搜索到
9
篇与
的结果
-
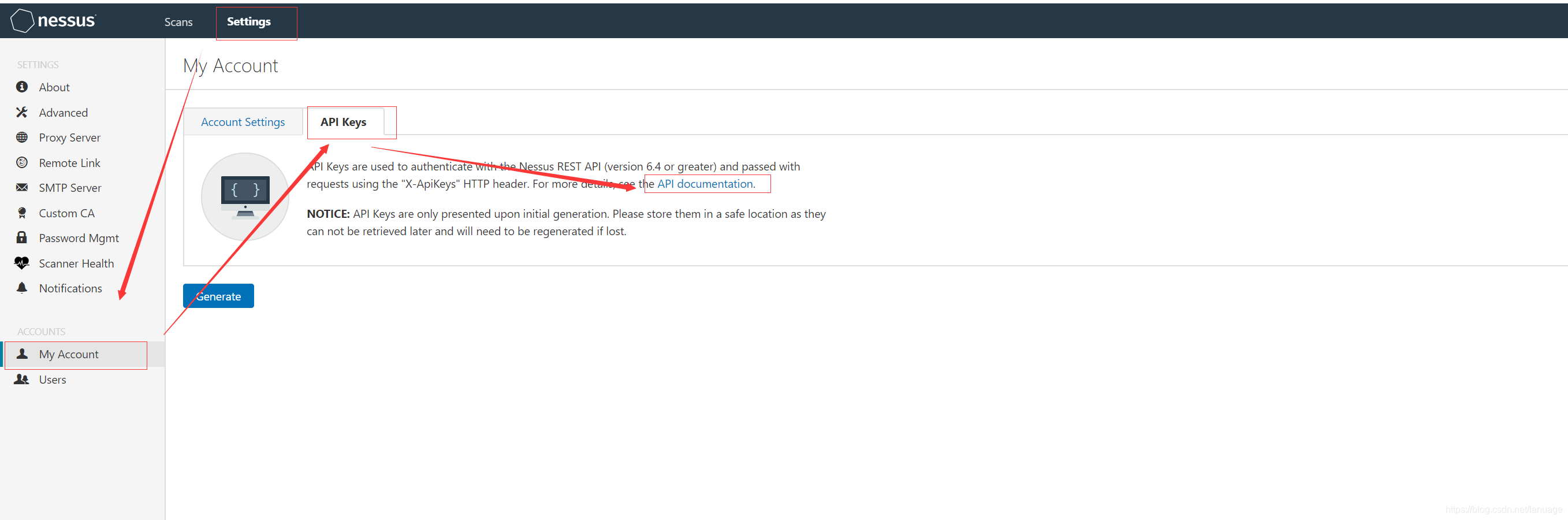
 使用Python调用Nessus 接口实现自动化扫描 之前在项目中需要接入nessus扫描器,研究了一下nessus的api,现在将自己的成果分享出来。Nessus提供了丰富的二次开发接口,无论是接入其他系统还是自己实现自动化扫描,都十分方便。同时Nessus也提供了完备的API文档,可以在 Settings->My Account->API Keys->API documentation认证nessus提供两种认证方式,第一种采用常规的登录后获取token的方式,在https://localhost:8834/api#/resources/session条目中可以找到这种方式,它的接口定义如下:POST /session { "username":{string}, "password":{string} }输入正确的用户名和密码,登录成功后会返回一个token{ "token": {string} }在后续请求中,将token放入请求头信息中请求头的key为X-Cookie,值为 token=xxxx,例如 :X-Cookie: token=5fa3d3fd97edcf40a41bb4dbdfd0b470ba45dde04ebc37f8;,下面是获取任务列表的例子import requests import json def get_token(ip, port, username, password): url = "https://{0}:{1}/session".format(ip, port) post_data = { 'username': username, 'password': password } respon = requests.post(url, data=post_data, verify=False) if response.status_code == 200: data = json.loads(response.text) return data["token"] def get_scan_list() # 这里ip和port可以从配置文件中读取或者从数据库读取,这里我省略了获取这些配置值得操作 url = "https://{ip}:{port}/scans".format(ip, port) token = get_token(ip, port, username, password) if token: header = { "X-Cookie":"token={0}".format(token), "Content-Type":"application/json" } response = requests.get(url, headers=header, verify=False) if response.status_code == 200: result = json.loads(respon.text) return result第二种方式是使用Nessus生成的API Key,这里我们可以依次点击 Settings->My Account->API Keys-->Generate按钮,生成一个key,后续使用时填入头信息中,还是以获取扫描任务列表作为例子def get_scan_list() accessKey = "XXXXXX" #此处填入真实的内容 secretKey = "XXXXXX" #此处填入真实内容 url = "https://{ip}:{port}/scans".format(ip, port) token = get_token(ip, port, username, password) if token: header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accessKey, secretkey=secretKey) "Content-Type":"application/json" } response = requests.get(url, headers=header, verify=False) if response.status_code == 200: result = json.loads(respon.text) return result对比来看使用第二种明显方便一些,因此后续例子都采用第二种方式来呈现策略模板配置策略模板的接口文档在 https://localhost:8834/api#/resources/policies 中。创建策略模板创建策略模板使用的是 策略模板的create接口,它里面有一个必须填写的参数 uuid 这个参数是一个uuid值,表示以哪种现有模板进行创建。在创建之前需要先获取系统中可用的模板。获取的接口是 /editor/{type}/templates,type 可以选填policy或者scan。这里我们填policy一般我们都是使用模板中的 Advanced 来创建,如下图下面是获取该模板uuid的方法,主要思路是获取系统中所有模板,然后根据模板名称返回对应的uuid值def get_nessus_template_uuid(ip, port, template_name = "advanced"): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/editor/scan/templates".format(ip=ip, port=port) response = requests.get(api, headers=header, verify=False) templates = json.loads(response.text)['templates'] for template in templates: if template['name'] == template_name: return template['uuid'] return None有了这个id之后,下面来创建策略模板,这个接口的参数较多,但是很多参数都是选填项。这个部分文档写的很简陋,很多参数不知道是干嘛用的,当时我为了搞清楚每个参数的作用,一个个的尝试,然后去界面上看它的效果,最后终于把我感兴趣的给弄明白了。 它的主体部分如下:{ "uuid": {template_uuid}, "audits": { "feed": { "add": [ { "id": {audit_id}, "variables": { "1": {audit_variable_value}, "2": {audit_variable_value}, "3": {audit_variable_value} } } ] } }, "credentials": { "add": { {credential_category}: { {credential_name}: [ { {credential_input_name}: {string} } ] } } }, "plugins": { {plugin_family_name}: { "status": {string}, "individual": { {plugin_id}: {string} } } }, "scap": { "add": { {scap_category}: [ { {scap_input_name}: {string} } ] } }, "settings": { "acls": [ permission Resource ], //其他的减值对,这里我将他们都省略了 }他们与界面上配置的几个大项有对应关系,能对应的上的我给做了标记,但是有的部分对应不上。settings 是给策略模板做基础配置的,包括配置扫描的端口范围,服务检测范围等等。credentials 是配置登录扫描的,主要包括 windows、ssh、telnet等等plugins 配置扫描使用的插件,例如服务扫描版本漏洞等等在settings中,对应关系如下图所示下面是创建扫描策略模板的实际例子:def create_template(ip, port, **kwargs): # kwargs 作为可选参数,用来配置settings和其他项 header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } policys = {} # 这里 grouppolicy_set 存储的是策略模板中各个脚本名称以及脚本是否启用的信息 for policy in grouppolicy_set: enabled = "enabled" if policy.enable else "disabled" policys[policy.name] = { "status": enabled } # settings里面的各小项必须得带上,否则会创建不成功 "settings": { "name": template.name, "watchguard_offline_configs": "", "unixfileanalysis_disable_xdev": "no", "unixfileanalysis_include_paths": "", "unixfileanalysis_exclude_paths": "", "unixfileanalysis_file_extensions": "", "unixfileanalysis_max_size": "", "unixfileanalysis_max_cumulative_size": "", "unixfileanalysis_max_depth": "", "unix_docker_scan_scope": "host", "sonicos_offline_configs": "", "netapp_offline_configs": "", "junos_offline_configs": "", "huawei_offline_configs": "", "procurve_offline_configs": "", "procurve_config_to_audit": "Saved/(show config)", "fortios_offline_configs": "", "fireeye_offline_configs": "", "extremeos_offline_configs": "", "dell_f10_offline_configs": "", "cisco_offline_configs": "", "cisco_config_to_audit": "Saved/(show config)", "checkpoint_gaia_offline_configs": "", "brocade_offline_configs": "", "bluecoat_proxysg_offline_configs": "", "arista_offline_configs": "", "alcatel_timos_offline_configs": "", "adtran_aos_offline_configs": "", "patch_audit_over_telnet": "no", "patch_audit_over_rsh": "no", "patch_audit_over_rexec": "no", "snmp_port": "161", "additional_snmp_port1": "161", "additional_snmp_port2": "161", "additional_snmp_port3": "161", "http_login_method": "POST", "http_reauth_delay": "", "http_login_max_redir": "0", "http_login_invert_auth_regex": "no", "http_login_auth_regex_on_headers": "no", "http_login_auth_regex_nocase": "no", "never_send_win_creds_in_the_clear": "yes" if kwargs["never_send_win_creds_in_the_clear"] else "no", "dont_use_ntlmv1": "yes" if kwargs["dont_use_ntlmv1"] else "no", "start_remote_registry": "yes" if kwargs["start_remote_registry"] else "no", "enable_admin_shares": "yes" if kwargs["enable_admin_shares"] else "no", "ssh_known_hosts": "", "ssh_port": kwargs["ssh_port"], "ssh_client_banner": "OpenSSH_5.0", "attempt_least_privilege": "no", "region_dfw_pref_name": "yes", "region_ord_pref_name": "yes", "region_iad_pref_name": "yes", "region_lon_pref_name": "yes", "region_syd_pref_name": "yes", "region_hkg_pref_name": "yes", "microsoft_azure_subscriptions_ids": "", "aws_ui_region_type": "Rest of the World", "aws_us_east_1": "", "aws_us_east_2": "", "aws_us_west_1": "", "aws_us_west_2": "", "aws_ca_central_1": "", "aws_eu_west_1": "", "aws_eu_west_2": "", "aws_eu_west_3": "", "aws_eu_central_1": "", "aws_eu_north_1": "", "aws_ap_east_1": "", "aws_ap_northeast_1": "", "aws_ap_northeast_2": "", "aws_ap_northeast_3": "", "aws_ap_southeast_1": "", "aws_ap_southeast_2": "", "aws_ap_south_1": "", "aws_me_south_1": "", "aws_sa_east_1": "", "aws_use_https": "yes", "aws_verify_ssl": "yes", "log_whole_attack": "no", "enable_plugin_debugging": "no", "audit_trail": "use_scanner_default", "include_kb": "use_scanner_default", "enable_plugin_list": "no", "custom_find_filepath_exclusions": "", "custom_find_filesystem_exclusions": "", "reduce_connections_on_congestion": "no", "network_receive_timeout": "5", "max_checks_per_host": "5", "max_hosts_per_scan": "100", "max_simult_tcp_sessions_per_host": "", "max_simult_tcp_sessions_per_scan": "", "safe_checks": "yes", "stop_scan_on_disconnect": "no", "slice_network_addresses": "no", "allow_post_scan_editing": "yes", "reverse_lookup": "no", "log_live_hosts": "no", "display_unreachable_hosts": "no", "report_verbosity": "Normal", "report_superseded_patches": "yes", "silent_dependencies": "yes", "scan_malware": "no", "samr_enumeration": "yes", "adsi_query": "yes", "wmi_query": "yes", "rid_brute_forcing": "no", "request_windows_domain_info": "no", "scan_webapps": "no", "start_cotp_tsap": "8", "stop_cotp_tsap": "8", "modbus_start_reg": "0", "modbus_end_reg": "16", "hydra_always_enable": "yes" if kwargs["hydra_always_enable"] else "no", "hydra_logins_file": "" if kwargs["hydra_logins_file"] else kwargs["hydra_logins_file"], # 弱口令文件需要事先上传,后面会提到上传文件接口 "hydra_passwords_file": "" if kwargs["hydra_passwords_file"] else kwargs["hydra_passwords_file"], "hydra_parallel_tasks": "16", "hydra_timeout": "30", "hydra_empty_passwords": "yes", "hydra_login_as_pw": "yes", "hydra_exit_on_success": "no", "hydra_add_other_accounts": "yes", "hydra_postgresql_db_name": "", "hydra_client_id": "", "hydra_win_account_type": "Local accounts", "hydra_win_pw_as_hash": "no", "hydra_cisco_logon_pw": "", "hydra_web_page": "", "hydra_proxy_test_site": "", "hydra_ldap_dn": "", "test_default_oracle_accounts": "no", "provided_creds_only": "yes", "smtp_domain": "example.com", "smtp_from": "[email protected]", "smtp_to": "postmaster@[AUTO_REPLACED_IP]", "av_grace_period": "0", "report_paranoia": "Normal", "thorough_tests": "no", "detect_ssl": "yes", "tcp_scanner": "no", "tcp_firewall_detection": "Automatic (normal)", "syn_scanner": "yes", "syn_firewall_detection": "Automatic (normal)", "wol_mac_addresses": "", "wol_wait_time": "5", "scan_network_printers": "no", "scan_netware_hosts": "no", "scan_ot_devices": "no", "ping_the_remote_host": "yes", "tcp_ping": "yes", "icmp_unreach_means_host_down": "no", "test_local_nessus_host": "yes", "fast_network_discovery": "no", "arp_ping": "yes" if kwargs["arp_ping"] else "no", "tcp_ping_dest_ports": kwargs["tcp_ping_dest_ports"], "icmp_ping": "yes" if kwargs["icmp_ping"] else "no", "icmp_ping_retries": kwargs["icmp_ping_retries"], "udp_ping": "yes" if kwargs["udp_ping"] else "no", "unscanned_closed": "yes" if kwargs["unscanned_closed"] else "no", "portscan_range": kwargs["portscan_range"], "ssh_netstat_scanner": "yes" if kwargs["ssh_netstat_scanner"] else "no", "wmi_netstat_scanner": "yes" if kwargs["wmi_netstat_scanner"] else "no", "snmp_scanner": "yes" if kwargs["snmp_scanner"] else "no", "only_portscan_if_enum_failed": "yes" if kwargs["only_portscan_if_enum_failed"] else "no", "verify_open_ports": "yes" if kwargs["verify_open_ports"] else "no", "udp_scanner": "yes" if kwargs["udp_scanner"] else "no", "svc_detection_on_all_ports": "yes" if kwargs["svc_detection_on_all_ports"] else "no", "ssl_prob_ports": "Known SSL ports" if kwargs["ssl_prob_ports"] else "All ports", "cert_expiry_warning_days": kwargs["cert_expiry_warning_days"], "enumerate_all_ciphers": "yes" if kwargs["enumerate_all_ciphers"] else "no", "check_crl": "yes" if kwargs["check_crl"] else "no", } credentials = { "add": { "Host": { "SSH": [], "SNMPv3": [], "Windows": [], }, "Plaintext Authentication": { "telnet/rsh/rexec": [] } } } try: if kwargs["snmpv3_username"] and kwargs["snmpv3_port"] and kwargs["snmpv3_level"]: level = kwargs["snmpv3_level"] if level == NessusSettings.LOW: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "No authentication and no privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"] }) elif level == NessusSettings.MID: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "Authentication without privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"], "auth_algorithm": NessusSettings.AUTH_ALG[kwargs["snmpv3_auth"][1]], "auth_password": kwargs["snmpv3_auth_psd"] }) elif level == NessusSettings.HIGH: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "Authentication and privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"], "auth_algorithm": NessusSettings.AUTH_ALG[kwargs["snmpv3_auth"]][1], "auth_password": kwargs["snmpv3_auth_psd"], "privacy_algorithm": NessusSettings.PPIVACY_ALG[kwargs["snmpv3_hide"]][1], "privacy_password": kwargs["snmpv3_hide_psd"] }) if kwargs["ssh_username"] and kwargs["ssh_psd"]: credentials["add"]["Host"]["SSH"].append( { "auth_method": "password", "username": kwargs["ssh_username"], "password": kwargs["ssh_psd"], "elevate_privileges_with": "Nothing", "custom_password_prompt": "", }) if kwargs["windows_username"] and kwargs["windows_psd"]: credentials["add"]["Host"]["Windows"].append({ "auth_method": "Password", "username": kwargs["windows_username"], "password": kwargs["windows_psd"], "domain": kwargs["ssh_host"] }) if kwargs["telnet_username"] and kwargs["telnet_password"]: credentials["add"]["Plaintext Authentication"]["telnet/rsh/rexec"].append({ "username": kwargs["telnet_username"], "password": kwargs["telnet_password"] }) data = { "uuid": get_nessus_template_uuid(terminal, "advanced"), "settings": settings, "plugins": policys, "credentials": credentials } api = "https://{0}:{1}/policies".format(ip, port) response = requests.post(api, headers=header, data=json.dumps(data, ensure_ascii=False).encode("utf-8"), # 这里做一个转码防止在nessus端发生中文乱码 verify=False) if response.status_code == 200: data = json.loads(response.text) return data["policy_id"] # 返回策略模板的id,后续可以在创建任务时使用 else: return None策略还有copy、delete、config等操作,这里就不再介绍了,这个部分主要弄清楚各参数的作用,后面的这些接口使用的参数都是一样的任务任务部分的API 在https://localhost:8834/api#/resources/scans 中创建任务创建任务重要的参数如下说明如下:uuid: 创建任务时使用的模板id,这个id同样是我们上面说的系统自带的模板idname:任务名称policy_id:策略模板ID,这个是可选的,如果要使用上面我们自己定义的扫描模板,需要使用这个参数来指定,并且设置上面的uuid为 custom 的uuid,这个值表示使用用户自定义模板;当然如果就想使用系统提供的,这个字段可以不填text_targets:扫描目标地址,这个参数是一个数组,可以填入多个目标地址,用来一次扫描多个主机创建任务的例子如下:def create_task(task_name, policy_id, hosts): # host 是一个列表,存放的是需要扫描的多台主机 uuid = get_nessus_template_uuid(terminal, "custom") # 获取自定义策略的uuid if uuid is None: return False data = {"uuid": uuid, "settings": { "name": name, "policy_id": policy_id, "enabled": True, "text_targets": hosts, "agent_group_id": [] }} header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/scans".format(ip=terminal.ip, port=terminal.port) response = requests.post(api, headers=header, data=json.dumps(data, ensure_ascii=False).encode("utf-8"), verify=False) if response.status_code == 200: data = json.loads(response.text) if data["scan"] is not None: scan = data["scan"] # 新增任务扩展信息记录 return scan["id"] # 返回任务id启动/停止任务启动任务的接口为 POST /scans/{scan_id}/launch scan_id 是上面创建任务返回的任务ID, 它有个可选参数 alt_targets,如果这个参数被指定,那么该任务可以扫描这个参数中指定的主机,而之前创建任务时指定的主机将被替代停止任务的接口为: POST /scans/{scan_id}/stop下面给出启动和停止任务的方法def start_task(task_id, hosts): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} data = { "alt_targets": [hosts] # 重新指定扫描地址 } api = "https://{ip}:{port}/scans/{scan_id}/launch".format(ip=ip, port=port, scan_id=scan_id) response = requests.post(api, data=data, verify=False, headers=header) if response.status_code != 200: return False else: return True def stop_task(task_id): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=terminal.reserved1, secretkey=terminal.reserved2), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/scans/{scan_id}/stop".format(ip=ip, port=port, task_id) response = requests.post(api, headers=header, verify=False) if response.status_code == 200 or response.status_code == 409: # 根据nessus api文档可以知道409 表示任务已结束 return True return False获取扫描结果使用接口 GET /scans/{scan_id} 可以获取最近一次扫描的任务信息,从接口文档上看,它还可以获取某次历史扫描记录的信息,如果不填这个参数,接口中会返回所有历史记录的id。如果不填历史记录id,那么会返回最近一次扫描到的漏洞信息,也就是说新扫描到的信息会把之前的信息给覆盖下面是返回信息的部分说明{ "info": { "edit_allowed": {boolean}, "status": {string}, //当前状态 completed 字符串表示结束,cancel表示停止 "policy": {string}, "pci-can-upload": {boolean}, "hasaudittrail": {boolean}, "scan_start": {string}, "folder_id": {integer}, "targets": {string}, "timestamp": {integer}, "object_id": {integer}, "scanner_name": {string}, "haskb": {boolean}, "uuid": {string}, "hostcount": {integer}, "scan_end": {string}, "name": {string}, "user_permissions": {integer}, "control": {boolean} }, "hosts": [ //按主机区分的漏洞信息 host Resource ], "comphosts": [ host Resource ], "notes": [ note Resource ], "remediations": { "remediations": [ remediation Resource ], "num_hosts": {integer}, "num_cves": {integer}, "num_impacted_hosts": {integer}, "num_remediated_cves": {integer} }, "vulnerabilities": [ vulnerability Resource //本次任务扫描到的漏洞信息 ], "compliance": [ vulnerability Resource ], "history": [ history Resource //历史扫描信息,可以从这个信息中获取历史记录的id ], "filters": [ filter Resource ] }这个信息里面vulnerabilities和host里面都可以拿到漏洞信息,但是 vulnerabilities中是扫描到的所有漏洞信息,而host则需要根据id再次提交请求,也就是需要额外一次请求,但它是按照主机对扫描到的漏洞进行了分类。而使用vulnerabilities则需要根据漏洞信息中的host_id 手工进行分类下面是获取任务状态的示例:def get_task_status(task_id): header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } api = "https://{ip}:{port}/scans/{task_id}".format(ip=ip, port=port, task_id=task_id) response = requests.get(api, headers=header, verify=False) if response.status_code != 200: return 2, "Data Error" data = json.loads(response.text) hosts = data["hosts"] for host in hosts: get_host_vulnerabilities(scan_id, host["host_id"]) # 按主机获取漏洞信息 if data["info"]["status"] == "completed" or data["info"]["status"] =='canceled': # 已完成,此时更新本地任务状态 return 1, "OK"获取漏洞信息在获取任务信息中,已经得到了本次扫描中发现的弱点信息了,只需要我们解析这个json。它具体的内容如下:"host_id": {integer}, //主机id "host_index": {string}, "hostname": {integer},//主机名称 "progress": {string}, //扫描进度 "critical": {integer}, //危急漏洞数 "high": {integer}, //高危漏洞数 "medium": {integer}, //中危漏洞数 "low": {integer}, //低危漏洞数 "info": {integer}, //相关信息数目 "totalchecksconsidered": {integer}, "numchecksconsidered": {integer}, "scanprogresstotal": {integer}, "scanprogresscurrent": {integer}, "score": {integer}根据主机ID可以使用 GET /scans/{scan_id}/hosts/{host_id} 接口获取主机信息,它需要两个参数,一个是扫描任务id,另一个是主机id。下面列举出来的是返回值得部分内容,只列举了我们感兴趣的部分:{ "info": { "host_start": {string}, "mac-address": {string}, "host-fqdn": {string}, "host_end": {string}, "operating-system": {string}, "host-ip": {string} }, "vulnerabilities": [ { "host_id": {integer}, //主机id "hostname": {string}, //主机名称 "plugin_id": {integer}, //策略id "plugin_name": {string}, //策略名称 "plugin_family": {string}, //所属策略组 "count": {integer}, //该种漏洞数 "vuln_index": {integer}, "severity_index": {integer}, "severity": {integer} } ], }根据上面获取任务信息中得到的主机id和任务id,我们可以实现这个功能def get_host_vulnerabilities(scan_id, host_id): header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } scan_history = ScanHistory.objects.get(id=scan_id) api = "https://{ip}:{port}/scans/{task_id}/hosts/{host_id}".format(ip=ip, port=port, task_id=scan_id, host_id=host_id) response = requests.get(api, headers=header, verify=False) if response.status_code != 200: return 2, "Data Error" data = json.loads(response.text) vulns = data["vulnerabilities"] for vuln in vulns: vuln_name = vuln["plugin_name"] plugin_id = vuln["plugin_id"] #插件id,可以获取更详细信息,包括插件自身信息和扫描到漏洞的解决方案等信息 #保存漏洞信息获取漏洞输出信息与漏洞知识库信息我们在nessus web页面中可以看到每条被检测到的漏洞在展示时会有输出信息和知识库信息,这些信息也可以根据接口来获取获取漏洞的知识库可以通过接口 GET /scans/{scan_id}/hosts/{host_id}/plugins/{plugin_id} , 它的路径为: https://localhost:8834/api#/resources/scans/plugin-output它返回的值如下:{ "info": { "plugindescription": { "severity": {integer}, //危险等级,从info到最后的critical依次为1,2,3,4,5 "pluginname": {string}, "pluginattributes": { "risk_information": { "risk_factor": {string} }, "plugin_name": {string}, //插件名称 "plugin_information": { "plugin_id": {integer}, "plugin_type": {string}, "plugin_family": {string}, "plugin_modification_date": {string} }, "solution": {string}, //漏洞解决方案 "fname": {string}, "synopsis": {string}, "description": {string} //漏洞描述 }, "pluginfamily": {string}, "pluginid": {integer} } }, "output": [ plugin_output:{ "plugin_output": {string}, //输出信息 "hosts": {string}, //主机信息 "severity": {integer}, "ports": {} //端口信息 } ] }有了这些信息,我们可以通过下面的代码获取这些信息:def get_vuln_detail(scan_id, host_id, plugin_id) header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } api = "https://{ip}:{port}/scans/{scan_id}/hosts/{host_id}/plugins/{plugin_id}".format(ip=ip, port=port, scan_id=scan_id, host_id=host_id, plugin_id=plugin_id) response = requests.get(api, headers=header, verify=False) data = json.loads(response.text) outputs = data["outputs"] return outputs最后总结这篇文章我们主要介绍了nessus API从扫描设置到扫描任务创建、启动、停止、以及结果的获取的内容,当然nessus的api不止这些,但是最重要的应该是这些,如果能帮助各位解决手头上的问题自然是极好的,如果不能或者说各位朋友需要更细致的控制,可以使用浏览器抓包的方式来分析它的请求和响应包。在摸索时最好的两个帮手是浏览器 F12工具栏中的 network和nessus api文档页面上的test工具了。我们可以先按 f12 打开工具并切换到network,然后在页面上执行相关操作,观察发包即可发现该如何使用这些API,因为Nessus Web端在操作时也是使用API。如下图:或者可以使用文档中的test工具,例如下面是测试 获取插件输出信息的接口
使用Python调用Nessus 接口实现自动化扫描 之前在项目中需要接入nessus扫描器,研究了一下nessus的api,现在将自己的成果分享出来。Nessus提供了丰富的二次开发接口,无论是接入其他系统还是自己实现自动化扫描,都十分方便。同时Nessus也提供了完备的API文档,可以在 Settings->My Account->API Keys->API documentation认证nessus提供两种认证方式,第一种采用常规的登录后获取token的方式,在https://localhost:8834/api#/resources/session条目中可以找到这种方式,它的接口定义如下:POST /session { "username":{string}, "password":{string} }输入正确的用户名和密码,登录成功后会返回一个token{ "token": {string} }在后续请求中,将token放入请求头信息中请求头的key为X-Cookie,值为 token=xxxx,例如 :X-Cookie: token=5fa3d3fd97edcf40a41bb4dbdfd0b470ba45dde04ebc37f8;,下面是获取任务列表的例子import requests import json def get_token(ip, port, username, password): url = "https://{0}:{1}/session".format(ip, port) post_data = { 'username': username, 'password': password } respon = requests.post(url, data=post_data, verify=False) if response.status_code == 200: data = json.loads(response.text) return data["token"] def get_scan_list() # 这里ip和port可以从配置文件中读取或者从数据库读取,这里我省略了获取这些配置值得操作 url = "https://{ip}:{port}/scans".format(ip, port) token = get_token(ip, port, username, password) if token: header = { "X-Cookie":"token={0}".format(token), "Content-Type":"application/json" } response = requests.get(url, headers=header, verify=False) if response.status_code == 200: result = json.loads(respon.text) return result第二种方式是使用Nessus生成的API Key,这里我们可以依次点击 Settings->My Account->API Keys-->Generate按钮,生成一个key,后续使用时填入头信息中,还是以获取扫描任务列表作为例子def get_scan_list() accessKey = "XXXXXX" #此处填入真实的内容 secretKey = "XXXXXX" #此处填入真实内容 url = "https://{ip}:{port}/scans".format(ip, port) token = get_token(ip, port, username, password) if token: header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accessKey, secretkey=secretKey) "Content-Type":"application/json" } response = requests.get(url, headers=header, verify=False) if response.status_code == 200: result = json.loads(respon.text) return result对比来看使用第二种明显方便一些,因此后续例子都采用第二种方式来呈现策略模板配置策略模板的接口文档在 https://localhost:8834/api#/resources/policies 中。创建策略模板创建策略模板使用的是 策略模板的create接口,它里面有一个必须填写的参数 uuid 这个参数是一个uuid值,表示以哪种现有模板进行创建。在创建之前需要先获取系统中可用的模板。获取的接口是 /editor/{type}/templates,type 可以选填policy或者scan。这里我们填policy一般我们都是使用模板中的 Advanced 来创建,如下图下面是获取该模板uuid的方法,主要思路是获取系统中所有模板,然后根据模板名称返回对应的uuid值def get_nessus_template_uuid(ip, port, template_name = "advanced"): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/editor/scan/templates".format(ip=ip, port=port) response = requests.get(api, headers=header, verify=False) templates = json.loads(response.text)['templates'] for template in templates: if template['name'] == template_name: return template['uuid'] return None有了这个id之后,下面来创建策略模板,这个接口的参数较多,但是很多参数都是选填项。这个部分文档写的很简陋,很多参数不知道是干嘛用的,当时我为了搞清楚每个参数的作用,一个个的尝试,然后去界面上看它的效果,最后终于把我感兴趣的给弄明白了。 它的主体部分如下:{ "uuid": {template_uuid}, "audits": { "feed": { "add": [ { "id": {audit_id}, "variables": { "1": {audit_variable_value}, "2": {audit_variable_value}, "3": {audit_variable_value} } } ] } }, "credentials": { "add": { {credential_category}: { {credential_name}: [ { {credential_input_name}: {string} } ] } } }, "plugins": { {plugin_family_name}: { "status": {string}, "individual": { {plugin_id}: {string} } } }, "scap": { "add": { {scap_category}: [ { {scap_input_name}: {string} } ] } }, "settings": { "acls": [ permission Resource ], //其他的减值对,这里我将他们都省略了 }他们与界面上配置的几个大项有对应关系,能对应的上的我给做了标记,但是有的部分对应不上。settings 是给策略模板做基础配置的,包括配置扫描的端口范围,服务检测范围等等。credentials 是配置登录扫描的,主要包括 windows、ssh、telnet等等plugins 配置扫描使用的插件,例如服务扫描版本漏洞等等在settings中,对应关系如下图所示下面是创建扫描策略模板的实际例子:def create_template(ip, port, **kwargs): # kwargs 作为可选参数,用来配置settings和其他项 header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } policys = {} # 这里 grouppolicy_set 存储的是策略模板中各个脚本名称以及脚本是否启用的信息 for policy in grouppolicy_set: enabled = "enabled" if policy.enable else "disabled" policys[policy.name] = { "status": enabled } # settings里面的各小项必须得带上,否则会创建不成功 "settings": { "name": template.name, "watchguard_offline_configs": "", "unixfileanalysis_disable_xdev": "no", "unixfileanalysis_include_paths": "", "unixfileanalysis_exclude_paths": "", "unixfileanalysis_file_extensions": "", "unixfileanalysis_max_size": "", "unixfileanalysis_max_cumulative_size": "", "unixfileanalysis_max_depth": "", "unix_docker_scan_scope": "host", "sonicos_offline_configs": "", "netapp_offline_configs": "", "junos_offline_configs": "", "huawei_offline_configs": "", "procurve_offline_configs": "", "procurve_config_to_audit": "Saved/(show config)", "fortios_offline_configs": "", "fireeye_offline_configs": "", "extremeos_offline_configs": "", "dell_f10_offline_configs": "", "cisco_offline_configs": "", "cisco_config_to_audit": "Saved/(show config)", "checkpoint_gaia_offline_configs": "", "brocade_offline_configs": "", "bluecoat_proxysg_offline_configs": "", "arista_offline_configs": "", "alcatel_timos_offline_configs": "", "adtran_aos_offline_configs": "", "patch_audit_over_telnet": "no", "patch_audit_over_rsh": "no", "patch_audit_over_rexec": "no", "snmp_port": "161", "additional_snmp_port1": "161", "additional_snmp_port2": "161", "additional_snmp_port3": "161", "http_login_method": "POST", "http_reauth_delay": "", "http_login_max_redir": "0", "http_login_invert_auth_regex": "no", "http_login_auth_regex_on_headers": "no", "http_login_auth_regex_nocase": "no", "never_send_win_creds_in_the_clear": "yes" if kwargs["never_send_win_creds_in_the_clear"] else "no", "dont_use_ntlmv1": "yes" if kwargs["dont_use_ntlmv1"] else "no", "start_remote_registry": "yes" if kwargs["start_remote_registry"] else "no", "enable_admin_shares": "yes" if kwargs["enable_admin_shares"] else "no", "ssh_known_hosts": "", "ssh_port": kwargs["ssh_port"], "ssh_client_banner": "OpenSSH_5.0", "attempt_least_privilege": "no", "region_dfw_pref_name": "yes", "region_ord_pref_name": "yes", "region_iad_pref_name": "yes", "region_lon_pref_name": "yes", "region_syd_pref_name": "yes", "region_hkg_pref_name": "yes", "microsoft_azure_subscriptions_ids": "", "aws_ui_region_type": "Rest of the World", "aws_us_east_1": "", "aws_us_east_2": "", "aws_us_west_1": "", "aws_us_west_2": "", "aws_ca_central_1": "", "aws_eu_west_1": "", "aws_eu_west_2": "", "aws_eu_west_3": "", "aws_eu_central_1": "", "aws_eu_north_1": "", "aws_ap_east_1": "", "aws_ap_northeast_1": "", "aws_ap_northeast_2": "", "aws_ap_northeast_3": "", "aws_ap_southeast_1": "", "aws_ap_southeast_2": "", "aws_ap_south_1": "", "aws_me_south_1": "", "aws_sa_east_1": "", "aws_use_https": "yes", "aws_verify_ssl": "yes", "log_whole_attack": "no", "enable_plugin_debugging": "no", "audit_trail": "use_scanner_default", "include_kb": "use_scanner_default", "enable_plugin_list": "no", "custom_find_filepath_exclusions": "", "custom_find_filesystem_exclusions": "", "reduce_connections_on_congestion": "no", "network_receive_timeout": "5", "max_checks_per_host": "5", "max_hosts_per_scan": "100", "max_simult_tcp_sessions_per_host": "", "max_simult_tcp_sessions_per_scan": "", "safe_checks": "yes", "stop_scan_on_disconnect": "no", "slice_network_addresses": "no", "allow_post_scan_editing": "yes", "reverse_lookup": "no", "log_live_hosts": "no", "display_unreachable_hosts": "no", "report_verbosity": "Normal", "report_superseded_patches": "yes", "silent_dependencies": "yes", "scan_malware": "no", "samr_enumeration": "yes", "adsi_query": "yes", "wmi_query": "yes", "rid_brute_forcing": "no", "request_windows_domain_info": "no", "scan_webapps": "no", "start_cotp_tsap": "8", "stop_cotp_tsap": "8", "modbus_start_reg": "0", "modbus_end_reg": "16", "hydra_always_enable": "yes" if kwargs["hydra_always_enable"] else "no", "hydra_logins_file": "" if kwargs["hydra_logins_file"] else kwargs["hydra_logins_file"], # 弱口令文件需要事先上传,后面会提到上传文件接口 "hydra_passwords_file": "" if kwargs["hydra_passwords_file"] else kwargs["hydra_passwords_file"], "hydra_parallel_tasks": "16", "hydra_timeout": "30", "hydra_empty_passwords": "yes", "hydra_login_as_pw": "yes", "hydra_exit_on_success": "no", "hydra_add_other_accounts": "yes", "hydra_postgresql_db_name": "", "hydra_client_id": "", "hydra_win_account_type": "Local accounts", "hydra_win_pw_as_hash": "no", "hydra_cisco_logon_pw": "", "hydra_web_page": "", "hydra_proxy_test_site": "", "hydra_ldap_dn": "", "test_default_oracle_accounts": "no", "provided_creds_only": "yes", "smtp_domain": "example.com", "smtp_from": "[email protected]", "smtp_to": "postmaster@[AUTO_REPLACED_IP]", "av_grace_period": "0", "report_paranoia": "Normal", "thorough_tests": "no", "detect_ssl": "yes", "tcp_scanner": "no", "tcp_firewall_detection": "Automatic (normal)", "syn_scanner": "yes", "syn_firewall_detection": "Automatic (normal)", "wol_mac_addresses": "", "wol_wait_time": "5", "scan_network_printers": "no", "scan_netware_hosts": "no", "scan_ot_devices": "no", "ping_the_remote_host": "yes", "tcp_ping": "yes", "icmp_unreach_means_host_down": "no", "test_local_nessus_host": "yes", "fast_network_discovery": "no", "arp_ping": "yes" if kwargs["arp_ping"] else "no", "tcp_ping_dest_ports": kwargs["tcp_ping_dest_ports"], "icmp_ping": "yes" if kwargs["icmp_ping"] else "no", "icmp_ping_retries": kwargs["icmp_ping_retries"], "udp_ping": "yes" if kwargs["udp_ping"] else "no", "unscanned_closed": "yes" if kwargs["unscanned_closed"] else "no", "portscan_range": kwargs["portscan_range"], "ssh_netstat_scanner": "yes" if kwargs["ssh_netstat_scanner"] else "no", "wmi_netstat_scanner": "yes" if kwargs["wmi_netstat_scanner"] else "no", "snmp_scanner": "yes" if kwargs["snmp_scanner"] else "no", "only_portscan_if_enum_failed": "yes" if kwargs["only_portscan_if_enum_failed"] else "no", "verify_open_ports": "yes" if kwargs["verify_open_ports"] else "no", "udp_scanner": "yes" if kwargs["udp_scanner"] else "no", "svc_detection_on_all_ports": "yes" if kwargs["svc_detection_on_all_ports"] else "no", "ssl_prob_ports": "Known SSL ports" if kwargs["ssl_prob_ports"] else "All ports", "cert_expiry_warning_days": kwargs["cert_expiry_warning_days"], "enumerate_all_ciphers": "yes" if kwargs["enumerate_all_ciphers"] else "no", "check_crl": "yes" if kwargs["check_crl"] else "no", } credentials = { "add": { "Host": { "SSH": [], "SNMPv3": [], "Windows": [], }, "Plaintext Authentication": { "telnet/rsh/rexec": [] } } } try: if kwargs["snmpv3_username"] and kwargs["snmpv3_port"] and kwargs["snmpv3_level"]: level = kwargs["snmpv3_level"] if level == NessusSettings.LOW: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "No authentication and no privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"] }) elif level == NessusSettings.MID: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "Authentication without privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"], "auth_algorithm": NessusSettings.AUTH_ALG[kwargs["snmpv3_auth"][1]], "auth_password": kwargs["snmpv3_auth_psd"] }) elif level == NessusSettings.HIGH: credentials["add"]["Host"]["SNMPv3"].append({ "security_level": "Authentication and privacy", "username": kwargs["snmpv3_username"], "port": kwargs["snmpv3_port"], "auth_algorithm": NessusSettings.AUTH_ALG[kwargs["snmpv3_auth"]][1], "auth_password": kwargs["snmpv3_auth_psd"], "privacy_algorithm": NessusSettings.PPIVACY_ALG[kwargs["snmpv3_hide"]][1], "privacy_password": kwargs["snmpv3_hide_psd"] }) if kwargs["ssh_username"] and kwargs["ssh_psd"]: credentials["add"]["Host"]["SSH"].append( { "auth_method": "password", "username": kwargs["ssh_username"], "password": kwargs["ssh_psd"], "elevate_privileges_with": "Nothing", "custom_password_prompt": "", }) if kwargs["windows_username"] and kwargs["windows_psd"]: credentials["add"]["Host"]["Windows"].append({ "auth_method": "Password", "username": kwargs["windows_username"], "password": kwargs["windows_psd"], "domain": kwargs["ssh_host"] }) if kwargs["telnet_username"] and kwargs["telnet_password"]: credentials["add"]["Plaintext Authentication"]["telnet/rsh/rexec"].append({ "username": kwargs["telnet_username"], "password": kwargs["telnet_password"] }) data = { "uuid": get_nessus_template_uuid(terminal, "advanced"), "settings": settings, "plugins": policys, "credentials": credentials } api = "https://{0}:{1}/policies".format(ip, port) response = requests.post(api, headers=header, data=json.dumps(data, ensure_ascii=False).encode("utf-8"), # 这里做一个转码防止在nessus端发生中文乱码 verify=False) if response.status_code == 200: data = json.loads(response.text) return data["policy_id"] # 返回策略模板的id,后续可以在创建任务时使用 else: return None策略还有copy、delete、config等操作,这里就不再介绍了,这个部分主要弄清楚各参数的作用,后面的这些接口使用的参数都是一样的任务任务部分的API 在https://localhost:8834/api#/resources/scans 中创建任务创建任务重要的参数如下说明如下:uuid: 创建任务时使用的模板id,这个id同样是我们上面说的系统自带的模板idname:任务名称policy_id:策略模板ID,这个是可选的,如果要使用上面我们自己定义的扫描模板,需要使用这个参数来指定,并且设置上面的uuid为 custom 的uuid,这个值表示使用用户自定义模板;当然如果就想使用系统提供的,这个字段可以不填text_targets:扫描目标地址,这个参数是一个数组,可以填入多个目标地址,用来一次扫描多个主机创建任务的例子如下:def create_task(task_name, policy_id, hosts): # host 是一个列表,存放的是需要扫描的多台主机 uuid = get_nessus_template_uuid(terminal, "custom") # 获取自定义策略的uuid if uuid is None: return False data = {"uuid": uuid, "settings": { "name": name, "policy_id": policy_id, "enabled": True, "text_targets": hosts, "agent_group_id": [] }} header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/scans".format(ip=terminal.ip, port=terminal.port) response = requests.post(api, headers=header, data=json.dumps(data, ensure_ascii=False).encode("utf-8"), verify=False) if response.status_code == 200: data = json.loads(response.text) if data["scan"] is not None: scan = data["scan"] # 新增任务扩展信息记录 return scan["id"] # 返回任务id启动/停止任务启动任务的接口为 POST /scans/{scan_id}/launch scan_id 是上面创建任务返回的任务ID, 它有个可选参数 alt_targets,如果这个参数被指定,那么该任务可以扫描这个参数中指定的主机,而之前创建任务时指定的主机将被替代停止任务的接口为: POST /scans/{scan_id}/stop下面给出启动和停止任务的方法def start_task(task_id, hosts): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey), 'Content-type': 'application/json', 'Accept': 'text/plain'} data = { "alt_targets": [hosts] # 重新指定扫描地址 } api = "https://{ip}:{port}/scans/{scan_id}/launch".format(ip=ip, port=port, scan_id=scan_id) response = requests.post(api, data=data, verify=False, headers=header) if response.status_code != 200: return False else: return True def stop_task(task_id): header = { 'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=terminal.reserved1, secretkey=terminal.reserved2), 'Content-type': 'application/json', 'Accept': 'text/plain'} api = "https://{ip}:{port}/scans/{scan_id}/stop".format(ip=ip, port=port, task_id) response = requests.post(api, headers=header, verify=False) if response.status_code == 200 or response.status_code == 409: # 根据nessus api文档可以知道409 表示任务已结束 return True return False获取扫描结果使用接口 GET /scans/{scan_id} 可以获取最近一次扫描的任务信息,从接口文档上看,它还可以获取某次历史扫描记录的信息,如果不填这个参数,接口中会返回所有历史记录的id。如果不填历史记录id,那么会返回最近一次扫描到的漏洞信息,也就是说新扫描到的信息会把之前的信息给覆盖下面是返回信息的部分说明{ "info": { "edit_allowed": {boolean}, "status": {string}, //当前状态 completed 字符串表示结束,cancel表示停止 "policy": {string}, "pci-can-upload": {boolean}, "hasaudittrail": {boolean}, "scan_start": {string}, "folder_id": {integer}, "targets": {string}, "timestamp": {integer}, "object_id": {integer}, "scanner_name": {string}, "haskb": {boolean}, "uuid": {string}, "hostcount": {integer}, "scan_end": {string}, "name": {string}, "user_permissions": {integer}, "control": {boolean} }, "hosts": [ //按主机区分的漏洞信息 host Resource ], "comphosts": [ host Resource ], "notes": [ note Resource ], "remediations": { "remediations": [ remediation Resource ], "num_hosts": {integer}, "num_cves": {integer}, "num_impacted_hosts": {integer}, "num_remediated_cves": {integer} }, "vulnerabilities": [ vulnerability Resource //本次任务扫描到的漏洞信息 ], "compliance": [ vulnerability Resource ], "history": [ history Resource //历史扫描信息,可以从这个信息中获取历史记录的id ], "filters": [ filter Resource ] }这个信息里面vulnerabilities和host里面都可以拿到漏洞信息,但是 vulnerabilities中是扫描到的所有漏洞信息,而host则需要根据id再次提交请求,也就是需要额外一次请求,但它是按照主机对扫描到的漏洞进行了分类。而使用vulnerabilities则需要根据漏洞信息中的host_id 手工进行分类下面是获取任务状态的示例:def get_task_status(task_id): header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } api = "https://{ip}:{port}/scans/{task_id}".format(ip=ip, port=port, task_id=task_id) response = requests.get(api, headers=header, verify=False) if response.status_code != 200: return 2, "Data Error" data = json.loads(response.text) hosts = data["hosts"] for host in hosts: get_host_vulnerabilities(scan_id, host["host_id"]) # 按主机获取漏洞信息 if data["info"]["status"] == "completed" or data["info"]["status"] =='canceled': # 已完成,此时更新本地任务状态 return 1, "OK"获取漏洞信息在获取任务信息中,已经得到了本次扫描中发现的弱点信息了,只需要我们解析这个json。它具体的内容如下:"host_id": {integer}, //主机id "host_index": {string}, "hostname": {integer},//主机名称 "progress": {string}, //扫描进度 "critical": {integer}, //危急漏洞数 "high": {integer}, //高危漏洞数 "medium": {integer}, //中危漏洞数 "low": {integer}, //低危漏洞数 "info": {integer}, //相关信息数目 "totalchecksconsidered": {integer}, "numchecksconsidered": {integer}, "scanprogresstotal": {integer}, "scanprogresscurrent": {integer}, "score": {integer}根据主机ID可以使用 GET /scans/{scan_id}/hosts/{host_id} 接口获取主机信息,它需要两个参数,一个是扫描任务id,另一个是主机id。下面列举出来的是返回值得部分内容,只列举了我们感兴趣的部分:{ "info": { "host_start": {string}, "mac-address": {string}, "host-fqdn": {string}, "host_end": {string}, "operating-system": {string}, "host-ip": {string} }, "vulnerabilities": [ { "host_id": {integer}, //主机id "hostname": {string}, //主机名称 "plugin_id": {integer}, //策略id "plugin_name": {string}, //策略名称 "plugin_family": {string}, //所属策略组 "count": {integer}, //该种漏洞数 "vuln_index": {integer}, "severity_index": {integer}, "severity": {integer} } ], }根据上面获取任务信息中得到的主机id和任务id,我们可以实现这个功能def get_host_vulnerabilities(scan_id, host_id): header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } scan_history = ScanHistory.objects.get(id=scan_id) api = "https://{ip}:{port}/scans/{task_id}/hosts/{host_id}".format(ip=ip, port=port, task_id=scan_id, host_id=host_id) response = requests.get(api, headers=header, verify=False) if response.status_code != 200: return 2, "Data Error" data = json.loads(response.text) vulns = data["vulnerabilities"] for vuln in vulns: vuln_name = vuln["plugin_name"] plugin_id = vuln["plugin_id"] #插件id,可以获取更详细信息,包括插件自身信息和扫描到漏洞的解决方案等信息 #保存漏洞信息获取漏洞输出信息与漏洞知识库信息我们在nessus web页面中可以看到每条被检测到的漏洞在展示时会有输出信息和知识库信息,这些信息也可以根据接口来获取获取漏洞的知识库可以通过接口 GET /scans/{scan_id}/hosts/{host_id}/plugins/{plugin_id} , 它的路径为: https://localhost:8834/api#/resources/scans/plugin-output它返回的值如下:{ "info": { "plugindescription": { "severity": {integer}, //危险等级,从info到最后的critical依次为1,2,3,4,5 "pluginname": {string}, "pluginattributes": { "risk_information": { "risk_factor": {string} }, "plugin_name": {string}, //插件名称 "plugin_information": { "plugin_id": {integer}, "plugin_type": {string}, "plugin_family": {string}, "plugin_modification_date": {string} }, "solution": {string}, //漏洞解决方案 "fname": {string}, "synopsis": {string}, "description": {string} //漏洞描述 }, "pluginfamily": {string}, "pluginid": {integer} } }, "output": [ plugin_output:{ "plugin_output": {string}, //输出信息 "hosts": {string}, //主机信息 "severity": {integer}, "ports": {} //端口信息 } ] }有了这些信息,我们可以通过下面的代码获取这些信息:def get_vuln_detail(scan_id, host_id, plugin_id) header = { "X-ApiKeys": "accessKey={accesskey};secretKey={secretkey}".format(accesskey=accesskey, secretkey=secretkey), "Content-Type": "application/json", "Accept": "text/plain" } api = "https://{ip}:{port}/scans/{scan_id}/hosts/{host_id}/plugins/{plugin_id}".format(ip=ip, port=port, scan_id=scan_id, host_id=host_id, plugin_id=plugin_id) response = requests.get(api, headers=header, verify=False) data = json.loads(response.text) outputs = data["outputs"] return outputs最后总结这篇文章我们主要介绍了nessus API从扫描设置到扫描任务创建、启动、停止、以及结果的获取的内容,当然nessus的api不止这些,但是最重要的应该是这些,如果能帮助各位解决手头上的问题自然是极好的,如果不能或者说各位朋友需要更细致的控制,可以使用浏览器抓包的方式来分析它的请求和响应包。在摸索时最好的两个帮手是浏览器 F12工具栏中的 network和nessus api文档页面上的test工具了。我们可以先按 f12 打开工具并切换到network,然后在页面上执行相关操作,观察发包即可发现该如何使用这些API,因为Nessus Web端在操作时也是使用API。如下图:或者可以使用文档中的test工具,例如下面是测试 获取插件输出信息的接口 -
关于Python的那点吐槽 之前听到过别人有说过Python只是一个玩具做不了大项目,我当时是嗤之以鼻的,不说豆瓣这样的公司采用Python做的网站,GitHub上那么多大项目都是用Python写的,怎么能说Python只是一个玩具呢。直到我参与维护一个Python项目。弱类型一般都说Python的弱类型是程序员的福音,程序员能够更灵活的控制代码,但问题是你在写代码的时候是灵活了,你想过日后维护没有,特别是那些没有注释的代码。基本上项目里面各种类型的变量随处定义,而且有的变量类型不知道什么时候就改变了。我之前遇到过这样一个错误,报的异常是int类型没有某个方法,我定位到对应的代码处,发现他是由函数参数带进来的一个变量,当时又没有声明,完全看不出它是一个什么类型,但是从函数的逻辑上看应该是一个自定义的类型。而且我在对应位置下断点的时候完全没有问题,而且后续出现的几率比较低,既然调试不了,只有一层层的查代码了。根据函数的调用顺序,我终于找到了它的结构。当时是查询数据库然后给返回了一个结构,只有当查询失败的时候会返回一个-1,但是当时写程序的那个家伙没有对这个-1做校验,而且失败基本上是不会出现的,至今我也没有弄明白为什么查询会失败,只是加了一个校验做了一下其他的处理,这个问题就解决了。这个时候我就深深的体会到弱类型语言在后续维护的恶心的,如果是一个强类型,在定义了类型就不会出现什么类型变了的情况。强制缩进这也是一个我觉得恶心的地方,作者的原意是好的,希望能写出更规范的代码。但是当时在维护的时候我习惯用vim,之前的代码不知道用什么写的,我习惯用4个空格,之前的同事可能习惯用tab键,于是灾难就发生了,从vim里面看,完全看不出那些是空格那些是tab,后来我直接使用替换将所有tab替换为4个空格。强制缩进还有一点就是函数代码一旦很长,嵌套稍微深一点,从维护上看完全看不出来哪块是哪个语句块的东西,而且它不支持{},一般根据{}可以很方便的判断。还有一个问题就是嵌套层数深了对于我们这些空格党来说敲的字符也就变多了,有的地方不明确的还得数着敲,一层嵌套是4个,两层8个,三层12个,用不了多久你就崩溃了独立特性的加载方式相比于C/C++的include ,Python采用import来加载所需要使用的库,对于C/C++来说加载库就仅仅是将库中的代码加载到进程的地址空间中,什么时候执行什么操作完全由用户自己控制,但是Python在你加载库的时候会默默的帮你执行初始化函数,平时是没有什么问题的,但是一旦你定义的变量与库中的相关内容重名的时候,灾难就来了,如果不是有百度、google这些搜索引擎可能我早就怀疑我的Python有问题,在重装无果后大骂Python并最终弃坑了。如果在代码中出现 import numpy as n这样的语句估计会被维护的程序员当场击毙库命名的随意Python的库一般以Py开头,比如说PyPy、PyPi、PyGame。但是也有Py在后面的,比如NumPy、SciPy,SymPy,还有不带Py的,比如常见的requests,Pillow, matplotlib, SQLAlchemy, 这些至少你能从名字上判断它是干嘛的,像BeautifulSoup这样的,打死都猜不到它竟然是一个XML解析库。库中使用的类、函数、全局变量也很随意,如果没有搜索引擎,我是绝对猜不到cv2 是opencv里面的东西安装也是一个麻烦,虽然大部分都可以使用pip 安装但是比如说你使用 pip install Django,事先好像不知道它适应与哪个版本,这也是不同Python版本不兼容带来的,还有像python-opencv python3-opencv,既然有的能根据Python版本来正确安装,为什么有的不行,非得指定的那么详细。拷贝与赋值的问题这个问题特别是在函数中间问题最大,一般的语言中值传递是不能修改实参的值的,但是在Python中,向字典这样的它就可以,而像list这样的好像不行,说实话至今我都弄不明白为什么,也记不住类型的可以哪些不行。而且它的深拷贝和浅拷贝我觉的跟其他语言差距很大,理解起来有点困难。最后再说一句吐槽了这么多,我并不是要完全否定Python,不得不说Python是一门非常简单实用的语言,而且社区强大,拥有各种功能的第三方库,说句夸张的,除了生孩子,Python能做任何事情。当然这些问题只是我对Python的理解不够,我也只限于实用它,而没有做到熟练或者精通的地步,这些问题可能在一些更Pythoner的程序员手中根本不是问题。不知道在哪看到这样一句话,没有烂语言,只有烂人,当你写不出足够优雅的代码时,留给后续接盘的人的只有一地鸡毛,各位程序员且行且珍惜
-
C++ 调用Python3 作为一种胶水语言,Python 能够很容易地调用 C 、 C++ 等语言,也能够通过其他语言调用 Python 的模块。Python 提供了 C++ 库,使得开发者能很方便地从 C++ 程序中调用 Python 模块。具体操作可以参考: 官方文档在调用Python模块时需要如下步骤:初始化Python调用环境加载对应的Python模块加载对应的Python函数将参数转化为Python元组类型调用Python函数并传入参数元组获取返回值根据Python函数的定义解析返回值初始化在调用Python模块时需要首先包含Python.h头文件,这个头文件一般在安装的Python目录中的 include文件中,所在VS中首先需要将这个路径加入到项目中包含完成之后可能会抱一个错误:找不到 inttypes.h文件,在个错误在Windows平台上很常见,如果报这个错误,需要去网上下载对应的inttypes.h文件然后放入到对应的目录中即可,我这放到VC的include目录中在包含这些文件完成之后可能还会抱一个错误,未找到Python36_d.lib 在Python环境中确实找不到这个文件,这个时候可以修改pyconfig.h文件,将这个lib改为python36.lib,具体操作请参考这个链接: https://blog.csdn.net/Chris_zhangrx/article/details/78947526还有一点要注意,下载的Python环境必须的与目标程序的类型相同,比如你在VS 中新建一个Win32项目,在引用Python环境的时候就需要引用32位版本的Python这些准备工作做完后在调用Python前先调用Py_Initialize 函数来初始化Python环境,之后我们可以调用Py_IsInitialized来检测Python环境是否初始化成功下面是一个初始化Python环境的例子BOOL Init() { Py_Initialize(); return Py_IsInitialized(); }调用Python模块调用Python模块可以简单的调用Python语句也可以调用Python模块中的函数。简单调用Python语句针对简单的Python语句(就好像我们在Python的交互式环境中输入的一条语句那样),可以直接调用 PyRun_SimpleString 函数来执行, 这个函数需要一个Python语句的ANSI字符串作为参数,返回int型的值。如果为0表示执行成功否则为失败void ChangePyWorkPath(LPCTSTR lpWorkPath) { TCHAR szWorkPath[MAX_PATH + 64] = _T(""); StringCchCopy(szWorkPath, MAX_PATH + 64, _T("sys.path.append(\"")); StringCchCat(szWorkPath, MAX_PATH + 64, lpWorkPath); StringCchCat(szWorkPath, MAX_PATH + 64, _T("\")")); PyRun_SimpleString("import sys"); USES_CONVERSION; int nRet = PyRun_SimpleString(T2A(szWorkPath)); if (nRet != 0) { return; } }这个函数主要用来将传入的路径加入到当前Python的执行环境中,以便可以很方便的导入我们的自定义模块函数首先通过字符串拼接的方式组织了一个 "sys.path.append('path')" 这样的字符串,其中path是我们传进来的参数,然后调用PyRun_SimpleString执行Python的"import sys"语句来导入sys模块,接着执行之前拼接的语句,将对应路径加入到Python环境中调用Python模块中的函数调用Python模块中的函数需要执行之前说的2~7的步骤加载Python模块(自定义模块)加载Python的模块需要调用 PyImport_ImportModule 这个函数需要传入一个模块的名称作为参数,注意:这里需要传入的是模块的名称也就是py文件的名称,不能带.py后缀。这个函数会返回一个Python对象的指针,在C++中表示为PyObject。这里返回模块的对象指针然后调用 PyObject_GetAttrString 函数来加载对应的Python模块中的方法,这个函数需要两个参数,第一个是之前获取到的对应模块的指针,第二个参数是函数名称的ANSI字符串。这个函数会返回一个对应Python函数的对象指针。后面需要利用这个指针来调用Python函数获取到函数的指针之后我们可以调用 PyCallable_Check 来检测一下对应的对象是否可以被调用,如果能被调用这个函数会返回true否则返回false接着就是传入参数了,Python中函数的参数以元组的方式传入的,所以这里需要先将要传入的参数转化为元组,然后调用 PyObject_CallObject 函数来执行对应的Python函数。这个函数需要两个参数第一个是上面Python函数对象的指针,第二个参数是需要传入Python函数中的参数组成的元组。函数会返回Python的元组对象,这个元组就是Python函数的返回值获取到返回值之后就是解析参数了,我们可以使用对应的函数将Python元组转化为C++中的变量最后需要调用 Py_DECREF 来解除Python对象的引用,以便Python的垃圾回收器能正常的回收这些对象的内存下面是一个传入空参数的例子void GetModuleInformation(IN LPCTSTR lpPyFileName, OUT LPTSTR lpVulName, OUT long& level) { USES_CONVERSION; PyObject *pModule = PyImport_ImportModule(T2A(lpPyFileName)); //加载模块 if (NULL == pModule) { g_OutputString(_T("加载模块[%s]失败"), lpPyFileName); goto __CLEAN_UP; } PyObject *pGetInformationFunc = PyObject_GetAttrString(pModule, "getInformation"); // 加载模块中的函数 if (NULL == pGetInformationFunc || !PyCallable_Check(pGetInformationFunc)) { g_OutputString(_T("加载函数[%s]失败"), _T("getInformation")); goto __CLEAN_UP; } PyObject *PyResult = PyObject_CallObject(pGetInformationFunc, NULL); if (NULL != PyResult) { PyObject *pVulNameObj = PyTuple_GetItem(PyResult, 0); PyObject *pVulLevelObj = PyTuple_GetItem(PyResult, 1); //获取漏洞的名称信息 int nStrSize = 0; LPTSTR pVulName = PyUnicode_AsWideCharString(pVulNameObj, &nStrSize); StringCchCopy(lpVulName, MAX_PATH, pVulName); PyMem_Free(pVulName); //获取漏洞的危险等级 level = PyLong_AsLong(pVulLevelObj); Py_DECREF(pVulNameObj); Py_DECREF(pVulLevelObj); } //解除Python对象的引用, 以便Python进行垃圾回收 __CLEAN_UP: Py_DECREF(pModule); Py_DECREF(pGetInformationFunc); Py_DECREF(PyResult); }在示例中调用了一个叫 getInformation 的函数,这个函数的定义如下:def getInformation(): return "测试脚本", 1下面是一个需要传入参数的函数调用BOOL CallScanMethod(IN LPPYTHON_MODULES_DATA pPyModule, IN LPCTSTR lpUrl, IN LPCTSTR lpRequestMethod, OUT LPTSTR lpHasVulUrl, int BuffSize) { USES_CONVERSION; //加载模块 PyObject* pModule = PyImport_ImportModule(T2A(pPyModule->szModuleName)); if (NULL == pModule) { g_OutputString(_T("加载模块[%s]失败!!!"), pPyModule->szModuleName); return FALSE; } //加载模块 PyObject *pyScanMethod = PyObject_GetAttrString(pModule, "startScan"); if (NULL == pyScanMethod || !PyCallable_Check(pyScanMethod)) { Py_DECREF(pModule); g_OutputString(_T("加载函数[%s]失败!!!"), _T("startScan")); return FALSE; } //加载参数 PyObject* pArgs = Py_BuildValue("ss", T2A(lpUrl), T2A(lpRequestMethod)); PyObject *pRes = PyObject_CallObject(pyScanMethod, pArgs); Py_DECREF(pArgs); if (NULL == pRes) { g_OutputString(_T("调用函数[%s]失败!!!!"), _T("startScan")); return FALSE; } //如果是元组,那么Python脚本返回的是两个参数,证明发现漏洞 if (PyTuple_Check(pRes)) { PyObject* pHasVul = PyTuple_GetItem(pRes, 0); long bHasVul = PyLong_AsLong(pHasVul); Py_DECREF(pHasVul); if (bHasVul != 0) { PyObject* pyUrl = PyTuple_GetItem(pRes, 1); int nSize = 0; LPWSTR pszUrl = PyUnicode_AsWideCharString(pyUrl, &nSize); Py_DECREF(pyUrl); StringCchCopy(lpHasVulUrl, BuffSize, pszUrl); PyMem_Free(pszUrl); return TRUE; } } Py_DECREF(pRes); return FALSE; }对应的Python函数如下:def startScan(url, method): if(method == "GET"): response = requests.get(url) else: response = requests.post(url) if response.status_code == 200: return True, url else: return FalseC++数据类型与Python对象的相互转化Python与C++结合的一个关键的内容就是C++与Python数据类型的相互转化,针对这个问题Python提供了一系列的函数。这些函数的格式为PyXXX_AsXXX 或者PyXXX_FromXXX,一般带有As的是将Python对象转化为C++数据类型的,而带有From的是将C++对象转化为Python,Py前面的XXX表示的是Python中的数据类型。比如 PyUnicode_AsWideCharString 是将Python中的字符串转化为C++中宽字符,而 Pyunicode_FromWideChar 是将C++的字符串转化为Python中的字符串。这里需要注意一个问题就是Python3废除了在2中的普通的字符串,它将所有字符串都当做Unicode了,所以在调用3的时候需要将所有字符串转化为Unicode的形式而不是像之前那样转化为String。具体的转化类型请参考Python官方的说明。上面介绍了基本数据类型的转化,除了这些Python中也有一些容器类型的数据,比如元组,字典等等。下面主要说说元组的操作。元组算是比较重要的操作,因为在调用函数的时候需要元组传参并且需要解析以便获取元组中的值。创建Python的元组对象创建元组对象可以使用 PyTuple_New 来创建一个元组的对象,这个函数需要一个参数用来表示元组中对象的个数。之后需要创建对应的Python对象,可以使用前面说的那些转化函数来创建普通Python对象,然后调用 PyTuple_SetItem 来设置元组中数据的内容,函数需要三个参数,分别是元组对象的指针,元组中的索引和对应的数据示例: PyObject* args = PyTuple_New(2); // 2个参数 PyObject* arg1 = PyInt_FromLong(4); // 参数一设为4 PyObject* arg2 = PyInt_FromLong(3); // 参数二设为3 PyTuple_SetItem(args, 0, arg1); PyTuple_SetItem(args, 1, arg2);或者如果元组中都是简单数据类型,可以直接使用 PyObject* args = Py_BuildValue(4, 3); 这种方式来创建元组解析元组Python 函数返回的是元组,在C++中需要进行对应的解析,我们可以使用 PyTuple_GetItem 来获取元组中的数据成员,这个函数返回PyObject 的指针,之后再使用对应的转化函数将Python对象转化成C++数据类型即可PyObject *pVulNameObj = PyTuple_GetItem(PyResult, 0); PyObject *pVulLevelObj = PyTuple_GetItem(PyResult, 1); //获取漏洞的名称信息 int nStrSize = 0; LPTSTR pVulName = PyUnicode_AsWideCharString(pVulNameObj, &nStrSize); StringCchCopy(lpVulName, MAX_PATH, pVulName); PyMem_Free(pVulName); //释放由PyUnicode_AsWideCharString分配出来的内存 //获取漏洞的危险等级 level = PyLong_AsLong(pVulLevelObj); //最后别忘了将Python对象解引用 Py_DECREF(pVulNameObj); Py_DECREF(pVulLevelObj); Py_DECREF(PyResult);Python中针对具体数据类型操作的函数一般是以Py开头,后面跟上具体的数据类型的名称,比如操作元组的PyTuple系列函数和操作列表的PyList系列函数,后面如果想操作对应的数据类型只需要去官网搜索对应的名称即可。这些代码实例都是我之前写的一个Demo中的代码,Demo放到了Github上: PyScanner
-
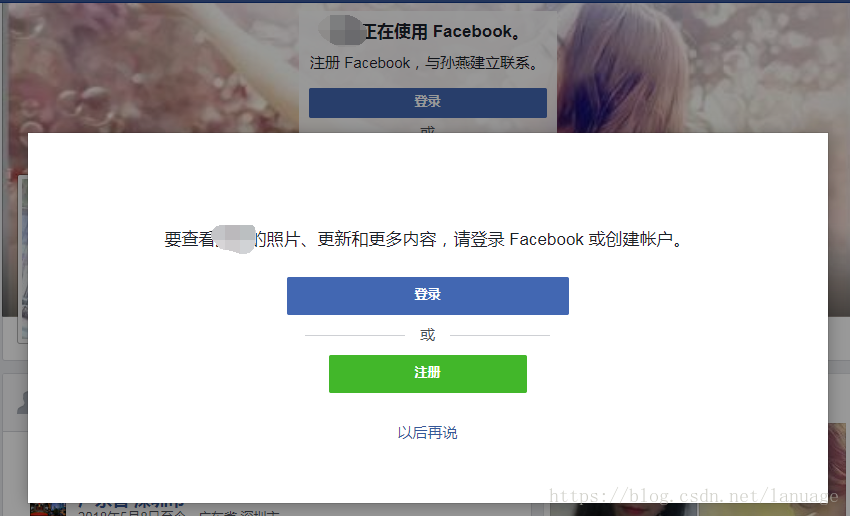
Facebook爬虫 初次接触到scrapy是公司要求编写一个能够解析JavaScript的爬虫爬取链接的时候听过过,当时我当时觉得它并不适合这个项目所以放弃这个方案,时隔一年多公司有了爬取Facebook用户信息的需求,这样才让我正式接触并使用到scrapy需求首先从文件或者数据库导入第一批用户做为顶层用户,并爬取顶层用户好友的发帖信息包括其中的图片将第一步中爬取到的用户好友作为第二层用户并爬取它们的发帖信息和好友信息将第二层用户中爬到的好友作为第三层用户并爬取它们的好友信息也就是说不断爬取用户的好友和它的发帖信息直到第三层为止根据这个需求首先来确定相关方案爬虫框架使用scrapy + splash:Facebook中大量采用异步加载,如果简单收发包必定很多内容是解析不到的,因此这里需要一个JavaScript渲染引擎,这个引擎可以使用selenium + chrome(handless) 这套,但是根据网上一位老哥的博客我知道了splash这种东西,在做相关比较之后我选择了使用splash,主要的理由有以下几点:a. 与selenium比较起来,它的官方文档更为全面b. 支持异步的方式,这个可以与scrapy的异步回调方式完美结合并充分发挥性能c. 它提供了一套与scrapy结合的封装库,可以像scrapy直接yield request对象即可,使用方式与scrapy类似降低了学习成本d. 它提供了lua脚本的方式可以很方便的操作浏览器对象e. 跨平台。相比于使用chrome作为渲染工具,它可以直接执行在Linux平台在scrapy中使用splash时可以安装对应的封装库scrapy_splash,这个库的安装配置以及使用网上基本都有详细的讲解内容,这里就不再提了当然它也有缺点,但是这并不在讨论之中,至于具体如何选择就是一个见仁见智的问题了开发语言: python3 ,python在开发爬虫方面有独特的优势,这个就不用我多说了,弄过爬虫的朋友都知道开发工具 pycharm, JB的pycharm几乎是Python IDE的首选设计与实现这里可能涉及到商业秘密,毕竟是签过保密协议的,所以在这部分我不会放出完整的代码,只会提供一个思路然后给出部分关键代码以供参考。这里我想根据我遇到的问题,以问题的方式来讲述这个项目,毕竟对于爬虫、框架这些东西大家都很熟再来讲这些也没有多大意思了用户登录在浏览器中操作的时候发现,如果是游客(也就是未登陆状态)的时候,当我们浏览相关用户的时间线时会得到下面这个界面在未登录的情况下查看用户信息的时候会弹出一个界面需要登录或者注册。因此从这里来看爬虫的第一个任务就应该是登录登录的时候scrapy提供了一个form_response的方法可以很方便的填写表单并提交,但是我发现用这种方式只能在返回的response对象中的request.headers里面找到cookie的字符串,而由于splash需要我们传入cookie的字典形式,这里我没有找到什么很好的办法,只能是采用splash 提供的方法。Facebook中登录页面为https://www.facebook/login。因此我重载爬虫的start_requests方法,提交一个针对这个登录页面url的请求。这个页面不涉及到渲染问题自然就使用Requests对象def start_requests(self): #开启爬取之前先登录 yield Request( url= self.login_url, # https://www.facebook.com/login callback= self.login, )当它请求的页面返回时触发login方法,在这个方法中我们提供了一个lua脚本自动填写用户名密码,然后提交请求,并最终返回成功的cookieyield SplashFormRequest.from_response( response, url = self.login_url, formdata={ "email":user, "pass": password }, endpoint="execute", args={ "wait": 30, "lua_source": lua_script, #这个参数是一个lua脚本的字符串 "user_name" : user, #user和password将会作为参数传入到lua脚本中 "user_passwd" : password, }, callback = self.after_login, errback = self.error_parse, )这里我们使用splash来发送请求包,这里我们主要向lua脚本中传入用户名和密码,下面是lua脚本的相关内容function main(splash, args) local ok, reason = splash:go(args.url) user_name = args.user_name user_passwd = args.user_passwd user_text = splash:select("#email") pass_text = splash:select("#pass") login_btn = splash:select("#loginbutton") if (user_text and pass_text and login_btn) then user_text:send_text(user_name) pass_text:send_text(user_passwd) login_btn:mouse_click({}) end splash:wait(math.random(5, 10)) return { url = splash:url(), cookies = splash:get_cookies(), headers = splash.args.headers, } end根据相关资料,SplashRequest 函数中的参数将会以lua table的形式被传入到splash形参中,而函数的args参数中的内容以 table的形式被传入到形参args中,所以这里要获取到用户名和密码只需要从args里面取即可上述lua代码首先请求对应的登录界面(我觉得这里应该不用请求,而直接使用response,但是这是我在写这篇文章的时候想到的还没有验证),然后通过css选择器找到填写用户名,密码的输入框和提交按钮。然后填写相关内容,最后点击按钮进行登录,然后等待一定时间,这里一定要等待以便Facebook服务器验证并跳转到对应的链接,最后我们是通过链接来判断是否登录成功。最后返回当前页面的url,cookie和对应的头信息在浏览器中执行登录操作的时候发现如果是新用户(没有填写相关信息用户)会跳转到www.facebook.com/?sk=welcome这个页面要求用户填入一定的信息,而老用户则会跳转到www.facebook.com 这个url,这个页面会显示用户关注的好友动态。因此在程序中我也根据跳转的新页面是否是这两个页面来进行判断是否登录成功的.登录成功后将脚本返回的cookie保存,脚本返回的信息在scrapy的response.data中作为字典的形式保存代理由于众所周知的原因,Facebook对于国内来说是一个404的站点,国内用户想要访问必须提供一个代理。在scrapy中代理可以设置在对应的下载中间件中,在下载中间件的process_request函数中设置request.meta["proxy"] = proxy但是这种方式针对splash时就不管用了,我找了很多资料发现可以在lua脚本中设置,每次在执行之前都需要相同的代码来设置代理,因此我们可以采用下面的模板function main(splash, args) splash:on_request(function(request) request:set_proxy{ host = '0.0.0.0', --代理服务器的IP port = 0, --代理服务器的端口 username = '', --登录的用户名和密码 password = '', type = "http", -- 代理的协议,根据官网的说法目前只支持http和ss5 ,目前就这个项目来说http就够了 } end) --do something end每次执行含有这段代码的脚本时首先执行on_request函数设置代理的相关信息,然后执行splash:go函数时就可以使用上面的配置访问对应站点了使爬虫保持登录状态根据splash的官方文档的说明,splash其实可以看做一个干净的浏览器,就好像我们在使用浏览器每次请求一个新页面的时候同时清理了里面的缓存一样,它不会保存之前的任何状态,所以这里的cookie只能每次在发包的同时给它设置上,好在splash给了相应的方法来设置和获取它,下面是关于cookie的模板local cookies = splash:get_cookies() -- ... do something ... splash:init_cookies(cookies) -- restore cookies至此我们的lua脚本的模板就变成了这样function main(splash, args) splash:init_cookies(splash.cookies) -- 这个cookie是通过SplashRequest函数的cookies参数传入的 splash:on_request(function(request) request:set_proxy{ host = '0.0.0.0', --代理服务器的IP port = 0, --代理服务器的端口 username = '', --登录的用户名和密码 password = '', type = "http", -- 代理的协议,根据官网的说法目前只支持http和ss5 ,目前就这个项目来说http就够了 } end) --do something return { cookie = splash:get_cookies() } end获取用户主页面我们在Facebook随便点击一个用户进入它的主页面,查看url如下可以看到针对用户名为英文的情况,它简单的将英文名作为二级目录,只不过将空格换成了点,而针对不为英文的用户,它以profile作为二级目录,并且后面带上一个参数id,这个ID就是用户的ID。其实根据后面我自己的实验不管上面的哪种用户都可以通过这个ID访问到,我们可以组成一个url:https://www.facebook.com/[id] 来访问用户首页,因此项目中要求提供的外部导入用户名必须是英文或者是ID,以便能直接通过url拼接的方式来获取用户首页除了这个区别之外,还有一种称之为公共主页的页面,比如下面是特朗普的公共主页对于公共主页来说它没有好友信息,没有时间线,因此针对这种页面的信息的解析可能需要别的方法。而光从url、id、和页面内容来看很难区分,而我在查找获取Facebook用户ID的相关内容的时候碰巧找到了它的区分方法,公共主页的HTML代码中只有一个page_id和profile_id,而个人的只有profile_id 其中用户ID就是这个profile_id比如下面分别是一个个人主页和公共主页搜索page_id的结果从上面的结果来看个人用户中page_id 只会出现在注释中,这是用浏览器请求的结果,其实在实际使用爬虫爬取到的结果中是搜不到这个id的,我们可以根据这个特性来区分,并且获取这两种主页的IDdef _get_user_info(self, html, url): key = "page_id=(\d+)" # 使用正则表达式获取page_id后面的id值 # page_id 只会出现在公共主页上,所以根据page_id来判断页面类型 pattern = re.compile(key) it = pattern.finditer(html) user_type = 0 try: it = next(it) #如果未找到这个地方会报StopIteration异常 user_type = TopUser.PUBLIC_PAGE # 公共主页 except StopIteration: # 未找到page_id 此时视为个人主页 key = "profile_id=(\d+)" #个人主页的id是profile_id的值 pattern = re.compile(key) it = pattern.finditer(html) try: it = next(it) user_type = TopUser.PRIVATE_PAGE except StopIteration: # 两个都没找到,此时视为页面错误,返回错误,爬虫停止 pass #TODO:解析对应的用户信息,这里主要解析用户id和页面类型获取时间线信息Facebook的用户时间线是通过异步加载的方式来进行的,我使用Chrome分析过它发送的异步请求,发现它里面是经过了加密的,因此不能通过解析它的响应包来获取相关信息,但是我们有splash这一大杀器,它就是一个浏览器,一般在加载更多信息的时候都会执行下来操作,所以说这里我们只要模拟这个下拉的操作就可以了,要操作这个浏览器当然是使用lua脚本了,下面是对应的lua脚本function main(splash, args) --前面是设置cookie和代理的操作 local ok, reason = splash:go(args.url) splash:wait(math.random(5, 10)) html = splash:html() old_html = "" flush_times = args.flush_times --这里是下拉次数,就好像操作浏览器一样每次下拉就会加载新的内容 i = 0 while(html ~= old_html) -- 当下拉得到的新页面与原来的相同,就认为它已经没有新的内容了,此时就返回 do old_html = html splash:runjs([[window.scrollTo(0, document.body.scrollHeight)]]) -- 执行js下拉页面 splash:wait(math.random(1,2)) -- 这里一定要等待,否则可能会来不及加载,根据我的实验只要大于1s就可以得到下拉加载的新内容,可能具体值需要根据不同的网络环境 if (flush_times ~= 0 and i == flush_times) then -- 当达到设置下拉上限并且不为0时推出,这里下拉次数为0表示一直下拉直到没有新内容 print("即将退出循环") break end html = splash:html() i = i + 1 end return { html = splash:html(), cookies = splash:get_cookies(), }上面的代码中,首先请求时间线的界面,然后获取相关的设置,主要是下拉次数。<br/>注意这里的下拉次数要根据超时值来设置,根据splash的官方文档,每个请求都有一个超时值,大于这个超时值会直接返回504 的错误这个时候就什么都得不到了,所以这里理想情况下是可以一直下拉的,但是由于有超时值的存在,必须给定一个下拉次数。我们可以在启动splash 的时候通过参数--wait-timeout给定。然后根据这个参数的设置一直下拉,直到没有更新或者达到最大下来次数。<br/>这个也有问题,如果网络不好或者其他情况导致没有加载出来,就认为它已经没有新内容了,这样会导致爬取内容不全这样我们就获取到了用户的时间线信息,具体的内容的解析就不再多说了,需要提醒一点的是,用户发帖中包含图片时分为三种情况,单个图片,多个图片(多个图片一般就被叫做albums——相册或者图集),简单的更新头像;这三种情况下页面的对应结构不同所以需要分情况,而且当时间线中包含视频的时候情况又不同获取公共主页的发帖信息公共主页中没有时间线,所以它的解析与个人主页的不同,好在Facebook提供了一种叫做图谱API的东西可以很方便的就可以获取到发帖信息。既然有这种API,为什么不用它获取个人用户信息呢?其实我也想用,就是要针对个人使用API就必须获取用户本人的确认,也就是要用户登录你的爬虫,然后授权给你,这自然是不可能的,所以针对个人用户只能简单的通过模拟浏览器的方式来解析HTML页面要使用Facebook的 API首先要获取一个access_token. 常规思路是先去去开发者平台注册一个开发者账号并建立一个应用。然后获取应用的token。但是我发现一般的应用Token 在获取公共主页的时候也存在一个授权的问题,好在Facebook提供了一个api的测试平台,而平台中提供了一个graph explore token,这个token可以不用授权,但是它只有一个小时的有效期,所以要使用API,首先就是从这个测试平台获取到这token。Facebook并没有提供任何有效方法来获取这个token,这个时候自然又要使用传统的方式,通过splash请求这个url,然后解析HTML获取对应token。针对这个问题,我处理的步骤如下:根据上一步获取到的页面类型,如果是公共页面,则先请求https://developers.facebook.com/tools/explorer/这个url,在登录状态下(前提是你的对应账号是Facebook的开发者账号),它会自动生成一个测试用的access_token就像下面这样输入框中就是token从该页面中获取到对应的token, 并调用对应的API获取公共主页的发帖信息,这里主要调用posts 并获取它的链接、ID、具体信息、图片、创建时间和编辑者 这些信息,具体的API文档参考Facebook官方文档,这里就不再介绍他们了def get_access_token(self, response): sel = Selector(response=response) access_token = sel.xpath('//label[@class="_2toh _36wp _55r1 _58ak"]/input[@class="_58al"]//@value').extract_first() #获取到token的值 #拼接API api = urljoin("https://graph.facebook.com/v3.0", response.meta["user_id"]) api = api + "/posts" + "?access_token=" + access_token + "&fields=link,id,message,full_picture,parent_id,created_time" yield Request( url=api, callback=self._get_public_posts, errback=self.error_parse )API返回的信息是以json格式返回的,下面是使用posts返回的一个例子,这里只是作为一个例子,请求返回的内容与项目中可能并不一样,但是并不影响针对它的分析{ "data": [ { "created_time": "2018-06-01T22:30:00+0000", "message": "Congratulations to our contest winners, Joseph and Dana! It’s always a pleasure to meet the people who make our MOVEMENT possible. Thank you!", "id": "153080620724_10161074525735725" }, ], "paging": { "cursors": { "before": "Q2c4U1pXNTBYM0YxWlhKNVgzTjBiM0o1WDJsa0R5QXhOVE13T0RBMk1qQTNNalE2T0RBeU9UTTROekExTURBek9UVTBNakkwTnc4TVlYQnBYM04wYjNKNVgybGtEeDR4TlRNd09EQTJNakEzTWpSZAk1UQXhOakV3TnpRMU1qVTNNelUzTWpVUEJIUnBiV1VHV3hISTZABRT0ZD", "after": "Q2c4U1pXNTBYM0YxWlhKNVgzTjBiM0o1WDJsa0R5QXhOVE13T0RBMk1qQTNNalE2T0RFMk9UZA3pOemN4TkRrMU1EWXpNVFEwTlE4TVlYQnBYM04wYjNKNVgybGtEeDR4TlRNd09EQTJNakEzTWpSZAk1UQXhOakV3TkRZANE1UazBNekEzTWpVUEJIUnBiV1VHV3dyV0FRRT0ZD" }, "next": "https://graph.facebook.com/v3.0/153080620724/posts?access_token=EAACEdEose0cBAMo5MUmbhGNfJlCGcrZArh7RBiCeSbwpqUq84tyEOs3HvO5KWoOtkWERRgkZBFjvOCb1DQ3go7PywUrA43SdJTqjeyjs5p2w3UanCFm0jxiE4Dt91A4qcGQYo9iobrLVrtCL0bdoNdkicQb6izFzxZBx0sPVauofQMLZCEFNLNcFqfkAinPWtSVeUQRxjQZDZD&pretty=0&limit=25&after=Q2c4U1pXNTBYM0YxWlhKNVgzTjBiM0o1WDJsa0R5QXhOVE13T0RBMk1qQTNNalE2T0RFMk9UZA3pOemN4TkRrMU1EWXpNVFEwTlE4TVlYQnBYM04wYjNKNVgybGtEeDR4TlRNd09EQTJNakEzTWpSZAk1UQXhOakV3TkRZANE1UazBNekEzTWpVUEJIUnBiV1VHV3dyV0FRRT0ZD" } }这个json主要分为两个部分一个是data,包含的是具体发帖的相关信息,另一个是paging,这个值里面包含了几个游标,其中next表示下一页的请求地址,我们只要判断出json中存在这个next就循环向这个next对应的url发包,当返回的json中不存在这个next时就标明已经到了最后一页。此时就解析了所有的发帖下面是具体的代码def _get_public_posts(self, response): rep_json = json.loads(response.text) data = rep_json["data"] post_user = response.meta["user"] for post in data: try: item = FbspiderItem() item["post_id"] = post["id"] item["post_user"] = post_user item["post_message"] = post["message"] item["post_time"] = post["created_time"] item["post_link"] = post["link"] yield item #存储图片的信息 item = FBPostImgItem() item["post_id"] = post["id"] item["img_url"] = post["full_picture"] yield item except KeyError: # 暂时不处理未找到帖子内容的情况 continue if "paging" not in rep_json: return paging = rep_json["paging"] if "next" in paging: api = paging["next"] yield Request( url = api, callback= self._get_public_posts, meta={"user" : post_user}, )获取好友信息获取好友的信息也需要采用模拟浏览器的方式,首先在用户页面上查找是否有好友的链接可以供点击,如果没有说明没有开放权限,当存在这个链接并点进去之后,可能并没有好友项,比如下面这样或者另外的情况,所以这里判断是否有好友信息需要两步,第一步是上面部分有好友这一栏,第二步是点进去之后在下面一栏中有全部好友这项内容。同样即使有好友,它也不会一次加载完毕,这里也用到下拉的相关操作。部分代码如下:function main(splash, args) -- 设置cookie和代理 local ok, reason = splash:go(args.url) splash:wait(math.random(5, 10)) friend_btn = splash:select("a[data-tab-key= 'friends']") --查找最上面那栏中是否有好友这个链接 if (friend_btn) then friend_btn:mouse_click({}) --点击进入好友页面 splash:wait(math.random(5, 10)) else return { hasFriend = false, cookie = splash:get_cookies(), } end return { hasFriend = true, html = splash:html(), cookie = splash:get_cookies(), url = splash:url(), } end执行完上述代码后,再分析是否有对应的好友信息,有的话就下拉刷新页面获取更多好友信息#当上面的代码执行完后进入这个函数 def _get_friends_page(self, response): hasFriend = response.data["hasFriend"] if not hasFriend: print("用户[%s]未开放好友查询权限" % response.meta["name"]) return html = response.data["html"] sel = Selector(response = response) friends = sel.xpath("//a[@name='全部好友']") if friends == []: print("用户[%s]未开放好友查询权限" % response.meta["name"]) return #获取代理,拼接对应的lua脚本 yield SplashRequest( url = response.data["url"], callback= self.parse_friends, endpoint="execute", cookies= random.choice(self.cookie), meta= {"level" : response.meta["level"], "name" : response.meta["name"]}, args={ "wait" : 30, "lua_source" : lua_script, } )当下拉结束之后就是解析页面获取页面中的好友信息了,在解析的时候发现,当点击某个好友进入它的主页面时,页面的链接为 https://www.facebook.com/profile.php?id=100011359746168&fref=pb&hc_location=friends_tab这个时候就会产生一种想法,这个id是不是就是用户id呢?我用这个id来直接访问用户主页行不行呢?经过我的实验,这个想法是对的,是可行的,因此对于好友这层用户我们可以直接拿到它的ID,不用向前面一样根据名称来拼接,下面是解析好友信息的部分代码def parse_friends(self, response): sel = Selector(response = response) friends = sel.xpath("//li[@class='_698']//div[@class='fsl fwb fcb']//a") #拼接lua脚本 for friend in friends: url = friend.xpath(".//@href").extract_first() name = friend.xpath(".//text()").extract_first() #记录当前好友关系 friend_item = FBUserItem() friend_item["user_name"] = response.meta["name"] friend_item["friend_name"] = name print("提取到好友信息%s : %s" % (friend_item["user_name"], friend_item["friend_name"])) yield friend_item #这里再次提交请求主要是为了获取好友的好友,以及获取好友发的帖子 #其实也可以在这个请求执行完成之后解析用户主页面得到用户的ID等信息 yield SplashRequest( url = url, endpoint="execute", callback= self.parse_main_page, meta={"name" : name, "level" : level}, cookies = random.choice(self.cookie), # 从cookie池中随机取出一个cookie args={ "wait": 30, "lua_source": lua_script, } )反爬虫的相关操作针对爬虫程序来说最头疼的就是有的站点在反爬虫这块做的太好了,Facebook就是这样的一个站点,我的测试账号在执行程序的时候被封过无数次。为了防止被封我主要采取了这样几个措施减少并发数,设置发包的延时这些内容主要在scrapy的配置文件中控制DOWNLOAD_DELAY = 5 # 发包延时 CONCURRENT_REQUESTS = 16 # 最大并发数设置代理池代理池的设置通过下载中间件的process_request函数来设置,设置的相关代码如下:def process_request(self, request, spider): if self.proxies != []: proxy = random.choice(self.proxies) # self.proxies 是一个含有多个代理的列表,从中随机取一个 print("启用代理:%s" % proxy) if "splash" in request.meta: #判断是否是一个splash请求 request.meta['splash']['args']['proxy'] = proxy# 设置splash代理 else: request.meta["proxy"] = proxy #设置scrapy的代理这里虽然判断了是否为一个splash,但是针对splash的请求,这种设置方式无效,需要采用之前介绍的方式在LUA脚本中设置,而随机设置的方法就是在一组代理中随机选择一个传入对应的LUA脚本中设置UA在下载中间件的process_request函数中来设置,设置的方法与设置代理的方法类似class RotateUserAgentMiddleware(UserAgentMiddleware): def __init__(self, user_agent=''): self.user_agent = user_agent def process_request(self, request, spider): ua = random.choice(self.user_agent_list) if ua: print("启用UA :%s" % ua) request.headers.setdefault('User-Agent', ua) user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] 设置多用户登录这里我设置了多个登录用户,通过从用户的登录cookie池中随机选取一个作为请求的cookie,在爬虫开始位置导入多个用户的用户名和密码信息,依次登录,登录成功后保存用户cookie到列表,后面每次发包前随机选取一个cookie设置SplashReuqests函数的等待时间就像前面代码中每个SplashRequest函数的args参数中总会带有 一个wait的键值,这个表示每次接到请求后等待的时长,加上这个是为了减慢爬虫运行速度防止由于发包过快导致账号被封至此,我已将之前涉及到的所有问题基本上都提到了,很多地方我自认为处理的不是很完美,但是写出来的内容勉强够用。这个爬虫项目我最大的收获就是知道了splash这个好用的东西,可惜的是它并没有中文的文档,所以像我这样刚过四级的人读起来还是有点吃力的。所以为了方便他人学习,以及提高我的英文水平我决定乘着这段时间我有空闲我想翻译它的官方文档。目前项目刚刚开始,地址为:splash中文文档PS: 不知道这个项目取这个名字会不会涉及到虚假宣传或者版权什么的,如果涉及到这些我会立马改名最后的最后列举出项目中参考的文档,在整个项目中参考的文档实在太多,不会一一列举,这里只列举我印象最深的一些回归爬虫,拥抱scrapy&splash。抓facebook public post like、comment、shareSplash官方文档Scrapy文档scrapy_splash项目文档最后再说两句没想到这个博客有这么多人来看并且评论,最近很长时间没有登录CSDN的博客,今天再登录上来才发现有许多新的留言,这些留言我没有及时回复,也不知道那些有问题的朋友,你们的问题解决了没有。在此我对自己的失误表示抱歉。另外我想额外说几点:之前有朋友通过qq联系到我,咨询相关问题,我基本上把我知道的都说出来了,我在这篇博客后面也贴出了splash相关的文档,有英文也有我自己翻译的中文的,各位朋友可以自己根据自己的情况结合着来看。在提问之前请仔细阅读相关文档,我想很多在文档上有的内容就不要来问我了。毕竟我翻译这个文档已经有些日子了,很多细节可能我自己都不太记得了。如果文档哪些地方翻译的不太清楚的,欢迎大家批评指正。另外有很多朋友私信我,问我想不想接一些私活什么的,在这里感谢这些朋友的信任。在这里我想说一下,暂时我没有接这方面的私活的准备。第一:我自己最近比较忙,在我的新年计划中提到,我目前正在进行角色转换,不仅有自己的事,也要盯着手下的人完成任务,加班比较多,没有什么时间来做私活。第二,不同的网站差距还是很大的,从用户权限验证到反爬虫机制都不一样,而且不同的私活需求也不一样,需要花大量的时间来分析目标网站。我自己并不想以后专门钻研爬虫,所以不太想花太多的时间在这种项目上。第三,我也有自己的职业规划,我希望自己能在多余时间内提升自己的职业技能。第四我自己其实没有多少信心来完成新接的项目,因为这个项目是延期的,大概延期了一周左右,而且很多地方没有我当初设想的那么简单,而且多多少少有一些问题最后无法解决,但是它并不是一个纯商业项目,只是一个简单的玩具而已。所以说实话我可能并没有独立开发一整套商用爬虫的能力。第五,大家都是在网上的陌生人,我也怕被骗,而且爬虫从某种程度上可能有法律上的风险。基于以上几点我想暂时不接受任何形式的私活,最后谢谢各位的信任
-
Python处理正则表达式超时的办法 title: Python处理正则表达式超时的办法tags: [python3, 正则表达式超时, re模块]date: 2018-04-27 21:40:21categories: Pythonkeywords: python3, 正则表达式, re模块, linux信号最近在项目中遇到一个问题,就是需要采用正则匹配一些疑似暗链和挂马的HTML代码,而公司的老大给的正则表达式有的地方写的不够严谨,导致在匹配的时候发生卡死的现象,而后面的逻辑自然无法执行了。虽然用正则表达式来判断暗链和挂马可能不那么准确或者行业内很少有人那么做,但是本文不讨论如何使用正确的姿势判断暗链挂马,只关注与正则超时的处理。在使用正则表达式的时候,如果正则写的太糟糕,所消耗的时间是惊人的,并且有可能会一直回溯,而产生卡死的现象,所以一般的大型公司都会有专门的人来对正则进行优化,从而提高程序效率。一般来说如果可能的话不要让用户来输入正则进行匹配。但是现在既没有专门的人进行正则的优化,本人也对正则了解的不够,所以只能从另外的角度来考虑处理超时的问题。首先我想到的方法是另外开启一个线程来进行匹配,而在主线程中进行等待,如果发现子线程在规定的时间内没有返回就kill掉子线程。这也是一个方案,但是我现在要介绍另外一种方案,该方案来自我在网上看到的一篇博客.博客地址该博客给出了另外一种办法,就是采用信号的方式,在正则匹配之前定义一个信号,并规定触犯时间和处理的函数,如果在规定时间内程序没有结束那么触发一个TimeoutError的异常,而主线程收到这个异常时就会中断执行,并处理这个异常,这样就从正则匹配中解脱出来,达到了我们要的结果。这个方法有两个不足之处:信号这个东西是Linux独有的,在Windows下不适用信号只能在主线程中使用,而如果在子线程中进行正则匹配,那么这个方法就不适用我的项目正在运行在Linux系统上,所以针对第一个不足来说可以接受,但是我的正则匹配都是在子线程中,所以乍看之下这个方案也不太靠谱,但是好在我在后面的评论中发现博主给出了针对第二种不足的解决方案——开辟一个子进程,将正则匹配放到子线程中,这样一来可以充分利用多核(毕竟Python中的多线程是个伪多线程),二来可以分方便的使用该方案解决问题,下面是实际的代码import re import multiprocessing import signal def time_out(b, c): raise TimeoutError def search_with_timeout(pipe, word, value): signal.signal(signal.SIGALRM, time_out) signal.alarm(1) r = re.compile(word) try: ret = r.search(value, re.I) b_ret = True if ret != None else False pipe.send(b_ret) except TimeoutError: pipe.send(False)在上面的代码中先的定义了一个信号,给定1s中以后触发,触发的函数为time_out然后执行正则表达式,如果在这1s中内无法完成,那么处理函数会被调用,会跑出一个异常,此时主线程终止当前任务的执行,进入到异常处理流程,这样就可以终止正则匹配,从而正常的返回。由于这个部分是一个新进程自然就涉及到不同进程之间的通信,在这个例子中我使用了管道进行通信。由于Python在创建子进程的时候可以进行参数的传入所以我只需要一个管道将数据从子进程中写入,再从朱金城中读取就好了。下面是调用该子进程的代码:pipe = multiprocessing.Pipe() p = multiprocessing.Process(target = search_with_timeout, args = (pipe[0], word, left_value)) p.start() p.join() #等待进程的结束 ret = pipe[1].recv() #获取管道中的数据
-
使用pyh生成HTML文档 最近在项目中需要将结果导出到HTML中,在网上搜索的时候发现了这个库,通过官方的一些文档以及网上的博客发现它的使用还是很简单的,因此选择在项目中使用它。在使用的时候发现在Python3中有些问题,网上很多地方都没有提到,因此我在这将它的使用以及我遇到的问题和解决方案整理出来供大家参考本文主要参考pyh中文文档下载的样本也是该文中提到的地址常规使用在使用时一般先导入模块:from phy import *然后可以创建一个PyH对象就像这样page = PyH(title)其中title是一个字符串,这个字符串将作为页面的标题显示,也就是说此时产生的HTML代码就是在头部加上一个title标签并将这个字符串作为文本值然后我们可以addCSS方法或者addJS方法引入外部的js文件或者css文件(调用这两个函数将在HTML的头部产生一个引入的代码,对于那种在body中添加style代码的我暂时没有找到什么办法)然后就是创建标签对象,对应标签类的名字所与在HTML中的对应的名称相同,传入对象的参数就是标签中的属性,除了class属性对应的参数名称是cl外,其余的参数名称与在HTML中的属性一一对应。比如我们要创建一个div标签可以这样写myDiv = div('测试div', id = 'div1', cl = "cls_div")最终生成的HTML代码如下:<div id = 'div1' class = 'cls_div'>测试div</div>将元素加入某个元素中可以使用<<符号,该符号返回的是最后被包含的符号对象。比如这样div(id = 'div1') << p('测试' cl = 'p_tag')这句代码会返回p元素对应的对象,而生成的HTML代码如下:<div id = 'div1'> <p class = 'p_tag'>测试</p> </div>当生成了合适的HTML文档后可以使用printOut方法将其打印,也可以使用render函数返回对应的HTML代码,以便我们进行存盘或者做进一步处理上面只是简单的做一下介绍,详细的使用方法请参看上面提到的一篇文章,这上面写的比较详细。下面来通过一个例子代码来说明我是如何处理一些出现的错误、做一些简单的扩展,并大致看看里面的源代码例子from pyh import * import codecs from xml.sax.saxutils import escape WORD_WIDTH = 100 def create_base(table_title, page): page.addCSS('base.css') #展示信息的表 base_table = page << table(cl = 'diff', id = 'difflib_chg_to0__top', cellspacing = '0', cellpadding = '0', rules = 'groups') for i in range(4): base_table << colgroup() #表头 t_head = base_table << thead() tr_tag = t_head << tr() tr_tag << th(cl = 'diff_next') << br() tr_tag << th(table_title, colspan = '2', cl = 'diff_header') t_body = base_table << tbody() return t_body #写入一行信息 def write_line(tr_tag, mark, data): tr_tag << td(mark, cl = 'diff_header') tr_tag << td(data) def txt2html(title, table_title, ifile, ofile): i_f = codecs.open(ifile, 'r',encoding='utf-8') lines = i_f.read().splitlines() i_f.close() page = PyH(title) t_body = create_base(table_title, page) lineno = 1 for data in lines: if len(data) >= WORD_WIDTH: for i in range(len(data) // WORD_WIDTH + 1): sub_data = data[WORD_WIDTH * i: min(WORD_WIDTH * (i + 1), len(data) - 1)] if i == 0: mark = str(lineno) else: mark = '>' tr_tag = t_body << tr() sub_data = escape(sub_data) sub_data = sub_data.replace(" ", " ") sub_data = sub_data.replace("\t", " ") write_line(tr_tag, mark, sub_data) else: tr_tag = t_body << tr() data = escape(data) data = data.replace(" ", " ") data = data.replace("\t", " ") write_line(tr_tag, str(lineno), data) lineno += 1 html = page.render() o_f = codecs.open(ofile, 'w', encoding= 'utf-8') o_f.write(html) o_f.close()这是一个将任意文本文件转化为HTML文档的例子,主要是在调用txt2html函数,该函数有4个参数,页面的标题,展示文本内容的表格的标题,输入文件路径,输出文件路径同时做了一些简单的处理,对原文档中的每行进行标号,同时设置一行只显示100个字符多余的进行换行,以便阅读最终打开生成的HTML大致如下:![最终效果]](https://img.masimaro.top/pyh/1.jfif)在Python3环境下直接运行发现它报了一个错误:在Python2中存在Unicode字符串和普通字符串的区别,但是在Python3中所有字符串都默认是Unicode的,它取消了关于Python2中unicode函数,这里报错主要是这个原因,因此我们定位到报错的地方,将代码进行修改,去掉unicode函数(在Python2中unicode函数需要传入一个普通字符串,因此这里我们只需要去掉unicode函数,保留原来的参数即可,对于进行字符号转化的直接注释或者改为pass即可解决了unicode问题之后再次运行,又报了这样一个错误定位到对应代码处,在原来的代码位置有这么一段代码:def TagFactory(name): class f(Tag): tagname = name f.__name__ = name return f thisModule = modules[__name__] for t in tags: setattr(thisModule, t, TagFactory(t))从这段代码上可以知道,每当我们通过对应名称创建一个标签时,会在tags里面里面寻找到对应的标签,然后调用工厂方法生成一个对应的标签,这个工厂方法生成的其实是一个Tag对象,并且所有HTML标签都是这个Tag类,因此可以猜测如果要添加新的标签对象,那么可以通过修改tags里面的值,我们加入对应的标签值之后发现代码可以运行了,至此问题都解决了。其实这些错误都是Python2代码移植到python3环境下常见的错误,至于它的源码我没怎么看太明白,主要是它生成标签的这一块,我也不知道为什么修改了tags之后就可以运行了,python类厂的概念我还是不太明白,看来要花时间好好补一下基础内容了。
-
python检测404页面 某些网站为了实现友好的用户交互,提供了一种自定义的错误页面,而不是显示一个大大的404 ,比如CSDN上的404提示页面如下:这样虽然提高了用户体验,但是在编写对应POC进行检测的时候如果只根据返回的HTTP头部信息判断,则很可能造成误报,为了能准确检测到404页面,需要从状态码和页面内容两个方面来进行判断。从状态码来判断比较简单。可以直接使用requests库发送http请求,得到响应码即可。从页面内容上进行判断的话,采用的思路是访问web站点上明显不存在的页面,获取页面内容进行保存,然后访问目标页面,将二者进行比较,如果相似度达到某一阈值,则该页面为404页面,否则为正常页面。为了判断两个页面的相似度,采用Python的simhash库,这个库具体实现的算法我不太懂,但是Python的好处就是:不懂无所谓,直接拿来用就行。这里也只是简单的拿来用一下:#-*- encoding:utf-8 -*- # 404 页面识别 from hashes.simhash import simhash import requests class page_404: def __init__(self, domain): #检测站点 self._404_page = [] # 404页面 self._404_url = [] #404 url self._404_path = ["test_404.html", "404_test.html", "helloworld.html", "test.asp?action=modify&newsid=122%20and%201=2%20union%20select%201,2,admin%2bpassword,4,5,6,7%20from%20shopxp_admin"] #404页面路径,用于生成一部分404页面 self._404_code = [200, 301, 302] #当前可能是404页面的http请求的返回值 #自己构造404url,以便收集一些404页面的信息 for path in self._404_path: for path in self._404_path: if domain[-1] == "/": url = domain + path else: url = domain + "/" + path response = requests.get(url) if response.status_code in self._404_code: self.kb_appent(response.content, url) def kb_appent(self, _404_page, _404_url): if _404_page not in self._404_page: self._404_page.append(_404_page) if _404_url not in self._404_url: self._404_url.append(_404_url) def is_similar_page(self, page1, page2): hash1 = simhash(page1) hash2 = simhash(page2) similar = hash1.similarity(hash2) if similar > 0.85: #当前阈值定义为0.85 return True else: return False def is_404(self, url): if url in self._404_url: return True response = requests.get(url) if response.status_code == 404: return True if response.status_code in self._404_code: for page in self._404_page: if self.is_similar_page(response.content, page): self.kb_appent(url, response.content) #如果是404页面,则保存当前的url和页面信息 return True else: return False return False上面的代码中,检测类中主要保存了这样几个信息:_404_page:404页面,用于与其他请求的页面进行相似度判断,以便识别404页面,这里用列表主要为了防止一个站点有多种404页面,这段代码运行时间越长它的准确度越高_404_url:404 页面的url,保存之前判断出页面是404的url,已经判断出来的就不再判断,为了提升效率_404_path:构建不存在页面的url,最后一个是一个sql注入的代码,这里为了识别出那些被防火墙拦截而显示的错误页面_404_code:可能返回404页面的响应码,如果响应码为这些,则需要对页面进行判断类在初始化时需要传入一个域名,根据这个域名来拼接几个不存在的或者会被防火墙拦截的请求并提交这些请求,得到返回信息,将这些信息作为判断的信息进行保存。在判断时首先根据之前保存的404 url信息进行判断,如果当前url是404页面则直接返回,提高效率。然后提交正常的http请求并获取响应信息,如果响应码为404则返回True,否则再状态码是否在_404_code列表中,最后再与之前保存的404页面信息进行比较得到结果。这段代码的测试代码如下:from page_404 import page_404 if __name__ == '__main__': domain = "http://xzylrd.gov.cn" check_404 = page_404(domain) dest_url = "http://xzylrd.gov.cn/TEXTBOX2.ASP?action=modify&newsid=122%20and%201=2%20union%20select%201,2,admin%2bpassword,4,5,6,7%20from%20shopxp_admin" print (check_404.is_404(dest_url))
-
lxml SAX方式解析xml python中lxml库是一个十分强大的xml解析库,最近在看《白帽子将web扫描》这本书的时候,里面提供了一种不同于以往的用法,因此在这将这个方法记录下来传统的lxml库的使用方法类似于下面这样:from lxml import etree tree = etree.HTML(html) #假定html是一个html文本字符串 tag_a = tree.xpath("//a")这是一种DOM的解析方法,它事先生成了一个一个dom树tree,然后在树中根据xpath字符串筛选出我们想要的元素,至于具体的用法就不再在这演示了,百度lxml可以搜到很多东西书中提供了一种类似于SAX模型的解析方法,但是又有些不同,SAX模型一般有一些固定的函数需要去重写,比如进入到标签中和退出标签等等。在这种情况下,我们只知道它进入到了标签开始位置,但是并不知道进入的是何种标签。书中的那个写法达到了一个很好的效果,它能做到为每一个标签定义一个对应的处理函数,比如刚进入到a标签,就会调用我们自己定义的处理这个事件的函数,并且可以获取它对应的属性的列表,废话不多说,直接上代码:from lxml import etree class HtmlParser: def __init__(self): #在函数中定义一些属性,比如解析出来的url或者希望保存的中间变量 parser = etree.HTMLParser(target=self, recover=True, encoding='utf-8') try: etree.fromstring(self._html, parser) except ValueError: pass def start(self, tag, attrbs): meth = getattr(self, "_handle_" + tag + "_tag_start") meth(tag, attrbs) def _handle_a_tag_start(self, tag, attrbs): #dosomething pass def end(tag): meth = getattr(self, "_handle_" + tag + "_tag_end") meth(tag, attrbs)在调用fromstring()将字符串转化为dom时每当进入一个标签开始位置将调用start函数,而当即将离开该标签时调用end函数,start函数传入标签名tag和标签的属性列表attrbs。在这两个函数中使用getattr函数获取类中对应名称的函数,这个函数名称以标签名作为唯一标识,如果有该函数则调用,这样根据不同函数的调用就知道到了哪个标签里面,针对不同的标签编写不同的处理代码即可。
-
ghost.py在代用JavaScript时的超时问题 在写爬虫的时候,关于JavaScript的解析问题,我在网上找到的一个解决方案是使用ghost.py这个模块,他是一个基于webkit封装的一个客户端,可以用来解析动态页面。它的使用非常简单,它从2.x版本开始,变化就有点大了,在这我主要是针对他的1.0版本。首先在GitHub上克隆它,然后在对应的文件中执行python setup.py install命令,这样就可以安装了,注意在这不要直接使用pip,使用pip会默认安装2.x版本。安装完成后,可以编写如下代码来加载一个网页:from ghost import Ghost gh = Ghost(display = True, wait_timeout = 60) page, res = gh.open(url) for item in res: print item.url这段代码可以打印在加载页面时,webkit向远程服务器请求了那些资源。对于AJAX请求来说,使用这个特性非常方便的就可以获取到对应的url它在里面提供了一些特定的方法用来处理页面的事件,比如鼠标单击某个标签时调用click,通过阅读它的源代码可以知道针对这些事件的处理,它调用的是JavaScript代码,比如说click事件,click事件的源码如下@client_utils_required @can_load_page def click(self, selector): """Click the targeted element. :param selector: A CSS3 selector to targeted element. """ if not self.exists(selector): raise Exception("Can't find element to click") return self.evaluate('GhostUtils.click("%s");' % selector)它上面的两个装饰器的代码分别如下:def can_load_page(func): """Decorator that specifies if user can expect page loading from this action. If expect_loading is set to True, ghost will wait for page_loaded event. """ @wraps(func) def wrapper(self, *args, **kwargs): expect_loading = False if 'expect_loading' in kwargs: expect_loading = kwargs['expect_loading'] del kwargs['expect_loading'] if expect_loading: self.loaded = False func(self, *args, **kwargs) return self.wait_for_page_loaded() return func(self, *args, **kwargs) return wrapper def client_utils_required(func): """Decorator that checks avabality of Ghost client side utils, injects require javascript file instead. """ @wraps(func) def wrapper(self, *args, **kwargs): if not self.global_exists('GhostUtils'): self.evaluate_js_file( os.path.join(os.path.dirname(__file__), 'utils.js')) return func(self, *args, **kwargs) return wrapper函数can_load_page是用来判断用户是否需要进行等待,等待的条件是页面加载完毕,在阅读它的源代码时可以知道,它自身给webkit注册了几个槽函数,一个用来处理页面开始加载的信息,一个用来处理页面加载结束的信息,在加载时将一个bool变量设置为true,加载结束时设置为false,另外在返回前调用等待函数,等待函数主要判断这个bool变量是否为false,为false则返回,否则就继续循环。这样当页面加载完毕后,就可以返回,同样的,这个can_load_page函数就是在执行JavaScript期间进行等待。直到页面加载完成后返回(当然,是否需要等待就看我们是否传入expect_load这个参数了,它默认是False,即不等待)client_utils_required函数主要负责读取utils.js这个文件中的JavaScript代码并执行它,这个文件中代码都是函数,在这所谓的执行只是为了将其加载到内存,准备随时调用。根据以上所说,大概能组织一下执行click函数时经历的步骤了:首先会调用client_utils_required函数,将对应的JavaScript函数代码加载起来,然后判断是否需要等待,如果需要等待将设置对应等待变量的值,然后真正调用对应的JavaScript函数来进行元素的点击,然后调用等待函数,如果需要等待,则会等待到新页面加载,否则直接返回,这样就完成了一个点击事件。根据这些我们扩展它的功能,从click函数的定义来看,它需要传入一个css选择器,但是我遇到的场景是我希望通过JavaScript得到的页面的dom元素,根据它的下标来进行点击,比如说document.getElementsByTagName("a")[3];我通过上面的代码获取到了这个元素,我现在要点击这个元素,自然不能直接调用click函数,ghost中也没有对应的函数可以使用,这个时候就需要我们进行扩展。当时我给出的代码入下:@client_utils_required @can_load_page def js_click(self, jscontent): #jscontent使用js来定位元素的代码 return self.evaluate('GhostUtils.jsclick("%s");' % jscontent);然后来扩展utils.js文件,在里面新加一个对应的函数jsclickjsclick: function(jscontent) { var elem = eval(jscontent); if (!elem) { return false; } var evt = document.createEvent("MouseEvents"); evt.initMouseEvent("click", true, true, window, 1, 1, 1, 1, 1, false, false, false, false, 0, elem); if (elem.dispatchEvent(evt)) { return true; } return false; }但是我在这发现,它可以调用成功的点击,但是超时率比较高,几乎达到了70%以上,这个问题一直使我困惑,后来我仔细阅读源代码后发现,问题出在expect_loading = True,也就是让其等待页面加载完毕。有很多页面都是使用AJAX技术的,它只是改变页面的状态而不会重新加载,这样自然那个等待函数不会返回,当时间一到自然也就超时了,但是如果不加这个参数,让他立即返回,那么我们就得不到请求的url,而在webkit中也没有办法判断一个JavaScript代码是否执行完毕,所以在这我采取了一个折中的方案,每次等待1s,所以将上面的jsclick函数改为:@client_utils_required def js_click(self, jscontent): #jscontent使用js来定位元素的代码 return self.main_frame.evaluateJavaScript('GhostUtils.jsclick("%s");' % jscontent); #执行js函数 for i in range(0, 100): time.sleep(0.01) Ghost._app.processEvents() #在等待的时候让QT的信号槽机制仍然运转这样可能会有一定的性能损失,但是目前我只能想到这个方案。