搜索到
16
篇与
的结果
-
 多结果集IMultipleResult接口 title: 多结果集IMultipleResult接口tags: [OLEDB, 数据库编程, VC++, 数据库]date: 2018-03-16 21:04:31categories: windows 数据库编程keywords: OLEDB, 数据库编程, VC++, 数据库, 结果集, 多结果集在某些任务中,需要执行多条sql语句,这样一次会返回多个结果集,在应用程序就需要处理多个结果集,在OLEDB中支持多结果集的接口是IMultipleResult。查询数据源是否支持多结果集并不是所有数据源都支持多结果集,可以通过查询数据源对象的DBPROPSET_DATASOURCEINFO属性集中的DBPROP_MULTIPLERESULTS属性来确定,该值是一个按位设置的4字节的联合值。它可取的值有下面几个:DBPROPVAL_MR_SUPPORITED:支持多结果集DBPROPVAL_MR_SONCURRENT:支持多结果集,并支持同时打开多个返回的结果集(如果它不支持同时打开多个结果集的话,在打开下一个结果集之前需要关闭已经打开的结果集)DBPROPVAL_MR_NOTSUPPORTED: 不支持多结果集这个属性可以通过接口IDBProperties接口的GetProperties方法来获取,该函数的原型如下:HRESULT GetProperties ( ULONG cPropertyIDSets, const DBPROPIDSET rgPropertyIDSets[], ULONG *pcPropertySets, DBPROPSET **prgPropertySets);它的用法与之前的SetProperties十分类似第一个参数是我们传入DBPROPIDSET数组元素的个数,第二个参数是一个DBPROPIDSET结构的参数,该结构的原型如下:typedef struct tagDBPROPIDSET { DBPROPID * rgPropertyIDs; ULONG cPropertyIDs; GUID guidPropertySet; } DBPROPIDSET;该结构与之前遇到的DBPROPSET类似,第一个参数是一个DBPROPID结构的数组的首地址,该值是一个属性值,表示我们希望查询哪个属性的情况,第二个参数表示我们总共查询多少个属性的值,第3个参数表示这些属性都属于哪个属性集。接口方法的第三个参数返回当前我们总共查询到几个属性集的内容。第四个参数返回具体查到的属性值。多结果集接口的使用多结果集对象的定义如下:CoType TMultipleResults { [mandatory] interface IMultipleResults; [optional] interface ISupportErrorInfo; }一般在程序中,使用多结果集有如下步骤查询数据源是否支持多结果集,如果不支持则要考虑其他的实现方案如果它支持多结果集,在调用ICommandText接口的Execute方法执行SQL语句时,让其返回一个IMultipleRowset接口。循环调用接口的GetResult方法获取结果集对象。使用结果集对象最后是一个完整的例子://判断是否支持多结果集 BOOL SupportMultipleRowsets(IOpenRowset *pIOpenRowset) { COM_DECLARE_BUFFER(); COM_DECLARE_INTERFACE(IDBInitialize); COM_DECLARE_INTERFACE(IDBProperties); COM_DECLARE_INTERFACE(IGetDataSource); BOOL bRet = FALSE; //定义相关结构用于获取关于多结果集的信息 DBPROPID dbPropId[2] = {0}; DBPROPIDSET dbPropIDSet[1] = {0}; dbPropId[0] = DBPROP_MULTIPLERESULTS; dbPropIDSet[0].cPropertyIDs = 1; dbPropIDSet[0].guidPropertySet = DBPROPSET_DATASOURCEINFO; dbPropIDSet[0].rgPropertyIDs = dbPropId; //定义相关结构用于接受返回的属性信息 ULONG uPropsets = 0; DBPROPSET *pDBPropset = NULL; //获取数据源对象 HRESULT hRes = pIOpenRowset->QueryInterface(IID_IGetDataSource, (void**)&pIGetDataSource); COM_SUCCESS(hRes, _T("查询接口IGetDataSource失败,错误码为:%08x\n"), hRes); hRes = pIGetDataSource->GetDataSource(IID_IDBInitialize, (IUnknown **)&pIDBInitialize); COM_SUCCESS(hRes, _T("获取数据源对象失败,错误码为:%08x\n"), hRes); //获取对应属性 hRes = pIDBInitialize->QueryInterface(IID_IDBProperties, (void**)&pIDBProperties); COM_SUCCESS(hRes, _T("查询IDBProperties接口失败,错误码为:%08x\n"), hRes); hRes = pIDBProperties->GetProperties(1, dbPropIDSet, &uPropsets, &pDBPropset); COM_SUCCESS(hRes, _T("获取属性信息失败,错误码:%08x\n"), hRes); //判断是否支持多结果集 if (pDBPropset[0].rgProperties[0].vValue.vt == VT_I4) { if (pDBPropset[0].rgProperties[0].vValue.intVal & DBPROPVAL_MR_CONCURRENT) { COM_PRINT(_T("支持多结果集\n")); }else if (pDBPropset[0].rgProperties[0].vValue.intVal & DBPROPVAL_MR_SUPPORTED) { COM_PRINT(_T("支持多结果集\n")); }else if (pDBPropset[0].rgProperties[0].vValue.intVal & DBPROPVAL_MR_NOTSUPPORTED) { COM_PRINT(_T("不支持多结果集\n")); goto __CLEAR_UP; } else { COM_PRINT(_T("未知\n")); goto __CLEAR_UP; } } bRet = TRUE; __CLEAR_UP: SAFE_RELSEASE(pIDBInitialize); SAFE_RELSEASE(pIDBProperties); SAFE_RELSEASE(pIGetDataSource); CoTaskMemFree(pDBPropset[0].rgProperties); CoTaskMemFree(pDBPropset); return bRet; } // 执行sql语句并返回多结果集对象 BOOL ExecSQL(LPOLESTR lpSQL, IOpenRowset *pIOpenRowset, IMultipleResults* &pIMultipleResults) { COM_DECLARE_BUFFER(); COM_DECLARE_INTERFACE(IDBCreateCommand); COM_DECLARE_INTERFACE(ICommandText); COM_DECLARE_INTERFACE(ICommandProperties); BOOL bRet = FALSE; DBPROP dbProp[2] = {0}; DBPROPSET dbPropset[1] = {0}; dbProp[0].colid = DB_NULLID; dbProp[0].dwOptions = DBPROPOPTIONS_REQUIRED; dbProp[0].dwPropertyID = DBPROP_UPDATABILITY; dbProp[0].vValue.vt = VT_I4; dbProp[0].vValue.intVal = DBPROPVAL_UP_CHANGE | DBPROPVAL_UP_DELETE | DBPROPVAL_UP_INSERT; //设置SQL语句 HRESULT hRes = pIOpenRowset->QueryInterface(IID_IDBCreateCommand, (void**)&pIDBCreateCommand); COM_SUCCESS(hRes, _T("查询接口IDBCreateCommand失败,错误码:%08x\n"), hRes); hRes = pIDBCreateCommand->CreateCommand(NULL , IID_ICommandText, (IUnknown**)&pICommandText); COM_SUCCESS(hRes, _T("创建接口ICommandText失败,错误码:%08x"), hRes); hRes = pICommandText->SetCommandText(DBGUID_DEFAULT, lpSQL); COM_SUCCESS(hRes, _T("设置SQL语句失败,错误码为:%08x\n"), hRes); //设置属性 hRes = pICommandText->QueryInterface(IID_ICommandProperties, (void**)&pICommandProperties); COM_SUCCESS(hRes, _T("查询接口ICommandProperties接口失败,错误码:%08x\n"), hRes); //执行SQL语句 hRes = pICommandText->Execute(NULL, IID_IMultipleResults, NULL, NULL, (IUnknown**)&pIMultipleResults); COM_SUCCESS(hRes, _T("执行SQL语句失败,错误码:%08x\n"), hRes); bRet = TRUE; __CLEAR_UP: SAFE_RELSEASE(pIDBCreateCommand); SAFE_RELSEASE(pICommandText); SAFE_RELSEASE(pICommandProperties); return bRet; } int _tmain(int argc, TCHAR *argv[]) { CoInitialize(NULL); COM_DECLARE_BUFFER(); COM_DECLARE_INTERFACE(IOpenRowset); COM_DECLARE_INTERFACE(IMultipleResults); COM_DECLARE_INTERFACE(IRowset); LPOLESTR pSQL = OLESTR("Select * From aa26 Where Left(aac031,2) = '11';\ Select * From aa26 Where Left(aac031,2) = '32';\ Select * From aa26 Where Left(aac031,2) = '21';"); if (!CreateSession(pIOpenRowset)) { goto __EXIT; } if (!SupportMultipleRowsets(pIOpenRowset)) { goto __EXIT; } if (!ExecSQL(pSQL, pIOpenRowset, pIMultipleResults)) { goto __EXIT; } //循环取结果集 while (TRUE) { HRESULT hr = pIMultipleResults->GetResult(NULL, DBRESULTFLAG_DEFAULT, IID_IRowset, NULL, (IUnknown**)&pIRowset); if (hr != S_OK) { break; } //后面的代码就是针对每个结果集来进行列的绑定与数据输出,在这就不列举出来了 __CLEAR_UP: CoTaskMemFree(pdbColumn); CoTaskMemFree(pColumsName); FREE(pDBBinding); FREE(pData); pIAccessor->ReleaseAccessor(hAccessor, NULL); SAFE_RELSEASE(pIColumnsInfo); SAFE_RELSEASE(pIAccessor); SAFE_RELSEASE(pIRowset); _tsystem(_T("PAUSE")); } __EXIT: SAFE_RELSEASE(pIOpenRowset); SAFE_RELSEASE(pIMultipleResults); CoUninitialize(); return 0; }最后贴出例子完整代码的链接:源代码查看
多结果集IMultipleResult接口 title: 多结果集IMultipleResult接口tags: [OLEDB, 数据库编程, VC++, 数据库]date: 2018-03-16 21:04:31categories: windows 数据库编程keywords: OLEDB, 数据库编程, VC++, 数据库, 结果集, 多结果集在某些任务中,需要执行多条sql语句,这样一次会返回多个结果集,在应用程序就需要处理多个结果集,在OLEDB中支持多结果集的接口是IMultipleResult。查询数据源是否支持多结果集并不是所有数据源都支持多结果集,可以通过查询数据源对象的DBPROPSET_DATASOURCEINFO属性集中的DBPROP_MULTIPLERESULTS属性来确定,该值是一个按位设置的4字节的联合值。它可取的值有下面几个:DBPROPVAL_MR_SUPPORITED:支持多结果集DBPROPVAL_MR_SONCURRENT:支持多结果集,并支持同时打开多个返回的结果集(如果它不支持同时打开多个结果集的话,在打开下一个结果集之前需要关闭已经打开的结果集)DBPROPVAL_MR_NOTSUPPORTED: 不支持多结果集这个属性可以通过接口IDBProperties接口的GetProperties方法来获取,该函数的原型如下:HRESULT GetProperties ( ULONG cPropertyIDSets, const DBPROPIDSET rgPropertyIDSets[], ULONG *pcPropertySets, DBPROPSET **prgPropertySets);它的用法与之前的SetProperties十分类似第一个参数是我们传入DBPROPIDSET数组元素的个数,第二个参数是一个DBPROPIDSET结构的参数,该结构的原型如下:typedef struct tagDBPROPIDSET { DBPROPID * rgPropertyIDs; ULONG cPropertyIDs; GUID guidPropertySet; } DBPROPIDSET;该结构与之前遇到的DBPROPSET类似,第一个参数是一个DBPROPID结构的数组的首地址,该值是一个属性值,表示我们希望查询哪个属性的情况,第二个参数表示我们总共查询多少个属性的值,第3个参数表示这些属性都属于哪个属性集。接口方法的第三个参数返回当前我们总共查询到几个属性集的内容。第四个参数返回具体查到的属性值。多结果集接口的使用多结果集对象的定义如下:CoType TMultipleResults { [mandatory] interface IMultipleResults; [optional] interface ISupportErrorInfo; }一般在程序中,使用多结果集有如下步骤查询数据源是否支持多结果集,如果不支持则要考虑其他的实现方案如果它支持多结果集,在调用ICommandText接口的Execute方法执行SQL语句时,让其返回一个IMultipleRowset接口。循环调用接口的GetResult方法获取结果集对象。使用结果集对象最后是一个完整的例子://判断是否支持多结果集 BOOL SupportMultipleRowsets(IOpenRowset *pIOpenRowset) { COM_DECLARE_BUFFER(); COM_DECLARE_INTERFACE(IDBInitialize); COM_DECLARE_INTERFACE(IDBProperties); COM_DECLARE_INTERFACE(IGetDataSource); BOOL bRet = FALSE; //定义相关结构用于获取关于多结果集的信息 DBPROPID dbPropId[2] = {0}; DBPROPIDSET dbPropIDSet[1] = {0}; dbPropId[0] = DBPROP_MULTIPLERESULTS; dbPropIDSet[0].cPropertyIDs = 1; dbPropIDSet[0].guidPropertySet = DBPROPSET_DATASOURCEINFO; dbPropIDSet[0].rgPropertyIDs = dbPropId; //定义相关结构用于接受返回的属性信息 ULONG uPropsets = 0; DBPROPSET *pDBPropset = NULL; //获取数据源对象 HRESULT hRes = pIOpenRowset->QueryInterface(IID_IGetDataSource, (void**)&pIGetDataSource); COM_SUCCESS(hRes, _T("查询接口IGetDataSource失败,错误码为:%08x\n"), hRes); hRes = pIGetDataSource->GetDataSource(IID_IDBInitialize, (IUnknown **)&pIDBInitialize); COM_SUCCESS(hRes, _T("获取数据源对象失败,错误码为:%08x\n"), hRes); //获取对应属性 hRes = pIDBInitialize->QueryInterface(IID_IDBProperties, (void**)&pIDBProperties); COM_SUCCESS(hRes, _T("查询IDBProperties接口失败,错误码为:%08x\n"), hRes); hRes = pIDBProperties->GetProperties(1, dbPropIDSet, &uPropsets, &pDBPropset); COM_SUCCESS(hRes, _T("获取属性信息失败,错误码:%08x\n"), hRes); //判断是否支持多结果集 if (pDBPropset[0].rgProperties[0].vValue.vt == VT_I4) { if (pDBPropset[0].rgProperties[0].vValue.intVal & DBPROPVAL_MR_CONCURRENT) { COM_PRINT(_T("支持多结果集\n")); }else if (pDBPropset[0].rgProperties[0].vValue.intVal & DBPROPVAL_MR_SUPPORTED) { COM_PRINT(_T("支持多结果集\n")); }else if (pDBPropset[0].rgProperties[0].vValue.intVal & DBPROPVAL_MR_NOTSUPPORTED) { COM_PRINT(_T("不支持多结果集\n")); goto __CLEAR_UP; } else { COM_PRINT(_T("未知\n")); goto __CLEAR_UP; } } bRet = TRUE; __CLEAR_UP: SAFE_RELSEASE(pIDBInitialize); SAFE_RELSEASE(pIDBProperties); SAFE_RELSEASE(pIGetDataSource); CoTaskMemFree(pDBPropset[0].rgProperties); CoTaskMemFree(pDBPropset); return bRet; } // 执行sql语句并返回多结果集对象 BOOL ExecSQL(LPOLESTR lpSQL, IOpenRowset *pIOpenRowset, IMultipleResults* &pIMultipleResults) { COM_DECLARE_BUFFER(); COM_DECLARE_INTERFACE(IDBCreateCommand); COM_DECLARE_INTERFACE(ICommandText); COM_DECLARE_INTERFACE(ICommandProperties); BOOL bRet = FALSE; DBPROP dbProp[2] = {0}; DBPROPSET dbPropset[1] = {0}; dbProp[0].colid = DB_NULLID; dbProp[0].dwOptions = DBPROPOPTIONS_REQUIRED; dbProp[0].dwPropertyID = DBPROP_UPDATABILITY; dbProp[0].vValue.vt = VT_I4; dbProp[0].vValue.intVal = DBPROPVAL_UP_CHANGE | DBPROPVAL_UP_DELETE | DBPROPVAL_UP_INSERT; //设置SQL语句 HRESULT hRes = pIOpenRowset->QueryInterface(IID_IDBCreateCommand, (void**)&pIDBCreateCommand); COM_SUCCESS(hRes, _T("查询接口IDBCreateCommand失败,错误码:%08x\n"), hRes); hRes = pIDBCreateCommand->CreateCommand(NULL , IID_ICommandText, (IUnknown**)&pICommandText); COM_SUCCESS(hRes, _T("创建接口ICommandText失败,错误码:%08x"), hRes); hRes = pICommandText->SetCommandText(DBGUID_DEFAULT, lpSQL); COM_SUCCESS(hRes, _T("设置SQL语句失败,错误码为:%08x\n"), hRes); //设置属性 hRes = pICommandText->QueryInterface(IID_ICommandProperties, (void**)&pICommandProperties); COM_SUCCESS(hRes, _T("查询接口ICommandProperties接口失败,错误码:%08x\n"), hRes); //执行SQL语句 hRes = pICommandText->Execute(NULL, IID_IMultipleResults, NULL, NULL, (IUnknown**)&pIMultipleResults); COM_SUCCESS(hRes, _T("执行SQL语句失败,错误码:%08x\n"), hRes); bRet = TRUE; __CLEAR_UP: SAFE_RELSEASE(pIDBCreateCommand); SAFE_RELSEASE(pICommandText); SAFE_RELSEASE(pICommandProperties); return bRet; } int _tmain(int argc, TCHAR *argv[]) { CoInitialize(NULL); COM_DECLARE_BUFFER(); COM_DECLARE_INTERFACE(IOpenRowset); COM_DECLARE_INTERFACE(IMultipleResults); COM_DECLARE_INTERFACE(IRowset); LPOLESTR pSQL = OLESTR("Select * From aa26 Where Left(aac031,2) = '11';\ Select * From aa26 Where Left(aac031,2) = '32';\ Select * From aa26 Where Left(aac031,2) = '21';"); if (!CreateSession(pIOpenRowset)) { goto __EXIT; } if (!SupportMultipleRowsets(pIOpenRowset)) { goto __EXIT; } if (!ExecSQL(pSQL, pIOpenRowset, pIMultipleResults)) { goto __EXIT; } //循环取结果集 while (TRUE) { HRESULT hr = pIMultipleResults->GetResult(NULL, DBRESULTFLAG_DEFAULT, IID_IRowset, NULL, (IUnknown**)&pIRowset); if (hr != S_OK) { break; } //后面的代码就是针对每个结果集来进行列的绑定与数据输出,在这就不列举出来了 __CLEAR_UP: CoTaskMemFree(pdbColumn); CoTaskMemFree(pColumsName); FREE(pDBBinding); FREE(pData); pIAccessor->ReleaseAccessor(hAccessor, NULL); SAFE_RELSEASE(pIColumnsInfo); SAFE_RELSEASE(pIAccessor); SAFE_RELSEASE(pIRowset); _tsystem(_T("PAUSE")); } __EXIT: SAFE_RELSEASE(pIOpenRowset); SAFE_RELSEASE(pIMultipleResults); CoUninitialize(); return 0; }最后贴出例子完整代码的链接:源代码查看 -
ATL模板库中的OLEDB与ADO 上次将OLEDB的所有内容基本上都说完了,从之前的示例上来看OLEDB中有许多变量的定义,什么结果集对象、session对象、命令对象,还有各种缓冲等等,总体上来说直接使用OLEDB写程序很麻烦,用很大的代码量带来的仅仅只是简单的功能。还要考虑各种缓冲的释放,各种对象的关闭,程序员的大量精力都浪费在无用的事情上,针对这些情况微软在OLEDB上提供了两种封装方式,一种是将其封装在ATL模板库中,一种是使用ActiveX控件来进行封装称之为ADO,这次主要写的是这两种方式ATL 模板中的OLEDB由于ATL模板是开源的,这种方式封装简洁,调试简易(毕竟源代码都给你了),各个模块相对独立,但是它的缺点很明显就是使用门槛相对较高,只有对C++中的模板十分熟悉的开发人员才能使用的得心应手。ATL中的OLEDB主要有两大模块,提供者模块和消费者模块,顾名思义,提供者模块是数据库的开发人员使用的,它主要使用这个模块实现OLEDB中的接口,对外提供相应的数据库服务;消费者模块就是使用OLEDB在程序中操作数据库。这里主要说的是消费者模块ATL主要封装的类ATL针对OLEDB封装的主要有这么几个重要的类:数据库对象CDataConnection 数据源连接类主要实现的是数据库的连接相关的功能,根据这个可以猜测出来它实际上封装的是OLEDB中的数据源对象和会话对象CDataSource:数据源对象CEnumerator: 架构结果集对象,主要用来查询数据库的相关信息,比如数据库中的表结构等信息CSession: 会话对象访问器对象:CAccessor: 常规的访问器对象CAccessorBase: 访问器对象的基类CDynamicAccessor:动态绑定的访问器CDynamicParamterAccessor:参数绑定的访问器,从之前博文的内容来看它应该是进行参数化查询等操作时使用的对象CDynamicStringAccessor:这个一般是要将查询结果显示为字符串时使用,它负责将数据库中的数据转化为字符串ALT中针对OLEDB的封装在头文件atldbcli.h中,在项目中只要包含它就行了模板的使用静态绑定针对静态绑定,VS提供了很好的向导程序帮助我们生成对应的类,方便了开发,使用的基本步骤如下:在项目上右键,选择添加类在类选择框中点击ATL并选择其中的ATL OLEDB使用者选择对应的数据源、数据库表和需要对数据库进行的操作注意如果要对数据库表进行增删改查等操作,一定要选这里的表选项点击数据源配置数据源连接的相关属性,最后点击完成。最终会在项目中生成对应的头文件这是最终生成的完整代码class Caa26Accessor { public: //value LONG m_aac031; TCHAR m_aaa146[51]; LONG m_aaa147; LONG m_aaa148; //status DBSTATUS m_dwaac031Status; DBSTATUS m_dwaaa146Status; DBSTATUS m_dwaaa147Status; DBSTATUS m_dwaaa148Status; //lenth DBLENGTH m_dwaac031Length; DBLENGTH m_dwaaa146Length; DBLENGTH m_dwaaa147Length; DBLENGTH m_dwaaa148Length; void GetRowsetProperties(CDBPropSet* pPropSet) { pPropSet->AddProperty(DBPROP_CANFETCHBACKWARDS, true, DBPROPOPTIONS_OPTIONAL); pPropSet->AddProperty(DBPROP_CANSCROLLBACKWARDS, true, DBPROPOPTIONS_OPTIONAL); pPropSet->AddProperty(DBPROP_IRowsetChange, true, DBPROPOPTIONS_OPTIONAL); pPropSet->AddProperty(DBPROP_UPDATABILITY, DBPROPVAL_UP_CHANGE | DBPROPVAL_UP_INSERT | DBPROPVAL_UP_DELETE); } HRESULT OpenDataSource() { CDataSource _db; HRESULT hr; hr = _db.OpenFromInitializationString(L"Provider=SQLOLEDB.1;Persist Security Info=False;User ID=sa; Password=XXXXXX;Initial Catalog=study;Data Source=XXXX;Use Procedure for Prepare=1;Auto Translate=True;Packet Size=4096;Workstation ID=LIU-PC;Use Encryption for Data=False;Tag with column collation when possible=False"); if (FAILED(hr)) { #ifdef _DEBUG AtlTraceErrorRecords(hr); #endif return hr; } return m_session.Open(_db); } void CloseDataSource() { m_session.Close(); } operator const CSession&() { return m_session; } CSession m_session; DEFINE_COMMAND_EX(Caa26Accessor, L" \ SELECT \ aac031, \ aaa146, \ aaa147, \ aaa148 \ FROM dbo.aa26") BEGIN_COLUMN_MAP(Caa26Accessor) COLUMN_ENTRY_LENGTH_STATUS(1, m_aac031, m_dwaac031Length, m_dwaac031Status) COLUMN_ENTRY_LENGTH_STATUS(2, m_aaa146, m_dwaaa146Length, m_dwaaa146Status) COLUMN_ENTRY_LENGTH_STATUS(3, m_aaa147, m_dwaaa147Length, m_dwaaa147Status) COLUMN_ENTRY_LENGTH_STATUS(4, m_aaa148, m_dwaaa148Length, m_dwaaa148Status) END_COLUMN_MAP() }; class Caa26 : public CCommand<CAccessor<Caa26Accessor> > { public: HRESULT OpenAll() { HRESULT hr; hr = OpenDataSource(); if (FAILED(hr)) return hr; __if_exists(GetRowsetProperties) { CDBPropSet propset(DBPROPSET_ROWSET); __if_exists(HasBookmark) { if( HasBookmark() ) propset.AddProperty(DBPROP_IRowsetLocate, true); } GetRowsetProperties(&propset); return OpenRowset(&propset); } __if_not_exists(GetRowsetProperties) { __if_exists(HasBookmark) { if( HasBookmark() ) { CDBPropSet propset(DBPROPSET_ROWSET); propset.AddProperty(DBPROP_IRowsetLocate, true); return OpenRowset(&propset); } } } return OpenRowset(); } HRESULT OpenRowset(DBPROPSET *pPropSet = NULL) { HRESULT hr = Open(m_session, NULL, pPropSet); #ifdef _DEBUG if(FAILED(hr)) AtlTraceErrorRecords(hr); #endif return hr; } void CloseAll() { Close(); ReleaseCommand(); CloseDataSource(); } };从名字上来看Caa26Accessor主要是作为一个访问器,其实它的功能也是与访问器相关的,比如创建访问器和数据绑定都在最后这个映射中。而后面的Caa26类主要是用来执行sql语句并根据上面的访问器类来解析数据,其实我们使用上主要使用后面这个类,这些代码都很简单,有之前的OLEDB基础很容易就能理解它们,这里就不再在这块进行展开了int _tmain(int argc, TCHAR *argv) { CoInitialize(NULL); Caa26 aa26; HRESULT hRes = aa26.OpenDataSource(); if (FAILED(hRes)) { aa26.CloseAll(); CoUninitialize(); return -1; } hRes = aa26.OpenRowset(); if (FAILED(hRes)) { aa26.CloseAll(); CoUninitialize(); return -1; } hRes = aa26.MoveNext(); COM_USEPRINTF(); do { COM_PRINTF(_T("|%-30u|%-30s|%-30u|%-30u|\n"), aa26.m_aac031, aa26.m_aaa146, aa26.m_aaa147, aa26.m_aaa148); hRes = aa26.MoveNext(); } while (S_OK == hRes); aa26.CloseAll(); CoUninitialize(); return 0; }动态绑定动态绑定主要是使用模板对相关的类进行拼装,所以这里需要关于模板的相关知识,只有掌握了这些才能正确的拼接出合适的类。一般需要拼接的是这样几个类结果集类,在结果集类的模板中填入对应的访问器类,表示该结果集将使用对应的访问器进行解析。访问器类可以系统预定义的,也向静态绑定那样自定义。Command类,在命令对象类的模板位置填入与命令相关的类,也就是执行命令生成的结果集、以及解析结果集所用的访问器,之后就主要使用Command类来进行数据库的相关操作了下面是一个使用的示例typedef CCommand<CDynamicAccessor, CRowset, CMultipleResults> CComRowset; typedef CTable<CDynamicAccessor, CRowset> CComTable; //将所有绑定的数据类型转化为字符串 typedef CTable<CDynamicStringAccessor, CRowset> CComTableString; int _tmain(int argc, TCHAR *argv[]) { CoInitialize(NULL); COM_USEPRINTF(); //连接数据库,创建session对象 CDataSource db; db.Open(); CSession session; session.Open(db); //打开数据库表 CComTableString table; table.Open(session, OLESTR("T_DecimalDemo")); HRESULT hRes = table.MoveFirst(); if (FAILED(hRes)) { COM_PRINTF(_T("表中没有数据,退出程序\n")); goto __CLEAN_UP; } do { //这里传入的参数是列的序号,注意一下,由于有第0列的行需要存在,所以真正的数据是从第一列开始的 COM_PRINTF(_T("|%-10s|%-20s|%-20s|%-20s|\n"), table.GetString(1), table.GetString(2), table.GetString(3), table.GetString(4)); hRes = table.MoveNext(); } while (S_OK == hRes); __CLEAN_UP: CoUninitialize(); return 0; }在上面的代码中我们定义了两个模板类,Ctable和CCommand类,没有发现需要的访问器类,查看CTable类可以发现它是继承于CAccessorRowset,而CAccessorRowset继承于TAccessor和 TRowset,也就是说它提供了访问器的相关功能而且它还可以使用OpenRowset方法不执行SQL直接打开数据表,因此在这里我们选择使用它在CTable的模板中填入CDynamicStringAccessor表示将会把得到的结果集中的数据转化为字符串。在使用上先使用CDataSource类的Open方法打开数据库连接,然后调用CTable的Open打开数据表,接着调用CTable的MoveFirst的方法将行句柄移动到首行。接着在循环中调用table的GetString方法得到各个字段的字符串值,并调用MoveNext方法移动到下一行其实在代码中并没有使用CCommand类,这是由于这里只是简单的使用直接打开数据表的方式,而并没有执行SQL语句,因此不需要它,在这里定义它只是简单的展示一下ADOATL针对OLEDB封装的确是方便了不少,但是对于像我这种将C++简单的作为带对象的C来看的人来说,它使用模板实在是太不友好了,说实话现在我现在对模板的认识实在太少,在代码中我也尽量避免使用模板。所以在我看来使用ATL还不如自己根据项目封装一套。好在微软实在太为开发者着想了,又提供了ADO这种针对ActiveX的封装方式。要使用ADO组件需要先导入,导入的语句如下:#import "C:\\Program Files\\Common Files\\System\\ado\\msado15.dll" no_namespace rename("EOF", "EndOfFile")这个路径一般是不会变化的,而EOF在C++中一般是用在文件中的,所以这里将它rename一下ADO中的主要对象和接口有:Connect :数据库的连接对象,类似于OLEDB中的数据源对象和session对象Command:命令对象,用来执行sql语句,类似于OLEDB中的Command对象Recordset: 记录集对象,执行SQL语句返回的结果,类似于OLEDB中的结果集对象Record: 数据记录对象,一般都是从Recordset中取得,就好像OLEDB中从结果集对象通过访问器获取到具体的数据一样Field:记录中的一个字段,可以简单的看做就是一个表字段的值,一般一个记录集中有多条记录,而一条记录中有个Field对象Parameter:参数对象,一般用于参数化查询或者调用存储过程Property:属性,与之前OLEDB中的属性对应-在ADO中大量使用智能指针,所谓的智能指针是它的生命周期结束后会自动析构它所指向的对象,同时也封装了一些常见指针操作,虽然它是这个对象但是它的使用上与普通的指针基本上相同。ADO中的智能指针对象一般是在类名后加上Ptr。比如Connect对象的智能指针对象是_ConnectPtr智能指针有利也有弊,有利的地方在于它能够自动管理内存,不需要程序员进行额外的释放操作,而且它在使用上就像普通的指针,相比于使用类的普通指针更为方便,不利的地方在于为了方便它的使用一般都经过了大量的重载,因此很多地方表面上看是一个普通的寻址操作,而实际上却是一个函数调用,这样就降低了性能。所以在特别强调性能的场合要避免使用智能指针。在使用上,一般经过这样几个步骤:定义数据库连接的Connect对象调用Connect对象的Open方法连接数据库,这里使用的连接字串的方式创建Command对象并调用对象Execute方法执行SQL,并获取对应的记录集。这里执行SQL语句也可以使用Recordset对象的Open方法。循环调用Recordse对象的MoveNext不断取出对应行的行记录下面是一个使用的简单例子#import "C:\\Program Files\\Common Files\\System\\ado\\msado15.dll" no_namespace rename("EOF", "EndOfFile") int _tmain(int argc, TCHAR *argv[]) { CoInitialize(NULL); _ConnectionPtr conn; _RecordsetPtr rowset; _bstr_t bstrConn = _T("Provider=SQLOLEDB.1;Persist Security Info=False;User ID=sa;Password = 123456;Initial Catalog=Study;Data Source=LIU-PC\\SQLEXPRESS;"); conn.CreateInstance(_T("ADODB.Connection")); conn->Open(bstrConn, _T("sa"), _T("123456"), adModeUnknown); if (conn->State) { COM_PRINTF(_T("连接到数据源成功\n")); }else { COM_PRINTF(_T("连接到数据源失败\n")); return 0; } rowset.CreateInstance(__uuidof(Recordset)); rowset->Open(_T("select * from aa26;"), conn.GetInterfacePtr(), adOpenStatic, adLockOptimistic, adCmdText); while (!rowset->EndOfFile) { COM_PRINTF(_T("|%-30u|%-30s|%-30u|%-30u|\n"), rowset->Fields->GetItem(_T("aac031"))->Value.intVal, rowset->Fields->GetItem(_T("aaa146"))->Value.bstrVal, rowset->Fields->GetItem(_T("aaa147"))->Value.llVal, rowset->Fields->GetItem(_T("aaa148"))->Value.llVal ); rowset->MoveNext(); } CoUninitialize(); return 0; }ADO与OLEDB混合编程ADO相比较OLEDB来说确实方便了不少,但是它也有它的问题,比如它是封装的ActiveX控件,从效率上肯定比不上OLEDB,而且ADO中记录集是一次性将结果中的所有数据加载到内存中,如果数据表比教大时这种方式很吃内存。而OLEDB是每次调用GetNextRow时加载一条记录到内存(其实根据之前的代码可以知道它加载的时机,加载的大小是可以控制的),它相对来说比教灵活。其实上述问题使用二者的混合编程就可以很好的解决,在处理结果集时使用OLEDB,而在其他操作时使用ADO这样既保留了ADO的简洁性也使用了OLEDB灵活管理结果集内存的能力。在ADO中,可以通过_Recordset查询出ADORecordsetConstruction接口,这个接口提供了将记录集转化为OLEDB中结果集,以及将结果集转化为Recordset对象的能力下面是一个简单的例子CoInitialize(NULL); try { _bstr_t bsCnct(_T("Provider=SQLOLEDB.1;Persist Security Info=False;User ID=sa;Password = 123456;Initial Catalog=Study;Data Source=LIU-PC\\SQLEXPRESS;")); _RecordsetPtr Rowset(__uuidof(Recordset)); Rowset->Open(_T("select * from aa26;") ,bsCnct,adOpenStatic,adLockOptimistic,adCmdText); //获取IRowset接口指针 ADORecordsetConstruction* padoRecordsetConstruct = NULL; Rowset->QueryInterface(__uuidof(ADORecordsetConstruction), (void **) &padoRecordsetConstruct); IRowset * pIRowset = NULL; padoRecordsetConstruct->get_Rowset((IUnknown **)&pIRowset); padoRecordsetConstruct->Release(); DisplayRowSet(pIRowset); pIRowset->Release(); GRS_PRINTF(_T("\n\n显示第二个结果集:\n")); //使用OLEDB方法打开一个结果集 IOpenRowset* pIOpenRowset = NULL; TCHAR* pszTableName = _T("T_State"); DBID TableID = {}; CreateDBSession(pIOpenRowset); TableID.eKind = DBKIND_NAME; TableID.uName.pwszName = (LPOLESTR)pszTableName; HRESULT hr = pIOpenRowset->OpenRowset(NULL,&TableID,NULL,IID_IRowset,0,NULL,(IUnknown**)&pIRowset); if(FAILED(hr)) { _com_raise_error(hr); } //创建一个新的ADO记录集对象 _RecordsetPtr Rowset2(__uuidof(Recordset)); Rowset2->QueryInterface(__uuidof(ADORecordsetConstruction), (void **) &padoRecordsetConstruct); //将OLEDB的结果集放置到ADO记录集对象中 padoRecordsetConstruct->put_Rowset(pIRowset); ULONG ulRow = 0; while(!Rowset2->EndOfFile) { COM_PRINTF(_T("|%10u|%10s|%-40s|\n") ,++ulRow ,Rowset2->Fields->GetItem("K_StateCode")->Value.bstrVal ,Rowset2->Fields->GetItem("F_StateName")->Value.bstrVal); Rowset2->MoveNext(); } } catch(_com_error & e) { COM_PRINTF(_T("发生错误:\n Source : %s \n Description : %s \n") ,(LPCTSTR)e.Source(),(LPCTSTR)e.Description()); } _tsystem(_T("PAUSE")); CoUninitialize(); return 0;这次就不再放上整体例子的链接了,有之前的基础应该很容易看懂这些,而且这次代码比较短,基本上将所有代码全粘贴了过来。
-
OLEDB事务 学过数据的人一般都知道事务的重要性,事务是一种对数据源的一系列更新进行分组或者批处理以便当所有更新都成功时同时提交更新,或者任意一个更新失败时进行回滚将数据库中的数据回滚到执行批处理中的所有操作之前的一种方法。使用事务保证了数据的完整性。这里不展开详细的说事务,只是谈谈OLEDB在事务上的支持ITransactionLocal接口OLEDB中支持事务的接口是ITransactionLocal接口,该接口是一个可选接口,OLEDB并不强制要求所有数据库都支持该接口,所以在使用之前需要先判断是否支持,好在现在常见的几种数据库都支持。该接口属于回话对象,因此要得到该接口只需要根据一个回话对象调用QueryInterface即可调用接口的StartTransaction方法开始一个事务该函数的原型如下HRESULT StartTransaction ( ISOLEVEL isoLevel, ULONG isoFlags, ITransactionOptions *pOtherOptions, ULONG *pulTransactionLevel); 第一个参数是事务并发的隔离级别,一般最常用的是ISOLATIONLEVEL_CURSORSTABILITY,表示只有最终提交之后才能查询对应数据库表的数据第二个参数是一个标志,目前它的值必须为0第3个参数是一个指针,它可以为空,或者是调用ITransactionLocal::GetOptionsObject函数返回的一个指针第4个参数是调用该函数创建一个事务后,该事务的并发隔离级别隔离级别是针对不同的线程或者进程的,比如有多个客户端同时在操作数据库时,如果我们设置为ISOLATIONLEVEL_CURSORSTABILITY,那么在同一事务中只有当其中一个客户端提交了事务更新后,另外一个客户端才能正常的进行查询等操作,可以简单的将这个标识视为它在数据库中上了锁,只有当它完成事务后其他客户端才可以正常使用数据库开始一个事务后正常的进行相关的数据库操作当所有步骤都正常完成后调用ITransaction::Commit方法提交事务所做的所有修改或者当其中有一步或者几步失败时调用ITransaction::Abort方法回滚所有的操作演示例子cppcpp//注意使用ISOLATIONLEVEL_CURSORSTABILITY表示最终Commint以后,才能读取这两个表的数据//注意使用ISOLATIONLEVEL_CURSORSTABILITY表示最终Commint以后,才能读取这两个表的数据hr = pITransaction->StartTransaction(ISOLATIONLEVEL_CURSORSTABILITY,0,NULL,NULL); hr = pITransaction->StartTransaction(ISOLATIONLEVEL_CURSORSTABILITY,0,NULL,NULL); //获取主表主键的最大值//获取主表主键的最大值 pRetData = pRetData = RunSqlGetValue(pIOpenRowset,_T("Select Max(PID) As PMax From T_Primary"));RunSqlGetValue(pIOpenRowset,_T("Select Max(PID) As PMax From T_Primary")); if(NULLif(NULL == pRetData)== pRetData) {{ goto CLEAR_UP;goto CLEAR_UP; }} iPID = iPID = *(int*)((BYTE*)pRetData +*(int*)((BYTE*)pRetData + sizeof(DBSTATUS)sizeof(DBSTATUS) ++ sizeof(ULONG));sizeof(ULONG)); //最大值总是加1,这样即使取得的是空值,起始值也是正常的1//最大值总是加1,这样即使取得的是空值,起始值也是正常的1 ++iPID;++iPID; TableID.eKind = DBKIND_NAME; TableID.eKind = DBKIND_NAME; TableID.uName.pwszName = TableID.uName.pwszName = (LPOLESTR)pszPrimaryTable;(LPOLESTR)pszPrimaryTable; hr = pIOpenRowset->OpenRowset(NULL,&TableID hr = pIOpenRowset->OpenRowset(NULL,&TableID ,NULL,IID_IRowsetChange,1,PropSet,(IUnknown**)&pIRowsetChange);,NULL,IID_IRowsetChange,1,PropSet,(IUnknown**)&pIRowsetChange); COM_COM_CHECK(hr,_T("打开表对象'%s'失败,错误码:0x%08X\n"),pszPrimaryTable,hr);COM_COM_CHECK(hr,_T("打开表对象'%s'失败,错误码:0x%08X\n"),pszPrimaryTable,hr); ulChangeOffset = ulChangeOffset = CreateAccessor(pIRowsetChange,pIAccessor,hChangeAccessor,pChangeBindings,ulRealCols);CreateAccessor(pIRowsetChange,pIAccessor,hChangeAccessor,pChangeBindings,ulRealCols); if(0if(0 == ulChangeOffset== ulChangeOffset |||| NULLNULL == hChangeAccessor== hChangeAccessor |||| NULLNULL == pIAccessor== pIAccessor |||| NULLNULL == pChangeBindings== pChangeBindings |||| 00 == ulRealCols)== ulRealCols) {{ goto CLEAR_UP;goto CLEAR_UP; }} //分配一个新行数据 设置数据后 插入//分配一个新行数据 设置数据后 插入 pbNewData = pbNewData = (BYTE*)COM_CALLOC(ulChangeOffset);(BYTE*)COM_CALLOC(ulChangeOffset); //设置第一个字段 K_PID//设置第一个字段 K_PID *(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[0].obLength)*(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[0].obLength) == sizeof(int);sizeof(int); *(int*)*(int*) (pbNewData + pChangeBindings[0].obValue)(pbNewData + pChangeBindings[0].obValue) = iPID;= iPID; //设置第二个字段 F_MValue//设置第二个字段 F_MValue *(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[1].obLength)*(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[1].obLength) == 8;8; StringCchCopy((WCHAR*)StringCchCopy((WCHAR*) (pbNewData + pChangeBindings[1].obValue)(pbNewData + pChangeBindings[1].obValue) ,pChangeBindings[1].cbMaxLen/sizeof(WCHAR),_T("主表数据"));,pChangeBindings[1].cbMaxLen/sizeof(WCHAR),_T("主表数据")); //插入新数据//插入新数据 hr = pIRowsetChange->InsertRow(NULL,hChangeAccessor,pbNewData,NULL); hr = pIRowsetChange->InsertRow(NULL,hChangeAccessor,pbNewData,NULL); COM_COM_CHECK(hr,_T("调用InsertRow插入新行失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("调用InsertRow插入新行失败,错误码:0x%08X\n"),hr); hr = pIRowsetChange->QueryInterface(IID_IRowsetUpdate,(void**)&pIRowsetUpdate); hr = pIRowsetChange->QueryInterface(IID_IRowsetUpdate,(void**)&pIRowsetUpdate); COM_COM_CHECK(hr,_T("获取IRowsetUpdate接口失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("获取IRowsetUpdate接口失败,错误码:0x%08X\n"),hr); hr = pIRowsetUpdate->Update(NULL,0,NULL,NULL,NULL,NULL); hr = pIRowsetUpdate->Update(NULL,0,NULL,NULL,NULL,NULL); COM_COM_CHECK(hr,_T("调用Update提交更新失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("调用Update提交更新失败,错误码:0x%08X\n"),hr); COM_SAFEFREE(pChangeBindings);COM_SAFEFREE(pChangeBindings); COM_SAFEFREE(pRetData);COM_SAFEFREE(pRetData); COM_SAFEFREE(pbNewData);COM_SAFEFREE(pbNewData); if(NULLif(NULL != hChangeAccessor &&!= hChangeAccessor && NULLNULL != pIAccessor)!= pIAccessor) {{ pIAccessor->ReleaseAccessor(hChangeAccessor,NULL); pIAccessor->ReleaseAccessor(hChangeAccessor,NULL); hChangeAccessor = hChangeAccessor = NULL;NULL; }} COM_SAFERELEASE(pIAccessor);COM_SAFERELEASE(pIAccessor); COM_SAFERELEASE(pIRowsetChange);COM_SAFERELEASE(pIRowsetChange); COM_SAFERELEASE(pIRowsetUpdate);COM_SAFERELEASE(pIRowsetUpdate); //插入第二个也就是从表的数据//插入第二个也就是从表的数据 TableID.eKind = DBKIND_NAME; TableID.eKind = DBKIND_NAME; TableID.uName.pwszName = TableID.uName.pwszName = (LPOLESTR)pszMinorTable;(LPOLESTR)pszMinorTable; hr = pIOpenRowset->OpenRowset(NULL,&TableID hr = pIOpenRowset->OpenRowset(NULL,&TableID ,NULL,IID_IRowsetChange,1,PropSet,(IUnknown**)&pIRowsetChange);,NULL,IID_IRowsetChange,1,PropSet,(IUnknown**)&pIRowsetChange); COM_COM_CHECK(hr,_T("打开表对象'%s'失败,错误码:0x%08X\n"),pszMinorTable,hr);COM_COM_CHECK(hr,_T("打开表对象'%s'失败,错误码:0x%08X\n"),pszMinorTable,hr); ulChangeOffset = ulChangeOffset = CreateAccessor(pIRowsetChange,pIAccessor,hChangeAccessor,pChangeBindings,ulRealCols);CreateAccessor(pIRowsetChange,pIAccessor,hChangeAccessor,pChangeBindings,ulRealCols); if(0if(0 == ulChangeOffset== ulChangeOffset |||| NULLNULL == hChangeAccessor== hChangeAccessor |||| NULLNULL == pIAccessor== pIAccessor |||| NULLNULL == pChangeBindings== pChangeBindings |||| 00 == ulRealCols)== ulRealCols) {{ goto CLEAR_UP;goto CLEAR_UP; }} //分配一个新行数据 设置数据后 插入//分配一个新行数据 设置数据后 插入 pbNewData = pbNewData = (BYTE*)COM_CALLOC(ulChangeOffset);(BYTE*)COM_CALLOC(ulChangeOffset); //设置第一个字段 K_MID//设置第一个字段 K_MID *(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[0].obLength)*(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[0].obLength) == sizeof(int);sizeof(int); //设置第二个字段 K_PID//设置第二个字段 K_PID *(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[1].obLength)*(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[1].obLength) == sizeof(int);sizeof(int); *(int*)*(int*) (pbNewData + pChangeBindings[1].obValue)(pbNewData + pChangeBindings[1].obValue) = iPID;= iPID; //设置第二个字段//设置第二个字段 *(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[2].obLength)*(DBLENGTH *)((BYTE *)pbNewData + pChangeBindings[2].obLength) == 8;8; StringCchCopy((WCHAR*)StringCchCopy((WCHAR*) (pbNewData + pChangeBindings[2].obValue)(pbNewData + pChangeBindings[2].obValue) ,pChangeBindings[2].cbMaxLen/sizeof(WCHAR),_T("从表数据"));,pChangeBindings[2].cbMaxLen/sizeof(WCHAR),_T("从表数据")); for(int i = iMIDS; i <= iMIDMax; i++)for(int i = iMIDS; i <= iMIDMax; i++) {//循环插入新数据{//循环插入新数据 //设置第一个字段 K_MID//设置第一个字段 K_MID *(int*)*(int*) (pbNewData + pChangeBindings[0].obValue)(pbNewData + pChangeBindings[0].obValue) = i;= i; hr = pIRowsetChange->InsertRow(NULL,hChangeAccessor,pbNewData,NULL); hr = pIRowsetChange->InsertRow(NULL,hChangeAccessor,pbNewData,NULL); COM_COM_CHECK(hr,_T("调用InsertRow插入新行失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("调用InsertRow插入新行失败,错误码:0x%08X\n"),hr); }} hr = pIRowsetChange->QueryInterface(IID_IRowsetUpdate,(void**)&pIRowsetUpdate); hr = pIRowsetChange->QueryInterface(IID_IRowsetUpdate,(void**)&pIRowsetUpdate); COM_COM_CHECK(hr,_T("获取IRowsetUpdate接口失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("获取IRowsetUpdate接口失败,错误码:0x%08X\n"),hr); hr = pIRowsetUpdate->Update(NULL,0,NULL,NULL,NULL,NULL); hr = pIRowsetUpdate->Update(NULL,0,NULL,NULL,NULL,NULL); COM_COM_CHECK(hr,_T("调用Update提交更新失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("调用Update提交更新失败,错误码:0x%08X\n"),hr); //所有操作都成功了,提交事务释放资源//所有操作都成功了,提交事务释放资源 hr = pITransaction->Commit(FALSE, XACTTC_SYNC, hr = pITransaction->Commit(FALSE, XACTTC_SYNC, 0);0); COM_COM_CHECK(hr,_T("事务提交失败,错误码:0x%08X\n"),hr);COM_COM_CHECK(hr,_T("事务提交失败,错误码:0x%08X\n"),hr); CLEAR_UP:CLEAR_UP://操作失败,回滚事务先,然后释放资源//操作失败,回滚事务先,然后释放资源 hr = pITransaction->Abort(NULL, FALSE, FALSE); hr = pITransaction->Abort(NULL, FALSE, FALSE);在上述代码中首先创建一个事务对象,然后在进行相关的数据库操作,这里主要是在更新和插入新数据,当所有操作成功后调用commit函数提交,当其中有错误时会跳转到CLEAR_UP标签下,调用Abort进行回滚 最后实例的完整代码: [Trancation](https://gitee.com/masimaro/codes/tcesnrul0g2yi76bam5dj19#Trancation) <!-- more -->
-
OLEDB 简单数据查找定位和错误处理 在数据库查询中,我们主要使用的SQL语句,但是之前也说过,SQL语句需要经历解释执行的步骤,这样就会拖慢程序的运行速度,针对一些具体的简单查询,比如根据用户ID从用户表中查询用户具体信息,像这样的简单查询OLEDB提供了专门的查询接口。使用该接口可以很大程度上提升程序性能。另外在之前的代码中,只是简单的通过HRESULT这个返回值来判断是否成功,针对错误没有具体的处理,但是OLEDB提供了自己的处理机制,这篇博文主要来介绍这两种情况下的处理方式简单数据查询和定位它的使用方法与之前的简单读取结果集类似,主要经历如下几部绑定需要在查询中做条件的几列(绑定的方式与之前的相同)分配一段内存,给定对应的条件值循环调用IRowsetFind接口的FindNextRow方法,传入对应的结果集、条件、条件值的缓冲,接收函数返回的新的结果集指针使用常规方法访问结果集FindNextRow函数的定义如下:HRESULT FindNextRow ( HCHAPTER hChapter, HACCESSOR hAccessor, //绑定查询条件的访问器,用于OLEDB组件访问用户传进来的条件 void *pFindValue, //之前的内存缓冲 DBCOMPAREOP CompareOp, // 查询条件,主要有:DBCOMPAREOPS_EQ、DBCOMPAREOPS_NE、DBCOMPAREOPS_LT等等,具体的请参看MSDN DBBKMARK cbBookmark, const BYTE *pBookmark, DBROWOFFSET lRowsOffset, DBROWCOUNT cRows, //一次返回的行数 DBCOUNTITEM *pcRowsObtained, //真实返回的行 HROW **prghRows); //返回的行访问器的句柄数组下面是一个具体的例子:HRESULT hRes = pIRowset->QueryInterface(IID_IRowsetFind, (void**)&pIRowsetFind); COM_SUCCESS(hRes, _T("查询接口IRowsetFind失败,错误码为:%08x\n"), hRes); hRes = pIRowset->QueryInterface(IID_IColumnsInfo, (void**)&pIColumnsInfo); COM_SUCCESS(hRes, _T("查询接口IColumnInfo失败,错误码为:%08x\n"), hRes); hRes = pIRowset->QueryInterface(IID_IAccessor, (void**)&pIAccessor); COM_SUCCESS(hRes, _T("查询接口IAccessor失败,错误码为:%08x\n"), hRes); hRes = pIColumnsInfo->GetColumnInfo(&cColumns, &rgColumnsInfo, &lpColumnsName); COM_SUCCESS(hRes, _T("查询列信息失败,错误码为:%08x\n"), hRes); rgQueryBinding[0].bPrecision = rgColumnsInfo[1].bPrecision; rgQueryBinding[0].bScale = rgColumnsInfo[1].bScale; rgQueryBinding[0].cbMaxLen = sizeof(ULONG); rgQueryBinding[0].dwMemOwner = DBMEMOWNER_CLIENTOWNED; rgQueryBinding[0].dwPart = DBPART_STATUS | DBPART_LENGTH | DBPART_VALUE; rgQueryBinding[0].eParamIO = DBPARAMIO_NOTPARAM; rgQueryBinding[0].iOrdinal = 4; //绑定第4列,也就是表中的所属行政区编号列 rgQueryBinding[0].obStatus = 0; rgQueryBinding[0].obLength = sizeof(DBSTATUS); rgQueryBinding[0].obValue = sizeof(DBSTATUS) + sizeof(ULONG); rgQueryBinding[0].wType = DBTYPE_I4; hRes = pIAccessor->CreateAccessor(DBACCESSOR_ROWDATA, 1, rgQueryBinding, 0, &hQueryAccessor, NULL); COM_SUCCESS(hRes, _T("创建访问器失败,错误码为:%08x\n"), hRes); pQueryBuff = COM_ALLOC(void, rgQueryBinding[0].obValue + sizeof(ULONG)); *(DBSTATUS*)((LPBYTE)pQueryBuff + rgQueryBinding[0].obValue) = DBSTATUS_S_OK; *(ULONG*)((LPBYTE)pQueryBuff + rgQueryBinding[0].obLength) = sizeof(ULONG); *(ULONG*)((LPBYTE)pQueryBuff + rgQueryBinding[0].obValue) = uId; hRes = pIRowsetFind->FindNextRow(DB_NULL_HCHAPTER, hQueryAccessor, pQueryBuff, DBCOMPAREOPS_EQ, 0, NULL, 0, 10, &cRowsObtained, &rgShowRows); COM_SUCCESS(hRes, _T("查询结果集失败,错误码为:%08x\n"), hRes); bRet = ReadRows(cColumns, rgColumnsInfo, cRowsObtained, rgShowRows, pIRowset);这段代码首先获取到对应列的列信息,然后根据这个列信息进行动态绑定,在这里我们绑定第4列,也就是之前行政区表的所属行政区编号列,接着针对这个绑定创建访问器,并分配缓冲存储对应的条件值,最后调用FindNextRow返回查询到的新的结果集,并调用对应的函数读取返回的结果集上面的代码并不复杂,从FindNextRow的第4个参数的值来看,它只能支持简单的大于小于等于等等操作,像sql语句中的模糊查询,多表查询,联合查询等等它是不能胜任的,因此说它只是一个简单查询,它在某些简单场合下可以节省性能,但是对于复杂的业务逻辑中SQL语句仍然是不二的选择错误处理在windows中定义了丰富的错误处理代码和错误处理方式,几乎每种类型的程序都有自己的一套处理方式,比如Win32 API中的GetLastError,WinSock中的WSAGetLastError, 其实在OLEDB中有它自己的处理方式。COM中可以使用GetErrorInfo函数得到一个错误的信息的接口,IErrorInfo,进一步可以根据该接口的对应函数可以得到具体的错误信息。IErrorInfo接口IErrorInfo 有时候自身包含一些出错信息,可以直接读取。IErrorInfo有时候只有一条错误信息,有时候是一个树形结构的错误信息通过调用QueryInterface函数查询错误对象的IErrorRecords接口来判定错误信息是否还有详细的子记录。如果有子记录。如果能得到IErrorRecords接口,就调用IErrorRecords::GetRecordCount获得错误信息记录个数,接着循环调用IErrorRecords::GetErrorInfo又取得子记录的IErrorInfo接口,并获取错误信息若没有子错误记录,那么直接调用IErrorInfo::GetDescription得到错误描述信息,调用IErrorInfo::GetSource得到错误来源信息以上所述IErrorInfo接口是COM定义的标准接口,IErrorRecords是OLEDB专门定义的错误信息记录接口。IErrorRecords接口其实IErrorRecords接口除了能获取子记录的IErrorInfo接口外还有一个重要的功能。调用接口的GetBasicErrorInfo方法可以得到一个指定索引错误记录的基本错误信息结构体ERRORINFO。该结构的定义如下:typedef struct tagERRORINFO { HRESULT hrError; DWORD dwMinor; CLSID clsid; IID iid; DISPID dispid; } ERRORINFO;根据这个结构可以得到指定错误的具体信息,有点类似于FormatMessage格式化错误码,得到错误码对应的错误提示信息。另外可以调用接口的GetCustomErrorObject给定一个错误码,得到一个具体的错误对象,一般在OLEDB中这个对象是ISQLErrorInfo接口这两个函数的第一个参数是一个编号,这个编号一般是第几个IErrorRecords中错误信息的编号。下面是一个具体的例子LPOLESTR lpSQL = OLESTR("select * where aa26;select * from aa26 where, aac031;"); HRESULT hRes =pIOpenRowset->QueryInterface(IID_IDBCreateCommand, (void**)&pIDBCreateCommand); COM_SUCCESS(hRes, _T("查询接口IDBCreateCommand失败,错误码为:%08x\n"), hRes); LPOLESTR lpErrorInfo = (LPOLESTR)CoTaskMemAlloc(1024 * sizeof(WCHAR)); hRes = pIDBCreateCommand->CreateCommand(NULL, IID_ICommandText, (IUnknown**)&pICommandText); COM_SUCCESS(hRes, _T("创建接口ICommandText失败,错误码为:%08x\n"), hRes); pICommandText->SetCommandText(DBGUID_DEFAULT, lpSQL); hRes = pICommandText->Execute(NULL, IID_IRowset, NULL, NULL, (IUnknown**)&pIRowset); if (FAILED(hRes)) { GetErrorInfo(0, &pIErrorInfo); HRESULT hr = pIErrorInfo->QueryInterface(IID_IErrorRecords, (void**)&pIErrorRecords); if (SUCCEEDED(hr)) { ULONG uRecordes = 0; hr = pIErrorRecords->GetRecordCount(&uRecordes); COM_SUCCESS(hr, _T("获取错误集个数失败,错误码为:%08x\n"), hr); for (int i = 0; i < uRecordes; i++) { ReadErrorRecords(lpErrorInfo, 1024 * sizeof(WCHAR), hRes, i, pIErrorRecords, lpSQL); COM_PRINTF(_T("%s"), lpErrorInfo); } }else { ReadErrorInfo(lpErrorInfo, 1024 * sizeof(WCHAR), hRes, pIErrorInfo); COM_PRINTF(_T("%s"), lpErrorInfo); } }在上述例子中,我们故意传入一个错误的SQL语句,让其出错,然后通过GetErrorInfo函数获取一个错误的IErrorInfo接口,尝试查询IErrorRecords,如果有那么在循环中遍历它的子集,并且得到每个子集的详细错误信息。否则直接调用函数ReadErrorInfo获取错误的具体信息BOOL ReadErrorRecords(LPOLESTR &lpErrorInfo, DWORD dwSize, HRESULT hErrRes, ULONG uRecordIndex, IErrorRecords *pIErrorRecords, LPWSTR lpSql) { ERRORINFO ErrorInfo = {0}; static LCID lcid = GetUserDefaultLCID(); HRESULT hRes = pIErrorRecords->GetBasicErrorInfo(uRecordIndex, &ErrorInfo); COM_CHECK_HR(hRes); hRes = pIErrorRecords->GetErrorInfo(uRecordIndex, lcid, &pIErrorInfo); COM_CHECK_HR(hRes); hRes = pIErrorInfo->GetDescription(&pstrDescription); COM_CHECK_HR(hRes); hRes = pIErrorInfo->GetSource(&pstrSource); COM_CHECK_HR(hRes); if (ReadSQLError(&bstrSQLErrorInfo, pIErrorRecords, uRecordIndex)) { StringCchPrintf(lpErrorInfo, dwSize, _T("\n(%s)\n错误信息: HRESULT=0x%08X\n描述: %s\nSQL错误信息: %s\n来源: %s"), lpSql, ErrorInfo.hrError, pstrDescription, bstrSQLErrorInfo, pstrSource); }else { StringCchPrintf(lpErrorInfo, dwSize, _T("\n(%s)\n错误信息: HRESULT=0x%08X\n描述: %s\n来源: %s"), lpSql, ErrorInfo.hrError, pstrDescription, pstrSource); } }该函数用于显示错误子集的信息,在函数中首先调用IErrorRecords接口的GetBasicErrorInfo函数传入子集的编号,获取子集的基本信息,然后再调用IErrorRecords接口的GetErrorInfo方法获取子集的IErrorInfo接口,接着调用IErrorInfo接口的相应函数获取错误的详细信息,在这个里面我们调用了另外一个自定义函数ReadSQLError,尝试获取在执行SQL语句时的错误,然后进行相关的输出。函数的部分代码如下:BOOL ReadSQLError(BSTR *pbstrSQL, IErrorRecords *pIErrorRecords, DWORD dwRecordIndex) { HRESULT hRes = pIErrorRecords->GetCustomErrorObject(dwRecordIndex, IID_ISQLErrorInfo, (IUnknown**)&pISQLErrorInfo); hRes = pISQLErrorInfo->GetSQLInfo(pbstrSQL, &lNativeErrror); }这个函数就简单的调用了IErrorRecords接口的GetCustomErrorObject方法传入子集的编号,获取到ISQLErrorInfo接口,最后调用ISQLErrorInfo接口的GetSQLInfo方法获取执行SQL语句时的错误。至于函数ReadErrorInfo,它的代码十分简单,就只是ReadErrorRecords函数中关于IErrorInfo处理的部分代码而已,在这就不在说明
-
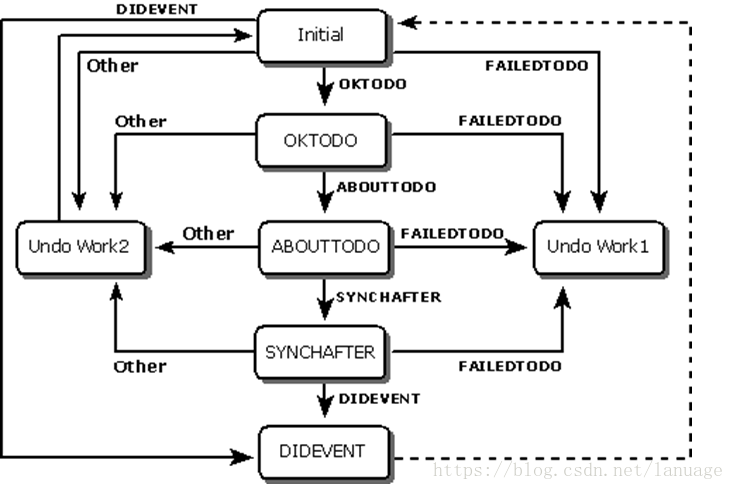
OLEDB 数据变更通知 除了之前介绍的接口,OLEDB还定义了其他一些支持回调的接口,可以异步操作OLEDB对象或者得到一些重要的事件通知,从而使应用程序有机会进行一些必要的处理。其中较有用的就是结果集对象的变更通知接口。通过这个接口可以及时得到结果集被增删改数据变化的情况,并有机会进行必要的数据合法性审核。除了之前介绍的接口,OLEDB还定义了其他一些支持回调的接口,可以异步操作OLEDB对象或者得到一些重要的事件通知,从而使应用程序有机会进行一些必要的处理。其中较有用的就是结果集对象的变更通知接口。通过这个接口可以及时得到结果集被增删改数据变化的情况,并有机会进行必要的数据合法性审核。数据变更通知的接口是IRowsetNotify,数据源对象要求的异步通知事件接口是IDBAsynchNotify。标准COM的回调方式为了更好的理解OLEDB的回调,先回忆一下标准COM的回调方式。COM组件除了提供函数供应用程序主动调用这种方式外,还提供了回调这种方式,这种方式由用户实现相应的接口,然后由COM组件来调用,这样我们就可以知道COM组件的运行状态,同时能针对一些情况进行处理,比如处理内存耗尽,获取用户输入等等。要支持事件回调的COM组件必须提供IConnectionPointContainer接口,调用者调用IConnectionPointContainer接口的FindConnectPoint接口,通过回调事件的IID找到特定的事件挂载点,然后调用接口的Advise方法将挂载点与对应的回调函数关联起来(一个事件可以对应多个回调函数)这样当事件发生时就可以调用对应的回调函数。这个机制有点类似于QT中的信号和槽函数机制,QT中的事件是实现定义好的,可以直接使用而这里是需要通过事件ID找到具体事件,拥有事件后,与QT步骤类似,都是需要将事件与对应的回调函数绑定。IRowsetNotify接口对于OLEDB结果集来说,最重要的事件接口是IRowsetNotify,该接口提供三个重要的通知函数:OnFieldChange:列数据发生变更OnRowChange: 行发生变化,尤其是删除或者插入行OnRowsetChange:修改数据被提交通过这些事件函数具体实现时设置不同的返回值可以控制结果集对象对修改做出的响应,比如:返回S_OK表示接受这个修改,返回S_FALSE明确拒绝接受这个修改。这样就给了一个最终反悔的机制。这些函数有两个重要的参数:DBREASON: 发生变化的原因DBEVENTPHASE:事件被触发的阶段通过对这两个参数组合的判定,可以准确的判断出结果集中数据变化的动态追踪及情况DBREASON 参数的相关值DBREASON_ROW_ASYNCHINSERT:异步插入DBREASON_ROWSET_FETCHPOSITIONCHANGE:结果集的行指针发生变化,当调用类似 IRowset::GetNextRows or IRowset::RestartPosition时触发DBREASON_ROWSET_RELEASE:当结果集被释放的时候触发DBREASON_ROWSET_CHANGED:数据库中某些元数据发生变化时触发,这里是指描述数据库表字段的一些信息发生变化,比如表字段的大小,类型这些数据,要修改这些数据需要用户具有一定的权限,一般情况下不会触发这个原因DBREASON_COLUMN_SET:当行数据被设置时触发(这里只是已存在的行数据被设置,不包括新增行),一般调用SetData时会触发DBREASON_COLUMN_RECALCULATED:当列的值发生变更时触发,一般是调用SetDataDBREASON_ROW_ACTIVATE:当用户修改行指针导致行的状态由未激活变为激活时触发DBREASON_ROW_RELEASE:当调用ReleaseRows释放某些行句柄的时候触发DBREASON_ROW_DELETE:当行被删除时触发DBREASON_ROW_FIRSTCHANGE:当某些行的某列被设置新值后又改变了当前行指针的指向时,它会被第一时间触发,并且它的触发会早于DBREASON_COLUMN_SET,这个事件只会在使用延迟更新的时候才会产生。DBREASON_ROW_INSERT:在插入新行的时候触发DBREASON_ROW_UNDOCHANGE:当调用Undo放弃修改的时候触发DBREASON_ROW_UNDOINSERT:当调用Undo放弃插入新行的时候触发DBREASON_ROW_UNDODELETE:当调用Undo放弃删除的时候触发DBREASON_ROW_UPDATE:当调用Update进行更新的时候触发DBEVENTPHASE这个参数表示当前执行的状态,一般操作数据结果集有5个状态,分别对应这样的5个值:DBEVENTPHASE_OKTODO:准备好了去做,当应用程序需要操作结果集的时候会发送一个DBEVENTPHASE_OKTODO到监听程序(在这暂时就理解为OLEDB的数据源),监听程序收到后不会立马去执行该动作,而是会返回S_OK表示它知道了这个请求,或者返回S_FALSE拒绝这个请求DBEVENTPHASE_ABOUTTODO:当数据源针对 DBEVENTPHASE_OKTODO返回S_OK时,应用程序会给一个信号,告知数据源可以进行执行动作之前最后的准备工作,这部完成之后,数据源会异步的执行相关请求操作DBEVENTPHASE_DIDEVENT:当数据源执行完这次的请求之后会到这个状态,此时数据库表的数据已经更新DBEVENTPHASE_FAILEDTODO:当之前的某一步发生错误时会进入这个状态,此时会产生回滚,将数据还原到最开始的状态。下面是数据状态迁移图,这个图很形象的展示了在某个操作执行过程中的各种状态变化结果集对象事件通知接口的使用方法定义一个派生自IRowsetNotify接口的类,并实现其接口中的所有方法设置结果集对象属性集DBPROPSET_ROWSET中的DBPROP_IConnectionPointContainer属性为VARIANT_TRUE获得结果集对象调用IRowset::QueryInterface方法得到IConnectionPointContainer接口指针调用IConnectionPointContainer::FindConnectionPoint方法得到IRowsetNotify接口对应的IConnectionPoint接口指针实例化一个第一步中创建的类调用IConnectionPoint::Advise并传递该对象指针对结果集对象进行操作,此时如果事件条件成立,结果集对象会调用该对象的相应方法通知调用者触发了什么事件详细的内容可以参考MSDN IRowsetNotify例子最后来看使用的具体例子class CCOMRowsetNotify: public IRowsetNotify { public: CCOMRowsetNotify(void); virtual ~CCOMRowsetNotify(void); protected: virtual HRESULT FindConnectionPointContainer(IUnknown *pIUnknown, REFIID rrid, IConnectionPoint* &pIcp); public: virtual HRESULT Addvise(IUnknown *pIUnknown, REFIID rrid); virtual HRESULT UnAddvise(IUnknown *pIUnknown, REFIID rrid); public: virtual STDMETHODIMP_(ULONG) AddRef(void); virtual STDMETHODIMP_(ULONG) Release(void); virtual STDMETHODIMP QueryInterface(REFIID riid, void **ppvObject); virtual STDMETHODIMP OnFieldChange (IRowset *pRowset, HROW hRow, DBORDINAL cColumns, DBORDINAL rgColumns[], DBREASON eReason, DBEVENTPHASE ePhase,BOOL fCantDeny); virtual STDMETHODIMP OnRowChange (IRowset *pRowset, DBCOUNTITEM cRows,const HROW rghRows[], DBREASON eReason, DBEVENTPHASE ePhase, BOOL fCantDeny); virtual STDMETHODIMP OnRowsetChange (IRowset *pRowset, DBREASON eReason, DBEVENTPHASE ePhase, BOOL fCantDeny); protected: ULONG m_uRef; DWORD m_dwCookie; };使用时首先定义一个派生自IRowsetNotify的类,并实现所有的接口方法if (!OpenTable(pIOpenRowset, pIRowsetChange)) { COM_PRINTF(_T("打开表失败\n")); goto __CLEAN_UP; } RowsetNotify.Addvise(pIRowsetChange, IID_IRowsetNotify); HRESULT CCOMRowsetNotify::FindConnectionPointContainer(IUnknown *pIUnknown, REFIID rrid, IConnectionPoint* &pIcp) { IConnectionPointContainer* pICpc = NULL; HRESULT hr = pIUnknown->QueryInterface(IID_IConnectionPointContainer,(void**)&pICpc); if(FAILED(hr)) { COM_PRINTF(_T("通过IRowset接口获取IConnectionPointContainer接口失败,错误码:0x%08X\n"),hr); return hr; } hr = pICpc->FindConnectionPoint(rrid,&pIcp); if(FAILED(hr)) { COM_PRINTF(_T("获取IConnectionPoint接口失败,错误码:0x%08X\n"),hr); COM_SAFE_RELEASE(pIcp); return hr; } return hr; } HRESULT CCOMRowsetNotify::Addvise(IUnknown *pIUnknown, REFIID rrid) { IConnectionPoint *pIcp = NULL; HRESULT hRes = FindConnectionPointContainer(pIUnknown, rrid, pIcp); if (S_OK != hRes) { return hRes; } hRes = pIcp->Advise(dynamic_cast<IRowsetNotify*>(this), &m_dwCookie); COM_SAFE_RELEASE(pIcp); return hRes; } 上述代码先打开数据结果集,然后调用类对象的Addvise方法传入IID_IRowsetNotify接口指针,在方法Addvise中做的主要操作是首先使用传入的接口指针查找到接口IConnectionPointContainer,然后利用IConnectionPointContainer接口的FindConnectionPoint方法找到对应的挂载点,最后调用IConnectionPointContainer的Advise方法将对应的类对象挂载到挂载点上,这样在后面操作结果集时就会调用对应的On函数,完成对应事件的处理
-
OLEDB 静态绑定和数据转化接口 title: OLEDB 静态绑定和数据转化接口tags: [OLEDB, 数据库编程, VC++, 数据库, 静态绑定, 数据转化对象接口]date: 2018-04-27 20:13:54categories: windows 数据库编程keywords: OLEDB, 数据库编程, VC++, 数据库, 静态绑定, 数据类型转化OLEDB 提供了静态绑定和动态绑定两种方式,相比动态绑定来说,静态绑定在使用上更加简单,而在灵活性上不如动态绑定,动态绑定在前面已经介绍过了,本文主要介绍OLEDB中的静态,以及常用的数据类型转化接口。静态绑定之前的例子都是根据返回的COLUMNINFO结构来知晓数据表中各项的具体信息,然后进行绑定操作,这个操作由于可以动态的针对不同的数据类型绑定为不同的类型,因此称之为动态绑定。动态绑定是建立在我们对数据库中表结构一无所知,而又需要对数据库进行编程,但是一般在实际的项目中开发人员都是知道数据库的具体结构的,而且一旦数据库设计好了后续更改的可能性也不太大,因此可以采取静态绑定的方式来减少编程的复杂度。在进行静态绑定时,一般针对每个数据库表结构定义一个结构体用来描述表的各项数据,然后利用结构体的偏移来绑定到数据库中。数据关系对应表一般静态绑定需要将数据库表的各项数据与结构体中的成员一一对应,这个时候就涉及到数据库数据类型到C/C++中数据类型的转化,下表列举了常见的数据库类型到C/C++数据类型的转化关系数据库类型OLEDB 类型C/C++类型binaryDBTYPE_BYTES/DBTYPE_IUNKNOWNBYTE[length]/BLOBvarbinaryDBTYPE_BYTES/DBTYPE_IUNKNOWNBLOBbitDBTYPE_BOOLVARIANT_BOOLcharDBTYPE_STRchar[length]varcharDBTYPE_STRchar[length]nvarcharDBTYPE_WSTRwchar_t[length]ncharDBTYPE_WSTRwchar_t[length]textDBTYPE_STR/DBTYPE_IUNKNOWNBLOBimageDBTYPE_BYTES/DBTYPE_IUNKNOWNBLOBntextDBTYPE_WSTR/DBTYPE_IUNKNOWNBLOBtinyintDBTYPE_UI1BYTEsmallintDBTYPE_I2SHORTintDBTYPE_I4LONGbigintDBTYPE_I8LARGE_INTEGERrealDBTYPE_R4floatfloatDBTYPE_R8doublemoneyDBTYPE_CYLARGE_INTEGERnumericDBTYPE_NUMERICtypedef struct tagDB_NUMERIC {<br/> BYTE precision;<br/> BYTE scale;<br/> BYTE sign;<br/> BYTE val[16];} DB_NUMERIC;decimalDBTYPE_NUMERICtypedef struct tagDB_NUMERIC {<br/> BYTE precision;<br/> BYTE scale;<br/> BYTE sign;<br/> BYTE val[16];<br/>} DB_NUMERIC;sysnameDBTYPE_WSTRwchar_t[length]datetimeDBTYPE_DBTIMESTAMPtypedef struct tagDBTIMESTAMP {<br/> SHORT year;<br/> USHORT month;<br/> USHORT day;<br/> USHORT hour;<br/> USHORT minute;<br/> USHORT second;<br/> ULONG fraction;<br/>}DBTIMESTAMP;timestampDBTYPE_BYTESBYTE[length]uniqueidentifierDBTYPE_GUIDGUID实例下面是一个静态绑定的例子//静态绑定的结构 typedef struct _tag_DBSTRUCT { DBSTATUS dbCodeStatus; ULONG uCodeLength; int nCode; DBSTATUS dbNameStatus; ULONG uNameLength; WCHAR szName[NAME_LENGTH]; }DBSTRUCT, *LPDBSTRUCT; dbBindings[0].bPrecision = 0; dbBindings[0].bScale = 0; dbBindings[0].cbMaxLen = sizeof(int); dbBindings[0].dwMemOwner = DBMEMOWNER_CLIENTOWNED; dbBindings[0].dwPart = DBPART_STATUS | DBPART_LENGTH | DBPART_VALUE; dbBindings[0].iOrdinal = pdbColumnInfo[0].iOrdinal; dbBindings[0].obStatus = offsetof(DBSTRUCT, dbCodeStatus); dbBindings[0].obLength = offsetof(DBSTRUCT, uCodeLength); dbBindings[0].obValue = offsetof(DBSTRUCT, nCode); dbBindings[0].wType = DBTYPE_I4; dbBindings[1].bPrecision = 0; dbBindings[1].bScale = 0; dbBindings[1].cbMaxLen = sizeof(WCHAR) * NAME_LENGTH; dbBindings[1].dwMemOwner = DBMEMOWNER_CLIENTOWNED; dbBindings[1].dwPart = DBPART_STATUS | DBPART_LENGTH | DBPART_VALUE; dbBindings[1].iOrdinal = pdbColumnInfo[1].iOrdinal; dbBindings[1].obStatus = offsetof(DBSTRUCT, dbNameStatus); dbBindings[1].obLength = offsetof(DBSTRUCT, uNameLength); dbBindings[1].obValue = offsetof(DBSTRUCT, szName); dbBindings[1].wType = DBTYPE_WSTR; hRes = pIAccessor->CreateAccessor(DBACCESSOR_ROWDATA, 2, dbBindings, 0, &hAccessor, NULL); pdbStruct = (DBSTRUCT*)COM_ALLOC(sizeof(DBSTRUCT) * cRows); while (TRUE) { hRes = pIRowset->GetNextRows(DB_NULL_HCHAPTER, 0, cRows, &cRowsObtained, &prghRows); if (hRes != S_OK && cRowsObtained == 0) { break; } ZeroMemory(pdbStruct, sizeof(DBSTRUCT) * cRows); for (int i = 0; i < cRowsObtained; i++) { hRes = pIRowset->GetData(prghRows[i], hAccessor, &pdbStruct[i]); if (!FAILED(hRes)) { COM_PRINTF(_T("%012d\t%s\n"), pdbStruct[i].nCode, pdbStruct[i].szName); } } pIRowset->ReleaseRows(cRowsObtained, prghRows, NULL, NULL, NULL); }我们针对之前的行政区表来进行演示,在这个表中我们只查询其中的两列数据,与之前的例子相似,针对每列定义3项数据,分别是状态,长度和真实的数据,在绑定的时候就不需要计算总体需要内存的大小,行内存大小就是结构体的大小,在绑定的时候我们结构体成员在结构体中的偏移作为返回数据时各项在缓冲中的偏移。而在访问数据时就需要自己计算偏移,直接使用结构体中的成员即可。从上面的例子,我总结了静态绑定和动态绑定之间的差别:其实从本质上将动态绑定和静态绑定没有区别,都是分配一段缓冲作为行集的缓冲,然后在使用的时候进行偏移的计算静态绑定是利用我们提前知道数据库的结构,实现通过结构体来安排各项在缓冲中的偏移所占内存的大小。动态绑定中所有成员的分配和所占内存大小都是根据COLUMNINFO结构事后动态分配的,需要自己计算偏移。相比于动态绑定来说,静态绑定不需要获取数据库的各项的属性信息,不需要自己计算各项的偏移,相对比较简单,适用于事先知道数据库的表结构,使用相对固定,一旦数据库结构改变就需要改变代码动态绑定可以适用于几乎任何情形,可扩展性强,几乎不需要考虑数据库表结构变更问题。代码灵活,但是需要自己计算偏移,自己分配管理内存,相对来说对程序员的功力要求更高一些。数据类型转化数据库中数据类型繁多,而对应到具体的编程语言上有不同的展示方式,具体的语言中对同一种数据库类型有不同的数据类型对应,甚至有的可能并没有什么类型可以直接对应,这就涉及到一个从数据库数据类型到具体编程语言数据类型之间进行转换的问题,针对这一问题OLEDB提供了一个接口——IDataConvert一般情况下任何数据类型都可以转化为相应格式的字符串,而对应的字符串又可以反过来转化为数据库中相应的数据类型。当然一些特殊转换也是允许的,比如:整型数据间的转换,浮点数间的转换等。这也是使用这个数据转化接口的主要原则。数据转换接口的使用使用COM标准的方式创建IDataConver接口(调用CreateInstance函数传入CLSID_OLEDB_CONVERSIONLIBRARY创建一个IID_IDataConvert接口)接着调用该接口的DataConvert方法可以进行数据转化调用接口的CanConvert可以知道两种数据类型之间能否进行转化。调用GetConversionSize可以知道源数据类型转化为指定类型时需要的缓冲大小。实例这个例子相对比较简单,就简单的在之前打印数据库数据中加了一句转化为字符串的操作,然后打印,就不在文中展示了,具体的例子见我放到码云中的代码片段例子代码:静态绑定数据类型转化
-
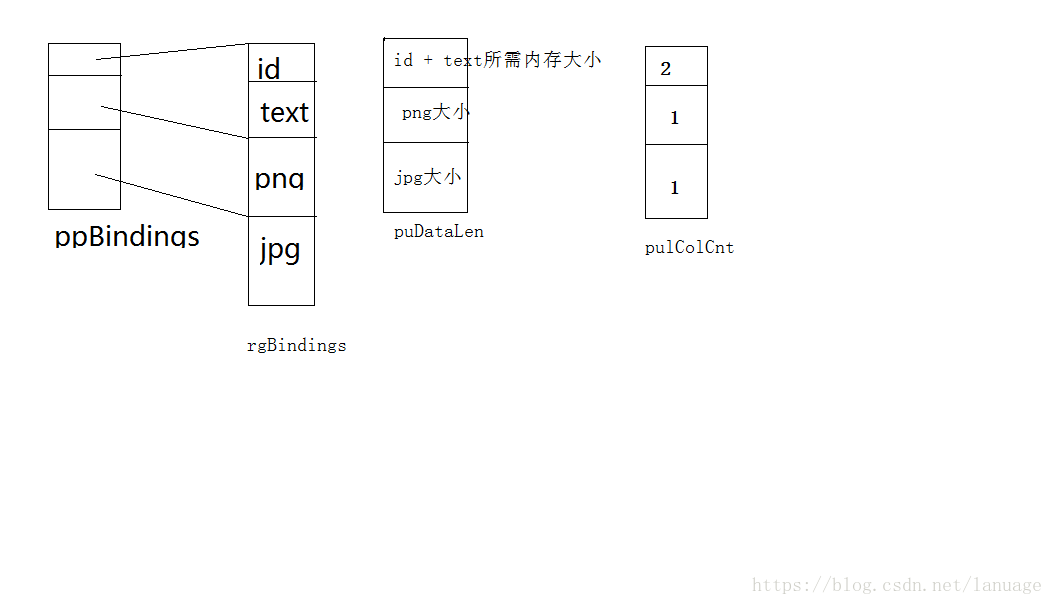
OLEDB存取BLOB型数据 现代数据库系统除了支持一些标准的通用数据类型以外,大多数还支持一种称之为BLOB型的数据。BLOB全称为big large object bytes, 大二进制对象类型,这种类型的数据通常用于存储文档、图片、音频等文件,这些文件一般体积较大,保存这些文件可以很方便的管理和检索这类信息。在MS SQLSERVER中常见的BLOB数据类型有text、ntext(n表示unicode)、image、nvarchar、varchar、varbinary等。其中image基本可以用来保存一切二进制文件,比如word、Excel、音频、视频等等类型。针对BLOB型数据,OLEDB也提供了对它的支持使用BLOB型数据的利弊一般数据库对BLOB型数据有特殊的处理方式,比如压缩等等,在数据库中存储BLOB数据可以方便的进行检索,展示,备份等操作。但是由于BLOB型数据本身比较大,存储量太大时数据量太大容易拖慢数据库性能,所以一般的说法都是尽量不要在数据库中存储这类信息。特别是图片,音视频。针对这类文件一般的做法是将其保存在系统的某个路径钟中,而在数据库中存储对应的路径操作BLOB型数据的一般方法一般针对BLOB不能像普通数据那样操作,而需要一些特殊的操作,在OLEDB中通过设置绑定结构中的一些特殊值最终指定获取BLOB型数据的一个ISequentialStream接口指针,最终会通过这个接口来进行BLOB型数据的读写操作判断一个列是否是BLOB型数据判断某个列是否是BLOB型数据一般通过如下两个条件:pColumnInfo[i].wType == DBTYPE_IUNKNOW : 包含当列信息的DBCOLUMNSINFO 结构体对象的wType值为DBTYPE_IUNKNOW,该列的类型为DBTYPE_IUNKNOW,该条件也被称为列类型判定pColumnInfo[i].dwFlags & DBCOLUMNFLAGS_ISLONG :当列信息中的dwFlag值为DBCOLUMNFLAGS_ISLONG,也就是说该列的标识中包含DBCOLUMNFLAGS_ISLONG属性,该判定条件也被称之为列标识判定当这两个条件之一成立之时,我们就可以断定这列为BLOB型数据BLOG型数据的绑定在进行BLOB型数据的绑定也有特殊要求,主要体现在下面几点:绑定结构的cbMaxLength 需要设置为0绑定结构的wType设置为DBTYPE_IUNKNOW为结构的pObject指针分配内存,大小等于DBOBJECT结构的大小指定pObject的成员 pObject->iid = IID_ISequentialStream pObject->dwFlags = STGM_READ为行缓冲长度加上一个IStream指针的长度,此时数据源不再提供查询到的数据而提供一个接口指针,后续对BLOB数据的操作都使用该指针进行最后使用完后记得释放pObject所指向的内存空间读取BLOB数据根据前面所说的创建绑定结构,并为绑定结构赋值,最终可以从结果集中获取到一个ISequentialStream接口指针。调用接口的Read方法可以读取到BLOB列中的数据,而BLOB数据的长度存储在绑定时指定的数据长度内存偏移处,这与普通列的长度存放返回方式是一样的,一般BLOB数据都比较长,这个时候就需要分段读取。在使用ISequentialStream接口操作BLOB型数据时需要注意的一个问题是,有的数据库不支持在一个访问器中访问多个BLOB数据列。一般BLOB数据列及其的消耗资源,并且数据库鼓励我们在设计数据库表结构的时候做到一行只有一列BLOB数据,因此很多数据库并不支持在一个访问器中读取多个BLOB数据。要判断数据库是否支持在一个访问器中读取多个BLOB数据,可以获取DBPROP_MULTIPLESTORAGEOBJECTS属性,该属性属于属性集DBPROPSET_ROWSET,它是一个只读属性,如果该属性的值为TRUE表示支持,为FALSE表示不支持。下面是一个读取BLOB型数据的例子,数据库中的表结构为:id(int)、text(image)、png(image)、jpg(image)void ReadBLOB(IRowset *pIRowset) { COM_DECLARE_INTERFACE(IColumnsInfo); COM_DECLARE_INTERFACE(IAccessor); DBORDINAL cColumns = 0; DBCOLUMNINFO* rgColumnsInfo = NULL; LPOLESTR lpszColumnsName = NULL; DBBINDING* rgBindings = NULL; DBBINDING** ppBindings = NULL; //绑定结构数组 DWORD *puDataLen = NULL; //当前访问器所需内存大小 DWORD *pulColCnt = NULL; //当前访问器中包含的项 ULONG ulBindCnt = 0; //访问器的数量 ULONG uBlob = 0; //当前有多少blob数据 HACCESSOR* phAccessor = NULL; HROW* hRow = NULL; DBCOUNTITEM ulGetRows = 0; ULONG uCols = 0; PVOID pData1 = NULL; //第1个访问器中数据的缓冲 PVOID pData2 = NULL; //第2个访问器中数据的缓冲 PVOID pData3 = NULL; //第3个访问器中数据的缓冲 HRESULT hRes = pIRowset->QueryInterface(IID_IColumnsInfo, (void**)&pIColumnsInfo); COM_SUCCESS(hRes, _T("查询接口pIColumnsInfo失败,错误码为:%08x\n"), hRes); hRes = pIColumnsInfo->GetColumnInfo(&cColumns, &rgColumnsInfo, &lpszColumnsName); COM_SUCCESS(hRes, _T("获取结果集列信息失败,错误码为:%08x\n"), hRes); ppBindings = (DBBINDING**)COM_ALLOC(sizeof(DBBINDING*)); rgBindings = (DBBINDING*)COM_ALLOC(sizeof(DBBINDING) * cColumns); pulColCnt = (DWORD*)COM_ALLOC(sizeof(DWORD)); puDataLen = (DWORD*)COM_ALLOC(sizeof(DWORD)); for (int i = 0; i < cColumns; i++) { //如果当前访问器对应的绑定结构的数组的首地址为空,将当前绑定结构指针作为绑定结构数组的首地址 if (NULL == ppBindings[ulBindCnt]) { ppBindings[ulBindCnt] = &rgBindings[i]; } ++pulColCnt[ulBindCnt]; rgBindings[i].bPrecision = rgColumnsInfo[i].bPrecision; rgBindings[i].bScale = rgBindings[i].bScale; rgBindings[i].cbMaxLen = 10 * sizeof(WCHAR); rgBindings[i].dwMemOwner = DBMEMOWNER_CLIENTOWNED; rgBindings[i].dwPart = DBPART_LENGTH | DBPART_STATUS | DBPART_VALUE; rgBindings[i].eParamIO = DBPARAMIO_NOTPARAM; rgBindings[i].iOrdinal = rgColumnsInfo[i].iOrdinal; rgBindings[i].obStatus = puDataLen[ulBindCnt]; rgBindings[i].obLength = puDataLen[ulBindCnt] + sizeof(DBSTATUS); rgBindings[i].obValue = rgBindings[i].obLength + sizeof(ULONG); rgBindings[i].wType = DBTYPE_WSTR; if (rgColumnsInfo[i].wType == DBTYPE_IUNKNOWN || rgColumnsInfo[i].dwFlags & DBCOLUMNFLAGS_ISLONG) { rgBindings[i].cbMaxLen = 0; rgBindings[i].wType = DBTYPE_IUNKNOWN; rgBindings[i].pObject = (DBOBJECT*)COM_ALLOC(sizeof(DBOBJECT)); rgBindings[i].pObject->iid = IID_ISequentialStream; rgBindings[i].pObject->dwFlags = STGM_READ; uBlob++; } //记录下每个访问器所需内存的大小 puDataLen[ulBindCnt] = rgBindings[i].obValue + rgBindings[i].cbMaxLen; if (rgBindings[i].wType == DBTYPE_IUNKNOWN) { puDataLen[ulBindCnt] = rgBindings[i].obValue + sizeof(ISequentialStream*); } puDataLen[ulBindCnt] = UPGROUND(puDataLen[ulBindCnt]); //判断当前是否需要创建单独的访问器 if ((uBlob || rgBindings[i].iOrdinal == 0)) { ulBindCnt++; ppBindings = (DBBINDING**)COM_REALLOC(ppBindings, sizeof(DBBINDING*) * (ulBindCnt + 1)); puDataLen = (DWORD*)COM_REALLOC(puDataLen, sizeof(DWORD) * (ulBindCnt + 1)); pulColCnt = (DWORD*)COM_REALLOC(pulColCnt, sizeof(DWORD) * (ulBindCnt + 1)); } } //创建访问器 phAccessor = (HACCESSOR*)COM_ALLOC( (ulBindCnt + 1) * sizeof(HACCESSOR)); hRes = pIRowset->QueryInterface(IID_IAccessor, (void**)&pIAccessor); COM_SUCCESS(hRes, _T("查询IAccessor接口失败,错误码为:%08x\n"), hRes); for (int i = 0; i < ulBindCnt; i++) { hRes = pIAccessor->CreateAccessor(DBACCESSOR_ROWDATA, pulColCnt[i], ppBindings[i], 0, &phAccessor[i], NULL); COM_SUCCESS(hRes, _T("创建访问器失败,错误码为:%08x\n"), hRes); } //读取其中的一行数据 hRes = pIRowset->GetNextRows(DB_NULL_HCHAPTER, 0, 1, &ulGetRows, &hRow); COM_SUCCESS(hRes, _T("读取行数据失败,错误码为:%08x\n"), hRes); //读取第一个绑定结构中的信息 pData1 = COM_ALLOC(puDataLen[0]); hRes = pIRowset->GetData(hRow[0], phAccessor[0], pData1); for(int i = 0; i < pulColCnt[0]; i++) { if (ppBindings[0][i].wType == DBTYPE_IUNKNOWN) { DBSTATUS dbStatus = *(DBSTATUS*)((BYTE*)pData1 + ppBindings[0][i].obStatus); if (dbStatus == DBSTATUS_S_OK) { ULONG uFileLen = *(ULONG*)((BYTE*)pData1 + ppBindings[0][i].obLength); if (uFileLen > 0) { DWORD dwReaded = 0; PVOID pFileData = COM_ALLOC(uFileLen); ZeroMemory(pFileData, uFileLen); ISequentialStream *pSeqStream = *(ISequentialStream**)((BYTE*)pData1 + ppBindings[0][i].obValue); pSeqStream->Read(pFileData, uFileLen, &dwReaded); WriteFileData(_T("1.txt"), pFileData, dwReaded); } } } } //后续的部分就不再写出来了,写法与上面的代码类似 pIRowset->ReleaseRows(1, hRow, NULL, NULL, NULL); __CLEAR_UP: //后面是清理的代码由于我们事先知道数据表的结构,它有3个BLOB型数据,所以这里直接定义了3个缓冲用来接收3个BLOB型数据。为了方便检测,我们另外写了一个的函数,将读取出来的BLOB数据写入到文件中,事后以文件显示是否正确来测试这段代码首先还是与以前一样,获取数据表的结构,然后进行绑定,注意这里由于使用的是SQL Server,它不支持一个访问器中访问多个BLOB,所以这里没有判断直接绑定不同的访问器。在绑定的时候使用ulBindCnt作为当前访问器的数量,在循环里面有一个判断当(uBlob || rgBindings[i].iOrdinal == 0) && (ulBindCnt != cColumns - 1)条件成立时将访问器的数量加1,该条件表示之前已经有blob型数据(之前SQL不支持一个访问器访问多个BLOB,如果之前已经有BLOB数据了,就需要另外创建访问器)或者当前是第0行(因为第0行只允许读,所以将其作为与BLOB型数据一样处理),当这些条件成立时会新增一个访问器,而随着访问器的增加,需要改变ppBindings数组中的元素,该数组存储的是访问器对应的绑定结构开始的指针。数组puDataLen表示的是当前访问器所需内存的大小,pulColCnt表示当前访问器中共有多少列,针对这个表最终这些结构的内容大致如下图:绑定完成之后,后面就是根据数组中的内容创建对应的访问器,然后绑定、读取数据,针对BLOB数据,我们还是一样从对应缓冲的obValue偏移处得到接口指针,然后调用接口的Read方法读取,最后写入文件BLOB数据的写入:要写入BLOB型数据也需要使用ISequentialStream接口,但是它不像之前可以直接使用接口的Write方法,写入的对象必须要自己从ISequentialStream接口派生,并指定一段内存作为缓冲,以便供OLEDB组件调用写方法时作为数据缓冲。这段缓冲必须要保证分配在COM堆上,也就是要使用CoTaskMemory分配内存。这里涉及到的对象主要有IStream、ISequentialStream、IStorage、ILockBytes,同样,并不是所有数据源都支持这4类对象,具体支持哪些可以查询DBPROPSET_DATASOURCEINFO属性集中的DBPROP_STRUCTUREDSTORAGE属性来判定,目前SQL Server中支持ISequentialStream接口。虽然我们可以使用这种方式来实现读写BLOB,但是每种数据源支持的程度不同,而且有的数据源甚至不支持这种方式,为了查询对读写BLOB数据支持到何种程度,可以查询DBPROPSET_DATASOURCEINFO属性集合的DBPROP_OLEOBJECTS属性来判定通常有以下几种支持方式(DBPROP_OLEOBJECTS属性的值,按位设置):DBPROPVAL_OO_BLOB: 就是之前介绍的接口方式,使用接口的方式来读写BLOB数据DBPROPVAL_OO_DIRECTBIND: 可以直接绑定在行中,通过行访问器像普通列一样访问,也就是说它不需要获取专门的指针来操作,他可以就像操作普通数据那样,分配对应内存就可以访问,但是要注意分配内存的大小,每行中对应列中BLOB的数据长度差别可能会很明显,比如有的可能是一部长达2小时的电影文件,而有的可能是一部短视频,它们之间的差距可能会达到上G,而按照最小的来可能会发生截断,按最大的分配可能会发生多达好几个G的内存浪费DBPROPVAL_OO_IPERSIST:通过IPersistStream, IPersistStreamInit, or IPersistStorage三个接口的Persist对象访问DBPROPVAL_OO_ROWOBJECT: 支持整行作为一个对象来访问,通过结果集对象的IGetRow接口来获得行对象,但是这种模式会破坏第三范式,所以一般数据库都不支持DBPROPVAL_OO_SCOPED: 通过IScopedOperations接口来暴露行对象,通过这个接口可以暴露一个树形的结果集对象DBPROPVAL_OO_SINGLETON: 直接通过ICommand::Execute和IOpenRowset::OpenRowset来打开行对象下面是插入BLOB数据的一个实例//自定义一个 class CSeqStream : public ISequentialStream { public: // Constructors CSeqStream(); virtual ~CSeqStream(); public: virtual BOOL Seek(ULONG iPos); //将当前内存指针偏移到指定位置 virtual BOOL CompareData(void* pBuffer); //比较两段内存中的值 virtual ULONG Length() { return m_cBufSize; }; virtual operator void* const() { return m_pBuffer; }; public: STDMETHODIMP_(ULONG) AddRef(void); STDMETHODIMP_(ULONG) Release(void); STDMETHODIMP QueryInterface(REFIID riid, LPVOID *ppv); //读写内存的操作,这些是必须实现的函数 STDMETHODIMP Read( /* [out] */ void __RPC_FAR *pv, /* [in] */ ULONG cb, /* [out] */ ULONG __RPC_FAR *pcbRead); STDMETHODIMP Write( /* [in] */ const void __RPC_FAR *pv, /* [in] */ ULONG cb, /* [out]*/ ULONG __RPC_FAR *pcbWritten); private: ULONG m_cRef; // reference count void* m_pBuffer; // buffer ULONG m_cBufSize; // buffer size ULONG m_iPos; // current index position in the buffer };//插入数据第一列BLOB数据 //这里由于已经事先知道每列的数据结构,因此采用偷懒的方法,一行行的插入 pData1 = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, pdwDataLen[nCol]); for(int i = 0; i < pulColCnt[nCol]; i++) { if (DBTYPE_IUNKNOWN == ppBindings[nCol][i].wType) { *(DBSTATUS*)((BYTE*)pData1 + ppBindings[nCol][i].obStatus) = DBSTATUS_S_OK; CSeqStream *pSeqStream = new CSeqStream(); GetFileData(_T("test.txt"), dwFileLen, pFileData); pSeqStream->Write(pFileData, dwFileLen, &dwWritten); pSeqStream->Seek(0); //写这个操作将缓存的指针偏移到了最后,需要调整一下,以便OLEDB组件在插入BLOB数据时从缓存中读取 HeapFree(GetProcessHeap(), 0, pFileData); *(ULONG*)((BYTE*)pData1 + ppBindings[nCol][i].obLength) = dwFileLen; *(ISequentialStream**)((BYTE*)pData1 + ppBindings[nCol][i].obValue) = pSeqStream; //此处不用release pSeqStream,COM组件会自动释放 }else { //根据数据库定义,此处应该为ID *(ULONG*)((BYTE*)pData1 + ppBindings[nCol][i].obLength) = 10; if (DBTYPE_WSTR == ppBindings[nCol][i].wType) { StringCchCopy((LPOLESTR)((BYTE*)pData1 + ppBindings[nCol][i].obValue), 10, SysAllocString(OLESTR("1"))); } } } hRes = pIRowsetChange->InsertRow(DB_NULL_HCHAPTER, phAccessor[nCol], pData1, &hNewRow); COM_SUCCESS(hRes, _T("插入第1列BLOB数据失败,错误码为:%08x\n"), hRes);在上面的代码中首先定义一个派生类,用来进行BLOB数据的读写,然后在后面的代码中演示了如何使用它在后面的一段代码中,基本步骤和之前一样,经过连接数据源、创建回话对象,打开表,然后绑定,获取行访问器,这里由于代码基本不变,为了节约篇幅所以省略它们,只贴出最重要的部分。在插入的代码中,首先查找访问器中的各个列的属性,如果是BLOB数据就采用BLOB数据的插入办法,否则用一般数据的插入办法。插入BLOB数据时,首先创建一个派生类的对象,注意此处由于后续要交给OLEDB组件调用,所以不能用栈内存。我们先调用类的Write方法将内存写入对应的缓冲中,然后调用Seek函数将内存指针偏移到缓冲的首地址,这个指针的作用就相当于文件的文件指针,COM组件在调用对应函数将它插入数据库时会采用这个内存的指针,所以必须将其置到首地址处。让后将对象的指针放入到对应的obvalues偏移中,设置对应的数据大小为BLOB数据的大小,最后只要像普通数据类型那样调用对应的更新方法即可实现BLOB数据的插入最后贴上两个例子的详细代码地址示例1:BLOB数据的读取示例2:BLOB数据的插入
-
OLEDB不使用SQL语句直接打开数据表 一般来说获取数据库表的方法是采用类似select * from table_name这样的sql语句。SQL语句必然伴随着数据库的解释执行,一般来说效率比较低下,而且使用SQL语句时需要数据库支持ICommandText对象,但是在OLEDB中它是一个可选接口,也就是有的数据库可能不支持,这个时候OLEDB给我们提供了一种方法让我们能够在不使用SQL的情况下操作数据库表对象。直接打开表对象需要使用IOpenRowset接口。该接口属于Session对象。打开数据库表的一般步骤声明一个DBID结构对象为结构对象的ekind(对象种类)字段赋值DBKIND_NAME值为结构对象的uName.pwszName字段赋值为表名调用IOpenRowset接口的OpenRowset方法,将DBID结构的指针传入,并让函数返回结果集对象IOpenRowset接口属于Session,可以在使用CreateSession时让其直接打开这个接口,而且该接口是必须实现的接口,因此不用担心获取不到的情况,得到这个接口后就可以直接使用接口的OpenRowset方法。OpenRowset函数原型如下:HRESULT OpenRowset( IUnknown *pUnkOuter, DBID *pTableID, //打开表时使用该结构 DBID *pIndexID, //打开索引时使用这个参数 REFIID riid, //返回对象的GUID ULONG cPropertySets, //给对应返回对象设置的属性集的个数 DBPROPSET rgPropertySets[], //给对应对象设置的属性集 IUnknown **ppRowset); // 返回的接口从函数定义上来,这种方式还可以用来打开索引使用实例BOOL OpenTable(IOpenRowset *pIOpenRowset, IRowset* &pIRowset) { DBID dbId = {0}; dbId.eKind = DBKIND_NAME; dbId.uName.pwszName = OLESTR("aa26"); DBPROP dbRowsetProp[4] = {0}; DBPROPSET dbRowsetPropset[1] = {0}; //运行直接使用对应接口函数对数据库进行增删改操作 dbRowsetProp[0].colid = DB_NULLID; dbRowsetProp[0].dwOptions = DBPROPOPTIONS_REQUIRED; dbRowsetProp[0].dwPropertyID = DBPROP_UPDATABILITY; dbRowsetProp[0].vValue.vt = VT_I4; dbRowsetProp[0].vValue.intVal = DBPROPVAL_UP_CHANGE | DBPROPVAL_UP_DELETE | DBPROPVAL_UP_DELETE; //运行在删改的同时插入数据 dbRowsetProp[1].colid = DB_NULLID; dbRowsetProp[1].dwOptions = DBPROPOPTIONS_REQUIRED; dbRowsetProp[1].dwPropertyID = DBPROP_CANHOLDROWS; dbRowsetProp[1].vValue.vt = VT_BOOL; dbRowsetProp[1].vValue.boolVal = VARIANT_TRUE; //打开IRowsetUpdate接口,实现延迟更新 dbRowsetProp[2].colid = DB_NULLID; dbRowsetProp[2].dwOptions = DBPROPOPTIONS_REQUIRED; dbRowsetProp[2].dwPropertyID = DBPROP_IRowsetUpdate; dbRowsetProp[2].vValue.vt = VT_BOOL; dbRowsetProp[2].vValue.boolVal = VARIANT_TRUE; dbRowsetPropset[0].cProperties = 3; dbRowsetPropset[0].guidPropertySet = DBPROPSET_ROWSET; dbRowsetPropset[0].rgProperties = dbRowsetProp; HRESULT hRes = pIOpenRowset->OpenRowset(NULL, &dbId, NULL, IID_IRowset, 1, dbRowsetPropset, (IUnknown**)&pIRowset); return SUCCEEDED(hRes); }详细的代码请参考: 完整代码
-
OLEDB 枚举数据源 在之前的程序中,可以看到有这样一个功能,弹出一个对话框让用户选择需要连接的数据源,并输入用户名和密码,最后连接;而且在一些数据库管理软件中也提供这种功能——能够自己枚举出系统中存在的数据源,同时还可以枚举出能够连接的SQL Server数据库的实例。其实这个功能是OLEDB提供的高级功能之一。枚举对象用于搜寻可用的数据源和其它的枚举对象(层次式),枚举出来的对象是一个树形结构。在程序中提供一个枚举对象就可以枚举里面的所有数据源,如果没有指定所使用的的上层枚举对象,则可以使用顶层枚举对象来枚举可用的OLEDB提供程序,其实我们使用枚举对象枚举数据源时它也是在注册表的对应位置进行搜索,所以我们可以直接利用操作注册表的方式来获取数据源对象,但是注册表中的信息过于复杂,而且系统对注册表的依赖比较严重,所以并不推荐使用这种方式。枚举对象的原型如下:CoType TEnumerator { [mandatory] IParseDisplayName; [mandatory] ISourcesRowset; [optional] IDBInitialize; [optional] IDBProperties; [optional] ISupportErrorInfo; }顶层枚举对象的获取和遍历要利用数据源枚举功能,第一个要获取的枚举对象就是顶层枚举对象。或者称之为根枚举器,根枚举器对象的CLSID是CLSID_OLEDB_ENUMNRATOR,顶层枚举对象可以使用标准的COM对象创建方式来创建,之后可以使用ISourceRowset对象的GetSourcesRowset,得到数据源组合成的结果集。接着可以根据行集中的行类型来判断是否是一个子枚举对象或者数据源对象。如果是子枚举对象,可以利用名字对象的方法创建一个新的子枚举对象,然后根据这个枚举对象来枚举其中的数据源对象。一般来说这颗数结构只有两层。OLEDB提供者结果集在上面我们说可以根据结果集中的行类型来判断是否是一个子枚举对象或者数据源对象,那么怎么获取这个行类型呢?这里需要了解返回的行集的结构。字段名称类型最大长度含义描述SOURCES_NAMEDBTYPE_WSTR128枚举对象或数据源名称SOURCES_PARSENAMEDBTYPE_WSTR128可以传递给IParseDisplayName接口并得到一个moniker对象的字符串(枚举对象或数据源的moniker)SOURCES_DESCRIPTIONDBTYPE_WSTR128枚举对象或数据源的描述SOURCES_TYPEDBTYPE_UI22(单位字节)枚举对象或实例的类型,有下列值:DBSOURCETYPE_BINDER (=4)- URLDBSOURCETYPE_DATASOURCE_MDP (=3) - OLAP提供者DBSOURCETYPE_DATASOURCE_TDP (=1) - 关系型或表格型数据源DBSOURCETYPE_ENUMERATOR (=2) - 子枚举对象SOURCES_ISPARENTDBTYPE_BOOL2(单位字节)是否是父枚举器在枚举时根据SOURCES_TYPE字段来判断是否是子枚举对象,如果是则使用第二列的数据获取子枚举器的对象。如果根据名称创建子枚举器这里需要使用IMoniker接口。名字对象(moniker)的创建方法,是一种标准的以名字解析方法创建一个COM对象及接口的方法。相比于直接使用CoCreateInstance来说是一种更加高级的方法。这是标准的COM 对象的创建方式,其原理就是通过一个全局唯一的名称在注册表中搜索得到对应的CLSID,然后根据ID调用CoCreateInstance来创建对象。具体搜索过程可以参考COM基础系列在数据源枚举的应用中,先从ISourcesRowset对象中Query出IParseDisplayName接口,再调用该接口的ParseDisplayName方法传入上述表格中SOURCES_PARSENAME的值,得到IMoniker接口,最后调用全局函数BindMinker传递IMoniker接口指针并指定需要创建的接口ID。具体例子最后是一个具体的例子这个例子中创建了一个MFC应用程序,最后效果类似于前面几个例子中的OLEDB的数据源选择对话框。在例子中最主要的代码有两段:IDBSourceDlg对话框的EnumDataSource方法,和IDBConnectDlg方法Initialize。这两个分别用来枚举系统中存在的数据源对象和数据源对象中对应的数据库实例。当用户根据界面的提示选择了对应的选项后点击测试连接按钮来尝试连接。这里展示的代码主要是3段,枚举数据源,枚举数据源中对应的数据库实例,以及根据选择的实例生成对应的数据源对象接口并测试连接。void IDBSourceDlg::EnumDataSource(ISourcesRowset *pISourceRowset) { COM_DECLARE_INTERFACE(IRowset); COM_DECLARE_INTERFACE(IAccessor); COM_DECLARE_INTERFACE(IMoniker); COM_DECLARE_INTERFACE(IParseDisplayName); HROW *rgRows = NULL; HACCESSOR hAccessor = NULL; ULONG cRows = 10; DWORD dwOffset = 0; PVOID pData = NULL; PVOID pCurrentData = NULL; DBCOUNTITEM cRowsObtained = 0; LPOLESTR lpParamName = OLESTR(""); //利用顶层枚举对象来枚举系统中存在的数据源 HRESULT hRes = pISourceRowset->GetSourcesRowset(NULL, IID_IRowset, 0, NULL, (IUnknown**)&pIRowset); ISourcesRowset *pSubSourceRowset = NULL; ULONG ulEaten = 0; if (FAILED(hRes)) { ComMessageBox(NULL, _T("OLEDB 错误"), MB_OK, __T("创建接口ISourcesRowset失败,错误码:%08x\n"), hRes); goto __CLEAR_UP; } DBBINDING rgBinding[3] = {0}; //这里只关心我们需要的列,不需要获取所有的列 for (int i = 0; i < 3; i++) { rgBinding[i].bPrecision = 0; rgBinding[i].bScale = 0; rgBinding[i].cbMaxLen = 128 * sizeof(WCHAR); rgBinding[i].dwMemOwner = DBMEMOWNER_CLIENTOWNED; rgBinding[i].dwPart = DBPART_VALUE; rgBinding[i].eParamIO = DBPARAMIO_NOTPARAM; rgBinding[i].wType = DBTYPE_WSTR; rgBinding[i].obLength = 0; rgBinding[i].obStatus = 0; rgBinding[i].obValue = dwOffset; dwOffset += rgBinding[0].cbMaxLen; } rgBinding[0].iOrdinal = 3; //第三项是数据源或者枚举器的描述信息,用于显示 rgBinding[1].wType = DBTYPE_UI2; rgBinding[1].iOrdinal = 4; //第四列是枚举出来的类型信息,用于判断是否需要递归 rgBinding[2].iOrdinal = 1; //第一列是枚举出来的类型信息,用于获取子枚举器 hRes = pIRowset->QueryInterface(IID_IAccessor, (void**)&pIAccessor); if (FAILED(hRes)) { ComMessageBox(NULL, _T("OLEDB 错误"), MB_OK, __T("查询接口pIAccessor失败,错误码:%08x\n"), hRes); goto __CLEAR_UP; } hRes = pIAccessor->CreateAccessor(DBACCESSOR_ROWDATA, 3, rgBinding, 0, &hAccessor, NULL); if (FAILED(hRes)) { ComMessageBox(NULL, _T("OLEDB 错误"), MB_OK, __T("创建访问器失败,错误码:%08x\n"), hRes); goto __CLEAR_UP; } pData = MALLOC(dwOffset * cRows); while (TRUE) { hRes = pIRowset->GetNextRows(DB_NULL_HCHAPTER, 0, cRows, &cRowsObtained, &rgRows); if(S_OK != hRes && cRowsObtained == 0) { break; } ZeroMemory(pData, dwOffset * cRows); for (int i = 0; i < cRowsObtained; i++) { pCurrentData = (BYTE*)pData + dwOffset * i; pIRowset->GetData(rgRows[i], hAccessor, pCurrentData); DATASOURCE_ENUM_INFO dbei = {0}; //将枚举到的相关信息存储到对应的结构中 dbei.csSourceName = (LPCTSTR)((BYTE*)pCurrentData + rgBinding[2].obValue); dbei.csDisplayName = (LPCTSTR)((BYTE*)pCurrentData + rgBinding[0].obValue); dbei.dbTypeEnum = *(DBTYPEENUM*)((BYTE*)pCurrentData + rgBinding[1].obValue); m_DataSourceList.AddString(dbei.csDisplayName); //显示数据源信息 g_DataSources.push_back(dbei); } pIRowset->ReleaseRows(cRowsObtained, rgRows, NULL, NULL, NULL); } pIAccessor->ReleaseAccessor(hAccessor, NULL); __CLEAR_UP: FREE(pData); CoTaskMemFree(rgRows); COM_SAFE_RELEASE(pIRowset); COM_SAFE_RELEASE(pIAccessor); }void IDBConnectDlg::Initialize(const CStringW& csSelected) { BSTR lpOleName = NULL; ULONG uEaten = 0; for (vector<DATASOURCE_ENUM_INFO>::iterator it = g_DataSources.begin(); it != g_DataSources.end(); it++) { if (it->csDisplayName == csSelected) { lpOleName = it->csSourceName.AllocSysString(); } } COM_DECLARE_INTERFACE(ISourcesRowset); COM_DECLARE_INTERFACE(IParseDisplayName); COM_DECLARE_INTERFACE(IMoniker); CoCreateInstance(CLSID_OLEDB_ENUMERATOR, NULL, CLSCTX_INPROC_SERVER, IID_ISourcesRowset, (void**)&pISourcesRowset); pISourcesRowset->QueryInterface(IID_IParseDisplayName, (void**)&pIParseDisplayName); pIParseDisplayName->ParseDisplayName(NULL, lpOleName, &uEaten, &pIMoniker); if (lpOleName != NULL) { SysFreeString(lpOleName); } HRESULT hRes = BindMoniker(pIMoniker, 0, IID_ISourcesRowset, (void**)&m_pConnSourceRowset); COM_SAFE_RELEASE(pIMoniker); COM_SAFE_RELEASE(pIParseDisplayName); if (FAILED(hRes)) { COM_SAFE_RELEASE(m_pConnSourceRowset); return; } COM_DECLARE_INTERFACE(IRowset) hRes = m_pConnSourceRowset->GetSourcesRowset(NULL, IID_IRowset, 0, NULL, (IUnknown**)&pIRowset); if (FAILED(hRes)) { return; } DBBINDING rgBind[1] = {0}; rgBind[0].bPrecision = 0; rgBind[0].bScale = 0; rgBind[0].cbMaxLen = 128 * sizeof(WCHAR); rgBind[0].dwMemOwner = DBMEMOWNER_CLIENTOWNED; rgBind[0].dwPart = DBPART_VALUE; rgBind[0].eParamIO = DBPARAMIO_NOTPARAM; rgBind[0].iOrdinal = 2; //绑定第二项,用于展示数据源 rgBind[0].obLength = 0; rgBind[0].obStatus = 0; rgBind[0].obValue = 0; rgBind[0].wType = DBTYPE_WSTR; HACCESSOR hAccessor = NULL; HROW *rghRows = NULL; PVOID pData = NULL; PVOID pCurrData = NULL; ULONG cRows = 10; COM_DECLARE_INTERFACE(IAccessor); hRes = pIRowset->QueryInterface(IID_IAccessor, (void**)&pIAccessor); if (FAILED(hRes)) { COM_SAFE_RELEASE(pIRowset); return; } hRes = pIAccessor->CreateAccessor(DBACCESSOR_ROWDATA, 1, rgBind, 0, &hAccessor, NULL); DBCOUNTITEM cRowsObtained; if (FAILED(hRes)) { COM_SAFE_RELEASE(pIRowset); COM_SAFE_RELEASE(pIAccessor); return; } pData = MALLOC(rgBind[0].cbMaxLen * cRows); while (TRUE) { hRes = pIRowset->GetNextRows(DB_NULL_HCHAPTER, 0, cRows, &cRowsObtained, &rghRows); if (S_OK != hRes && cRowsObtained == 0) { break; } for (int i = 0; i < cRowsObtained; i++) { pCurrData = (BYTE*)pData + rgBind[0].cbMaxLen * i; pIRowset->GetData(rghRows[i], hAccessor, pCurrData); m_ComboDataSource.AddString((LPOLESTR)pCurrData); } pIRowset->ReleaseRows(cRowsObtained, rghRows, NULL, NULL, NULL); } FREE(pData); pIAccessor->ReleaseAccessor(hAccessor, NULL); }void IDBConnectDlg::OnBnClickedBtnConnectTest() { // TODO: 在此添加控件通知处理程序代码 CStringW csSelected = _T(""); ULONG chEaten = 0; m_ComboDataSource.GetWindowText(csSelected); COM_DECLARE_INTERFACE(IParseDisplayName); COM_DECLARE_INTERFACE(IMoniker); if (m_pConnSourceRowset == NULL) { MessageBox(_T("连接失败")); return; } HRESULT hRes = m_pConnSourceRowset->QueryInterface(IID_IParseDisplayName, (void**)&pIParseDisplayName); if (FAILED(hRes)) { return; } hRes = pIParseDisplayName->ParseDisplayName(NULL, csSelected.AllocSysString(), &chEaten, &pIMoniker); COM_SAFE_RELEASE(pIParseDisplayName); if (FAILED(hRes)) { MessageBox(_T("连接失败")); return; } COM_DECLARE_INTERFACE(IDBProperties); hRes = BindMoniker(pIMoniker, 0, IID_IDBProperties, (void**)&pIDBProperties); COM_SAFE_RELEASE(pIMoniker); if (FAILED(hRes)) { MessageBox(_T("连接失败")); return; } //获取用户输入 CStringW csDB = _T(""); CStringW csUser = _T(""); CStringW csPasswd = _T(""); GetDlgItemText(IDC_EDIT_USERNAME, csUser); GetDlgItemText(IDC_EDIT_PASSWORD, csPasswd); GetDlgItemText(IDC_EDIT_DATABASE, csDB); //设置链接属性 DBPROP connProp[5] = {0}; DBPROPSET connPropset[1] = {0}; connProp[0].colid = DB_NULLID; connProp[0].dwOptions = DBPROPOPTIONS_REQUIRED; connProp[0].dwPropertyID = DBPROP_INIT_DATASOURCE; connProp[0].vValue.vt = VT_BSTR; connProp[0].vValue.bstrVal = csSelected.AllocSysString(); connProp[1].colid = DB_NULLID; connProp[1].dwOptions = DBPROPOPTIONS_REQUIRED; connProp[1].dwPropertyID = DBPROP_INIT_CATALOG; connProp[1].vValue.vt = VT_BSTR; connProp[1].vValue.bstrVal = csDB.AllocSysString(); connProp[2].colid = DB_NULLID; connProp[2].dwOptions = DBPROPOPTIONS_REQUIRED; connProp[2].dwPropertyID = DBPROP_AUTH_USERID; connProp[2].vValue.vt = VT_BSTR; connProp[2].vValue.bstrVal = csUser.AllocSysString(); connProp[3].colid = DB_NULLID; connProp[3].dwOptions = DBPROPOPTIONS_REQUIRED; connProp[3].dwPropertyID = DBPROP_AUTH_PASSWORD; connProp[3].vValue.vt = VT_BSTR; connProp[3].vValue.bstrVal = csPasswd.AllocSysString(); connPropset[0].cProperties = 4; connPropset[0].guidPropertySet = DBPROPSET_DBINIT; connPropset[0].rgProperties = connProp; hRes = pIDBProperties->SetProperties(1, connPropset); if (FAILED(hRes)) { COM_SAFE_RELEASE(pIDBProperties); return; } COM_DECLARE_INTERFACE(IDBInitialize); hRes = pIDBProperties ->QueryInterface(IID_IDBInitialize, (void**)&pIDBInitialize); COM_SAFE_RELEASE(pIDBProperties); if (FAILED(hRes)) { return; } hRes = pIDBInitialize->Initialize(); if (FAILED(hRes)) { MessageBox(_T("连接失败")); }else { MessageBox(_T("连接成功")); } pIDBInitialize->Uninitialize(); COM_SAFE_RELEASE(pIDBInitialize); }最后,这次由于是一个MFC的程序,涉及到的代码文件比较多,因此就不像之前那样以代码片段的方式方上来了,这次我将其以项目的方式放到GitHub上供大家参考。项目地址
-
OLEDB 调用存储过程 除了常规调用sql语句和进行简单的插入删除操作外,OLEDB还提供了调用存储过程的功能,存储过程就好像是用SQL语句写成的一个函数,可以有参数,有返回值。存储过程除了像普通函数那样返回一般的值以外,还可以返回结果集,对于返回的内容可以使用输出参数的方式获取,但是如果返回的是结果集,一般不推荐使用输出参数来获取,一般采用的是使用多结果集来接收。另外对于输入参数一般采用参数化查询的方式进行,因此它的使用与参数化查询类似,但是相比于参数化查询来说要复杂一些。存储过程的使用对于输出参数,在绑定DBBINDING 结构的时候,将结构的eParamIO指定为DBPARAMIO_OUTPUT,调用存储过程可以使用类似下面的格式{? = call myProc(?, ?)}这个样式中两个大括号是必须的,其中?代表的输入输出参数,call表示调用存储过程,也是必须的。一般来说,存储过程的参数位置只接受输入,不作为输出参数,而存储过程的返回值位置只作为输出,不作为输入。另外最需要注意的一点是:当存储过程返回结果集的时候,返回的结果集指针如果没有被释放的话,输出参数的缓冲是不会被刷新的,也就是接收不到输出参数。这是由于数据提供者在返回这些数据的时候是按照流的方式。而结果集的流在输出参数和返回值的流之前,所以在结果集未被释放之前,应用程序是接收不到输出参数的。针对他的这个特性,我们一般是先使用存储过程返回的结果集,然后释放结果集的相关指针,接着从输出参数的缓冲中取出数据,最后释放这些缓冲。存储过程使用的例子BOOL ExecUsp(IOpenRowset *pIOpenRowset) { IAccessor *pParamAccessor = NULL; LPOLESTR pSQL = OLESTR("{? = call Usp_InputOutput(?,?)}"); DB_UPARAMS cParams = 0; DBPARAMINFO* rgParamInfo = NULL; DBBINDING* rgParamBind = NULL; LPOLESTR pParamNames = NULL; DWORD dwOffset = 0; HACCESSOR hAccessor = NULL; TCHAR szInputBuffer[11] = _T(""); DBPARAMS dbParams = {0}; BOOL bRet = FALSE; HRESULT hRes = pIOpenRowset->QueryInterface(IID_IDBCreateCommand, (void**)&pIDBCreateCommand); hRes = pIDBCreateCommand->CreateCommand(NULL, IID_ICommandText, (IUnknown**)&pICommandText); hRes = pICommandText->SetCommandText(DBGUID_DEFAULT, pSQL); hRes = pICommandText->QueryInterface(IID_ICommandPrepare, (void**)&pICommandPrepare); hRes = pICommandPrepare->Prepare(0); hRes = pICommandText->QueryInterface(IID_ICommandWithParameters, (void**)&pICommandWithParameters); hRes = pICommandWithParameters->GetParameterInfo(&cParams, &rgParamInfo, &pParamNames); //参数绑定 rgParamBind = (DBBINDING*)MALLOC(sizeof(DBBINDING) * cParams); for (int i = 0; i < cParams; i++) { rgParamBind[i].bPrecision = 11; rgParamBind[i].bScale = rgParamInfo[i].bScale; rgParamBind[i].cbMaxLen = rgParamInfo[i].ulParamSize; //由于都是int型,所以这里就不需要指定多余的缓冲 rgParamBind[i].iOrdinal = rgParamInfo[i].iOrdinal; rgParamBind[i].dwPart = DBPART_VALUE; //当发现参数是输入参数的时候,在eParamIO中加一个输入参数的性质, if (rgParamInfo[i].dwFlags & DBPARAMFLAGS_ISINPUT) { rgParamBind[i].eParamIO |= DBPARAMIO_INPUT; } //同上 if (rgParamInfo[i].dwFlags & DBPARAMFLAGS_ISOUTPUT) { rgParamBind[i].eParamIO |= DBPARAMIO_OUTPUT; } rgParamBind[i].dwMemOwner = DBMEMOWNER_CLIENTOWNED; rgParamBind[i].obLength = 0; rgParamBind[i].obStatus = 0; rgParamBind[i].obValue = dwOffset; dwOffset = rgParamBind[i].obValue + rgParamBind[i].cbMaxLen; rgParamBind[i].wType = rgParamInfo[i].wType; //其实他们都是int型 } //创建参数的访问器 hRes = pICommandText->QueryInterface(IID_IAccessor, (void**)&pParamAccessor); COM_SUCCESS(hRes, _T("查询接口pParamAccessor失败,错误码为:%08x\n"), hRes); hRes = pParamAccessor->CreateAccessor(DBACCESSOR_PARAMETERDATA, cParams, rgParamBind, dwOffset, &hAccessor, NULL); COM_SUCCESS(hRes, _T("创建访问器失败,错误码为:%08x\n"), hRes); //设置参数值 dbParams.pData = MALLOC(dwOffset); ZeroMemory(dbParams.pData , dwOffset); dbParams.cParamSets = cParams; dbParams.hAccessor = hAccessor; for (int i = 0; i < cParams; i++) { if (rgParamBind[i].eParamIO & DBPARAMIO_INPUT) { COM_PRINT(_T("请输入第%d个参数的值[%s]:"), i + 1, rgParamInfo[i].pwszName); while (S_OK != StringCchGets(szInputBuffer, 11)); *(int*)((BYTE*)dbParams.pData + rgParamBind[i].obValue) = _ttoi(szInputBuffer); ZeroMemory(szInputBuffer, 11 * sizeof(TCHAR)); } } hRes = pICommandText->Execute(NULL, IID_IMultipleResults, &dbParams, NULL, (IUnknown**)&pIMultipleResults); //读取结果集 ReadRowset(pIMultipleResults); COM_PRINT(_T("返回值为:%d\n"), *(int*)dbParams.pData) bRet = TRUE; __CLEAR_UP: CoTaskMemFree(rgParamInfo); FREE(rgParamBind); CoTaskMemFree(pParamNames); FREE(dbParams.pData); SAFE_RELEASE(pIDBCreateCommand); SAFE_RELEASE(pICommandText); SAFE_RELEASE(pICommandPrepare); SAFE_RELEASE(pICommandWithParameters); SAFE_RELEASE(pParamAccessor); SAFE_RELEASE(pIMultipleResults); return bRet; }上述代码中调用的存储过程如下:ALTER PROCEDURE [dbo].[Usp_InputOutput] @input int, @output int Output AS BEGIN select @input, @output set @output = 2 return 7 END该存储过程输入两个参数,并通过select返回有这两个参数组成的结果集。存储过程的输出参数为7.在上述代码中,先定义了一个调用存储过程的sql语句,接着在ICommandText对象中设置该存储过程,然后获取参数的相关信息,然后绑定参数,提供输出、输出参数的缓冲,然后执行存储过程获取结果集。接着读取结果集。最后读取返回值。上面我们说过如果不释放返回的结果集的指针的话,是接收不到返回值的,但是在这段代码中好像在读取返回值之前没有释放返回的IMultipleResults指针的操作,但是还是可以取到结果集的,这是为什么呢?其实之前说的是返回的结果集,但是并没有说是多行结果集,这里释放的主要是结果集。针对多行结果集,我们只要释放它里面包含的所有结果集对象就可以了。释放结果集的代码在函数ReadRowset中,这里并没有列举出来。最后:完整的代码:请点击这里查看