搜索到
35
篇与
的结果
-
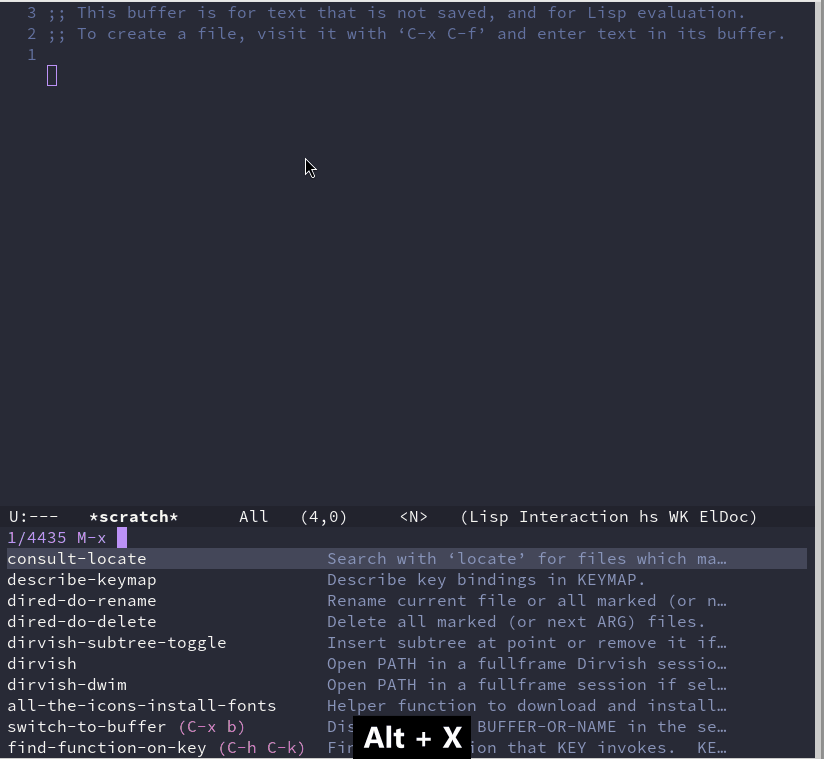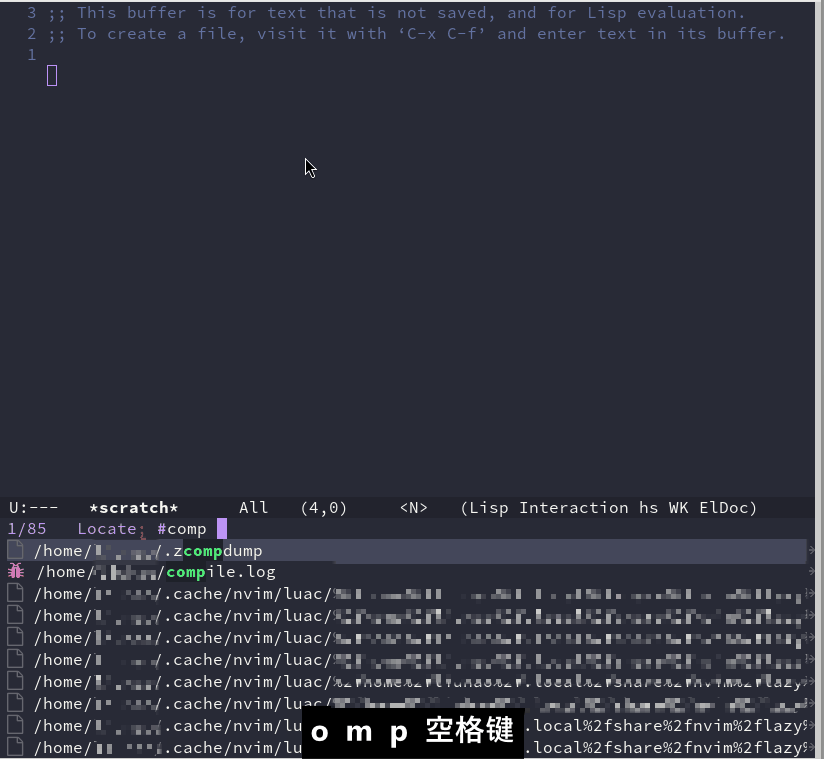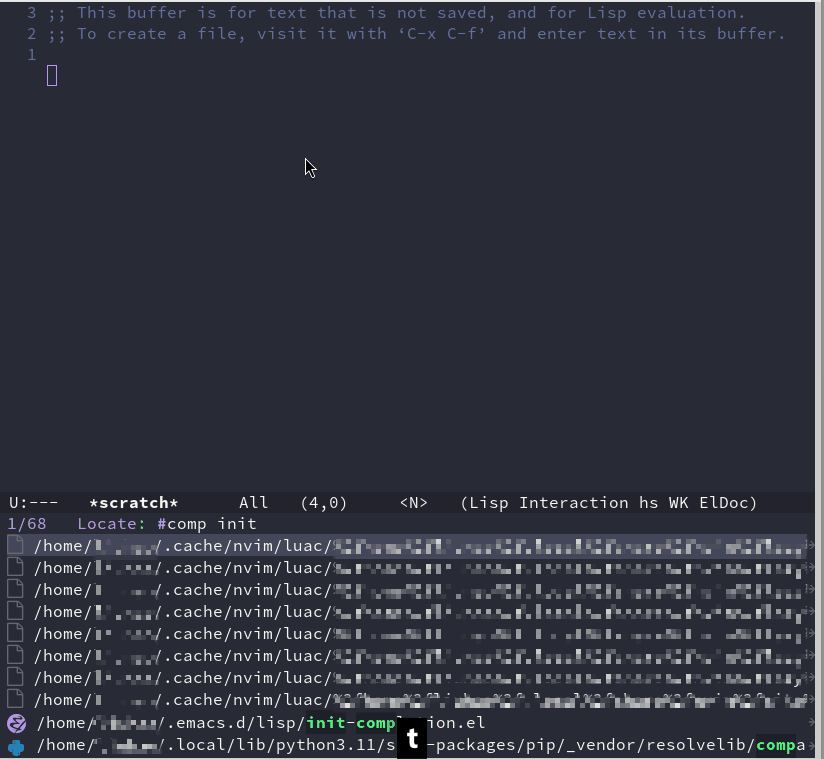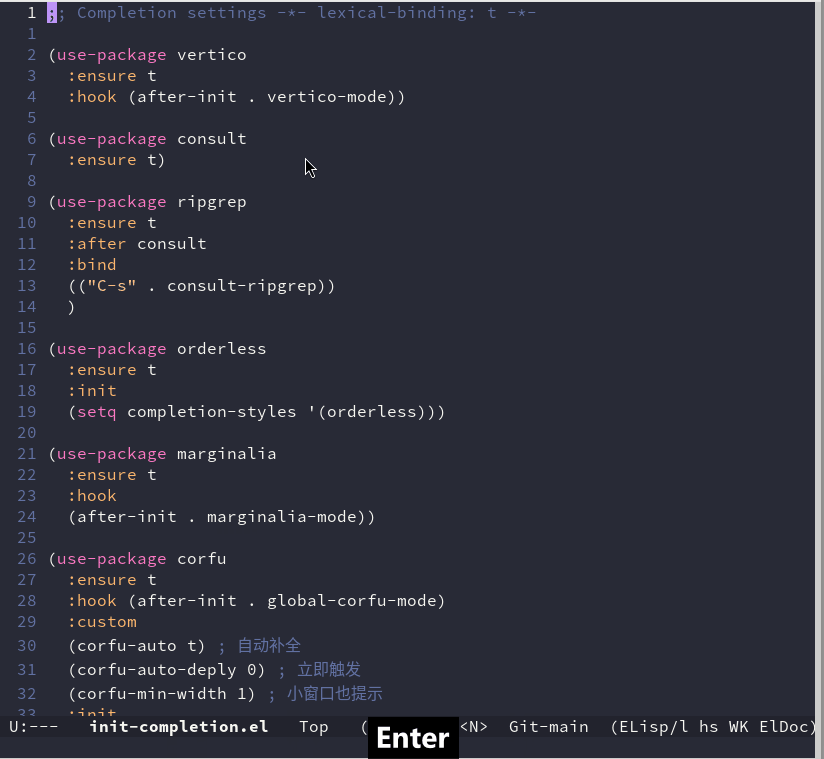
 Emacs 折腾日记(二十五)——目录管理 在之前的文章中,分了几篇着重介绍了Emacs编辑方面的功能改造。作为一个文本编辑器,要想坚持用下去首先应该改造成自己熟悉的编辑方式。本节我们来介绍Emacs的目录管理Dired ModeEmacs自带一个名为 Dired (Directory Editor) 的插件,它负责对目录进行操作。默认的,我们可以使用 C-x d 来进入Dired Mode。启动后它会等待用户输入想进入的目录,默认是当前目录。Dired Mode 是提供了一种类似操作文本的方式来操作目录。我们可以像操作文本那样来对目录进行类似于拷贝剪切粘贴删除创建跳转查找重命名批量操作得益于前面的篇章配置的一些插件,可以很方便的使用Dired Modedired 美化在正式介绍dired 使用之前,先稍微对它进行一些美化,原始的界面太素了,看着不太好看。首先介绍 diredfl ,原始的dired 只能使用两种颜色来区别文件和目录,而 diredfl 可以使用多种颜色,让dired显示的更加漂亮(use-package diredfl :ensure t :hook (dired-mode . diredfl-mode))接着我们再使用 all-the-icons-dired 来给dired显示的前面加上一个图标。这个插件依赖 all-the-icons 插件。(use-package all-the-icons :ensure t :when (display-graphic-p) :commands all-the-icons-install-fonts) ;; 安装完成之后需要执行 all-the-icons-install-fonts 命令安装对应字体 (use-package all-the-icons-dired :ensure t :hook (dired-mode . all-the-icons-dired-mode))我们也可以通过安装 all-the-icons-completion 插件,给minibuffer中的补全系统也加上图标(use-package all-the-icons-completion :ensure t :hook ((after-init . all-the-icons-completion-mode) (marginalia-mode . all-the-icons-completion-mode)))dirvish 增强direddirvish 是在dired 基础之上的文件管理增强插件。相对与dired 它提供快速跳转、实时预览、并且能兼容对dired的一些扩展。(use-package dirvish :ensure t :hook (after-init . dirvish-override-dired-mode) :bind( ("C-x d" . dirvish) )) 我们使用命令 dirvish 就能打开对应的窗口,或者像上面那样绑定快捷键来打开对应的窗口使用vim的方式来操作目录这里的使用vim的方式来操作多少有点标题党的意思。我无法做到完全按照vim编辑文本那样来编辑目录,但是这里我可以修改以下对应的快捷键已达到某些操作可以使用vim的快捷键。(use-package dirvish :ensure t :hook (after-init . dirvish-override-dired-mode) :bind(:map dired-mode-map ("C-x d" . dirvish) ("y" . dired-do-copy) ;; 拷贝粘贴 ("d" . dired-do-delete) ;; 删除 ("r" . dired-do-rename) ;; 重命名 ("a" . dired-create-empty-file) ;; 创建空文件 ("+" . dired-create-directory) ;; 创建文件 ("SPC" . nil) ;; 取消空格键的绑定 ) :config (with-eval-after-load 'evil (evil-define-key 'normal dired-mode-map "r" 'dired-do-rename)) ;; 排除evil模式下默认键的覆盖 (my-leader-def "j" #'dired-goto-file) )在上述的配置中,我绑定的快捷键如下快捷键功能C-x d打开diredy拷贝d删除r重命名a创建空文件+创建空目录SPC j跳转到指定文件需要注意的是,在 config 中调用了这样的语句 (with-eval-after-load 'evil (evil-define-key 'normal dired-mode-map "r" 'dired-do-rename))with-eval-after-load 表示在某个插件加载之后,这句代码的意思是,在evil插件加载后,在normal模式下,我们定义dired mode 下快捷键 r 绑定到 dired-do-rename,也就是重命名这个功能。之所以要这么做是因为在evil插件加载后会覆盖我们定义的快捷键。另外为了正常使用 leader键,这里特意取消了空格键在dired 中的定义,原本它被定义为跳转到下一行。这些功能都比较简单,所以这里就不演示了。搜索文件并跳转正常情况下,当项目文件和代码量上来之后,再一个目录一个目录的找就不太现实了。常见的是根据代码中函数定义来找文件或者根据文件来找函数定义。前者我们通过consult-rg 已经实现了。这里介绍以下如何通过文件名来查找并快速打开文件我们可以使用 consult-locate 来搜索文件,结合前面介绍的orderless,我们只需要对文件有一个相对的映像就可以找到。想要使用 consult-locate 需要安装 locate 程序,在Arch Linux 中可以使用下面的命令安装sudo pacman -S mlocate sudo updatedb ;; 更新数据库我们以打开配置文件中的 init-completion.el 为例。我们可以直接使用 M-x 输入命令 consult-locate并回车 , 接着在命令提示符后输入一个大概的内容,然后在minibuffer的候选项中找到对应的文件即可我们也可以结合 embark-act 命令来做到跳转到文件所在的 dired 中,这里我们在 embark 的配置中添加一个快捷键定义(use-package embark :ensure t :after consult :bind (("C-e" . embark-export) ("C-;" . embark-act))) ;; 添加 embark-act 快捷键这样在定位到文件之后,可以直接使用 C-; 调出对应的动作,最后使用 j 来完成进入dired的动作有了 consult-locate 和 embark-act,前面介绍的 dired中的跳转操作的实用性就大大降低了,如果我们记得文件的全路径,直接使用 find-file 打开就好了。如果只有一个模糊的映像,那么使用 consult-locate 配合 orderless,比进入dired 然后执行跳转要快的多到这里,Emacs中关于目录管理的部分就介绍完了。使用dired配合键盘操作能极大的提升的效率
Emacs 折腾日记(二十五)——目录管理 在之前的文章中,分了几篇着重介绍了Emacs编辑方面的功能改造。作为一个文本编辑器,要想坚持用下去首先应该改造成自己熟悉的编辑方式。本节我们来介绍Emacs的目录管理Dired ModeEmacs自带一个名为 Dired (Directory Editor) 的插件,它负责对目录进行操作。默认的,我们可以使用 C-x d 来进入Dired Mode。启动后它会等待用户输入想进入的目录,默认是当前目录。Dired Mode 是提供了一种类似操作文本的方式来操作目录。我们可以像操作文本那样来对目录进行类似于拷贝剪切粘贴删除创建跳转查找重命名批量操作得益于前面的篇章配置的一些插件,可以很方便的使用Dired Modedired 美化在正式介绍dired 使用之前,先稍微对它进行一些美化,原始的界面太素了,看着不太好看。首先介绍 diredfl ,原始的dired 只能使用两种颜色来区别文件和目录,而 diredfl 可以使用多种颜色,让dired显示的更加漂亮(use-package diredfl :ensure t :hook (dired-mode . diredfl-mode))接着我们再使用 all-the-icons-dired 来给dired显示的前面加上一个图标。这个插件依赖 all-the-icons 插件。(use-package all-the-icons :ensure t :when (display-graphic-p) :commands all-the-icons-install-fonts) ;; 安装完成之后需要执行 all-the-icons-install-fonts 命令安装对应字体 (use-package all-the-icons-dired :ensure t :hook (dired-mode . all-the-icons-dired-mode))我们也可以通过安装 all-the-icons-completion 插件,给minibuffer中的补全系统也加上图标(use-package all-the-icons-completion :ensure t :hook ((after-init . all-the-icons-completion-mode) (marginalia-mode . all-the-icons-completion-mode)))dirvish 增强direddirvish 是在dired 基础之上的文件管理增强插件。相对与dired 它提供快速跳转、实时预览、并且能兼容对dired的一些扩展。(use-package dirvish :ensure t :hook (after-init . dirvish-override-dired-mode) :bind( ("C-x d" . dirvish) )) 我们使用命令 dirvish 就能打开对应的窗口,或者像上面那样绑定快捷键来打开对应的窗口使用vim的方式来操作目录这里的使用vim的方式来操作多少有点标题党的意思。我无法做到完全按照vim编辑文本那样来编辑目录,但是这里我可以修改以下对应的快捷键已达到某些操作可以使用vim的快捷键。(use-package dirvish :ensure t :hook (after-init . dirvish-override-dired-mode) :bind(:map dired-mode-map ("C-x d" . dirvish) ("y" . dired-do-copy) ;; 拷贝粘贴 ("d" . dired-do-delete) ;; 删除 ("r" . dired-do-rename) ;; 重命名 ("a" . dired-create-empty-file) ;; 创建空文件 ("+" . dired-create-directory) ;; 创建文件 ("SPC" . nil) ;; 取消空格键的绑定 ) :config (with-eval-after-load 'evil (evil-define-key 'normal dired-mode-map "r" 'dired-do-rename)) ;; 排除evil模式下默认键的覆盖 (my-leader-def "j" #'dired-goto-file) )在上述的配置中,我绑定的快捷键如下快捷键功能C-x d打开diredy拷贝d删除r重命名a创建空文件+创建空目录SPC j跳转到指定文件需要注意的是,在 config 中调用了这样的语句 (with-eval-after-load 'evil (evil-define-key 'normal dired-mode-map "r" 'dired-do-rename))with-eval-after-load 表示在某个插件加载之后,这句代码的意思是,在evil插件加载后,在normal模式下,我们定义dired mode 下快捷键 r 绑定到 dired-do-rename,也就是重命名这个功能。之所以要这么做是因为在evil插件加载后会覆盖我们定义的快捷键。另外为了正常使用 leader键,这里特意取消了空格键在dired 中的定义,原本它被定义为跳转到下一行。这些功能都比较简单,所以这里就不演示了。搜索文件并跳转正常情况下,当项目文件和代码量上来之后,再一个目录一个目录的找就不太现实了。常见的是根据代码中函数定义来找文件或者根据文件来找函数定义。前者我们通过consult-rg 已经实现了。这里介绍以下如何通过文件名来查找并快速打开文件我们可以使用 consult-locate 来搜索文件,结合前面介绍的orderless,我们只需要对文件有一个相对的映像就可以找到。想要使用 consult-locate 需要安装 locate 程序,在Arch Linux 中可以使用下面的命令安装sudo pacman -S mlocate sudo updatedb ;; 更新数据库我们以打开配置文件中的 init-completion.el 为例。我们可以直接使用 M-x 输入命令 consult-locate并回车 , 接着在命令提示符后输入一个大概的内容,然后在minibuffer的候选项中找到对应的文件即可我们也可以结合 embark-act 命令来做到跳转到文件所在的 dired 中,这里我们在 embark 的配置中添加一个快捷键定义(use-package embark :ensure t :after consult :bind (("C-e" . embark-export) ("C-;" . embark-act))) ;; 添加 embark-act 快捷键这样在定位到文件之后,可以直接使用 C-; 调出对应的动作,最后使用 j 来完成进入dired的动作有了 consult-locate 和 embark-act,前面介绍的 dired中的跳转操作的实用性就大大降低了,如果我们记得文件的全路径,直接使用 find-file 打开就好了。如果只有一个模糊的映像,那么使用 consult-locate 配合 orderless,比进入dired 然后执行跳转要快的多到这里,Emacs中关于目录管理的部分就介绍完了。使用dired配合键盘操作能极大的提升的效率 -
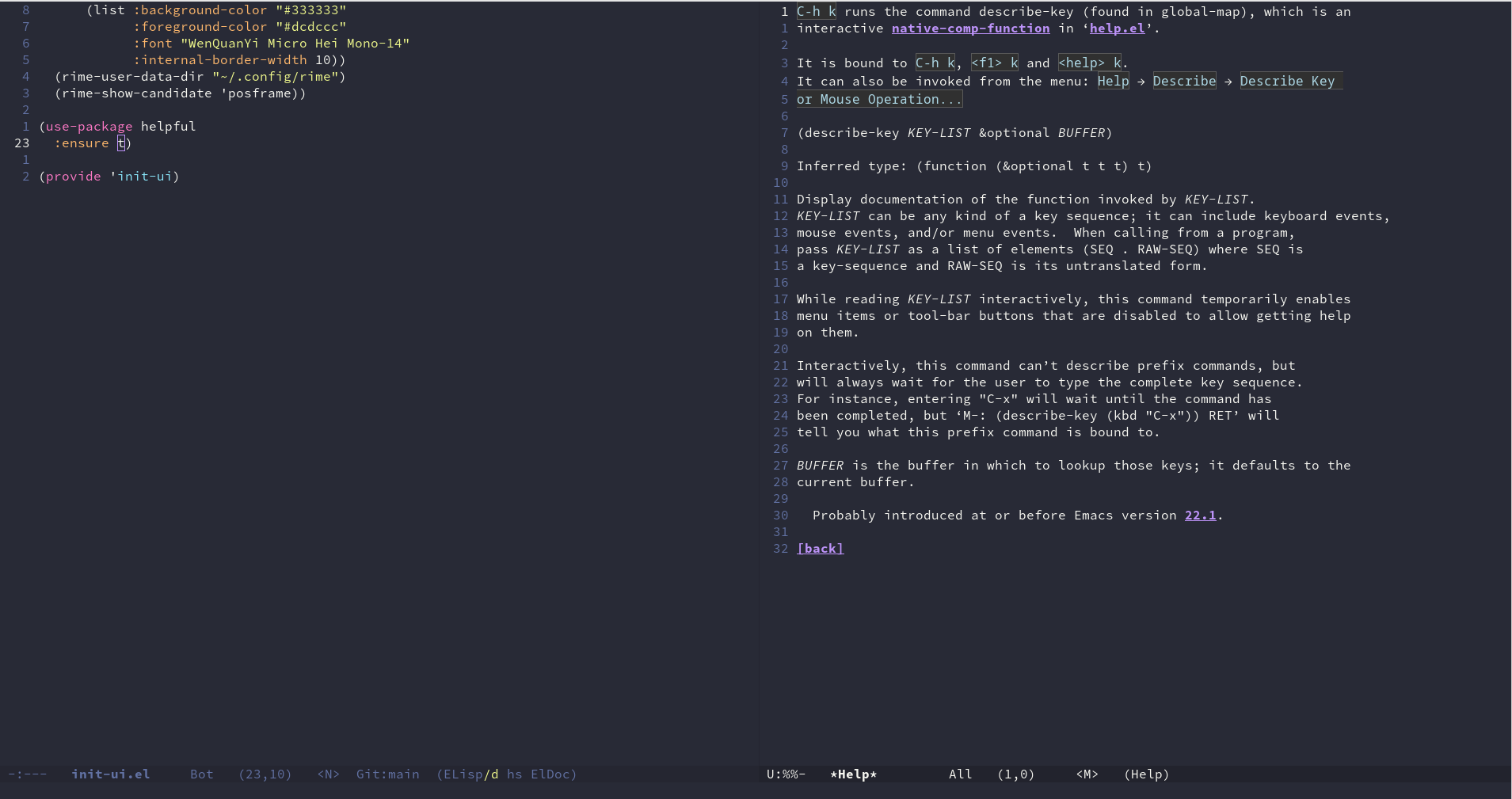
Emacs 折腾日记(二十四)——帮助信息的一些优化 Emacs 是一个自文档的系统,任何有关Emacs的信息都可以通过Emacs自身查阅。包括基础的入门手册、elisp手册、以及各种插件的相关说明信息。一般遇到不懂的变量直接使用 C-h v。查看它的说明。使用 C-h f 查阅相关函数、使用 C-h k 来查找对应快捷键绑定的函数。一般来说阅读官方一手的文档比从任何论坛或者搜索引擎来的更快更准确,而且有不少Emacs高手都推荐多多阅读Emacs的官方文档。本节就着重介绍一下我了解的关于阅读文档的一些姿势。查找相关定义最开始介绍过使用 C-h f 之类的查看相关文档,Emacs所谓的子文档不光指的是查看文档,而且还可以查看相关的源代码。有些我们可以通过文档中给出的源码链接点进去看,但是还是不如直接查看源码。直接查看源码可以使用 find-function、find-variable、find-function-on-key。它们分别对应着查找函数、变量、以及快捷键绑定的函数定义。我们可以绑定一些快捷键(global-set-key (kbd "C-h C-f") 'find-function) (global-set-key (kbd "C-h C-v") 'find-variable) (global-set-key (kbd "C-h C-k") 'find-function-on-key)对默认文档显示的优化我觉得官方的文档显得比较素,比较原始。为了提高阅读的体验我们可以对文档进行美化。这里可以使用 helpful来增强一下。(use-package helpful :ensure t :bind (("C-h f" . helpful-callable) ("C-h v" . helpful-variable) ("C-h k" . helpful-key) ("C-h s" . helpful-symbol) ))我们针对 C-h k 这个快捷键来对比一下原始的文档和 helpful 增强之后的文档显示效果对比发现,helpful 不光对显示效果进行了一些改进,而且显示的内容更加丰富。特别是它已经可以直接显示出相关定义的源代码,在某种程度上替换默认的 find-function 等函数。which-key在介绍配置 neovim 的时候,介绍了 which-key 插件,它可以根据用户输入的快捷键前缀显示所有可能的匹配,使我们记忆快捷键的负担减轻。Emacs上也有类似的插件。在Emacs 30以后内置了 which-key 插件,我们只需要启用(use-package which-key :ensure t :hook (after-init . which-key-mode) :custom (which-key-idle-delay 0.7))
-
Emacs 折腾日记(二十三)——进一步提升编辑效率 在前面的几篇,我们完成了Emacs的vim模拟器、中文输入、多行编辑以及基本的补全功能的添加。这一篇没有具体的提升哪一方面的能力,这一篇我想整合我在其他教程中看到的我认为对我比较有用的用法和插件,算是对前期功能的一个总结。让Emacs记住一些信息一般的编辑器都会在下次打开时记住上次的一些信息,例如记住之前打开过的文件,执行过的命令,或者记住上次的窗口布局。记住上次执行的命令我们每次使用 M-x 执行命令时,minibuffer中显示的提示都是一样的,那些常用命令要么不在上面要么太靠下了,我们希望能记住某些命令,以便能快速找到它。记住上次执行的命令可以使用 savehist 插件。它是一个Emacs自带的插件,默认是关闭的状态,我们可以通过将 use-package 来加载它,但是因为是自带的,不需要从镜像中下载所以它的 :ensure 项应该设置为 nil(use-package savehist :ensure nil :hook (after-init . savehist-mode) :custom (savehist-file (locate-user-emacs-file "custom/savehist")) ;; 设置保存文件的位置 (savehist-additional-variables '(kill-rings shell-command-history)) ;; 额外保存剪切板和shell命令行历史 (savehist-ignored-variables '(message-history)) ;; 不保存消息历史 (history-delete-duplicates t) ;; 自动去重 (history-length 1000) ;; 保存历史数据条目 )在执行一些操作关掉Emacs之后,我们会发现它在 ~/.emacs.d/custom 生成了一个名为 savehist 的文件,它记录了之前在minibuffer中执行的命令。为了保持git工程的干净,我打算将这种历史文件排除在git管理之外,所以单独将它放到custom目录,并忽略它其实该插件不光可以保留执行的命令,minibuffer中的许多信息它都可以保存和持久化。minibuffer-history (所有 minibuffer 输入历史)command-history (执行过的命令)search-ring (搜索历史)regexp-search-ring (正则搜索历史)extended-command-history (M-x 命令历史)file-name-history (文件路径历史)记住上次打开的文件一般的编辑器都可以记录上次打开的文件,并列出来。Emacs也有一个类似的内置插件—— recentf(use-package recentf :ensure nil :hook (after-init . recentf-mode) :custom (recentf-max-menu-item 10) ;; 最多只记录10条历史记录 (recentf-save-file (locate-user-emacs-file "custom/.recentf")) ;; 定义保存历史记录的临时文件路径 )搜索功能的增强实现全局搜索我们可以依赖Linux上的命令行工具 grep 和最近(也不算近了)的 ripgrep。之前在介绍vim的时候,vim内部集成了 grep。但是我们使用更为强大的 ripgrep。在Emacs中可以配合插件 consult 和 ripgrep,调用 consult-ripgrep 来进行全局搜索。它会自动搜索当前项目下的所有目录。我们对之前 consult 插件的配置代码进行一些修改,并添加 ripgrep 的配置(use-package consult :ensure t) (use-package ripgrep :ensure t :after consult :bind (("C-s" . consult-ripgrep)) )这里我们将 C-s 绑定的快捷键修改为 consult-ripgrep。神奇的是,配合之前安装的orderless,我们只需要按照一个模糊的记忆来匹配想要的内容。同时它也能支持输入中文批量替换批量替换这个功能,根据我找到的教程,它需要依赖 embark、consult、和 wgrep 这么三个插件。其中 consult 用来进行搜索,而 embark 可以为不同场景下的文本/候选项(如搜索结果、补全列表、文件路径等)提供动态的快捷操作菜单。简化了minibuffer上的一些操作。而 wgrep 则是其中的核心插件,用来批量修改内容并保存(use-package embark :ensure t :after consult :bind (("C-e" . embark-export))) (use-package embark-consult :ensure t :after embark) (use-package wgrep :ensure t :custom (wgrep-auto-save-buffer t) ;; 自动保存修改 )这里我们使用 :after 来保证插件的加载顺序依次为 consult、embark、embark-consult,特别是 embark-consult,它依赖 consult 和 embark,一定要将它放到后面加载。下面来演示如何进行批量替换,这里我们将配置中所有 use-package 修改为 package-install,修改之前记得使用git等版本管理工具进行备份首先,使用 C-s 搜索 use-package 关键字接着使用 C-e, 也就是上面绑定的快捷键来将结果从 minibuffer 导出到 buffer然后使用 C-c C-p 调用 wgrep-change-to-wgrep-mode 将 buffer 的mode由 grep-mode 修改为 wgrep-mode接着使用 M-% 调用 query-replace 进行替换,这个时候它需要输入被替换的字符和替换后的字符确定后,对于每个待替换的位置使用 y 或者 n 来表示替换或者不替换。也可以使用 ! 替换所有最后使用 C-c C-c 调用 wgrep-finish-edit 来结束编辑,配置之前设置的自动保存,此时修改内容已经被保存了修改之后如何不满意,可以使用 C-c C-k 撤销修改小节这应该是最后一篇关于Emacs自身编辑功能的增强了,在这一块我没有使用太多的Emacs经验。倒是在vim上有点经验,所以很多东西我不自觉地就往vim上面靠,总想着vim在编辑上有些功能Emacs上还没有,该如何进行添加,这几篇就显得比较分散,总是想到什么功能就往上面堆。为此造成各位读者阅读体验不佳,我表示道歉。谢谢各位读者的支持和鼓励!
-
Emacs 折腾日记(二十二)——补全强化 在之前的一系列文章中,我们对Emacs做了一些小范围的定制,目前它已经可以很好的模拟vim的一些基础功能。我们也在模拟vim基础功能之上做了一些能力的提升。本篇我们将对Emacs自带的补全系统做一个升级,并且给出一些搜索和替换的方案,进一步提升Emacs的效率Emacs上有很多很好用的补全插件,著名的有前期的 ivy 体系和当前社区比较火的vertico 体系。为了与时俱进,而且Emacs-China中的很多帖子也推荐使用vertico,所以这里我也介绍这个体系中的插件。vertico 体系中包括下面几个插件:verticoconsultcorfumarginaliaorderlessconsultconsult 插件提供了一系列的查找和补全命令(use-package consult :ensure t :bind (("C-s" . consult-line)))这样我们可以通过使用 C-s 来进行搜索vertico默认情况下,我们使用M-x 输入命令时没有补全提示,但是可以使用TAB 键补全。我们可以通过命令 icomplete-mode 来启用这个mode,以便在输入命令时能拥有一个补全。但是这个补全采用的是横向排版的方式,显示上也不太直观。这里我们可以通过vertico 插件对补全进行增强。vertico 提供了一个垂直样式的补全系统。我们可以通过下列代码来安装并启用它(use-package vertico :ensure t :hook (after-init . vertico-mode))重启emacs之后,再执行 M-x 之后发现它已经可以竖直的显示命令,并且会列出可能的命令了。可以使用 C-n、C-p 来选择下一个或者上一个命令orderless顾名思义,orderless 提供一种无序补全。它可以将一个搜索的范式变成数个以空格分隔的部分,各部分之间没有顺序,你要做的就是根据记忆输入关键词、空格、关键词。它改变了我们使用和思考的习惯,我们不再需要关心信息的顺序,我们只需要在脑海中搜索关键信息片段,然后把这些片段组合起来即可,剩下的都交给Emacs。例如我们要输入 package-refresh-contents 来刷新包管理里面的源。常规的做法我们需要先输入 pack 等等字符,然后由补全信息给我们提示,加入 orderless 之后,可以凭借模糊的记忆输入类似 refre pack 这样的片段来进行匹配(use-package orderless :ensure t :init (setq completion-styles '(orderless)))orderless 是针对整个minibuffer进行增强的,只要是使用minibuffer的地方都可以使用。例如我们上面使用了 consult 插件并且绑定了 C-s 来进行搜索,这里我们就可以使用orderless 来配合完成搜索功能marginaliamarginalia 可以给minibuffer中候选条目显示一段注释或者其他信息。其实不光是执行命令的时候marginalia是启用的,现在只要是minibuffer中的选项,marginalia都是可以使用的,例如使用 switch-buffer 和 find-file 或者使用帮助信息的时候也可以展示相关信息corfucorfu 可以让我们通过弹窗进行补全。(use-package corfu :ensure t :hook (after-init . global-corfu-mode) :custom (corfu-auto t) (corfu-auto-deply 0) (corfu-min-width 1) :init (corfu-history-mode) (corfu-popupinfo-mode))在安装完成之后,我们在编写相关配置的时候可以配合orderless,只输入函数的部分,仅仅凭借模糊的记忆让Emacs自己来匹配我们想要的内容,极大的提高了输入的效率capecorfu 插件仅仅是一个补全的前端,它需要补全后端提供数据。好在Emacs 自己提供了有关elisp 的补全后端,所以上面在测试corfu补全的时候可以出现。但是在其他文本类型不会产生补全选项。而cape则是集成了多种补全后端,它与corfu联合起来可以起到很好的补全效果(use-package cape :ensure t :init (add-to-list 'completion-at-point-functions #'cape-dabbrev) (add-to-list 'completion-at-point-functions #'cape-file) (add-to-list 'completion-at-point-functions #'cape-keyword) (add-to-list 'completion-at-point-functions #'cape-ispell) (add-to-list 'completion-at-point-functions #'cape-dict) (add-to-list 'completion-at-point-functions #'cape-symbol) (add-to-list 'completion-at-point-functions #'cape-line))上述代码中 completion-at-point-functions 保存的是Emacs在补全时调用的相关函数来获取补全项,我们将cape 的相关函数添加到这个列表中,供Emacs在触发补全时调用。到此为止,我们对Emacs自身的补全进行了加强。进一步提升了编辑的效率
-
Emacs 折腾日记(二十一)——编辑能力提升 上一篇文章,我们补充了一些基本的配置,并且关闭了一些默认的行为。这里我们继续对它进行配置。本篇将要使用一些插件来修改默认的编辑行为进一步提高编辑文本的效率。avy 插件基础用法在vim中有 easymotion 可以使用,在Emacs中可以使用 avy 插件。它的功能于前面介绍的easymotion 类似。通过下面的代码来安装(use-package avy :ensure t :after general ;; 确保 general 插件已经安装 :config (setq avy-timeout-seconds 0.5) (my-leader-def "f" 'avy-goto-char-timer))我们在安装配置的时候使用之前定义的leader键来定义它的一些行为。首先定义 SPC-f 来进行快速跳转。avy-goto-char-timer 的功能与 easymotion 类似,将要查找的字符使用不同的字母进行标识,然后根据下一步的输入来确定光标的位置,例如下面的例子我们可以连续输入一段内容减少待筛选项。当然这个速度要快,否则在一定时间内没有输入文本之后,avy会认为已经结束输入了。这个等待的时间我们在上面通过 avy-timeout-seconds 定义的是 0.5。当然也可以扩大这个时间范围进阶用法这个简单的功能只是 avy 功能的冰山一角。它还有许多有用的功能,如果能熟练使用将会极大的提高编辑文本的效率。实际上avy 在筛选、跳转之前可以执行用户指定的动作,它支持哪些动作呢?我们可以在输入筛选的部分文本后输入?,查看支持的动作。我们来举一个例子:下面有一段文本,我希望将text1复制到最后一行,那么可以这么操作使用<leader>f 激活 avy,然后输入筛选文本输入 Y 表示复制整行输入对应字符表示选中text1 所在行此时我们会发现,text1 已经被复制到光标所在行了多行操作和块操作在vim中我们介绍了多行操作,主要是使用C-v 来选中某些行,然后通过使用A 或者 I 来选中行尾或者行首,并进入插入模式。这种方式可以同时在对应位置插入多个相同的字符。emacs 中的 evil 插件也可以进行相同的操作。但是对于行间或者每行在不同位置插入的情况就不适用了。我们可以使用插件 evil-multiedit 来达到这一效果。evil-multiedit 深度绑定了vim的快捷键,在选中区域之后可以直接使用vim中的 I/A 来编辑选中区域的首部或者尾部。也可以使用 ciw 之类的同时修改多个选中区域。在选区时既可以使用vim 中的 * 来查找并选中,也可使用 / 来搜索并且同时选中多个。这个插件相当于增强了vim的多行编辑功能我们使用下列的代码来安装和简单的配置(use-package evil-multiedit :ensure t :after evil :config (evil-multiedit-default-keybinds) (my-leader-def "m m" #'evil-multiedit-match-and-next ; 标记当前符号并跳转下一个 "m M" #'evil-multiedit-match-and-prev ; 标记当前符号并跳转上一个 "m a" #'evil-multiedit-match-all ; 标记所有相同符号 "m r" #'evil-multiedit-restore ; 恢复单光标模式 "m c" #'evil-multiedit-toggle-or-restrict ; 切换选区/限制编辑区域 ))我们可以使用 <leader> mm 来选中符合条件的项也可以使用 <leader> ma 来选择所有符合条件的项好了,本节到此也就结束了,本节依靠两个插件,进一步模拟vim相关的功能,并且对vim原有的功能进行了一定程度的补强。熟练使用这两个插件将会对编程的效率有一个进一步的提升。作为一个普通的文本编辑器也足够了。
-
Emacs 折腾日记(二十)——修改emacs的一些默认行为 上一篇我们完成了emacs输入法的配置以及将emacs配置成了使用vim的操作方式。但是emacs目前有些默认行为我不太喜欢,这节我们一起来修改它备份设置我们打开emacs的配置文件所在路径,发现有大量的~结尾的文件,这是emacs的备份文件。这里,我们不使用这个特性,可以通过git等版本管理软件进行版本的控制和备份的管理。而且去掉这些还能让目录干净点。(setq make-backup-files nil) ; 不自动备份 (setq auto-save-default nil) ; 不使用Emacs自带的自动保存将用户设置独立开来在修改这些配置的时候经常会发现在init.el 中出现类似下面的代码被修改(custom-set-variables ;; custom-set-variables was added by Custom. ;; If you edit it by hand, you could mess it up, so be careful. ;; Your init file should contain only one such instance. ;; If there is more than one, they won't work right. '(package-selected-packages nil)) (custom-set-faces ;; custom-set-faces was added by Custom. ;; If you edit it by hand, you could mess it up, so be careful. ;; Your init file should contain only one such instance. ;; If there is more than one, they won't work right. )这里保存的是使用编辑器接口产生的配置信息。如果让它们随意堆砌在init.el 中不利于版本的管理,我们将它放入到另一个文件中(setq custom-file (expand-file-name "~/.emacs.d/custom.el")) (load custom-file 'no-error 'no-message)之前我们用 require 来加载一个代码文件,这里我们使用 load 来加载代码文件。它们有什么区别呢?首先 require 需要加载一个已经被定义为库的代码文件,也就是通过 provide 定义的库文件。而load传入文件路径来加载其次 require 会根据 provide 定义的库文件自动处理库文件,每个库文件只加载一次,并且会自动处理依赖。而 load 这些操作都需要手动进行load 可以根据if条件来有选择的加载不同的库文件。而 require 则无法做到load 可以进行错误处理,例如上面我们定义在加载时通过 noerror 限制错误,通过 no-message 不输出信息。而 require 是严格报错的。其他的一些基础设置这里再添加一些其他的基础配置(fset 'yes-or-no-p 'y-or-n-p) ;; 将所有的 yes-or-no-p 都替换为 y-or-n-p (setq confirm-kill-emacs #'y-or-n-p) ; 在关闭 Emacs 前询问是否确认关闭,防止误触 (electric-pair-mode t) ; 自动补全括号 (column-number-mode t) ; 在 Mode line 上显示列号 (global-auto-revert-mode t) ; 当另一程序修改了文件时,让 Emacs 及时刷新 Buffer (delete-selection-mode t) ; 选中文本后输入文本会替换文本(更符合我们习惯了的其它编辑器的逻辑) (add-hook 'prog-mode-hook #'hs-minor-mode) ; 编程模式下,可以折叠代码块 (add-hook 'prog-mode-hook #'show-paren-mode) ; 编程模式下,光标在括号上时高亮另一个括号(fset 'yes-or-no-p 'y-or-n-p) 将所有的 yes-or-no-p 都替换为 y-or-n-p。这样在每次确定的时候能从 yes 或者 no的输入变成输入 y 或者 n,能少输入几个字符。这里又看到了一个新的符号# ,它代表的意思是取符号的函数部分。前面我们介绍符号的时候说,符号有两个部分的值,变量值和函数值。我们可以通过 function 来获取符号的函数部分的值。它的作用等同于 `(setq confirm-kill-emacs (function y-or-n-p))` 。这里又有一个新的函数 function。我们在介绍符号的时候介绍过使用 symbol-function 来获取符号的函数,那么他们两个有什么区别呢?首先 function 返回的是函数对象,而 symbol-function 返回函数本身。这个比较的抽象,我们使用例子来说明(setq bar "I am a bar variable") (defun bar() "I am a bar function") (function bar) ;; ==> bar (symbol-function 'bar) ;; ==> #[nil ("I am a bar function") (t)] (functionp bar) ;; ==> nil (functionp (function bar)) ;; ==> t上面的例子中,我们实际上定义了bar的变量部分和函数部分的值。同一 bar 符号它既可以作为变量使用,也可以作为函数使用。我们在使用 function 对 bar 求值的时候,得到的返回虽然也是 bar 但是它返回的是它的函数部分,而 symbol-function 则直接返回函数的结构,因为lisp代码本身就是一个列表结构,所以这里它返回的实际上是函数的代码。它返回的比 function 更加的底层。下面我们使用 functionp 进行了测试,发现 function 返回的是一个函数对象。虽然在理解上有些差别,但是都可以直接通过 funcall 来调用(bar) ;; ==> "I am a bar function" (funcall bar) ;; ==> error (funcall (function bar)) ;; ==> "I am a bar function" (funcall (symbol-function 'bar)) ;; ==> "I am a bar function"我们发现当一个符号既有值部分,又有函数部分,是无法通过 funcall 来直接调用的。所以上述代码使用 # 这个语法糖来保证后续正常调用这个符号对应的函数部分。
-
Emacs 折腾日记(十九)——配置输入法和vim操作方式 上一篇文章中,我们将Emacs变得稍微好看了点。换成了自己喜欢的主题和颜色,这样每天用起来也比较养眼,不会特别排斥。本篇文章的主要任务就是配置输入法方便输入中文以及将vim的操作模式搬到Emacs中。进一步提到Emacs的可用性配置中文输入法系统基本环境配置在配置输入法之前,需要系统支持中文,并且有对应的中文字体可以显示中文,而且还需要对应的输入法框架支持。首先我们安装中文字体和语言包,本人之前有一篇介绍如何搭建wsl2+archlinux的文章,已经完成了这一步。但是为了没看过那篇文章的读者不用再去费劲的找那篇文章,我还是把命令贴出来:sudo pacman -S wqy-zenhei wqy-microhei noto-fonts-cjk # 安装中文字体 sudo pacman -S fcitx5-im fcitx5-chinese-addons # 安装中文输入法框架及中文引擎 sudo pacman -S fcitx5-qt fcitx5-gtk # GUI支持接着配置 Locale ,我们需要编辑 /etc/locale.gen 文件,取消下面两行的注释en_US.UTF-8 UTF-8 zh_CN.UTF-8 UTF-8编辑完成之后,调用 sudo locale-gen 命令生成 locale。接着我们需要在 ~/.bashrc 或者 ~/.zshrc 又或者其他shell的配置文件中加入输入法的配置export GTK_IM_MODULE=fcitx5 export QT_IM_MODULE=fcitx5 export XMOIFIERS=@im=fcitx5然后我们启动fcitx5服务dbus-launch fcitx5 --disable=wayland -d &这个时候我们可以启动emacs,并且执行 M-x toggle-input-method 或者使用 C-\ 来切换输入法。只是默认的 chinese-py 输入法比较难用。所以我们需要换一个输入法并且给出拼音的词库emacs-rime 配置这个配置是我在 Emacs-China论坛 的一篇文章中发现这个输入法。可以访问 输入法源代码地址 ,它已发布到 Melpa,所以我们可以通过use-package 或者emacs自带的package来安装和管理。这里还是使用 use-package在安装之前,需要安装librime 和 fcitx5-rime。在arch中使用sudo pacman -S librime fcitx5-rime接着安装雾凇拼音,但是根据emacs-rime 官方文档的说法,最好不要将~emacs-rime~ 与 ~fcitx-rime~ 共用用户数据目录。所以这里我们我们将它放到其他目录git clone https://github.com/iDvel/rime-ice ~/.config/rime --depth=1然后我们进行emacs-rime的配置和安装(use-package rime :ensure t :custom (default-input-method "rime") (rime-posframe-properties (list :background-color "#333333" :foreground-color "#dcdccc" :font "WenQuanYi Micro Hei Mono-14" :internal-border-width 10)) (rime-user-data-dir "~/.config/rime") (rime-show-candidate 'posframe))到这里我们使用 C-\ 就可以愉快的输入中文了Vim 操作方式本系列文章并没有像一般的Emacs教程那样给各位读者介绍Emacs的操作和快捷键。因为我觉得Emacs可以很方便的变成跟vim一样的编辑器,既然读者们都熟悉vim,那就没必要单独的学习一套Emacs操作,直接继承vim的操作就行。这里说一个题外话,我觉得一个编辑器如果不支持vim的操作模式,要么就是使用的人不多,要么就是不够开放。对我来说这种编辑器平时就没有学习和使用的必要了。我们使用evil 插件来模拟vim的操作。(use-package evil :ensure t :init (evil-mode))我们执行完这句代码之后会发现已经进入了vim的normal模式了。这个时候又可以愉快的使用vim的操作方式来编辑文本了。但是查阅了关于evil的文档后发现,evil本身并不支持像vim那样设置leaderkey,我们要结合其他插件来达到这一效果。我们使用 general 插件来模拟并设置leaderkey(use-package general :ensure t :config (general-evil-setup t))插件安装完成之后可以使用下面的代码来设置leaderkey(general-create-definer my-leader-def :states '(normal insert visual emacs) :prefix "SPC" :non-normal-prefix "C-,")这里使用 general 提供的 general-create-definer 来定义自己的leader键,它可以定义leader键的作用范围和触发方式。my-leader-def 是一个符号它代表着我们在这里定义的leader键,后续可以通过它来结合其他按键来实现快捷键绑定。这里的 :states 表示作用的范围,在启用evil插件之后我们在 normal、insert、visual、emacs 这几个模式中启用这个leader键。通过 :prefix 定义leader键,这里我定义leader键为空格。最后一个参数 :non-normal-prefix 定义在非normal 模式下使用 C-, 来作为leader键。后面我们就可以通过这个 my-leader-def 这个符号来绑定快捷键了。下面提供一个例子来演示如何绑定快捷键。前面介绍vim相关内容的时候提到过,我们使用 <leader>ee 来快速打开配置文件,使用 <leader>ss 来重新加载配置,在这里实现以下emacs版本的这套功能。我们先来实现这两个功能函数(defun open-my-emacs-config() (interactive) (find-file "~/.emacs.d/init.el")) (defun source-my-emacs-config() (interactive) (eval-buffer (get-buffer "~/.emacs.d/init.el")))实现了这样的函数之后就是针对这些命令来绑定快捷键了。我们使用下面的代码来绑定(my-leader-def "ss" 'open-my-emacs-config) (my-leader-def "ee" 'source-my-emacs-config)至此我们使用evil 和 general 插件完成了一个简单的Emacs vim化的改造。利用这些简单的配置后面在使用的时候应该会更加的得心应手。随着代码越来越多,需要用git管理起来,每篇文章更新的代码我都会传到GitHub上供读者参考本篇代码
-
Emacs 折腾日记(十八)——改变Emacs的样貌 截止到上一篇文章为止,之前教程 的内容都看完了,虽然它的后记部分提供了一些后续进阶的内容需要我们自己读手册。但是我不太想继续在elisp上死磕了。看着自己学了那么久的elisp,但是自己的emacs仍然没有半点改变,这个时候各位读者的兴趣一定会大打折扣,是时候试试配置一下自己的emacs了。教程后记中提到的内容等配置的时候涉及到了再来了解吧所谓人靠衣装马靠鞍,一个编辑器好不好用首先要看的就是它好不好看,对于难看的编辑器可能一眼就要给它发卡了——“你是一个很优秀的编辑器,但是我们不合适”。所有配置时第一件事就是将emacs变帅变好看。emacs的基础配置Emacs 在加载的时候会首先读取 ~/.emcas.d/init.el 中的代码。整个配置程序的入口就在这里。但是如果我们一股脑将所有代码都写在这个文件中日后想要维护肯定是不方便的,所以在写配置之前需要了解一些它的模块化提供一个模块,我们只需要在代码文件最后的位置写上 (provide 'package-name) 这样的代码即可。这里的 provide。可以理解为导出,后面是导出模块的名称。在需要引入模块时,只需要添加一行 (require 'basic)。但是与其他语言类似,有时候会出现找不到对应的模块,这里涉及到一个查找路径的问题。Emacs 中加载路径被保存在变量 load-path 中。该变量是一个list,我们可以将指定路径放入到这个变量中来添加用户定义代码的路径。load-path 中的目录顺序决定了 Emacs 搜索文件的优先级。如果多个目录中存在同名的 Lisp 文件,Emacs 会优先加载 load-path 中靠前的目录中的文件。因此,你可以通过调整 load-path 的顺序来控制加载的优先级。为了添加路径到 load-path 中,我们要了解一个新的函数, add-to-list。为什么这里我们不使用 push 或者其他之前学过的操作list的函数呢?最关键的一点是 add-to-list 具有去重的功能,能避免多次重复加入同一个路径。如果我们将用户代码放入到 ~/.emacs.d/lisp 这个目录中,我们可以使用下面的代码;; init.el (add-to-list 'load-path "~/.emacs.d/lisp")前面的知识介绍完了,现在我们新建 ~/.emacs.d/lisp/basic.el 文件,进行基础的配置。目前添加的代码主要是取消Emacs上的滚动条、菜单栏、工具栏、以及每次打开的开始界面。;; basic.el ;; 禁止菜单栏、工具栏、滚动条模式,禁止启动屏幕和文件对话框 (menu-bar-mode -1) (tool-bar-mode -1) (scroll-bar-mode -1) (setq inhibit-splash-screen t) ;; 禁止启动画面 ;; 显示行号 (setq display-line-numbers-type 'relative) ;;显示相对行号 (global-display-line-numbers-mode 1) (provide 'basic)然后在启动的时候使用它;; init.el (add-to-list 'load-path "~/.emacs.d/lisp") (require 'basic)重启Emacs就能看到具体的效果了使用包管理器要想它变的好看,最好的办法是加载开源大佬提供的主题。作为一个小菜鸡不太可能自己开发重型的功能,我们要做的这是将大佬提供的包整合到自己的配置中。所以我们先来介绍包和包管理器。这里的包我们可以理解为提供了某种功能的模块,有点类似与C/C++ 的静态库或者Java的类库。Emacs中的包管理主要通过 package.el 模块提供。它包含了模块的查找,下载,更新以及删除等操作。它的一些常用命令如下:M-x list-packages:列出所有可用的包,并进入包管理界面。M-x package-install:安装指定的包。M-x package-refresh-contents:刷新包列表,获取最新的包信息。M-x package-upgrade:更新所有已安装的包。M-x package-delete:删除指定的包。Emacs中默认的仓库是 Emacs 默认使用 MELPA(Milkypostman’s Emacs Lisp Package Archive)作为主要的包仓库。MELPA 提供了大量高质量的第三方包。除此之外,还有其他仓库,如:GNU ELPA:官方仓库,包含 Emacs 自带的包。MELPA Stable:提供稳定版本的包。NonGNU ELPA:包含一些非 GNU 的包。因为国内的网络环境,我们常常需要使用国内的源。这里我们创建一个新的文件 package 用来管理包。;; package-conf.el (require 'package) (setq package-enable-at-startup nil) (setq package-archives '(("gnu" . "https://mirrors.tuna.tsinghua.edu.cn/elpa/gnu/") ("nongnu" . "https://mirrors.tuna.tsinghua.edu.cn/elpa/nongnu/") ("melpa" . "https://mirrors.tuna.tsinghua.edu.cn/elpa/melpa/"))) (package-initialize) ;; You might already have this line (provide 'package-conf)这里我使用清华源,各位读者可以选择自己喜欢的源。上面的代码我们使用 package-enable-at-startup 来控制Emacs是否自动初始化package包管理器。这里为了更灵活我们禁止它自动初始化,改由手动初始化。我们可以在代码中使用类似于 (package-install 'package-name) 的方式来自动安装包,但是这里介绍更加高级的包管理器——use-package。如果使用Emacs原生的包管理器,那么就是先安装,然后想办法组织包配置的代码,这样将安装与配置分散起来了,不利于管理。使用use-package 可以方便的将它们组织起来。本质上use-package 提供了一系列的宏将包的安装和包的配置组合到一起,方便维护。而且它还提供了一些高级的特性方便我们灵活的控制各种配置生效的时间。我们可以使用如下语句进行安装;; package-conf.el (unless (package-installed-p 'use-package) (package-refresh-contents) (package-install 'use-package))它的基本语法如下:(use-package package-name :keyword1 value1 :keyword2 value2 ...)它的常用关键字如下::ensure: 确保包已安装。如果包未安装,use-package 会自动安装它,一般使用Emacs自带的包这里设置成nil,安装第三方的包,这里设置成t:init:在包加载之前执行的代码:config: 在包加载之后执行的代码:bind: 为包中的函数绑定快捷键:mode: 为特定文件类型启用包:hook: 在特定模式下启用包:defer: 延迟加载包,直到首次使用包:custom: 设置包的变量除了这些我们可以使用 :if 或 :when 关键字实现更复杂的条件加载。或者通过 :requires 关键字来指定包的依赖项配置主题说了这么多,我们使用 use-package 来安装一个主题来提高一下Emacs的颜值。这里我选用 doom-themes 包中的 doom-dracula 主题。关于ui部分的配置,我们都放在 ~/.emacs.d/lisp/init-ui.el 中;; init-ui.el (use-package doom-themes :ensure t :config (load-theme 'doom-dracula t)) (provide 'init-ui)我们在init.el 中加载init-ui之后,再次打开效果如下:设置字体我们在介绍文本属性的时候使用过face这个属性,Emacs中跟文字显示相关的属性都是face,它包括:字体、字号、颜色、背景。我们之前介绍了一系列的函数来处理字体字号,但是之前介绍的只能绑定到具体的文字上,默认的字体字号使用那些函数是无法设置的。我们可以使用 set-face-attribute 来设置字体属性。该函数的定义如下(set-face-attribute FACE FRAME &rest ARGS)参数face 表示设置的是哪个部分的字体属性,例如 default(默认字体) 、mode-line (状态栏字体)、region (选中区域字体)等。我们可以使用 M-x list-faces-display 来查看支持的face参数 frame 表示需要设置哪个窗口框架(通常用 nil 表示当前窗口或所有窗口)的字体属性。参数 ARGS 来设置具体的字体属性。以下属性可用于控制字体和样式:属性名功能描述示例值:family字体名称(需系统已安装)"Fira Code", "Consolas":height字号(以百分比或绝对点数表示,默认 100 = 10pt)120(12pt), 14(14pt):weight字重(如正常、加粗)'normal, 'bold:slant字体倾斜'normal, 'italic:width字体宽度(如压缩或扩展)'normal, 'condensed:underline下划线样式nil(无), t(实线):foreground前景色(文本颜色)"#FFFFFF", "red":background背景色"#333333":inherit继承其他 FACE 的属性'fixed-pitch这里我打算使用 Source Code Pro 字体,可以在init-ui.el 中这么设置(set-face-attribute 'default nil :family "Source Code Pro" :height 120)到此为止我们已经给Emacs做了基本的美化,日常使用也不那么碍眼了。
-
Emacs 折腾日记(十七)——文本属性 我们在上一篇中介绍了如何对文件中的文本进行操作,本篇主要来介绍关于文本的属性。是的,文本也有属性。这里的文本属性有点类似于Word中的文字属性,文本中对应的字符只是文本属性的一种,它还包括文本大小、字体、颜色等等内容。Emacs中的文本也是类似的。于符号的属性类似,文本的属性也是由键值对构成。名 字和值都可以是一个 lisp 对象,但是通常名字都是一个符号,这样可以用这个 符号来查找相应的属性值。复制文本通常都会复制相应的字符的文本属性,但是 也可以用相应的函数只复制文本字符串,比如 substring-no-properties、 insert-buffer-substring-no-properties、buffer-substring-no-properties。产生一个带属性的字符串可以用 propertize 函数。(propertize "abc" 'face 'bold) ;; ⇒ #("abc" 0 3 (face bold))这里我们使用 face 来设置它的字体为粗体。或者我们可以使用C-x C-f 任意的打开或者创建一个文本文件,在文件中输入(insert (propertize "abc" 'face 'bold))我们可以看到它会在当前光标后面插入一个粗体的 abc 字符串。需要注意的是,我们在*scratch* buffer 中是无法看到这个效果的。因为*scratch* buffer 中开启了font-lock-mode。正如它的名字表示的那样,它锁定了字体,它里面的字体属性都是实时计算出来的。在插入文本之后它的属性很快就被修改了。因为*scratch* buffer 本质上还是一个elisp的编程环境,它里面有关于elisp的语法高亮、自动对齐等特性。它会自动的修改输入的文本属性。我们可以使用 (font-lock-mode - 1) 来关闭这个mode,然后执行上述代码就可以看到具体的效果了。虽然文本属性的名字可以是任意的,但是一些名字是有特殊含义的。属性名含义category值必须是一个符号,这个符号的属性将作为这个字符的属性face控制文本的字体和颜色font-lock-face和 face 相似,可以作为 font-lock-mode 中静态文本的 facemouse-face当鼠标停在文本上时的文本 facefontified记录是否使用 font lock 标记了 facedisplay改变文本的显示方式,比如高、低、长短、宽窄,或者用图片代替help-echo鼠标停在文本上时显示的文字keymap光标或者鼠标在文本上时使用的按键映射local-map和 keymap 类似,通常只使用 keymapsyntax-table字符的语法表read-only不能修改文本,通过 stickness 来选择可插入的位置invisible不显示在屏幕上intangible把文本作为一个整体,光标不能进入field一个特殊标记,有相应的函数可以操作带这个标记的文本cursor(不知道具体用途)pointer修改鼠标停在文本上时的图像line-spacing新的一行的距离line-height本行的高度modification-hooks修改这个字符时调用的函数insert-in-front-hooks与 modification-hooks 相似,在字符前插入调用的函数insert-behind-hooks与 modification-hooks 相似,在字符后插入调用的函数point-entered当光标进入时调用的函数point-left当光标离开时调用的函数composition将多个字符显示为一个字形这些东西我觉得也不需要记住,在需要的时候查查文档就好了。但是我参考的教程把它列出来了,那么我也在这里列出来把。由于字符串和缓冲区都可以有文本属性(如果没有特别指定文本对象的属性,那么默认使用缓冲区定义的文本属性),所以下面的函数通常不提供特定参数就是检 查当前缓冲区的文本属性,如果提供文本对象,则是操作对应的文本属性。查看文本属性查看文本对象在某处的文本属性可以用 get-text-property 函数。(setq foo (propertize "abc" 'face 'bold)) ;; ⇒ #("abc" 0 3 (face bold)) (get-text-property 0 'face foo) ;; ⇒ bold这里有两个问题需要注意一下,首先我们使用 propertize 为abc设置了文本属性face的值为bold,也就是将字符串设置为粗体。但是其中的0 和 3 代表什么呢?这里的0和3代表的是采用这个属性的字符在字符串中的范围,上面的代码中,整个abc字符串都采用整个属性,所以它的范围是[0, 3) 这个区间。要验证这一点我们可以使用下列代码(setq foo (concat "abc" (propertize "cde" 'face 'bold))) ;; ⇒ #("abccde" 3 6 (face bold)) (insert foo) 我们插入foo发现,它会插入 "abccde" 这么几个字符串,但是只有 "cde" 三个是加粗的根据这个提示,很明显的,get-text-property 中输入的0代表的就是“abc”字符串第0个,也就是字符a的属性。get-char-property 和 get-text-property 相似,但是它是先查找 overlay 的 文本属性。overlay 是缓冲区文字在屏幕上的显示方式,它属于某个缓冲区,具 有起点和终点,也具有文本属性,可以修改缓冲区对应区域上文本的显示方式。get-text-property 是查找某个属性的值,用 text-properties-at 可以得到某 个位置上文本的所有属性。修改文本属性put-text-property 可以给文本对象添加一个属性。它也是需要传入一个范围值,例如我们在前面foo的基础上使用以下代码(put-text-property 0 3 'face 'italic foo)我们再针对 foo 执行插入操作,此时会发现 abc 这个子串变成斜体了。和 put-text-property 类似,add-text-properties 可以给文本对象添加一系列的属性。和 add-text-properties 不同,可以用 set-text-properties 直接设置文本属性列表。你可以用 (set-text-properties start end nil) 来除去 某个区间上的文本属性。也可以用 remove-text-properties 和 remove-list-of-text-properties 来除去某个区域的指定文本属性。这两个函数的属性列表参数只有名字起作用,值是被忽略的。以下的例子还是建立在之前的 foo 变量之上,此时它的值为 #("baccde" 0 3 (face italic) 3 6 (face bold))。也就是前三个字符是斜体,后三个是加粗(set-text-properties 0 1 nil foo) ;; 取消了 a 字符的文本属性 foo ;; ⇒ #("abccde" 1 3 (face italic) 3 6 (face bold)) (remove-text-properties 2 4 '(face nil) foo) foo ;; ⇒ #("abccde" 1 2 (face italic) 4 6 (face bold)) (remove-list-of-text-properties 4 6 '(face nil) foo) foo ;; ⇒ #("abccde" 1 2 (face italic))查找文本属性文本属性通常都是连成一个区域的,所以查找文本属性的函数是查找属性变化的 位置。这些函数一般都不作移动,只是返回查找到的位置。使用这些函数时最好 使用 LIMIT 参数,这样可以提高效率,因为有时一个属性直到缓冲区末尾也没 有变化,在这些文本中可能就是多余的。next-property-change 查找从当前位置起任意一个文本属性发生改变的位置。 next-single-property-change 查找指定的一个文本属性改变的位置。 next-char-property-change 把 overlay 的文本属性考虑在内查找属性发生改 变的位置。next-single-property-change 类似的查找指定的一个考虑 overlay 后文本属性改变的位置。这四个函数都对应有 previous- 开头的函数,用于查找当前位置之前文本属性改变的位置(setq foo (concat "abc" (propertize "edf" 'face 'bold) (propertize "hij" 'pointer 'hand))) ;; ⇒ #("abcdefhji" 3 6 (face italic) 6 9 (face bold)) (next-property-change 1 foo) ;; ⇒ 3 (next-single-property-change 1 'pointer foo) ;; ⇒ 6text-property-any 查找区域内第一个指定属性值为给定值的字符位置。 text-property-not-all 和它相反,查找区域内第一个指定属性值不是给定值的 字符位置。(text-property-any 0 9 'face 'bold foo) ;; ⇒ 3 (text-property-not-all 3 9 'face 'bold foo) ;; ⇒ 6
-
Emacs 折腾日记(十六)——文本操作 作为一个文本编辑器,编辑文本是最基本,也是最重要的功能。本文将介绍关于文件操作的一系列操作,比如查找文件,读写文件,文件信息、读取目录、文件名操作等。在之前关于vim的介绍时,已经详细的介绍过关于文件、缓冲和窗口的关系。相信各位读者不会弄混这些概念。在emacs从硬盘上读取文件到缓冲并且显示的过程与vim类似。只是vim会根据后缀设置file type,并根据file type加载相关配置和代码。而emacs会加载各种mode和mode的配置。文件读写从硬盘读取一个文件可以使用快捷键 C-x C-f ,它对应的命令是 find-file。它的主要作用是从输入的路径中找到硬盘上存储的文件,并且从文件中读取内容到缓冲区,然后显示缓冲区到窗口。保存缓冲到文件可以使用 C-x C-s,它对应的命令是 save-buffer。它会将当前缓冲写入到指定的文件中。在打开文件的过程中,会调用 find-file-noselect,它是打开文件的核心操作,与 find-file 不同,它只返 回访问文件的缓冲区。这两个函数都有一个特点,如果 emacs 里已经有一个缓冲 区访问这个文件的话,emacs 不会创建另一个缓冲区来访问文件,而只是简单返 回或者转到这个缓冲区。(find-file "~/.zshrc") ;; ==> #<buffer .zshrc> ;; 等效与 find-file (progn (setq foo (find-file-noselect "~/.zshrc")) (set-window-buffer nil foo))如何判断一个缓冲区是否关联了一个文件呢?每个和文件关联的缓冲区都有一个对应的 buffer-local 变量 buffer-file-name。但是不要直 接设置这个变量来改变缓冲区关联的文件。而是使用 set-visited-file-name 来 修改。同样不要直接从 buffer-list 里搜索buffer-file-name 来查找和某个文件关联的缓冲区。应该使用get-file-buffer 或者 find-buffer-visiting(setq foo (find-file-noselect "~/.zshrc")) (buffer-file-name foo) ;; ==> "home/xxx/.zshrc" (get-file-buffer "~/.zshrc") ;; ==> #<buffer .zshrc> (find-buffer-visiting "~/.zshrc") ;; ==> #<buffer .zshrc在打开文件过程中会调用 find-file-hook。这里的hook有点像vim中的事件,之前聊到过vim的自动命令,自动命令需要绑定到事件上触发。emacs中有大量的hook,我们通过在hook中添加一些操作来达到这个修改emacs默认行为或者增加新行为的特性。这个我们在后面再说。另外保存文件会调用一些hook和函数,保存文件之前会调用 before-save-hook,保存之后会调用 after-save-hook。一般来说,在配置emacs的时候,如果需要使用这些函数来读取文件,一般是读取上次退出时保存的临时文件,例如保存工程窗口布局的session文件。这些我们希望读取完成之后不将它们保留到buffer中。这个需求使用 find-file-noselect 是做不到的。必须使用更底层的函数。可以使用 insert-file-contents 和 write-region(insert-file-contents filename &optional visit beg end replace) (write-region start end filename &optional append visit lockname mustbenew)insert-file-contents 可以插入文件中指定部分到当前缓冲区中。如果指定 visit 则会标记缓冲区的修改状态并关联缓冲区到文件,一般是不用的。 replace 是指是否要删除缓冲区里其它内容,这比先删除缓冲区其它内容后插入文 件内容要快一些,但是一般也用不上。insert-file-contents 会处理文件的编 码,如果不需要解码文件的话,可以用 insert-file-contents-literally。write-region 可以把缓冲区中的一部分写入到指定文件中。如果指定 append 则是添加到文件末尾。和 insert-file-contents 相似,visit 参数也会把缓冲 区和文件关联,lockname 则是文件锁定的名字,mustbenew 确保文件存在时会 要求用户确认操作文件信息文件是否存在可以使用 file-exists-p 来判断。对于目录和一般文件都可以用 这个函数进行判断,但是符号链接只有当目标文件存在时才返回 t。如何判断文件是否可读或者可写呢?file-readable-p、file-writable-p, file-executable-p 分用来测试用户对文件的权限。文件的位模式还可以用 file-modes 函数得到(file-readable-p "~/.zshrc") ;; ==>t (file-writable-p "~/.zshrc") ;; ==>t (file-executable-p "~/.zshrc") ;; ==>nil (file-modes "~/.zshrc") ;; ==> 420文件类型判断可以使用 file-regular-p、file-directory-p、file-symlink-p, 分别判断一个文件名是否是一个普通文件(不是目录,命名管道、终端或者其它 IO 设备)、文件名是否一个存在的目录、文件名是否是一个符号链接。其中 file-symlink-p 当文件名是一个符号链接时会返回目标文件名。文件的真实名字也就是除去相对链接和符号链接后得到的文件名可以用 file-truename 得到。 事实上每个和文件关联的 buffer 里也有一个缓冲区局部变量 buffer-file-truename 来记录这个文件名。文件更详细的信息可以用 file-attributes 函数得到。这个函数类似系统的 stat 命令,返回文件几乎所有的信息,包括文件类型,用户和组用户,访问日 期、修改日期、status change 日期、文件大小、文件位模式、inode number、 system number临时文件如果要产生一个临时文件,可以使用 make-temp-file 这个函数按给定前缀产 生一个不和现有文件冲突的文件,并返回它的文件名。如果给定的名字是一个相 对文件名,则产生的文件名会用 temporary-file-directory 进行扩展。也可以用这个函数产生一个临时文件夹。如果只想产生一个不存在的文件名,可以用 make-temp-name 函数(make-temp-file "foo") (make-temp-name "foo")读取目录内容可以用 directory-files 来得到某个目录中的全部或者符合某个正则表达式的 文件名。;; 获取用户目录的文件名称 (directory-files "~/") ;; 获取用户目录的文件全路径 (directory-files "~/") ;; 获取目录中所有cpp文件 (directory-files "~/demo/src" t "\\.cpp$")另外也可以写一段简单的代码来遍历某个路劲下所有文件(defun my-list-files (dir) "递归遍历目录 DIR 下的所有文件并返回路径列表。" (let ((files (directory-files dir t "^[^.]")) (result '())) (dolist (file files result) (if (file-regular-p file) (push file result) (when (and (file-directory-p file) (not (file-symlink-p file)) (file-readable-p file)) (setq result (append result (my-list-files file)))))))) (my-list-files "~/.emacs.d")在调用 directory-files 的时候通过一个正则表达式过滤掉所有以.开头的文件,这里主要是为了过滤掉 . 和 .. 防止进入无线递归。但是它也误伤了所有隐藏文件。后面就是比较常规的操作了,遍历返回的list,如果是文件则加入到现有结果集中,如果是目录则进入递归。directory-files-and-attributes 和 directory-files 相似,但是返回的列表 中包含了 file-attributes 得到的信息。file-name-all-versions 用于得到某个文件在目录中的所有版本,file-expand-wildcards 可以用通配符来得到目录中的文件列表。修改文件信息重命名和复制文件可以用 rename-file 和 copy-file。删除文件使用 delete-file。创建目录使用 make-directory 函数。不能用 delete-file 删除 目录,只能用 delete-directory 删除目录。当目录不为空时会产生一个错误。设置文件修改时间使用 set-file-times。设置文件位模式可以用 set-file-modes 函数。set-file-modes 函数的参数必须是一个整数。你可以用位 函数 logand、logior 和 logxor 函数来进行位操作。(set-file-modes FILENAME MODE &optional FLAG)其中mode是数字,数字的含义与与chmode 命令类似,例如下面的调用(set-file-modes "example.txt" #o740)