 0; i <= LSHIFT; i++) { dwCnt += ((uMask & dwTest) ? 1 : 0); dwTest /= 2; } return dwCnt; }这个程序首先采用两次调用的方式分配一个合适的缓冲区,用来接收函数的返回,然后分别统计CPU数目,物理处理器数目以及逻辑处理器数量。我们根据MSDN上面得到的信息,首先判断缓冲区中有多少个结构体,也就是由多少条处理器的信息,然后根据第二个成员的值,来判断当前存储的是哪种信息。并将对应的值加1,当计算逻辑处理器的数目时需要考虑超线程的问题,所谓超线程就是intel提供的一个新的技术,可以将一个处理器虚拟成多个处理器来使用,已达到多核处理器的效果,如果它支持超线程,那么久不能简单的根据是否为核心处理器而加1,这个时候需要采用计算位掩码的方式来统计逻辑存储器,根据MSDN上说的当flag为1时表示支持超线程。windows下的进程windows中进程是已装入内存中,准备或者已经在执行的程序,磁盘上的exe文件虽说可以执行,但是它只是一个文件,并不是进程,一旦它被系统加载到内存中,系统为它分配了资源,那么它就是一个进程。进程由两个部分组成,一个是系统内核用来管理进程的内核对象,一个是它所占的地址空间。windows下的进程主要分为3大类:控制台,窗口应用,服务程序。写过控制台与窗口程序的人都知道,控制台的主函数是main,而窗口应用的主函数是WinMain,那么是否可以根据这个来判断程序属于那种呢,很遗憾,windows并不是根据这个来区分的。在VS编译器上可以通过设置将Win32 控制台程序的主函数指定为WinMain,或者将窗口程序的主函数指定为main,设置方法:属性-->连接器-->系统-->子系统,将这项设置为/SUBSYSTEM:CONSOLE,那么它的主函数为main,设置为/SUBSYSTEM:WINDOWS那么它的主函数为WinMain,甚至我们可以自己设置主函数。我们知道在C/C++语言中main程序是从main函数开始的,但是这个函数只是语法上的开始,并不是真正意义上的入口,在VC++中,系统会首先调用mainCRTStartup,在这个函数中调用main或者WinMain, 这个函数主要负责对C/C++运行环境的初始化,比如堆环境或者C/C++库函数环境的初始化。如果需要自定义自己的入口,那么这些环境将得不到初始化,也就意味着我们不能使用C/C++库函数。只能使用VC++提供的API,这么做也有一定的好处,毕竟这些库函数都是在很早之前产生的,到现在来看有很多问题,有许多有严重的安全隐患,使用API可以避免这些问题。下面是一个简单的例子:#include <Windows.h> #include <tchar.h> #include <strsafe.h> #define PRINTF(...) \ {\ TCHAR szBuf[4096] = _T("");\ StringCchPrintf(szBuf, sizeof(szBuf), __VA_ARGS__);\ size_t nStrLen = 0;\ StringCchLength(szBuf, STRSAFE_MAX_CCH, &nStrLen);\ WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), szBuf, nStrLen, NULL, NULL);\ } int LHMain() { PRINTF(_T("this is a %s"), _T("test hello world\n")); return 0; }这个例子中,入口函数是LHMain我们完全使用API的方式来编写程序,如果想要做到自定义入口,那么需要进行这样的设置:属性-->高级-->入口点,在入口点中输出我们希望作为入口点的函数名称即可。入口参数各个参数的含义现在这部分主要说明main函数以及WinMain函数。int main()这是main函数的一种原型,这种原型不带入任何参数int main(int argc, char *argv[])这种原型主要接受命令行输入的参数,参数以空格隔开,第一个参数表示输入命令行参数的总数,第二个是一个字符串指针数组,每个字符串指针成员代表的是具体输入的命令以及参数,这些信息包括我们输入的程序的名称,比如我们输入test.exe -s -a -t 来启动程序,那么argc = 4 ,argv[0] = "test.exe" argv[1] = "-s" argv[2] = "-a" argv[3] = "-t"int main(int argc, char argv[], char envs[])这个原型中第一个和第二个参数的函数与上述的带有两个参数的main函数相同,多了一个表示环境变量的指针数组,它会将环境变量以”变量名=值“的形式来组织字符串。int WINAPI WinMain(HANDLE hInstance, HANDLE hPrevInstance, LPSTR lpszCmdLine, int nCmdShow);函数中的WINAPI表示函数的调用约定为__stdcall的调用方式,函数的调用方式主要与参数压栈方式以及环境回收的方式有关。在这就不再说明这部分的内容,有兴趣的可以看本人另外一篇博客专门讲解了这部分的内容,点击这里hInstance:进程的实例句柄,该值是exe文件映射到虚拟地址控件的基址hPrevInstance:上一个进程的实例句柄,为了防止进程越界访问,这个是16位下的产物,在32位下,这个没有作用。lpszCmdLine:启动程序时输入的命令行参数nCmdShow:表示程序的显示方式。进程的环境变量与工作路径进程的环境变量可以通过main函数的第三个参数传入,也可以在程序中利用函数GetEnvrionmentStrings和GetEnvrionVariable获取,下面是获取进程环境变量的简答例子: setlocale(CP_ACP, "chs"); TCHAR **ppArgs = NULL; int nArgCnt = 0; ppArgs = CommandLineToArgvW(GetCommandLine(), &nArgCnt); for (int i = 0; i < nArgCnt; i++) { _tprintf(_T("%d %s\n"), i, ppArgs[i]); } HeapFree(GetProcessHeap(), 0, ppArgs);函数的第一个参数是开启这个进程需要的完整的命令行字符串,这个字符串使用函数GetCommandLine来获取,第二个参数是一个接受环境变量的字符串指针数组。函数返回数组中元素个数。一般情况下不推荐使用环境变量的方式来保存程序所需的数据,一般采用文件或者注册表的方式,但是最好的办法是采用xml文件的方式来村粗。至于进程的工作目录可以通过函数GetCurrentDirectory方法获取。进程创建在windows下进程创建采用API函数CreateProcess,该函数的原型如下:BOOL CreateProcess( LPCWSTR pszImageName, LPCWSTR pszCmdLine, LPSECURITY_ATTRIBUTES psaProcess, LPSECURITY_ATTRIBUTES psaThread, BOOL fInheritHandles, DWORD fdwCreate, LPVOID pvEnvironment, LPWSTR pszCurDir, LPSTARTUPINFOW psiStartInfo, LPPROCESS_INFORMATION pProcInfo ); 该函数参数较多,下面对这几项做重点说明,其余的请自行查看MSDN。pszImageName:表示进程对应的exe文件所在的完整路径或者相对路径pszCmdLine:启动进程传入的命令行参数,这是一个字符串类型,需要注意的是,这个命令行参数可以带程序所在的完整路径,这样就可以将第一个参数设置为NULL。参数中的安全描述符表示的是创建的子进程的安全描述符,与当前进程的安全描述符无关。fInheritHandles表示,可否被继承,这个继承关系是指父进程中的信息能否被子进程所继承psiStartInfo规定了新进程的相关启动信息,主要有这样几个重要的值:对于窗口程序: LPTSTR lpTitle; DWORD dwX; DWORD dwY; DWORD dwXSize; DWORD dwYSize;这些值规定了窗口的标题和所在的屏幕位置与长高的相关信息,对于控制台程序,主要关注: HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError;标准输入、输出、以及标准错误 下面是一个创建控制台与创建窗口的简单例子: STARTUPINFO si = {0}; si.dwXSize = 400; si.dwYSize = 300; si.dwX = 10; si.dwY = 10; PROCESS_INFORMATION pi = {0}; SECURITY_ATTRIBUTES sa = {sizeof(SECURITY_ATTRIBUTES)}; //创建一个窗口应用的进程,其中szExePath表示进程所在exe文件的路径,而szAppDirectory表示exe所在的目录 CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, 0, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动控制台窗口,与父进程公用输入输出环境 ZeroMemory(szExePath, sizeof(TCHAR) * (MAX_PATH + 1)); StringCchPrintf(szExePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("SubConsole.exe")); ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, 0, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动控制台,在新的控制台上做输入输出 ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, CREATE_NEW_CONSOLE, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread);上述程序中,对于窗口程序,在创建时没有给出特别的创建标志,窗口本身就是一个个独立的,并且我们通过指定si的部分成员指定了窗口的显示位置,而对于控制台,如果在创建时不特别指定创建的标志,那么它将与父进程共享一个输入输出控制台。为了区分子进程和父进程的输入输出,一般通过标志CREATE_NEW_CONSOLE为新进程新建一个另外的控制台。进程输入输出重定向输入输出重定向的实现可以通过函数CreateProcess在参数psiStartInfo中的HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError中指定,但是需要注意的是,在父进程中如果采用了Create之类的函数创建了输入输出对象的句柄时一定要指定他们可以被子进程所继承。下面是一个重定向的例子: //启动控制台,做输入输出重定向到文件中 TCHAR szFilePath[MAX_PATH + 1] = _T(""); //指定文件对象可以被子进程所继承,以便子进程可以使用这个内核对象句柄 sa.bInheritHandle = TRUE; ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); StringCchPrintf(szFilePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("input.txt")); HANDLE hInputFile = CreateFile(szFilePath, GENERIC_READ | GENERIC_WRITE, 0, &sa, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); ZeroMemory(szFilePath, sizeof(szFilePath)); StringCchPrintf(szFilePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("output.txt")); HANDLE hOutputFile = CreateFile(szFilePath, GENERIC_READ | GENERIC_WRITE, 0, &sa, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); si.hStdInput = hInputFile; si.hStdOutput = hOutputFile; si.dwFlags = STARTF_USESTDHANDLES; CreateProcess(szExePath, szExePath,NULL, NULL, TRUE, DETACHED_PROCESS, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(hOutputFile); CloseHandle(hInputFile); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动ping命令,并将输出重定向到管道中 StringCchPrintf(szExePath, MAX_PATH, _T("ping 127.0.0.1")); DWORD dwLen = 0; BYTE byte[1024] = {0}; HANDLE hReadP = NULL; HANDLE hWriteP = NULL; sa.bInheritHandle = TRUE; CreatePipe(&hReadP, &hWriteP, &sa, 1024); si.dwFlags = STARTF_USESTDHANDLES | STARTF_USESHOWWINDOW; si.wShowWindow = SW_HIDE; si.hStdOutput = hWriteP; CreateProcess(NULL, szExePath, NULL, NULL, TRUE, DETACHED_PROCESS, NULL, szAppDirectory, &si, &pi); //关闭管道的写端口,不然读端口会被阻塞 CloseHandle(hWriteP); dwLen = 1000; DWORD dwRead = 0; while (ReadFile(hReadP, byte, dwLen, &dwRead, NULL)) { if ( 0 == dwRead ) { break; } //写入管道的数据为ANSI字符 printf("%s\n", (char*)byte); ZeroMemory(byte, sizeof(byte)); }进程的退出进程在遇到如下情况中的任意一种时会退出:进程中任意一个线程调用函数ExitProcess进程的主线程结束进程中最后一个线程结束调用TerminateProcess在这针对第2、3中情况作特别的说明:这两种情况看似矛盾不是吗,当主线程结束时进程就已经结束了,这个时候还会等到最后一个线程吗。其实真实的情况是主线程结束,进程结束这个限制是VC++上的,之前在自定义入口的时候说过,main函数只是语法上的,并不是实际的入口,在调用main之前会调用mainCRTStartup,这个函数会负责调用main函数,当main函数调用结束后,这个函数会隐式的调用ExitProcess结束进程,所以只有当我们自定了程序入口才会看到3所示的现象,下面的例子说明了这点:DWORD WINAPI ThreadProc(LPVOID lpParam); #define PRINT(s) \ {\ size_t sttLen = 0;\ StringCchLengthA(s, 1024, &sttLen);\ WriteConsoleA(GetStdHandle(STD_OUTPUT_HANDLE), s, sttLen, NULL, NULL);\ } int LHMain(int argc, char *argv[]) { CreateThread(NULL, 0, ThreadProc, NULL, 0, NULL); return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { PRINT("main thread is ending,this is child thread\r\n"); return 0; }这种程序,如果我们采用系统中规定的main函数的话,是看不到线程中输出的信息的,因为主线程先结束的话,整个进程就结束了,线程还来不及输出,就被终止了。但是我们采用自定义入口的方式,屏蔽了这个特性,所以它会等到所有线程执行完成后才会结束,这个时候就会看到这句话输出了。进程在终止时会发生以下事件:关闭进程打开的对象句柄,但是对象本身不一定会关闭,这是因为每个对象都有一个计数器,每当有一个线程在使用这个对象时计数器会加1,而释放它的句柄时会减一,只有当计数器为0时才会销毁这个对象。对象是可以跨进程访问的,而且所有相同的对象在内存中只有一份,所以需要一个计数器以便在没有被任何进程访问的时候系统删除它。进程对象的状态设为有信号,以便所有等待该进程对象信号的函数(像函数WaitForSingleObject)能够正常返回。进程的终止状态从STILL_ACTIVE变成进程的退出码,可以通过这个特性判断某个进程是否在运行,具体的方式是通过函数GetExitProcess获取进程的终止码,如果函数返回STILL_ACTIVE,则说明进程仍在运行。
-
windows 安全模型简介 操作系统中有些资源是不能由用户代码直接访问的,比如线程进程,文件等等,这些资源必须由系统级代码由RING3层进入到RING0层操作,并且返回一些标识供用户程序使用,一般调用某个函数陷入到内核,这样的函数叫做系统调用,而有些不直接陷入到内核,一般叫做系统API,linux中使用系统调用,而windows中封装了一系列的API。windows对象与句柄windows对象操作系统为了安全,提供了一种保护机制,这种机制会禁止用户操作某些资源,避免用户过于关注细节,或者由于操作不当而造成系统崩溃。windows中将所有这些资源封装成了一个个对象。对象就是操作系统为了维护这些资源而定义的一系列的数据结构。对象这个词我们很容易联想到面向对象编程语言中的对象,对象其实就是对一些数据以及操作这些数据的一个封装,而windows是采用面向对象思想开发的,所以我们可以将windows中的对象想象成面向对象中的对象,而windows针对每种对象都提供了操作函数,这些函数一般都会以句柄作为第一个参数,这就有点像类函数中传入的this指针。而这操作对象的函数就是类函数。windows中总共有三种对象:GUI对象、GDI对象、内核对象。windows中的句柄windows中对象的操作是由系统提供的一系列的API函数来完成,这些函数有一个共同特点,就是以HANDLE 句柄作为第一个参数,windows中采用句柄来唯一标识每个内核对象。在windows中句柄的定义如下:typedef void * HANDLE从上面的定义可以看出,这个句柄应该是指向这个对象的结构体的指针。由于每次在程序启动时内存都是随机分配的,所以句柄不要使用硬编码的方式,同时在复制内核对像的时候,并不是简单的复制它的句柄,对象的复制有专门的函数,DuplicateHandle,该函数原型如下:BOOL DuplicateHandle( HANDLE hSourceProcessHandle, //源对象所在进程句柄 HANDLE hSourceHandle, //源对象句柄 HANDLE hTargetProcessHandle, //目标对象所在进程句柄 LPHANDLE lpTargetHandle, //返回目标对象的句柄 DWORD dwDesiredAccess, //以何种权限复制 BOOL bInheritHandle, //复制的对象句柄是否可继承 DWORD dwOptions //标记一些特殊的动作 );下面是一个例子代码:HANDLE hMutex = CreateMutex(NULL, FALSE, NULL); HANDLE hMutexDup, hThread; DWORD dwThreadId; DuplicateHandle(GetCurrentProcess(),hMutex,GetCurrentProcess(),&hMutexDup, 0,FALSE,DUPLICATE_SAME_ACCESS);上述代码在本进程中复制了一个互斥对象对象的句柄。windows 安全对象模型windows中的内核对象由进程和线程进行操作,而对象就好像一个被锁上的房间,进程想要访问对象,并对对象进程某种操作,就必须获取这个对象的钥匙,而线程就好像拥有钥匙的人,只有钥匙是对的,才可以访问。这把锁能够由不同的钥匙打开,这些钥匙信息存储在ACE中,而只有当ACE中的信息与访问字串这个钥匙匹配才可以打开。我们一般把这个钥匙称为访问字串(Token)访问字串访问字串主要包括:用户标识、组标识、优先权信息、以及其他访问信息。用户标识:用于唯一标识每个用户,就好像为每个用户都分配了一个唯一的用户ID组标识:用户所属组的唯一标识ID优先权:一般系统对每个用户以及它所属组分配了一些权限,而有的时候这些权限并不够,这个时候需要通过这个优先权信息额外新增一些权限当用户登录windows系统时,系统就为这个用户分配了一个带有该用户信息的访问字串,该用户创建的每个安全对象都有这个访问字串的拷贝,当用户打开的进程试图访问某个安全对象时系统就在对象的ACL中查找该用户是否有某项权限。有这个权限才能对对象进行这项操作。子进程的访问字串一般继承与父进程,但是子进程也可以自行创建访问字串来覆盖原来的访问字串。操作访问字串所使用的API主要有以下几个:OpenProcessToken //打开进程的访问令牌OpenThreadToken //打开线程的访问令牌AdjustTokenGroups //改变用户组的访问令牌AdjustTokenPrivileges //改变令牌的访问特权GetTokenInformation //获取访问令牌的信息SetTokenInformation //设置访问令牌信息下面主要介绍一下函数GetTokenInformation 的用法:BOOL WINAPI GetTokenInformation( __in HANDLE TokenHandle, //访问字串的句柄 __in TOKEN_INFORMATION_CLASS TokenInformationClass, //需要返回访问字串哪方面的信息 __out_opt LPVOID TokenInformation, //用于接收返回信息的缓冲 __in DWORD TokenInformationLength, //缓冲的长度 __out PDWORD ReturnLength //实际所需的缓冲的长度 ); 这个函数可以返回访问令牌多方面的信息,具体返回哪个方面的信息,需要通过第二个参数来指定,这个参数是一个枚举类型,表示需要获取的信息,每个方面的信息都定义了对应的结构体,这些信息可以由MSDN中查到。另外这个函数支持两次调用,第一次传入NULL指针和0长度,这样通过最后一个参数可以得到具体所需要的缓冲的大小。SID访问字串中用户与用户组采用安全标识符的方式唯一标识(Security Indentifer SID),系统中的SID是唯一的。它主要用来标识下面的这些内容:安全描述符中的所有者和用户组被ACE认可的访问者访问字串的用户和组SID的长度是可变的,在使用时不应该使用SID这个数据类型,因为这个时候还不知道需要的长度是多少,应该由系统来创建并返回它的指针,所以在使用时需要使用SID的指针。下面是一些操作SID的APIAllocateAndInitializeSid //初始化一个SIDFreeSid //释放一个SIDCopySid //拷贝一个SIDEqualSid //判断两个SID是否相等GetLengthSid //获取SID的长度IsValidSid //是否是有效的SIDConvertSidToStringSid //将SID转化为字符串的方式下面是一个利用这些API获取系统用户组的SID和当前登录用户的SID的例子:BOOL GetLoginSid(HANDLE hToken, PSID *ppsid); //SID本身大小是不可知的,所以在传入参数时应该传入2级指针,由函数自己决定大小 void FreeSid(PSID *ppsid); int _tmain(int argc, TCHAR* argv[]) { setlocale(LC_ALL, "chs"); HANDLE hProcess = GetCurrentProcess(); HANDLE hToken = NULL; OpenProcessToken(hProcess, TOKEN_ALL_ACCESS, &hToken); PSID pSid = NULL; GetLoginSid(hToken, &pSid); LPTSTR pStringSid = NULL; ConvertSidToStringSid(pSid, &pStringSid); _tprintf(_T("当前登录的用户sid = %s\n"), pStringSid); FreeSid(&pSid); return 0; } BOOL GetLoginSid(HANDLE hToken, PSID *ppsid) { TOKEN_GROUPS *ptg = NULL; BOOL bSuccess = FALSE; DWORD dwLength = 0; if(!GetTokenInformation(hToken, TokenGroups, ptg, 0, &dwLength)) { if (ERROR_INSUFFICIENT_BUFFER != GetLastError()) { goto __CLEAN_UP; } ptg = (TOKEN_GROUPS*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); if (!GetTokenInformation(hToken, TokenGroups, ptg, dwLength, &dwLength)) { goto __CLEAN_UP; } } _tprintf(_T("共找到%d个组SID\n"), ptg->GroupCount); LPTSTR pStringSid = NULL; for (int i = 0; i < ptg->GroupCount; i++) { ConvertSidToStringSid(ptg->Groups[i].Sid, &pStringSid); _tprintf(_T("\t id = %d sid = %s"), i, pStringSid); if ((ptg->Groups[i].Attributes & SE_GROUP_LOGON_ID) == SE_GROUP_LOGON_ID) { _tprintf(_T("此用户为当前登录的用户")); *ppsid = (PSID)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); CopySid(dwLength, *ppsid, ptg->Groups[i].Sid); } _tprintf(_T("\n")); } __CLEAN_UP: if (ptg != NULL) { HeapFree(GetProcessHeap(), 0, ptg); } return bSuccess; } void FreeSid(PSID *ppsid) { HeapFree(GetProcessHeap(), 0, *ppsid); *ppsid = NULL; }这个例子是MSDN中的一个例子,上述代码中首先获取进程的访问令牌,然后通过函数GetTokenInformation 获取访问令牌的信息。通过传入TokenGroups这个值获取当前用户所在用户组的访问字串。并将信息保存到结构体TOKEN_GROUPS中最后通过(ptg->Groups[i].Attributes & SE_GROUP_LOGON_ID) == SE_GROUP_LOGON_ID这样一个表达式来判断当前的SID是否是登录用户的。优先权优先权是由字符串标识的局部唯一的标识符(LUID)优先权是由系统管理员分配给对应的用户,一般不能通过编程的方式提升用户的优先权,但是有时候即使用户具有某个优先权,但是它启动的程序并不具有相关的优先权。这个时候可以通过编程的方式提升用户进程特权。系统有3个值代表一个优先权:字符串名,整个系统上都有意义,称为全局名,这个字符串并不是一个可读的字符串,显示出来的信息不一定能看得懂。显示给用户的可读名称;如:改变系统时间(可以在组策略中查看)每个计算机都不同的局部值;下面有几个常用的优先权:#define SE_DEBUG_NAME TEXT("SeDebugPrivilege") //调试进程 #define SE_LOAD_DRIVER_NAME TEXT("SeLoadDriverPrivilege") //装载驱动 #define SE_LOCK_MEMORY_NAME TEXT("SeLockMemoryPrivilege") //锁定内存页面 #define SE_SHUTDOWN_NAME TEXT("SeShutdownPrivilege") //关机下面是几个优先权函数LookupPrivilegeValue //查询优先权的值LookupPrivilegeDisplayName //查询优先权的输出名LookupPrivilegeName //查询优先权的名称PrivilegeCheck //优先权信息检查下面是一个获取用户特权信息的代码:int _tmain(int argc, TCHAR *argv[]) { setlocale(LC_ALL, "chs"); HANDLE hToken = NULL; HANDLE hProcess = GetCurrentProcess(); OpenProcessToken(hProcess, TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY, &hToken); TOKEN_PRIVILEGES* ptg = NULL; DWORD dwTgSize = 0; TCHAR szName[255] = _T(""); TCHAR szDisplay[255] = _T(""); DWORD languageID = GetUserDefaultLangID(); if (!GetTokenInformation(hToken, TokenPrivileges, ptg, 0, &dwTgSize)) { if (ERROR_INSUFFICIENT_BUFFER != GetLastError()) { _tprintf(_T("获取令牌失败\n")); return 0; } ptg = (TOKEN_PRIVILEGES*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwTgSize); if (!GetTokenInformation(hToken, TokenPrivileges, ptg, dwTgSize, &dwTgSize)) { _tprintf(_T("读取令牌信息失败\n")); return 0; } } _tprintf(_T("用户的特权信息:\n")); for(int i = 0; i < ptg->PrivilegeCount; i++) { DWORD dwName = sizeof(szName) / sizeof(TCHAR); DWORD dwDisplay = sizeof(szDisplay) / sizeof(TCHAR); LookupPrivilegeName(NULL, &ptg->Privileges[i].Luid, szName, &dwName); LookupPrivilegeDisplayName(NULL, szName, szDisplay, &dwDisplay, &languageID); _tprintf(_T("\t 特权名%s %s"), szName, szDisplay); if (ptg->Privileges[i].Attributes & ((SE_PRIVILEGE_ENABLED | SE_PRIVILEGE_ENABLED_BY_DEFAULT))) { _tprintf(_T("特权开放\n")); }else { _tprintf(_T("特权关闭\n")); } } HeapFree(GetProcessHeap(), 0, ptg); return 0; }下面是进程提权的代码:int _tmain(int argc, TCHAR *argv[]) { HANDLE hToken = NULL; HANDLE hProcess = GetCurrentProcess(); SetPrivileges(hToken, SE_TCB_NAME , TRUE); return 0; } BOOL SetPrivileges(HANDLE hToken, LPTSTR lpPrivilegesName, BOOL bEnablePrivilege) { //获取Token的特权信息 LUID uid = {0}; LookupPrivilegeValue(NULL, lpPrivilegesName, &uid); TOKEN_PRIVILEGES tp = {0}; tp.PrivilegeCount = 1; tp.Privileges[0].Luid = uid; if (bEnablePrivilege) { tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED; }else { tp.Privileges[0].Attributes = 0; } AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(TOKEN_PRIVILEGES), NULL, NULL); if ( GetLastError() == ERROR_NOT_ALL_ASSIGNED ) { _tprintf(_T("分配指定的特权(%s)失败. \n"),lpPrivilegesName); return FALSE; } return TRUE; }安全描述符安全描述符中通常包含信息:所有者、主组、任选访问控制列表(DACL)、系统访问控制列表(SACL)安全描述符是以SECURITE_DESCRIPTOR结构开始,后面连续跟着安全描述符的其它信息访问控制列表访问控制列表(Access Control List ACL)主要由多个访问访问控制入口(Access Control Entries ACE)组成。ACE用于标识一个用户、组或局部组以及它们中每一个允许的访问权;安全描述符的创建在创建安全访问对象的函数中一般都需要填入一个SECURITY_ATTRIBUTES结构体的指针,我们要么给定一个NULL值使其具有默认的安全属性,或者自己创建一个安全描述符并将他的指针传入。创建一个安全描述符主要有下面几步:用函数 AllocateAndInitializeSid 创建用户的SID。函数的定义如下:BOOL WINAPI AllocateAndInitializeSid( __in PSID_IDENTIFIER_AUTHORITY pIdentifierAuthority, //用于表示该SID标识的颁发机构 __in BYTE nSubAuthorityCount, //SID有多少个子部分 __in DWORD dwSubAuthority0, //第0个子部分 __in DWORD dwSubAuthority1, __in DWORD dwSubAuthority2, __in DWORD dwSubAuthority3, __in DWORD dwSubAuthority4, __in DWORD dwSubAuthority5, __in DWORD dwSubAuthority6, __in DWORD dwSubAuthority7, __out PSID* pSid //返回一个PSID的指针 );SID主要由一个颁发机构以及一个或者多个32位的唯一的RID组成这些RID通过参数dwSubAuthority0到dwSubAuthority7生成。对应的用户SID都有固定的组合。这个我还没找到具体的用户与SID是如何定义的。为该用户SID分配访问控制权限,主要通过填充结构体EXPLICIT_ACCESS成员来实现,这个结构体的定义如下:typedef struct _EXPLICIT_ACCESS { DWORD grfAccessPermissions; //制定用户权限 ACCESS_MODE grfAccessMode; //用于表示允许、拒绝、审查特定用户的权限 DWORD grfInheritance; //当前的权限是否可以继承 TRUSTEE Trustee; //这是一个访问托管 } EXPLICIT_ACCESS, *PEXPLICIT_ACCESS;3.用API SetEntriesInAcl将上述结构体放入到ACL中分配并初始化SECURITY_DESCRIPTOR结构体,初始化该结构体所用到的API 是InitializeSecurityDescriptor将SECURITY_DESCRIPTOR结构加入到安全描述符中,安全描述符的结构体是:SECURITY_ATTRIBUTES下面是一个具体的例子(这个例子来自MSDN): SID_IDENTIFIER_AUTHORITY SIDAuthorityNT = SECURITY_WORLD_SID_AUTHORITY; SID_IDENTIFIER_AUTHORITY SIDAuthorityWord = SECURITY_NT_AUTHORITY; PSID pEveryOneSid = NULL; PSID pAdminSid = NULL; EXPLICIT_ACCESS ea[2] = {0}; PACL pAcl = NULL; //创建everyone用户的SID AllocateAndInitializeSid(&SIDAuthorityWord, 1, SECURITY_WORLD_RID, 0, 0, 0, 0, 0, 0, 0, &pEveryOneSid); PSECURITY_DESCRIPTOR pSD = NULL; //定义everyone 的访问控制信息 ea[0].grfAccessMode = SET_ACCESS; //用于表示允许、拒绝、审查特定用户的权限 ea[0].grfAccessPermissions = KEY_READ; //制定用户权限 ea[0].grfInheritance = FALSE; ea[0].Trustee.TrusteeType = TRUSTEE_IS_WELL_KNOWN_GROUP; ea[0].Trustee.TrusteeForm = TRUSTEE_IS_SID; ea[0].Trustee.ptstrName = (LPTSTR)pEveryOneSid; //创建administor用户组的SID AllocateAndInitializeSid(&SIDAuthorityNT, 2, SECURITY_BUILTIN_DOMAIN_RID,DOMAIN_ALIAS_RID_ADMINS, 0, 0, 0, 0, 0, 0, &pAdminSid); ea[1].grfAccessMode = SET_ACCESS; ea[1].grfAccessPermissions = KEY_ALL_ACCESS; ea[1].grfInheritance = FALSE; ea[1].Trustee.TrusteeForm = TRUSTEE_IS_SID; ea[1].Trustee.TrusteeType = TRUSTEE_IS_GROUP; ea[1].Trustee.ptstrName = (LPTSTR)pAdminSid; //将以上两个SID加入到ACL中 SetEntriesInAcl(2, ea, NULL, &pAcl); pSD = (PSECURITY_DESCRIPTOR) HeapAlloc(GetProcessHeap(), 0, SECURITY_DESCRIPTOR_MIN_LENGTH); //初始化一个SECURITY_DESCRIPTOR结构 InitializeSecurityDescriptor(&pSD, SECURITY_DESCRIPTOR_REVISION); //将SECURITY_DESCRIPTOR结构加入到安全描述符中 SECURITY_ATTRIBUTES sa = {0}; sa.bInheritHandle = FALSE; sa.lpSecurityDescriptor = pSD; sa.nLength = sizeof(SECURITY_ATTRIBUTES); HKEY hkSub = NULL; DWORD dwDisposition = 0; RegCreateKeyEx(HKEY_CURRENT_USER, _T("mykey"), 0, _T(""), 0, KEY_READ | KEY_WRITE, &sa, &hkSub, &dwDisposition); if (pEveryOneSid) { FreeSid(pEveryOneSid); } if (pAdminSid) { FreeSid(pAdminSid); } if (pAcl) { LocalFree(pAcl); } HeapFree(GetProcessHeap(), 0, pSD); if (hkSub) { RegCloseKey(hkSub); }
-
windows平台调用函数堆栈的追踪方法 在windows平台,有一个简单的方法来追踪调用函数的堆栈,就是利用函数CaptureStackBackTrace,但是这个函数不能得到具体调用函数的名称,只能得到地址,当然我们可以通过反汇编的方式通过地址得到函数的名称,以及具体调用的反汇编代码,但是对于有的时候我们需要直接得到函数的名称,这个时候据不能使用这个方法,对于这种需求我们可以使用函数:SymInitialize、StackWalk、SymGetSymFromAddr、SymGetLineFromAddr、SymCleanup。原理基本上所有高级语言都有专门为函数准备的堆栈,用来存储函数中定义的变量,在C/C++中在调用函数之前会保存当前函数的相关环境,在调用函数时首先进行参数压栈,然后call指令将当前eip的值压入堆栈中,然后调用函数,函数首先会将自身堆栈的栈底地址保存在ebp中,然后抬高esp并初始化本身的堆栈,通过多次调用最终在堆栈段形成这样的布局这里对函数的原理做简单的介绍,有兴趣的可以看我的另一篇关于C函数原理讲解的博客,点击这里跳转VC++编译器在编译时对函数名称与地址都有详细的记录,编译出来的程序都有一个符号常量表,将符号常量与它对应的地址形成映射,在搜索时首先根据这些堆栈环境找到对应地址,然后根据地址在符号常量表中,找到具体调用的信息,这是一个很复杂的工程,需要对编译原理和汇编有很强的基础,幸运的是,如今这些工作不需要程序员自己去做,windows帮助我们分配了一组API,在编写程序时只需要调用API即可函数说明SymInitialize:这个函数主要用作初始化相关环境。SymCleanup:清楚这个初始化的相关环境,在调用SymInitialize之后需要调用SymCleanup,进行释放资源的操作StackWalk:程序的功能主要由这个函数实现,函数会从初始化时的堆栈顶开始向下查找下一个堆栈的信息,原型如下:BOOL WINAPI StackWalk( __in DWORD MachineType, //机器类型现在一般是intel的x86系列,这个时候填入IMAGE_FILE_MACHINE_I386 __in HANDLE hProcess, //追踪的进程句柄 __in HANDLE hThread, //追踪的线程句柄 __in_out LPSTACKFRAME StackFrame, //记录的追踪到的堆栈信息 __in_out PVOID ContextRecord, //记录当前的线程环境 __in PREAD_PROCESS_MEMORY_ROUTINE ReadMemoryRoutine, __in PFUNCTION_TABLE_ACCESS_ROUTINE FunctionTableAccessRoutine, __in PGET_MODULE_BASE_ROUTINE GetModuleBaseRoutine, __in PTRANSLATE_ADDRESS_ROUTINE TranslateAddress //后面的四个参数都是回掉函数,有系统自行调用,而且这些函数都是定义好的,只需要填入相应的函数名称 );需要注意的一点是,在首次调用该函数时需要对StackFrame中的AddrPC、AddrFrame、AddrStack这三个成员进行初始化,填入相关值,以便函数从此处线程堆栈的栈顶进行搜索,否则调用函数将失败,具体如何填写请看MSDN。SymGetSymFromAddr:根据获取到的函数地址得到函数名称、堆栈大小等信息,这个函数的原型如下: BOOL WINAPI SymGetSymFromAddr( __in HANDLE hProcess, //进程句柄 __in DWORD Address, //函数地址 __out PDWORD Displacement, //返回该符号常量的位移或者填入NULL,不获取此值 __out PIMAGEHLP_SYMBOL Symbol//返回堆栈信息 );SymGetLineFromAddr:根据得到的地址值,获取调用函数的相关信息。主要记录是在哪个文件,哪行调用了该函数,下面是函数原型:BOOL WINAPI SymGetLineFromAddr( __in HANDLE hProcess, __in DWORD dwAddr, __out PDWORD pdwDisplacement, __out PIMAGEHLP_LINE Line );它参数的含义与SymGetSymFromAddr,相同。通过上面对函数的说明,我们可以知道,为了追踪函数调用的详细信息,大致步骤如下:首先调用函数SymInitialize进行相关的初始化工作。填充结构体StackFrame的相关信息,确定从何处开始追踪。循环调用StackWalk函数,从指定位置,向下一直追踪到最后。每次将获取的地址分别传入SymGetSymFromAddr、SymGetLineFromAddr,得到函数的详细信息调用SymCleanup,结束追踪但是需要注意的一点是,函数StackWalk会顺着线程堆栈进行查找,如果在调用之前,某个函数已经返回了,它的堆栈被回收,那么函数StackWalk自然不会追踪到该函数的调用。具体实现void InitTrack() { g_hHandle = GetCurrentProcess(); SymInitialize(g_hHandle, NULL, TRUE); } void StackTrack() { g_hThread = GetCurrentThread(); STACKFRAME sf = { 0 }; sf.AddrPC.Offset = g_context.Eip; sf.AddrPC.Mode = AddrModeFlat; sf.AddrFrame.Offset = g_context.Ebp; sf.AddrFrame.Mode = AddrModeFlat; sf.AddrStack.Offset = g_context.Esp; sf.AddrStack.Mode = AddrModeFlat; typedef struct tag_SYMBOL_INFO { IMAGEHLP_SYMBOL symInfo; TCHAR szBuffer[MAX_PATH]; } SYMBOL_INFO, *LPSYMBOL_INFO; DWORD dwDisplament = 0; SYMBOL_INFO stack_info = { 0 }; PIMAGEHLP_SYMBOL pSym = (PIMAGEHLP_SYMBOL)&stack_info; pSym->SizeOfStruct = sizeof(IMAGEHLP_SYMBOL); pSym->MaxNameLength = sizeof(SYMBOL_INFO) - offsetof(SYMBOL_INFO, symInfo.Name); IMAGEHLP_LINE ImageLine = { 0 }; ImageLine.SizeOfStruct = sizeof(IMAGEHLP_LINE); while (StackWalk(IMAGE_FILE_MACHINE_I386, g_hHandle, g_hThread, &sf, &g_context, NULL, SymFunctionTableAccess, SymGetModuleBase, NULL)) { SymGetSymFromAddr(g_hHandle, sf.AddrPC.Offset, &dwDisplament, pSym); SymGetLineFromAddr(g_hHandle, sf.AddrPC.Offset, &dwDisplament, &ImageLine); printf("当前调用函数 : %08x+%s(FILE[%s]LINE[%d])\n", pSym->Address, pSym->Name, ImageLine.FileName, ImageLine.LineNumber); } } void UninitTrack() { SymCleanup(g_hHandle); }测试程序如下:void func1() { OPEN_STACK_TRACK; } void func2() { func1(); } void func3() { func2(); } void func4() { printf("hello\n"); } int _tmain(int argc, TCHAR* argv[]) { func4(); func3(); func3(); return 0; }OPEN_STACK_TRACK是一个宏,它的定义如下:#define OPEN_STACK_TRACK\ HANDLE hThread = GetCurrentThread();\ GetThreadContext(hThread, &g_context);\ __asm{call $ + 5}\ __asm{pop eax}\ __asm{mov g_context.Eip, eax}\ __asm{mov g_context.Ebp, ebp}\ __asm{mov g_context.Esp, esp}\ InitTrack();\ StackTrack();\ UninitTrack();这个程序需要注意以下几点:如果想要追踪所有调用的函数,需要将这个宏放置到最后调用的位置,当然前提是此时之前被调函数的堆栈仍然存在。当然可以在调用前简单的计算,找出在哪个位置是所有函数都没有调用完成的,不过这样可能就与程序的初衷相悖,毕竟程序本身就是为了获取堆栈的调用信息。。。。IMAGEHLP_SYMBOL的结构体中关于Name的成员,只有一个字节,而函数SymGetSymFromAddr在填入值时是没有关心这个实际大小,它只是简单的填充,这就造成了缓冲区溢出的情况,为了避免我们需要在Name后面额外给一定大小的缓冲区,用来接收数据,这也就是我们定义这个结构体SYMBOL_INFO的原因。另外IMAGEHLP_SYMBOL中的MaxNameLength成员是指Name的最大长度,需要根据给定的缓冲区,进行计算。从测试程序来看,在进行追踪时func4已经调用完成,而我们在获取线程的运行时环境g_context时函数GetThreadContext,也在堆栈中,最终得到的结果中必然包含GetThreadContext的调用信息,如果想去掉这个信息,只需要修改获得信息的值,既然函数StackWalk是根据堆栈进行追踪,那么只需要修改对应堆栈的信息即可,需要修改eip 、ebp、esp的值,关于esp ebp的值很好修改,可以在对应函数中esp ebp这些寄存器的值,而eip的值就不那么好获取,本生利用mov指令得到eip的值它也是指令,会改变eip的值,从而造成获取到的eip的值不准确,所以我们利用call指令,先保存当前eip的值到堆栈,然后再从堆栈中取出。call指令的实质是 push eip和jmp addr指令的组合,并不一定非要调用函数。call指令的大小为5个字节,所以call $ + 5表示先保存eip在跳转到它的下一跳指令处。这样就可以有效的避免检测到GetThreadContext中的相关函数调用。
-
windows错误处理 在调用windows API时函数会首先对我们传入的参数进行校验,然后执行,如果出现什么情况导致函数执行出错,有的函数可以通过返回值来判断函数是否出错,比如对于返回句柄的函数如果返回NULL 或者INVALID_HANDLE_VALUE,则函数出错,对于返回指针的函数来说如果返回NULL则函数出错,但是对于有的函数从返回值来看根本不知道是否成功,或者为什么失败,对此windows提供了一大堆的错误码,用于标识API函数是否出错以及出错原因。在windows中为每个线程准备了一个存储区,专门用来存储当前API执行的错误码,想要获取这个错误码可以通过函数GetLastError。在这需要注意的是当前API执行返回的错误码会覆盖之前API返回的错误码,所以在调用API结束后需要立马调用GetLastError来获取该函数返回的错误码。但是windows中的错误码实在太多,有的时候错误码并不直观,windows为每个错误码都关联了一个错误信息的文本,想要通过错误码获取对应的文本信息,可以通过函数FormatMessage来获取。下面是一个具体的例子:#include <windows.h> #include <tchar.h> #include <stdio.h> #include <strsafe.h> #define GRS_OUTPUT(s) WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), s, _tcsclen(s), NULL, NULL) int _tmain(int argc, TCHAR *argv[]) { if (INVALID_HANDLE_VALUE == CreateFile(_T("C:\\Test.txt"), GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL)) { LPTSTR lpMsg = NULL; DWORD dwLastError = GetLastError(); FormatMessage(FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_IGNORE_INSERTS | FORMAT_MESSAGE_FROM_SYSTEM, NULL, dwLastError, GetUserDefaultLangID(), (LPTSTR)&lpMsg, 0, NULL); if (NULL != lpMsg) { TCHAR szErrorInfo[1024] = {0}; StringCchPrintf(szErrorInfo, sizeof(szErrorInfo), _T("打开文件失败,失败原因为:%s"), lpMsg); GRS_OUTPUT(szErrorInfo); HeapFree(GetProcessHeap(), 0, lpMsg); } } return 0; }在这段代码中我们没有使用C标准库中的printf,而是使用了windows自带的控制台函数WriteConsole,为了简单,我们定义了一个宏,用来输出字符串。函数WriteConsole的原型如下:BOOL WINAPI WriteConsole( __in HANDLE hConsoleOutput, __in const VOID* lpBuffer, __in DWORD nNumberOfCharsToWrite, __out LPDWORD lpNumberOfCharsWritten, LPVOID lpReserved );函数的第一个参数是控制台的句柄,可以通过函数GetStdHandle来获取,这个函数主要传入一个标志,表示需要获取哪个控制台的句柄,主要有:STD_INPUT_HANDLE(标准输入)、STD_OUTPUT_HANDLE(标准输出)、STD_ERROR_HANDLE(标准错误)第二个参数是字符串的指针,第三个参数是字符个数,第四个参数是实际写入字符个数,由函数返回,如果不关心可以给NULL,最后一个windows作为保留参数通常给NULL。程序首先以打开已存在文件的方式打开一个文件,由于这个文件并不存在,所以函数出错,我们通过GetLastError获取错误码,然后通过FormatMessage来进行转化,该函数原型如下:DWORD FormatMessage( DWORD dwFlags, //标志 LPCVOID lpSource, //根据第一个参数的不同而有不同的解释 DWORD dwMessageId, //错误码 DWORD dwLanguageId, //语言ID LPTSTR lpBuffer, //字符缓冲区,用来存放最终生成的格式字符串 DWORD nSize, //缓冲区大小 va_list* Arguments//作为不定参数类似于printf函数格式化字符串后面的参数 ); 第一个参数是标志,在这我们传入FORMAT_MESSAGE_ALLOCATE_BUFFER,表示字符串缓冲区由该函数为我们分配,而不用自己分配,这个时候为了接受返回的字符缓冲区指针,需要使用二级指针。传入FORMAT_MESSAGE_IGNORE_INSERTS表示忽略插入的信息,也就是说不需要进行sprintf那样的格式化字符串的操作,传入FORMAT_MESSAGE_FROM_SYSTEM表示错误信息的字符串来自于系统定义的。然后进行简单的格式化之后输出错误字符串,最后需要释放内存,虽然FormatMessage函数帮我们分陪了缓冲,但是它不负责释放,需要我们自行释放。另外我们也可以自行进行错误码的设置,利用函数SetLastError可以达到这个效果,以模拟API调用时返回错误码的操作。在windows上一般遵循这样的格式:|位|31~30|29|28|27~16|15~0||:-|:----|:-|:-|:----|:---||用途|严重性|系统错误码|保留位|设备码|异常代码||含义|0 成功 <br/>1供参考<br/>2警告<br/>3错误|0系统定义<br/>1自定义|总为0|系统设备码|具体错误码|除了获取错误信息之外,还可以获取调用堆栈的快照,可以用函数CaptureStackBackTrace获取,只是这个函数只能获取调用堆栈的线性地址,不能获取到具体的函数名称。下面是它具体的一个例子: const int nCount = 128; PVOID BackTrace[nCount] = {NULL}; int iCnt = CaptureStackBackTrace(0, nCount, BackTrace, NULL); for (int i = 0; i < iCnt; i++) { printf("调用堆栈索引%d, 函数地址:0x%08x\n", i, BackTrace[i]); } return 0;这段代码非常简短,函数只需要四个参数,第一个参数是表示从当前栈顶开始的第几个栈开始便利,第二个参数是共便利多少个栈信息,第三个参数是一个缓冲区,用来存储得到的栈信息,具体就是栈的地址。第四个参数是一个哈希数组,由函数本身返回,如果不需要这个可以设置为NULL。
-
windows 堆管理 windows堆管理是建立在虚拟内存管理的基础之上的,每个进程都有独立的4GB的虚拟地址空间,其中有2GB的属于用户区,保存的是用户程序的数据和代码,而系统在装载程序时会将这部分内存划分为4个段从低地址到高地址依次为静态存储区,代码段,堆段和栈段,其中堆的生长方向是从低地址到高地址,而栈的生长方向是从高地址到低地址。程序申请堆内存时,系统会在虚拟内存的基础上分配一段内存,然后记录下来这块的大小和首地址,并且在对应内存块的首尾位置各有相应的数据结构,所以在堆内存上如果发生缓冲区溢出的话,会造成程序崩溃,这部分没有硬件支持,所有管理算法都有开发者自己设计实现。堆内存管理的函数主要有HeapCreate、HeapAlloc、HeapFree、HeapRealloc、HeapDestroy、HeapWalk、HeapLock、HeapUnLock。下面主要通过一些具体的操作来说明这些函数的用法。堆内存的分配与释放堆内存的分配主要用到函数HeapAlloc,下面是这个函数的原型:LPVOID HeapAlloc( HANDLE hHeap, //堆句柄,表示在哪个堆上分配内存 DWORD dwFlags, //分配的内存的相关标志 DWORD dwBytes //大小 );堆句柄可以使用进程默认堆也可以使用用户自定义的堆,自定义堆使用函数HeapCreate,函数返回堆的句柄,使用GetProcessHeap可以获取系统默认堆,返回的也是一个堆句柄。分配内存的相关标志有这样几个值:HEAP_NO_SERIALIZE:这个表示对堆内存不进行线程并发控制,由于系统默认会进行堆的并发控制,防止多个线程同时分配到了同一个堆内存,如果程序是单线程程序则可以添加这个选项,适当提高程序运行效率。HEAP_ZERO_MEMORY:这个标志表示在分配内存的时候同时将这块内存清零。HeapCreate函数的原型如下:HANDLE HeapCreate( DWORD flOptions, //堆的相关属性 DWORD dwInitialSize, //堆初始大小 DWORD dwMaximumSize //堆所占内存的最大值 );flOptions的取值如下:HEAP_NO_SERIALIZE:取消并发控制HEAP_SHARED_READONLY:其他进程可以以只读属性访问这个堆dwInitialSize, dwMaximumSize这两个值如果都是0,那么堆内存的初始大小由系统分配,并且堆没有上限,会根据具体的需求而增长。下面是使用的例子: //在系统默认堆中分配内存 srand((unsigned int)time(NULL)); HANDLE hHeap = GetProcessHeap(); int nCount = 1000; float *pfArray = (float *)HeapAlloc(hHeap, HEAP_ZERO_MEMORY | HEAP_NO_SERIALIZE, nCount * sizeof(float)); for (int i = 0; i < nCount; i++) { pfArray[i] = 1.0f * rand(); } HeapFree(hHeap, HEAP_NO_SERIALIZE, pfArray); //在自定义堆中分配内存 hHeap = HeapCreate(HEAP_GENERATE_EXCEPTIONS, 0, 0); pfArray = (float *)HeapAlloc(hHeap, HEAP_ZERO_MEMORY | HEAP_NO_SERIALIZE, nCount * sizeof(float)); for (int i = 0; i < nCount; i++) { pfArray[i] = 1.0f * rand(); } HeapFree(hHeap, HEAP_NO_SERIALIZE, pfArray); HeapDestroy(hHeap);遍历进程中所有堆的信息:便利堆的信息主要用到函数HeapWalk,该函数的原型如下:BOOL WINAPI HeapWalk( __in HANDLE hHeap,//堆的句柄 __in_out LPPROCESS_HEAP_ENTRY lpEntry//返回堆内存的相关信息 );下面是PROCESS_HEAP_ENTRY的原型:typedef struct _PROCESS_HEAP_ENTRY { PVOID lpData; DWORD cbData; BYTE cbOverhead; BYTE iRegionIndex; WORD wFlags; union { struct { HANDLE hMem; DWORD dwReserved[3]; } Block; struct { DWORD dwCommittedSize; DWORD dwUnCommittedSize; LPVOID lpFirstBlock; LPVOID lpLastBlock; } Region; }; } PROCESS_HEAP_ENTRY, *LPPROCESS_HEAP_ENTRY;这个结构中的公用体具体使用哪个与wFlags相关,下面是这些值得具体含义:wFlags堆入口含义lpDatacbDatacbOverhead块前堆数据结构大小iRegionIndexBlockRegionPROCESS_HEAP_ENTRY_BUSY被分配的内存块首地址内存块大小内存块前堆数据结构所在区域索引无意义无意义PROCESS_HEAP_ENTRY_DDESHAREDDE共享内存块首地址内存块大小内存块前堆数据结构所在区域索引无意义无意义PROCESS_HEAP_ENTRY_MOVEABLE可移动的内存块(兼容GlobalAllocLocalAlloc)首地址(可移动内存句柄的首地址)内存块大小内存块前堆数据结构所在区域索引与PROCESS_HEAP_ENTRY_BUSY标志一同指定可移动内存句柄值无意义PROCESS_HEAP_REGION已提交的堆虚拟内存区域区域开始地址区域大小区域前堆数据结构区域索引无意义虚拟内存区域详细信息PROCESS_HEAP_UNCOMMITTED_RANGE未提交的堆虚拟内存区域区域开始地址区域大小区域前堆数据结构区域索引无意义无意义下面是时遍历堆内存的例子: PHANDLE pHeaps = NULL; //当传入的参数为0和NULL时,函数返回进程中堆的个数 int nCount = GetProcessHeaps(0, NULL); pHeaps = new HANDLE[nCount]; //获取进程所有堆句柄 GetProcessHeaps(nCount, pHeaps); PROCESS_HEAP_ENTRY phe = {0}; for (int i = 0; i < nCount; i++) { cout << "Heap handle: 0x" << pHeaps[i] << '\n'; //在读取堆中的相关信息时需要将堆内存锁定,防止程序向堆中写入数据 HeapLock(pHeaps[i]); HeapWalk(pHeaps[i], &phe); //输出堆信息 cout << "\tSize: " << phe.cbData << " - Overhead: " << static_cast<DWORD>(phe.cbOverhead) << '\n'; cout << "\tBlock is a"; if(phe.wFlags & PROCESS_HEAP_REGION) { cout << " VMem region:\n"; cout << "\tCommitted size: " << phe.Region.dwCommittedSize << '\n'; cout << "\tUncomitted size: " << phe.Region.dwUnCommittedSize << '\n'; cout << "\tFirst block: 0x" << phe.Region.lpFirstBlock << '\n'; cout << "\tLast block: 0x" << phe.Region.lpLastBlock << '\n'; } else { if(phe.wFlags & PROCESS_HEAP_UNCOMMITTED_RANGE) { cout << "n uncommitted range\n"; } else if(phe.wFlags & PROCESS_HEAP_ENTRY_BUSY) { cout << "n Allocated range: Region index - " << static_cast<unsigned>(phe.iRegionIndex) << '\n'; if(phe.wFlags & PROCESS_HEAP_ENTRY_MOVEABLE) { cout << "\tMovable: Handle is 0x" << phe.Block.hMem << '\n'; } else if(phe.wFlags & PROCESS_HEAP_ENTRY_DDESHARE) { cout << "\tDDE Sharable\n"; } } else cout << " block, no other flags specified\n"; } cout << std::endl; HeapUnlock(pHeaps[i]); ZeroMemory(&phe, sizeof(PROCESS_HEAP_ENTRY)); } delete[] pHeaps;另外堆还有其他操作,比如使用HeapSize获取分配的内存大小,使用HeapValidate可以校验一个对内存的完整性,从而提早发现”野指针”等等。
-
windows虚拟内存管理 内存管理是操作系统非常重要的部分,处理器每一次的升级都会给内存管理方式带来巨大的变化,向早期的8086cpu的分段式管理,到后来的80x86 系列的32位cpu推出的保护模式和段页式管理。在应用程序中我们无时不刻不在和内存打交道,我们总在不经意间的进行堆内存和栈内存的分配释放,所以内存是我们进行程序设计必不可少的部分。CPU的内存管理方式段寄存器怎么消失了?在学习8086汇编语言时经常与寄存器打交道,其中8086CPU采用的内存管理方式为分段管理的方式,寻址时采用:短地址 * 16 + 偏移地址的方式,其中有几大段寄存器比如:CS、DS、SS、ES等等,每个段的偏移地址最大为64K,这样总共能寻址到2M的内存。但是到32位CPU之后偏移地址变成了32位这样每个段就可以有4GB的内存空间,这个空间已经足够大了,这个时候在编写相应的汇编程序时我们发现没有段寄存器的身影了,是不是在32位中已经没有段寄存器了呢,答案是否定了,32位CPU中不仅有段寄存器而且它们的作用比以前更大了。在32位CPU中段寄存器不再作为段首地址,而是作为段选择子,CPU为了管理内存,将某些连续的地址内存作为一页,利用一个数据结构来说明这页的属性,比如是否可读写,大小,起始地址等等,这个数据结构叫做段描述符,而多个段描述符则组成了一个段描述符表,而段寄存器如今是用来找到对应的段描述符的,叫做段选择子。段寄存器仍然是16位其中高13位表示段描述符表的索引,第二位是区分LDT(局部描述符表)和GDT(全局描述符表),全局描述符表是系统级的而LDT是每个进程所独有的,如果第二位表示的是LDT,那么首先要从GDT中查询到LDT所在位置,然后才根据索引找到对应的内存地址,所以现在寻址采用的是通过段选择子查表的方式得到一个32位的内存地址。由于这些表都是由系统维护,并且不允许用户访问及修改所以在普通应用程序中没有必要也不能使用段寄存器。通过上面的说明,我们可以推导出来32位机器最多可以支持2^(13 + 1 + 32) = 64T内存。段页式管理通过查表方式得到的32位内存地址是否就是真实的物理内存的地址呢,这个也是不一定的,这个还要看系统是否开启了段页式管理。如果没有则这个就是真实的物理地址,如果开启了段页式管理那么这个只是一个线性地址,还需要通过页表来寻址到真实的物理内存。32位CPU专门新赠了一个CR3寄存器用来完成分页式管理,通过CR3寄存器可以寻址到页目录表,然后再将32位线性地址的高10位作为页目录表的索引,通过这个索引可以找到相应的页表,再将中间10为作为页表的索引,通过这个索引可以寻址到对应物理内存的起始地址,最后通过这个其实地址和最后低12位的偏移地址找到对应真实内存。下面是这个过程的一个示例图:为什么要使用分页式管理,直接让那个32位线性地址对应真实的内存不可以吗。当然可以,但是分页式管理也有它自身的优点:可以实现页面的保护:系统通过设置相关属性信息来指定特权级别和其他状态可以实现物理内存的共享:从上面的图中可以看出,不同的线性地址是可以映射到相同的物理内存上的,只需要更改页表中对应的物理地址就可以实现不同的线性地址对应相同的物理内存实现内存共享。可以方便的实现虚拟内存的支持:在系统中有一个pagefile.sys的交互页面文件,这个是系统用来进行内存页面与磁盘进行交互,以应对内存不够的情况。系统为每个内存页维护了一个值,这个值表示该页面多久未被访问,当页面被访问这个值被清零,否则每过一段时间会累加一次。当这个值到达某个阈值时,系统将页面中的内容放入磁盘中,将这块内存空余出来以便保存其他数据,同时将之前的线性地址做一个标记,表名这个线性地址没有对应到具体的内存中,当程序需要再次访问这个线性地址所对应的内存时系统会再次将磁盘中的数据写入到内存中。虽说这样做相当于扩大了物理内存,但是磁盘相对于内存来说是一个慢速设备,在内存和磁盘间进行数据交换总是会耗费大量的时间,这样会拖慢程序运行,而采用SSD硬盘会显著提高系统运行效率,就在于SSD提高了与内存进行数据交换的效率。如果想显著提高效率,最好的办法是加内存毕竟在内存和硬盘间倒换数据是要话费时间的。保护模式在以前的16位CPU中采用的多是实模式,程序中使用的地址都是真实的物理地址,这样如果内存分配不合理,会造成一个程序将另外一个程序所在的内存覆盖这样对另外一个程序将造成严重影响,但是在32位保护模式下,不再会产生这种问题,保护模式将每个进程的地址空间隔离开来,还记得上面的LDT吗,在不同的程序中即使采用的是相同的地址,也会被LDT映射到不同的线性地址上。保护模式主要体现在这样几个方面:1.同一进程中,使用4个不同访问级别的内存段,对每个页面的访问属性做了相应的规定,防止错误访问的情况,同时为提供了4中不同代码特权,0特权的代码可以访问任意级别的内存,1特权能任意访问1...3级内存,但不能访问0级内存,依次类推。通常这些特权级别叫做ring0-ring3。对于不同的进程,将他们所用到的内存等资源隔离开来,一个进程的执行不会影响到另一个进程。windows系统的内存管理windows内存管理器我们将系统中实际映射到具体的实际内存上的页面称为工作集。当进程想访问多余实际物理内存的内存时,系统会启用虚拟内存管理机制(工作集管理),将那些长时间未访问的物理页面复制到硬盘缓冲文件上,并释放这些物理页面,映射到虚拟空间的其它页面上;系统的内存管理器主要由下面的几个部分组成:工作集管理器(优先级16):这个主要负责记录每个页面的年龄,也就有多久未被访问,当页面被访问这个年龄被清零,否则每过一段时间就进行累加1的操作。进程/栈交换器(优先级23):主要用于在进行进程或者线程切换时保存寄存器中的相关数据用以保存相关环境。已修改页面写出器(优先级17):当内存映射的内容发生改变时将这个改变及时的写入到硬盘中,防止由于程序意外终止而造成数据丢失映射页面写出器(优先级17):当页面的年龄达到一定的阈值时,将页面内容写入到硬盘中解引用段线程(优先级18):释放以写入到硬盘中的空闲页面零页面线程(优先级0):将空闲页面清零,以便程序下次使用,这个线程保证了新提交的页面都是干净的零页面进程虚拟地址空间的布局windows为每个进程提供了平坦的4GB的线性地址空间,这个地址空间被分为用户分区和内核分区,他们各占2GB大小,其中内核分区在高地址位,用户分区在低地址位,下面是内存分布的一个表格:分区地址范围NULL指针区0x00000000-0x0000FFFF用户分区0x00010000-0x7FFEFFFF64K禁入区0x7FFF0000-0x7FFFFFFF内核分区0x80000000-0xFFFFFFFF从上面的图中可以看出,系统的内核分区是2GB而用户可用的分区并没有2GB,在用户分区的头64K和尾部的64K不允许用户使用。另外我们可以压缩内核分区的大小,以便使用户分区占更多的内存,这就是/3GB方式,下面是这种方式的具体内存分布:分区地址范围NULL指针区0x00000000-0x0000FFFF用户分区0x00010000-0xBFFEFFFF64K禁入区0xBFFF0000-0xBFFFFFFF内核分区0xC0000000-0xFFFFFFFFwindows虚拟内存管理函数VirtualAllocVirtualAlloc函数主要用于提交或者保留一段虚拟地址空间,通过该函数提交的页面是经过0页面线程清理的干净的页面。LPVOID VirtualAlloc( LPVOID lpAddress, //虚拟内存的地址 DWORD dwSize, //虚拟内存大小 DWORD flAllocationType,//要对这块的虚拟内存做何种操作 DWORD flProtect //虚拟内存的保护属性 ); 我们可以指定第一个参数来告知系统,我们希望操作哪块内存,如果这个地址对应的内存已经被保留了那么将向下偏移至64K的整数倍,如果这块内存已经被提交,那么地址将向下偏移至4K的整数倍,也就是说保留页面的最小粒度是64K,而提交的最小粒度是一页4K。第三个参数是指定分配的类型,主要有以下几个值值含义MEM_COMMIT提交,也就是说将虚拟地址映射到对应的真实物理内存中,这样这块内存就可以正常使用MEM_RESERVE保留,告知系统以这个地址开始到后面的dwSize大小的连续的虚拟内存程序要使用,进程其他分配内存的操作不得使用这段内存。MEM_TOP_DOWN从高端地址保留空间(默认是从低端向高端搜索)MEM_LARGE_PAGES开启大页面的支持,默认一个页面是4K而大页面是2M(这个视具体系统而定)MEM_WRITE_WATCH开启页面写入监视,利用GetWriteWatch可以得到写入页面的统计情况,利用ResetWriteWatch可以重置起始计数MEM_PHYSICAL用于开启PAE第四个参数主要是页面的保护属性,参数可取值如下:值含义PAGE_READONLY只读PAGE_READWRITE可读写PAGE_EXECUTE可执行PAGE_EXECUTE_READ可读可执行PAGE_EXECUTE_READWRITE可读可写可执行PAGE_NOACCESS不可访问PAGE_GUARD将该页设置为保护页,如果试图对该页面进行读写操作,会产生一个STATUS_GUARD_PAGE 异常下面是该函数使用的几个例子:页面的提交/保留与释放//保留并提交 LPVOID pMem = VirtualAlloc(NULL, 4 * 4096, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); srand((unsigned int)time(NULL)); float* pfMem = (float*)pMem; for (int i = 0; i < 4 * 4096 / sizeof(float); i++) { pfMem[i] = rand(); } //释放 VirtualFree(pMem, 4 * 4096, MEM_RELEASE); //先保留再提交 LPBYTE pByte = (LPBYTE)VirtualAlloc(NULL, 1024 * 1024, MEM_RESERVE, PAGE_READWRITE); VirtualAlloc(pByte + 4 * 4096, 4096, MEM_COMMIT, PAGE_READWRITE); pfMem = (float*)(pByte + 4 * 4096); for (int i = 0; i < 4096/sizeof(float); i++) { pfMem[i] = rand(); } //释放 VirtualFree(pByte + 4 * 4096, 4096, MEM_DECOMMIT); VirtualFree(pByte, 1024 * 1024, MEM_RELEASE);大页面支持//获得大页面的尺寸 DWORD dwLargePageSize = GetLargePageMinimum(); LPVOID pBuffer = VirtualAlloc(NULL, 64 * dwLargePageSize, MEM_RESERVE, PAGE_READWRITE); //提交大页面 VirtualAlloc(pBuffer, 4 * dwLargePageSize, MEM_COMMIT | MEM_LARGE_PAGES, PAGE_READWRITE); VirtualFree(pBuffer, 4 * dwLargePageSize, MEM_DECOMMIT); VirtualFree(pBuffer, 64 * dwLargePageSize, MEM_RELEASE);VirtualProtectVirtualProtect用来设置页面的保护属性,函数原型如下:BOOL VirtualProtect( LPVOID lpAddress, //虚拟内存地址 DWORD dwSize, //大小 DWORD flNewProtect, //保护属性 PDWORD lpflOldProtect //返回原来的保护属性 ); 这个保护属性与之前介绍的VirtualAlloc中的保护属性相同,另外需要注意的一点是一般返回原来的属性的话,这个指针可以为NULL,但是这个函数不同,如果第四个参数为NULL,那么函数调用将会失败LPVOID pBuffer = VirtualAlloc(NULL, 4 * 4096, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); float *pfArray = (float*)pBuffer; for (int i = 0; i < 4 * 4096 / sizeof(float); i++) { pfArray[i] = 1.0f * rand(); } //将页面改为只读属性 DWORD dwOldProtect = 0; VirtualProtect(pBuffer, 4 * 4096, PAGE_READONLY, &dwOldProtect); //写入数据将发生异常 pfArray[9] = 0.1f; VirtualFree(pBuffer, 4 * 4096, MEM_RELEASE);VirtualQuery这个函数用来查询某段虚拟内存的属性信息,这个函数原型如下:DWORD VirtualQuery( LPCVOID lpAddress,//地址 PMEMORY_BASIC_INFORMATION lpBuffer, //用于接收返回信息的指针 DWORD dwLength //缓冲区大小,上述结构的大小 ); 结构MEMORY_BASIC_INFORMATION的定义如下:typedef struct _MEMORY_BASIC_INFORMATION { PVOID BaseAddress; //该页面的起始地址 PVOID AllocationBase;//分配给该页面的首地址 DWORD AllocationProtect;//页面的保护属性 DWORD RegionSize; //页面大小 DWORD State;//页面状态 DWORD Protect;//页面的保护类型 DWORD Type;//页面类型 } MEMORY_BASIC_INFORMATION; typedef MEMORY_BASIC_INFORMATION *PMEMORY_BASIC_INFORMATION; AllocationProtect与Protect所能取的值与之前的保护属性的值相同。State的取值如下:MEM_FREE:空闲MEM_RESERVE:保留MEM_COMMIT:已提交Type的取值如下:MEM_IMAGE:映射类型,一般是映射到地址控件的可执行模块如DLL,EXE等MEM_MAPPED:文件映射类型MEM_PRIVATE:私有类型,这个页面的数据为本进程私有数据,不能与其他进程共享下面是这个的使用例子:#include<windows.h> #include <stdio.h> #include <tchar.h> #include <atlstr.h> CString GetMemoryInfo(MEMORY_BASIC_INFORMATION *pmi); int _tmain(int argc, TCHAR *argv[]) { SYSTEM_INFO sm = {0}; GetSystemInfo(&sm); LPVOID dwMinAddress = sm.lpMinimumApplicationAddress; LPVOID dwMaxAddress = sm.lpMaximumApplicationAddress; MEMORY_BASIC_INFORMATION mbi = {0}; _putts(_T("BaseAddress\tAllocationBase\tAllocationProtect\tRegionSize\tState\tProtect\tType\n")); for (LPVOID pAddress = dwMinAddress; pAddress <= dwMaxAddress;) { if (VirtualQuery(pAddress, &mbi, sizeof(MEMORY_BASIC_INFORMATION)) == 0) { break; } _putts(GetMemoryInfo(&mbi)); //一般通过BaseAddress(页面基地址) + RegionSize(页面长度)来寻址到下一个页面的的位置 pAddress = (BYTE*)mbi.BaseAddress + mbi.RegionSize; } } CString GetMemoryInfo(MEMORY_BASIC_INFORMATION *pmi) { CString lpMemoryInfo = _T(""); int iBaseAddress = (int)(pmi->BaseAddress); int iAllocationBase = (int)(pmi->AllocationBase); CString szProtected = _T("\0"); if (pmi->Protect & PAGE_READONLY) { szProtected = _T("R"); }else if (pmi->Protect & PAGE_READWRITE) { szProtected = _T("RW"); }else if (pmi->Protect & PAGE_WRITECOPY) { szProtected = _T("WC"); }else if (pmi->Protect & PAGE_EXECUTE) { szProtected = _T("X"); }else if (pmi->Protect & PAGE_EXECUTE_READ) { szProtected = _T("RX"); }else if (pmi->Protect & PAGE_EXECUTE_READWRITE) { szProtected = _T("RWX"); }else if (pmi->Protect & PAGE_EXECUTE_WRITECOPY) { szProtected = _T("WCX"); }else if (pmi->Protect & PAGE_GUARD) { szProtected = _T("GUARD"); }else if (pmi->Protect & PAGE_NOACCESS) { szProtected = _T("NOACCESS"); }else if (pmi->Protect & PAGE_NOCACHE) { szProtected = _T("NOCACHE"); }else { szProtected = _T(" "); } CString szAllocationProtect = _T("\0"); if (pmi->AllocationProtect & PAGE_READONLY) { szProtected = _T("R"); }else if (pmi->AllocationProtect & PAGE_READWRITE) { szProtected = _T("RW"); }else if (pmi->AllocationProtect & PAGE_WRITECOPY) { szProtected = _T("WC"); }else if (pmi->AllocationProtect & PAGE_EXECUTE) { szProtected = _T("X"); }else if (pmi->AllocationProtect & PAGE_EXECUTE_READ) { szProtected = _T("RX"); }else if (pmi->AllocationProtect & PAGE_EXECUTE_READWRITE) { szProtected = _T("RWX"); }else if (pmi->AllocationProtect & PAGE_EXECUTE_WRITECOPY) { szProtected = _T("WCX"); }else if (pmi->AllocationProtect & PAGE_GUARD) { szProtected = _T("GUARD"); }else if (pmi->AllocationProtect & PAGE_NOACCESS) { szProtected = _T("NOACCESS"); }else if (pmi->AllocationProtect & PAGE_NOCACHE) { szProtected = _T("NOCACHE"); }else { szProtected = _T(" "); } DWORD dwRegionSize = pmi->RegionSize; CString strState = _T(""); if (pmi->State & MEM_FREE) { strState = _T("Free"); }else if (pmi->State & MEM_RESERVE) { strState = _T("Reserve"); }else if (pmi->State & MEM_COMMIT) { strState = _T("Commit"); }else { strState = _T(" "); } CString strType = _T(""); if (pmi->Type & MEM_IMAGE) { strType = _T("Image"); }else if (pmi->Type & MEM_MAPPED) { strType = _T("Mapped"); }else if (pmi->Type & MEM_PRIVATE) { strType = _T("Private"); } lpMemoryInfo.Format(_T("%08X %08X %s %d %s %s %s\n"), iBaseAddress, iAllocationBase, szAllocationProtect, dwRegionSize, strState, szProtected, strType); return lpMemoryInfo; }VirtualLock和VirtualUnlock这两个函数用于锁定和解锁页面,前面说过操作系统会将长时间不用的内存中的数据放入到系统的磁盘文件中,需要的时候再放回到内存中,这样来回倒腾,必定会造成程序效率的底下,为了避免这中效率底下的操作,可以使用VirtualLock将页面锁定在内存中,防止页面交换,但是不用了的时候需要使用VirtualUnlock来解锁,不然一直锁定而不解锁会造成真实内存的不足。另外需要注意的是,不能一次操作超过工作集规定的最大虚拟内存,这样会造成程序崩溃,我们可以通过函数SetProcessWorkingSetSize来设置工作集规定的最大虚拟内存的大小。下面是一个使用例子:SetProcessWorkingSetSize(GetCurrentProcess(), 1024 * 1024, 2 * 1024 * 1024); LPVOID pBuffer = VirtualAlloc(NULL, 4 * 4096, MEM_RESERVE, PAGE_READWRITE); //不能锁定超过进程工作集大小的虚拟内存 VirtualLock(pBuffer, 3 * 1024 * 1024); //不能一次提交超过进程工作集大小的虚拟内存 VirtualAlloc(pBuffer, 3 * 1024 * 1024, MEM_COMMIT, PAGE_READWRITE); float *pfArray = (float*)pBuffer; for (int i = 0; i < 4096 / sizeof(float); i++) { pfArray[i] = 1.0f * rand(); } VirtualUnlock(pBuffer, 4096); VirtualFree(pBuffer, 4096, MEM_DECOMMIT); VirtualFree(pBuffer, 4 * 4096, MEM_RELEASE);VirtualFreeVirtualFree用于释放申请的虚拟内存。这个函数支持反提交和释放,这两个操作由第三个参数指定:MEM_DECOMMIT:反提交,这样这个线性地址就不再映射到具体的物理内存,但是这个地址仍然是保留地址。MEM_RELEASE:释放,这个范围的地址不再作为保留地址