搜索到
348
篇与
的结果
-
 读《贪婪的多巴胺》 为什么我们会对一些事物上瘾?为什么戒除这些上瘾的东西并像想象中那么容易?这本书可能能给一些答案书中主要讲述多巴胺的作用,或者说多巴胺是如何与其他激素共同调节我们的行为。书中的核心其实就是一句话:我们的身体受到“向上”和“向下”两类物质的控制。“向下”指的是控制当下的神经递质,它们决定我们当前的感受;“向上”则是指多巴胺,决定了我们的长远规划、愿景、未来期望。简单来说多巴胺控制我们期待美好的未来,而当下因子例如血清素、酮睾素让我们感受当下的美好,享受当下的一切。书中剩余的内容其实都在围绕这这个主题进行展开。为什么有些人对感情不专一容易出轨,而有些人比较专情。因为多巴胺是未来激素,会促使我们寻求未来那种不确定的惊喜。感情刚开始处于新鲜期时多巴胺分泌,让我们沉浸在对美好未来的憧憬中;而一旦感情进入未定期,多巴胺减少分泌,而大脑对于多巴胺的渴望会促使人们进入下一段感情。为什么戒毒那么难,甚至可以说不可能完全戒断。因为我们追求美好事物时大脑产生的多巴胺相比起毒品刺激产生的多巴胺来说简直少的可怜。另外我们日常中的心理和行为控制主要依靠多巴胺和当下分子联合作用,但是毒品会摧毁大脑中分泌当下分子的区域。吸毒者无法体会当下的美好,普通人可以享受到的陪伴、亲情、温柔的阳光等在吸毒者面前毫无作用。他们变成了一个只追求大量多巴胺的怪物。吸毒者从大脑结构和心理上与正常人相差太大,我们无法用正常人的思维去理解他们。为什么说天才与疯子仅在一线之间,之前还有一本书《天才在左,疯子在右》。多巴胺给予我们创造的力量。它让我们想象不真实的事物,把看似不相关的事物联系起来。。但是前面说过,人类的行为和心理是多巴胺和当下分子共同控制,一旦多巴胺过多,影响当下分子的产生,就会产生各种心理疾病。具体的病理书中没有细说,我也不太了解,但是我知道了精神病和心理疾病并不是我之前想象的是需求得不到满足,只要给予一些爱或者陪伴和理解就能很好的治愈。现在看来这类病症主要是大脑激素分泌出了问题,必要的时候需要使用药物进行治疗。在当今的消费主义社会当中,整个社会似乎都为我们分泌多巴胺服务。一般商家会通过铺天盖地的广告让我们对某件商品疯狂,我们期待拆开商品时那种分泌多巴胺的快乐,但是一旦我们完成了这个操作,多巴胺分泌开始减少,我们又想去购买新的商品,一直循环往复,最终商品买了一堆但是真正能长期使用的少之又少。游戏从某种程度上来说也是这样。一般游戏会构造一个虚拟的但是充满未知的世界。这个未知世界会引导我们去探索,在探索的过程中会分泌多巴胺,而当多巴胺减少时,大脑对于多巴胺的渴望又会引导我们继续在游戏世界探索。现在的游戏还出现了类似赌博原理的抽奖机制。杀怪有几率掉落极品装备,抽奖有可能会抽到稀有角色和装备。一旦我们开出来自己想要的游戏装备或者角色大脑会因为欲望得到满足而分泌多巴胺,但是随着时间的推移,我们需要新的多巴胺刺激,此时对于多巴胺的渴望会诱导我们不断的进行抽奖。短视频目前来说也是类似的,相对于传统的视频网站那样将所有你感兴趣的列在首页由你自己来选则想要观看的视频来说短视频那种全屏滑动的操作模式更具有成瘾性。我们无法提前知晓下一个短视频内容是什么,但是对于不确定未来的探索欲望会驱使我们疯狂的上划以观看下一个视频寻求新的刺激。相对长视频的时长来说,短视频可能刚刚好在我们对视频失去兴趣时结束这样新的一轮刺激马上到来,引导我们沉迷其中。一回过神发现一天时间已经过去了。上面列举了几样让人上瘾的东西,是不是一样也不碰呢?我觉得任何时期都要追求动态的平衡。多了不好,少了也不好。多巴胺虽然会造成成瘾,但是正常人无法做到离开多巴胺,就像上面介绍的,我们是靠着未来因子和当下因子的动态平衡而成为一个正常人。一个人不管是过度关注未来,还是过度享受现在,都会丧失正常的行动力。对于沉迷于多巴胺的人,如何戒除对多巴胺的依赖,书中给出了一些小的建议:可以培养一些当下的爱好,例如手工、乐器、烹饪、绘画等需要动手的活动一次只专心一个任务,不要手上做着活心里想着另一件事在家人和朋友的陪伴下完成一件事物,书中给出的例子是和父母一起完成木工、绘画等工作
读《贪婪的多巴胺》 为什么我们会对一些事物上瘾?为什么戒除这些上瘾的东西并像想象中那么容易?这本书可能能给一些答案书中主要讲述多巴胺的作用,或者说多巴胺是如何与其他激素共同调节我们的行为。书中的核心其实就是一句话:我们的身体受到“向上”和“向下”两类物质的控制。“向下”指的是控制当下的神经递质,它们决定我们当前的感受;“向上”则是指多巴胺,决定了我们的长远规划、愿景、未来期望。简单来说多巴胺控制我们期待美好的未来,而当下因子例如血清素、酮睾素让我们感受当下的美好,享受当下的一切。书中剩余的内容其实都在围绕这这个主题进行展开。为什么有些人对感情不专一容易出轨,而有些人比较专情。因为多巴胺是未来激素,会促使我们寻求未来那种不确定的惊喜。感情刚开始处于新鲜期时多巴胺分泌,让我们沉浸在对美好未来的憧憬中;而一旦感情进入未定期,多巴胺减少分泌,而大脑对于多巴胺的渴望会促使人们进入下一段感情。为什么戒毒那么难,甚至可以说不可能完全戒断。因为我们追求美好事物时大脑产生的多巴胺相比起毒品刺激产生的多巴胺来说简直少的可怜。另外我们日常中的心理和行为控制主要依靠多巴胺和当下分子联合作用,但是毒品会摧毁大脑中分泌当下分子的区域。吸毒者无法体会当下的美好,普通人可以享受到的陪伴、亲情、温柔的阳光等在吸毒者面前毫无作用。他们变成了一个只追求大量多巴胺的怪物。吸毒者从大脑结构和心理上与正常人相差太大,我们无法用正常人的思维去理解他们。为什么说天才与疯子仅在一线之间,之前还有一本书《天才在左,疯子在右》。多巴胺给予我们创造的力量。它让我们想象不真实的事物,把看似不相关的事物联系起来。。但是前面说过,人类的行为和心理是多巴胺和当下分子共同控制,一旦多巴胺过多,影响当下分子的产生,就会产生各种心理疾病。具体的病理书中没有细说,我也不太了解,但是我知道了精神病和心理疾病并不是我之前想象的是需求得不到满足,只要给予一些爱或者陪伴和理解就能很好的治愈。现在看来这类病症主要是大脑激素分泌出了问题,必要的时候需要使用药物进行治疗。在当今的消费主义社会当中,整个社会似乎都为我们分泌多巴胺服务。一般商家会通过铺天盖地的广告让我们对某件商品疯狂,我们期待拆开商品时那种分泌多巴胺的快乐,但是一旦我们完成了这个操作,多巴胺分泌开始减少,我们又想去购买新的商品,一直循环往复,最终商品买了一堆但是真正能长期使用的少之又少。游戏从某种程度上来说也是这样。一般游戏会构造一个虚拟的但是充满未知的世界。这个未知世界会引导我们去探索,在探索的过程中会分泌多巴胺,而当多巴胺减少时,大脑对于多巴胺的渴望又会引导我们继续在游戏世界探索。现在的游戏还出现了类似赌博原理的抽奖机制。杀怪有几率掉落极品装备,抽奖有可能会抽到稀有角色和装备。一旦我们开出来自己想要的游戏装备或者角色大脑会因为欲望得到满足而分泌多巴胺,但是随着时间的推移,我们需要新的多巴胺刺激,此时对于多巴胺的渴望会诱导我们不断的进行抽奖。短视频目前来说也是类似的,相对于传统的视频网站那样将所有你感兴趣的列在首页由你自己来选则想要观看的视频来说短视频那种全屏滑动的操作模式更具有成瘾性。我们无法提前知晓下一个短视频内容是什么,但是对于不确定未来的探索欲望会驱使我们疯狂的上划以观看下一个视频寻求新的刺激。相对长视频的时长来说,短视频可能刚刚好在我们对视频失去兴趣时结束这样新的一轮刺激马上到来,引导我们沉迷其中。一回过神发现一天时间已经过去了。上面列举了几样让人上瘾的东西,是不是一样也不碰呢?我觉得任何时期都要追求动态的平衡。多了不好,少了也不好。多巴胺虽然会造成成瘾,但是正常人无法做到离开多巴胺,就像上面介绍的,我们是靠着未来因子和当下因子的动态平衡而成为一个正常人。一个人不管是过度关注未来,还是过度享受现在,都会丧失正常的行动力。对于沉迷于多巴胺的人,如何戒除对多巴胺的依赖,书中给出了一些小的建议:可以培养一些当下的爱好,例如手工、乐器、烹饪、绘画等需要动手的活动一次只专心一个任务,不要手上做着活心里想着另一件事在家人和朋友的陪伴下完成一件事物,书中给出的例子是和父母一起完成木工、绘画等工作 -
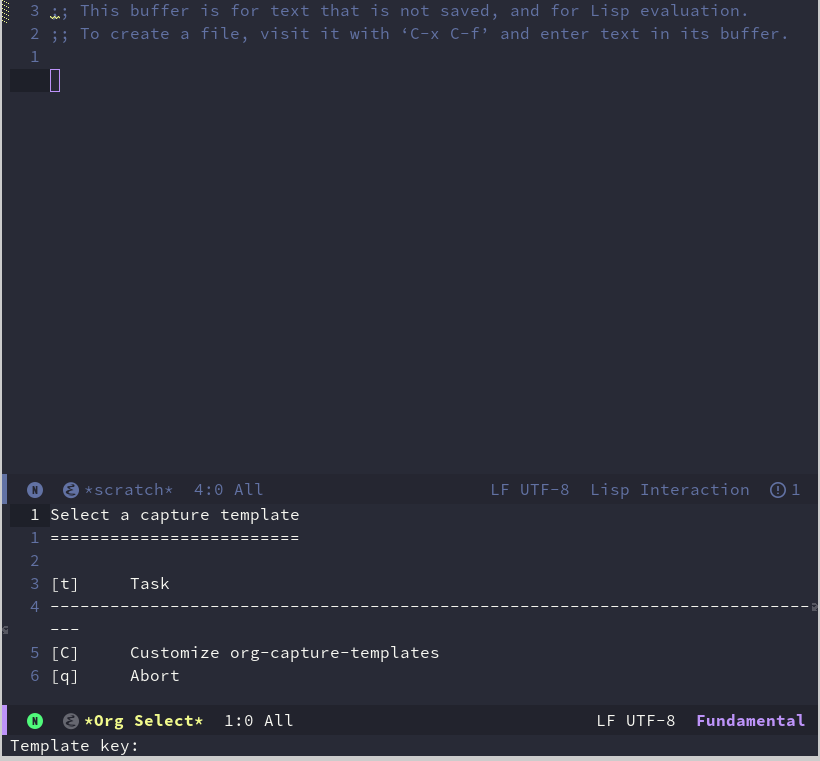
Emacs折腾日记(三十三)——org capture 在日常的工作生活中有各种各样的琐事,如果不及时记录下来很可能后面就忘了。或者在日常软件开发中有很多想法想要实现但是时间一长自己就忘了。这种情况下我们需要一个系统来记录收集想法并且后续需要追踪甚至回顾。我们需要一套适合的管理系统让大脑摆脱待办事项的纠缠,让大脑专注于当前要做的事物。目前我采取的方式是GTD+ 番茄工作法。GTD 简介GTD(Getting Things Done),是由戴维·艾伦于2002年提出的时间管理方法。其核心在于通过收集、整理、组织、回顾、执行五个步骤,将任务从大脑中移出,减轻心理压力以提升效率,强调两分钟内可完成事项立即处理的原则。用我的理解,我们需要事先准备几个速记的笔记本,一旦脑海中出现了想法就将它记录下来,这步叫做收集。在一天中的空闲时间例如下班前或者睡觉前打开看看之前记录的内容,将内容按照一定的规则重新组织例如分为工作、生活、学习之类的想法,将它们转化成可以执行的任务。并且为每个事项定一个紧急程度,这个就是整理、组织。在每天开始的时候或者结束的时候可以根据上面的分类安排一下当前或者明天的任务,这个是执行任务。在每周或者每天的时候回忆一下当前的任务看看哪些完成了、哪些未完成、从任务中有何感想,有哪些可以记录下来作为重要的日志或者日后博客的灵感来源,这个就是最后的回顾总结过程。番茄工作法再完美的系统,如果不执行或者不认真执行也是白搭的。对我来说GTD主要解决的是要做哪些事,如何安排时间的问题。至于如何高效的执行任务专注到任务上,我采用的番茄工作法。番茄工作法的简单理解就是将任务的时间拆分成几个不可分割的最小单元,在这个时间片单元内一心一意、专心到任务上。一旦分心就需要终止当前番茄钟,并记录分心的原因,如果是有新来的新任务就需要采用记录的方式记录,如果是紧急且重要的任务可能还要修改当前的任务计划。当然番茄工作法有一整套的收集、整理、执行、归纳总结的流程,但是对我来说我喜欢GTD的流程和番茄工作法的时间管理方式,所以我采用的是它们二者的结合。但是主要用在工作中,日常生活中的场景都是一些简单的琐事,例如收拾卫生、做饭、对我来说不合适这种形式。org capture目前来说市面上没有完全符合我心目中最佳时间管理理论的工具,但是Emacs中的org 是十分强大的,完全可以稍加改造成符合自己心意的时间管理系统。首先要解决的就是如何收集想法的问题。这个功能可以使用 org-capture,顾名思义它就是使用org的格式来快速记录当前的想法。我们使用 org-capture 命令可以看到下面的界面下方提示我们可以使用前面的字母符号来选择一个模板,默认只提供了一个名为 Task 的模板。我们可以使用 org-capture 中 来实现GTD中的分类记录的功能。在我们选定需要使用的模板之后,Emacs会调用 org-capture-select-template 函数来选中模板并且根据模板来创建默认的org 模板。默认的Task 模板如下:("t" "Task" entry (file+headline "" "Tasks") "* TODO %?\n %u\n %a")它们的含义如下t 标识选择模板时的快捷键。Task 模板的描述,让用户了解当前模板作用的说明文字。后面一个部分就是新增的内容新增的内容比较复杂,我们一个个的说。第一个部分是新增模板的type。type 可以是下面的内容type描述entry带有 headline 的一个 Org mode 节点item一个列表项checkitem一个 checkbox 列表项table-line一个表格行plain普通文本type 的不同,后面跟的内容也不一样。例如如果当前是 entry 的话,后面需要添加 "* headline" 作为标题行的形式,如果是 item 后面需要跟上 - item 作为一个项。如果是 checkitem 需要跟 [ ] item 作为一个checkbox项。如果使用 table-line,需要跟 | colum 1 | colum 2 | colum3 | 作为一个表格项目。如果是 plain 则没有特殊要求。接下来看看 (file+headline "" "Tasks") 中各个部分的含义,前面的 file+headline 表示将记录的内容保存到哪个位置。除了这两个标识还有其他的一些常用标识标识含义file文件id某个特定id的headlinefile+headline某个文件中的某个headlinefile+olp文件中某个headline的路径file+regexp文件以及被正则匹配的headlinefile+datetree文件中当日所在的datetreefile+datetree+prompt文件中的datetree 会弹出日期选择file+weektree文件中当日所属的 weektreefile+weektree+prompt文件中 weektree 会弹出日期选择file+function文件中被函数匹配的headlineclock当前正在计时中的任务所在位置function自定义函数的所定义的位置后面两个参数根据前面的内容来决定,例如如果使用 file+headline 的话,第二个参数就是文件路径,第三个参数就是具体的 headline 的名称。如果文件名参数为空的话,那么会使用 org-default-notes-file 所对应的文件路径为 ~/.notes 这些内容如果觉得有些比较难以理解的,可以查看 org-capture-tempetes 变量的详细说明"* TODO %?\n %u\n %a" 部分都是一些格式字符串和占位符,在选中模板之后会自动生成我们想要的模板文字。这里的占位符如果写过代码应该很容易理解,首先占位符都是 以%开头,后面根据不同的字符表示不同的含义时间相关的占位符占位符含义%<>表示自定义时间的时间戳,两个<>之间可以使用字符表示不同的时间格式,例如 %<%Y-%m-%d> 表示年月日的格式,年是4位字符的形式%t当前仅包含日期的时间戳%T当前包含日期时间的时间戳%u包含当前未激活的时间戳%U表示当前未激活的包含日期时间的时间戳%^t类似于 %t,但是会弹出日历供用户选择%^T类似于%T,但是会弹出日期和时间供用户选择%^u与上面的类似%^U与上面类似这里所谓的激活,在Emacs的文档中使用的词是 interactive 我不知道翻译为激活是否准确。未激活的时间戳日后不会出现在 org-agenda 中,至于什么是 org-agenda 请继续往下看剪切板相关的占位符占位符含义%c当前 kill ring 中的第一条内容%x当前系统剪贴板中的内容%^C交互式地选择 kill ring 或剪贴板中的内容%^L类似 %^C,但是将选中的内容作为链接插入后面还有更多更复杂的占位符,但是目前来说我用不到那么多,也就不一一列举了,各位读者如果感兴趣可以查看 org-capture-templetes 来查阅更多类型的占位符,至于 %?它什么也不往文件里面添加,它会在模板文本添加成功后将光标移动到它所在位置,方便用于自己输入内容除此以外,它还支持自定义函数的形式来插入内容,它的形式为 %(sexp) 括号中间就是lisp函数,假设我们有一个 custom-placeholder 那么这里就可以写成 %(custom-placeholder) 有了这些内容我们就可以定义自己的各种任务的模板个人日常任务模板对我个人来说,日常任务主要有:阅读清单、博客计划、工作任务。下面我希望通过这三大类任务来定制一些模板阅读清单首先是阅读清单,阅读清单主要记录一些我通过各种渠道了解到的并计划在后续需要读的书。根据我之前读的《如何有效阅读一本书:超实用笔记读书法》 的说法,记录要读的书,可以记录下面几个内容:书名作者出版社其他(可以是ISBN号)如果只根据书名可能会有书名重复的现象,所以根据这几条信息就可以唯一确认一本书因为Emacs提供的默认模板我不太喜欢,所以这里我先使用 (setq org-capture-templates nil) 来清空模板,后续由我自己实现各种模板(use-package org-capture :ensure nil :custom (org-capture-templates nil) (org-capture-templates '(("r" "Reading List" entry (file+olp "~/org/reading.org" "Reading" "Book") "*** TODO 《%^{书名}》\n作者:%^{作者}\n出版社:%^{出版社}:\n备注:%^{备注}\n添加时间:%U\n" :clock-int t :clock-resume t))))我们按照之前分析的模板中各个部分的组成来看看它是什么意思。首先第一个部分,我们定义通过快捷键 r 来选中并生成这个模板,Reading List 表示在模板展示时显示的内容。后面的entry 表示我需要添加一个带有 headline 的 org mode 节点,它后面跟着的子列表里面使用 file+olp 表示我需要在文件中的某个headline 下添加这条记录作为它的子内容部分。后面跟的就是文件路径、以及需要插入到当前文件下Reading 里面的 Book 下,作为子节点。最后定义的就是具体的内容了, 因为Reading 作为一级标题,它下面的 Book 作为二级标题,所以这里添加的阅读清单记录就是三级标题,所以我在它前面加了一个 *** 作为三级标题。前面的TODO是关键词,表示待做。后面就是输入的常规的内容了,包括出版社、作者等信息。它的运行效果如下:新建博客文章org-mode实际上是支持转换成markdown并通过hugo之类的静态网站生成程序来生成博客的。对于hugo 来说如果希望将markdown格式的内容转化成博客,我们需要在markdown文件头位置加入这些内容title: "Test" date: categories: blog tags: blog draft: true根据这些信息我们可以很容易的搭建基础的模板。针对这种场景,我希望它能在固定的位置生成一个以时间命名的 .md文档,这个位置一般位于hugo安装目录下的 posts 目录下。我们可以写下这样的配置 (add-to-list 'org-capture-templates `("b" "Blog" plain (file ,(concat "~/org/" (format-time-string "%Y-%m-%d.md"))) ,(concat "---\n" "tile: %^{标题}\n" "date: %U\n" "categories: %^{分类}\n" "tags: %^{标签}\n" "draft: %^{草稿|true|false}\n" "---\n" "%?")))它的效果如下:最终在我们保存之后它会在~/org 目录下生成一个以时间命名的markdown文件这种模式我个人不太喜欢,因为对我而言org-capture 仅仅只是一个收集的动作,我们应该快速记录想要写的博客以及博客的主要论点,而不应该开始编写具体的内容。至于如何使用org-mode来写博客,后面我想单独写一篇博客来介绍创建工作计划作为一个程序员来说,日常工作总会与程序打交道,比如开发新功能、写接口文档、修改bug、搭建开发测试环境、开会等等。有时候需要一个人负责多个多个项目。对于工作任务我们还需要分一个轻重缓急,我一般习惯于将它们分为:重要且紧急、重要但不紧急、紧急但不重要、不重要不紧急。那么对于工作任务的需求就很明确了。首先任务可以归属到不同的项目中,日后可以根据任务进行筛选任务可以细分为开发新功能、修复bug、搭建环境、写文档、开会等等任务可以划分轻重缓急日后通过todolist可以看到任务的轻重缓急,目前使用重要且紧急、重要但不紧急、不重要但紧急、不紧急不重要我们采用下面的代码 (add-to-list 'org-capture-templates `("w" "Work Task" entry (file+headline "~/org/working.org" "Work") "* TODO %^{任务描述} :%^{任务类型|dev|bugfix|env|doc|meeting}:\n SCHEDULED: %^t\n PRIORITY: %^{优先级|A|B|C|D}\n %?\n %i")))它的效果如下:到目前为止,介绍了关于org capture的相关内容,并演示了如何利用capture 实现一个任务的捕捉功能。gtd 后面的流程还有任务的分配、执行、记录等等功能,这些内容将在后面介绍。感谢各位读者的支持
-
读《在细雨中呼唤》 在我映像中余华一直是写悲剧,写苦难人生的一个作家。他总是用他的笔将社会中最残酷的现象摆在你面前,让他的读者为书中的人物流泪。一般来说我看余华的书要好久才能缓过来,然后隔好长一段时间才有勇气看他的下一本。关于这本书我想谈谈他的写作手法,我文学素养不高,看的文学作品也不多。这本书的写作手法有点让我耳目一新的感觉,书中的故事不断的在各种人物和各种时间线来回穿插,书中的“我”像一个见证者,见证者各种人物的各种经历。我觉得它是一本属于普通底层人的纪传体史书。“我”是一个亲历各种事件的史官。其他的事件我也不太好说,令我映像最深的是关于父亲、苏宇和爷爷。父亲早些年是传统的农名形象,他是家庭的顶梁柱,说一不二。日夜在田间劳作,撑起一个家。在小儿子死后似乎有点自甘堕落,夜爬寡妇床,为了寡妇将家中本就不多的家具往寡妇家搬。在大儿子成年需要娶妻之后甚至调戏未来儿媳妇惹得儿子找他拼命。最后他是一个彻头彻尾的人渣。苏宇我书中“我”的好朋友,一起在中学上学。苏宇的家庭算是一个知识分子,父亲是医生,但是被寡妇勾引被迫离开了村子。苏宇的家庭因为溺爱小儿子苏杭,他在家中一直是个保姆的形象,不光要伺候父母,也需要照顾弟弟。这么一个家庭中的透明人与“我”最终成了朋友,我们二人都是自卑敏感性的人,二人从最开始认识到最后成为朋友没有什么戏剧性的情节就好像上天要他们成为朋友那样,自然的走在一起。在苏宇的故事中,“我”到了青春期性萌芽的时候,“我”会在深夜幻想着班上最漂亮的女士完成自慰行为。书中将一个少年被性所困扰,但是又在事后自责甚至认为自己是一个丑陋恶心的人,为此“我”认为自己不配与苏宇做朋友,一度尝试远离苏宇。直到最后苏宇说“我也这样做”才打开了“我的”心结。最后苏宇的结局令我感到惋惜,甚至有点恨他的家人,苏宇在需要早起的时候突发脑溢血,本来是有机会送到医院抢救的,但是他的家人从来没有关心过他,在他病重无法起床时也只当他犯懒病,而自顾自的离开。苏宇在发病的时候本来依靠的求生的本能尝试发出求救,挣扎着想要起来,而这种挣扎在家人自顾自从他房间离开并且关上家门之后彻底熄灭了。书中的爷爷早些年也是一个硬汉形象,他娶了奶奶,并且一辈子关爱呵护奶奶,虽然奶奶一直心系前夫,从来没有爱过他。晚年的爷爷因为干活时不慎摔伤了腰,成为了家里的负担。他有两个儿子,但是两个儿子都嫌弃他,虽然两个儿子约定每人养他一个月,但是没有人主动去接,靠着爷爷自己的双脚,穿梭在两个儿子家中间。而父亲一直认为爷爷是一个累赘,盼望着他早死,甚至故意将饭桌抬高不给爷爷吃菜。我想这是底层人民的无奈,谁又愿意自己的亲生父亲早死呢,主要还是生产力不发达,种出来的粮食就那么多,多一个人吃饭就意味着大家都吃不饱。就像父亲自己认为的“又多了一个吃饭的”。爷爷的高光是在某一年即将去世的时候,他可能也意识到自己大限将至。村里已经持续几天下起了大雨,再这么下今年地里可能就要颗粒无收了。此时的爷爷挨家挨户劝说村民将家中供奉的菩萨拿出来扔掉,认为菩萨一点用都没有。甚至在雨中对着老天大骂,说出了本书中十分出名的句子“老天爷,你下屌吧,操死我吧。”。我觉得这是底层人对于老天的不公,以及自己命运坎坷无声的控诉。下面是我摘录的书中的一些好的句子:我不再装模作样地拥有很多朋友,而是回到了孤单之中,以真正的我开始了独自的生活。有时我也会因为寂寞而难以忍受空虚的折磨,但我宁愿以这样的方式来维护自己的自尊,也不愿以耻辱为代价去换取那种表面的朋友她只是沉浸在我当时年龄还无法理解的自我与孤独之中,她站在生与死的界线上,同时被两者抛弃。于是我找到了生与死之间的不同,活着的人是无法看清太阳的,只有临死之人的眼睛才能穿越光芒看清太阳。总之当我们凶狠地对待这个世界时,这个世界突然变得温文尔雅了。再也没有比孤独的无依无靠的呼喊声更让人战栗了,在雨中空旷的黑夜里。当我虚构的人物越来越真实时,我忍不住会去怀疑自己真正的现实是否正在被虚构。我开始喜欢行走,这是苏宇遗留给我的爱好。行走时思维的不断延伸,总能使我轻而易举地抵达过去,和昔日的苏宇相视而笑。阳光是很想照到这里来的,是山把它半路上劫走了。
-
读《饥饿的盛世》 乾隆朝是中国古代封建王朝的又一个顶峰,在乾隆朝,GDP达到世界的三分之一,比今天美国占世界GDP的比重都要高。人口达到封建王朝的历史之最。封建集权达到顶峰。另外乾隆朝的疆域是中国历史之最。但是就是这个从文治武功的角度看都到达顶峰的国家,与西方世界存在着巨大的差距:乾隆十三年(1748年),孟德斯鸠发表了名著《论法的精神》。乾隆四十一年(1776年),美国宣布独立。乾隆五十四年(1789年),法国爆发资产阶级大革命,提出了“主权在民原则”。乾隆皇帝退位后的第二年(1797年),华盛顿宣布拒绝担任第三任总统,完善了美国的民主政体。18世纪,世界文明大潮的主流是通过立宪制和代议制“实现了对统治者的驯化,把他们关到法律的笼子里”。在英国访问团到达大清之后得出结论——这是一个饥饿的盛世。他们看清了大清的不堪一击,为最终英国下定决心与1840年发动鸦片战争埋下了伏笔。光鲜的面子中国式皇权,一言以蔽之,就是剥削天下的权力,其自私性决定了它终日处于被觊觎和窥伺之中。贯穿乾隆政治生涯的第一条原则是大权独揽。纵观中国古代政治,秩序的崩塌一般源于外戚干政、宦官专权、党争、农名起义。乾隆朝对外戚,皇族的防范也达到严苛的程度,在上任做皇帝之后,乾隆皇帝自己在心中已经没了兄弟之情,与兄弟之间只有君臣之分。乾隆多次下旨敲打亲兄弟弘昼。同时提前处理了庄亲王,主要是因为一些对朝廷不满的皇亲国戚时不时会到庄亲王府中谈论朝政,发泄不满。对于宦官来说,乾隆是防范太监最成功的皇帝之一。刚刚登上皇位两个月的乾隆就迫不及待地开始敲打太监。清朝初期,宫廷典制并不完备,为有效管理太监,乾隆总结了积累近百年的管理经验,下令编纂“宫廷法典”—《钦定宫中现行则例》和《国朝宫史》。除了详细规定太监的等级、职掌和待遇外,还对太监的管理及处分做了详细而严格的规定。虽然天生重感情的乾隆也与许多太监建立了不错的个人关系,但是太监一旦犯错,他决不宽假。由于时刻提防,坚持不懈,所以终乾隆朝六十年,太监们始终没有对皇权构成任何干扰和威胁。对于大臣,人很容易因为政治见解不同分成不同的党派。而清代大臣形成朋党不光是政治间接。清代的官员主要是采用科举选拔,在科举中主考官可能会将考中的人聚集形成门生。或者大臣们根据中举的时间形成同科、同窗等关系。而朝中的大臣也不断拉拢新人形成一个个利益共同体。他们不再是为了国家利益,或仅仅因为政治不同开展公开的辩论,而是在私下拉帮结派,互相攻伐,消极怠工的方式来给对方使绊子,造成政令不畅,行政机构效率低下。雍正朝开始,雍正皇帝为了刷新吏治已经开始打压一些朋党。乾隆还是在未登基之前,就已经通过史书,对朋党政治的历史和危害有了深入了解。乾隆朝期间处理鄂尔泰和张廷玉,很难想象像张廷玉那种以谨小慎微,办事兢兢业业,一生小心勤勉的人会因为礼节上的罪名被一而再再而三的斥责。虽然活着的时候被乾隆下旨取消了配享太庙的权利,不过在死后乾隆于心不忍还是恢复了这项权利,但是张廷玉是感受不到这种皇恩浩荡了。。。在文治方面,乾隆朝前期整个官僚系统高效,而且算是比较廉洁。这个廉洁主要建立在雍正时期对整个官僚体系的严厉整顿。在乾隆初期,乾隆采取的是宽仁的政策,这个时期社会风气好转,官僚百姓都觉得整个社会被松绑了,让人感觉如沐春风。在武功方面,乾隆时期彻底解决了康雍时期遗留的准格尔部,而且拼接大小金川战争整个疆域版图空前。乾隆二十四年(1759年)统一新疆后,中国疆域极盛,北起萨彦岭、额尔古纳河、外兴安岭,南至南海诸岛,西起巴尔喀什湖、帕米尔高原,东至库页岛,领土面积1453多万平方公里。黑暗的里子乾隆甚至整个清王朝都是面子上光亮,但是底色是黑的。首先由于满洲人得位不正,满汉矛盾从未真正解决,而且满人虽然表面上学习儒家得孔孟之道,但是背地里一直采用得是奴隶社会得奴才与主子的关系。整个清王朝统治的早期经历了像扬州十日、嘉定三屠这样的大屠杀。而且清朝一直盛行文字狱。整个社会都处在一种高压的社会环境下。因为统治者最热爱的是稳定,而维护稳定的最核心手段则是维护纲常。一旦纲常紊乱,则统治者必然受到威胁。乾隆对老百姓有两幅面孔:对于安分守己的“良民”,他“视如赤子”。他一直体现着爱民如子,乾隆朝对于民生的支出是整个封建王朝的历史之最。对于不守本分的“刁民”,他则视如仇敌,必欲除之而后快。对于民众自发组织的抗议和上访,乾隆第一反应不是处理贪官恶吏,保护百姓,而是恐惧。因为这种民间的自发组织很容易引起大的骚乱,甚至发展成农民起义,威胁皇权。对于这种民间百姓自发组织起来的抗税抗租行为,他更是严厉打击,决不手软。面对汹汹民情,乾隆全力以赴,高筑坝垒,将其约束在“纲纪”的河道内。另外为了防止民众聚集形成势力,乾隆朝破天荒的开始打击讲学。在中国历史上,民间讲学现象非常普遍。孔子收徒三千,就首开民间讲学之先河,也正式创立了儒家学派。到了宋代,书院大量出现,名儒大家各自以书院为据点,传授自己体悟到的圣人心法,讲学之风空前繁盛,理学由此兴起并成为儒学的主流。及至明朝,讲学之风达于极盛。大儒王阳明极重讲学,认为这是开启智慧、传播学术的最佳方式,故其一生讲学不休,甚至军旅之中也日夜不辍。王阳明的后学们光大乃师之风,或依托于书院,或约期于山水,甚至庙堂林野,寺观名胜,招朋引众,讲学辩论,宗风所及,几乎无处不讲学,无人不讲学。清初统治者反对讲学,主要是怕汉人借此进行阴谋集会。及至乾隆时期,这种威胁几乎已经不存在了。乾隆认为,讲学的最大威胁在于容易滋生朋党倾向。乾隆朝的专制政治发展到了极致,它打破一切民间自发组织的可能,把一切社会能量纳入政治控制之下。在乾隆的严厉打击下,汉人儒者过去讲究自身人格的崇高和自由,原始儒学要求其信徒能在权力面前挺起腰杆,而不做随声附和的应声虫。因此有陶渊明的不为五斗米折腰,有李白的“仰天大笑出门去,我辈岂是蓬蒿人”,有文天祥的“人生自古谁无死,留取丹心照汗青”,也有于谦的“粉身碎骨浑不怕,要留清白在人间”。他们的人格追求,在专制达到极峰的清代就成了君权的障碍。乾隆认为应该由皇帝垄断所有的伟大、光荣、正确,不给其他人留一点荣誉空间。乾隆皇帝所需要的,不是站立着的大写的人,而仅仅是工具和奴才。在乾隆的严厉打击下,清代后期士大夫道德与精神的迅速堕落,乾隆朝的大臣,虽然不乏能臣,却有一个共同的特点,那就是有才华而无思想,有能力而乏操守,除功名利禄外无所关心,他们都是被乾隆打断了脊梁骨。在皇帝明察秋毫的情况下,他们老老实实兢兢业业,以图飞黄腾达,一旦皇帝昏庸,掌控的不严,他们立马化身帝国的硕鼠,大肆贪污,尽一切可能盗窃皇帝的家产。另外为了维护这种不光彩的得位历史,整个清朝前期都盛行文字狱,并且文字狱在乾隆时期达到了高潮。文字狱不光处置了一大批藏有所谓反书得读书人,而且乾隆为了体现文治开始了修书得工程。修书主要有这么几个目的:一是为天下臣民“御制”了一部标准的历史。主要是美化进关后的历史,希望建立一种天下各族都是一家人的概念来强化身为异族统治者的合法性修改一些历史人物的评价,过去像吴三桂这种帮助清兵入关,是清王朝的大恩人,在雍正朝及以前都是正面的典型。但是在乾隆朝为了防止后人有样学样,直接将这种行为定为不忠,并列入《贰臣传》。三是大规模整理中国历史文献,营造博大恢宏的文治气象,以证盛世“文治之极隆”。在修书期间大量查获民间所谓的“反书”,将书送往京城集中销毁,而对于藏书者来说,个人落得个身首异处,家庭成员则为奴为仆。通过大量的抓典型、严惩私藏反书的藏书者,逼迫私人藏书者自查自毁。官方销毁的加上民间自行销毁的书不知道有多少,乾隆朝“文治”的本质,是中国历史上最大的一场文化浩劫。对于书籍的管控只能管理到上层能读书识字的士绅阶层。但是大量民众都是目不识丁的底层农民,如何将官方的意识型态植入最底层人们的心中呢?答案是采用戏曲的方式。清代最有威力的娱乐方式,非戏曲莫属了。作为资深戏迷,皇帝很清楚,不分青红皂白地禁戏是极不明智的作法。“禁”的力量是有限的,甚至有的时候,会导致“逆向消费”。你越禁,老百姓就越想看。官方不给推出“弘扬正气的历史正剧”,民间可能就会流行一些歪“门邪道的野史”。因此乾隆把禁戏的重点,从禁地点、禁规模、禁时间转移到审查、修改、禁止演出的内容。乾隆皇帝抓戏曲,有三方面内容,一是禁,二是改,三是创。禁止的戏目一般是有民族情绪、政治上有违碍,二是才子佳人爱情戏,三是大量水浒戏,四是某些反映宫廷政治斗争的戏,五是有凶杀暴力内容的戏。对于民族情绪的戏很好理解,毕竟清朝是少数名族当政。才子佳人的戏,乾隆认为里面充满了男女调情的情节,其眉来眼去之状,足以让未成年观众萌动不良想法,毒害他们的心灵。禁水浒戏理由更加充分,水浒本是一部宣扬造反有理的“邪书”,宋江等人是以抢劫起家的黑社会组织,而祝家庄等民团则是维护社会秩序的义民,水浒在里面“颠倒黑白”。至于宫廷戏,那个时候的百姓不太懂政治,不懂治国,不懂圣人之道,只知道故事要猎奇,因此会充分发挥想象力,将宫廷内容妖魔化,丑恶化,有损当今天子和高官的形象。乾隆并非禁戏的第一人,但是却是能想到改编戏曲创造新戏曲的第一个统治者。戏改工作按三个对头原则进行:一、思想感情对头,即对清王朝要怀拥护忠爱之情,对少数民族不得存歧视污蔑之处;二、基本情节对头,人物身份和关系应有伦次,扮演应使人信服、不可过分夸张;三、时代气息对头,不可乱用本朝服色,坚决纠正演员在着装、语言以及整体风格方面低俗媚俗现象。虽然乾隆大力扶持戏曲行业,但是乾隆朝的戏曲发展却呈现出一种怪异的走势:既繁荣,又荒芜;既热闹,又单调;既豪华排场,又内容空洞。风暴来临的前夕乾隆朝外表光鲜亮丽,创造了出色的成就。但是骨子里是一个黑暗的盛世,虚弱的盛世,是一个一潭死水没有人气的盛世,封建王朝的人吃人达到的顶峰。专制政治中,皇帝是整个国家的神经中枢,官僚体系的精神状态就是皇帝一个人精神状态的放大。早年的乾隆还算励精图治,政治上还算清明,在这一时期人口剧增达到封建王朝的历史之最。但是万年的乾隆开始沉迷享受,他开始对各种奇珍异宝感兴趣,并要求各地官员进贡。大量的官员借着给皇帝进贡的机会大肆贪赃敛财,盘剥百姓。并且开始上行下效,各地各级官员也刮起了一种贪图享乐,互相攀比的奢侈之风。各级官员不仅要给皇帝进贡,还需要给各个上级进贡,相当于逼着官员盘剥百姓,从民间搜索各种奇珍异宝供上层享乐。而且和珅还发明了议罪银制度,简单来说,官员犯罪可以交一笔罚银以减轻或者不处罚。有这种制度的支持,各级官员开始大肆敛财。历朝历代都存在着大大小小的官员贪腐事件,大部分时候,贪污之所以能被限制在一定范围之内,原因不外有二:一是在儒学价值观有效运转下人格操守的约束;再一个是从上而下的政治高压,也就是说,最高统治者的反腐决心和虎视眈眈的监视。而在乾隆后期,由于对儒者传统价值的破坏导致大大小小的官员都没有了做人的底线,没有了为民请命的使命感。而乾隆本人在后期也沉迷享受,甚至开发了议罪银制度,导致整个法律层间对贪污腐败没有处罚手段。贪腐之风自然如一匹野马肆意奔驰再也控制不住。乾隆朝中后期的贪污有这么几个特点:一是涉案数额从小到大,腐败案件由少到多。二是腐败官员由底层向高层发展,涉案高官越来越多。三是贿赂公行,窝案串案迅速增多,腐败呈集团化、公开化趋势。在这个时期横向对比东西方文明发现,西方国力经过了资产阶级革命,生产力空前发展,而且马上要进入到工业革命了;而乾隆朝时期整个社会由盛转衰,人格被压制,专制制度达到顶峰。各级管理贪污腐败。贪腐政治一个不变的规律是,个人从贪腐中所得的,与给国家造成的损失相比,往往微不足道,国家在经过各级官员的层层盘剥,慢慢的已经开始进入积贫积弱的状态。在乾隆时期,西方曾今为了与中国做生意,曾今来华访问,并亲自见到了乾隆皇帝。他们希望乾隆皇帝能满足他们的以下请求:希望能多开放几个通商口岸,当前只有一个广州希望能公开关税征收标准,并且最好能降低关税。当前只能通过广州十三行,而且洋人卸货需要经过各级官员的层层盘剥希望能有一块地准许商人长期居住并且也能接家人共同居住在英国大使马戛尔尼在来中国之前是一个中国迷,中国过去经过马可波罗的宣传以及欧洲文艺复兴和思想启蒙时被作为模范进行宣传。早期中国在外国人心目中是一个神秘,制度国力等全方面领先西方国家,对大多数西方人来说是伊甸园的存在。但是种种幻想在来华之后破灭。在英国使团来华后看到的是人民衣不蔽体,饥不择食,王权和官宦对民众的压迫达到顶峰。在这里的人只有生存权没有人权,民众见官必须下跪,官员可以随意掠夺家产,一言不合就当众扒光衣服打板子。另外英国人后面也了解到,在中国,所有的富人几乎同时都是权力的所有者。也就是说,中国人的财富积累主要是靠权力来豪夺。中国的专制是超经济的,经济永远屈居于政治之下,也就是说,财富永远受权力的支配,一旦没有权力做靠山,财富也很容易化为乌有。乾隆皇帝在得到英国将来来华时只当一个远邦的一个名为英吉利的小国又来称臣纳贡,而且对西方的奇技淫巧甚是好奇,希望能通过这次朝贡见到新奇的外国玩意。这次的访华,英国使团带来了大量的诸如最新的天体望远镜,天体运行模型,万有引力定律等自然科学的新发现,以此展示他们的大国形象并希望大清王朝能重视他们这个贸易伙伴,准许他们的请求。特别是英国人通过胡可发现的弹性定理利用弹簧发明了新型马车,这种马车比起传统马车来说更为稳当,在崎岖的路面上也不颠簸,也代表了西方科学技术的进步。但是乾隆对洋人带来的这些科学发现毫无兴趣,甚至因为英国使臣不肯下跪而大为恼火,至于那辆马车,皇帝认为在乘坐马车时车夫做前面而皇帝则在后面有失地位。最终乾隆原来打算郑重接待也变成敷衍了事。上面的皇帝是这个心态,那么地下的官员也不打算认真对待。虽然表面上客客气气,但是西方使团提出的几点请求却一点都不答应。最终西方无功而返。在这次访华之后,马戛尔尼对东方的美好幻想完全消失,他们见到的是一个愚昧无知,而且自大的黑暗的东方大国。对自己受骗上当的经历痛心疾首、恼羞成怒的欧洲人从一个极端到另一个极端”。马戛尔尼的出使使欧洲得出了这样的结论:如果不用武力,就无法打开中国的大门。最终在当初访华团队的一个孩子——小斯当东的推动下,英国通过了对华发动鸦片战争的提议。清朝的统治者完全没有重视这次访华,也没有从英国人带来的新奇玩意中意识到此时东西方已经有了巨大差距。英国带来的物品中,那几样最精美,最大的物品被放到圆明园供皇帝欣赏把玩,最终在第二次鸦片战争中又被抢劫一空。当时最高水平的军火还有那驾没法被皇帝看见的马车则被锁进仓库,最终在英军攻破北京城之后被发现,英国人很奇怪中国人为什么放着这么好的武器不用,而一直以自己那笨重过时的火绳枪与他们较量。后记本书虽然完整介绍了乾隆朝的各种历史,后面乾隆又禅让给十五子嘉庆皇帝,乾隆凭借着超高的统治时间、高压的政治统治、完美的禅让,成就了他十全老人的名号。虽然说大清朝的皇帝比起历朝历代,也算是励精图治,很少出现那种荒淫无道的离谱皇帝,但是政治制度,生产力的落后无法通过个人的努力勤政进行弥补。读这段历史时令人唏嘘不已,也让人浮想联翩,如果当初中国不采取闭关锁国的政策,而是开眼看世界,跟随世界的脚步完成思想启蒙、工业革命,那么是不是就没有近代的百年屈辱史,中国是不是也跟当前不太一样。但是历史没有假设,中国就这样在乾隆朝时期错过了世界留给它的最后机会。
-
读《定投十年,财务自由》 这本书是 《指数基金定投指南》的姊妹篇,书中的内容与定投指南差不多,甚至它是定投指南的子集。如果读过定投指南那么就不用读这本书了,如果没读过,那么推荐读《指数基金定投指南》。在选指数基金时有几个要点:秘诀一:基金规模小于1亿元不要选,从某种程度上选择规模在2亿元以上的品种秘诀二:挑选费用较低的基金,指数基金的费用主要是:申购费、赎回费、管理费、托管费。秘诀三:选择追踪误差较小的基金;因为指数基金只是按照指数中的成分股和对应比例进行购买,存在股票的买卖那么就不可能持股比例与指数完全一样,并且指数只是体现股价的,并不能体现股票分红的回报,所以二者之间是有误差的,一般来说指数基金的回报要稍稍高于指数。而在买卖的时候一般在高估的时候卖出,低估的时候买入,至于如何判断判断高估和低估在《指数基金定投指南》中有详细的描述,这里我觉得没必要再写一次。另外如果不太确定某个指数采用哪种估值方式可以参考作者的微信公众号——银行螺丝钉,里面每天会更新各种指数的估值表。总的来说,我之前读过《指数基金定投指南》,后来我想看看这本书对《指数基金定投指南》有没有什么补充的,发现基本没有。读下来有点浪费时间
-
读《史蒂夫乔布斯传》 最初知道乔布斯这个人还是我在上高中的时候,那个时候看新闻说苹果公司的创始人乔布斯因为癌症逝世。从这个时候我知道了苹果,知道了iPhone和iPad。在这段时间内我各个渠道都听到对乔布斯的各种夸赞,使我对这个人有了好奇心,我想知道被所有人成为天才,称之为神的的人到底是个什么样。我在学校对面的书店看到了好多版本的乔布斯传,那个时候也不知道到底哪一个是官方版本,我就找了一个价钱我能接受的。当时买的那本书现在来看就是某个小作坊生产的盗版书,但是书中已经给我描述了一个神一样的乔布斯形象。仿佛他生下来就是要改变这个世界的,特别是他想挖走百事的斯卡利时说的那句“你想要继续卖糖水还是跟我一起改变世界”。但是这次我读的是官方版本或者说乔布斯亲自授权版本。从这本书的开始就可以看到,这本书是乔布斯亲自请求作者为他做传,并且亲自为作者提供了大量的一手资料,这本书不管从真实性还是可读性来说是接近完美的。乔布斯本身是被父母抛弃,由养父母抚养,虽然养父母待他如亲生骨肉甚至待他比亲儿子还亲,但是自从乔布斯知道自己是被亲生父母被抛弃之后心理出现了很大的阴影,甚至后来他的同事都暗戳戳的表示他那难以与人相处的性格可能是因为这件事导致的。乔布斯在很小的时候就是一个叛逆的孩子,他从来不循规蹈矩,与那个时候的美国青年一样,他喜欢嬉皮士、喜欢致幻剂、充满叛逆精神。在上大学的时候养父母斥巨资送他去了里德学院,但是在学校上学不久他以学校的课程他不感兴趣为由退学了,但是他并没有离开学校而是花了大量时间旁听了艺术学和书法课程。这段经历养成了他独特的审美。另外乔布斯也沉迷禅宗,并且为了学习禅宗教义亲自到印度访问各种大师,乔布斯认为比起依赖专业知识的理性思维,他更相信灵机一动的直觉,并且他认为这种直觉是可以由禅宗、冥想而来的。从这一点看苹果的产品确实有很多是乔布斯灵机一动的创意,比起那种方方正正的标准工业品的计算机,苹果的计算机更加灵动,更加活泼,也更加具有人文精神。在他青年时期,美国电子计算机开始发展,他对这一新兴事物充满兴趣,这个时候他认识了另一个史蒂夫——史蒂夫沃兹尼亚克。沃兹是一个真正的黑客,一个充满理想主义的理工男。他们二人最早合作开发了蓝盒子,这是一种利用电信漏洞来免费打电话的工具,从这个时候起,乔布斯的商人特质开始显现,他们通过卖蓝盒子赚了一大笔钱。后来二人合作成立了苹果计算机公司,苹果公司的另一位创始人是马库拉,他对于乔布斯来说就像父亲般的人物,他告诉乔布斯“你永远不该怀着赚钱的目的去创办一家公司。你的目标应该是做出让你自己深信不疑的产品,创办一家生命力很强的公司。”,乔布斯与沃兹尼亚克二人合作开发了首款Apple电脑以及后面大获成功的Apple II电脑。在这个过程中乔布斯的工作模式已经初现端倪。首先乔布斯及其注重细节,这得益于他的父亲从小就教他的“追求完美意味着:即便在别人看不到的地方,对其工业也必须尽心尽力”,苹果的电脑即使在机箱内部小到每一颗螺丝、每一片区域的颜色,哪怕里面的整个电路板都必须做到接近完美。另外也体现了乔布斯的“现实扭曲力场”,乔布斯总能让别人相信他,包括他能说服你完成之前你认为不能完成的事。马库拉也教了乔布斯如何做营销:第一点是共鸣(empathy),就是紧密结合顾客的感受。第二点是专注(focus)。“为了做好我们决定做的事情,我们必须拒绝所有不重要的机会。”。第三点也是同样重要的一点原则,有一个让人困惑的措辞:灌输(impute),如果我们以创新的、专业的方式展示产品,那么优质的形象也就被灌输到顾客的思想中了。”这几点在乔布斯准备发布会、准备产品广告的时候被体现的凌厉尽致,苹果公司一个特别出名的广告就是模仿1984的场景,广告中暗示IBM就是小说中的老大哥,它控制了用户,而苹果则是破局者,苹果打破了老大哥的垄断,用苹果就是标新立异,打破传统。不墨守成规的天才都使用苹果,苹果也为这种天才提供改变世界的趁手的工具。早期的Apple II靠着乔布斯自己的对于细节的打磨以及出圈的广告获得了极大的成功乔布斯在细节的强大控制既造就的Apple II的成功,也间接的导致后续的丽萨电脑和Mac的失败,这两款产品因为乔布斯的过于精益求精导致发布时间一再延迟、成本也随之攀升,最后的销量也不及预期。Mac的研发期间,乔布斯参观了施乐研究所并且在那里见到了颠覆性的技术,GUI图形界面的操作方式,并且也见识到了使用鼠标来控制光标。在此基础之上乔布斯完善了操作逻辑。乔布斯完善了桌面的概念,完成了窗口的拖拽以及重叠的交互逻辑,可以说现代计算机的操作逻辑是从乔布斯那里演变过来的。除此之外Mac还有漂亮的字体和颜色,这得益于乔布斯在里德学院旁听的艺术课和书法课。我想乔布斯当初旁听书法课时并没有想到书法课的内容未来可以用在Mac上,当初他决定旁听书法课也仅仅是因为他喜欢、感兴趣。这对我的启示就是技多不压身,现在感兴趣深入研究的看起来无用的学问将来在某个时刻可能会发挥巨大的作用。后来比尔盖茨在为Mac开发Office套件时发现了这一操作系统大为震惊,并且在此基础上秘密开发了Windows操作系统。为此乔布斯和盖茨打了一些官司但是最终以盖茨继续为苹果电脑开发电子表格程序为条件双发达成了和解。在二人争论的过程中,盖茨打了一个形象的比喻“我们旁边住着一个有钱的邻居——施乐,一天我想去邻居那里偷点东西,当我进去时发现乔布斯已经把邻居的电视抱走了。”。虽然二人的GUI操作系统都是从施乐那里得到的灵感,但是施乐当初只有一个粗糙到完全无法商用的原型并且也不太重视这个项目,可以说是躺在金矿边上要饭。还是乔布斯让这项技术发扬光大。随着Mac和丽萨的失败,以及乔布斯刻薄的性格,苹果的高层动了赶走他的念头,而乔布斯因为无暇管理整个公司所以答应公司找人担任CEO的职责,而他专心管理Mac项目组。随后公司找到百事总裁,约翰斯卡利,希望由他接任苹果CEO。为此乔布斯专门找过他几次,刚开始斯卡利并不了解计算机,也不打算管理科技公司,他只想凭借着百事的大量股票过富足的生活,但是乔布斯的话打动了他“你是想卖一辈子糖水呢,还是想抓住机会来改变世界?”斯卡利与乔布斯也有一段蜜月期,在蜜月期内乔布斯不停的向他展示最新的技术,展示每一个新的点子,斯卡利也为乔布斯这种全身心投入工作创造奇迹的特质所吸引,但是好景不长,因为乔布斯的性格,二人最终分道扬镳,并且斯卡利在最终的斗争中成功的赶走了乔布斯。乔布斯离开苹果之后成立了新公司,新公司专注于制作高性能的工作站,它被取名为NeXT。同样的NeXT因为乔布斯精益求精的特质,以及不计成本的调整最终只有一款面向对象的操作获得了市场的认可。虽然有厂商希望授权使用NeXT的操作系统但是乔布斯不能忍受自己精心打磨的操作系统运行在被他认为是一堆电子垃圾的电脑中,所以授权的事也就作罢。 乔布斯在NeXT失败之后,看重了计算机图形技术,并且为此收购了卢卡斯电影的计算机部门并且成立了皮克斯,早期的皮克斯并没有打算制作动画,乔布斯打算做一款能够进行3D渲染的软件进行售卖并且希望利用一段电脑制作的动画短片来展示他的软件和电脑。但是公司制作的一款动画短片(也就是现在皮克斯电影开头的顽皮台灯)使乔布斯看到了计算机图形与艺术结合的可能。为此他与迪士尼合作开发了《玩具总动员》。早期的玩具总动员由迪士尼负责牵头,产出了好几版剧本但是乔布斯都不满意,主要是主角的性格令人讨厌,无法引起观众的共鸣。乔布斯多次更改主角人设最终两家差点闹掰,迪士尼早期投入的资金不够用了,被迫勒令停止了玩具总动员的制作,为了继续动画的制作乔布斯只得掏腰包完成了电影的制作。最终《玩具总动员》大火。而皮克斯也因为电影的大火而成功上市。苹果公司随着乔布斯的离开也一蹶不振,股价连续下跌,股东终于忍不了斯卡利的无能,慢慢的开始想把乔布斯请回来担任CEO。对此乔布斯因为皮克斯的成功也不太想要离开。最终随着一系列的谈判双方达成共识,苹果公司重组董事会由乔布斯挑选董事会成员,乔布斯只担任临时CEO,或者说顾问,乔布斯将它称之为iCEO。并且在担任苹果公司iCEO的同时也继续着皮克斯的事务。乔布斯回归苹果之后的第一件事就是砍掉了不重要的产品线,仅保留少数他认可的,紧接着就是裁员,将他认为是笨蛋的开出仅留下他认可的天才。每年,乔布斯都会带着他最有价值的员工进行一次“百杰”外出集思会。在每一次秘密会议结束时,乔布斯会站在一块白板前,问大家“我们下一步应该做的10件事情是什么?”。他将大家讨论的答案写在白板上,但是他最后其他7件全部画掉,然后宣布:“我们只能做前三件。”,乔布斯用这种办法保留了苹果的专注力,只做最应该做的事。在此期间,乔布斯将苹果电脑作为电子中枢围绕着苹果电脑开发了音乐制作,视频制作软件。他整合各种数字设备,包括音乐播放器、录像机,以及相机。你可以用计算机连接并同步所有这些设备,它也可以管理你的音乐、图片、视频、信息,以及乔布斯称为“数字生活方式”中包含的方方面面。不久之后乔布斯认为数字音乐将是未来的大趋势,人们可以使用计算机制作、保存属于自己的音乐,为此开发了iTunes。这是一款可以制作音乐并且可以将制作的音乐刻录到CD上的软件,这样苹果电脑就集制作、刻录、播放音乐与一体。但是带着这么大一个电脑听音乐属实有点不妥,而且日本在此时兴起随身听。乔布斯意识到可以做一个简便的音乐播放工具,iPod项目就此诞生了。iPod 同样体现了乔布斯的设计审美以及大胆的创意,他通过自己的“显示扭曲力场”将iPod做的体积特别小但是有巨大的容量,号称可以随心携带3000首歌曲。并且取消了下一首、上一首的按钮,首创随机歌单的功能。与其让用户准备歌单顺序,随机歌单更能给用户带来惊喜。为了解决盗版问题,乔布斯设计了iTunes音乐商店,并且为苹果电脑和iPod之间开通了同步音乐的通道,但是只允许电脑到iPod 的单向通道。乔布斯认为人们使用盗版不一定是因为道德感的缺失,而是正版下载渠道做的没有盗版方便。随着iTunes的推出,用户可以每首歌仅花费0.99美元就可以拥有高品质的音乐,再也不用满世界找带有杂音或者音质不纯的盗版了。iPod最终大火,甚至连美国总统都有一台。乔布斯通过iPod重新定义了数字时代的音乐市场。并且iPod也成功带动了苹果电脑的销量。乔布斯并没有趁着iPod的爆火继续推出iPod各个系列,而是通过手写屏幕再一次看到了未来。乔布斯利用最新的触摸屏技术打造出了一款能浏览照片、听音乐、看视频、打电话的机器——iPhone。iPhone相当于革了iPod的命,乔布斯认为好的公司应该以创造革命性的产品为己任,各个部门之间不应该有利益冲突而是大家团结协作。烂公司会因为各种利益关系而内部纷争不止。就像iPhone代替iPod一样,虽然iPhone会影响iPod的销量但是大家都明白iPhone又是一次颠覆,各个部门都会为了一个共同的目标而前进。在推出iPhone之后,乔布斯又推出了iPad,并且为iPad联系了多家出版社完成了图书的电子化,人们可以在iPad上看书。至此乔布斯又打造了一款封神的产品,二十几岁,他就改变了个人电脑,现在,他将同样改变音乐播放器、唱片产业的商业模式、移动电话、应用软件、平板电脑、书籍,以及新闻业。为了将这些数据管理起来,乔布斯敏锐的意识到了数据的重要性,为此他推出了iCloud云服务,苹果的用户可以通过唯一的apple id将各种设备的数据进行同步管理,iPhone上保存的图片、书籍、音乐等数据可以无缝的在ipad、mac上查看。乔布斯不光能创造产品,对于产品的营销也是专家,他在回归苹果之后开始建立线下的直营体验店,在装修体验店时他坚持将店面放到人流充足的繁荣区,并且站在顾客的角度聘用专业的销售人员耐心的为顾客介绍产品。在建立线下体验店时,乔布斯与他手下的约翰逊一起参与设计装修,在最终要装修完成时候,在深夜约翰逊被一个恐怖的念头惊醒:他们犯了一些根本性的错误。他们围绕着苹果的主要产品线把商店分成若干个区域:有Power Mac、iMac、iBook和PowerBook。但是乔布斯开始发展出一个新的概念:使计算机成为你所有数字生活的中枢。换句话说,你的计算机能够处理相机里的视频和照片,或许有一天也能用作音乐播放器来听歌,或者阅读书和杂志。黎明时分,约翰逊计上心头:商店内部不能只按照公司的四款计算机产品线进行划分,还应该考虑到顾客想做什么。他说:“比如,我想可以有一个‘电影区’,在那里我们可以用几台Mac电脑和PowerBook,运行iMovie软件,向顾客展示怎么从摄像机中导入文件并编辑。”,乔布斯在第二天得到这个想法的时候爆发了“你知道这个变化有多大吗?”他嚷道,“我他妈为这个商店玩命干了6个月,你今天才告诉我全部都要改。”然后他突然安静下来:“我累了,我不知道还能不能从零开始设计一间商店。”。但是随后乔布斯按照约翰逊的想法重新改造了线下零售店。他说:“如果你发现有些事做得不对,你不能只是忽略它,然后说‘以后再处理’,这是其他公司的做法。”。最终线下体验店爆火,正是这种精益求精的精神成就了苹果,成就了乔布斯的神话。乔布斯似乎总是走在时代前列,想用户之所想,创造用户真正需要的东西。苹果的东西总是 “诗意与工程紧密相连,艺术、创意和科技完美结合,设计风格既醒目又简洁”。乔布斯虽然早早的因为癌症离开人世,但是他给苹果留下了丰厚的遗产。他说“我的激情所在是打造一家可以传世的公司,这家公司里的人动力十足地创造伟大的产品,其他一切都是第二位的。当然,能赚钱很棒,因为那样你才能够制造伟大的产品。但是动力来自产品,而不是利润”。在乔布斯时代,苹果的产品似乎永远领先市场一步。乔布斯认为“我们的责任是提前一步搞清楚他们将来想要什么”,而不是给用户现在想要的。我记得亨利·福特曾说过,“如果我最初问消费者他们想要什么,他们应该是会告诉我,‘要一匹更快的马!”。人们不知道想要什么,直到你把它摆在他们面前。正因如此,乔布斯似乎从不依靠市场研究。他的任务是读懂还没落到纸面上的东西。乔布斯离开这么些年,苹果目前在电子产品领域虽然仍然占据大头,但是我个人感觉已经没有往日那种发布产品给人的震撼了。现在给我的感觉是iPhone出了使用iOS系统和iCloud以外,它的外观、配置已经跟安卓机没什么区别了。我了解苹果、认识乔布斯比较晚,但是我想如何他还在世,还能继续掌握苹果,我可能会见识到更加先进、更加吃惊、更加炫酷的产品。
-
Emacs折腾日记(三十二)——org mode的基本美化 在上一篇,已经介绍了org mode的基础知识,它与markdown非常相似,并且也十分容易上手,但是它的可扩展性比markdown要强很多。如果将来打算重度使用org mode,那么此时可以对它进行一些基本的配置和美化基本配置org mode 的配置可以通过Emacs自带的org 包来进行管理,可以配置一些标签显示的图形以及一些特殊语句块的高亮(use-package org :ensure nil :mode ("\\.org\\'" . org-mode) :hook ((org-mode . visual-line-mode) (org-mode . my/org-prettify-symbols)) :commands (org-find-exact-headline-in-buffer org-set-tags) :custom-face ;; 设置org mode标题以及美级标题行的大小 (org-document-title ((t (:height 1.75 :weight bold)))) (org-level-1 ((t (:height 1.4 :weight bold)))) (org-level-2 ((t (:height 1.35 :weight bold)))) (org-level-3 ((t (:height 1.3 :weight bold)))) (org-level-4 ((t (:height 1.25 :weight bold)))) (org-level-5 ((t (:height 1.2 :weight bold)))) (org-level-6 ((t (:height 1.15 :weight bold)))) (org-level-7 ((t (:height 1.1 :weight bold)))) (org-level-8 ((t (:height 1.05 :weight bold)))) (org-level-9 ((t (:height 1.0 :weight bold)))) ;; 设置代码块用上下边线包裹 (org-block-begin-line ((t (:underline t :background unspecified)))) (org-block-end-line ((t (:overline t :underline nil :background unspecified)))) :config ;; 设置org mode中某些标签的显示字符 (defun my/org-prettify-symbols() (setq prettify-symbols-alist '(("[ ]" . 9744) ;; ☐ ("[x]" . 9745) ;; ☑ ("[-]" . 8863) ;; ⊟ ("#+begin_src" . 9998) ;; ✎ ("#+end_src" . 9633) ;; □ ("#+results:" . 9776) ;; ☰ ("#+attr_latex:" . "🄛") ("#+attr_html:" . "🄗") ("#+attr_org:" . "🄞") ("#+name:" . "🄝") ("#+caption:" . "🄒") ("#+date:" . 128197) ;; 📅 ("#+author:" . 128100) ;; 💁 ("#+setupfile:" . 128221) ;;📝 ("#+email:" . 128231) ;;📧 ("#+startup" . 10034) ;; ✲ ("#+options:" . 9965) ;; ⛭ ("#+title:" . 10162) ;; ➲ ("#+subtitle:" . 11146) ;; ⮊ ("#+downloaded" . 8650) ;; ⇊ ("#+language:" . 128441) ;;🖹 ("#+begin_quote" . 187) ;; » ("#+end_quote" . 171) ;; « ("#+begin_results" . 8943) ;; ⋯ ("#+end_results" . 8943) ;; ⋯ )) (setq prettify-symbols-unprettify-at-point t) (prettify-symbols-mode 1)) :custom (org-fontify-whole-heading-line t) ;; 设置折叠符号 (org-ellipsis " ▾") ) 上述配置比较简单,核心部分就是我们使用 prettify-symbols-alist 来使将这些特定的 property 字符串替换成更加美观的图标。它是一个列表,列表种的每个子元素又是一个cell,用cell的两个元素来表示替换关系。配置之后,一个org文件大致的效果如下:org-modern 美化为了使文档的显示效果更好,我们需要依靠一个名为 org-modern 的插件,它是一个为Emacs Org模式提供现代化视觉美化的项目,它通过精心设计的样式和布局,能够显著的提升Org文档的可读性和美观度。我们可以使用 use-package 直接安装(use-package org-modern :ensure t :hook (after-init . (lambda () (setq org-modern-hide-stars 'leading) (global-org-modern-mode t))) :config ;; 定义各级标题行字符 (setq org-modern-star ["◉" "○" "✸" "✳" "◈" "◇" "✿" "❀" "✜"]) (setq-default line-spacing 0.1) (setq org-modern-label-border 1) (setq org-modern-table-vectical 2) (setq org-modern-table-horizontal 0) ;; 复选框美化 (setq org-modern-checkbox '((?X . #("▢✓" 0 2 (composition ((2))))) (?- . #("▢–" 0 2 (composition ((2))))) (?\s . #("▢" 0 1 (composition ((1))))))) ;; 列表符号美化 (setq org-modern-list '((?- . "•") (?+ . "◦") (?* . "▹"))) ;; 代码块左边加上一条竖边线 (setq org-modern-block-fringe t) ;; 属性标签使用上述定义的符号,不由 org-modern 定义 (setq org-modern-block-name nil) (setq org-modern-keyword nil) )现在org 文档显示的就更加漂亮了到此我们对org-mode 显示的效果进行了初步的美化,现在的文档看起来比原始的要好看多了,用org来编写文档至少也显得赏心悦目了。
-
读《哈利布朗永久投资组合》 作为一个普通的尝试投资的新手,我希望不用择时买入或者卖出、不用预测经济的走势,也不用看公司财报,搜集公司信息,不用尝试理解企业经营也能做到跑赢通胀?有没有一种投资方式对投资者没有什么要求只要按计划执行就可以获得不错的收益,跑赢通胀呢?还真有这种方式,这就是哈利布朗上世纪提出的永久投资组合。这部书详细介绍了永久投资组合的逻辑以及各种资产是如何应对不同的经济状况,更好的是书中也提供了具体的实践方式甚至推荐了一些投资品种,这对于想实践永久投资组合的新手小白来说是一本即介绍理论,又给出实际操作的好书永久投资组合好就好在一不用择时、二不用预测未来、三对于任何经济状况都有对应的资产来获取收益。理论简介永久投资组合简单来说就是将资产分为:25%的现金、25%的黄金、25%的债券和25%的股票。它们是怎么有机的组合以达到在各个经济状况下都能有收益呢?哈利布朗认为经济状况可以分为:繁荣期、衰退期、通货膨胀和通货紧缩这几个时期。在经济的各个时期,总有资产会上涨或者下跌,也就是我们常说的东边不亮西边亮。在各种经济状况下利好的资产如下表所示经济状况利好资产繁荣期股票+债券衰退期现金通货膨胀黄金通货紧缩现金+债券开始时按照每种25%的比例买入各种资产,随着时间的推移各种资产的涨跌幅度不同最终会偏离这个比例,当我们进行再平衡时就是在卖出高估的品种,买入低估品种,最终随着时间的推移,经济在这四种情况下不断的循环,我们也间接的不断低买高卖,最终获得不错的收益根据回测美国市场,永久投资组合在过去的40年间获得了年均9%以上的收益,书中没有提到最大回撤多少,但是比各种单一资产的回撤要低得多。购买各种资产股票对于股票来说,因为永久投资组合不对未来做预测仅仅期望获取股票市场的平均收益,那么投资股票市场就是买入能代表整个股市的指数基金。对于美国市场来说,可以购买纳斯达克指数或者标普500指数。对于国内的投资者我认为可以购买沪深300或者中证500指数。是否要购买能代表其他国家股市的指数基金呢?作者认为美国股票市场包括那些约占世界经济产值一半的公司,也就是说全球最赚钱的公司都在美国股市,所以永久投资组合不必要关注美国以外的指数。最为国内的投资者也可以考虑把国内的指数基金换成纳斯达克100指数和标普500指数。如果实在是怕美股崩盘了想要投资一下其他国家的股市可以考虑其他国家的股票指数占整个投资组合的5%~10%债券对于债券来说,作者只推荐美国的20~30年长期债券。可以在银行柜台直接买入长期国债或者直接投资于购买了长期国债的指数基金。需要注意的是,如果自己直接购买债券的话当某个债券的品种到期时间小于20年话要卖掉小于20年的债券然后再次购买25~30年到期的债券。以下是上述过程的步骤:(1)购买25~30年期的美国长期国债;(2)持有债券,直到它有20年的到期时间(意思是它在你的账户中会支付给你5~10年的利息);(3)卖出20年期债券,并在必要的时候利用该收益购买新的25~30年期债券;(4)适当地重复这一过程,以维持你的资产配置。如果购买的是拥有长期债券的指数基金,这个步骤通常由基金经理来帮你完成。作为个人投资者在国内银行柜台最长只能买到7到10年期的国债,甚至有时候还抢不到。30年期国债因为主要不是为个人投资者发行的,所以基本抢不到。而在证券交易所直接购买30年期国债会有资金要求。而场外的基金我只能找到7~10年国开债。所以如果想要实践关于持有30年期国债的投资我觉得可以考虑30年期国债指数的ETF黄金对于黄金,作者推荐直接购买实物黄金,并且推荐在全球各个国家和商业银行购买实物黄金并且分散保存到各个银行的保险柜中,用于分散风险。作者不推荐纸黄金这种基金或者合约。作为国内的投资者我们可以去银行柜台买入黄金并存储到银行的保险柜中。永久投资组合需要抵御各种风险,包括经济、政治等等因素所以对于黄金这种贵金属来说比较严谨和讲究安全,在国内来说其实我们无法实践这种方式,更多的还是购买黄金etf或者相关的基金现金现金这里指的不是真实拿在手上的纸币,而是买入一些方便变现的资产,例如活期存款、货币基金、国债逆回购。再平衡再平衡是重要的操作,是间接的实现低买高卖的一种方式。书中作者根据回测数据得出结论:根据阈值触发再平衡策略是收益最高的做法。并且在这种方式下操作频率为每2~3年一次。我们提前给每种资产设置一个涨幅的阈值,只要达到这个值就触发一次再平衡。例如书中推荐只要某一个资产通过上涨价值占比达到35%或者因为下跌占比达到15%就触发一次再平衡。一些实操的问题书中也考虑到实际操作种的一些小问题。通过回答这些问题可以更方便我们理解和操作:资金是一次买入还是分批买入?作者认为等待是预测市场时机的一种委婉的说法,于永久投资组合不做预测只做应对的理念相悖。并且在长期持有的过程中,短暂的定投摊平成本的方式可能节约的成本可以忽略不记反而因为多次操作而损失手续费。并且如果预测错误反而会错失投资机会投资股票市场获得的股息如何操作一般的投资建议是股息复投收获更多的股票份额,但是永久投资组合不建议这么做,因为有可能股票当前处于高位,这样做会被迫追高;更好的做法是将股息放入现金部分,当现金部分超过35%,触发再平衡时再来进行操作新增资金怎么办?普通的投资者一般有一个稳定的工作,他们会将收入的一部分拿来进行投资,实行定投。对于这部分资金永久投资组合建议先放入现金部分,如果现金部分超过了25%,再投资买入其中表现最差的品种如何再平衡?触发了再平衡之后如何操作呢?书中给出几条原则:尽量用现金来补充完成再平衡尽量将资金投资到目前表现最差的品种当需要卖出的时候,优先卖出持有时间最长、收益最好的品种书中还提供了各种不同国家版本的永久投资组合,但是遗憾的是作者没有提供中国大陆的投资方式。书中一些笔记划线安全、稳定和简单。他强调,永久投资组合应该能够保护你,使你能自如地应对所有的经济前景,并保证获得稳定的回报,它还很容易实现大道至简,好的投资方式一定是安全稳定并且很容易复刻的真正的现实世界总是不可预期、不可知且出人意料的。它假定没有人可以预期未来,而且你的主要目标应该是用全天候的投资策略来保护你一生的财富永久投资的主旨就是不做预测只做应对如果你对于某项投资具有怀疑,或者是对于某种做法很是紧张时,尽可能采取最保守的做法就是把回测当作一个工具来证明和反驳一个策略,而不是机械地把过去的市场业绩投射到未来的市场中去投资者应该建立分散化投资组合的想法,立足点在于把资金投入到不同的资产中,这样就没有哪个单一灾难性事件可以对整个投资组合造成巨大损失真正的分散应该是分散投资与那些非正相关,甚至是负相关的资产未来永远都是未知数,而投资者却需要建立一个投资策略来加以应对。重要的是投资者应该完全理解,没有哪个经济学者、投资系统或者专家可以告诉你市场的下一步动态是什么。这点领悟形成了投资策略的基础在实施永久投资组合时,遵循基本策略比完美地执行更重要再好的策略也需要完善的执行现实是永久投资组合是设计用来在不腐败的经济体中发挥作用的挑选能真正给投资者带来实惠的投资市场很重要
-
读《巴菲特致股东的信》 之前看段永平问答录的时候他推荐看投资的书就看巴菲特写的东西,而这本《巴菲特致股东的信》是巴菲特每年写给伯克希尔股东信件的一个汇总,它按照一定的主题进行了汇编,包括了巴菲特对公司、管理、投资、以及一些政策的看法和意见。这部书关于美国投资税和会计方面的东西我没太看懂,我重点关注了巴菲特对于公司管理层和投资方面的内容,下面截取一些精彩的观点列举出来, 有的我会给出我自己的理解以及批注坚持与合适的人、合适的企业打交道,与人为善、良性互动、相濡以沫、相互尊重、相得益彰、交相辉映,这是巴菲特多年一直保持成功的关键在伯克希尔公司,我们通常会换位思考,设想如果我们自己处于股东的位置,应该得到什么样的信息,我们会从这样的角度向股东披露完整的报告看公司年报也是这样,看看公司是否愿意把投资者关心的内容毫无保留的披露出来;如果公司年报上遮遮掩掩,甚至有造假嫌疑就应该坚决排除芒格格和我都认为,CEO们预测公司增长速度,是骗人的和危险的。当然,他们是被分析师和公司自己的投资者关系部门怂恿裹挟着这么做。但他们应该拒绝,因为这样预测多了会招致麻烦。因为未来不可预测,过去的业界不代表未来。有时候过于关注所谓的预测反而会导致管理层为了实现预测目标开始不择手段,甚至造假。只要是好的生意就不愁未来没有业绩给投资者三个建议: 第一,小心那些展示弱会计的公司。如果一个公司没有费用选项,或养老金假设如天马行空,对于这样的公司要小心。当公司管理层在公开的方面使用低下的手段,那么他们在背后可能采用同样的手法。厨房里如果有蟑螂,绝不可能只有一只;第二,不知所云的注脚往往意味着靠不住的管理层。如果你看不懂财务报告中的某个注释或其他管理解释,这通常是因为CEO们不想让你明白;第三,对于那些大肆鼓吹盈利成长预测的公司保持警惕董事会的三种形式:第一种情形最为常见,董事会里没有控股股东。在这种情况下,我认为董事们的行为应该像那些缺席的股东一样,想方设法着眼于公司的长期利益;第二种情形存在于伯克希尔公司中,在这里,控股股东同时也是公司高管;第三种公司治理的情形发生在控股股东没有参与公司管理的情况下董事会是由股东选出来为股东利益负责拥有实际权力的机构;而管理层是由董事会选择来具体实行管理权力的。股票早期就是用来投资探险船的。按照这个理解,股东是直接投资探险船的,最终会分的获取的宝藏,而船上的船长应该是由股东选择出来来指定航向的。管理层则是执行的水手。第一种、第二种情况下股东参与公司的日常管理为了自己的利益而指定公司政策,肯定会以股东利益为优先。而第三种股东脱离与公司管理之外,有可能会造成管理层只顾自己利益而不顾股东;这给我的启示是在分析公司时需要考虑公司的管理层是否长期持有本公司的股票;是否发生过高管大量减持股票的情况芒格非常喜欢本·富兰克林的一句话:“一盎司的预防,胜过一磅的治愈。”但是,有时候,无论多少的治愈也无法弥补犯过的错误我们着眼于公司的经济前景,负责管理的人,我们支付的价格。我们心中没有想过什么时间和以什么价格去出售就是所谓的好的生意模式、好的管理、好的价格;有这三个因素在,买入之后长期持有,只要这三个方面不变就一直持有,而不在乎当前的股价;或者说买入卖出的决定因素一定不是股价的涨跌一个投资者如果想成功,必须将两种能力结合在一起,一是判断优秀企业的能力,一是将自己的思维和行为与市场中弥漫的极易传染的情绪隔离开来的能力在自己的能力圈投资,能力圈就是能看懂的生意。并且在投资时应该忽略短期市场的涨跌,买股票买的是公司不是股票本身的涨跌甚至也有时候,我们会以平价或低于价值的价格卖出一些持有的股票,因为,我们需要资金抓住低估更多的投资机会,或买入我们认为更为了解的股票好公司、好管理、好价格;这三个条件是相对的,卖出的理由可以是当前不满足这三个条件,也可以是有更好的投资机会。我们非常愿意持有任何股票,持有的期限是永远,只要公司的资产回报前景令人满意,管理层能力优秀且为人诚实,以及市场没有高估股市是一个不断重新定位的地方,在这里,钱会从活跃者手中流向耐心者手中。我们专注于寻找那些可以跨越的1英尺[插图]跨栏,而不是我们具有了跨越7英尺跨栏的能力。认清自己的能力圈比自己拥有多大的能力圈更重要。投资可以等待自己能力圈中的机会出现,一旦出现就要下重注。一生中这样的机会很多,重要的是机会来临时有本钱参与恐惧和贪婪,这是资本市场上时不时会爆发的两种具有超级传染性的病症,而且它们会一直存在;我们的目标很简单:在别人贪婪的时候恐惧,在别人恐惧的时候贪婪这里并不是说与大众相反的心态就是对的,而是说在能力圈范围内,在自己能承受损失的范围内贪婪投资者的整体回报,随着交易频率的上升而减少。这里巴菲特说,股票买卖是一个投资者卖给另一个投资者,交易时也是一个投资出钱,另一个投资者收钱。如果将拥有这家公司股票的所有投资者看作一个整体或者说看作一个家族的成员,那么随着交易的进行在这个家族中的整体财富并没有提升,因为交易之间付出的金钱都在家族内部流转,反而会因为频繁交易产生费用从而吞噬家族财富。对于拥有这家公司股票的这个家族来说最好的办法就是停止交易并安心拿公司回馈给股东的收益公司留存的每一美元,要为股东创造至少一美元市值这里谈的是分红;巴菲特认为分红与否也是一个机会成本的问题,是将利润分红产生的收益更大还是将利润用于再投资产生的收益更大;对于高速成长的公司来说再投资产生的收益更大,但是对于那些市场规模稳定,不需要进行大量再投资的公司而言给股东分红比随意扩张,乱花钱要好相比一家掌握在自私自利的管理层手中的公司,投资者应该给那些被证明关心股东利益的管理层手中的公司出更高的价如何回馈股东,一般是股息分红或者回购公司股票,也可以进行再投资。它们是一个机会成本的问题,应该优先选择那种能最大限度利用公司利润的方式。芒格和我认为回购的发生应该满足两个条件:首先,一家公司有充足的现金以备运营和流动性之需;其次,股价远低于保守计算的内在价值对于这种情况,巴菲特举了一个反例。有些公司选择在公司股价超过内在价值时回购,甚至不惜借钱回购,然后用回购的股票给公司管理层发放股票期权,这种行为严重损害了股东利益,相当于从股东钱包里面拿钱。所以对于回购股票的行为我们应该辩证的看,不是所有回购股票的都是好公司如果一些事情不值得做,也就不值得做好。这里巴菲特做了一个很形象的比喻,对于有些热衷于在垃圾股中淘金的投资者来说,就像在癞蛤蟆堆里寻找王子,可能稳了一堆癞蛤蟆也没有一个王子,找靠谱王子最好的方式还是在王子堆里找内在价值的定义也很简单:一个公司的内在价值是其存续期间所产生现金流的折现值。警惕那些油嘴滑舌,往你脑子里灌输幻象的顾问们,他们同时在往自己的口袋里装佣金。
-
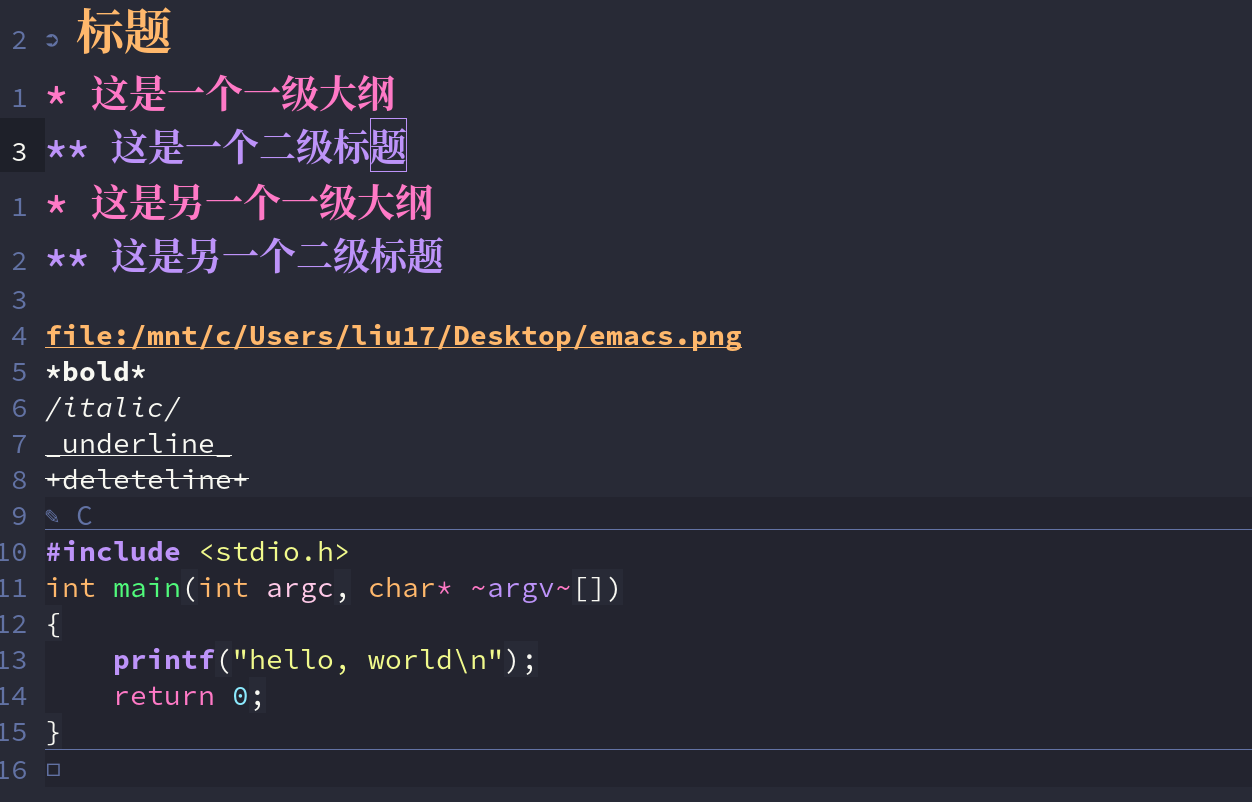
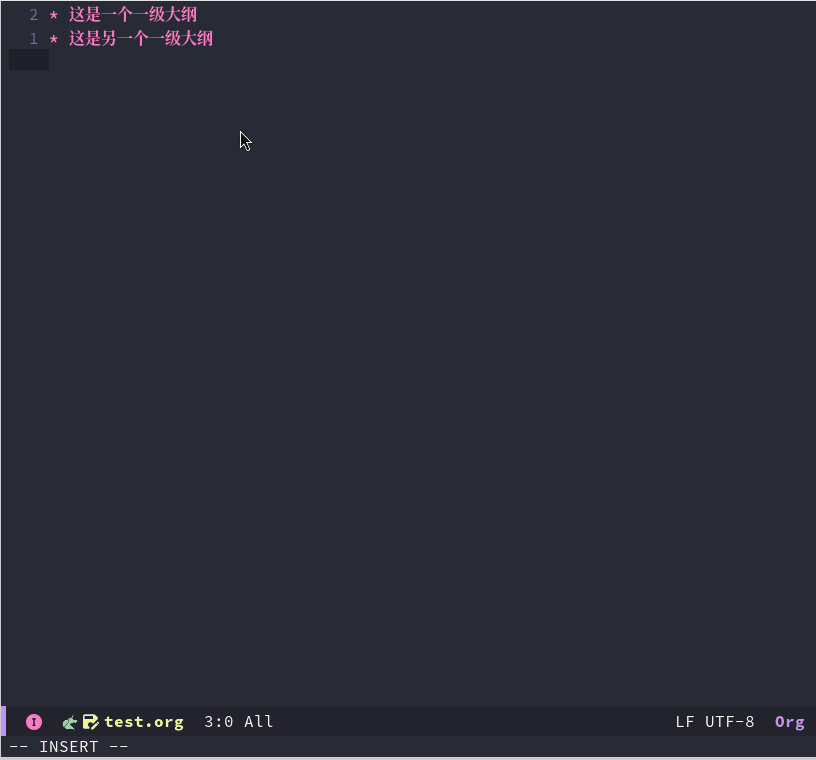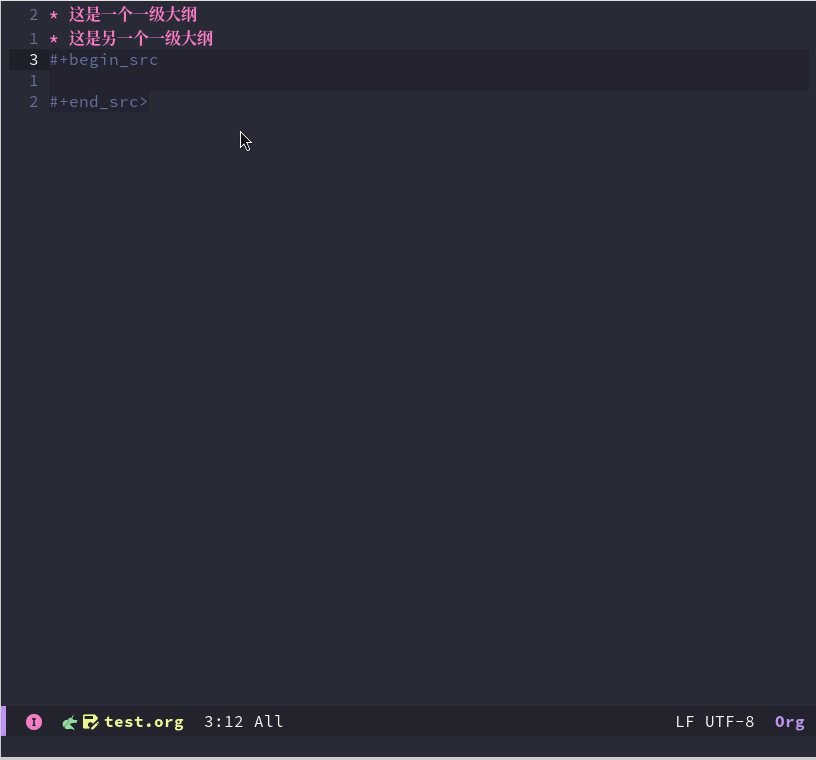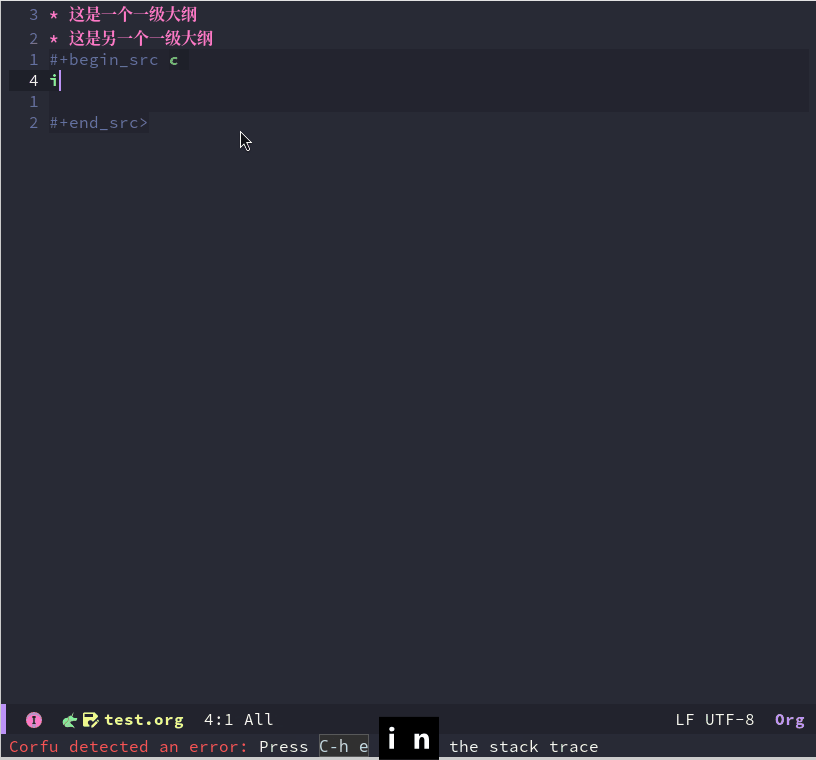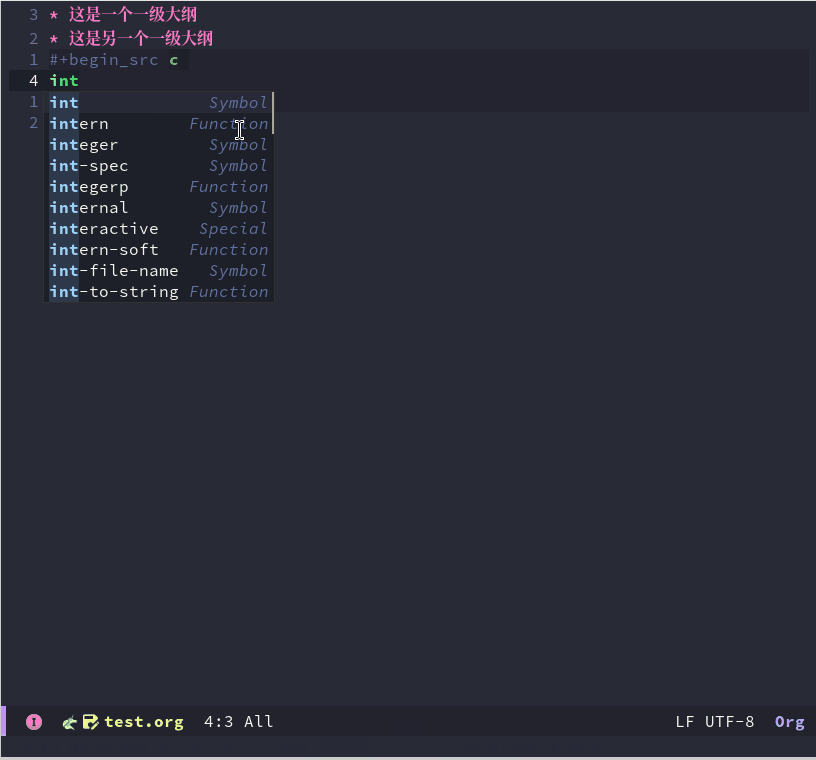
Emacs折腾日记(三十一)——org mode入门 之前我介绍了Emacs相关配置以及对应的知识,主要包括:vim模式、编辑的优化、补全、代码跳转、调试等等,旨在将它打造成另一个vscode、也许是我技术能力有限,不仅在使用体验上赶不上vscode,在配置的简便化以及开箱即用的程度上都比不上。如果是使用Emacs仅仅因为它复杂一般人不那么容易学会,那么就有点装x的嫌疑了。我使用Emacs的原因主要有三点:高度自由、elisp语言的魅力以及org mode。可以说没有org mode我可能不会考虑Emacs。我认为 org mode是Emacs的灵魂也是目前市面上没有任何一款软件能替代的。什么是org mode、它与markdown相比有什么优势呢?本文将对org mode做一个入门的介绍什么是org mode实际上 Org mode 是一种轻量级标记语言,它与markdown、RST类似,但是功能上要比它们强得多,不仅可以用来完成日常的文章编写,还可以进行任务管理、项目规划、笔记收集整理等各种操作。并且配合elisp编程可以千变万化。作为一门标记语言org mode实际是十分容易的,它保存的文档以 .org 作为扩展名基本使用大纲大纲可以理解为多级的标题,了解markdown的肯定知道这个意思。一个 * 代表一级大纲,两个代表二级大纲,然后依次类推。对于大纲我们可以手动输入 *,可以使用Emacs提供的快捷键快捷键功能备注在后面创建一个与光标所在位置同级的大纲如果没有大纲则默认创建一个新的一级大纲M-降低当前大纲的等级 M-升高当前大纲的等级 M-将当前大纲及其内容整体向上移动 M-将当前大纲以及内容整体向下移动 大纲这部分有点像思维导图,我们可以将某些知识点以这种大纲的形式组织起来。有些思维导图软件可以点击某个模块将它的子模块隐藏起来,与这类似的,org mode也可以在大纲上按tab键来显示或者隐藏大纲底下的内容。我们可以定义和切换整个org 文档的大纲显示样式,它主要有三种Folded: 对于当前的大纲只显示大纲本身不显示其子大纲以及内容children: 只显示当前大纲的子大纲,不显示更下一级的内容subtree: 完全展开整个大纲代码块代码块放在 #+BEGIN_SRC 和 #+END_SRC 之间,在Emacs中有一个快捷键 <s <TAB> 来快速输入这个标识. 另外也可以在 后面接上 语言类型,例如下面是一段对应的c++代码#+BEGIN_SRC c++ int main(int argc, char* argv[]) { return 0; } #+END_SRC当我们进入到代码块中编写代码时它会开启对应语言的major mode,前面我们配置了c++ lsp 补全相关的内容也可以在编辑代码块时使用超链接超链接我们可以采用 [[<link url>][<text>]] 的语法,例如 [[https://www.baidu.com][百度一下,你就知道]]图片本地图片可以使用 file:/path/to/image.png 的形式来写上本地图片的位置,然后开启 iimage-mode 显示图片字体样式字体样式主要有:粗体:我们可以使用 ** 来包裹文字以便显示为粗体斜体: 可以使用 // 来包裹文字显示斜体下划线: 可以使用 一前一后两个 _ _来包裹文字将它显示为带下划线的样式删除线: 可以使用 + 前后包裹来显示为删除线其实org mode 与markdown一样都非常简单,日常写博客或者写文档的话,我觉得这些基本知识差不多就够用了。