搜索到
378
篇与
的结果
-
 Emacs折腾日记(三)——简单的elisp 入门 Emacs本身的使用并不复杂,利用帮助文档,差不多半小时左右就能把一些常见的操作方式和快捷键过一遍,剩下的就是慢慢使用并且熟悉了。Emacs真正有价值的是它高度的客制化。任何人都可以利用elisp代码将Emacs改造成只属于自己的编辑器。会elisp 的不一定是高手,但是高手没有一个是不会elisp的。学习Emacs也绕不开elisp。下面我们就来简单的学点elisp一个简单的 Hello Word(message "hello world")这是一个简单的elisp版本的hello world程序。麻雀虽小但是五脏俱全。从这个简单的程序来说我们可以看出lisp的最大特点,就是以括号作为作为一个完整的表达式。曾今有一个段子说苏联的特工冒死偷到了美国阿波罗计划代码的最后一页,结果回来一看全是括号。这也鲜明的表达了一个lisp的特点,那就是大量的括号我们简单的解析一下上面的代码,上面的代码调用了一个函数,函数的参数就是一个字符串的 hello world。我们可以打开Emacs,进入 scratch buffer,输入上述代码。之后可以将光标移动到代码尾部,按下快捷键 C-x C-e 来执行代码,或者使用 M-x 输入命令 eval-buffer 来看效果。我们可以看到,mini-buffer 位置出现了 "hello world" 的字符串变量我们可以使用 setq 来定义变量,它类似于C/C++ 中的= ,用来给变量赋值或者定义并初始化一个变量。例如我们可以改一下上述的代码(setq name "Emacs") (message "hello, %s" name)将上述代码输入到scratch buffer之后就需要依次在每行的最后执行 C-x C-e 或者直接执行eval-buffer 命令,这样就可以看到效果了上面我们说,elisp的表达式是使用括号来表示的,但是如果在上面代码的基础上加上一句(name)此时就会报错,显示的错误为 void-function name 。我们的本意是想让解释器返回name的值,但是解释器将它作为了一个函数。通过这个错误我们能了解到,elisp基本的表达式中函数需要用括号括起来,但是变量自己本身被作为一个完整的表达式。除了使用setq我们还可以使用 defvar 来定义变量,defvar 的使用如下(defvar variable-name value "variable document")例如(defvar name "Emacs" "a defvar demo name") name ;; ==> "Emacs"我们将光标放到name上,按下 C-h v 可以看到关于name的说明文档。需要注意的是,defvar与setq 除了defvar可以指定变量的说明文档外,还有一个区别就是defvar在定义变量前,这个变量已经有值的话,defvar不会改变变量的值例如下面的例子(setq foo "foo") (defvar foo "this is foo" "document for variable foo") (defvar bar "this is bar" "document for variable bar") foo ;; =>"foo" bar ;; =>"this is bar"C-x C-e(eval-last-sexp) treatsdefvarexpressions specially. Normally, evaluating adefvarexpression does nothing if the variable it defines already has a value. But this command unconditionally resets the variable to the initial value specified by thedefvar; this is convenient for debugging Emacs Lisp programs.defcustomanddeffaceexpressions are treated similarly. Note the other commands documented in this section, excepteval-defun, do not have this special feature.上述英文翻译过来就是 eval-last-sexp 对 defvar 做了特殊处理,默认情况下 defvar 在变量有值的情况下不做任何操作,但是在这个命令中,defvar 会无条件的将变量值重置为它指定的值。主要是为了方便调试代码。同时 defcustom 和 deface 做了同样的操作。请注意在本节中记录的其他命令(eval-defun 除外)没有做这样的处理这就解释了为什么我们使用 C-x C-e 执行的时候 foo 的值发生了改变函数函数的定义与使用作为一门函数式编程语言,函数是elisp的一等公民。如何使用一个函数我们已经在前面的hello world程序中见识过了,那么如何定义一个函数呢?定义一个函数使用 defun 关键字。它的语法如下(defun func-name(args) "document string" body)第一行代表一个函数名和函数的参数列表,第二行表示可以使用一个双引号包含函数的说明文档,Emacs是一个自文档的系统,后续我们可以查看这里写的文档。最后一行是函数的主体内容,例如下面的例子(defun say-hello(name) "say hello to define user" (message "hello, %s" name)) (say-hello "emacs") ;; => "hello, emacs"执行将会输出对应的信息。我们将光标移动到say-hello这个函数上,执行 C-h f 默认回车将会得到我们针对函数写的文档lambda 表达式其实像C++、Java、Python 之类的语言也有lambda表达式,它就是一个匿名函数。一般我们使用函数都是先定义同时给函数取一个名字,但是有时候我们仅仅需要一个临时函数作为参数或者仅仅只会在某些地方调用一次,这个时候就可以使用匿名函数。lambda表达式的形式与defun类似,它的使用规则如下(lambda (args) "document string" body)除了关键字变了,就是不用写函数名称了。我们使用 funcall 来调用一个lambda表达式(funcall (lambda (name) (message "hello, %s" name)) "emacs")我们执行它将会在mini-buffer中看到显示的字符串信息另外我们也可以将一个lambda表达式赋值给一个变量,最后通过funcall 来调用(setq say-hello (lambda (name) (message "hello, %s" name))) (funcall say-hello "emacs") (say-hello "emacs") ;; error, void-function say-hello知乎的大牛指出,这里原本有一个错误,在这里更正:defun 会把函数值绑定到符号的 function-cell 上,setq 会绑定到符号的 value-cell 上上述的说法,我查过 funcall 、value-cell 以及 function-cell 相关的文档,里面涉及到的一些知识点比较复杂,目前我还没有完全搞明白,而且把它贴出来作为入门来讲有点过于复杂了。变量作用域elisp默认使用 setq 定义的变量不管是在函数内还是函数外全都是全局变量,它们的作用域是全局作用域,例如(defun say-hello () (setq name "Emacs") (message "hello, %s" name)) (say-hello) ;;需要执行一下函数解释器才能执行到定义`name`变量的位置 (message name)一般来说代码如果都是全局变量的话,会给代码的编写和维护带来很大的不便。elisp中同样支持定义局部变量,我们可以使用 let 和 let* 它们的用法类似(let (bindings) body)其中的 bindings 可以是单个值,也可以是括号包裹的键值对。如果是单个值,则默认赋值nil,也就是空。如果是键值对,则将值赋值给对应的键。let定义的变量只能作用在let语句块内,例如下面一个计算圆面积的函数,这里知乎的大牛告诉我,pi 是emacs中的内置变量,我采用PI来定义圆周率(defun circle-area (radix) (let ((PI 3.1415926) area) (setq area (* PI radix radix)) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3) (message "%f" area) ;; error void-variable area其中我们在let语句块中定义了两个变量,pi初始化为3.1415926,area 初始化为 nil同样的,可以使用 let* 改写上面的程序(defun circle-area (radix) (let* ((PI 3.1415926) area) (setq area (* PI radix radix)) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3)let* 与 let 的区别在于,let* 可以在binding时候使用前面已经定义过的变量。例如上面的代码可以改写成(defun circle-area (radix) (let* ((PI 3.1415926) (area (* PI radix radix))) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3)我们使用 let 来改写一下这个程序,发现它会报错(defun circle-area (radix) (let ((PI 3.1415926) (area (* PI radix radix))) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3) ;; error void-variable PI好了本篇也该结束了,本篇主要了解了基本的elisp语法,下面进行一下总结:使用 defvar 和 setq 来定义全局变量,其中defvar可以给变量设置一个说明文档,我们使用 C-h v 来查看这个文档使用 let 和 let 来定义变量,其中 let 可以在变量定义的时候使用前面定义过的变量使用 defun 来定义函数使用lambda 来定义一个lambda表达式,使用funcall 来调用lambda,lambda可以赋值给变量,后续使用funcall来调用
Emacs折腾日记(三)——简单的elisp 入门 Emacs本身的使用并不复杂,利用帮助文档,差不多半小时左右就能把一些常见的操作方式和快捷键过一遍,剩下的就是慢慢使用并且熟悉了。Emacs真正有价值的是它高度的客制化。任何人都可以利用elisp代码将Emacs改造成只属于自己的编辑器。会elisp 的不一定是高手,但是高手没有一个是不会elisp的。学习Emacs也绕不开elisp。下面我们就来简单的学点elisp一个简单的 Hello Word(message "hello world")这是一个简单的elisp版本的hello world程序。麻雀虽小但是五脏俱全。从这个简单的程序来说我们可以看出lisp的最大特点,就是以括号作为作为一个完整的表达式。曾今有一个段子说苏联的特工冒死偷到了美国阿波罗计划代码的最后一页,结果回来一看全是括号。这也鲜明的表达了一个lisp的特点,那就是大量的括号我们简单的解析一下上面的代码,上面的代码调用了一个函数,函数的参数就是一个字符串的 hello world。我们可以打开Emacs,进入 scratch buffer,输入上述代码。之后可以将光标移动到代码尾部,按下快捷键 C-x C-e 来执行代码,或者使用 M-x 输入命令 eval-buffer 来看效果。我们可以看到,mini-buffer 位置出现了 "hello world" 的字符串变量我们可以使用 setq 来定义变量,它类似于C/C++ 中的= ,用来给变量赋值或者定义并初始化一个变量。例如我们可以改一下上述的代码(setq name "Emacs") (message "hello, %s" name)将上述代码输入到scratch buffer之后就需要依次在每行的最后执行 C-x C-e 或者直接执行eval-buffer 命令,这样就可以看到效果了上面我们说,elisp的表达式是使用括号来表示的,但是如果在上面代码的基础上加上一句(name)此时就会报错,显示的错误为 void-function name 。我们的本意是想让解释器返回name的值,但是解释器将它作为了一个函数。通过这个错误我们能了解到,elisp基本的表达式中函数需要用括号括起来,但是变量自己本身被作为一个完整的表达式。除了使用setq我们还可以使用 defvar 来定义变量,defvar 的使用如下(defvar variable-name value "variable document")例如(defvar name "Emacs" "a defvar demo name") name ;; ==> "Emacs"我们将光标放到name上,按下 C-h v 可以看到关于name的说明文档。需要注意的是,defvar与setq 除了defvar可以指定变量的说明文档外,还有一个区别就是defvar在定义变量前,这个变量已经有值的话,defvar不会改变变量的值例如下面的例子(setq foo "foo") (defvar foo "this is foo" "document for variable foo") (defvar bar "this is bar" "document for variable bar") foo ;; =>"foo" bar ;; =>"this is bar"C-x C-e(eval-last-sexp) treatsdefvarexpressions specially. Normally, evaluating adefvarexpression does nothing if the variable it defines already has a value. But this command unconditionally resets the variable to the initial value specified by thedefvar; this is convenient for debugging Emacs Lisp programs.defcustomanddeffaceexpressions are treated similarly. Note the other commands documented in this section, excepteval-defun, do not have this special feature.上述英文翻译过来就是 eval-last-sexp 对 defvar 做了特殊处理,默认情况下 defvar 在变量有值的情况下不做任何操作,但是在这个命令中,defvar 会无条件的将变量值重置为它指定的值。主要是为了方便调试代码。同时 defcustom 和 deface 做了同样的操作。请注意在本节中记录的其他命令(eval-defun 除外)没有做这样的处理这就解释了为什么我们使用 C-x C-e 执行的时候 foo 的值发生了改变函数函数的定义与使用作为一门函数式编程语言,函数是elisp的一等公民。如何使用一个函数我们已经在前面的hello world程序中见识过了,那么如何定义一个函数呢?定义一个函数使用 defun 关键字。它的语法如下(defun func-name(args) "document string" body)第一行代表一个函数名和函数的参数列表,第二行表示可以使用一个双引号包含函数的说明文档,Emacs是一个自文档的系统,后续我们可以查看这里写的文档。最后一行是函数的主体内容,例如下面的例子(defun say-hello(name) "say hello to define user" (message "hello, %s" name)) (say-hello "emacs") ;; => "hello, emacs"执行将会输出对应的信息。我们将光标移动到say-hello这个函数上,执行 C-h f 默认回车将会得到我们针对函数写的文档lambda 表达式其实像C++、Java、Python 之类的语言也有lambda表达式,它就是一个匿名函数。一般我们使用函数都是先定义同时给函数取一个名字,但是有时候我们仅仅需要一个临时函数作为参数或者仅仅只会在某些地方调用一次,这个时候就可以使用匿名函数。lambda表达式的形式与defun类似,它的使用规则如下(lambda (args) "document string" body)除了关键字变了,就是不用写函数名称了。我们使用 funcall 来调用一个lambda表达式(funcall (lambda (name) (message "hello, %s" name)) "emacs")我们执行它将会在mini-buffer中看到显示的字符串信息另外我们也可以将一个lambda表达式赋值给一个变量,最后通过funcall 来调用(setq say-hello (lambda (name) (message "hello, %s" name))) (funcall say-hello "emacs") (say-hello "emacs") ;; error, void-function say-hello知乎的大牛指出,这里原本有一个错误,在这里更正:defun 会把函数值绑定到符号的 function-cell 上,setq 会绑定到符号的 value-cell 上上述的说法,我查过 funcall 、value-cell 以及 function-cell 相关的文档,里面涉及到的一些知识点比较复杂,目前我还没有完全搞明白,而且把它贴出来作为入门来讲有点过于复杂了。变量作用域elisp默认使用 setq 定义的变量不管是在函数内还是函数外全都是全局变量,它们的作用域是全局作用域,例如(defun say-hello () (setq name "Emacs") (message "hello, %s" name)) (say-hello) ;;需要执行一下函数解释器才能执行到定义`name`变量的位置 (message name)一般来说代码如果都是全局变量的话,会给代码的编写和维护带来很大的不便。elisp中同样支持定义局部变量,我们可以使用 let 和 let* 它们的用法类似(let (bindings) body)其中的 bindings 可以是单个值,也可以是括号包裹的键值对。如果是单个值,则默认赋值nil,也就是空。如果是键值对,则将值赋值给对应的键。let定义的变量只能作用在let语句块内,例如下面一个计算圆面积的函数,这里知乎的大牛告诉我,pi 是emacs中的内置变量,我采用PI来定义圆周率(defun circle-area (radix) (let ((PI 3.1415926) area) (setq area (* PI radix radix)) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3) (message "%f" area) ;; error void-variable area其中我们在let语句块中定义了两个变量,pi初始化为3.1415926,area 初始化为 nil同样的,可以使用 let* 改写上面的程序(defun circle-area (radix) (let* ((PI 3.1415926) area) (setq area (* PI radix radix)) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3)let* 与 let 的区别在于,let* 可以在binding时候使用前面已经定义过的变量。例如上面的代码可以改写成(defun circle-area (radix) (let* ((PI 3.1415926) (area (* PI radix radix))) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3)我们使用 let 来改写一下这个程序,发现它会报错(defun circle-area (radix) (let ((PI 3.1415926) (area (* PI radix radix))) (message "半径为 %.2f 的圆的面积是 %.2f" radix area))) (circle-area 3) ;; error void-variable PI好了本篇也该结束了,本篇主要了解了基本的elisp语法,下面进行一下总结:使用 defvar 和 setq 来定义全局变量,其中defvar可以给变量设置一个说明文档,我们使用 C-h v 来查看这个文档使用 let 和 let 来定义变量,其中 let 可以在变量定义的时候使用前面定义过的变量使用 defun 来定义函数使用lambda 来定义一个lambda表达式,使用funcall 来调用lambda,lambda可以赋值给变量,后续使用funcall来调用 -
Emacs 折腾日记(二)——Emacs简单入门 环境 准备这里我们根据之前博客 配置的wsl2+archlinux环境,安装Emacssudo pacman -S emacs如果之前配置的关于gui的部分正确,那么在终端输入 emacs 来启动 或者在Windows的开始菜单中能找到emacs(Arch) 之类的启动项目。当然你也可以使用 emacs -nw 来开始一个终端的emacs程序Emacs 主要界面展示打开之后,映入眼帘的是一个比较丑陋原始的充满历史感的软件,看着都有点让人倒胃口我们能不能将Emacs改造的漂亮一点呢?记住在Emacs上永远不要问能不能,而应该问怎么做。Emacs上没有不可能上面的图中,我将Emacs的各个区域都给标记了一下,很好理解,一般的软件都有这些部分。中间显示的是欢迎信息,欢迎界面中这些链接都是Emacs的帮助信息,都可以点进入看。而下面的状态栏显示了一些基本的信息。最下面的部分我们称之为mini-buffer,会显示一些运行信息我们可以使用q 来退出欢迎界面,进入该界面需要注意下面几个地方软件中间位置已经出现了输入的光标,我们可以在里面输入内容下面有一个 scratch 的字样,它表示当前处于scratch buffer (草稿),顾名思义,它就是一个输入临时内容的地方。它没有绑定任何的文件后面的 Lisp Interaction 和 ElDoc表示当前的mode,会加载一些有关mode的配置,例如lispmode会加载一些有关lisp的高亮等至于状态栏每个字符都代表什么意思,这里就不解释了,后面我们希望对Emacs进行一些美化,美化完成之后就看不到这些信息了。Emacs 的一些概念介绍在学习玩Vim之后,Emacs 的一些概念就变得很好理解了,很多东西都根vim是相似的bufferVim 中的buffer与文件有关联,将来可以保存在文件中,但是Emacs的buffer除了包括vim中buffer相关的内容之外,也有一些其他类型的buffer,目前我知道的有:minibuffer: 界面最下方的一栏,主要显示当前状态和一些其他内容,后续可以对它进行一些定制,可以显示很多有用的信息scratch buffer: 顾名思义,就是草稿箱的概念,用来输入一些临时的内容Message buffer: 用来显示一些信息,例如message 函数的内容modemode,模式。Emacs中一个十分重要的概念,一般来说buffer都会有mode加载在其上,给buffer提供额外的支持。mode 分为两种, major mode 和 minor mode。一般一个buffer只能有一个major mode,但是可以有多个minor mode。每个mode都有一些额外的特征和快捷键绑定,与vim中的文件类型有点类似。不知道小伙伴还记不记得,我们可以针对vim中的文件类型,给每个类型指定额外的快捷键和语法高亮等信息。同样的Emacs的mode也具有这些功能。例如 elisp mode 里面有语法高亮、快速执行lisp代码的一些快捷键。另外也可以做到同样的功能在不同的mode中体现出不一样的效果。相比于vim的文本类型来说,mode的方式更加的灵活,我们可以将一些在不同文件类型中同样的功能抽出来,放到一个mode中,然后在需要的时候以minor mode的形式加载到buffer中。windowwindow的概念与vim中的相同,都是同时显示多个buffer。frame相比vim来说,Emacs多出来了一个frame的概念。上述emacs 的界面就是一个frame,每创建一个frame,就会多出来一个上面的带有标题栏的窗口。相信各位读者也看出来了,只有gui的Emacs可以创建多个frame。一般来说我们使用到window就已经足够了,特别是要进行全键盘操作的时候,多个frame反而是一个负担Emacs 的重要快捷键介绍快捷键之前,我们先来介绍一下Emacs相关的键位。Ctrl:ctrl键,一般简写为CMeta: 一般是Windows键盘布局中的 Alt 键盘,简写为 MSupper: 一般是WIndows键盘布局中的Win 键,简写为S因为vim利用不同的模式来映射快捷键,所以vim能用较少的按键实现很多的功能,而Emacs本身不具备mode的功能,所以它需要很多前缀来将不同的功能进行映射。对于一个vim转Emacs的用户来说,Emacs的快捷键统统不重要,第一,后续肯定会将它改造成vim的按键模式。主要是相比于vim来说,Emacs的文本操作快捷键太长了,没有vim那么简洁。第二,没有人会去特意记忆那么多快捷键,以我使用vim的经验来说,都是慢慢用,慢慢形成肌肉记忆的。作为一个初学者一上来就告诉他,需要记住这些快捷键,很容易就把人吓跑了。但是Emacs毕竟不同与vim,我们还是需要记忆一些特别重要的快捷键快捷键功能C-h f查看函数的帮助信息C-h v查看变量的帮助信息C-f k查看快捷键的帮助信息M-x执行命令前三个主要是查看各种帮助信息,Emacs有一个特点叫自文档,就是它很多东西都自带文档,一切都可以通过查询文档来了解。所以在使用和熟悉的过程中,我们离不开前三个快捷键。它可以互相查,例如忘记了某个功能的快捷键,可以使用 C-h f 输入对应的函数就可以找到它对应的快捷键。或者忘记了某个快捷键绑定到哪个命令了,可以使用 C-h k来查看关于快捷键绑定命令的信息。对于最后一个快捷键,一般来说Emacs的功能都绑定到了一个命令或者说一个函数上,即使我们忘记了快捷键,也可以通过M-x 输入命令来完成操作,有些时候配合自动补全,输入命令不比使用快捷键慢。vim与Emacs的很多地方都是相通的,学习了vim之后,Emacs的很多概念都不需要细说,很快就能上手用了,但是想要用好,用出个性来,还是要对elisp有一定的了解,后面可以会陆续介绍一些elsip的知识。
-
-
emacs 折腾日记(一)——序言 初次知道emacs这个东西是在《程序员的呐喊》这本书。书中的作者提倡学习编译原理,推崇emacs。现在距离我知道emacs已经过去了快8年,期间不断的重复学习——放弃——学习的路子。与过去学习vim类似,vim我也经历过放弃到学习,最后有项目需要使用Vim在Linux上开发,没办法慢慢学会了它的操作,以及一些简单的配置。后来我写了vim的操作和配置,我发现这样做很有用首先就是在写vim操作的时候,相关的概念和操作技巧我又重新梳理了一遍,加深了它的印象,过去一些不怎么用的操作我发现在之后我用的越来越顺手。其次就是我目前使用的配置在出错或者需要做修改的时候根据之前的文章我又梳理了一遍,很方便我回顾之前的思路能快速定位到每个模块当初的思路以及一些被遗忘的知识点。既然之前的教程对我有这么大的帮助,那么我想这次学习emacs就采用这种策略。首先日常记笔记,记录工作的日志之类的操作就从markdown转化到emacs的org-mode中以便熟悉emacs的日常操作。另外通过写博客的方式记笔记,记录自己做的一些配置以及一些操作技巧。日后用来回顾也好或者仅仅为了加深印象也好都可以。另外我想这一系列既然是折腾日记,而且我还是emacs的小白,那么这一系列的文章自然是不成体系的,基本上是想到什么就写什么。如果看这一系列的文章的读者存在问题我可能也没有能力解答。在这里给读者说一声抱歉。emacs 是什么任何技术或者工具我都喜欢从这几个方面先了解一下,再考虑是不是值得学。首先一个问题就是“是是什么”,其次是“为什么”,最后是“怎么做”。我想现在就来说说我对这几个问题的理解首先Emacs是什么呢?Emacs 其实并不特指某一款编辑器,而是一个文本编辑器大家族的统称。最初由理查德·斯托曼于1975年在MIT协同盖伊·史提尔二世共同完成。这一创意的灵感来源于TECO宏编辑器TECMAC和TMACS。这里我们提到Emacs主要特指 GNU EMacs,它是由理查德·斯托曼于1984年开始开发,至今已经有40多年的历史。它的核心理念官网上是这么介绍的An extensible, customizable, free/libre text editor — and more它是一个 可扩展、可定制、自由的文本编辑器,并且远不止于此。EMacs 是自由软件,它没有对用户做出任何限制,包括内核代码完全是开放的。你可以在此基础之上进行任何改动。同时它提供了一个完成的lisp解释器,随着这些年的发展,它的插件系统已经特别丰富了,利用插件几乎可以实现任何功能。有人戏称Emacs是一个伪装成文本编辑器的操作系统,在Emacs上几乎无所不能。emacs 是否值得学我个人认为Emacs还是很值的学习的。说说我学习Emacs的理由:它是一个与vim齐名的编辑器,因为它的插件丰富,结构设计良好,它几乎可以做到vim能做的所有事情,包括vim那一套操作逻辑它使用lisp作为扩展语言,我目前掌握了面向过程的语言C,面向对象的语言 C++/Python,但是还从来没有完整的学习过函数式编程语言,而且《黑客与画家》的作者也推荐lisp语言。平时写普通的脚本我都是用shell 或者 python 就搞定了,没什么几乎接触到lisp的实战,借这个机会学习一下lisp并且用于实战,也是一个不错的选择emacs 的 orgmode很吸引我,它的功能比markdown要丰富,借助Emacs这个平台能提供非常棒的体验,包括但不限于写博客,做计划,管理日程,甚至能在里面运行代码如何学下面是一张网上流传的图,各个编辑器的难易程度虽然有点夸张,但是Emacs的学习过程并不算简单。目前我也没有好的学习路径,而且这一系列的文章只是我的尝试。目前我也没有掌握Emacs,甚至是一个小白。我想以写文章的方式来慢慢学习关于Emac的内容网上有很多Emacs的教程,最经典应该要数这篇 一年成为Emacs高手但是我之前尝试过使用高手的配置,总是用着不是那么舒服,总想要折腾出一套属于自己的配置,后面慢慢的就放弃了。这次我想慢慢的根据其他人的教程折腾出一套属于自己的配置,然后通过使用 org-mode 来写博客、记笔记、并且进行日程管理,后续慢慢的将写脚本之类的简单开发工作转移到Emacs上,通过折腾配置并且多用Emacs来学习。祝我好运吧。
-
在wsl2中安装archlinux 在之前的博客中,我介绍了如何在虚拟机或者真实机上安装archlinux并且进行一定的配置,但是实际上Linux不管怎么配置在日常使用中都没有Windows简单便利,在开发有关Linux的程序时过去用虚拟机或者直接在Windows上使用ssh在远程服务器上进行开发。但是微软发布了wsl以及后续更新的wsl2,可以很方便的实现在Windows中拥有两个系统,并且两个系统可以进行互联。在不改变Windows操作习惯的基础之上操作Linux。进一步提升了Linux的便捷易用性。晚上的教程大多数都是使用wsl安装Ubuntu的,作为一个铁archlinux党,我不太用得惯Ubuntu,那么就要想办法安装自己习惯的arch,好在在网上有现成的教程。终于完成了这一工作准备工作安装wsl2,需要Windows 11或者Windows 10 的19041 及更高版本。因此如果系统版本不够需要提前进行系统的更新操作我们需要在Windows功能中开启 "适用于Linux的Windows子系统",如下图所示勾选之后可能需要重启。或者也可以在应用商店进行安装。这里就不得不吐槽一下微软的应用商店了,它居然能做到挂梯子和不挂梯子一样卡。我这里死活登录不上,就不演示这种方式了安装完成之后可以在powershell中查看它的版本wsl -v从图上可以看到,我们已经安装上了wsl2安装 archlinux安装完wsl2 之后,我们可以在GitHub官网上下载最新的ArchWSL。这里我们要下载两个东西,一个是不带online 标识的appx文件以及同名的cer文件。下载完成之后双击 .cer 文件,点击“安装证书”,选择“本地计算机”,在下一个页面中选择“将所有的证书都放入下列存储”,点击“浏览”,选择“受信任的根证书颁发机构”,执行安装。证书安装完成之后,我们双击下载的appx 文件,直接点击安装appx文件安装完成之后,可以使用wsl --list来查看当前wsl中的Linux子系统此时已经有了对应的系统了我们在命令行输入 arch 即可进入archlinux子系统,此时是以root的身份进入的配置arch配置普通用户新系统安装之后的第一件事就是创建一个普通用户,并且永远以这个普通用户进行登录,在需要的时候使用 sudo 来申请某些管理员权限进行操作我们在之前安装archlinux的教程中已经提到过对应的操作方式useradd -m -G wheel -s /bin/bash arch我们创建一个名为 arch 的用户,并指定shell为 bash接下来我们使用passwd arch passwd root来设置root和arch两个用户的密码。因为archlinux中安装的编辑器是vim,所以我们先将vim设置一个名为vi的别名ln -sf /usr/bin/vim /usr/bin/vi然后 使用visudo 将文件中 #%whell ALL=(ALL) ALL 这行的注释去掉,以便当前用户能够使用 sudo 命令接着可以使用su arch 将当前用户切换到arch。并且使用命令sudo pacman -Syyu来更新系统,同时测试一下输入用户密码之后能否执行一些root命令之后我们推出 arch 子系统,在powershell中执行Arch.exe config --default-user arch来指定默认使用arch 来登录系统设置完登录用户之后,在powershell中输入 arch 进入archlinux子系统中,此时我们发现,登录用户已经变成arch了初始化密钥环和更新源接着我们执行以下命令,来初始化密钥环sudo pacman-key --init sudo pacman-key --populate sudo pacman -Syy archlinux-keyring sudo pacman -Su鉴于目前国内的网络环境,上述几条命令有可能执行出问题或者卡着不动,我们可以进行换源的操作,这里我采用清华源在/etc/pacman.d/mirrorlist 文件的最顶端添加Server = https://mirrors.tuna.tsinghua.edu.cn/archlinux/$repo/os/$arch开启32位软件库支持与ArchLinuxCN库的支持按照之前博客中的内容,我们先打开 32位软件的支持,在 /etc/pacman.conf 中去掉[multilib]一节中两行的注释,来开启 32 位库支持。然后在该文件的结尾处加入下面的文字,来开启 ArchLinuxCN 源[archlinuxcn] Server = https://mirrors.tuna.tsinghua.edu.cn/archlinuxcn/$arch之后通过以下命令安装 archlinuxcn-keyring 包导入 GPG key。pacman -Sy archlinuxcn-keyring具体的使用可以看镜像的官方文档如果报错可以看官网或者看我博客的办法是否能解决上述命令都成功之后使用 sudo pacman -S yay 来安装 yay成功之后我们可以试着安装一下neofetchyay -S neofetch安装成功之后,执行neofetch 就可以看到系统信息了配置终端基础内容安装完成之后,我们可以对终端进行一下美化和配置,毕竟日常使用上大部分时间都是直接在终端中使用,有一个漂亮点的终端用起来也舒服一点我们首先安装一下必要的组件sudo pacman -S net-tools man-db man-pages man-pages-zh_cn texinfo ntfs-3g tree pacman-contrib neofetch wget git usbutils pciutils acpi base-devel接着我们安装一下相应的字体sudo pacman -S adobe-source-han-serif-cn-fonts wqy-zenhei sudo pacman -S noto-fonts-cjk noto-fonts-emoji noto-fonts-extra ## 这里我把官方推荐的所有带unicode标识的全装上了,这样后续就不太会出现乱码的情况了 yay -S ttf-ubraille ttf-symbola otf-cm-unicode ttf-arphic-ukai ttf-arphic-uming ttf-dejavu gnu-free-fonts ttf-google-fonts-git nerd-fonts-complete ttf-hack ttf-joypixels默认的bash 功能比较弱,我们采用zshsudo pacman -S zsh然后将默认的shell 设置为 zshchsh -l # 列出系统中存在的所有shell chsh -s /bin/zsh #根据上一个命令得到的shell路径,设置当前shell我们推出系统再次登录的时候,shell已经切换到zsh了,我们按照提示生成一个默认的 .zshrc 文件即可为了支持终端上显示一些图形,我们需要安装 nerd-font 。可以在GitHub上找到 nerd-font可以通过git clone https://github.com/ryanoasis/nerd-fonts.git --depth=1来克隆,也可以通过在宿主机上下载zip包,然后传入archlinux 中。我们可以直接在Windows的文件资源管理器上输入 \\wsl$ 来访问archlinux的文件系统在获取项目之后,在项目的根目录执行 sh ./install.sh 来执行安装需要注意的是,如果你是通过本地的windows terminal 来ssh到远程archlinux化,本地也需要安装 nerd-font 因为这个时候显示的责任在宿主机的终端程序。需要宿主机本身也有那些字体。Windows上可以使用 .\install.ps1 来安装字体准备好后,我们可以使用 powerlevel10k 来美化终端git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ~/powerlevel10k echo 'source ~/powerlevel10k/powerlevel10k.zsh-theme' >>~/.zshrc source ~/.zshrc接着按照它的提示选择样式即可,如果不满意了,可以在 .zshrc 中对应的配置,直接重新选择样式即可。完成之后,可以看到终端相对来说比较好看了接下来我们对zsh 进行一些简单的配置安装 zsh-autosuggestions ,它是一个命令提示插件,当你输入命令时,会自动推测你可能需要输入的命令,按下右键可以快速采用建议git clone https://github.com/zsh-users/zsh-autosuggestions ~/.zsh/zsh-autosuggestions在 .zshrc 中添加下列代码source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zsh安装完成之后效果如下我们可以按TAB自动补全zsh-syntax-highlighting 是一个命令语法校验插件,在输入命令的过程中,若指令不合法,则指令显示为红色,若指令合法就会显示为绿色。git clone https://github.com/zsh-users/zsh-syntax-highlighting.git echo "source ${(q-)PWD}/zsh-syntax-highlighting/zsh-syntax-highlighting.zsh" >> ${ZDOTDIR:-$HOME}/.zshrc安装完成之后效果如下autojump 是一个懒人神奇,有了它,当我们此前跳转过某个路径之后,可以很方便的跳转到之前路径。例如我们之前跳转到/usr/bin /home/arch那么我们可以直接使用 j b 跳转到 /usr/bin 中,或者在其他目录使用 j a 跳转到家目录中,如果跳转的目录路径有相似的字符,可能需要多输入一些字符来区分我们下面来安装它git clone https://github.com/wting/autojump.git cd autojump ./install.py安装好之后,它会提示我们需要手动将下列命令加入到 /zshrc 中,我们添加就好了thefuck 这也是一个懒人神奇,当命令输入错误的时候只要fuck一下就好了在archlinux中,我们可以直接使用sudo pacman -S thefuck我们将下列代码放入到 .zshrc 中eval $(thefuck --alias)安装完成之后,效果如下使用gui程序在Windows11和Windows 10 的内部版本在19045以上的时候,wsl本身就可以直接在打开Linux的gui程序。这里我们安装一个firefox作为测试例子sudo pacman -S firefox firefox-i18n-zh-cn我们启动firefox,这个时候报错了不要慌,这里我们需要链接wslg的接口套接字到x11sudo rm -r /tmp/.X11-unix ln -s /mnt/wslg/.X11-unix /tmp/.X11-unix可以将这段代码手动添加到 .zshrc 中,以便重启之后仍然能生效if ! [ -S /tmp/.X11-unix/X0 ]; then sudo ln -sf /mnt/wslg/.X11-unix/X0 /tmp/.X11-unix/X0 fi这个时候再打开就能在Windows上看到firefox的界面了还有一个惊喜,那就是我们可以从开始菜单中找到对应的Linux gui程序,并且直接点击就能打开。使用rdp连接除了这种使用方式,我们还可以使用rdp通过Windows的远程连接来进入archlinux子系统。这里我不太推荐这种方式,因为上面那种方式可以直接在Windows上使用linux gui程序,已经特别方便了,而且这种方式需要有桌面环境,需要消耗资源,但是当你的Windows版本不够的时候,可以考虑使用这种方式来使用gui程序这里我们先安装桌面环境sudo pacman -S xfce4 xfce4-goodies这里我采用轻量的xfce4,不管是使用kde 还是gnome,感觉都比较重接着我们下载rdp相关的软件yay -S xrdp xorgxrdp-glamor pulseaudio-module-xrdp根据 arch wiki 的说法,xrdp 仅支持使用XVNC作为后端,所以这里我们需要安装一下 vncsudo pacman -S tigervnc安装完成之后,需要在home目录下,添加一个.xinitrc 文件,这个文件会在rdp新建一个虚拟桌面的时候执行,文件的内容如下unset SESSION_MANAGER unset DBUS_SESSION_BUS_ADDRESS exec dbus-launch startxfce4最后我们启动一个rdp服务sudo systemctl start xrdp.service最后我们就可以使用Windows远程桌面连接上Linux的桌面了好了,配置到这里也就基本结束了,希望各位小伙伴在其中玩的愉快。总体来说Windows的wsl用起来还是很香的,特别是使用wslg服务在Windows中使用Linux的gui程序。它用起来就跟在Windows上开启一个gui程序一样丝滑,可以很好的将Linux程序融入到Windows的工作流中。
-
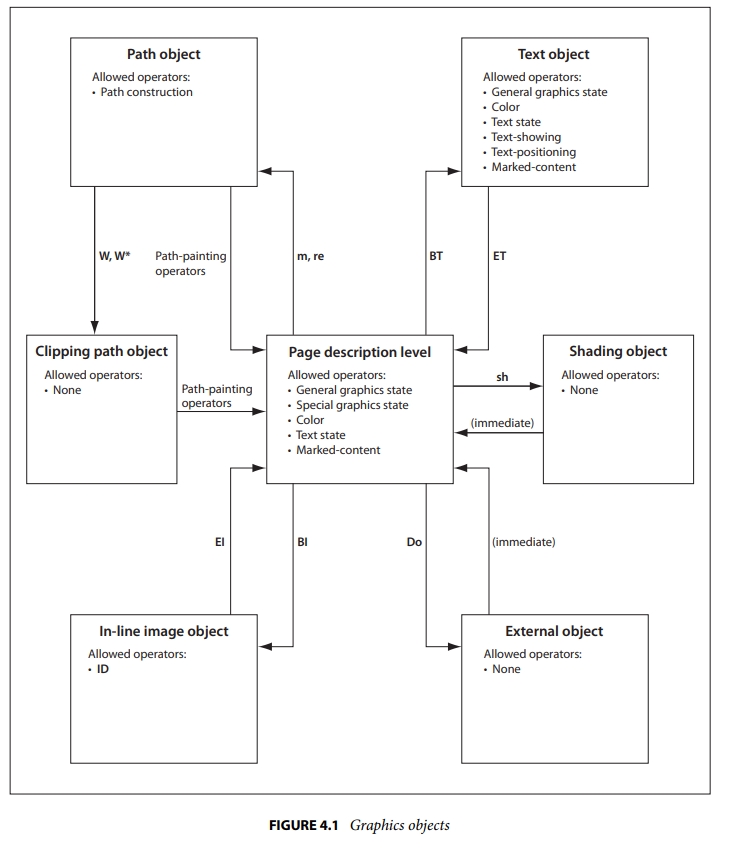
PDF标准详解(五)——图形状态 在第三节中,我们说到Q/q 这一对操作符是用来保存和还原图形状态的,那个时候只有一个简单的概念,变换矩阵是图形状态的一员,那么什么是图形状态,以及有哪些图形状态呢?本节将要描述这部分的内容图形状态一个PDF应用程序维护内部数据结构称为图形状态,它保存了当前图形控制参数。这些参数定义在全局框架,在全局框架内可执行图形操作符。例如:f(填充)操作符隐式调用当前颜色这个参数,S(描边)操作符调用了当前线框这个参数从图形状态。这个说法比较的官方,我个人的理解就是它保存了画笔画刷,线性等一系列跟画图相关的属性,在调用图形操作符时,直接采用图形状态中的参数来填充画笔画刷等。目前设备无关的图形状态参数主要有下面几个参数类型值CTMarray当前变换矩阵,例如: a b c d e f cmclipping path(internal)当前剪切路径,初始值:CropBoxcolor spaceName or array当前颜色空间,分为 fill color(填充色) & stroke color(描边色),初始值:DeviceGraycolor(various)当前颜色。初始值:blacktext statevarious有9个图形状态参数组成,用于文本显示。line widthnumber线宽。初始值:1.0line capinteger线帽,线2端的样式。初始值:0 J(square butt cap)line joininteger线连接的样式 。初始值:0 j (miter join)miter limitinteger尖角限量。 初始值:10 M (11.5°)dash patternarray and number虚线。初始值:[] 0 dblend modename or array当前混合模式。初始值:Normalsoft maskdictionary or name指定阴影的形状或阴影不透明值用于透明图像模式。初始值:Nonealpha constantnumber透明度。初始值:1.0。 CA(for stroke) ca(fill)alpha sourcebooleanTrue: 由 SMask 指定透明模式 <br/>false:由 CA 或 ca 指定透明值我们目前介绍过的图形状态主要有变换矩阵以及裁剪区域。剩下的会在后面的内容中依次介绍图形对象的状态变更在pdf 1.7 的标准中,有这么一张图这张图描述了图形状态描述对象的变更。图最中间的是页面对象层,包括图形状态、颜色、文本状态和标记对象等等。坐上角的连线表示,图形对象可以通过 m/re 等操作符进入对路径对象的描述,路径对象在描述完毕后可以使用f、s等操作符显示路径并回到页面对象层,或者可以通过W/W* 来进入对裁剪区域对象的描述。其他的连线也是同样的道理。理解了这个图,也就理解了基本的PDF图形操作逻辑,一般想要的绘制的图形未显示或者裁剪区域未发生作用,一般都是进入的状态不对。按照此思路进行查漏补缺一般可以解决问题本节的内容,不涉及到具体的操作符,仅仅是概念的介绍。后续将会陆续介绍上面提到的图形状态
-
PDF标准详解(四)——图形操作符 上一节,我们了解了PDF中cm操作符,它是定义变换矩阵的。同时也了解到re是创建一个矩阵的。上一节也说过,它用来构建一个路径,具体什么是路径,路径有什么作用呢?这些将在本节给出解释图形操作符是用来在pdf中构建内容并输出到相关设备上进行显示的。pdf中我们能看到的内容几乎都是由图形操作构成的。PDF中主要有6中图形操作符:图形状态操作符(Graphics state operator):CTM当前变换矩阵、 current color、 current clipping path。路径构造操作符(Path construction operators):线的轨迹,,各种图形。绘制路径操作符(Path-painting operators):填充, 描边, 或定义一个剪切区域。其他绘图操作符(自我描述图形对象): 图像(image),shading。文本操作符(Text operator):从字体(代表文本字符的字面/版式(TYPE-FACES)的描述)中选择,显示字符字形字符操作,例如前面显示hello,world 用到的Tj 操作符标记内容操作符(Marked-content Operator): Layers这一次我们主要介绍前两个,后面的等后续慢慢介绍路径路径构建操作符路径对象主要由直线、矩形框(re)、3次贝塞尔曲线构成。对于直线来说,我们需要先使用m(moveto) 来将画笔移动到指定位置,然后使用l(lineto) 来表示将画笔移动到某一个点。例如有下面的例子3 0 obj % 页面内容流 << >> stream % 流的开始 400 400 m 100 100 l s endstream % 流结束 endobj这里我们定义了一个从 (400, 400) 到(100, 100) 的直线。在画直线的时候,m只能有一个,作为起点,而l可以有多个,每有一个l都表示从画笔的上一个点画一条直线到新的位置。例如我们可以模拟一个画一个矩形3 0 obj % 页面内容流 << >> stream % 流的开始 400 400 m 100 100 l s 100 100 m 300 100 l 300 300 l 100 300 l 100 100 l S endstream % 流结束 endobj矩形的例子比较简单,这里就不给出了。我们只需要指定起点坐标并且加上长宽最后用re 操作符作为结束符即可构建对于贝塞尔曲线来说,我们需要4个点来画出一条曲线,它们的位置如下图所示我们需要一个起始和结束位置的点,并且加上两个控制点共同组成一条贝塞尔曲线。贝塞尔曲线我们使用c来作为操作符,在构建的时候需要使用m来规定起始位置的坐标,然后再跟上上图p1, p2, p3 的坐标来控制曲线。例如下面的例子3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c S endstream % 流结束 endobj这样我们构建了一条如下图所示的曲线我们对上面出现的操作符做一个总结操作符含义m设置点的起始位置(moveto)l从当前位置构建一条直线到对应位置 (lineto)re构建矩形路径c构建贝塞尔曲线路径显示操作符上述操作符只能构建一个路径,而这个路径究竟该如何显示,用作何种用途,需要另外给出操作,如果仅仅构建路径,那么页面上是不会有任何显示的,例如上述的内容流,我们稍微做一下更改,去掉最后的S 操作符,我们可以发现之前显示的内容现在不显示了3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c % 只构建路径,而不对路径做任何操作,页面不会有路径的内容 endstream % 流结束 endobj想要显示路径,我们需要使用 S 操作符。上面的路径,我们在最后加上S 就能显示出图形了。另外我们可以使用h操作符来构建一个闭合的路径,它是在原来图形的基础之上,使用一条直线将起始点到终点的两个点连接起来构成要给封闭的区间。例如上面使用直线画矩形的例子,我们可以删掉最后一个l 操作符,并使用h 闭合,照样能形成矩形3 0 obj % 页面内容流 << >> stream % 流的开始 400 400 m 100 100 l s 100 100 m 300 100 l 300 300 l 100 300 l h S endstream % 流结束 endobj去掉h 我们将得到一个开口的矩形。这个读者可以自行尝试,这里就不给出结果了。对于上面的贝塞尔曲线的例子3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c h S endstream % 流结束 endobj加上h 之后将得到下面的结果描边与填充操作这里我们采用S对路径勾画出了边框,也就是描边路径,它对应的英文单词是stroke,我们也可以使用f 或者F(fill)来对路径构成的封闭区间进行填充。默认采用黑色进行填充。3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 m 200 300 300 400 400 200 c h f endstream % 流结束 endobj当然也可以提前指定画刷颜色,这个我们在后面介绍颜色空间的时候再介绍如何定义画刷和画笔。另外也可以使用b或者B(both) 来同时进行描边和填充操作。非0缠绕规则和奇偶绕组规则上述图形,我们很明确的仅定义了一个简单的区域,当出现重叠的复杂区域时,该如何进行填充呢?这里有两套不同的填充规则,即非0缠绕规则和奇偶绕组规则。3 0 obj % 页面内容流 << >> stream % 流的开始 100 350 200 200 re %生成矩形左上角坐标 (100, 350) 宽高都是200 120 370 160 160 re f %按照非0缠绕规则 400 350 200 200 re %生成矩形左上角坐标 (400, 350) 宽高都是200 420 370 160 160 re f* %按照奇偶缠绕规则 endstream % 流结束 endobj这里显示的效果如下我们在这里定义了两组矩形,每组有两个矩形路径进行了重叠。第一组采用非0缠绕规则,第二组采用奇偶规则来填充。我们先以这两个图形为例,来说明这两个规则非0规则:初始化环绕数到 0 。从图形中的任意一点 P 向外任意引一条射线。每遇到一条与该线的交叉线,如果射线与路劲的顺时针相交则计数加一,否则计数减一假如环绕数不等于 0 ,则点 P 在多边形内。但是这个方法有局限性 , 不适合相交 , 或者选一条正切的射线 . 因为射线的方向是任意的 , 这个规则简单的选用射线并不碰到这些情况例如上面我们定义了两个矩形,这两个矩形划分出了两个区域,也就是图中A和B所在区域。我们从A区域随意一点往外引一条射线。从图上看,射线与两条路劲相交,并且都是顺时针相交,所以这里的技术是2。同理,B点与一条顺时针路径路径计数是1。这两个区域的计数都不是0,所以他们都需要进行填充,因此它显示的是上图左侧的效果奇偶规则:从区域内某一点向外引一条射线。简单计算与该射线相交线的数量。如果这个数是奇数,则认为点在图形内。根据这个规则,我们看到A点的计数是2,是偶数,Bdian的计数是1,是奇数。按照奇偶规则,B点需要填充,而A点不需要进行填充。所以它显示的是上图右侧的效果我们再看一个例子3 0 obj % 页面内容流 << >> stream % 流的开始 150 50 m 150 250 l 250 50 l 50 150 l 350 150 l h f 550 50 m 550 250 l 650 50 l 450 150 l 750 150 l h f* endstream % 流结束 endobj这里我们画了两个五角星,线条的顺序按照m给出的为起点,每一个l代表笔画移动的一个端点,根据上述给出的值我们可以得到对应路径的环绕方向,具体的分析过程这里就不展开了,有兴趣的小伙伴可以自己尝试着画图分析一下,然后使用pdf阅读软件打开看看效果与预估的是否一样定义裁剪区域我们利用一些操作符来定义一个路径,这些路径可以作为图形显示出来,也可以作为一个裁剪区域,在该区域中的内容显示出来,不在该区域的内容则丢弃。对于给出的路径,我们使用W (非0缠绕)或者 W*(奇偶规则)来定义一个裁剪区域。例如下面有一个例子3 0 obj % 页面内容流 << >> stream % 流的开始 100 100 200 200 re h W %将上述路径设置为裁剪路径 150 150 m 200 200 l S %在裁剪路径中,所以会显示 0 0 m 500 800 l S %只显示裁剪路径中的内容 endstream % 流结束 endobj这里我们定义了一个长宽都为200的矩形,并且使用h 将矩形区域封闭,然后使用W来将矩形内部作为裁剪区域,然后在(150, 150) 的位置画一条直线到 (200, 200) 的位置。这两个点都在矩形内部,所以会显示出来,另外再画一条从 (0, 0) 到 (500, 800) 的线条,因为这条线有一部分在裁剪区域外,一部分在裁剪区域内,所以只会显示一部分线条。最终图形呈现的效果如下总结本文主要介绍PDF中基本的图形操作符。一般构建图形的操作符有3中使用m 定义画笔的起始位置,然后使用 l 来画一条直线或者直接使用 re 操作符来绘制一个矩形还可以使用c 来构建贝塞尔曲线对于构建的路径,可以使用 h 来进行画笔起始位置和终点位置的连线,这个连线一般是一条直线。对于这个路径我们可以使用 S (stroke) 来对路劲进行描边显示或者使用 f(非0缠绕) f*(奇偶规则)进行内容的填充,又或者使用 b(B) 来描边和填充。我们可以使用 W (非0缠绕)或者 W*(奇偶规则) 来将路径作为一个裁剪区域
-
PDF标准详解(三)—— PDF坐标系统和坐标变换 之前我们了解了PDF文档的基本结构,并且展示了一个简单的hello world。这个hello world 虽然只在页面中显示一个hello world 文字,但是包含的内容却是不少。这次我们仍然以它为切入点,来了解PDF的坐标系统以及坐标变换的相关知识图形学中二维图形变换中学我们学习了平面直角坐标系,x轴沿着水平方向从左往右递增,Y轴沿着竖直方向,从下往上坐标递增。而PDF的坐标系与数学中的坐标系相同。但是PDF的坐标是有单位的,PDF的坐标单位为磅,一般来说他们与英寸等的转化关系为1 磅 = 1/72 英寸因为PDF需要做到设备无关,也是就是在不同的显示像素和打印机上,显示的长度都一致,所以这里不能采用像素做单位。但是我们可以通过相关的接口来将这个单位转化为像素。例如在Windows平台可以通过下列的代码来获取一英寸有多少像素HDC hdc = GetDC(NULL); short cxInch = GetDeviceCaps(hdc, LOGPIXELSX); short cyInch = GetDeviceCaps(hdc, LOGPIXELSY); ReleaseDC(NULL, hdc);对于我的显示器来说,水平和竖直方向都是 1英寸=96像素有了这些概念之后,我们来看一个例子,下面是在页面的(200, 200) 位置画一个 长宽都为100的正方形3 0 obj % 页面内容流<< >>stream % 流的开始200 200 100 100 re Sendstream % 流结束endobj之前说过,页面显示内容在页面流中,因此这里我们将内容放置到页面流对象中。前面的200 200 是矩形的起始位置。后面的100 100 分别是长和宽。re 代表我们要构建一个矩形,最后的S表示要显示这个图形。严格意义上来说,re 和S都是路径构造所使用的操作符。这里的矩形也不单单是一个图形,它是一个路径。关于他们的概念将在后面继续介绍。下面我们来介绍基本的2D图形变换平移假设一个点原始坐标是(x1, x2),那么沿着x轴平移a,y轴平移b,那么平移之后点的坐标为 (x1 + a, x2 + b) ,转换成矩阵就是$$ \begin{bmatrix} x & y & 1\end{bmatrix} \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ a & b & 1 \end{bmatrix} = \begin{bmatrix}x + a & y + b & 1\end{bmatrix} $$旋转利用中学的知识可以知道$$ x_1 = r * cos(\theta+\psi) \ = r*(cos\theta*cos\psi-sin\theta*sin\psi) \ = x*cos\theta-ysin\theta $$同理,我们可以得到$$ y_1 = r * sin(\theta+\psi) \ = r * (sin\theta*cos\psi+cos\theta*sin\psi)\ = x*sin\theta+y*cos\theta $$转换成矩阵就是$$ \begin{bmatrix} x & y & 1\end{bmatrix} \begin{bmatrix} cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ 0 & 0 & 1 \end{bmatrix} = \begin{bmatrix}x*cos\theta - y*sin\theta & x*sin\theta+y*cos\theta & 1\end{bmatrix} $$缩放缩放就是将坐标扩大或者缩小为原来的多少倍,我们可以很清楚的知道$$ x_1=x*a y_1=y*b $$这里的a和b都是缩放的系数利用矩阵表示就是$$ \begin{bmatrix} x & y & 1\end{bmatrix} \begin{bmatrix} a & 0 & 0 \\ 0 & b & 0 \\ 0 & 0 & 1\end{bmatrix} $$pdf 矩阵变换还有另外几种变换,这里就不一一列举了。现在我们知道二维图形的变换使用一个矩阵就能进行描述。所以PDF在变换图形的时候直接使用的是变换的矩阵。另外我们观察到对于二维变换来说,最后一列一直都是 0 0 1这三个数字。所以pdf中设置变换矩阵时忽略最后一列,仅仅保留前两列,采用6个数字$$ \begin{bmatrix}a & b & 0 \\ c & d & 0 \\ e & f & 1\end{bmatrix} $$这个矩阵在PDF中表现为 a b c d e f。回到我们之前hello的例子中,我们在 hello world 字符流开始的时候,给定了几个数字1. 0. 0. 1. 50. 700. cm各个数字之间采用空格隔开,这里数字后面跟的点表示它是一个浮点数。我们可以将这一列数字写成如下的矩阵$$ \begin{bmatrix}1.0 & 0.0 & 0 \\ 0.0 & 1.0 & 0 \\ 50.0 & 700.0 & 1 \end{bmatrix} $$这个矩阵我们叫做当前变换矩阵 (Current Transformation Matrix CTM),最后的cm表示使用该矩阵进行图形变换。它是current matrix 的缩写所以上述这一串数值的意思就是将 hello world 这个字符串平移到页面坐标 (50, 700) 的位置PDF 中控制图形变换的操作符现在我们利用这个上述知识来做一个小练习。我们将一个长宽都为100 的矩形在 (200, 200) 位置逆时针旋转45°绕任意点旋转,可以先将该点移动到坐标原点,然后按照坐标原点的进行旋转的公式进行计算,最后再将坐标点平移回原来的位置。这个过程产生3个变换矩阵平移矩阵$$ \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ -C_x & -C_y & 1\end{bmatrix} $$旋转矩阵$$ \begin{bmatrix}cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ 0 & 0 & 1\end{bmatrix} $$平移矩阵$$ \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ C_x & C_y & 1\end{bmatrix} $$我们将这三个矩阵相乘$$ \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ -C_x & -C_y & 1\end{bmatrix} * \begin{bmatrix}cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ 0 & 0 & 1\end{bmatrix} * \begin{bmatrix}1 & 0 & 0 \\ 0 & 1 & 0 \\ C_x & C_y & 1\end{bmatrix} $$最终得到这样一个矩阵$$ \begin{bmatrix}cos\theta & sin\theta & 0 \\ -sin\theta & cos\theta & 0 \\ C_x - C_xcos\theta+C_ysin\theta & C_y-C_xsin\theta-C_ycos\theta & 1\end{bmatrix} $$因此这里可以这样写3 0 obj % 页面内容流 << >> stream % 流的开始 200 200 100 100 re S %原始矩形 0.7 0.7 -0.7 0.7 200 -80 cm%进行坐标变换 200 200 100 100 re S %变换后的矩形 endstream % 流结束 endobj这样我们可以得到如下所示的图形这个时候我们会发现,同样是(200, 200) 的位置,在变换前和变换后,得到不一样的图形,这就说明我们的坐标系统被改变了。不再是水平和竖直方向的x y轴了。如果我们想要它变回原来的位置该怎么办?在GDI或者其他框架的图形编程中,在改变画笔、画刷等图形状态的时候,会首先保存原来的,然后更新,最后再还原。同样在PDF中,也存在有这样的保存和还原的操作符。我们使用q/Q这么一对操作符来完成保存和还原的操作。我在原来的基础上,再加一个矩形,在(400, 400) 位置画一个长宽都是100的矩形3 0 obj % 页面内容流 << >> stream % 流的开始 200 200 100 100 re S %原始矩形 0.7 0.7 -0.7 0.7 200 -80 cm%进行坐标变换 200 200 100 100 re S %变换后的矩形 400 400 100 100 re S % 这个矩形是相对于 (200, 200) 这个点旋转了45°的矩形 endstream % 流结束 endobj我们再采用q/Q这一对操作符来保存和还原图形状态3 0 obj % 页面内容流 << >> stream % 流的开始 200 200 100 100 re S %原始矩形 q 0.7 0.7 -0.7 0.7 200 -80 cm%进行坐标变换 200 200 100 100 re S %变换后的矩形 Q 400 400 100 100 re S endstream % 流结束 endobj这个时候我们发现它已经在(400, 400) 这个位置画了一个矩形。没有任何的图形变换PDF中将图形状态保存成一个栈结构,每次执行q就是将当前图形状态进行入栈,使用Q将之前保存在栈顶的图形状态进行出栈,并还原成当前图形状态。一般来说q/Q必须成对出现。好了,本节到这里就结束了。本节主要介绍了图形变换矩阵以及PDF中变换矩阵的操作符cm以及q/Q 这一对保存和还原图形状态的操作符
-
2024 年阅读清单 2024 年都过去这么久了才更新读书清单,我是在是有点过于懒惰了。我也忘记了去年最后一次更新读书清单是什么时候了,只知道我在看一套书,这套书花了差不多块5个月了。前几天刚刚看完,终于可以更新新一年的读书清单了《清明上河图密码》这本书就是我去年看了由个多月的一套书,本书有6部,读起来虽然不累,但是文字众多也算是比较花时间吧。本书是我最近几年第一次也是唯一一次看的大部头的书。书中人物众多,据说有名有姓的有800多人。对于一些小人物前面几部出现了几次后面再出现有时候确实不太记得,还好微信读书上有不少书友提醒。我对本书有一些看法,先来说说优点本书的优点一个是书中人物众多,特别是主线人物。每个人物都有名有姓,性格特征鲜明,许多人物都是让人印象深刻,京城十二绝,念奴十二娇,天工十二巧、各种店铺、官差、贩夫走卒等等。还有许多有名有姓的小人物。每个人物似乎都与主线有着某种联系,缺一不可在一个就是书中各种谜团永远牵动着人的好奇心,让我忍不住一直读下去。而且每部书中都有一个大案牵扯若干个小案,最终回这些大案又牵扯出一个惊天布局,我在阅读的过程中一直停不下来。而且作者一直采用各种人物视角切换的方式进行叙事,一直吊起人的好奇心。书中对小人物的心理描写极其细腻,读起来很是亲切。书中各种人物似乎都能在现实中找到一些影子。与其说在写故事,不如说在写现实中的芸芸众生。书中对于宋代的世代风貌描述的特别生动,特别是热闹的大街,大大小小的各种商贩。为我呈现了一个活灵活现的大宋都城汴京。对于缺点我觉得有下面两个明显的缺点人物故事切换太过频繁。这个是优点也是缺点,它确实可以调动读者的积极性,而且也体现了作者写故事,写人物的实力。但是过于频繁而且套路都一样,看多了容易让人视觉疲劳,这点在第5篇尤为明显。第5篇通过众多人物视角写了王家上上下下快60人与王小槐的种种恩怨和这些人之间的关系。都是一个套路,在阅读过程中,有几次都感觉读不下去第二个不能算是缺点吧,我个人认为书中的诡计或者作案手法过于随意,不够惊喜,没有那种让人眼前一亮的感觉。有些时候给出的线索不足,模糊。作为推理小说它总是差那么点意思。但是作为悬疑类小说,它确实足够优秀。书中最喜欢的人物应该是作绝——张用。他作为第四部的主角,与其他几部不同,他有种超脱俗世的洒脱,给人一种庄子的感觉。对于俗世,他洒脱、不拘小节、我行我素、有自己的一套行事标准,不被世俗规矩所束缚。对于朋友他总是热情、帮助朋友时是那种充分考虑朋友性格,让你觉得相处十分舒服的人。而且在第四部中,作者对人物性格描写惟妙惟肖,张用对人性的把握,对待不同人的不同态度,最终使与他接触的人都获得了心灵上的解脱。他算是我的人生榜样。最喜欢的应该是最后一部。对于最后一部的大揭秘没有让我眼前一亮的感觉。我最喜欢的应该是最后关于大宋灭亡的描写。在金人即将攻进来的时候,百姓的同仇敌忾与官方统治者的胆小懦弱、妥协形成鲜明的对比。大宋的统治者辜负了百姓、辜负了爱国将领,活该受此靖康之耻,被金人羞辱并封为昏德公纯粹是咎由自取。王朝灭亡最苦的还是百姓。前几部都城的繁荣与最后的人间地狱形成鲜明的反差。我觉得最后一部分是本书最有价值的内容《毛泽东传》这是我读的第二本毛泽东传纪。当初读毛选的时候,我对毛主席生平有了特别大的兴趣。特别是早期在中央几上几下,从被排挤到最后四渡赤水,到带领革命胜利,最后将中国从积贫积弱的农业国变成了一个世界强盛的工业国。这等丰功伟绩,古往今来也没有几个能做到。他的功绩哪怕减少一半在古代来说也可以被称之为千古一帝。他的人生是那样令人着迷但是这本书从某种意义上来说存在那种老外写传记的时的常规问题。书过于平淡,而且充斥了作者无端的联想。似乎老外可能不太懂得中国人为万世开太平那种胸襟。整本书有那么一种阴谋论的味道在里面。书中仅仅只是将毛主席的生平做了一个类似流水账似的讲述。故事性不是那么浓重,可能偏学术的传记都是这样的吧。总的来说我觉得这本书的可读性有,但是总体来说不太合我的胃口。想要了解主席生平事迹可能不能光看他一个人的传记。可能得从一些革命历史或者其他领导人的传记中找寻。《消失的第13级台阶》十几年前一对名叫佐津木的老夫妻被残忍杀害,而在凶案现场发生了一起交通事故。驾驶摩托车的树原亮刚好去拜访过佐津木夫妇,而且树原亮刚刚刑满释放,目前在佐津木夫妇的监护下,慢慢回归社会。在现场未发现其他可疑人员,而树原亮似乎与佐津木闹的不欢而散。而且树原亮自称因为事故而发生失意,不记得当天的情形,只记得当天经过一些台阶,但是现场都没有发现有台阶。就这样树原亮被认定是这起案件的凶手,被关押并等待执行死刑。主人公纯一在数年前因为过失致人死亡罪被判刑,但是因为在法庭上痛哭流涕,并且在狱中有悔改倾向,被提前释放,目前刚刚出狱,但是需要接受指定的监护,一旦发现有不良的表现就会被送回监狱。在回归家庭之后的纯一发现自己家因为需要偿还被害人一大笔钱,家里已经家徒四壁,目前需要一大笔钱。此时身为监狱死刑执行官的南乡约着纯一一起调查树原亮的案件。此时距离树原亮被执行死刑的时间所剩无几,但是案件又扑朔迷离,警察找到的所有线索似乎都指向树原亮,目前他们仅有的线索就是树原亮记得他曾今走在台阶上。在调查的过程中,纯一道出了他在十年前高中的时候曾今跟女友偷偷出去穷游,并且被警察教育过。根据警察的回忆,当时纯一与女友精神恍惚,纯一手臂上还有伤,并且手中还有大量的现金。这个数目不是穷游的高中生应该有的数目。纯一到底有着怎样的过去?在调查的过程中,委托人多次告诫,禁止纯一参与调查,但是都被南乡打哈哈给拒绝了,因为他觉得纯一天性善良,这是他回归社会的好机会。随着调查的深入,发现佐津木夫妇留有大量的遗产,这笔钱并不是作为普通教师所能挣到的数目,南乡猜测佐津木夫妇利用监护人的身份敲诈这些刑满释放人员而积累起来的不义之财。最终经中森检察官介绍,南乡与纯一知道了在当时凶案现场的山上存在一座佛寺,因为山体滑坡被掩埋起来。此时南乡与纯一在被掩埋的佛寺中发现了被藏起来的证物,证物中的存折可能记录了谁向佐津木转帐。最终在警方的鉴定下,存折出现了纯一的指纹。凶手会是纯一吗?纯一有着怎样的过去?委托人为何禁止纯一参加调查?真正的凶手是谁?这本推理小说居然是作者的处女作,实在是让人很难相信。我不得不感慨日本的推理作家横出,似乎总是后继有人。这本书这些谜题一直吸引我读下去,很久都没有读到这么酣畅淋漓的书了。但是比起常规的推理小说来说,他一直最后时刻还有人物登场,而且线索也不是在最终揭秘之前给到读者。可能这就是所谓的社会派推理小说吧,总是喜欢披着推理的皮讨论一些社会问题。但它并不是那种纯粹的诡计的比拼,不是那种纯粹的读者与作者智力比拼之类的小说。虽然有些不太满意但是并不影响本书的精彩程度。13级台阶有一个象征意义,据说在日本,从法院正式判决执行死刑到最后死刑实行需要经过13道审批手续。不知道这个说法对不对。这本书作者探讨了这样几个问题如何确定犯人是真心悔改还是仅仅希望减刑而作出的欺骗行为,进一步来说,刑法的意义到底是导人向善还是起到惩戒威慑犯人的作用?执行死刑是否有必要?杀死死刑犯的执行官是否需要为他们剥夺生命而产生负罪感?这个应该是日本文学作品的通病,对模糊的大义夸夸其谈,但是对眼前的苦难却视而不见。监护人制度是否应该存在,单凭监护人的监护记录是否就能断定犯人已经改过自新,或者重新将犯人送回监狱?是否值得为了复仇而影响自己的人生。针对问题每个人都有自己的答案,对我来说,刑法的作用肯定是威慑和报复,保护普通民众。毕竟犯罪已经造成很严重的后果,正常人几乎不会进行犯罪活动。对于犯罪分子应该以最严厉的刑罚进行惩罚。希望犯罪分子改过自新重新回归社会是对被害人的二次伤害。作为善良的普通人,我不希望日后当我成为被犯罪对象,并且这次犯罪活动对我造成巨大伤害之后,犯罪分子能在若干年后堂而皇之的融入社会,并且对之前对我造成的伤害只字不提,留我独自活在痛苦之中。《罗杰疑案》金斯艾伯特村落坐落着两座豪宅。皇家围场是其中之一,而居住在其中的弗拉尔斯太太刚刚过世。不久之后,她的情人,居住在另一座豪宅中的罗杰•艾克罗伊德先生便得知,弗拉尔斯太太是因为谋杀丈夫,并且最近被人勒索而心怀愧疚而自杀。罗杰当时邀请主人公也就是谢泼德医生共进晚餐,同时告知医生这件事,正当要揭秘勒索者是谁时,罗杰却拒绝告知医生信中后面关于勒索者的内容。当谢泼德医生离开后的当晚,罗杰被一把银剑插进了他的后颈而死亡。当时参加晚宴的人可谓各怀鬼胎,每个人都在警察的询问中隐瞒了一些事实。当调查陷入困境时,罗杰的侄女,邀请了谢泼德医生的邻居,已经退休隐居在此的大侦探波洛出马。随着调查,凶手以及当时的真相慢慢的浮出水面。虽然我爱推理小说,但是这还是第一次看阿婆的书。与福尔摩西不同的是,阿婆的书语言更加简练,笔下的侦探也更加朴实,他不是福尔摩斯那种天生的侦探形象,更像是身边不起眼的小人物一样。但是这种小人物一旦到他的领域就会发挥巨大的作用。阅读起来是另一种风格,整本书篇幅不大,但是铺垫特别多,比起福尔摩斯系列来说,阿婆的风格更像是一个舞台剧,或者一个箱庭模式。这部书中也可以看作是一个暴风雪山庄模式。我特别想多说一些书中的内容,但是感觉哪怕多说出任何一点都可能会造成剧透,给其他未读过此书的人造成不好的体验。这本书不适合写阅读体验,也不适合看剧情简介,它适合自己一页页的慢慢阅读,自己阅读的体验一定是好过读别人写的读后感或者评价的《小岛经济学》本书没有什么高深莫测的经济学概念,有的只是一个个小小的故事,通过故事来描述其中暗藏的经济学规律,对于没有经济学基础的读者来说,它很形象的讲解了经济活动是如何产生的,以及如何发展最后经济为什么会崩溃本书的故事从小岛出发,假设有两个人都以捕鱼为生,他们每天需要消耗一条鱼,并且只能补到一条鱼。但是随着其中一人省吃俭用,存下一笔供几天食用的鱼,并且利用这几天的时间发明了渔网,大大提升了捕鱼效率,从而产生了多余的鱼。也就是产生了资本的积累。随着技术的积累,岛上的鱼越来越多,也就产生了发展其他行业的可能。可以利用存储的鱼投资其他行业,例如自动捕鱼机,或者生产冲浪板以供娱乐,又或者与临近的岛屿交换它们的乐器等。总之随着生产效率的提高,个人财富会随着增加,个人娱乐需求也会产生,随着这些变化,经济会迎来正向的增长,普通人的生活也会越来越好。在某一时刻,岛上的居民会思考出制作自动捕鱼机,但是需要投入大量的时间和鱼,目前他手上没有这么多资源,而技术的发展会导致个人手中的鱼变多,而鱼的存储就会导致问题,这个时候银行就诞生了,银行利用利息来吸引居民将多余的鱼存储到银行,并且为需要大量鱼的人提供贷款。当有足够的鱼来支持研发自动捕鱼机,并且成功之后会导致捕鱼效率进一步提升,银行会因为这比成功的投资获得大量鱼的回报,并且也有多余的鱼来支持对应的居民存款利息。这一切都是这么这么自然并且都在像好的地方发展。随着交易的越来越频繁,采用真鱼来进行交易会显得越来越不方便,这个时候银行就发行纸币,并且规定一定的兑换比例,例如1元兑换1斤鱼。随着纸币的产生和发展,方便了岛上的交易。随着效率的提升,人口的增多,也需要一个组织来准备保护个人的财产以及保护岛上的居民。这个时候居民会自动的组织成立政府来完成诸如打击罪犯,保护个人和岛上的财产。政府是由居民组织成立,并且政府官员和工作人员也是由岛民选举产生。政府成立之后,政府工作人员不从事捕鱼工作,完全由居民纳税供养。随着政府部分越分越细,负责的事物越来越多,同时政客为了自己连任从而许诺给居民远超财力的福利,政府会越来越入不敷出。这个时候有专家就想到办法了,成立中央银行,并且掌握了发行纸币的权利。在早期靠着超发纸币,可以解决政府一部分的财力问题,因为纸币还不算太多,中央银行还有足够的鱼来完成部分居民的部分兑换需求。随着政府开销的进一步加大,纸币数量进一步加大,此时居民会发现有时候并不能从中央银行及时的兑换出需要的鱼。为了防止露馅,中央银行会规定每人每次只能兑换一定数量的鱼,并且超过这个数量需要提前进行预约。这暂时缓解了兑换的危机,但是鱼不足的情况依旧存在。然后又有专家有了新的注意,我们可以在鱼中加入其他物质,来填充重量。鱼的重量没变,但是鱼真正有效的部分却减少了。每个人每天都需要吃一定的鱼,往鱼里填充无效的部分会导致每个人需要鱼的重量增加,从而导致所有物价上涨。随着时间的推移,岛上的经济出现重大问题,例如房屋贷款的过度发放,房地产的野蛮生长导致了经济危机。这个时候居民看到隔壁岛上生产的便宜商品,并且岛上的政府早些年通过武力或者其他手段迫使周围岛屿都是用纸币进行交易,此时该岛是用不再那么值钱的纸币去购买其他岛屿廉价的物品,而周围岛屿则用收到的货币购买自动捕鱼机等高精尖的产品。随着其他岛屿捕鱼效率的提高,而且他们也发现这个纸币的价值越来越低,在机缘巧合之下,他们可能会考虑绕过该岛的纸币,利用鱼或者其他的纸币进行交易,这个时候该岛终于迎来了经济的彻底崩溃。总体而言,《小岛经济学》以简单易懂的故事形式,生动地阐述了奥地利经济学派的观点,强调生产、储蓄对于经济增长的重要性,批判了过度的《杀死一只知更鸟》这是一本关于爱和成长的故事,书中描述了一个伟大又充满爱的父亲——阿迪克斯。故事发生在一个美国的小镇——梅科姆。镇上有一些奇奇怪怪的,像刻薄的老太太——杜博斯太太,也有怪人拉德利,还有黑人。在那个黑人不被承认人权的年代,黑人一直被人看不起,视为社会的垃圾,有什么坏事都会栽赃给黑人。书中的阿迪克斯会陪着孩子一起读报,他会温柔的听孩子的倾诉,给孩子讲解道理。阿迪克丝对他的女儿说:“斯库特,当你最终了解他们时,你会发现,大多数人都是好人。”,他又说只有完全站在他人的角度看问题才能真正了解一个人。阿迪克斯一直隐瞒他是一个神枪手的事实,因为他意识到上帝给了他一个对其他动物不公平的优势,于是就把枪放下了。书中刻薄的杜波斯太太在临终前一直在戒毒瘾。对此阿迪克斯说“勇敢是:当你还未开始就已知道自己会输,可你依然要去做,而且无论如何都要把它坚持到底”。书中的怪人拉德利一直在他的屋子里面从没出过门,当时在邻居中流传着关于拉德利的恐怖传说。在孩子门去拉德利庭院探险时,吉姆的裤子被篱笆钩破并且无法及时取回。当吉姆再去取时发现裤子已经被补好并且整齐的放在椅子上。日后在树洞中也陆陆续续出现了送给孩子们的礼物。书中的第二部分是关于懒惰,卑鄙的尤厄尔家族家族控告黑人汤姆强奸的案子。在庭审上阿迪克斯通过多种证据已经证明这个是很明显的诬告,但只是因为被告汤姆是一个黑人而被判罚有罪,并面临着死刑。这个庭审在书中的描写特别精彩,算是书中的一个高潮部分。最终在庭审结束时,汤姆输掉了官司,阿迪克斯在明知汤姆无辜而瘫坐下来。之后成年人中间充斥了关于黑鬼的诅咒,认为汤姆罪有应得。只有孩子在为无辜的汤姆流泪。就像书中说的“杀死一只知更鸟就是一桩罪恶。知更鸟只唱歌给我们听,什么坏事也不做。它们不吃人们园子里的花果蔬菜,不再玉米仓里做窝,它们只是衷心地为我们唱歌。”因为不满阿迪克斯在法庭上揭露真相,尤厄尔选择在深夜袭击阿迪克斯的孩子但是最终死在自己的刀下,具体是如何被自己的刀杀死的,书中并没有给出。但是在黑夜中经历了搏斗,怪人拉德利也及时的出现保护了受伤的孩子。书中“我”——斯库特对着在墙角的拉德利微笑着说“你好,阿瑟”。我不知道作者想表达一种怎么的心情。但是我读到这里有一种多年老友重逢的感觉,特别奇妙,有一种感动,有一种喜悦,有一丝温暖。有一种心里的漏洞被填补的,暖心的感觉。我的孩子今年两岁了,我想以书中阿迪克斯为榜样,让我的孩子生活在充满父母关爱与包容的环境中。在未来我想跟我的孩子一起重读一下这本书。《怪诞行为学》这本书书名取的不太准确,乍一看以为是讲某些怪异行为的心理学书籍,但是实际上是讲行为经济学。传统经济学假设每个人在进行决策时会理性的考虑成本与收益的问题,但是实际上人都是非理性的,做决策时并没有考虑那么多,而是自己一时兴起冲动决定的。因此行为经济学诞生了,行为经济学利用心理学的相关知识和实验方法来研究人们日常生活中做决策时受到哪些因素的影响并以此来预测人的行为。本书是关于行为经济学的一本书。全书总共有4本,其中最有价值的应该是第一本,第一本列举了在实践中影响人们做决策的一些因素,后3本都是对前一本的补充。喜欢攀比,有时候我们并不知道自己需要哪个,但是我们可以知道哪个更好。有几种选择的时候,我们会选择相对比较好的,而忽略自己原本真正需要的。例如书中举了一个约会的例子,带上各方面都不如你的朋友,约会成功的可能性会大大提高,因为女生也不太清楚自己心中的白马王子具体是什么样子的,但是通过对比你与朋友,那么她可能会得出你是她心中向往的那个对象。书中还有一个例子,当我们买450美金的西服时,如果发现15分钟路程外的的一件服装店只卖435,能节省15美金。另一种情况下,我们要买一支钢笔25美金,但是另外一家店距离此处15分钟同样的钢笔只卖10美金。我们会如何选择,大部分人在面对西服时会选择购买450美金的。而在面对钢笔这种情况时会选择花15分钟节省这15美金。同样是花15分钟节省15美金,但是我们的选择却不同,因为通过比较前面一种请款是在450美金的情况下省15美金,而另外一种情况则是从25美金中省下15美金。所以商家一般会玩一个套路,就是降价不那么明显的会以折扣的形式给出。例如原来卖4块的东西现在卖2块,商家会标注降价50%,这样看起来就很诱人。人类行为的一个重要定律,就是要让人们渴望做一件事,只需使这件事的机会难以获得即可。例如所谓的饥饿营销,明明供货充足甚至面临仓库压仓的危险,商家仍然限购,甚至设计的一个等待的系统,只要让人知道想买到这个产品花一番功夫,自然就会勾起人们购物的狂热。有时候买房也是,房产中介会故意设置一些障碍,比如告诉你有很多人在等机会摇号。再比如北京的车牌摇号,有些人可能现在买不起车或者没有买车的计划,但是因为拿到车牌很困难。这算是人为的制造一些额外的需求免费的代价,人人都喜欢免费的东西,例如书中举例,15美元的电子版杂志,20美元的纸质版杂志,20美元的纸质版+电子版杂志。部分原本打算买电子版的,而且只需要电子版的即可,但是看到第三个套餐会觉得,20美元是白送了电子版的套餐,结果就选了第三个套餐,完全没有意识到自己只需要电子版的就够了。对应国内的例子就是各个购物网站会会推出免运费的套餐,例如购物满68免运费,本来就想买一个东西,但是一想到再买点别的就能免运费,可能就会多花钱买一些自己并不需要的东西。再或者连锁餐厅推出的充值100这顿饭免单或者充100送一百。后续不一定会再来,但是面对一顿免费的午餐我们有时候会抵抗不了这种诱惑。社会规范的成本:我们会免费的干一些志愿者活动,但是对同等工作量的工作有时候却嫌弃报酬少。我们的大脑中会有一个社会规范和市场规范,进入市场规范时会考虑成本与收益。但是在社会规范下会愿意不计成本的付出,例如去串亲戚时随便带点礼品的效果可能会比直接给钱要好,给礼品会让对方进入社会规范的考量,因为亲戚会原因给你提供丰盛的晚餐。直接给钱对方会进入市场规范,会计算晚餐的付出与得到的回报。另外公司一直想让员工为公司考虑,希望员工将公司当成自己的家,为自己的家全心全意的服务。如果在工资之外给钱的效果不如给一些小礼品或者给钱意外的关怀。提供各类福利,营造亲善的氛围。性兴奋的影响:在情绪亢奋下做出的决策与在平静心态下做出的决策不同,就像我们经常说的头脑发热一样。但是我们并没有意识到这一点。例如在面对性诱惑时,我们觉得自己会抵御住这种诱惑,但是实际上在处于这种诱惑状态下我们根本把持不住。最好的做法就是不让诱惑到来,当你意识到自己即将处于这种亢奋状态时,停止继续。对应国内的一些例子我觉得就是一些促销活动常常选择在深夜,在深夜的时候人们容易犯困,精神比较迷糊容易做出不理智的行为。拖沓的恶习与自我控制:我们经常信誓旦旦的做一些决定,例如早睡早起,减肥等,并且低估它们的难度,总是等最后时期再开始行动。最好的办法就是承认自己拖沓的习惯,不要总是把事情等到最后再做,而是指定严格的计划并提前按照计划进行。例如我们习惯将工作放到最后,总觉得时间来得及,后面做也没问题。但实际上最后再做效果并不好,应该按计划一点点的将工作往前推进所有权的个性:我们会依恋现在所拥有的一切。会过高的估计自己的房子,车子,甚至身边的亲人,例如总觉得自己的孩子比别人的可爱,聪明。我们总是把注意力集中到自己会失去什么,而不是会得到什么。我们对于损失有一种强烈的恐惧。这就是心理学中的“厌恶损失”原理。心理学上说我们损失造成的痛苦需要得到双倍才能挽回。商家对应的套路就是免费适用,或者首充优惠,让我们以极少的代价得到之后,因为我们在使用过程中已经产生依赖,觉得这是自己的东西,一旦到期或者需要返还时就会产生痛苦最终决定花大价钱给它“赎回”多种选择的困境,我们总希望选择越多越好。有时候维持这种选择要花费很大的代价。现代社会里,困扰人们的不是缺乏机会,而是机会太多,令人眼花缭乱。而我们可能往往认识不到,在面临机会选择的时候,妄图保留余地会让我们活得很累,而且最终的收获也不如坚持到底来的多。就像有些渣男渣女,背地里谈了好几个对象,明明知道该如何取舍,但是就是舍不得,想要都留着。最终一个都留不下来。老话讲当断不断,必受其乱。有时候应该果断放弃那些已经不是机会的机会。预期的效应:如果我们事先相信某种东西好,那么事后在实际使用时及时它没有那么好,我们也会提高对它的评价。预期改变品味。比如现在的小红书或者抖音流行什么精致女孩或者精致男孩。告诉你他们用了这个产品就变得精致,但是产品实际并没有多么出色,我们在实际使用中也有一种它使我们变得精致的错觉。但是这种错觉也有积极的用途,那就是善意的谎言,在面对一些病人时,如果告诉它某种药治好了同样的病症,那么在服药期间,安慰剂也将变得有效期来。价格的魔力,有些时候我们喜欢免费的东西,但是某些时候价格高反而会引起购买的欲望。 例如那些本来平平的商品经过华丽的包装卖高价,人们依然趋之若鹜。实际上去除包装它并不值这个价钱。人性的弱点:为什么我们不诚实?实验表明在某些情况下我们会选择作弊来提高收益,但是作弊的程度不取决于获得的收益也不取决于作弊的难易程度。简单来说就是人们不会因为给的报酬多而选择多作弊,他们会在某种程度上停下里,只靠作弊获取微薄的额外利益。另外我们也不会因为作弊比较简单而选择大量作弊,我们不会在不诚信的路上越走越远,大多数都只会浅尝辄止。另外我们在涉及金钱方面会额外谨慎,例如寝室的同学会顺走辣条但是不会顺走放在桌上的1块钱。尽管从经济上看顺走一包辣条比顺走1块钱要严重。想减少这种作弊或者不诚实的现象,就是将行为与金钱明显挂钩,书中举了一个例子,针对医院科室的笔总是丢失的情况下,可以考虑在笔上粘贴1块钱的纸币。啤酒与免费午餐:羊群效应,羊群会跟着领头羊走,我们的一些行为会受到其他人的影响,也就是从众心理。书中给出了点菜的例子,当所有人都向服务员大声说出自己想点的菜时,因为受到他人的影响,导致后面点菜的人要么想要避开前人的选择或者想要跟前面的人一样,最终得不到自己真实想吃的菜。而另一组采用的是将想点的菜写在纸条上的方式,结果就是这一组都对菜品有比较高的评价,认为他们都得到了自己想要的。商家对应的套路就是网红餐厅雇人排队,网红景区打卡,他们并没有那么值得去但是因为大家都去了,所以我也要去。想要知道网红餐厅是否值得去的标准就是等待一段时间,例如半年或者一年。如果餐厅照样人头攒动,人流不减的化,可能就真的值得一去。这本书分析一些影响人们决策的非理性因素。了解了这些因素之后我们对商家的一些套路有了理性的认识,但是是否在日后做决策时会自动避开这些呢,我自己的答案是未必,可能未来我会在又买了一堆垃圾之后抱着书直呼“又上当了!”
-
PDF标准详解(二)——PDF 对象 上一篇文章我们介绍了一个PDF文档应该包含的最基本的结构,并且手写了一个最简单的 “Hello World” 的PDF文档。后面我们介绍新的PDF标准给出示例时将以这个文档为基础,而不再给出完整的文档示例,小伙伴想自己测试可以根据上一节的文档来进行配置。对象上一节我们看到一个个奇奇怪怪的元素,可能也好奇它们的写法,现在我们来正式介绍它们的相关内容,它们就是PDF文档中一个个的对象。PDF 支持5种基本对象:整数和实数:例如43和12.2 这种数字字符串,PDF种字符串被包裹在小括号中,例如上一节中的 (hello world), 我们也可以给字符串制定编码,这个在后面介绍名称:一般用于字典中的键,以/ 开头,例如上一节中的 /Page 就是一个名称的对象布尔值: 由关键字 true 和 false表示null 对象,由关键字 null 表示PDF支持3种复合对象数组: 包含其他对象的有序集合,数组中的元素可以是其他任何类型的对象,例如可以像 [0 0 0 0 1] 这样只包含数字,也可以像上一节中的 [2 0 R] 包含其他对象的一个引用字典: 字典是由无序对的集合组成,将名称映射到对象。字典中的映射被包含在 <<>> 对中,例如 <</Kids [2 0 R]>> 就是一个字典,它将Kids这个名称映射到 [2 0 R] 这个间接引用的对象上流:流中一般包含二进制的数据流以及描述属性的字典,一般page中的content都是一个个的流对象。间接引用间接引用形成从一个对象到另一个对象的链接,为了将PDF拆分成一个个单独的对象,我们通过间接引用将它们链接在一起,例如上一篇文章中提到的1 0 obj << /Kids [2 0 R] /Count 1 /Type /Pages >>对象中就包含间接引用,PDF解析器,知道这个对象是一个Pages对象之后,可以通过Kids 对象指定的间接引用对象知道,当前PDF文档只有一页,这个页面对象就是2 0 这个对象。 这里的R 代表 reference 也就是引用,它是一个关键字,前面的 2 0 代表的是对象编号是2,世代号是0(这里我们不考虑世代号,默认的世代号都是0)流和过滤器流用于存储二进制数据,它们由字典和一大块二进制数据组成,字典根据流所放置的特定用途,列出数据的长度,以及可选的其他参数。从语法上将,流由字典组成,后跟 stream 关键字,换行符,0个或者多个字节的数据,另一个换行符,最后是一个endstream 关键字。根据上一篇文章中给出的页面流对象的定义来看4 0 obj << /Length 202 % 流的长度 >> stream %关键字 1. 0. 0. 1. 50. 700. cm % 202 字节的数据,这里是图形流,下面是图形流的数据 BT /F0 36. Tf (Hello, World!) Tj ET endstream % 流对象结束的关键字 endobj