搜索到
378
篇与
的结果
-
 PE文件简介 PE文件的全称是Portable Executable,意为可移植的可执行的文件,常见的EXE、DLL、OCX、SYS、COM都是PE文件,PE文件是微软Windows操作系统上的程序文件(可能是间接被执行,如DLL)。它是跨win32平台的,只要运行在Windows上,不管是在什么体系的CPU上都可以运行PE文件使用平面的地址空间,所有代码和数据都合并在一起,组成一个很大的结构,文件的内容被分为不同的区块,块中包含代码和数据,每个区块在内存中都有其对应的权限,比如有的快只读,有的只写或者有的只可执行。一般有以下区块:.text : 是在编译或者汇编结束时产生的一种区块,是指令的代码.rdata :是运行时的只读数据,也就是所说的const常量.data:初始化的数据块,也就是全局变量.idata:包含其他外来dll的函数以及数据信息,即输入表.rsrc:包含全部的资源,如图标、菜单、位图等等每个区块在内存中按页边界对齐,区块没有大小限制,是一个连续的结构,每个块都有对应的属性pe文件的优势:磁盘上的数据结构与在内存中的结构是一致的相关名词:入口点(EntryPoint):程序执行的第一条指令所在的内存地址文件偏移地址(FileOffset)PE文件存储在磁盘上的时候,各个数据的地址相对于文件头的距离为文件的偏移地址虚拟地址(VirtuallAddress VA)应用程序访问的逻辑地址也就是它的虚拟地址基地址(ImageBase):文件被映射到内存时,初始地址叫做基地址pe文件大致结构如下图所示:一般在说到PE文件时都会涉及到以下几个名词基地址(ImageBase):PE文件被加载到内存中的首地址,是这个模块的句柄,可以使用函数GetModuleHandle来获取文件的偏移地址:PE文件中各个部分相对于文件头的偏移相对虚拟地址(RVA):PE结构被映射到内存中后,某个位置所在内存相对于基地址的偏移一般可执行文件被PE加载器加载到内存中后,文件的基本格式不会发生改变,只是会将各个块按照页来进行对其,PE文件在磁盘与在内存中的对应关系大致如下图所示:
PE文件简介 PE文件的全称是Portable Executable,意为可移植的可执行的文件,常见的EXE、DLL、OCX、SYS、COM都是PE文件,PE文件是微软Windows操作系统上的程序文件(可能是间接被执行,如DLL)。它是跨win32平台的,只要运行在Windows上,不管是在什么体系的CPU上都可以运行PE文件使用平面的地址空间,所有代码和数据都合并在一起,组成一个很大的结构,文件的内容被分为不同的区块,块中包含代码和数据,每个区块在内存中都有其对应的权限,比如有的快只读,有的只写或者有的只可执行。一般有以下区块:.text : 是在编译或者汇编结束时产生的一种区块,是指令的代码.rdata :是运行时的只读数据,也就是所说的const常量.data:初始化的数据块,也就是全局变量.idata:包含其他外来dll的函数以及数据信息,即输入表.rsrc:包含全部的资源,如图标、菜单、位图等等每个区块在内存中按页边界对齐,区块没有大小限制,是一个连续的结构,每个块都有对应的属性pe文件的优势:磁盘上的数据结构与在内存中的结构是一致的相关名词:入口点(EntryPoint):程序执行的第一条指令所在的内存地址文件偏移地址(FileOffset)PE文件存储在磁盘上的时候,各个数据的地址相对于文件头的距离为文件的偏移地址虚拟地址(VirtuallAddress VA)应用程序访问的逻辑地址也就是它的虚拟地址基地址(ImageBase):文件被映射到内存时,初始地址叫做基地址pe文件大致结构如下图所示:一般在说到PE文件时都会涉及到以下几个名词基地址(ImageBase):PE文件被加载到内存中的首地址,是这个模块的句柄,可以使用函数GetModuleHandle来获取文件的偏移地址:PE文件中各个部分相对于文件头的偏移相对虚拟地址(RVA):PE结构被映射到内存中后,某个位置所在内存相对于基地址的偏移一般可执行文件被PE加载器加载到内存中后,文件的基本格式不会发生改变,只是会将各个块按照页来进行对其,PE文件在磁盘与在内存中的对应关系大致如下图所示: -
hook键盘驱动中的分发函数实现键盘输入数据的拦截 我自己在看《寒江独钓》这本书的时候,书中除了给出了利用过滤的方式来拦截键盘数据之外,也提到了另外一种方法,就是hook键盘分发函数,将它替换成我们自己的,然后再自己的分发函数中获取这个数据的方式,但是书中并没有明确给出代码,我结合书中所说的一些知识加上网上找到的相关资料,自己编写了相关代码,并且试验成功了,现在给出详细的方法和代码。用这种方式时首先根据ObReferenceObjectByName函数来根据对应的驱动名称获取驱动的驱动对象指针。该函数是一个未导出函数,在使用时只需要先声明即可,函数原型如下:NTSTATUS ObReferenceObjectByName( PUNICODE_STRING ObjectName, //对应对象的名称 ULONG Attributes, //相关属性,一般给OBJ_CASE_INSENSITIVE PACCESS_STATE AccessState, //描述信息的一个结构体指针,一般给NULL ACCESS_MASK DesiredAccess, //以何种权限打开,一般给0如果或者FILL_ALL_ACCESS给它所有权限 POBJECT_TYPE ObjectType, //该指针是什么类型的指针,如果是设备对象给IoDeviceObjectType如果是驱动对象则给IoDriverObjectType KPROCESSOR_MODE AccessMode, //一般给NULL PVOID ParseContext, //附加参数,一般给NULL PVOID *pObject //用来接收相关指针的输出参数 );IoDeviceObjectType或者IoDriverObjectType也是未导出的,在使用之前需要先申明他们,例如extern POBJECT_TYPE IoDriverObjectType; extern POBJECT_TYPE IoDeviceObjectType;然后将该驱动对象中原始的分发函数保存起来,以便在hook之后调用或者在驱动卸载时恢复接下来hook相关函数,要截取键盘的数据,一般采用的是hook read函数在read函数中设置IRP的完成例程,然后调用原始的分发函数,一定要注意调用原始的分发函数,否则自己很难实现类似的功能,一旦实现不了,那么Windows上的键盘功能将瘫痪。在完成例程中解析穿回来的IRP就可得到对应键盘的信息。下面是具体的实现代码#define KDB_DRIVER_NAME L"\\Driver\\KbdClass" //键盘驱动的名称为KbdClass NTSTATUS ObReferenceObjectByName( PUNICODE_STRING ObjectName, ULONG Attributes, PACCESS_STATE AccessState, ACCESS_MASK DesiredAccess, POBJECT_TYPE ObjectType, KPROCESSOR_MODE AccessMode, PVOID ParseContext, PVOID *pObject); extern POBJECT_TYPE IoDriverObjectType; PDRIVER_OBJECT g_pKdbDriverObj; //键盘的驱动对象,保存这个是为了在卸载时还原它的分发函数 PDRIVER_DISPATCH g_oldDispatch[IRP_MJ_MAXIMUM_FUNCTION+1]; int g_KeyCount = 0; //记录键盘IRP的数量,当键盘的请求没有被处理完成时不能卸载这个驱动 VOID DriverUnload(PDRIVER_OBJECT DriverObject) { LARGE_INTEGER WaitTime; int i = 0; DbgPrint("KBD HOOK: Entry DriverUnload\n"); //等待5s WaitTime = RtlConvertLongToLargeInteger(-5 * 1000000000 / 100); //如果IRP没有被处理完成,等待5s再检测是否处理完成 while(0 != g_KeyCount) { KeDelayExecutionThread(KernelMode, FALSE, &WaitTime); } for(i = 0; i < IRP_MJ_MAXIMUM_FUNCTION + 1; i++) { //还原对应的分发函数 g_pKdbDriverObj->MajorFunction[i] = g_oldDispatch[i]; } } NTSTATUS c2cReadComplete( IN PDEVICE_OBJECT DeviceObject, IN PIRP Irp, IN PVOID Context ) { PUCHAR pBuffer; ULONG uLength; int i = 0; if(NT_SUCCESS(Irp->IoStatus.Status)) { pBuffer = (PUCHAR)(Irp->AssociatedIrp.SystemBuffer); uLength = Irp->IoStatus.Information; for(i = 0; i < uLength; i++) { //在完成函数中只是简单的输出了对应的16进制数 DbgPrint("cap2ctrl: Key %02x\r\n", pBuffer[i]); } } //每当一个IRP完成时,未完成的IRP数量都需要减一 g_KeyCount--; if(Irp->PendingReturned) { IoMarkIrpPending( Irp ); } return Irp->IoStatus.Status; } NTSTATUS c2cReadDispathc( IN PDEVICE_OBJECT DeviceObject, IN PIRP Irp ) { PIO_STACK_LOCATION pIroStack; DbgPrint("Hook By Me!\n"); //每当进入这个分发函数时都需要将这个未完成IRP数量加一 g_KeyCount++; //设置完成函数 //在这只能用这种方式,我自己试过用IoSetCompletionRoutine ,它注册的完成函数没有被调用,我也不知道为什么 pIroStack = IoGetCurrentIrpStackLocation(Irp); pIroStack->Control = SL_INVOKE_ON_SUCCESS|SL_INVOKE_ON_ERROR|SL_INVOKE_ON_CANCEL; pIroStack->CompletionRoutine = (PIO_COMPLETION_ROUTINE)c2cReadComplete; //调用原始的分发函数 return (g_oldDispatch[IRP_MJ_READ])(DeviceObject, Irp); } NTSTATUS DriverEntry(PDRIVER_OBJECT pDriverObject, PUNICODE_STRING pRegistryPath) { int i = 0; PDRIVER_OBJECT pKbdDriverObj; UNICODE_STRING uKbdDriverName; NTSTATUS status; UNREFERENCED_PARAMETER(pRegistryPath); DbgPrint("cap2ctrl: Entry DriverEntry\n"); RtlInitUnicodeString(&uKbdDriverName, KDB_DRIVER_NAME); status = ObReferenceObjectByName(&uKbdDriverName, OBJ_CASE_INSENSITIVE, NULL, 0, IoDriverObjectType, KernelMode, NULL, &g_pKdbDriverObj); if(!NT_SUCCESS(status)) { return status; } //保存原始的派遣函数 for(i = 0; i < IRP_MJ_MAXIMUM_FUNCTION+1; i++) { g_oldDispatch[i] = g_pKdbDriverObj->MajorFunction[i]; } //HOOK读请求的派遣函数 g_pKdbDriverObj->MajorFunction[IRP_MJ_READ] = c2cReadDispathc; pDriverObject->DriverUnload = DriverUnload; //绑定设备 return STATUS_SUCCESS; }
-
遍历系统中加载的驱动程序以及通过设备对象指针获取设备对象名称 遍历系统中加载的驱动可以在R3层完成,通过几个未导出的函数:ZwOpenDirectoryObject、ZwQueryDirectoryObject,下面是具体的代码。//在这定义些基本的数据结构,这些本身是在R0层用的比较多的 typedef struct _UNICODE_STRING { USHORT Length; USHORT MaximumLength; PWSTR Buffer; } UNICODE_STRING, *PUNICODE_STRING; typedef ULONG NTSTATUS; // 对象属性定义 typedef struct _OBJECT_ATTRIBUTES { ULONG Length; HANDLE RootDirectory; UNICODE_STRING *ObjectName; ULONG Attributes; PSECURITY_DESCRIPTOR SecurityDescriptor; PSECURITY_QUALITY_OF_SERVICE SecurityQualityOfService; } OBJECT_ATTRIBUTES, *POBJECT_ATTRIBUTES; // 基本信息定义 typedef struct _DIRECTORY_BASIC_INFORMATION { UNICODE_STRING ObjectName; UNICODE_STRING ObjectTypeName; } DIRECTORY_BASIC_INFORMATION, *PDIRECTORY_BASIC_INFORMATION; // 返回值或状态类型定义 #define OBJ_CASE_INSENSITIVE 0x00000040L #define DIRECTORY_QUERY (0x0001) #define STATUS_SUCCESS ((NTSTATUS)0x00000000L) // ntsubauth #define STATUS_MORE_ENTRIES ((NTSTATUS)0x00000105L) #define STATUS_BUFFER_TOO_SMALL ((NTSTATUS)0xC0000023L) // 初始化对象属性宏定义 #define InitializeObjectAttributes( p, n, a, r, s ) { \ (p)->Length = sizeof(OBJECT_ATTRIBUTES); \ (p)->RootDirectory = r; \ (p)->Attributes = a; \ (p)->ObjectName = n; \ (p)->SecurityDescriptor = s; \ (p)->SecurityQualityOfService = NULL; \ } // 字符串初始化 //用来存储设备驱动对象名称的链表 extern vector<CString> g_DriverNameList; vector<DRIVER_INFO> g_DriverNameList; typedef VOID(CALLBACK* RTLINITUNICODESTRING)(PUNICODE_STRING, PCWSTR); RTLINITUNICODESTRING RtlInitUnicodeString; // 打开对象 typedef NTSTATUS(WINAPI *ZWOPENDIRECTORYOBJECT)( OUT PHANDLE DirectoryHandle, IN ACCESS_MASK DesiredAccess, IN POBJECT_ATTRIBUTES ObjectAttributes ); ZWOPENDIRECTORYOBJECT ZwOpenDirectoryObject; // 查询对象 typedef NTSTATUS (WINAPI *ZWQUERYDIRECTORYOBJECT)( IN HANDLE DirectoryHandle, OUT PVOID Buffer, IN ULONG BufferLength, IN BOOLEAN ReturnSingleEntry, IN BOOLEAN RestartScan, IN OUT PULONG Context, OUT PULONG ReturnLength OPTIONAL ); ZWQUERYDIRECTORYOBJECT ZwQueryDirectoryObject; // 关闭已经打开的对象 typedef NTSTATUS (WINAPI *ZWCLOSE)(IN HANDLE Handle); ZWCLOSE ZwClose; BOOL EnumDriver() { HMODULE hNtdll = NULL; UNICODE_STRING strDirName; OBJECT_ATTRIBUTES oba; NTSTATUS ntStatus; HANDLE hDirectory; hNtdll = LoadLibrary(_T("ntdll.dll")); if (NULL == hNtdll) { return FALSE; } RtlInitUnicodeString = (RTLINITUNICODESTRING)GetProcAddress(hNtdll, "RtlInitUnicodeString"); ZwOpenDirectoryObject = (ZWOPENDIRECTORYOBJECT)GetProcAddress(hNtdll, "ZwOpenDirectoryObject"); ZwQueryDirectoryObject = (ZWQUERYDIRECTORYOBJECT)GetProcAddress(hNtdll, "ZwQueryDirectoryObject"); ZwClose = (ZWCLOSE)GetProcAddress(hNtdll, "ZwClose"); RtlInitUnicodeString(&strDirName, _T("\\Driver")); InitializeObjectAttributes(&oba, &strDirName, OBJ_CASE_INSENSITIVE, NULL, NULL); ntStatus = ZwOpenDirectoryObject(&hDirectory, DIRECTORY_QUERY, &oba); if (ntStatus != STATUS_SUCCESS) { return FALSE; } PDIRECTORY_BASIC_INFORMATION pBuffer = NULL; PDIRECTORY_BASIC_INFORMATION pBuffer2 = NULL; ULONG ulLength = 0x800; // 2048 ULONG ulContext = 0; ULONG ulRet = 0; // 查询目录对象 do { if (pBuffer != NULL) { free(pBuffer); } ulLength = ulLength * 2; pBuffer = (PDIRECTORY_BASIC_INFORMATION)malloc(ulLength); if (NULL == pBuffer) { if (pBuffer != NULL) { free(pBuffer); } if (hDirectory != NULL) { ZwClose(hDirectory); } return FALSE; } ntStatus = ZwQueryDirectoryObject(hDirectory, pBuffer, ulLength, FALSE, TRUE, &ulContext, &ulRet); } while (ntStatus == STATUS_MORE_ENTRIES || ntStatus == STATUS_BUFFER_TOO_SMALL); if (STATUS_SUCCESS == ntStatus) { pBuffer2 = pBuffer; while ((pBuffer2->ObjectName.Length != 0) && (pBuffer2->ObjectTypeName.Length != 0)) { CString strDriverName; strDriverName = pBuffer2->ObjectName.Buffer; g_DriverNameList.push_back(strDriverName); pBuffer2++; } } if (pBuffer != NULL) { free(pBuffer); } if (hDirectory != NULL) { ZwClose(hDirectory); } return TRUE; }通过设备对象的地址来获取设备对象的名称一般是在R0层完成,下面是具体的代码//定义相关的结构体和宏 typedef struct _OBJECT_CREATE_INFORMATION { ULONG Attributes; HANDLE RootDirectory; PVOID ParseContext; KPROCESSOR_MODE ProbeMode; ULONG PagedPoolCharge; ULONG NonPagedPoolCharge; ULONG SecurityDescriptorCharge; PSECURITY_DESCRIPTOR SecurityDescriptor; PSECURITY_QUALITY_OF_SERVICE SecurityQos; SECURITY_QUALITY_OF_SERVICE SecurityQualityOfService; } OBJECT_CREATE_INFORMATION, * POBJECT_CREATE_INFORMATION; typedef struct _OBJECT_HEADER { LONG PointerCount; union { LONG HandleCount; PSINGLE_LIST_ENTRY SEntry; }; POBJECT_TYPE Type; UCHAR NameInfoOffset; UCHAR HandleInfoOffset; UCHAR QuotaInfoOffset; UCHAR Flags; union { POBJECT_CREATE_INFORMATION ObjectCreateInfo; PVOID QuotaBlockCharged; }; PSECURITY_DESCRIPTOR SecurityDescriptor; QUAD Body; } OBJECT_HEADER, * POBJECT_HEADER; #define NUMBER_HASH_BUCKETS 37 typedef struct _OBJECT_DIRECTORY { struct _OBJECT_DIRECTORY_ENTRY* HashBuckets[NUMBER_HASH_BUCKETS]; struct _OBJECT_DIRECTORY_ENTRY** LookupBucket; BOOLEAN LookupFound; USHORT SymbolicLinkUsageCount; struct _DEVICE_MAP* DeviceMap; } OBJECT_DIRECTORY, * POBJECT_DIRECTORY; typedef struct _OBJECT_HEADER_NAME_INFO { POBJECT_DIRECTORY Directory; UNICODE_STRING Name; ULONG Reserved; #if DBG ULONG Reserved2 ; LONG DbgDereferenceCount ; #endif } OBJECT_HEADER_NAME_INFO, * POBJECT_HEADER_NAME_INFO; #define OBJECT_TO_OBJECT_HEADER( o ) \ CONTAINING_RECORD( (o), OBJECT_HEADER, Body ) #define OBJECT_HEADER_TO_NAME_INFO( oh ) ((POBJECT_HEADER_NAME_INFO) \ ((oh)->NameInfoOffset == 0 ? NULL : ((PCHAR)(oh) - (oh)->NameInfoOffset))) void GetDeviceName(PDEVICE_OBJECT pDeviceObj) { POBJECT_HEADER ObjectHeader; POBJECT_HEADER_NAME_INFO ObjectNameInfo; if ( pDeviceObj == NULL ) { DbgPrint( "pDeviceObj is NULL!\n" ); return; } // 得到对象头 ObjectHeader = OBJECT_TO_OBJECT_HEADER( pDeviceObj ); if ( ObjectHeader ) { // 查询设备名称并打印 ObjectNameInfo = OBJECT_HEADER_TO_NAME_INFO( ObjectHeader ); if ( ObjectNameInfo && ObjectNameInfo->Name.Buffer ) { DbgPrint( "Driver Name:%wZ - Device Name:%wZ - Driver Address:0x%x - Device Address:0x%x\n", &pDeviceObj->DriverObject->DriverName, &ObjectNameInfo->Name, pDeviceObj->DriverObject, pDeviceObj ); } // 对于没有名称的设备,则打印 NULL else if ( pDeviceObj->DriverObject ) { DbgPrint( "Driver Name:%wZ - Device Name:%S - Driver Address:0x%x - Device Address:0x%x\n", &pDeviceObj->DriverObject->DriverName, L"NULL", pDeviceObj->DriverObject, pDeviceObj ); } } }
-
如何利用git shell提交代码到github 在很早之前我根据找到的一些资料以及自己的实践总结了一篇如何将VS2015上的代码上传到GitHub上,后来我发现有小伙伴私信我,说跟我上面写的不一样,但是那段时间也比较忙,当我发现有人私信的时候差不过过了一个多月了,也就没有回复,最近重新装了系统,在重新下载相关插件时速度太慢了,实在是受不了,故在网上找了些资料,来试试使用命令行,将项目上传到GitHub上,废话不多说,直接说操作步骤。首先在GitHub上新建一个代码仓库,并记录下它的地址:打开GitHub客户端中的git shell(客户端请在网上自行下载)利用cd命令切换到项目目录下利用命令git init 初始化一个代码仓库利用命令 git add . (注意后面有一个点,代表将本地项目工作区的所有文件添加到暂存区)利用命令 git commit -m “注释" 将暂存区的文件添加到本地的代码库中将本地代码库关联到GitHub上git remote add origin 之前保存的代码仓库的地址将本地仓库上传git push -u origin master这样再次在GitHub上查看,可以看到我们的文件已经被上传上来了如何提交更改提交新建的文件为了演示这个,我们在项目中添加两个文件,分别为EnumDriver.h和EnumDriver.cpp由于里面有新建的文件,所以第一步利用cd命令切入到这两个文件所在的目录中首先将这两个代码文件加入到暂存区中cd SimWinObj git add EnumDriver.h EnumDriver.cpp可以使用命令git status 可以查看当前项目的改变(后面有文件被改变是由于我之前编译过整个项目,所以可能某些配置文件存在被改变的情况)从上面的图中可以很清楚的看出那些文件被修改,哪些是新加的文件确认没有问题后,使用命令git commit提交更改,注意:这里仍然需要加上-m"注释" 不然会拒绝提交后使用命令git push -u origin master将这些更改提交到远程仓库中这些执行完成后发现这些修改已经提交到GitHub上了
-
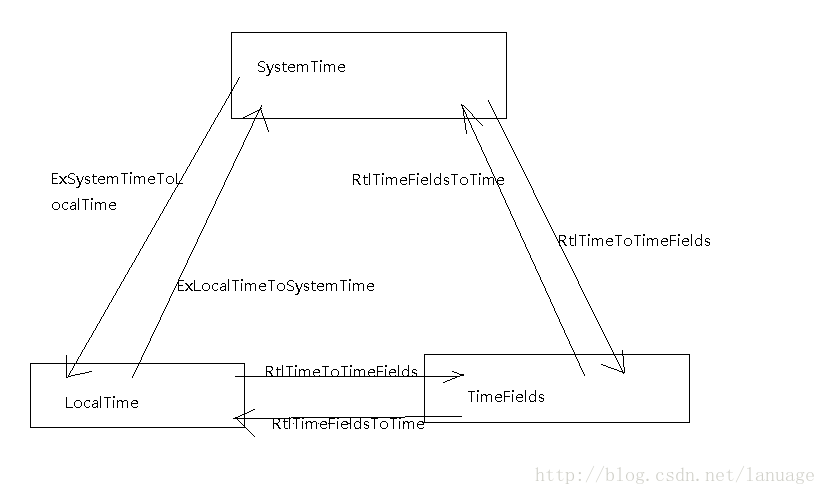
驱动开发中的常用操作 这篇文章会持续更新,由于在驱动中,有许多常用的操作代码几乎不变,而我自己有时候长时间不用经常忘记,所以希望在这把一些常用的操作记录下来,当自己遗忘的时候,有个参考创建设备对象创建设备对象使用函数IoCreateDevice,它的参数如下:NTSTATUS IoCreateDevice( IN PDRIVER_OBJECT DriverObject, IN ULONG DeviceExtensionSize, IN PUNICODE_STRING DeviceName OPTIONAL, IN DEVICE_TYPE DeviceType, IN ULONG DeviceCharacteristics, IN BOOLEAN Exclusive, OUT PDEVICE_OBJECT *DeviceObject );第一个参数是驱动对象第二个参数是设备对象扩展的大小,它会自动根据大小生成一个内存空间,与对应设备绑定第三个参数是驱动名称第四个参数是驱动的类型,一般用作过滤设备的驱动类型为FILE_DEVICE_UNKNOWN第五个参数一般给FILE_DEVICE_SECURE_OPEN第六个参数表示设备是否为独占模式,一般给FALSE第七个参数是设备驱动的二级指针,用来返回生成的设备驱动的指针创建一个过滤设备的代码如下://创建设备对象 status = IoCreateDevice(pDriverObject, sizeof(LIST_ENTRY), &uDeviceName, FILE_DEVICE_UNKNOWN, FILE_DEVICE_SECURE_OPEN, FALSE, &pDeviceObject); //为设备对象设置相关标识 pDeviceObject->Flags |= DO_BUFFERED_IO;IRP的完成在某些我们不需要进行特殊处理,但是又得需要对这个IRP进行处理的时候,一般采用完成处理的方式,这种方式主要使用函数IoCompleteRequest,使用例子如下:Irp->IoStatus.Information = 0; //设置返回给应用层的缓冲区的大小 Irp->IoStatus.Status = STATUS_SUCCESS;//给应用层当前IO操作返回成功 IoCompleteRequest(Irp, IO_NO_INCREMENT);//结束IRP在派遣函数中拿IRP的主功能号IRP中保存了它的主功能号和副功能号,他们都被存储在IRP的栈中,下面是基本的代码pStack = IoGetCurrentIrpStackLocation(Irp); //获取IRP栈 IrpCode = pStack->MajorFunction;在MJ_DEVICE_CONTROL类型的IRP中得到对应的控制码CtrlCode = pStack->Parameters.DeviceIoControl.IoControlCode;获取驱动所在的进程这个方法目前只在XP上实验过,win7或者更高版本可能有些不同。获取当前进程主要在EPROCESS结构找到名为ProcessName的项,由于这个结构微软并没有公开,所以可能以后会根据系统版本的不同它的偏移可能也有些许不同。下面是具体的代码pCurrProcess = IoGetCurrentProcess(); RtlInitUnicodeString(&uProcessName, (PTSTR)((ULONG)pCurrProcess + 0x174)); //这个偏移量是在xp上有效,是通过WinDbg获取到的,如果有变化,也可以通过windbg重新得到数据 代码所处内存的划分在驱动程序中,一定要非常小心的为每个函数,数据划分内存块,否则会出现蓝屏现象,比如处在DISPATCH_LEVEL的代码,只能位于非分页内存,因为这个IRQL下的代码不能被打断,如果发生缺页中断,那么只会造成蓝屏现象。而PASSIVE_LEVLE的代码则没有这个限制。下面是定义函数和数据在不同内存页的写法#define PAGEDCODE code_seg("PAGE") //分页内存 #define LOCKEDCODE code_seg()//非分页内存 #define INITCODE code_seg("INIT")//处在这种类型的代码,当函数执行完成后,系统会立马回收它所在的内存页 #define PAGEDDATA data_seg("PAGE") #define LOCKEDDATA data_seg() #define INITDATA data_seg("INIT") //下面是使用这些宏的例子,使用时只需要在函数或者数据前加上对应的宏 LOCKEDCODE void test() { }给编译器提示,函数某些参数在函数中不使用一般在编译驱动时,如果函数参数或者在函数内部定义了某些变量在函数中没有使用的话,编译器会报错,但是有的函数原型是系统规定,但是有些参数又确实用不到,这个时候有两种方式,一种是关掉相关的编译选项,另一种是使用宏告知编译器,这个变量在函数中不使用.UNREFERENCED_PARAMETER(RegistryPath);获取系统时间这里的获取系统时间一般是指获取时间并将它转化我们熟悉的年月日、时分秒的格式,一般的步骤如下:利用函数KeGetSystemTime()获取系统时间,这个时间是格林尼治时间从1601年起至今经历的时间,单位为100ns利用ExSystemTimeToLocalTime()将上述的格林尼治时间转化为本时区的时间,这个值得含义和单位与上述的相同利用函数RtlTimeToTimeFields()将本地时间转化为带有年月日格式的时间函数的第二个参数是TIME_FIELDS结构,他的定义如下:typedef struct TIME_FIELDS { CSHORT Year; CSHORT Month; CSHORT Day; CSHORT Hour; CSHORT Minute; CSHORT Second; CSHORT Milliseconds; CSHORT Weekday; } TIME_FIELDS;下面是一个时间转化的例子 LARGE_INTEGER current_system_time; TIME_FIELDS time_fields; LARGE_INTEGER current_local_time; KeQuerySystemTime(¤t_system_time); ExSystemTimeToLocalTime(¤t_system_time, ¤t_local_time); RtlTimeToTimeFields(¤t_local_time, &time_fields); DbgPrint("Current Time: %d/%d/%d %d:%d:%d\n", time_fields.Year, time_fields.Month, time_fields.Day, time_fields.Hour, time_fields.Minute, time_fields.Second);他们三个可以互相转化,下面是它们之间转化的一个示意图:文件读写文件读写一般需要进行这样几步使用InitializeObjectAttributes初始化一个OBJECT_ATTRIBUTES对象使用ZwCreateFile创建一个文件句柄调用ZwReadFile或者ZwWriteFile读写文件这里面复杂的是InitializeObjectAttributes和ZwCreateFile传参的问题,好在这两个函数在调用时,一般传参都是固定的。VOID InitializeObjectAttributes( OUT POBJECT_ATTRIBUTES InitializedAttributes, IN PUNICODE_STRING ObjectName, //传希望打开的文件名称或者设备对象名称 IN ULONG Attributes, //权限一般给OBJ_CASE_INSENSITIVE IN HANDLE RootDirectory, //根目录,一般给NULL IN PSECURITY_DESCRIPTOR SecurityDescriptor//安全属性,一般给NULL );NTSTATUS ZwCreateFile( __out PHANDLE FileHandle, //返回的文件句柄 __in ACCESS_MASK DesiredAccess, //权限,如果希望对文件进行同步操作,需要额外加上SYNCHRONIZE __in POBJECT_ATTRIBUTES ObjectAttributes, __out PIO_STATUS_BLOCK IoStatusBlock, //一般不怎么用这个输出参数,但是的给值 __in_opt PLARGE_INTEGER AllocationSize,//一般给NULL __in ULONG FileAttributes,//文件属性,一般给FILE_ATTRIBUTE_NORMAL __in ULONG ShareAccess,//共享属性一般给0 __in ULONG CreateDisposition,//创建的描述信息,根据MSDN很容易决定 __in ULONG CreateOptions, //如果是同步操作,一般加上FILE_SYNCHRONOUS_IO_NONALERT,如果是异步操作一般给0 __in_opt PVOID EaBuffer, //一般给NULL __in ULONG EaLength//一般给0 );下面是读写不同设备的相关代码//同步读取驱动的设备对象 NTSTATUS status; HANDLE hDeviceA; OBJECT_ATTRIBUTES ObjAtrribute; UNICODE_STRING uDeviceName; IO_STATUS_BLOCK status_block; RtlInitUnicodeString(&uDeviceName, DEVICE_NAME); InitializeObjectAttributes(&ObjAtrribute, &uDeviceName, OBJ_CASE_INSENSITIVE, NULL, NULL); status = ZwCreateFile(&hDeviceA, SYNCHRONIZE | FILE_READ_ATTRIBUTES, &ObjAtrribute,&status_block, NULL, FILE_ATTRIBUTE_NORMAL, FILE_SHARE_READ, FILE_OPEN, FILE_SYNCHRONOUS_IO_NONALERT, NULL, 0); if(!NT_SUCCESS(status)) { return status; } ZwReadFile(hDeviceA, NULL, NULL, NULL, &status_block, NULL, 0, NULL, NULL); ZwClose(hDeviceA); return STATUS_SUCCESS;//同步读取文件 HANDLE hFile = NULL; OBJECT_ATTRIBUTES ObjAttribute; IO_STATUS_BLOCK IoStatusBlock; UNICODE_STRING uFileName; WCHAR wFname[] = L"\\??\\C:\\log.txt"; CHAR buf[] = "Hello World\r\n"; NTSTATUS status = STATUS_SUCCESS; FILE_STANDARD_INFORMATION fsi = {0}; PCHAR pBuffer = NULL; RtlInitUnicodeString(&uFileName, wFname); InitializeObjectAttributes(&ObjAttribute, &uFileName, OBJ_CASE_INSENSITIVE, NULL, NULL); //打开文件或者创建文件 status = ZwCreateFile(&hFile, GENERIC_WRITE | GENERIC_READ, &ObjAttribute, &IoStatusBlock, NULL, 0, 0, FILE_OPEN_IF, FILE_SYNCHRONOUS_IO_NONALERT, NULL, NULL); if(!NT_SUCCESS(status)) { DbgPrint("Create File Error\n"); return; } //写文件 status = ZwWriteFile(hFile, NULL, NULL, NULL, &IoStatusBlock, buf, sizeof(buf), NULL, NULL); if(NT_SUCCESS(status)) { DbgPrint("Write File Success%u", IoStatusBlock.Information); } //读取文件长度 status = ZwQueryInformationFile(hFile, &IoStatusBlock, &fsi, sizeof(fsi), FileStandardInformation); if(NT_SUCCESS(status)) { DbgPrint("file length:%u\n", fsi.EndOfFile.QuadPart); } //读文件 pBuffer = (PCHAR)ExAllocatePoolWithTag(PagedPool, fsi.EndOfFile.QuadPart * sizeof(CHAR), 'eliF'); if(NULL != pBuffer) { status = ZwReadFile(hFile, NULL, NULL, NULL, &IoStatusBlock, pBuffer, fsi.EndOfFile.QuadPart * sizeof(CHAR), NULL, NULL); if(NT_SUCCESS(status)) { DbgPrint("Read File %s lenth: %u", pBuffer, fsi.EndOfFile.QuadPart * sizeof(CHAR)); } } //关闭文件句柄 ZwClose(hFile); ExFreePool(pBuffer);
-
定时器的实现 使用IO定时器IO定时器每隔1s就会触发一次,从而进入到定时器例程中,如果某个操作是每n秒执行一次(n为正整数)可以考虑在定时器例程中记录一个计数器大小就为n,每次进入定时器例程中时将计数器减一,当计数器为0时,表示到达n秒,这个时候可以执行操作。IO定时器只适合处理整数秒的情况在使用IO定时器之前需要对定时器进行初始化,初始化函数为IoInitializeTimer,定义如下:NTSTATUS IoInitializeTimer( IN PDEVICE_OBJECT DeviceObject, //设备对象指针 IN PIO_TIMER_ROUTINE TimerRoutine,//定时器例程 IN PVOID Context//传给定时器例程的函数 );初始化完成后可以使用IoStartTimer来启动定时器,使用IoStopTimer来停止定时器,下面是一个例子#define PAGEDCODE code_seg("PAGE") #define LOCKEDCODE code_seg() #define INITCODE code_seg("INIT") #define PAGEDDATA data_seg("PAGE") #define LOCKEDDATA data_seg() #define INITDATA data_seg("INIT") typedef struct _tag_DEVICE_EXTENSION { PDEVICE_OBJECT DeviceObject; UNICODE_STRING uDeviceName; UNICODE_STRING uSymbolickName; LONG lTimerCount; //定时器触发时间,以秒为单位 }DEVICE_EXTENSION, *PDEVICE_EXTENSION; NTSTATUS DriverEntry(DRIVER_OBJECT *DriverObject, PUNICODE_STRING RegistryPath) { NTSTATUS status; LONG i; PDEVICE_OBJECT pDeviceObject; UNREFERENCED_PARAMETER(RegistryPath); DriverObject->DriverUnload = DriverUnload; //设置派遣函数,这些代码在这就省略了 status = CreateDevice(DriverEntry, &pDeviceObject); IoStartTimer(pDeviceObject); return status; } #pragma LOCKEDCODE VOID IoTimer(DEVICE_OBJECT *DeviceObject,PVOID Context) { LONG ret; PDEVICE_EXTENSION pDeviceExtension; UNICODE_STRING uProcessName; PEPROCESS pCurrProcess; UNREFERENCED_PARAMETER(Context); pDeviceExtension = (PDEVICE_EXTENSION)(DeviceObject->DeviceExtension); ASSERT(NULL != pDeviceExtension); //采用互锁操作将定时器数减一 InterlockedDecrement(&pDeviceExtension->lTimerCount); //判断当前时间是否到达3秒 ret = InterlockedCompareExchange(&pDeviceExtension->lTimerCount, TIME_OUT, 0); if(0 == ret) { DbgPrint("3s time out\n"); } pCurrProcess = IoGetCurrentProcess(); RtlInitUnicodeString(&uProcessName, (PTSTR)((ULONG)pCurrProcess + 0x174)); DbgPrint("the current process %wZ", uProcessName); } #pragma INITCODE NTSTATUS CreateDevice(PDRIVER_OBJECT pDriverObject,PDEVICE_OBJECT *ppDeviceObject) { NTSTATUS status; UNICODE_STRING uDeviceName; UNICODE_STRING uSymbolickName; PDEVICE_EXTENSION pDeviceExtension; RtlInitUnicodeString(&uDeviceName, DEVICE_NAME); RtlInitUnicodeString(&uSymbolickName, SYMBOLICK_NAME); if(NULL != ppDeviceObject) { //创建设备对象并填充设备扩展中的变量 ... IoInitializeTimer(*ppDeviceObject, IoTimer, NULL); status = IoCreateSymbolicLink(&uSymbolickName, &uDeviceName); if(!NT_SUCCESS(status)) { //出错的话就做一些清理工作 ... return status; } if(NULL != pDeviceExtension) { RtlInitUnicodeString(&pDeviceExtension->uSymbolickName, SYMBOLICK_NAME); } return status; } return STATUS_UNSUCCESSFUL; }需要注意的是IO定时器例程是位于DISPATCH_LEVEL,所以它不能使用分页内存,所以在函数前加上一句#pragma LOCKEDCODE,表示它在非分页内存中DPC定时器DPC定时器相比IO定时器来说更加灵活,它可以指定任何时间间隔。DPC内部使用KTIMER这个内核对象进行定时,每当时间到达设置的时间,那么系统就会将对应的DPC例程加入到DPC队列中,当系统读取DPC队列时,这个DPC例程就会被执行,使用DPC定时器的步骤一般是:分别调用KeInitializeTimer和KeInitializeDpc初始化KTIMER对象和DPC对象用KeSetTimer开启定时器在DPC例程中再次调用KeSetTimer开启定时器调用KeCancelTimer关闭定时器由于每次执行KeSetTimer都只会触发一次DPC例程,所以如果想要周期性的调用DPC例程,需要在DPC例程中再次调用KeSetTimer。这些函数的定义如下:VOID KeInitializeDpc( IN PRKDPC Dpc, //DPC对象 IN PKDEFERRED_ROUTINE DeferredRoutine, //DPC例程 IN PVOID DeferredContext//传给DPC例程的参数 ); BOOLEAN KeSetTimer( IN PKTIMER Timer,//定时器 IN LARGE_INTEGER DueTime, //隔多久触发这个DPC例程,这个值是正数则表示从1601年1月1日到触发这个DPC例程所经历的时间,为负数,则表示从当前时间,间隔多长时间后触发,单位为100ns IN PKDPC Dpc OPTIONAL //传入上面初始化的DPC对象 );下面是一个使用的例子typedef struct _tag_DEVICE_EXTENSION { PDEVICE_OBJECT pDeviceObj; UNICODE_STRING uDeviceName; UNICODE_STRING uSymbolickName; KTIMER timer; KDPC Dpc; }DEVICE_EXTENSION, *PDEVICE_EXTENSION; NTSTATUS DriverEntry(PDRIVER_OBJECT pDriverObject, PUNICODE_STRING pRegistryPath) { PDEVICE_EXTENSION pDeviceExtension; PDEVICE_OBJECT pDeviceObj; int i; NTSTATUS status; LARGE_INTEGER time_out; UNREFERENCED_PARAMETER(pRegistryPath); pDriverObject->DriverUnload = DriverUnload; //设置派遣函数 ... status = CreateDevice(pDriverObject, &pDeviceObj); //失败处理 ... //设置定时器 time_out.QuadPart = -1 * 10000000; //1s = 1000000000ns status = KeSetTimer(&pDeviceExtension->timer,time_out, &pDeviceExtension->Dpc); return STATUS_SUCCESS; } VOID DriverUnload(PDRIVER_OBJECT pDriverObject) { //该函数主要用来清理相关资源 ... } NTSTATUS DefauleDispatch(IN PDEVICE_OBJECT DeviceObject, IN PIRP Irp) { //默认返回成功 } NTSTATUS CreateDevice(PDRIVER_OBJECT pDriverObj, PDEVICE_OBJECT *ppDeviceObj) { PDEVICE_EXTENSION pDevEx; PDEVICE_OBJECT pDevObj; UNICODE_STRING uDeviceName; UNICODE_STRING uSymbolicName; NTSTATUS status; //创建设备对象,填充扩展设备内容 ... //初始化KTIMER DPC KeInitializeTimer(&pDevEx->timer); KeInitializeDpc(&pDevEx->Dpc, TimerDpc, pDevObj); //设置连接符号 ... return STATUS_SUCCESS; } VOID TimerDpc( __in struct _KDPC *Dpc, __in_opt PVOID DeferredContext, __in_opt PVOID SystemArgument1, __in_opt PVOID SystemArgument2 ) { static int i = 0; PTSTR pProcessName; PEPROCESS pEprocess; LARGE_INTEGER time_out; PDEVICE_OBJECT pDevObj = (PDEVICE_OBJECT)DeferredContext; PDEVICE_EXTENSION pDevEx = (PDEVICE_EXTENSION)(pDevObj->DeviceExtension); ASSERT(NULL != pDevObj); pEprocess = PsGetCurrentProcess(); pProcessName = (PTSTR)((ULONG)pEprocess + 0x174); DbgPrint("%d Call TimerDpc, Process: %s\n", i, pProcessName); time_out.QuadPart = -1 * 10000000; //1s = 1000000000ns KeSetTimer(&pDevEx->timer, time_out, &pDevEx->Dpc); i++; }
-
派遣函数 驱动程序的主要功能是用来处理IO请求,而大部分的IO请求是在派遣函数中完成的,用户模式下所有的IO请求都会被IO管理器封装为一个IRP结构,类似于Windows窗口程序中的消息,不同的IRP被发送到不同的派遣函数中处理IRP与派遣函数IRPIRP(I/O Request Package)输入输出请求包,IRP的两个最基本的结构是MajorFunction和MinorFunction,分别记录IRP的主要类型和子类型,它们是一组函数指针数组,不同的项纪录的是处理当前请求的回调函数,可以在这些派遣函数中继续通过MinorFunction来判断每个驱动都有一个唯一的DRIVER_OBJECT结构,这个结构中有一个MajorFunction数组,通过这个数组可以将IRP与处理它的派遣函数关联起来,当应用层有一个针对于某个设备对象的I/O请求时,会根据这个设备对象所在驱动找到对应的MajorFunction结构,再根据请求类型来找到它对应的处理函数。IRP类型与应用层中有不同的消息类型,系统会根据消息类型调用具体消息处理函数类似,IRP也有不同的类型,在应用层调用不同的函数时会产生不同的IRP类型,例如调用应用层函数CreateFile或者内核函数ZwCreateFile会产生IRP_MJ_CREATE类型的IRP。下面是不同操作所对应产生的IRP请求列表IRP类型来源IRP_MJ_CREATE创建设备,CreateFile会产生此IRPIRP_MJ_CLOSE关闭设备,CloseHandle会产生此IRPIRP_MJ_CLEANUP清除工作,CloseHandle会产生此IRPIRP_MJ_DEVICE_CONTROLDeviceIoControl函数会产生此IRPIRP_MJ_PNP即插即用消息,NT驱动不支持此中IRP,只有WDM驱动才支持此中驱动IRP_MJ_POWER在操作系统处理电源消息时会产生此IRPIRP_MJ_QUERY_INFORMATION获取文件长度,GetFileSize会产生此IRPIRP_MJ_READ读取设备内容,ReadFile会产生此IRPIRP_MJ_SET_INFORMATION设置文件长度,SetFileSize会产生此IRPIRP_MJ_SHUTDOWN关闭系统前会产生此IRPIRP_MJ_SYSTEM_CONTROL系统内部产生控制信息,蕾西与调用DeviceIoControl函数IRP_MJ_WRITE对设备进行WriteFile时会产生此IRP对派遣函数的简单处理大部分的I/O请求都来自于应用层调用相应的API对设备进行I/O操作类似于CreateFile、ReadFile等函数产生,最简单的做法是将IRP设置为成功,然后结束IRP请求,并让派遣函数返回成功,结束这个IRP调用函数IoCompleteRequest。VOID IoCompleteRequest( IN PIRP Irp, //代表要结束的IRP IN CCHAR PriorityBoost//代笔线程恢复时的优先级别 );其实当应用层调用相关函数进行I/O操作时,会陷入睡眠或者阻塞状态,等待派遣函数成功返回,当派遣函数返回时会唤醒之前的等待线程,而第二个参数就是制定这个被唤醒的线程以何种优先级别运行。一般设置为IO_NO_INCREMENT表示不增加优先级,对于键盘,或者鼠标一类的需要更快的相应,这个时候可以设置为IO_MOUSE_INCREMENT 或者IO_KEYBOARD_INCREMENT下面是完成优先级的一个表在应用层打开设备在应用层一般通过设备名称打开驱动中的设备对象,设备名称一般只能在内核层使用,应用层能看到的是设备的符号链接名,符号链接名一般以"??\"开头,在应用层的写法有些不同,应用层设备的符号链接名称以“\.\开头”,因此在内核层符号链接为:"??\HelloDevice"到了应用层则应该写为"\.\HelloDevice"。设备栈驱动对象会创建多个设备对象,并将这些设备对象叠成一个垂直的结构,这种垂直结构被称作设备栈,IRP请求首先被发往设备栈上的顶层设备上,如果这个设备不处理可以将它下发到下层的设备对象中,直到某个设备结束这个IRP请求。为了记录IRP在每层设备中做的操作,IRP中有一个IO_STACK_LOCATION数组,这个数组对应于设备栈中各个设备对IRP所做的操作。在本层的设备中可以使用函数IoGetCurrentIrpStackLocation得到本层设备对应的IO_STACK_LOCATION结构,下面是它对应的结构图缓冲区方式读写操作在调用IoCreateDeivce函数完成设备对象的创建之后,需要设置该设备对象的缓冲区读写方式,这个值是由DEVICE_OBJECT中的Flag来设置,主要有三种DO_DIRECT_IO、DO_BUFFERED_IO 、0。应用层在对设备进行读写操作时,会提供一个缓冲区用于保存需要传入到设备对象或者保存由设备对象传入的数据,Flag值规定就规定了设备对象是如何使用这个缓冲区的。DO_DIRECT_IO:内核直接通过地址映射的方式将那块缓冲区映射为内核地址,然后在驱动中使用。当使用这种方式时内核可以在IO_STACK_LOCATION结构中的MdlAddress拿到这块内存,通过函数MmGetSystemAddressFromMdlSafe传入MdlAddress值可以得到应用层传下来的缓冲区地址DO_BUFFERED_IO:内核会在内核的地址空间空另外开辟一段内存,将缓冲区的数据简单拷贝到这个新开辟的空间中。通过这种方式的读写可以在IRP结构的AssociatedIrp.SystemBuffer中获取。0:内核直接使用应用层的地址,对那块内存进行操作,这种方式是十分危险的,如果进行线程切换,这个地址就不一定指向之前的内存,这样就可能造成系统崩溃蓝屏。这种方式可以通过IRP中的UserBuffer拿到缓冲区地址另外缓冲区的长度可以通过IO_STACK_LOCATION中的Parameters.Read.Length和Parameters.WriteLength分别获取读写缓冲区的长度IO设备控制操作DeviceIoControl与驱动设备交互BOOL DeviceIoControl( HANDLE hDevice, //驱动对象句柄 DWORD dwIoControlCode, //控制码 LPVOID lpInBuffer, //传入到驱动中的数据缓冲 DWORD nInBufferSize, //缓冲大小 LPVOID lpOutBuffer, //驱动传出数据的缓冲 DWORD nOutBufferSize, //输出数据缓冲区的大小 LPDWORD lpBytesReturned, //实际返回数据的大小 LPOVERLAPPED lpOverlapped//异步函数 );这是一个应用层的API函数,用于向驱动发送控制码,在驱动中,根据控制吗的不同而采用不同的处理方式进行处理,应用层可以通过后面几个参数实现与驱动的数据共享。控制码采用宏CTL_CODE来定义#define CTL_CODE(DeviceType, Function, Method, Access)这个宏有四个参数,第一个是设备对象的类型,就是在调用IoCreateDevice创建设备对象时传入的DeviceType的值,第二个参数是设备对象的控制码,为了与系统定义的区分开,一般用户自定义的取值在0x800之上。第三个参数是操作模式,主要有这样几个值:METHOD_BUFFERED、METHOD_IN_DIRECT、METHOD_OUT_DIRECT、METHOD_NEITHER,这些值主要针对的是设备对象的三种缓冲区的读写方式。第四个参数是访问权限,一般给FILL_ANY_ACCESS;这个函数在使用的时候需要注意下面几点:这个函数是在应用层调用,所以必须在调用这个函数前使用CreateFile打开这个设备对象。在调用CreateFile时会向I/O管理器发送一个Create请求,这个请求被I/O管理器包装成IRP,这个IRP的类型为IRP_MJ_CREATE,I/O管理器需要根据驱动的返回值来判断怎么处理这个请求,只有当驱动向I/O管理器返回一个成功的时候才会为其分配句柄,所以驱动中需要自己实现Create的分发派遣函数。驱动中需要自定义一个分发函数用于处理这个IOControl发下来的信息,函数中可以从IO_STACK_LOCATION结构中的Parameters.DeviceIoControl.IoControlCode获得用户层传下来的控制码默认情况下我们会在结束IOControl这个IRP的时候会给定一个返回长度为0,这个时候I/O管理器会将这个值回填到DeviceIoControl函数中的倒数第二个参数中,因此DeviceIoControl的这个参数不能为NULL,否则会造成程序崩溃
-
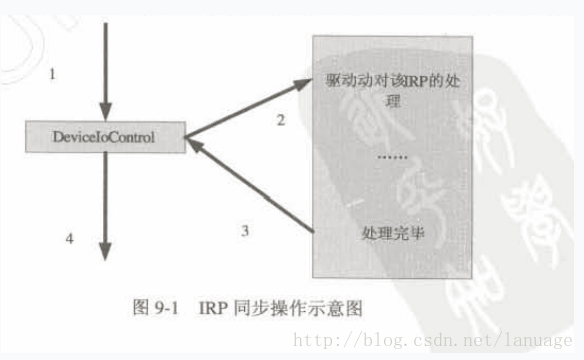
IRP的同步 应用层对设备的同步与异步操作以WriteFile为例,一般的同步操作是调用WriteFile完成后,并不会返回,应用程序会在此处暂停,一直等到函数将数据写入文件中并正常返回,而异步操作则是调用WriteFile后会马上返回,但是操作系统有另一线程在继续执行写的操作,这段时间并不影响应用程序的代码往下执行,一般异步操作都有一个事件用来通知应用程序,异步操作的完成,以下图分别来表示同步和异步操作:在调用这些函数时可以看做操作系统提供一个专门的线程来处理,然后如果选择同步,那么应用层线程会等待底层的线程处理完成后接着执行才执行后面的操作,而异步则是应用层线程接着执行后面的代码,而由操作系统来通知,因此一般来说异步相比较与同步少去了等待操作返回的过程,效率更高一些,但是选择同步还是异步,应该具体问题具体分析同步操作设备如果需要对设备进行同步操作,那么在使用CreateFile时就需要以同步的方式打开,这个函数的第六个参数dwFlagsAndAttributes是同步和异步操作的关键,如果给定了参数FILE_FLAG_OVERLAPPED则是异步的,否则是同步的。一旦用这个函数指定了操作方式,那么以后在使用这个函数返回的句柄进行操作时就是该中操作方式,但是这个函数本身不存在异步操作方式,一来这个函数没有什么耗时的操作,二来,如果它不正常返回,那么针对这个设备的操作也不能进行。一般像WriteFile、ReadFile、DeviceIoControl函数最后一个参数lpOverlapped,是一个OVERLAPPED类型的指针,如果是同步操作,需要给这个参数赋值为NULL异步操作方式设置Overlapped参数实现同步一般能够异步操作的函数都设置一个OVERLAPPED类型的参数,它的定义如下typedef struct _OVERLAPPED { ULONG_PTR Internal; ULONG_PTR InternalHigh; DWORD Offset; DWORD OffsetHigh; HANDLE hEvent; } OVERLAPPED; 对于这个参数在使用时,其余的我们都不需要关心,一般只使用最后一个hEvent成员,这个成员是一个事件对象的句柄,在使用时,先创建一个事件对象,并设置事件对象无信号,并将句柄赋值给这个成员,一旦异步操作完成,那么系统会将这个事件设置为有信号,在需要同步的地方使用Wait系列的函数进行等待即可。int main() { HANDLE hDevice = CreateFile("test.dat", GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL|FILE_FLAG_OVERLAPPED,//此处设置FILE_FLAG_OVERLAPPED NULL ); if (hDevice == INVALID_HANDLE_VALUE) { printf("Read Error\n"); return 1; } UCHAR buffer[BUFFER_SIZE]; DWORD dwRead; //初始化overlap使其内部全部为零 OVERLAPPED overlap={0}; //创建overlap事件 //设置事件采用自动赋值的方式,且初始化为无信号,这样操作系统才能在异步操作完成时自动给其赋值为有信号 overlap.hEvent = CreateEvent(NULL,FALSE,FALSE,NULL); //这里没有设置OVERLAP参数,因此是异步操作 ReadFile(hDevice,buffer,BUFFER_SIZE,&dwRead,&overlap); //做一些其他操作,这些操作会与读设备并行执行 //等待读设备结束 WaitForSingleObject(overlap.hEvent,INFINITE); CloseHandle(hDevice); return 0; }使用完成函数来实现异步操作异步函数是在异步操作完成时由操作系统调用的函数,所以我们可以在需要同步的地方等待一个同步对象,然后在异步函数中将这个对象设置为有信号。使用异步函数必须使用带有Ex的设备操作函数,像ReadFileEx,WriteFileEx等等,Ex系列的函数相比于不带Ex的函数来说,多了最后一个参数,LPOVERLAPPED_COMPLETION_ROUTINE 类型的回调函数,这个函数的原型如下:VOID CALLBACK FileIOCompletionRoutine( __in DWORD dwErrorCode, __in DWORD dwNumberOfBytesTransfered, __in LPOVERLAPPED lpOverlapped );第一个参数是一个错误码,如果异步操作出错,那么他的错误码可以由这个参数得到,第二个参数是实际操作的字节数对于Write类型的函数来说这个就是实际读取的字节数,第三个是一个异步对象。在使用这个方式进行异步时Ex函数中的OVERLAPPED参数一般不需要为其设置事件句柄,只需传入一个已经清空的OVERLAPPED类型的内存地址即可。当我们设置了该函数后,操作系统会将这个函数插入到相应的队列中,一旦完成这个异步操作,系统就会调用这个函数,Windows中将这种机制叫做异步过程调用(APC Asynchronous Produre Call);这种机制也不是一定会执行,一般只有程序进入警戒状态时才会执行,想要程序进入警戒状态需要调用带有Ex的等待函数,包括SleepEx,在其中的bAlertable设置为TRUE那么当其进入等待状态时就会调用APC队列中的函数,需要注意的是所谓的APC就是系统借当前线程的线程环境来执行我们提供的回调函数,是用当前线程环境模拟了一个轻量级的线程,这个线程没有自己的线程上下文,所以在回调函数中不要进行耗时的操作,否则一旦原始线程等到的它的执行条件而被唤醒,而APC例程还没有被执行完成的话,就会造成一定的错误。下面是使用这种方式进行异步操作的例子:VOID CALLBACK MyFileIOCompletionRoutine( DWORD dwErrorCode, // 对于此次操作返回的状态 DWORD dwNumberOfBytesTransfered, // 告诉已经操作了多少字节,也就是在IRP里的Infomation LPOVERLAPPED lpOverlapped // 这个数据结构 ) { SetEvent(lpOverlapped->hEvent); printf("IO operation end!\n"); } int main() { HANDLE hDevice = CreateFile("test.dat", GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL|FILE_FLAG_OVERLAPPED,//此处设置FILE_FLAG_OVERLAPPED NULL ); if (hDevice == INVALID_HANDLE_VALUE) { printf("Read Error\n"); return 1; } UCHAR buffer[BUFFER_SIZE]; //初始化overlap使其内部全部为零 //不用初始化事件!! OVERLAPPED overlap={0}; //这里没有设置OVERLAP参数,因此是异步操作 overlap.hEvent = CreateEvent(NULL, FALSE, FALSE, NULL); ReadFileEx(hDevice, buffer, BUFFER_SIZE,&overlap,MyFileIOCompletionRoutine); //做一些其他操作,这些操作会与读设备并行执行 printf("在此处可以执行其他操作\n"); //进入alterable,只是为了有机会执行APC函数 SleepEx(1000, TRUE); //在此处进行同步,只有当读操作完成才关闭句柄 WaitForSingleObject(overlap.hEvent, INFINITE); CloseHandle(hDevice); return 0; }在最后SleepEx让线程休眠而使其有机会执行APC例程,然后使用WaitForSingleObject来等待事件,我们在APC例程中将事件置为有信号,这样只有当异步操作完成,才会返回,利用这个可以在关键的位置实现同步,在这里按理来说可以直接用WaitForSingleObjectEx来替换这两个函数的调用,但是不知道为什么使用WaitForSingleObjectEx时,即使我没有设置为有信号的状态它也能正常返回,所以为了体现这点,我是使用了SleepEx和WaitForSingleObject两个函数。IRP中的同步和异步操作上述的同步和异步操作必须得到内核的支持,其实所有对设备的操作最终都会转化为IRP请求,并传递到相应的派遣函数中,在派遣函数中可以直接结束IRP,或者让派遣函数返回,在以后的某个时候处理,由于应用层会等待派遣函数返回,所以直接结束IRP的方式可以看做是同步,而先返回以后处理的方式可以看做是异步处理。在CreateFile中没有异步的方式,所以它会一直等待派遣函数调用IoCompleteRequest结束,所以当调用CreateFile打开一个自己写的设备时需要编写一个用来处理IRP_MJ_CREATE的派遣函数,并且需要在函数中结束IRP,否则CreateFile会报错,之前本人曾经犯过这样的错误,没有为设备对象准备IRP__MJ_CREATE的派遣函数,结果CreateFile直接返回-1.对于ReadFile和WriteFile来说,它们支持异步操作,在调用这两个函数进行同步操作时,内部会生成一个事件并等待这个事件,这个事件会和IRP一起发送的派遣函数中,当IRP被结束时,事件会被置为有信号,这样函数中的等待就可以正常返回。而异步操作就不会产生这个事件。而是使用函数中的overlapped参数,这时它内部不会等待这个事件,而由程序员自己在合适的位置等待。而调用带有Ex的I/O函数则略有不同,他不会设置overlapped参数中的事件,而是当进入警告模式时调用提供的APC函数。在派遣函数中可以调用IoCompleteRequest函数来结束IRP的处理或者调用IoMarkIrpPending来暂时挂起IRP,将IRP进行异步处理。该函数原型如下:VOID IoMarkIrpPending( IN OUT PIRP Irp );下面的例子演示了如何进行IRP的异步处理typedef struct IRP_QUEUE_struct { LIST_ENTRY IRPlist; PIRP pPendingIrp; }IRP_QUEUE, *LPIRP_QUEUE; NTSTATUS DefaultDispatch( IN PDEVICE_OBJECT DeviceObject, IN PIRP Irp ) { NTSTATUS status; PIO_STACK_LOCATION pIrpStack; pIrpStack = IoGetCurrentIrpStackLocation(Irp); switch(pIrpStack->MajorFunction) { case IRP_MJ_READ: { PLIST_ENTRY pQueueHead; LPIRP_QUEUE pQueue; Irp->IoStatus.Information = 0; Irp->IoStatus.Status = STATUS_PENDING; pQueue = (LPIRP_QUEUE)ExAllocatePoolWithTag(PagedPool, sizeof(IRP_QUEUE), TAG); if(pQueue != NULL) { pQueue->pPendingIrp = Irp; pQueueHead = (PLIST_ENTRY)(DeviceObject->DeviceExtension); InsertHeadList(pQueueHead, &(pQueue->IRPlist)); } IoMarkIrpPending(Irp); return STATUS_PENDING; } break; case IRP_MJ_CLEANUP: { PLIST_ENTRY pQueueHead; LPIRP_QUEUE pQueue; PLIST_ENTRY pDelete; pQueueHead = (PLIST_ENTRY)(DeviceObject->DeviceExtension); if(NULL != pQueueHead) { while(!IsListEmpty(pQueueHead)) { pDelete = RemoveHeadList(pQueueHead); pQueue = CONTAINING_RECORD(pDelete, IRP_QUEUE, IRPlist); IoCompleteRequest(pQueue->pPendingIrp, IO_NO_INCREMENT); ExFreePoolWithTag(pQueue, TAG); pQueue = NULL; } } } default: { Irp->IoStatus.Information = 0; Irp->IoStatus.Status = STATUS_SUCCESS; IoCompleteRequest(Irp, IO_NO_INCREMENT); return STATUS_SUCCESS; } break; } } VOID DriverUnload(IN PDRIVER_OBJECT DriverObject) { UNICODE_STRING uDeviceName; UNICODE_STRING uSymbolickName; UNREFERENCED_PARAMETER(DriverObject); RtlInitUnicodeString(&uDeviceName, DEVICE_NAME); RtlInitUnicodeString(&uSymbolickName, SYMBOLIC_NAME); IoDeleteSymbolicLink(&uSymbolickName); IoDeleteDevice(DriverObject->DeviceObject); DbgPrint("GoodBye World\n"); } NTSTATUS DriverEntry(IN PDRIVER_OBJECT DriverObject, IN PUNICODE_STRING RegistryPath) { NTSTATUS status; int i = 0; PDEVICE_OBJECT pDeviceObject; UNREFERENCED_PARAMETER(RegistryPath); DriverObject->DriverUnload = DriverUnload; status = CreateDevice(DriverObject, &pDeviceObject); for(i = 0; i < IRP_MJ_MAXIMUM_FUNCTION + 1; i++) { DriverObject->MajorFunction[i] = DefaultDispatch; } DbgPrint("Hello world\n"); return status; } NTSTATUS CreateDevice(PDRIVER_OBJECT pDriverObject,PDEVICE_OBJECT *ppDeviceObject) { NTSTATUS status; PLIST_ENTRY pIrpQueue = NULL; UNICODE_STRING uDeviceName; UNICODE_STRING uSymbolickName; RtlInitUnicodeString(&uDeviceName, &DEVICE_NAME); RtlInitUnicodeString(&uSymbolickName, SYMBOLIC_NAME); if(NULL != ppDeviceObject) { status = IoCreateDevice(pDriverObject, sizeof(LIST_ENTRY), &uDeviceName, FILE_DEVICE_UNKNOWN, FILE_DEVICE_SECURE_OPEN, FALSE, ppDeviceObject); if(!NT_SUCCESS(status)) { return status; } (*ppDeviceObject)->Flags |= DO_BUFFERED_IO; status = IoCreateSymbolicLink(&uSymbolickName, &uDeviceName); if(!NT_SUCCESS(status)) { IoDeleteDevice(*ppDeviceObject); *ppDeviceObject = NULL; return status; } pIrpQueue = (PLIST_ENTRY)((*ppDeviceObject)->DeviceExtension); InitializeListHead(pIrpQueue); return status; } return STATUS_UNSUCCESSFUL; }在上述代码中,定义一个链表用来保存未处理的IRP,然后在DriverEntry中创建一个设备对象,将链表头指针放入到设备对象的扩展中,在驱动的IRP_MJ_READ请求中,将IRP保存到链表中,然后直接调用IoMarkIrpPending,将IRP挂起。一般的IRP_MJ_CLOSE用来关闭内核创建的内核对象,对应用层来说也就是句柄,而IRP_MJ_CLEANUP用来处理被挂起的IRP,所以在这我们需要对CLEANUP的IRP进行处理,在处理它时,我们从链表中依次取出IRP,调用IoCompleteRequest直接结束并清除这个节点。对于其他类型的IRP则直接结束掉即可。在应用层,利用异步处理的方式多次调用ReadFile,最后再IrpTrace工具中可以看到,有多个显示状态位Pending的IRP。在处理IRP时除了调用IoCompleteRequest结束之外还可以调用IoCancelIrp来取消IRP请求。这个函数原型如下:BOOLEAN IoCancelIrp( IN PIRP Irp );当调用这个函数取消相关的IRP时,对应的取消例程将会被执行,在DDK中可以使用函数IoSetCancelRoutine,该函数可以通过第二个参数为IRP设置一个取消例程,如果第二个参数为NULL,那么就将之前绑定到IRP上的取消例程给清除。函数原型如下:PDRIVER_CANCEL IoSetCancelRoutine( IN PIRP Irp, IN PDRIVER_CANCEL CancelRoutine );在调用IoCancelIrp函数时系统在内部会获取一个名为cancel的自旋锁,然后进行相关操作,但是自旋锁的释放需要自己来进行,一般在取消例程中进行释放操作。这个自旋锁可以通过函数IoAcquireCancelSpinLock来获取,通过IoReleaseCancelSpinLock来释放,下面是一个演示如何使用取消例程的例子。//取消例程 VOID CancelReadIrp( IN PDEVICE_OBJECT DeviceObject, IN PIRP Irp ) { Irp->IoStatus.Information = 0; Irp->IoStatus.Status = STATUS_CANCELLED; IoCompleteRequest(Irp, IO_NO_INCREMENT); IoReleaseCancelSpinLock(Irp->CancelIrql); } //IRP_MJ_READ 处理 case IRP_MJ_READ: { Irp->IoStatus.Information = 0; Irp->IoStatus.Status = STATUS_PENDING; IoSetCancelRoutine(Irp, CancelReadIrp); IoMarkIrpPending(Irp); return STATUS_PENDING; }在R3层可以利用CancelIO,来使系统调用取消例程。这个API传入的是设备的句柄,当调用它时所有针对该设备的被挂起的IRP都会调用对应的取消例程,在这就不需要像上面那样保存被挂起的IRP,每当有READ请求过来时都会调用case里面的内容,将该IRP和取消例程绑定,每当有IRP被取消时都会调用对应的取消例程,就不再需要自己维护了。另外在取消时,系统会自己获取这个cancel自旋锁,并提升对应的IRQL,IRP所处的IRQL被保存在IRP这个结构的CancelIrql成员中,而调用IoReleaseCancelSpinLock函数释放自旋锁时需要的参数正是这个IRP对应的IRQL,所以这里直接传入Irp->CancelIrql
-
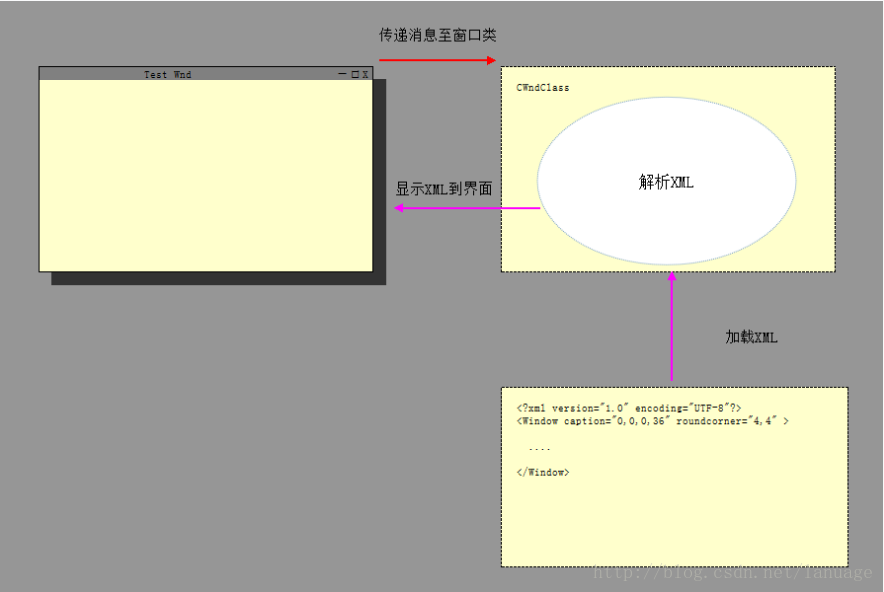
duilib基本流程 duilib的基本流程如上图,通过解析一个xml文件,将文件中的内容渲染为窗口界面,这个解析过程由WindowImplBase类来完成。基本框架如下:首先在公共头文件中加入如下内容:#include <objbase.h> #include <DuiLib\UIlib.h> using namespace DuiLib; #ifdef _DEBUG #pragma comment(lib, "DuiLib_ud.lib"); #else #pragma comment(lib, "DuiLib_d.lib"); #endif这个是duilib的一些基本配置从WindowImplBase类中派生一个类,然后实现这样3个基本函数:virtual CDuiString GetSkinFolder() { return _T("skin"); }; virtual CDuiString GetSkinFile() { return _T("HelloWnd.xml"); }; virtual LPCTSTR GetWindowClassName(void) const { return _T("HelloWnd"); };这三个函数的说明如下:1、 GetSkinFolder () 需要返回 皮肤XML 所在的文件夹2、GetSkinFile () 需要返回 皮肤 XML 的文件名(也可以包含路径)3、GetWindowClassName () 需要返回这个窗口的类名,这个类名用于 RegisterClass.这三个函数告知duilib库应该从哪个文件夹下解析哪个xml文件,并定义对应窗口的名字,以后这个类就代表这个xml文件所描述的窗口需要注意的是这些函数必须在头文件中这样写,我自己写在CPP文件中它在运行时报错,可能是库本身的bug在WinMain主函数中添加如下代码int APIENTRY _tWinMain(_In_ HINSTANCE hInstance, _In_opt_ HINSTANCE hPrevInstance, _In_ LPTSTR lpCmdLine, _In_ int nCmdShow) { CPaintManagerUI::SetInstance(hInstance);// 加载XML的时候,需要使用该句柄去定位EXE的路径,才能加载XML的路径 CHelloWnd* wnd = new CHelloWnd; // 生成对象 wnd->Create(NULL, NULL, UI_WNDSTYLE_DIALOG, 0); // 创建DLG窗口 wnd->CenterWindow(); // 窗口居中 // wnd->ShowWindow();//作为非模态对话框显示 wnd->ShowModal(); // 显示 // CPaintManagerUI::MessageLoop(); // 消息循环,是一个默认的消息循环,什么消息都不响应 delete wnd; // 删除对象 return 0; }在这创建了一个对话框,但是如果加上消息循环就表示它是一个非模态对话框,这个窗口我没有给它菜单栏,也就没有关闭按钮,如果作为非模态对话框,要加上一句CPaintManagerUI::MessageLoop();给它一个消息循环。但是它将不能关闭,只能通过任务管理器强制结束,使用ShowModal表示将它作为模态对话框,在win32中模态对话框使用它自己的消息循环,也就不需要自己给它一个消息循环,它可以在任务栏上被关闭。类的Create函数定义如下:HWND Create(HWND hwndParent, LPCTSTR pstrName, DWORD dwStyle, DWORD dwExStyle, int x = CW_USEDEFAULT, int y = CW_USEDEFAULT, int cx = CW_USEDEFAULT, int cy = CW_USEDEFAULT, HMENU hMenu = NULL);可以看到它就是对WIN32中CreateWindow的封装,在这duilib为窗口自定义了一些类型,其中主要的类型如下:#define UI_WNDSTYLE_CONTAINER (0) #define UI_WNDSTYLE_FRAME (WS_VISIBLE | WS_OVERLAPPEDWINDOW) #define UI_WNDSTYLE_CHILD (WS_VISIBLE | WS_CHILD | WS_CLIPSIBLINGS | WS_CLIPCHILDREN) #define UI_WNDSTYLE_DIALOG (WS_VISIBLE | WS_POPUPWINDOW | WS_CAPTION | WS_DLGFRAME | WS_CLIPSIBLINGS | WS_CLIPCHILDREN) //下面是窗口的扩展类型 #define UI_WNDSTYLE_EX_FRAME (WS_EX_WINDOWEDGE) #define UI_WNDSTYLE_EX_DIALOG (WS_EX_TOOLWINDOW | WS_EX_DLGMODALFRAME) //下面是窗口类类型 #define UI_CLASSSTYLE_CONTAINER (0) #define UI_CLASSSTYLE_FRAME (CS_VREDRAW | CS_HREDRAW) #define UI_CLASSSTYLE_CHILD (CS_VREDRAW | CS_HREDRAW | CS_DBLCLKS | CS_SAVEBITS) #define UI_CLASSSTYLE_DIALOG (CS_VREDRAW | CS_HREDRAW | CS_DBLCLKS | CS_SAVEBITS)大部分都是对win32中窗口类型的一个组合。如果熟悉WIN32编程,那么很容易知道这些都代表什么
-
驱动程序的同步处理 驱动程序运行在系统的内核地址空间,而所有进程共享这2GB的虚拟地址空间,所以绝大多数驱动程序是运行在多线程环境中,有的时候需要对程序进行同步处理,使某些操作是严格串行化的,这就要用到同步的相关内容。异步是指两个线程各自运行互不干扰,而当某个线程运行取决与另一个线程,也就是要在线程之间进行串行化处理时就需要同步机制。中断请求级别在进行I/O操作时会产生中断,以便告知CPU当前I/O操作已完成,此时CPU会停下手头的工作,来处理这个中断请求,在Windows操作系统中,分为硬件中断和软件中断。并且将这些中断映射为不同级别的中断请求级。硬件中断是由硬件产生的中断,软件中断是由int指令产生的。在传统的PC中,一般可以接收16种中断信号,每个信号对应一个中断号。硬件中断分为可屏蔽中断和不可屏蔽中断。可屏蔽中断是由可编程中断控制器(PIC)产生,这是一个硬件设备。在后面的PC机中采用了高级可编程中断控制器(APIC)代替。在APIC中将中断扩展为24个,每个都有对应的优先级,一般正在运行的线程可以被中断打断,进入中断处理程序,当优先级高的中断来临时处在低优先级的中断也会被打断。在Windows中中断请求级别有32个,但是在编程或者在MSDN上只需要关心两类级别,PASSIVE_LEVEL:用户级别,这个中断级别最低。DISPATCH_LEVEL:级别相对较高。在运用内核函数时可以查看MSDN,运行在低优先级的函数不能进行高优先级的一些操作。下面是一些常用函数的优先级函数优先级DriverEntry AddDevice DriverUnload等函数PASSIVE_LEVEL各种分发派遣函数PASSIVE_LEVEL完成函数DISPATCH_LEVELNDIS回调函数DISPATCH_LEVEL在内核模式中可以调用KeGetCurrentIrql得到当前的IRQL需要注意的是,线程优先级只针对于应用程序,只有在IRQL处于PASSIVE_LEVEL级别才有意义。当线程运行在PASSIVE_LEVEL级别的时候可以进行线程切换,而当IRQL提升到DISPATCH_LEVEL,就不再出现线程切换PASSIVE_LEVEL是应用层的中断级别,可以有线程切换,处在这个IRQL下的程序是位于进程上下文,可以进行线程的切换休眠等操作,而处于DISPACTH_LEVEL的程序属于中断上下文,CPU会一直执行这个环境下的代码,没有线程切换,不能进行线程的休眠操作,否则,一旦休眠则没有线程能够唤醒。在内存的使用上,PASSIVE_LEVEL级别的程序可以使用分页内存,一旦发生缺页中断,系统可以进行线程切换,切换到其他进程,将缺页装载在内存,但是在DISPATCH_LEVEL没有线程切换,一旦发生缺页中断就会导致系统崩溃,所以DISPATCH_LEVEL只能使用非分页内存。我们可以在程序中手动提升和降低当前的IRQL。VOID KeRaiseIrql( IN KIRQL NewIrql, //新IRQL OUT PKIRQL OldIrql//当前的IRQL ); VOID KeLowerIrql( IN KIRQL NewIrql //新IRQL );自旋锁自旋锁是一种同步机制,他能保证某个资源只被一个线程所拥有。在初始化自旋锁的时候,处于解锁状态,这个时候线程可以获取自旋锁并访问同步资源,一旦有一个线程获取到自旋锁,必须等到它释放以后,才能被其他线程获取。自旋锁被锁上之后当切换到另外的线程时,线程会不停的询问是否可以获取自旋锁。此时线程处于空转的情况,白白浪费了CPU资源,所以一般要慎用自旋锁使用方法自旋锁用结构体KSPIN_LOCK来表示使用自旋锁的时候需要对其进行初始化,初始化可以使用函数KeInitializeSpinLock,一般在驱动加载函数DriverEntry或者AddDevice函数中初始化自旋锁。VOID KeInitializeSpinLock( IN PKSPIN_LOCK SpinLock );申请自旋锁可以使用函数KeAcquireSpinLock。VOID KeAcquireSpinLock( IN PKSPIN_LOCK SpinLock, OUT PKIRQL OldIrql //自旋锁以前所处的IRQL );释放自旋锁可以使用函数KeReleaseSpinLock内核模式下线程的创建在内核模式中线程使用PsCreateSystemThread;该函数的原型如下:NTSTATUS PsCreateSystemThread( OUT PHANDLE ThreadHandle, //线程的句柄指针,这个参数作为一个输出参数 IN ULONG DesiredAccess,//新线程的权限,在驱动中这个值一般给0 IN POBJECT_ATTRIBUTES ObjectAttributes OPTIONAL,//线程的属性,一般给NULL IN HANDLE ProcessHandle OPTIONAL,//该线程所属的进程句柄,如果给NULL表示创建一个系统进程的线程 OUT PCLIENT_ID ClientId OPTIONAL,//指向客户结构的一个指针,在驱动中这个值一般给NULL IN PKSTART_ROUTINE StartRoutine,//新线程的函数地址 IN PVOID StartContext//线程函数的参数 );第4个参数表示创建线程的类型,如果给NULL则表示创建一个系统线程,否则表示将创建一个用户线程,DDK提供了一个宏NtCurrentThread()来获取当前进程的句柄,这个当前进程表示的是像驱动发送IRP请求的进程的句柄。获取进程名在XP中EPROCESS结构的0X174偏移位置记录着线程名,我们可以使用IoGetCurrentProcess()函数来获取当前进程的EPROCESS结构,这样我们 可以利用这样的代码来获取进程名:PEPROCESS pEprocess = IoGetCurrentProcess(); ASSERT(NULL != pEprocess); DbgPrint("the process name is %S\n", (PTSTR)((ULONG)pEprocess + 0x174));下面是一个使用线程的例子VOID MyProcessThread(PVOID pContext) { //获取当前发送IRP请求的线程名 PEPROCESS pCurrProcess = IoGetCurrentProcess(); PTSTR pProcessName = (PTSTR)((CHAR*)pCurrProcess + 0x174); // UNREFERENCED_PARAMETER(pContext); DbgPrint("MyProcessThread Current Process %s\n", pProcessName); PsTerminateSystemThread(0); } VOID SystemThread(PVOID pContext) { //获取系统进程名 PEPROCESS pCurrProcess = IoGetCurrentProcess(); PTSTR pProcessName = (PTSTR)((CHAR*)pCurrProcess + 0x174); // UNREFERENCED_PARAMETER(pContext); DbgPrint("MyProcessThread Current Process %s\n", pProcessName); PsTerminateSystemThread(0); } VOID CreateThread_Test() { HANDLE hSysThread = NULL; HANDLE hMyProcThread = NULL; NTSTATUS status; //创建系统进程 status = PsCreateSystemThread(&hSysThread, 0, NULL, NULL, NULL, SystemThread, NULL); //创建用户进程 status = PsCreateSystemThread(&hMyProcThread, 0, NULL, NtCurrentProcess(), NULL, MyProcessThread, NULL); } 内核模式下的同步对象内核模式下的同步对象与应用层的大致相同,所以理解了应用的线程同步对象,那么内核层的也很好理解内核模式下的等待函数内核模式下的等待函数是KeWaitForSingleObject 和 KeWaitForMultipleObjects,一个是用来等待单个事件,一个是用来等待多个事件。NTSTATUS KeWaitForSingleObject( IN PVOID Object, /第一个参数是一个指向同步对象的指针 IN KWAIT_REASON WaitReason,//第二个参数是等待原因,在驱动中这个值应该被设置为Executive IN KPROCESSOR_MODE WaitMode,//等待模式,处在低优先级的驱动应该将这个值设置为KernelMode IN BOOLEAN Alertable,//是否是警惕的 IN PLARGE_INTEGER Timeout OPTIONAL//等待时间,如果是正数则表示从1601年1月1日到现在的时间如果是负数则表示从现在算起的时间,单位是100ns );函数如果是等待到了对应的事件则返回STATUS_SUCCESS如果是由于等待时间到了,则返回STATUS_TIMEOUT内核模式下的事件对象在内核中用KEVENT来表示一个事件对象,在使用事件对象时需要对其进行初始化,使用函数KeInitializeEventVOID KeInitializeEvent( IN PRKEVENT Event, //事件对象的指针 IN EVENT_TYPE Type, //事件类型,一般分为两种:NotificationEvent 通知事件和同步事件SynchronizationEvent IN BOOLEAN State//是否是激发状态 );所谓的激发状态就是有信号状态,没有线程拥有这个事件。在这个状态下其他线程中的等待函数可以等到这个事件这两种类型的事件对象的区别在于如果是通知事件需要程序员手动的更改事件的状态,如果是同步事件,在等待函数等到这个事件对象后会自动将这个对象设置为无信号状态可以使用函数KeSetEvent设置事件为有信号,这样其他线程的等待函数就可以等到这个事件LONG KeSetEvent( IN PRKEVENT Event, //事件对象的指针 IN KPRIORITY Increment,//被唤起的线程将以何种优先级执行,这个参数与IoCompleteRequest的第二个参数含义相同 IN BOOLEAN Wait //一般给FALSE );下面是这个它的使用例子VOID Event_Test() { KEVENT keEvent; HANDLE hThread; //初始化事件对象,并设置为无信号 KeInitializeEvent(&keEvent, NotificationEvent, FALSE); //创建新线程,将事件对象传入线程函数中,新线程将会设置事件对象为有状态 PsCreateSystemThread(&hThread, 0, NULL, NULL, NULL, EventThread, &keEvent); if(NULL == hThread) { DbgPrint("Create Event Thread Error!\n"); return; } KeWaitForSingleObject(&keEvent, Executive, KernelMode, FALSE, NULL); } VOID EventThread(PVOID pContext) { PKEVENT pEvent = (PKEVENT)pContext; DbgPrint("This is Event Thread\n"); KeSetEvent(pEvent, IO_NO_INCREMENT, FALSE); PsTerminateSystemThread(0); }驱动程序与应用程序交互事件对象本质上用户层和内核层的事件对象是同一个东西,在用户层用句柄代替,看不到它的具体结构,在内核层是一个KEVENT,能知道它的具体数据成员。我们可以先在应用层创建一个事件对象的句柄,然后通过DeviceIoControl传到应用层,然后利用函数ObReferenceObjectByHandle将这个句柄转化为对应的事件对象,在利用这个函数转化成功后会将事件对象的计数 + 1所以在使用完后应该调用函数ObDereferenceObject使计数减1NTSTATUS ObReferenceObjectByHandle( IN HANDLE Handle, //用户层传下来的内核对象句柄 IN ACCESS_MASK DesiredAccess, //访问权限对于同步事件一般给EVENT_MODIFY_STATE IN POBJECT_TYPE ObjectType OPTIONAL,//转化何种类型的内核结构 IN KPROCESSOR_MODE AccessMode,//模式,一般有KernelMode和UserMode OUT PVOID *Object,//对应结构的指针 OUT POBJECT_HANDLE_INFORMATION HandleInformation OPTIONAL//这个参数在内核模式下为NULL );第三个参数根据转化的内核结构的不同可以有下面的结构。参数值对应的结构*IoFileObjectTypePFILE_OBJECT*ExEventObjectTypePKEVENT*PsProcessTypePEPROCESS或者PKPROCESS*PsThreadTypePETHREAD或者PKTHREAD下面是内核层的例子else if(IOCTL_TRANS_EVENT == pIrps->Parameters.DeviceIoControl.IoControlCode) { //接收从应用层下发的下来的事件句柄 hEvent = *(PHANDLE)(Irp->AssociatedIrp.SystemBuffer); if(NULL == hEvent) { DbgPrint("Invalied Handle\n"); goto __RET; } status = ObReferenceObjectByHandle(hEvent, EVENT_MODIFY_STATE, *ExEventObjectType, KernelMode, &pkEvent, NULL); if(!NT_SUCCESS(status)) { //失败 DbgPrint("Translate Event Error\n"); goto __RET; } //将事件设置为有信号 KeSetEvent(pkEvent, IO_NO_INCREMENT, FALSE); //引用计数 -1 ObDereferenceObject(pkEvent); }驱动程序与驱动程序交互事件对象在内核驱动中可以通过给某个内核对象创建一个命名对象,然后在另一个驱动中通过名字来获取这个对象,然后操作它来实现两个驱动之间的内核对象的通讯,针对事件对象来说,要实现两个驱动交互事件对象,通过这样几步:在驱动A中调用IoCreateNotificationEvent或者IoCreateSynchronizationEvent来创建一个通知事件对象或者同步事件对象在驱动B中调用 IoCreateNotificationEvent或者IoCreateSynchronizationEvent获取已经有名字的内核对象的句柄在驱动B中调用ObReferenceObjectByHandle根据上面两个函数返回的句柄来获取A中的事件对象,并操作它操作完成后调用ObDereferenceObject解引用PKEVENT IoCreateNotificationEvent( IN PUNICODE_STRING EventName, OUT PHANDLE EventHandle );如果指定名称的事件存在那么将会通过EventHandle来返回这个事件对象的句柄,如果不存在则会创建一个事件并通过返回值直接返回这个事件对象的结构指针,需要注意的是这个名字必须以L"\BaseNamedObjects\” 开头另外不能在DriverEntry中等待过长时间,否则会造成系统蓝屏内核模式下的信号量在操作系统相关的书籍中但凡说到线程的同步问题就会涉及到信号量,当多个线程共享一个公共资源时在某一时刻只能有一个线程在运行,这个时候一般用事件对象控制,而当多个线程共享多个公共资源时,可以有多个线程同时在运行,这个时候就可以用信号量,可以把信号量想象成一个盒子,里面有多盏灯,当只要有一盏灯是亮的,就有线程可以执行,每当有一个线程在访问共享资源时,亮灯的数量-1,当线程不再访问共享资源时,亮灯的数目 +1而当灯全部熄灭时就不再允许线程访问。当盒子中只有一盏灯的时候,就相当于一个互斥体信号量的初始化函数为KeInitializeSemaphoreVOID KeInitializeSemaphore( IN PRKSEMAPHORE Semaphore,//将要被初始化的信号量的指针 IN LONG Count,//当前信号量中有多少个灯亮 IN LONG Limit//总共有多少灯 );释放信号量会增加信号灯计数。对应的函数是KeReleaseSemaphore。可以利用这个函数指定增量值,获得的信号灯可以使用Wait函数等待如果获得就熄灭一盏灯,否则就陷入等待。。利用函数KeReadStateSemaphore可以得到当前有多少盏灯是亮的下面是使用的例子VOID Semaphore_Test() { KSEMAPHORE keSemaphore; HANDLE hThread; NTSTATUS status = STATUS_SUCCESS; ULONG uCount = 0;//当前有多少盏灯亮着 //初始化,使其里面有两盏灯,两盏灯全亮 KeInitializeSemaphore(&keSemaphore, 2, 2); if(!NT_SUCCESS(status)) { DbgPrint("Initialize Semaphore Error\n"); return; } //当前有多少盏灯亮着 uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //函数会成功返回并熄灭一盏灯 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //函数会成功返回并熄灭一盏灯 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); uCount = KeReadStateSemaphore(&keSemaphore); DbgPrint("the count = %ul", uCount); //创建新线程 PsCreateSystemThread(&hThread, 0, NULL, NULL, NULL, SemaphoreThread, &keSemaphore); //这时没有灯亮,函数会陷入等待状态 KeWaitForSingleObject(&keSemaphore, Executive, KernelMode, FALSE, 0); }VOID SemaphoreThread(PVOID pContext) { //线程函数 PKSEMAPHORE pkeSemaphore = (PKSEMAPHORE)pContext; DbgPrint("Entry My Thread\n"); //点亮其中的一盏灯 KeReleaseSemaphore(pkeSemaphore, IO_NO_INCREMENT, 1, FALSE); //结束线程 PsTerminateSystemThread(0); }内核模式下的互斥体互斥体在内核结构中的定义为KMUTEX使用前需要使用函数KeInitializeMutex进行初始化VOID KeInitializeMutex( IN PRKMUTEX Mutex, IN ULONG Level//系统保留参数一般给0 );初始化之后就可以使用Wait系列的函数进行等待,一旦函数返回,那么该线程就拥有了该互斥体,线程可以调用函数KeReleaseMutex来主动释放互斥体LONG KeReleaseMutex( IN PRKMUTEX Mutex, IN BOOLEAN Wait );与同步对象相比,互斥体可以在某个线程中递归获取,这个时候每当获取一次,那么它被引用的次数也将加1,在释放时,被引用多少次就应该释放多少次,只有当计数为0时才能被其他线程获取互锁操作进行同步互锁操作就是定义了一个原子操作,当原子操作没有完成时,线程是不允许切换的,系统会保证原子操作要么都完成了,要么都没有完成。在Windows中为一些常用的操作定义了一组互锁操作函数