搜索到
191
篇与
的结果
-
 windows 多任务与进程 多任务,进程与线程的简单说明多任务的本质就是并行计算,它能够利用至少2处理器相互协调,同时计算同一个任务的不同部分,从而提高求解速度,或者求解单机无法求解的大规模问题。以前的分布式计算正是利用这点,将大规模问题分解为几个互不不相关的问题,将这些计算问题交给局域网中的其他机器计算完成,然后再汇总到某台机器上,显示结果,这样就充分利用局域网中的计算机资源。相对的,处理完一步接着再处理另外一步,将这样的传统计算模式称为串行计算。在提高处理器的相关性能主要有两种方式,一种是提高单个处理器处理数据的速度,这个主要表现在CPU主频的调高上,而当前硬件总有一个上限,以后再很难突破,所以现在的CPU主要采用的是调高CPU的核数,这样CPU的每个处理器都处理一定的数据,总体上也能带来性能的提升。在某些单核CPU上Windows虽然也提供了多任务,但是这个多任务是分时多任务,也就是每个任务只在CPU中执行一个固定的时间片,然后再切换到另一个任务,由于每个任务的时间片很短,所以给人的感觉是在同一时间运行了多个任务。单核CPU由于需要来回的在对应的任务之间切换,需要事先保存当前任务的运行环境,然后通过轮循算法找到下一个运行的任务,再将CPU中寄存器环境改成新任务的环境,新任务运行到达一定时间,又需要重复上述的步骤,所以在单核CPU上使用多任务并不能带来性能的提升,反而会由在任务之间来回切换,浪费宝贵的资源,多任务真正使用场合是多核的CPU上。windows上多任务的载体是进程和线程,在windows中进程是不执行代码的,它只是一个载体,负责从操作系统内核中分配资源,比如每个进程都有4GB的独立的虚拟地址空间,有各自的内核对象句柄等等。线程是资源分配的最小单元,真正在使用这些资源的是线程。每个程序都至少有一个主线程。线程是可以被执行的最小的调度单位。进程的亲缘性进程或者线程只在某些CPU上被执行,而不是由系统随机分配到任何可用的CPU上,这个就是进程的亲缘性。例如某个CPU有8个处理器,可以通过进程的亲缘性设置让该进程的线程只在某两个处理器上运行,这样就不会像之前那样在8个CPU中的任意几个上运行。在windows上一般更倾向于优先考虑将线程安排在之前执行它的那个处理器上运行,因为之前的处理器的高速缓存中可能存有这个线程之前的执行环境,这样就提高的高速缓存的命中率,减少了从内存中取数据的次数能从一定程度上提高性能。需要注意的是,在拥有三级高速缓存的CPU上,这么做意义就不是很大了,因为三级缓存一般作为共享缓存,由所有处理器共享,如果之前在2号处理器上执行某个线程,在三级缓存上留下了它的运行时的数据,那么由于三级缓存是由所有处理器所共享的,这个时候即使将这个线程又分配到5号处理器上,也能访问这个公共存储区,所以再设置线程在固定的处理器上运行就显得有些鸡肋,这也是拥有三级缓存的CPU比二级缓存的CPU占优势的地方。但是如果CPU只具有二级缓存,通过设置亲缘性可以发挥高速缓存的优势,提高效率。亲缘性可以通过函数SetProcessAffinityMask设置。该函数的原型如下:BOOL WINAPI SetProcessAffinityMask( __in HANDLE hProcess, __in DWORD_PTR dwProcessAffinityMask );第一个参数是设置的进程的句柄,第二个参数是DWORD类型的指针,是一个32位的整数,每一位代表一个处理器的编号,当希望设置进程中的线程在此处理器上运行的话,将该位设置为1,否则为0。为了设置亲缘性,首先应该了解机器上CPU的情况,根据实际情况来妥善安排,获取CPU的详细信息可以通过函数GetLogicalProcessInformation来完成。该函数的原型如下:BOOL WINAPI GetLogicalProcessorInformation( __out PSYSTEM_LOGICAL_PROCESSOR_INFORMATION Buffer, __in_out PDWORD ReturnLength );第一个参数是一个结构体的指针,第二个参数是需要缓冲区的大小,也就是说这个函数我们可以采用两次调用的方式来合理安排缓冲区的大小。结构体SYSTEM_LOGICAL_PROCESSOR_INFORMATION的定义如下: typedef struct _SYSTEM_LOGICAL_PROCESSOR_INFORMATION { ULONG_PTR ProcessorMask; LOGICAL_PROCESSOR_RELATIONSHIP Relationship; union { struct { BYTE Flags; } ProcessorCore; struct { DWORD NodeNumber; }NumaNode; CACHE_DESCRIPTOR Cache; ULONGLONG Reserved[2]; }; } SYSTEM_LOGICAL_PROCESSOR_INFORMATION, *PSYSTEM_LOGICAL_PROCESSOR_INFORMATION;ProcessorMask是一个位掩码,每个位代表一个逻辑处理器,第二个参数是一个标志,表示该使用第三个共用体中的哪一个结构体,这三个分别表示核心处理器,NUMA节点,以及高速缓存的信息。下面是使用的一个例子代码:#include <windows.h> #include <tchar.h> #include <stdio.h> #include <locale.h> DWORD CountBits(ULONG_PTR uMask); typedef BOOL (WINAPI *CPUINFO)(PSYSTEM_LOGICAL_PROCESSOR_INFORMATION Buffer, PDWORD ReturnLength); int _tmain(int argc, TCHAR *argv[]) { _tsetlocale(LC_ALL, _T("chs")); CPUINFO pGetCpuInfo = (CPUINFO)GetProcAddress(GetModuleHandle(_T("kernel32")), "GetLogicalProcessorInformation"); if (NULL == pGetCpuInfo) { _tprintf(_T("系统不支持该函数,程序结束\n")); return 0; } PSYSTEM_LOGICAL_PROCESSOR_INFORMATION plpt = NULL; DWORD dwLength = 0; if (!pGetCpuInfo(plpt, &dwLength)) { if (ERROR_INSUFFICIENT_BUFFER == GetLastError()) { plpt = (PSYSTEM_LOGICAL_PROCESSOR_INFORMATION)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); }else { _tprintf(_T("函数调用失败\n")); return 0; } } if (!pGetCpuInfo(plpt, &dwLength)) { _tprintf(_T("函数调用失败\n")); return 0; } DWORD dwSize = dwLength / sizeof(SYSTEM_LOGICAL_PROCESSOR_INFORMATION); PSYSTEM_LOGICAL_PROCESSOR_INFORMATION pOffsite = plpt; DWORD dwCacheCnt = 0; DWORD dwCoreCnt = 0; DWORD dwPackageCnt = 0; DWORD dwNodeCnt = 0; for (int i = 0; i < dwSize; i++) { switch (pOffsite->Relationship) { case RelationCache: dwCacheCnt++; break; case RelationNumaNode: dwNodeCnt++; break; case RelationProcessorCore: { if (pOffsite->ProcessorCore.Flags) { dwCoreCnt++; }else { dwCoreCnt += CountBits(pOffsite->ProcessorMask); } } break; case RelationProcessorPackage: dwPackageCnt++; break; default: break; } pOffsite++; } _tprintf(_T("处理器个数:%d\n"), dwPackageCnt); _tprintf(_T("处理器核数:%d\n"), dwCoreCnt); _tprintf(_T("NUMA个数:%d\n"), dwNodeCnt); _tprintf(_T("高速缓存的个数:%d\n"), dwCacheCnt); return 0; } DWORD CountBits(ULONG_PTR uMask) { DWORD dwTest = 1; DWORD LSHIFT = sizeof(ULONG_PTR) * 8 -1; dwTest = dwTest << LSHIFT; DWORD dwCnt = 0; for (int i = 0; i <= LSHIFT; i++) { dwCnt += ((uMask & dwTest) ? 1 : 0); dwTest /= 2; } return dwCnt; }这个程序首先采用两次调用的方式分配一个合适的缓冲区,用来接收函数的返回,然后分别统计CPU数目,物理处理器数目以及逻辑处理器数量。我们根据MSDN上面得到的信息,首先判断缓冲区中有多少个结构体,也就是由多少条处理器的信息,然后根据第二个成员的值,来判断当前存储的是哪种信息。并将对应的值加1,当计算逻辑处理器的数目时需要考虑超线程的问题,所谓超线程就是intel提供的一个新的技术,可以将一个处理器虚拟成多个处理器来使用,已达到多核处理器的效果,如果它支持超线程,那么久不能简单的根据是否为核心处理器而加1,这个时候需要采用计算位掩码的方式来统计逻辑存储器,根据MSDN上说的当flag为1时表示支持超线程。windows下的进程windows中进程是已装入内存中,准备或者已经在执行的程序,磁盘上的exe文件虽说可以执行,但是它只是一个文件,并不是进程,一旦它被系统加载到内存中,系统为它分配了资源,那么它就是一个进程。进程由两个部分组成,一个是系统内核用来管理进程的内核对象,一个是它所占的地址空间。windows下的进程主要分为3大类:控制台,窗口应用,服务程序。写过控制台与窗口程序的人都知道,控制台的主函数是main,而窗口应用的主函数是WinMain,那么是否可以根据这个来判断程序属于那种呢,很遗憾,windows并不是根据这个来区分的。在VS编译器上可以通过设置将Win32 控制台程序的主函数指定为WinMain,或者将窗口程序的主函数指定为main,设置方法:属性-->连接器-->系统-->子系统,将这项设置为/SUBSYSTEM:CONSOLE,那么它的主函数为main,设置为/SUBSYSTEM:WINDOWS那么它的主函数为WinMain,甚至我们可以自己设置主函数。我们知道在C/C++语言中main程序是从main函数开始的,但是这个函数只是语法上的开始,并不是真正意义上的入口,在VC++中,系统会首先调用mainCRTStartup,在这个函数中调用main或者WinMain, 这个函数主要负责对C/C++运行环境的初始化,比如堆环境或者C/C++库函数环境的初始化。如果需要自定义自己的入口,那么这些环境将得不到初始化,也就意味着我们不能使用C/C++库函数。只能使用VC++提供的API,这么做也有一定的好处,毕竟这些库函数都是在很早之前产生的,到现在来看有很多问题,有许多有严重的安全隐患,使用API可以避免这些问题。下面是一个简单的例子:#include <Windows.h> #include <tchar.h> #include <strsafe.h> #define PRINTF(...) \ {\ TCHAR szBuf[4096] = _T("");\ StringCchPrintf(szBuf, sizeof(szBuf), __VA_ARGS__);\ size_t nStrLen = 0;\ StringCchLength(szBuf, STRSAFE_MAX_CCH, &nStrLen);\ WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), szBuf, nStrLen, NULL, NULL);\ } int LHMain() { PRINTF(_T("this is a %s"), _T("test hello world\n")); return 0; }这个例子中,入口函数是LHMain我们完全使用API的方式来编写程序,如果想要做到自定义入口,那么需要进行这样的设置:属性-->高级-->入口点,在入口点中输出我们希望作为入口点的函数名称即可。入口参数各个参数的含义现在这部分主要说明main函数以及WinMain函数。int main()这是main函数的一种原型,这种原型不带入任何参数int main(int argc, char *argv[])这种原型主要接受命令行输入的参数,参数以空格隔开,第一个参数表示输入命令行参数的总数,第二个是一个字符串指针数组,每个字符串指针成员代表的是具体输入的命令以及参数,这些信息包括我们输入的程序的名称,比如我们输入test.exe -s -a -t 来启动程序,那么argc = 4 ,argv[0] = "test.exe" argv[1] = "-s" argv[2] = "-a" argv[3] = "-t"int main(int argc, char argv[], char envs[])这个原型中第一个和第二个参数的函数与上述的带有两个参数的main函数相同,多了一个表示环境变量的指针数组,它会将环境变量以”变量名=值“的形式来组织字符串。int WINAPI WinMain(HANDLE hInstance, HANDLE hPrevInstance, LPSTR lpszCmdLine, int nCmdShow);函数中的WINAPI表示函数的调用约定为__stdcall的调用方式,函数的调用方式主要与参数压栈方式以及环境回收的方式有关。在这就不再说明这部分的内容,有兴趣的可以看本人另外一篇博客专门讲解了这部分的内容,点击这里hInstance:进程的实例句柄,该值是exe文件映射到虚拟地址控件的基址hPrevInstance:上一个进程的实例句柄,为了防止进程越界访问,这个是16位下的产物,在32位下,这个没有作用。lpszCmdLine:启动程序时输入的命令行参数nCmdShow:表示程序的显示方式。进程的环境变量与工作路径进程的环境变量可以通过main函数的第三个参数传入,也可以在程序中利用函数GetEnvrionmentStrings和GetEnvrionVariable获取,下面是获取进程环境变量的简答例子: setlocale(CP_ACP, "chs"); TCHAR **ppArgs = NULL; int nArgCnt = 0; ppArgs = CommandLineToArgvW(GetCommandLine(), &nArgCnt); for (int i = 0; i < nArgCnt; i++) { _tprintf(_T("%d %s\n"), i, ppArgs[i]); } HeapFree(GetProcessHeap(), 0, ppArgs);函数的第一个参数是开启这个进程需要的完整的命令行字符串,这个字符串使用函数GetCommandLine来获取,第二个参数是一个接受环境变量的字符串指针数组。函数返回数组中元素个数。一般情况下不推荐使用环境变量的方式来保存程序所需的数据,一般采用文件或者注册表的方式,但是最好的办法是采用xml文件的方式来村粗。至于进程的工作目录可以通过函数GetCurrentDirectory方法获取。进程创建在windows下进程创建采用API函数CreateProcess,该函数的原型如下:BOOL CreateProcess( LPCWSTR pszImageName, LPCWSTR pszCmdLine, LPSECURITY_ATTRIBUTES psaProcess, LPSECURITY_ATTRIBUTES psaThread, BOOL fInheritHandles, DWORD fdwCreate, LPVOID pvEnvironment, LPWSTR pszCurDir, LPSTARTUPINFOW psiStartInfo, LPPROCESS_INFORMATION pProcInfo ); 该函数参数较多,下面对这几项做重点说明,其余的请自行查看MSDN。pszImageName:表示进程对应的exe文件所在的完整路径或者相对路径pszCmdLine:启动进程传入的命令行参数,这是一个字符串类型,需要注意的是,这个命令行参数可以带程序所在的完整路径,这样就可以将第一个参数设置为NULL。参数中的安全描述符表示的是创建的子进程的安全描述符,与当前进程的安全描述符无关。fInheritHandles表示,可否被继承,这个继承关系是指父进程中的信息能否被子进程所继承psiStartInfo规定了新进程的相关启动信息,主要有这样几个重要的值:对于窗口程序: LPTSTR lpTitle; DWORD dwX; DWORD dwY; DWORD dwXSize; DWORD dwYSize;这些值规定了窗口的标题和所在的屏幕位置与长高的相关信息,对于控制台程序,主要关注: HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError;标准输入、输出、以及标准错误 下面是一个创建控制台与创建窗口的简单例子: STARTUPINFO si = {0}; si.dwXSize = 400; si.dwYSize = 300; si.dwX = 10; si.dwY = 10; PROCESS_INFORMATION pi = {0}; SECURITY_ATTRIBUTES sa = {sizeof(SECURITY_ATTRIBUTES)}; //创建一个窗口应用的进程,其中szExePath表示进程所在exe文件的路径,而szAppDirectory表示exe所在的目录 CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, 0, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动控制台窗口,与父进程公用输入输出环境 ZeroMemory(szExePath, sizeof(TCHAR) * (MAX_PATH + 1)); StringCchPrintf(szExePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("SubConsole.exe")); ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, 0, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动控制台,在新的控制台上做输入输出 ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, CREATE_NEW_CONSOLE, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread);上述程序中,对于窗口程序,在创建时没有给出特别的创建标志,窗口本身就是一个个独立的,并且我们通过指定si的部分成员指定了窗口的显示位置,而对于控制台,如果在创建时不特别指定创建的标志,那么它将与父进程共享一个输入输出控制台。为了区分子进程和父进程的输入输出,一般通过标志CREATE_NEW_CONSOLE为新进程新建一个另外的控制台。进程输入输出重定向输入输出重定向的实现可以通过函数CreateProcess在参数psiStartInfo中的HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError中指定,但是需要注意的是,在父进程中如果采用了Create之类的函数创建了输入输出对象的句柄时一定要指定他们可以被子进程所继承。下面是一个重定向的例子: //启动控制台,做输入输出重定向到文件中 TCHAR szFilePath[MAX_PATH + 1] = _T(""); //指定文件对象可以被子进程所继承,以便子进程可以使用这个内核对象句柄 sa.bInheritHandle = TRUE; ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); StringCchPrintf(szFilePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("input.txt")); HANDLE hInputFile = CreateFile(szFilePath, GENERIC_READ | GENERIC_WRITE, 0, &sa, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); ZeroMemory(szFilePath, sizeof(szFilePath)); StringCchPrintf(szFilePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("output.txt")); HANDLE hOutputFile = CreateFile(szFilePath, GENERIC_READ | GENERIC_WRITE, 0, &sa, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); si.hStdInput = hInputFile; si.hStdOutput = hOutputFile; si.dwFlags = STARTF_USESTDHANDLES; CreateProcess(szExePath, szExePath,NULL, NULL, TRUE, DETACHED_PROCESS, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(hOutputFile); CloseHandle(hInputFile); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动ping命令,并将输出重定向到管道中 StringCchPrintf(szExePath, MAX_PATH, _T("ping 127.0.0.1")); DWORD dwLen = 0; BYTE byte[1024] = {0}; HANDLE hReadP = NULL; HANDLE hWriteP = NULL; sa.bInheritHandle = TRUE; CreatePipe(&hReadP, &hWriteP, &sa, 1024); si.dwFlags = STARTF_USESTDHANDLES | STARTF_USESHOWWINDOW; si.wShowWindow = SW_HIDE; si.hStdOutput = hWriteP; CreateProcess(NULL, szExePath, NULL, NULL, TRUE, DETACHED_PROCESS, NULL, szAppDirectory, &si, &pi); //关闭管道的写端口,不然读端口会被阻塞 CloseHandle(hWriteP); dwLen = 1000; DWORD dwRead = 0; while (ReadFile(hReadP, byte, dwLen, &dwRead, NULL)) { if ( 0 == dwRead ) { break; } //写入管道的数据为ANSI字符 printf("%s\n", (char*)byte); ZeroMemory(byte, sizeof(byte)); }进程的退出进程在遇到如下情况中的任意一种时会退出:进程中任意一个线程调用函数ExitProcess进程的主线程结束进程中最后一个线程结束调用TerminateProcess在这针对第2、3中情况作特别的说明:这两种情况看似矛盾不是吗,当主线程结束时进程就已经结束了,这个时候还会等到最后一个线程吗。其实真实的情况是主线程结束,进程结束这个限制是VC++上的,之前在自定义入口的时候说过,main函数只是语法上的,并不是实际的入口,在调用main之前会调用mainCRTStartup,这个函数会负责调用main函数,当main函数调用结束后,这个函数会隐式的调用ExitProcess结束进程,所以只有当我们自定了程序入口才会看到3所示的现象,下面的例子说明了这点:DWORD WINAPI ThreadProc(LPVOID lpParam); #define PRINT(s) \ {\ size_t sttLen = 0;\ StringCchLengthA(s, 1024, &sttLen);\ WriteConsoleA(GetStdHandle(STD_OUTPUT_HANDLE), s, sttLen, NULL, NULL);\ } int LHMain(int argc, char *argv[]) { CreateThread(NULL, 0, ThreadProc, NULL, 0, NULL); return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { PRINT("main thread is ending,this is child thread\r\n"); return 0; }这种程序,如果我们采用系统中规定的main函数的话,是看不到线程中输出的信息的,因为主线程先结束的话,整个进程就结束了,线程还来不及输出,就被终止了。但是我们采用自定义入口的方式,屏蔽了这个特性,所以它会等到所有线程执行完成后才会结束,这个时候就会看到这句话输出了。进程在终止时会发生以下事件:关闭进程打开的对象句柄,但是对象本身不一定会关闭,这是因为每个对象都有一个计数器,每当有一个线程在使用这个对象时计数器会加1,而释放它的句柄时会减一,只有当计数器为0时才会销毁这个对象。对象是可以跨进程访问的,而且所有相同的对象在内存中只有一份,所以需要一个计数器以便在没有被任何进程访问的时候系统删除它。进程对象的状态设为有信号,以便所有等待该进程对象信号的函数(像函数WaitForSingleObject)能够正常返回。进程的终止状态从STILL_ACTIVE变成进程的退出码,可以通过这个特性判断某个进程是否在运行,具体的方式是通过函数GetExitProcess获取进程的终止码,如果函数返回STILL_ACTIVE,则说明进程仍在运行。
windows 多任务与进程 多任务,进程与线程的简单说明多任务的本质就是并行计算,它能够利用至少2处理器相互协调,同时计算同一个任务的不同部分,从而提高求解速度,或者求解单机无法求解的大规模问题。以前的分布式计算正是利用这点,将大规模问题分解为几个互不不相关的问题,将这些计算问题交给局域网中的其他机器计算完成,然后再汇总到某台机器上,显示结果,这样就充分利用局域网中的计算机资源。相对的,处理完一步接着再处理另外一步,将这样的传统计算模式称为串行计算。在提高处理器的相关性能主要有两种方式,一种是提高单个处理器处理数据的速度,这个主要表现在CPU主频的调高上,而当前硬件总有一个上限,以后再很难突破,所以现在的CPU主要采用的是调高CPU的核数,这样CPU的每个处理器都处理一定的数据,总体上也能带来性能的提升。在某些单核CPU上Windows虽然也提供了多任务,但是这个多任务是分时多任务,也就是每个任务只在CPU中执行一个固定的时间片,然后再切换到另一个任务,由于每个任务的时间片很短,所以给人的感觉是在同一时间运行了多个任务。单核CPU由于需要来回的在对应的任务之间切换,需要事先保存当前任务的运行环境,然后通过轮循算法找到下一个运行的任务,再将CPU中寄存器环境改成新任务的环境,新任务运行到达一定时间,又需要重复上述的步骤,所以在单核CPU上使用多任务并不能带来性能的提升,反而会由在任务之间来回切换,浪费宝贵的资源,多任务真正使用场合是多核的CPU上。windows上多任务的载体是进程和线程,在windows中进程是不执行代码的,它只是一个载体,负责从操作系统内核中分配资源,比如每个进程都有4GB的独立的虚拟地址空间,有各自的内核对象句柄等等。线程是资源分配的最小单元,真正在使用这些资源的是线程。每个程序都至少有一个主线程。线程是可以被执行的最小的调度单位。进程的亲缘性进程或者线程只在某些CPU上被执行,而不是由系统随机分配到任何可用的CPU上,这个就是进程的亲缘性。例如某个CPU有8个处理器,可以通过进程的亲缘性设置让该进程的线程只在某两个处理器上运行,这样就不会像之前那样在8个CPU中的任意几个上运行。在windows上一般更倾向于优先考虑将线程安排在之前执行它的那个处理器上运行,因为之前的处理器的高速缓存中可能存有这个线程之前的执行环境,这样就提高的高速缓存的命中率,减少了从内存中取数据的次数能从一定程度上提高性能。需要注意的是,在拥有三级高速缓存的CPU上,这么做意义就不是很大了,因为三级缓存一般作为共享缓存,由所有处理器共享,如果之前在2号处理器上执行某个线程,在三级缓存上留下了它的运行时的数据,那么由于三级缓存是由所有处理器所共享的,这个时候即使将这个线程又分配到5号处理器上,也能访问这个公共存储区,所以再设置线程在固定的处理器上运行就显得有些鸡肋,这也是拥有三级缓存的CPU比二级缓存的CPU占优势的地方。但是如果CPU只具有二级缓存,通过设置亲缘性可以发挥高速缓存的优势,提高效率。亲缘性可以通过函数SetProcessAffinityMask设置。该函数的原型如下:BOOL WINAPI SetProcessAffinityMask( __in HANDLE hProcess, __in DWORD_PTR dwProcessAffinityMask );第一个参数是设置的进程的句柄,第二个参数是DWORD类型的指针,是一个32位的整数,每一位代表一个处理器的编号,当希望设置进程中的线程在此处理器上运行的话,将该位设置为1,否则为0。为了设置亲缘性,首先应该了解机器上CPU的情况,根据实际情况来妥善安排,获取CPU的详细信息可以通过函数GetLogicalProcessInformation来完成。该函数的原型如下:BOOL WINAPI GetLogicalProcessorInformation( __out PSYSTEM_LOGICAL_PROCESSOR_INFORMATION Buffer, __in_out PDWORD ReturnLength );第一个参数是一个结构体的指针,第二个参数是需要缓冲区的大小,也就是说这个函数我们可以采用两次调用的方式来合理安排缓冲区的大小。结构体SYSTEM_LOGICAL_PROCESSOR_INFORMATION的定义如下: typedef struct _SYSTEM_LOGICAL_PROCESSOR_INFORMATION { ULONG_PTR ProcessorMask; LOGICAL_PROCESSOR_RELATIONSHIP Relationship; union { struct { BYTE Flags; } ProcessorCore; struct { DWORD NodeNumber; }NumaNode; CACHE_DESCRIPTOR Cache; ULONGLONG Reserved[2]; }; } SYSTEM_LOGICAL_PROCESSOR_INFORMATION, *PSYSTEM_LOGICAL_PROCESSOR_INFORMATION;ProcessorMask是一个位掩码,每个位代表一个逻辑处理器,第二个参数是一个标志,表示该使用第三个共用体中的哪一个结构体,这三个分别表示核心处理器,NUMA节点,以及高速缓存的信息。下面是使用的一个例子代码:#include <windows.h> #include <tchar.h> #include <stdio.h> #include <locale.h> DWORD CountBits(ULONG_PTR uMask); typedef BOOL (WINAPI *CPUINFO)(PSYSTEM_LOGICAL_PROCESSOR_INFORMATION Buffer, PDWORD ReturnLength); int _tmain(int argc, TCHAR *argv[]) { _tsetlocale(LC_ALL, _T("chs")); CPUINFO pGetCpuInfo = (CPUINFO)GetProcAddress(GetModuleHandle(_T("kernel32")), "GetLogicalProcessorInformation"); if (NULL == pGetCpuInfo) { _tprintf(_T("系统不支持该函数,程序结束\n")); return 0; } PSYSTEM_LOGICAL_PROCESSOR_INFORMATION plpt = NULL; DWORD dwLength = 0; if (!pGetCpuInfo(plpt, &dwLength)) { if (ERROR_INSUFFICIENT_BUFFER == GetLastError()) { plpt = (PSYSTEM_LOGICAL_PROCESSOR_INFORMATION)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); }else { _tprintf(_T("函数调用失败\n")); return 0; } } if (!pGetCpuInfo(plpt, &dwLength)) { _tprintf(_T("函数调用失败\n")); return 0; } DWORD dwSize = dwLength / sizeof(SYSTEM_LOGICAL_PROCESSOR_INFORMATION); PSYSTEM_LOGICAL_PROCESSOR_INFORMATION pOffsite = plpt; DWORD dwCacheCnt = 0; DWORD dwCoreCnt = 0; DWORD dwPackageCnt = 0; DWORD dwNodeCnt = 0; for (int i = 0; i < dwSize; i++) { switch (pOffsite->Relationship) { case RelationCache: dwCacheCnt++; break; case RelationNumaNode: dwNodeCnt++; break; case RelationProcessorCore: { if (pOffsite->ProcessorCore.Flags) { dwCoreCnt++; }else { dwCoreCnt += CountBits(pOffsite->ProcessorMask); } } break; case RelationProcessorPackage: dwPackageCnt++; break; default: break; } pOffsite++; } _tprintf(_T("处理器个数:%d\n"), dwPackageCnt); _tprintf(_T("处理器核数:%d\n"), dwCoreCnt); _tprintf(_T("NUMA个数:%d\n"), dwNodeCnt); _tprintf(_T("高速缓存的个数:%d\n"), dwCacheCnt); return 0; } DWORD CountBits(ULONG_PTR uMask) { DWORD dwTest = 1; DWORD LSHIFT = sizeof(ULONG_PTR) * 8 -1; dwTest = dwTest << LSHIFT; DWORD dwCnt = 0; for (int i = 0; i <= LSHIFT; i++) { dwCnt += ((uMask & dwTest) ? 1 : 0); dwTest /= 2; } return dwCnt; }这个程序首先采用两次调用的方式分配一个合适的缓冲区,用来接收函数的返回,然后分别统计CPU数目,物理处理器数目以及逻辑处理器数量。我们根据MSDN上面得到的信息,首先判断缓冲区中有多少个结构体,也就是由多少条处理器的信息,然后根据第二个成员的值,来判断当前存储的是哪种信息。并将对应的值加1,当计算逻辑处理器的数目时需要考虑超线程的问题,所谓超线程就是intel提供的一个新的技术,可以将一个处理器虚拟成多个处理器来使用,已达到多核处理器的效果,如果它支持超线程,那么久不能简单的根据是否为核心处理器而加1,这个时候需要采用计算位掩码的方式来统计逻辑存储器,根据MSDN上说的当flag为1时表示支持超线程。windows下的进程windows中进程是已装入内存中,准备或者已经在执行的程序,磁盘上的exe文件虽说可以执行,但是它只是一个文件,并不是进程,一旦它被系统加载到内存中,系统为它分配了资源,那么它就是一个进程。进程由两个部分组成,一个是系统内核用来管理进程的内核对象,一个是它所占的地址空间。windows下的进程主要分为3大类:控制台,窗口应用,服务程序。写过控制台与窗口程序的人都知道,控制台的主函数是main,而窗口应用的主函数是WinMain,那么是否可以根据这个来判断程序属于那种呢,很遗憾,windows并不是根据这个来区分的。在VS编译器上可以通过设置将Win32 控制台程序的主函数指定为WinMain,或者将窗口程序的主函数指定为main,设置方法:属性-->连接器-->系统-->子系统,将这项设置为/SUBSYSTEM:CONSOLE,那么它的主函数为main,设置为/SUBSYSTEM:WINDOWS那么它的主函数为WinMain,甚至我们可以自己设置主函数。我们知道在C/C++语言中main程序是从main函数开始的,但是这个函数只是语法上的开始,并不是真正意义上的入口,在VC++中,系统会首先调用mainCRTStartup,在这个函数中调用main或者WinMain, 这个函数主要负责对C/C++运行环境的初始化,比如堆环境或者C/C++库函数环境的初始化。如果需要自定义自己的入口,那么这些环境将得不到初始化,也就意味着我们不能使用C/C++库函数。只能使用VC++提供的API,这么做也有一定的好处,毕竟这些库函数都是在很早之前产生的,到现在来看有很多问题,有许多有严重的安全隐患,使用API可以避免这些问题。下面是一个简单的例子:#include <Windows.h> #include <tchar.h> #include <strsafe.h> #define PRINTF(...) \ {\ TCHAR szBuf[4096] = _T("");\ StringCchPrintf(szBuf, sizeof(szBuf), __VA_ARGS__);\ size_t nStrLen = 0;\ StringCchLength(szBuf, STRSAFE_MAX_CCH, &nStrLen);\ WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), szBuf, nStrLen, NULL, NULL);\ } int LHMain() { PRINTF(_T("this is a %s"), _T("test hello world\n")); return 0; }这个例子中,入口函数是LHMain我们完全使用API的方式来编写程序,如果想要做到自定义入口,那么需要进行这样的设置:属性-->高级-->入口点,在入口点中输出我们希望作为入口点的函数名称即可。入口参数各个参数的含义现在这部分主要说明main函数以及WinMain函数。int main()这是main函数的一种原型,这种原型不带入任何参数int main(int argc, char *argv[])这种原型主要接受命令行输入的参数,参数以空格隔开,第一个参数表示输入命令行参数的总数,第二个是一个字符串指针数组,每个字符串指针成员代表的是具体输入的命令以及参数,这些信息包括我们输入的程序的名称,比如我们输入test.exe -s -a -t 来启动程序,那么argc = 4 ,argv[0] = "test.exe" argv[1] = "-s" argv[2] = "-a" argv[3] = "-t"int main(int argc, char argv[], char envs[])这个原型中第一个和第二个参数的函数与上述的带有两个参数的main函数相同,多了一个表示环境变量的指针数组,它会将环境变量以”变量名=值“的形式来组织字符串。int WINAPI WinMain(HANDLE hInstance, HANDLE hPrevInstance, LPSTR lpszCmdLine, int nCmdShow);函数中的WINAPI表示函数的调用约定为__stdcall的调用方式,函数的调用方式主要与参数压栈方式以及环境回收的方式有关。在这就不再说明这部分的内容,有兴趣的可以看本人另外一篇博客专门讲解了这部分的内容,点击这里hInstance:进程的实例句柄,该值是exe文件映射到虚拟地址控件的基址hPrevInstance:上一个进程的实例句柄,为了防止进程越界访问,这个是16位下的产物,在32位下,这个没有作用。lpszCmdLine:启动程序时输入的命令行参数nCmdShow:表示程序的显示方式。进程的环境变量与工作路径进程的环境变量可以通过main函数的第三个参数传入,也可以在程序中利用函数GetEnvrionmentStrings和GetEnvrionVariable获取,下面是获取进程环境变量的简答例子: setlocale(CP_ACP, "chs"); TCHAR **ppArgs = NULL; int nArgCnt = 0; ppArgs = CommandLineToArgvW(GetCommandLine(), &nArgCnt); for (int i = 0; i < nArgCnt; i++) { _tprintf(_T("%d %s\n"), i, ppArgs[i]); } HeapFree(GetProcessHeap(), 0, ppArgs);函数的第一个参数是开启这个进程需要的完整的命令行字符串,这个字符串使用函数GetCommandLine来获取,第二个参数是一个接受环境变量的字符串指针数组。函数返回数组中元素个数。一般情况下不推荐使用环境变量的方式来保存程序所需的数据,一般采用文件或者注册表的方式,但是最好的办法是采用xml文件的方式来村粗。至于进程的工作目录可以通过函数GetCurrentDirectory方法获取。进程创建在windows下进程创建采用API函数CreateProcess,该函数的原型如下:BOOL CreateProcess( LPCWSTR pszImageName, LPCWSTR pszCmdLine, LPSECURITY_ATTRIBUTES psaProcess, LPSECURITY_ATTRIBUTES psaThread, BOOL fInheritHandles, DWORD fdwCreate, LPVOID pvEnvironment, LPWSTR pszCurDir, LPSTARTUPINFOW psiStartInfo, LPPROCESS_INFORMATION pProcInfo ); 该函数参数较多,下面对这几项做重点说明,其余的请自行查看MSDN。pszImageName:表示进程对应的exe文件所在的完整路径或者相对路径pszCmdLine:启动进程传入的命令行参数,这是一个字符串类型,需要注意的是,这个命令行参数可以带程序所在的完整路径,这样就可以将第一个参数设置为NULL。参数中的安全描述符表示的是创建的子进程的安全描述符,与当前进程的安全描述符无关。fInheritHandles表示,可否被继承,这个继承关系是指父进程中的信息能否被子进程所继承psiStartInfo规定了新进程的相关启动信息,主要有这样几个重要的值:对于窗口程序: LPTSTR lpTitle; DWORD dwX; DWORD dwY; DWORD dwXSize; DWORD dwYSize;这些值规定了窗口的标题和所在的屏幕位置与长高的相关信息,对于控制台程序,主要关注: HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError;标准输入、输出、以及标准错误 下面是一个创建控制台与创建窗口的简单例子: STARTUPINFO si = {0}; si.dwXSize = 400; si.dwYSize = 300; si.dwX = 10; si.dwY = 10; PROCESS_INFORMATION pi = {0}; SECURITY_ATTRIBUTES sa = {sizeof(SECURITY_ATTRIBUTES)}; //创建一个窗口应用的进程,其中szExePath表示进程所在exe文件的路径,而szAppDirectory表示exe所在的目录 CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, 0, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动控制台窗口,与父进程公用输入输出环境 ZeroMemory(szExePath, sizeof(TCHAR) * (MAX_PATH + 1)); StringCchPrintf(szExePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("SubConsole.exe")); ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, 0, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动控制台,在新的控制台上做输入输出 ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); CreateProcess(szExePath, szExePath, &sa, &sa, FALSE, CREATE_NEW_CONSOLE, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(pi.hProcess); CloseHandle(pi.hThread);上述程序中,对于窗口程序,在创建时没有给出特别的创建标志,窗口本身就是一个个独立的,并且我们通过指定si的部分成员指定了窗口的显示位置,而对于控制台,如果在创建时不特别指定创建的标志,那么它将与父进程共享一个输入输出控制台。为了区分子进程和父进程的输入输出,一般通过标志CREATE_NEW_CONSOLE为新进程新建一个另外的控制台。进程输入输出重定向输入输出重定向的实现可以通过函数CreateProcess在参数psiStartInfo中的HANDLE hStdInput; HANDLE hStdOutput; HANDLE hStdError中指定,但是需要注意的是,在父进程中如果采用了Create之类的函数创建了输入输出对象的句柄时一定要指定他们可以被子进程所继承。下面是一个重定向的例子: //启动控制台,做输入输出重定向到文件中 TCHAR szFilePath[MAX_PATH + 1] = _T(""); //指定文件对象可以被子进程所继承,以便子进程可以使用这个内核对象句柄 sa.bInheritHandle = TRUE; ZeroMemory(&si, sizeof(STARTUPINFO)); ZeroMemory(&pi, sizeof(PROCESS_INFORMATION)); StringCchPrintf(szFilePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("input.txt")); HANDLE hInputFile = CreateFile(szFilePath, GENERIC_READ | GENERIC_WRITE, 0, &sa, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); ZeroMemory(szFilePath, sizeof(szFilePath)); StringCchPrintf(szFilePath, MAX_PATH, _T("%s%s"), szAppDirectory, _T("output.txt")); HANDLE hOutputFile = CreateFile(szFilePath, GENERIC_READ | GENERIC_WRITE, 0, &sa, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); si.hStdInput = hInputFile; si.hStdOutput = hOutputFile; si.dwFlags = STARTF_USESTDHANDLES; CreateProcess(szExePath, szExePath,NULL, NULL, TRUE, DETACHED_PROCESS, NULL, szAppDirectory, &si, &pi); WaitForSingleObject(pi.hProcess, INFINITE); CloseHandle(hOutputFile); CloseHandle(hInputFile); CloseHandle(pi.hProcess); CloseHandle(pi.hThread); //启动ping命令,并将输出重定向到管道中 StringCchPrintf(szExePath, MAX_PATH, _T("ping 127.0.0.1")); DWORD dwLen = 0; BYTE byte[1024] = {0}; HANDLE hReadP = NULL; HANDLE hWriteP = NULL; sa.bInheritHandle = TRUE; CreatePipe(&hReadP, &hWriteP, &sa, 1024); si.dwFlags = STARTF_USESTDHANDLES | STARTF_USESHOWWINDOW; si.wShowWindow = SW_HIDE; si.hStdOutput = hWriteP; CreateProcess(NULL, szExePath, NULL, NULL, TRUE, DETACHED_PROCESS, NULL, szAppDirectory, &si, &pi); //关闭管道的写端口,不然读端口会被阻塞 CloseHandle(hWriteP); dwLen = 1000; DWORD dwRead = 0; while (ReadFile(hReadP, byte, dwLen, &dwRead, NULL)) { if ( 0 == dwRead ) { break; } //写入管道的数据为ANSI字符 printf("%s\n", (char*)byte); ZeroMemory(byte, sizeof(byte)); }进程的退出进程在遇到如下情况中的任意一种时会退出:进程中任意一个线程调用函数ExitProcess进程的主线程结束进程中最后一个线程结束调用TerminateProcess在这针对第2、3中情况作特别的说明:这两种情况看似矛盾不是吗,当主线程结束时进程就已经结束了,这个时候还会等到最后一个线程吗。其实真实的情况是主线程结束,进程结束这个限制是VC++上的,之前在自定义入口的时候说过,main函数只是语法上的,并不是实际的入口,在调用main之前会调用mainCRTStartup,这个函数会负责调用main函数,当main函数调用结束后,这个函数会隐式的调用ExitProcess结束进程,所以只有当我们自定了程序入口才会看到3所示的现象,下面的例子说明了这点:DWORD WINAPI ThreadProc(LPVOID lpParam); #define PRINT(s) \ {\ size_t sttLen = 0;\ StringCchLengthA(s, 1024, &sttLen);\ WriteConsoleA(GetStdHandle(STD_OUTPUT_HANDLE), s, sttLen, NULL, NULL);\ } int LHMain(int argc, char *argv[]) { CreateThread(NULL, 0, ThreadProc, NULL, 0, NULL); return 0; } DWORD WINAPI ThreadProc(LPVOID lpParam) { PRINT("main thread is ending,this is child thread\r\n"); return 0; }这种程序,如果我们采用系统中规定的main函数的话,是看不到线程中输出的信息的,因为主线程先结束的话,整个进程就结束了,线程还来不及输出,就被终止了。但是我们采用自定义入口的方式,屏蔽了这个特性,所以它会等到所有线程执行完成后才会结束,这个时候就会看到这句话输出了。进程在终止时会发生以下事件:关闭进程打开的对象句柄,但是对象本身不一定会关闭,这是因为每个对象都有一个计数器,每当有一个线程在使用这个对象时计数器会加1,而释放它的句柄时会减一,只有当计数器为0时才会销毁这个对象。对象是可以跨进程访问的,而且所有相同的对象在内存中只有一份,所以需要一个计数器以便在没有被任何进程访问的时候系统删除它。进程对象的状态设为有信号,以便所有等待该进程对象信号的函数(像函数WaitForSingleObject)能够正常返回。进程的终止状态从STILL_ACTIVE变成进程的退出码,可以通过这个特性判断某个进程是否在运行,具体的方式是通过函数GetExitProcess获取进程的终止码,如果函数返回STILL_ACTIVE,则说明进程仍在运行。 -
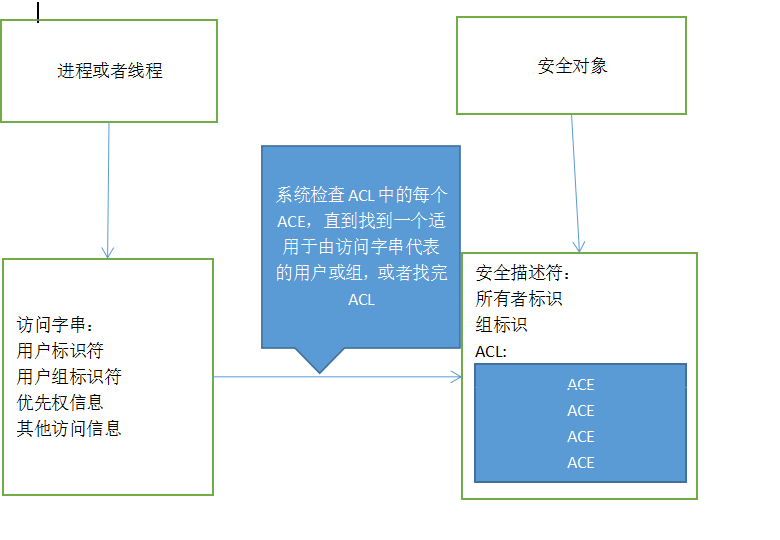
windows 安全模型简介 操作系统中有些资源是不能由用户代码直接访问的,比如线程进程,文件等等,这些资源必须由系统级代码由RING3层进入到RING0层操作,并且返回一些标识供用户程序使用,一般调用某个函数陷入到内核,这样的函数叫做系统调用,而有些不直接陷入到内核,一般叫做系统API,linux中使用系统调用,而windows中封装了一系列的API。windows对象与句柄windows对象操作系统为了安全,提供了一种保护机制,这种机制会禁止用户操作某些资源,避免用户过于关注细节,或者由于操作不当而造成系统崩溃。windows中将所有这些资源封装成了一个个对象。对象就是操作系统为了维护这些资源而定义的一系列的数据结构。对象这个词我们很容易联想到面向对象编程语言中的对象,对象其实就是对一些数据以及操作这些数据的一个封装,而windows是采用面向对象思想开发的,所以我们可以将windows中的对象想象成面向对象中的对象,而windows针对每种对象都提供了操作函数,这些函数一般都会以句柄作为第一个参数,这就有点像类函数中传入的this指针。而这操作对象的函数就是类函数。windows中总共有三种对象:GUI对象、GDI对象、内核对象。windows中的句柄windows中对象的操作是由系统提供的一系列的API函数来完成,这些函数有一个共同特点,就是以HANDLE 句柄作为第一个参数,windows中采用句柄来唯一标识每个内核对象。在windows中句柄的定义如下:typedef void * HANDLE从上面的定义可以看出,这个句柄应该是指向这个对象的结构体的指针。由于每次在程序启动时内存都是随机分配的,所以句柄不要使用硬编码的方式,同时在复制内核对像的时候,并不是简单的复制它的句柄,对象的复制有专门的函数,DuplicateHandle,该函数原型如下:BOOL DuplicateHandle( HANDLE hSourceProcessHandle, //源对象所在进程句柄 HANDLE hSourceHandle, //源对象句柄 HANDLE hTargetProcessHandle, //目标对象所在进程句柄 LPHANDLE lpTargetHandle, //返回目标对象的句柄 DWORD dwDesiredAccess, //以何种权限复制 BOOL bInheritHandle, //复制的对象句柄是否可继承 DWORD dwOptions //标记一些特殊的动作 );下面是一个例子代码:HANDLE hMutex = CreateMutex(NULL, FALSE, NULL); HANDLE hMutexDup, hThread; DWORD dwThreadId; DuplicateHandle(GetCurrentProcess(),hMutex,GetCurrentProcess(),&hMutexDup, 0,FALSE,DUPLICATE_SAME_ACCESS);上述代码在本进程中复制了一个互斥对象对象的句柄。windows 安全对象模型windows中的内核对象由进程和线程进行操作,而对象就好像一个被锁上的房间,进程想要访问对象,并对对象进程某种操作,就必须获取这个对象的钥匙,而线程就好像拥有钥匙的人,只有钥匙是对的,才可以访问。这把锁能够由不同的钥匙打开,这些钥匙信息存储在ACE中,而只有当ACE中的信息与访问字串这个钥匙匹配才可以打开。我们一般把这个钥匙称为访问字串(Token)访问字串访问字串主要包括:用户标识、组标识、优先权信息、以及其他访问信息。用户标识:用于唯一标识每个用户,就好像为每个用户都分配了一个唯一的用户ID组标识:用户所属组的唯一标识ID优先权:一般系统对每个用户以及它所属组分配了一些权限,而有的时候这些权限并不够,这个时候需要通过这个优先权信息额外新增一些权限当用户登录windows系统时,系统就为这个用户分配了一个带有该用户信息的访问字串,该用户创建的每个安全对象都有这个访问字串的拷贝,当用户打开的进程试图访问某个安全对象时系统就在对象的ACL中查找该用户是否有某项权限。有这个权限才能对对象进行这项操作。子进程的访问字串一般继承与父进程,但是子进程也可以自行创建访问字串来覆盖原来的访问字串。操作访问字串所使用的API主要有以下几个:OpenProcessToken //打开进程的访问令牌OpenThreadToken //打开线程的访问令牌AdjustTokenGroups //改变用户组的访问令牌AdjustTokenPrivileges //改变令牌的访问特权GetTokenInformation //获取访问令牌的信息SetTokenInformation //设置访问令牌信息下面主要介绍一下函数GetTokenInformation 的用法:BOOL WINAPI GetTokenInformation( __in HANDLE TokenHandle, //访问字串的句柄 __in TOKEN_INFORMATION_CLASS TokenInformationClass, //需要返回访问字串哪方面的信息 __out_opt LPVOID TokenInformation, //用于接收返回信息的缓冲 __in DWORD TokenInformationLength, //缓冲的长度 __out PDWORD ReturnLength //实际所需的缓冲的长度 ); 这个函数可以返回访问令牌多方面的信息,具体返回哪个方面的信息,需要通过第二个参数来指定,这个参数是一个枚举类型,表示需要获取的信息,每个方面的信息都定义了对应的结构体,这些信息可以由MSDN中查到。另外这个函数支持两次调用,第一次传入NULL指针和0长度,这样通过最后一个参数可以得到具体所需要的缓冲的大小。SID访问字串中用户与用户组采用安全标识符的方式唯一标识(Security Indentifer SID),系统中的SID是唯一的。它主要用来标识下面的这些内容:安全描述符中的所有者和用户组被ACE认可的访问者访问字串的用户和组SID的长度是可变的,在使用时不应该使用SID这个数据类型,因为这个时候还不知道需要的长度是多少,应该由系统来创建并返回它的指针,所以在使用时需要使用SID的指针。下面是一些操作SID的APIAllocateAndInitializeSid //初始化一个SIDFreeSid //释放一个SIDCopySid //拷贝一个SIDEqualSid //判断两个SID是否相等GetLengthSid //获取SID的长度IsValidSid //是否是有效的SIDConvertSidToStringSid //将SID转化为字符串的方式下面是一个利用这些API获取系统用户组的SID和当前登录用户的SID的例子:BOOL GetLoginSid(HANDLE hToken, PSID *ppsid); //SID本身大小是不可知的,所以在传入参数时应该传入2级指针,由函数自己决定大小 void FreeSid(PSID *ppsid); int _tmain(int argc, TCHAR* argv[]) { setlocale(LC_ALL, "chs"); HANDLE hProcess = GetCurrentProcess(); HANDLE hToken = NULL; OpenProcessToken(hProcess, TOKEN_ALL_ACCESS, &hToken); PSID pSid = NULL; GetLoginSid(hToken, &pSid); LPTSTR pStringSid = NULL; ConvertSidToStringSid(pSid, &pStringSid); _tprintf(_T("当前登录的用户sid = %s\n"), pStringSid); FreeSid(&pSid); return 0; } BOOL GetLoginSid(HANDLE hToken, PSID *ppsid) { TOKEN_GROUPS *ptg = NULL; BOOL bSuccess = FALSE; DWORD dwLength = 0; if(!GetTokenInformation(hToken, TokenGroups, ptg, 0, &dwLength)) { if (ERROR_INSUFFICIENT_BUFFER != GetLastError()) { goto __CLEAN_UP; } ptg = (TOKEN_GROUPS*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); if (!GetTokenInformation(hToken, TokenGroups, ptg, dwLength, &dwLength)) { goto __CLEAN_UP; } } _tprintf(_T("共找到%d个组SID\n"), ptg->GroupCount); LPTSTR pStringSid = NULL; for (int i = 0; i < ptg->GroupCount; i++) { ConvertSidToStringSid(ptg->Groups[i].Sid, &pStringSid); _tprintf(_T("\t id = %d sid = %s"), i, pStringSid); if ((ptg->Groups[i].Attributes & SE_GROUP_LOGON_ID) == SE_GROUP_LOGON_ID) { _tprintf(_T("此用户为当前登录的用户")); *ppsid = (PSID)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwLength); CopySid(dwLength, *ppsid, ptg->Groups[i].Sid); } _tprintf(_T("\n")); } __CLEAN_UP: if (ptg != NULL) { HeapFree(GetProcessHeap(), 0, ptg); } return bSuccess; } void FreeSid(PSID *ppsid) { HeapFree(GetProcessHeap(), 0, *ppsid); *ppsid = NULL; }这个例子是MSDN中的一个例子,上述代码中首先获取进程的访问令牌,然后通过函数GetTokenInformation 获取访问令牌的信息。通过传入TokenGroups这个值获取当前用户所在用户组的访问字串。并将信息保存到结构体TOKEN_GROUPS中最后通过(ptg->Groups[i].Attributes & SE_GROUP_LOGON_ID) == SE_GROUP_LOGON_ID这样一个表达式来判断当前的SID是否是登录用户的。优先权优先权是由字符串标识的局部唯一的标识符(LUID)优先权是由系统管理员分配给对应的用户,一般不能通过编程的方式提升用户的优先权,但是有时候即使用户具有某个优先权,但是它启动的程序并不具有相关的优先权。这个时候可以通过编程的方式提升用户进程特权。系统有3个值代表一个优先权:字符串名,整个系统上都有意义,称为全局名,这个字符串并不是一个可读的字符串,显示出来的信息不一定能看得懂。显示给用户的可读名称;如:改变系统时间(可以在组策略中查看)每个计算机都不同的局部值;下面有几个常用的优先权:#define SE_DEBUG_NAME TEXT("SeDebugPrivilege") //调试进程 #define SE_LOAD_DRIVER_NAME TEXT("SeLoadDriverPrivilege") //装载驱动 #define SE_LOCK_MEMORY_NAME TEXT("SeLockMemoryPrivilege") //锁定内存页面 #define SE_SHUTDOWN_NAME TEXT("SeShutdownPrivilege") //关机下面是几个优先权函数LookupPrivilegeValue //查询优先权的值LookupPrivilegeDisplayName //查询优先权的输出名LookupPrivilegeName //查询优先权的名称PrivilegeCheck //优先权信息检查下面是一个获取用户特权信息的代码:int _tmain(int argc, TCHAR *argv[]) { setlocale(LC_ALL, "chs"); HANDLE hToken = NULL; HANDLE hProcess = GetCurrentProcess(); OpenProcessToken(hProcess, TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY, &hToken); TOKEN_PRIVILEGES* ptg = NULL; DWORD dwTgSize = 0; TCHAR szName[255] = _T(""); TCHAR szDisplay[255] = _T(""); DWORD languageID = GetUserDefaultLangID(); if (!GetTokenInformation(hToken, TokenPrivileges, ptg, 0, &dwTgSize)) { if (ERROR_INSUFFICIENT_BUFFER != GetLastError()) { _tprintf(_T("获取令牌失败\n")); return 0; } ptg = (TOKEN_PRIVILEGES*)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, dwTgSize); if (!GetTokenInformation(hToken, TokenPrivileges, ptg, dwTgSize, &dwTgSize)) { _tprintf(_T("读取令牌信息失败\n")); return 0; } } _tprintf(_T("用户的特权信息:\n")); for(int i = 0; i < ptg->PrivilegeCount; i++) { DWORD dwName = sizeof(szName) / sizeof(TCHAR); DWORD dwDisplay = sizeof(szDisplay) / sizeof(TCHAR); LookupPrivilegeName(NULL, &ptg->Privileges[i].Luid, szName, &dwName); LookupPrivilegeDisplayName(NULL, szName, szDisplay, &dwDisplay, &languageID); _tprintf(_T("\t 特权名%s %s"), szName, szDisplay); if (ptg->Privileges[i].Attributes & ((SE_PRIVILEGE_ENABLED | SE_PRIVILEGE_ENABLED_BY_DEFAULT))) { _tprintf(_T("特权开放\n")); }else { _tprintf(_T("特权关闭\n")); } } HeapFree(GetProcessHeap(), 0, ptg); return 0; }下面是进程提权的代码:int _tmain(int argc, TCHAR *argv[]) { HANDLE hToken = NULL; HANDLE hProcess = GetCurrentProcess(); SetPrivileges(hToken, SE_TCB_NAME , TRUE); return 0; } BOOL SetPrivileges(HANDLE hToken, LPTSTR lpPrivilegesName, BOOL bEnablePrivilege) { //获取Token的特权信息 LUID uid = {0}; LookupPrivilegeValue(NULL, lpPrivilegesName, &uid); TOKEN_PRIVILEGES tp = {0}; tp.PrivilegeCount = 1; tp.Privileges[0].Luid = uid; if (bEnablePrivilege) { tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED; }else { tp.Privileges[0].Attributes = 0; } AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(TOKEN_PRIVILEGES), NULL, NULL); if ( GetLastError() == ERROR_NOT_ALL_ASSIGNED ) { _tprintf(_T("分配指定的特权(%s)失败. \n"),lpPrivilegesName); return FALSE; } return TRUE; }安全描述符安全描述符中通常包含信息:所有者、主组、任选访问控制列表(DACL)、系统访问控制列表(SACL)安全描述符是以SECURITE_DESCRIPTOR结构开始,后面连续跟着安全描述符的其它信息访问控制列表访问控制列表(Access Control List ACL)主要由多个访问访问控制入口(Access Control Entries ACE)组成。ACE用于标识一个用户、组或局部组以及它们中每一个允许的访问权;安全描述符的创建在创建安全访问对象的函数中一般都需要填入一个SECURITY_ATTRIBUTES结构体的指针,我们要么给定一个NULL值使其具有默认的安全属性,或者自己创建一个安全描述符并将他的指针传入。创建一个安全描述符主要有下面几步:用函数 AllocateAndInitializeSid 创建用户的SID。函数的定义如下:BOOL WINAPI AllocateAndInitializeSid( __in PSID_IDENTIFIER_AUTHORITY pIdentifierAuthority, //用于表示该SID标识的颁发机构 __in BYTE nSubAuthorityCount, //SID有多少个子部分 __in DWORD dwSubAuthority0, //第0个子部分 __in DWORD dwSubAuthority1, __in DWORD dwSubAuthority2, __in DWORD dwSubAuthority3, __in DWORD dwSubAuthority4, __in DWORD dwSubAuthority5, __in DWORD dwSubAuthority6, __in DWORD dwSubAuthority7, __out PSID* pSid //返回一个PSID的指针 );SID主要由一个颁发机构以及一个或者多个32位的唯一的RID组成这些RID通过参数dwSubAuthority0到dwSubAuthority7生成。对应的用户SID都有固定的组合。这个我还没找到具体的用户与SID是如何定义的。为该用户SID分配访问控制权限,主要通过填充结构体EXPLICIT_ACCESS成员来实现,这个结构体的定义如下:typedef struct _EXPLICIT_ACCESS { DWORD grfAccessPermissions; //制定用户权限 ACCESS_MODE grfAccessMode; //用于表示允许、拒绝、审查特定用户的权限 DWORD grfInheritance; //当前的权限是否可以继承 TRUSTEE Trustee; //这是一个访问托管 } EXPLICIT_ACCESS, *PEXPLICIT_ACCESS;3.用API SetEntriesInAcl将上述结构体放入到ACL中分配并初始化SECURITY_DESCRIPTOR结构体,初始化该结构体所用到的API 是InitializeSecurityDescriptor将SECURITY_DESCRIPTOR结构加入到安全描述符中,安全描述符的结构体是:SECURITY_ATTRIBUTES下面是一个具体的例子(这个例子来自MSDN): SID_IDENTIFIER_AUTHORITY SIDAuthorityNT = SECURITY_WORLD_SID_AUTHORITY; SID_IDENTIFIER_AUTHORITY SIDAuthorityWord = SECURITY_NT_AUTHORITY; PSID pEveryOneSid = NULL; PSID pAdminSid = NULL; EXPLICIT_ACCESS ea[2] = {0}; PACL pAcl = NULL; //创建everyone用户的SID AllocateAndInitializeSid(&SIDAuthorityWord, 1, SECURITY_WORLD_RID, 0, 0, 0, 0, 0, 0, 0, &pEveryOneSid); PSECURITY_DESCRIPTOR pSD = NULL; //定义everyone 的访问控制信息 ea[0].grfAccessMode = SET_ACCESS; //用于表示允许、拒绝、审查特定用户的权限 ea[0].grfAccessPermissions = KEY_READ; //制定用户权限 ea[0].grfInheritance = FALSE; ea[0].Trustee.TrusteeType = TRUSTEE_IS_WELL_KNOWN_GROUP; ea[0].Trustee.TrusteeForm = TRUSTEE_IS_SID; ea[0].Trustee.ptstrName = (LPTSTR)pEveryOneSid; //创建administor用户组的SID AllocateAndInitializeSid(&SIDAuthorityNT, 2, SECURITY_BUILTIN_DOMAIN_RID,DOMAIN_ALIAS_RID_ADMINS, 0, 0, 0, 0, 0, 0, &pAdminSid); ea[1].grfAccessMode = SET_ACCESS; ea[1].grfAccessPermissions = KEY_ALL_ACCESS; ea[1].grfInheritance = FALSE; ea[1].Trustee.TrusteeForm = TRUSTEE_IS_SID; ea[1].Trustee.TrusteeType = TRUSTEE_IS_GROUP; ea[1].Trustee.ptstrName = (LPTSTR)pAdminSid; //将以上两个SID加入到ACL中 SetEntriesInAcl(2, ea, NULL, &pAcl); pSD = (PSECURITY_DESCRIPTOR) HeapAlloc(GetProcessHeap(), 0, SECURITY_DESCRIPTOR_MIN_LENGTH); //初始化一个SECURITY_DESCRIPTOR结构 InitializeSecurityDescriptor(&pSD, SECURITY_DESCRIPTOR_REVISION); //将SECURITY_DESCRIPTOR结构加入到安全描述符中 SECURITY_ATTRIBUTES sa = {0}; sa.bInheritHandle = FALSE; sa.lpSecurityDescriptor = pSD; sa.nLength = sizeof(SECURITY_ATTRIBUTES); HKEY hkSub = NULL; DWORD dwDisposition = 0; RegCreateKeyEx(HKEY_CURRENT_USER, _T("mykey"), 0, _T(""), 0, KEY_READ | KEY_WRITE, &sa, &hkSub, &dwDisposition); if (pEveryOneSid) { FreeSid(pEveryOneSid); } if (pAdminSid) { FreeSid(pAdminSid); } if (pAcl) { LocalFree(pAcl); } HeapFree(GetProcessHeap(), 0, pSD); if (hkSub) { RegCloseKey(hkSub); }
-
windows 异常处理 为了程序的健壮性,windows 中提供了异常处理机制,称为结构化异常,异常一般分为硬件异常和软件异常,硬件异常一般是指在执行机器指令时发生的异常,比如试图向一个拥有只读保护的页面写入内容,或者是硬件的除0错误等等,而软件异常则是由程序员,调用RaiseException显示的抛出的异常。对于一场处理windows封装了一整套的API,平台上提供的异常处理机制被叫做结构化异常处理(SEH)。不同于C++的异常处理,SEH拥有更为强大的功能,并且采用C风给的代码编写方式。异常处理机制的流程简介一般当程序发生异常时,用户代码停止执行,并将CPU的控制权转交给操作系统,操作系统接到控制权后,将当前线程的环境保存到结构体CONTEXT中,然后查找针对此异常的处理函数。系统利用结构EXCEPTION_RECORD保存了异常描述信息,它与CONTEXT一同构成了结构体EXCEPTION_POINTERS,一般在异常处理中经常使用这个结构体。异常信息EXCEPTION_RECORD的定义如下typedef struct _EXCEPTION_RECORD { DWORD ExceptionCode; //异常码 DWORD ExceptionFlags; //标志异常是否继续,标志异常处理完成后是否接着之前有问题的代码 struct _EXCEPTION_RECORD* ExceptionRecord; //指向下一个异常节点的指针,这是一个链表结构 PVOID ExceptionAddress; //异常发生的地址 DWORD NumberParameters; //异常附加信息 ULONG_PTR ExceptionInformation[EXCEPTION_MAXIMUM_PARAMETERS]; //异常的字符串 } EXCEPTION_RECORD, *PEXCEPTION_RECORD;当系统在用户程序中查找异常处理代码时主要通过查找当前的这个链表。下面详细说明异常发生时操作系统是如何处理的:如果程序是被调试运行的(比如我们在VS编译器中调试运行程序),当异常发生时,系统首先将异常信息交给调试程序,如果调试程序处理了那么程序继续运行,否则系统便在发生异常的线程栈中查找可能的处理代码。若找到则处理异常,并继续运行程序如果在线程栈中没有找到,则再次通知调试程序,如果这个时候仍然不能处理这个异常,那么操作系统会对异常进程默认处理,比如强制终止程序。SEH的基本框架结构化异常处理一般有下面3个部分组成:保护代码体过滤表达式异常处理块其中保护代码体:是指有可能发生异常的代码,一般在SEH中是用__try{}包含的那部分过滤表达式:是在__except表达式的括号中的部分,一般可以是函数或者表达式,过滤表达式一般只能返回3个值:EXCEPTION_CONTINUE_SEARCH表示继续向下寻找异常处理的程序,也就是说本__exception不能处理这个异常;EXCEPTION_CONTINUE_EXECUTION表示异常已被处理,继续执行当初发生异常的代码;EXCEPTION_EXECUTE_HANDLER:表示异常已被处理,直接跳转到__exception(){}代码块中执行,这个时候就有点像C++中的异常处理了。一般一个__try块可以跟随多个__except块异常处理块:是指__except大括号中的代码块另外可以在过滤表达式中调用GetExceptionCode和GetExceptionInformagtion函数取得正在处理的异常信息,这两个函数不能再过滤表达式中使用,但是可以作为过滤表达式中的函数参数。下面是一个异常处理的简单的例子:#define PAGELIMIT 1024 DWORD dwPageCnt = 0; LPVOID lpPrePage = NULL; DWORD dwPageSize = 0; INT FilterFunction(DWORD dwExceptCode) { if(EXCEPTION_ACCESS_VIOLATION != dwExceptCode) { return EXCEPTION_EXECUTE_HANDLER; } if(dwPageCnt >= PAGELIMIT) { return EXCEPTION_EXECUTE_HANDLER; } if(NULL == VirtualAlloc(lpPrePage, dwPageSize, MEM_COMMIT, PAGE_READWRITE)) { return EXCEPTION_EXECUTE_HANDLER; } lpPrePage = (char*)lpPrePage + dwPageSize; dwPageCnt++; return EXCEPTION_CONTINUE_EXECUTION; } int _tmain(int argc, TCHAR *argv[]) { SYSTEM_INFO si = {0}; GetSystemInfo(&si); dwPageSize = si.dwPageSize; char* lpBuffer = (char*)VirtualAlloc(NULL, dwPageSize * PAGELIMIT, MEM_RESERVE, PAGE_READWRITE); lpPrePage = lpBuffer; for(int i = 0; i < PAGELIMIT * dwPageSize; i++) { __try { lpBuffer[i] = 'a'; } __except(FilterFunction(GetExceptionCode())) { ExitProcess(0); } } VirtualFree(lpBuffer, dwPageSize * PAGELIMIT, MEM_FREE); return 0; }这段代码我们通过结构化异常处理实现了内存的按需分配,首先程序保留了4M的地址空间,但是并没有映射到具体的物理内存,接着向这4M的空间中写入内容,这个时候会造成非法的内存访问异常,系统会执行过滤表达式中调用的函数,在函数中校验异常的异常码,如果不等于EXCEPTION_ACCESS_VIOLATION,也就是说这个异常并不是读写非法内存造成的,那么直接返回EXCEPTION_EXECUTE_HANDLER,这个时候会执行__exception块中的代码,也就是结束程序,如果是由于访问非法内存造成的,并且读写的范围没有超过4M那么就提交一个物理页面供程序使用,并且返回EXCEPTION_CONTINUE_EXECUTION,让程序接着从刚才的位置执行也就是说再次执行写入操作,这样保证了程序需要多少就提交多少,节约了物理内存。终止处理块终止处理块是结构化异常处理特有的模块,它保证了当__try块执行完成后总会执行终止处理块中的代码。一般位于__finally块中。只有当线程在__try中结束,也就是在__try块中调用ExitProcess或者ExitThread。由于系统为了保证__try块结束后总会调用__finally所以某些跳转语句如:goto return break等等就会添加额外的机器码以便能够跳入到__try块中,所以为了效率可以用__leave语句代替这些跳转语句。另外需要注意的一点是一个__try只能跟一个__finally块但是可以跟多个__except块。同时__try块后面要么跟__except要么跟__finally这两个二选一,不能同时跟他们两个。抛出异常在SEH中抛出异常需要使用函数:RaiseException,它的原型如下:void WINAPI RaiseException(DWORD dwExceptionCode, DWORD dwExceptionFlags, DWORD nNumberOfArguments, const ULONG_PTR* lpArguments);第一个是异常代码,第二个参数是异常标志,第三个是异常参数个数,第四个是参数列表,这个函数主要是为了填充EXCEPTION_RECORD结构体并将这个节点添加到链表中,当发生异常时系统会查找这个链表,下面是一个简单的例子:DWORD FilterException() { wprintf(_T("1\n")); return EXCEPTION_EXECUTE_HANDLER; } int _tmain(int argc, TCHAR *argv[]) { __try { __try { RaiseException(1, 0, 0, NULL); } __finally { wprintf(_T("2\n")); } } __except(FilterException()) { wprintf(_T("3\n")); } _tsystem(_T("PAUSE")); return 0; }上面的程序使用RaiseException抛出一个异常,按照异常处理的流程,程序首先会试着执行FilterException,以便处理这个异常,所以首先会输出1,然后根据返回值EXCEPTION_EXECUTE_HANDLER决定下一步会执行异常处理块__except中的内容,这个时候也就表示最里面的__try块执行完了,在前面说过,不管遇到什么情况,执行完__try块,都会接着执行它对应的__finally块,所以这个时候会首先执行__finally块,最后执行外层的__except块,最终程序输出结果为1 2 3win32下的向量化异常处理为什么向量化异常要强调是win32下的呢,因为64位windows不支持这个特性理解这个特性还是回到之前说的操作系统处理异常的顺序上面,首先会交给调试程序,然后再由用户程序处理,根据过滤表达式返回的值决定这个异常是否被处理,而这个向量化异常处理,就是将异常处理的代码添加到这个之前,它的代码会先于过滤表达式之前执行。我们知道异常是由内层向外层一层一层的查找,如果在内层已经处理完成,那么外层是永远没有机会处理的,这种情况在我们使用第三方库开发应用程序,而这个库又不提供源码,并且当发生异常时这个库只是简单的将线程终止,而我们想处理这个异常,但是由于内部处理了,外层的try根本捕获不到,这个时候就可以使用向量化异常处理了。这样我们可以编写异常处理代码先行处理并返回继续执行,这样库中就没有机会处理这个异常了。使用这个机制通过AddVectoredExceptionHandler函数可以添加向量化异常处理过滤函数,而调用RemoveVectoredExceptionHandler可以移除一个已添加的向量化异常处理过滤函数。下面是一个简单的例子:int g_nVal = 0; void Func(int nVal) { __try { nVal /= g_nVal; } __except(EXCEPTION_EXECUTE_HANDLER) { printf("正在执行Func中的__try __except块\n"); ExitProcess(0); } } LONG CALLBACK VH1(PEXCEPTION_POINTERS pExceptionInfo) { printf("正在执行VH1()函数\n"); return EXCEPTION_CONTINUE_SEARCH; } LONG CALLBACK VH2(PEXCEPTION_POINTERS pExceptionInfo) { printf("正在执行VH2()函数\n"); if (EXCEPTION_INT_DIVIDE_BY_ZERO == pExceptionInfo->ExceptionRecord->ExceptionCode) { g_nVal = 25; return EXCEPTION_CONTINUE_EXECUTION; } return EXCEPTION_CONTINUE_SEARCH; } LONG CALLBACK VH3(PEXCEPTION_POINTERS pExceptionInfo) { printf("正在执行VH3()函数\n"); return EXCEPTION_CONTINUE_SEARCH; } LONG SEH1(EXCEPTION_POINTERS *pEP) { //除零错误 if (EXCEPTION_INT_DIVIDE_BY_ZERO == pEP->ExceptionRecord->ExceptionCode) { g_nVal = 34; return EXCEPTION_EXECUTE_HANDLER; } return EXCEPTION_CONTINUE_SEARCH; } int _tmain(int argc, TCHAR *argv[]) { LPVOID lp1 = AddVectoredExceptionHandler(0, VH1); LPVOID lp2 = AddVectoredExceptionHandler(0, VH2); LPVOID lp3 = AddVectoredExceptionHandler(1, VH3); __try { Func(g_nVal); printf("Func()函数执行完成后g_nVal = %d\n", g_nVal); } __except(SEH1(GetExceptionInformation())) { printf("正在执行main()中的__try __except块"); } RemoveVectoredExceptionHandler(lp1); RemoveVectoredExceptionHandler(lp2); RemoveVectoredExceptionHandler(lp3); return 0; }上述的程序模拟了调用第三方库的情况,比如我们调用了第三方库Func进行某项操作,我们在外层进行了异常处理,但是由于在Func函数中有异常捕获的代码,所以不管外层如何处理,总不能捕获到异常,外层的异常处理代码总是不能执行,这个时候我们注册了3个向量处理函数,由于VH1返回的是EXCEPTION_CONTINUE_SEARCH,这个时候会在继续执行后面注册的向量函数——VH2,VH2返回EXCEPTION_CONTINUE_SEARCH,会继续执行VH3,VH3还是返回EXCEPTION_CONTINUE_SEARCH,那么它会继续执行库函数内层的异常处理,内层的过滤表达式返回EXCEPTION_EXECUTE_HANDLER,这个时候会继续执行异常处理块中的内容,结束程序,如果我们将3个向量函数中的任何一个的返回值改为EXCEPTION_CONTINUE_EXECUTION,那么库中的异常处理块中的内容将不会被执行。函数AddVectoredExceptionHandler中填入的处理函数也就是上述代码中的VH1 VH2 VH3只能返回EXCEPTION_CONTINUE_EXECUTION和EXCEPTION_CONTINUE_SEARCH,对于其他的值操作系统不认。将SEH转化为C++异常C++异常处理并不能处理所有类型的异常而将SEH和C++异常混用,可以达到使用C++异常处理处理所有异常的目的要混用二者需要在项目属性->C/C++->代码生成->启动C++异常的选项中打开SEH开关。在混用时可以在SEH的过滤表达式的函数中使用C++异常,当然最好的方式是将SEH转化为C++异常。通过调用_set_se_translator这个函数指定一个规定格式的回调函数指针就可以利用标准C++风格的关键字处理SEH了。下面是它们的定义:_set_se_translator(_se_translator_function seTransFunction); typedef void (*_se_translator_function)(unsigned int, struct _EXCEPTION_POINTERS* );使用时,需要自定义实现_se_translator_function函数,在这个函数中通常可以通过throw一个C++异常的方式将捕获的SEH以标准C++EH的方式抛出下面是一个使用的例子:class SE_Exception { public: SE_Exception(){}; SE_Exception(DWORD dwErrCode) : dwExceptionCode(dwErrCode){}; ~SE_Exception(){}; private: DWORD dwExceptionCode; }; void STF(unsigned int ui, PEXCEPTION_POINTERS pEp) { printf("执行STF函数\n"); throw SE_Exception(); } void Func(int i) { int x = 0; int y = 5; x = y / i; } int _tmain(int argc, TCHAR *argv[]) { try { _set_se_translator(STF); Func(0); } catch(SE_Exception &e) { printf("main 函数中捕获到异常 \n"); } return 0; }程序首先调用_set_se_translator函数定义了一个回掉函数,当异常发生时,系统调用回掉函数,在函数中抛出一个自定义的异常类,在主函数中使用C++的异常处理捕获到了这个异常并成功输出了一条信息。
-
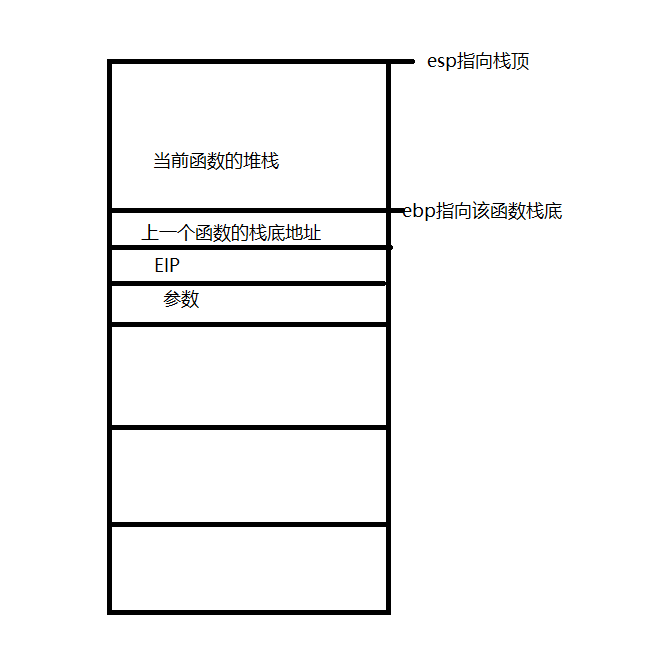
windows平台调用函数堆栈的追踪方法 在windows平台,有一个简单的方法来追踪调用函数的堆栈,就是利用函数CaptureStackBackTrace,但是这个函数不能得到具体调用函数的名称,只能得到地址,当然我们可以通过反汇编的方式通过地址得到函数的名称,以及具体调用的反汇编代码,但是对于有的时候我们需要直接得到函数的名称,这个时候据不能使用这个方法,对于这种需求我们可以使用函数:SymInitialize、StackWalk、SymGetSymFromAddr、SymGetLineFromAddr、SymCleanup。原理基本上所有高级语言都有专门为函数准备的堆栈,用来存储函数中定义的变量,在C/C++中在调用函数之前会保存当前函数的相关环境,在调用函数时首先进行参数压栈,然后call指令将当前eip的值压入堆栈中,然后调用函数,函数首先会将自身堆栈的栈底地址保存在ebp中,然后抬高esp并初始化本身的堆栈,通过多次调用最终在堆栈段形成这样的布局这里对函数的原理做简单的介绍,有兴趣的可以看我的另一篇关于C函数原理讲解的博客,点击这里跳转VC++编译器在编译时对函数名称与地址都有详细的记录,编译出来的程序都有一个符号常量表,将符号常量与它对应的地址形成映射,在搜索时首先根据这些堆栈环境找到对应地址,然后根据地址在符号常量表中,找到具体调用的信息,这是一个很复杂的工程,需要对编译原理和汇编有很强的基础,幸运的是,如今这些工作不需要程序员自己去做,windows帮助我们分配了一组API,在编写程序时只需要调用API即可函数说明SymInitialize:这个函数主要用作初始化相关环境。SymCleanup:清楚这个初始化的相关环境,在调用SymInitialize之后需要调用SymCleanup,进行释放资源的操作StackWalk:程序的功能主要由这个函数实现,函数会从初始化时的堆栈顶开始向下查找下一个堆栈的信息,原型如下:BOOL WINAPI StackWalk( __in DWORD MachineType, //机器类型现在一般是intel的x86系列,这个时候填入IMAGE_FILE_MACHINE_I386 __in HANDLE hProcess, //追踪的进程句柄 __in HANDLE hThread, //追踪的线程句柄 __in_out LPSTACKFRAME StackFrame, //记录的追踪到的堆栈信息 __in_out PVOID ContextRecord, //记录当前的线程环境 __in PREAD_PROCESS_MEMORY_ROUTINE ReadMemoryRoutine, __in PFUNCTION_TABLE_ACCESS_ROUTINE FunctionTableAccessRoutine, __in PGET_MODULE_BASE_ROUTINE GetModuleBaseRoutine, __in PTRANSLATE_ADDRESS_ROUTINE TranslateAddress //后面的四个参数都是回掉函数,有系统自行调用,而且这些函数都是定义好的,只需要填入相应的函数名称 );需要注意的一点是,在首次调用该函数时需要对StackFrame中的AddrPC、AddrFrame、AddrStack这三个成员进行初始化,填入相关值,以便函数从此处线程堆栈的栈顶进行搜索,否则调用函数将失败,具体如何填写请看MSDN。SymGetSymFromAddr:根据获取到的函数地址得到函数名称、堆栈大小等信息,这个函数的原型如下: BOOL WINAPI SymGetSymFromAddr( __in HANDLE hProcess, //进程句柄 __in DWORD Address, //函数地址 __out PDWORD Displacement, //返回该符号常量的位移或者填入NULL,不获取此值 __out PIMAGEHLP_SYMBOL Symbol//返回堆栈信息 );SymGetLineFromAddr:根据得到的地址值,获取调用函数的相关信息。主要记录是在哪个文件,哪行调用了该函数,下面是函数原型:BOOL WINAPI SymGetLineFromAddr( __in HANDLE hProcess, __in DWORD dwAddr, __out PDWORD pdwDisplacement, __out PIMAGEHLP_LINE Line );它参数的含义与SymGetSymFromAddr,相同。通过上面对函数的说明,我们可以知道,为了追踪函数调用的详细信息,大致步骤如下:首先调用函数SymInitialize进行相关的初始化工作。填充结构体StackFrame的相关信息,确定从何处开始追踪。循环调用StackWalk函数,从指定位置,向下一直追踪到最后。每次将获取的地址分别传入SymGetSymFromAddr、SymGetLineFromAddr,得到函数的详细信息调用SymCleanup,结束追踪但是需要注意的一点是,函数StackWalk会顺着线程堆栈进行查找,如果在调用之前,某个函数已经返回了,它的堆栈被回收,那么函数StackWalk自然不会追踪到该函数的调用。具体实现void InitTrack() { g_hHandle = GetCurrentProcess(); SymInitialize(g_hHandle, NULL, TRUE); } void StackTrack() { g_hThread = GetCurrentThread(); STACKFRAME sf = { 0 }; sf.AddrPC.Offset = g_context.Eip; sf.AddrPC.Mode = AddrModeFlat; sf.AddrFrame.Offset = g_context.Ebp; sf.AddrFrame.Mode = AddrModeFlat; sf.AddrStack.Offset = g_context.Esp; sf.AddrStack.Mode = AddrModeFlat; typedef struct tag_SYMBOL_INFO { IMAGEHLP_SYMBOL symInfo; TCHAR szBuffer[MAX_PATH]; } SYMBOL_INFO, *LPSYMBOL_INFO; DWORD dwDisplament = 0; SYMBOL_INFO stack_info = { 0 }; PIMAGEHLP_SYMBOL pSym = (PIMAGEHLP_SYMBOL)&stack_info; pSym->SizeOfStruct = sizeof(IMAGEHLP_SYMBOL); pSym->MaxNameLength = sizeof(SYMBOL_INFO) - offsetof(SYMBOL_INFO, symInfo.Name); IMAGEHLP_LINE ImageLine = { 0 }; ImageLine.SizeOfStruct = sizeof(IMAGEHLP_LINE); while (StackWalk(IMAGE_FILE_MACHINE_I386, g_hHandle, g_hThread, &sf, &g_context, NULL, SymFunctionTableAccess, SymGetModuleBase, NULL)) { SymGetSymFromAddr(g_hHandle, sf.AddrPC.Offset, &dwDisplament, pSym); SymGetLineFromAddr(g_hHandle, sf.AddrPC.Offset, &dwDisplament, &ImageLine); printf("当前调用函数 : %08x+%s(FILE[%s]LINE[%d])\n", pSym->Address, pSym->Name, ImageLine.FileName, ImageLine.LineNumber); } } void UninitTrack() { SymCleanup(g_hHandle); }测试程序如下:void func1() { OPEN_STACK_TRACK; } void func2() { func1(); } void func3() { func2(); } void func4() { printf("hello\n"); } int _tmain(int argc, TCHAR* argv[]) { func4(); func3(); func3(); return 0; }OPEN_STACK_TRACK是一个宏,它的定义如下:#define OPEN_STACK_TRACK\ HANDLE hThread = GetCurrentThread();\ GetThreadContext(hThread, &g_context);\ __asm{call $ + 5}\ __asm{pop eax}\ __asm{mov g_context.Eip, eax}\ __asm{mov g_context.Ebp, ebp}\ __asm{mov g_context.Esp, esp}\ InitTrack();\ StackTrack();\ UninitTrack();这个程序需要注意以下几点:如果想要追踪所有调用的函数,需要将这个宏放置到最后调用的位置,当然前提是此时之前被调函数的堆栈仍然存在。当然可以在调用前简单的计算,找出在哪个位置是所有函数都没有调用完成的,不过这样可能就与程序的初衷相悖,毕竟程序本身就是为了获取堆栈的调用信息。。。。IMAGEHLP_SYMBOL的结构体中关于Name的成员,只有一个字节,而函数SymGetSymFromAddr在填入值时是没有关心这个实际大小,它只是简单的填充,这就造成了缓冲区溢出的情况,为了避免我们需要在Name后面额外给一定大小的缓冲区,用来接收数据,这也就是我们定义这个结构体SYMBOL_INFO的原因。另外IMAGEHLP_SYMBOL中的MaxNameLength成员是指Name的最大长度,需要根据给定的缓冲区,进行计算。从测试程序来看,在进行追踪时func4已经调用完成,而我们在获取线程的运行时环境g_context时函数GetThreadContext,也在堆栈中,最终得到的结果中必然包含GetThreadContext的调用信息,如果想去掉这个信息,只需要修改获得信息的值,既然函数StackWalk是根据堆栈进行追踪,那么只需要修改对应堆栈的信息即可,需要修改eip 、ebp、esp的值,关于esp ebp的值很好修改,可以在对应函数中esp ebp这些寄存器的值,而eip的值就不那么好获取,本生利用mov指令得到eip的值它也是指令,会改变eip的值,从而造成获取到的eip的值不准确,所以我们利用call指令,先保存当前eip的值到堆栈,然后再从堆栈中取出。call指令的实质是 push eip和jmp addr指令的组合,并不一定非要调用函数。call指令的大小为5个字节,所以call $ + 5表示先保存eip在跳转到它的下一跳指令处。这样就可以有效的避免检测到GetThreadContext中的相关函数调用。
-
windows错误处理 在调用windows API时函数会首先对我们传入的参数进行校验,然后执行,如果出现什么情况导致函数执行出错,有的函数可以通过返回值来判断函数是否出错,比如对于返回句柄的函数如果返回NULL 或者INVALID_HANDLE_VALUE,则函数出错,对于返回指针的函数来说如果返回NULL则函数出错,但是对于有的函数从返回值来看根本不知道是否成功,或者为什么失败,对此windows提供了一大堆的错误码,用于标识API函数是否出错以及出错原因。在windows中为每个线程准备了一个存储区,专门用来存储当前API执行的错误码,想要获取这个错误码可以通过函数GetLastError。在这需要注意的是当前API执行返回的错误码会覆盖之前API返回的错误码,所以在调用API结束后需要立马调用GetLastError来获取该函数返回的错误码。但是windows中的错误码实在太多,有的时候错误码并不直观,windows为每个错误码都关联了一个错误信息的文本,想要通过错误码获取对应的文本信息,可以通过函数FormatMessage来获取。下面是一个具体的例子:#include <windows.h> #include <tchar.h> #include <stdio.h> #include <strsafe.h> #define GRS_OUTPUT(s) WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), s, _tcsclen(s), NULL, NULL) int _tmain(int argc, TCHAR *argv[]) { if (INVALID_HANDLE_VALUE == CreateFile(_T("C:\\Test.txt"), GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL)) { LPTSTR lpMsg = NULL; DWORD dwLastError = GetLastError(); FormatMessage(FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_IGNORE_INSERTS | FORMAT_MESSAGE_FROM_SYSTEM, NULL, dwLastError, GetUserDefaultLangID(), (LPTSTR)&lpMsg, 0, NULL); if (NULL != lpMsg) { TCHAR szErrorInfo[1024] = {0}; StringCchPrintf(szErrorInfo, sizeof(szErrorInfo), _T("打开文件失败,失败原因为:%s"), lpMsg); GRS_OUTPUT(szErrorInfo); HeapFree(GetProcessHeap(), 0, lpMsg); } } return 0; }在这段代码中我们没有使用C标准库中的printf,而是使用了windows自带的控制台函数WriteConsole,为了简单,我们定义了一个宏,用来输出字符串。函数WriteConsole的原型如下:BOOL WINAPI WriteConsole( __in HANDLE hConsoleOutput, __in const VOID* lpBuffer, __in DWORD nNumberOfCharsToWrite, __out LPDWORD lpNumberOfCharsWritten, LPVOID lpReserved );函数的第一个参数是控制台的句柄,可以通过函数GetStdHandle来获取,这个函数主要传入一个标志,表示需要获取哪个控制台的句柄,主要有:STD_INPUT_HANDLE(标准输入)、STD_OUTPUT_HANDLE(标准输出)、STD_ERROR_HANDLE(标准错误)第二个参数是字符串的指针,第三个参数是字符个数,第四个参数是实际写入字符个数,由函数返回,如果不关心可以给NULL,最后一个windows作为保留参数通常给NULL。程序首先以打开已存在文件的方式打开一个文件,由于这个文件并不存在,所以函数出错,我们通过GetLastError获取错误码,然后通过FormatMessage来进行转化,该函数原型如下:DWORD FormatMessage( DWORD dwFlags, //标志 LPCVOID lpSource, //根据第一个参数的不同而有不同的解释 DWORD dwMessageId, //错误码 DWORD dwLanguageId, //语言ID LPTSTR lpBuffer, //字符缓冲区,用来存放最终生成的格式字符串 DWORD nSize, //缓冲区大小 va_list* Arguments//作为不定参数类似于printf函数格式化字符串后面的参数 ); 第一个参数是标志,在这我们传入FORMAT_MESSAGE_ALLOCATE_BUFFER,表示字符串缓冲区由该函数为我们分配,而不用自己分配,这个时候为了接受返回的字符缓冲区指针,需要使用二级指针。传入FORMAT_MESSAGE_IGNORE_INSERTS表示忽略插入的信息,也就是说不需要进行sprintf那样的格式化字符串的操作,传入FORMAT_MESSAGE_FROM_SYSTEM表示错误信息的字符串来自于系统定义的。然后进行简单的格式化之后输出错误字符串,最后需要释放内存,虽然FormatMessage函数帮我们分陪了缓冲,但是它不负责释放,需要我们自行释放。另外我们也可以自行进行错误码的设置,利用函数SetLastError可以达到这个效果,以模拟API调用时返回错误码的操作。在windows上一般遵循这样的格式:|位|31~30|29|28|27~16|15~0||:-|:----|:-|:-|:----|:---||用途|严重性|系统错误码|保留位|设备码|异常代码||含义|0 成功 <br/>1供参考<br/>2警告<br/>3错误|0系统定义<br/>1自定义|总为0|系统设备码|具体错误码|除了获取错误信息之外,还可以获取调用堆栈的快照,可以用函数CaptureStackBackTrace获取,只是这个函数只能获取调用堆栈的线性地址,不能获取到具体的函数名称。下面是它具体的一个例子: const int nCount = 128; PVOID BackTrace[nCount] = {NULL}; int iCnt = CaptureStackBackTrace(0, nCount, BackTrace, NULL); for (int i = 0; i < iCnt; i++) { printf("调用堆栈索引%d, 函数地址:0x%08x\n", i, BackTrace[i]); } return 0;这段代码非常简短,函数只需要四个参数,第一个参数是表示从当前栈顶开始的第几个栈开始便利,第二个参数是共便利多少个栈信息,第三个参数是一个缓冲区,用来存储得到的栈信息,具体就是栈的地址。第四个参数是一个哈希数组,由函数本身返回,如果不需要这个可以设置为NULL。
-
duilib基本框架 最近我一个同学在项目中使用到了duilib框架,但是之前并没有接触过,他与我讨论这方面的内容,看着官方给出的精美的例子,我对这个库有了很大的兴趣,我自己也是初学这个东东,我在网上花了不少时间来找相关的资料,但是找到的不多,官方给的文档又不全面,但是我还是找到了一些博主贡献的优秀的博文,现在我是通过博文上的讲解加上自己查看源代码的一些心得,正在艰难的前行。现在正在看的是博主Alberl在博客园中的duilib基础教程中的内容,下面的代码都是在他博客中给出代码的基础上做了一点小小的修改。点击这里跳转到对应的博客,以及博主夜雨無聲的博客,博客地址duilib的简介国内首个开源 的directui 界面库,它提供了一个所见即所得的开发工具——UIDesigner,它只有主框架窗口,其余的空间全部采用绘制的方式实现,所以对于控件来说没有句柄和窗口类等内容,它通过UIDesigner工具将用户定义的窗口保存在xml文件中,在创建窗口时读取xml文件中的内容,来绘制相应的控件。目前有许多界面采用duilib编写,大家可以去网上搜集相关资料。环境的配置首先我们去github上获取相关的源代码,这个是对应的项目地址:https://github.com/duilib/duilib下载完后,在目录中找到一个.sln结尾的文件,使用visual studio编译器打开,打开后发现有一个duilib的项目,以及其他,其实真正有用的就是这个duilib,其余的都是官方给出的例子代码。一般只需要编译这个duilib项目就可以了,当初没注意直接点了编译全部的,结果报了一堆错误,其实都是没有对应的lib和dll文件造成的。在VS环境下有一个编译选项,如下图所示上面有4个编译选项,最好将所有的都编译一遍,这样在对应项目的bin目录下会生成四个dll文件,这几个文件分别是debug下的UNICODE编码文件、ANSI文件以及Release版本下的UNICODE编码文件、ANSI文件。u代表unicode d代表debug。另外在lib目录下会生成对应的lib文件。在新建的工程中,点击属性在属性对话框中选择VC++目录,在源文件,库文件,包含文件中将对应的路径添加进去,分别是项目目录和lib文件目录。如下图(刚开始有点问题所以添加的内容有点多,但是不影响正常使用):最后可以在环境变量的Path变量中添加对应的dll路径,这样就不需要将dll文件拷贝到自己项目的exe文件所在位置处。其实上述的环境可以不用设置,如果不设置,在编写程序包含相关路径时就需要给定完整的路径。到此处为止,整个开发环境就已经搭建好了,剩下的就是代码的编写了。基本的框架窗口首先新建一个Win32类型的项目,添加主函数。然后创建一个新类,我们叫做CDuiFrameWnd,下面是类的源代码//头文件 #include <DuiLib\UIlib.h> using namespace DuiLib; class CDuiFrameWnd : public CWindowWnd { public: CDuiFrameWnd(); ~CDuiFrameWnd(); virtual LPCTSTR GetWindowClassName() const; virtual LRESULT HandleMessage(UINT uMsg, WPARAM wParam, LPARAM lParam); protected: CPaintManagerUI m_PaintManager; };//cpp文件 LPCTSTR CDuiFrameWnd::GetWindowClassName() const { return _T("DuiFrameWnd"); } LRESULT CDuiFrameWnd::HandleMessage(UINT uMsg, WPARAM wParam, LPARAM lParam) { LRESULT lRes = 0; if (WM_CLOSE == uMsg) { ::CloseWindow(m_hWnd); ::DestroyWindow(m_hWnd); } if (WM_DESTROY == uMsg) { ::PostQuitMessage(0); } return __super::HandleMessage(uMsg, wParam, lParam); }为了能够使用对应的dll文件,还需要引入对应的lib文件,我们在公共的头文件中加入如下代码#ifdef _DEBUG # ifdef _UNICODE # pragma comment(lib, "Duilib_ud.lib") # else # pragma comment(lib, "Duilib_d.lib") # endif #else # ifdef _UNICODE # pragma comment(lib, "Duilib_u.lib") # else # pragma comment(lib, "Duilib.lib") # endif #endif在主函数中的代码如下:int APIENTRY wWinMain(_In_ HINSTANCE hInstance, _In_opt_ HINSTANCE hPrevInstance, _In_ LPWSTR lpCmdLine, _In_ int nCmdShow) { CPaintManagerUI::SetInstance(hInstance); CDuiFrameWnd duiFrame; //#define UI_WNDSTYLE_FRAME (WS_VISIBLE | WS_OVERLAPPEDWINDOW) duiFrame.Create(NULL, _T("测试"), UI_WNDSTYLE_FRAME, WS_EX_WINDOWEDGE); duiFrame.ShowWindow(); CPaintManagerUI::MessageLoop(); return 0; }这些代码就可以帮助我们生成基本的框架窗口,另外我们需要时刻记住的是duilib是对win32 API的封装,所以可以直接使用win32的编程方式,如果以后有不会用的地方完全可以使用win32 的API来完成相关的功能的编写。框架的剖析既然它能够生成单文档的框架窗口,那么代码中所做的几步基本上与用纯粹的win32 API相同,所以我们沿着这个思路来进行框架的简单剖析。主函数中首先是代码CPaintManagerUI::SetInstance(hInstance);至于类CPaintManagerUI到底有什么作用,这个我也不太清楚,现在我还没有仔细看关于这个类的相关代码,这句话主要还是获取了进程的实例句柄。现在先不关心这个。下面的几步主要是在类CDuiFrameWnd中完成或者说在它的基类CWindowWnd中完成。创建窗口类主函数中的第二段代码主要完成的是类CDuiFrameWnd对象的创建,我们跟到对应的构造函数中发现它并没有做多余的操作,现在先不管它是如何构造的,它下面就是调用了类的Create函数创建了一个窗口,这个函数的代码如下:HWND CWindowWnd::Create(HWND hwndParent, LPCTSTR pstrName, DWORD dwStyle, DWORD dwExStyle, int x, int y, int cx, int cy, HMENU hMenu) { if( GetSuperClassName() != NULL && !RegisterSuperclass() ) return NULL; if( GetSuperClassName() == NULL && !RegisterWindowClass() ) return NULL; m_hWnd = ::CreateWindowEx(dwExStyle, GetWindowClassName(), pstrName, dwStyle, x, y, cx, cy, hwndParent, hMenu, CPaintManagerUI::GetInstance(), this); ASSERT(m_hWnd!=NULL); return m_hWnd; }我们主要来看第二个if中的代码,首先获得了父窗口的字符串为NULL,然后执行RegisterWindowClass,我们进一步跟到RegisterWindowClass中,它的代码如下:bool CWindowWnd::RegisterWindowClass() { WNDCLASS wc = { 0 }; wc.style = GetClassStyle(); wc.cbClsExtra = 0; wc.cbWndExtra = 0; wc.hIcon = NULL; wc.lpfnWndProc = CWindowWnd::__WndProc; wc.hInstance = CPaintManagerUI::GetInstance(); //之前设置的实例句柄在这个地方使用 wc.hCursor = ::LoadCursor(NULL, IDC_ARROW); wc.hbrBackground = NULL; wc.lpszMenuName = NULL; wc.lpszClassName = GetWindowClassName(); ATOM ret = ::RegisterClass(&wc); ASSERT(ret!=NULL || ::GetLastError()==ERROR_CLASS_ALREADY_EXISTS); return ret != NULL || ::GetLastError() == ERROR_CLASS_ALREADY_EXISTS; }我们发现首先进行的是窗口类的创建,在创建窗口类时主要关心的是窗口类的lpfnWndProc成员和lpszClassName 。lpszClassName 调用了函数GetWindowClassName,这个函数我们在派生类中进行了重写,所以根据多态它会调用派生类的GetWindowClassName函数,将我们给定的字符串作为窗口类的类名注册窗口类从上面的代码可以看出注册的代码也是放在RegisterWindowClass中。在最后调用了RegisterClass函数完成了注册。创建窗口当RegisterWindowClass执行完成后,会接着执行下面的代码,也就是 m_hWnd = ::CreateWindowEx(dwExStyle, GetWindowClassName(), pstrName, dwStyle, x, y, cx, cy, hwndParent, hMenu, CPaintManagerUI::GetInstance(), this);完成创建窗口的任务。显示窗口Create函数执行完成后,会接着执行下面的duiFrame.ShowWindow();我们跟到这个函数中,函数代码如下:void CWindowWnd::ShowWindow(bool bShow /*= true*/, bool bTakeFocus /*= false*/) { ASSERT(::IsWindow(m_hWnd)); if( !::IsWindow(m_hWnd) ) return; ::ShowWindow(m_hWnd, bShow ? (bTakeFocus ? SW_SHOWNORMAL : SW_SHOWNOACTIVATE) : SW_HIDE); }函数ShowWindow默认传入参数为bShow = true bTakeFocus = false;在最后进行ShowWindow函数的调用时,根据bShow和bTakeFocus来进行值得传入,根据代码我们发现,当不传入参数时调用的其实是这样的代码ShowWindow(m_hWnd, SW_SHOWNOACTIVATE);消息循环消息循环其实是通过代码CPaintManagerUI::MessageLoop();完成,我们跟到MessageLoop函数中看 MSG msg = { 0 }; while( ::GetMessage(&msg, NULL, 0, 0) ) { if( !CPaintManagerUI::TranslateMessage(&msg) ) { ::TranslateMessage(&msg); ::DispatchMessage(&msg); } }在这个函数中完成了消息循环。回调函数上面我们留了一个lpfnWndProc函数指针没有说,现在来说明这个部分,跟进到对应的构造函数中,发现类本身不做任何操作,但是父类的构造函数进行了相关的初始化操作,下面是对应的代码CWindowWnd::CWindowWnd() : m_hWnd(NULL), m_OldWndProc(::DefWindowProc), m_bSubclassed(false) { }这样就将lpfnWndProc指向了__WndProc,用于处理默认的消息。这是一个静态的处理函数,下面是它的代码:LRESULT CALLBACK CWindowWnd::__WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam) { CWindowWnd* pThis = NULL; if( uMsg == WM_NCCREATE ) { LPCREATESTRUCT lpcs = reinterpret_cast<LPCREATESTRUCT>(lParam); pThis = static_cast<CWindowWnd*>(lpcs->lpCreateParams); pThis->m_hWnd = hWnd; //当开始创建窗口将窗口类对象的指针放入到对应的GWLP_USERDATA字段中 ::SetWindowLongPtr(hWnd, GWLP_USERDATA, reinterpret_cast<LPARAM>(pThis)); } else { //取出窗口类对象的指针 pThis = reinterpret_cast<CWindowWnd*>(::GetWindowLongPtr(hWnd, GWLP_USERDATA)); if( uMsg == WM_NCDESTROY && pThis != NULL ) { LRESULT lRes = ::CallWindowProc(pThis->m_OldWndProc, hWnd, uMsg, wParam, lParam); ::SetWindowLongPtr(pThis->m_hWnd, GWLP_USERDATA, 0L); if( pThis->m_bSubclassed ) pThis->Unsubclass(); pThis->m_hWnd = NULL; pThis->OnFinalMessage(hWnd); return lRes; } } if( pThis != NULL ) { return pThis->HandleMessage(uMsg, wParam, lParam); } else { return ::DefWindowProc(hWnd, uMsg, wParam, lParam); } }上述的代码,在创建窗口时将窗口类对象指针存入到对应的位置便于在其他位置取出并使用。通过return pThis->HandleMessage(uMsg, wParam, lParam);这句话调用的具体对象的HandleMessage,我们在对应的派生类中定义了相应的虚函数,所以根据多态它会调用我们重写的虚函数来处理具体消息,至于我们不关心的消息,它会调用LRESULT lRes = ::CallWindowProc(pThis->m_OldWndProc, hWnd, uMsg, wParam, lParam);或者DefWindowProc,通过对基类的构造函数的查看,我们发现其实m_OldWndProc就是DefWindowProc。总结上面我们说明了duilib的基本框架,下面来总结一下:CPaintManagerUI::SetInstance(hInstance);设置进程的实例句柄,这个值会在注册窗口类时使用在CWindowWnd类中由Create函数完成窗口类的创建于注册,以及窗口的创建工作CWindowWnd类中的ShowWindow函数用于显示窗口消息循环由CPaintManagerUI::MessageLoop();代码完成最后需要重写MessageHandle函数用于处理我们感兴趣的消息。并且在最后需要调用基类的MessageHandle函数,主要是为了调用DefWindowProc处理我们不感兴趣的消息。
-
Windows平台下的内存泄漏检测 在C/C++中内存泄漏是一个不可避免的问题,很多新手甚至有许多老手也会犯这样的错误,下面说明一下在windows平台下如何检测内存泄漏。在windows平台下内存泄漏检测的原理大致如下。在分配内存的同时将内存块的信息保存到相应的结构中,标识为已分配当内存释放时在结构中查找,并将相应的标识设置为已释放在需要的位置调用HeapWalk,遍历整个堆内存,找到对应的内存块的首地址,并与定义的结构中的数据相匹配,根据结构中的标识判断是否释放,未释放的话给出相应的提示信息。另外在VS系列的编译器中如果输出的调试信息的格式为:文件名(行号)双击这样的输出信息,会自动跳转到对应的位置,利用这点可以很容易的定位到未释放的内存的位置。为了实现上述功能,我们使用重载new和delete的方式。下面是具体的代码:#define MAX_BUFFER_SIZE 1000 typedef struct tag_ST_BLOCK_INFO { TCHAR m_szSourcePath[MAX_PATH]; INT m_iLine; BOOL m_bDelete; void *pBlock; }ST_BLOCK_INFO, *LP_ST_BLOCK_INFO; class CMemoryLeak { public: CMemoryLeak(void); ~CMemoryLeak(void); void MemoryLeak(); void add(LPCTSTR m_szSourcePath, INT m_iLine, void *pBlock); int GetLength(); ST_BLOCK_INFO& operator [](int nSite); protected: HANDLE m_heap;//自定义堆 LP_ST_BLOCK_INFO m_pBlockInfo; int m_BlockSize; //当前缓冲区大小 int m_hasInfo;//当前记录了多少值 };CMemoryLeak::CMemoryLeak(void) { if (m_heap == NULL) { //打开异常检测 m_heap = HeapCreate(HEAP_GENERATE_EXCEPTIONS,0,0); ULONG HeapFragValue = 2; //允许系统记录堆内存的使用 HeapSetInformation( m_heap,HeapCompatibilityInformation,&HeapFragValue ,sizeof(HeapFragValue)) ; } if (NULL == m_pBlockInfo) { m_pBlockInfo = (LP_ST_BLOCK_INFO)HeapAlloc(m_heap, HEAP_ZERO_MEMORY, MAX_BUFFER_SIZE * sizeof(ST_BLOCK_INFO)); m_BlockSize = MAX_BUFFER_SIZE; m_hasInfo = 0; } } void CMemoryLeak::add(LPCTSTR m_szSourcePath, INT m_iLine, void *pBlock) { //当前缓冲区已满 if (m_hasInfo >= m_BlockSize) { //扩大缓冲区容量 HeapReAlloc(m_heap, HEAP_ZERO_MEMORY, m_pBlockInfo, m_BlockSize * 2 * sizeof(ST_BLOCK_INFO)); m_BlockSize *= 2; } m_pBlockInfo[m_hasInfo].m_bDelete = FALSE; m_pBlockInfo[m_hasInfo].m_iLine = m_iLine; _tcscpy(m_pBlockInfo[m_hasInfo].m_szSourcePath, m_szSourcePath); m_pBlockInfo[m_hasInfo].pBlock = pBlock; m_hasInfo++; } CMemoryLeak::~CMemoryLeak(void) { HeapFree(m_heap, 0, m_pBlockInfo); HeapDestroy(m_heap); } void CMemoryLeak::MemoryLeak() { TCHAR pszOutPutInfo[2*MAX_PATH]; //调试字符串 BOOL bRecord = FALSE; //当前内存是否被记录 PROCESS_HEAP_ENTRY phe = {}; HeapLock(GetProcessHeap()); //检测时锁定堆防止对堆内存进行写入 OutputDebugString(_T("开始检查内存泄露情况.........\n")); while (HeapWalk(GetProcessHeap(), &phe)) { //当这块内存正在使用时 if( PROCESS_HEAP_ENTRY_BUSY & phe.wFlags ) { bRecord = FALSE; for(UINT i = 0; i < m_hasInfo; i ++ ) { if( phe.lpData == m_pBlockInfo[i].pBlock) { //校验这块内存是否被释放 if(!m_pBlockInfo[i].m_bDelete) { StringCchPrintf(pszOutPutInfo,2*MAX_PATH,_T("%s(%d):内存块(Point=0x%08X,Size=%u)\n") ,m_pBlockInfo[i].m_szSourcePath,m_pBlockInfo[i].m_iLine,phe.lpData,phe.cbData); OutputDebugString(pszOutPutInfo); } bRecord = TRUE; break; } } if( !bRecord ) { StringCchPrintf(pszOutPutInfo,2*MAX_PATH,_T("未记录的内存块(Point=0x%08X,Size=%u)\n") ,phe.lpData,phe.cbData); OutputDebugString(pszOutPutInfo); } } } HeapUnlock(GetProcessHeap()); OutputDebugString(_T("内存泄露检查完毕.\n")); } int CMemoryLeak::GetLength() { return m_hasInfo; } ST_BLOCK_INFO& CMemoryLeak::operator [](int nSite) { return m_pBlockInfo[nSite]; } CMemoryLeak g_MemoryLeak; void* __cdecl operator new(size_t nSize,LPCTSTR pszCppFile,int iLine) { //在分配内存的时候将这块内存信息记录到相应的结构中 void *p = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, nSize); g_MemoryLeak.add(pszCppFile, iLine, p); return p; } void __cdecl operator delete(void *p, TCHAR *pstrPath, int nLine) { ::operator delete(p); HeapFree(GetProcessHeap(), 0, p); } void __cdecl operator delete(void* p) { //依次遍历结构体数组,找到对应内存块的记录,将标志设置为已删除 for (int i = 0; i < g_MemoryLeak.GetLength(); i++) { if (p == g_MemoryLeak[i].pBlock) { g_MemoryLeak[i].m_bDelete = TRUE; } } HeapFree(GetProcessHeap(), 0, p); }下面是一个测试的例子#ifdef _UNICODE //将__FILE__转化为对应的UNICODE版本 #define GRS_WIDEN2(x) L ## x #define GRS_WIDEN(x) GRS_WIDEN2(x) #define __WFILE__ GRS_WIDEN(__FILE__) //这段代码不能与重载的申明在同一个头文件下,否则在编译时会将定义的new函数进行替换 #define new new(__WFILE__,__LINE__) #define delete(p) ::operator delete(p,__WFILE__,__LINE__) #else #define new new(__FILE__,__LINE__) #define delete(p) ::operator delete(p,__FILE__,__LINE__) #endif int _tmain() { int* pInt1 = new int; int* pInt2 = new int; float* pFloat1 = new float; BYTE* pBt = new BYTE[100]; delete[] pBt; //在DEBUG环境下启用检测 #ifdef _DEBUG g_MemoryLeak.MemoryLeak(); #endif return 0; }上面的代码中,定义了一个结构体 ST_BLOCK_INFO来保存每个分配的内存块的信息,同时采用数组的方式来保存多个内存块的信息,为了便于管理这些信息,专门定义了一个类来操作这个数组,类中记录了数组的首地址,当前保存的信息总量和当前能够容纳的信息总量,同时这个数组支持动态扩展。在遍历时利用HeapWalk函数遍历系统默认堆中的所有内存,找到正在使用的内存,并在结构数组中查找判断内存是否被释放,如果未背释放则输出调试信息。在主函数中利用宏定义的方式,使程序只在debug环境下来校验内存泄漏,方便调试同时在发行时不会拖累程序运行。最后对程序再做最后几点说明:动态数组不要使用new 和delete来分配和释放空间,因为我们重载了这两个函数,这样在检测的时候会有一定的影响new本身的定义如下: void* operator new(size_t size) throw(std::bad_alloc)平时在使用上例如void p = new int 其实等于void p = new(sizeof(int)),同时如果使用void p = new int[10] 等于 void p = new(sizeof(int) 10) 上面定义的#define new new(__WFILE__,__LINE__) 其实在调用时相当于void p = new(__WFILE__,__LINE__) int,也就是等于void *p = new(sizeof(int), __WFILE__,__LINE__)当然delete也是同理在申请数组空间时不要使用系统默认的堆,因为重载new和delete使用的就是系统默认堆,检测的也是默认堆,如果用默认堆来保存数组数据,会对结果产生影响。当然用这样的方式写有点浪费内存资源,如果一个程序需要new出大量的数据,那么需要的额外内存也太多,所以可以使用链表来保存,当调用delete时将结点从链表中删除,这样只要链表中存在的都是未被删除的;或者使用数组,当有一个被删除,将这个位置的索引用队列的方式记录下来,每当要新增数组数据时根据队列中保存的索引找到对应的位置进行覆盖操作。这样可以节省一定的空间。
-
windows PAE扩展和AWE编程 在32位windows上只能看到最大3GB的内存空间,而且每个应用程序只能访问4GB的的内存,这个限制是windows独有的,为了使程序能够访问大于4GB的内存空间,需要使用AWE编程接口,同时需要开启PAE,让系统支持大于3GB的内存,开启PAE最大能支持128GB的内存。PAE开启在windows 7及以上的系统主要使用BCDEdit命令而XP系统使用的是修改boot.ini文件的方式,下面主要介绍的是windows 7 上开启PAE的方式在命令行下输入BCDEdit /set PAE forceenable windows另外如果需要扩大用户分区可以打开/3GB开关,这个开关在windows 7上用命令:BCDEdit /set IncreaseUseVa 3072(后面的数字代表的是用户分区的大小,3072正是3GB)另外编译选项需要打开/LARGEADDRESSAWARE开关AWE编程接口开启PAE之后想要自己的程序能够访问到超过4GB的内存,需要使用AWE的编程接口,AWE(Address Windowing Extensions)是地址窗口扩展。使用AWE时,所有物理页面的交换控制就由应用程序自己控制使用的基本步骤:使用VirtualAlloc + MEM_PHYSICAL分配保留一段地址空间准备用于存储页表的数组申请分配物理内存(AllocateUserPhysicalPages)将物理内存映射到“窗口”中(MapUserPhysicalPages)对映射的内存进行读写操作释放物理内存页面(FreeUserPhysicalPages)释放对应的保留地址空间下面是使用AWE的简单例子#define MEMORY_REQUESTED 1024 * 1024 * 1024 //1GB BOOL bResult; // generic Boolean value ULONG_PTR NumberOfPages; // number of pages to request ULONG_PTR NumberOfPagesInitial; // initial number of pages requested ULONG_PTR *aPFNs1; // page info; holds opaque data ULONG_PTR *aPFNs2; // page info; holds opaque data PVOID lpMemReserved; // AWE window SYSTEM_INFO sSysInfo; // useful system information int PFNArraySize; // memory to request for PFN array TCHAR* pszData; TCHAR pszReadData[100]; MEMORYSTATUSEX ms = {sizeof(MEMORYSTATUSEX)}; GlobalMemoryStatusEx(&ms); //使用VirtualAlloc + MEM_PHYSICAL分配保留一段地址空间 lpMemReserved = VirtualAlloc( NULL,MEMORY_REQUESTED, MEM_RESERVE | MEM_PHYSICAL, PAGE_READWRITE ); //计算需要的物理页面大小 以及物理页面需要的页表数组大小 GetSystemInfo(&sSysInfo); // fill the system information structure //向上取整,计算出需要多少个页表项 NumberOfPages = (MEMORY_REQUESTED + sSysInfo.dwPageSize - 1)/sSysInfo.dwPageSize; PFNArraySize = NumberOfPages * sizeof (ULONG_PTR); //2 准备物理页面的页表数组数据 aPFNs1 = (ULONG_PTR *) HeapAlloc(GetProcessHeap(), 0, PFNArraySize); aPFNs2 = (ULONG_PTR *) HeapAlloc(GetProcessHeap(), 0, PFNArraySize); NumberOfPagesInitial = NumberOfPages; //3 分配物理页面 bResult = AllocateUserPhysicalPages( GetCurrentProcess(),&NumberOfPages,aPFNs1 ); bResult = AllocateUserPhysicalPages( GetCurrentProcess(),&NumberOfPages,aPFNs2 ); //4 映射第一个1GB到保留的空间中 bResult = MapUserPhysicalPages( lpMemReserved,NumberOfPages,aPFNs1 ); pszData = (TCHAR*)lpMemReserved; _tcscpy(pszData,_T("这是第一块物理内存")); //5 映射第二个1GB到保留的空间中 bResult = MapUserPhysicalPages( lpMemReserved,NumberOfPages,aPFNs2 ); _tcscpy(pszData,_T("这是第二块物理内存")); //6 再映射回第一块内存,并读取开始部分 bResult = MapUserPhysicalPages( lpMemReserved,NumberOfPages,aPFNs1 ); _tcscpy(pszReadData,pszData); //7 取消映射 bResult = MapUserPhysicalPages( lpMemReserved,NumberOfPages,NULL ); //8 释放物理页面 bResult = FreeUserPhysicalPages( GetCurrentProcess(),&NumberOfPages,aPFNs1 ); bResult = FreeUserPhysicalPages( GetCurrentProcess(),&NumberOfPages,aPFNs2 ); //9 释放保留的"窗口"空间 bResult = VirtualFree( lpMemReserved,0, MEM_RELEASE ); //10 释放页表数组 bResult = HeapFree(GetProcessHeap(), 0, aPFNs1); bResult = HeapFree(GetProcessHeap(), 0, aPFNs2); _tsystem(_T("PAUSE"));上述代码中,虽然只保留了1GB的虚拟地址空间,但是这1GB的虚拟地址空间通过映射的方式,映射到具体不同的真实内存中,这个就是PAE能访问大于4GB内存的秘密,通过对分页机制的了解,4字节的虚拟地址空间能够映射4KB的一页内存,所以经过简单的计算,其实没多映射1GB的内存其实只需要1M的数组来存储这些页表项。64位的windows不再也没有必要支持AWE技术,因为这个技术就是为了解决应用程序访问内存不足的情况,但是在64位系统中不存在这个问题,也许有朝一日64位的操作系统也会出现能够访问的内存太少的情况,这个时候说不定会出现类似于AWE的技术
-
windows 堆管理 windows堆管理是建立在虚拟内存管理的基础之上的,每个进程都有独立的4GB的虚拟地址空间,其中有2GB的属于用户区,保存的是用户程序的数据和代码,而系统在装载程序时会将这部分内存划分为4个段从低地址到高地址依次为静态存储区,代码段,堆段和栈段,其中堆的生长方向是从低地址到高地址,而栈的生长方向是从高地址到低地址。程序申请堆内存时,系统会在虚拟内存的基础上分配一段内存,然后记录下来这块的大小和首地址,并且在对应内存块的首尾位置各有相应的数据结构,所以在堆内存上如果发生缓冲区溢出的话,会造成程序崩溃,这部分没有硬件支持,所有管理算法都有开发者自己设计实现。堆内存管理的函数主要有HeapCreate、HeapAlloc、HeapFree、HeapRealloc、HeapDestroy、HeapWalk、HeapLock、HeapUnLock。下面主要通过一些具体的操作来说明这些函数的用法。堆内存的分配与释放堆内存的分配主要用到函数HeapAlloc,下面是这个函数的原型:LPVOID HeapAlloc( HANDLE hHeap, //堆句柄,表示在哪个堆上分配内存 DWORD dwFlags, //分配的内存的相关标志 DWORD dwBytes //大小 );堆句柄可以使用进程默认堆也可以使用用户自定义的堆,自定义堆使用函数HeapCreate,函数返回堆的句柄,使用GetProcessHeap可以获取系统默认堆,返回的也是一个堆句柄。分配内存的相关标志有这样几个值:HEAP_NO_SERIALIZE:这个表示对堆内存不进行线程并发控制,由于系统默认会进行堆的并发控制,防止多个线程同时分配到了同一个堆内存,如果程序是单线程程序则可以添加这个选项,适当提高程序运行效率。HEAP_ZERO_MEMORY:这个标志表示在分配内存的时候同时将这块内存清零。HeapCreate函数的原型如下:HANDLE HeapCreate( DWORD flOptions, //堆的相关属性 DWORD dwInitialSize, //堆初始大小 DWORD dwMaximumSize //堆所占内存的最大值 );flOptions的取值如下:HEAP_NO_SERIALIZE:取消并发控制HEAP_SHARED_READONLY:其他进程可以以只读属性访问这个堆dwInitialSize, dwMaximumSize这两个值如果都是0,那么堆内存的初始大小由系统分配,并且堆没有上限,会根据具体的需求而增长。下面是使用的例子: //在系统默认堆中分配内存 srand((unsigned int)time(NULL)); HANDLE hHeap = GetProcessHeap(); int nCount = 1000; float *pfArray = (float *)HeapAlloc(hHeap, HEAP_ZERO_MEMORY | HEAP_NO_SERIALIZE, nCount * sizeof(float)); for (int i = 0; i < nCount; i++) { pfArray[i] = 1.0f * rand(); } HeapFree(hHeap, HEAP_NO_SERIALIZE, pfArray); //在自定义堆中分配内存 hHeap = HeapCreate(HEAP_GENERATE_EXCEPTIONS, 0, 0); pfArray = (float *)HeapAlloc(hHeap, HEAP_ZERO_MEMORY | HEAP_NO_SERIALIZE, nCount * sizeof(float)); for (int i = 0; i < nCount; i++) { pfArray[i] = 1.0f * rand(); } HeapFree(hHeap, HEAP_NO_SERIALIZE, pfArray); HeapDestroy(hHeap);遍历进程中所有堆的信息:便利堆的信息主要用到函数HeapWalk,该函数的原型如下:BOOL WINAPI HeapWalk( __in HANDLE hHeap,//堆的句柄 __in_out LPPROCESS_HEAP_ENTRY lpEntry//返回堆内存的相关信息 );下面是PROCESS_HEAP_ENTRY的原型:typedef struct _PROCESS_HEAP_ENTRY { PVOID lpData; DWORD cbData; BYTE cbOverhead; BYTE iRegionIndex; WORD wFlags; union { struct { HANDLE hMem; DWORD dwReserved[3]; } Block; struct { DWORD dwCommittedSize; DWORD dwUnCommittedSize; LPVOID lpFirstBlock; LPVOID lpLastBlock; } Region; }; } PROCESS_HEAP_ENTRY, *LPPROCESS_HEAP_ENTRY;这个结构中的公用体具体使用哪个与wFlags相关,下面是这些值得具体含义:wFlags堆入口含义lpDatacbDatacbOverhead块前堆数据结构大小iRegionIndexBlockRegionPROCESS_HEAP_ENTRY_BUSY被分配的内存块首地址内存块大小内存块前堆数据结构所在区域索引无意义无意义PROCESS_HEAP_ENTRY_DDESHAREDDE共享内存块首地址内存块大小内存块前堆数据结构所在区域索引无意义无意义PROCESS_HEAP_ENTRY_MOVEABLE可移动的内存块(兼容GlobalAllocLocalAlloc)首地址(可移动内存句柄的首地址)内存块大小内存块前堆数据结构所在区域索引与PROCESS_HEAP_ENTRY_BUSY标志一同指定可移动内存句柄值无意义PROCESS_HEAP_REGION已提交的堆虚拟内存区域区域开始地址区域大小区域前堆数据结构区域索引无意义虚拟内存区域详细信息PROCESS_HEAP_UNCOMMITTED_RANGE未提交的堆虚拟内存区域区域开始地址区域大小区域前堆数据结构区域索引无意义无意义下面是时遍历堆内存的例子: PHANDLE pHeaps = NULL; //当传入的参数为0和NULL时,函数返回进程中堆的个数 int nCount = GetProcessHeaps(0, NULL); pHeaps = new HANDLE[nCount]; //获取进程所有堆句柄 GetProcessHeaps(nCount, pHeaps); PROCESS_HEAP_ENTRY phe = {0}; for (int i = 0; i < nCount; i++) { cout << "Heap handle: 0x" << pHeaps[i] << '\n'; //在读取堆中的相关信息时需要将堆内存锁定,防止程序向堆中写入数据 HeapLock(pHeaps[i]); HeapWalk(pHeaps[i], &phe); //输出堆信息 cout << "\tSize: " << phe.cbData << " - Overhead: " << static_cast<DWORD>(phe.cbOverhead) << '\n'; cout << "\tBlock is a"; if(phe.wFlags & PROCESS_HEAP_REGION) { cout << " VMem region:\n"; cout << "\tCommitted size: " << phe.Region.dwCommittedSize << '\n'; cout << "\tUncomitted size: " << phe.Region.dwUnCommittedSize << '\n'; cout << "\tFirst block: 0x" << phe.Region.lpFirstBlock << '\n'; cout << "\tLast block: 0x" << phe.Region.lpLastBlock << '\n'; } else { if(phe.wFlags & PROCESS_HEAP_UNCOMMITTED_RANGE) { cout << "n uncommitted range\n"; } else if(phe.wFlags & PROCESS_HEAP_ENTRY_BUSY) { cout << "n Allocated range: Region index - " << static_cast<unsigned>(phe.iRegionIndex) << '\n'; if(phe.wFlags & PROCESS_HEAP_ENTRY_MOVEABLE) { cout << "\tMovable: Handle is 0x" << phe.Block.hMem << '\n'; } else if(phe.wFlags & PROCESS_HEAP_ENTRY_DDESHARE) { cout << "\tDDE Sharable\n"; } } else cout << " block, no other flags specified\n"; } cout << std::endl; HeapUnlock(pHeaps[i]); ZeroMemory(&phe, sizeof(PROCESS_HEAP_ENTRY)); } delete[] pHeaps;另外堆还有其他操作,比如使用HeapSize获取分配的内存大小,使用HeapValidate可以校验一个对内存的完整性,从而提早发现”野指针”等等。
-
windows虚拟内存管理 内存管理是操作系统非常重要的部分,处理器每一次的升级都会给内存管理方式带来巨大的变化,向早期的8086cpu的分段式管理,到后来的80x86 系列的32位cpu推出的保护模式和段页式管理。在应用程序中我们无时不刻不在和内存打交道,我们总在不经意间的进行堆内存和栈内存的分配释放,所以内存是我们进行程序设计必不可少的部分。CPU的内存管理方式段寄存器怎么消失了?在学习8086汇编语言时经常与寄存器打交道,其中8086CPU采用的内存管理方式为分段管理的方式,寻址时采用:短地址 * 16 + 偏移地址的方式,其中有几大段寄存器比如:CS、DS、SS、ES等等,每个段的偏移地址最大为64K,这样总共能寻址到2M的内存。但是到32位CPU之后偏移地址变成了32位这样每个段就可以有4GB的内存空间,这个空间已经足够大了,这个时候在编写相应的汇编程序时我们发现没有段寄存器的身影了,是不是在32位中已经没有段寄存器了呢,答案是否定了,32位CPU中不仅有段寄存器而且它们的作用比以前更大了。在32位CPU中段寄存器不再作为段首地址,而是作为段选择子,CPU为了管理内存,将某些连续的地址内存作为一页,利用一个数据结构来说明这页的属性,比如是否可读写,大小,起始地址等等,这个数据结构叫做段描述符,而多个段描述符则组成了一个段描述符表,而段寄存器如今是用来找到对应的段描述符的,叫做段选择子。段寄存器仍然是16位其中高13位表示段描述符表的索引,第二位是区分LDT(局部描述符表)和GDT(全局描述符表),全局描述符表是系统级的而LDT是每个进程所独有的,如果第二位表示的是LDT,那么首先要从GDT中查询到LDT所在位置,然后才根据索引找到对应的内存地址,所以现在寻址采用的是通过段选择子查表的方式得到一个32位的内存地址。由于这些表都是由系统维护,并且不允许用户访问及修改所以在普通应用程序中没有必要也不能使用段寄存器。通过上面的说明,我们可以推导出来32位机器最多可以支持2^(13 + 1 + 32) = 64T内存。段页式管理通过查表方式得到的32位内存地址是否就是真实的物理内存的地址呢,这个也是不一定的,这个还要看系统是否开启了段页式管理。如果没有则这个就是真实的物理地址,如果开启了段页式管理那么这个只是一个线性地址,还需要通过页表来寻址到真实的物理内存。32位CPU专门新赠了一个CR3寄存器用来完成分页式管理,通过CR3寄存器可以寻址到页目录表,然后再将32位线性地址的高10位作为页目录表的索引,通过这个索引可以找到相应的页表,再将中间10为作为页表的索引,通过这个索引可以寻址到对应物理内存的起始地址,最后通过这个其实地址和最后低12位的偏移地址找到对应真实内存。下面是这个过程的一个示例图:为什么要使用分页式管理,直接让那个32位线性地址对应真实的内存不可以吗。当然可以,但是分页式管理也有它自身的优点:可以实现页面的保护:系统通过设置相关属性信息来指定特权级别和其他状态可以实现物理内存的共享:从上面的图中可以看出,不同的线性地址是可以映射到相同的物理内存上的,只需要更改页表中对应的物理地址就可以实现不同的线性地址对应相同的物理内存实现内存共享。可以方便的实现虚拟内存的支持:在系统中有一个pagefile.sys的交互页面文件,这个是系统用来进行内存页面与磁盘进行交互,以应对内存不够的情况。系统为每个内存页维护了一个值,这个值表示该页面多久未被访问,当页面被访问这个值被清零,否则每过一段时间会累加一次。当这个值到达某个阈值时,系统将页面中的内容放入磁盘中,将这块内存空余出来以便保存其他数据,同时将之前的线性地址做一个标记,表名这个线性地址没有对应到具体的内存中,当程序需要再次访问这个线性地址所对应的内存时系统会再次将磁盘中的数据写入到内存中。虽说这样做相当于扩大了物理内存,但是磁盘相对于内存来说是一个慢速设备,在内存和磁盘间进行数据交换总是会耗费大量的时间,这样会拖慢程序运行,而采用SSD硬盘会显著提高系统运行效率,就在于SSD提高了与内存进行数据交换的效率。如果想显著提高效率,最好的办法是加内存毕竟在内存和硬盘间倒换数据是要话费时间的。保护模式在以前的16位CPU中采用的多是实模式,程序中使用的地址都是真实的物理地址,这样如果内存分配不合理,会造成一个程序将另外一个程序所在的内存覆盖这样对另外一个程序将造成严重影响,但是在32位保护模式下,不再会产生这种问题,保护模式将每个进程的地址空间隔离开来,还记得上面的LDT吗,在不同的程序中即使采用的是相同的地址,也会被LDT映射到不同的线性地址上。保护模式主要体现在这样几个方面:1.同一进程中,使用4个不同访问级别的内存段,对每个页面的访问属性做了相应的规定,防止错误访问的情况,同时为提供了4中不同代码特权,0特权的代码可以访问任意级别的内存,1特权能任意访问1...3级内存,但不能访问0级内存,依次类推。通常这些特权级别叫做ring0-ring3。对于不同的进程,将他们所用到的内存等资源隔离开来,一个进程的执行不会影响到另一个进程。windows系统的内存管理windows内存管理器我们将系统中实际映射到具体的实际内存上的页面称为工作集。当进程想访问多余实际物理内存的内存时,系统会启用虚拟内存管理机制(工作集管理),将那些长时间未访问的物理页面复制到硬盘缓冲文件上,并释放这些物理页面,映射到虚拟空间的其它页面上;系统的内存管理器主要由下面的几个部分组成:工作集管理器(优先级16):这个主要负责记录每个页面的年龄,也就有多久未被访问,当页面被访问这个年龄被清零,否则每过一段时间就进行累加1的操作。进程/栈交换器(优先级23):主要用于在进行进程或者线程切换时保存寄存器中的相关数据用以保存相关环境。已修改页面写出器(优先级17):当内存映射的内容发生改变时将这个改变及时的写入到硬盘中,防止由于程序意外终止而造成数据丢失映射页面写出器(优先级17):当页面的年龄达到一定的阈值时,将页面内容写入到硬盘中解引用段线程(优先级18):释放以写入到硬盘中的空闲页面零页面线程(优先级0):将空闲页面清零,以便程序下次使用,这个线程保证了新提交的页面都是干净的零页面进程虚拟地址空间的布局windows为每个进程提供了平坦的4GB的线性地址空间,这个地址空间被分为用户分区和内核分区,他们各占2GB大小,其中内核分区在高地址位,用户分区在低地址位,下面是内存分布的一个表格:分区地址范围NULL指针区0x00000000-0x0000FFFF用户分区0x00010000-0x7FFEFFFF64K禁入区0x7FFF0000-0x7FFFFFFF内核分区0x80000000-0xFFFFFFFF从上面的图中可以看出,系统的内核分区是2GB而用户可用的分区并没有2GB,在用户分区的头64K和尾部的64K不允许用户使用。另外我们可以压缩内核分区的大小,以便使用户分区占更多的内存,这就是/3GB方式,下面是这种方式的具体内存分布:分区地址范围NULL指针区0x00000000-0x0000FFFF用户分区0x00010000-0xBFFEFFFF64K禁入区0xBFFF0000-0xBFFFFFFF内核分区0xC0000000-0xFFFFFFFFwindows虚拟内存管理函数VirtualAllocVirtualAlloc函数主要用于提交或者保留一段虚拟地址空间,通过该函数提交的页面是经过0页面线程清理的干净的页面。LPVOID VirtualAlloc( LPVOID lpAddress, //虚拟内存的地址 DWORD dwSize, //虚拟内存大小 DWORD flAllocationType,//要对这块的虚拟内存做何种操作 DWORD flProtect //虚拟内存的保护属性 ); 我们可以指定第一个参数来告知系统,我们希望操作哪块内存,如果这个地址对应的内存已经被保留了那么将向下偏移至64K的整数倍,如果这块内存已经被提交,那么地址将向下偏移至4K的整数倍,也就是说保留页面的最小粒度是64K,而提交的最小粒度是一页4K。第三个参数是指定分配的类型,主要有以下几个值值含义MEM_COMMIT提交,也就是说将虚拟地址映射到对应的真实物理内存中,这样这块内存就可以正常使用MEM_RESERVE保留,告知系统以这个地址开始到后面的dwSize大小的连续的虚拟内存程序要使用,进程其他分配内存的操作不得使用这段内存。MEM_TOP_DOWN从高端地址保留空间(默认是从低端向高端搜索)MEM_LARGE_PAGES开启大页面的支持,默认一个页面是4K而大页面是2M(这个视具体系统而定)MEM_WRITE_WATCH开启页面写入监视,利用GetWriteWatch可以得到写入页面的统计情况,利用ResetWriteWatch可以重置起始计数MEM_PHYSICAL用于开启PAE第四个参数主要是页面的保护属性,参数可取值如下:值含义PAGE_READONLY只读PAGE_READWRITE可读写PAGE_EXECUTE可执行PAGE_EXECUTE_READ可读可执行PAGE_EXECUTE_READWRITE可读可写可执行PAGE_NOACCESS不可访问PAGE_GUARD将该页设置为保护页,如果试图对该页面进行读写操作,会产生一个STATUS_GUARD_PAGE 异常下面是该函数使用的几个例子:页面的提交/保留与释放//保留并提交 LPVOID pMem = VirtualAlloc(NULL, 4 * 4096, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); srand((unsigned int)time(NULL)); float* pfMem = (float*)pMem; for (int i = 0; i < 4 * 4096 / sizeof(float); i++) { pfMem[i] = rand(); } //释放 VirtualFree(pMem, 4 * 4096, MEM_RELEASE); //先保留再提交 LPBYTE pByte = (LPBYTE)VirtualAlloc(NULL, 1024 * 1024, MEM_RESERVE, PAGE_READWRITE); VirtualAlloc(pByte + 4 * 4096, 4096, MEM_COMMIT, PAGE_READWRITE); pfMem = (float*)(pByte + 4 * 4096); for (int i = 0; i < 4096/sizeof(float); i++) { pfMem[i] = rand(); } //释放 VirtualFree(pByte + 4 * 4096, 4096, MEM_DECOMMIT); VirtualFree(pByte, 1024 * 1024, MEM_RELEASE);大页面支持//获得大页面的尺寸 DWORD dwLargePageSize = GetLargePageMinimum(); LPVOID pBuffer = VirtualAlloc(NULL, 64 * dwLargePageSize, MEM_RESERVE, PAGE_READWRITE); //提交大页面 VirtualAlloc(pBuffer, 4 * dwLargePageSize, MEM_COMMIT | MEM_LARGE_PAGES, PAGE_READWRITE); VirtualFree(pBuffer, 4 * dwLargePageSize, MEM_DECOMMIT); VirtualFree(pBuffer, 64 * dwLargePageSize, MEM_RELEASE);VirtualProtectVirtualProtect用来设置页面的保护属性,函数原型如下:BOOL VirtualProtect( LPVOID lpAddress, //虚拟内存地址 DWORD dwSize, //大小 DWORD flNewProtect, //保护属性 PDWORD lpflOldProtect //返回原来的保护属性 ); 这个保护属性与之前介绍的VirtualAlloc中的保护属性相同,另外需要注意的一点是一般返回原来的属性的话,这个指针可以为NULL,但是这个函数不同,如果第四个参数为NULL,那么函数调用将会失败LPVOID pBuffer = VirtualAlloc(NULL, 4 * 4096, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); float *pfArray = (float*)pBuffer; for (int i = 0; i < 4 * 4096 / sizeof(float); i++) { pfArray[i] = 1.0f * rand(); } //将页面改为只读属性 DWORD dwOldProtect = 0; VirtualProtect(pBuffer, 4 * 4096, PAGE_READONLY, &dwOldProtect); //写入数据将发生异常 pfArray[9] = 0.1f; VirtualFree(pBuffer, 4 * 4096, MEM_RELEASE);VirtualQuery这个函数用来查询某段虚拟内存的属性信息,这个函数原型如下:DWORD VirtualQuery( LPCVOID lpAddress,//地址 PMEMORY_BASIC_INFORMATION lpBuffer, //用于接收返回信息的指针 DWORD dwLength //缓冲区大小,上述结构的大小 ); 结构MEMORY_BASIC_INFORMATION的定义如下:typedef struct _MEMORY_BASIC_INFORMATION { PVOID BaseAddress; //该页面的起始地址 PVOID AllocationBase;//分配给该页面的首地址 DWORD AllocationProtect;//页面的保护属性 DWORD RegionSize; //页面大小 DWORD State;//页面状态 DWORD Protect;//页面的保护类型 DWORD Type;//页面类型 } MEMORY_BASIC_INFORMATION; typedef MEMORY_BASIC_INFORMATION *PMEMORY_BASIC_INFORMATION; AllocationProtect与Protect所能取的值与之前的保护属性的值相同。State的取值如下:MEM_FREE:空闲MEM_RESERVE:保留MEM_COMMIT:已提交Type的取值如下:MEM_IMAGE:映射类型,一般是映射到地址控件的可执行模块如DLL,EXE等MEM_MAPPED:文件映射类型MEM_PRIVATE:私有类型,这个页面的数据为本进程私有数据,不能与其他进程共享下面是这个的使用例子:#include<windows.h> #include <stdio.h> #include <tchar.h> #include <atlstr.h> CString GetMemoryInfo(MEMORY_BASIC_INFORMATION *pmi); int _tmain(int argc, TCHAR *argv[]) { SYSTEM_INFO sm = {0}; GetSystemInfo(&sm); LPVOID dwMinAddress = sm.lpMinimumApplicationAddress; LPVOID dwMaxAddress = sm.lpMaximumApplicationAddress; MEMORY_BASIC_INFORMATION mbi = {0}; _putts(_T("BaseAddress\tAllocationBase\tAllocationProtect\tRegionSize\tState\tProtect\tType\n")); for (LPVOID pAddress = dwMinAddress; pAddress <= dwMaxAddress;) { if (VirtualQuery(pAddress, &mbi, sizeof(MEMORY_BASIC_INFORMATION)) == 0) { break; } _putts(GetMemoryInfo(&mbi)); //一般通过BaseAddress(页面基地址) + RegionSize(页面长度)来寻址到下一个页面的的位置 pAddress = (BYTE*)mbi.BaseAddress + mbi.RegionSize; } } CString GetMemoryInfo(MEMORY_BASIC_INFORMATION *pmi) { CString lpMemoryInfo = _T(""); int iBaseAddress = (int)(pmi->BaseAddress); int iAllocationBase = (int)(pmi->AllocationBase); CString szProtected = _T("\0"); if (pmi->Protect & PAGE_READONLY) { szProtected = _T("R"); }else if (pmi->Protect & PAGE_READWRITE) { szProtected = _T("RW"); }else if (pmi->Protect & PAGE_WRITECOPY) { szProtected = _T("WC"); }else if (pmi->Protect & PAGE_EXECUTE) { szProtected = _T("X"); }else if (pmi->Protect & PAGE_EXECUTE_READ) { szProtected = _T("RX"); }else if (pmi->Protect & PAGE_EXECUTE_READWRITE) { szProtected = _T("RWX"); }else if (pmi->Protect & PAGE_EXECUTE_WRITECOPY) { szProtected = _T("WCX"); }else if (pmi->Protect & PAGE_GUARD) { szProtected = _T("GUARD"); }else if (pmi->Protect & PAGE_NOACCESS) { szProtected = _T("NOACCESS"); }else if (pmi->Protect & PAGE_NOCACHE) { szProtected = _T("NOCACHE"); }else { szProtected = _T(" "); } CString szAllocationProtect = _T("\0"); if (pmi->AllocationProtect & PAGE_READONLY) { szProtected = _T("R"); }else if (pmi->AllocationProtect & PAGE_READWRITE) { szProtected = _T("RW"); }else if (pmi->AllocationProtect & PAGE_WRITECOPY) { szProtected = _T("WC"); }else if (pmi->AllocationProtect & PAGE_EXECUTE) { szProtected = _T("X"); }else if (pmi->AllocationProtect & PAGE_EXECUTE_READ) { szProtected = _T("RX"); }else if (pmi->AllocationProtect & PAGE_EXECUTE_READWRITE) { szProtected = _T("RWX"); }else if (pmi->AllocationProtect & PAGE_EXECUTE_WRITECOPY) { szProtected = _T("WCX"); }else if (pmi->AllocationProtect & PAGE_GUARD) { szProtected = _T("GUARD"); }else if (pmi->AllocationProtect & PAGE_NOACCESS) { szProtected = _T("NOACCESS"); }else if (pmi->AllocationProtect & PAGE_NOCACHE) { szProtected = _T("NOCACHE"); }else { szProtected = _T(" "); } DWORD dwRegionSize = pmi->RegionSize; CString strState = _T(""); if (pmi->State & MEM_FREE) { strState = _T("Free"); }else if (pmi->State & MEM_RESERVE) { strState = _T("Reserve"); }else if (pmi->State & MEM_COMMIT) { strState = _T("Commit"); }else { strState = _T(" "); } CString strType = _T(""); if (pmi->Type & MEM_IMAGE) { strType = _T("Image"); }else if (pmi->Type & MEM_MAPPED) { strType = _T("Mapped"); }else if (pmi->Type & MEM_PRIVATE) { strType = _T("Private"); } lpMemoryInfo.Format(_T("%08X %08X %s %d %s %s %s\n"), iBaseAddress, iAllocationBase, szAllocationProtect, dwRegionSize, strState, szProtected, strType); return lpMemoryInfo; }VirtualLock和VirtualUnlock这两个函数用于锁定和解锁页面,前面说过操作系统会将长时间不用的内存中的数据放入到系统的磁盘文件中,需要的时候再放回到内存中,这样来回倒腾,必定会造成程序效率的底下,为了避免这中效率底下的操作,可以使用VirtualLock将页面锁定在内存中,防止页面交换,但是不用了的时候需要使用VirtualUnlock来解锁,不然一直锁定而不解锁会造成真实内存的不足。另外需要注意的是,不能一次操作超过工作集规定的最大虚拟内存,这样会造成程序崩溃,我们可以通过函数SetProcessWorkingSetSize来设置工作集规定的最大虚拟内存的大小。下面是一个使用例子:SetProcessWorkingSetSize(GetCurrentProcess(), 1024 * 1024, 2 * 1024 * 1024); LPVOID pBuffer = VirtualAlloc(NULL, 4 * 4096, MEM_RESERVE, PAGE_READWRITE); //不能锁定超过进程工作集大小的虚拟内存 VirtualLock(pBuffer, 3 * 1024 * 1024); //不能一次提交超过进程工作集大小的虚拟内存 VirtualAlloc(pBuffer, 3 * 1024 * 1024, MEM_COMMIT, PAGE_READWRITE); float *pfArray = (float*)pBuffer; for (int i = 0; i < 4096 / sizeof(float); i++) { pfArray[i] = 1.0f * rand(); } VirtualUnlock(pBuffer, 4096); VirtualFree(pBuffer, 4096, MEM_DECOMMIT); VirtualFree(pBuffer, 4 * 4096, MEM_RELEASE);VirtualFreeVirtualFree用于释放申请的虚拟内存。这个函数支持反提交和释放,这两个操作由第三个参数指定:MEM_DECOMMIT:反提交,这样这个线性地址就不再映射到具体的物理内存,但是这个地址仍然是保留地址。MEM_RELEASE:释放,这个范围的地址不再作为保留地址