搜索到
1
篇与
的结果
-
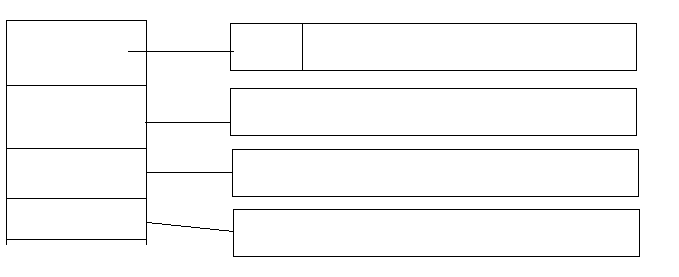
 数组的剖析 C语言中数组是十分重要的一种结构,数组采用的是连续存储的方式,下面通过反汇编的方式来解析编译器对数组的操作。数组作为局部变量在任意一个函数当中定义的变量都会被当做局部变量,它们的生命周期与函数的调用有关,下面是一个例子:int main() { int nArray[5] = {1, 2, 3, 4, 5}; int num1 = 1; int num2 = 2; int num3 = 3; int num4 = 4; int num5 = 5; printf("%d\n", num1); printf("%d\n", nArray[0]); printf("%d\n", nArray[1]); return 0; }下面是它对应的反汇编代码00401268 mov dword ptr [ebp-14h],1 0040126F mov dword ptr [ebp-10h],2 00401276 mov dword ptr [ebp-0Ch],3 ... 10: int num1 = 1; 0040128B mov dword ptr [ebp-18h],1 11: int num2 = 2; 00401292 mov dword ptr [ebp-1Ch],2 12: int num3 = 3; ... 16: printf("%d\n", num1); 004012AE mov eax,dword ptr [ebp-18h] 004012B1 push eax ... 17: printf("%d\n", nArray[0]); 004012BF mov ecx,dword ptr [ebp-14h] 004012C2 push ecx ... 18: printf("%d\n", nArray[1]); 004012D0 mov edx,dword ptr [ebp-10h] 004012D3 push edx ...为了节省篇幅,上面的汇编代码只截取了部分有代表性的内容,从上面的部分可以看到,数组采用连续的存储方式,在内存中从低地址部分到高地址部分依次存储,而普通的局部变量则是先定义的在高地址部分。在使用上也都是采用寄存器间接寻址的方式。在初始化时数组是从第0项开始依次向后赋值。但是如果我们将所有的数组成员都赋值为相同值时会怎样?9: int nArray[5] = {1}; 00401268 mov dword ptr [ebp-14h],1 0040126F xor eax,eax 00401271 mov dword ptr [ebp-10h],eax 00401274 mov dword ptr [ebp-0Ch],eax 00401277 mov dword ptr [ebp-8],eax 0040127A mov dword ptr [ebp-4],eax从上面的汇编代码可以看到,当初始化的值相同的时候,仍是采用依次赋值的方式。下面再来看看字符数组的初始化。0040126E mov eax,[string "Hello World!" (0042e01c)] 00401273 mov dword ptr [ebp-100h],eax 00401279 mov ecx,dword ptr [string "Hello World!"+4 (0042e020)] 0040127F mov dword ptr [ebp-0FCh],ecx 00401285 mov edx,dword ptr [string "Hello World!"+8 (0042e024)] 0040128B mov dword ptr [ebp-0F8h],edx 00401291 mov al,[string "Hello World!"+0Ch (0042e028)] 00401296 mov byte ptr [ebp-0F4h],al 0040129C mov ecx,3Ch 004012A1 xor eax,eax 004012A3 lea edi,[ebp-0F3h] 004012A9 rep stos dword ptr [edi] 004012AB stos word ptr [edi] 10: char *pszBuf = "Hello World!"; 004012AD mov dword ptr [ebp-104h],offset string "Hello World!" (0042e01c)字符串是特殊的字符数组,约定字符串的最后一个值为NULL。上面的代码显示出,对于字符串的初始化采用的是用寄存器的方式依次赋值4个字节的内容,而对于字符指针,在初始化的时候在程序的全局变量中存储了一个字符串,并将这个字符串的首地址赋值给对应的变量,这个字符串是位于常量内存区,所以只能寻址,而不能更改它。数组作为函数的参数当数组作为函数参数时传递的是数组的首地址,而不会拷贝整个内存区,这点许多人容易搞错。下面通过反汇编的方式来说明:void ShowArray(int a[5]) { for (int i = 0; i < 5; i++) { printf("%d\n", a[i]); } } int main() { int nArray[5] = {1, 2, 3, 4, 5}; ShowArray(nArray); return 0; }19: ShowArray(nArray); 004012FB lea eax,[ebp-14h];取[ebp - 14h]的地址 004012FE push eax 004012FF call @ILT+0(ShowArray) (00401005) 00401304 add esp,4 ;ShowArray函数 00401268 mov dword ptr [ebp-4],0;初始化i = 0 0040126F jmp ShowArray+2Ah (0040127a) 00401271 mov eax,dword ptr [ebp-4] 00401274 add eax,1 00401277 mov dword ptr [ebp-4],eax 0040127A cmp dword ptr [ebp-4],5 ;比较 i 与 5 0040127E jge ShowArray+49h (00401299);当i >= 5时跳出循环 11: { 12: printf("%d\n", a[i]); 00401280 mov ecx,dword ptr [ebp-4] ;ecx = i 00401283 mov edx,dword ptr [ebp+8] ;edx = 数组的首地址 00401286 mov eax,dword ptr [edx+ecx*4];寻址数组中的第i个元素 00401289 push eax 从上面的反汇编代码可以看出,在传值时只是将数组的首地址作为参数传入,而在函数的使用中直接通过传入的首地址来寻址数组中的各个元素,如果再函数的代码中添加一句sizeof来求这个数组的长度,那么返回的一定是4,而不是20。由于数组作为函数参数时函数不会记录数组的长度,那么为了防止越界,需要通过某种方式告知函数内部数组的长度,一般有两种方式,一种是想字符串那样规定一个结束标记,当到达这个结束标记时不再访问其下一个元素,二是通过传入一个参数表示数组的长度。另外数组作为返回值时与数组作为参数相同,都是通过指针的方式返回,但是需要牢记的一点是不要返回局部变量的地址或者引用。数组的成员的访问方式数组成员可以采用下标访问方式,也可以采用指针寻址方式,指针寻址不仅没有下标寻址方便,效率也没有下标寻址方式高。下面来看这两种方式的具体差距。11: int nArray[5] = {1, 2, 3, 4, 5}; 00401268 mov dword ptr [ebp-14h],1 ... 12: int *p = nArray; 0040128B lea eax,[ebp-14h] 0040128E mov dword ptr [ebp-18h],eax 13: printf("%d\n", nArray[3]); 00401291 mov ecx,dword ptr [ebp-8] 00401294 push ecx ... 14: printf("%d\n", p + 3); 004012A2 mov edx,dword ptr [ebp-18h] 004012A5 add edx,0Ch 004012A8 push edx从上面的代码可以看出,指针寻址会另外开辟一个4字节的内存空间用来存储这个指针变量,同时使用指针也需要进行地址变换,首先通过指针p的地址找到p的值,然后通过p存储的值再次间接寻址找到对应的值。而数组下标法寻址,只通过直接寻址找到对应的元素并取出即可。如果下标中是整型变量,则直接通过公式addr + sizeof(type) * n(其中addr为数组的首地址,type为数组元素的值,n为下标值)来寻址,而下标为整型表达式,则先计算表达式的值,然后在通过这一公式来寻址。多维数组多维数组,我们主要来说明二维数组11: int nArray[2][3] = {{1, 2, 3}, {4, 5, 6}}; 00401268 mov dword ptr [ebp-18h],1 0040126F mov dword ptr [ebp-14h],2 00401276 mov dword ptr [ebp-10h],3 0040127D mov dword ptr [ebp-0Ch],4 00401284 mov dword ptr [ebp-8],5 0040128B mov dword ptr [ebp-4],6通过汇编代码,对于多维数组在内存中存储的方式仍然为线性存储方式,对于多维数组会转化为一维数组数组,然后再依次存储各个一维数组的值,例如上面的例子中将二维数组转化为两个一维数组,然后分别在内存中对它们进行初始化。对于多维数组的寻址,例如int nArray2这样的数组,首先拆分为2个有3个元素的一维数组,在寻址时首先找到对应的一维数组的首地址,然后在对应的一维数组中寻址找到对应元素的值。这样对于多维数组都是转化为多个低一级的多维数组最终转化为一维数组的方式来解决。虽说多维数组是采用线性存储的方式来存储数据,但是在理解上我们可以将高维数组看成存储多个低维数组的特殊一维数组,比如int a4 可以看成一个有四个元素的一维数组,每一一维数组都存储了一个5个整型元素的一维数组,通过图来表示就是这样:上述的数组看做一个一维数组,这个一维数组有4个成员,每个成员都存储了一个5个一维数组的数组名,这样就可以很好的理解a 表示的是二维数组的首地址,而a[0]则表示的是第一个元素的首地址,同时也可以很好理解为何定义二维数组的指针时为何需要第二个下标,因为二维数组存储的是一维数组,它的类型就是多个一维数组,所以需要将一维数组的大小作为类型值来定义指针。函数指针函数指针的定义格式如下type (*pname)(args);函数的内容存储在代码段中,函数指针指向的就是函数的第一句代码所在的内存位置,而在调用函数需要知道函数的返回值,以及函数的参数列表,特别是参数列表,只有知道这些信息,在通过函数指针调用时才能知道其栈环境是如何配置的,函数类型其实是函数的返回值加上其参数列表,所以在定义函数时需要知道这些信息。
数组的剖析 C语言中数组是十分重要的一种结构,数组采用的是连续存储的方式,下面通过反汇编的方式来解析编译器对数组的操作。数组作为局部变量在任意一个函数当中定义的变量都会被当做局部变量,它们的生命周期与函数的调用有关,下面是一个例子:int main() { int nArray[5] = {1, 2, 3, 4, 5}; int num1 = 1; int num2 = 2; int num3 = 3; int num4 = 4; int num5 = 5; printf("%d\n", num1); printf("%d\n", nArray[0]); printf("%d\n", nArray[1]); return 0; }下面是它对应的反汇编代码00401268 mov dword ptr [ebp-14h],1 0040126F mov dword ptr [ebp-10h],2 00401276 mov dword ptr [ebp-0Ch],3 ... 10: int num1 = 1; 0040128B mov dword ptr [ebp-18h],1 11: int num2 = 2; 00401292 mov dword ptr [ebp-1Ch],2 12: int num3 = 3; ... 16: printf("%d\n", num1); 004012AE mov eax,dword ptr [ebp-18h] 004012B1 push eax ... 17: printf("%d\n", nArray[0]); 004012BF mov ecx,dword ptr [ebp-14h] 004012C2 push ecx ... 18: printf("%d\n", nArray[1]); 004012D0 mov edx,dword ptr [ebp-10h] 004012D3 push edx ...为了节省篇幅,上面的汇编代码只截取了部分有代表性的内容,从上面的部分可以看到,数组采用连续的存储方式,在内存中从低地址部分到高地址部分依次存储,而普通的局部变量则是先定义的在高地址部分。在使用上也都是采用寄存器间接寻址的方式。在初始化时数组是从第0项开始依次向后赋值。但是如果我们将所有的数组成员都赋值为相同值时会怎样?9: int nArray[5] = {1}; 00401268 mov dword ptr [ebp-14h],1 0040126F xor eax,eax 00401271 mov dword ptr [ebp-10h],eax 00401274 mov dword ptr [ebp-0Ch],eax 00401277 mov dword ptr [ebp-8],eax 0040127A mov dword ptr [ebp-4],eax从上面的汇编代码可以看到,当初始化的值相同的时候,仍是采用依次赋值的方式。下面再来看看字符数组的初始化。0040126E mov eax,[string "Hello World!" (0042e01c)] 00401273 mov dword ptr [ebp-100h],eax 00401279 mov ecx,dword ptr [string "Hello World!"+4 (0042e020)] 0040127F mov dword ptr [ebp-0FCh],ecx 00401285 mov edx,dword ptr [string "Hello World!"+8 (0042e024)] 0040128B mov dword ptr [ebp-0F8h],edx 00401291 mov al,[string "Hello World!"+0Ch (0042e028)] 00401296 mov byte ptr [ebp-0F4h],al 0040129C mov ecx,3Ch 004012A1 xor eax,eax 004012A3 lea edi,[ebp-0F3h] 004012A9 rep stos dword ptr [edi] 004012AB stos word ptr [edi] 10: char *pszBuf = "Hello World!"; 004012AD mov dword ptr [ebp-104h],offset string "Hello World!" (0042e01c)字符串是特殊的字符数组,约定字符串的最后一个值为NULL。上面的代码显示出,对于字符串的初始化采用的是用寄存器的方式依次赋值4个字节的内容,而对于字符指针,在初始化的时候在程序的全局变量中存储了一个字符串,并将这个字符串的首地址赋值给对应的变量,这个字符串是位于常量内存区,所以只能寻址,而不能更改它。数组作为函数的参数当数组作为函数参数时传递的是数组的首地址,而不会拷贝整个内存区,这点许多人容易搞错。下面通过反汇编的方式来说明:void ShowArray(int a[5]) { for (int i = 0; i < 5; i++) { printf("%d\n", a[i]); } } int main() { int nArray[5] = {1, 2, 3, 4, 5}; ShowArray(nArray); return 0; }19: ShowArray(nArray); 004012FB lea eax,[ebp-14h];取[ebp - 14h]的地址 004012FE push eax 004012FF call @ILT+0(ShowArray) (00401005) 00401304 add esp,4 ;ShowArray函数 00401268 mov dword ptr [ebp-4],0;初始化i = 0 0040126F jmp ShowArray+2Ah (0040127a) 00401271 mov eax,dword ptr [ebp-4] 00401274 add eax,1 00401277 mov dword ptr [ebp-4],eax 0040127A cmp dword ptr [ebp-4],5 ;比较 i 与 5 0040127E jge ShowArray+49h (00401299);当i >= 5时跳出循环 11: { 12: printf("%d\n", a[i]); 00401280 mov ecx,dword ptr [ebp-4] ;ecx = i 00401283 mov edx,dword ptr [ebp+8] ;edx = 数组的首地址 00401286 mov eax,dword ptr [edx+ecx*4];寻址数组中的第i个元素 00401289 push eax 从上面的反汇编代码可以看出,在传值时只是将数组的首地址作为参数传入,而在函数的使用中直接通过传入的首地址来寻址数组中的各个元素,如果再函数的代码中添加一句sizeof来求这个数组的长度,那么返回的一定是4,而不是20。由于数组作为函数参数时函数不会记录数组的长度,那么为了防止越界,需要通过某种方式告知函数内部数组的长度,一般有两种方式,一种是想字符串那样规定一个结束标记,当到达这个结束标记时不再访问其下一个元素,二是通过传入一个参数表示数组的长度。另外数组作为返回值时与数组作为参数相同,都是通过指针的方式返回,但是需要牢记的一点是不要返回局部变量的地址或者引用。数组的成员的访问方式数组成员可以采用下标访问方式,也可以采用指针寻址方式,指针寻址不仅没有下标寻址方便,效率也没有下标寻址方式高。下面来看这两种方式的具体差距。11: int nArray[5] = {1, 2, 3, 4, 5}; 00401268 mov dword ptr [ebp-14h],1 ... 12: int *p = nArray; 0040128B lea eax,[ebp-14h] 0040128E mov dword ptr [ebp-18h],eax 13: printf("%d\n", nArray[3]); 00401291 mov ecx,dword ptr [ebp-8] 00401294 push ecx ... 14: printf("%d\n", p + 3); 004012A2 mov edx,dword ptr [ebp-18h] 004012A5 add edx,0Ch 004012A8 push edx从上面的代码可以看出,指针寻址会另外开辟一个4字节的内存空间用来存储这个指针变量,同时使用指针也需要进行地址变换,首先通过指针p的地址找到p的值,然后通过p存储的值再次间接寻址找到对应的值。而数组下标法寻址,只通过直接寻址找到对应的元素并取出即可。如果下标中是整型变量,则直接通过公式addr + sizeof(type) * n(其中addr为数组的首地址,type为数组元素的值,n为下标值)来寻址,而下标为整型表达式,则先计算表达式的值,然后在通过这一公式来寻址。多维数组多维数组,我们主要来说明二维数组11: int nArray[2][3] = {{1, 2, 3}, {4, 5, 6}}; 00401268 mov dword ptr [ebp-18h],1 0040126F mov dword ptr [ebp-14h],2 00401276 mov dword ptr [ebp-10h],3 0040127D mov dword ptr [ebp-0Ch],4 00401284 mov dword ptr [ebp-8],5 0040128B mov dword ptr [ebp-4],6通过汇编代码,对于多维数组在内存中存储的方式仍然为线性存储方式,对于多维数组会转化为一维数组数组,然后再依次存储各个一维数组的值,例如上面的例子中将二维数组转化为两个一维数组,然后分别在内存中对它们进行初始化。对于多维数组的寻址,例如int nArray2这样的数组,首先拆分为2个有3个元素的一维数组,在寻址时首先找到对应的一维数组的首地址,然后在对应的一维数组中寻址找到对应元素的值。这样对于多维数组都是转化为多个低一级的多维数组最终转化为一维数组的方式来解决。虽说多维数组是采用线性存储的方式来存储数据,但是在理解上我们可以将高维数组看成存储多个低维数组的特殊一维数组,比如int a4 可以看成一个有四个元素的一维数组,每一一维数组都存储了一个5个整型元素的一维数组,通过图来表示就是这样:上述的数组看做一个一维数组,这个一维数组有4个成员,每个成员都存储了一个5个一维数组的数组名,这样就可以很好的理解a 表示的是二维数组的首地址,而a[0]则表示的是第一个元素的首地址,同时也可以很好理解为何定义二维数组的指针时为何需要第二个下标,因为二维数组存储的是一维数组,它的类型就是多个一维数组,所以需要将一维数组的大小作为类型值来定义指针。函数指针函数指针的定义格式如下type (*pname)(args);函数的内容存储在代码段中,函数指针指向的就是函数的第一句代码所在的内存位置,而在调用函数需要知道函数的返回值,以及函数的参数列表,特别是参数列表,只有知道这些信息,在通过函数指针调用时才能知道其栈环境是如何配置的,函数类型其实是函数的返回值加上其参数列表,所以在定义函数时需要知道这些信息。