搜索到
348
篇与
的结果
-
 读《段永平投资问答录》 这本书是段永平在各种公共场合回答网友的关于投资问题的一个汇总,里面包含了段永平关于投资方方面面的知识,下面是本书中我觉得书中比较有价值的部分买股票就是买公司、就是买公司未来现金流的折现大多数人认为买股票就是买未来的涨跌,低价买入高价卖出,因此出现了许多所谓的技术流派,这部分投资者热衷于分析k线图,分析市场行情,分析热点信息,试图预测市场未来的涨跌;而这里段永平却认为买公司股票赚的是未来企业盈利的钱,是否买一家公司的股票要看你是否原因成为公司合伙人,是否愿意买下一整个公司,假设在未来公司的股票无法再进行买卖是否还愿意持有。折现率实际上是相对于投资人的机会成本而言的。最低的机会成本就是无风险回报率,比如美国国债的利率钱在每个时间段都有不同的价值,现在的100元与未来的100元价值是不一样的。假设银行定期存款利率为2%,那么现在的100在1年后可能只值98元左右,因为用现在的98元存银行就可以在1年以后获取100元。也就是说资金是有时间成本的。所谓未来的折现就是使用一个折现率来计算未来公司现金流折现到现在大概值多少钱然后判断是否需要投资。所谓的折现率每个人用的算法都不一样,可以使用无风险利率也就是国债、可以使用通胀率、或者使用待投资公司所在行业的平均回报率。做对的事情在实际中往往就变成不对的事情不要做。我对做对的事情的看法是:发现错了马上改,不管多大的代价都是最小的代价这句话的本意是,对的事情就是买股票就是买公司、就是买公司未来现金流的折现;而不对的事就是看涨跌,关注价格。但是映射到做人和做事上也可以有不一样的理解。与其考虑把事做对,幻想着找到一件能成功的事去做,不如先常识不做某事。例如不撒谎、不沉迷享乐。可以给自己准备一个 do not list 的清单,时刻提醒自己不做清单上的事,相信时间的力量。如果长期不做不对的事,那么时间的复利会带给巨大的奖励巴菲特说知道自己能力圈有多大比能力圈有多大要重要的多。在这句话前面书中说,看不懂的不买、管理层不诚实的不买、价格贵的离谱的不买。能力圈也就是自己能不能真正看懂这家公司。虽然道理看起来很简单,但是实际上很多时候我们是不知道自己不知道,一旦问题超过我们的预期或者我们无力改变,这个时候我们才知道自己原来并不知道所以在做对的事情过程当中所犯的错误和因为做错的事情而带来的结果要严格区分开来这句话的本意是说,即使买的股票涨了,也要区分是靠追涨杀跌,靠K线、关注股价得来的还是靠买优质公司自身迎来的。如果不是走在买股票就是买公司、就是买公司未来现金流折现这条正确的道路上,那么未来肯定也会因为做错误的事亏掉当初赚的钱在自己懂的东西上投资最重要的就是能看到风险在哪结合前面说的能力圈的概念,自己懂就是知道自己这笔投资赚钱在哪,有可能亏在哪。结合机会与损失来确定是否值得投资。在下注投资的那一刻起未来发生的一切不说都在预料之内,未来短期的损失在自己的承受范围。一个是“做对的事情”,就是去找好公司,关注公司长远的未来;另一个是“如何把事情做对”,就是如何找到好公司,如何看到公司的未来。好业务、好管理、好价格好公司就是这三样;好业务就是这个公司现在赚钱、未来不管发生什么重大事件也不影响它赚钱、而且它赚钱的方式方法别的公司还学不来;好的管理层就是为公司股东利益考虑、诚实守信;好价格结合上面说的“在自己懂的东西上投资最重要的就是能看到风险在哪”,即使发生风险也能将损失降低到可控范围之内。在自己估值逻辑计算的价格之下。我觉得看财报最重要的就是剔除不想投的公司,不赚钱的生意多少营业额都是没用的这与我之前看的关于公司财报的书吻合、财报是用来排除企业的。看财报最重要的就是了解当前公司是否赚钱、而未来是否赚钱、是否有其他公司和重大事件能影响该公司赚钱这个需要长期的考察,靠自己对公司的了解,也就是懂公司未来现金流的意思是扣除了再投资以后的现金增加量。长期来讲未来现金流是最说明问题的有一类重资产公司,虽然每年能赚不少钱,但是需要大量投入、实际可用于分配的资金没多少。这类公司不合适投资,它们属于那种轻微的风险就能影响未来赚钱的公司“净资产收益率”是个很好的指标,可以用来排除那些你不喜欢的公司,但不能作为“核心指标”去决定你是否要投的公司。这个指标如果好的话,你首先要看的是债务;如果没有债务问题则马上要看文化,看这种获利是否可以持续。最后还是要回到“right business, right people, right price”。收益率高的公司当然是不错的,说明公司的盈利能力强。净资产收益率低的公司一般都不太好,但成长型公司的初期可能净资产收益率会很低。关键还是看你能不能看懂公司的未来(现金流)看图看线实际上就是看目前(这个时刻或时段)别人对股票的看法。所谓的价值投资者的心中是无图无线的!巴菲特说不想持有一支股票10年就不要拥有它10分钟;靠股价涨跌赚钱实际上是靠有人接盘,从其他投资者手中挣钱。将所有此类投资者看作一个整体,那么在这个整体之外是没有资金流入流出的,也就说这类投资方式没有产生任何有效的利润,就像一个人有多个股票账号,今年将这个账号中的股票卖给那个账号,明天将那个账号中的股票卖给这个账号,这个人虽然每个账号的盈利情况各不相同,但是这个人的总资产是维持不变的,而且频繁的交易就是在给券商送手续费。靠企业获取利润是实打实的利润,是企业将赚到的钱分一部分给投资者买股就是仿若买没有上市交易的企业,2、投资要用闲钱,(不是闲钱的就不能用),3、不看到十年就不投,(4、不懂的谈不上看到十年后,所以不懂的不会投),5、投资不等于长期持有,若有更好的标的,要换股。因为投资有机会成本,失去了不知何时再有当有人非要把金子按铜的价钱卖给你的时候,你是不需要勇气的,你只要确认那真的是金就行了(有可能其实是镀金的铁块或石头)。但是我有个理解,就是无论什么时候卖都不要和买的成本联系起来。卖的理由可能有很多,唯一不该用的理由就是“我已经赚钱了”。就像很多散户说的,回本就卖或者涨到多少就卖。这实际上还是没有看懂公司的未来,或者说还是在按照价格考虑买卖,因为恐惧未来会跌导致亏损所以常常卖飞,失去了未来赚钱的机会
读《段永平投资问答录》 这本书是段永平在各种公共场合回答网友的关于投资问题的一个汇总,里面包含了段永平关于投资方方面面的知识,下面是本书中我觉得书中比较有价值的部分买股票就是买公司、就是买公司未来现金流的折现大多数人认为买股票就是买未来的涨跌,低价买入高价卖出,因此出现了许多所谓的技术流派,这部分投资者热衷于分析k线图,分析市场行情,分析热点信息,试图预测市场未来的涨跌;而这里段永平却认为买公司股票赚的是未来企业盈利的钱,是否买一家公司的股票要看你是否原因成为公司合伙人,是否愿意买下一整个公司,假设在未来公司的股票无法再进行买卖是否还愿意持有。折现率实际上是相对于投资人的机会成本而言的。最低的机会成本就是无风险回报率,比如美国国债的利率钱在每个时间段都有不同的价值,现在的100元与未来的100元价值是不一样的。假设银行定期存款利率为2%,那么现在的100在1年后可能只值98元左右,因为用现在的98元存银行就可以在1年以后获取100元。也就是说资金是有时间成本的。所谓未来的折现就是使用一个折现率来计算未来公司现金流折现到现在大概值多少钱然后判断是否需要投资。所谓的折现率每个人用的算法都不一样,可以使用无风险利率也就是国债、可以使用通胀率、或者使用待投资公司所在行业的平均回报率。做对的事情在实际中往往就变成不对的事情不要做。我对做对的事情的看法是:发现错了马上改,不管多大的代价都是最小的代价这句话的本意是,对的事情就是买股票就是买公司、就是买公司未来现金流的折现;而不对的事就是看涨跌,关注价格。但是映射到做人和做事上也可以有不一样的理解。与其考虑把事做对,幻想着找到一件能成功的事去做,不如先常识不做某事。例如不撒谎、不沉迷享乐。可以给自己准备一个 do not list 的清单,时刻提醒自己不做清单上的事,相信时间的力量。如果长期不做不对的事,那么时间的复利会带给巨大的奖励巴菲特说知道自己能力圈有多大比能力圈有多大要重要的多。在这句话前面书中说,看不懂的不买、管理层不诚实的不买、价格贵的离谱的不买。能力圈也就是自己能不能真正看懂这家公司。虽然道理看起来很简单,但是实际上很多时候我们是不知道自己不知道,一旦问题超过我们的预期或者我们无力改变,这个时候我们才知道自己原来并不知道所以在做对的事情过程当中所犯的错误和因为做错的事情而带来的结果要严格区分开来这句话的本意是说,即使买的股票涨了,也要区分是靠追涨杀跌,靠K线、关注股价得来的还是靠买优质公司自身迎来的。如果不是走在买股票就是买公司、就是买公司未来现金流折现这条正确的道路上,那么未来肯定也会因为做错误的事亏掉当初赚的钱在自己懂的东西上投资最重要的就是能看到风险在哪结合前面说的能力圈的概念,自己懂就是知道自己这笔投资赚钱在哪,有可能亏在哪。结合机会与损失来确定是否值得投资。在下注投资的那一刻起未来发生的一切不说都在预料之内,未来短期的损失在自己的承受范围。一个是“做对的事情”,就是去找好公司,关注公司长远的未来;另一个是“如何把事情做对”,就是如何找到好公司,如何看到公司的未来。好业务、好管理、好价格好公司就是这三样;好业务就是这个公司现在赚钱、未来不管发生什么重大事件也不影响它赚钱、而且它赚钱的方式方法别的公司还学不来;好的管理层就是为公司股东利益考虑、诚实守信;好价格结合上面说的“在自己懂的东西上投资最重要的就是能看到风险在哪”,即使发生风险也能将损失降低到可控范围之内。在自己估值逻辑计算的价格之下。我觉得看财报最重要的就是剔除不想投的公司,不赚钱的生意多少营业额都是没用的这与我之前看的关于公司财报的书吻合、财报是用来排除企业的。看财报最重要的就是了解当前公司是否赚钱、而未来是否赚钱、是否有其他公司和重大事件能影响该公司赚钱这个需要长期的考察,靠自己对公司的了解,也就是懂公司未来现金流的意思是扣除了再投资以后的现金增加量。长期来讲未来现金流是最说明问题的有一类重资产公司,虽然每年能赚不少钱,但是需要大量投入、实际可用于分配的资金没多少。这类公司不合适投资,它们属于那种轻微的风险就能影响未来赚钱的公司“净资产收益率”是个很好的指标,可以用来排除那些你不喜欢的公司,但不能作为“核心指标”去决定你是否要投的公司。这个指标如果好的话,你首先要看的是债务;如果没有债务问题则马上要看文化,看这种获利是否可以持续。最后还是要回到“right business, right people, right price”。收益率高的公司当然是不错的,说明公司的盈利能力强。净资产收益率低的公司一般都不太好,但成长型公司的初期可能净资产收益率会很低。关键还是看你能不能看懂公司的未来(现金流)看图看线实际上就是看目前(这个时刻或时段)别人对股票的看法。所谓的价值投资者的心中是无图无线的!巴菲特说不想持有一支股票10年就不要拥有它10分钟;靠股价涨跌赚钱实际上是靠有人接盘,从其他投资者手中挣钱。将所有此类投资者看作一个整体,那么在这个整体之外是没有资金流入流出的,也就说这类投资方式没有产生任何有效的利润,就像一个人有多个股票账号,今年将这个账号中的股票卖给那个账号,明天将那个账号中的股票卖给这个账号,这个人虽然每个账号的盈利情况各不相同,但是这个人的总资产是维持不变的,而且频繁的交易就是在给券商送手续费。靠企业获取利润是实打实的利润,是企业将赚到的钱分一部分给投资者买股就是仿若买没有上市交易的企业,2、投资要用闲钱,(不是闲钱的就不能用),3、不看到十年就不投,(4、不懂的谈不上看到十年后,所以不懂的不会投),5、投资不等于长期持有,若有更好的标的,要换股。因为投资有机会成本,失去了不知何时再有当有人非要把金子按铜的价钱卖给你的时候,你是不需要勇气的,你只要确认那真的是金就行了(有可能其实是镀金的铁块或石头)。但是我有个理解,就是无论什么时候卖都不要和买的成本联系起来。卖的理由可能有很多,唯一不该用的理由就是“我已经赚钱了”。就像很多散户说的,回本就卖或者涨到多少就卖。这实际上还是没有看懂公司的未来,或者说还是在按照价格考虑买卖,因为恐惧未来会跌导致亏损所以常常卖飞,失去了未来赚钱的机会 -
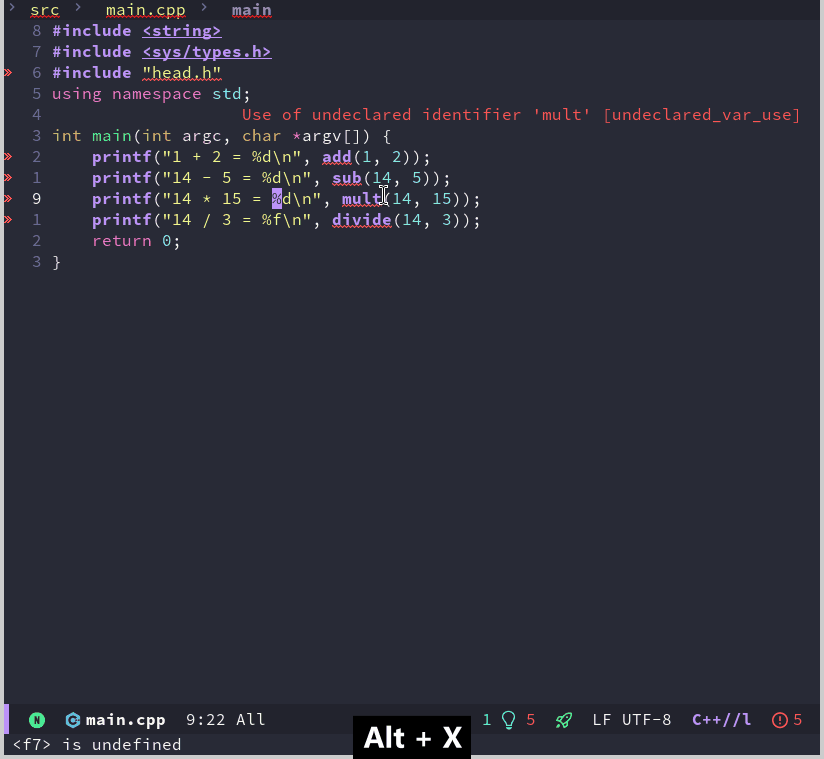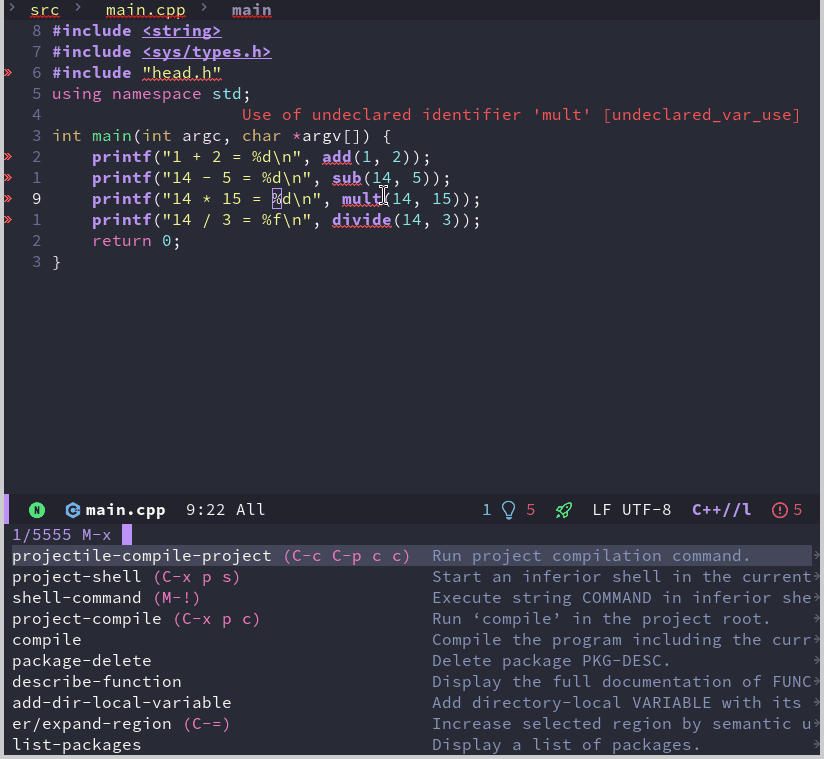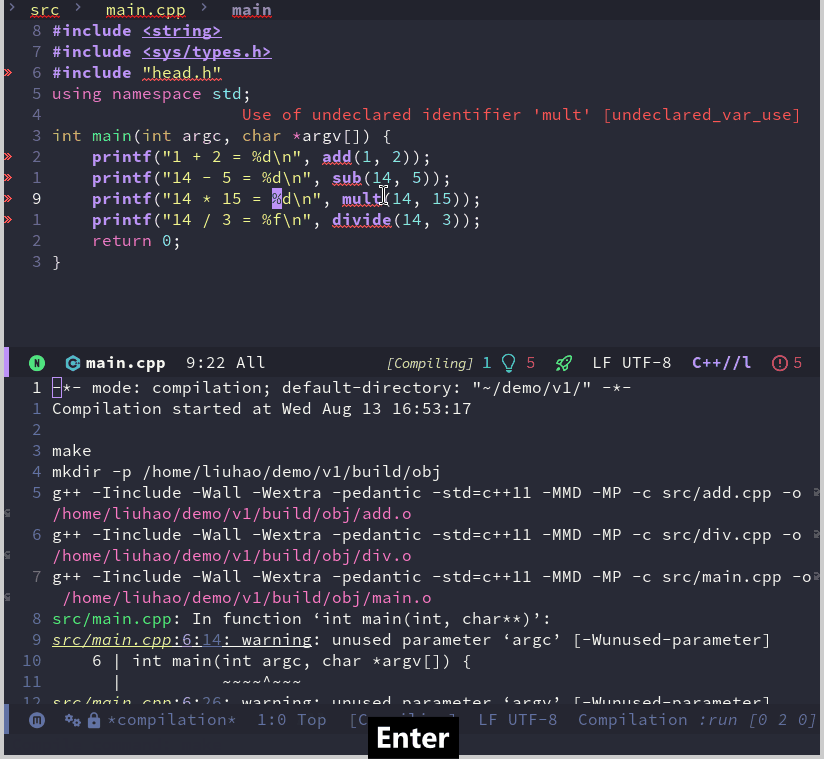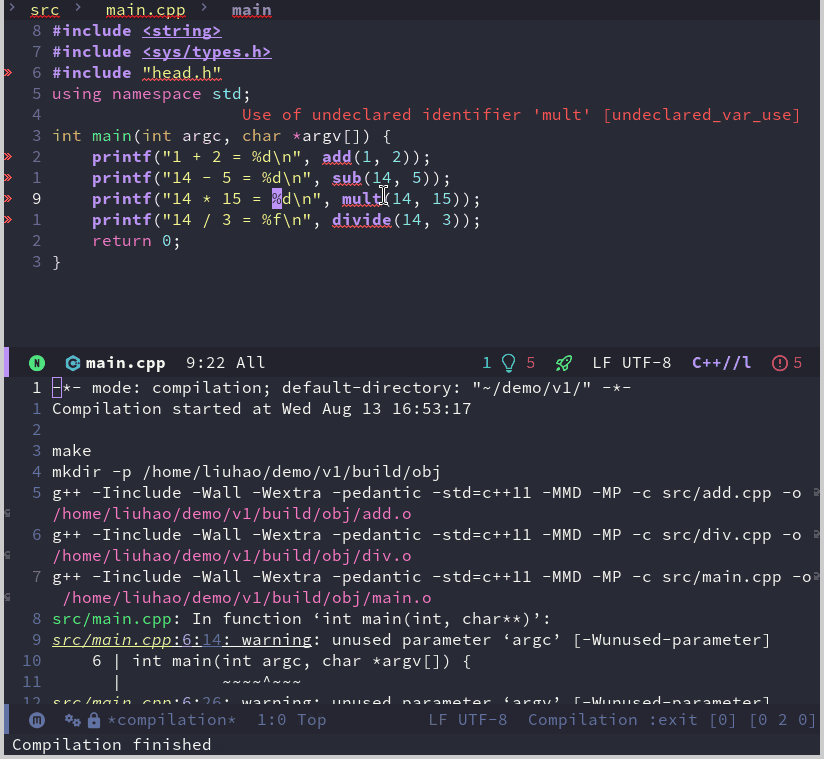
Emacs 折腾日记(三十)——打造C++ IDE 续 上一篇博客中,我完成了C++ IDE初步工作,包括代码的高亮、折叠、跳转以及补全等工作。但是作为IDE来说功能还有点不够,就我个人而言作为IDE来说它还需要具备一键编译运行和调试功能。这篇文章就来记录我是如何实现上述功能的编译运行我使用的演示项目比较简单,它的文件结构如下:. ├── include │ └── head.h └── src ├── add.cpp ├── div.cpp ├── main.cpp ├── mult.cpp └── sub.cpp它分为两个目录分别保存头文件和源文件。其中头文件只有一个定义各个接口函数,而接口函数的实现就放到各自定义的cpp文件中。这里使用加减乘除的四则运算的实现来作为演示。这里我分别演示一下Make文件和CMake构建的项目是如何实现一键编译运行的。Make构建的项目针对上前面介绍的简单项目,我们可以写出如下的Makefile# 编译器设置 # 定义项目根目录 ROOT_DIR := $(dir $(abspath $(lastword $(MAKEFILE_LIST)))) CXX := g++ CXXFLAGS := -Iinclude -Wall -Wextra -pedantic -std=c++11 -MMD -MP LDFLAGS := EXE_OUTPUT := $(ROOT_DIR)bin TARGET := $(EXE_OUTPUT)/app $(info TARGET = $(TARGET)) # 源文件和对象文件设置 SRC_DIR := src SRCS := $(wildcard $(SRC_DIR)/*.cpp) OBJ_DIR := $(ROOT_DIR)build/obj OBJS := $(patsubst $(SRC_DIR)/%.cpp,$(OBJ_DIR)/%.o,$(SRCS)) DEPS := $(OBJS:.o=.d) # 默认目标(第一个目标) all: $(TARGET) # 链接生成可执行文件 $(TARGET): $(OBJS) @mkdir -p $(@D) $(CXX) $(LDFLAGS) $^ -o $@ # 编译源文件并生成依赖 $(OBJ_DIR)/%.o: $(SRC_DIR)/%.cpp | $(OBJ_DIR) $(CXX) $(CXXFLAGS) -c $< -o $@ # 创建对象文件目录 $(OBJ_DIR): mkdir -p $@ # 包含自动生成的依赖关系 -include $(DEPS) # 清理生成的文件 clean: rm -rf $(TARGET) build .PHONY: all clean 上面我们定义了头文件路径为include 目录,并且规定了中间文件生成在 build/obj 中,最后定义了生成可执行程序在 bin/app 中对于编译来说,Emacs内置了 compile 命令,它会自动执行 make -k 命令,但是如果我在使用Emacs的过程中切换到了其他目录的话,还需要特别指定Makefile 所在的路径,对我来说我希望能在尽可能少输入参数的情况下完成同样的操作,不太希望每次都指定项目根目录,好在之前配置的projectile 插件帮助我们识别出来了项目的根目录。所以这里可以使用 projectile-compile-project 来自动指定根目录并编译。从上面的截图可以看到,flycheck 提示了几个错误,这是因为项目没有生成 compile_commands.json文件,所以lsp服务器无法跨文件分析,导致找不到头文件。原始的make 命令并不支持生成 compile_commands.json 文件,我们可以通过 bear 命令来完成这个工作,它的用法比较简单,只需要使用 bear -- <your-build-command> 即可, 对于使用make编译的项目来说 <your-build-command> 代表的就是 make 命令。我们需要考虑的一个问题是,如何将bear加入到编译命令中,也就是将它自动生成的 make -k 给替换掉,第二个问题是如果当前目录在其他目录下,如何保证 compile_commands.json 永远生成在根目录下Emacs中有一个变量 compile-command 保存了编译的命令,如果我们使用Emacs自带的compile来编译可以通过修改它来实现,而 projectile-compile-project 则是通过变量 projectile-project-compilation-cmd 来保存编译命令,默认是nil,对于使用 projectile 我们通过修改这个变量的值从而修改编译时使用的命令。另外既然 projectile 可以得到项目的根目录,我们就可以利用这个插件来获取项目的根目录,有了这些信息通过一个函数就可以重新生成一个编译命令(defun my/general-compile-command() (concat "bear --output " projectile-project-root "compile_commands.json" " -- make -k"))这个函数的代码非常简单,通过 projectile-project-root 来获取项目的根目录,然后通过字符串拼接的方式来得到编译命令生成 compile_commands.json 成功之后,我们重启 lsp 服务后可以看到错误都消失了,只有两个警告了了解了编译的一些情况,下面来看看如何在Emacs中执行生成的可执行程序。Emacs中可以使用 shell-command 来执行可执行 shell 命令。例如我们可以在项目的根目录下执行 shell-command ./bin/app。很明显如果每次都指定程序的路径是非常麻烦的事,我希望能有一个命令或者函数来自动执行可执行程序。但是Makefile构建的项目比较古老也灵活,Makefile中没有一个固定的方式或者写法来指定可执行程序的生成路径,也就是说没有一个通用的方式来根据Makefile获取可执行文件的路径。一种折中的方案就是针对每个项目都定义一个 execuable-path 的变量来指定可执行程序的路径,然后再通过elisp代码来根据这个变量执行程序(defun my/run-program() (interactive) (shell-command (concat projectile-project-root executable-path)))我们可以针对每个项目单独设置一个 executable-path 变量。Emacs会读取项目根目录中的 .dir-locals.el 文件,并且将文件中定义的变量作为项目的局部变量,所以我们只需要在该文件中定义好 executable-path 就可以了。我们可以通过命令 add-dir-local-variable 来往该文件中添加一个局部变量,也可以自己手写该文件实现这一操作添加完变量之后,项目根目录中的 .dir-locals.el 文件内容如下;;; Directory Local Variables -*- no-byte-compile: t -*- ;;; For more information see (info "(emacs) Directory Variables") ((c++-mode . ((executable-path . "bin/app"))))在重启Emacs之后,执行这个函数就可以做到一键运行了有了这些,我希望能将它们有机的组合起来,也就是说按下某个快捷键,这里我暂时定义为 <F7>。它直接同时执行编译和运行的操作。通过 C-<F7> 来完成重编译的操作。;; 重新编译 (defun my/rebuild-program () (interactive) (let ((root (file-name-as-directory (projectile-project-root)))) (shell-command (concat "make clean -C " root)) (setq compile-command (concat "bear --output " root "compile_commands.json" " -- make -k -C " root)) (compile compile-command))) ;; 绑定快捷键 (setq compilation-read-command nil) ;; 取消编译时确定命令行 (evil-define-key 'normal c++-mode-map (kbd "<f7>") #'projectile-compile-project) (evil-define-key 'normal c++-mode-map (kbd "C-<f7>") #'my/rebuild-program))) 这里的代码比较简单,对于编译来说只需要将之前执行的 projectile-compile-project 绑定到对应的快捷键;对于重编译,我通过函数 my/rebuild-program 来完成。这个函数主要操作是先执行 make clean 命令然后重新执行 make。在正式绑定快捷键之前,有一句 (setq compilation-read-command nil) 。projectile-compile-project 和 compile 命令都是交互式命令,执行时会首先显示对应的编译命令,需要用户手动执行回车确认命令,这句代码的意思是不取消它们需要确认的步骤,直接执行命令。本来我打算在重编译函数中也采用 projectile-compile-project 但是它这个交互式我一直取消不了,所以这里我直接采用 compile 指定根目录的方式来完成这个操作。如果想要绑定一键运行的操作也可以采用这个思路,将快捷键绑定到 my/run-program 函数中,这个函数也可以添加一个编译命令确保执行的是最新代码生成的可执行程序CMake工程CMakeLists.txt 文件内容如下:cmake_minimum_required(VERSION 3.15) set(CMAKE_CXX_STANDARD 11) project(test) # aux_source_directory(${PROJECT_SOURCE_DIR} source) file(GLOB source ${CMAKE_SOURCE_DIR}/src/*.cpp) include_directories(${CMAKE_SOURCE_DIR}/include) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) add_executable(app ${source})这个CMakeLists.txt 文件中主要定义了编译使用到的源文件、头文件目录路径和生成的exe路径emacs 中有一个名为 cmake-ide 的包,它用于读取cmake配置中的各项参数并将参数传递到对应的包中,虽然用它可以很方便的针对cmake配置,但是它依赖rtags,并且没有支持lsp-mode。所以这里就淘汰它,还是想办法自己实现针对cmake来说,要生成 compile_commands.json 比较简单,我们可以在命令行中使用cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1也可以在cmake配置文件中,project命令之后添加set (CMAKE_EXPORT_COMPILE_COMMANDS ON)这里我采用将命令写到cmake文件中的方式。对于cmake 编译的过程主要由两个部分组成,首先是cmake构建项目生成Makefile,然后使用make 命令编译项目。我们要实现自动编译也需要模拟这两个命令。与上面类似,这里我只需要将 my/general-compile-command 函数做少许改动即可(defun my/cmake-general-compile-command () (concat "cmake -B " (projectile-project-root) "build -DCMAKE_BUILD_TYPE=Debug " (projectile-project-root) " && ln -sf " (projectile-project-root) "build/compile_commands.json " (projectile-project-root) "compile_commands.json" " && cmake --build " (projectile-project-root) "build --config Debug"))这个函数生成的命令主要完成三个工作,将构建编译生成的临时文件放到 build 目录下;因为生成的 compile_commands.json 文件也一起放在了 build 目录中,所以我加一个软链接到项目根目录的操作;最后就是执行编译操作了。至于重编译则于上面的步骤相似,cmake一般我习惯删除存放临时文件的build目录然后重新执行cmake构建。所以这里还是模拟这个过程(defun my/cmake-rebuild-program () (interactive) (let ((root (file-name-as-directory (projectile-project-root)))) (shell-command (concat "rm -rf " root "build")) (setq compile-command (my/cmake-general-compile-command)) (compile compile-command)))至于运行程序,我们还是可以采用上面介绍的指定程序生成路径的方式。也就是不管使用cmake或者Makefile 构建的工程都可以使用上面定义的 my/run-program 函数来运行程序调试作为IDE的一个重要或者说基础的功能,调试功能是必不可少的。emacs 自身支持使用gdb进行调试,我们可以执行 M-x gdb 来启动一个调试示例,这个时候我们一边通过gdb的调试命令来控制程序语句的执行一边观看代码的上下文。但是目前流行的方式是使用 dap 来调试程序,至于什么是dap,我在配置vim的时候已经介绍过了,这里就不再赘述了emacs 中有一个名为dap-mode 的插件通过这个插件可以实现dap相关的功能。因为在介绍vim配置的时候我使用的是vscode中的 cpptools插件,这里我打算也使用它来作为dap的调试后端,可以通过cpptools官方仓库 进行下载接着需要安装lldb-vscode,它是针对vscode的一个插件,我们可以在 官方仓库 中找到对应的下载包。下载完成之后可以直接解压到对应目录,这里我解压到 ~/.emacs.d/cpptools 目录中。此时对应的调试后端程序为 ~/.emacs.d/cpptools/extension/debugAdapters/bin/OpenDebugAD7。我们需要赋予它可执行的权限。在这些工作都做好之后,可以使用下面的代码来安装dap-mode(use-package dap-mode :ensure t :after (lsp-mode) :config (dap-auto-configure-mode) ; 可选:启用自动配置 (setq dap-cpptools-debug-program '("~/.emacs.d/cpptools/extension/debugAdapters/bin/OpenDebugAD7")) )我们可以通过命令 dap-debug-edit-template 创建一个调试的模板。对给出的模板做一些简单的修改(dap-register-debug-template "cpptools::Run Configuration" (list :type "cppdbg" :request "launch" :name "cpptools::Run Configuration" :MIMode "gdb" :program "${workspaceFolder}/bin/hello" :cwd "${workspaceFolder}" :environment [] :miDebuggerPath "/usr/bin/gdb")) 我们执行一下这个代码就会向Emacs注册一个调试的模板。接着直接调用 dap-debug 即可启动调试。虽然我们可以将上述注册的代码放到主配置文件中,但是其中的一些关键的字段,例如程序的位置,使用的环境变量,以及对应的调试参数都无法做到所有程序都统一,所以这里我觉得还是需要的时候直接修改就好了。dap-mode 的一些命令如下:dap-debug 和 dap-continue : 启动调试或者运行到下一个断点处dap-next : 执行下一句代码dap-step-in : 执行下一行代码并进入函数内部dap-step-out : 执行到函数返回dap-breakpoint-toggle : 创建或者删除端点我们可以对这些命令进行键位绑定(use-package dap-mode :ensure t :after (lsp-mode) :config (dap-auto-configure-mode) ; 可选:启用自动配置 (require 'dap-cpptools) (setq dap-cpptools-debug-program '("~/.emacs.d/cpptools/extension/debugAdapters/bin/OpenDebugAD7")) (evil-define-key 'normal dap-mode-map (kbd "<f10>") #'dap-next) (evil-define-key 'normal dap-mode-map (kbd "<f9>") #'dap-breakpoint-toggle) (evil-define-key 'normal dap-mode-map (kbd "<f5>") #'dap-debug) )这样我们可以使用上述快捷键来进行调试操作总结这篇文章花了好长时间才弄出来,主要是我对于emacs和lisp语言不太熟悉,中间在尝试编写一键运行和配置dap时耗费了大量的时候。最终我还是成功了,至少我完成我当初想要的一些ide的基本功能,当然在使用上还是比不过vscode,但是在折腾中总能找到一丝乐趣。本文中的配置仅仅经过我自己机器的检验,本来想弄的更加灵活更加接近vscode的体验,有一些我自己想要的功能还没加上,仅仅做了一个可用的玩具。但是我没有想到什么办法,而且这篇文章已经憋了好久了,再不写点东西出来我感觉马上就要放弃了,我想先弄点东西出来给自己一个激励,让我有动力继续深入学习一下Emacs的其他内容。等我多学了一点Emacs多写了一点elisp代码之后可能会对调试和编译方面的代码做一个大的更新。最后如果有读者觉得这篇文章写的有那么一点帮助,那将是我的荣幸,感谢读者在百忙之中能读完本文。
-
Ubuntu 20.04 安装gcc5.4 与 cmake3.16 编译环境 因为公司的编译环境使用的是Ubuntu 20.04 搭配 gcc5.4 和 cmake3.16。所以我也在自己的开发机上安装了配套的环境Ubuntu 就使用 WSL2 直接安装就行,编译环境因为Ubuntu 20.04 默认使用的是gcc 9的版本,所以配置起来还是需要稍微费点功夫的。这里记录一下有效的步骤防止后续又需要配置这套环境的时候满世界找因为gcc5.4 相对来说比较老了,这一版Ubuntu 的官方软件源仓库中没有,需要添加额外的软件源仓库我们可以选择先备份原始的软件源,然后将下列源添加到 /etc/apt/sources.list 文件的末尾deb http://archive.ubuntu.com/ubuntu xenial main universe然后执行sudo apt update && sudo apt upgrade更新软件源接着安装gcc 5.4 以及对应的32位环境支持sudo apt install -y gcc-5 g++-5 gcc-5-multilib g++-5-multilib sudo apt install -y libc6-dev-i386 lib32stdc++6 lib32gcc1默认情况下,ubuntu 20.04 中安装的gcc版本是9.0,如果我们自行安装了 gcc5.4,系统中会有多个gcc版本有时候会导致冲突,我们可以使用下面的命令来管理多个gcc版本# 配置备选版本 sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50 sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 50 # 切换版本(选 5.4 对应的编号) sudo update-alternatives --config gcc sudo update-alternatives --config g++此时使用 gcc --version 将会看到当前gcc的版本是5.4Ubuntu 20.04 官方的软件源中cmake的版本就是 3.16,所以对于cmake直接使用sudo apt install cmake
-
读 《动物农场》 故事发生在一个月黑风高的晚上,农场中德高望重的老猪“上校”在即将因为衰老而死去之前召集了农场中的众多动物,决定将它所获得的智慧传授给这些其他动物。农场中的动物劳作一生,却仅仅只能勉强活下去,温饱自然不能奢求,它们的一生只有受苦受难受奴役。但是这些并不是因为农场地穷土薄。这一切都是因为人类偷走了动物的劳动果实,人类不进行生产活动却获得了动物们辛勤劳作的产出。只有打倒人类,劳动成功就是自己的了,几乎在一夜之前就能变得富足、自由。“上校”也强调在赶走人类之后切不可落到去效仿人类,即使征服了人类,也不可将它们的恶习继承下来。最后动物们歌唱了《英格兰的生灵》“上校”在三天后就去世了,但是革命的种子在此就种下了了。教育和组织动物的职责落到了被认为动物中最聪明的猪身上,它们分别是雪球和拿破仑以及一只叫做吱嘎的小肥猪。吱嘎的最大本事就是将白的说成黑的。在动物中宣传革命理论也不是那么容易的,有些动物还是认为它们有义务支持农场主琼斯先生,并且认为“我们是琼斯先生养活的,要是他死了,我们就得饿死”。有一次琼斯忘记给动物喂食导致母牛擅自将饲料棚打开。动物们自行从料箱取食,这激怒了琼斯,在琼斯对着动物们拳打脚踢并且拿鞭子抽打动物的时候,动物们实在是忍无可忍,最终动物们决定反抗。在冲突中动物们最终取得胜利,并且将琼斯赶出了农场。在革命成功后,动物们将曾今琼斯用来奴役动物的马嚼子、鼻环、狗链、缰绳、眼罩等工具付之一炬。并且封锁了琼斯的房间,里面的酒、床等被视作堕落腐化的象征并且禁止任何动物进入。曾今领导革命的猪头头们将动物主义的原理精简为《七戒》写到大谷仓的外墙上:凡是用两条腿行走的都是敌人凡是用四条腿行走的或者长翅膀的都是朋友凡是动物不可穿衣服凡是动物不可睡床铺凡是动物不可饮酒凡是动物不可杀戮别的动物凡是动物一律平等最终这个庄园被命名为动物农场、由鸽子向外其他农场输出革命理论。在农场中诞生了九只小狗崽,拿破仑将它们从母亲身边带走,说是要对它们的教育负责,它将小狗崽放到阁楼中,并且对外仅仅隐蔽。在农场中发生了牛奶和苹果丢失的事件,不久之后发出了公告,牛奶和苹果被拌入猪食。别的动物对此颇有微词。但是吱嘎解释道“并不是猪们贪图享受,只是农场的组织部门需要猪们动用大脑,是脑力劳动,吃苹果喝牛奶只是为了补充脑力,更好的为动物们的福祉进行工作,更好的为了动物谋福利”。并且吱嘎还威胁到如果猪不能恪尽厥责,琼斯将会回来。动物对此就不再有异议了。雪球在日以继夜的研究做一种风车,有了风车动物们就可以有电力,有热水澡可以洗,并且也可以使用电力来转动磨盘减轻动物的劳动负担。在雪球向动物们发表它的政见鼓励动物们赞成建造风车时,拿破仑公开反对制造风车并且发动了政变。它利用之前收养教育的九条长大的小狗崽将雪球驱逐出动物农场。拿破仑掌权后,取消了每周日的民主碰头会,接着成立了一个专门的委员会来决定农场运作的所有事务,成员全都由猪担任,它自己担任委员会的主席。动物们在星期日上午聚在一起向农场的场旗致敬,唱《英格兰的生灵》,接受下达给它们的一周工作任务。但是不再有之前的民主讨论。雪球被驱逐的事虽然在动物圈中引起了一定的讨论但是吱嘎向动物们解释称雪球与琼斯勾结,最终还是以一句“同志们,你们也不希望琼斯回来吧”打消了动物们的疑虑。在雪球被驱逐的三周以后拿破仑决定要建造风车,对此吱嘎向动物们解释这是拿破仑的策略,表面上反对实际是一种迂回战术。在拿破仑当权的那一年动物们自始至终像奴隶一样干活,但是它们清楚的意识到它们干活主要是为了自己,而不是为了不劳而获,转世盗窃的人类。它们每周要工作60小时,这种劳动遵循自愿原则,但是按照多劳多得的原则,不参加加班的动物需要减去一半口粮。动物委员会宣布,它们将会与人类进行交易,动物们虽然有意见,但是在吱嘎的忽悠下也打消了疑虑。动物们在农场上看到拿破仑四肢着地却对着两脚站立的人类下达命令,一股自豪感在它们心中油然而生。在此之后猪们打开了之前封锁的琼斯的阁楼,并且住了进去。动物们虽有疑虑但是吱嘎说,作为动物农场的首脑部门需要一个安静的工作环境,住楼房比住猪圈更能体现伟大领袖的尊贵身份。并且猪们堂而皇之的谁在了人类的床上。动物们明明记得当初的《七戒》规定了凡是动物不可睡床铺。但是吱嘎却说“床的意思仅仅是睡觉的地方而已,戒律针对的是被单,我们已经把被单从农场主宅内的床上撤去,睡在上下两条毯子中间”。并且吱嘎说舒服的睡眠是为了更好的为动物服务,阻止琼斯将来回来。拿破仑为了与人类进行贸易宣布要从母鸡那里拿鸡蛋,并且规定母鸡每天需要产一定数量的鸡蛋,在母鸡进行反抗之后拿破仑宣布停止给母鸡饲料并且也禁止任何动物给母鸡哪怕一颗玉米粒,最终在有9只母鸡死亡的情况下终于停止了反抗。最终死亡的母鸡被埋葬,最终拿破仑宣布母鸡死于疾病。在这个时期风车建造失败了,但是拿破仑将这一切归咎于逃走的雪球并且将农场中发生的一系列不好的事都归咎于雪球,就这样雪球莫名其妙的背负了诸如偷吃谷物、打破鸡蛋、践踏苗床等等罪过,就像它的名字那样,它的罪过也像滚雪球一样越滚越大。哪怕它在反抗琼斯的斗争中身先士卒并且也为之负伤,这也被描述成它事先与琼斯勾结故意演戏。甚至在之后的批判中被认为是雪球一伙的几个动物被处决,墙上的《七戒》中“凡是动物不可杀戮别的动物”这一条也被修改为“凡动物不可杀戮别的动物,如果没有什么理由的话”。动物们付出了比过去更加辛苦的劳动但是仍然食不果腹,仍然生活在饥寒之中。每周日吱嘎总是会工具一串串的数字,从数字上来看各档粮食产量一直在增加,但是它们就是吃不饱。动物们宁愿少听点数字,多得到点吃的。在一段时间之后,其他动物也不能随便直呼拿破仑的名号,在任何时候需要称它为“我们的领袖拿破仑同志”。猪们同时也为它冠以“动物之父”、“人见愁”、“羊圈守护神”、“小鸭之友”的头衔。农场无论取得什么成绩都要归功于拿破仑英明的领导。《七戒》中“凡是动物一律平等”也被修改为“凡是动物一律平等,但是有的动物比其他动物更平等”。慢慢的《七戒》中“凡是动物不可饮酒”被修改为“凡是动物不可饮酒过量”。拿破仑与猪们也开始饮酒,并且将原来准备给动物们安度晚年的一块水果园改种大麦。后面经历过几次人类的反扑,动物中最任劳任怨,力气最大的马——拳击手在一次反抗人类侵略的战争种受伤了,但是它仍然为了建立风车辛苦劳作,终于在某一天它再也起不来了。拿破仑在得知此事之后吱嘎现身了,它对拳击手带来了来自拿破仑的慰问,同时代表拿破仑对拳击手表示了同情和关怀,他承诺会将拳击手送到医院接受治疗。但是在医院的车准备将拳击手拉走之时,它的好友驴子本杰明却发了疯的组织车子的离开,本杰明在后面狂追医院的车。动物们都十分惊讶本杰明的样子,它过去的形象是沉稳中带有点不谙世事,它似乎从来没有将什么事放在心上。在追车失败之后怒喝道“笨蛋,都是笨蛋!难道你们每瞧见车身上写的什么字?”在动物们惊诧的眼神中,本杰明公布了真相,这辆车并不是医院的车,而是屠马场的车。吱嘎回来之后虚构了拳击手在医院的场景,宣布拳击手在医院不治身亡的消息,并且说拳击手在临死之前告知农场的同志们“动物农场万岁、拿破仑万岁,拿破仑永远正确”。又过了几年之后,动物们都到了原来约定的退休时间但是似乎没有动物能真的退休。同时动物们还发现猪们开始用后退走路,前腿夹着一条鞭子。此时猪们似乎更像人了。此时年老的动物们发现动物农场中《七戒》的其他几条都消失了,只剩下一条“凡是动物一律平等,但是有的动物比其他动物更平等”。在夜晚,动物们趴在墙头发现拿破仑与人类正在饮酒。故事在这个高潮中结束了,最后的一句结束语写的十分震撼人心“敢情动物们从窗外朝里看,目光从猪移动到人,再从人移动到猪,又从猪移动到人,要分清哪张脸是猪,哪张脸是人已经不可能了!”本文是乔治奥威尔讽刺集权主义的反乌托邦小说,在阅读的过程中我见识到了一个屠龙者终成恶龙的故事,见识到了集权者对人民的愚弄,舆论的管控,以及它们可笑的面孔。这个故事中极权主义的框架又在他的另一本书《1984》中被发扬光大。
-
-
读 《博格论指数基金》 本书的作者,约翰博格是指数基金之父。本书主要在强调一个主题,那就是从长期来看普通投资者投资被动指数基金的收益要大于投资主动型基金,原因主要有以下几点:相对与主动基金来说,被动指数基金的费用更低,而低费用经过长年累月的积累将是一大笔钱,如果按照收益来算相当于每年多出1到2个百分点的收益长期打败市场很困难,可能在短暂的时间内收益会超过市场的平均收益,但是投资者长期来看能获得与市场相同的收益也十分的不容易主动基金的高收益只是暂时的,未来大部分主动基金最多只能获得市场的平均收益;主动基金短期内的高收益有可能是市场过热的假象,而且主动基金一旦表现良好会导致大量投资者涌入,而主动基金的投资规则不允许基金经理留存大量的现金,导致这些现金必须投入市场有可能会高位接盘,最终在市场震荡向下时给投资者带来损失通过以上几点可以得出结论,普通投资者最好的投资方式就是投资低成本的指数基金。本书的内容十分的简单,但是书中会将一些概念反复的说,并且引用各种名人点评来为这些观点进行论证,虽然可以提到可可信度,但是不免显得有些啰嗦,其实我读这本书主要希望看到作者从他的角度聊聊指数基金的一些常识以及挑选指数基金的方式,没有看到这些我有些失望,也是我不太喜欢这本书的一个原因。但是书中对于投资也给出了一些名言警句,值得反复阅读:股市中价值和价格的关系就像是遛狗时人和狗的关系。价格有时高于价值,有时低于价值,但迟早会回归价值忽略金融市场上的那些短期噪声,关注企业经营的长期状况。想要投资成功,就要摆脱股票价格的预期市场,融入企业的真实市场。当我们试图战胜市场的时候……为了战胜市场而耗费的成本,很有可能会让我们成为输家投资中,真正的钱是创造出来的—就像我们最初用汗水赚到的那笔钱一样,真正的财富不可能来自买卖,只能源于买入证券并长期持有,收取利息和红利,从而实现价值的增长。如果你面前出现了一顿貌似免费的午餐,除非你有足够有说服力的证据,否则它就不是免费的
-
读 《手把手教你读财报》 最近在研究股票投资相关的内容,研究公司阅读财报是必须要经历的步骤。我虽然读过一些财报方面的书,掌握了一些理论,但是一旦遇到真正的财报发现理论与现实还是有一些差距的。介绍财报的书上来就是三大报表:资产负债表、利润表和现金流量表。但是真实的财报不光有这些财务报表,还有重要事项提示、公司情况说明、董事会针对未来公司的一些说明等等。这些信息该如何理解,如何结合财务报表来看这些数据呢?并且公司的财务报表中的科目与之前教科书上的说法有些不太一样。我急需一本能结合具体财报来讲解如何阅读财报、如何根据财报来评估公司的书,碰巧这本《手把手教你读财报》满足我的需求作者在副标题就开门见山的说,财报是用来排除企业的,财报不合格,不清晰的,或者对财报有疑问的应该优先排除利用财报排除企业优秀的企业各有各的优点,而垃圾企业的财报却有一些相似。我们通过阅读财报能首先排除一些不值得投资的企业,根据本书的内容,财报有问题的企业大致有下面的一些问题:无法按时发布年报第三方独立的会计事务所未出示标准无保留意见资产无法核算,例如书中举例养鱼池中的鱼鳖无法核算只能通过进货的发票来计算,存在大量的造假空间跨界开展业务的,比如原来是做食品行业的,最近看到ai比较火慢慢转入到ai行业公司突然改变会计政策,例如改变折旧计算的规则或者更改会计事务所账上没几个钱还容忍其他企业长时间欠款存货周转期变长但是伴随着营业额增加存货在销售额未增加的情况下大量增加,有可能是货卖不出去了公司的利润主要来自于偶然的营业外收入长时间经营现金流为负的需要持续大量现金投入才能产生利润的企业,虽然看着利润或者经营性现金流很多,但是扣除来年的投入实际没剩多少在建工程持续投入增大并且长时间没有看到回报管理层变化巨大,董事会集体辞职优秀企业的财报特征“其他应收款”和“其他应付款”科目涉及金额极小,甚至为零有息负债率低。(原则上说,如果有息负债率超过总资产的60%,企业算比较激进)轻资产公司优于重资产公司。【“当年税前利润总额/生产资产”,得出的比值如果显著高于社会平均资本回报率(按银行贷款标准利率的两倍毛估),则属于“轻公司”,反之则属于重公司。】选择高毛利率的企业。一般来说,毛利率能保持在40%以上的企业,通常都具有某种持续竞争优势。费用(销售费用、管理费及正的财务费用之和)能够控制在毛利润的30%以内,就算是优秀的企业了;费用超过70%的企业关注价值不大。如果只用一个指标来衡量企业的优劣,净资产收益率(ROE)是首选企业现金流肖像中,选择“老母鸡型”和“奶牛型”这两类重点关注。(老母鸡型企业:经营活动的现金流有流入、投入活动的现金流入、融资活动的现金流流出,一般这类企业可以靠经营挣钱并且在通过股利分红来回馈股东或者还债;奶牛型企业:经营活动的现金流流入、投资活动的现金流流出、融资活动的现金流流出;这类企业经营不错并且有计划增加投资来扩大生产以其未来有更好的营业收入,并且融资活动的现金流流出说明在还债或者回馈股东)虽然我总结一些特征,并不是说要严格按照这个标准来筛选企业,按照本书副标题——财报是用来排除企业的,在阅读财报的时候应该假设这份财报有问题带着怀疑的眼光来看,对每个数据多留点心,稍微有疑问的应该去财报中尝试找到解释,一旦发现解释不了或者你不信任财报中给出的解释,那么它就属于垃圾企业,不值得投资
-
wsl 启动报错:Wsl/0x80080005 周末结束过来上班的时候发现公司电脑上安装的wsl2 中的arch和Ubuntu 都无法打开了,表现出来的现象是通过终端打开系统时长时间无法进入系统,等待大概半小时左右会出现提示:Wsl/0x80080005通过网络上查找,这种一般是系统坏了,或者是服务没启动,又或者是网络协议栈出现问题。对应的办法就是重置Linux系统(这种是最坏的情况,一般留到最后实在没办法了再尝试)、启动 LxxManager 服务,重置网络协议。通过尝试我发现我的属于网络协议栈问题,通过powershell 命令(需要管理员权限)netsh winsock reset # 重置网络套接字 netsh int ip reset # 重置 IP 协议然后重启电脑问题就解决啦!
-
Emacs 折腾日记(二十九)—— 打造C++ IDE 在介绍vim配置的时候介绍过lsp的相关基础知识。简单来说lsp是一个协议,它以C/S架构的形式进行组织,lsp负责分析语法,给出具体的语法单元,完成跳转等功能的核心实现。而客户端则负责接收用户的操作请求并呈现具体结果。这样做的好处是将核心服务和客户端显示分离出来,核心部分重用,客户端则可以由各个编辑器自己实现,使各种编辑器都有相同的核心功能体验。对于Emacs来说,由lsp-mode 提供核心客户端库,管理服务器生命周期、消息路由及基础功能。另外也有 lsp-ui 这种增强UI模块,提供实时信息侧边栏(lsp-ui-sideline)、代码透镜(Code Lens)、悬浮文档等下面来介绍如何使用它们配置一个基础的lsp功能lsp-mode根据官方给出的配置,我们可以组一个基础的配置(use-package lsp-mode :ensure t :init ;; set prefix for lsp-command-keymap (few alternatives - "C-l", "C-c l") (setq lsp-keymap-prefix "C-c l") :hook ( ;; if you want which-key integration (lsp-mode . lsp-enable-which-key-integration)) :commands (lsp lsp-deferred))这里我们只是安装了一个客户端,想要真正实现lsp的功能,还需要针对具体的语言下载一个服务端,可以通过 lsp-install-server 来下载如果我们希望能像vscode那样,以悬浮窗口的形式显示符号的定义、声明或者注释文档,那么我们需要使用 lsp-ui 这个插件(use-package lsp-ui :ensure t :after (lsp-mode) :config (setq lsp-ui-doc-position 'top))这里我通过 lsp-ui-doc-position 来定义显示的窗口在上方,一般的编辑器默认是显示在光标所在的位置,但是我觉得显示在光标位置会影响我阅读后续的代码,所以我将它显示在上面,如果各位读者希望它像其他编辑器那样显示在光标位置可以修改参数为 at-point项目管理上述的lsp配置完之后,它只能使用当前buffer中的内容进行语法补全提示,也就是说我在其他的位置定义的函数和类在当前buffer中是无法识别到的。我们需要结合项目一起来使用。我们可以使用名为 projectile 的插件来进行项目管理(use-package projectile :ensure t :init (setq projectile-project-search-path '("~/projects/" "~/work/" "~/playground")) :config (define-key projectile-mode-map (kbd "C-c C-p") 'projectile-command-map) (global-set-key (kbd "C-c p") 'projectile-command-map) (projectile-mode +1)) (use-package counsel-projectile :ensure t :after(projectile) :init (counsel-projectile-mode))这里我们额外安装了 counsel-projectile 用来与 counsel 结合进行搜索语法检查语法检查方面,目前主流的插件是 flycheck 和 flymake,但是好像 flycheck 使用的人多一些,所以这里我也采用 flycheck。(use-package flycheck :ensure t :config (setq truncate-lines nil) ; 如果单行信息很长会自动换行 :hook (prog-mode . flycheck-mode))这里我们仅在编程的时候开启语法检查。同样的, flycheck 是一个前端,用来显示结果的,具体检查的核心功能是通过后端来实现的。后端的程序可以在官方网站上找到。状态栏显示相关的lsp信息现在是时候来修改以下状态栏的显示了,根据配置vim的经验,我还是希望主要显示当前编辑的模式、文件名、文件编码、lsp服务器、语法错误信息等。这里我使用 doom-modeline 来完成这个功能(use-package doom-modeline :ensure t :init (doom-modeline-mode 1) :config (setq doom-modeline-height 30) (setq doom-modeline-bar-width 5) (setq doom-modeline-icon t) (setq doom-modeline-lsp t) (setq doom-modeline-major-mode-icon t) (setq doom-modeline-buffer-state-icon t) (setq doom-modeline-buffer-file-name-style 'truncate-with-project) (setq doom-modeline-check-simple-format t) )通过上述代码来简单的配置一下,就可以有丰富的显示信息每种语言都对应了一个lsp的后端程序,lsp-mode官方网站 给出了每种语言对应的lsp后端程序,我们可以使用 lsp-install-server 来安装,这里我准备安装 clangd 这个后端在安装了lsp之后,再次打开一个cpp文件,可以发现它的界面如下:上面我们完成了lsp配置的基础准备工作,下面将要来针对具体的语言探索一下实际的使用方式和使用体验状态栏下分别显示了当前的模式(N代表normal模式)、文件类型、文件名称、当前编码方式等等,最后一个是flycheck 语法检查的结果,这里的代码比较简单,所以它没有检测出来任何问题,最后以绿色圆圈中的一个勾来显示。需要注意的是状态栏中的小火箭表示lsp服务已启用,如果没有这个标志可以手动的执行 lsp 命令选中项目的根目录C++ 项目实例C/C++ 项目需要明确的编译信息,clangd 通过 compile_commands.json 文件获取这些信息。对于cmake构建的项目cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1另外我希望每种语言对应的lsp配置放入到不同的配置文件中,做到模块化处理,因此我在配置中新建了一个lsp目录,并且按编程语言每种语言一个配置文件。目前c++语言的配置如下:(require 'lsp-mode) (add-hook 'c++-mode-hook (lambda () (setq lsp-project-identification-methods '(:root ("compile_commands.json" ".git" ".clangd" "CMakeLists.txt" "Makefile"))) (setq lsp-clients-clangd-args '("-background-index" "--clang-tidy" "--completion-style=detailed")) (setq-local completion-at-point-functions '( cape-file cape-keyword cape-dabbrev)) (lsp-deferred))) (provide 'cpp)为了实现不同的语言加载不同的配置,这里通过对应模式的hook来实现。一般每种模式都有一个对应的hook变量,它里面保存了一个函数,当启用该模式时会执行对应的代码,这里c++-mode 对应的是 c++-mode-hook。在这个hook中,主要做了四件事:第一,我们定义了项目根目录的标识;第二,定义了clangd启动的一些参数;最后也是最关键的一点,我们重新定义了补全端的函数。在配置Emacs的补全时,提供了一大堆补全方式,很多在编程时是用不到的,而且Emacs在补全时会依次根据 completion-at-point-functions 列表中保存的补全函数来查找补全项,一旦前一个函数返回了补全项,那么就不再往后查找。在编程的过程中前面定义的很多补全功能并没有lsp提供的补全好用,而且还会影响lsp的补全导致它出不来,所以我们去掉一些没用的,仅仅保留关键的部分。lsp-mode 会提供一个名为 lsp-completion-at-point 的补全函数注册到 completion-at-point-functions 中,因此这里我们不需要单独的写出来,当然写出来也没问题。我们可以通过 describe-variable 命令来查看 completion-at-point-functions 的值。Its value is (lsp-completion-at-point cape-file cape-keyword cape-dabbrev) Local in buffer main.cpp; global value is (cape-line cape-elisp-symbol cape-dict cape-ispell cape-keyword cape-file cape-dabbrev tags-completion-at-point-function) 最后一件事就是调用 lsp-deferred 来延迟加载lsp。因为 lsp-deferred 需要等到缓冲区完全加载完成之后才加载,所以将它放到最后面代码跳转在vim中,有几个关于跳转的关键的快捷键,gd 表示 goto declaration 跳转到定义,gD 表示 goto definition 跳转到定义,使用 gf 来跳转到头文件,跳转之后可以使用 ` 再次回来,这些快捷键 evil` 也为我们保留了,我们不需要额外的配置只要lsp能加载起来就能使用。显示符号文档信息vim配置中定义了 gh 显示符号的文档信息,我们可以使用 define-key 来定义快捷键。既然显示文档的功能由 lsp-ui 来提供,这里就将代码放入到 lsp-ui 位置(define-key lsp-ui-mode-map (kbd "gh") #'lsp-ui-doc-glance)tree-sitter在配置vim的时候提到过tree-sitter 是轻量级的语法分析器,而lsp是进行语义分析的重量级工具,tree-sitter 是对 lsp 的一个补充,并且我们用tree-sitter 进行了语法高亮和代码片段的折叠,这里尝试在Emacs中使用tree-sitter(use-package tree-sitter :ensure t :hook (prog-mode . tree-sitter-hl-mode) ;;启用语法高亮 :config (global-tree-sitter-mode)) (use-package tree-sitter-langs :ensure t :after tree-sitter)安装完成之后,我们通过命令 tree-sitter-langs-install-grammars 来安装对应的语言支持,默认是安装所有语言的支持,这里我就使用默认的就好下面尝试启用在vim中 zc、和 zo的功能。它们主要是用来折叠和展开代码块。我们来安装一个名为 ts-fold 的插件,该插件没有被放入到 elpa,所以需要手动下载然后加载(use-package ts-fold :load-path "~/.emacs.d/ts-fold" :config (global-ts-fold-mode 1) (with-eval-after-load 'evil (evil-define-key 'normal 'global "zc" #'ts-fold-close "zo" #'ts-fold-open)))最终的效果如下:基于tree-sitter,我们还可以实现一个非常重要的功能——增量选择代码块。在vim配置中我使用回车来扩大选区,使用退格键来减小选区,这里仍然沿用这种配置增量选择的功能可以使用 expand-region(use-package expand-region :ensure t ; 从ELPA自动安装 :bind ("C-=" . er/expand-region) :config (defun my/incremental-expand-region() (interactive) (if (region-active-p) (er/expand-region 1) (er/mark-word)) (setq deactivate-mark nil)) (defun my/contract-region() (interactive) (if (region-active-p) (er/contract-region 1) (call-interactively 'evil-backward-char))) (with-eval-after-load 'evil (dolist (state '(normal visual motion)) (evil-define-key state 'global (kbd "RET") nil) (evil-define-key state 'global (kbd "<backspace>") nil)) (evil-define-key 'normal 'global (kbd "RET") #'my/incremental-expand-region) (evil-define-key 'normal 'global (kbd "<backspace>") #'my/contract-region)))原版的增量选择,如果没有选中某个部分无法执行增量,所以对它进行稍微的改造,如果当前没有选中任何部分,先选中当前光标所在的单词。然后继续进行增量选择。与增加选区类似的,减少选区也是先判断如果已经没有选中区域的话还是延续vim中退格键的功能。本篇到此就先结束了,但是我们的IED的功能并没有配置完,后面我计划加上自动编译运行、调试等功能,这些就在后面的文章中给出
-
Emacs折腾日记(二十八)——代码片段 在前面的章节中,介绍了 vertico 体系的补全,已经实现了在各个buffer中的补全功能,但是作为程序员,使用Emacs主要用来编程,对于编程来说上述的补全体系仍然不够完整,我们还需要基于lsp的补全以及基于代码片段模板的补全,这里先介绍代码片段。在之前写vim的配置时已经介绍过代码片段的概念以及基于vim 的配置,感兴趣的读者可以自行在我往期的博客中寻找,这里就不对它进行详细的介绍了。直接来使用它。在Emacs中,我们使用插件 yasnippet 来支持这个功能(use-package yasnippet :ensure t :hook ((after-init . yas-reload-all) ((prog-mode LaTeX-mode org-mode) . yas-minor-mode)) :config (setq yas-snippet-dirs '("~/.emacs.d/snippets")))我们通过上面的代码就能把它启用起来,yas-reload-all 表示在Emacs启动时重新加载所有已启动的代码片段;yas-minor-mode代表启动代码片段补全的功能。但是我们做了限制,只在编写代码、LaTeX和org-mode 文件时启动。如果各位读者希望在markdown 中也启动的话,也可以加上 markdown-mode 的选项。但是既然使用了Emacs,当然要用比 markdown 更加强大的 org-mode 了现在Emacs已经支持了代码片段,它的快捷键与vim中的一致都是使用tab 来进行补全。那么接下来就是通过代码片段文件来提高我们编程的效率了。添加代码片段文件我们可以使用已经写好的,也可以自己根据自己的习惯来定制。下载通用的代码片段官方虽然提供了一些代码片段,但是数量较少,使用起来并不那么方便,我们可以下载网络上的一些公共库来丰富我们的代码片段。这里我介绍一下 Doom Emacs Snippets Library。它是专门为doom emacs 用户打造的代码片段库,使用者不少。其他的代码片段库的安装与使用与它类似,读者可以依葫芦画瓢来安装。 首先找到官方的代码仓库,然后将它克隆下来,我将它放到 ~/.emacs.d/emacs-snippets 目录中。然后通过(use-package doom-snippets :ensure nil :load-path "~/.emacs.d/doom-snippets" :after yasnippet)来加载它。之后需要 Yasnippet 插件能找到这个目录,所以我们修改一下上面的配置(use-package yasnippet :ensure t :hook ((after-init . yas-reload-all) ((prog-mode LaTeX-mode org-mode) . yas-minor-mode)) :config (setq yas-snippet-dirs '("~/.emacs.d/snippets" "~/.emacs.d/doom-snippets"))) ;; 添加一行代码片段的加载路径此时再编写代码发现多了一些代码片段自定义代码片段与 doom emacs snippets library 代码片段类似,我们也需要按照具体的mode来组织代码片段的文件目录。每一个关键字一个文件例如~/.emacs.d/snippets/ ├── python-mode/ │ ├── for ; for 循环模板 │ └── class ; 类定义模板 └── c++-mode/ └── foreach ; for-each 循环模板有了这些准备的前提条件,我们可以自行创建自己的代码片段了。在emacs 中执行 yas-new-snippet 可以打开一个新的buffer,并显示代码片段的模板# -*- mode: snippet -*- # name: # key: # -- name后面跟着的是代码片段的名称,在补全时会以补全项显示这个名称;key代表关键字,表示用哪个缩写来触发。例如我们定义一个 prt 来展开成 printf 语句,那么就可以写成 name:prt key: prt尝试生成第一个代码片段后面的写具体展开的代码,例如我们编写一个自动生成hello world的模板# -*- mode: snippet -*- # name: create-hello # key: hello # -- #include <stdio.h> int main(int argc, char* argv[]) { printf("hello world\n"); return 0; } 在编写完成之后使用快捷键 C-c C-c 来保存,Emacs在保存时会让你输入对应的 mode 并且给出需要保存的位置。当我们修改完适用的 mode 和 保存的位置之后,我们发现它在对应位置生成了文件。重启Emacs或者 使用命令 yas-reload-all 来重新加载所有的代码片段。之后输入hello就可以看到它为我们生成了 c 版本的 hello world 程序占位符我们希望的代码大体上不变但是关键地方由我们自己来填充,这个时候可以使用占位符。占位符的格式为 ${} 大括号中填入数字序号。或者使用 ${1: default} 来表示这个位置默认填写default字符。下面是一个具体的例子# -*- mode: snippet -*- # name: qt-class # key: qcls # -- class ${1} : public ${2:QObject} { Q_OBJECT public: ${1}(${2}* parent = nullptr); ${1}(const ${1}& other); ${1}& operator=(const ${1}& other); ~${1}(); signals: slots: protected: }上面我们定义了一个快速生成继承自 QObject 类的子类的模板,上面有两个占位符,第一个占位符表示名称,它没有默认值,一旦确定了它的也就是类型,它会自动生成类的无参构造、拷贝构造、赋值运算符重载和析构函数的定义。第二个占位符指出了它的父类,它的默认值是 QObject 类,它的效果如下使用elisp代码生成动态信息我们可以使用 `` 来包裹elisp代码,生成动态信息。一般在C/C++ 代码的头文件中会包含一些注释信息,用来说明文件的用途包含的接口信息等等。我们希望生成这么一段注释的代码片段# -*- mode: snippet -*- # name: Custom File Header # key: hdoc # -- /** * @file `(file-name-nondirectory (buffer-file-name))` * @bref ${1:brief description} * @details ${2:detailed explanation} * @date `(format-time-string "%Y-%m-%d")` * @commit history: * \t v${3:1.0}: ${4:Initial version} */ $0上面我们使用 elisp代码 (file-name-nondirectory (buffer-file-name)) 来获取对应的文件名,通过 (format-time-string "%Y-%m-%d") 来获取时间。并且最后使用 $0 来将光标定位到这个位置,这个位置将会在我们使用tab处理过所有tab之后自动跳转。本文到此就结束了。本文主要介绍了在Emacs中使用代码片段,并且介绍了编写代码片段的一些方式。有了这些在编写代码时会更加得心应手。